
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をQ&A形式を用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.
紹介する論文は以下の10本となります.
- Scaling the leading accuracy of deep equivariant models to biomolecular simulations of realistic size (発行日:2023年04月20日)
- Architectures of Topological Deep Learning: A Survey on Topological Neural Networks (発行日:2023年04月20日)
- Evaluating Verifiability in Generative Search Engines (発行日:2023年04月19日)
- Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models (発行日:2023年04月19日)
- Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models (発行日:2023年04月18日)
- Learning to Compress Prompts with Gist Tokens (発行日:2023年04月17日)
- Generative Disco: Text-to-Video Generation for Music Visualization (発行日:2023年04月17日)
- Visual Instruction Tuning (発行日:2023年04月17日)
- DINOv2: Learning Robust Visual Features without Supervision (発行日:2023年04月14日)
- ChatGPT: Applications, Opportunities, and Threats (発行日:2023年04月14日)
Scaling the leading accuracy of deep equivariant models to biomolecular simulations of realistic size
著者:Albert Musaelian, Anders Johansson, Simon Batzner, Boris Kozinsky
発行日:2023年04月20日
最終更新日:2023年04月20日
URL:http://arxiv.org/pdf/2304.10061v1
カテゴリ:Computational Physics, Machine Learning, Chemical Physics, Biomolecules
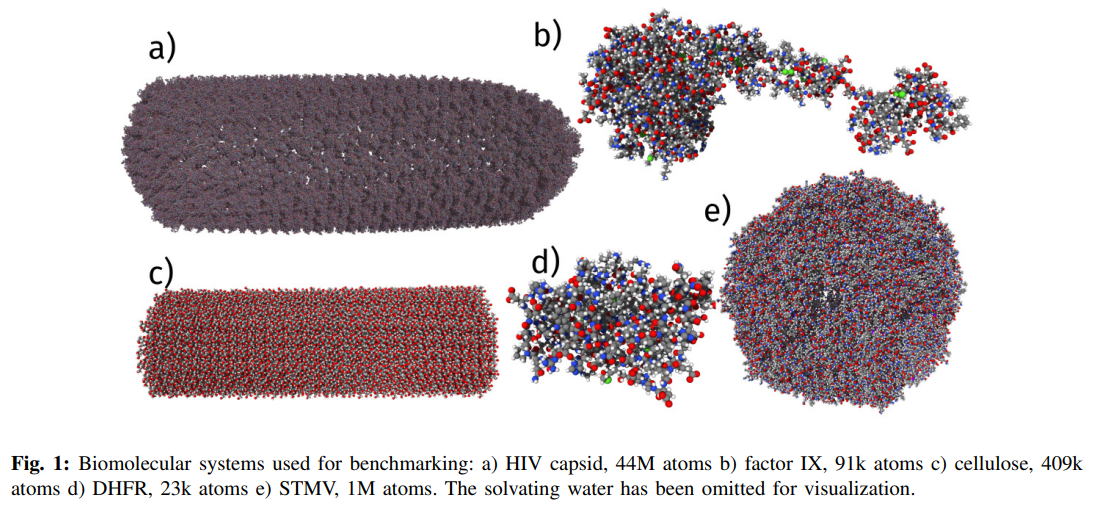
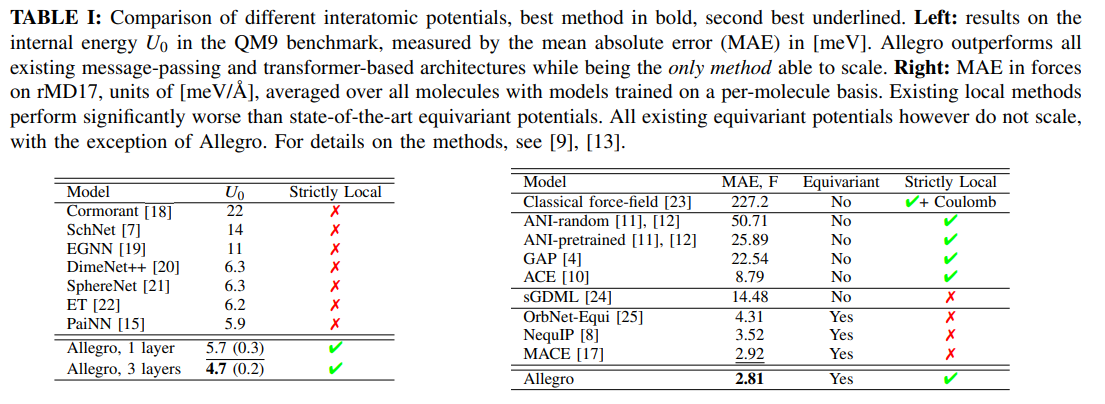
概要:
この研究は、深層同変ニューラルネットワークの優れた精度、サンプル効率、堅牢性を、極端な計算スケールにまで拡張することを目的としています.この目的を達成するために、革新的なモデルアーキテクチャ、大規模並列化、そして効率的なGPU利用を最適化したモデルや実装を組み合わせたAllegroアーキテクチャが開発されました.このアーキテクチャは、原子レベルのシミュレーションの精度と速度のトレードオフを解消し、前例のない複雑な構造のダイナミクスを量子的な信頼性で記述することが可能になります.Allegroのスケーラビリティを示すために、タンパク質のダイナミクスの安定したナノ秒スケールのシミュレーションを行い、Perlmutterスパコン上の44ミリオン原子構造の完全な、全原子、明示的に溶媒化したHIVカプシドにスケールアップします.100万原子までの優れたストロングスケーリングと、5120 A100 GPUの70%のウィークスケーリングを実証しています.
Q&A:
Q: Allegroアーキテクチャは、深い同変ニューラルネットワークにおいて、極端な計算スケールで先進的な精度、サンプル効率性、堅牢性をどのように達成していますか?
A: Allegroアーキテクチャは、革新的なモデルアーキテクチャ、大規模な並列化、そして効率的なGPU利用のために最適化されたモデルと実装の組み合わせにより、著名な正確性、サンプル効率、堅牢性を実現しています.
Q: Allegroアーキテクチャで使用される革新的なモデルアーキテクチャは何ですか?
A: Allegro architectureのモデルアーキテクチャは、dense linear algebra operationsによってTensor ProductとScalar Track MLPsを含み、各順序付けられた近隣ペアに対して高い効率性を確保し、GPUの利用を最適化するように最適化されています.これにより、イントラネット規模の高容量equivariant Allegroモデルが実現され、量子の忠実度で過去には不可能だったシステムの動的性質を記述することが可能になりました.また、PyTorchとKokkos パフォーマンスポータブルライブラリの組み合わせにより、CPUおよびNVIDIA、AMD、IntelなどのGPUなどのコンピューティングアーキテクチャ上に状態の良い引き合い可能なモデルアーキテクチャを展開することができます.
Q: モデルと実装は、効率的なGPUの利用のためにどのように最適化されていますか?
A: Allegroのアーキテクチャは、GPUの並列処理能力を最大限に活用するように最適化されています.Allegroでは、テンソル積とスカラートラックMLPを使用して密な線形代数演算を行い、GPUリソースの並列処理を利用します.さらに、Allegroはストライドメモリレイアウトを使用して、異なる回転オーダーのテンソル特徴を最適な方法でメモリに格納します.この最適化により、Allegroは高い効率でGPUを使用し、モデルのトレーニングと実装の両方に効果的です.
Q: :MDは、新しい材料の理解や設計を進めるためにどのように利用できますか?
A: MDは原子スケールで分子や材料の力学を理解し、設計することを可能にする計算科学の基盤であり、実験では提供できない分解能、理解、制御を提供することにより、新しい分子や材料の理解と設計を進めるための非常に強力なツールとなっています.
Q: 機械学習による原子間ポテンシャル(MLIP)の約束とは何ですか?
A: 機械学習相互原子ポテンシャル(MLIP)は、高い精度の参照データからエネルギーと力を学習し、原子の数と線形にスケーリングすることを目指すことで、長年のジレンマを回避するという約束を持っています.
Q: MLIPは高精度の基準データからエネルギーと力をどのように学習するのですか?
A: 機械学習相互作用ポテンシャル(MLIPs)は、高精度なリファレンスデータからエネルギーと力を学習するプロセスです.これは、原子数に線形スケーリングしながら実現されます.初期の試みでは、手作りの記述子とガウス過程または浅いニューラルネットワークを組み合わせました.
Q: 相互原子間ポテンシャルにおいて対称性はどの程度重要で、特にどのような対称性が重視されていますか?
A: すべての原子間ポテンシャルに共通しているのは、対称性に焦点を当てていることです.特に、エネルギーは、並進、回転、反射の観点から不変である必要があります.対称性は原子間ポテンシャルにとって非常に重要であると言えます.
Q: メッセージパッシングニューラルネットワーク(MPNN)とは、深層学習インターアトミックポテンシャルでどのように使用されますか?
A: メッセージ伝達ニューラルネットワーク(MPNN)とは何か、そしてどのように深層学習の界面電位に使用されているのか? MPNNは、中央のノードからその隣接ノードへの情報伝達を利用するアーキテクチャであり、測定可能な距離範囲内の相互作用によって周辺アトムへの情報伝達を拡大します.これらは深層学習の界面電位の構築に利用され、各層で情報伝達が行われますが、そのための計算容量が大きく必要になります.
Q: Allegroが最先端のポテンシャルと比較してベンチマークのパフォーマンスの例を提供できますか?
A: Allegroは、QM9およびrevMD17ベンチマークでの小分子のエネルギーおよび力の状態を含め、最先端のポテンシャルを超えることができます.同様に、Allegroは、DeepMDポテンシャルよりも優れた性能を発揮することができます.
Q: この論文で紹介された方法の古い方法と比較しての利点は何ですか?」
A: この論文で紹介された方法は、従来の方法に比べて多くの利点があります.例えば、高度にスケーラブルであり、巨大な系のシミュレーションにも対応できます.また、高い精度で分子構造を再現することができます.さらに、量子力学的効果や化学的変換も捉えることができます.
Q: 新しい手法を実装するためにどのくらいの計算リソースが必要ですか?
A: 論文で導入された新しい方法を実装するために必要な計算リソースは、Perlmutterスーパーコンピュータで44百万原子構造の完全な、全原子、明示的に溶媒和されたHIVカプシドにスケールアップすることで、100百万原子まで優れたストロングスケーリングを実証しており、5120 A100 GPUsで70%のウィークスケーリングを実現しています.全アプリケーションを含むウォールタイム、タイムステップ/秒での結果が報告されています.計算リソースには、CPUおよびNVIDIA、AMD、Intel GPUが含まれます.
Q: この論文の理論貢献は何ですか?
A: 論文の理論的貢献は、深層同変性モデルの力やエネルギーの不確かさを定量化し、自動トレーニングセットの構築のためにアクティブラーニングを実行することである.また、混合ガウスモデルの自然な適応は、アンサンブルではなく単一のモデルを使用して大規模な不確実性のあるシミュレーションが可能になる可能性を開く.さらに、同変モデルの示した正確性の主要な意義は、量子電子構造計算の正確性と効率を改善する必要性であり、これは現在、計算化学、生物学、材料科学における主要な正確性のボトルネックになっている.
Q: この新しい方法で見つかった困難とは何ですか?
A: 新しい方法の実装において、両方のアプローチは遅くなるため、大規模な時間尺度のシミュレーションには不適切であり、特に生物系のアプリケーションにおいてはほぼ完全に除外される.また、ニューラルネットワークのメッセージパッシングをMDソフトウェアの空間分解メッセージパッシングと共に動作させるために、大規模なソフトウェア開発が必要となる.
Q: 今後の研究に残された課題は何ですか?
A: 今後の研究には、量子電子構造計算の精度と効率を向上させることが急務であり、機械学習を用いた相互作用ポテンシャルのトレーニングセット自動生成のための能動学習、スケーラビリティの向上や大規模不確実性アウェアシミュレーションのための高度なMLIPの開発などが必要である.また、バイオロジカルシステムの高精度・高速なシミュレーションにおいて、量子アプローチが現状の支配的な手法であるため、さらなる研究と発展も重要である.
Architectures of Topological Deep Learning: A Survey on Topological Neural Networks
著者:Mathilde Papillon, Sophia Sanborn, Mustafa Hajij, Nina Miolane
発行日:2023年04月20日
最終更新日:2023年04月20日
URL:http://arxiv.org/pdf/2304.10031v1
カテゴリ:Machine Learning
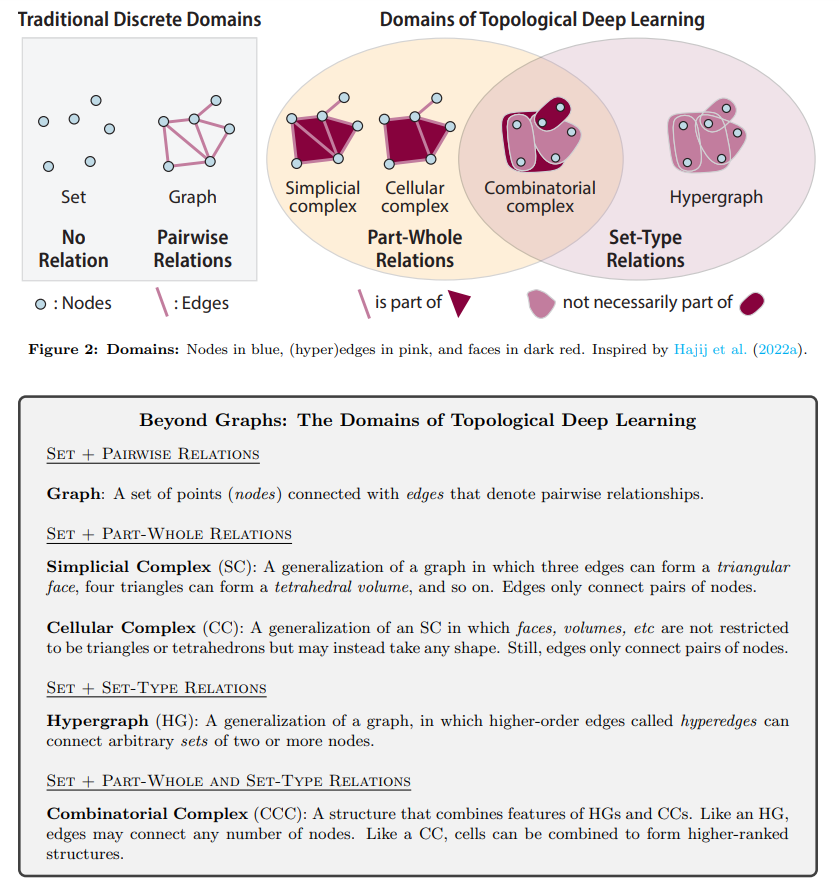
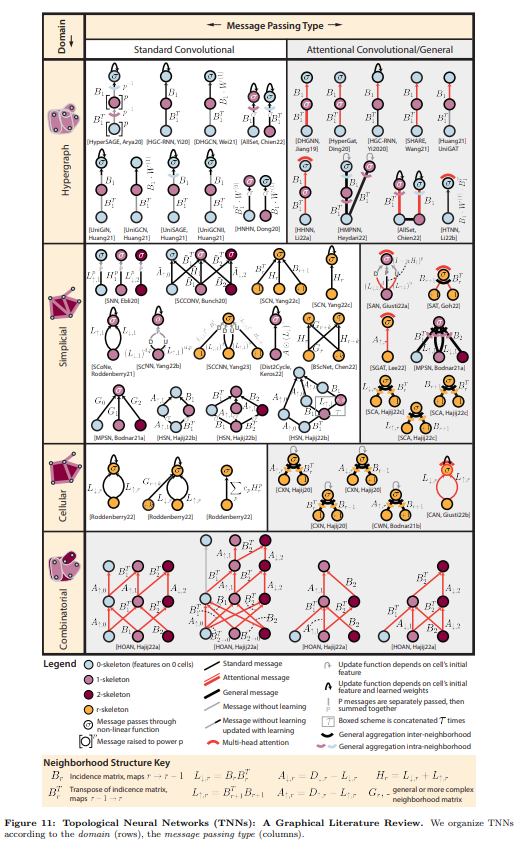
概要:
自然界は、社会ネットワーク内の個人間の社会的相互作用からタンパク質内の原子間の静電相互作用まで、そのコンポーネント間の複雑な関係が特徴的な複雑なシステムで満たされています.トポロジカル・ディープ・ラーニング(TDL)は、個人が属する社会コミュニティを予測することや、タンパク質を薬剤開発の有望なターゲットとすることなど、これらのシステムに関連するデータから知識を処理・抽出する包括的なフレームワークを提供します.TDLは、応用科学をはじめとしたさまざまな分野で地を切る可能性がある理論的・実践的な利点を実証しています.
しかしながら、TNNアーキテクチャの間で記号や言語の統一性が欠けていたため、既存の作品を基にすることや、TNNを新しい現実世界の問題に展開することが困難でした.そこで、私たちはTDLの理解しやすい導入を提供し、最近出版されたTNNを数学的・グラフィカルな符号とともに比較し、数理的・視覚的な表現方法を提供することで、TDLの進展につながる価値ある洞察を抽出しました.
より具体的には、直感的かつ批判的なレビューを通じて、TNNを新しい問題に展開する上での障害を解決する方法について考察し、数理的・グラフィカルな表現方法によって、TDLのさらなる発展に向けた可能性を示しました.こうしたアプローチは、TDLが応用科学をはじめとする多岐にわたる分野で導入され、地を切る可能性があることを実証しています.
Q&A:
Q: Topological Deep Learning(TDL)の定義は何ですか?
A: Topological Deep Learning(TDL)とは、より高次の関係構造を持つデータを処理するためのより一般的な抽象化を利用することで、理論的に保証されたモデルであるTopological Neural Networks(TNNs)を使用して知識を抽出する包括的なフレームワークです.TDLは、多くの機械学習タスクで最先端のパフォーマンスを実現し、応用科学などの分野で高い潜在能力を示しています.
Q: :TDLの理論的および実用的な利点は何ですか?
A: Topological Deep Learningの利用の理論的および実用的な利点は、複雑なシステムのデータを処理し、知識を抽出する包括的なフレームワークを提供することです.これにより、個人が所属する社会コミュニティを予測したり、薬剤開発のための良いターゲットとなるかどうかを予測したりすることができます.Topological Deep Learningは、応用科学やその先に飛躍的な進歩をもたらす可能性がある理論的および実用的な利点を示しています.
Q: :TDLの分野で現在直面している課題と将来の成長のチャンスは何ですか?
A: TDLの数学的表記の抽象化と分裂は、分野のアクセシビリティを制限し、モデルの比較を複雑にし、将来の開発の可能性を覆い隠している.しかし、数学的およびグラフィカルな表記法を統一して使用し、新しい現実世界の問題にTNNを展開するために、より良いツールを提供することによって、この問題に対処することができます.現在の課題としては、注意深く選択されたアプリケーションに焦点を当て、ハイパーグラフやシンプリシャル複体などの新しい拡張を組み込むことがあります.将来の研究では、TDLの理論的背景を拡張し、新しいTNNアーキテクチャを探求することで、TDLの可能性をさらに追求することができます.
Evaluating Verifiability in Generative Search Engines
著者:Nelson F. Liu, Tianyi Zhang, Percy Liang
発行日:2023年04月19日
最終更新日:2023年04月19日
URL:http://arxiv.org/pdf/2304.09848v1
カテゴリ:Computation and Language, Information Retrieval

概要:
ジェネラティブ検索エンジンは、情報収集を目的とするユーザーの主要なツールとして、特にその信頼性の表向きによって重要性が高まっています.我々は、このような信頼性の高いジェネラティブ検索エンジンの開発を更に推進し、既存の商用システムの不備を理解するために研究者やユーザーに役立つことを願っています.
Q&A:
Q: 研究の焦点は何であり、生成検索エンジンにおいて検証可能性が重要な理由は何ですか?
A: この研究は、信頼できる生成型検索エンジンの重要な特徴である検証可能性に焦点を当てています.具体的には、外部の世界に関する生成された文が直接引用され、各提供された引用がそれに関連する文をサポートすることが求められます.検証可能性は、読者が生成された文が引用されたソースによってサポートされていることを簡単に確認できるようにするために必要です.
Q: 人間の評価に使用された情報検索クエリのタイプと測定された寸法は何ですか?
A: 人間による評価では、GoogleのNaturalQuestionsからの様々な種類の歴史的なユーザークエリやRedditから収集されたオープンエンドの質問など、情報収集クエリの多様なセットが使用されました.測定対象は、文章の流暢性、有用性、引用の回収と精度の4つの側面でした.
Q: :コピーされた文言が反応の流暢さと知覚される有用性に与える影響は何ですか?
A: 研究において、コピーされた文による応答の流暢さと知覚される有用性は低下すると考えられています.コピーされた文は、応答の流暢さと全体的な応答の適切性に関係ない場合があり、応答の流暢さと知覚される有用性が逆相関する可能性があります.
Q: 流暢さ、知用性、検証可能性を決定するために使用された具体的な方法は何ですか?
A: この研究では、フルエンシー、知性的有用性、信頼性の測定方法について、注釈者にユーザークエリ、生成された回答、または「返答がフルエンシーで緻密である」という主張を示して、5段階のリカート尺度で評価を求めました.また、信頼性の検証に関連するステートメントを特定し、そのステートメントが完全にサポートされているかどうかを判断することによって、引用の再呼出しを測定しました.
Q: 応答の中で検証が必要な文言はどのように特定されますか?
A: 研究では、応答内の検証に値する文を特定することが必要です.文が検証に値するかどうかは、外部世界に関する生成されたすべての文が検証に値すると見なされます.明らかなもの、自明なもの、あるいは「常識的な」ものであっても、検証不可能性を犠牲にする代わりに、すべての生成された文に対してソースを提供することがシステムの目標であると考えています.また、簡単に検証可能な応答内の文をすべて提示することは実用的ではないが、すべての生成された文に対して検証可能なソースを提供することが望ましいと信じています.これにより、編集者は応答内の任意の文を容易に検証することができます.
Q: 人間評価研究から主な観察や分析は何でしたか?
A: 研究における人間の評価調査からの主な観察と分析は何でしたか?-略- システムの強みと弱点に包括的な理解を得るために、多様な設定を提供するdavinci-debate、ELI5(Live)、およびWikiHowKeywordsで試験を行い、人間の評価注釈をリリースしました.評価には34人の注釈者が参加し、高い合意率(82.0%以上のペアワイズ合意率と91.0F1のすべての判断に対する)が確認されました.注釈者は1つのクエリ応答ペアに対して3つのステップのプロセスを完了するために平均して約4分かかり、クエリ応答ペアに対して1.00ドル(参考文献を伴う応答)または0.38ドル(参考文献を伴わない応答)を受け取りました.また、各設定から150個、7つのNaturalQuestionsデータ・セットから100個ずつのランダムサンプルされたクエリ・レスポンス・ペアを使用して、合計1450件のクエリを評価しました.
Q: :ジェネレーティブサーチエンジンにおいて引用精度と再現率を増加させる要因は何で、流暢性と知覚ユーティリティを減少させますか?
A: 引用精度と再現率の増加が、生成型検索エンジンにおいて流暢さと知覚される有用性の低下と関連している主な要因は、システムが引用したウェブページから文をコピーまたは近似してしまう傾向があるためだと仮説されています.これによって、引用精度と再現率が増加し、一方で流暢さと知覚される有用性が低下することにつながっています.
Q: この検証で見つかった困難点は何ですか?
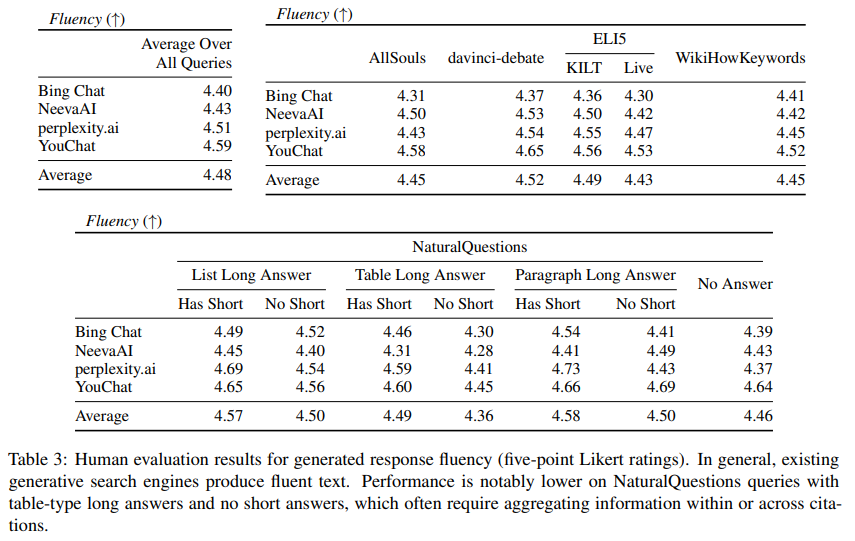
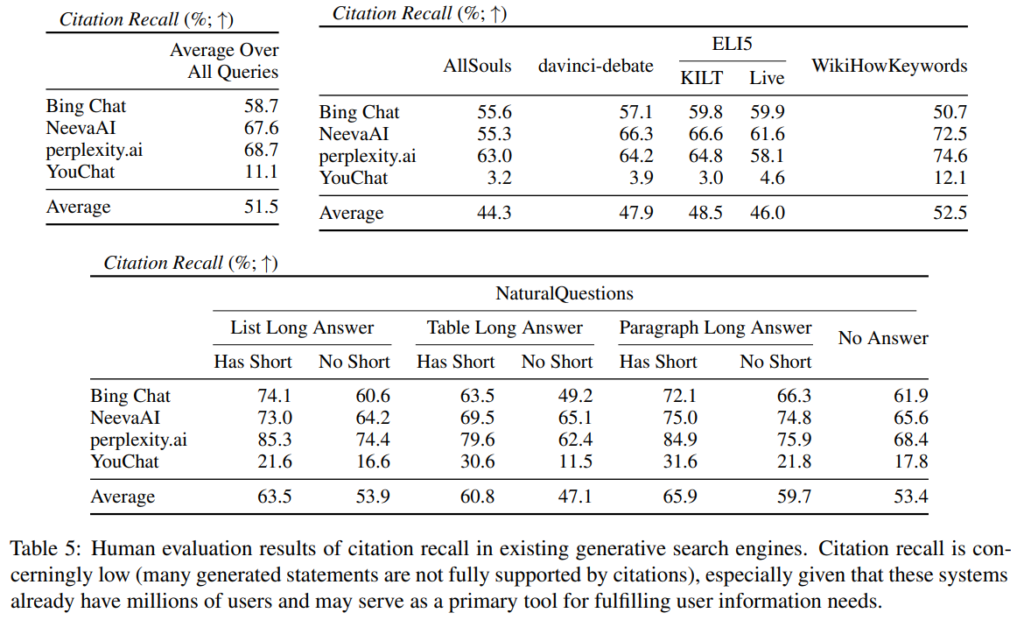
A: 既存の生成型検索エンジンは信頼できる回答を提供することはできますが、未検証の主張や不正確な引用が多く存在し、所与の文脈で完全に正当化されているかどうかを判断できないことが困難であることがわかりました.生成された文のうち、51.5%の文のみが引用によって完全にサポートされており、74.5%の引用がそれらの関連文をサポートしていることが、関連する文書の引用漏れと精度低下の問題があると指摘されています.
Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models
著者:Pan Lu, Baolin Peng, Hao Cheng, Michel Galley, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, Jianfeng Gao
発行日:2023年04月19日
最終更新日:2023年04月19日
URL:http://arxiv.org/pdf/2304.09842v1
カテゴリ:Computation and Language, Artificial Intelligence, Computer Vision and Pattern Recognition, Machine Learning
概要:
大規模言語モデル(LLM)は、新しい能力を持つ様々な自然言語処理タスクで驚異的な進歩を遂げています.しかし、up-to-dateな情報にアクセスできない、外部ツールを使用できない、または正確な数学的推論ができないなど、固有の制限に直面しています.本論文では、これらの課題に対処するためにLLMsを拡張するためのプラグアンドプレイの構成的な推論フレームワークであるChameleonを紹介します.
Chameleonは、GPT-4を基盤としたLLMとして使用した場合、ScienceQAで86.54%の精度を達成し、最高の数値である11.37%を改善することができました.さらに、TabMWPでは、Chameleonは、先進的なモデルの増幅率17.8%を達成し、98.78%の全体的な精度を実現しました.他のLLM(ChatGPTなど)と比較した場合、GPT-4をプランナーとして使用することで、より一貫性があり合理的なツール選択ができ、指示に基づいて潜在的な制約を推論することが可能であるという研究結果が示されました.Chameleonの柔軟性と効果を2つのタスクで紹介し、その性能の高さを示しました.
Q&A:
Q: LLMはどのような新たな能力を示したか?
A: LLMsは、文脈学習や数学的推論、常識推論などの新しい能力を示し、ゼロショット環境で多様なタスクを解決でき、人間のような計画や意思決定能力を持つことが示されています.
Q: カメレオンとは何ですか?また、LLMの制限にどのように対応していますか?
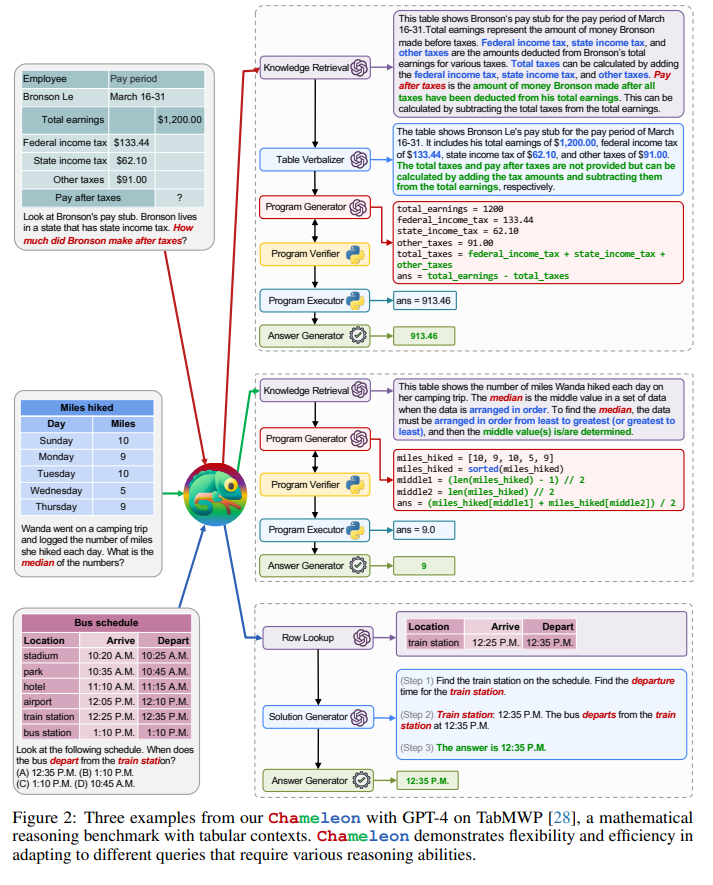
A: Chameleonは、LLMsの限界を補うためのプラグアンドプレイの合成推論フレームワークであり、大規模言語モデルを効果的に活用して、幅広い思考タスクに対処することができます. Chameleonは、LLMs、既製のビジョンモデル、Web検索エンジン、Python関数、およびユーザーの興味に合わせたルールベースのモジュールの様々なツールを統合し、実世界の問いに答えるための汎用的で適応可能なAIシステムを構築することができます. Chameleonは、LLMを自然言語プランナーとしてベースに構築され、各ツールの説明やツール使用の例に基づいてプランナーは、ユーザークエリの最終応答を生成するために組み合わせおよび実行する適切なツールのシーケンスを推論することができます. Chameleonは、ドメイン固有のプログラムを生成する従来のアプローチとは対照的に、自然言語プログラムを生成し、エラーが少なく、デバッグが容易で、プログラミング経験が限られている人にも親しみやすく、新しいモジュールの使用に効率的に拡張することができます. Chameleonは、プログラムとしてのシーケンシャルモジュールの構成により、次のモジュールの実行は、以前のキャッシュされたコンテキストと更新されたクエリを利用することができます.
Q: 科学びTabMWPタスクに対して、カメレオンはどの程度効果的ですか?
A: ChameleonはScienceQAとTabMWPの2つの課題でどの程度有効かについて述べられています.使用するLLMにはGPT-4が含まれ、ScienceQAでは最高のfew-shotモデルを11.37%上回り、86.54%の正確性を達成し、TabMWPではCoT GPT-4より7.97%、SOTAモデルより17.8%の向上を達成し、98.78%の全体的な正確性を達成しました.これらの成果は、Chameleonが異なるタイプとドメインを横断する多様なツールを協調させる能力を示しています.
Q: カメレオンは既存の推論フレームワークやアプローチとどう違うのですか?
A: Chameleonは大規模言語モデルの能力を利用し、様々なツールを合成して幅広い問い合わせに対処できるプラグアンドプレイの合成型推論フレームワークです.既存のアプローチとは異なり、Chameleonは多様なツールを使用すること、学習済みモデルに追加のトレーニングやツール固有のプロンプトが必要ないこと、新しいツールの追加や指示の更新に適応できることなどにより、柔軟性と効果性を実証しています.
Q: 外部ツールやモジュラーアプローチはLLMをどのように補完できますか?
A: 外部ツールやモジュールアプローチを使用することによって、大規模言語モデル(LLMs)の能力をどのように強化できるかについてどのような方法があるか? LLMsの制限を克服するために、外部ツールとリソースを利用した拡張、プラグアンドプレイモジュラーなアプローチを探索することが注目されています.これにより、実時間情報にアクセスすることができるようになり、繰り返し利用されるドメインに特化した知識が利用できます.また、条件付きルールとしての知識を使用して、シンボル的な推論をステップバイステップで実行することができます.
Q: 拡張LLMはどのように、ドメイン固有の知識を活用し、なぜそれが重要なのでしょうか?
A: 外部ツールとモジュラーアプローチを用いることで、LLM(大規模言語モデル)にドメイン固有の知識を活用することができます.特定のドメインにおいて問題を解決するために、背景情報を生成し、タスクの文脈を提供することで、知識検索やBing検索などの外部ツールはLLMの性能を向上させることができます.ドメイン固有の知識を活用することは、複雑な問題に対処するために重要です.
Q: カメレオンは、指示を更新して新しいタスクに適応する方法はどのようになりますか?
A: Chameleonは、タスクに適応するために、新しいタスクに対応するために更新された指示がどのような役割を果たしているかを考慮しています.更新された指示により、ユーザーの要求に応じて、適切なツールを選択し、プログラムを生成できます.また、Chameleonは、モジュールをシーケンシャルなプログラムとして組み合わせることで、前のキャッシュされたコンテキストと更新されたクエリを活用しながらモジュールを順次実行することができます.
Q: この論文で導入された方法の利点は、従来の方法と比較して何ですか?
A: この論文で導入された手法は、従来の手法と比較して、大規模言語モデルの制限を効果的に利用し、様々な推論タスクに対応し、適応性と柔軟性に優れたAIシステムを構築することができます.また、著者らは多様なベンチマーク、ScienceQAとTabMWPでのフレームワークの適応性と有効性を実証しています.
Q: この論文の実際的な貢献は何ですか?
A: 本論文の実用的な貢献は以下の通りです:(1)Chameleonという組成的推論フレームワークを開発し、大規模言語モデルの限界を効果的に利用し、幅広い推論タスクに対処できるようにしました. (2)LLMを含む様々なツールを統合して、汎用性の高いAIシステムを構築し、現実世界のクエリに答えることができます. (3)本フレームワークの適応性と効果性をScienceQAとTabMWPの2つの異なるベンチマークで紹介し、最先端の状態を大幅に向上させました.
Q: 今後の研究で残されたタスクは何ですか?
A: 今後の研究課題は何ですか?- 外部ツールや資源の統合、プラグインとプレイモジュラーアプローチの活用など、言語モデルを拡張することが必要です.また、LLMが持つ限界に対処するために、更新された情報を取得したり、外部ツールを活用したり、正確な数理推論を行うことができる方法を探る必要があります.
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
著者:Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, Karsten Kreis
発行日:2023年04月18日
最終更新日:2023年04月18日
URL:http://arxiv.org/pdf/2304.08818v1
カテゴリ:Computer Vision and Pattern Recognition, Machine Learning

概要:
Latent Diffusion Models(LDM)は、低次元の潜在空間で拡散モデルをトレーニングすることによって、高品質のイメージ合成を実現しながら、過度の演算要件を回避することができます.本研究では、特にリソースを消費するタスクである高解像度のビデオ生成にLDMパラダイムを適用します.そして、既存の最先端のテキストから画像へのLDMであるStable Diffusionを効率的かつ簡単に利用することで、LDMにおける時系列の利用により、テキストからビデオへの変換に成功し、解像度は最大1280 x 2048に達します.この方法で訓練された時系列層は汎用性が高く、異なる微調整されたテキストから画像へのLDMに一般化することができ、個人用のテキストからビデオを生成する初の成果を示し、今後のコンテンツ作成に向けた方向性を開拓しました.詳細はこちらのプロジェクトページをご覧ください:https://research.nvidia.com/labs/toronto-ai/VideoLDM/.
Q&A:
Q: 潜在拡散モデル(LDM)とは何ですか?どのようにして高品質な画像合成を実現し、過剰な計算要件を回避するのですか?
A: Latent Diffusion Models (LDMs)は高品質な画像合成を可能にする一方で、計算負荷を避けることができるモデルです.これは、より低次元の潜在的空間に拡散モデルをトレーニングすることによって達成されます.
Q: :LDMsにおける対立的目的の目的は何であり、どのように実装されているのですか?
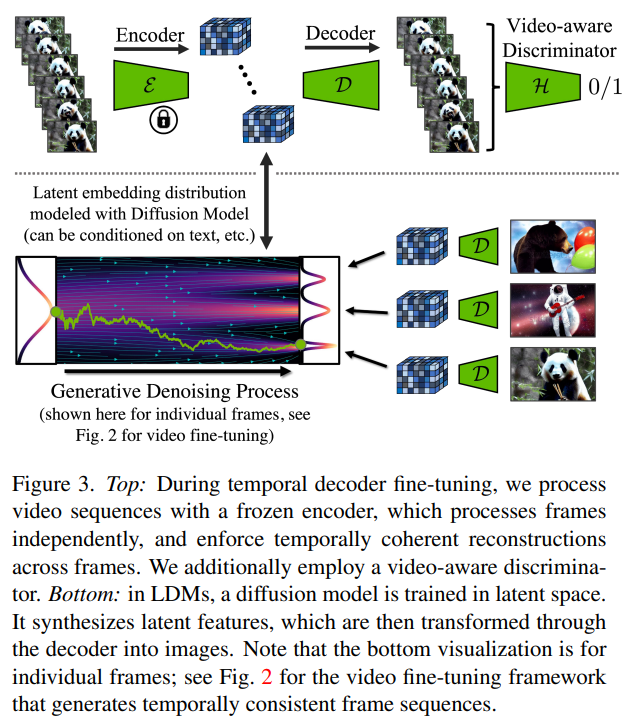
A: LDMのadversarial objectiveの目的は、生成された画像が実際の画像に似ているように見えるように、生成器を訓練することです.これは、ディスクリミネータを使用して実際の画像と生成された画像を区別することによって実装されます.
Q: 実装されている時間混合層の2種類とその違いは何ですか?
A: LDMに実装されている2種類の時間混合層とは、コンテキスト誘導層とアテンション層です.コンテキスト誘導層は、現在のフレームを少し低解像度にして、多数のコンテキストフレームを高解像度で入力することで動画を生成します.一方、アテンション層は、フレームごとにネットワークを別々に処理し、注意機構によって時間的な依存関係をモデル化します.
Q: リアルドライビングシーン(RDS)データとは何ですか?そして、ビデオLDMパイプラインでどのように使用されていますか?
A: 「RealDriving Scene(RDS)」データは、解像度512×1024(H×W)で8秒の実際のドライビング動画683,060本からなるデータで、夜/昼のラベルと混雑度に関するアノテーションが付いています.このデータは、主に低混雑の空いた高速道路のシーンが含まれています.Video LDMパイプラインでは、夜/昼のラベルと混雑度に基づいて訓練され、4xピクセル空間のビデオアップサンプラーとともに使用されます.訓練中にこれらのラベルをランダムに削除して、クラシファイアなしでのガイダンスや無条件の合成を可能にしています.また、境界ボックスに基づいた条件付きイメージLDMの訓練に使用する独立したフレームデータがあります.
Q: 潜在キーフレームの生成プロセスおよび時間補間にどのように使用されるかについて説明できますか?
A: LDMにおいて、潜在キーフレームを生成するには、まず画像LDMを用いて単一のフレームを生成し、その後、予測モデルを実行し、単一のフレームに基づいて一連のキーフレームを生成します.そして、ビデオを拡張する場合には、2つのフレームに基づいて予測モデルを調整し、統一された動きを表現するようにします.次に、2ステップの時間的補間を実行してビデオを高速化します.これらの操作はすべて、同じ画像バックボーンを共有するLDMを使用して行われます.そして、最後に、潜在ビデオをピクセル空間にデコードし、動画のアップサンプラーが必要な場合にはそれを適用します.
Q: 圧縮モデルのデコーダーをビデオ微調整することの効果は何ですか?これは、RDSデータセットの非ビデオ微調整対照と比較してどのように分析されていますか?
A: 圧縮モデルのデコーダーをビデオファインチューニングすると、画像再構築の精度が大幅に向上し、表3に示されるように、RDSデータセットの非ビデオファインチューニングの対象と比較した場合、改善が数桁以上になることが確認されました.
Q: 動画予測と補完の拡散モデルとは何であり、これらのタスクの他のモデルとはどう違うのでしょうか?
A: Diffusion models(DMs)は、強固かつスケーラブルなトレーニング目的を提供し、transformerに基づくモデルよりも少ないパラメータであるため、他のモデルに比べて望ましい優位性を持っています.しかし、画像ドメインの進歩に対して、ビデオモデリングは遅れています.これは、ビデオデータでトレーニングする際の膨大な計算コストと、大規模で一般的かつ公開されたビデオデータセットの欠如によるものです.以前のビデオDMに比べて、高解像度で長いビデオを生成することに成功した最近の研究もあります.しかし、ほとんどの作品は比較的低解像度で短いビデオしか生成していません.
Q: StyleGAN-vとStyleGAN2の技術的な違いについて話していただけますか?
A: StyleGAN-vとStyleGAN2の技術的な違いは何ですか?
StyleGAN-vは、StyleGAN2と比較して長時間間隔を備えた高解像度のビデオ合成を実現するために、低解像度と高解像度のモデルを組み合わせることで、スケールアップレイヤーを使用します.また、テキストプロンプトに基づいて条件づけられているため、autoregressiveマスキングを必要としません.さらに、スタイルガン2よりも少ないパラメーターが必要であり、CogVideoよりも優れたテキストからビデオ合成が実現できます.
Q: StyleGAN-vはどのように連続した動画を生成しますか?
A: StyleGAN-vは、低解像度と高解像度のモデルを組み合わせて、比較的長い時間間隔で高解像度のビデオ合成を実現しています.このアプローチの利点は、低解像度と高解像度のモデルを使うことで、より効率的かつ正確なビデオ合成を実現できることです.
Q: StyleGAN-vは、ビデオ生成における一般的な制限にどのように対処していますか?
A: StyleGAN-vは、高解像度の長いビデオ生成など、ビデオモデリングによる実世界の問題に焦点を当てています.これは、以前のビデオDMを含む多くの作品が、比較的低解像度かつ短いビデオしか生成していない、ビデオ生成の共通の限界を解決することを意味しています.
Q: StyleGAN-vのパフォーマンスはどのように評価されましたか?
A: 研究では、StyleGAN-vの性能は人間の評価とInception Score、CLIP Similarityの評価によって評価されました.人間の評価は、Amazon Mechanical Turkで行われ、100個の4秒のビデオを生成し、各ペアについて2つのビデオを提示し、参加者が好ましいビデオを選択するように指示された.Inception ScoreやCLIP Similarityは、モデルの出力を評価する指標です.
Q: StyleGAN-vの潜在的なユースケースやアプリケーションについて詳しく説明してください.
A: StyleGAN-vの潜在的な使用例やアプリケーションには、高解像度のビデオ合成、長時間のビデオシーケンスの生成、テキストからビデオ合成、ドライブシーンの生成などが含まれます.さらに、個人的なテキストから画像生成、不均一な時間感覚を持つ映像の生成、タイムラプス映像の生成などの分野での利用が考えられます.
Q: StyleGAN-vの今後の方向性や潜在的な改善点について議論することはできますか?
A: 可能性のある改善点や将来の方向性としては、より長い時間間隔で高解像度のビデオ合成を実現するために、低解像度と高解像度のモデルを組み合わせたLongVideoGANのような方法があります.また、テキストから画像・ビデオを生成するためのモデルのさまざまな手法があり、中でも連続した意味空間を使用したDMGANは、高い性能を発揮しています.さらに、より多様なデータセットを扱うために、StyleGAN-XLのような手法も開発されています.これらの手法を組み合わせ、様々な条件での生成に対する汎用性を向上させることが、StyleGAN-vの改善や将来の方向性として考えられます.
Q: この論文で紹介された方法のメリットは、従来の方法と比較して何ですか?
A: StyleGAN-vは、StyleGAN2と同等の画像品質と利点を持つ連続的なビデオジェネレータである.以前のGANベースの方法に比べ、長時間の解像度の高いビデオ合成を達成するLongVideoGAN、単純なオブジェクト重心ビデオ用にMoCoGAN-HDやStyleVideoGANなどがあるが、この方法は、連続的なデザインモデルに依存し、パラメータが少なく、CogVideoよりもテキストからビデオを合成することで性能を発揮していることが特徴的である.また、タクスト提示に基づく調整レイヤーも異なる方法で実装されるため、自己回帰マスキングを必要としない.さらに、追加のビデオファインチューニングアップサンプラーモジュールを採用して運転シーン生成もし、テキストからビデオを生成するためのモデルは、他にも多数存在している.
Q: この論文の実用的な貢献は何ですか?
A: StyleGAN-vは、継続的な映像生成器であり、StyleGAN2と同じ画質と特典を持ちます.また、低解像度モデルと高解像度モデルを組み合わせて、比較的長い時間間隔で高解像度ビデオ合成を実現するLongVideoGANなどのGANベースの方法と比較して、テキスト対ビデオ合成で優れたパフォーマンスを示します. さらに、テキストへの自己アテンション機能の導入により、既存のテキスト対映像生成手法を拡張しています.
Q: この新しい方法で見つかった困難点は何ですか?
A: StyleGAN-vの実装において遭遇する困難は、テンポラルな詳細の一貫性を保つことが若干難しいことです.FVDメトリックは、写真的なリアリズムよりも短期的な「滑らかさ」を重視するため、このメソッドでは性能が低下する傾向があります.しかし、全体的な品質やリアリズムは人間の評価者によって最もよく評価されるべきであり、この点ではLVGを上回っています.
Learning to Compress Prompts with Gist Tokens
著者:Jesse Mu, Xiang Lisa Li, Noah Goodman
発行日:2023年04月17日
最終更新日:2023年04月17日
URL:http://arxiv.org/pdf/2304.08467v1
カテゴリ:Computation and Language
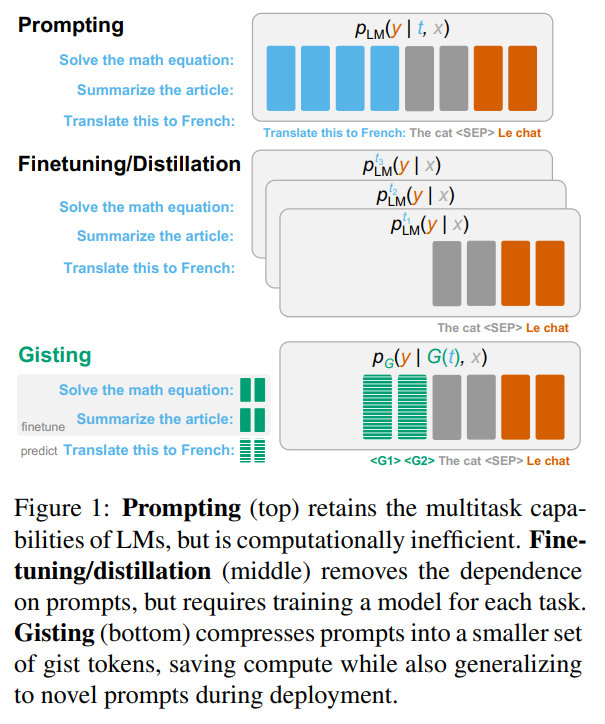
概要:
語言模型(LM)のマルチタスク機能を活用する主要な方法は、プロンプトを使用することであるが、プロンプトは入力コンテキストウィンドウで貴重なスペースを占め、同じプロンプトを再エンコードすることは計算的に効率が悪い.Finetuningと蒸留方法は、プロンプトなしでLMを特化させることができるが、各タスクのためにモデルを再トレーニングする必要がある.完全なトレードオフを回避するために、私たちはジスティングを提供する.これは、LMをトレーニングして、プロンプトをより小さな「要約」トークンのセットに圧縮し、計算効率のために再利用できるようにするものである.ジスティングモデルは、プロンプトの圧縮を促す制限された注意マスクを介して簡単に指示ファインチューニングの一部としてトレーニングできる.デコーダー(LLaMA-7B)とエンコーダー・デコーダー(FLAN-T5-XXL)LMでは、ジスティングにより、プロンプトの26倍の圧縮が可能になり、40%のFLOPsの削減、4.2%の壁時速度向上、ストレージの節約、そして出力品質の最小の損失が発生する.
Q&A:
Q: gistingとは何ですか?どのように機能しますか?
A: gistingはLM(Language Model)でのプロンプト圧縮のためのアモーティズド・フレームワークであり、Transformerの注意マスクを変更して簡単にgistモデルを実装する方法です.これにより、スタンダードな命令fine-tuningに追加のコストをかけずに、ガイドモデルが実装できます.LMのmeta-contextの蒸留や圧縮、特に教示に従うアプリケーションで、コンテキストウィンドウに収まらないpromptを圧縮することによって、元の性能を維持したままより少ないFLOPを実現します.将来の作業のために、更に多くの研究方向を開く有望な手法として考えられます.
Q: ストレージコストにおいて、ジスティングは従来のプロンプトキャッシングアプローチと比べてどうですか?
A: ジスティングと従来のプロンプトキャッシングアプローチのストレージコストには大きな差があります.ジスティングでは、同じ量のストレージを使用しながら、26倍以上のプロンプトをキャッシュすることができます.
Q: prefix-/prompt-tuningやadaptersなどのパラメータ効率の良い微調整方法の利点は何ですか?
A: プリフィックス-/プロンプト調整やアダプターなどのパラメータ効率の良いチューニング方法の利点は、完全なチューニングのコストの一部で行えることです.また、これらの方法により、元のモデルと同じようにモデルを調整することができます.
Q: Transformerのattentionマスクには、instruction fine-tuning中にどのような修正が加えられますか?
A: アテンションマスクを変更して、プロンプトの圧縮を促す特別なgistトークンを追加します.これにより、学習コストは通常の指示の微調整の上に発生せず、学習コストを負担する必要はありません.注意制限の下で、このシーケンスをモデルに送信します.入力トークンがgistトークンの前のプロンプトトークンにアテンションできないため、モデルはプロンプトの情報をgistトークンに圧縮するように強制されます.具体的な変更内容は、Decoder-Only LMsでは、自己回帰的な意味のあるアテンションマスクを使用している場合は、三角形の左下隅をマスクアウトします.Encoder-Decoder LMsの場合は、入力トークンがプロンプトトークンにアテンションできないようにする必要があります.
Q: Gistモデルは、トレーニング分布外にあるプロンプトを信頼できる圧縮できますか?
A: はい、gistモデルはトレーニング分布外のプロンプトをある程度信頼できる圧縮力で圧縮することができます.
Q: ギストトークンモデルがプロンプトを完璧に圧縮できない失敗例の例をいくつか提供できますか?
A: gistトークンモデルがプロンプトを完全に圧縮できない失敗例として、特定の詳細を含む指示がある場合があります.例えば、アウトプットに文字をそのままコピーする必要があるフレーズなどです.また、Human validation splitにおいてこの失敗例が起こることがあります.
Generative Disco: Text-to-Video Generation for Music Visualization
著者:Vivian Liu, Tao Long, Nathan Raw, Lydia Chilton
発行日:2023年04月17日
最終更新日:2023年04月17日
URL:http://arxiv.org/pdf/2304.08551v1
カテゴリ:Human-Computer Interaction, Artificial Intelligence

概要:
音楽を体験する上で視覚要素は重要な役割を担っており、それによって音楽が伝える感情やメッセージが強化される.しかし、音楽ビジュアライゼーションを作成することは複雑で、時間やリソースを要するプロセスである.本研究では、大規模な言語モデルやテキスト・トゥ・イメージモデルを使ったジェネラティブAIシステム「Generative Disco」を紹介する.ユーザーは、ビジュアライズしたい音楽の区間を選択し、開始と終了のプロンプトを定義してビジュアライズをパラメータ化する.これらのプロンプトは楽曲のビートに合わせて変形して生成され、オーディオリアクティブなビデオが生成される.また、ビデオの改善を図る「トランジション」と「ホールド」の設計パターンも紹介する.プロフェッショナルの専門家による調査では、このシステムは楽しく探求することができ、非常に表現力があると評価された.最後に、Generative Discoのプロフェッショナル向けのユースケースや、AI生成コンテンツがクリエイティブな仕事の風景を変えつつあることについて言及する.
Q&A:
Q: ジェネラティブディスコとは何ですか?その音、言語、映像をどのように接続してビデオ生成につながるのでしょうか?
A: Generative Discoとは、音楽の視覚化のためのテキストからビデオを生成するAIシステムです.音楽クリップを使って、音、言語、画像を結びつける提示文を生成し、ビデオクリップを生成することができます.音、言語、画像を密接に結びつけるワークフローを持つため、音楽以外でも応用可能です.
Q: Generative Discoは、大規模言語モデルとテキスト・イメージ変換モデルのパイプラインを用いて、音楽視覚化のためのテキスト・ビデオ生成をどのように促進しますか?
A: Generative Discoは、音楽クリップから音、言語、画像を結びつけるプロンプトを生成し、ビデオクリップを生成するAIシステムです.大規模言語モデルとテキストから画像を生成するモデルを使用しています.参加者は、高いレベルの目標である「ディスコでダンスする」を表示するためのプロンプトをブレインストーミングし、ビデオクリップの生成を生成するための始点と終点のプロンプトをパラメータ化することができます.ビデオクリップは、トラックエリアに生成され、ビデオエリアでレンダリングされます.
Q: :音楽ビデオ制作システムで視覚的な物語を作成するために、ユーザーに提供されるべき編集機能は何ですか?
A: ユーザーには、音楽の構造に合わせたカット、トランジション、ホールドによるビジュアルナラティブの構築ができる機能が与えられるべきであり、歌詞や楽器の要素と特定のプロンプトを繋げることができ、視覚的で音楽に関連性がある方法も提供する必要があります.
Q: ジェネレーティブ・ディスコは創造性支援指標(CSI)メトリックスでどの程度の成果を上げましたか?
A: Generative Discoは創造性支援指標(CSI)のメトリクスで良好な結果を出しました.全ての質問に対する回答は7点リケールスケールで、表3の中央の描写に視覚化されました.全12人の参加者からの回答には高い評価がありました.Generative Discoは音楽の解釈に合わせた音楽ビジュアルの制作にプロフェッショナルに大いに役立つことを結論づけました.
Q: Generative Discoを使用して参加者が生成したビデオの種類の例を示せますか?
A: 参加者がGenerative Discoを使用して作成したビデオの例には、Lana Del Reyの「Lucky Ones」のダイナミックな歌詞ビデオにキネティックタイポグラフィを追加したP5のビデオ、独自のビデオスタイルで後処理されたP9のビデオが含まれています.他にも、12曲の異なる音楽に対して音楽ビデオが生成されました.
Q: ジェネレーティブディスコは、参加者の通常のワークフローにどのように役立つのかについて議論できますか?
A: Generative Discoは参加者が音楽の解釈に合ったビジュアル表現を制作するのにかなり役立ったため、高い評価を受けました.特に、抽象的および具象的な要素、感情、記号、ビート、歌詞などの表現にいくつかの意味のあるトランジションとホールドを使用して表現するための多様な手法を提供しました.また、プロフェッショナルは新しい方法で作成することができるようになり、簡単に学習できることが示されました.もっと詳しくは、セクション6のQualitative Feedbackで説明されています.
Q: :この論文で導入された方法の旧来の方法と比較しての利点は何ですか?
A: この論文で紹介されている方法の利点は、過去の方法と比較して、音楽に基づくビデオの生成において、AIワークフローを活用しやすく、簡単に利用できることです.また、参加者はこの方法を外部効果を使用せずに探索し、音楽に基づく生成プロセスに完全に没頭することができました.さらに、参加者は特に音楽への親和性や音声と映像の整合性について肯定的な評価を行いました.
Q: 実験やデータ分析からの主な発見は何ですか?
A: Generative Discoは音楽のイメージングに優れた性能を発揮し、抽象的および具体的な要素を表現するために異なる意味のある遷移や保持を提供し、専門家がイメージングに取り組むのを支援したことが示された.ユーザーは簡単にジェネレーティブなワークフローを学習し、15分ですべての機能を使用できることを明らかにし、参加者は実験後のアンケート調査でその体験について尋ねられた.Generative Discoは12曲の音楽のために動画を生成し、クリエイティブサポート指数メトリックスでは良好な成績を収めた.
Q: :今後の研究に残る課題は何ですか?
A: Generative Discoの将来の課題の1つに、より特定されたアニメーションがあります.また、より長い動画の生成にも取り組む必要があります.新しいテキストトビデオモデルが登場しており、より微細な制御が可能になる可能性がありますが、時間がかかる場合もあります.
Visual Instruction Tuning
著者:Haotian Liu, Chunyuan Li, Qingyang Wu, Yong Jae Lee
発行日:2023年04月17日
最終更新日:2023年04月17日
URL:http://arxiv.org/pdf/2304.08485v1
カテゴリ:Computer Vision and Pattern Recognition, Artificial Intelligence, Computation and Language, Machine Learning

概要:
この論文では、大規模な自然言語モデル(LLM)の指示のチューニングに、機械生成の指示に従うデータを使用することで、新しいタスクにおけるゼロショット能力が向上しているが、マルチモーダル分野ではこのアイデアが探求されていないことが指摘される.そこで、本論文では、言語のみを処理するGPT-4を使用して、マルチモーダルな言語-画像の指示に従うデータを生成し、その生成されたデータを用いて指示チューニングを行うことで、Large Language and Vision Assistant(LLaVA)を提案する.LLaVAは、ビジョンエンコーダーとLLMをつなぎ合わせた大規模なマルチモーダルモデルであり、一般的な視覚と言語の理解を可能にする.実験の結果、LLaVAは印象的なマルチモデルチャット能力を示しており、未知の画像/指示に対してマルチモーダルGPT-4の振る舞いを表し、合成マルチモーダル指示に従うデータセットにおいて、GPT-4に比べて85.1%の相対スコアを示した.また、Science QAでファインチューニングされたLLaVAとGPT-4の相乗効果により、新たな最高精度92.53%を達成した.GPT-4が生成した視覚的な指示のチューニングデータ、モデル、コードベースを公開している.
Q&A:
Q: 大規模言語モデルのインストラクション調整の主な目的は何ですか?
A: 大規模言語モデルにおける指示チューニングの主な目的は何ですか?
指示チューニングの主な目的は、機械生成された指示に従って大規模言語モデルを調整することで、新しいタスクに対するゼロショット機能を向上させることです.
Q: タスク指示の明示的な言語表現が神経アシスタントの適応性と相互作用を改善する方法について、どのように考えられますか?
A: 自然言語での明示的なタスクの指示を組み込むことで、ニューラルアシスタントの適応性と相互作用を向上させる潜在的な利点があります.これにより、タスクの指示を言語で明確に表現することができ、その指示に応じてアシスタントを適切に調整し、問題を解決することができるようになります.更に、こうしたアプローチは、アシスタントの柔軟性と相互作用を高めることができ、ユーザーのニーズに適応して、自然な対話を可能にすることができます.
Q: オープンソースLLMsの開発の意義は何ですか、そして将来の仕事でどのように使用される可能性がありますか?
A: オープンソースのLLMを開発することの意義は、様々なタスク指示を明示的に言語で表現し、 end-to-end トレーニングされたニューラルアシスタントを特定のタスクに切り替えて解決することができる、汎用的なアシスタントのための言語の普遍的なインターフェースを提供できることです.これにより、ユーザーの指示に対して相互作用性と適応性が豊富なモデルが構築できます.将来の研究では、これらのモデルがより効率的で正確なタスク解決に貢献することが期待されます.
Q: 著者たちは、機械生成の高品質な指示に従うサンプルをどのように活用して、LLMのアラインメント能力を向上させましたか?
A: 著者たちは機械生成された高品質の指示文によるサンプルを活用し、LLMの位置合わせ能力を向上させました.これにより、プロプライエタリなLLMと比較して印象的なパフォーマンスを報告しました.重要なことに、この研究はテキストのみを対象としています.
Q: :ビジョン・ランゲージによる指示の追従のためのデータ開発における課題は何ですか?
A: ビジョンと言語を統合した命令に従うデータを開発する上での課題は、ビジョンと言語の統合に関する研究が少ないため、ビジョンと言語の統合に関するデータの不足が主な課題となる.また、人間のクラウドスカウリングを考えると、プロセスが時間がかかるため、データ収集が限定されることも課題の一つである.
Q: :多様なモードによる指示に従うデータ収集に提案されるアプローチは何ですか?
A: マルチモーダルな指示に従うデータの収集にはどのようなアプローチが提案されていますか? → ChatGPT/GPT-4を使って、画像とテキストのペアを適切な指示に従う形式に変換するデータリフォーメーションの観点とパイプラインが提案されています.また、これによりLMMの指示チューニングに生成されたデータを利用することができ、実際的なヒントが提供されています.
Q: :7.プロポーズされたデータ生成手法を利用したビジュアル指示チューニングのアプローチは、以前の手法とどのように異なるのでしょうか?
A: 従来の方法と比較して、GPTによる視覚命令データの生成を利用した視覚命令チューニングの提案手法の違いは何ですか?
Q: PaLM-Eとは何であり、具体化人工知能とどのように関係していますか?
A:
PaLM-Eは、Language Modeling for Embodied Agents Challenge(モデル化されたエージェントのための言語モデリングチャレンジ)の分野で最も優れた性能を発揮した自然言語処理のモデルです.PaLM-Eは、人間の言語や場面理解のような知覚、行動、認知を含めた体験的な情報を学習することができます.これにより、PaLM-Eは、具体化人工知能に非常に適しています.具体化人工知能は、人間の身体的な経験や能力を模倣する人工知能の形態であり、機械のインタラクション能力や対話能力を向上させることができます.PaLM-Eは、具体化人工知能の開発において、人間らしい言語処理を実現するための重要なツールの1つとなっています.
A: PaLM-Eは、具現化AI用のLLM(Large Language Model)であり、ゼロショットタスクの転移やコンテキスト学習でも強い性能を発揮することから、関連性があります.
Q: LLaVAモデルのトレーニングにおいて特徴量アラインメントのための事前トレーニングプロセスとは何ですか?
A: LLaVAモデルのトレーニングにおける特徴の整列のための事前トレーニングプロセスは何ですか?事前トレーニングは、画像とテキストのセットの一部であるCC3Mのサブセットに限定され、可視化エンコーダーとLLMの両方の重みを凍結して、訓練可能なパラメーター「W」(投影行列)のみで(3)の尤度を最大化することによって行われます.これにより、画像機能Hvは事前トレーニング済みのLLMの単語埋め込みと整列できます.この段階は、凍結LLMの互換性のある視覚トークナイザーのトレーニングと理解できます.
Q: 10.LLaVAはどのように指示に従う能力を発揮しますか?
A: LLaVAは、与えられた指示に従って適切に回答することができる能力を示しています.それに対し、BLIP-2やOpenFlamingoは、画像の説明に焦点を合わせており、指示に従って回答することができない場合があります.また、LLaV Aはテストデータセットでの予測精度が高く、ChatGPT/GPT-4を使用して生成された多様な instruction-following データセットの生成に成功しています.
Q: LLaVAは、元のGPT-4論文の例に対してどのようなパフォーマンスを示しますか?
A: LLaVAは、元のGPT-4論文の例に対してはうまく機能することが示されています.画像に関する質問に適切に答えることができます.読者には、LLaV Aのパフォーマンスを研究するために、実際に対話してみることをお勧めします.
Q: LLaVAの指示に従う能力を測定するために活用される定量的な尺度は何ですか?
A: LLaVAのinstruction-following能力を測定するために使用される定量的な指標は、相対スコアです.具体的には、合成された多重指示-followingデータセットにおけるGPT-4との比較によって85.1%の相対スコアが得られています.また、Science QAでのfine-tuningにより、LLaV AとGPT-4のシナジーにより、92.53%の最新の正確性が達成されました.
Q: LLaVAは、質問と視覚入力画像に基づいて回答を予測する方法はどのようにしていますか?
A: LLaVAは、質問と視覚的な入力画像を使用して答えを予測します.具体的には、提案されたデータ生成パイプラインを使用して、COCO検証セットから30の画像をランダムに選択し、会話、詳細な記述、複雑な推論の3種類の質問を生成します.LLaV Aは、質問と視覚的な入力画像に基づいて答えを予測します.GPT-4は、質問、グラウンドトゥルースの境界ボックスとキャプションに基づいて、参照予測を行い、教師モデルの上限を示します.両方から回答を取得した後、質量指標を使用してLLaV Aのパフォーマンスを測定します.
Q: トレーニングデータセットを変化させることが、指示に従うデータの種類の効果にどのような影響を与えましたか?
A: 訓練データセットを変化させることで、指示に従うデータの異なるタイプの有効性にどのような影響があるかを調べました.指示の調整により、モデルの能力が50ポイント以上改善し、詳細な説明と複雑な推論問題を少量追加することにより、モデルの総合能力が7ポイント向上しました.また、モデルの性能も向上しました.
質問:15. 詳細な説明や複雑な推論の質問を少量追加した場合、モデルの推論能力は全体的にどの程度改善しましたか?
A: 少量の詳細な説明と複雑な推論の質問を追加することで、モデルの全体的な推論能力は7ポイント向上しました.
Q: :この論文で紹介されている方法と従来の方法とを比較した場合の、この方法の利点は何ですか?
A: この論文で紹介された手法は、以前の手法に比べて75.17%から78.57%の精度向上が見られました.また、GPT-4が十分な文脈がないと報告することが多く、その場合には本手法とGPT-4の結果を組み合わせることが可能です.
Q: :この新しい方法にはどのような困難がありますか?
A: この新しい方法を実施する際には、主にヒトの集団追跡を考慮するために、プロセスが時間がかかり、十分に定義されていなかったため、多くの困難が発生しました.また、この多様なInstruction-Following Dataを扱うためのChatGPT / GPT-4の現在の能力の限界があるため、この新しい方法を実装するのに苦労しました.
DINOv2: Learning Robust Visual Features without Supervision
著者:Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski
発行日:2023年04月14日
最終更新日:2023年04月14日
URL:http://arxiv.org/pdf/2304.07193v1
カテゴリ:Computer Vision and Pattern Recognition
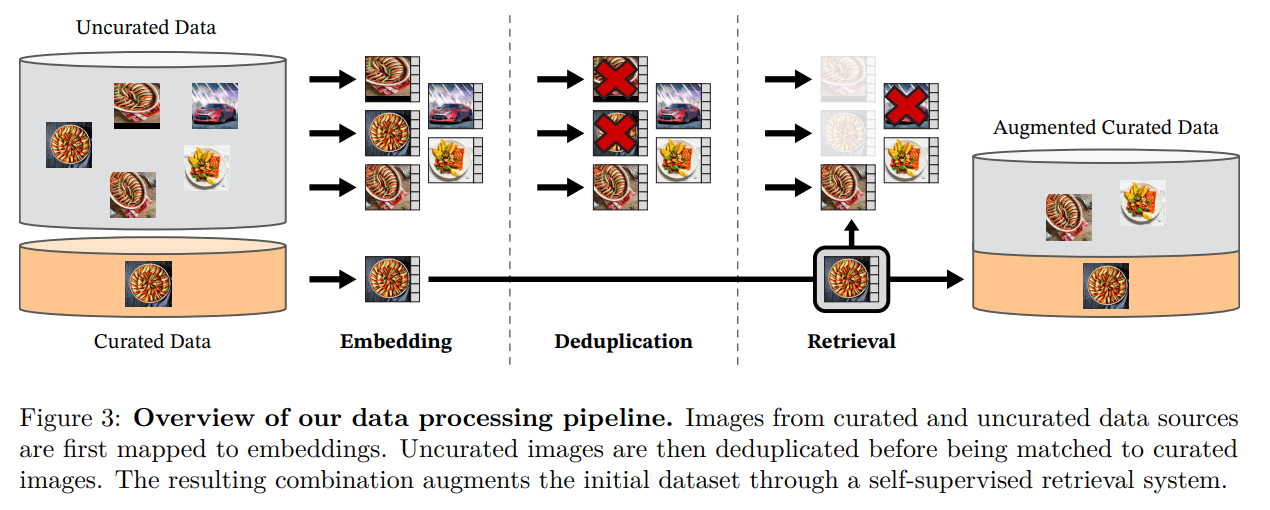
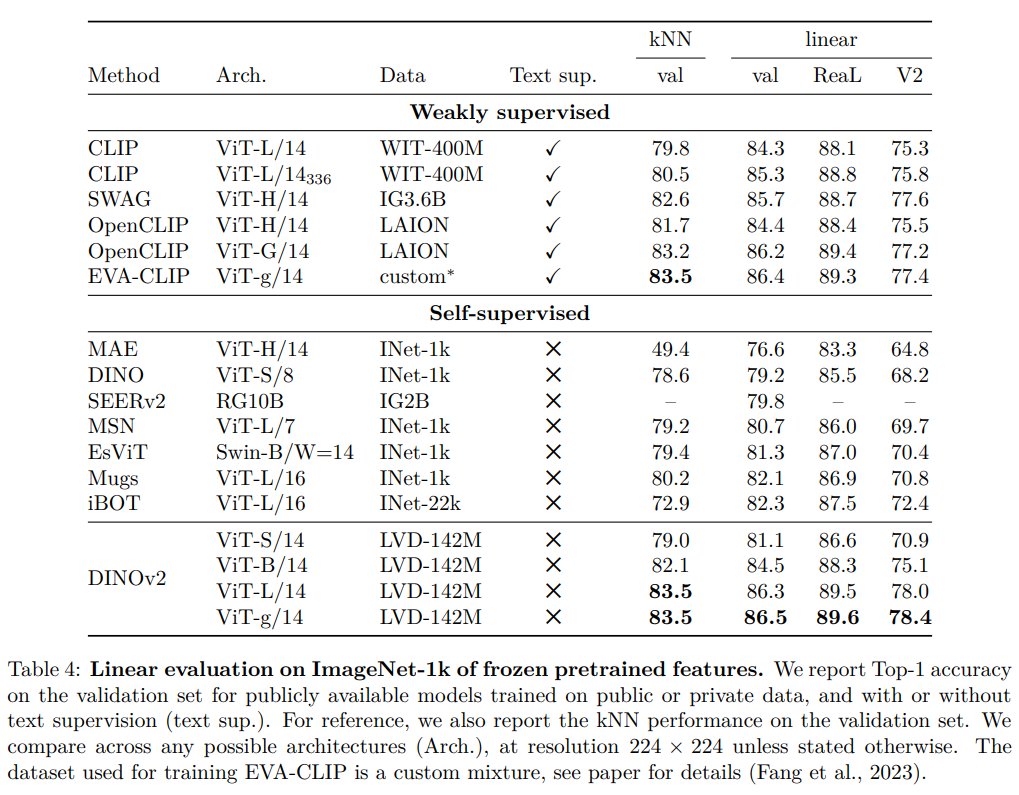
概要:
最近のブレークスルーにより、自然言語処理における大量のデータを使ったモデルのプリトレーニングが可能になったことは、同様の技術がコンピュータビジョンにも応用できることを示しています.研究によれば、自己教師あり学習手法を用いて、様々なソースから精選された専用の画像データセットをトレーニングすることで、調整なしに画像配布やタスクを超えて動作する特徴を生成することができます.研究では、既存のアプローチを再検討し、ランダムに選択されたよりも専用のデータセットを使用することで、大規模なトレーニングを加速し、安定化することを目的としています.また、ViTモデルを使用して、1Bパラメータでトレーニングし、小さなモデルに蒸留することで、最高のオールパーパスの特徴であるOpenCLIPを超える特徴が生成されます.新しい文脈を追加すると、シリーズの小さなモデルでも、これまで最高とされてきたOpenCLIPよりも優れた性能を発揮することになります.この研究は、画像やピクセルのベンチマークにおいて、多数のタスクにおいて、最高のオールパーパスの特徴を有するOpenCLIPを上回ることが示されています.
Q&A:
Q: :自然言語処理における大量データのモデル事前学習に関する最近のブレイクスルーは何ですか?
A: 自然言語処理におけるモデルの事前学習において、大量の生のテキストを前提とするpretext目的、例えば言語モデリングや単語ベクトルを使用するpretrainingが成功を収めている.これは、従来のタスク固有モデルを使用するよりもはるかに優れた結果を生み出すことができるということを意味している.また、このNLPのパラダイムシフトに伴い、コンピュータビジョンでも同様の「基盤」モデルが登場することが期待されており、これらのモデルは、画像レベル(画像分類など)やピクセルレベル(セグメンテーションなど)のいずれのタスクでも即座に動作するビジュアル特徴を生成する必要がある.
Q: モデルのサイズのスケーリングは、事前学習されたエンコーダーの性能にどのように影響しますか?
A: 事前学習エンコーダーのサイズと性能には関係があり、大きなサイズのエンコーダーほど良い性能が得られることが示されています.これは、より多くのパラメーターによって、より豊富な特徴表現を学習できるためです.また、スケーリングアップに伴う課題を克服するための技術的貢献もあります.
Q: Faissライブラリとは何ですか?そして、そのライブラリはパイプラインの重複排除と検索段階をどのようにサポートしていますか?
A: Faissライブラリは、GPUを使ったインデックスの効率的な計算や最近傍埋め込みのバッチ検索を行うために使用されます.具体的には、逆ファイルインデックスとプロダクト量子化コードを使用して、GPUアクセラレーションされたインデックスのサポートを活用します.これらの機能により、パイプラインの重複除去および検索ステージがサポートされます.
Q: :KoLeoの損失とは何ですか?ImageNet-1k、ADE-20kセグメンテーション、Oxford-Mの最近傍画像検索にどのような影響を与えますか?
A: KoLeoロスは、KoLeo regularizerによって導出され、バッチ内の特徴量の均一なスパンを促進する正則化項です.このロスは、インスタンスの検索パフォーマンスを8%以上向上させ、他のメトリックに悪影響を与えません.ImageNet-1k、ADE-20k segmentation、およびOxford-Mに対する最近傍画像検索の結果を表に示しています.
Q: 提案手法に見られる性能向上の意義は何ですか?
A: テーブル3aと3bの結果から、KoLeo損失とマスクされた画像モデリング用語が使用された場合、モデルの出力空間での特徴の拡散が改善され、密な予測タスクの性能がほぼ3%向上したことが示されています.また、小さいモデルの事前トレーニングの有効性も示されており、大きなモデルをスクラッチからトレーニングする代わりに、大きなモデルを蒸留することで、性能が向上することが示されました.また、提案手法で抽出されたパッチレベルの特徴が、セマンティック画像セグメンテーションやモノクル深度推定などの密なダウンストリームタスクにおいて良好な品質を持つことが示されました.
Q: モデルのパフォーマンスは、iNaturalistの変種においてOpenCLIP ViT-G/14と比較してどうですか?
A: iNaturalistのバリアントにおいて、モデルとOpenCLIP ViT-G/14の性能比較はどうですか?モデルはiNaturalist 2018、iNaturalist 2021の両方でOpenCLIP ViT-G/14よりも顕著に性能が向上しています(それぞれ+8.6%、+9.7%).ただし、Places 205ではOpenCLIP ViT-G/14にわずかに劣っています(-2.3%).
Q: モデルはビデオアクション認識でどのように機能しますか?
A: モデルは、ビデオアクション認識においても性能が良く、self-supervisedアプローチの中でも新しいState of the artを設定しています.UCFとKineticsではOpenCLIPの特徴量と精度が一致し、SSv2では優れた結果を示しています.しかし、ビデオフレームのより豊富な理解が必要なSSv2ではOpenCLIPを大幅に上回っています.
Q: この論文で紹介されている方法が従来の方法と比較して優れている点は何ですか?
A: この論文で導入された手法には、従来の方法に比べて優れた点があります.具体的には、SSLの最先端手法と比較して、より高い頑健性(Aで+29.6%、Rで+22.1%、Sketch 11で+23.0%)を示し、また、ゼロからトレーニングするよりもバックボーンの蒸留方法により優れたパフォーマンスを発揮することが確認されました.さらに、著者らはアブレーションスタディを行い、技術的な改良、事前トレーニングデータ、モデル蒸留の影響など、さまざまな要因がパフォーマンス向上に貢献していることを示しました.
ChatGPT: Applications, Opportunities, and Threats
著者:Aram Bahrini, Mohammadsadra Khamoshifar, Hossein Abbasimehr, Robert J. Riggs, Maryam Esmaeili, Rastin Mastali Majdabadkohne, Morteza Pasehvar
発行日:2023年04月14日
最終更新日:2023年04月14日
URL:http://arxiv.org/pdf/2304.09103v1
カテゴリ:Computers and Society, Computation and Language
概要:
OpenAIが開発したChatGPTは、教師あり機械学習および強化学習技術を用いて微調整された人工知能技術であり、コンピュータが完全自律的に自然言語会話を生成できるようになっています. ChatGPTは、トランスフォーマーアーキテクチャに基づいて構築され、さまざまなソースからの数百万の会話で訓練されています.このシステムは、事前にトレーニングされた深層学習モデルの力とプログラム可能性レイヤーを組み合わせて、自然言語会話を生成するための強力な基盤を提供します.本研究では、既存の文献をレビューした後、ビジネスおよび産業、教育を含む10の主要な分野でChatGPTの応用、機会、脅威を検討し、詳細な例を提供しています.また、GPT-3.5とGPT-4の有効性を確認し、パフォーマンスを比較する実験的研究を行い、後者のパフォーマンスが有意に優れていることを発見しました.自然言語応答を生成する能力に優れているにもかかわらず、著者らは、ChatGPTが人間と同じレベルの理解力、共感力、創造性を持っていないと考えています.そのため、ChatGPTは人間を完全に置き換えることはできず、ほとんどの状況で、人間と同等の能力を持っていません.
Q&A:
Q: ChatGPTテクノロジーとは何ですか?どのように機能しますか?
A: ChatGPTとは、OpenAIによって開発された高度な自然言語処理技術です.数十億のウェブページやドキュメントを含む膨大なデータに基づいて訓練されており、人間に近いテキスト応答を生成することができます.Transformerアーキテクチャに基づいており、教育やビジネス、科学技術などのさまざまな分野で活用できます.ChatGPTは、監視された機械学習と強化学習技術によって微調整されており、自己完結型の自然言語会話を生成するコンピュータに対して強力な基盤を提供しています.
Q: ChatGPTの制限と課題は何ですか?
A: ChatGPTの制限と課題は、以下のようになります.
- 探求できるトピックの制限:ChatGPTは、汎用的な対話システムであり、あらゆるトピックに対して説明することはできます.しかし、ChatGPTは特定の領域に特化した専門用語を習得することができません.
- 文脈理解の制限:ChatGPTは、前の会話の文脈や、ユーザーの個人情報にアクセスできないため、その文脈に基づいた返答をすることができません.
- プライバシーの問題:ChatGPTは、ウェブに接続されており、ユーザーや会話内容についての情報がサードパーティに漏れる可能性があります.このため、ChatGPTを使用する前に、ユーザーのプライバシー保護に関する注意点を確認する必要があります.
- 静的なデータ:ChatGPTは、人工知能が学習している過去のデータに基づいているため、最新の情報に追随できない場合があります.
Q: ChatGPTの潜在的な応用、機会、および脅威は何ですか?
A: ChatGPTの潜在的なアプリケーション、機会、および脅威には、以下のようなものがあります.ビジネスや産業分野における供給チェーン管理、科学技術分野、政府や政治における選挙、行政、憲法や契約、軍事における情報分析や戦術の最適化などが挙げられます.ChatGPTの脅威には、プライバシーやセキュリティの問題、偏見を含む推奨事項、誤解、データの不正確性、幻覚などがあげられます.一方、ChatGPTは大量のデータを迅速に処理・分析する能力を持ち、ビジネスや産業の意思決定や運営の改善に役立ちます.しかし、技術に過度に依存し過ぎることや、潜在的なエラーやバイアスに注意する必要があります.政治や政府分野においても同様であり、個人の税金申告や法的調査、兵器の装備や輸送の最適化などが可能ですが、プライバシーやセキュリティの問題、倫理的な懸念、バイアスやミスの可能性などが挙げられます.
Q: ChatGPTはどの程度のドメインをカバーしており、それらは何ですか?
A: ChatGPTは、さまざまなトピックのドメインをカバーしています.主なドメインには、科学、カルチャー、エンターテインメント、ライフスタイル、人間関係、健康、教育、技術などがあります.ChatGPTは、多様な興味を持つ人々にとって、知識を拡張し、娯楽と学習を結び合わせた場を提供しています.
Q: GPT-4がテキスト生成、質問応答、言語翻訳などのタスクでどのように優れたパフォーマンスを発揮できるか、具体的な例を提供できますか?
A: GPT-4の学習後のアラインメントプロセスにより、事実性と望ましい動作の整列性が向上し、2つのタスクでより良いパフォーマンスを発揮することが示されました.具体的な例としては、教育やビジネス分野での自然言語生成が挙げられます.ただし、ChatGPTは人間の理解力や共感力、創造力に達していないため、すべてのタスクや状況で人間に完全に代わることはできないと考えられています.
Q: ビジネスや産業分野におけるChatGPTの主な適用分野は何ですか?
A: ChatGPTのビジネスおよび産業分野での主要なアプリケーションは、オペレーションおよびマネジメント、サプライチェーンマネジメント、ビジネスアナリティクス、トランスポート、人事、マーケティング、Eコマース、会計、金融、小売り、不動産、および保険業界において、効率性とコスト削減の向上、意思決定およびリスク軽減の改善、より正確な予測精度と最適化された計画、作業負荷の軽減、不正検出などです.サプライチェーンマネジメントでは、需要予測、在庫最適化、サプライヤーの選定と評価などにChatGPTが役立つことができます.
Q: ビジネスや産業領域におけるChatGPTに関連する機会と脅威は何ですか?
A: ビジネスおよび産業の領域でのChatGPTの機会には、大量のデータを迅速に処理および分析する能力による業務プロセスの改善、および競争力の維持および強化が含まれます.一方、依存する高品質なデータ、信頼性およびバイアスのある結果、ハロシネーション、透明性およびデータプライバシーの懸念、サイバーセキュリティリスクといった潜在的な脅威にも注意を払う必要があります.具体的には、供給チェーン管理においてChatGPTを依存しすぎるリスクがあり、信頼性のある結果を得るために高品質なデータが重要であること、バイアスやミスリードのリスクも存在することを認識する必要があります.
Q: ChatGPTはどのようにして企業のストックアウトを軽減するのに役立ちますか?そうであれば、どのように?
A: ChatGPTは、企業の在庫管理において重要な役割を果たすことができます.具体的には、ChatGPTは迅速な情報収集とリアルタイムの在庫管理を支援することができます.これにより、企業は常に在庫の状況を把握し、補充する必要がある場合は迅速かつ正確な情報を得ることができます.また、ChatGPTは、自動化された在庫管理システムを活用することができます.このシステムは、在庫の状況を自動的にモニタリングし、ストックアウトが発生した場合には自動的に補充を行います.これにより、企業はストックアウトのリスクを軽減し、顧客満足度を高めることができます.
ChatGPTは、在庫切れを減らすために以下のような手順でビジネスを支援できます.
- ChatGPTは、仕入れ先選択と評価に基づいて、品質、価格、リードタイム、信頼性などの要因を分析し、最適なサプライヤーを特定することができます.
- ChatGPTは、物流の最適化に役立ち、ルート最適化、キャリア選択、その他の物流タスクなどをサポートし、適切かつ効率的な商品の配達を確保します.
- ChatGPTは、サプライチェーンデータを分析して、潜在的なリスクを特定し、サプライチェーンの中断の場合、代替サプライヤーの特定など、リスクを軽減するための推奨事項を提供することができます.
これらのアプリケーションを活用することで、ビジネスや産業はより良い判断を下し、運営を改善することができます. ChatGPTは、大量のデータを高速で処理、分析する能力を持っているため、ビジネスはサプライチェーンを向上させることができます.
Q: ChatGPTは、供給チェーンデータを分析して潜在的なリスクを特定する方法はどのようになっていますか?
A: ChatGPTはサプライチェーンのデータを分析し、品質、価格、リードタイム、信頼性などの要因に基づいて潜在的なサプライヤーを特定して評価することができます.また、ルート最適化、キャリア選択、その他の物流タスクを手助けして、商品のタイムリーかつ効率的な配送を確保することができます.さらに、サプライチェーンのデータを分析して潜在的なリスクを特定し、代替サプライヤーの特定など、リスクを軽減するための提言を行うことができます.
Q: ChatGPTは、サプライチェーンにおける潜在的なリスクを軽減するためにどのような推奨事項を提供できますか?
A: 供給チェーンにおける潜在的なリスクを軽減するためのChatGPTの推奨事項は、偏りがなく完全な情報源を定期的に監視すること、不正確さを特定し修正するための明確なプロトコルを確立すること、すべての関係者が正確で包括的なデータセットにアクセスできるようにすることなどです.また、人間の判断と技術の健全なバランスを維持し、データに関する適切なガバナンスポリシーを採用し、専門家を利用してChatGPTの公正性と正確性を慎重に評価することも重要です.さらに、強力なサイバーセキュリティ対策を実施し、ChatGPTの効果的で有用な機能にインパクトを与える可能性がある潜在的なリスクに備える必要があります.
Q: :ChatGPTのアプリケーションを活用することで、企業や産業はどのような利益を得ることができますか?
A: ChatGPTのアプリケーションを活用することで、ビジネスや産業は大量のデータを迅速に処理・分析する能力を持ち、より良い意思決定を行い、業務を改善することができます.その結果、様々な利益を得ることができ、競争力を維持し、現代の高速なビジネス環境で繁栄することができます.
Q: ChatGPTの供給チェーン管理でどのようなサイバーセキュリティのリスクがありますか?
A: ChatGPTを供給チェーン管理に使用する場合のサイバーセキュリティリスクには、大量のデータが必要であるため、サイバー攻撃に対して脆弱性があることが挙げられます.ハッカーがアクセス権を取得した場合、ChatGPTを利用して情報を盗むことや、サプライチェーンのデータを操作することが可能です.
Q: 偏向したまたは不完全なデータがChatGPTの予測および推奨事項の精度にどのように影響するか?
A: ChatGPTの予測や推奨に対するデータのバイアスや不完全さは、正確性に影響を与える可能性があります.バイアスや不完全なデータによって推定結果が誤ってしまうため、推奨される行動や決定が正確でなく、供給チェーンに影響を与えることがあります.そのため、データのバイアスや不完全さに対処するために、定期的にデータソースを監視し、正確で包括的なデータセットを確保するために、明確なプロトコルを確立する必要があります.
Q: ChatGPTがサプライチェーン管理に統合されることで生じる倫理的な懸念は何ですか?
A: ChatGPTのサプライチェーン管理への統合に伴って、AIが雇用、プライバシー、その他の倫理的な問題にどのように影響を与えるかという懸念が存在しています.企業は、自社の利害関係者に対するChatGPTの潜在的な負の影響を慎重に考慮し、それらを緩和するための措置を講じる必要があります.

