
ここでは、トピックに絞って複数の関連性がある論文を同次に紹介しています.流れが少しでも把握できるように、一番新しいものから並べています.論文の概要やQ&A形式を用いて要点を記載しており、OpenReviewが既存であれば、意見をまとめたものを投稿しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.
説明可能AI (Explainable AI) や解釈可能AI (Interpretable AI)について詳しくは以下で:
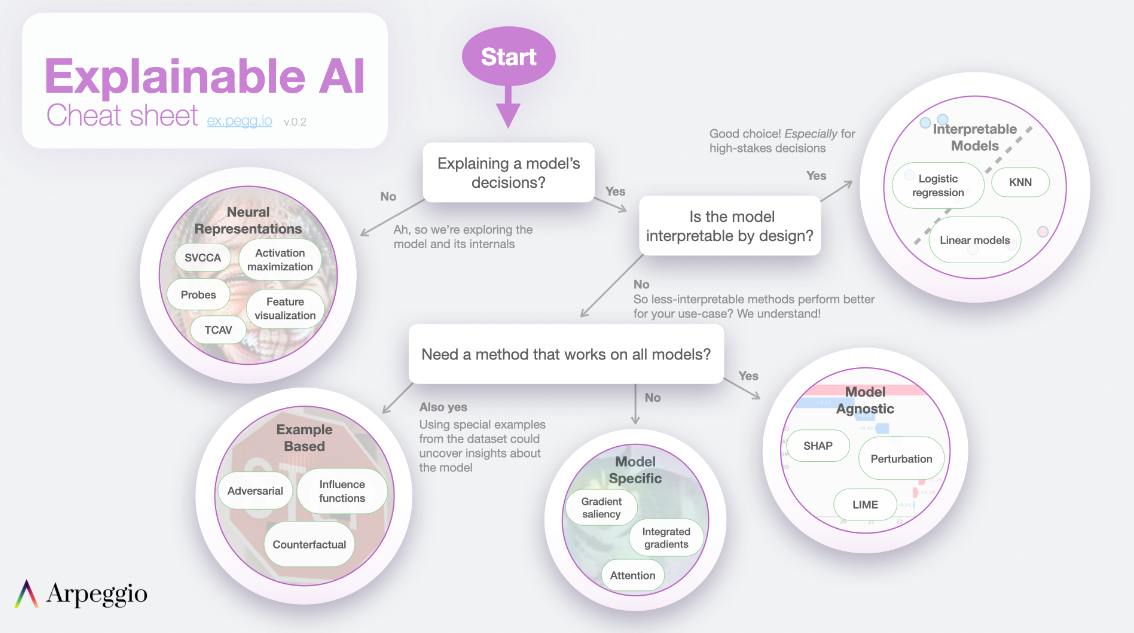
- 概要や様々な資料のリンクが載せられているサイト、 https://ex.pegg.io/
- オンラインで読めるこの分野の日本語に訳されている専門書、https://hacarus.github.io/interpretable-ml-book-ja/index.html
ここで、紹介する論文は以下の6本となります.
- Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI (発行日:2019年10月22日)
- A Survey on Explainable Artificial Intelligence (XAI): Towards Medical XAI (発行日:2019年07月17日)
- Attention is not Explanation (発行日:2019年02月26日)
- Stop Explaining Black-Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead (発行日:2018年11月26日)
- Saliency Map は説明にならないことことを示唆している。
- 精度-解釈性のトレードオフが神話であることを示唆している。
- Sanity Checks for Saliency Maps (発行日:2018年10月08日)
- A Benchmark for Interpretability Methods in Deep Neural Networks (発行日:2018年06月28日)
Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI
著者:Alejandro Barredo Arrieta, Natalia Díaz-Rodríguez, Javier Del Ser, Adrien Bennetot, Siham Tabik, Alberto Barbado, Salvador García, Sergio Gil-López, Daniel Molina, Richard Benjamins, Raja Chatila, Francisco Herrera
発行日:2019年10月22日
最終更新日:2019年12月26日
URL:http://arxiv.org/pdf/1910.10045v2
カテゴリ:Artificial Intelligence, Machine Learning, Neural and Evolutionary Computing
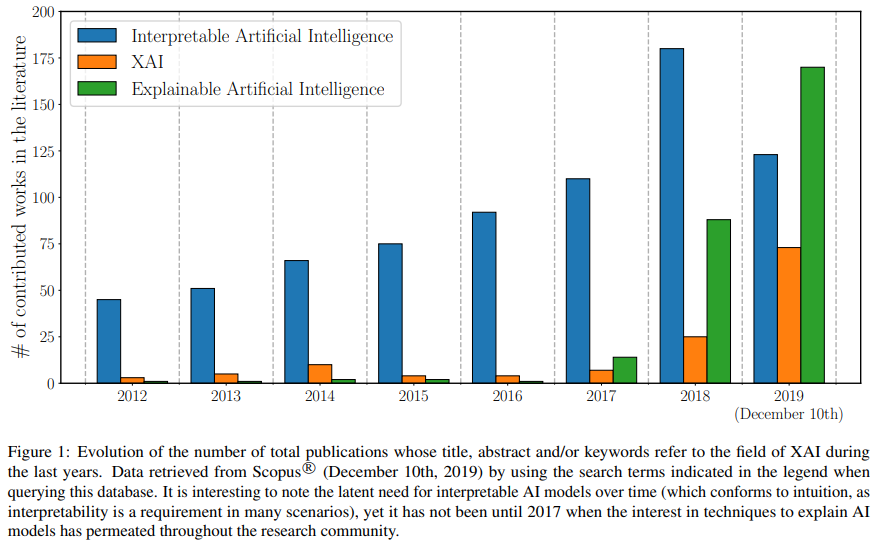
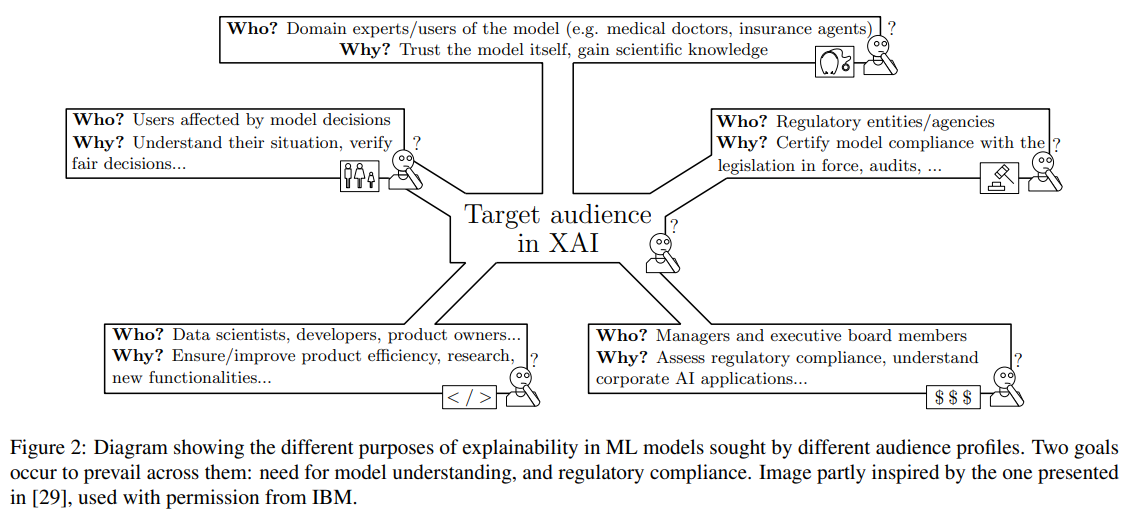
概要:
最近、人工知能(AI)は多くの分野で期待される成果を生み出す可能性があるほどの著しい勢いを見せています.しかし、AI技術であるアンサンブルやディープニューラルネットワークのようなサブシンボリズムによってもたらされる説明不能問題は、AIの最新技術には避けて通れない問題です.この問題に取り組んでいるのが、eXplainable AI(XAI)分野です.XAIは、AIモデルの実用的な展開に必要不可欠な機能として認められています.このレビューではXAI分野における既存文献を検討し、今後の展望についても取り上げます.機械学習における説明可能性を定義するための以前の取り組みをまとめ、説明可能性を求める対象の観点に重点を置いた新しい定義を提唱します.さらに、データの融合と説明可能性というXAIが直面する課題について、この分野の背景を提供します.そして、私たちの展望は、公正性、モデルの説明可能性、責任を中心に実際の組織でAI手法を大規模に導入するための方法論である「責任ある人工知能」の概念へと向かいます.私たちの最終的な目標は、XAIの初心者に参考資料を提供することで将来の研究の進展を促すだけでなく、解釈性の欠如に対する先入観を持たずに、他の専門分野の専門家やプロフェッショナルが自分たちの業界でAIの恩恵を受け入れることを奨励することです.
Q&A:
Q: 説明可能な人工知能(XAI)の定義と、その定義に従って対処する必要がある2つの概念を教えてください.
A: XAIの定義は、「人間のユーザーが、人工知能を持つ新世代のパートナーを理解し、適切に信頼し、効果的に管理することを可能にする一連の機械学習技術」です.事前に取り組むべき概念は、「理解」と「信頼」の2つです.
Q: 説明可能なAIモデルの第一の目的と、その重要性は?
A: 説明可能なAIモデルの主な目的は、観客がモデルの出力に対して信頼性を高めることです.これは、銀行、金融、セキュリティ、健康などの分野で規制の遵守を確保し、ビジネスセクターでの浸透を実現するために重要です.
Q: XAIは、データの偏りを浮き彫りにするためにどのように役立つのでしょうか?
A: SHAPのようなXAI技術は、入力特徴に関するモデルの出力を分析し、差別の原因となりうる入力変数間の隠れた相関関係を明らかにするために使用することができます.XAI技術によって保護された特徴と保護されていない特徴の間の暗黙の相関関係を特定することで、モデル設計者はデータの偏りを強調することができます.また、XAIは公平性とも関係があり、ネガティブな影響の最小化と報告に貢献することができます.
Q: モデルの解釈可能性を高めるために用いられるポストホックテクニックにはどのようなものがあるか?
A: モデルの解釈可能性を高めるためのポストホックテクニックには、大きく分けて、モデルに依存しないテクニックと、特定のMLモデル(浅いモデルや深層学習モデルを含む)に特化したテクニックの2種類があります.さらに、その技法は、その意図、利用される方法、利用されるデータの種類によって分類される.ポストホック説明可能性技法の分類法は、与えられた文脈の中で詳細に提示される.
Q: モデル出力の理解を深めるために、可視化を他の手法とどのように組み合わせればよいのでしょうか?
A: 機械学習におけるモデル出力の理解を向上させるために、モデルの簡略化や特徴関連性といった事後的な説明可能性技法を用いて、視覚化と他の技法を連動させ、モデル解釈のタスクを容易にすることができる.また、視覚的説明技術や特徴関連性の可視化などの可視化技術は、モデルにとらわれない説明を実現し、統計的結論を対象者に提示するために採用することができます.
Q: MLのXAIにおける多層ニューラルネットワークの役割、説明可能性との関連について教えてください.
A: 多層ニューラルネットワークは、Deep Learningモデルの一種で、説明に適したXAIメソッドが必要なモデルです.これらのXAI手法は、層別説明、表現ベクトル、注意など、Deep Learningモデルのファミリーと密接に関連している.モデルの処理の説明とモデルの表現の説明に基づくXAI手法の分類は、モデルの実行軌跡と内部データ構造の区別につながるため、関連性が高い.
Q: LRP(Layer-wise Relevance Propagation)技術とは、入力画像の各単一画素の予測への寄与をどのように可視化するのか?
A: 古典的なCNNの解釈可能性を高めるために、Layer-wise Relevance Propagation (LRP) テクニックを使用します.これは、入力画像の各単一画素の予測への寄与をヒートマップの形で可視化するものである.この手法は、活性化マップでの偏導関数ではなく、予測点に近いテイラー級数に依存しており、畳み込み特徴マップ上の出力層の重みを逆投影することで、特定のオブジェクトクラスで特に重要だった画像領域を特定するのに役立つ.
Q: Gradient-weighted Class Activation Mapping(Grad-CAM)法とはどのような方法で、勾配を利用して粗い局在マップを作成するのか.
A: Gradient-weighted Class Activation Mapping (Grad-CAM) は、画像中の重要な領域を可視化し、概念を予測するために用いられる帰属法である.最終畳み込み層に流入する任意のターゲット概念の勾配を利用して、粗い局在化マップを生成することができる.このローカライゼーションマップは、コンセプトを予測するための画像中の重要な領域を強調する.
Q: 入力例のどの部分が、特定の方法でネットワークを活性化させる原因になっているかを、帰属法で表示するにはどうしたらよいでしょうか?
A: 属性付与方法は、機械学習モデルが予測を行う方法を理解するためのXAI(説明可能なAI)で使用される技術です.ピクセル関連に頼って、入力例の一部を表示し、ネットワークが特定の方法で活性化するのに責任がある部分を表示します.属性付与方法の例には、ヒートマップ、サリエンシーマップ、Grad-CAM(勾配重み付きクラスアクティベーションマッピング)などのクラスアクティベーション方法が含まれます.
Q: 本論文の実用的な貢献は何ですか?
A: この論文は、eXplainable Artificial Intelligence (XAI)の目標に関する定義を統合して列挙し、XAIの研究機会を特定する.また、システムの出力に対する入力の影響度の定量化に取り組むための様々な既存の方法と手段についても論じている.さらに、本論文では、AIにおける解釈可能性と説明可能性の共通理解の欠如を強調している.
Q: 本論文の理論的な貢献は何ですか?
A: この論文では、XAIゴールの定義を統合して列挙し、XAIの研究機会を特定し、AIにおける解釈可能性と説明可能性の共通理解の欠如を強調している.
Q: 実験やデータ解析で得られた主な知見は何ですか?
A: 与えられた文脈の中で具体的な実験やデータ分析が語られることはないので、報告すべき大きな発見はない.代わりに本文では、再現性、協調的センスメイキング、XAI技術、プライバシー保護、データフュージョンなど、データサイエンスや機械学習に関連する概念や関心事に焦点を当てています.
Q: 今後の研究課題として残っているものは何でしょうか?
A: 記事では、責任あるAIの原則の徹底、実現可能性とコンプライアンスの問題への対処、ドメインエキスパートとユーザーの間でのモデルへの信頼の構築、規制機関/団体とのモデルのコンプライアンスの証明、モデルの決定によって影響を受けるユーザーの状況の把握、規制コンプライアンスの評価、製品の効率の確保/改善など、XAI分野における今後の研究の課題をいくつか挙げている.
A Survey on Explainable Artificial Intelligence (XAI): Towards Medical XAI
著者:Erico Tjoa, Cuntai Guan
発行日:2019年07月17日
最終更新日:2020年08月11日
URL:http://arxiv.org/pdf/1907.07374v5
カテゴリ:Machine Learning, Artificial Intelligence
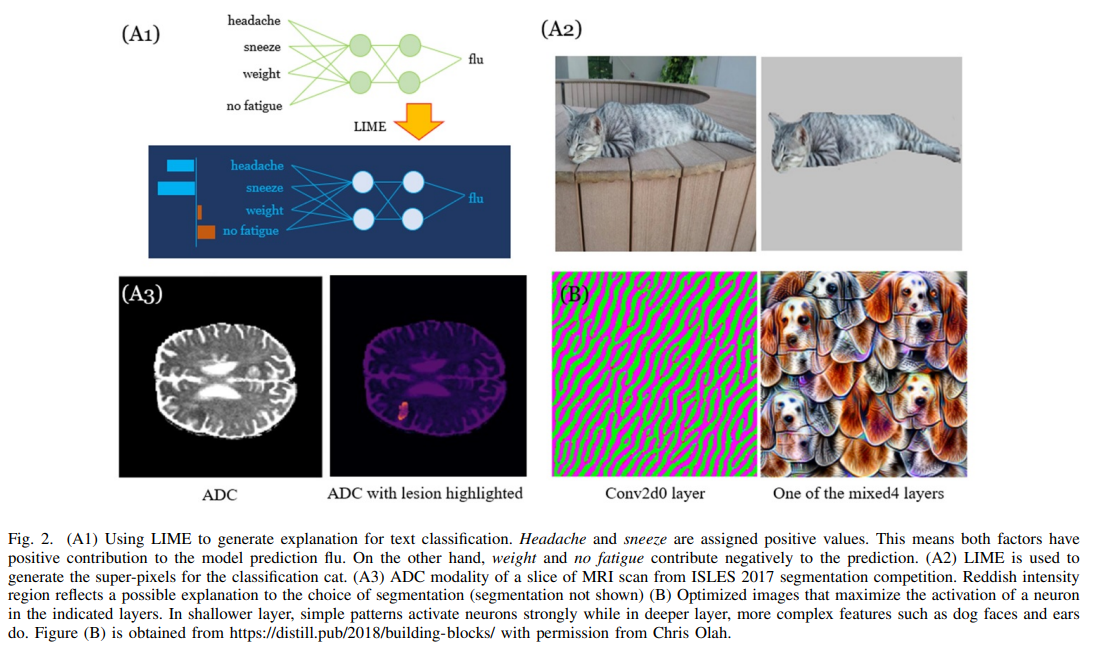
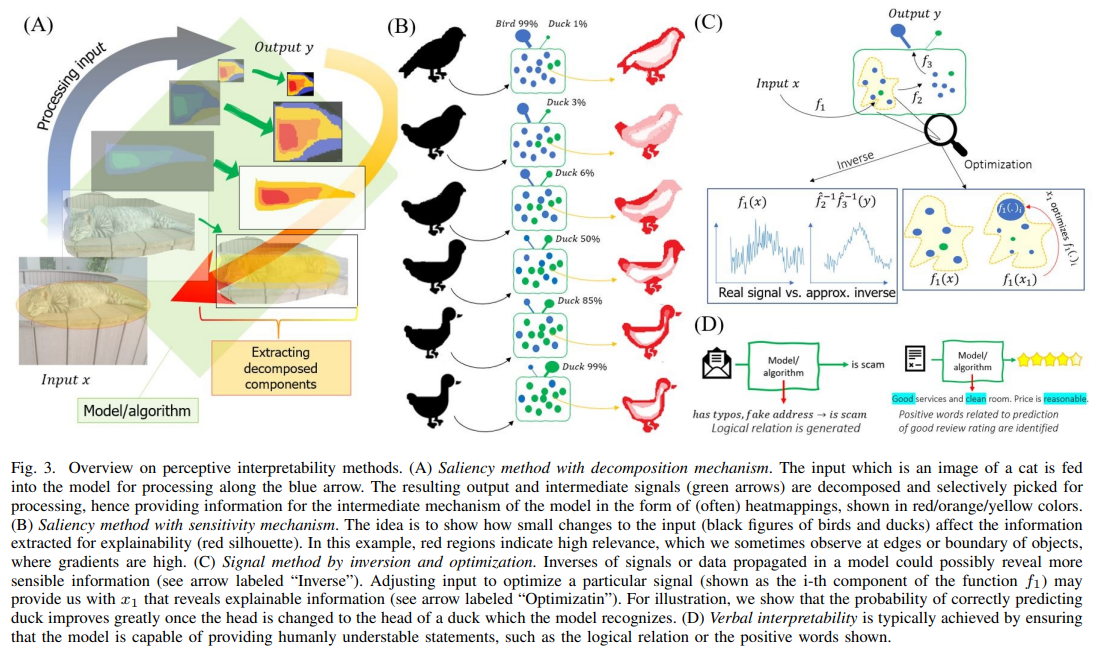
概要:
特にディープラーニングの登場により、人工知能や機械学習は画像処理から自然言語処理まで多くのタスクで驚くべき性能を発揮しており、研究の進歩に伴い、多くの分野や学問に影響を及ぼしています.医療分野など、高い責任と透明性が求められる場合には、機械の意思決定や予測に対する説明が必要であり、信頼性を正当化するために解釈可能性が高められる必要があります.この論文では、様々な研究による解釈可能性についてのレビューとそれらを分類することで、解釈可能性に対して異なる次元を示していることがわかった.必要な情報が「明らかに」解釈できるアプローチから複雑なパターンを研究するものまで、異なるカテゴリーが提供されています.同じ分類を医療研究に適用することで、医療従事者や臨床医がこれらの方法に用心深くアプローチできるようになり、解釈可能性に関する洞察が生まれ、医療実践を考慮した取り組みが促進され、データに基づく数学的・技術的に根拠のある医療教育の推進が期待されます.ただし、ディープラーニングのブラックボックスの性質はまだ解決されておらず、多くの機械の意思決定は未だに理解されていない状況があることを認識し、より解釈可能性が必要であることを念頭に置く必要があります.
Q&A:
Q: 解釈可能性についての洞察は、医療現場への配慮にどのようにつながるのでしょうか?
A: 解釈可能性に関する洞察は、臨床医や実務家が解釈可能性手法に慎重に取り組み、解釈可能性を扱う強固な方法が開発されるまでは、解釈可能性情報を医療行為の補完的サポートとして考えるのに役立ちます.これは、データに基づき、数学的、技術的に根拠のある医学教育を推進する取り組みを後押しすることになります.また、医学研究におけるインタープリタビリティの手法の比較研究も有効であり、ヒートマップなどのインタープリタビリティのアウトプットを明確に表示し、比較することが必要である.全体として、患者の安全を確保しつつ、医療現場における解釈可能性手法の導入と有用性を向上させることが、潜在的なインパクトとなる.
Q: シグナルメソッドを用いてブラックボックスメカニズムを理解する上で、どのような課題や未解決の問題があるのでしょうか?
A: シグナルメソッドを使ってブラックボックスメカニズムを理解する場合、多くの課題や未解決の疑問があります.その中には、再構成された画像や活性化を最適化した画像をどうするか、逆信号を近似的に学習することで解釈可能性をさらに高めることができるか、近似画像を再構成する中間過程での成分や部品を活用できるか、活性化の最適化につながる中間信号を見ることでニューロンの集合体の役割を突き止めることができるか、モデル内の一部のユニットの活性化の強さや重み間の規定の相互作用をどう解釈できる情報に変換していくかなどがあります.さらに、テキスト関連タスクでテキストを生成するために使用される基本的なメカニズムは必ずしも説明されておらず、これらのタスクで使用されるニューラルネットワークや共通の変種/コンポーネントをトラブルシューティングすることは困難である.さらに、機械学習アルゴリズムを使用する際に「正しい」モデルを策定することは困難であり、特定のモデルに特化した最適化パラダイムを持つことは、解釈可能な機械学習の新しい側面に貢献する可能性があります.
Q: 類似セグメントを生成する際のフィルタ-属性確率密度関数の重要性は?
A: A:フィルタ属性の確率密度関数は、似たようなセグメントを生成する上で重要です.それは、特定のフィルタの活性化と特定の属性の関係を改善するために役立ちます.これにより、モデルの意思決定に貢献している特徴をより良く理解し、解釈性を改善するのに役立ちます.
Q: ネットワークの解剖は、視覚的表現の解釈可能性にどのように関係するのでしょうか?
A: 参考文献[36]は、視覚的表現の解釈可能性のためにネットワーク・ディスセクションを使用することを提案し、同様にそれを定量化する方法を提供している.したがって、ネットワーク・ディスセクションは、視覚的表現の解釈可能性を実現するための手法として使用することができる.
Q: 局在化、勾配、摂動に依存する手法は、感性の範疇ではどのように機能するのか?
A: 局所化、勾配、摂動に依存する方法は、微積分における小さな変化の概念や、メトリック空間における点の近傍に基づくため、解釈可能性手法における感度のカテゴリに分類されます.これらの方法は、入力ノイズやデータ点の近傍に敏感であり、モデルが局所的に忠実か不忠実かを判断するために、ある入力の局所性に依存している.これらの手法の目的は、ニューラルネットワークへの入力xの変動に対して説明を与え、その信頼性と性能を向上させることである.
Q: LRPとは何か、画像や音声の分類にどのように使われているのか?
A: LRPはLayer-wise Relevance Propagationの略で、解釈可能な顕著性マップを構築するために使用される手法である.画像と音声の分類の両方に適用可能である.LRPを用いて顕著性マップを構築した論文には、[13]、[45]~[50]があり、ビデオ処理にも用いられている[51].LRPは、各層のスコアの合計が出力に等しくなるように重要度スコアが分解される分解法と考えられています.
Q: 本論文の実用的な貢献は何ですか?
A: この論文は、医療分野における解釈可能な機械学習の課題と将来的な展望を議論し、さらなる処理のために解釈可能な情報を抽出し、そのプロセスを文書化して良い普及につなげることを意識的かつ一貫した実践を推奨しています.また、これらのアルゴリズムの可能性を実現するための医療分野における教育の必要性を強調し、解釈可能性研究にはまだ広大な未開拓の機会があることを示唆している.
Q: この新方式に見られる困難は何ですか?
A: 医療分野における数学と人間の直感の統合の難しさ、特に解釈可能性手法に関する情報を提供します.臨床医や実務家は、解釈可能性手法の欠点を認めつつも、医療行為に適した形で扱うことに苦慮しているかもしれない.また、手法間の不整合も露呈することがあり、関係者からの評価に開かれたインタープリタビリティ研究が求められている.また、解釈可能性研究をアルゴリズム中心の研究から脱却し、さらなる処理のために解釈可能な情報を体系的に抽出するプロセスを文書化する必要性があるかもしれない.さらに、画像解析でテキストを生成するために使用される基礎的なメカニズムは、特にRNNやLSTMニューラルネットワークなどのブラックボックスコンポーネントに関連して、必ずしも説明されていないかもしれません.単語の埋め込み最適化も首尾一貫した説明がない場合があり、埋め込みの形状を解釈することで、アルゴリズムのメカニズムを照らし出すことができるかもしれません.
Q: 今後の研究課題として残っているものは何でしょうか?
A: 解釈可能な機械学習の分野では、意識的に一貫して解釈可能な情報を抽出して処理すること、そのプロセスを体系的に記録して良い普及を図ること、精度や性能の向上にとどまらない解釈可能性研究の機会を探ること、データに基づき、数学的・技術的根拠に基づいた医学教育を推進する取り組みを展開することが今後の課題として挙げられる.さらに、異なるタスクにおいてどのような解釈可能性が必要かを決定することも、さらなる研究の重要な領域である.
Attention is not Explanation
著者:Sarthak Jain, Byron C. Wallace
発行日:2019年02月26日
最終更新日:2019年05月08日
URL:http://arxiv.org/pdf/1902.10186v3
カテゴリ:Computation and Language, Artificial Intelligence
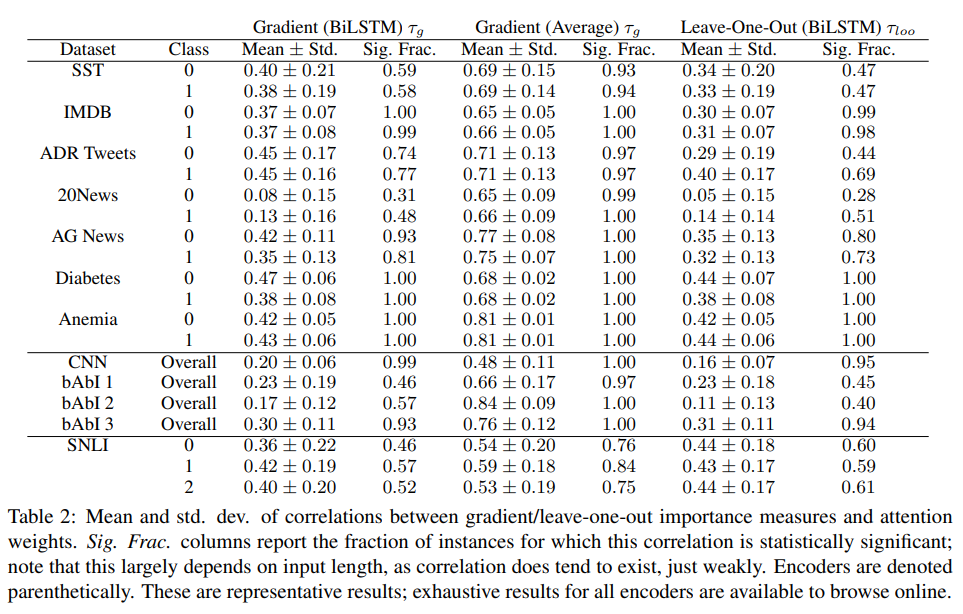
概要:
注目機構は、神経NLPモデルで広く採用されています.予測性能を向上させることに加えて、これらはしばしば透明性を提供することが言われる:注目機構を備えたモデルは、注目する入力単位に分布を提供し、これはしばしば(少なくとも暗黙的に)入力の相対的な重要性を伝えることとして提示されます.しかし、注目ウェイトとモデル出力の関係は明確ではありません.この作品では、NLPタスクのさまざまな実験を行い、注目ウェイトが予測に対して有意義な「説明」を提供する程度を評価することを目的としています.我々は、それらがそれを主として行いません.たとえば、学習された注目ウェイトは、特徴の重要度に基づく勾配ベースの測定と相関しないことがよくあり、同等の予測を与える異なる注目分布を特定することができます.私たちの調査結果は、標準的な注目モジュールが有意義な説明を提供せず、そのように扱われるべきではないことを示しています.すべての実験のコードはhttps://github.com/successar/AttentionExplanationで入手できます.
Q&A:
Q: 通路で言及されている研究の主な焦点と研究貢献は何ですか?
A: この研究の主な焦点は、RNNベースのモデルにおいて、注意がどの程度モデルの透明性と忠実な説明を提供するかを調べることです.研究貢献としては、誘導された注意重みと特徴の重要性の尺度の間の相関を調査すること、および代替の注意重みが異なる予測をもたらすかどうかを調査することです.これらの質問に関して、リカレント(BiLSTM)エンコーダにおける注意重みに関する知見をまとめた.
Q: Adverse Drug Reactionデータセットの中で、副作用に言及したツイートと判断するための基準は何ですか?
A: Adverse Drug Reactionデータセット内のツイートは、ドメインエキスパートによって、副作用について言及するようアノテーションされています.
Q: 電子カルテのMIMIC IIIデータセットとはどのようなもので、どのようなデータが含まれているのでしょうか?
A: 電子カルテのMIMIC IIIデータセットには、退院サマリーのサブセットが含まれています.一つのタスクは、与えられた要約が糖尿病のICD9コードや貧血のタイプ(急性か慢性か)でラベル付けされているかどうかを認識することである.このデータセットには学習済みの単語埋め込みも含まれており、語彙に存在しない単語は標準ガウスからのサンプルを用いて初期化される.このデータセットは、臨床テキストからの医療コード予測に使用される.
Q: 貧血に関するMIMIC IIIデータセットの退院サマリーのサブセットで実行されている具体的なタスクは何ですか?
A: レポートごとに貧血の種類を急性(0)か慢性(1)かで区別する作業です.
Q: ニューラルNLPモデルにおける注意メカニズムの目的と、予測性能の向上について教えてください.
A: ニューラルNLPモデルでは、予測性能を向上させるためにアテンション機構が用いられている.アテンション機構は、アテンションされた入力ユニットに対する分布を提供するが、アテンション重みとモデル出力の間にどのような関係が存在するかは不明である.しかし、入力の相対的な重要性を伝えることで、透明性を確保することができるとして、よく利用されている.
Q: bAbIデータセットとはどのようなもので、その中で提示されている3つのタスクとは何でしょうか?
A: bAbIデータセットは、QA(Question Answering)タスクに用いられるデータセットである.オリジナルのbAbIデータセットで提示された3つのタスクが含まれているが、この作品ではこの3つのタスクが何であるかは明記されていない.
Q: 平均的な埋め込み型モデルにおける注目重みと勾配の対応関係は?
A: 平均的なエンベッディングベースのモデルでは、注目重みと勾配の相関は、注目重みとLOOスコアの相関ほど強くはないです.
Q: 文書の長さは、注目度重みと特徴重要度スコアの相関にどのような影響を与えるか?
A: この質問に対する明確な回答は本文にはありません.注目度の重みと特徴の重要度のスコアの相関は一般的に弱く、タスク間で一貫性がないことは書かれていますが、この相関に影響を与える要因として、文書の長さは特に言及されていません.
Q: 本論文の理論的な貢献は何ですか?
A: この論文の理論的な貢献としては、アテンションウェイトがモデル予測に意味のある洞察を与えるかどうかの検証、アテンションウェイトと特徴の重要性の尺度の相関の調査、代替アテンションウェイトが異なる予測をもたらすかどうかの検証などがあります.また、この論文では、モデルの出力について「まあまあの物語」を構築するためにアテンションウェイトを使用しないように注意を促しています.
Q: 本稿で紹介した新手法の実装はどこにあるのでしょうか?
A: 論文で紹介された新手法の実装は、https://successar.github.io/AttentionExplanation/docs/ で公開されています.
Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead
著者:Cynthia Rudin
発行日:2018年11月26日
最終更新日:2019年09月22日
URL:http://arxiv.org/pdf/1811.10154v3
カテゴリ:Machine Learning, Machine Learning


概要:
現在、ブラックボックス機械学習モデルは、医療、刑事司法、他の領域でも高いリスクを伴う意思決定に使用されており、問題が起こっています.これらのブラックボックスモデルを説明するための方法を作成することで、これらの問題のいくつかを緩和することができると期待する人々がいますが、ブラックボックスモデルを説明する代わりに、最初から解釈可能なモデルを作成することが、悪い実践を継続させ、社会に致命的な害をもたらす可能性があります.解釈可能なモデルを設計することが、事実上の解釈可能なモデルを使用する解明とブラックボックスモデルを使うことを回避するための方法です.この論文は、ブラックボックスを説明することと解釈可能なモデルを使用することの違いを明確にし、高リスクの意思決定において説明可能なブラックボックスを回避するべきいくつかの主要な理由を示し、解釈可能な機械学習における課題を特定し、犯罪司法、医療、コンピュータビジョンなどの例アプリケーションを提供して、解釈可能なモデルがブラックボックスモデルを置き換える可能性があることを説明しています.
Q&A:
Q: ブラックボックス型機械学習モデルとはどのようなもので、現在、ハイステークスの意思決定においてどのように活用されているのか?
A: ブラックボックス化した機械学習モデルは、社会全体、特に医療と刑事司法において、利害関係の大きい意思決定に使用されています.これらのモデルは、その予測を人間が理解できるように説明していないため、誤った仮釈放の拒否や、危険な犯罪者の釈放につながる保釈の判断ミスなど、深刻な結果をもたらす可能性があります.
Q: 医療や刑事司法においてブラックボックスモデルを使用する際の問題点は何か、また、ブラックボックスモデルを説明することでこれらの問題点を軽減することができるか.
A: ブラックボックスの機械学習モデルの透明性と説明責任の欠如は、医療や刑事司法において、人々が誤って仮釈放を拒否されたり、保釈の判断が甘くなったり、汚染モデルが正しくなかったりといった深刻な結果をもたらすことがあります.これらのモデルを説明するためのメソッドを作成する傾向がありますが、これには問題があり、誤解を招く可能性があります.その代わりに、本質的に解釈可能なモデルを設計することが解決策であることが示唆されています.ブラックボックス化されたモデルを利害関係の強い意思決定に使用することは、機械学習のビジネスモデルにおける責任の衝突につながる可能性もある.なぜなら、これらのモデルから利益を得る企業は、必ずしも個々の予測の品質に対して責任を負わないからである.これらのモデルがゲームやリバースエンジニアリングされるのを防ぐために隠しておくという主張は、一般的には意味をなさないかもしれません.全体として、解釈可能な機械学習の重要な問題は計算上の問題であるが、政策によってこれを回避する方法があるのかもしれない.
Q: ブラックボックス化した機械学習モデルをハイステークスリーディングに用いることで生じる問題点とは何でしょうか?
A: ブラックボックスの機械学習モデルを利害関係の強い意思決定に用いることは、これらのモデルから利益を得る企業と個々の予測の質との間の責任の衝突、これらのモデルの設計と性能に対する説明責任の欠如、社会に対する潜在的な破滅的損害などの問題を引き起こす可能性があります.さらに、ブラックボックスモデルに依存することは、悪しき慣習を永続させ、新しい政策を台無しにする可能性があり、これらのモデルが正確でない、または完全でない可能性がある.また、ブラックボックスモデルは透明性を妨げる可能性があり、ヘルスケアや医療などの領域では、これらのモデルが訓練された完全なデータベースが、起こりうる状況のすべてを表していない可能性があり、問題となることがある.
Q: ハイステークスデシジョンにおけるブラックボックスモデルによる問題点を解決するために、どのような方法が提案されているのか.
A: ブラックボックス化したモデルを説明するのではなく、本質的に解釈可能なモデルを設計することが提案されています.そのためには、利害関係の強い意思決定には解釈可能なモデルを使用することを義務付ける政策を作り、同じように正確で透明なモデルが存在するにもかかわらずブラックボックスモデルを製造・販売する組織には責任を負わせる必要があります.機械学習のビジネスモデルを変える必要があります.不透明性は知的財産を保護するために不可欠と考えられていますが、多くの分野の要求とは相容れないものだからです.
Q: 「精度-解釈性のトレードオフ」とは何ですか?また、この仮説に賛成・反対する論拠は何ですか?
A: 「精度-解釈性のトレードオフ」仮説は、より精度の高いモデルは解釈性が低く、その逆もまた真であると述べています.しかし、これは常に正しいわけではなく、解釈性が高いモデルが同じくらい精度が高い場合もあります.一部の人々は、トレードオフは神話であり、精度と解釈性を両立させることが可能であると主張していますが、他の人々は、一部の場合にはトレードオフが存在する可能性があるが、それは明確に定義されておらず、特定のデータやモデルによって異なる可能性があると考えています.
Q: 解釈可能な機械学習にはどのような課題がありますか?
A: 研究者は、すでに意味のある特徴を持つ標準的な構造化データであっても、解釈可能なモデルを設計する上で、手ごわい計算上のハードルに直面しています.精度と解釈可能性の間には常にトレードオフの関係があるという考えから、多くの研究者は解釈可能なモデルを作成することを見送っています.さらに、研究者は現在、深層学習の訓練を受けているが、解釈可能な機械学習は受けていない.機械学習アルゴリズムのツールキットは、解釈可能な機械学習手法のための有用なインターフェイスをほとんど提供していない.また、一般的に解釈可能性と精度のトレードオフは発生するが、利害関係の強い意思決定に完全なブラックボックスが必要なアプリケーションドメインが存在する可能性もある.今のところ、講演者はそのようなアプリケーションに遭遇したことはない.
Q: Explainable MLとはどのようなもので、ブラックボックスモデルの透明性や説明責任の欠如をどのように解決するのでしょうか?
A: 説明可能なMLとは、ブラックボックスモデルの予測を人間が理解できるように説明するための第2のモデルを作成する最近の研究分野である.仮釈放が誤って却下されたり、保釈の判断が甘かったりといった、誤った予測による深刻な結果を潜在的に防ぐことができる説明を提供することで、ブラックボックスモデルの透明性と説明責任の欠如に対処するものです.しかし、著者は、本質的に解釈可能なモデルを作成することが、この問題に対するより良い解決策であると主張している.
Q: 解釈可能性において、なぜドメイン固有の知識が重要なのでしょうか?
A: 機械学習モデルで解釈可能性を実現するためには、特定のドメインやアプリケーションに基づいて解釈可能性を定義する必要があるため、ドメイン固有の知識を持つことが重要であると言えます.ドメインが異なれば、解釈可能性を構成する考え方も異なるでしょうし、ドメインに応じた解釈可能性の定義や、機械学習のための特徴を構築するためには、ドメイン固有の知識が必要です.さらに、解釈可能なモデルを構築するには、計算とドメインの専門知識の両面から多大な労力を必要とします.ドメイン固有の知識がなければ、解釈可能性を定義し、その特定の要件を満たすモデルを作成することは困難である.
Q: データサイエンスの実践において、結果を解釈する能力はどの程度重要か?
A: データサイエンスの実践において、結果を解釈する能力は、全体的な精度の向上や性能の改善につながるため、非常に重要です.機械学習アルゴリズム間のわずかな性能差は、結果を解釈し、次の反復でより良いデータ処理を行う能力で圧倒することができます.特に利害関係の強い意思決定には、高品質のモデル構築に余分な労力とコストを割く価値があるのです.しかし、多くの組織には、解釈可能なモデルを構築するためのトレーニングや専門知識を持つアナリストが全くいない.
Q: 解釈可能性を高めることは、全体の精度を高めることにつながるのでしょうか?
A: はい、解釈可能性を高めることで、機械学習モデルの全体的な精度を高めることができるケースもあります.これは、特に利害関係の強い意思決定において、過度に複雑でなく、欠陥のない高品質のモデルを持つことが重要である場合に当てはまります.さらに、根拠がなく、完全で、きれいなデータに対しては、一般的にブラックボックスの機械学習法を使う方が簡単ですが、より複雑で乱雑なデータに対しては、解釈可能性を高めることで、より良いデータ処理が可能になり、データ生成プロセスに関する誤った仮定が明らかになるため、パフォーマンスの向上につながることがあります.
Q: 解釈可能なモデルを構築するという点で、説明法は最適化問題とどう違うのでしょうか?
A: 説明手法は通常、導関数に基づくもので、勾配に基づく最適化が容易になる一方、解釈可能性制約(スパース性など)は、最悪の場合、計算上困難であることが証明されている最適化問題を引き起こす.理論的に難しいからといって、これらの問題が解けないわけではありませんが、実際のケースでは、これらの最適化問題を解くのは難しいことが多いです.
Q: ブラックボックスモデルが、ユーザーがこれまで意識していなかったデータの隠れたパターンを発見するという考えについて教えてください.
A: ブラックボックスモデルが、ユーザーがこれまで気づかなかったデータの隠れたパターンを発見するというのは、モデルの複雑さによって、人間が見逃していたような微妙なパターンを明らかにすることができるという考え方です.しかし、研究者が十分に熟練していれば、透明なモデルでも同じパターンを発見することは可能です.
Q: 解釈可能なモデルは、データの重要なパターンを明らかにする上で、どのようにすれば同じように効果的なのでしょうか?
A: ブラックボックスモデルがより良い予測を得るためにそれを活用できるほど、データ中のパターンが重要であれば、解釈可能なモデルも同じパターンを見つけてそれを利用するかもしれません.これは、機械学習研究者の学習作成能力に依存します.透明なモデルであれば、同じパターンを発見できるかもしれない.
Q: 実験やデータ解析で得られた主な知見は何ですか?
A: この文章では、機械学習の課題、構造化データに対する支配的なアルゴリズムの欠如、解釈可能なモデルの重要性について論じています.また、ニューヨークの送電網の故障を予測する取り組みや、解釈可能なモデルがいかに性能の大幅な向上につながったかに言及している.また、機械学習研究における選択的報告の文化や、ブラックボックスモデルに対する特定の説明方法の限界についても警告しています.実験やデータ解析から得られた主要な知見については、特に言及されていません.
Q: 今後の研究課題として残っているものは何でしょうか?
A: 解釈可能な機械学習モデルの分野では、特にコンピュータビジョンの場合、特定のドメインに対する解釈可能性を定義し、それに応じた手法を作成するなど、今後の研究課題がいくつか残されています.さらに、高い計算コストや解釈可能なモデルを設計するための専門知識の欠如などの障壁に対処する必要があります.最後に、知的財産をブラックボックス化したモデルに依存する企業の利益動機に関する懸念に対処する必要がある.
Sanity Checks for Saliency Maps
著者:Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, Been Kim
発行日:2018年10月08日
最終更新日:2020年11月06日
URL:http://arxiv.org/pdf/1810.03292v3
カテゴリ:Computer Vision and Pattern Recognition, Machine Learning, Machine Learning
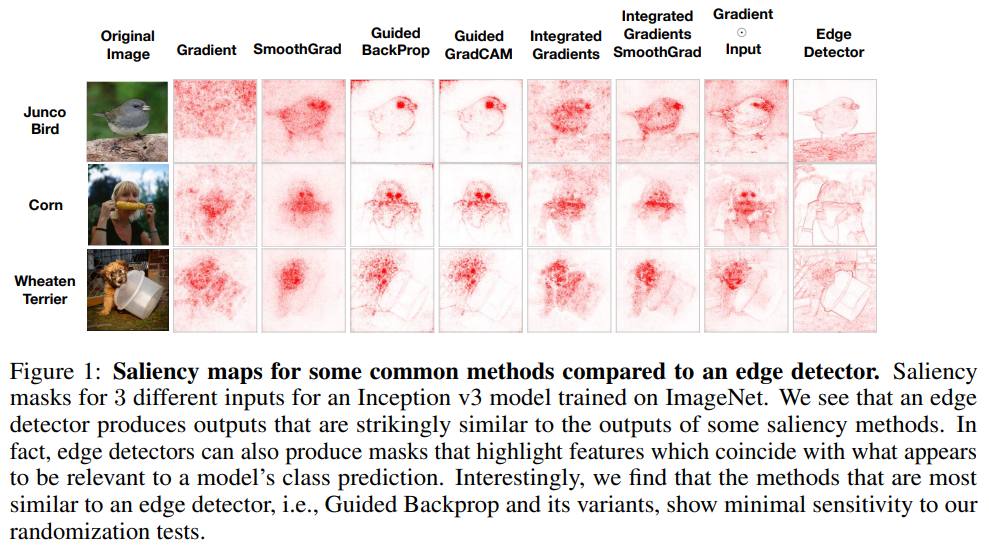
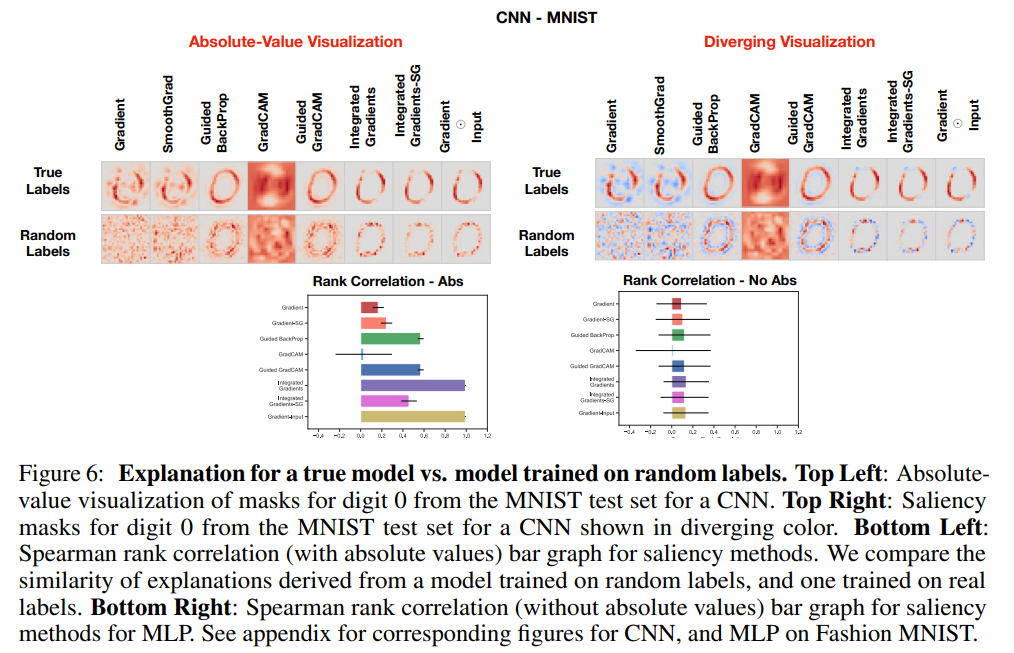
概要:
本研究では、サリエンシー法が、学習モデルの予測に関連する特徴を強調するための一般的なツールとして現れている.これにより、多くのサリエンシー法が提案されており、多くは画像データによって視覚的にガイドされています.本研究では、与えられた方法が提供できる説明の種類を評価するための実行可能な方法論を提案しています.視覚的評価に頼ることは誤解を招くことがあるため、本研究では詳細な実験を通じて、既存のサリエンシー法のいくつかが、モデルやデータ生成プロセスに独立していることを明らかにしています.そのため、提案されたテストに合格しない方法は、データまたはモデルに敏感なタスクには不適切であり、データ内の外れ値を見つけたり、モデルが学習した入力と出力の関係を説明したり、モデルのデバッグをすることができない.また、画像のエッジ検出とのアナロジーにより、線形モデルと単一層の畳み込みニューラルネットワークの場合の理論が私たちの実験的な発見をサポートしています.
Q&A:
Q: 入力中の特徴を強調するために、顕著性手法とはどのようなものか、またどのように使われているのか.
A: 顕著性法は、特に画像データに対して、学習済みモデルの予測に関連すると考えられる入力中の特徴を強調するために使用されるツールである.
Q: 関連性」の定義は、顕著性マップのアプリケーションによってどのように異なるのでしょうか?
A: 本研究では、顕著性マップにおける「関連性」の定義が用途によって異なる可能性があり、視覚的な評価だけでは誤解を招く可能性があることを提案しています.提案する手法は、ある手法がどのような説明を提供できるかを評価することを目的としており、データまたはモデルのいずれかに敏感なタスクでは、いくつかの手法が不十分であることを示す.本研究は、いくつかの顕著性評価法が、モデルに敏感な説明を提供するのではなく、教師なし画像処理技術を暗黙のうちに実装している可能性があることを示唆する.
Q: Guided Backpropagation(GBP)について、DeConvNetの説明手法の上にどのように構築されているのか、教えてください.
A: GBPはニューラルネットワークにおけるReLUの勾配をバックプロパゲートする方法の変更を指定する説明方法である.DeConvNetの説明法と異なる点は、GBPは上位層のパラメータに不変であり、部分的な入力回復が可能であるのに対し、DeConvNetは意図しない操作が可能であることである.
Q: Guided GradCAMとは何か、またGradCAMの説明方法との関連は?
A: Guided GradCAMは、与えられた文脈で記述された研究において、他の説明方法と比較してテストされた説明方法である.GradCAM法と関連しているのは、要素ごとの積によってGuided Backpropagationと組み合わせることができる点である.しかし、本研究では、Guided GradCAMとGuided BackPropは、上位層のパラメータに不変であり、提案したテストに失敗し、モデルやデータ生成過程に対して忠実な説明を行うことができないことがわかった.
Q: SHAPの説明について、シャプレー値とどのように関連し、いくつかの既存の手法を統一しているのか、詳しく教えてください.
A: この抜粋で提供される文脈は、SHAPの説明やシャプレー値との関係には触れていません.したがって、AIの言語モデルとして、私は答えを提供することができません.
Q: SmoothGradの目的と、ノイズや視覚の拡散を緩和する方法について教えてください.
A: SmoothGradは、入力のノイズを含む説明マップを平均化することにより、顕著性マップのノイズと視覚的拡散を緩和することを目指す手法である.与えられた説明マップEに対して、SmoothGradはEsg(x)=1/N∑E(x gi)と定義され、ノイズベクトルgiは正規分布から描かれる.この方法は、顕著性マップを滑らかにし、ノイズを減らすのに役立つ.
Q: 広く展開されているサリエンシー手法に関して、意外な発見があったのでしょうか?
A: 広く普及している顕著性手法の中には、モデルが学習したデータとモデルパラメータの両方に依存しないものがあることが判明しました.
Q: データセットやモデルアーキテクチャをまたいで説明手法を用いた実験を行った結果、どのような結果が出たのでしょうか?
A: データセットやモデルアーキテクチャをまたいだ説明手法の実験を行った結果、広く普及している顕著性手法の中には、モデルが学習したデータとモデルパラメータの両方に依存しないものがあることがわかりました.
Q: 説明アプローチの評価について、具体的にどのような実行可能なサニティチェックを提案されていますか?
A: 説明手法の範囲と質を評価するための、具体的で実施しやすい2つのテスト、モデルパラメータ無作為化テストとデータ無作為化テストです.
Q: 本稿で紹介した方法は、従来の方法と比較してどのようなメリットがあるのでしょうか?
A: 本論文では、説明手法の妥当性を評価するためのランダム化テストに基づく方法論を紹介している.これは、実装が容易で、与えられたタスクに対する説明手法の適性を評価するのに役立つ.この方法論は、モデルの説明方法の範囲を評価する際に研究者に指針を与える方法として提案され、視覚的評価のみに頼るよりも信頼性が高いことが示されている.
Q: 本論文の理論的な貢献は何ですか?
A: 本論文は、説明アプローチの妥当性を評価するためのランダム化テストに基づく方法論を提案する.提案するランダム化テストは実装が容易であり、あらゆる説明アプローチに一般性をもって適用できる.また、本論文では、データセットやモデルアーキテクチャを横断して、いくつかの説明手法の大規模な実験を行い、説明手法の範囲と品質を評価するための2つの具体的で実装が容易なテスト、すなわちモデルパラメータ無作為化テストとデータ無作為化テストを提案する.本論文の理論的な貢献としては、新しい説明手法の厳密な評価を提供すること、特定のタスクに対する手法の適切性を除外する具体的な方法を与えることができる説明手法の不変性を特定することが挙げられる.
Q: 実験やデータ解析で得られた主な知見は何ですか?
A: ニューラルネットワークによる画像分類のために広く使われているいくつかの顕著性手法は、モデルが学習したデータとモデルパラメータの両方に依存しないこと、顕著性手法は、画像処理技術におけるエッジ検出と同様に、ほとんどが画像のエッジを利用することなどが主な発見であった.提案するランダム化テストは、手元にある与えられたタスクに対する説明手法の適合性を評価するのに役立ち、手法を実際に展開する前のサニティチェックの役割を果たすことができる.
Q: 今後の研究課題として残っているものは何でしょうか?
A: 論文の結論は、顕著性手法と説明アプローチの分野における今後の研究は、学習済みモデルの入力と出力の間の関係に対する有用な洞察を提供し、データ内の異常値をデバッグして特定するのを助けることができる、より堅牢でモデルに敏感な説明方法の開発に焦点を当てるべきであることを示唆しています.さらに、説明手法の範囲と品質を評価するための、より原則的で標準化された評価手法が必要であることを示唆している.
Q: 本稿で紹介した新手法の実装はどこにあるのでしょうか?
A: 論文で提案されたランダム化テストに基づく新しい方法論の実装は、https://goo.gl/hBmhDt にあります.
A Benchmark for Interpretability Methods in Deep Neural Networks
著者:Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, Been Kim
発行日:2018年06月28日
最終更新日:2019年11月05日
URL:http://arxiv.org/pdf/1806.10758v3
カテゴリ:Machine Learning, Artificial Intelligence, Machine Learning
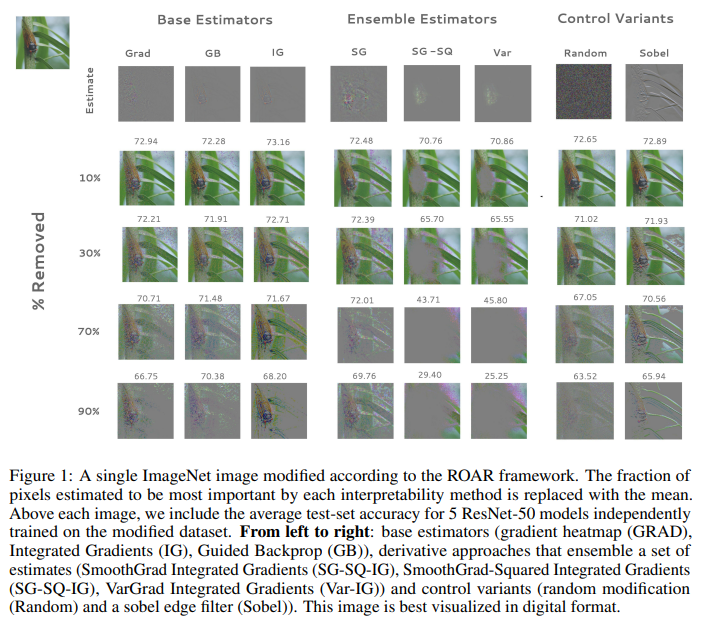
概要:
深層ニューラルネットワークにおける特徴重要度推定の近似精度の経験的な尺度を提案します.私たちの結果は、いくつかの大規模な画像分類データセットにわたるもので、多くの人気のある解釈手法が、特徴重要度の推定をランダムな設定と同等のものにしか生み出していないことを示しています.VarGradとSmoothGrad-Squaredという一部のアンサンブルベースの手法だけが、ランダムな重要度割当よりも優れた結果を出しています.アンサンブルの方法は重要であり、いくつかの手法は下位メソッドと同程度の成果しか出せず、計算負荷がはるかに高いことが示されています.
Q&A:
Q: 本稿で提案した深層ニューラルネットワークにおける特徴量重要度推定の近似精度を示す経験的指標は何か?
A: 本論文で提案する経験則は、特徴量のランダム割り当てに対する特徴量推定値の比較である.
Q: いくつかの大規模な画像分類データセットで解釈可能性手法をテストした結果はどうだったのでしょうか?
A: この結果は、多くの一般的な解釈可能性手法が、特徴の重要度をランダムに指定するよりも良くない推定値を出すことを示している.ある種のアンサンブルベースのアプローチ(VarGradとSmoothGrad-Squared)だけが、このようなランダムな重要度の指定よりも優れている.アンサンブルの方法は依然として重要であり、いくつかのアプローチは基本的な方法と変わらないが、はるかに高い計算負荷がかかる.
Q: ROARとはどのようなもので、これまでの特徴を消す戦略とはどう違うのか?
A: ROARはRemOveAndRetrainの略で、重要だと推定される特徴が取り除かれたときに、再トレーニングされたモデルの精度がどのように低下するかを検証することによって、解釈可能性手法を評価するために用いられるアプローチである.このアプローチは、従来の特徴除去の方法とは異なり、単に特徴を除去して精度への影響を観察するのではなく、元々得られていた特徴の重要度推定値の割合を置き換えるというものである.
Q: ベースアプローチに加え、特徴量の重要性を評価した3つのアンサンブル手法とはどのようなものか?
A: ベースアプローチに加えて、特徴の重要性を評価した3つのアンサンブル方法がありました:古典的なSmoothGrad(SG)、SmoothGrad2(SG-SQ)、そしてVarGrad(Var)です.SGとSG-SQはガウスノイズを注入して生成したノイズのある推定値の集合を用い、VarGradはノイズのある集合の分散を用いた.この研究では、VarGradとSmoothGrad-Squaredのみが、特徴の重要度をランダムに割り当てるよりも優れていることがわかった.
Q: Classic SmoothGrad(SG)とはどのようなもので、どのように構築され、どのように評価されるのでしょうか?
A: Classic SmoothGrad (SG)は特徴量のアンサンブル手法であり、基本的な手法(GRAD、IG、GB)に従って計算された特徴量のノイズのある推定値のセットを平均化するものである.ノイズの多い推定値は、1つの入力に独立したガウスノイズをJ回注入することで構築される.この研究では、古典的なSmoothGrad (SG)は、単一の推定値よりも精度が低いか同等で、テストセットの精度をランダムな推測よりも低下させることが判明した.また、GRADとIGについては、SmoothGradは単一の推定値よりも性能が悪い.この研究で評価された他のアンサンブル手法には、平均化する前に各推定値を二乗するSmoothGrad2(SG-SQ)と、平均値ではなくノイズ集合の分散を計算することによって推定値を集約するVarGrad(Var)があります.SG-SQとVarの両方は、精度の面でクラシックSmoothGradと他の制御変種を凌駕する.これらのアンサンブルアプローチに最適な基礎推定量の選択は、タスクによって異なる場合があります.
Q: VarGrad(Var)とはどのようなもので、特徴量の重要度についてノイズの多い推定値の集合をどのように構築し、評価するのですか?
A: VarGrad (Var)は、Classic SmoothGrad (SG)と同様に、特徴の重要性に関するノイズの多い推定値の集合を構築するものである.これは、tJ個のノイズの推定値のセットを作成するために、単一の入力にガウスノイズをt回注入することから始まる.次に、SGが行うようにノイズの集合の平均を計算する代わりに、VarGradはノイズの集合の分散を計算し、推定値を集約する.その結果、特徴の重要度の推定値は計算された分散となる.この方法は、ROARを用いた特徴重要度の推定において、その精度が評価され、ランダムベースラインや他の基礎推定器と比較して、大きな精度の向上をもたらすことが示された.最適な基礎推定器はタスクによって異なるかもしれないが、VarGradは一貫してパフォーマンスを向上させる.
Q: モデルの動作の説明が信頼できるかどうかを評価するには、どのような課題があるのでしょうか?
A: モデル動作の説明の信頼性を評価する際の課題として、グランドトゥルースの欠如、どの解釈可能性手法を選択するかの不確実性、手法を正しく設定する必要性が挙げられます.また、既存の様々な解釈可能性手法の相対的なメリットと信頼性を経験的に検証することが重要です.
Q: ROARの性能は、ディープニューラルネットワークとリニアモデルでどう違うのでしょうか?
A: ROARは、ディープニューラルネットワークでもリニアモデルでも有効であることに変わりはありません.
Q: ROARの評価に使用された3つのオープンソースの画像データセットと、各データセットと推定器に使用された特徴修正の異なる割合の対応を教えてください.
A: ROARの評価に用いたオープンソースの画像データセットは、ImageNet、Birdsnap、Food 101の3つです.各データセットと推定器について、特徴量の修正割合(t=[0.1,0.3,0.5,0.7,0.9])と最も重要な画素を削除するか残すかの違いに対応して、それぞれ新しい訓練セットとテストセットが10個生成されています.
Q: 評価対象は全部で何人のエスティケーターで、その内容は?
A: 評価した推定量は18個で、基本推定量、各基本推定量を包むアンサンブルアプローチ、二乗推定量のセットなどです.
Q: 修正されていないImageNetデータセットで学習したResNet-50が達成した平均精度と、[14]が報告した性能との比較は?
A: 未修正のImageNetデータセットで学習させたResNet-50は、76.68%の平均精度を達成しました.この性能は、参考文献[14]で報告されたものと同等である.
Q: BirdsnapとFood 101データセットで達成されたベースライン性能と、Kornblithら[21]が報告した性能との比較は?
A: BirdsnapとFood 101データセットで達成されたベースライン性能は、それぞれ66.65%と84.54%です.
と84.54%である.これらのベースライン性能は、Kornblithら[21]が報告した性能と同等である.
Q: 本稿で紹介した方法は、従来の方法と比較してどのようなメリットがあるのでしょうか?
A: 論文で紹介された方法は、修正されたデータセットでランダム初期化からモデルを再学習することを必要としており、推論時に修正された画像を再度スコアリングするのではなく、最も重要と推定されるピクセルを固定された非情報的な値で置き換えることによって導入されたアーティファクトによるモデルのパフォーマンスの低下が結果であるかどうかを分離することができます.これは従来の修正ベースの評価尺度よりも優れた利点です.
Q: この新方式に見られる困難は何ですか?
A: 新しいベンチマークでは、推論時に修正画像を再スコアするのではなく、修正データセットに対してランダムな初期化からモデルを再トレーニングする必要があり、実装に困難が伴う可能性があります.
Q: 実験やデータ解析で得られた主な知見は何ですか?
A: 実験では、訓練性能は入力特徴を削除しても頑健であることが示され、意思決定には小さな特徴のサブセットで十分であることが示唆されました.評価した基本手法は、情報量の多い特徴を見つけるのに、ランダムな推定と変わらないか、同等であったが、SmoothGrad-SquaredやVargradのようなアンサンブル手法は、より良い性能を示した.この論文では、解釈可能性手法のさまざまな評価尺度について議論し、解釈可能性手法の評価ではなく、特徴の重要度を推定する再帰的特徴除去とは異なるアプローチであることを指摘している.各データセットの学習手順とハイパーパラメータが詳細に説明されており、ImageNetデータセットでは76.68の精度を達成し、修正前の Birdsnap と Food 101 データセットでは 66.65と84.54の精度を達成した.

コメント