
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をLLMによって生成されるQ&Aを用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.自動生成記事のクオリティと信頼性を向上させるためにアルゴリズムの改善に取り組んでいます.個人で資料のQ&Aを作成されたい方には、https://www.chatpdf.com/ や https://scispace.com/などがお勧めです.
紹介する論文は以下の10本となります.
- Controllable Text Generation for Large Language Models: A Survey
発行日:2024年08月22日
LLMsの制御可能なテキスト生成(CTG)技術の進歩についての総説で、特定の条件に従いつつ高品質なテキストを生成する方法や評価方法に焦点を当てている. - LLM Pruning and Distillation in Practice: The Minitron Approach
発行日:2024年08月21日
Llama 3.1 8BおよびMistral NeMo 12Bモデルを4Bおよび8Bに圧縮するためのプルーニングと蒸留に関する包括的な報告書を提供し、新しいモデルを生成しました. - The Vizier Gaussian Process Bandit Algorithm
発行日:2024年08月21日
Google Vizierは、ベイズ最適化を使用してGoogleの研究および製品システムを最適化し、成功を収めていることを示しています. - Enhancing Robustness in Large Language Models: Prompting for Mitigating the Impact of Irrelevant Information
発行日:2024年08月20日
LLMsの推論能力を向上させるために、無関係な情報を自己軽減する新しい自動構築方法ATFが提案され、GSMIRデータセットでの実験結果は有望である. - Language Modeling on Tabular Data: A Survey of Foundations, Techniques and Evolution
発行日:2024年08月20日
表形データの言語モデリングに関する包括的な調査が行われ、異なるデータ構造やモデリング技術、課題、GitHubページが提供されている. - MagicDec: Breaking the Latency-Throughput Tradeoff for Long Context Generation with Speculative Decoding
発行日:2024年08月20日
MagicDecは、仮説的デコーディングを使用して、長いコンテキストリクエストを処理する際に高いスループット推論レジームを実現し、バッチサイズとシーケンス長の増加に対応するためにスパースKVキャッシュを活用しています. - Challenges and Responses in the Practice of Large Language Models
発行日:2024年08月18日
AI分野の幅広い問題を要約し、読者に深い洞察を提供する論文.計算能力、ソフトウェア、データ、アプリケーション、脳科学の5つの次元からAI知識を体系的に整理し、革新的な思考を促進する. - PEDAL: Enhancing Greedy Decoding with Large Language Models using Diverse Exemplars
発行日:2024年08月16日
セルフアンサンブリング技術は、多様な推論経路を持つ手法が大規模言語モデルを用いたテキスト生成において性能向上を示し、PEDALアプローチは多様な例示とLLMの集約を組み合わせて性能を向上させることができる. - Automated Design of Agentic Systems
発行日:2024年08月15日
研究者は、自動的に強力なエージェントシステムを設計する新しい研究領域、Automated Design of Agentic Systems(ADAS)を提案し、Meta Agent Searchアルゴリズムを使用して前例のない新しいエージェントを進化的に発明することを示している. - Graph Retrieval-Augmented Generation: A Survey
発行日:2024年08月15日
RAGはLLMの課題に成功し、GraphRAGはエンティティ間の構造情報を活用して検索を改善し、関係性の知識を捉え、正確な応答を促進している.
Controllable Text Generation for Large Language Models: A Survey
著者:Xun Liang, Hanyu Wang, Yezhaohui Wang, Shichao Song, Jiawei Yang, Simin Niu, Jie Hu, Dan Liu, Shunyu Yao, Feiyu Xiong, Zhiyu Li
発行日:2024年08月22日
最終更新日:2024年08月22日
URL:http://arxiv.org/pdf/2408.12599v1
カテゴリ:Computation and Language
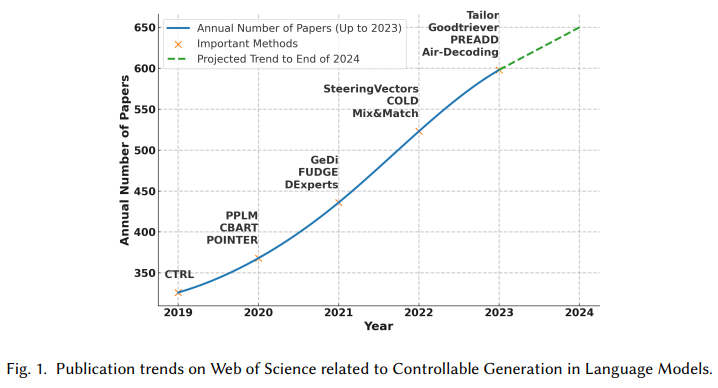
概要:
自然言語処理(NLP)において、大規模言語モデル(LLMs)は高いテキスト生成品質を示しています.しかし、実世界のアプリケーションでは、LLMsはますます複雑な要件を満たさなければなりません.誤解を招くまたは不適切なコンテンツを避けるだけでなく、LLMsは特定のユーザーのニーズにも対応することが期待されており、特定の文章スタイルを模倣したり、詩的な豊かさを持つテキストを生成したりする必要があります.これらのさまざまな要求により、制御可能なテキスト生成(CTG)技術の開発が進んでおり、出力が事前に定義された制御条件に従いつつ、助けになる、流暢で多様性の高い基準を維持することが保証されています.
この論文では、LLMsのためのCTGの最新の進歩を体系的にレビューし、その中心的な概念の包括的な定義を提供し、制御条件とテキスト品質の要件を明確にします.CTGタスクをコンテンツ制御と属性制御の2つの主要なタイプに分類し、モデルの再トレーニング、ファインチューニング、強化学習、プロンプトエンジニアリング、潜在空間の操作、およびデコーディング時の介入など、主要な方法について議論します.さらに、プロンプトエンジニアリング、潜在空間の操作、およびデコーディング時の介入などの方法の特性、利点、制限を分析し、生成制御を実現するための微妙な洞察を提供します.また、CTGの評価方法を検討し、さまざまな領域での応用を要約し、現在の研究における主要な課題、例えば流暢性や実用性の低下についても取り上げます.さらに、将来の研究において実世界の応用に重点を置くなど、いくつかの提案を行います.この論文は、この分野の研究者や開発者に貴重な指針を提供することを目的としています.参考文献リストと中国語版は、https://github.com/IAAR-Shanghai/CTGSurvey でオープンソースで提供されています.
Q&A:
Q: 大規模言語モデル(LLM)のための制御可能なテキスト生成(CTG)におけるコンテンツ制御と属性制御の主な違いは何か?
A: コンテントコントロールとアトリビュートコントロールの主な違いは、生成されるテキストの制御方法にあります.コンテントコントロール(または言語的コントロール/ハードコントロール)は、生成されるテキストの具体的な要素、例えばその構造や語彙に焦点を当てます.このタイプのコントロールは、事前に定められたルールに従ってテキストコンテンツを正確に生成することをモデルに要求します.したがって、生成されるテキストの特定の形式や内容に直接影響を与えるため、「ハードコントロール」と呼ばれます.一方、アトリビュートコントロール(またはセマンティックコントロール/ソフトコントロール)は、モデルの構造やトレーニングデータの修正を通じて、コンテンツの属性を調整します.具体的には、セキュリティ、感情、トピック、スタイルなどの属性を満たすことに焦点を当てています.これにより、生成されるテキストの品質を維持しつつ、事前に定められた制御属性を満たすことが求められます.
Q: 世代制御を実現する方法としてのモデル再トレーニングの利点と限界について詳しく教えてください.
A: モデルの再学習(リトレーニング)にはいくつかの利点と制限があります.利点としては、生成されるテキストが特定の制御属性に厳密に従うことができる点が挙げられます.これは、フォーマットや構造、特定の語彙要件に厳密に従う必要があるタスクにおいて特に優れています.また、再学習はモデルのアーキテクチャを調整することが可能であり、これにより制御ニーズによりよく対応することができます.しかし、再学習には大きな計算資源と広範なデータセットが必要であり、迅速な展開が求められるシナリオやリソースが限られた環境では実用的ではないことが多いです.これにより、再学習は特定の条件下でのみ有効な手法となります.
Q: CTGの文脈では、ファインチューニングとプロンプト・エンジニアリングはどう違うのか?
A: コンテキストに基づくテキスト生成(CTG)において、ファインチューニングとプロンプトエンジニアリングは異なるアプローチを取ります.ファインチューニングは、モデルの重みを調整することによって、特定のタスクやドメインに対してモデルを適応させるプロセスです.これは通常、追加のデータセットを用いてモデルを再訓練することを含みます.ファインチューニングは、モデルの内部構造を変更するため、時間と計算資源を要することがあります.
一方、プロンプトエンジニアリングは、モデルの入力に直接影響を与える方法であり、ハードプロンプトとソフトプロンプトの2種類があります.ハードプロンプトは明示的な自然言語の指示を使用し、ソフトプロンプトはトレーニング可能なベクトルを使用してより細かい制御を行います.プロンプトエンジニアリングは、追加のモデル訓練を必要とせず、迅速に生成戦略を調整するのに適していますが、その効果はモデルのプロンプトに対する感受性と解釈の正確さに依存します.
Q: テキスト生成の制御性を高めるために、強化学習はどのような役割を果たすのか?
A: 強化学習は、テキスト生成の制御性を向上させるために重要な役割を果たします.強化学習では、報酬信号を用いてモデルの出力を特定の制御目標に向けて誘導します.これにより、モデルは反復的な最適化を通じて、出力をこれらの目標に一致させることを学習します.特に、強化学習は、生成されたテキスト全体で特定のスタイルや感情を維持するような複雑なタスクに適しています.数式で表すと、モデルの出力 \( \small O \) が報酬 \( \small R \) によって最適化される過程は、次のように表されます: $$ \small \text{max}_{\theta} \mathbb{E}[R(O; \theta)]$$
ここで、\( \small \theta \) はモデルのパラメータを表します.強化学習の主な課題には、長い反復的なトレーニングサイクルが必要であることや、効果的で偏りのない報酬関数を定義することの難しさが含まれます.
Q: CTGにおける潜在的空間操作の概念とその意義について教えてください.
A: 潜在空間操作(Latent Space Manipulation)は、生成されたテキストの特性を調整するために、モデルの潜在空間に制御ベクトルを導入する手法でございます.この手法は、モデルの活性化状態を直接操作することにより、特に多属性タスクにおいて精密な制御を可能にいたします.潜在空間操作は、以下のように形式的に表現されます:
[ h_{\text{mod}} = h_{\text{orig}} + \Delta h ]
ここで、( h_{\text{orig}} ) はモデルの関連層の元の活性化を表し、( \Delta h ) は誘導ベクトルを表します.この誘導ベクトル ( \Delta h ) は、モデルを再訓練することなく、出力特性に特定の変化をもたらすように戦略的に計算されます.潜在空間を微妙に変更することにより、( \Delta h ) はモデルの出力を望ましい制御パラメータに合わせることを目的としております.この手法は、モデル自体を再訓練または微調整する必要がないという利点がございます.
Q: CTGのテクニックを導入する際に、流暢さを維持するための主な課題は何ですか?
A: CTG技術を実装する際に流暢さを維持することに関連する主な課題は、生成されたテキストの一貫性の欠如、意味の曖昧さ、冗長性などが挙げられます.特に複雑なタスクや正確な応答が求められる場合において、これらの問題が発生しやすいです.これらの欠点は、生成されたコンテンツの実用的な価値を著しく低下させる可能性があります.したがって、流暢さと実用性の向上が求められています.
Q: デコーディング時の介入は、LLMにおける生成テキストの全体的な品質にどのように寄与するのか?
A: デコーディング時の介入は、LLMの生成するテキストの品質に大きく寄与します.デコーディング時の介入は、モデルの出力のロジットや確率分布を操作することで、生成されるテキストを望ましい特徴や制御属性に向けて誘導します.これにより、生成プロセスにおいて動的な制御が可能となり、出力が指定された要件に合致するように調整されます.この技術は、特に長いテキストを生成する場合や複数の反復が必要な場合において、リアルタイムアプリケーションの実現可能性に影響を与えることがあります.したがって、デコーディング時間を大幅に短縮しつつ、テキストの品質を損なわないことが重要な課題となっており、モデルアーキテクチャの最適化やデコーディングアルゴリズムの改善に関する詳細な研究が必要とされています.
Q: CTG技術の有効性を評価するために、現在どのような評価方法が用いられているか?
A: CTG技術の効果を評価するために現在使用されている評価方法は、主に自動評価、人間評価、そしてLLMベースの評価方法の3つに分類されます.自動評価は、特定のメトリクスやモデルを使用し、一般的な評価とタスク特化型の評価に分けられます.一般的なメトリクスは、様々なCTGタスクにおける全体的なテキストの質を評価し、タスク特化型の評価は特定の属性に基づいて質を評価します.一般的なメトリクスは、計算方法に応じて、n-gramオーバーラップベースのメトリクス、言語モデルベースのメトリクス、距離ベースのメトリクスなどに分けられます.人間評価は、自動評価の限界を補完し、カスタマイズされた評価とより正確な結果を提供するために有用です.
Q: CTGはさまざまな領域でどのように応用できるのか、具体的な例を挙げてください.
A: CTGは、さまざまなドメインにおいて多様な方法で適用されることができます.特に、垂直ドメインアプリケーションと一般タスクアプリケーションに分けられます.垂直ドメインアプリケーションは、特定の業界内の特定のタスクに特化しており、専門性と精度に焦点を当てています.具体的な例として、ニュース生成においては、DeepPressが事前学習モデルを統合してトピックに配慮したニュースコンテンツを生成し、客観性と一貫性を高めています.また、SeqCTGは論理的一貫性を確保しています.これらの例は、CTGの一般的なタスクとアプリケーションシナリオを表しており、コンテンツ制御や属性制御の領域内で多くの豊かなタスクが存在し、CTGの広範な研究領域に貢献しています.
LLM Pruning and Distillation in Practice: The Minitron Approach
著者:Sharath Turuvekere Sreenivas, Saurav Muralidharan, Raviraj Joshi, Marcin Chochowski, Ameya Sunil Mahabaleshwarkar, Gerald Shen, Jiaqi Zeng, Zijia Chen, Yoshi Suhara, Shizhe Diao, Chenhan Yu, Wei-Chun Chen, Hayley Ross, Oluwatobi Olabiyi, Ashwath Aithal, Oleksii Kuchaiev, Daniel Korzekwa, Pavlo Molchanov, Mostofa Patwary, Mohammad Shoeybi, Jan Kautz, Bryan Catanzaro
発行日:2024年08月21日
最終更新日:2024年12月09日
URL:http://arxiv.org/pdf/2408.11796v4
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning
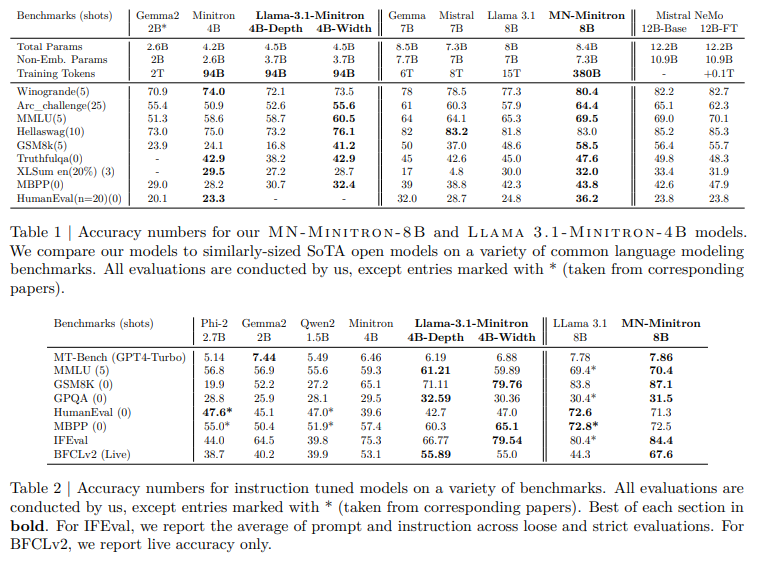
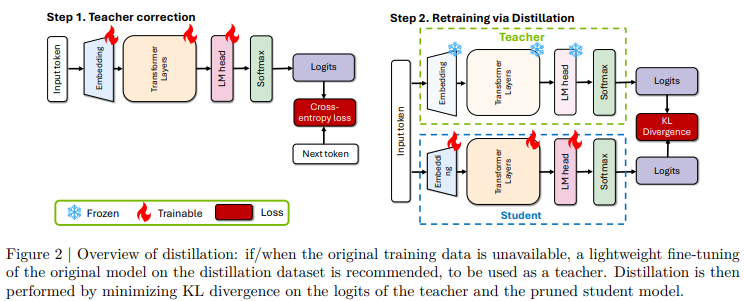
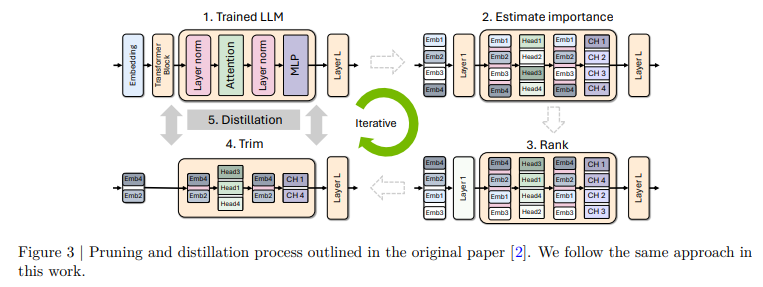
概要:
この報告書では、Llama 3.1 8BおよびMistral NeMo 12Bモデルをそれぞれ4Bおよび8Bのパラメータに圧縮するためのプルーニングと蒸留に関する包括的な報告書を提供します.我々は2つの異なるプルーニング戦略、つまり(1)深さプルーニングと(2)共通のベンチマークからの評価を行い、NeMo Alignerでモデルを整列させ、instruct-tunedバージョンでテストしました.このアプローチにより、Llama 3.1 8Bから魅力的な4Bモデルが生成され、Mistral NeMo 12Bから最先端のMistral-NeMo-Minitron-8B(MN-Minitron-8Bと略す)モデルが生成されました.元のデータにアクセスできない場合、蒸留データセットで教師モデルをわずかに微調整することが有益であることがわかりました.我々は、Hugging Faceで基本モデルの重みをオープンソース化し、許可されたライセンスで提供しています.
Q&A:
Q: Depthプルーニングとhidden/attention/MLP(width)プルーニングの違いについて、その実装方法とモデルのパフォーマンスへの影響について詳しく教えてください.
A: 深さプルーニングと幅プルーニング(隠れ層/注意/MLPの共同プルーニング)の違いについて説明いたします.
深さプルーニングは、モデルの層を削減する手法であり、特に連続した層を取り除くことによって行われます.文脈によれば、層の削減はモデルの初期層や終端層が重要であることが示されています.深さプルーニングの実装においては、層の削減がモデルの性能にどのように影響を与えるかを慎重に評価する必要があります.特に、連続した層を削除することが一般的ですが、非連続の層を削除することでさらに良い結果が得られる場合もあります.
一方、幅プルーニングは、モデルの幅、すなわち隠れ層の次元や注意ヘッド、MLPの中間次元を削減する手法です.幅プルーニングは、モデルのパラメータ数を維持しつつ、特定の次元を削減することで行われます.文脈によれば、幅プルーニングは初期の損失を低く抑え、深さプルーニングよりも一貫して優れた性能を示すことが観察されています.
これらのプルーニング手法の実装とモデル性能への影響は、モデルの特性やタスクに依存しますが、幅プルーニングは一般的により良い性能を示す傾向があります.
Q: 蒸留データセット上での教師モデルの微調整は、蒸留モデルのパフォーマンスにどのような影響を与えたのだろうか?
A: 教師モデルを蒸留データセットで微調整することにより、蒸留されたモデルの性能が向上しました.具体的には、教師モデルの微調整は新しいデータセットに適応させるために行われ、これにより言語モデルの検証損失が6%以上減少しました.これは、教師モデルが元のデータセットと異なるデータセットで蒸留される際に、サブワードトークンの分布が変化することによる影響を軽減するためです.したがって、教師モデルの微調整は、蒸留プロセスが新しいデータセットで最適に機能するために重要であると考えられます.
Q: Hugging Faceのベースモデルの重みのオープンソース化は、研究コミュニティにどのように貢献するのでしょうか?
A: オープンソースとしてHugging Faceで基盤モデルの重みを公開することは、研究コミュニティに多大な貢献をいたします.まず、研究者や開発者がこれらのモデルを自由に利用し、独自の研究やプロジェクトに組み込むことが可能になります.これにより、モデルの性能を向上させるための新しい手法やアルゴリズムの開発が促進されます.また、オープンソース化により、モデルの透明性が向上し、再現性のある研究が可能になります.さらに、異なる規模や計算予算に応じたモデルの選択肢が増えることで、さまざまなアプリケーションに適したモデルを選ぶことができ、研究の多様性が広がります.これらの要素は、研究コミュニティ全体の知識の共有と進歩を促進するものと考えられます.
The Vizier Gaussian Process Bandit Algorithm
著者:Xingyou Song, Qiuyi Zhang, Chansoo Lee, Emily Fertig, Tzu-Kuo Huang, Lior Belenki, Greg Kochanski, Setareh Ariafar, Srinivas Vasudevan, Sagi Perel, Daniel Golovin
発行日:2024年08月21日
最終更新日:2024年12月06日
URL:http://arxiv.org/pdf/2408.11527v3
カテゴリ:Machine Learning, Artificial Intelligence, Optimization and Control
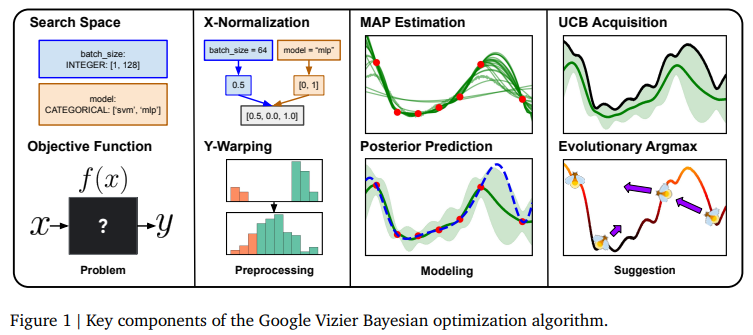
概要:
Google Vizierは、Googleの多くの研究および製品システムを最適化し、ベイズ最適化が大規模なサービスとして成功を収めていることを示しています.数年にわたり、そのアルゴリズムは、多くの研究努力やユーザーフィードバックの集合的な経験を通じてかなり改善されてきました.この技術レポートでは、Open Source Vizierによって提供される現在のデフォルトアルゴリズムの実装の詳細と設計選択について議論します.標準化されたベンチマークでの実験では、このアルゴリズムが、複数の実用的なモードにおいて、確立された業界基準に対してその堅牢性と汎用性を示しています.
Q&A:
Q: Google Vizierで使われているベイズ最適化アプローチの主な特徴は何ですか?
A: Google Vizierにおけるベイズ最適化のアプローチの主な特徴は、ガウス過程バンディット最適化に基づいていることです.このアプローチは、後悔(regret)や最適性ギャップ(optimality gap)といった標準的な性能指標を改善するだけでなく、ユーザーエクスペリエンス、推論速度、柔軟性、スケーラビリティ、信頼性も向上させるように進化してきました.具体的には、UCB(Upper Confidence Bound)取得関数を用いたり、前処理やモデリングの提案、X正規化、Yワーピングなどの技術が含まれています.また、後部予測やMAP推定、進化的アルグマックスといった手法も採用されています.これらの要素により、Google Vizierは多くの実用的なモードにおいて、業界の確立されたベースラインに対して堅牢性と多様性を示しています.
Q: Vizierアルゴリズムは様々なタイプの最適化問題をどのように扱うのですか?
A: Vizierアルゴリズムは、さまざまな最適化問題を扱うために、いくつかの手法を用いております.まず、探索空間 \( \small X \) は、DOUBLE、INTEGER、DISCRETE、CATEGORICAL の各タイプのパラメータの直積として定義されており、CATEGORICAL タイプを除く各パラメータには、線形、対数、逆対数のスケーリングタイプが関連付けられることが可能です.また、測定空間 \( \small Y \subseteq \mathbb{R}^M \) は、ブラックボックス目的関数からの \( \small M \) 個のメトリクスで構成されております.Vizierは、業界標準のベンチマークに対してその競争力と堅牢性を示しており、高次元、カテゴリカル、バッチ、および多目的最適化においても優れた性能を発揮しております.さらに、ゼロ次進化的取得最適化器を使用するという非従来型の設計選択を行い、その主要な強みについても議論されております.
Q: あなたの実験では、どのような標準化されたベンチマークが使われましたか?
A: 実験で使用された標準化されたベンチマークは、DTLZ (1-7)、WFG (1-9)、および ZDT (1-4, 6) のマルチオブジェクティブベンチマークです.これらのベンチマークは、optproblems パッケージを使用して実装されました.ZDT5 は変数の次元を許可しないため使用されませんでした.これらのベンチマークは、異なるスケールがハイパーボリュームの優先順位に悪影響を及ぼす可能性があるため、メトリックの正規化が必要とされる多目的最適化の評価において広く使用されているため選ばれました.
Q: Vizierのアルゴリズムは、効率性と有効性という点で、他の業界のベースラインと比較してどうですか?
A: Vizierアルゴリズムは、業界のベースラインと比較して、効率性と効果性の両面で競争力があるとされています.特に、高次元、カテゴリカル、バッチ、および多目的最適化において、その堅牢性が実証されています.Vizierのデフォルトアルゴリズムは、ガウス過程バンディット最適化に基づいており、後悔や最適性ギャップといった標準的な性能指標だけでなく、ユーザーエクスペリエンス、推論速度、柔軟性、スケーラビリティ、信頼性の向上も図られています.これにより、Vizierは多くの実用的なモードにおいて、確立された業界ベースラインに対してその堅牢性と多様性を示しています.
Q: Vizierアルゴリズムの継続的な開発において、ユーザーからのフィードバックはどのような役割を果たしていますか?
A: ユーザーフィードバックは、Vizierアルゴリズムの継続的な開発において重要な役割を果たしております.具体的には、ユーザーからのフィードバックを通じて、アルゴリズムが大規模なサービスとしてのベイズ最適化の成功を示すことができ、また、複数年にわたってアルゴリズムが大幅に改善されてきたことが示されております.このように、ユーザーフィードバックは、アルゴリズムの設計選択や実装の詳細に影響を与え、研究者や実務者にとって有用な情報を提供することに寄与しております.
Q: 最適化問題の次元が大きくなると、Vizier Gaussian Process Bandit Algorithmはどのようにスケールアップするのでしょうか?
A: 与えられた文脈から、Vizier Gaussian Process Bandit Algorithmは高次元の最適化問題において、特にFireflyを使用することで、より良い性能を示すことがわかります.Fireflyは信頼領域を利用することで、異なる獲得関数の実装を効果的に最適化することが可能であり、その結果、高次元での性能がさらに向上することが示されています.しかし、具体的なスケーリングの詳細や数式は文脈に含まれていないため、詳細な説明はできません.
Enhancing Robustness in Large Language Models: Prompting for Mitigating the Impact of Irrelevant Information
著者:Ming Jiang, Tingting Huang, Biao Guo, Yao Lu, Feng Zhang
発行日:2024年08月20日
最終更新日:2024年08月20日
URL:http://arxiv.org/pdf/2408.10615v1
カテゴリ:Computation and Language
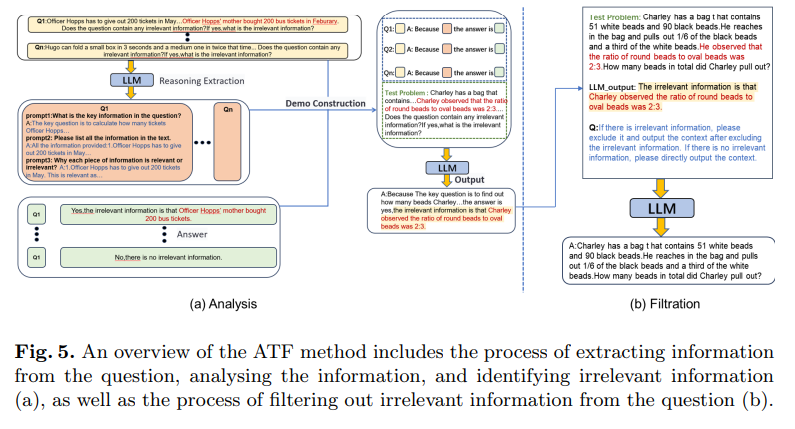
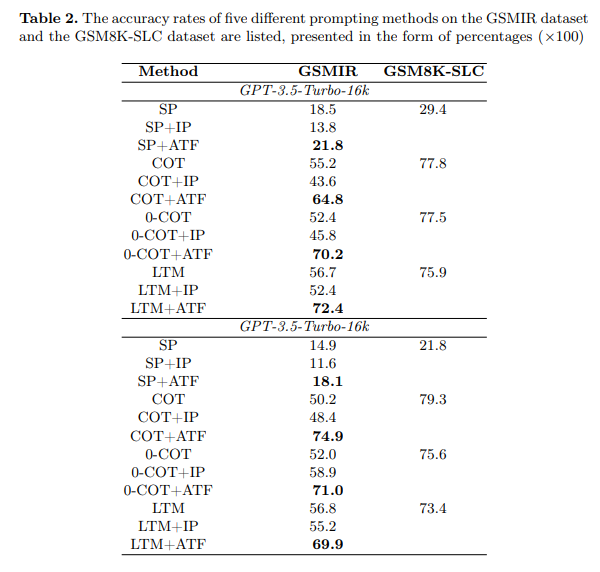
概要:
近年、大規模言語モデル(LLMs)は、複雑な推論タスクにおける優れた性能により、注目を集めています.しかし、最近の研究では、問題の記述に無関係な情報が含まれている場合、進んだプロンプティング技術を使用しても、その推論能力が著しく低下する可能性があります.この問題をさらに調査するために、無関係な情報を含む小学校の数学問題のデータセットであるGSMIRが構築されました.このデータセットで主要なLLMsやプロンプティング技術をテストした結果、LLMsは無関係な情報を識別できるものの、一旦それを識別した後の干渉を効果的に軽減することができません.この欠点を解決するために、無関係な情報の影響を識別し自己軽減するLLMsの能力を向上させる新しい自動構築方法であるATFが提案されています.この方法は、無関係な情報の分析とフィルタリングの2つのステップで動作します.実験結果によると、ATF方法は、GSMIRデータセットにおける無関係な情報の存在にもかかわらず、LLMsやプロンプティング技術の推論性能を著しく向上させることが示されています.
Q&A:
Q: GSMIRデータセットでは、具体的にどのような高度なプロンプト技術がテストされたのか?
A: GSMIRデータセットでテストされた特定の高度なプロンプト技術には、ATF(Analysis to Filtration Prompting)とIP(Irrelevant Information Prompting)が含まれていました.これらの技術は、言語モデルが無関係な情報に対してより堅牢になるように設計されています.特に、ATFは、無関係な情報を含む質問に対する推論の精度を大幅に向上させることが示されました.例えば、COT(Chain of Thought)メソッドでは、精度が50.2%から74.9%に向上しました.
Q: GSMIRデータセットはどのように構築され、どのような基準で無関係な情報を定義したのか?
A: GSMIRデータセットは、GSM8Kに基づいて構築され、問題の解決に役立たない文を含むように設計されています.この文は「無関係な情報」として定義され、問題の標準的な解法に影響を与えないように挿入されています.無関係な情報は、元の内容とテーマ的に関連し、論理的に接続されているため、現実世界のシナリオをよりよくシミュレートしています.これにより、LLMが無関係な情報からの干渉に抵抗する能力を評価することが目的とされています.
Q: ATF法の結果は、LLMの無関係な情報を軽減する既存の技術と比較してどうなのか?
A: ATF法は、既存の手法と比較して、LLMが無関係な情報を特定する能力を向上させることが示されています.特に、ATF-Shuffleは他の手法を一貫して上回り、無関係な情報の位置に影響されずにそれを認識する能力を示しています.したがって、ATF法は、LLMが無関係な情報を特定し、その影響を自己緩和する能力を強化するための効果的な手法であると考えられます.
Q: LLMが無関係な情報を識別する能力は、推論タスクにおける彼らの総合的なパフォーマンスにどのような影響を与えるのだろうか?
A: LLMの推論タスクにおける全体的なパフォーマンスに対する、無関係な情報を識別する能力の影響について説明いたします.文脈によれば、LLMは無関係な情報を識別する能力において高い率を示していますが、それにもかかわらず、識別率と正確率の間には依然として大きなギャップが存在します.これは、LLMが無関係な情報を認識しているにもかかわらず、誤った回答を提供する場合があることを示唆しています.したがって、無関係な情報を効果的に識別できない場合、LLMはその後の推論プロセスでそれを除外することができず、結果としてパフォーマンスの低下を招く可能性があります.これにより、LLMの推論能力において、無関係な情報を識別し、除外する能力が重要であることが示されています.
Language Modeling on Tabular Data: A Survey of Foundations, Techniques and Evolution
著者:Yucheng Ruan, Xiang Lan, Jingying Ma, Yizhi Dong, Kai He, Mengling Feng
発行日:2024年08月20日
最終更新日:2024年08月20日
URL:http://arxiv.org/pdf/2408.10548v1
カテゴリ:Computation and Language
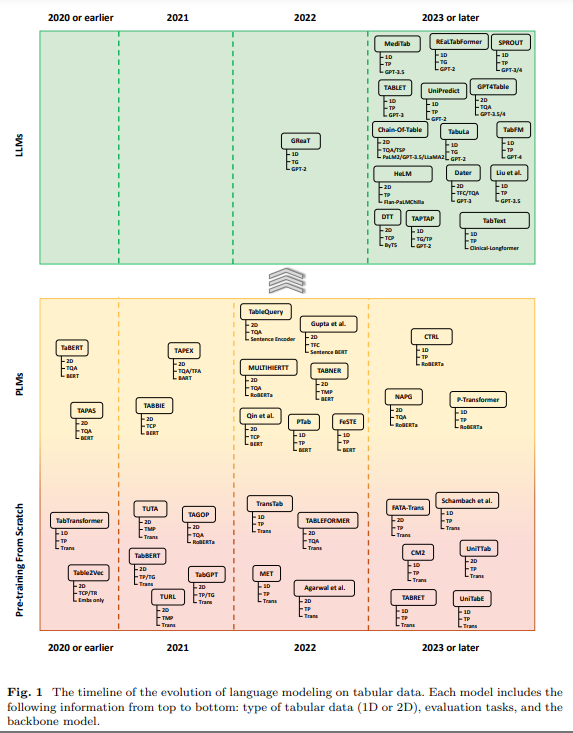
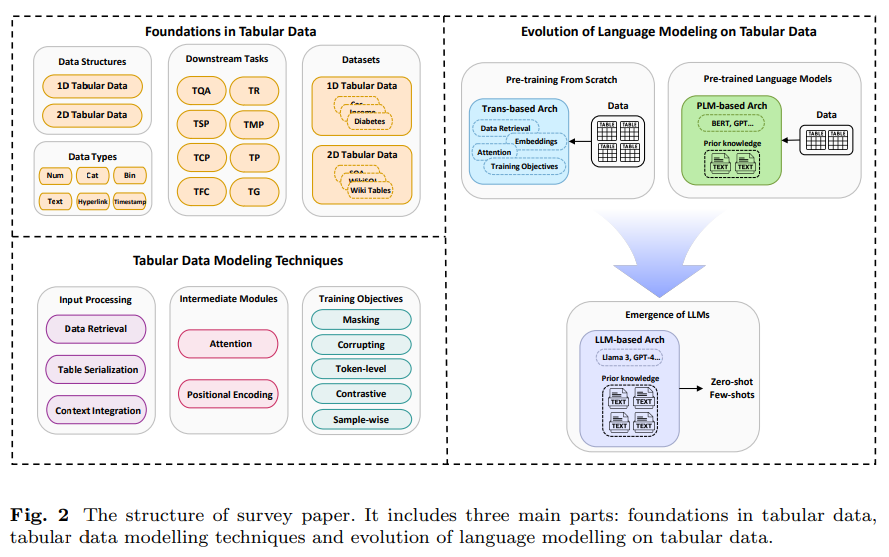
概要:
表形データの言語モデリングの発展に関する包括的な調査はまだ存在していませんが、この論文はそのギャップを埋めるために、以下を包括しています:(1)異なる表形データ構造とデータタイプの分類、(2)モデルトレーニングに使用される主要なデータセットと評価タスクのレビュー、(3)広く採用されているデータ処理方法、人気のあるアーキテクチャ、およびトレーニング目標を含むモデリング技術の概要、(4)伝統的な事前学習/事前学習言語モデルの適応から大規模な言語モデルの利用への進化、(5)表形データ分析のための言語モデリングにおける持続的な課題と将来の研究方向の特定.この調査に関連するGitHubページは、以下のリンクからアクセスできます:.” rel=”nofollow”>https://github.com/lanxiang1017/Language-Modeling-on-Tabular-Data-Survey.git.
Q&A:
Q: 予測性能に影響を与える表データの異種混合性には、具体的にどのような課題がありますか?
A: 文脈から、異質な性質を持つ表形式データが予測性能に影響を与える具体的な課題として、行、列、全体のテーブル間の相互作用が挙げられます.これにより、データの複雑な構造が生じ、予測モデルの構築が困難になります.特に、異なるデータ型が存在する場合、これらの相互作用はさらに複雑化します.例えば、表形式データのサンプルは単一の行や列だけでなく、時にはネストされたテーブルを含むこともあります.このような複雑な構造は、モデルがデータのパターンを学習し、正確な予測を行うことを難しくします.したがって、表形式データの異質性は、予測性能において重要な課題となります.
Q: 表形式データ用のトランスフォーマーをゼロから事前学習する際に発生するスケーラビリティの問題について詳しく教えてください.
A: トランスフォーマーモデルをゼロから事前学習する際に直面するスケーラビリティの問題について詳しく説明いたします.まず、トランスフォーマーモデルは通常、大量のデータを必要とし、そのデータを処理するための計算資源も膨大です.特に、タブularデータに特化したトランスフォーマーをゼロから学習させる場合、データの収集と前処理に多大な労力がかかります.さらに、モデルのパラメータ数が多いため、学習には高性能なハードウェアが必要となり、計算コストが非常に高くなります.これらの要因が、特に医療分野のようなデータが限られている領域では、実用的でない場合があります.したがって、スケーラビリティの問題は、データの量と計算資源の両方に関連しており、これがトランスフォーマーの事前学習を困難にしています.
Q: BERTのような事前に訓練された言語モデルは、従来の手法と比較して、表データモデリングのパフォーマンスをどのように向上させるのか?
A: 事前学習済み言語モデル(PLM)であるBERTは、従来の方法と比較して、タブularデータのモデリングにおいていくつかの点で性能を向上させることができます.まず、BERTのようなPLMは、事前に大規模なテキストデータで学習されているため、少ないデータで高い予測性能を発揮することができます.これは、特にデータが限られている分野において重要です.次に、BERTは深い意味的理解を必要とするタスクに適しており、テキストとタブularデータを同時に処理する能力を持っています.さらに、BERTはタスク固有のデータセットに対して微調整が可能であり、これによりモデリングプロセスの効率と効果が向上します.これらの特性により、BERTは従来の方法よりも優れた性能を発揮することができます.
Q: 今回の調査でモデルのトレーニングに使用した主なデータセットの例を教えてください.
A: 調査で使用された主要なデータセットの例として、UCIアダルトインカム(Income)データセットとOpenMLの糖尿病データセットが挙げられます.UCIアダルトインカムデータセットは、年齢、職業クラス、教育レベルなどの国勢調査変数を含む有名なデータセットであり、年収が50Kドルを超えるかどうかを示すラベルを持つ二値分類データセットです.また、OpenMLの糖尿病データセットは、人口統計学的および臨床的属性を使用して糖尿病の発症を予測することを目的とした二値分類の課題を提供します.
Q: 調査では、さまざまな表データ構造やデータタイプをどのように分類していますか?
A: この調査では、表形式データセットをその構造的特徴に基づいて2つの主要なカテゴリに分類しております.まず、1D表形式データセットは通常、単一のテーブルを含んでおります.次に、2D表形式データセットは複数のテーブルを含むことが多いです.また、表形式データのドメインで見られる異なるデータ型についても議論しております.具体的には、数値データ、カテゴリーデータ、バイナリデータ、テキストデータ、ハイパーリンク、タイムスタンプなどが含まれます.
Q: 表形式データ分析のための言語モデリングにおいて、どのような根強い課題があり、どのように対処することを提案しますか?
A: 文脈から、タブラー データの言語モデリングにおける持続的な課題として、計算効率、解釈可能性、バイアス、データ型の 4 つが特定されています.これらの課題に対処するためには、以下のようなアプローチが考えられます.
- 計算効率: 計算効率を向上させるためには、モデルの軽量化や効率的なアルゴリズムの開発が必要です.例えば、モデルのパラメータ数を削減するためのプルーニング技術や、計算資源を最適化するための分散処理技術が考えられます.
- 解釈可能性: モデルの解釈可能性を向上させるためには、モデルの出力を人間が理解しやすい形で説明する手法が求められます.具体的には、特徴量の重要度を可視化する手法や、モデルの予測に寄与した要因を明示する手法が有効です.
- バイアス: バイアスの問題に対処するためには、データの収集段階から多様性を確保し、モデルの学習過程でバイアスを検出・修正する手法が必要です.例えば、データのサンプリングバイアスを軽減するためのリサンプリング技術や、モデルの公平性を評価するためのメトリクスの導入が考えられます.
- データ型: データ型の多様性に対応するためには、異なるデータ型に対して柔軟に適応できるモデルの設計が求められます.特に、1D および 2D タブラー データに対する異なるアプローチを統合することが重要です.
Q: 伝統的な事前トレーニングから大規模な言語モデルの使用まで、テクニックの進化についてまとめていただけますか?
A: 与えられた文脈から、言語モデリングの進化は二つの重要な段階で批判的にレビューされていることがわかります.最初の段階では、タブラーコンテキストに対する特注の事前学習調整と、BERTのような事前学習済みモデルの統合による意味理解の向上が含まれています.次の段階では、大規模言語モデル(LLM)の活用へのシフトが見られ、これはより複雑なタブラー データの課題に対処するための範囲を広げる重要なパラダイムシフトを表しています.この進化は、言語モデリングの分野における重要な進展を示しており、今後の研究のための明確なロードマップを提供しています.
Q: 表形式データの言語モデリングの分野で、将来どのような研究の方向性が考えられますか?
A: 文脈から、将来の研究の方向性として、以下のようなものが考えられます.まず、言語モデルを用いたタブラー形式データの解析において、1次元および2次元のデータ形式に対する体系的なレビューが行われていることから、これらのデータ形式に特化した新しいモデルの開発が期待されます.特に、数値データ、カテゴリカルデータ、テキストデータなどの異種データ型を統合的に扱う手法の研究が重要です.また、列と行の間の複雑な関係をより効果的にモデル化するための新しいアーキテクチャの設計も考えられます.さらに、事前学習された言語モデル(PLM)をタブラー形式データに適用する際の課題を克服するための研究も進められるでしょう.これには、データの前処理や特徴抽出の最適化、モデルの解釈性の向上などが含まれます.これらの研究は、タブラー形式データの解析における予測性能とロバスト性の向上に寄与することが期待されます.
MagicDec: Breaking the Latency-Throughput Tradeoff for Long Context Generation with Speculative Decoding
著者:Jian Chen, Vashisth Tiwari, Ranajoy Sadhukhan, Zhuoming Chen, Jinyuan Shi, Ian En-Hsu Yen, Beidi Chen
発行日:2024年08月20日
最終更新日:2024年08月23日
URL:http://arxiv.org/pdf/2408.11049v3
カテゴリ:Computation and Language
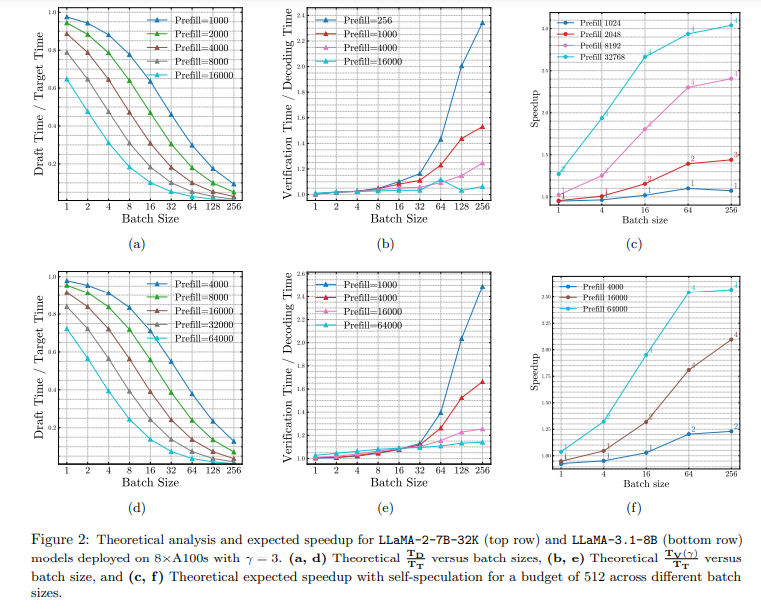
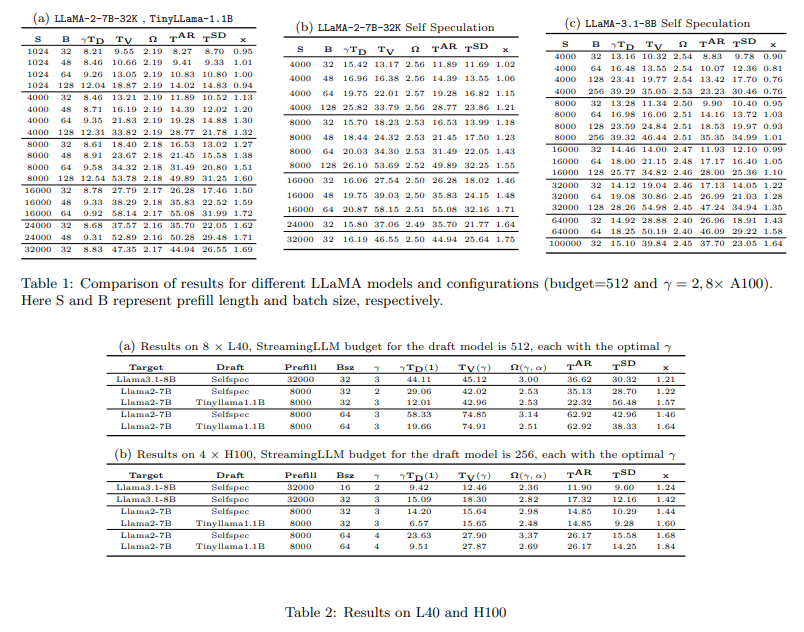
概要:
大規模言語モデル(LLMs)は、対話型チャットボット、文書分析、エージェントワークフローなどの長いコンテキストアプリケーションでより一般的になっていますが、低遅延で高スループットで長いコンテキストリクエストを処理することは難しいです.仮説的デコーディング(SD)は、性能を犠牲にすることなく遅延を減らすために広く使用されていますが、従来の知恵はその有効性が小さなバッチサイズに限定されていると示唆しています.MagicDecでは、驚くほどSDが中程度から長いシーケンスに対しても高いスループット推論レジームでスピードアップを実現できることを示しています.さらに興味深いことに、賢明な起案戦略により、バッチサイズが増加するにつれてより良いスピードアップが実現できることを厳密な分析に基づいて示しています.MagicDecは、バッチサイズとシーケンス長が増加するにつれてボトルネックのシフトを特定し、これらの洞察を活用して高スループット推論のために仮説的デコーディングを効果的に展開します.そして、シーケンス長とバッチサイズの両方にスケーリングするKVボトルネックに対処するために、スパースKVキャッシュを持つドラフトモデルを活用します.この発見は、仮説的デコーディングの広範な適用可能性を強調しています.この研究結果は、LLaMA-2-7B-32KおよびLLaMA-3.1-8Bにおいて、32から256までのバッチサイズを8つのNVIDIA A100 GPUで提供する際に、中程度から長いシーケンスに対して最大2倍のスピードアップを実証しています.コードはhttps://github.com/Infini-AI-Lab/MagicDec/で入手可能です.
Q&A:
Q: MagicDecの従来の投機的デコード技術に、より大きなバッチサイズに対する有効性を高めるために、具体的にどのような修正を加えたのですか?
A: MagicDecにおいて、従来の推測デコーディング技術を改良し、大きなバッチサイズに対する効果を高めるために、いくつかの特定の変更が行われました.まず、MagicDecはバッチサイズとシーケンス長の増加に伴うボトルネックの変化を特定し、これらの洞察を活用して高スループット推論のために推測デコーディングをより効果的に展開します.次に、シーケンス長とバッチサイズの両方にスケールするKVボトルネックに対処するために、スパースKVキャッシュを備えたドラフトモデルを活用します.これにより、長いコンテキストの提供において推測デコーディングの広範な適用可能性が強調され、精度を損なうことなくスループットを向上させ、レイテンシを削減することができます.
Q: MagicDecで使用されているインテリジェントな作図戦略と、バッチサイズの増加に伴うスピードアップへの貢献について詳しく教えてください.
A: MagicDecにおけるインテリジェントドラフティング戦略は、バッチサイズの増加に伴うスピードアップに寄与する方法として、ボトルネックのシフトを特定し、それに基づいて推測デコーディングをより効果的に展開することにあります.この戦略は、シーケンスの長さとバッチサイズの両方にスケールするKVボトルネックに対処するために、スパースKVキャッシュを持つドラフトモデルを活用します.これにより、長いコンテキストの提供において、スループットを向上させ、精度を損なうことなくレイテンシーを削減することが可能となります.具体的には、MagicDecは、バッチサイズとシーケンス長の増加に伴うボトルネックのシフトを特定し、これらの洞察を活用して、推測デコーディングを高スループット推論のためにより効果的に展開します.さらに、バッチサイズが増加するにつれて、推測デコーディングの効果がより顕著になることが示されています.
Q: MagicDecは、バッチサイズとシーケンス長の増加に伴うボトルネックシフトをどのように特定しますか?
A: MagicDecは、バッチサイズとシーケンス長の増加に伴うボトルネックのシフトを特定するために、理論的な分析を行います.この分析により、メモリが制約となる中で、推測デコーディングを用いることで、特に中程度から長いシーケンス長および大きなバッチサイズにおいて、効率的に加速できることが示されています.具体的には、KVキャッシュが支配的なボトルネックとなることを特定し、これがバッチサイズとシーケンス長の両方にスケールすることを利用して、推測デコーディングをより効果的に展開します.
Q: 高スループット推論における投機的解読の展開に役立つ厳密な分析から得られた重要な洞察とは?
A: この分析から得られた主な洞察は、長いコンテキストシナリオにおけるスループットとレイテンシのトレードオフを再評価することにあります.特に、推測デコーディングを使用することで、スループットを向上させ、レイテンシを削減し、精度を維持することができると示されています.理論的および実証的な分析により、シーケンスの長さとバッチサイズが増加するにつれて、ボトルネックが計算に依存するものからメモリに依存するものにシフトすることが明らかになりました.このシフトにより、長いシーケンスでも大きなバッチサイズでも、推測デコーディングを効果的に使用することが可能となり、LLaMA-2-7B-32Kでは最大2倍、LLaMA-3.1-8Bでは1.84倍のスピードアップが8つのA100 GPUで達成されました.さらに、KVキャッシュがスパースなドラフトモデルを使用することで、より大きなバッチでもさらに良いスピードアップが達成できることが示されています.これらの結果は、スループットを向上させ、レイテンシを削減し、精度を損なうことなく、推測デコーディングを使用することの必要性を強調しています.
Q: スパースKVキャッシュを持つドラフトモデルの使用は、KVのボトルネックにどのように対処するのか、また、シーケンス長とバッチサイズにはどのような影響があるのか?
A: ドラフトモデルにおけるスパースなKVキャッシュの使用は、KVキャッシュのボトルネックを解消するために重要でございます.具体的には、StreamingLLMを用いることで、初期トークンのKVを注意シンクとして活用し、スライディングウィンドウKVを用いた注意計算を行います.これにより、無限に長いコンテキストを安定的かつトレーニング不要で処理することが可能となります.KVキャッシュがモデルの重みよりも主要なボトルネックとなるため、ターゲットモデルにおいてもStreamingLLMキャッシュを活用することが推奨されます.理論的な分析によれば、バッチサイズが256の場合、自己推測ドラフトの相対コストはシーケンス長が大きくなるにつれて0に近づくことが示されています.さらに、GQAドラフトモデルは、KVサイズが通常のMHAモデルよりも数倍小さいため、バッチサイズとシーケンス長が大きい場合において、StreamingLLMキャッシュに基づくドラフトコストをさらに削減することが可能でございます.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: この論文で紹介された新しい手法のコード実装のurlは、https://github.com/Infini-AI-Lab/MagicDec/ でございます.
Challenges and Responses in the Practice of Large Language Models
著者:Hongyin Zhu
発行日:2024年08月18日
最終更新日:2024年08月21日
URL:http://arxiv.org/pdf/2408.09416v2
カテゴリ:Computation and Language, Artificial Intelligence
概要:
この論文は、現在注目されているAI分野に焦点を当て、産業動向、学術研究、技術革新、ビジネスアプリケーションなど、複数の次元をカバーする幅広いかつ深遠な問題を丹念に要約しています.この論文は、考えさせられると同時に実践的な関連性のある質問を精選し、それぞれに微妙で洞察に富んだ回答を提供しています.読者の理解と参照を容易にするために、この論文は、計算能力インフラ、ソフトウェアアーキテクチャ、データリソース、アプリケーションシナリオ、脳科学という5つのコア次元から、これらの質問を体系的かつ丹念に分類・整理しています.この論文の目的は、読者に包括的で深い、最先端のAI知識フレームワークを提供し、あらゆる分野の人々がAIの発展の脈を掴み、革新的な思考を刺激し、産業の進歩を促進することです.
Q&A:
Q: 現在、大規模言語モデルの開発を妨げているコンピューティング・パワー・インフラの具体的な課題とは?
A: 現在、大規模言語モデルの開発を妨げている計算力インフラストラクチャにおける具体的な課題としては、以下の点が挙げられます.まず第一に、高い計算資源の消費が問題となっています.大規模モデルのトレーニングには、高性能なGPUや大量のストレージスペースが必要であり、これによりトレーニングコストが高くなり、ハードウェア資源に対する要求も高くなります.これにより、計算資源の確保が困難となり、開発の妨げとなっています.さらに、ハイパーパラメータの探索も重要な課題です.大規模モデルのトレーニング効果はハイパーパラメータに直接関連しており、これらの最適化には多大な計算資源と時間が必要です.
Q: 脳科学は大規模な言語モデルの設計や機能にどのような影響を与えるのか?
A: 脳科学は、大規模言語モデルの設計と機能において重要な洞察を提供しています.特に、トランスフォーマーモデルにおける自己注意メカニズムは、脳の効率的な情報処理戦略を簡略化したシミュレーションであると考えられています.脳は複雑な情報に直面したとき、重要な情報に素早く焦点を当て、冗長な詳細を無視することができる、高度に選択的な注意配分メカニズムを持っています.また、脳の記憶メカニズムもモデルに貴重なインスピレーションを提供しています.人間の脳は短期記憶と長期記憶を含む複雑で洗練された記憶システムを持ち、効率的な記憶の保存と検索メカニズムを備えています.これらの生物学的特性は、モデルの設計において重要な役割を果たしています.
Q: 大規模な言語モデルを効果的に活用し、ビジネスを前進させるにはどうすればいいのだろうか?
A: 企業が大規模言語モデルを効果的に活用する方法として、まず、ビジネスの効率性と正確性の向上が挙げられます.大規模モデルは強力な適合能力と一般化性能を持ち、多くの伝統的なデータ処理や意思決定のタスクを自動的に完了することができ、これにより企業の業務の効率性と正確性が向上します.また、データのプライバシーと機密性の保護も重要です.企業が独自の大規模モデルを持つことで、ビジネスの秘密やデータのプライバシーをより良く保護し、データ漏洩や外部からの攻撃のリスクを回避し、企業の核心的な利益と競争優位性を守ることができます.さらに、長文のテキストを処理し、長距離の依存関係を理解する必要があるシナリオ、例えば法的研究、医療診断、金融分析などの分野において、長文コンテキストの言語モデルが特に適しています.
PEDAL: Enhancing Greedy Decoding with Large Language Models using Diverse Exemplars
著者:Sumanth Prabhu
発行日:2024年08月16日
最終更新日:2024年08月19日
URL:http://arxiv.org/pdf/2408.08869v2
カテゴリ:Computation and Language, Machine Learning

概要:
セルフアンサンブリング技術は、Self-Consistencyなどの多様な推論経路を持つ手法が、大規模言語モデル(LLMs)を用いたテキスト生成において顕著な性能向上を示しています.しかし、このような手法は、複数の出力を集約するための正確な回答抽出プロセスの利用に依存しています.さらに、Greedy Decodingと比較して、出力トークンの数が比較的多いため、推論コストが高くなります.研究によると、Self-Consistencyからの自由形式のテキスト出力は、LLMsを使用して信頼性の高い集約が可能であり、最終的な出力を生成することができます.さらに、LLM推論の最近の進歩により、プロンプトに多様な例示を使用することで、LLMの出力に多様性をもたらすことができます.これらの実証された技術は、テキスト生成において優れた結果を得るために、セルフアンサンブリングベースのアプローチに簡単に拡張することができます.本論文では、PEDAL(LLMsを使用して集約された多様な例示に基づくプロンプト)というハイブリッドセルフアンサンブリングアプローチを紹介し、多様な例示に基づくプロンプトとLLMに基づく集約の強みを組み合わせて、全体的な性能を向上させることを目指しています.さらに、公開されているSVAMPとARCデータセットを用いた実験では、PEDALがGreedy Decodingに基づく戦略よりも高い精度を達成し、Self Consistencyに基づくアプローチと比較して推論コストが低いことが示されました.
Q&A:
Q: PEDALの自己組織化アプローチには、具体的にどのような技術が用いられたのですか?
A: PEDALの自己アンサンブルアプローチの実装には、以下の具体的な技術が使用されました.まず、多様な例示を活用してLLMプロンプトを生成し、Greedy Decodingを用いて複数の候補応答を生成します.その後、これらの候補応答をLLMを用いて集約し、最終的な応答を生成します.この方法により、Greedy Decodingベースの戦略よりも高い精度を達成し、SCベースの戦略と比較して推論コストを低く抑えることが可能です.
Q: PEDALの性能は、グリーディ・デコーディングや自己一貫性と比べて、どのような指標で評価されたのでしょうか?
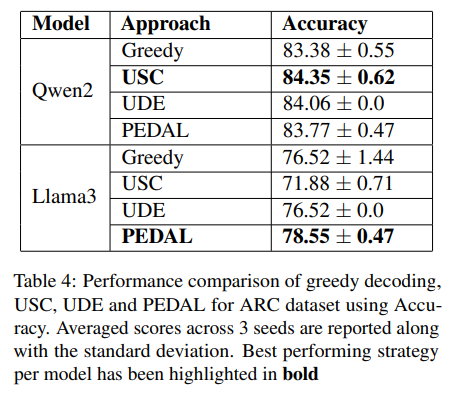
A: 与えられた文脈から、PEDALの性能は主に精度(accuracy)を用いて評価されていることがわかります.具体的には、PEDALはGreedy Decodingと比較して、SV AMPデータセットおよびARCデータセットにおいて精度の向上を示しています.また、USC(Self-Consistency)と比較して、出力トークンの数において優れているとされています.したがって、評価指標としては精度と出力トークン数が用いられていると考えられます.
Q: トークン生成の点で、PEDALの推論コストは、従来のグリーディ・デコーディングや自己無撞着と比較してどうでしょうか?
A: PEDALの推論コストは、トークン生成において、従来のGreedy DecodingおよびSelf-Consistency(SC)と比較して、より効率的であると示されています.具体的には、PEDALはGreedy Decodingよりも高い精度を達成し、SCに比べて推論コストが低いことが示されています.例えば、Qwen2モデルにおいて、PEDALは1,343の入力トークンと192の出力トークンを処理し、USCは903の入力トークンと503の出力トークンを処理します.これにより、PEDALは出力トークンのコストがUSCの4分の1以下であるため、コスト効率が高いとされています.Llama3モデルでも同様に、PEDALは1,262の入力トークンと198の出力トークンを処理し、USCは694の入力トークンと924の出力トークンを処理します.このように、PEDALは出力トークンのコストにおいて、他の手法よりも優れていると考えられます.
Q: PEDALの集計プロセスはどのように行われ、LLMはどのような役割を果たしているのですか?
A: PEDALにおける集約プロセスは、LLM(大規模言語モデル)を使用して行われます.具体的には、まず多様な例示を基にしたプロンプトを用いて、LLMが複数の候補応答を生成します.その後、これらの候補応答は再びLLMを用いて集約され、最終的な応答が生成されます.このプロセスにおいて、LLMは多様な候補応答を統合し、最も適切な応答を選択する役割を果たします.これにより、グリーディデコーディングに基づく戦略よりも高い精度を達成し、自己一貫性に基づくアプローチと比較して推論コストを低く抑えることが可能となります.
Automated Design of Agentic Systems
著者:Shengran Hu, Cong Lu, Jeff Clune
発行日:2024年08月15日
最終更新日:2024年08月15日
URL:http://arxiv.org/pdf/2408.08435v1
カテゴリ:Artificial Intelligence
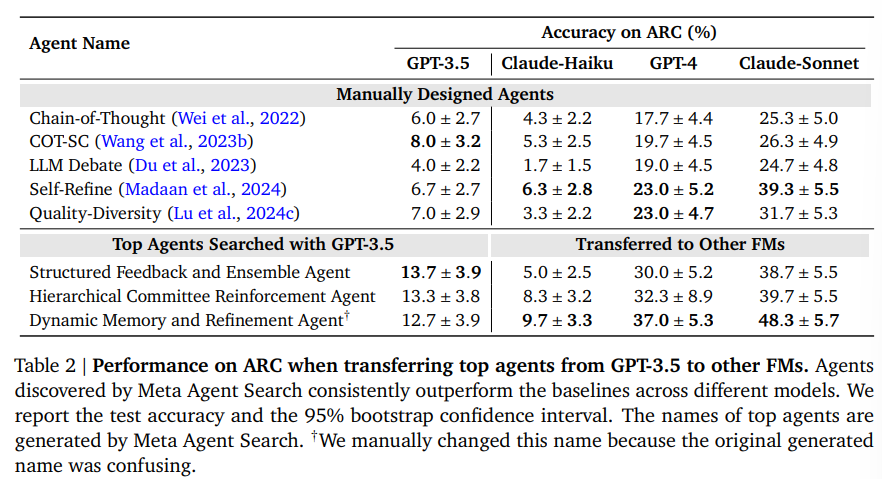
概要:
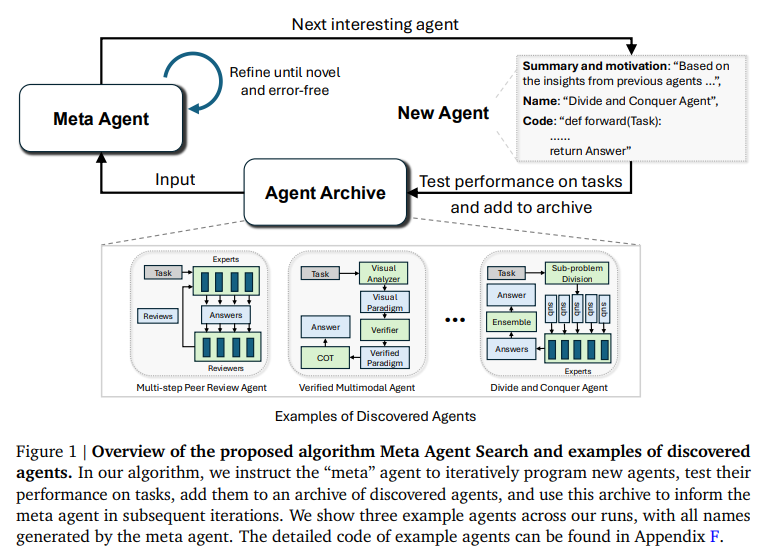
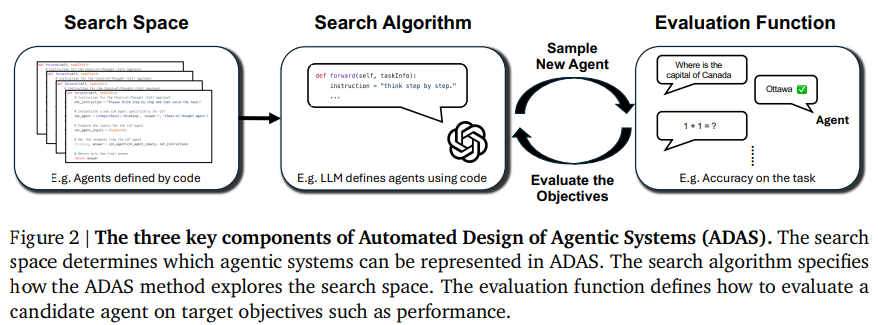
研究者は、強力な汎用エージェントを開発するために多大な努力を投入しており、Foundation Modelsはエージェントシステム内のモジュールとして使用されています(例:Chain-of-Thought、Self-Reflection、Toolformer).しかし、機械学習の歴史は、手作りの解決策が最終的に学習された解決策に置き換えられることを教えてくれます.私たちは、自動的に強力なエージェントシステムの設計を作成することを目的とする新しい研究領域、Automated Design of Agentic Systems(ADAS)を提案します.これには、新しい構築ブロックを発明したり、それらを新しい方法で組み合わせたりすることが含まれます.さらに、エージェントをコードで定義し、メタエージェントがコードでより良いエージェントをプログラムすることで、新しいエージェントを自動的に発見できる未開拓の有望なアプローチがADAS内に存在することを示します.プログラミング言語がチューリング完全であることから、このアプローチは理論的には任意の可能なエージェントシステムの学習を可能にします:新しいプロンプト、ツールの使用、制御フロー、およびそれらの組み合わせを含むものも含まれます.このアイデアを示すために、Meta Agent Searchというシンプルで効果的なアルゴリズムを提案します.ここでは、メタエージェントが興味深い新しいものを繰り返しプログラムすることで、このアイデアを実証します.さらに、私たちは、Meta Agent Searchによって前例のない新しいエージェントを逐次発明することができることを示すために、コーディング、科学、数学などのさまざまな分野での広範な実験を通じて、私たちのアルゴリズムが、最先端の手作りエージェントを大幅に上回る新しい設計のエージェントを進化的に発明できることを示します.重要なことは、Meta Agent Searchによって発明されたエージェントが、ドメインやモデルを超えて転送された場合でも、優れたパフォーマンスを維持する驚くべき結果が一貫して観察され、その堅牢性と汎用性が示されていることです.安全に開発すれば、私たちの研究は、人類の利益のためにますます強力なエージェントシステムを自動的に設計する新しい研究方向の可能性を示しています.
Q&A:
Q: メタ・エージェント探索アルゴリズムによって作成されたエージェントのパフォーマンスを評価するために、具体的にどのような基準を用いていますか?
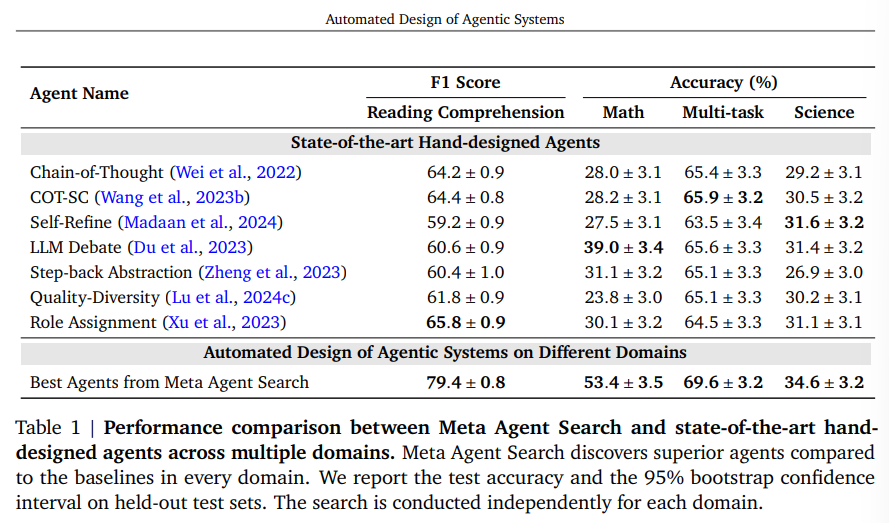
A: メタエージェントサーチアルゴリズムによって作成されたエージェントの性能を評価するために、成功率やF1スコアといったパフォーマンス指標と95%ブートストラップ信頼区間が用いられます.これらの指標は、エージェントの性能を最大化するための基準として計算されます.具体的には、エージェントはタスクに対して5回評価され、その結果から中央値の精度と95%ブートストラップ信頼区間が報告されます.
Q: メタ・エージェントの反復プログラミング・プロセスの文脈で、「興味深い新しいエージェント」をどのように定義しますか?
A: 与えられた文脈において、「興味深い新しいエージェント」は、メタエージェントが反復的にプログラムする過程で、既存のオープンエンデッドネスアルゴリズムに類似して、人間の興味深さの概念を活用することによって定義されます.具体的には、メタエージェントは、これまでに発見されたエージェントのアーカイブを基にして、新規性や価値のあるエージェントを探索することが奨励されます.このプロセスは、メタエージェントが新しいエージェントをプログラムし、その性能をタスクでテストし、発見されたエージェントのアーカイブに追加し、そのアーカイブを次の反復での新しいエージェントの創造に役立てるという流れで行われます.
Q: 機能性や適応性の面で、従来の手作業でデザインされたエージェントと、あなたのアプローチで作られたエージェントの違いは何ですか?
A: 私たちのアプローチによって作成されたエージェントは、従来の手作りのエージェントと比較して、機能性と適応性の面でいくつかの重要な違いがあります.まず、これらのエージェントは、Meta Agent Searchによって自動的に設計されており、手動で設計されたエージェントを上回る性能を示しています.さらに、これらのエージェントは、異なるドメインやモデルに移行しても優れた性能を維持することが観察されており、その堅牢性と一般性が示されています.これにより、エージェントシステムの設計を自動化することで、より強力なエージェントシステムを開発する新しい研究の方向性が示されています.これらのエージェントは、コード内でエージェントシステム全体を定義し、新しいエージェントが自動的に発見されるという柔軟な設計パターンを持っており、Pythonのようなチューリング完全なプログラミング言語を使用して実装されています.
Q: ADASとそのアプリケーションの進歩に伴い、倫理的な検討事項や潜在的な社会的影響はありますか?
A: ADASの進展とその応用に関して、いくつかの倫理的考慮事項や潜在的な社会的影響が考えられます.まず、ADASアルゴリズムが強力であり、簡単に作成できることが示されていますが、これにより悪意のある目的での利用が懸念されます.特に、検索中に有害なコードを実行しないようにすることや、不正直で役に立たない、または有害なエージェントを作成しないようにすることが重要です.さらに、ADASの安全性を確保するための研究が推奨されており、例えば、訓練中に安全であることを求め、役に立ち、無害で、正直なエージェントのみを作成するようにすることが考えられます.これには、憲法AIのようなアイデアを取り入れることが含まれます.これらの点を考慮することで、より安全なAIシステムの構築が可能になると考えられます.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: この論文で紹介された新しい方法のコード実装のurlは、https://github.com/ShengranHu/ADAS でございます.
Graph Retrieval-Augmented Generation: A Survey
著者:Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, Siliang Tang
発行日:2024年08月15日
最終更新日:2024年09月10日
URL:http://arxiv.org/pdf/2408.08921v2
カテゴリ:Artificial Intelligence, Computation and Language, Information Retrieval

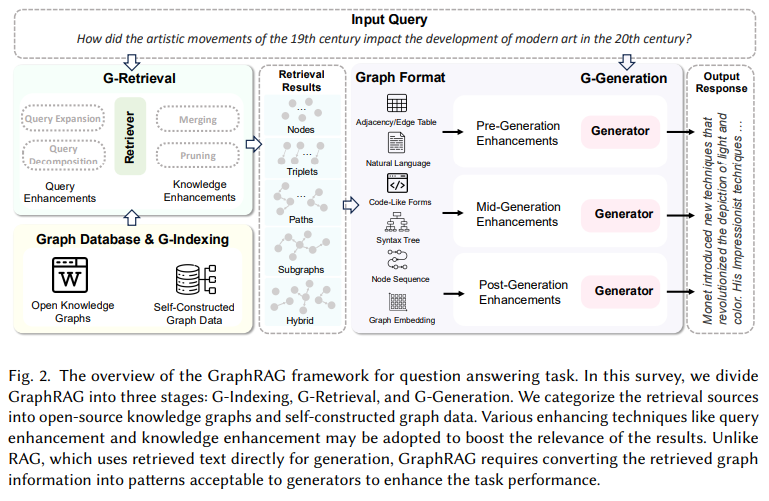
概要:
最近、Retrieval-Augmented Generation(RAG)は、再トレーニングを必要とせずに大規模言語モデル(LLMs)の課題に取り組む上で顕著な成功を収めています.外部知識ベースを参照することで、RAGはLLMの出力を洗練し、幻覚、特定のドメイン知識の不足、情報の古さなどの問題を効果的に軽減しています.しかし、データベース内の異なるエンティティ間の複雑な関係構造は、RAGシステムにとって課題を提供しています.これに対応するために、GraphRAGはエンティティ間の構造情報を活用して、より正確かつ包括的な検索を可能にし、関係性の知識を捉え、より正確でコンテキストに即した応答を促進しています.GraphRAGの新規性と潜在性を考慮すると、現在の技術の体系的なレビューが必要です.この論文では、GraphRAGの方法論に関する初の包括的な概要を提供します.我々は、GraphRAGのワークフローを形式化し、Graph-Based Indexing、Graph-Guided Retrieval、Graph-Enhanced Generationを包括しています.そして、各段階での主要な技術とトレーニング方法を概説します.さらに、下流タスク、応用領域、評価方法論、およびGraphRAGの産業利用事例を検討します.最後に、今後の研究方向を探求し、さらなる研究を促進するための進展を目指します.この分野の最新の進歩を追跡するために、\url{https://github.com/pengboci/GraphRAG-Survey}にリポジトリを設定しました.
Q&A:
Q: データベースにおけるエンティティ間の複雑な関係構造は、RAGシステムにとって具体的にどのような課題をもたらすのだろうか?
A: RAGシステムにおいて、データベース内のエンティティ間の複雑な関係構造がもたらす具体的な課題としては、以下の点が挙げられます.まず、RAGはテキスト情報を取得することで、ある程度の問題を緩和しますが、テキストの長さやエンティティ関係の柔軟な自然言語表現のために、特に「影響」関係を強調することが難しいという問題があります.さらに、テキストコンテンツは孤立しているわけではなく、相互に関連していますが、従来のRAGは意味的類似性だけでは表現できない重要な構造化された関係知識を捉えることができません.例えば、引用ネットワークでは、論文が引用関係によってリンクされていますが、従来のRAG手法はクエリに基づいて関連する論文を見つけることに焦点を当てる一方で、論文間の重要な引用関係を見落としがちです.これらの課題は、RAGが単にテキストスニペットをプロンプトとして連結する形で内容を再現するため、コンテキストが過度に長くなり、「中間で失われる」ジレンマを引き起こすことにもつながります.
Q: 従来のRAG手法と比較して、グラフラグはどのように関係知識を捉えるのか、詳しく教えてください.
A: GraphRAGは、従来のRAGメソッドと比較して、関係知識をより効果的に捉えることができます.従来のRAGはテキストコーパスから関連情報を取得するのに対し、GraphRAGは事前に構築されたグラフデータベースからグラフ要素を取得します.これらの要素には、ノード、トリプル、パス、サブグラフなどが含まれ、これらを用いて応答を生成します.GraphRAGはテキスト間の相互接続を考慮し、関係情報のより正確で包括的な取得を可能にします.さらに、グラフデータはテキストデータの抽象化と要約を提供し、入力テキストの長さを大幅に短縮し、冗長性の懸念を軽減します.グラフデータの構築中に、生のテキストデータはフィルタリングと要約のプロセスを経ることがあり、グラフデータ内の情報の精緻化が促進されます.これにより、GraphRAGは構造情報をテキスト以外の追加知識として組み込み、明示的なエンティティと関係の表現を活用して、関連する構造化情報を正確に取得することが可能となります.
Q: GraphRAGのワークフローにおける、Graph-Based Indexing、Graph-Guided Retrieval、Graph-Enhanced Generationの主な違いは?
A: GraphRAGワークフローにおけるGraph-Based Indexing、Graph-Guided Retrieval、Graph-Enhanced Generationの主な違いについて説明いたします.
まず、Graph-Based Indexing(G-Indexing)は、GraphRAGの初期段階を構成し、下流のタスクに適合するグラフデータベースGを特定または構築し、それにインデックスを設定することを目的としております.このプロセスでは、ノードとエッジのプロパティをマッピングし、接続されたノード間にポインタを設定し、データを整理して迅速なトラバーサルと検索操作をサポートすることが含まれます.
次に、Graph-Guided Retrieval(G-Retrieval)は、最適なサブグラフ𝐺∗を抽出するためにグラフリトリーバーを使用し、その後、生成器が取得したサブグラフに基づいて回答を生成する段階でございます.この段階では、グラフデータにおける明示的なエンティティと関係の表現を活用し、関連する構造化情報を正確に取得することが可能です.
最後に、Graph-Enhanced Generation(G-Generation)は、取得したサブグラフを基に回答を生成する段階であり、グラフデータの構造を活用して、より正確で関連性の高い回答を生成することを目指しております.
これらの段階は、GraphRAGの全体的なワークフローを形成し、それぞれが異なる役割を果たしております.
Q: グラフグラフのワークフローの各段階では、どのようなコア技術が活用されているのか?
A: GraphRAGのワークフローにおける各段階で利用されるコア技術は、G-Indexing、G-Retrieval、G-Generationでございます.G-Indexingは、知識グラフやデータベースから情報を効率的にインデックス化する技術であり、情報の迅速なアクセスを可能にいたします.G-Retrievalは、インデックス化されたデータから関連情報を効果的に検索する技術であり、情報の精度と関連性を向上させることを目的としております.最後に、G-Generationは、取得した情報を基に新しいコンテンツを生成する技術であり、生成されたコンテンツの質と一貫性を高めることを目指しております.
Q: GraphRAGが大きな改善を示した具体的な下流タスクやアプリケーション・ドメインは?
A: GraphRAGは、特に自然言語処理(NLP)タスクにおいて、質問応答や情報抽出などの下流タスクで適用されております.これらのタスクにおいて、GraphRAG技術はその性能を向上させることが示されております.
Q: グラフRAGとその方法論の発展について、今後どのような研究の方向性が予想されますか?
A: GraphRAGの開発とその方法論に関する将来の研究方向として、いくつかの重要な課題が挙げられます.まず、動的かつ適応的なグラフの開発が求められています.現在の多くのGraphRAGの手法は静的なデータベースに基づいていますが、時間の経過とともに新しいエンティティや関係が出現するため、これらの変化を迅速に更新することが重要です.動的な更新と新しいデータのリアルタイム統合のための効率的な方法を開発することは、GraphRAGシステムの効果と関連性を大幅に向上させるでしょう.次に、多モーダル情報の統合が挙げられます.多くの知識グラフは主にテキスト情報を含んでいますが、画像、音声、ビデオなどの他のモダリティを含めることで、データベースの全体的な質と豊かさを大幅に向上させる可能性があります.
Q: GitHubにGraphRAG分野の進捗を追跡するためのリポジトリを作成した動機は何ですか?
A: GraphRAGの分野における最近の進展を追跡するために、GitHubにリポジトリが設置されたことが動機となっております.このリポジトリは、研究の進展を記録し、研究者や開発者が最新の情報にアクセスしやすくするためのものでございます.
