
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をLLMによって生成されるQ&Aを用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.自動生成記事のクオリティと信頼性を向上させるためにアルゴリズムの改善に取り組んでいます.個人で資料のQ&Aを作成されたい方には、https://www.chatpdf.com/ や https://scispace.com/などがお勧めです.
紹介する論文は以下の10本となります.
- Unsupervised speech-to-speech translation from monolingual data
発行日:2023年12月01日
「Translatotron 3」は、非監督学習を使用してスピーチ・トゥ・スピーチ・トランスレーションを実現する新しいアーキテクチャであり、非テキストの翻訳にも適用可能であることが示されています.この手法は、合成翻訳を使用してソース言語からターゲット言語への翻訳を行い、スペイン語と英語の実験結果では優れた性能を示しています. - Multilingual Expressive and Streaming Speech Translation
発行日:2023年11月30日
最近の自動音声翻訳の進歩により、言語カバレッジが拡大し、マルチモーダル機能が向上し、さまざまなタスクや機能が可能になりました.本研究では、ストリーミング形式でエンドツーエンドの表現豊かで多言語対応の翻訳を可能にするモデル群を紹介します.SeamlessM4T v2は、少ないリソースの言語データで訓練され、合計76言語に対応しています.SeamlessExpressiveは声のスタイルと韻律を保持した翻訳を可能にし、SeamlessStreamingは低遅延の目標翻訳を生成します.これらのモデルの性能を理解するために、私たちは韻律、遅延、および堅牢性を評価するために、既存の自動評価指標の新しいバージョンや修正版を組み合わせました.さらに、私たちはマルチモーダル機械翻訳のための初めての既知のレッドチーミング試験、有害性の検出と緩和のためのシステム、ジェンダーバイアスの体系的な評価、および聞き取りにくいローカライズされた透かしを実装しました.最後に、Seamlessは、リアルタイムで表現豊かな異言語コミュニケーションを実現するために必要な技術的基盤を提供する、初めて一般に公開されたシステムです. - Generative AI could revolutionize health care — but not if control is ceded to big tech
発行日:2023年11月30日
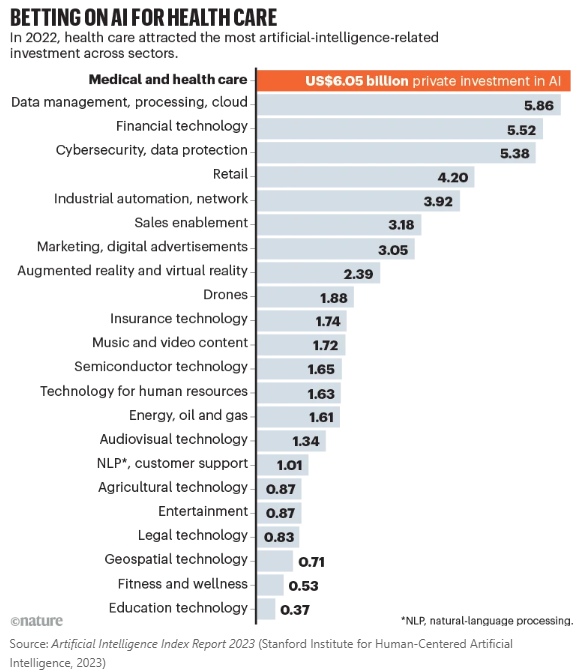
テクノロジー企業が主導権を握っているが、医療従事者がAIの安全な医療展開を主導し、プライバシーを保護する必要がある.アメリカとイギリスはAIの研究と展開に多額の予算を割り当てており、欧州連合も同様に予算を充てる予定.技術企業との協力により、多様な利害関係者がLLMの開発と採用を導き、AIが医療を向上させることが重要. - Scaling deep learning for materials discovery
発行日:2023年11月29日
本研究では、機械学習を使用して材料の安定性を予測し、材料の発見を導く初めてのモデルを開発しました.このモデルは、新しい対称性を考慮した部分置換やランダム構造探索を活用し、グラフニューラルネットワークを使用して材料の特性をモデリングします.この手法により、2.2百万以上の安定な構造を発見し、エネルギーの予測精度も向上しました.さらに、生成されたデータセットは新たなモデリングの可能性を開拓することが示されました. - Adversarial Diffusion Distillation
発行日:2023年11月28日
この論文では、高品質な画像を効率的にサンプリングするための新しいトレーニングアプローチであるAdversarial Diffusion Distillation(ADD)が紹介されています.ADDは、わずか1〜4ステップで大規模な画像拡散モデルをサンプリングし、従来のモデルよりも優れた性能を示すことが示されています.また、拡張版のADD-XLも提案され、より高い解像度での性能向上が実証されています. - Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
発行日:2023年11月28日
Medpromptを使用したGPT-4は、複数のプロンプティング戦略を組み合わせることで、医療問題だけでなく他の領域でも高い性能を発揮し、最先端の結果を達成している. - ChatGPT’s One-year Anniversary: Are Open-Source Large Language Models Catching up?
発行日:2023年11月28日
2022年末にリリースされたChatGPTは、AIの全体的な景色に地殻変動をもたらし、LLMへの関心が高まっている.この研究では、オープンソースのLLMがChatGPTと同等またはそれ以上の性能を持つと主張しているすべてのタスクについて概要を提供する. - UniIR: Training and Benchmarking Universal Multimodal Information Retrievers
発行日:2023年11月28日
従来の情報検索モデルは多様なユーザーのニーズに対応できないため、UniIRという統一された指示ガイドのマルチモーダルリトリーバーが導入され、8つの異なるリトリーバルタスクを処理することができることが示された.UniIRは10のマルチモーダルIRデータセットで訓練され、堅牢なパフォーマンスと新しいタスクへのゼロショットの汎化能力を持つことが実証された.また、M-BEIRというマルチモーダルリトリーバルベンチマークも構築され、ユニバーサルなマルチモーダル情報検索の評価が標準化された. - MEDITRON-70B: Scaling Medical Pretraining for Large Language Models
発行日:2023年11月27日
MEDITRONは、オープンソースの大規模言語モデル(LLM)であり、医学知識へのアクセスを向上させることができ、他のモデルよりも優れた性能を持っています. - On Bringing Robots Home
発行日:2023年11月27日
私たちは、家庭での多目的なロボット操作のためのDobb-Eというシステムを紹介し、実験を通じてその成功率を81%に向上させ、家庭用ロボットの研究を加速するためにオープンソース化することを目指しています.
Unsupervised speech-to-speech translation from monolingual data
著者:Eliya Nachmani, Michelle Tadmor Ramanovich
発行日:2023年12月01日
最終更新日:不明
URL:https://blog.research.google/2023/12/unsupervised-speech-to-speech.html
カテゴリ:不明
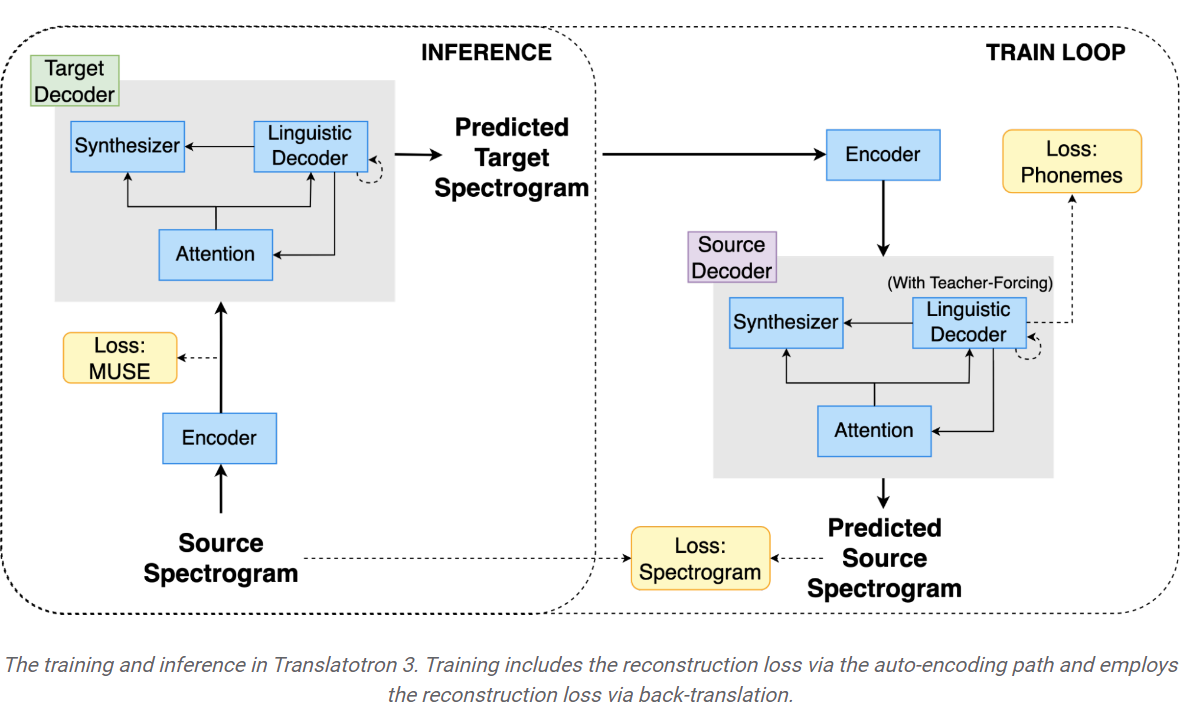
概要:
スピーチ・トゥ・スピーチ・トランスレーション(S2ST)は、話された言語を別の言語に変換する技術です.この技術は言語の壁を取り払い、異なる文化や背景を持つ人々のコミュニケーションを促進する可能性があります.以前、私たちは初めて直接スピーチを2つの言語間で翻訳できるモデルであると紹介しました.しかし、これらのモデルは監督学習の設定で訓練されており、並列スピーチデータが必要でした.並列スピーチデータの不足は、この分野での主要な課題であり、ほとんどの公開データセットはテキストから半合成または完全合成されています.これにより、テキストには表現されていないスピーチ属性の翻訳と再構築に追加の障壁が生じます.
しかし、新しい非監督スピーチ・トゥ・スピーチ・トランスレーションアーキテクチャである「Translatotron 3」では、単一言語データだけからスピーチ・トゥ・スピーチ・トランスレーションのタスクを学習できることを示しています.この方法により、より多くの言語ペア間の翻訳だけでなく、非テキストの翻訳にも道が開かれます.具体的には、Translatotron 3は、一部の非テキストのスピーチ属性(一時停止、話す速度、話者のアイデンティティなど)の翻訳を可能にすることができます.この手法は、対象言語への直接的な監督を必要とせず、ソーススピーチのパラ言語的な特徴(音調、感情など)が翻訳を通じて保持される方向性であると考えられます.
スピーチ・トゥ・スピーチ・トランスレーションを実現するために、Translatotron 3では非監督機械翻訳(UMT)の技術である合成翻訳を使用します.これにより、ソース言語の合成的な翻訳がターゲット言語への翻訳に使用されます.スペイン語と英語のスピーチ・トゥ・スピーチ・トランスレーションの実験結果では、Translatotron 3がベースラインのカスケードシステムよりも優れた性能を発揮することが示されています.
Q&A:
Q: 音声対音声翻訳(S2ST)の定義とは?
A: 音声から音声への翻訳(S2ST)は、話された言語を別の言語に変換する技術です.この技術は言語の壁を取り払い、異なる文化や背景を持つ人々のコミュニケーションを促進する潜在能力を持っています.
Q: S2ST技術の潜在的な影響とは?
A: S2ST技術の潜在的な影響は、言語の壁を取り払い、異なる文化や背景を持つ人々の間でのコミュニケーションを容易にすることです.
Q: 音声対音声翻訳の分野での主な課題は何ですか?
A: 音声から音声への翻訳の分野における主要な課題は、パラレル音声データの不足です.
Q: パラレル音声データの希少性は、翻訳学習や音声属性の再構成にどのような影響を与えるのか?
A: パラレル音声データの不足は、翻訳と音声属性の再構築の学習に大きな課題となります.ほとんどの公開データセットは、テキストから半合成または完全合成されています.これにより、テキストには表現されていない音声属性の翻訳や再構築に追加の障壁が生じます.
Q: トランスラトトロン3の主な貢献は何ですか?
A: Translatotron 3の主な貢献は、バイリンガル音声データセットの必要性を排除することです.
Q: トランスラトトロン3は、トレーニングデータの点で以前のモデルとどう違うのですか?
A: トランスラトトロン3は、教師なし音声対音声翻訳(S2ST)の問題に対処し、バイリンガル音声データセットの必要性を排除することで、学習データの点でこれまでのモデルとは異なります.これは、機械翻訳、バックトランスレーション、モノリンガルデータの使用という3つの重要な側面を取り入れることで実現されています.トランスラトトロン3の学習プロセスには、自動符号化パスと逆翻訳による再構成ロスが含まれています.これにより、トランスラトトロン3は対訳テキストデータセットを必要とせずにテキストを翻訳することができます.
Q: トランスラトトロン3が翻訳できるテキスト以外の音声属性にはどのようなものがありますか?
A: トランスラトトロン3は、間、話す速度、話者のアイデンティティなど、テキスト以外の音声属性を翻訳することができます.
Q: トランスラトトロン3は、翻訳中、どのようにソース音声のパラ言語学的特徴を保持するのですか?
A: トランスラトトロン3は、教師なし機械翻訳(UMT)とソース言語の合成翻訳を使用することで、翻訳中にソース音声のパラ言語的特徴を保持します.これは、ターゲット言語への直接の監視なしに、単言語データのみから音声対音声の翻訳タスクを学習します.これにより、間、発話速度、話者の同一性などのパラ言語的特徴を翻訳間で保持することができる.この方法では、埋め込み空間の最近傍を使用して翻訳を作成するため、高い翻訳品質、話者の類似性、音声品質が得られます.さらに、Translatotron 3は、グランドトゥルースの音声サンプルと同様の音声の自然さを実現しています.
Q: トランスラトトロン3は、ベースラインのカスケードシステムと性能面でどのように比較されますか?
A: Translatotron 3は、翻訳品質、話者の類似性、音声品質において、ベースラインのカスケードシステムを凌駕しています.特に翻訳品質の面で優れています.
Multilingual Expressive and Streaming Speech Translation
著者:Abinesh Ramakrishnan, Alex Mourachko, Alice Rakotoarison, Amanda Kallet, Ann Lee, Anna Sun, Artyom Kozhevnikov, Benjamin Peloquin, Bokai Yu, Brian Ellis, Can Balioglu, Carleigh Wood, Changhan Wang, Christophe Ropers, Christophe Touret, Christopher Klaiber, Corinne Wong, Cynthia Gao, Daniel Licht, David Dale, ElaheKalbassi, Ethan Ye, Francisco Guzm´an, Gabriel Mejia Gonzalez, GuillaumeWenzek, Hady Elsahar, Hirofumi Inaguma, Holger Schwenk, Hongyu Gong, Ilia Kulikov, Ivan Evtimov, Jean Maillard, Jeff Wang, John Hoffman, Juan Pino, Justin Haaheim, Justine Kao, Kaushik Ram Sadagopan, Kevin Heffernan, Lo¨ıc Barrault, Maha Elbayad, Mariano Coria Meglioli, MarkDuppenthaler, Marta R Costajussa, Mary Williamson, MinJaeHwang, Ning Dong, Paden Tomasello, PaulAmbroise Duquenne, PengJen Chen, Pengwei Li, Pierre Andrews, Pierre Fernandez, Prangthip Hansanti, Robin San Roman, RuslanMavlyutov, Safiyyah Saleem, Skyler Wang, Somya Jain, Sravya Popuri, Tuan Tran, XutaiMa, Yilin Yang, YuAn Chung
発行日:2023年11月30日
最終更新日:不明
URL:https://ai.meta.com/research/seamless-communication/?utm_source=twitter&utm_medium=organic_social&utm_campaign=fair10&utm_content=thread
カテゴリ:不明
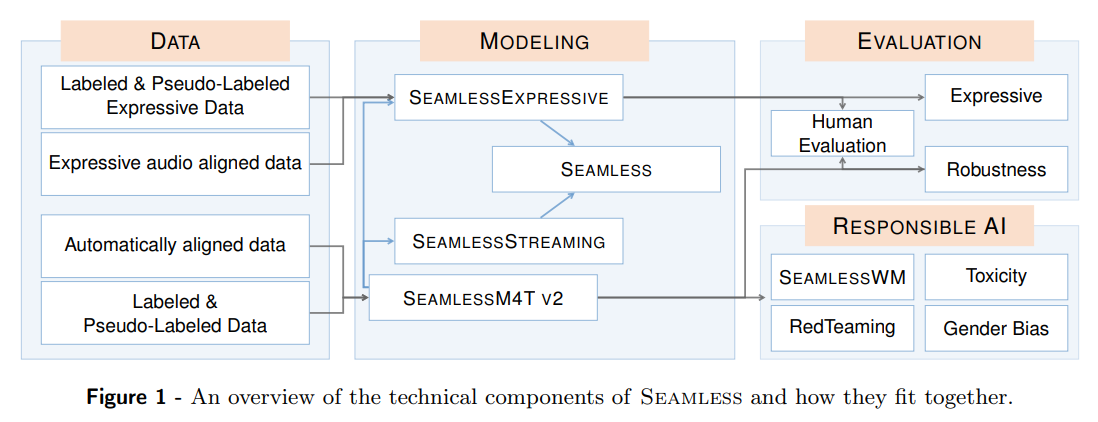
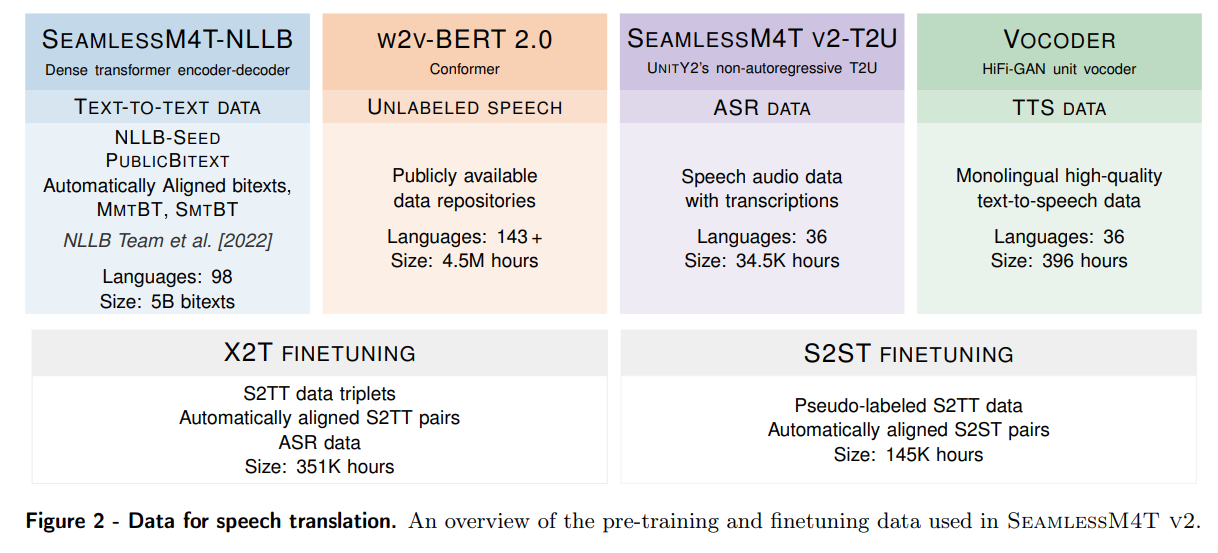
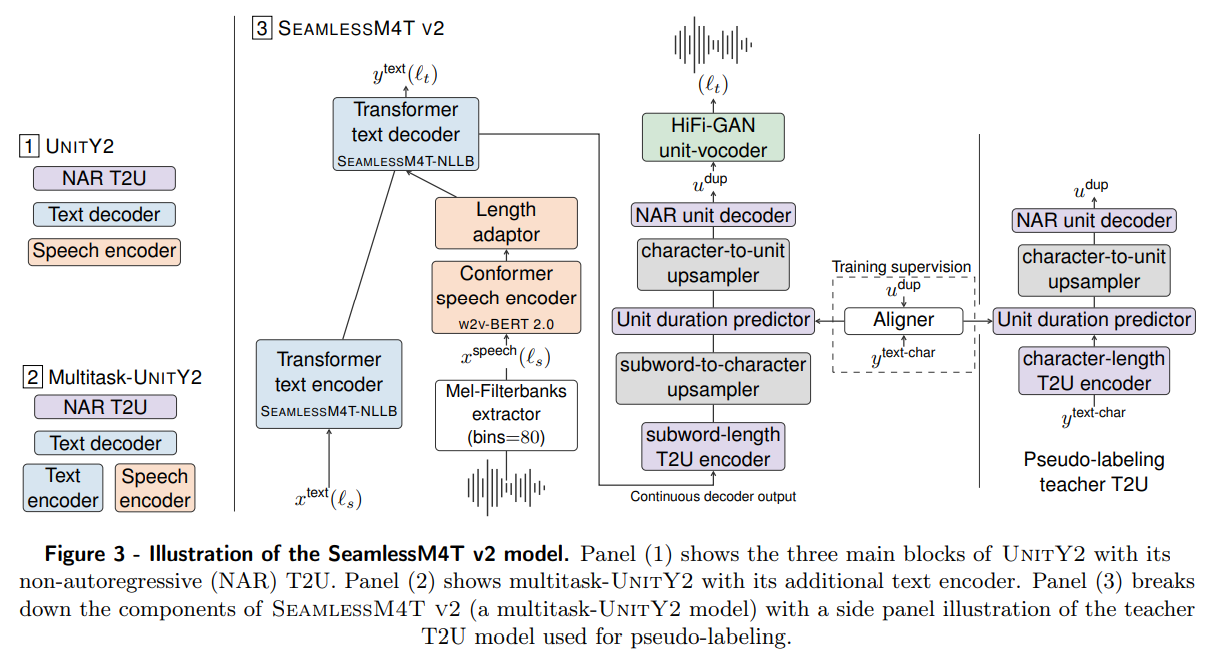
概要:
最近の自動音声翻訳の進歩により、言語カバレッジが大幅に拡大し、マルチモーダル機能が向上し、さまざまなタスクや機能が可能になりました.ただし、現在の大規模な自動音声翻訳システムには、人間との対話と比較して、機械を介したコミュニケーションがシームレスに感じられるための重要な機能が欠けています.本研究では、ストリーミング形式でエンドツーエンドの表現豊かで多言語対応の翻訳を可能にするモデル群を紹介します.
まず、私たちは大規模な多言語・マルチモーダルのSeamlessM4Tモデルの改良版であるSeamlessM4T v2を提案します.この新しいモデルは、更新されたUnitY2フレームワークを取り入れ、より少ないリソースの言語データで訓練されました.SeamlessAlignの拡張版では、自動的にアラインされたデータが114,800時間追加され、合計76言語に対応しています.SeamlessM4T v2は、私たちの最新の2つのモデル、SeamlessExpressiveとSeamlessStreamingの基盤となります.
SeamlessExpressiveは、声のスタイルと韻律を保持した翻訳を可能にします.従来の表現的な音声研究に比べて、私たちの研究は特定の課題に取り組んでいます.例えば、話速や一時停止といった韻律の未開拓な側面を扱っています.さらに、人間の評価では、意味の保存、自然さ、表現力の最も関連性の高い属性を測定するために、既存のプロトコルを適応させました.さらに、最新の研究では、言語モデル、フローマッチング、拡散モデルなどのアプローチが提案され、これらのアプローチは音声のスタイルや品質を保持するためのS2STモデルの設計に影響を与えました.しかし、これまでに、音声のスタイルや韻律を保持した翻訳を含む包括的なS2STシステムは実現されていません.
SeamlessStreamingは、効率的な単調なマルチヘッドアテンション(EMMA)メカニズムを活用して、完全なソース発話を待たずに低遅延の目標翻訳を生成します.SeamlessStreamingは、複数のソース言語とターゲット言語に対して同時の音声-音声/テキスト翻訳を可能にする、そのようなモデルとして初めてのものです.最近の研究では、ルールベースや学習可能なポリシーなど、さまざまな同時翻訳ポリシーの展開が検討され、低遅延と高品質の翻訳のバランスを取るシステムが開発されてきました.ただし、これまでのストリーミング翻訳の研究は、音声からテキストへの翻訳(S2TT)に焦点を当てており、S2STに対応したものは言語カバレッジが限られています.さらに、ほとんどのストリーミング翻訳システムは、2言語間のコミュニケーションに焦点を当てており、複数の異なる言語で会話する場面では有用性が制限されています.
これらのモデルの性能を理解するために、私たちは韻律、遅延、および堅牢性を評価するために、既存の自動評価指標の新しいバージョンや修正版を組み合わせました.さらに、私たちはマルチモーダル機械翻訳のための初めての既知のレッドチーミング試験、有害性の検出と緩和のためのシステム、ジェンダーバイアスの体系的な評価、および聞き取りにくいローカライズされた透かしを実装しました.最後に、Seamlessは、リアルタイムで表現豊かな異言語コミュニケーションを実現するために必要な技術的基盤を提供する、初めて一般に公開されたシステムです.また、SeamlessM4T v2は、SeamlessExpressiveとSeamlessStreamingの基盤となるモデルであり、ほぼ100の言語を入力としてサポートすることができます.
評価のために、私たちは新しいバージョンや修正版の自動評価指標を使用し、韻律、遅延、および堅牢性を評価しました.さらに、マルチモーダル機械翻訳のための新たな試験やシステムも実装され、Seamlessは、リアルタイムで表現豊かな異言語コミュニケーションを実現するための技術的基盤を提供する初めて一般に公開されたシステムです.さらに、私たちはレッドチーミング、有害性検出と緩和、ジェンダーバイアス評価、および透かしの実装についても詳細を提供し、私たちの取り組みの社会的影響と将来展望についても議論しています.
Q&A:
Q: シームレスな機械媒介コミュニケーションを実現するために、現在の大規模な自動音声翻訳システムに欠けている重要な機能とは何か?
A: 現在の大規模な自動音声翻訳システムには、機械を介したコミュニケーションが人間との対話と同様にシームレスに感じるために必要な重要な機能が欠けています.
Q: SeamlessM4T v2モデルは、前バージョンと比べてどのような点が改善されましたか?
A: SeamlessM4T v2では、入力長に依存しないT2U復号化時間が旧バージョンより改善された.この改善により、S2STの推論速度が3倍以上向上した.
Q: SeamlessAlignの拡張版では、何時間分の自動アライメントデータが追加されたのですか?
A: 拡張版のSeamlessAlignには、114,800時間の自動的に整列されたデータが追加されました.
Q: SeamlessExpressiveは、翻訳においてどのように声調や韻律を保持するのですか?
A: SeamlessExpressiveは、音声のスタイルと韻律を保持するために、以下の技術を使用しています.まず、SeamlessM4T v2を基礎として高い翻訳品質を実現しています.次に、Prosody UnitY2を提案し、SeamlessM4T v2に表現力のエンコーダを統合して、適切なリズム、話速、休止を持つユニットの生成をガイドしています.さらに、SeamlessM4T v2のユニットHiFi-GANボコーダをPRETSSELに置き換え、表現力のあるユニットから音声を生成しています.
Q: SeamlessStreamingが低レイテンシーのターゲット翻訳を生成するために使用するメカニズムは何ですか?
A: SeamlessStreamingは、Efficient Monotonic Multihead Attention(EMMA)メカニズムを利用して、完全なソース発話を待たずに低遅延のターゲット翻訳を生成します.
Q: SeamlessStreamingは、どのようにして複数のソース言語とターゲット言語の同時音声合成/テキスト翻訳を可能にするのですか?
A: シームレスストリーミングは、シームレスM4Tv2モデルの言語カバレッジと意味の正確さを利用して、リアルタイムで音声から音声およびテキストへの直接翻訳を行うことができます.SeamlessStreamingは、音声入力の101のソース言語、音声出力の36のターゲット言語、およびテキスト出力の96のターゲット言語をサポートしています.モノトニック・マルチヘッド・アテンション(EMMA)によって強化された同時テキスト・デコーダと、基礎となるシームレスM4T v2モデルからのファインチューニングおよびストリーミング推論を特徴としています.
Q: 韻律、遅延、ロバスト性の観点からモデルの性能を評価するために、どのような指標が用いられたのか?
A: 評価のために使用されたメトリクスは、ASR-BLEUによる内容の保存の評価、AutoPCPスコアによる声のスタイルの保存と抑揚の評価、スピーチレートの相関とポーズの整列スコアによるレイテンシの評価でした.さらに、PCPとMOSプロトコルによる人間の評価も含まれていました.
Q: モデルの人間による評価には、どのようなプロトコルが適応されたのか?
A: 人間評価のためには、意味の保存、自然さ、表現力の最も関連性の高い属性を測定するために既存のプロトコルを適応しました.
Q: 追加毒性の検出と緩和、ジェンダーバイアスの評価など、モデルの安全で責任ある使用を保証するためにどのような努力がなされたか?
A: モデルの安全で責任ある使用を確保するために、以下の取り組みが行われました.まず、研究者はモデルを使用する際に「追加の有害性」に対する信頼性の向上策を実装することを検討する必要があります.また、モデルのトキシシティやバイアスの検出と軽減に関して、Mariano Coria Meglioli氏がトキシシティ分類器を担当し、Marta R. Costa-juss` a氏がトキシシティ/バイアスの研究リードを務め、Prangthip Hansanti氏、Gabriel Mejia Gonzalez氏、Christophe Ropers氏がトキシシティの注釈を行い、Bokai Yu氏がトキシシティの軽減とジェンダーバイアスの研究を行いました.さらに、安全性に関しては、Hady Elsahar氏がウォーターマーキングの研究リードを務めました.
Q: この作品で公開されたモデル、コード、電子透かし検出器はどこで入手できますか?
A: この研究で公開されたモデル、コード、およびウォーターマーク検出器は、以下のリンクでアクセスできます:.” rel=”nofollow”>https://github.com/facebookresearch/seamless_communication.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: https://github.com/facebookresearch/seamless_communication
Generative AI could revolutionize health care — but not if control is ceded to big tech
著者:Augustin Toma, Barry Rubin, Bo Wang, Patrick R Lawler, Senthujan Senkaiahliyan
発行日:2023年11月30日
最終更新日:不明
URL:https://www.nature.com/articles/d41586-023-03803-y
カテゴリ:不明
概要:
テクノロジー企業が主導権を握っている一方で、医療従事者が開発と展開を主導することで、人々のプライバシーを保護するために、生成AIを安全に医療に展開する必要があります.医療機関や他の組織は、技術企業に対抗するために、自身のリソースと専門知識を結集し、透明性のある評価が可能で、現地の機関のニーズに合致するLLMを開発することができます.アメリカ合衆国大統領ジョー・バイデンが先月署名したAIに関する行政命令では、アメリカ保健福祉省やアメリカ退役軍人省などの組織が、医療におけるAIの安全な実装方法を調査するように指示されています.イギリスの国民保健サービスは、AIの開発と評価に1億2300万ポンド(約153億円)以上、展開にさらに2100万ポンド(約26億円)を割り当てています.同様に、欧州連合も6,000万ユーロ(約65億円)を医療におけるAIの研究と展開に充てる予定です.したがって、技術企業との協力を通じて、慎重に管理されたオープンな協力関係によって、多様な利害関係者がLLMの開発と採用を導き、AIが医療を向上させることができるようにすることが重要です.
Q&A:
Q: ChatGPTはいつ公開されたのですか?
A: ChatGPTは2022年11月30日に一般公開されました.
Q: GPT-4とGoogleのMed-PaLMの目的は、医療分野で何ですか?
A: GPT-4とGoogleのMed-PaLMは、医療を変革する可能性を秘めた大規模言語モデル(LLM)です.これらは臨床ノートの作成、フォームの記入、請求の支援、医師の診断と治療計画の支援など、さまざまな医療業務に活用できます.これらのLLMは疾患の診断において重要なツールとなる可能性があります.GPT-4とMed-PaLMの医療における目的は、生成型AI技術を活用して医療プロセスの効率と正確性を向上させることです.医療関係者はこれらのモデルの開発と展開を推進し、人々のプライバシーを保護する必要があります.また、医療において生成型AIを安全に展開するためには、モデルはオープンソースである必要があります.GPT-4とMed-PaLMは、医療領域での印象的な能力を示しており、医師に好まれる臨床ノートの生成や医療テストの合格などが可能です.これらは神経外科や医学物理学など、さまざまな専門分野を革新する可能性を秘めています.
Q: 大規模言語モデルを医療にどう活用できるか?
A: 大規模言語モデルは、医療分野でさまざまな方法で活用されることができます.例えば、大規模言語モデルは、臨床ノートの生成やフォームの入力などのタスクを自動化することができます.また、疾患の診断や治療計画の支援にも役立つことが期待されています.さらに、大規模言語モデルは、医療専門家が開発と展開を主導することで、プライバシー保護を確保しながら安全に展開することができます.医療分野においては、オープンソースのモデルが必要とされており、様々なステークホルダーの協力によって、AIが医療を向上させるための開発と採用が進められることが期待されています.
Q: 医療における生成型AIモデルの開発と展開において、人々のプライバシーを保護することの重要性は何ですか?
A: 医療の発展と展開において、人々のプライバシーを保護することは非常に重要です.ジェネレーティブAIモデルは、病気の診断において重要なツールとなる可能性があります.しかし、これらのモデルは患者の個人情報を含む医療データを使用するため、プライバシーの保護が必要です.患者の個人情報が漏洩したり、不正に使用されたりすると、患者の安全や信頼性に悪影響を及ぼす可能性があります.また、プライバシーの保護は、医療従事者がジェネレーティブAIモデルの開発と展開を主導する必要性を示しています.医療従事者が主導することで、患者のプライバシーを適切に保護しながら、安全で信頼性の高いモデルを開発し、展開することができます.
Q: ジェネレーティブAIは病状の診断にどのように役立つのか?
A: 生成AIは、診断に役立つことができます.生成AIは、クリニカルノートの作成やフォームの記入、診断や治療計画の支援など、さまざまな方法で医療に貢献することができます.
Q: LLMの医療への統合に関して、マイクロソフトとエピックはどのような話し合いをしましたか?
A: マイクロソフトとエピックは、電子健康記録に使用されるソフトウェアの主要な提供業者であるエピックと協力して、LLMを医療に統合する方法について議論を始めました.
Q: カリフォルニア大学サンディエゴ校医療システムとスタンフォード大学医療センターでは、すでにどのような取り組みが行われていますか?
A: 現在、カリフォルニア大学サンディエゴ保健システムとスタンフォード大学医療センターでは、既にイニシアチブが進行中です.
Q: グーグルは医療機関とどのような提携を発表したのか?
A: グーグルは、メイヨークリニックなどの医療機関との提携を発表した.
Q: Amazon Web ServicesのHealthScribeの目的は何ですか?
A: Amazon Web ServicesのHealthScribeの目的は、臨床文書化サービスにおいて生成型人工知能(AI)を提供することです.
Q: 既製のプロプライエタリなLLMの医療への導入ラッシュは、患者のケア、プライバシー、安全性にどのようなリスクをもたらすのか?
A: 医療における既製の専有型LLMの急速な展開は、患者のケア、プライバシー、安全性にリスクをもたらす可能性があります.これらのLLMは、企業によって制御され、評価が困難であり、サービスが利益を生まなくなった場合には修正またはオフラインにすることができます.これにより、患者のケア、プライバシー、安全性が損なわれる可能性があります.また、LLMの使用によって不平等が悪化する可能性もあります.したがって、患者のケアに関わる人々がモデルの開発と展開を主導する必要があります.
Scaling deep learning for materials discovery
著者:Amil Merchant, Ekin Dogus Cubuk, Gowoon Cheon, Muratahan Aykol, Samuel S. Schoenholz, Simon Batzner
発行日:2023年11月29日
最終更新日:不明
URL:https://deepmind.google/discover/blog/millions-of-new-materials-discovered-with-deep-learning/
カテゴリ:不明
概要:
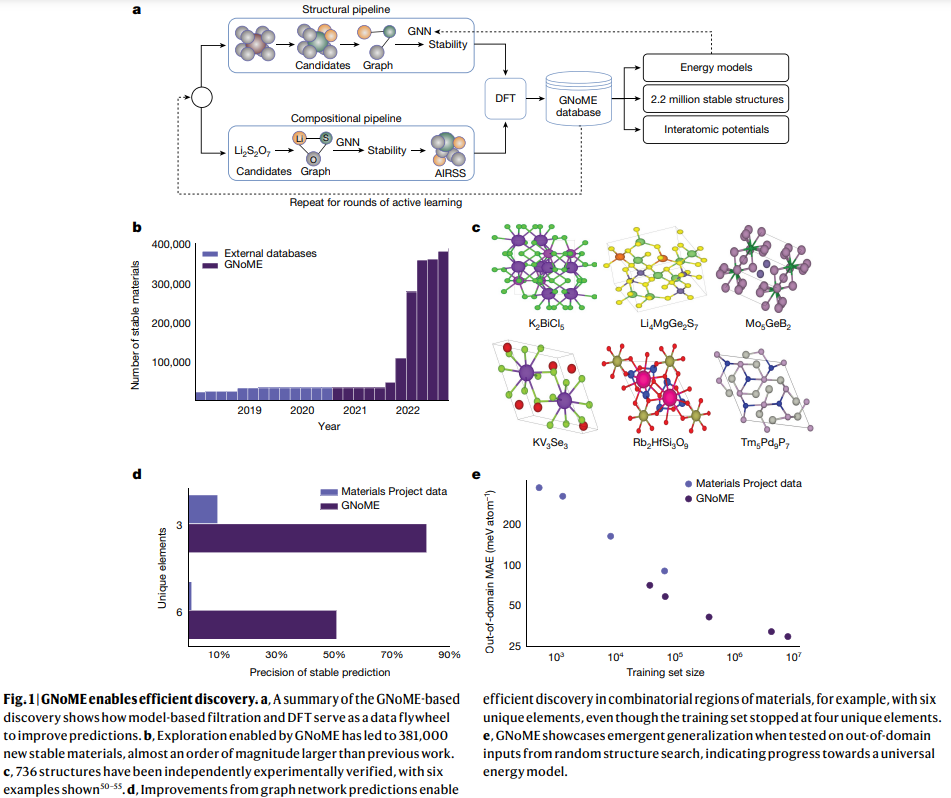
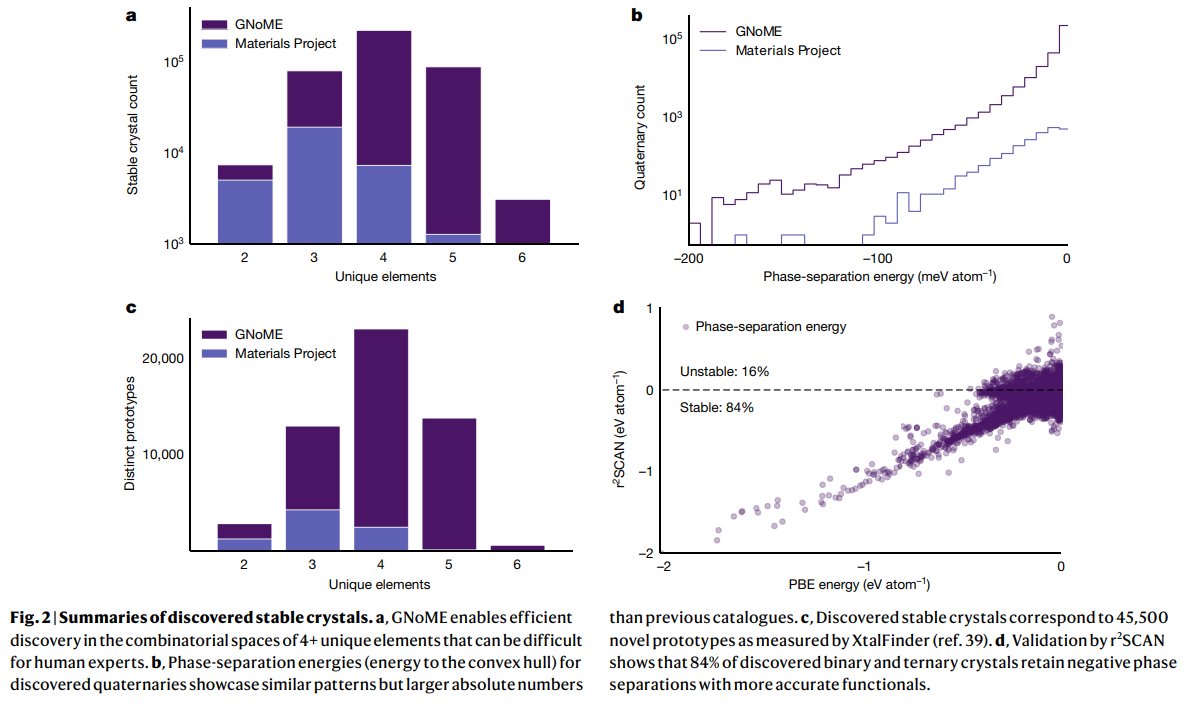
本研究では、材料の探索において機械学習を大規模に拡大し、安定性を正確に予測し、材料の発見を導く初めてのモデルを開発しました.このアプローチは、新しい対称性を考慮した部分置換(SAPS)やランダム構造探索などを活用して、多様な候補構造を生成する方法として使用されました.また、最先端のグラフニューラルネットワーク(GNN)を使用して、構造や組成に基づいて材料の特性をモデリングしました.これらのグラフネットワークは、利用可能なデータでトレーニングされ、候補構造をフィルタリングするために使用されます.フィルタリングされた候補のエネルギーは、DFTを使用して計算され、モデルの予測を検証すると同時に、次のラウンドのアクティブラーニングでより堅牢なモデルをより大規模なデータセットでトレーニングするためのデータフライホイールとして機能します.
この反復的な手法により、GNoMEモデルは、以前の研究に比べて安定しているとされる2.2百万以上の構造を発見しました.特に、計算と実験のデータを包括したデータセットを含んでいます.これにより、材料の発見を支援するデータ駆動型の手法が大幅に進歩しました.さらに、最終的なGNoMEモデルは、エネルギーを11 meV/atomまで正確に予測し、安定な予測の精度(ヒット率)を構造では80%以上、組成のみでは100試行あたり33%に向上させました.これは、以前の研究では1%に過ぎませんでした.さらに、これらのネットワークは、新たな化学空間の効率的な探索のために、トレーニングに含まれていない5つ以上の異なる元素を持つ構造の正確な予測を可能にしました.予測結果は、実験結果や高精度な計算結果と比較して検証されました.
さらに、本研究では、GNoMEの発見によって生成されたデータセットが、下流の応用において新たなモデリングの可能性を開拓することを示しました.構造と緩和の軌跡は、学習された等価性を持つ原子間ポテンシャルの訓練を可能にし、これまでにない精度とゼロショットの汎化能力を持つものです.
Q&A:
Q: 新規機能性素材の技術的応用とは?
A: 新しい機能性材料の技術的な応用は、クリーンエネルギーから情報処理まで、さまざまな分野にわたります.
Q: ディープラーニングモデルは、言語、視覚、生物学における予測能力をどのように向上させたのか?
A: 深層学習モデルは、増加するデータと計算によって、言語、ビジョン、生物学の予測能力を向上させることが示されています.
Q: 継続的な研究で、何個の安定結晶が確認されましたか?
A: 継続的な研究で特定された安定した結晶は48,000個でした.
Q: 大規模に訓練されたグラフネットワークを使用することで、材料探索の効率はどのように改善されたのだろうか?
A: グラフネットワークのトレーニングにより、材料の発見の効率が桁違いに向上しました.
Q: 現在の凸包の下にいくつの構造物が発見されたのか?
A: 現在の凸包以下で2,200,000の構造が発見されました.
Q: この仕事を通じて、人類が知っている安定した素材のいくつが拡大されたのだろうか?
A: この研究によって、人類が知っている安定した材料の数は桁違いに拡大しました.
Q: 安定した構造のうち、すでに実験的に実現したものはいくつあるのか?
A: 安定した構造のうち、736個が既に実験的に実現されています.
Q: 何億もの第一原理計算の川下への応用とは?
A: 数億もの第一原理計算の下流応用には、高精度で堅牢な学習済み原子間ポテンシャルの発見、凝縮相分子動力学シミュレーションやイオン伝導性の高精度なゼロショット予測などが含まれます.
Q: 学習された原子間ポテンシャルはどの程度正確でロバストなのか?
A: 学習された原子間ポテンシャルは、高い精度と堅牢性を持っています.
Q: 凝縮相分子動力学シミュレーションやイオン伝導度のゼロショット予測に、学習した原子間ポテンシャルをどのように利用できるか?
A: 学習された原子間ポテンシャルは、凝縮相分子動力学シミュレーションやイオン伝導率のゼロショット予測に使用することができます.原子間ポテンシャルは、物質の構造やエネルギーをモデル化するために使用されます.これにより、分子動力学シミュレーションにおいて物質の振る舞いや性質を予測することができます.また、学習されたポテンシャルを使用することで、新しい材料のイオン伝導率を予測することも可能です.
Adversarial Diffusion Distillation
著者:Andreas Blattmann, Axel Sauer, Dominik Lorenz, Robin Rombach
発行日:2023年11月28日
最終更新日:不明
URL:https://stability.ai/research/adversarial-diffusion-distillation
カテゴリ:不明

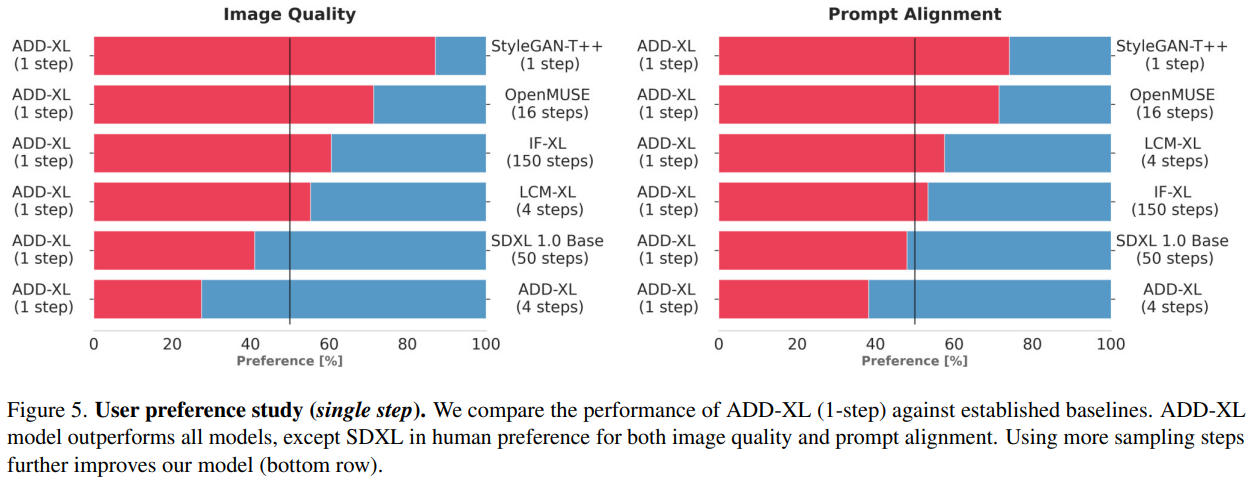
概要:
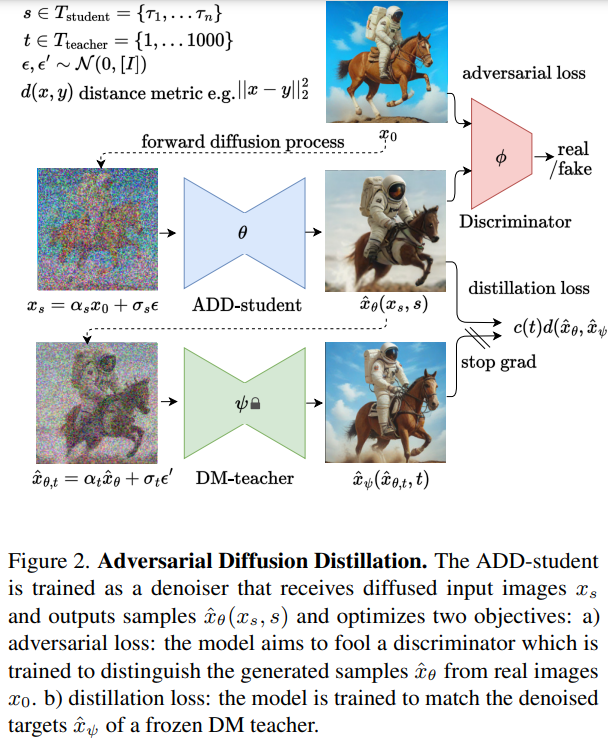
この論文では、Adversarial Diffusion Distillation(ADD)という新しいトレーニングアプローチを紹介しています.ADDは、高い画像品質を維持しながら、わずか1〜4ステップで大規模な基礎的な画像拡散モデルを効率的にサンプリングする方法です.従来の拡散モデル(DMs)は、自由な形式のテキストプロンプトからの画像合成などの複雑なタスクを処理できる反復的な性質を持っていますが、推論プロセスには多くのサンプリングステップが必要であり、リアルタイムの応用には制約があります.一方、Generative Adversarial Networks(GANs)は、シングルステップの形式と高速性が特徴ですが、サンプルの品質ではDMsに劣ることが多いです.この研究の目的は、DMsの優れたサンプル品質とGANsの高速性を組み合わせることです.
私たちのアプローチは概念的にシンプルで、事前にトレーニングされた拡散モデルの推論ステップ数を1〜4に減らし、高いサンプリングの忠実度を維持し、モデルの全体的な性能をさらに向上させるAdversarial Diffusion Distillation(ADD)を提案しています.このために、2つのトレーニング目的を組み合わせています:(i)敵対的な損失と(ii)スコア蒸留サンプリング(SDS)に対応する蒸留損失.敵対的な損失は、モデルが直接サンプルを生成するように強制し、蒸留損失はスコア蒸留サンプリング(SDS)に対応しています.私たちの分析は、ADDが既存の数ステップ法(GAN、潜在的な一貫性モデル)を明確に上回り、4ステップで最先端の拡散モデル(SDXL)の性能に達することを示しています.ADDは、基礎モデルによるシングルステップのリアルタイム画像合成を実現する最初の手法です.
また、この研究では、ADD-XLという拡張版も提案しています.ADD-XLは、4つのサンプリングステップを使用して、5122 pxの解像度で教師モデルであるSDXL-Baseを上回る性能を発揮します.
Q&A:
Q: 逆説的拡散蒸留(ADD)アプローチの主な目的は何ですか?
A: Adversarial Diffusion Distillation (ADD)の主な目的は、事前にトレーニングされた拡散モデルの推論ステップの数を1〜4のサンプリングステップに減らすことであり、高いサンプリングの忠実度を維持しながら、モデルの全体的な性能をさらに向上させることです.
Q: 大規模な基礎画像拡散モデルを効率的にサンプリングするために、ADDはいくつのサンプリングステップを必要とするか?
A: ADDは、大規模な基礎画像拡散モデルを効率的にサンプリングするために、1~4のサンプリングステップを必要とする.
Q: ADDは、教師信号として市販の画像拡散モデルをどのように活用するのか?
A: ADDは、スコア蒸留を用いることで、教師信号として市販の画像拡散モデルを活用する.スコア蒸留は、モデルが教師モデルの高品質な出力から学習することを可能にする技術である.教師モデルは、生成された画像の品質の尺度である教師信号を提供する.そして、敵対的損失は、1~2サンプリングステップの低ステップ領域でも高い画像忠実度を保証するために、教師信号と組み合わせて使用されます.このスコア蒸留と敵対的損失の組み合わせにより、ADDは教師モデルから学習し、わずか1~4サンプリングステップで高品質な画像を生成することができる.
Q: ADDにおける敵失の役割とは?
A: ADDの敵対的損失の役割は、モデルが各フォワードパスで実際の画像の多様体上にあるサンプルを直接生成することを強制することです.これにより、他の蒸留手法で一般的に観察されるぼやけや他のアーティファクトを回避することができます.
Q: ADDはどのようにして低ステップ領域でも高い画像忠実度を確保しているのだろうか?
A: ADDは、教師信号と敵対的損失を併用することで、低ステップ領域でも高い画像忠実度を保証する.教師信号は、入力画像から付加的な情報を提供することで、高品質な画像を生成するようモデルをガイドするのに役立ちます.これにより、ADDモデルは入力を効果的に利用し、初期サンプルを改善することができる.敵対的損失は、生成された画像のリアリズムをさらに向上させ、特に毛皮、布地、皮膚などのテクスチャを強調し、拡散モデルのサンプルによく見られるオーバースムージングを低減します.
Q: ADDは、既存の少数ステップの手法(GAN、潜在的整合性モデル)と性能の点でどのように比較するか?
A: ADDは、1ステップで既存の数ステップ手法(GAN、潜在一貫性モデル)を明らかに上回り、わずか4ステップで最先端の拡散モデル(SDXL)の性能に達する.
Q: ADDは最先端の拡散モデル(SDXL)と性能面でどのように比較されますか?
A: ADD-XLは、その教師モデルであるSDXL-Baseを、品質と迅速なアライメントの両面で上回ったが、その代償としてサンプルの多様性がわずかに低下した.
Q: ADDが、基礎モデルを使ったシングルステップのリアルタイム画像合成を可能にした最初の手法であることの意義は?
A: ADDは、基礎モデルを使用してシングルステップでリアルタイムの画像合成を解除する最初の方法です.これは、ADDが高品質の画像をリアルタイムで生成することができるということであり、サンプリングステップを1つだけ使用することができるため、重要な成果です.以前の方法では、GANや潜在的な一貫性モデルなど、同様の画像品質を達成するために複数のステップが必要でした.ADDの高速かつ高品質な画像生成能力は、画像合成の分野において画期的な方法となります.
Q: ADDは、拡散モデルの優れたサンプル品質とGAN固有のスピードをどのように組み合わせるのだろうか?
A: ADDは、敵対的訓練とスコア蒸留の新しい組み合わせを使用することにより、拡散モデルの優れたサンプル品質とGANの固有の速度を組み合わせている.敵対的学習は、1~2サンプリングステップの低ステップ領域でも高い画像忠実度を保証し、スコア蒸留は、教師信号として大規模な既製の画像拡散モデルを活用します.これにより、ADDは、高画質を維持しながら、大規模な基礎画像拡散モデルをわずか1~4ステップで効率的にサンプリングすることができる.
Q: ADDで導入された2つのトレーニング目標とは何ですか?また、それらが推論ステップ数の削減にどのように貢献するのですか?
A: ADDは、敵対的損失と蒸留損失という2つの学習目標を導入する.敵対的損失は、モデルに実画像の多様体上に位置するサンプルを生成させ、ぼやけやアーチファクトを回避させる.蒸留損失は、事前に訓練されたDMを教師として使用し、その知識を効果的に利用し、構成性を保持する.これら2つの目的は、ADD-Studentがわずか1~4回のサンプリングステップで高品質のサンプルを生成できるようにすることで、推論ステップ数の削減に貢献する.
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
著者:Harsha Nori, Yin Tat Lee, Sheng Zhang, Dean Carignan, Richard Edgar, Nicolo Fusi, Nicholas King, Jonathan Larson, Yuanzhi Li, Weishung Liu, Renqian Luo, Scott Mayer McKinney, Robert Osazuwa Ness, Hoifung Poon, Tao Qin, Naoto Usuyama, Chris White, Eric Horvitz
発行日:2023年11月28日
最終更新日:2023年11月28日
URL:http://arxiv.org/pdf/2311.16452v1
カテゴリ:Computation and Language
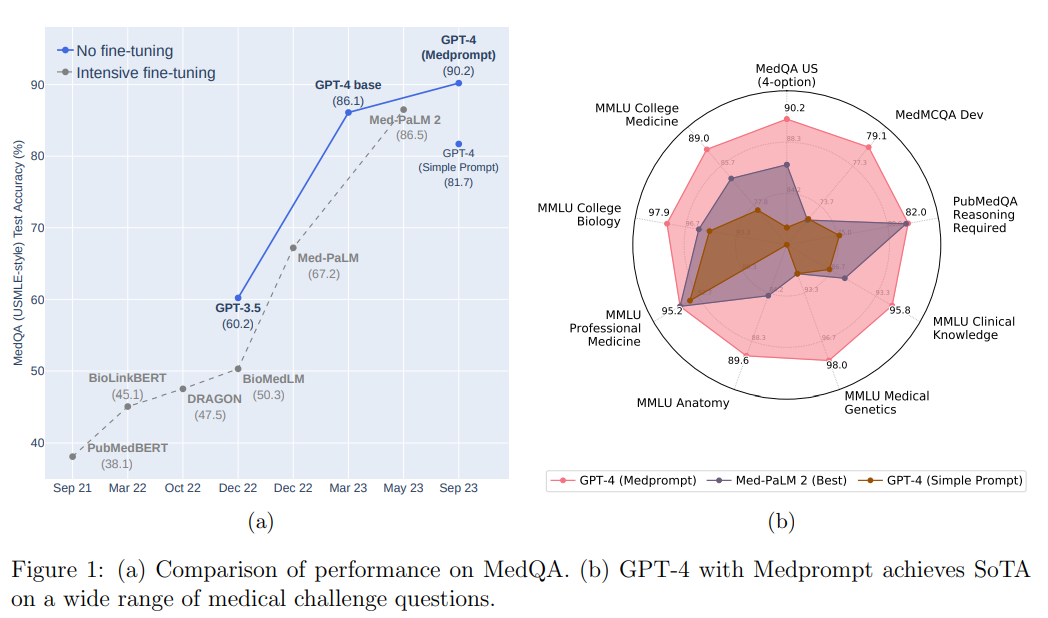
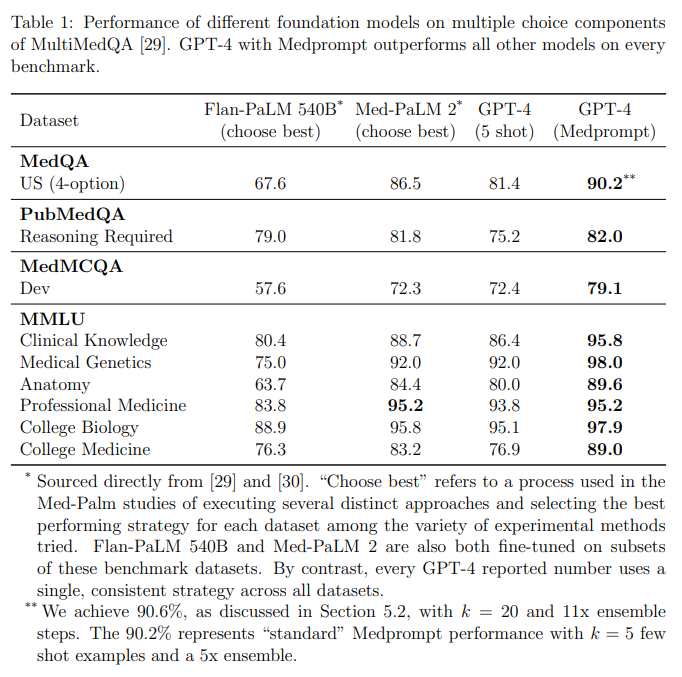
概要:
本研究では、複数のプロンプティング戦略を組み合わせたMedpromptを使用しています.Medpromptを用いることで、GPT-4はMultiMedQAスイートの9つのベンチマークデータセット全てで最先端の結果を達成しています.この手法は、Med-PaLM 2などの主要な専門モデルと比較して、モデルへの呼び出し回数を桁違いに減らすことで大幅な改善を実現しています.Medpromptを用いたGPT-4は、MedQAデータセットにおいて、これまでの最良手法よりも27%のエラーレートの削減を達成し、初めて90%以上のスコアを達成しています.医療問題に限らず、Medpromptの汎用性を示すために、電気工学、機械学習、哲学、会計、法律、看護、臨床心理学の試験においてもこの手法の有用性を実証しています.
Q&A:
Q: ジェネラリスト的な基礎モデルと比較した場合、ファインチューンド・モデルのスペシャリスト的な能力については、どのような仮説が一般的なのだろうか?
A: 専門的な能力を持つファインチューニングされたモデルは、一般的な基礎モデルに比べて優れた能力を持たないという前提が広く存在しています.
Q: 領域別トレーニングを活用した医療コンピテンシーベンチマークの過去の研究例を教えてください.
A: 本研究では、医療の専門能力のベンチマークを探求するために、ドメイン固有の事前学習を利用した先行研究がいくつか存在します.これらの先行研究では、医療応用における基礎モデルの能力を評価するために、ドメイン固有のタスクに特化した微調整が行われています.これにより、医療の専門領域においても優れたパフォーマンスが実現されることが示されています.
Q: GPT-4の医療課題ベンチマークにおける能力に関する研究は、以前の研究とどのように異なるのですか?
A: GPT-4の医療の課題ベンチマークにおける能力に関するこの研究は、特別なトレーニングや調整のない状態でのGPT-4の専門的な能力についての以前の研究とは異なり、システマティックなプロンプトエンジニアリングの探索を行い、パフォーマンスを向上させるためのイノベーションを行っています.
Q: この研究でプロンプト・エンジニアリングを体系的に探求する目的は何ですか?
A: この研究におけるシステマティックなプロンプトエンジニアリングの目的は、パフォーマンスを向上させるために深い専門能力を引き出すことです.
Q: プロンプト・イノベーションによって解き放たれたスペシャリストの能力について、どのような発見があったのだろうか?
A: GPT-4のプロンプトイノベーションによって解放された専門能力に関する調査結果は、先行研究の医療に関する質問応答データセットの結果を容易に上回ることを示しています.
Q: GPT-4のパフォーマンスは、医療ベンチマークにおいてMed-PaLM 2などの主要な専門モデルと比較してどのようになりますか?
A: GPT-4の医療ベンチマーク、特にMedQAデータセットにおけるパフォーマンスは、Med-PaLM 2などの主要な専門モデルよりも優れています.専門モデルで最も優れた手法と比較して、エラーレートが27%減少しています.GPT-4 with Medpromptは初めて90%以上のスコアを達成し、これは重要な改善です.研究の共著者は、基本的なプロンプティング戦略を使用して、GPT-4の印象的な生物医学的な能力を医療の課題ベンチマークで「そのまま」デモンストレーションしました.GPT-4 with Medpromptは、さまざまな医療の課題に関する最先端のパフォーマンスを達成しています.GPT-4のパフォーマンスは、高価なタスク固有の微調整やMed-PaLM 2のような複雑なプロンプティング戦略なしで達成されていることに注意することが重要です.
Q: この研究で導入されたプロンプティング法であるMedpromptの構成と方法について説明していただけますか?
A: Medpromptは、いくつかのプロンプティング戦略の組み合わせに基づいており、GPT-4のパフォーマンスを大幅に向上させ、MultiMedQAスイートの9つのベンチマークデータセットすべてで最先端の結果を達成しています.このメソッドは、Med-PaLM 2などの最先端の専門モデルと比較して、モデルへの呼び出し回数を桁違いに減らすことで大幅に優れた結果を出しています.Medpromptを使用してGPT-4を操作することで、MedQAデータセット(USMLE試験)において、これまでの最良の手法よりも27%のエラーレートの削減を実現し、初めて90%以上のスコアを達成しています.さらに、Medpromptの性能を医学以外の6つの分野で評価した結果から、Medpromptとその派生物が多くの学問領域で専門能力を引き出すために貴重なものであることが示唆されています.特に、一般的なMedPrompt戦略を非選択式の質問に適応するという観点から、プロンプトをさらに洗練させる可能性があります.
Q: GPT-4とMedpromptは、MultiMedQAスイートのベンチマークデータセットでどのような結果を得ましたか?
A: Medpromptを搭載したGPT-4は、MultiMedQAスイートのすべてのベンチマークで最高のパフォーマンスを達成した.
Q: Medpromptの汎用性と幅広い適用性が示された他の領域の例を教えてください.
A: Medpromptの一般化と広範な適用性が示された他のドメインの例として、電気工学、機械学習、哲学、会計、法律、看護、臨床心理学のコンピテンシーエグザムが挙げられます.
ChatGPT’s One-year Anniversary: Are Open-Source Large Language Models Catching up?
著者:Hailin Chen, Fangkai Jiao, Xingxuan Li, Chengwei Qin, Mathieu Ravaut, Ruochen Zhao, Caiming Xiong, Shafiq Joty
発行日:2023年11月28日
最終更新日:2023年11月29日
URL:http://arxiv.org/pdf/2311.16989v2
カテゴリ:Computation and Language
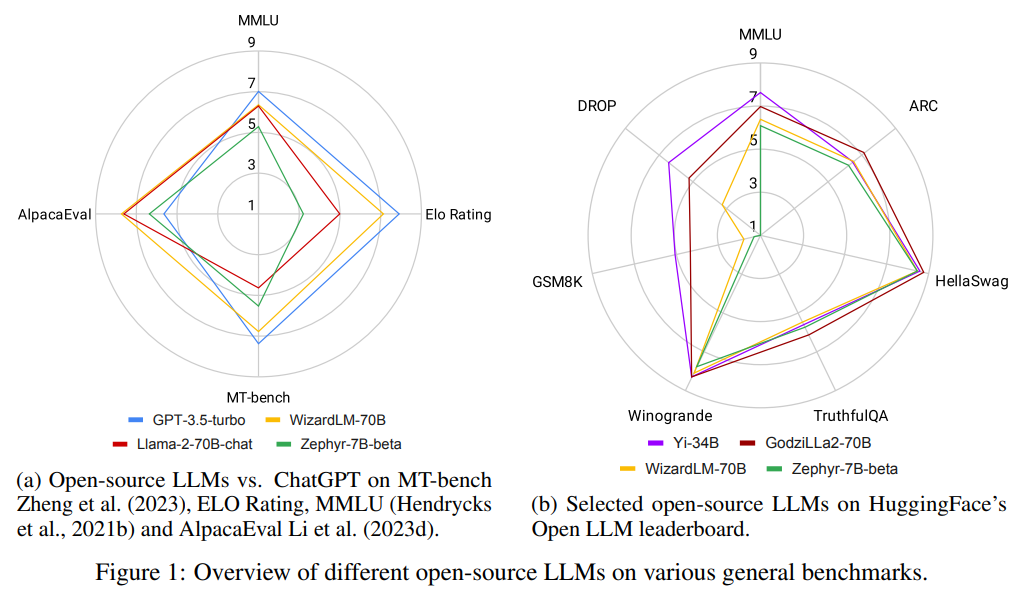
概要:
2022年末にリリースされたChatGPTは、研究と商業の両方において、AIの全体的な景色に地殻変動をもたらしました.大規模言語モデル(LLM)を教師あり微調整と人間のフィードバックからの強化学習で調整することにより、このモデルは幅広いタスクで人間の質問に答えたり指示に従ったりすることができることを示しました.この成功に続いて、LLMへの関心が高まり、学界や産業界で頻繁に新しいLLMが登場しています.これには、LLMに特化した多くのスタートアップ企業も含まれています.クローズドソースのLLM(例:OpenAIのGPT、AnthropicのClaude)は一般的にオープンソースの対抗よりも優れた性能を発揮しますが、後者の進歩も急速であり、特定のタスクでは同等またはそれ以上の性能を達成したと主張しています.これは、研究だけでなくビジネスにも重要な影響を与えます.本研究では、ChatGPTの1周年を迎えるにあたり、オープンソースのLLMがChatGPTと同等またはそれ以上の性能を持つと主張しているすべてのタスクについて包括的な概要を提供します.
Q&A:
Q: ChatGPTの2022年末リリースの意義は何ですか?
A: ChatGPTのリリースは、AIの研究と商業の両方において、地殻変動をもたらしました.ChatGPTは、大規模な言語モデル(LLM)を教示チューニングし、人間のフィードバックによる教師付き微調整と強化学習を行うことで、人間の質問に答えることができるモデルであり、そのリリースからわずか2ヶ月で1億人のユーザーを獲得しました.これは、TikTokやYouTubeなどの他の人気アプリよりもはるかに速いペースです.また、ChatGPTは、労働コストの削減、ワークフローの自動化、さらには顧客への新しい体験の提供などの可能性から、巨額のビジネス投資を集めています.しかし、ChatGPTはオープンソースではなく、そのアクセスは私企業によって制御されているため、その技術的な詳細のほとんどは不明です.そのため、ChatGPTのリリースは、いくつかの重要な問題を引き起こしています.まず、パフォーマンスが時間とともに変化するため、再現可能な結果が妨げられます.第二に、ChatGPTは複数の障害を経験しており、2023年11月だけでも2つの大規模な障害が発生し、ChatGPTのウェブサイトとAPIへのアクセスが完全にブロックされました.最後に、ChatGPTを採用する企業は、APIの呼び出しの重いコスト、サービスの障害、データの所有権などに懸念を抱くかもしれません.
Q: ChatGPTはどのようにAIの状況に激震をもたらしたのか?
A: ChatGPTは、AIの全体的な景色に地殻変動をもたらしました.それは、大規模な言語モデル(LLM)を教示チューニングし、人間のフィードバックによる教師付き微調整と強化学習を行うことで、モデルが人間の質問に答えることができることを示しました.これまでにないほど、ChatGPTは、要約や質問応答など、従来は事前学習されたモデルによって行われていた自然言語のタスクを驚くほどうまくこなすことができます.ChatGPTは、一般の人々の関心を引きつけ、ローンチからわずか2か月で1億人のユーザーに到達しました.また、労働コストの削減、ワークフローの自動化、顧客への新しい体験の提供など、ビジネスへの潜在的な利点から、巨額の投資を集めました.しかし、ChatGPTはオープンソースではなく、アクセスは私企業によって制御されているため、その技術的な詳細のほとんどは不明です.このようなクローズドソースの性質は、いくつかの重要な問題を引き起こします.まず、オープンソースの対応物と比較して、後者の進歩は迅速であり、特定のタスクで同等またはそれ以上の成果を上げていると主張されています.これは、研究だけでなくビジネスにも重要な影響を与えます.この研究では、ChatGPTの1周年を迎えて、オープンソースのLLMがChatGPTと同等またはそれ以上であると主張しているすべてのタスクについて包括的な概要を提供します.
Q: ChatGPTの大規模言語モデル(LLM)のチューニングには、どのような方法が用いられたのでしょうか?
A: ChatGPTのLLMを調整するためには、教師ありの微調整と人間のフィードバックによる強化学習を用いて、大規模な言語モデル(LLM)を指示調整しました.
Q: ChatGPTは人間の質問に答え、指示に従う能力をどのように発揮したのでしょうか?
A: ChatGPTは、大規模な言語モデル(LLM)を教師あり微調整と人間のフィードバックからの強化学習で調整することにより、人間の質問に答える能力と指示に従う能力を示しました.このプロセスにより、モデルはほとんどの質問に対して役立つ、安全で詳細な回答を提供する方法を学び、以前の間違いを認めて修正することもできるようになりました.ChatGPTは、要約や質問応答などの自然言語タスクにおいて、非常に優れたパフォーマンスを発揮しました.ChatGPTは、人間の質問に答える能力と指示に従う能力が迅速に人気を集め、ローンチからわずか2ヶ月で1億人のユーザーに達しました.ただし、クローズドソースの性質から、ChatGPTのアーキテクチャ、事前学習データ、微調整データの正確な詳細は不明です.
Q: ChatGPTの成功は、LLMへの関心にどのような影響を与えていますか?
A: ChatGPTの成功により、LLMへの関心が高まりました.多くの新しいLLMが学界や産業界で頻繁に登場し、LLMに特化した多くのスタートアップも存在します.クローズドソースのLLM(例:OpenAIのGPT、AnthropicのClaude)は一般的にオープンソースのLLMよりも優れた性能を発揮しますが、後者の進歩も急速であり、特定のタスクでは同等またはそれ以上の成果を上げていると主張されています.これは研究だけでなくビジネスにも重要な影響を与えています.
Q: クローズド・ソースのLLMは、オープン・ソースのLLMと比較して、一般的にどのようなパフォーマンスを見せているのだろうか?
A: クローズドソースのLLMは、オープンソースのLLMと比較して一般的にどのようなパフォーマンスを発揮するかは明確ではありません.
Q: オープンソースのLLMでは、特定のタスクで同等以上のパフォーマンスを達成するために、どのような進展があったのでしょうか?
A: オープンソースのLLMは、一部のタスクにおいて同等またはそれ以上の性能を達成するために進展がありました.
Q: オープンソースLLMの進展は、研究やビジネスにどのような影響を与えるのだろうか?
A: この調査は、研究コミュニティとビジネスセクターの両方にとって重要な情報源となることが期待されます.研究者にとっては、オープンソースのLLMsの現在の進歩と将来の可能性についての詳細な総合的なまとめを提供し、将来の研究の有望な方向性を示しています.ビジネスセクターにとっては、この調査は貴重な洞察とガイダンスを提供し、オープンソースのLLMsの採用の適用性と利点を評価する意思決定者を支援します.
Q: 1周年を迎えたChatGPTについて、オープンソースLLMの成功の概要を教えてください.
A: ChatGPTの1周年を記念して、オープンソースのLLMがChatGPTと同等またはそれ以上の成果を上げたタスクについて、包括的な概要を提供しています.この調査では、オープンソースのLLMがChatGPTを超える高性能なモデルについて体系的にレビューし、その成果や潜在的な問題について分析しています.オープンソースのLLMの有望な方向性を明らかにし、オープンソースのLLMの研究と開発を促進し、有料のLLMとの差を縮める手助けをすることを目的としています.
UniIR: Training and Benchmarking Universal Multimodal Information Retrievers
著者:Cong Wei, Yang Chen, Haonan Chen, Hexiang Hu, Ge Zhang, Jie Fu, Alan Ritter, Wenhu Chen
発行日:2023年11月28日
最終更新日:2023年11月28日
URL:http://arxiv.org/pdf/2311.17136v1
カテゴリ:Computer Vision and Pattern Recognition, Artificial Intelligence, Computation and Language, Information Retrieval
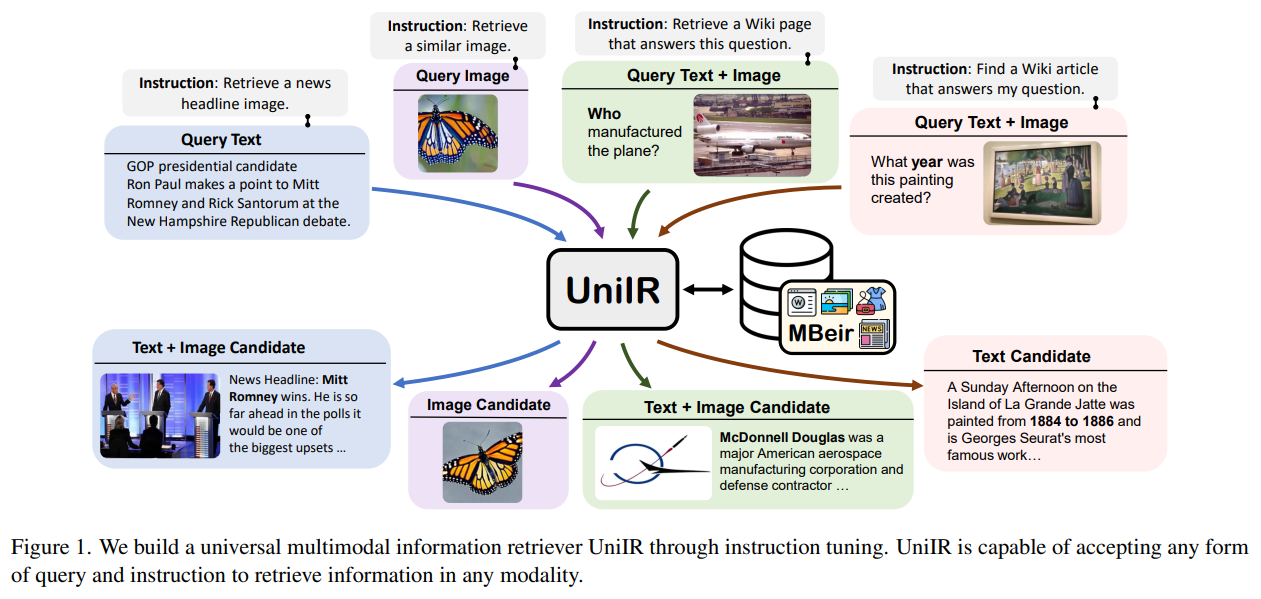

概要:
従来の情報検索(IR)モデルは、均質な形式を前提としており、テキストの説明を持つ画像を検索したり、見出し画像を持つニュース記事を検索したり、クエリ画像と似た写真を見つけたりするといった、多様なユーザーのニーズには適用できない場合があります.このような異なる情報検索の要求に対応するために、私たちはUniIRを導入します.UniIRは、ユーザーの指示を解釈してさまざまな検索タスクを実行することができる統一された指示ガイドのマルチモーダルリトリーバーであり、モダリティを横断して8つの異なるリトリーバルタスクを処理することができます.UniIRは、10の多様なマルチモーダルIRデータセットで共同訓練された単一のリトリーバーシステムであり、既存のデータセットに対して堅牢なパフォーマンスを示し、新しいタスクへのゼロショットの汎化能力を示しています.私たちの実験は、マルチタスクトレーニングと指示の調整がUniIRの汎化能力の鍵であることを示しています.さらに、私たちは包括的な結果を持つマルチモーダルリトリーバルベンチマークであるM-BEIRを構築し、ユニバーサルなマルチモーダル情報検索の評価を標準化しています.
Q&A:
Q: 既存の情報検索モデルのフォーマットの限界とは?
A: 既存の情報検索モデルの制約は、均質な形式に基づいていることです.これにより、テキストの説明を持つ画像を検索したり、見出し画像を持つニュース記事を検索したり、クエリ画像と類似した写真を見つけたりするなど、さまざまなユーザーのニーズに対応することが制限されます.
Q: UniIRは情報検索における多様なユーザーニーズにどのように対応しているのか?
A: UniIRは、モダリティを横断した8つの異なる検索タスクを処理できる統一された指示に従ったマルチモーダルリトリーバーであり、情報検索における多様なユーザーのニーズに対応しています.UniIRはユーザーの指示を解釈し、さまざまな検索タスクを実行することで、既存のデータセットでの堅牢なパフォーマンスと新しいタスクへのゼロショット汎化を示しています.従来のIRシステムとは異なり、UniIRは指示に従って異種のクエリを取り扱い、多様なモダリティを持つ数百万の候補者プールから検索を行います.クエリの指示はユーザーの検索意図を定義するために編集され、情報検索プロセスをガイドします.
Q: UniIRにおける「指示誘導型マルチモーダル検索」のコンセプトについて教えてください.
A: UniIRは、異種のクエリを取得し、異種の候補プールから情報を取得するための指示に従う必要があります.UniIRモデルを訓練するために、既存の10種類の多様なデータセットを統一的なタスク形式で統合し、指示に従ってマルチモーダル検索タスクを構築するためのベンチマークであるM-BEIRを構築します.クエリの指示は、ユーザーの検索意図を定義するためにキュレーションされ、情報検索プロセスをガイドします.UniIRモデルは、CLIPやBLIPなどの事前訓練済みのビジョン言語モデルに基づいて、M-BEIRの30万の訓練インスタンスで異なるマルチモーダル融合メカニズム(スコアレベル融合と特徴レベル融合)を使用して訓練されます.UniIRモデルは、異種の候補プールから指示に従って所望のターゲットを正確に取得することができます.
Q: UniIRはモダリティを横断してどれだけの検索タスクを処理できるのか?
A: UniIRはモダリティを超えて8つの異なる検索タスクを扱うことができる.
Q: 多様なマルチモーダルIRデータセットに対して、UniIRはどのようにトレーニングされたのか?
A: UniIRは、M-BEIRというベンチマークを構築し、10の異なるデータセットを統一的なタスク形式にまとめ、その上でトレーニングされました.M-BEIRは、既存の多様なデータセットを利用して、異なるモダリティのクエリとターゲットを統一的に定義するためのものです.
Q: UniIRは、既存のデータセットに対してどのように堅牢な性能を実証しているのか?
A: UniIRは、M-BEIRのベースラインに対して大幅な改善を示すことで、既存のデータセットに対して堅牢な性能を実証している.平均Recall@5はそれぞれ12.8と10.9増加した.また、UniIRのモデルは、複数のタスクにおいて、最新の検索エンジンやマルチタスク訓練ベースラインを凌駕している.さらに、図6に示すように、UniIRは未見のタスクやデータセットに対して優れた汎化能力を示す.マルチタスク微調整と命令チューニングを含むUniIRフレームワークは、UniIRの頑健な性能に寄与している.
Q: UniIRの一般化能力に寄与する主要な要因は何ですか?
A: マルチタスクトレーニングと指示の調整がUniIRの汎化能力に貢献しています.
Q: M-BEIRベンチマークの構成と目的を説明していただけますか?
A: M-BEIRベンチマークは、さまざまなドメインと画像ソースからの10のデータセットと8つのマルチモーダル検索タスクで構成されています.各タスクには、人間が作成した指示が付属しており、合計で150万のクエリと560万の検索候補が含まれています.このベンチマークは、さまざまなモダリティを持つクエリと候補を統一するために作成されており、M-BEIRデータセットの各クエリインスタンスには、テキストと画像のモダリティをサポートするクエリqと候補c、および検索タスクの意図を指定する人間が作成した指示qinstが含まれています.M-BEIRベンチマークは、さまざまなマルチモーダル検索タスクを統合するための検索フレームワークを提供することを目的としています.
Q: M-BEIRベンチマークは、普遍的なマルチモーダル情報検索の評価をどのように標準化するのか?
A: M-BEIRベンチマークは、異なるモダリティを持つクエリと候補を含むマルチモーダル検索タスクを統一するために、クエリと候補のセット、および人間が作成した指示を提供することで、評価を標準化しています.
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models
著者:Zeming Chen, Alejandro Hernández Cano, Angelika Romanou, Antoine Bonnet, Kyle Matoba, Francesco Salvi, Matteo Pagliardini, Simin Fan, Andreas Köpf, Amirkeivan Mohtashami, Alexandre Sallinen, Alireza Sakhaeirad, Vinitra Swamy, Igor Krawczuk, Deniz Bayazit, Axel Marmet, Syrielle Montariol, Mary-Anne Hartley, Martin Jaggi, Antoine Bosselut
発行日:2023年11月27日
最終更新日:2023年11月27日
URL:http://arxiv.org/pdf/2311.16079v1
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning
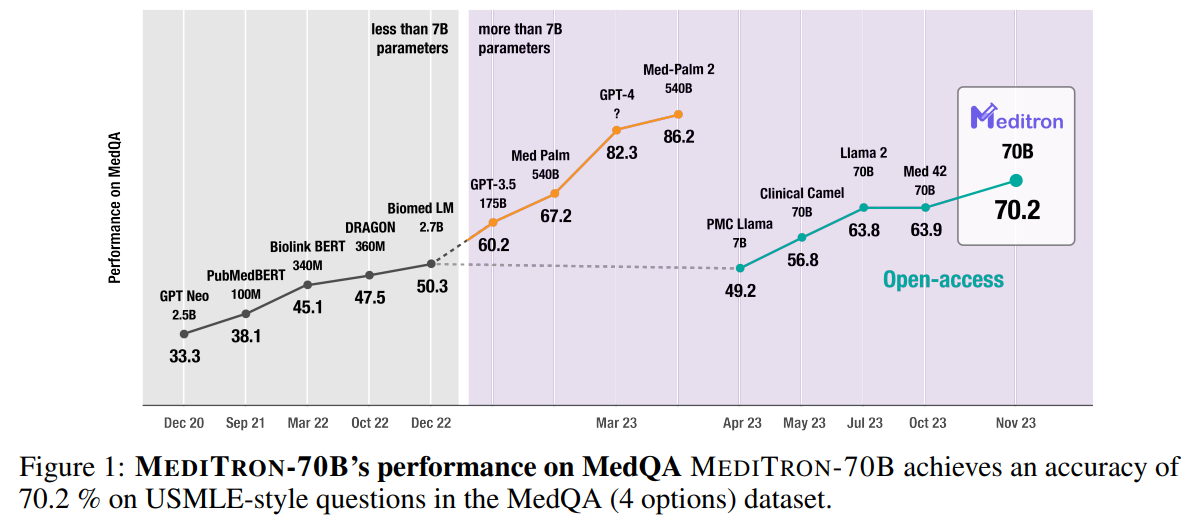
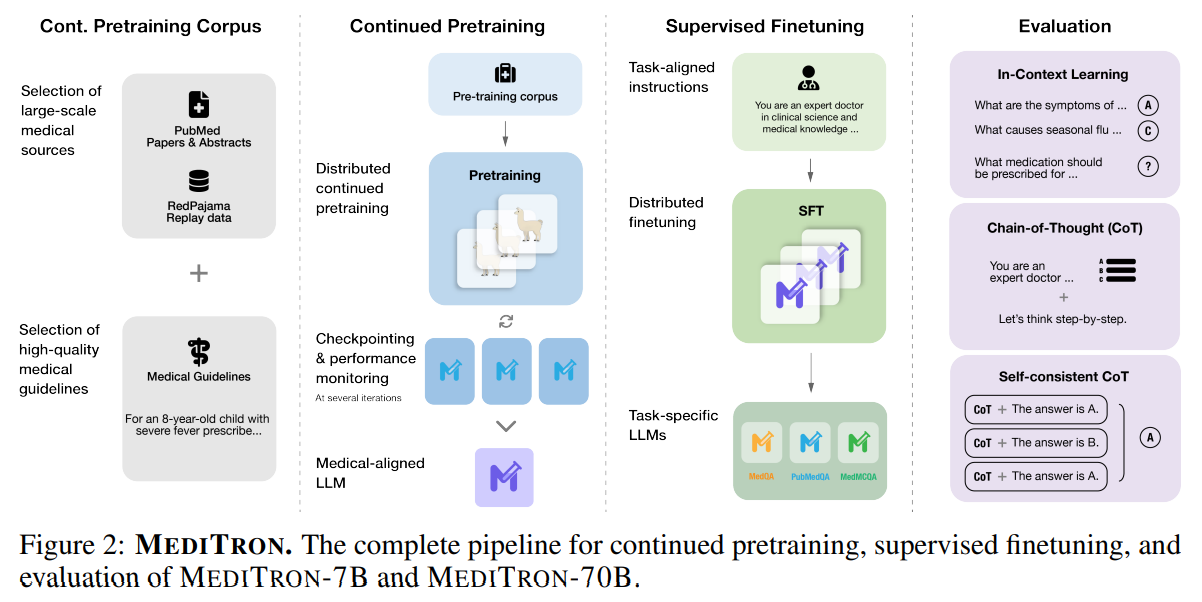
概要:
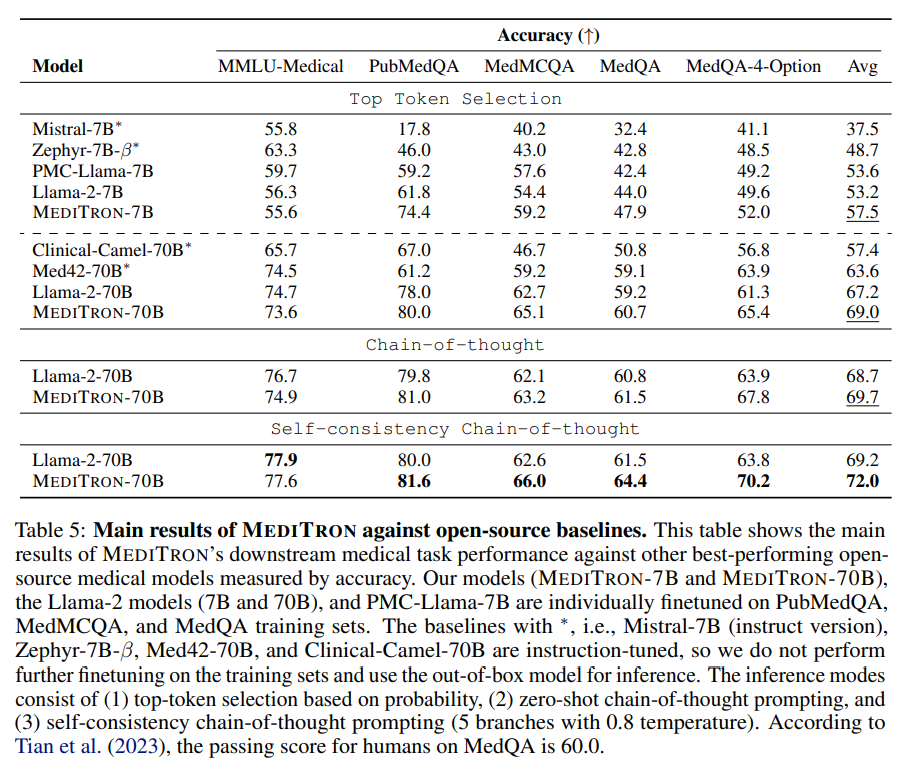
大規模言語モデル(LLM)は、医学知識へのアクセスを民主化する可能性があります.LLMの医学的な知識と推論能力を活用し改善するために、多くの取り組みが行われてきましたが、その結果得られたモデルはクローズドソース(例:PaLM、GPT-4)であるか、スケールが制限されています(13Bパラメータ以下).これにより、これらのモデルの能力が制約されています.本研究では、医学領域に適応した7Bおよび70BパラメータのオープンソースLLMのアクセスを向上させるために、MEDITRONをリリースします.MEDITRONは、Llama-2をベースに構築されており(NvidiaのMegatron-LM分散トレーナーの適応を通じて)、選択されたPubMedの記事、要約、国際的に認識された医学ガイドラインを含む包括的にキュレーションされた医学コーパスでの事前学習を拡張しています.4つの主要な医学ベンチマークを使用した評価では、タスク固有のファインチューニング前後でいくつかの最先端のベースラインに比べて、大幅な性能向上が示されました.全体的に、MEDITRONはそのパラメータクラスで最も優れたパブリックベースラインに対して6%の絶対的な性能向上を達成し、Llama-2からファインチューニングした最強のベースラインに対して3%の向上を達成します.クローズドソースのLLMと比較して、MEDITRON-70Bは医学知識へのアクセスを向上させることができます.さらに、私たちはMEDITRONのモデルウェイトと医学の事前学習コーパスのキュレーションコードを公開し、より能力の高いオープンソースの医学LLMの開発を促進します.MEDITRON-70Bは、GPT-3.5やMed-PaLMを上回り、GPT-4には5%以内、Med-PaLM-2には10%以内に収まる性能を発揮しています.
Q&A:
Q: メディトロン-70Bの目的は何ですか?
A: MEDITRON-70Bの目的は、医療アプリケーションにおいて高品質のエビデンス情報を提供することです.
Q: MEDITRON-70Bのパラメーター数は?
A: メディトロン-70bはパラメータ数が70bです.
Q: MEDITRONは、他のクローズドソースLLMと比べて性能面でどうですか?
A: MEDITRON-70BはGPT-3.5とMed-PaLMを上回り、GPT-4の5%以内、Med-PaLM-2の10%以内である.
Q: メディトロンの性能評価にはどのようなベンチマークが用いられたのですか?
A: MEDITRONはPubMedQA、MedMCQA、MedQA、MedQA-4-optionを含むいくつかのベンチマークで評価された.
Q: MEDITRONが、そのパラメータクラスで最高のパブリックベースラインに対して達成した絶対的なパフォーマンス利得は何ですか?
A: MEDITRONは、そのパラメータクラスにおいて、最高の公開ベースラインに対して6%の絶対的な性能向上を達成した.
Q: GPT-3.5やMed-PaLMと比較して、メディトロン-70Bの性能はどうですか?
A: MEDITRON-70Bは、GPT-3.5およびMed-PaLMと比較して、パフォーマンスが優れています.
Q: Llama-2から微調整された最強のベースラインに対して、MEDITRONはどの程度の性能向上を達成したのでしょうか?
A: MEDITRONは、Llama-2から微調整された最も強力なベースラインに対して、平均で5%の性能向上を達成しています.
Q: 包括的にキュレーションされた医療コーパスで事前トレーニングを行う目的は何でしょうか?
A: 医療コーパスを包括的に編集して事前学習する目的は、医療領域の大規模言語モデルの研究をより包括的に行うためです.これにより、医療専門知識を持つ言語モデルを開発し、医療関連のタスクにおいて高い性能を発揮することが期待されます.
Q: メディトロンの事前トレーニングに使用した医療コーパスの詳細を教えてください.
A: MEDITRONのドメイン適応型事前学習コーパスGAP-REPLAYは、4つのデータセットから48.1Bトークンを結合しています.それらのデータセットは、臨床ガイドライン、PubMedの記事、要約、そして国際的に認識された医療ガイドラインです.
Q: NVIDIAのMegatron-LM分散トレーナーをMEDITRONに適応するプロセスを説明していただけますか?
A: NvidiaのMegatron-LM分散トレーナーをMEDITRONに適応するプロセスは、Megatron-LLM分散トレーニングライブラリを開発することで行われました.このライブラリは、NvidiaのMegatron-LMを拡張して、最近リリースされた3つの人気のあるオープンソースのLLM(Llama、Falcon、Llama-2)のトレーニングをサポートしています.また、データ並列性(DP)、パイプライン並列性(PP)、テンソル並列性(TP)など、分散トレーニングのためのいくつかの形式の補完的な並列性をサポートしています.さらに、MEDITRONは、MEDITRONモデルの事前学習に使用するために、包括的にキュレーションされた医療コーパスを使用しています.このプロセスにより、MEDITRONは、いくつかの最先端のベースラインに比べて、タスク固有のファインチューニング前後で大幅なパフォーマンスの向上を実現しています.
On Bringing Robots Home
著者:Nur Muhammad Mahi Shafiullah, Anant Rai, Haritheja Etukuru, Yiqian Liu, Ishan Misra, Soumith Chintala, Lerrel Pinto
発行日:2023年11月27日
最終更新日:2023年11月27日
URL:http://arxiv.org/pdf/2311.16098v1
カテゴリ:Robotics, Artificial Intelligence, Computer Vision and Pattern Recognition, Machine Learning

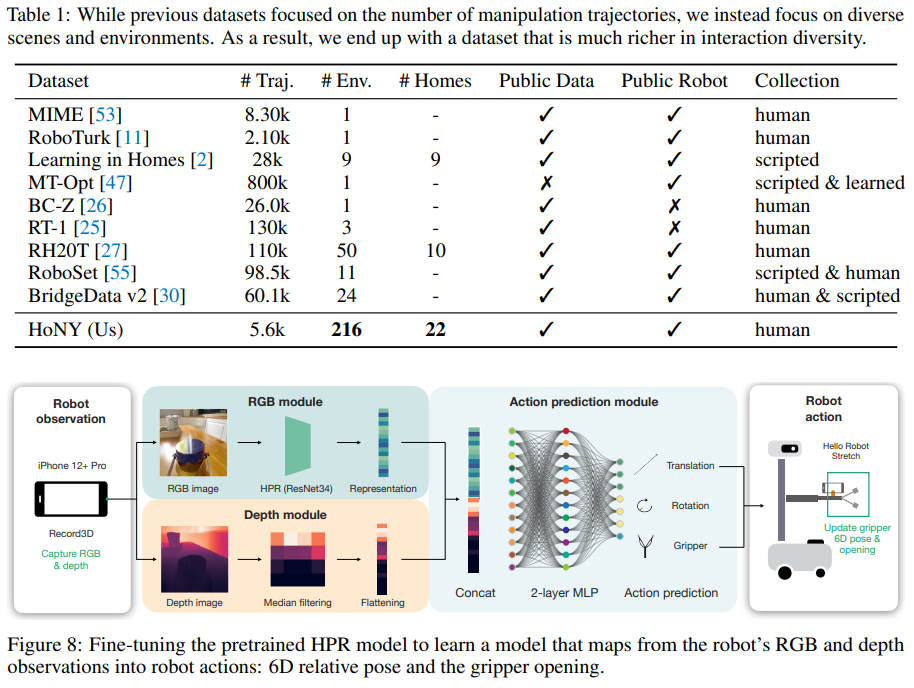
概要:
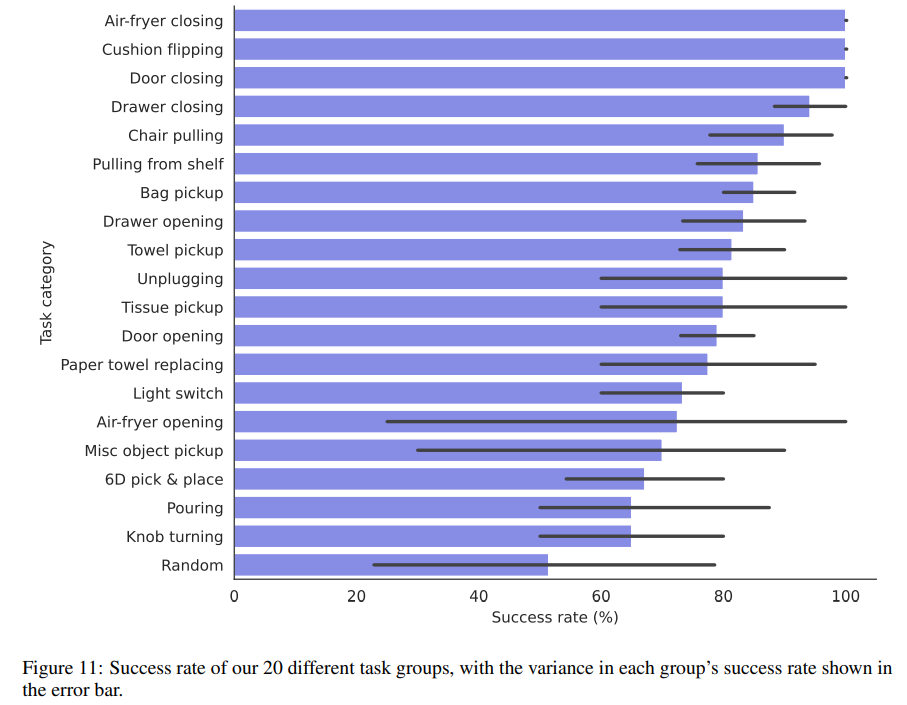
歴史を通じて、私たちはさまざまな機械を家庭に成功裏に統合してきました.食器洗い機、洗濯機、スタンドミキサー、ロボット掃除機などが最近の例です.しかし、これらの機械は効果的に単一のタスクをこなすことに優れています.家庭用の「総合的な機械」という概念は、ロボット工学の目標の一つであり、数十年にわたって着実に追求されてきました.本研究では、家庭環境での学習ロボット操作のための手頃な価格で多目的なシステムであるDobb-Eを紹介することで、この目標に向けた大規模な取り組みを開始します.Dobb-Eは、ユーザーが5分間で新しいタスクを教えることで学習することができます.これは、安価な部品とiPhoneで作成したデモ収集ツール(「The Stick」)によるものです.私たちは「The Stick」を使用して、ニューヨーク市の22軒の家庭で13時間のデータを収集し、Home Pretrained Representations(HPR)をトレーニングします.そして、新しい家庭環境で、5分間のデモンストレーションと15分間のHPRモデルの適応を行うことで、Dobb-Eが信頼性のあるタスクを解決できることを示します.さらに、HPRモデルの適応によって、市場で入手可能なモバイルロボットであるStretch上でDobb-Eがタスクを解決できることを示します.ニューヨーク市および周辺地域の家庭で約30日間の実験を行い、10軒の家庭で109の異なる環境でのタスクをテストし、最終的に81%の成功率を達成しました.成功率の向上に加えて、実験では、実験室のロボットには存在しないまたは無視されているさまざまな困難が明らかになりました.これらは、強い影響の影響から、非専門家のユーザーによるデモンストレーションの品質のばらつきまで様々です.家庭用ロボットの研究を加速し、いずれは家庭ごとにロボット執事を見ることを目指して、私たちはDobb-Eのソフトウェアスタックとモデル、データ、ハードウェア設計をhttps://dobb-e.comでオープンソース化します.
Q&A:
Q: この文章で述べられている研究の主な目的は何ですか?
A: 研究の主な目標は、人間のデモンストレーターがデモを完了する時間と、ロボットがタスクを達成する成功率との関係を理解することです.
Q: Dobb-Eは、現在家庭で使われている他の機械とどう違うのですか?
A: Dobb·Eは、家庭環境でのロボット操作の学習のための汎用システムであり、他の現在の家庭用機械とは異なります.単一のタスクに優れた他の機械とは異なり、Dobb·Eはユーザーのニーズに適応し学習するように設計されています.ユーザーが5分間で新しいタスクを教えるだけで、新しいタスクを学習することができます.これは、「The Stick」と呼ばれるデモ収集ツールのおかげです.Dobb·Eは、効率のために大規模なデータと現代の機械学習ツールを活用し、安全性のためにわずかな人間のデモンストレーションから学習し、ユーザーの快適さのためにエルゴノミックなデモ収集ツールを備えています.さらに、Dobb·Eには、3Dプリントされた部品を備えた手頃な価格のリーチャーグラバーとiPhoneを含むハードウェアコンポーネントがあり、ドメイン適応を必要とせずにStickから直接データを転送することができます.全体的に、Dobb·Eは、コスト効果的でありながら、ユーザーのニーズに適応し学習する家庭用の汎用機械を実現する目標に向けた重要な一歩です.
Q: Dobb-Eが新しいタスクを習得するのにかかる時間は?
A: Dobb-Eは、ユーザーがそのやり方を5分間教えるだけで、新しいタスクを学習することができる.
Q: ザ・スティック」とは何ですか?
A: 「The Stick」とは、オンラインで簡単に購入できるグラバースティックであり、3DプリントされたiPhoneマウントと組み合わせて使用されます.このツールは、以前の研究で使用されたツールの自然な進化です.このStickは、ユーザーがロボットの制約に直感的に適応するのを助ける役割を果たしており、大量の力を加えることを困難にします.また、iPhone Pro(バージョン12以降)は、カメラセットアップと内部ジャイロスコープを備えており、Stickは30フレーム/秒でRGB画像と深度データを収集することができます.さらに、iPhoneの6D位置(移動と回転)も取得できます.このStickは、iPhone Pro(12以降)を単にiPhoneと呼びます.
Q: データ収集に携わったのは、ニューヨーク市内にある何軒の家庭ですか?
A: データ収集プロセスには22軒の家が関与していました.
Q: Dobb-Eがさまざまな環境でのタスク解決で達成した成功率とは?
A: Dobb-Eは、さまざまな環境でのタスク解決で81%の総合成功率を達成した.
Q: 家庭での実験中に遭遇したユニークな課題とは?
A: 実験中には、強い影響や非専門家のユーザーによる変動するデモンストレーションの品質など、実験室のロボットでは存在しないまたは無視されていたさまざまな困難が明らかになりました.
Q: Dobb-Eのソフトウェアスタックとモデルをオープンソース化する意義は何ですか?
A: Dobb-Eのソフトウェアスタックとモデルをオープンソース化することの意義は、将来の家庭用ロボット技術の発展と研究を促進することです.オープンソース化により、他の研究者や開発者がDobb-Eの成果を再現し、改良することが可能となります.また、ソフトウェアスタックとモデルのオープンソース化により、共有知識のプールに貢献し、研究プロジェクトが進展することが期待されます.
Q: Dobb-Eは、市販されているどのような移動ロボットにも使用できますか?
A: いいえ、Dobb-Eは市場で利用可能などのモバイルロボットとは互換性がありません.
Q: Dobb-Eのソフトウェアスタック、モデル、データ、ハードウェア設計にアクセスできるウェブサイトは?
A: Dobb-Eのソフトウェアスタック、モデル、データ、およびハードウェアデザインにアクセスできるウェブサイトはhttps://docs.dobb-e.comです.
