
今回のテーマ:Metaによる音声生成モデルVoicebox
ここでは、大規模言語モデル (LLM) を活用して生成した記事を投稿しています.自動生成記事のクオリティと信頼性を向上させるためにアルゴリズムの改善に取り組んでいます.
Voiceboxの特徴
Voiceboxは、最も多機能なテキストガイドの音声生成モデルです.このモデルは、音声コンテキストから音声を生成するためにトレーニングされており、テキスト入力から自然な音声クリップを生成することができます.Voiceboxは、音声スタイルを推測するために音声コンテキストを使用し、テキストの内容はトランスクリプトを通じて指定されます.
このモデルは、音声スタイルのラベルを必要とせず、これは他の先行研究とは異なる特徴です.先行研究では、ラベルを使用して入力(テキストと音声スタイル)と出力(音声)のマッピングを行っています.
Voiceboxは、音声の長さに制約されず、従来の最先端技術を上回る性能を発揮します.さらに、Voiceboxは多様でリアルな音声を生成することができます.Voiceboxによって生成された合成音声のみを使用してASRシステムをトレーニングすることができ、Librispeechのテストデータにおいて実データを使用した場合と比較して、わずかなWERの増加しかありません.これに対して、従来のTTSモデルでは、18.2%以上のWERの増加があります.
Voiceboxの機能
2秒の音声サンプルをスタイルガイドとして使用して、テキスト入力から音声を生成することができる.この新しい技術は、少量のデータで誰かの話し方を学ぶことができるという利点があります.また、音声編集とノイズリダクションも可能です.
モデルは、50,000時間以上の音声でトレーニングされており、GPTと同様に多くのタスクを実行することができます.しかし、Voiceboxはより柔軟であり、将来の文脈に基づいて条件付けることもできます.Voiceboxは、モノリンガルまたはクロスリンガルのゼロショットテキストから音声合成、ノイズ除去、コンテンツ編集、スタイル変換、多様なサンプル生成などのタスクに使用することができます.
最新のゼロショットTTSモデルV ALL-Eよりも優れた性能を発揮し、理解度(5.9%対1.9%の単語エラーレート)とオーディオの類似性(0.580対0.681)の両方で優れています.さらに、Voiceboxは最大20倍高速です.Voiceboxのモデルのデモは、voicebox.metademolab.comでご覧いただけます.
Voiceboxの応用
Voiceboxは、非自己回帰型のフローマッチングモデルであり、音声を埋めるためにトレーニングされた最も多目的なテキストガイドの生成モデルです.Voiceboxは、音声コンテキストから音声スタイルを推測し、テキストの内容をトランスクリプトを通じて指定するという、ガイド付きのインコンテキスト学習問題として考えることができます.
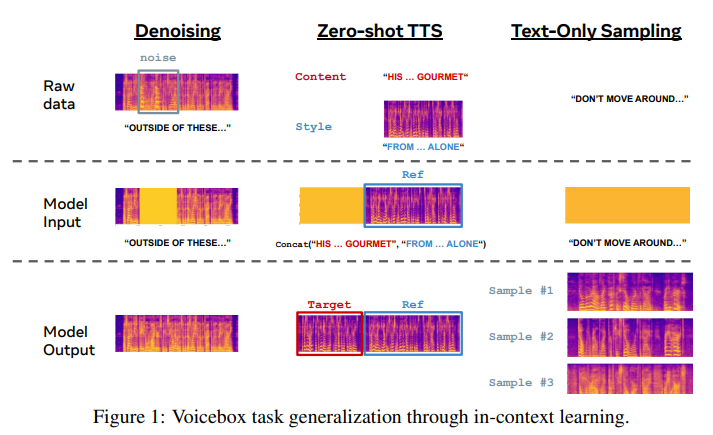
Voiceboxは、スピーカー、感情、ノイズなどのオーディオスタイルラベルを必要とせず、これは以前の研究とは異なります.以前の研究では、これらのラベルが広範に使用されています.Voiceboxは、入力(テキストとオーディオスタイル)と出力(音声)のマッピングをより簡単にするためにラベルを使用しません.
Voiceboxの利点と懸念事項
視覚障害者が馴染みのある声でメッセージを読み上げることにより、よりつながりを感じるのに役立つ可能性がある.Voiceboxは、友人や家族の声でメッセージを読んでもらったり、お気に入りの本をお気に入りの著者やナレーターに読んでもらったりすることができる技術です.
また、Voiceboxは、コンテンツクリエーターにとっても役立ちます.ビデオやポッドキャストのオーディオトラックを簡単に作成・変更できるため、効率的で創造的かつ適応性のある作業が可能です.さらに、Voiceboxは、音声の品質と統一性を保ちながら、オーディオの内容やスタイルを素早く変更できるため、多くの使い道があります.
しかし、Voiceboxを使用することで、他人の許可や知識なしに、その人の声を使った偽のオーディオクリップを生成することができてしまいます.そのような懸念からモデルは一般公開されていません.
まとめ
- Voiceboxは、音声コンテキストから音声を生成するためのテキストガイドの音声生成モデルである.
- 音声の長さに制約されず、多様でリアルな音声を生成することができる.
- Voiceboxによって生成された合成音声のみを使用してASRシステムをトレーニングすることができ、わずかなWERの増加しかない.
- 2秒の音声サンプルをスタイルガイドとして使用して、テキスト入力から音声を生成することができる.
- 50,000時間以上の音声でトレーニングされており、多くのタスクを実行することができる.
- モノリンガルまたはクロスリンガルのゼロショットテキストから音声合成、ノイズ除去、コンテンツ編集、スタイル変換、多様なサンプル生成などのタスクに使用することができる.
- 最新のゼロショットTTSモデルV ALL-Eよりも優れた性能を発揮し、理解度とオーディオの類似性の両方で優れている.
- モデルのデモは、voicebox.metademolab.comでご覧いただける.
- Voiceboxは、非自己回帰型のフローマッチングモデルであり、音声を埋めるためにトレーニングされた最も多目的なテキストガイドの生成モデルである.
- 音声コンテキストから音声スタイルを推測し、テキストの内容をトランスクリプトを通じて指定するという、ガイド付きのインコンテキスト学習問題として考えることができる.
- スピーカー、感情、ノイズなどのオーディオスタイルラベルを必要とせず、これは以前の研究とは異なる特徴である.
- 視覚障害者が馴染みのある声でメッセージを読み上げることにより、よりつながりを感じるのに役立つ可能性がある.
- 友人や家族の声でメッセージを読んでもらったり、お気に入りの本をお気に入りの著者やナレーターに読んでもらったりすることができる技術である.
- コンテンツクリエーターにとっても役立ち、ビデオやポッドキャストのオーディオトラックを簡単に作成・変更できるため、効率的で創造的かつ適応性のある作業が可能である.
- 音声の品質と統一性を保ちながら、オーディオの内容やスタイルを素早く変更できるため、多くの使い道がある.
- しかし、Voiceboxを使用することで、他人の許可や知識なしに、その人の声を使った偽のオーディオクリップを生成することができてしまうため、モデルは一般公開されていない.
参考文献:
[1] AI Revolution – Meta’s New AI is so Insanely Good, It’s actually Scary!, (2023-06-22). Accessed: 2023-06-30 [Online Video]. Available: https://www.youtube.com/watch?v=rcapt7ButFc
[2] Matthew Le, Apoorv Vyas, Bowen Shi, Brian Karrer, Leda Sari, Rashel Moritz, Mary Williamson, Vimal Manohar, Yossi Adi, Jay Mahadeokar, Wei-Ning Hsu, “Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale” arXiv, 2023-06-23 doi: 10.48550/2306.15687v1
