
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をQ&A形式を用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.
紹介する論文は以下の9本となります.
- Zip-NeRF: Anti-Aliased Grid-Based Neural Radiance Fields (発行日:2023年04月13日)
- AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models (発行日:2023年04月13日)
- Emergent autonomous scientific research capabilities of large language models (発行日:2023年04月11日)
- Teaching Large Language Models to Self-Debug (発行日:2023年04月11日)
- ChemCrow: Augmenting large-language models with chemistry tools (発行日:2023年04月11日)
- Automatic Gradient Descent: Deep Learning without Hyperparameters (発行日:2023年04月11日)
- OpenAGI: When LLM Meets Domain Experts (発行日:2023年04月10日)
- Generative Agents: Interactive Simulacra of Human Behavior (発行日:2023年04月07日)
- One Small Step for Generative AI, One Giant Leap for AGI: A Complete Survey on ChatGPT in AIGC Era (発行日:2023年04月04日)
Zip-NeRF: Anti-Aliased Grid-Based Neural Radiance Fields
著者:Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, Peter Hedman
発行日:2023年04月13日
最終更新日:2023年04月13日
URL:http://arxiv.org/pdf/2304.06706v1
カテゴリ:Computer Vision and Pattern Recognition, Graphics, Machine Learning

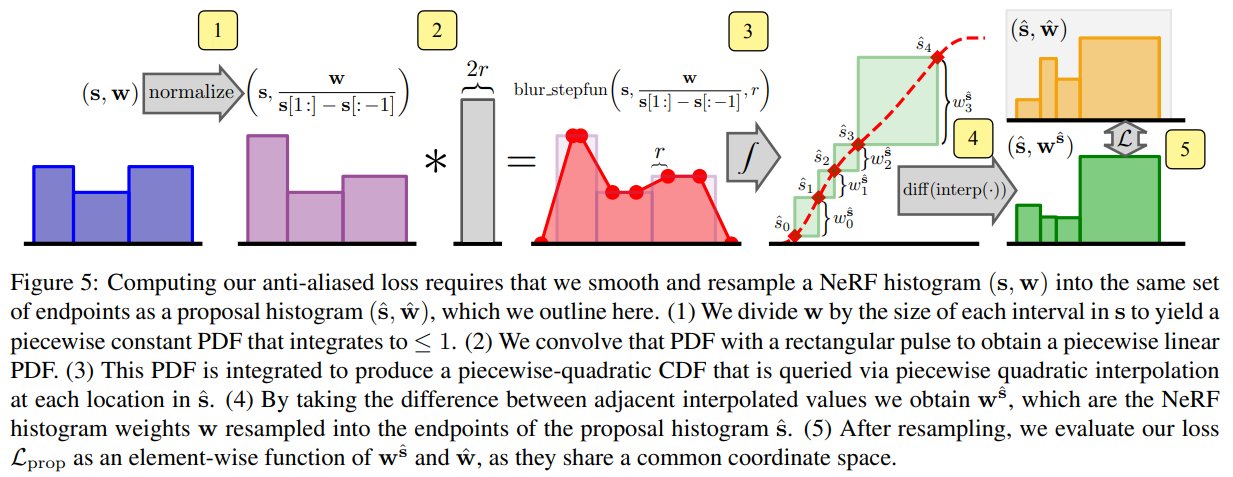
概要:
ニューラル放射場のトレーニングは、空間座標から色と体積密度へのNeRFの学習済みマッピングにおいて、グリッドベースの表現を使用することによって加速できます.ただし、これらのグリッドベースのアプローチにはスケールの明示的な理解が欠けているため、通常、ジャギーやシーンのコンテンツが欠落する形でエイリアシングが導入されます.エイリアシングは、以前はmip-NeRF 360で対処されてきました.これは、ベクトルの代わりに錐を沿ってサブボリュームについて推論する方法ですが、このアプローチは現在のグリッドベースの技術とネイティブで互換性がありません.本研究では、レンダリングと信号処理のアイデアを組み合わせて、mip-NeRF 360とInstant NGPなどのグリッドベースのモデルを組み合わせることで、これまでの技術よりもエラー率が8%~76%低くなり、mip-NeRF 360よりも22倍高速にトレーニングができる技術を構築する方法を示しました.
Q&A:
Q: Zip-NeRFとはどのようなもので、最先端のベースラインとの比較はどのようなものですか?
A: Zip-NeRFは、スケールアウェアなアンチエイリアスNeRFと高速グリッドベースNeRFトレーニングを統合したモデルです.エラーレートを最大76%削減することができます
mip-NeRF 360ベンチマークのマルチスケールバリアントにおいて、ndトレインは従来の最先端技術より22倍速くなりました.また、ジッパー状のエイリアシングアーチファクトも修正されています.
Q: Zip-NeRFモデルの他のデータセットやアプリケーションへの汎用性、また開発時の限界や課題について教えてください.
A: Zip-NeRFモデルの開発中に遭遇した限界と課題は、グリッドベースの表現によってもたらされる空間的およびz-aliasingアーティファクトで、これはシーンのコンテンツの欠落やジャギーをもたらすことがあります.このモデルは、マルチサンプリングとプレフィルタを統合することでこれを克服し、先行技術よりも8%~76%低いエラーレートと、mip-NeRF 360よりも22倍速いトレーニングを実現しています.他のデータセットや逆レンダリングタスクを含むアプリケーションにも適用可能です.
Q: Zip-NeRFの開発や応用について、今後どのような方向性があるのでしょうか?
A: この論文では、Zip-NeRFで提示されたエイリアシングに関するツールと分析が、NeRFのような逆レンダリング技術の品質、スピード、サンプル効率の改善に向けてさらなる進展を可能にすることを示唆しています.したがって、将来の方向性として、他のNeRFライクなインバースレンダリングモデルに同様の技術を開発し適用することが考えられる.
Q: Mip-NeRFでは、サブボリューム内の座標の位置エンコードに対する積分を近似するために、どのように特徴量を用いているのですか?
A: Mip-NeRFは、サブボリューム内の座標の位置エンコードに対する積分を近似する特徴を使用します.これは、NeRFでは、キャストされるコーンに沿った円錐形のフラストラムを指します.この結果、各正弦波の周期がガウスの標準偏差より大きければ、振幅が小さいフーリエ特徴量が得られます.この特徴量は、サブボリュームの大きさよりも大きい波長でのみ、サブボリュームの空間的な位置を表現しています.この特徴は位置とスケールの両方を符号化するため、これを消費するMLPはマルチスケール表現を学習することができる.
Q: マルチサンプリング技術は、どのようにして小さなサンプルセットを構築し、それらのマルチサンプルの情報を集約して表現するのですか?
A: マルチサンプリング技術は、円錐形のフラストラムの形状に近似した小さなサンプルセットを構築します.これらのサンプルは、情報を集約して表現するために使用され、高価なレンダリングプロセスに提供されます.この戦略は、iNGPモデルで使用されているアプローチに似ています.小さなマルチサンプルのセットを使用し、情報をプールすることで、iNGPモデルはエイリアシングを減らし、レンダリング画像の品質を向上させることができる.
Q: Neural Radiance Field(NeRF)トレーニングにおいて、グリッドベースの表現を使用する目的は何でしょうか?
A: ニューラル・ラディアンス・フィールド(NeRF)トレーニングにおいてグリッドベース表現を使用する目的は、多層パーセプトロン(MLP)をボクセルグリッドに似たデータ構造で置き換えたり補強することでトレーニングを加速させることです.例えば、インスタントNGP(iNGP)は、粗いグリッドと細かいグリッドのピラミッドを使用して学習した特徴を構築し、小さなMLPによって処理されます.しかし、グリッドベースのアプローチでは、スケールを明示的に理解することができないため、通常はジャギーやシーンコンテンツの欠落という形で、エイリアシングが発生することが多い.
Q: Mip-NeRFとはどのようなもので、「ジャギー」の問題をどのように解決しているのでしょうか?
A: Mip-NeRFは、3Dグラフィックスのレンダリングにおける高速アンチエイリアシングに使用されるデータ構造である.レンダリング画像の各ピクセルを表す円錐の形状に近似したマルチサンプルのセットを事前に計算する.これにより、画像内のオブジェクトのエッジがギザギザにならず、滑らかになることを保証します.マルチサンプリング、統計学、信号処理のアイデアを、最終的な画像出力をレンダリングするニューラルネットワークと組み合わせて活用することで、これを実現しています.
Q: 第3節で導入された新しい損失関数とは何か、またオンライン蒸留時のz-aliasingの問題にどのように対処しているのか.
A: 3章で紹介した新しい損失関数は、オンライン蒸留の際に各レイに沿ってプレフィルタリングを行い、アンチエイリアスの性質により、すべての深さで前景と背景の両方を捉える提案分布を予測することにより、Zエイリアシングに対処することができます.
Q: レイがシーンコンテンツを「スキップ」する結果生じるアーティファクトはどのようなもので、どのように対処することができますか?
A: 光線がシーンコンテンツを「スキップ」するアーティファクトは、図4に見られるように、mip-NeRF 360の提案MLPにおける入力座標から出力体積密度への非平滑マッピングが原因であることがわかります.このアーティファクトは、提案ネットワークにMLPの代わりにNGPバックエンドを使用し、新しいアンチエイリアスレベル間損失関数を実装することで対処することができます.提案ネットワークを監督するために使用される以前の「レベル間損失」は、NeRFと提案ヒストグラムのビンが部分的に重なっていても、完全に重なっていても、同等の損失を割り当て、結果としてz-エイリアシングが発生しました.
Q: 本稿で紹介した新手法の実装はどこにあるのでしょうか?
A: 論文で紹介した新手法の実装は、http://github.com/google-research/google-research/tree/master/jaxnerf にあります.
AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models
著者:Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, Nan Duan
発行日:2023年04月13日
最終更新日:2023年04月13日
URL:http://arxiv.org/pdf/2304.06364v1
カテゴリ:Computation and Language, Artificial Intelligence
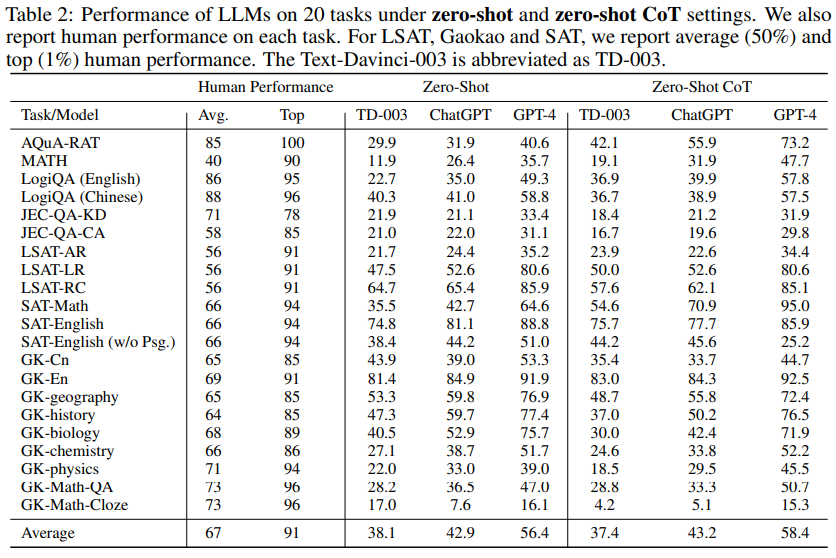
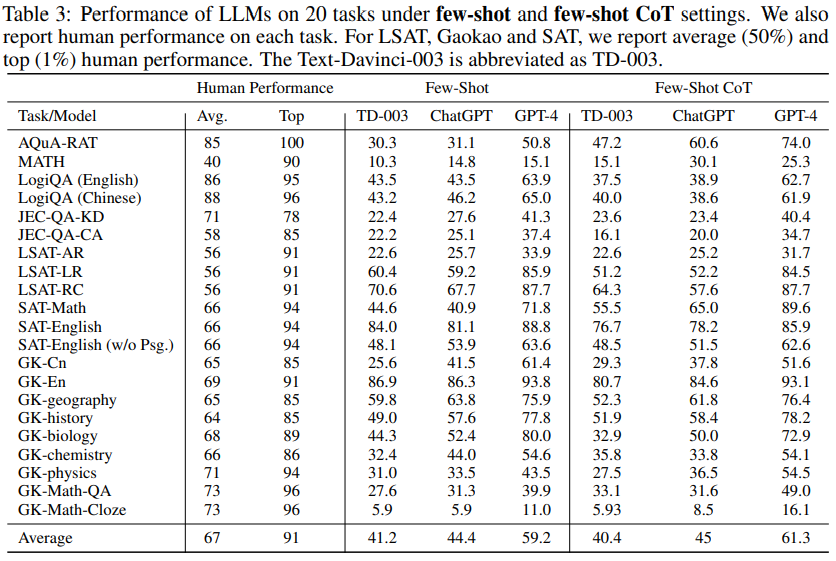
概要:
AGI(人工知能の一般的知的能力)の追求における基礎モデルの開発と適用において、特定のドメイン知識や複雑な推論が必要なタスクに対処することは、重要な課題です.本研究では、人間の認知と意思決定に関連するタスクに集中し、より意味のある評価ができるように特別に設計されたベンチマークであるAGIEvalを導入しました.基礎モデルの能力を評価するために、GPT-4、ChatGPT、Text-Davinci-003などの最新の基礎モデルをこのベンチマークで評価しました.そして、我々の包括的な研究は、これらのモデルの理解、知識、推論、計算能力を分析して、これらのモデルの強みと限界を明らかにしました.さらに、GitHubでデータ、コード、すべてのモデルの出力を公開しました.これらの結果は未来のAGIの追求に向けて、基礎モデルの一般的能力を向上させるための重要な示唆を提供します.
Q&A:
Q: AGIEvalの開発のきっかけは?
A: 人工的なデータセットに依存し、人間レベルの能力を正確に表現できない従来のベンチマークの限界から、人間の推論や問題解決に関連するタスクのコンテキストで基礎モデルをしっかりと評価できる、より人間中心のベンチマークであるAGIEvalの開発に着想を得ました.
Q: AGIEvalは従来のベンチマークとどう違うのですか?
A: AGIEvalは、大学入学試験、法科大学院入試試験、数学コンテスト、弁護士資格試験など、人間の認知や問題解決に関連するタスクで、基礎モデルの一般的な能力を評価するために特別に設計されたベンチマークです.オフィシャルで高い水準の一般的な人間のテスト・テイカー向け入学試験や資格試験から派生しており、中国語と英語の両方でバイリンガルなタスクをカバーするため、モデルの能力をより総合的に評価することができます. AGIEvalは、人工的なデータセットに依存する従来のベンチマークと比較して、人間中心のベンチマークを提供し、人間レベルの能力を正確に表現することができます.
Q: 今後、ファンデーションモデルの汎用的な機能を強化するために、どのような方向性が考えられるか?
A: 今後、基礎モデルの一般的な機能を強化するために、以下のような提案があります:
1.外部知識・公式の取り込み
2.多言語推論能力の強化
3.評価の枠組みをマルチモーダルなタスクに拡張する
4.人間中心のタスクに対して、より強固で意味のある自動評価指標を開発する.
5.モデルの推論能力の頑健性を向上させる.
このような将来の方向性に取り組むことで、基礎モデルはさらに発展し、人間の認知に近いより高度な機能を発揮できるようになり、最終的には、より正確で信頼性の高い、人間を中心とした幅広い複雑なタスクに取り組むことができるようになります.
Q: AIシステムの信頼性・信用性は、多様な場面でどのように確保されるのか?
A: 外部の知識や数式でモデルを豊かにする、多言語推論機能を強化する、マルチモーダルなタスクを含む評価フレームワークを拡張する、人間中心のタスクのためのより良い自動評価メトリックを開発する、推論機能の堅牢性を改善する、コンテキストや入力データが変化しても一貫した推論パフォーマンスを維持する技術を探求するなど、いくつかの将来の方向性が提案されています.これらの方向性は、現在のモデルに見られる弱点や限界に対処し、より広範で複雑な人間中心のタスクに取り組む際の性能を高めることを目的としています.
Q: Liangら(2022)が行ったNLP評価では、どのようなデータセットが使われたのでしょうか?
A: Liangら(2022)が行った評価は、Openbook QAやテキスト分類など、人間をテストする実世界のシナリオではなく、主に人工的にキュレーションしたNLPデータセットで行われました.しかし、この研究はChatGPTやGPT-4といった最新のLLMを対象としていなかった.
Q: OpenAIが公開したGPT-4の公式テクニカルレポート(2023年)には何が記載されているのか?
A: 2023年にOpenAIが公開したGPT-4の公式技術レポートでは、モデルの行動を人間の試験で評価することの重要性が強調され、GPT-4のいくつかの試験におけるパフォーマンスが分析されました.ただし、ベンチマークと対応するモデルの出力は公開されておらず、スコアリングは人間の専門家に依存しています.
Q: :AGIEvalを使用して実世界のシナリオで基礎モデルのパフォーマンスを評価することから得られる洞察は何ですか?
A: AGIEvalを通じた基盤モデルの性能評価は、実世界シナリオにおけるモデルの実地応用性、強みや限界、そして人間中心のタスクに対する正確性や信頼性を提供するインサイトをもたらすことができます.このベンチマークにより、改善が必要な領域を特定し、モデルのパフォーマンスを向上させることができ、最終的には幅広いアプリケーションにおいてユーザーのニーズにより適した、より効果的で信頼性の高いAIシステムを生み出すことができます.
Q: 言語モデルの推論能力、信頼性、実世界での適用性について、どのような懸念があるのでしょうか?
A: 様々なベンチマークで素晴らしい性能を発揮しているにもかかわらず、言語モデルの推論能力、信頼性、実世界での適用性についての懸念が提起されている.人間中心のタスクにおける大規模な基礎モデルの一般的な推論能力を評価する、より包括的なベンチマークが必要である.さらに、言語モデルは時に解を特定するのに苦労し、文脈の乱れに弱く、時にはある概念を別の類似の概念で密かに置き換え、不正確な推論や誤解を招くことがある.
Q: GLUE、SuperGLUEとはどのようなもので、言語モデルの性能をどのように評価するのですか?
A: GLUEとSuperGLUEは、言い換え識別や感情分析など、様々な自然言語処理タスクにおける言語モデルのパフォーマンスを評価する人気のベンチマークです.GLUEシリーズのベンチマークは、言語モデルの開発に大きな影響を与え、研究者にモデルの汎化能力を高めることを促しています.これらのベンチマークは、人間の行動を評価することを目的とした実世界の問題ではなく、特定のマシンスキルを評価するために設計された人工的なキュレーションデータセットで主に構成されています.その結果、これらのベンチマークは、実世界に適用可能な複雑な推論能力ではなく、より単純なテキスト理解に主眼を置いています.SuperGLUEは、言語モデルの評価基準をより厳しく設定した、汎用的な言語理解システムのための、より強固なベンチマークです.
Q: LAMBADA言語モデリングタスクの目的と、その評価について教えてください.
A: LAMBADA言語モデリングタスクの目的は、テキストの長距離依存関係を捉える言語モデルの能力を評価することです.与えられた文章の文脈情報に基づいて、最後の単語を予測するようモデルに要求することで、言語の理解能力を評価します.
Q: DecaNLPとはどのようなもので、どのように言語モデルを評価するのですか?
A: この文脈では、DecaNLPに関する情報は提供されていません.しかし、この文脈における言語モデルの評価基準は、大学入学試験や専門資格試験のような高水準の公的試験から得られた人間中心のタスクに基づいており、異なる言語や文化圏における言語モデルをより包括的に評価するために英語と中国の両方のタスクを網羅しています.その目的は、より人間の認知に近いモデルの開発を促進し、より幅広い複雑な人間中心のタスクに精度や信頼性を高めて取り組むことができるようにすることです.
Q: :高校数学競技大会の問題をベンチマークに取り入れることで、言語モデルが複雑で創造的な数学問題に対処する能力を評価する方法は何ですか?
A: 高校数学競技大会、例えばアメリカ数学競技会(AMC)やアメリカ招待数学試験(AIME)から課題を取り入れることで、言語モデルが複雑で創造的な数学問題を解く能力や新しい解決策を生み出す能力をより詳しく評価することができます.
Q: 人間中心ベンチマークは、現実世界の人間レベルの推論シナリオにおいて、基礎モデルの性能をどのように効果的に測定するのでしょうか?
A: A:ヒューマンセントリックな基準には、現実のシナリオに関連し、人間レベルの推論能力や問題解決能力が必要なタスクが含まれます.これらのタスクは、高等教育や新しいキャリアパスへの入学を希望する数百万人が受験する公式の入学試験、資格試験、コンペティションから派生しています.人間レベルの能力を評価するための公式に認められた基準に従うことにより、ベンチマーク設計は、モデルのパフォーマンス評価が人間の意思決定や認知能力に直接関係することを保証します.さらに、ベンチマークは、リアルワールドのタスクの微妙なニュアンスや複雑さを考慮しながら、モデルの理解力、知識、推論能力を評価します.
Q: GPT-4の実力と、GPTシリーズの従来機との比較について教えてください.
A: GPT-4は、GPTシリーズの前作と比較して性能が向上し、幅広い知識ベースを持つ、最先端の大規模な生成的事前訓練済みトランスモデルです.多くのシナリオで人間レベルの性能を発揮し、敵対的テストやChatGPTから得た知見をもとに繰り返し調整され、事実性、操縦性、ガードレールの遵守が著しく改善されました.GPT-4は、LSAT、SAT、数学の競技において、ゼロショット思考連鎖(CoT)設定で人間の平均的なパフォーマンスを上回り、人間中心のタスクでその能力を実証しています.しかし、GPT-4と人間の平均的な成績との間にはまだ差があり、今後の改善の余地があることが示されました.
Q: CoTプロンプティングは、モデルの推論能力を評価するためにどのように役立ちますか?
A: CoT促進法は、モデルが問題の理解と解決に必要な推論プロセスについて詳細な説明を生成するよう促すことで、モデルの推論能力を評価することができます.その後、モデルには自己生成された説明を考慮して回答を提供するよう求められます.このプロセスにより、モデルが自己の推論を使用して一貫性のある正確な解決策を導き出す能力がテストされます.これは、人間が問題を解決する際に自分の理解と内部推論プロセスに頼ることがよくあるように、シミュレートされます.
Q: 本稿で紹介した方法は、従来の方法と比較してどのようなメリットがあるのでしょうか?
A: 本稿で紹介する人間中心ベンチマークは、従来のベンチマークと比較して、人間の認知や問題解決に近いタスクに焦点を当て、より有意義かつ包括的に基礎モデルの一般的能力を評価する点で有利である.また、実社会で重要な意味を持つ課題に重点を置き、一般的な受験者を対象とした公的、公的、高水準の入学試験や資格試験を多様に用いている.さらに、このベンチマークは標準化された自動評価指標をサポートしており、人間の専門家による採点なしでは評価が難しい主観的な質問と比較して、より堅牢で標準的なものとなっています.
Q: 本論文の実用的な貢献は何ですか?
A: A:論文で紹介された人間中心のベンチマークは、現実世界での様々な人間レベルの推論シナリオにおける基礎モデルのパフォーマンスを測定し、政策決定、意思決定、および公共サービス提供プロセスへの貢献能力を評価するために設計されています.このベンチマークは、人間の認知と問題解決に密接に関連するタスクに重点を置き、実世界の状況に重要な意味を持つタスクに重点を置いています.入学や資格試験から派生したタスクを選択することにより、ベンチマークの設計はモデル性能の評価が人間の意思決定能力や認知能力に直接関連していることを保証します.最終的に、ベンチマークは、より信頼性が高く、実用的で、様々な実世界の問題に対処するのに適したAIシステムの開発に貢献することを目的としています.
Q: 本論文の理論的な貢献は何ですか?
A: この論文は、人間レベルのタスクの文脈で基礎モデルを評価することの重要性を強調し、そのような評価のためのベンチマークを提供します.また、理解、知識利用、推論、計算の観点から、これらのモデルの長所と限界についての洞察を提供します.本論文は、改善すべき点を特定し、その限界を理解することで、人工知能(AGI)に向けて前進する、より効果的で信頼性の高いAIアシスタントの作成に向けたイノベーションを推進することを目的としています.最終的には、幅広い用途でユーザーのニーズをよりよく満たす、より強力で信頼性の高いAIシステムを開発することを目標としています.
Q: この新方式に見られる困難は何ですか?
A: 論文では、主観的な質問に対するモデルの性能評価は、人間の専門家による採点なしでは困難であるため、一貫した評価のためにそのような質問はベンチマークから削除された、と述べています.また、他のベンチマークも存在しますが、この新しいベンチマークは、人間中心のタスクにおける大規模な基礎モデルの一般的な推論能力と実世界での適用可能性を評価することを目的としています.新ベンチマークの実装自体に問題があるとの指摘はない.
Q: 実験やデータ解析で得られた主な知見は何ですか?
A: この論文では、人間中心のタスクに取り組む上で、現在の大規模言語モデルのいくつかの長所と短所を明らかにしました.弱点は、変数置換の難しさ、複雑な数学の概念や記号への挑戦、類似の概念への混乱などです.一方、長所としては、問題解決などの領域で顕著な性能を発揮することが挙げられました.また、多様な知識ソースを取り入れることの重要性を強調し、モデル内でこれらの情報をより効果的に統合しアクセスできる技術を探求しています.
Q: 今後の研究課題として残っているものは何でしょうか?
A: 人間中心のタスクのためのファウンデーションモデルの能力の評価と強化には、多言語一般化の推論能力の強化、マルチモーダルタスクを含めた評価枠組みの拡大、より堅牢で意味のある自動評価指標の開発、モデルの推論能力の堅牢性の改善、そして一貫した推論パフォーマンスを維持する能力を強化する技術の探索を含む、さらなる研究が必要である.
Emergent autonomous scientific research capabilities of large language models
著者:Daniil A. Boiko, Robert MacKnight, Gabe Gomes
発行日:2023年04月11日
最終更新日:2023年04月11日
URL:http://arxiv.org/pdf/2304.05332v1
カテゴリ:Chemical Physics, Computation and Language
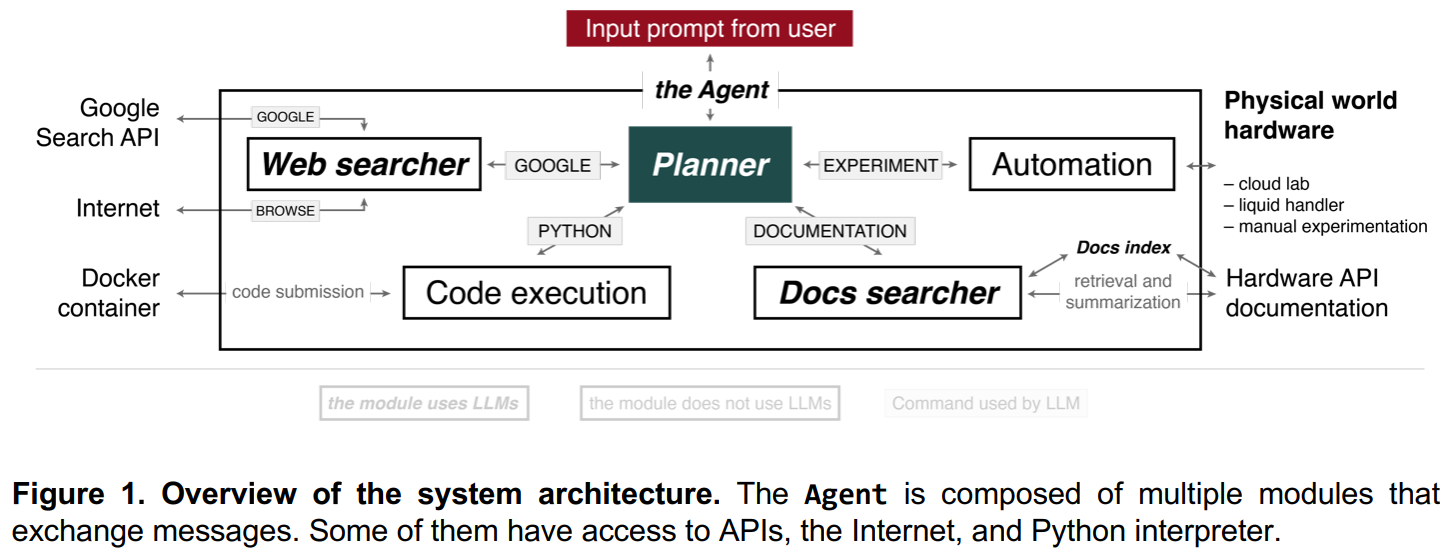
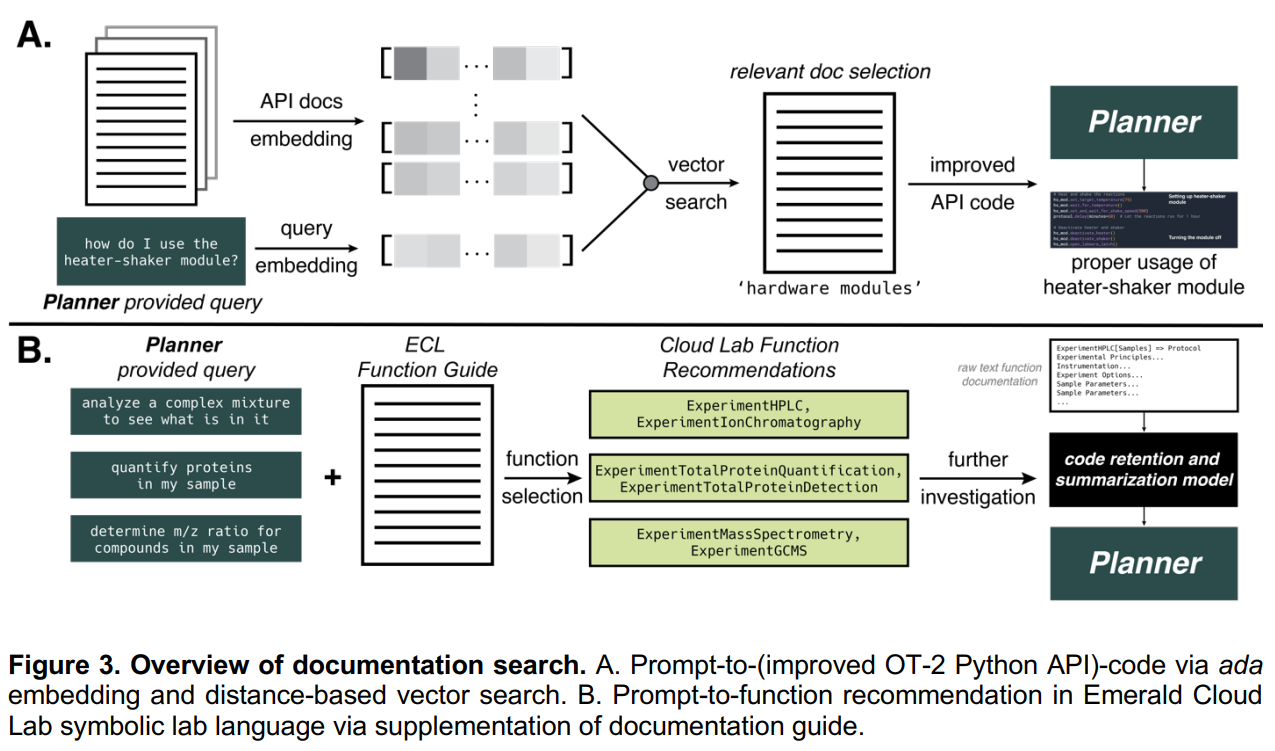
概要:
大規模言語モデルをベースにした機械学習技術は、自然言語、生物学、化学、そしてコンピュータプログラミングなどにわたる様々な分野で急速に進歩しています.極端なスケールと人間からのフィードバックを元にした強化学習により、生成されたテキストの品質が大幅に向上し、これらのモデルは様々なタスクを実行し、選択の理由を推論することができるようになりました.本論文では、多数の大規模言語モデルを組み合わせた「インテリジェント・エージェント・システム」を提示し、科学実験の自律的な設計、計画、実行に使用することを提案しています.複数の例を示し、最も複雑なものは触媒クロスカップリング反応の成功したパフォーマンスです.最後に、このようなシステムの安全性について議論し、誤用を防止するための措置を提案します.
Q&A:
Q: 大規模言語モデルはどのようなドメインへの適用に成功しているのでしょうか?
A: トランスフォーマーに基づく大規模言語モデルは、自然言語、生物学・化学研究、コード生成など、さまざまな領域への応用に成功している.
Q: 人間のフィードバックによる強化学習とはどのようなもので、大規模な言語モデルをどのように強化することができるのか?
A: 人間からのフィードバックによる強化学習は、生成されるテキストの品質や、大規模言語モデルが判断を推論しながら様々なタスクを実行する能力を高めることができる手法である.この手法では、特定の指示に従うようにモデルを訓練し、人間からのフィードバックを受けてパフォーマンスを向上させます.
Q: どの技術が生成されたテキストの品質を向上させ、モデルが決定について推論する際に多様なタスクを実行できるようにすることができますか?
A: 人間からのフィードバックによる強化学習は、生成されるテキストの品質や、大規模な言語モデルの能力を向上させ、その決定について推論しながら多様なタスクを実行することができる技術である.人間からのフィードバックを収集し、それを学習に取り入れることで、これらのモデルは問題解決能力を向上させ、複雑なタスクをより効果的に実行することができます.
Q: この文章に書かれている研究の目的は何でしょうか?
A: この研究の目的は、インターネットからのデータを組み合わせ、必要な計算を行い、液体ハンドラーのコードを書くことによって、複雑な化学実験を実行するエージェント(機械学習モデル)の性能を評価することである.また、この研究では、分子機械学習モデルをデュアルユース目的で使用することの安全性への影響も評価されています.
Q: この研究で評価された3つのタスクとは何ですか?
A: この研究は、エージェントが画期的な抗がん剤の開発、スズキ反応の機構の研究、そして触媒付きクロスカップリング反応の成功においてのパフォーマンスを評価しました.
Q: 資源や専門知識の乏しい研究者に対して、具体的にどのように科学資源を民主化するのでしょうか?
A: 論文で言及されたシステムは、リソースや専門知識が限られている研究者が科学実験をより利用しやすくする可能性があり、小規模な研究グループや個人が大規模な言語モデルやクラウドラボのサポートを受けて複雑な実験を行うことができ、より包括的な科学コミュニティを促進することができます.
Q: 創薬にAIを用いる場合、どのような倫理的配慮が必要でしょうか?
A: 創薬にAIを使用する際に考慮すべき倫理的配慮には、潜在的な二重使用の結果や、有害な目的での技術の誤用の可能性が含まれます.特に有害な物質や方法論が含まれる可能性のある実験など、センシティブな実験のレビューと承認のために、ヒューマンインザループの要素を取り入れることが推奨されます.さらに、データソースを継続的にキュレーション・更新し、複数のコンポーネントを安全に統合することで、データの品質と信頼性を維持することが重要である.
Q: 本論文の実用的な貢献は何ですか?
A: この論文では、実験プロセスを自動化し効率化することが可能なシステムの開発が提案され、これにより研究コストを削減し、科学的実験をより身近にし、異分野の協力を促進することができる.さらに、このシステムは教育ツールとしても活用できる.ただし、論文はシステムの責任ある、倫理的な利用を確保するために、解決する必要がある潜在的な課題やリスクも認識している.論文では、このシステムによって新しい抗がん剤の開発やスズキ反応のメカニズムの研究などの実例も紹介されている.
Q: この新方式に見られる困難は何ですか?
A: この論文は、科学実験を行うために機械学習システムや自動化された方法を使用することがもたらす潜在的な二重使用の結果と安全への影響について、特に不正活動の拡散と安全保障上の脅威に関連して懸念を示しています.本稿では特に、これらのツールを用いた違法薬物や化学兵器の合成に関連するリスクについて取り上げている.
Teaching Large Language Models to Self-Debug
著者:Xinyun Chen, Maxwell Lin, Nathanael Schärli, Denny Zhou
発行日:2023年04月11日
最終更新日:2023年04月11日
URL:http://arxiv.org/pdf/2304.05128v1
カテゴリ:Computation and Language, Artificial Intelligence
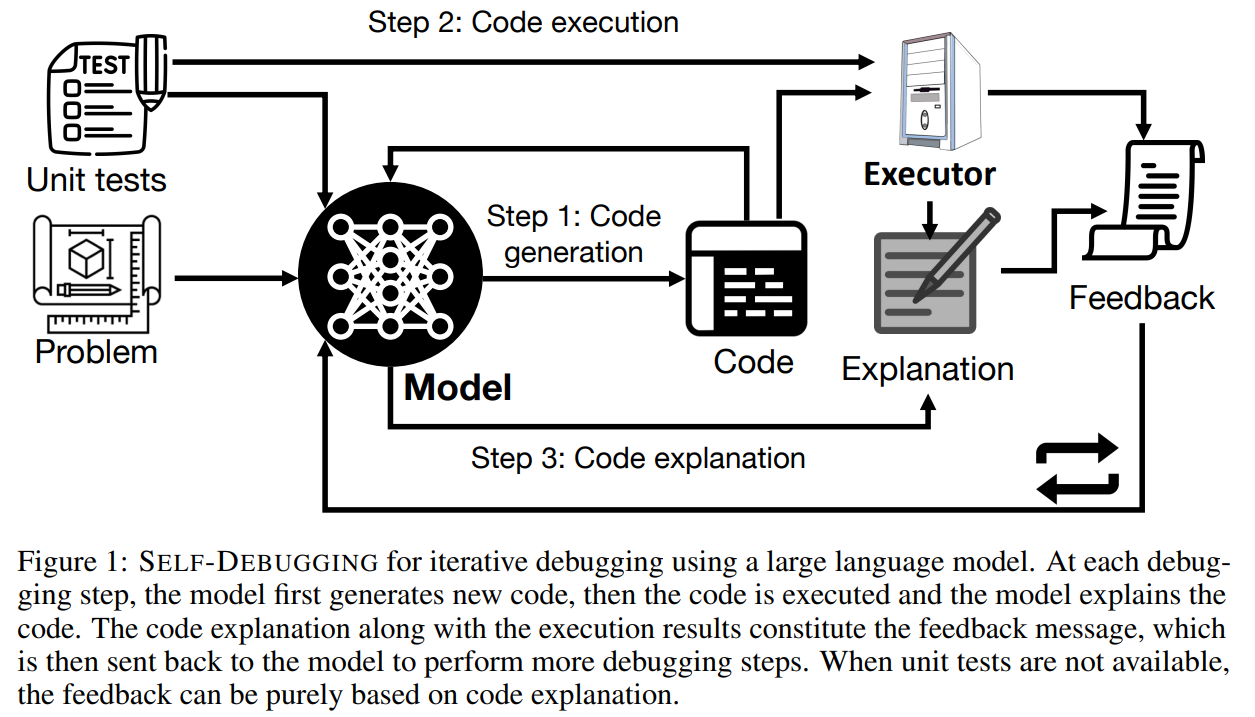
概要:
この研究では、自己デバッグという手法が提案され、大規模言語モデルを使用して、フュージョン・デモンストレーションによる予測プログラムのデバッグが可能になりました.この手法は、コード生成ベンチマークにおいて最先端のパフォーマンスを発揮し、最も難しい問題の予測精度を9%改善することができます.また、自己デバッグによって、テキストからPython生成のMBPPやC++からPythonへの変換のTransCoderなどで単体テストが可能なコード生成タスクにおいて、ベースラインの精度を最大12%改善することができます.さらに、失敗した予測を再利用し、フィードバックメッセージを活用することで、サンプルの効率性を高め、候補プログラムを10倍以上生成するベースラインモデルと同等以上の性能を発揮することができます.
Q&A:
Q: 人間の手を借りないセルフデバッグに言語モデルを使用する場合、どのような制限や課題が考えられるでしょうか?
A: この論文では、大規模な言語モデルに、数発のプロンプトによって自分自身が予測したコードをデバッグすることを教える、SELF-DEBUGGINGを提案しています.著者らは、外部からのフィードバックなしに、生成されたコードを自然言語で説明することを通じて、モデルが自分の間違いを特定し、ラバーダックデバッグを行うことができることを実証しています.しかし、言語モデルが、より複雑なプログラミングタスクに対して、人間の支援なしに自分自身で完全にデバッグできるかどうかは、まだ不明である.言語モデルを人間の支援なしに自己デバッグに使用することの潜在的な限界と課題は、依然として不確かなままです.
Q: ユニットテストを活用することで、デバッグのパフォーマンスはどのように向上するのでしょうか?
A: ユニットテストを活用することで、デバッグ性能が大幅に向上し、ユニットテストが利用できるコード翻訳やテキストからPythonへの生成タスクでは、最大で12%の精度の向上が期待できます.また、失敗したユニットテストの実行結果をフィードバックメッセージに表示することで、デバッグのための情報をより豊富に提供します.
Q: ユニットテストの実行やコードの説明を取り入れると、デバッグのパフォーマンスにどのような影響があるのでしょうか?
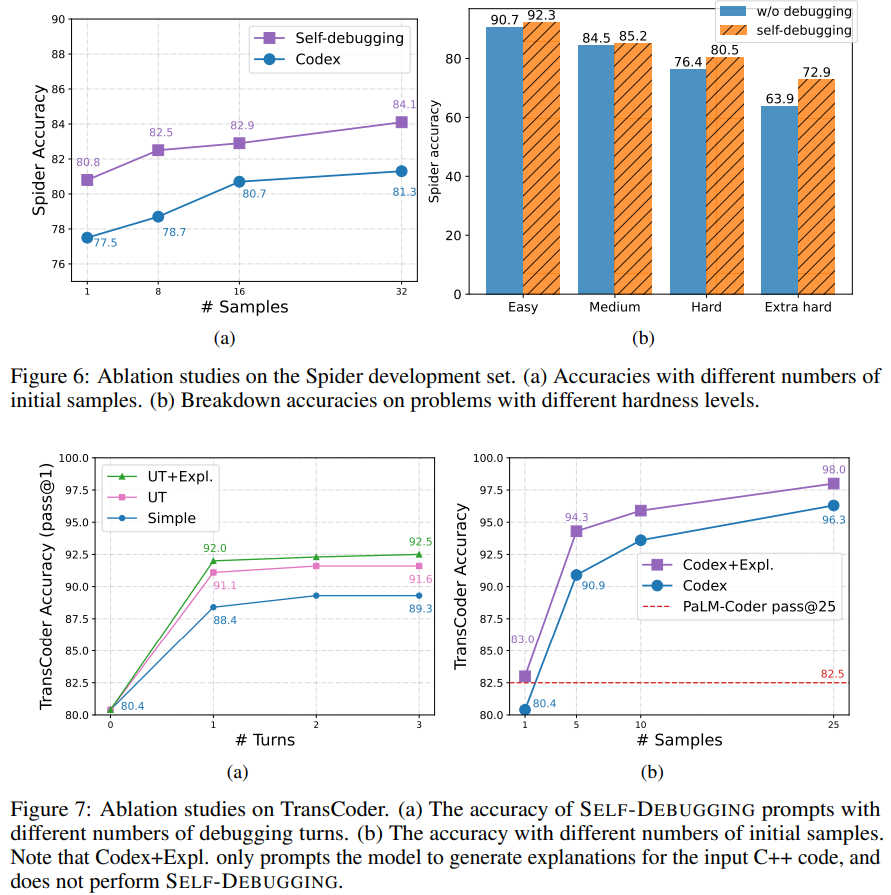
A: 図9と図10に示すように、ユニットテストの実行とコードの説明の両方を取り入れることで、デバッグのパフォーマンスが向上します.SELF-DEBUGGINGを行わず、コード説明のみを活用した場合も、サンプル数の違いで2~3程度の一貫した性能向上が見られます.しかし、ユニットテストが利用可能なコード生成タスクでは、コード説明による改善はあまり顕著ではありません.
Q: TransCoderデータセットとはどのようなもので、SELF-DEBUGGINGの実験にどのように利用されているのでしょうか?
A: TransCoderデータセットは、異なるプログラミング言語の並列関数のテストセットをユニットテストとともに含むデータセットである.SELF-DEBUGGINGの実験では、CコードをPythonコードに翻訳するタスクにTransCoderデータセットを使用し、予測されたPythonコードがすべてのユニットテストに合格しない場合にのみSELF-DEBUGGINGが適用されます.これにより、SELF-DEBUGGINGはコード翻訳の精度を最大12%向上させる.
Q: SELF-DEBUGGINGをgreedy decodingに適用した場合、5サンプルと10サンプルでのベースライン精度と比較してどうなるか?
A: SELF-DEBUGGINGを適用したgreedy decodingは、5サンプルでベースラインの精度を上回り、10サンプルでベースラインの精度に近づきました.
Q: Spider、TransCoder、MBPPベンチマークにおいて、SELF-DEBUGGINGは最先端のアプローチと比較してどうなのか?
A: SELF-DEBUGGINGは、3つのベンチマーク(Spider、TransCoder、MBPP)すべてで最先端を達成し、デバッグを行わないベースラインと比較して性能を大幅に向上させた.ユニットテストが利用できないSpiderベンチマークでは、SELF-DEBUGGINGは常にベースラインを2-3%改善し、最も難しいラベルの問題では予測精度を9%向上させた.ユニットテストが利用できるTransCoderとMBPPでは、SELF-DEBUGGINGはベースラインの精度を最大で12%向上させる.
Q: セルフデバッグはどのように予測精度を向上させるのでしょうか?
A: SELF-DEBUGGINGは、モデルにゼロから正しいコードを生成させるのではなく、言語モデル自身が繰り返しデバッグするように教えることで、言語モデルの予測精度を向上させます.コードを理解し、エラーを特定し、エラーメッセージに従ってバグを修正するようにモデルに指示します.このアプローチにより、ユニットテストが利用可能なタスクでは、ベースラインの精度が最大12%まで大幅に向上します.さらに、SELF-DEBUGGINGは、いくつかのコード生成領域で最先端の性能を達成し、サンプルの効率を顕著に向上させる.
Q: SELF-DEBUGGINGに関連して、「リッチなフィードバック信号」とはどういう意味か?
A: A:SELF-DEBUGGINGにおける、より「リッチなフィードバック信号」とは、コードが正しいかどうかを示すだけの単純なフィードバックではなく、ユニットテストの実行結果やコードの説明などの付加情報を提供するフィードバックメッセージのことです.これらの付加的なシグナルは、大規模言語モデルのデバッグ性能の向上に貢献します.
Q: 本稿で紹介した方法は、従来の方法と比較してどのようなメリットがあるのでしょうか?
A: 本論文で紹介するSELF-DEBUGGINGという手法は、いくつかのコード生成領域において最先端の性能を達成し、サンプルの効率を顕著に向上させることができます.また、この手法では、大規模な言語モデルがラバーダックデバッグを行うことができ、人間の指示なしにバグを特定し修正することができる.コード修復モデルのための追加トレーニングや、再ランク付けのための数十のサンプルを必要とする以前のアプローチと比較して、SELF-DEBUGGINGはコード生成タスクに対してより効率的で効果的なソリューションを提案する.
Q: 本論文の実用的な貢献は何ですか?
A: 本稿で紹介するSELF-DEBUGGING法の実用的な貢献は、大規模言語モデルが自ら生成したコードをデバッグできること、複数のコード生成領域で最先端の性能を発揮すること、サンプル効率を向上させることです.また、ラバーダックデバッグを実行し、人間の指示なしにバグを特定し修正することをモデルに可能にする.本手法は、タスクに指定されたユニットテストがないtext-to-SQL生成では一貫してベースラインを2~3%改善し、ユニットテストがあるコード翻訳とtext-to-Python生成タスクではベースラインの精度を最大で12%改善することができました.
Q: この新方式に見られる困難は何ですか?
A: この論文は、ユニットテストや人の指示などの外部フィードバックがない場合、大規模な言語モデルがコードを修正する能力をまだ持っていないことを示唆しており、SELF-DEBUGGING方法の実装には課題があることを示唆しています.さらに、論文では、モデルがコードを理解するすべてのステップを実行し、エラーを特定し、エラーメッセージに従ってバグを修正する能力を向上させることの重要性についても議論されており、外部のガイダンスなしにモデルに自己デバッグの能力を完全に教えることにまだ困難がある可能性があると示唆されています.
Q: 実験やデータ解析で得られた主な知見は何ですか?
A: 論文における実験とデータ分析から得られた主な結果は、SELF-DEBUGGINGがコード生成タスクにおいて最先端の性能を達成し、サンプル効率を向上させ、ユニットテストが利用できるタスクではベースラインの精度を最大12%まで大幅に向上させるというものであった.また、この方法は、ユニットテストが指定されていないタスクでは、一貫してベースラインを2〜3%向上させ、最も難しい問題で9%の性能向上を実現する.さらに、本論文では、コード説明能力の向上がデバッグ性能の向上につながることを示唆し、大規模言語モデルに自身の予測値を反復的にデバッグするように教えることで、コーディング性能の向上が期待できることを強調しています.
Q: 今後の研究課題として残っているものは何でしょうか?
A: SELF-DEBUGGINGの実装後にさらなる研究の課題として考えられるのは、モデルがデバッグに関わるすべてのステップ、つまりコードの理解、エラーの特定、エラーメッセージの追跡などを実行する能力を向上させることです.また、潜在的なバグの説明など、モデルフィードバックに追加のデバッグ情報を含める研究方向もあります.
ChemCrow: Augmenting large-language models with chemistry tools
著者:Andres M Bran, Sam Cox, Andrew D White, Philippe Schwaller
発行日:2023年04月11日
最終更新日:2023年04月12日
URL:http://arxiv.org/pdf/2304.05376v2
カテゴリ:Chemical Physics, Machine Learning
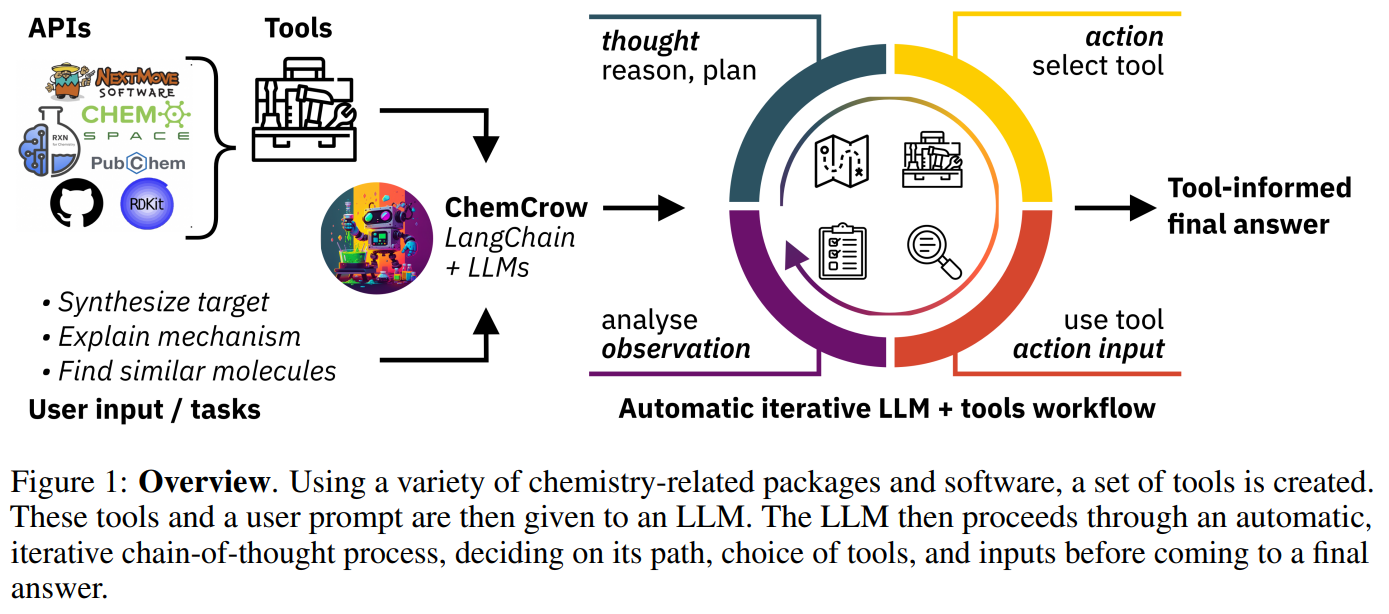
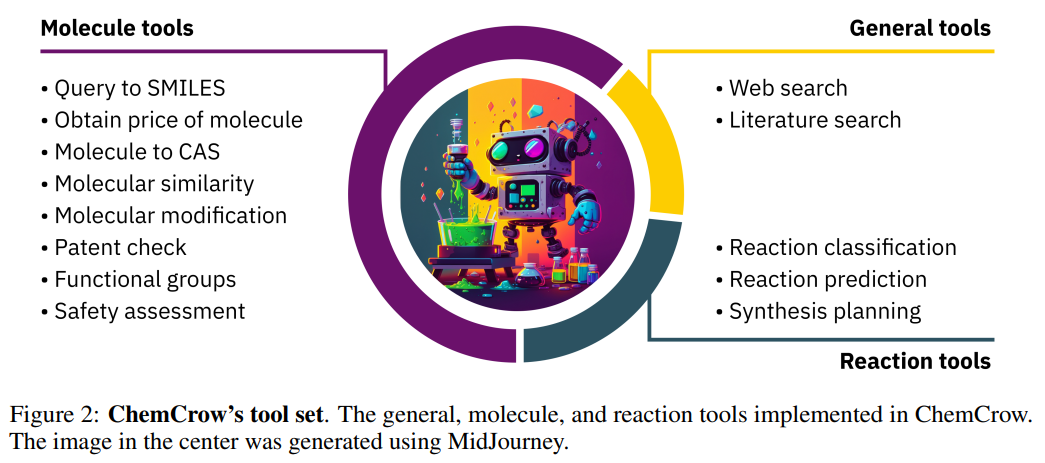
概要:
最近の大規模言語モデル(LLM)は、様々な分野で強力なパフォーマンスを示していますが、化学に関連する問題には苦戦しています.さらに、これらのモデルは外部の知識源にアクセスできないため、科学的な応用においてその有用性が制限されています.本研究では、有機合成、薬物発見、材料設計といった様々な化学タスクを自動化するために設計されたLLMの「ChemCrow」を発表します.13の専門家によって設計されたツールを統合することで、ChemCrowは化学におけるLLMのパフォーマンスを向上させ、新しい機能が生まれます.専門家による人間の評価とLLMによる評価を両方含めた評価により、ChemCrowが様々な化学タスクの自動化に効果的であることが示されました.驚くべきことに、評価者としてGPT-4を用いたところ、間違っていると明らかなGPT-4の完了とGPT-4 + ChemCrowのパフォーマンスを区別することができませんでした.このようなツールの誤用のリスクがあることを指摘し、その潜在的な危険性について議論しました.適切に利用されれば、ChemCrowは専門家化学者を支援し、非専門家のバリアを下げるだけでなく、実験と計算化学の間のギャップを埋めることで科学の進歩を促すことができます.
Q&A:
Q: 大規模言語モデル(LLM)の限界と苦手とするタスクは?
A: LLMはしばしば基本的な数学や化学の操作に苦しみ、数字の乗算やIUPAC名を対応する分子グラフに変換するなど、一貫して正確に作業を実行できないことがあります.これらの制限は、モデルの中心的な設計に起因しており、その設計は次の単語を予測することに焦点を当てています.
Q: ChemCrowは一般的な化学エンジンとどう違うのですか?
A: ChemCrowは、一般的な化学エンジンとは異なり、化学関連のタスクにおいて大規模言語モデルの性能を強化するために、専門家が設計した13のツールを統合しています.さらに、ChemCrowは正確な化学知識にアクセスするためのシンプルなインターフェースを提供しているため、専門家でなくても簡単に使用することができます.しかし、実験には十分な実験経験が必要であるため、結果を評価するための化学的推論や適切な実験トレーニングを持たない非専門家にとっては、潜在的なリスクが発生する可能性があることに注意する必要があります.
Q: LLM搭載エンジンが提供する情報を批判的に評価し、確立された文献や専門家の意見と相互参照することをユーザーに促すメリットは何でしょうか?
A: LLM(機械学習)エンジンによって提供される情報を確立された文献や専門家の意見と照合することで、欠陥のある推論に依存するリスクをさらに低減することができます.ユーザーに情報を批判的に評価するよう促すことで、ChemCrowのようなLLMエンジンの全体的な効果を高めることができます.これは、不十分な化学知識がエンジンの推論プロセスに与える影響を最小限に抑えることで、LLMエンジンを安全かつ責任ある方法で適用することが重要です.
Q: LLMを搭載した化学エンジンを責任を持って開発・使用するために、倫理的な問題や知的財産の問題に対処することが極めて重要なのはなぜですか?
A: ChemCrowのような生成AIモデルの責任ある開発と使用を保証するためには、倫理的な懸念と知的財産の問題に対処することが必要です.知的財産を保護するために、生成された化学構造や材料の所有権、および専有情報の悪用の可能性に関するより明確なガイドラインやポリシーを確立する必要があります.法律や倫理の専門家、業界の関係者とのコラボレーションは、こうした複雑な問題を解決し、適切な対策を実施する上で役立ちます.
Q: 高度な化学概念の理解を強化するためにトレーニングデータの品質と幅をいかに改善できるか.
A: LLM駆動の化学エンジンの品質と幅を向上させるためのいくつかの方法には、より高度な化学知識を取り入れることや、複雑な化学概念のLLMの理解を改善することが含まれます.開発者はまた、より広い範囲の化学反応や物性を含むトレーニングデータの範囲を拡大することに重点を置くことができます.
Q: LLMを搭載した化学エンジンに関するリスクを最小限に抑えるために、どのような効果的な緩和策を講じることができるのか.
A: LLMプラウアード化学エンジンに関連するリスクを最小限に抑えるために実装できる効果的な緩和戦略には、モデル幻覚の問題を緩和するための専門家デザインのツールを統合し、複雑な化学概念のエンジンの理解を向上させるためのトレーニングデータの品質と幅を向上させ、アクセス制御、安全指導、倫理方針を実施することが含まれます.エンジンの出力に明確な安全警告とガイドラインを含める、生成された化学構造物または物質の所有権に関するより明確なガイドラインと方針を確立する、知的財産を保護し倫理に準拠する適切な措置を実施するために法的および倫理的専門家、業界利害関係者と協力することが含まれます.さらに、検証またはピアレビューシステムを内蔵し、LLMパワードエンジンによって提供される情報を批判的に評価するようユーザーを奨励することでリスクをさらに緩和できます.
Q: ChemCrowが解決できる化学分野の推論タスクにはどのようなものがありますか?
A: ChemCrowは、標的分子の合成、安全管理、類似の作用モードを持つ分子の検索など、有機合成、創薬、材料設計にわたるタスクを実行できます.
Q: ChemCrowは、将来のケミカルアシスタントの開発において、どのような可能性を示しているのでしょうか?
A: ChemCrowは、化学分野における大規模言語モデルの性能を増強するために専門家が設計したツールを統合し、有機合成、創薬、材料設計など多岐にわたる化学作業を自動化することで、将来の化学アシスタントの発展の可能性を示しています.また、正確な化学知識にアクセスするためのシンプルなインターフェースを提供し、専門家である化学者のアシスタントとして機能すると同時に、非専門家にとっての参入障壁を低くしています.ただし、化学の専門家でない場合、結果を評価するための化学的な推論や適切なラボのトレーニングが必要であり、潜在的なリスクが生じる可能性があることに留意する必要がある.
Q: 今後の研究課題として残っているものは何でしょうか?
A: LLMを活用した化学エンジン及び関連するAIモデルの開発・利用における今後の課題として、LLMの限界への対応、生成された化学構造物や材料の所有権及び潜在的な誤用に関する明確なガイドラインや政策の策定、モデルの幻覚リスクを軽減するための専門家が設計したツールの統合、複雑な化学概念を理解するエンジンのトレーニングデータの質と範囲の向上、アクセス制御、安全ガイドライン、倫理的ポリシーなどの有効な緩和策の実装が含まれます.また、開発者、利用者、業界関係者による協力と監視が、LLMを活用した化学エンジン分野における責任あるイノベーションと進歩の促進に必須です.
Automatic Gradient Descent: Deep Learning without Hyperparameters
著者:Jeremy Bernstein, Chris Mingard, Kevin Huang, Navid Azizan, Yisong Yue
発行日:2023年04月11日
最終更新日:2023年04月11日
URL:http://arxiv.org/pdf/2304.05187v1
カテゴリ:Machine Learning, Artificial Intelligence, Numerical Analysis, Neural and Evolutionary Computing, Numerical Analysis, Machine Learning
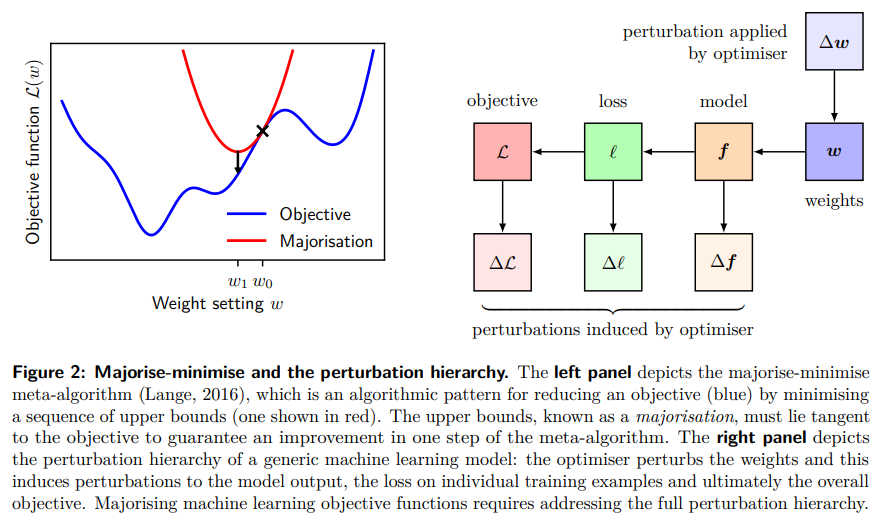
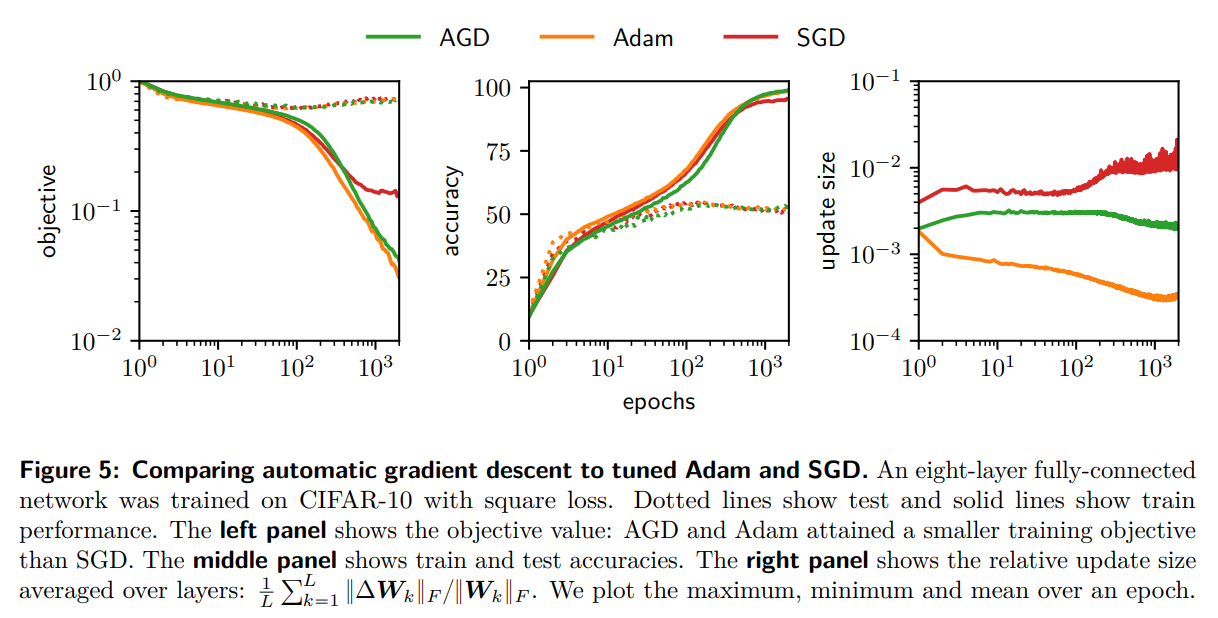
概要:
この論文では、ニューラルネットワークのアーキテクチャに着目した最適化アルゴリズムを導き出す新しいフレームワークを構築し、非凸性のある複合目的関数に対するBregman距離を変換することで、ミラー降下法を深層ニューラルネットワークに適用することができることが明らかになりました.また、ハイパーパラメータを必要としない自動勾配降下法が導出できるため、完全に接続されたネットワークや畳み込みネットワークの両方の学習で使用でき、ImageNetスケールでも適用可能です.これにより、次世代の深層ニューラルネットワークのための厳密な理論的基盤を提供し、アーキテクチャに依存する最適化フレームワークを自動的に、かつハイパーパラメータなしで動作可能にすることができます.詳細な実装は、https://github.com/jxbz/agdにてPyTorchで提供されています.
Q&A:
Q: 論文の焦点は何ですか?
A: この論文の焦点は、凸解析と深層相対信頼のツールを使用して、損失関数や重みとのネットワークの相互作用を分析する「次世代」ニューラルネットワークの理論的な基盤を提供することにあります.論文のわかりやすさは、将来の開発の良い出発点となります.
Q: ディープネットワークの学習に関して、AGDはAdamやSGDと何が違うのでしょうか?
A: AGDは、デフォルトのハイパーパラメータを持つAdamやSGDが訓練できないネットワークを訓練することができます.また、AGDはCIFAR-10上のResNet-18でAdamとSGDのベストチューニング性能と同等の性能を達成し、ImageNetの訓練にもスケールアップする.
Q: ディープラーニングにおけるハイパーパラメータを排除するための解決策を提案してください.
A: 深層学習におけるハイパーパラメーターを排除するためのソリューションとして、ハイパーパラメーターを持たないニューラルネットワークの最適化である自動勾配降下(AGD)の利用を提案しています.これは、深層学習の構成要素を個別に、またそれらがどのように相互作用するかを特徴付けることによって達成され、調整すべき自由度を残さない.このアプローチは、一般的な機械学習のワークフローを自動化し、ハイパーパラメータの豊富さと不透明さを低減するのに役立つ可能性があります.
Q: 機械学習の目的関数のメジャー化において、完全な摂動階層に対応するためにはどのような手順が必要でしょうか?
A: 機械学習の目的関数のメジャー化において、摂動階層を完全に扱うために必要なステップは、現在の反復における目的関数の線形化の妥当性の領域を理解し、摂動階層の観点から機械学習システムの線形化誤差の非常に一般的な分解を導き、重み、モデル出力、個々の学習例における損失、最終的に全体的な目的関数に対して最適化が引き起こす摂動を扱うことです.機械学習の目的関数を主要化するには、摂動階層をすべて扱う必要があります.
Q: majorize-minimizeメタアルゴリズムは、機械学習における一般的な最適化問題にどのように適用されるのか、また、関数展開という新しい手法とはどのようなものか.
A: majorize-minimizeメタアルゴリズムは、機械学習における最適化アルゴリズムの導出に用いられるアルゴリズムパターンであり、ある整数kに対してテイラー級数のk次までの目的と一致する目的の上界を導出する.これは、機械学習における非凸複合目的関数に対する最適化アルゴリズムを導くための枠組みである関数展開という新しい技術で実現することができます.これは、新しい損失関数に対してはブレグマンダイバージェンスを、新しい機械学習モデルに対してはアーキテクチャ摂動境界を書き出すことで適用することができる.このフレームワークは、機械学習システムにおけるハイパーパラメータの多さと不透明さを軽減するように設計されている.
Q: 安定ランクはどのように行列のランクの近似値を提供するのか、また、なぜこれが特定のアプリケーションで有用なのか?
A: 行列の安定ランクは、小さな特異値を無視することでそのランクを近似します.これは、入力データやパラメータの小さな摂動が、行列の全体的な構造に大きく寄与しない小さな特異値をもたらすような状況で有用である.例えば、機械学習の用途では、安定ランクはデータセットやモデルの有効次元を特定するのに役立ち、モデル選択や正則化を支援することができる.その他、線形回帰、画像処理、数値最適化などにも応用されています.
Q: 本論文の理論的な貢献は何ですか?
A: この論文の理論的な貢献は、ブレグマンダイバージェンスを用いて、ニューラルネットワークが損失関数とどのように相互作用するかを特徴付けることと、深層相対信頼を用いて、重みとネットワーク出力の間の非線形性の高い相互作用を特徴付けることです.
OpenAGI: When LLM Meets Domain Experts
著者:Yingqiang Ge, Wenyue Hua, Jianchao Ji, Juntao Tan, Shuyuan Xu, Yongfeng Zhang
発行日:2023年04月10日
最終更新日:2023年04月12日
URL:http://arxiv.org/pdf/2304.04370v2
カテゴリ:Artificial Intelligence, Computation and Language, Machine Learning
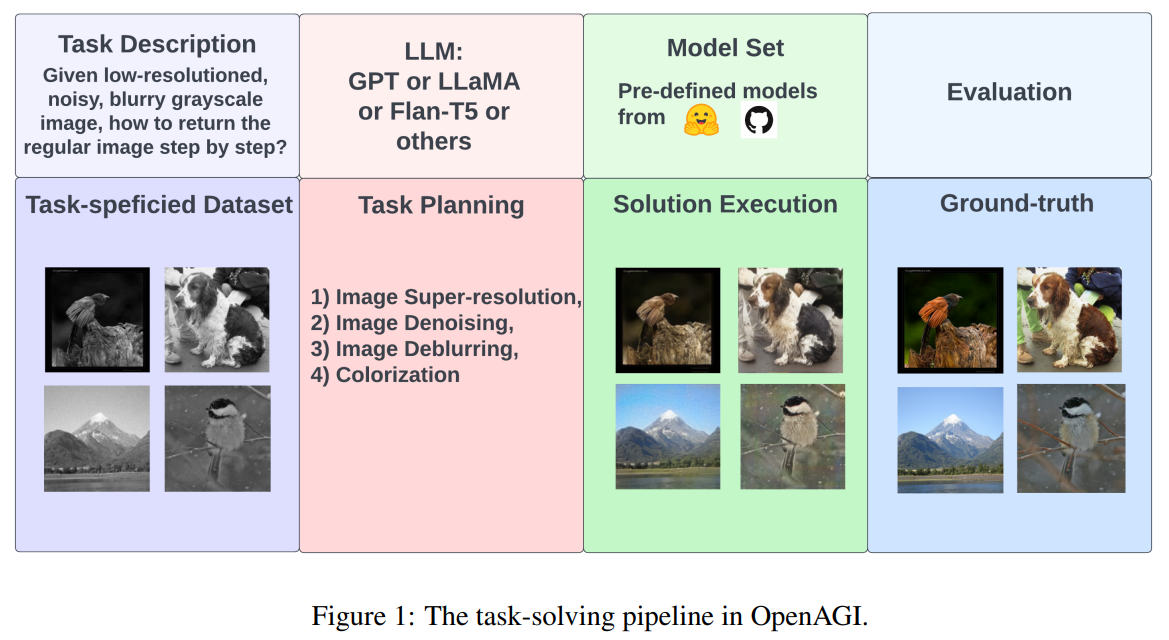
概要:
人工知能(AI)にとっても同じく重要であり、大規模で包括的な知能モデルを開発することと同様に、専門的なモデルを組み合わせて複雑なタスク解決のための能力を備えることが重要であると主張されています.最近の大規模言語モデル(LLMs)の発展により、驚異的な学習能力と推論能力が示され、複雑なタスクを解決するための外部モデルの選択、合成、実行に適したコントローラーとして有望視されています.このプロジェクトでは、オープンソースのAGI研究プラットフォームであるOpenAGIを開発しています.OpenAGIは、自然言語クエリを複雑なタスクとして定式化し、LLMの入力として提供します.その後、LLMはOpenAGIが提供するモデルを選択し、合成し、実行してタスクを解決します.OpenAGIプロジェクトでは、OpenAGIが提供するモデルを実行することでタスク解決に責任を持つLLMによる外部モデルの選択、合成、実行が行われます.また、OpenAGIでは、タスク解決の結果をフィードバックとして使用するRLTFメカニズムを提案しています.これにより、LLMは複雑なタスクを解決するために様々な外部モデルを合成できる一方、RLTFはタスク解決能力を改善するフィードバックを提供し、自己改善するAIのフィードバックループを実現します.今後AGIの長期的な改善と評価を促進するため、OpenAGIプロジェクトのコード、ベンチマーク、評価方法は、https://github.com/agiresearch/OpenAGIでオープンソース化されます.
Q&A:
Q: この研究プロジェクトの目的は何ですか?
A: この研究プロジェクトの目的は、AGI研究者がオープンソースパイプラインを構築し、言語生成タスクの分野における共同進歩に貢献し、コミュニティの長期的な発展を促進することです.
Q: OpenAGIとはどのようなもので、どのような目的で作られたのでしょうか?
A: OpenAGIの目的は、LLM駆動の(オープンドメインの)モデル合成に焦点を当て、様々なドメインエキスパートモデルの操作を通じて、複雑で多段階のタスクを解決する大規模言語モデル(LLM)の開発および評価を促進することである.このプラットフォームは、Hugging FaceとGitHubのリソースを主に利用し、拡張可能なモデルとデータセットを幅広く提供します.このプラットフォームは、LLMの包括的な計画・タスク解決能力の定量化を支援し、最終的に人工知能(AGI)の追求に貢献することを目的としています.
Q: OpenAGIでは、複雑な課題を解決するためにLLMをどのように利用しているのでしょうか?
A: OpenAGIの複雑なタスクの解決に向けたアプローチは、LLMsをコントローラーとして使用し、タスク解決のためにさまざまな外部エキスパートモデルを選択、合成、実行します.このアプローチはLLM + RLTFアプローチと呼ばれ、タスクから得られるフィードバックを使用して、LLMの計画戦略を磨き上げ、LLMの全体的なパフォーマンスとタスク解決能力を向上させます.OpenAGIはまた、各種の拡張可能なモデルを提供し、これらのタスクを効果的に解決するために合成することができます.プラットフォームは、複雑なタスクを自然言語クエリとして定式化し、LLMに入力として提供します.
Q: OpenAGIプラットフォームに外部ユーザーはどのように貢献できるのか、また、コードやデータセットをオープンソース化するメリットは何か?
A: OpenAGIプラットフォームでコードとデータセットをオープンソース化するメリットは、コミュニティにおけるAGI能力のオープンで長期的な改善と評価を促進することです.外部ユーザーは、コードとデータセットを利用してAGIモデルを開発し、その結果や改善点をコミュニティと共有することで、プラットフォームに貢献することができます.
Q: Reinforcement Learning from Task Feedback (RLTF)メカニズムは、LLMの計画戦略をどのように改良しますか?
A: OpenAGIプラットフォームのRLTFメカニズムは、タスク解決の結果をフィードバックとして使用し、LLMのタスク解決能力を向上させるために使用されます. Large Language Model(LLM)は、複雑なタスクを解決するためにさまざまな外部モデルを選択、合成、実行します.これらのタスクから得られたフィードバックを使用して、LLMの計画戦略を磨き、全体的なパフォーマンスとタスク解決能力を向上させます.このように、プラットフォームは自己改善型AIのフィードバックループを可能にします.
Q: 非線形タスクプランニングは、複数の入力に対する並列処理という課題にどのように対処しているのでしょうか?
A: 非線形タスクプランニングは、多様な入力をより効果的に統合し、より効率的にモデルの並列処理を行い、目的の結果を得ることを可能にするために提案された手法である.ビームサーチを半自己回帰的な復号化手法として利用し、異なる仮説を競合する仮説としてではなく、異なる入力に対する並列的な実行可能解として扱うことができる.複数の入力に対する並列処理が必要なタスクの場合、各入力に対する実行可能な解を生成し、並列に実行することができます.これにより、複数の並列解を効率的に実行することができ、複数の入力に対する並列処理の課題を解決することができる.
Q: OpenAGIプラットフォームが、複雑なマルチタスクを処理するために特別に設計されていることを説明してもらえますか?
A: OpenAGIプラットフォームは、複雑なマルチステップのタスクを、それぞれのデータセット、評価方法、そしてこれらのタスクを効果的に解決するために合成できる多様な拡張可能なモデルとともに提供するように特別に設計されています.
Q: 本論文で提案したアプローチに限界はありますか、あるとすれば今後どのように対処していくのでしょうか?
A: この研究で提案された手法の制限は、拡張性、非線形タスクプランニング、定量的評価の欠如です.今後の研究でこれらの制限に対処するために、著者らは、各単一ステップタスク内に複数のモデルを統合し、ビデオやオーディオなどの代替モダリティからのデータセットを統合し、評価メカニズムを強化し、人間をループに組み込み、自動化されたタスク生成技術を探求することを目指しています.また、タスクから得られたパフォーマンスフィードバックに基づいてLLMの計画戦略を洗練するための強化学習フロムタスクフィードバック(RLTF)というメカニズムも紹介しています.
Q: OpenAGIでは、複雑なタスクをどのように策定しているのか、また、タスク解決プロセスにおけるLLMの役割は何か?
A: OpenAGIは、複雑なタスクを自然言語クエリとして定式化し、大規模言語モデル(LLM)への入力として使用します.LLMは、OpenAGIが提供する外部のエキスパートモデルを選択、合成、実行し、タスクに対処します.LLMは、複雑なタスクを解決するために様々な外部モデルの合成を担当し、タスクフィードバックからの強化学習(RLTF)メカニズムが、タスク解決能力を向上させるためのフィードバックを提供します.これにより、自己改善型AIのためのフィードバックループが形成されます.LLMは、異なるドメインの知識やスキルを統合することで、Open-domain Model Synthesis(OMS)において重要な役割を果たし、人工知能(AGI)の開発を推進する可能性を持っています.
Q: 拡張言語モデル(ALM)の分野が目指している、従来のLLMの限界とは何でしょうか?
A: ALMは、従来のLLMの限界である、不正確な予測をすることがある、専門的な知識が必要な問題に対処することが難しいといった問題を解決することを目的としています.そのために、LLMに推論能力を強化し、外部リソースを利用する機能を持たせています.
Q: RLTFや非線形タスクプランニングとは何か、また、分布外汎化(OOD)に関する課題をどのように解決するのか.
A: RLTF(Reinforcement Learning from Task Feedback) は、タスクからのパフォーマンスフィードバックを取り入れて、LLMの計画戦略を改良し、より適応性の高いシステムを実現するメカニズムである.このアプローチは、OODの汎化問題(ドメイン固有モデルが訓練データの分布に依存するため、汎化能力に限界がある)を解決するのに役立ちます.一方、非線形タスクプランニングでは、異なるモデルを組み合わせて解を生成するため、最適なアプローチを特定することが困難な場合があります.RLTFと非線形タスクプランニングの組み合わせは、LLMがOOD問題に対処するための選択肢の幅を広げることになります.
Q: OpenAGIプラットフォームが、コミュニティにおけるAGI能力のオープンで長期的な改善・評価を促進することをどのように想定していますか?
A: OpenAGIプラットフォームは、様々なドメインエキスパートモデルを操作することで、複雑で多段階のタスクを解決する大規模言語モデル(LLM)の開発と評価を促進します.Hugging FaceやGitHubのリソースを活用し、拡張可能なモデルやデータセットを幅広く提供しています.さらに、このプラットフォームでは、タスクフィードバックからの強化学習(RLTF)や非線形タスク計画などの革新的な手法を導入し、分布外汎化(OOD)、最適タスク計画、非線形タスク構造に関する課題に取り組んでいます.OpenAGIプラットフォームが、コミュニティにおけるAGI能力のオープンで長期的な改善と評価を支援することが期待されます.
Q: 本稿で紹介した方法は、従来の方法と比較してどのようなメリットがあるのでしょうか?
A: この論文で紹介された手法は、より多くのモデルパラメータを装備する競合他社を凌駕する潜在力があり、Reinforcement Learning from Task Feedback(RLTF)と呼ばれるメカニズムを導入し、LLMの計画戦略を効果的に改善することで、改良されたより適応性の高いシステムを生み出します.さらに、拡張性、非線形タスクプランニング、量的評価など、いくつかの注目すべき課題に対処しています.
Q: 今後の研究課題として残っているものは何でしょうか?
A: 今後の課題としては、各シングルステップのタスク内に複数のモデルを組み込むこと、代替モダリティからのデータセットを統合すること、評価メカニズムを強化すること、複雑なタスクの解決に人間をループ内に巻き込むこと、自動タスク生成技術を探求することなどが挙げられます.
Q: 本稿で紹介した新手法の実装はどこにあるのでしょうか?
A: 論文で紹介した新しい手法の実装は、GitHubの提供リンクから見ることができます.https://github.com/agiresearch/OpenAGIarXiv:2304.04370v2 [cs.AI] 12 Apr 2023.
Generative Agents: Interactive Simulacra of Human Behavior
著者:Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, Michael S. Bernstein
発行日:2023年04月07日
最終更新日:2023年04月07日
URL:http://arxiv.org/pdf/2304.03442v1
カテゴリ:Human-Computer Interaction, Artificial Intelligence, Machine Learning
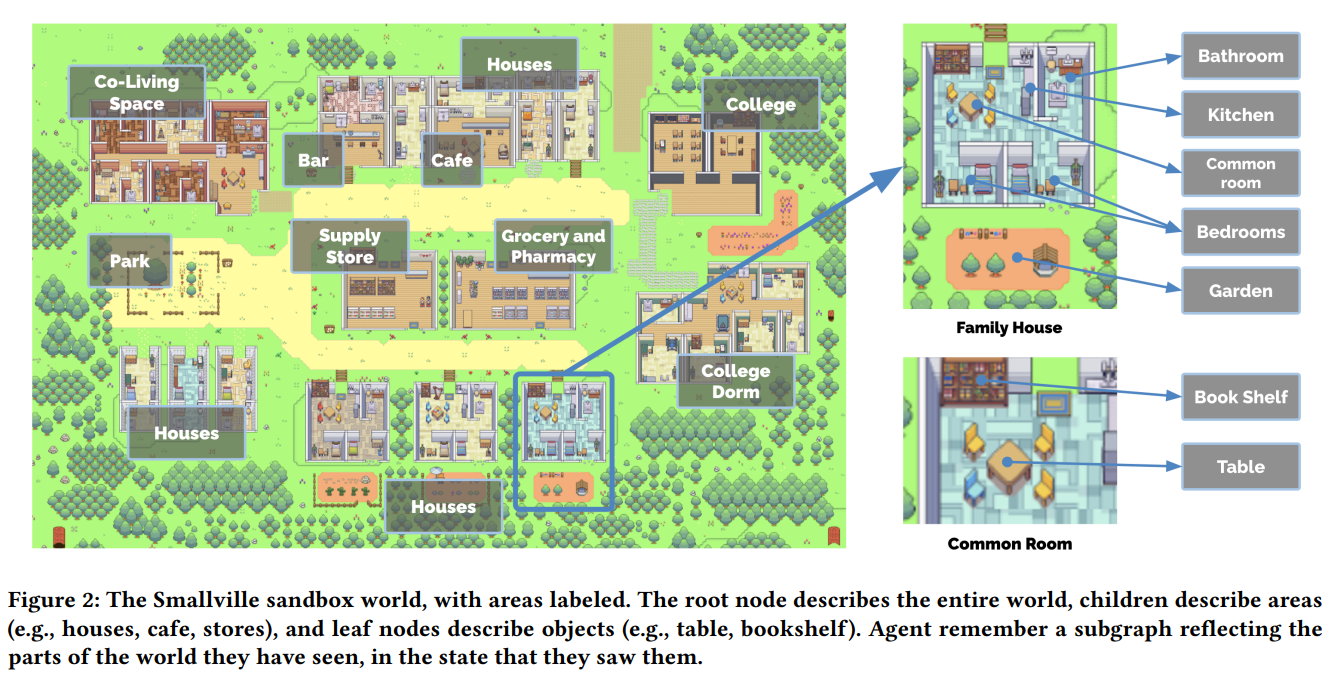
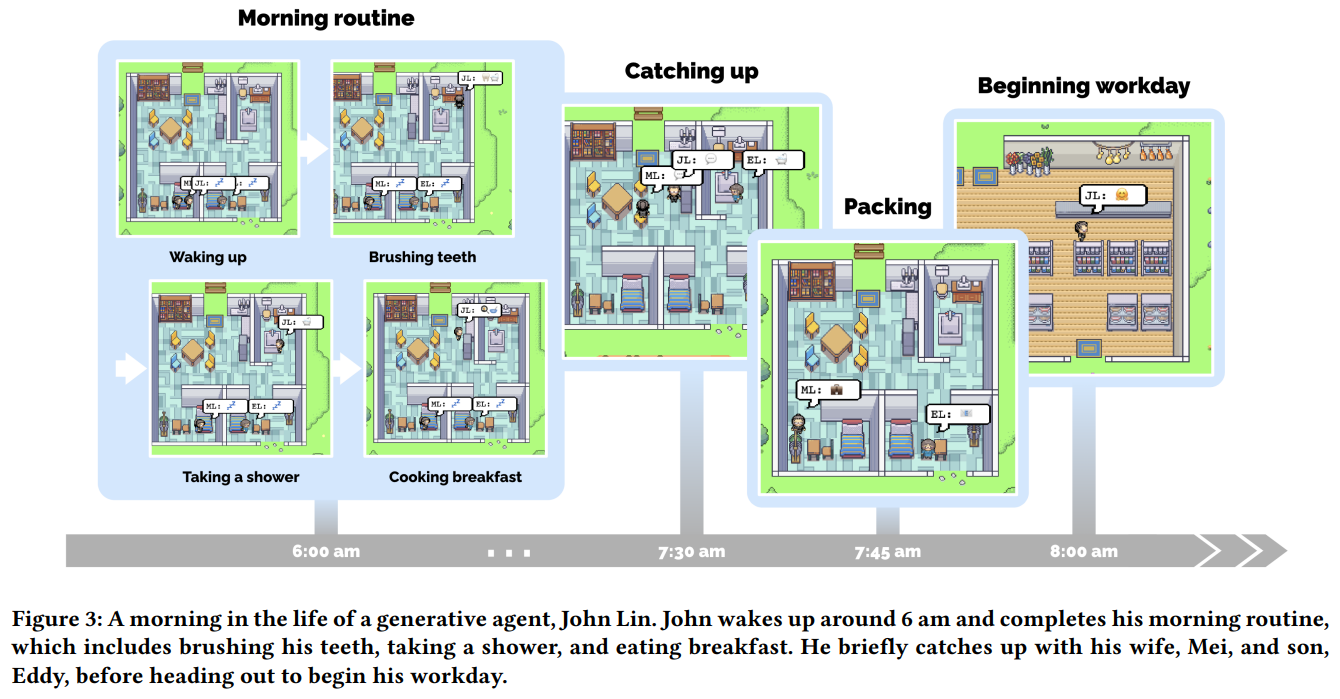
概要:
人間の行動の信頼できるプロキシは、没入型の環境から人間関係のリハーサルスペース、プロトタイピングツールまで、多種多様なインタラクティブアプリケーションに力を与えることができます.本論文では、信憑性のある人間の行動をシミュレートするため、自然言語を用いた生成エージェントを紹介します.この生成エージェントは、起き上がって朝食を作ったり、芸術家が絵を描いたり、作家が執筆することで、個別および新興社会的行動を生み出します.私たちは、25人の生成エージェントで構成された小さな町を作成し、自然言語を使用して対話型のサンドボックス環境を実現しました.この実験により、1つのエージェントがバレンタインデーのパーティーを開催することを発表しただけで、他のエージェントも自律的にパーティーの招待状を広め、新しい知り合いを作ってお互いにデートの誘いをして、正しい時間に集合することまで調整するというような、自然な集団行動を実現しました.また、私たちは評価のために、生成エージェントを構成する要素の観察、計画、反省が信憑性にどのように寄与するかを検証しました.自然言語モデルと計算可能なインタラクションエージェントを融合させることで、信憑性のある人間行動のシミュレーションを可能にするアーキテクチャやインタラクションパターンを提案します.
Q&A:
Q: 論文で説明されているエージェントアーキテクチャの焦点と潜在的なアプリケーションは何ですか?
A: エージェントアーキテクチャの焦点は、動的に進化する状況を通じて、記憶、検索、対話、反映、計画を行うことができる生成的なエージェントにあります.潜在的な用途としては、オープンワールドでの行動のフレームワークを提供すること、他のエージェントとの相互作用に関与すること、環境の変化に反応することが挙げられます.また、設計の初期段階におけるアイデアのプロトタイプや、実際の人間の参加者を使ったテストが困難または危険な理論のテストにも使用できます.この文章では、ジェネレーティブ・エージェントの展開に伴う倫理的配慮や社会的リスクについても論じています.
Q: 生成エージェントの効果はどのように評価されたのか、また、評価で確認されたアーキテクチャの構成要素の因果関係は?
A: 生成エージェントの有効性を判断するために、統制評価とエンドツーエンド評価の2つの評価が行われました.評価では、記憶検索の重要性などアーキテクチャの構成要素の因果関係を特定し、不適切な記憶検索に起因する故障を特定しました.
Q: インタラクティブシステムにおける生成エージェントには、どのような倫理的・社会的リスクがあるのか、またそのリスクはどのように軽減されるのか.
A: インタラクティブシステム内の生成エージェントに関連する倫理的および社会的リスクには、適切でない場合でも人々がエージェントとのパラソーシャル関係を形成するリスク、エージェントによる誤りの影響、エージェントへの過度の依存のリスク、および深い偽装や誤報の生成など、生成AIに関連する既存のリスクの悪化が含まれます.これらのリスクは、生成エージェントが計算的な存在であることを明示するようにし、エージェントが価値に合わせており、不適切な行動を取らないようにすること、本物の人間の入力を生成エージェントで代替しないこと、そして入力と生成された出力の監査ログを維持して悪用に対処することで緩和できます.より多くの研究が、生成エージェントの堅牢性問題を包括的にテストするために行われることができます.
Q: デザインプロセスにおいて、人間のステークホルダーを置き換えるのではなく、補完する形でジェネレーティブエージェントを適用するにはどうしたらよいでしょうか?
A: ジェネレーティブ・エージェントは、参加者を集めるのが困難な場合や、実際の参加者を使ってテストするのが難しい、あるいはリスクの高い理論をテストする場合、デザインの初期段階でアイデアをプロトタイプ化するために使用できます.ジェネレーティブ・エージェントは、研究やデザインプロセスにおける実際の人間の入力に代わるものであってはなりません.また、人間のパターンとテクノロジーとの相互作用をモデル化するために使用することもでき、人の代理として機能し、その人の生活に基づいて、もっともらしい行動と反射のセットを学習することができる.
Q: 生成エージェントによって強化された人間の行動の信じられるsimulacraは、どのようなアプリケーションで恩恵を受けることができますか?また、生成エージェントの現実のアプリケーションの可能性と限界は何でしょうか?
A: 生成エージェントは、オンラインフォーラムで会話スレッドを生成する無国籍ペルソナであり、社会システムや理論のテストやプロトタイプ作成、新しいインタラクティブ体験の作成など、人間の行動のより強力なシミュレーションを作成する上で、実生活に応用できる可能性があります.また、人間中心設計プロセスにおいて、個人の生活パターンやテクノロジーとの相互作用に基づき、個人の行動や反映をもっともらしくモデル化し、学習するために使用することもできます.しかし、ユーザーが生成エージェントと寄生的な関係を築いたり、エラーが発生した場合の影響など、倫理的な懸念が生じる可能性があります.これらのリスクを軽減するために、生成エージェントは、計算主体としての性質を明示的に開示し、文脈から不適切な行動をとらないようにする必要があります.
Q: 仮想空間やコミュニティにおける人間行動のシミュレーションには、どのような用途が考えられるでしょうか.また、人間行動のシミュレーションは、希少でありながら困難な対人関係の状況に対処するためのトレーニングに、どのように活用することができるでしょうか.
A: 仮想空間やコミュニティにおける人間の行動のシミュレーションは、社会科学の理論の検証、ユビキタスコンピューティングアプリケーションやソーシャルロボットの動力源、プレイアブルではないゲームキャラクターの作成など、さまざまな目的で使用することができます.また、稀にしか発生しない難しい対人関係への対処法のトレーニングにも利用できます.
Q: 信じられる計算エージェントの作成に関連する課題や、人間の行動をシミュレートする上での現在の限界は何でしょうか?
A: 人間の行動空間は広大で複雑であり、信頼できる計算エージェントを作ることは困難である.過去の経験と一致した行動をとり、環境に対して信憑性のある反応をするエージェントの作成は進歩していますが、人間の行動をシミュレートすることにはまだ限界があります.これまでのアプローチは、環境やエージェントの行動の次元を単純化することが多く、生成エージェントは有望なソリューションとして紹介されていますが、その可能性を十分に発揮するためには、さらなる研究が必要です.
Q: 記憶検索プロセスは、エージェントの記憶の最も関連性の高い部分が必要に応じて取得され、合成されるようにどのように確保されますか?
A: A:生成エージェントにおけるメモリーの呼び出しプロセスには、現在の状況を入力として受け取り、言語モデルに渡すためのメモリーストリームのサブセットを返す呼び出し関数が含まれます.この関数は、最近読み取られたメモリーオブジェクトに高いスコアを割り当てる「最近性」、「平凡な記憶」と重要な記憶を区別する「重要性」、およびエージェントの現在の状況に関連する観察を識別する「関連性」の3つの主要なコンポーネントを考慮します.これにより、エージェントの瞬時の行動に関する情報が必要になったときに、最も関連性の高いメモリーが合成され、呼び出されることが保証されます.
Q: リフレクションプロセスは、エージェントが誰と時間を過ごすかなどの意思決定にどのように役立つのでしょうか?
A: A:エージェントアーキテクチャの反射処理により、エージェントは時間の経過とともにメモリを総合してより高次の推論を行い、自分自身や他者についての結論を導き、より適切な行動指針を示せるようになります.本文で言及されたシナリオの中では、反射メモリにアクセスできるエージェントは、Wolfgang Schulzの興味を基に自信を持ってギフトを選択することができました.同様に、反射処理は意思決定にも役立ちます.特に、過去の相互作用や経験に基づいてその人の興味や好みについて推論を行い、誰と時間を過ごすかを選択することができます.
Q: より長い時間軸での計画と対応という課題を克服するために、この文章に書かれているアプローチはどのように役立つのでしょうか?
A: この文章で説明されているアプローチは、生成エージェントが生の観察記憶だけで一般化や推論を行うことに苦労しているという課題を克服するのに役立ちます.これは、エージェントが過去の経験を振り返り、将来の行動を向上させるための有意義な考察に統合することを可能にするものです.これにより、エージェントは、他のエージェントや周囲の環境との相互作用や関係に基づいて、より深く、より情報に基づいた意思決定を行うことができます.
Q: 本論文の実用的な貢献は何ですか?
A: 本文で説明されているエージェントアーキテクチャの実用的な貢献には、エージェントの経験の包括的な記録を保存する機構、覚え、取り出し、反映、他のエージェントとの相互作用、動的に進化する状況を通じて計画を立てる能力、およびアーキテクチャのコンポーネントの重要性の因果関係を確立する2つの評価が含まれます.さらに、このアーキテクチャは、大型言語モデルの強力な提示機能を活用し、これらの機能を補完して長期的なエージェントの一貫性をサポートします.著者らは、対話型システムにおける生成エージェントの機会、倫理的および社会的リスクについても議論し、これらのエージェントはデザインプロセスの人間の関係者を置き換えるのではなく、補完する方法で使用する必要があると主張しています.
Q: 本論文の理論的な貢献は何ですか?
A: このアーキテクチャは、大規模な言語モデルのプロンプト機能を活用し、より長期的なエージェントの一貫性、動的に進化する記憶を管理する能力、および再帰的に多くの世代を生成する能力をサポートするためにそれらの能力を補完します.また、ロールプレイやソーシャルプロトタイピングから仮想世界やゲームまで、様々な領域での応用を示唆しています.
Q: この新方式に見られる困難は何ですか?
A: エージェントアーキテクチャを実装する際に直面する困難のひとつは、信じられるエージェントを作るためには、膨大な過去の経験が必要であることです.また、生成エージェントに頼りすぎるのも問題で、デザインプロセスにおける人間のインプットを決して置き換えるべきではありません.最後に、自分自身でアーキテクチャを構築するのは時間がかかるものです.
Q: 実験やデータ解析で得られた主な知見は何ですか?
A: 生成エージェントの効果を判定し、アーキテクチャの構成要素の因果関係を特定するために使用した評価から得られた主な結果は、生成エージェントのフルアーキテクチャは、すべての研究条件の中で最も信じられる行動を生成するというものです.また、アーキテクチャの構成要素の重要性の因果関係を明らかにし、不適切な記憶検索に起因する故障を特定した.記憶、反射、計画という各構成要素は、インタビュータスク全体で強力なパフォーマンスを発揮するために重要である.最も一般的なエラーは、エージェントが関連する記憶を検索できなかったり、エージェントの記憶に装飾を捏造したり、言語モデルから過度にフォーマルなスピーチや振る舞いを受け継いだりした場合に発生しました.
Q: 今後の研究課題として残っているものは何でしょうか?
A: 今後の研究では、本論文で概説された生成エージェントアーキテクチャのモジュールを拡張し、文脈に合わせたより関連性の高い情報を取得するリトリーバルモジュールを強化し、リアルタイムの相互作用を強化するために並列化エージェントを探索し、エージェントのパフォーマンスを向上させることができます.今後の研究では、生成エージェントの行動を長期間観察し、将来のシミュレーションで使用されるエージェントの基礎モデルやハイパーパラメータを変更して比較することが望まれます.また、エージェントのバイアスや制限を軽減することも必要です.さらに、生成エージェントの倫理的かつ社会的に責任ある展開を確保する必要があります.
One Small Step for Generative AI, One Giant Leap for AGI: A Complete Survey on ChatGPT in AIGC Era
著者:Chaoning Zhang, Chenshuang Zhang, Chenghao Li, Yu Qiao, Sheng Zheng, Sumit Kumar Dam, Mengchun Zhang, Jung Uk Kim, Seong Tae Kim, Jinwoo Choi, Gyeong-Moon Park, Sung-Ho Bae, Lik-Hang Lee, Pan Hui, In So Kweon, Choong Seon Hong
発行日:2023年04月04日
最終更新日:2023年04月04日
URL:http://arxiv.org/pdf/2304.06488v1
カテゴリ:Computers and Society, Artificial Intelligence, Computation and Language, Computer Vision and Pattern Recognition, Machine Learning
概要:
OpenAIが最近ChatGPT plus(通称GPT-4)をリリースし、これは生成型AI(GAI)にとっては1つの小さなステップであり、人工一般知能(AGI)にとっては1つの偉大な飛躍であることが示されました.2022年11月に公式リリースされたChatGPTは、大々的なメディア報道により多数のユーザーを瞬く間に獲得しました.このような前例のない注目は、多数の研究者が様々な側面からChatGPTを調査することを促しました.Google Scholarによると、ChatGPTをタイトルに含むか、または抄録で言及した記事は500を超えます.これを考慮すると、総合的なレビューが急務であり、この業務がそのギャップを埋めます.本研究は、ChatGPTの技術、アプリケーション、および課題について包括的なレビューを行う初めてのものです.さらに、ChatGPTが一般的な目的のAIGC(通称AI-generated content)を実現するためにどのように進化する可能性があるかを展望し、これはAGIの開発にとって重要なマイルストーンとなるでしょう.
Q&A:
Q: ChatGPTの目的、AGIとの関係性について教えてください.
A: ChatGPTの目標は、汎用人工知能生成コンテンツ(AIGC)の実現であり、これは人工一般知能(AGI)の実現に向けた重要なマイルストーンと考えられています.論文では、ChatGPTとAGIのギャップを埋めるための2つのロードマップが提案されています.
Q: ChatGPTを利用する上で、倫理や規制を遵守するためにどのような対策が取られていますか?
A: 人工一般知能の実現に向けたChatGPTの活用に関する様々な倫理的・規制的な懸念について論じています.一部の学者は、ChatGPTの悪用を防ぐために、記事作成に基づく課題の取り消しやAIコンテンツ検出器の開発などの規制を提案しています.また、機密性の高い個人情報の収集や悪用される可能性についての懸念も指摘されている.GPTのような大規模な言語モデルがどのように動作して回答を生成するのか、透明性がないことも懸念される.しかし、この記事では、人工一般知能の実現に向けたChatGPTの活用において、倫理や規制の遵守を確保するために現在行われている具体的な対策は示されていない.
Q: 生成AIやAGIの分野で、さらにどのような研究を進めるとよいでしょうか?
A: A:この記事は、今後の研究について具体的な提言を提供していませんが、AGIの開発に伴う課題や懸念点について議論し、ChatGPT(または他の類似製品)をAGIに向けて推進する際の意識と注意の必要性を提唱しています.
Q: 近年の大規模言語モデルの開発において、Transformerの技術はどのように不可欠になっているのでしょうか?
A: Transformerアーキテクチャは、GPT-2やGPT-3など、近年の大規模言語モデル開発の中核をなす技術である.これまで主流だったRNNアーキテクチャに取って代わり、言語理解における重要な要素である「注意」を利用することで知られています.Transformerアーキテクチャは、入力テキストの異なる部分に異なる理解レベルを割り当てる、自己注意を可能にします.これにより、言語モデリングが大幅に改善され、自然言語処理コミュニティにおけるディープラーニングの発展に寄与しています.
Q: BERTやGPTなど、Transformerの技術を用いたモデルの具体的な説明をお願いします.
A: BERTやGPTのようなTransformer技術に基づくモデルは、ラベルのないテキストデータセットから学習するために、自己教師付き学習で注意ベースのTransformerを使用します.BERTは、マスクされた言語トークンをマスクされていない言語トークンから予測するマスク・モデリングを用い、GPTは、次の単語を推測しようとする自己回帰モデリングを用いる.BERTとGPTはともに、さまざまな下流タスクで微調整が可能で、競争力のある性能を発揮する.BERTとGPTの決定的な違いは、その事前学習戦略にある.
Q: GPTとBERTの事前学習戦略はどのように違うのでしょうか?
A: GPTは自己回帰モデリング、BERTはTransformerの技術に基づく事前学習戦略としてマスクド・ランゲージ・モデリングを使用しています.
Q: GPT-1がゼロショットタスクで良好な性能を発揮するという観測は、何を示しているのでしょうか?
A: GPT-1のゼロショットタスクでの性能は、自然言語推論、質問応答、意味類似性、テキスト分類など12タスク中9タスクで、特定のタスクで学習したモデルを凌駕し、高い汎用性を示していることがわかります.
Q: ChatGPTは、具体的にどのように学生の評価・査定補助として活用できるのでしょうか?
A: ChatGPTは、自動採点やパフォーマンス・エンゲージメント分析など、学生の評価・査定アシスタントとして活用することができます.参考文献[10, 209, 211]にあるように、複数の研究者がChatGPTのこのアプリケーションを調査しています.
Q: ChatGPTの心理学への応用について、どのような研究がなされているのでしょうか?
A: ChatGPTの心理学への応用については、いくつかの研究があるようです.ChatGPTは、強力なテキスト生成チャットボットとして、心理学に関するエッセイを簡単に書くことができます[ 176].さらに、この論説[176]では、ChatGPTが人々の社交を助け、特定の状況についてフィードバックを与えることができると論じています.しかし、ChatGPTが感情的な入力を処理する能力はまだわかっていない.
Q: :ChatGPTの医療分野での能力を評価した研究は何ですか?
A: ChatGPTの医療分野での活用については、肝硬変や肝細胞がんなどの病気の診断や予防に関する基本的な質問に対する回答や、医師免許試験での評価など、いくつかの研究が行われています.また、ChatGPTは、患者さんにやさしいクリニカルノートの作成にも利用されており、臨床判断支援の一助となる可能性を示しています.しかし、高度な医学的概念に対する理解はまだ不十分であり、適切な診断と評価を受けるためには、資格を持った医療従事者の診察を受けることが推奨されます.
Q: ChatGPTの医療問題解決への可能性と、医療への利用適性を評価する際に考慮すべき要素は何ですか?
A: ChatGPTは、医療診断、病気に関する質問への回答、医療支援に役立つ可能性を示しています.また、デバッグの支援や説明を提供することで、ソフトウェア開発を支援することも可能です.しかし、医療分野によっては、批判的思考や高度な知識が必要であるなど、その限界も考慮する必要があります.正確な診断と治療のためには、免許を持った医療従事者の診察を受けることが重要です.ChatGPTは、複雑な患者のカルテを要約し、患者にやさしいバージョンのクリニカルノートを提供し、コミュニケーションコストを削減するために使用することができます.また、医療現場での使用にあたっては、正確性や専門家との比較といった要素も考慮する必要があります.
Q: 実験やデータ解析で得られた主な知見は何ですか?
A: この記事では、ChatGPTを使って行われた複数の実験やデータ分析タスクについて述べています.その中には、データ処理、文献レビュー、数学的オブジェクトの検索、さらには経済学や法律試験のような非STEM科目の質問に対する回答といったタスクが含まれています.記事では、短文物理エッセイや10万人の医療従事者の模擬データセットのデータ解析など、いくつかのタスクで有望な結果を示していますが、文献レビューや高度な数学といったタスクは、ChatGPTにとってまだ課題となっています.しかし、ChatGPTは将来的に様々な分野の研究効率を大幅に向上させる可能性があることが示唆されています.
Q: 今後の研究課題として残っているものは何でしょうか?
A: この文章では、ChatGPTの文献レビューの能力がまだ弱いとされていますが、研究者の効率を向上するために近い将来広く使用されると期待されています.また、ChatGPTの金融、法務、社会分析、会計などの分野での応用を探求することができる可能性があるとも示唆されています.さらに、文章は技術的制約や倫理的懸念があることに言及し、将来の研究は言語モデルの改善やこれらの懸念に対処することに焦点を当てることができるとしています.

コメント