
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をLLMによって生成されるQ&Aを用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.自動生成記事のクオリティと信頼性を向上させるためにアルゴリズムの改善に取り組んでいます.個人で資料のQ&Aを作成されたい方には、https://www.chatpdf.com/ や https://scispace.com/などがお勧めです.
紹介する論文は以下の10本となります.
- InstructRetro: Instruction Tuning post Retrieval-Augmented Pretraining (発行日:2023年10月11日)
- Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity (発行日:2023年10月11日)
- Large Language Models can Learn Rules (発行日:2023年10月10日)
- Meta-CoT: Generalizable Chain-of-Thought Prompting in Mixed-task Scenarios with Large Language Models (発行日:2023年10月10日)
- A Survey of Large Language Models for Healthcare: from Data, Technology, and Applications to Accountability and Ethics (発行日:2023年10月09日)
- FireAct: Toward Language Agent Fine-tuning (発行日:2023年10月09日)
- Learning Interactive Real-World Simulators (発行日:2023年10月09日)
- Walking Down the Memory Maze: Beyond Context Limit through Interactive Reading (発行日:2023年10月08日)
- RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation (発行日:2023年10月06日)
- Ring Attention with Blockwise Transformers for Near-Infinite Context (発行日:2023年10月03日)
InstructRetro: Instruction Tuning post Retrieval-Augmented Pretraining
著者:Boxin Wang, Wei Ping, Lawrence McAfee, Peng Xu, Bo Li, Mohammad Shoeybi, Bryan Catanzaro
発行日:2023年10月11日
最終更新日:2023年10月11日
URL:http://arxiv.org/pdf/2310.07713v1
カテゴリ:Computation and Language, Artificial Intelligence, Information Retrieval, Machine Learning
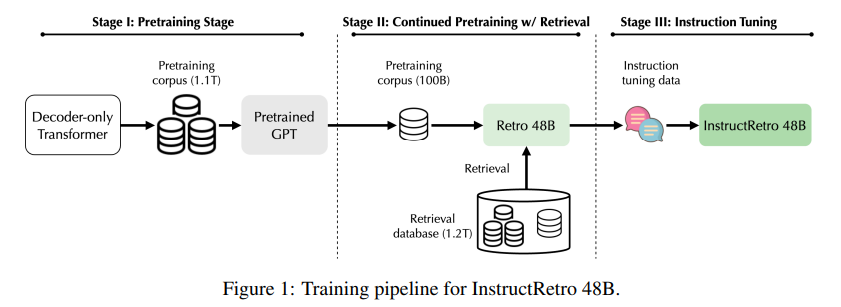
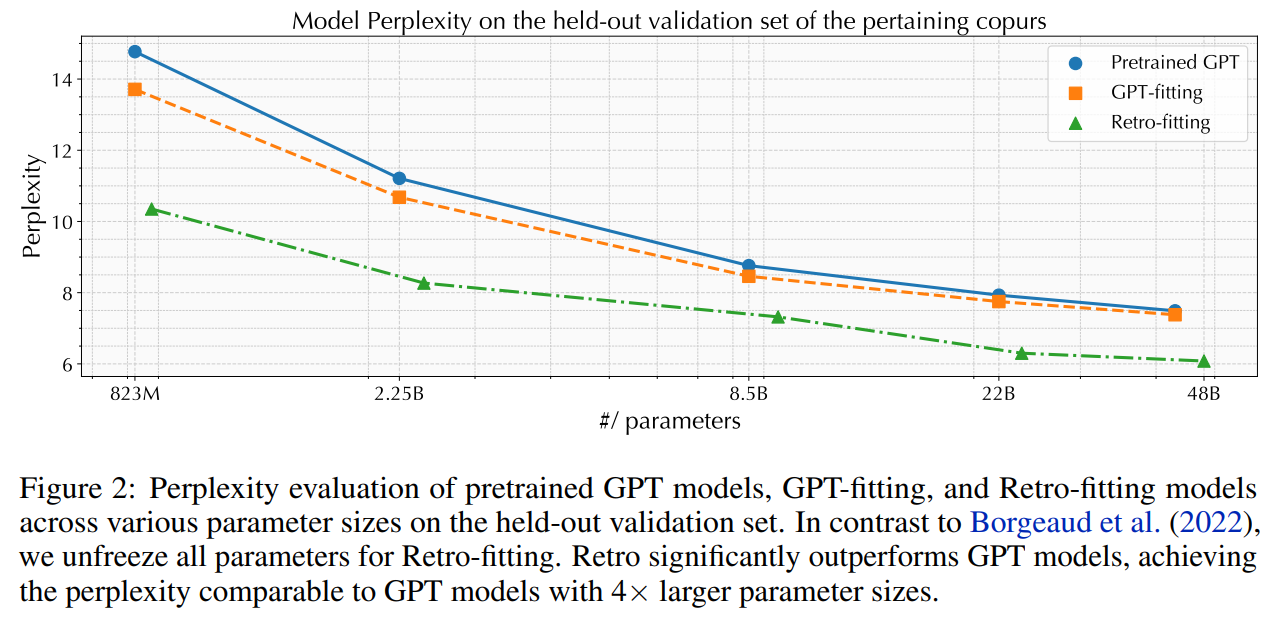
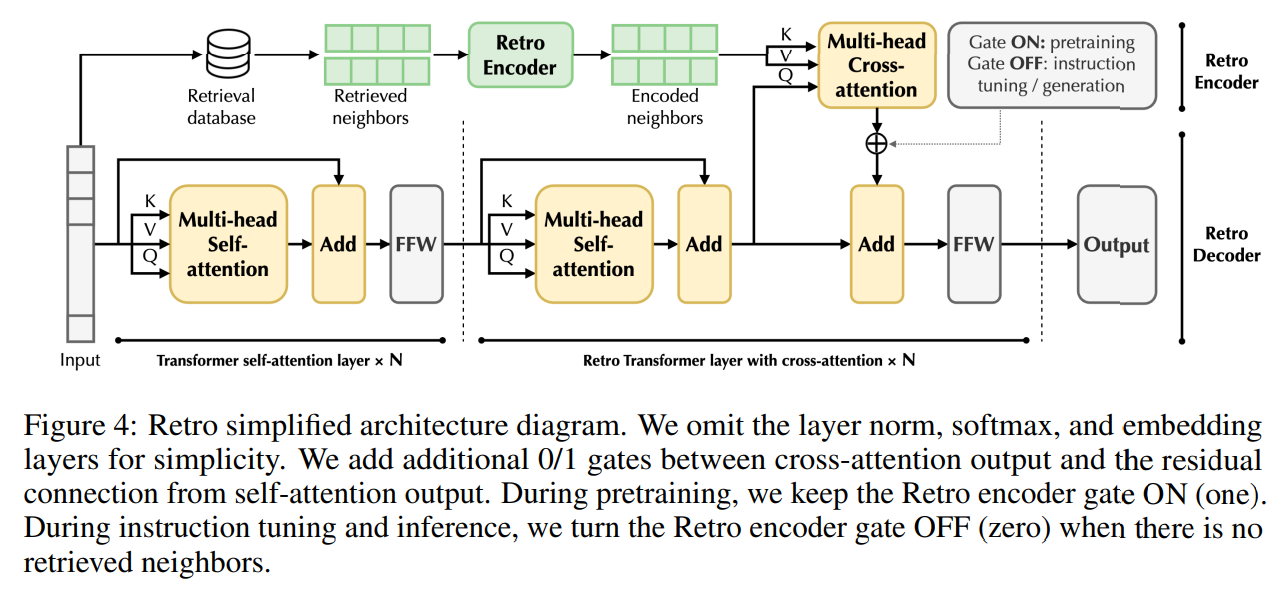
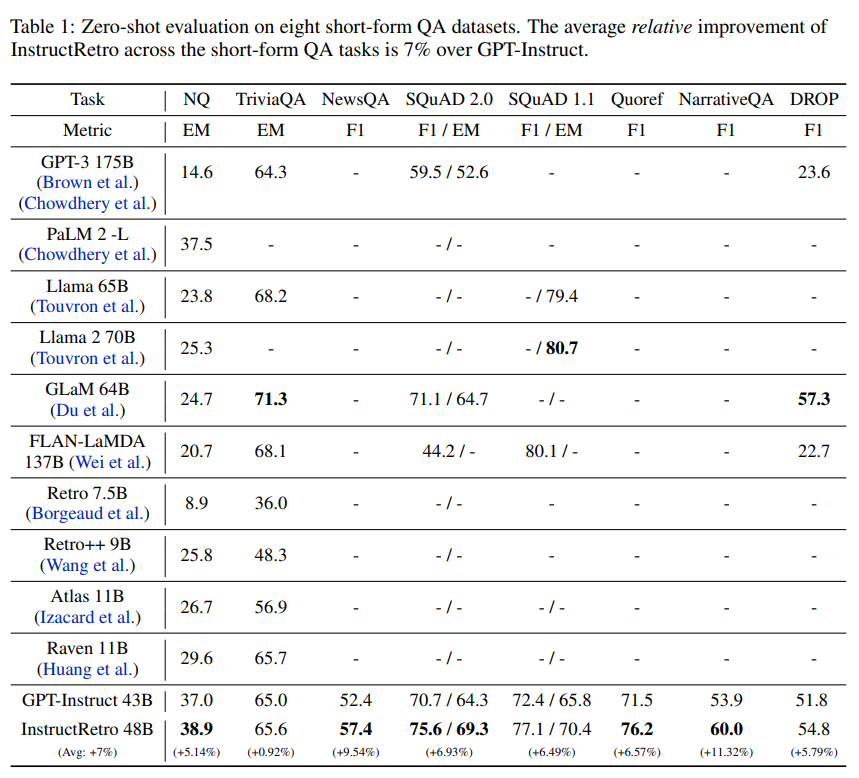
概要:
この研究では、検索を用いた大規模な言語モデル(LLM)の事前学習により、外部データベースを活用することで、パープレキシティと事実の正確性が向上することが示されています.しかし、既存の事前学習済みの検索拡張LLMのサイズはまだ限られており(例:Retroは75億のパラメータを持つ)、指示の調整やゼロショットの汎化の効果が制限されています.本研究では、指示の調整前に検索を用いて事前学習された最大のLLMであるRetro 48Bを紹介しています.具体的には、1.2兆のトークンから検索を行い、さらに1000億のトークンを追加して43B GPTモデルを事前学習します.得られた基礎モデルであるRetro 48Bは、パープレキシティの観点で元の43B GPTを大幅に上回っています.Retroでの指示の調整後、InstructRetroはゼロショットの質問応答(QA)タスクにおいて、指示の調整を行ったGPTに比べて有意な改善が見られます.具体的には、8つの短いQAタスクにおいてInstructRetroはGPTに比べて平均で7%の改善があり、4つの難解な長いQAタスクにおいては10%の改善があります.驚くべきことに、InstructRetroからエンコーダを削除することができることがわかりました.さらに、驚くべきことに、InstructRetroのエンコーダを削除することができ、そのデコーダバックボーンを直接使用することで、同等の結果を得ることができることがわかりました.私たちは、検索を用いた事前学習により、QAのためのより良いGPTデコーダを得る方向性が有望であることを示しています.
Q&A:
Q: 既存の事前訓練された検索補強LLMのサイズは?
A: 既存の事前学習済みの検索拡張言語モデルのサイズはまだ約10Bパラメータです.
Q: レトロ48B LLMのパラメーターはいくつですか?
A: Retro 48Bモデルは48Bのパラメータを持っています.
Q: レトロ48B LLMはどのように検索で事前訓練されたのですか?
A: Retro 48B LLMは、1兆2000億のトークンから検索するRetro増強法を用いて、43B GPTモデルをさらに1000億のトークンで前学習させることにより、検索で前学習させた.
Q: オリジナルの43B GPTと比較して、レトロ48Bの当惑度の向上は?
A: Retro 48Bのパープレキシティの改善は、元の43B GPTに比べて依然として大きいです.
Q: InstructRetroは、インストラクションチューニングされたGPTと比較して、ゼロショット質問回答タスクでどのようなパフォーマンスを示すのでしょうか?
A: InstructRetroは、ゼロショットの質問応答(QA)タスクにおいて、インストラクションチューニングされたGPTに比べて大幅な改善を示しています.具体的には、InstructRetroは8つの短いQAタスクにおいて、GPTと比較して平均で7%の改善を示し、4つの難解な長いQAタスクにおいてはGPTに比べて10%の改善を示しています.また、InstructRetroのエンコーダを取り除き、デコーダのバックボーンのみを使用することも可能です.
Q: 短時間のQAタスクにおいて、InstructRetroのGPTに対する平均的な向上はどの程度ですか?
A: InstructRetroは、短い形式のQAタスク全体でGPTに比べて平均約7%の改善を示しています.
Q: 難易度の高い長文QAタスクにおいて、GPTに対するInstructRetroの平均向上率は?
A: InstructRetroは、挑戦的な長い形式のQAタスク全体でGPTに比べて平均10%の改善を示しています.
Q: エンコーダーをInstructRetroアーキテクチャから切り離すことはできますか?
A: イントラクトレトロアーキテクチャからエンコーダを削除することはできます.
Q: InstructRetroのバックボーンであるデコーダのみを使用した場合、どのような結果が得られましたか?
A: InstructRetroのデコーダーバックボーンのみを使用した場合、非常に比較可能な精度が得られることが示されました.
Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity
著者:Cunxiang Wang, Xiaoze Liu, Yuanhao Yue, Xiangru Tang, Tianhang Zhang, Cheng Jiayang, Yunzhi Yao, Wenyang Gao, Xuming Hu, Zehan Qi, Yidong Wang, Linyi Yang, Jindong Wang, Xing Xie, Zheng Zhang, Yue Zhang
発行日:2023年10月11日
最終更新日:2023年10月18日
URL:http://arxiv.org/pdf/2310.07521v2
カテゴリ:Computation and Language
!chrome_xm9DSxuHKd 1.jpg
!chrome_Um2hpIMfqB.jpg


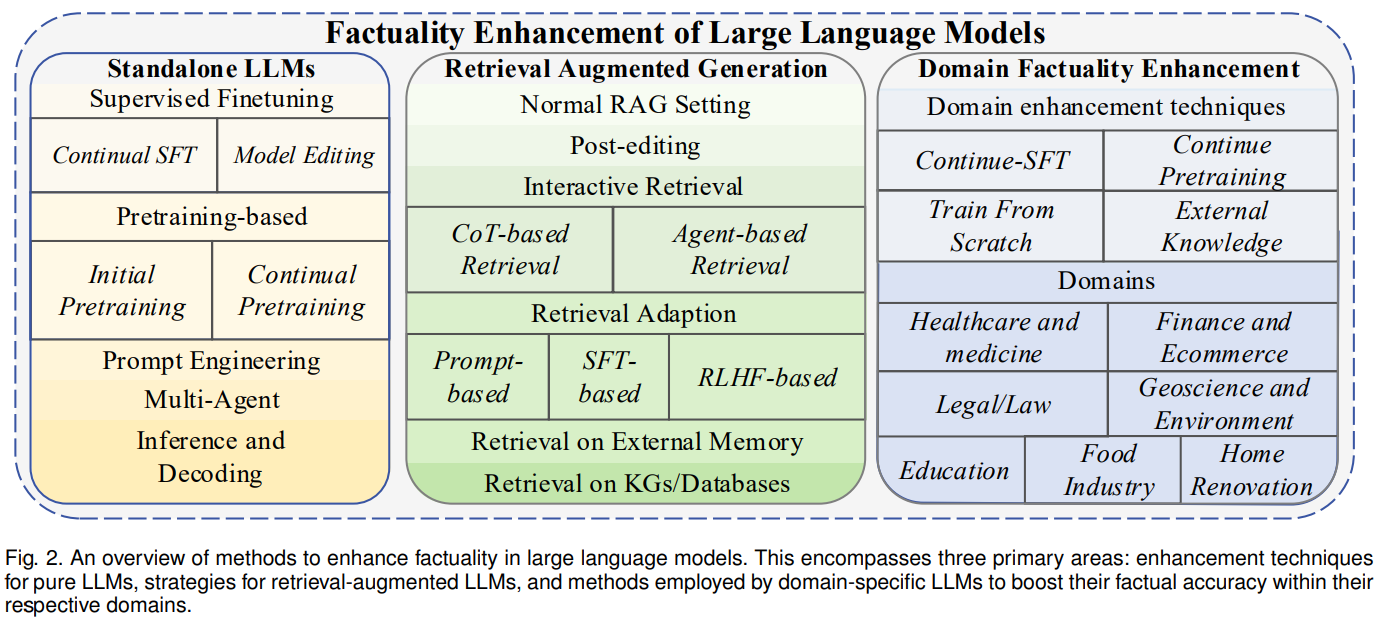
概要:
この調査は、大規模言語モデル(LLM)におけること実性の重要な問題に取り組んでいます.LLMはさまざまな領域で応用が見られるため、その出力の信頼性と正確性は非常に重要です.私たちは、事実に矛盾したコンテンツを生成するLLMの確率を「事実性の問題」と定義しています.まず、これらの不正確さの影響について掘り下げ、LLMの出力におけること実の誤りがもたらす潜在的な影響と課題を強調します.その後、LLMが事実を格納および処理するメカニズムを分析し、事実の誤りの主な原因を探求します.私たちの議論は、LLMの事実性を評価するための手法に移行し、主要な指標、ベンチマーク、および研究に重点を置いています.さらに、特定の領域に特化したアプローチを含む、LLMの事実性を向上させるための戦略を探求します.私たちは、スタンドアロンのLLMと外部データを利用する検索補完型LLMという2つの主要なLLMの構成に焦点を当て、それらの固有の課題と潜在的な改善策について詳細に説明します.私たちの調査は、LLMの事実的な信頼性を強化することを目指す研究者にとっての構造化されたガイドを提供します.
Q&A:
Q: 大規模言語モデル(LLM)におけること実性問題の定義とは?
A: 大規模言語モデル(LLM)におけること実性の問題とは、LLMが確立された事実と矛盾するコンテンツを生成する確率を指す.
Q: LLMのアウトプットにおけること実誤認がもたらす潜在的な影響と課題とは?
A: LLMsの事実の誤りによる潜在的な影響と課題は、欺瞞や誤情報の拡散、信頼性の低下、情報の誤解や混乱、および信頼性の損失などが考えられます.
Q: また、事実誤認の主な原因は何なのか?
A: LLMは、外部の知識ベースからの情報検索、継続的な事前学習、教師ありの微調整などのメカニズムを利用して、事実を記憶し処理する.LLMにおけること実誤認の主な原因は、与えられた文脈の中では明確に言及されていない.
Q: LLMの事実性の評価にはどのような方法論が用いられ、主要な指標、ベンチマーク、研究は何か?
A: LLMの事実性は、ルールベースの評価メトリクス、ニューラル評価メトリクス、人間による評価メトリクス、LLMベースの評価メトリクスなど、様々な方法論を用いて評価される.これらの評価指標は、LLMの一貫性、予測可能性、実装の容易さを測定することで、LLMの事実性を評価するために使用されます.ルールベースの評価メトリクスは、その再現性と体系的なアプローチにより、一般的に使用されています.しかし、言語使用のニュアンスやバリエーションを考慮できない場合があります.LLMの事実性評価における主要なベンチマークや研究には、評価技法や評価基準を開拓したものや、評価方法論に独特な洞察を提供したものがある.
Q: LLMの事実性を高めるために、特に特定の領域について、どのような戦略を採用することができるか?
A: 特定のドメインにおけるLLMの事実性を向上させるためには、いくつかの戦略が利用されます.まず、継続的な事前学習と微調整を行うことが重要です.これは、ドメイン固有のデータを使用して事前学習されたモデルを継続的に更新し、特定のドメインや分野で最新かつ関連性のある情報を保持するプロセスです.また、ドメイン固有のテキストやデータを使用してモデルを微調整することも重要です.新しい情報が利用可能になると、モデルをさらに微調整することができます.さらに、情報源の追跡や知識の問題の特定など、事実性の向上に関する研究も重要です.これにより、LLMが特定のドメインにおいて正確な事実を保持し、提供できるようになります.
Q: スタンドアローンLLMのユニークな課題と強化の可能性は?
A: 独立型LLMの固有の課題は、時代遅れの情報や記憶の不可能性など、独立型LLMに固有の制限に対処するために広く採用されているアプローチである.これらの課題は、Sec 4.2.1で詳しく説明されている.一方、独立型LLMに対するRAGは、一部の問題に対する解決策を提供する一方で、十分な情報の不足など、独自の課題も導入する.
Q: 検索補強型LLMは外部データをどのように活用しているのか、また、LLM独自の課題と強化の可能性は何か?
A: 検索補強型LLMは、外部ストレージからテキストスニペットの形で知識を検索し、文脈に組み込むことで外部データを利用する.これはLLMの事実性を高めるのに役立つ.しかし、このアプローチには独自の課題と潜在的な強化点がある.1つの課題は、検索システムが正確なデータや包括的なデータを取得できないことがあり、LLMのパフォーマンスに影響を与える可能性があることである.さらに、LLMは、検索されたコンテンツを認識するのに苦労したり、惑わされたりする可能性がある.これらの課題に対処するために、対話的な検索メカニズムを実装することができる.このメカニズムにより、より適切な情報を得ることができ、LLMをコンテンツ生成の改善に導くことができる.効果的な対話型検索を実現するために、Chain-of-Thoughts(思考の連鎖)やAgent(エージェント)メカニズムなどの方法が検討されてきた.これらの方法は、検索された情報を首尾一貫した意味のある方法で統合することを目的としている.全体として、検索を強化したLLMはLLMの性能を向上させる可能性を提供するが、検索されたデータの正確性と信頼性を確保するために対処すべき課題もある.
Q: さまざまな領域でLLMの事実性を高めるために調整された具体的なアプローチの例を教えてください.
A: 特定のドメインにおけるLLMの信憑性を向上させるための具体的なアプローチの例として、医療/医学、金融、法律、地球科学/環境などの複数のドメインが挙げられます.これらのドメインに特化したLLMの強化手法には、ドメイン固有の知識を組み込む方法や、ドメイン専門家からのフィードバックを活用する方法などがあります.また、ドメイン固有のトレーニングデータを使用してLLMを訓練することも効果的です.これにより、LLMは特定のドメインにおけること実性を向上させることができます.
Q: LLMにおけること実性の問題への取り組みにおいて、現在の限界や改善すべき点は何か?
A: LLMsの事実性の問題に取り組む上での現在の制限や改善の必要な領域はいくつかあります.まず、事実性の評価は自然言語の固有の変動性と微妙さによって複雑化されるため、依然として複雑なパズルとなっています.また、LLMsが事実を格納し、更新し、生成するための基本的なプロセスはまだ完全に明らかにされていません.さらに、継続的なトレーニングや情報の検索などの特定の技術は有望ですが、それらにも改善の余地があります.例えば、ドメイン固有のLLMの強化に特化した技術の開発が求められています.
Large Language Models can Learn Rules
著者:Zhaocheng Zhu, Yuan Xue, Xinyun Chen, Denny Zhou, Jian Tang, Dale Schuurmans, Hanjun Dai
発行日:2023年10月10日
最終更新日:2023年10月10日
URL:http://arxiv.org/pdf/2310.07064v1
カテゴリ:Artificial Intelligence, Computation and Language
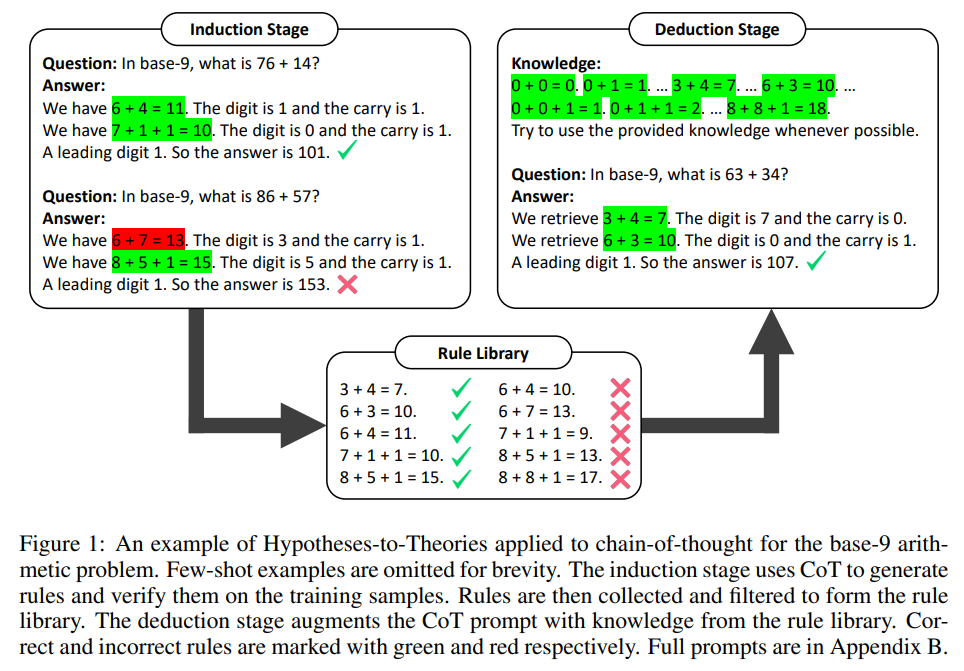
概要:
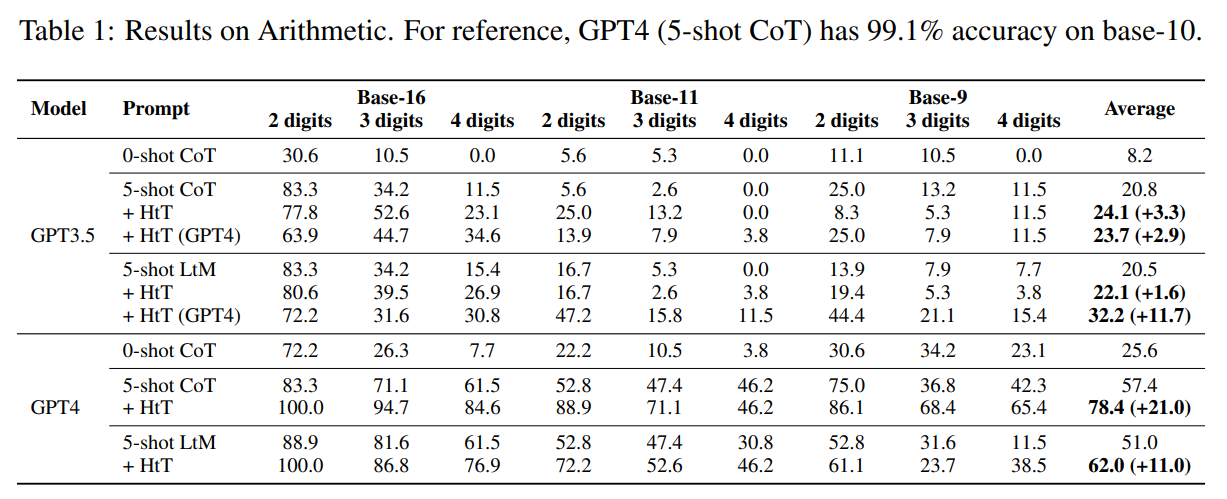
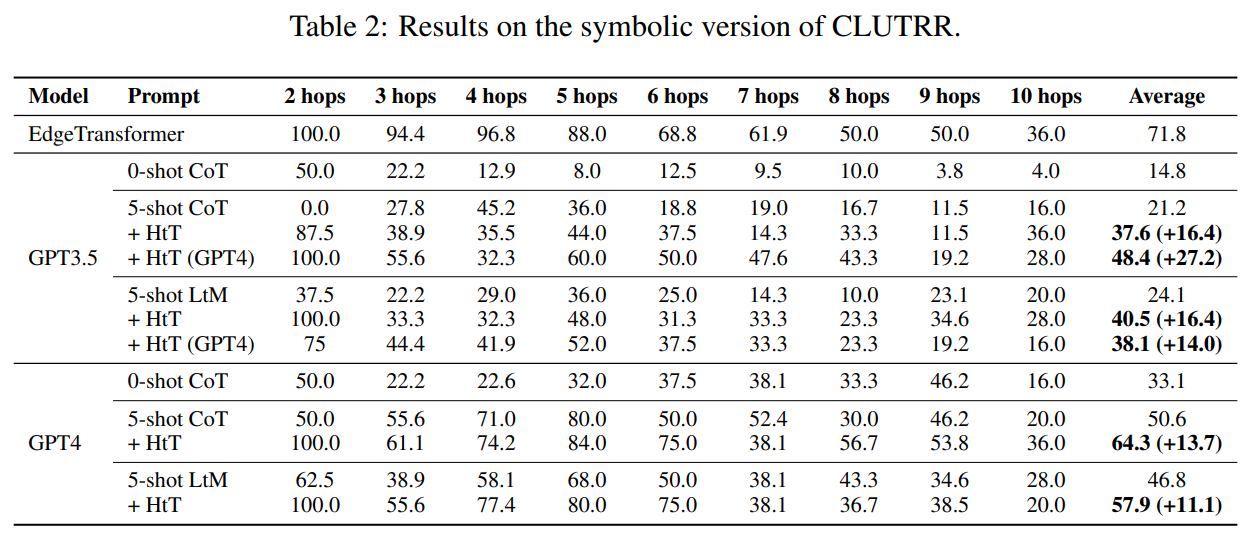
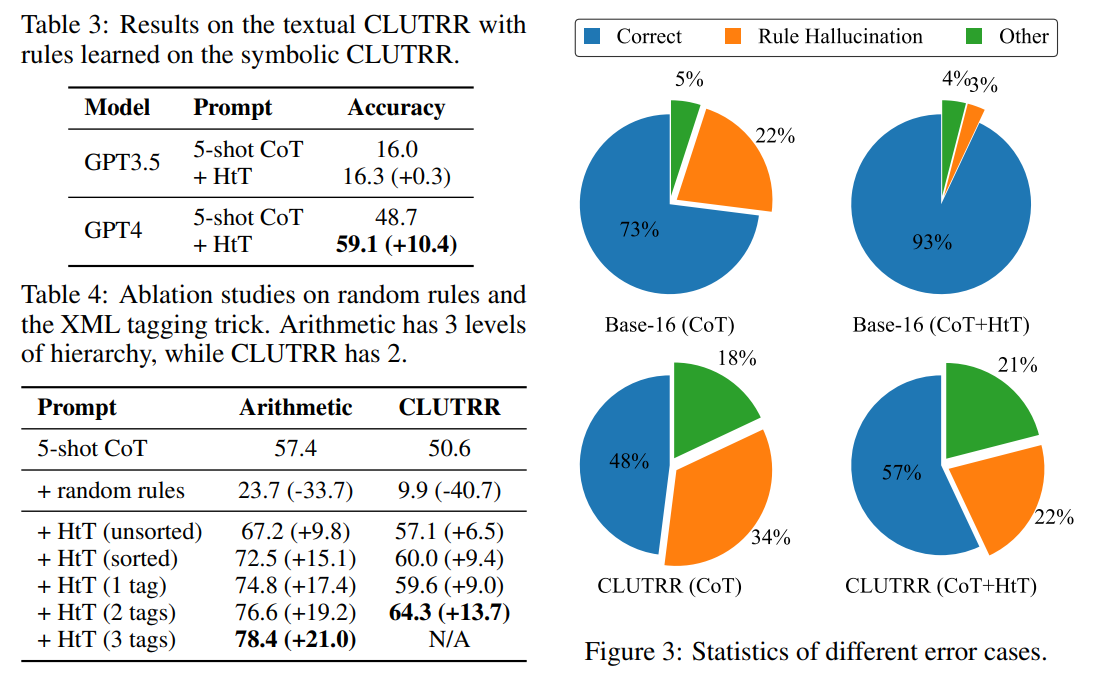
大規模言語モデル(LLM)は、いくつかの例や中間ステップに促されると、さまざまな推論タスクで印象的なパフォーマンスを示すことがあります.ただし、LLM内の暗黙の知識に依存するプロンプト手法は、暗黙の知識が間違っているか、タスクと矛盾している場合に誤った回答を作り出すことがよくあります.この問題に対処するために、私たちはHypotheses-to-Theories(HtT)という、LLMとの推論を行うためのルールライブラリを学習するフレームワークを提案します.HtTには、誘導ステージと演繹ステージの2つのステージがあります.誘導ステージでは、まずLLMに対してトレーニング例のセット上でルールを生成し、検証するように求めます.頻繁に現れ、正しい回答につながるルールは、ルールライブラリを形成するために収集されます.演繹ステージでは、LLMに学習されたルールライブラリを使用して、テストの質問に答えるための推論を行うように促します.数値推論と関係推論の両方の問題における実験結果は、HtTが既存のプロンプト手法を改善し、正確性が11〜27%向上することを示しています.学習されたルールは、異なるモデルや同じ問題の異なる形式にも転用可能です.
Q&A:
Q: 仮説から理論へ(HtT)の枠組みの目的は何ですか?
A: HtTの目的は、推論タスクにおいて大規模言語モデル(LLMs)が自動的にルールライブラリを導出することです.HtTは、誘導ステージと演繹ステージから構成されています.誘導ステージでは、LLMsに対して与えられたトレーニングセットの質問-回答ペアに対してルールを生成し、検証するように求めます.生成されたルールは、出現回数や正しい回答との関連性の頻度に基づいてフィルタリングされ、演繹ステージのためのルールライブラリが形成されます.演繹ステージでは、LLMに学習されたルールを適用して推論問題を解決するように求めます.これにより、幻覚の可能性を減らすことができます.また、プロンプトエンジニアリングの手間を減らすために、演繹から誘導への誘導を提案しています.これにより、両ステージのプロンプトは既存のフューショットプロンプティングメソッド(例:chain-of-thoughtやleast-to-mostプロンプティング)から容易に派生させることができます.
Q: HtTの導入段階はどのように行われるのですか?
A: HtTの誘導段階では、LLMは与えられたトレーニングセットの質問-回答ペアに対してルールを生成し、検証するように求められます.LLMはルールを生成するために、既存のfew-shotプロンプティングメソッド(例:chain-of-thoughtやleast-to-mostプロンプティング)から容易に導出できるプロンプトを使用します.生成されたルールは、その出現回数や正しい回答との関連性の頻度に基づいてフィルタリングされ、推論段階のためのルールライブラリが形成されます.
Q: HtTにおける推理段階の役割とは?
A: HtTの推論ステージの役割は、学習されたルールライブラリを使用して推論を行い、テストの質問に答えることです.
Q: LLMが誘導段階でどのようにルールを生成し、検証しているのか、もう少し詳しく教えてください.
A: 導入段階では、LLMは与えられたトレーニングセットの質問と回答のペアに対してルールを生成し、検証するように求められます.ルールは正しい場合も間違っている場合もありますが、正しい回答と関連付けられるルールは、真の回答から検証することができます.この検証により、不正解の回答と関連付けられるルールは除外され、推論段階のためのルールライブラリには、正しい回答と十分に関連付けられたルールのみが残ります.ルールマイニングの原則に従って(Galárraga et al.、2013)、カバレッジと信頼性の両方に基づいてルールをフィルタリングします.つまり、ルールが十分に頻繁であり、正しい回答を示す必要があります.
Q: HtTのルールライブラリを形成するために、ルールはどのように収集されるのですか?
A: HtTはLLMに与えられた訓練セットの質問と答えのペアに対してルールを生成し、検証するよう求めることでルールを収集する.その後、ルールは出現回数と正解との関連頻度に基づいてフィルタリングされ、推論段階のルールライブラリが形成される.
Q: 学習されたルールライブラリが推論段階でどのように採用されるのか、説明できますか?
A: 学習されたルールライブラリは、推論ステージでどのように使用されるかについて説明します.ルールライブラリは、学習モデルの予測から抽出されます.推論ステージでは、ルールライブラリをプロンプトに追加し、LLMにルールを取得して推論を行うように要求します.この方法により、LLMは明示的なルールを使用して推論を行うことができます.しかし、提供されるルールの数が多いため、強力なLLM(例:GPT4)でも正しいルールを正確に取得するのは困難です.そのため、XMLタグ付けトリックを開発し、コンテキスト内の検索能力を強化しています.
Q: HtTを評価する実験では、どのような推論課題が用いられたのですか?
A: 実験では、数値推論と関係推論の問題が使用されました.
Q: 精度の向上という点では、実験の結果はどうでしたか?
A: HtTはGPT4のCoTを平均精度で21.0%という大きな差をつけて向上させた.GPT3.5での性能向上はそれほど顕著ではない.
Q: この文章で言及されているラーニング・ルールの移籍可能性について詳しく教えてください.
A: 学習されたルールは、テキスト版のCLUTRRに直接転送することができます.これにより、以前の推論手法と比べて実用的な利点が得られます.
Q: HtTフレームワークの限界や潜在的な課題はありますか?
A: HtTの制約の一つは、ベースモデルが十分な知識と検索能力を持っている必要があることです.GPT3.5の場合、非10進数系の知識が不足しているため、HtTの利益は非常に限定的です.GPT4によって誘導されたルールライブラリを使用しても、GPT3.5は正しいルールを取得する際に問題があります.特に、基数11や基数9などの非現実的な設定では、問題が発生する可能性があります.このような問題は、検索データセットでの微調整によって解決できる可能性があります.もう一つの制約は、ルールの数がLLMのコンテキスト長に制限されることです.LLMの入力コンテキストにルールライブラリが収まらない場合、帰納的推論のスケーリングアップは未解決の課題です.
Meta-CoT: Generalizable Chain-of-Thought Prompting in Mixed-task Scenarios with Large Language Models
著者:Anni Zou, Zhuosheng Zhang, Hai Zhao, Xiangru Tang
発行日:2023年10月10日
最終更新日:2023年10月11日
URL:http://arxiv.org/pdf/2310.06692v2
カテゴリ:Computation and Language, Artificial Intelligence
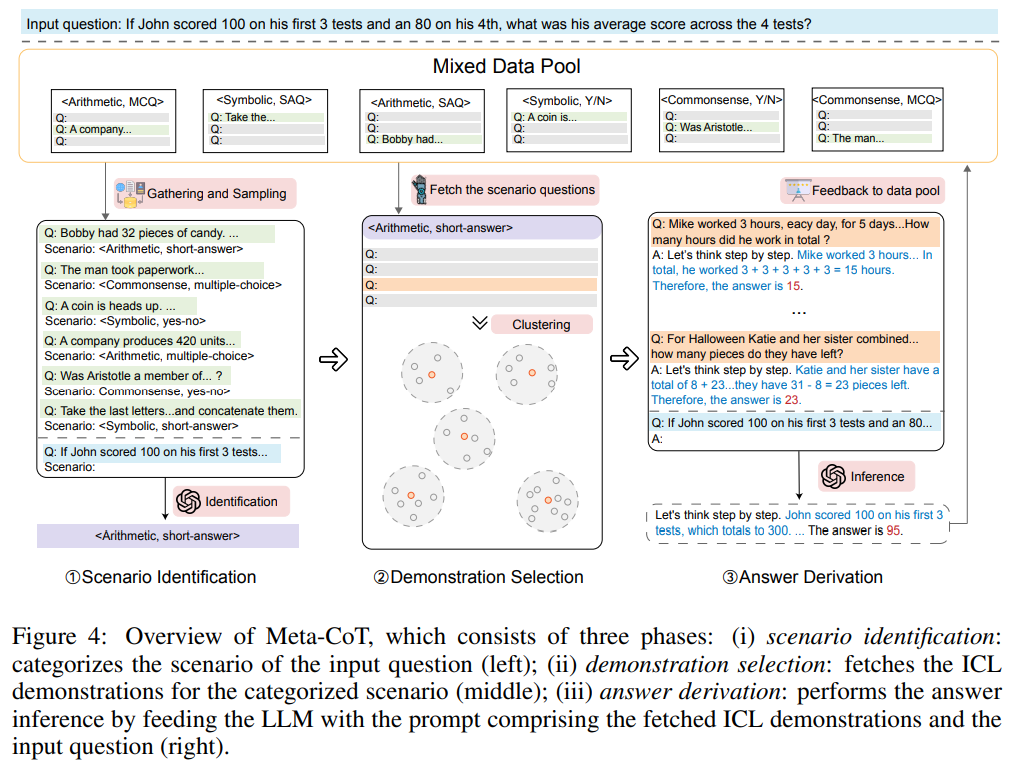
概要:
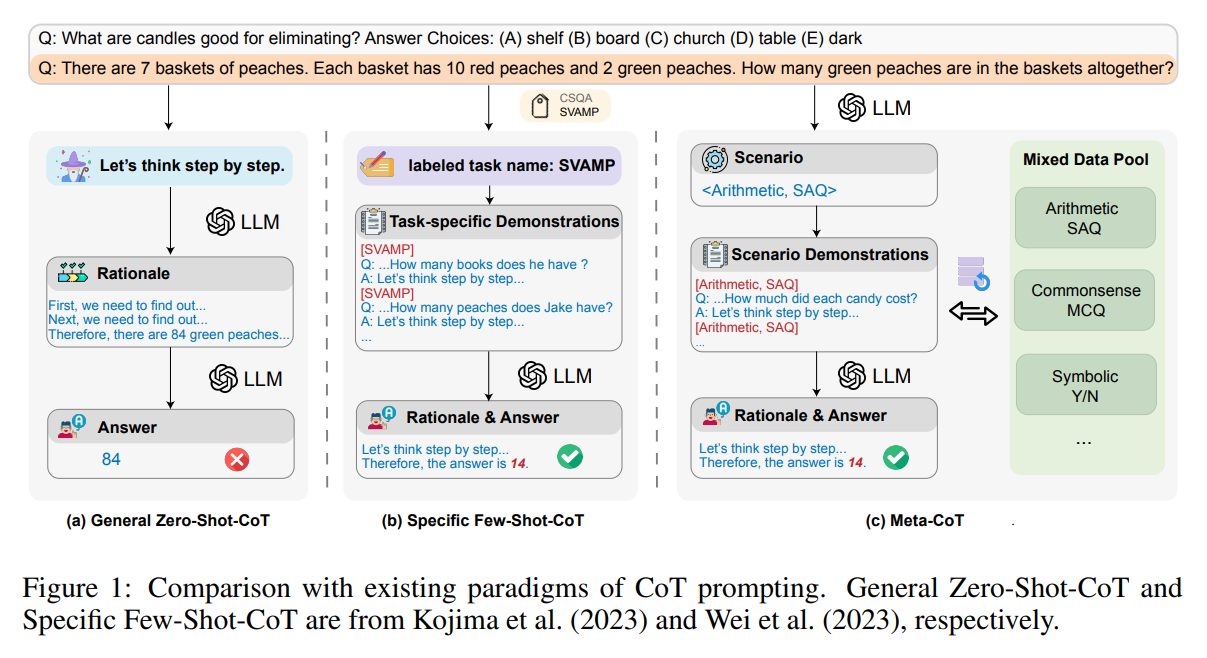
大規模言語モデル(LLM)は、連鎖思考(CoT)プロンプティングを利用して、驚くべきな推論能力を明らかにしています.CoTプロンプティングは、回答を導くための根拠となる中間の推論チェーンを生成することで、その能力を発揮します.しかし、現在のCoTの手法は、単に「ステップバイステップで考えてみましょう」といった一般的なプロンプトを使用するか、あるいは手作業で作成されたタスク固有のデモンストレーションに大いに依存して好ましいパフォーマンスを達成しようとするため、パフォーマンスと汎化の間に避けられないギャップを生じさせています.このギャップを埋めるために、我々はMeta-CoTという、入力質問のタイプが不明な混合タスクシナリオでの汎用的なCoTプロンプティング手法を提案しています.Meta-CoTは、まず入力質問に基づいてシナリオを分類し、その後、対応するデータプールからさまざまなデモンストレーションを自動的に構築します.Meta-CoTは、10の公開ベンチマーク推論タスクで驚くべきパフォーマンスを発揮し、優れた汎化能力を持っています.特に、Meta-CoTはSVAMP(93.7%)で最先端の結果を達成しており、追加のプログラム支援手法なしでそれを実現しています.さらに、5つの分布外データセットでの実験により、Meta-CoTの安定性と汎用性が確認されています.
Q&A:
Q: 大規模言語モデル(LLM)が示す推論能力とは?
A: 大規模言語モデル(LLM)によって明らかにされた推論能力は、CoT技術の一般化を大幅に広げ、ゼロショットの推論者としてのLLMの能力を解放しました.
Q: 現在、思考連鎖(CoT)プロンプトにはどのような方法が使われているのか?
A: 現在のCoTプロンプティングの方法は、一般的なプロンプト(例:ステップバイステップで考えましょう)を単純に使用するか、タスク固有の手作業のデモンストレーションに重点を置いている.しかし、これらの方法はパフォーマンスと一般化の間に避けられないギャップを生じさせている.
Q: 現在のCoTメソッドは、パフォーマンスと汎化のギャップをどのように埋めているのだろうか?
A: 現在のCoTメソッドは、パフォーマンスと一般化のギャップを埋めるために、以下の方法を使用しています.まず、Meta-CoTは、入力質問のタイプに基づいてシナリオを分類し、対応するデータプールからさまざまなデモンストレーションを自動的に構築します.これにより、パフォーマンスの向上と同期して一般性を実現します.また、Meta-CoTは、未知のタイプの入力質問を自動的かつ労働フリーのパターンで適応することができる一方、一般的なCoT技術はパフォーマンスの低下を目撃します.したがって、Meta-CoTは、LLMsのパフォーマンスと一般化の相互シナジーに光を当てることができます.
Q: 汎化可能なCoTプロンプトのための提案手法「Meta-CoT」とは?
A: Meta-CoTは、入力質問のシナリオを分類し、それに基づいて対応するデータプールから多様なデモンストレーションを自動的に構築することで、一般化可能なCoTプロンプティング手法です.
Q: Meta-CoTは、入力された質問に基づき、どのようにシナリオを分類するのか?
A: Meta-CoTは、シナリオ識別を行うことで、入力された質問に基づいてシナリオを分類する.このフェーズでは、入力された質問のシナリオを分類することを目的とする.入力質問であるqinを使用し、その特徴を分析することで、その質問が属するシナリオを決定する.目標は、パフォーマンスと汎化のギャップを埋めることである.Meta-CoTは、入力質問に基づいてシナリオを自動的に分類し、対応するデータプールから多様なデモを自動パターンで構築する、汎化可能なCoTプロンプト手法を提案する.
Q: Meta-CoTはどのように対応するデータプールから多様なデモンストレーションを構築するのか?
A: メタ-CoTは、混合データプールから対応するデモンストレーションを収集し、それらを入力データ全体の一般的な推論プロンプトとして活用します.
Q: Meta-CoTはどのようなベンチマークの推論タスクで高い性能を発揮するのか?
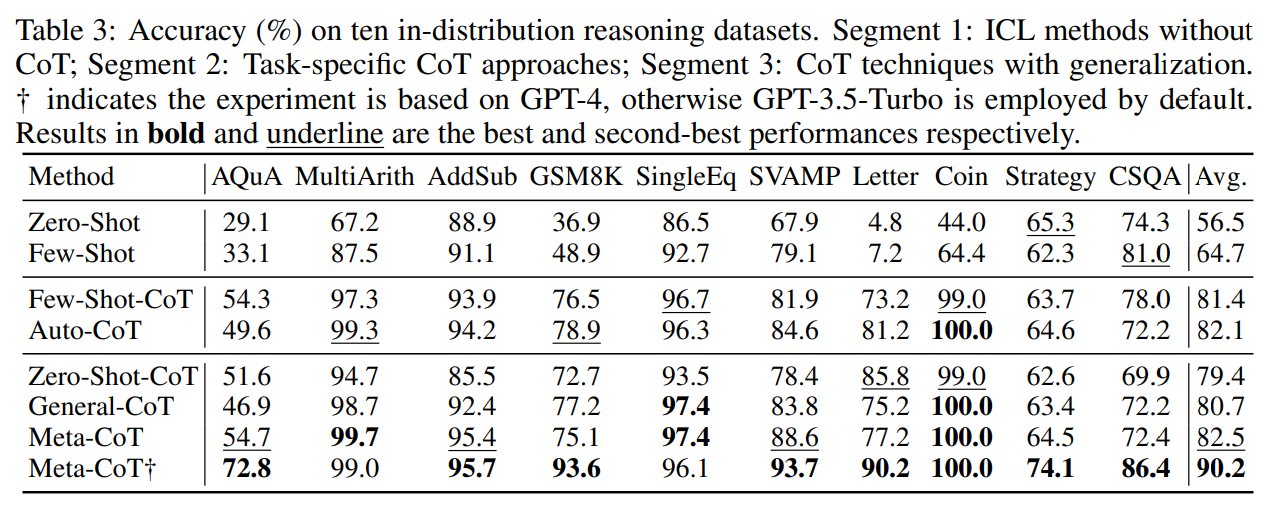
A: Meta-CoTは、算術的推論、常識的推論、記号的推論を含む10種類の分布内推論タスクで良好な結果を示した.
Q: 汎化能力という点で、Meta-CoTは他の手法と比べてどうなのか?
A: Meta-CoTは他の方法と比較して、汎化能力において優れています.一般的なCoT技術は性能の低下を示す一方で、Meta-CoTは性能を持続的に向上させることができます.
Q: SVAMPタスクでMeta-CoTが達成した最先端の結果は?
A: Meta-CoTは、SV AMPタスクで93.7%という最先端の結果を達成した.
Q: Meta-CoTは分布外のデータセットでどのような性能を発揮するか?
A: Meta-CoTは分布外のデータセットで良好な性能を発揮し、良好な安定性を維持しながら適切な性能を達成した.この結果は、入力データが特定のタイプで定義されていない現実的な状況に対するMeta-CoTの適用性を証明するものである.さらに、<常識的な、イエスかノーかの質問>シナリオの実証でも同等の結果が得られたが、これはおそらく、LLMの一般性を助ける常識的知識の広い範囲によるものであろう.
A Survey of Large Language Models for Healthcare: from Data, Technology, and Applications to Accountability and Ethics
著者:Kai He, Rui Mao, Qika Lin, Yucheng Ruan, Xiang Lan, Mengling Feng, Erik Cambria
発行日:2023年10月09日
最終更新日:2023年10月09日
URL:http://arxiv.org/pdf/2310.05694v1
カテゴリ:Computation and Language
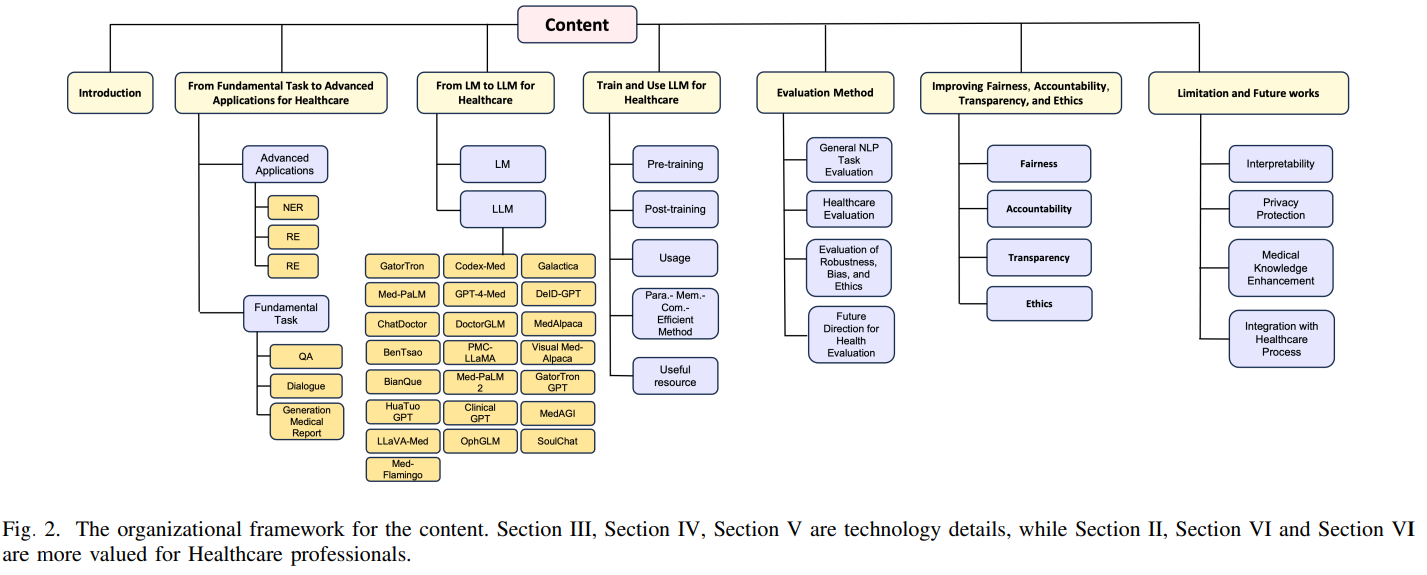
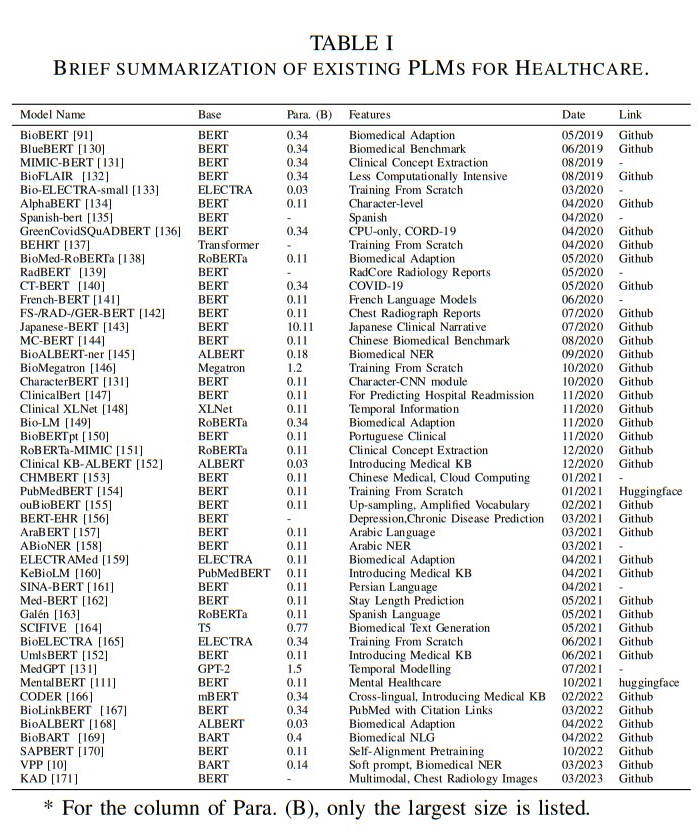
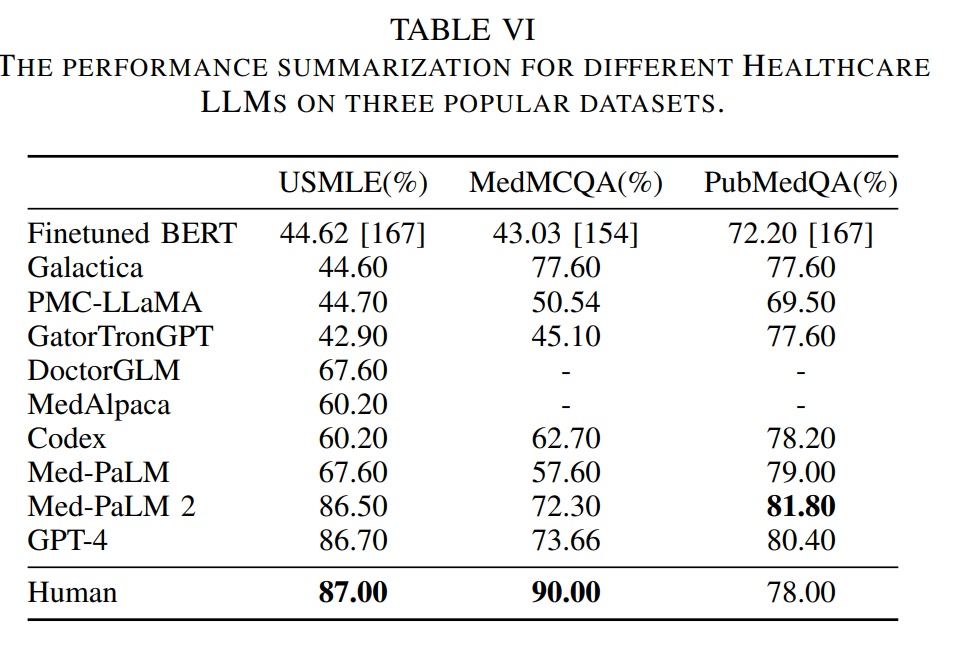
概要:
大規模言語モデル(LLM)の医療領域での利用は、専門的な知識を持ったフリーテキストのクエリに効果的に応答する能力により、興奮と懸念を引き起こしています.この調査では、現在開発されているLLMの能力を概説し、従来の事前学習済み言語モデル(PLM)からLLMへの開発ロードマップの概要を提供することを目的としています.具体的には、まず、LLMがさまざまな医療アプリケーションの効率と効果を向上させる潜在能力を探求し、強みと制約を強調します.次に、以前のPLMと最新のLLM、およびさまざまなLLM同士を比較します.その後、関連する医療トレーニングデータ、トレーニング方法、最適化戦略、および使用法をまとめます.さらに、コンピュータ科学の観点からの包括的な調査に加えて、医療の懸念についての議論を行い、アクセス可能なデータセット、最新の手法、コードの実装、評価基準などのオープンソースリソースのコレクションをGithubで提供して、コンピュータ科学コミュニティをサポートしています.要約すると、PLMからLLMへの重要なパラダイムシフトが進行中であり、これには差別的なAIアプローチから生成的なAIアプローチへの移行、およびモデル中心の方法論からデータ中心の方法論への移行が含まれます.
Q&A:
Q: 現在開発されているヘルスケアのための大規模言語モデル(LLM)の能力はどのようなものでしょうか?
A: 現在開発されている大規模言語モデル(LLM)の医療への能力は、自由なテキストクエリに対して特定の専門知識を持って効果的に応答する能力により、興奮と懸念を引き起こしています.この調査では、医療分野で開発されたLLMの能力を概説し、その開発プロセスを明らかにすることを目的としています.具体的には、まず、LLMがさまざまな医療アプリケーションの効率と効果を向上させる潜在能力を探求し、その強みと制限を強調します.次に、以前のPLMと最新のLLM、およびさまざまなLLM同士を比較します.さらに、関連する医療トレーニングデータ、トレーニング方法、最適化戦略、および使用法をまとめます.最後に、LLMを医療設定で展開する際に関連する独自の懸念事項、特に公平性、説明責任、透明性、倫理について調査します.この調査は、コンピュータサイエンスと医療専門分野の両方の視点から包括的な調査を提供します.医療に関する懸念に加えて、私たちはGithub1でアクセス可能なデータセット、最新の方法論、コード実装、評価ベンチマークなどのオープンソースリソースのコレクションを編纂することで、コンピュータサイエンスコミュニティを支援しています.要約すると、PLMからLLMへの重要なパラダイムシフトが進行中であり、これには識別的なAIアプローチから生成的なAIアプローチへの移行、およびモデル中心の方法論からデータ中心の方法論への移行が含まれます.
Q: LLMは様々なヘルスケア・アプリケーションの効率性と有効性をどのように高めるのか?
A: LLMは、特定の臨床要件に合致したLLMを的確に選択するための貴重なリソースを提供することにより、様々なヘルスケアアプリケーションの効率性と有効性を高める.LLMは、詳細な技術の要約、様々な医療応用、公平性、説明責任、透明性、倫理に関する議論を提供する.LLMは、データ分析、パターン認識、意思決定の能力を活用することで、医療における臨床、教育、研究業務の効率と効果を向上させることができる.LLMは、医療現場において急速に進化するLLMの状況を理解し、医療従事者が十分な情報に基づいた意思決定を行い、患者ケアを改善できるようサポートする可能性を秘めている.LLMはまた、大量の患者データを分析し、オーダーメイドの治療法を提案することで、個別化医療の発展にも貢献できる.さらに、LLMは複雑なデータセットを分析し、人間には容易に検出できないパターンや相関関係を特定することで、医学研究を支援することができる.全体として、LLMは、データ分析、パターン認識、意思決定の能力を活用することで、さまざまなヘルスケア・アプリケーションの効率と有効性を高める可能性を秘めている.
Q: 以前の事前学習済み言語モデル(PLM)は、最新のLLMと比べてどうなのか?
A: 以前の事前学習済み言語モデル(PLMs)と最新のLLMsを比較すると、LLMsはより優れた性能を示し、さまざまなNLP関連のタスクや科学的な知識においても優れたパフォーマンスを発揮しています.また、LLMsは医療領域に特化したモデルも存在し、医療試験の質問において「専門家」レベルの正確さを達成しています.PLMsのサイズも過去5年間で驚異的に増加しており、これらのモデルを単純にスケーリングするだけでも新たな振る舞いが生じ、質的に異なる能力を可能にしています.
Q: 異なるLLMは互いにどのように比較されますか?
A: 与えられた文脈では、異なるLLM同士の比較についての具体的な情報は提供されていません.
Q: ヘルスケアのLLMに使用されるトレーニングデータとは?
A: 医療LLMのトレーニングデータは、EHR(電子健康記録)、科学文献、ウェブデータ、公共の知識ベースなどが一般的なデータソースとして使用されます.データの構造を考慮すると、QA(質問応答)データと対話データが最もよく使用されます.
Q: ヘルスケアにおけるLLMのトレーニング方法と最適化戦略とは?
A: 医療のLLMのトレーニング方法と最適化戦略には、事前トレーニング方法と最適化技術が含まれます.事前トレーニング方法では、一般的なLLMと同様に、大規模なテキストデータセットを使用してモデルをトレーニングします.一般的なLLMとは異なり、医療のLLMでは、医療に関連するデータセットを使用してトレーニングを行います.最適化技術としては、LoRA、ZeRO、およびモデルの量子化が一般的に使用されます.これらの技術は、モデルのサイズを削減し、トレーニングと推論の効率を向上させるために使用されます.
Q: 医療現場でLLMを導入する際に、特に公平性、説明責任、透明性、倫理性に関して、どのような懸念がありますか?
A: 医療設定でLLMsを展開する際には、公平性、説明責任、透明性、倫理に関連する独自の懸念が存在します.この調査では、コンピュータ科学と医療の両観点から包括的な調査が提供されており、公平性、説明責任、透明性、倫理に関する問題が詳細に検討されています.特に、医療設定でのLLMsの展開における公平性、説明責任、透明性、倫理に関する懸念が探求されています.LLMsの誤用のインスタンスからも、これらの評価研究からも、LLMsは医療分野でさまざまな応用の可能性を秘めていることがわかっていますが、この領域での利用を向上させるためにはいくつかの重要な問題が解決される必要があります.
Q: ヘルスケアのLLMに関連して、コンピュータ・サイエンスのコミュニティが利用できるオープンソースのリソースにはどのようなものがありますか?
A: 医療LLMのトレーニングや微調整に適した適切なデータセットを容易に特定するために、私たちは、さまざまなデータセットを収集し、整理しています.text/visual-instruction-tuning-dataset14、およびAwesome-instruction-tuning15が含まれています.
Q: ヘルスケアにおけるPLMからLLMへのシフトは、AIのアプローチや方法論においてどのようなパラダイムシフトを意味するのでしょうか?
A: PLMs to LLMsの移行は、AIのアプローチと方法論の観点から見て、パラダイムシフトを表しています.これは、識別的なAIアプローチから生成的なAIアプローチへの移行、およびモデル中心の方法論からデータ中心の方法論への移行を含んでいます.
FireAct: Toward Language Agent Fine-tuning
著者:Baian Chen, Chang Shu, Ehsan Shareghi, Nigel Collier, Karthik Narasimhan, Shunyu Yao
発行日:2023年10月09日
最終更新日:2023年10月09日
URL:http://arxiv.org/pdf/2310.05915v1
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning

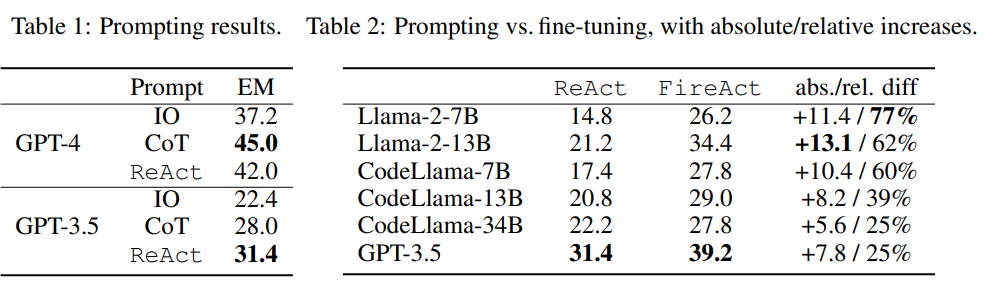
概要:
最近の取り組みでは、外部ツールや環境を言語モデル(LM)に組み込むことで、推論や行動が可能な言語エージェントの開発が進んできた.しかし、これらのエージェントのほとんどは、既製のLMを用いたフューショットのプロンプティング技術に依存している.本論文では、LMをファインチューニングして言語エージェントを得るという見落とされている方向性について調査し、主張する.この研究は、エージェントのためのLMのファインチューニングの包括的な利点を確立し、初期の成果を提供している.さらに、実験デザイン、洞察、およびオープンな問題についても示しており、LMのファインチューニングによる言語エージェントのさらなる改善に向けた展望を提供している.
Q&A:
Q: 論文の主眼は何か?
A: この論文の主な焦点は、言語エージェントの微調整に関するものであり、QAという単一のタスクとGoogle検索という単一のツールに制約されています.将来の研究では、より多くのタスクやグラウンディングのセットアップ(例:より多くのAPIツール、ウェブ、物理世界)にFireActによって提起された研究問題を適用することができます.また、ReAct、CoT、Reflexionという3つの手法に焦点を当てました.
Q: 最近の取り組みでは、言語モデルを外部のツールや環境でどのように補強しているのだろうか?
A: 最近の取り組みでは、言語モデル(LMs)を外部ツールや環境と組み合わせて拡張しています.これにより、言語エージェントが推論や行動ができるようになりました.
Q: 現在、多くの語学エージェントが採用しているアプローチとは?
A: ほとんどの言語エージェントは、利便性と柔軟性のために既製の言語モデルをプロンプトしています.
Q: 言語モデルの微調整の方向性とは?
A: 本論文では、言語モデルのファインチューニングを行うことで言語エージェントを得るという方向性が提案されています.
Q: 言語モデルの微調整を調査するために、どのようなセットアップが使われたのですか?
A: 本研究では、Googleの検索APIを使用した質問応答(QA)のセットアップを使用して、さまざまなベースの言語モデル、プロンプティング方法、ファインチューニングデータ、およびQAタスクを探索しました.
Q: 異なるベースLM、プロンプトの方法、微調整データ、QAタスクは、この研究でどのように検討されたのか?
A: 研究では、異なるベースのLM、プロンプティング方法、ファインチューニングデータ、QAタスクが探索されました.具体的には、GPT-4によって生成された500のエージェントの軌跡を使用してLlama2-7Bをファインチューニングすることで、HotpotQAのパフォーマンスが77%向上しました.さらに、FireActという新しいアプローチを提案し、複数のタスクとプロンプティング方法からの軌跡を使用してLMをファインチューニングすることで、さらなる改善が見られました.
Q: GPT-4で生成した500エージェントの軌道をLlama2-7Bにファインチューニングした結果、性能はどの程度向上したのでしょうか?
A: GPT-4によって生成された500のエージェントの軌跡でLlama2-7Bをファインチューニングした結果、HotpotQAのパフォーマンスが77%向上しました.
Q: FireActとは何か、そしてLMの微調整にどのように貢献するのか?
A: FireActは、複数のタスクやプロンプティング方法から生成されたエージェントの軌跡を使用して、LMを微調整するための新しい方法です.FireActは、オープンドメインの質問応答タスクとGoogleの検索APIへのアクセス、およびGPT-4(OpenAI、2023b)を使用して、微調整データの生成を行います.FireActは、さまざまなベースのLM(OpenAI、2023a; Touvron et al.、2023a; Roziere et al.、2023)、プロンプティング方法(Yao et al.、2022b; Wei et al.、2022b; Shinn et al.、2023)、微調整データ、およびタスク(Yang et al.、2018; Press et al.、2022; Hendrycks et al.、2021; Geva et al.、2021)を徹底的に調査し、エージェントの言語微調整のさまざまな利点を示しています.FireActは、エージェントの言語微調整に向けたさまざまな新しい問題を提起する初めの一歩となっています.
Q: より多様なファインチューニング・データを持つことで、エージェントはどのように改善されるのか?
A: より多様なファインチューニングデータを持つことによって、エージェントの性能が向上します.ファインチューニングデータの多様性が増すことで、エージェントはより広範なタスクに対して適応し、新しいタスクに対しても強力な汎化能力を持つようになります.また、ノイズや敵対的な環境に対してもより堅牢な性能を発揮し、推論時間を短縮することができます.さらに、ファインチューニングは大規模な産業ソリューションにおいても費用効果が高く、効率的な推論を実現することができます.
Q: 代理店にとって、LMを微調整することの総合的なメリットは何だろうか?
A: この研究によれば、LMをエージェントに対してファインチューニングすることには、包括的な利点があります.具体的には、エージェントの性能向上、スケーリング効果、頑健性、汎化性、効率性、コスト削減などが挙げられます.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: 本論文で導入された新しい手法のコード実装のurlはhttps://fireact-agent.github.ioです.
Learning Interactive Real-World Simulators
著者:Mengjiao Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Dale Schuurmans, Pieter Abbeel
発行日:2023年10月09日
最終更新日:2023年10月09日
URL:http://arxiv.org/pdf/2310.06114v1
カテゴリ:Artificial Intelligence
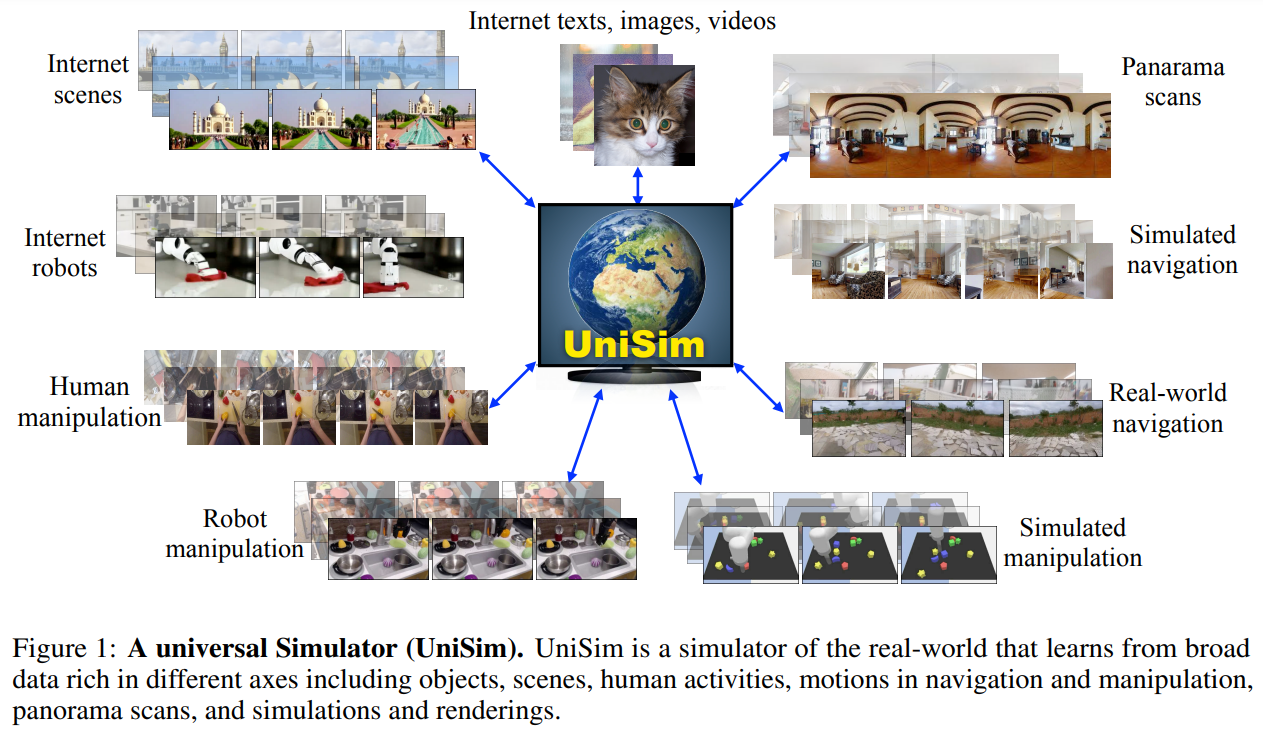
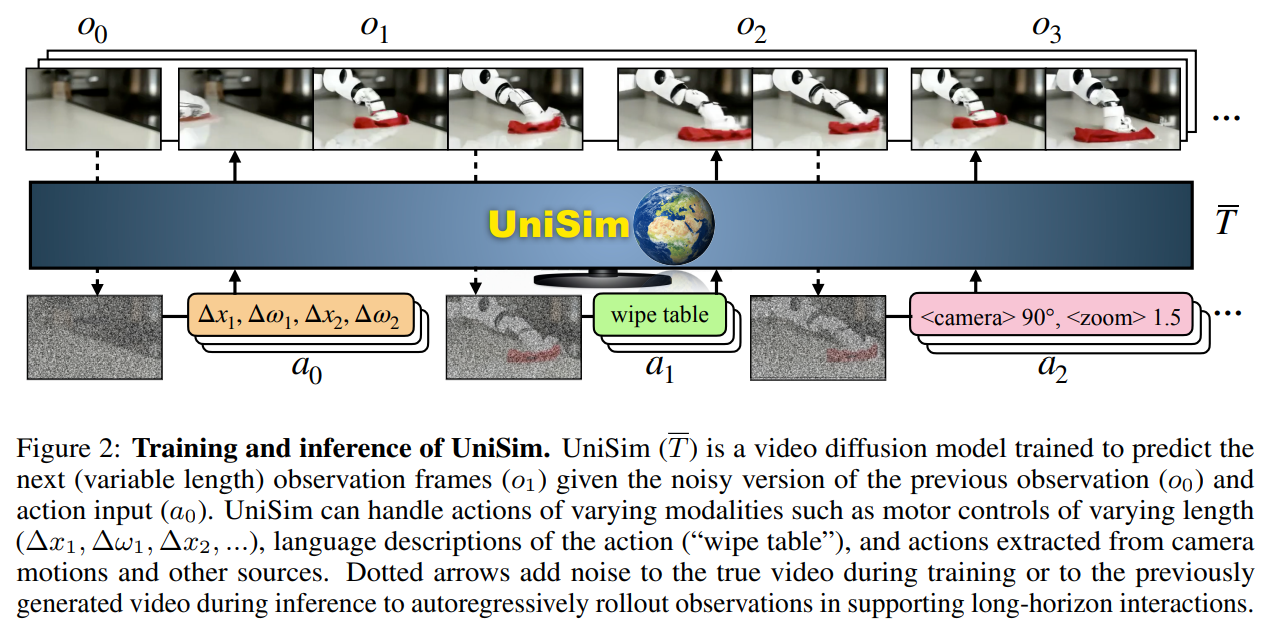
概要:
インターネットデータで訓練された生成モデルは、テキスト、画像、動画コンテンツの作成方法を革新しました.おそらく、生成モデルの次のマイルストーンは、人間、ロボット、その他のインタラクティブなエージェントが行動に対して現実的な体験をシミュレートすることです.現実世界のシミュレータの応用範囲は、ゲームや映画での制御可能なコンテンツの作成から、シミュレーションだけで直接現実世界に展開できる具体的なエージェントのトレーニングまでさまざまです.私たちは、生成モデリングを通じて現実世界の相互作用の普遍的なシミュレータ(UniSim)を学習する可能性を探求しています.まず、現実世界のシミュレータを学習するために利用できる自然なデータセットは、しばしば異なる軸に沿って豊富です(例:画像データの豊富なオブジェクト、ロボティクスデータの密なサンプリングされたアクション、ナビゲーションデータの多様な移動).異なるデータセットを慎重に組み合わせることで、UniSimは「引き出しを開ける」といった高レベルの指示や、人間やエージェントが世界とどのように相互作用するかをシミュレートすることができます.さらに、UniSimを使用して、静的なシーンやオブジェクトから「引き出しを開ける」といった高レベルの指示や「x、y方向に移動する」といった低レベルの制御など、高度な指示や制御を実現することも可能です.このような現実世界のシミュレータには、さまざまな用途があります.例えば、私たちはUniSimを使用して、高レベルのビジョン言語プランナーや低レベルの強化学習ポリシーの両方をトレーニングし、学習した現実世界のシミュレータでのトレーニングの後にゼロショットの現実世界への転送を実現しています.また、UniSimでのシミュレートされた経験によるトレーニングは、ビデオキャプションモデルなどの他のタイプの知能にも恩恵をもたらすことを示しており、さらに広範な応用が可能です.詳細なデモは、https://universal-simulator.github.ioでご覧いただけます.
Q&A:
Q: インターネットデータで訓練された生成モデルの目的は?
A: インターネットデータでトレーニングされた生成モデルの目的は、人間が経験する世界のあらゆる側面をシミュレートすることです.これにより、人間はさまざまなシーンやオブジェクトと「対話」することができ、ロボットは物理的な損傷のリスクを冒さずにシミュレートされた経験から学習することができます.また、大量の「現実世界」のデータをシミュレートして他のタイプの機械知能をトレーニングすることも可能です.
Q: 現実的な経験をシミュレートするために、どのように生成モデルを使うことができるのか?
A: 生成モデルは、人間やロボット、他のインタラクティブなエージェントが行動を起こすことに対して現実的な体験をシミュレートするために使用することができます.これにより、ゲームや映画で制御可能なコンテンツの作成、シミュレーション上で直接展開できる実世界のエージェントのトレーニングなど、さまざまなアプリケーションが可能になります.
Q: 実戦シミュレーターの潜在的な用途とは?
A: リアルワールドシミュレーターの潜在的な応用は、ゲームや映画の制御可能なコンテンツ作成から、シミュレーションだけで直接現実世界に展開できる具現化エージェントのトレーニングまで、幅広いものです.
Q: 普遍的なシミュレーターを作るために、多様なデータセットをどのようにオーケストレーションできるのか?
A: 様々なデータセットを組み合わせることで、ユニバーサルシミュレータを作成することができます.これにより、自然なシーン、オブジェクト、人間の活動、ロボットのアクション、カメラの動きなど、世界のさまざまな側面をシミュレートすることが可能です.
Q: UniSimは人間やエージェントと世界との相互作用をどのようにエミュレートしているのか?
A: UniSimは、人間とロボットのアクションリッチでロングホライズンなインタラクションをシミュレートすることで、人間とエージェントの世界とのインタラクションをエミュレートします.人間とのインタラクションや自律型エージェントのトレーニングにおいて、非常にリアルな体験をシミュレートすることができる.UniSimは、テキストからロボットの制御に至るまで、様々なアクション入力に応じて現実世界の普遍的なシミュレータを学習することでこれを実現します.UniSimは、無制限の環境アクセス、実世界のような観察、柔軟な時間制御頻度などの利点を利用しています.これらの利点は、並列化可能なビデオサーバ、フォトリアリスティックな拡散出力、低レベルのロボット制御と高レベルのテキストアクションにまたがる時間的に拡張されたアクションによって達成される.しかし、他の最新の基礎モデルと同様に、学習には大規模な計算資源を必要とする.この制限にもかかわらず、著者らはUniSimが機械知能を向上させるために実世界のシミュレータを学習し、適用することへの幅広い関心を生み出すことを期待している.
Q: UniSimは高度な視覚言語プランナーのトレーニングに使えるか?
A: はい、UniSimは高レベルのビジョン言語プランナーのトレーニングに使用することができます.
Q: UniSimは低レベルの強化学習ポリシーの訓練に使えるか?
A: はい、UniSimは低レベルの強化学習ポリシーのトレーニングに使用することができます.
Q: UniSimでの疑似体験によるトレーニングは、ビデオキャプションモデルにどのようなメリットをもたらすのか?
A: UniSimのシミュレートされた経験によるトレーニングは、ビデオキャプションモデルに以下の利点をもたらします.まず、UniSimは高レベルの指示(例:「引き出しを開ける」)や低レベルの制御(例:「x、y方向に移動する」)から、静止したシーンやオブジェクトの視覚的な結果をシミュレートすることができます.これにより、ビデオキャプションモデルは、シミュレーションでのトレーニングによって実世界においてゼロショットの転送を実現することができます.さらに、UniSimでのシミュレートされた経験によるトレーニングは、ビデオキャプションモデルのパフォーマンス向上にもつながります.具体的には、UniSimで生成されたデータのみを使用してビデオキャプションタスクを実行するビジョン言語モデルのCIDErスコアが向上しました.
Q: UniSimのビデオデモはどこで見られますか?
A: ビデオデモはuniversal-simulator.github.ioで見つけることができます.
Q: UniSimはどのようにしてトレーニング後のゼロショット実戦移籍を可能にしているのか?
A: UniSimは、モデルベースの強化学習を活用し、現実世界とほぼ視覚的に区別できないシミュレータを使用することで、トレーニング後のゼロショット実世界移行を可能にします.高レベルの視覚言語プランナーと低レベルの制御ポリシーは、純粋にシミュレーションで訓練され、実際のロボット設定に一般化することができます.これは、異なる軸で豊富な多様なデータセットを組み合わせ、統一されたビデオ生成フレームワークを使用することで達成される.UniSimは実世界をシミュレートするため、UniSimで訓練されたポリシーは、追加の訓練や微調整を必要とせずに、実世界でロングホライズンタスクを直接実行することができる.
Walking Down the Memory Maze: Beyond Context Limit through Interactive Reading
著者:Howard Chen, Ramakanth Pasunuru, Jason Weston, Asli Celikyilmaz
発行日:2023年10月08日
最終更新日:2023年10月08日
URL:http://arxiv.org/pdf/2310.05029v1
カテゴリ:Computation and Language
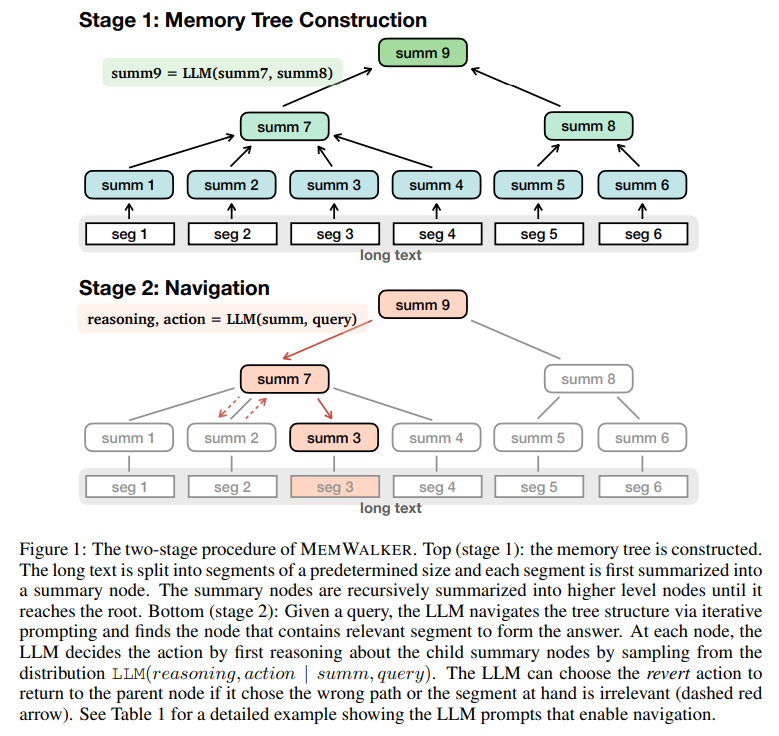
概要:
大規模言語モデル(LLM)は、すべてのトークンを一度に処理および比較する自己注意メカニズムの効果により、大きな進歩を遂げてきました.しかし、このメカニズムには根本的な問題があります.事前に決められたコンテキストウィンドウは限られているためです.位置埋め込みを外挿したり、再帰を使用したり、長いシーケンスの重要な部分を選択的に取得するなどの方法を用いてコンテキストウィンドウを拡張しようとしても、長いテキストの理解は依然として課題です.私たちは代わりに、LLMを対話型エージェントとして扱い、反復的なプロンプティングによってテキストを読む方法を決定させることを提案します.私たちはMemWalkerという手法を導入し、まず長いコンテキストをサマリーノードのツリーに変換します.クエリを受け取ると、モデルはこのツリーをナビゲートして関連情報を探し、十分な情報を収集したら応答します.長いテキストの質問応答タスクでは、私たちの手法は長いコンテキストウィンドウ、再帰、および検索を使用するベースライン手法を上回ります.私たちは、効果的な読み取りに加えて、MemWalkerが説明可能性を向上させることを示しています.さらに、私たちは、MemWalkerがテキストを対話的に読む際に推論のステップを強調し、クエリに関連するテキストセグメントを特定することで、説明可能性を向上させることを示しています.
Q&A:
Q: 大規模言語モデルにおける自己注視メカニズムの根本的な問題とは?
A: 大規模言語モデルにおける自己注意機構の根本的な問題は、長いシーケンスに対してメモリ使用量が増加し、その結果、コンテキストウィンドウのサイズが制限されることです.
Q: 大規模な言語モデルにおいて、コンテキストウィンドウを拡張するために試みられてきた方法にはどのようなものがあるか?
A: 大規模言語モデルのコンテキストウィンドウを拡張するために試みられたいくつかの方法には、位置埋め込みの外挿、再帰を使用すること、または長いシーケンスの重要な部分を選択的に取得することなどがあります.
Q: MemWalkerメソッドは、大規模な言語モデルを対話型エージェントとしてどのように扱うのか?
A: M EMWALKERは、LLMを対話型エージェントとして扱い、反復的なプロンプティングを通じてテキストの読み方を決定します.具体的には、M EMWALKERは長いコンテキストを要約ノードのツリーに変換し、クエリを受け取るとこのツリーをナビゲートして関連情報を収集し、十分な情報を収集した後に応答します.
Q: MemWalkerは、要約ノードのツリーをどのようにナビゲートして関連情報を検索するのですか?
A: MEMWALKERは、反復的なプロンプトプロセスを使用することで、サマリーノードのツリーをナビゲートし、関連する情報を検索する.クエリが与えられると、MEMWALKERのLLM(言語モデル)はツリーのルートノードから開始し、現在のサマリーノードとクエリでLLMに繰り返しプロンプトを出す.次にLLMは、分布LLM(reasoning, action | sum, query)からサンプリングすることで、子サマリーノードについて推論する.この推論に基づき、LLMは取るべきアクションを決定し、次の子サマリーノードに進むか、親ノードに戻るかを決定する.この反復プロセスは、LLM が答えを形成する関連セグメントを含むノードを見つけるまで続く.
Q: MemWalkerは、クエリに応答するのに十分な情報を収集したとき、どのように判断するのですか?
A: MEMWALKERは、構築されたメモリツリーをナビゲートすることで、クエリに応答するのに十分な情報がいつ集まったかを判断する.反復的なLLMプロンプトを使用してツリーを走査し、テキストの様々な部分を検査して、クエリに答えるのに関連するパスとセグメントを特定する.LLMはツリーのルートノードからナビゲーションを開始し、適切な回答を作成するのに十分な情報を収集するまで続ける.これにより、MEMWALKERはコンテキストの制限を超え、テキストを効率的に処理し、追加的な微調整なしに長いテキストの重要なセグメントを特定することができる.
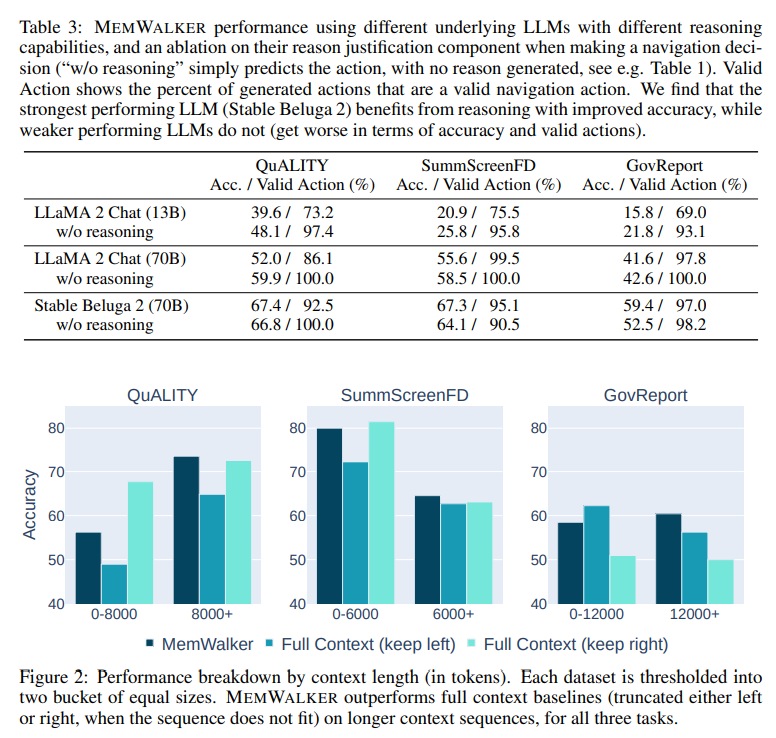
Q: メムウォーカーのパフォーマンスは、長いコンテキストウィンドウ、再帰、および長いテキストの質問応答タスクでの検索を使用するベースラインアプローチと比較してどのようになりますか?
A: M EMWALKERは、長文質問応答タスクにおいて、長いコンテキストウィンドウ、再帰、検索を使用するベースラインアプローチを凌駕する.
Q: MemWalkerは長文質問応答タスクにおいてどのように説明可能性を高めるのか?
A: M EMWALKERは、対話的にテキストを読みながら推論ステップをハイライトし、クエリに関連するテキストセグメントをピンポイントで特定することで、長文質問応答タスクにおける説明可能性を向上させる.これは、モデルがロングコンテクストを表すツリーデータ構造をナビゲートし、適切な回答を作成するための情報を収集する反復プロンプトによって達成される.推論のステップと関連するテキスト・セグメントを視覚的に表示することで、M EMWALKERは、どのようにして答えにたどり着くのか、明確で透明性のある説明を提供する.
Q: MemWalkerは、テキストをインタラクティブに読みながら、推論のステップをどのようにハイライトするのですか?
A: M EMWALKERモデルは、テキストを対話的に読む際に推論のステップを強調することで、説明可能性を向上させます.モデルは、長い文脈を要約ノードのツリーに変換し、クエリに関連する情報を探すためにこのツリーをナビゲートします.モデルがテキストを読む際に、推論のステップをハイライトすることで、どのように情報を収集しているかを明示的に示します.
Q: MemWalkerは、クエリに関連するテキストセグメントをどのように特定するのか?
A: M EMWALKERは、ロング・コンテキストから構築したツリー・データ構造を走査することで、クエリに関連するテキスト・セグメントをピンポイントで特定する.ツリーのルートノードから開始し、情報を収集し、適切な応答を作成するために、構造内を反復的にナビゲートする.このナビゲーション・プロセスは、反復的なLLMプロンプトによって達成される.LLMプロンプトでは、モデルがテキストのさまざまな部分を検査し、クエリへの回答に関連するパスとセグメントを特定する.そうすることで、M EMWALKERはコンテキストの制限を超え、テキストを効率的に処理することができ、追加的な微調整なしに長いテキストの重要なセグメントを特定することができる.
Q: MemWalkerが長文理解や問題解答の向上に有効であることを示す具体的な例やケーススタディがあれば教えてください.
A: MemWalkerは、ロングコンテクストをツリーデータ構造に分解し、この構造をナビゲートして適切な応答を作成するための関連情報を収集することで、ロングテキストの理解と質問応答を改善する.長いコンテキストのウィンドウ、再帰、検索を使用するベースラインアプローチを凌駕する.MemWalkerはまた、対話的にテキストを読みながら推論ステップをハイライトし、クエリに関連するテキストセグメントをピンポイントで特定することで、説明可能性を高める.しかし、MemWalkerの有効性を示す具体的な例やケーススタディは提供されていない.
RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation
著者:Fangyuan Xu, Weijia Shi, Eunsol Choi
発行日:2023年10月06日
最終更新日:2023年10月06日
URL:http://arxiv.org/pdf/2310.04408v1
カテゴリ:Computation and Language



概要:
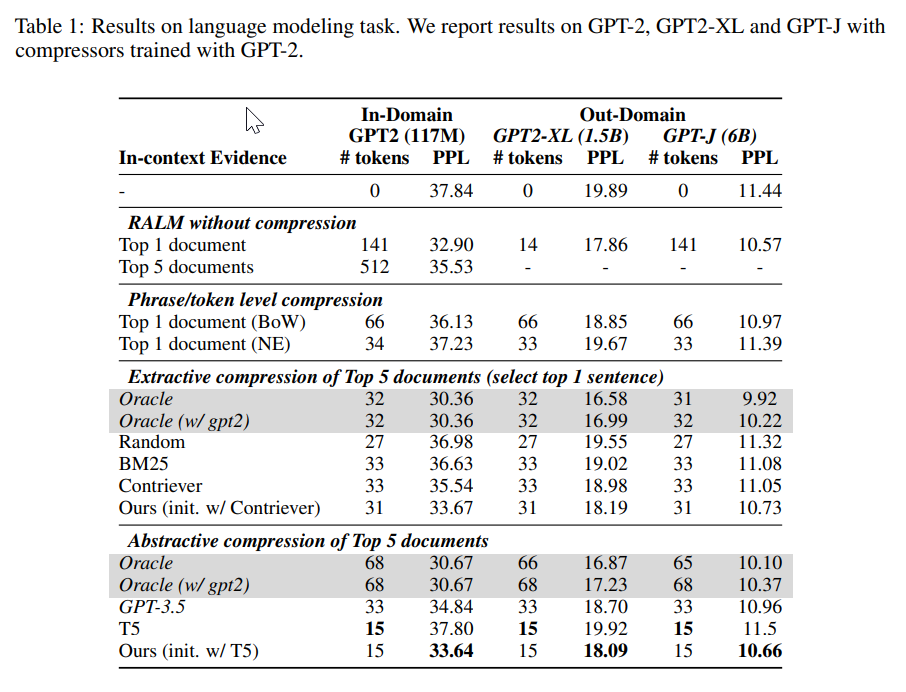
私たちは、言語モデリングタスクとオープンドメインの質問応答タスクでアプローチを評価します.私たちの圧縮器は、最小限のパフォーマンス低下で、6%という非常に低い圧縮率を実現し、既存の要約モデルを大幅に上回ります.また、私たちは、言語モデリングタスクにおいて、他のLMにも転移可能な圧縮器を訓練し、検索された文書に忠実な要約を提供することを示しています.
Q&A:
Q: 提案されているアプローチの主な目的は何ですか?
A: 提案されたアプローチの主な目的は、LMのために有用な簡潔なテキストを生成することです.
Q: ドキュメントの検索とプリペンドは、言語モデルのパフォーマンスをどのように向上させるのか?
A: 文書の検索と先頭に追加することにより、言語モデルの性能が向上します.先頭に追加された文書は、モデルによって参照され、追加の情報を提供します.これにより、モデルはより多くの文脈を持つことができ、より正確な予測を行うことができます.
Q: 検索された文書をテキスト要約に圧縮する目的は?
A: 検索された文書をテキストの要約に圧縮する目的は、計算コストを削減しながら正しい回答を生成するためです.
Q: 検索された文書を圧縮することで、どのように計算コストが削減されるのか?
A: 取得した文書を圧縮することにより、計算コストを削減することができます.圧縮された文書は、元の文書よりもトークン数が少なくなるため、エンコードする際の計算コストが低くなります.
Q: 抽出的コンプレッサーと抽象的コンプレッサーのアプローチの違いは?
A: 抽出的な圧縮器は、初期の検索単位(段落)とは異なる入力の粒度(文)を考慮しますが、抽象的な圧縮器はそうではありません.
Q: 最終タスクにおける言語モデルのパフォーマンスを向上させるために、コンプレッサーはどのようにトレーニングされるのか?
A: 圧縮器は、ブラックボックスの言語モデルからのエンドタスクの信号を利用して、有用な要約を生成し、圧縮モデルが選択的な拡張を行うためのトレーニングスキームを設計されています.
Q: コンプレッサーは、検索された文書が無関係であったり、追加情報を提供しない場合、空の文字列を返すことができますか?
A: はい、コンプレッサーは、取得したドキュメントが関連性がないか追加情報を提供しない場合には空の文字列を返すことができます.
Q: ある言語モデル用に訓練されたコンプレッサーは、他の言語モデルに移植できるのか?
A: はい、圧縮器は一つの言語モデルで訓練された場合でも、他の言語モデルに転送することができます.
Ring Attention with Blockwise Transformers for Near-Infinite Context
著者:Hao Liu, Matei Zaharia, Pieter Abbeel
発行日:2023年10月03日
最終更新日:2023年10月12日
URL:http://arxiv.org/pdf/2310.01889v3
カテゴリ:Computation and Language
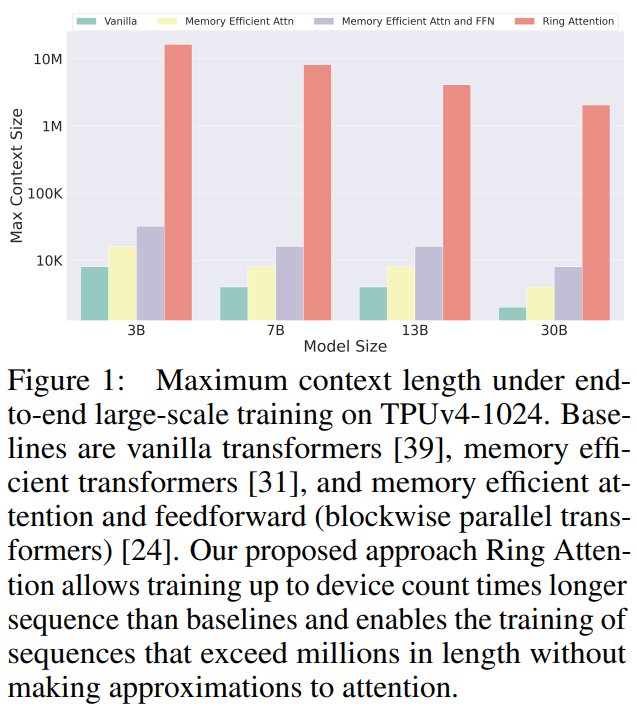
!IqDOhgupwx.jpg

概要:
トランスフォーマーは、多くの最先端のAIモデルにおいて選ばれるアーキテクチャとなり、幅広いAIアプリケーションで優れたパフォーマンスを発揮しています.しかし、トランスフォーマーによって要求されるメモリの需要は、長いシーケンスを処理する能力を制限し、拡張されたシーケンスや長期的な依存関係を持つタスクに課題をもたらしています.私たちは、リングアテンションという独自のアプローチを提案します.リングアテンションは、セルフアテンションのブロックごとの計算を活用し、長いシーケンスを複数のデバイスに分散させると同時に、キーバリューブロックの通信をブロックごとのアテンションの計算と重ならせることで、メモリ効率の向上を図ります.リングアテンションにより、従来のメモリ効率のトランスフォーマーよりもデバイス数倍長いシーケンスのトレーニングと推論が可能となり、個々のデバイスに課せられるメモリ制約を効果的に排除します.言語モデリングタスクにおける詳細な実験は、リングアテンションの効果を示し、大きなシーケンスの入力サイズを許容し、パフォーマンスを向上させることを示しています.
Q&A:
Q: トランスフォーマーが長いシークエンスを扱う上で直面する主な課題は何ですか?
A: Transformersの主な課題は、自己注意機構のメモリコストが入力シーケンスの長さに対して二次的に増加するため、長いシーケンスをスケーリングすることが困難であることです.
Q: リング・アテンションは、トランスフォーマーが課すメモリー要求にどのように対処しているのか?
A: リング・アテンションは、リング内のホスト間でキー・バリュー・ブロックの通信をオーバーラップさせながら、長いシーケンスを複数のデバイスに分散させるために、自己アテンションのブロック単位の計算を活用することによって、トランスフォーマーによって課されるメモリ需要に対処する.このアプローチでは、個々のデバイスによって課されるメモリの制約を排除し、デバイスの数に比例してスケーリングされる長さのシーケンスの学習と推論を可能にし、実質的に無限に近いコンテキストサイズを実現する.入力シーケンスをブロックに分割し、それらを並列処理することで、各デバイスはブロックサイズに比例したメモリしか必要とせず、元の入力シーケンス長に依存しない.これにより、Ring Attentionは、メモリ制約の制限を受けることなく、長いシーケンスや、拡張シーケンスや長期的な依存関係を含むタスクを処理することができます.
Q: リング・アテンションにおける自己アテンションのブロックワイズ計算の概念について説明していただけますか?
A: Ring Attentionは、ブロック単位のセルフアテンションの計算を利用して、長いシーケンスを複数のデバイスに分散させると同時に、キー値ブロックの通信をブロック単位のアテンションの計算と重ならせます.このアプローチは、内部ループのキー値ブロック操作の順序不変性の特性を活用しています.つまり、クエリブロックとキー値ブロックのグループ間のセルフアテンションは、任意の順序で計算できます.各ブロックの統計が正しく組み合わされて再スケーリングされる限り、計算の順序は重要ではありません.Ring Attentionでは、すべてのホストがリング構造を形成していると考えられます.各ホストは、注意計算に使用されるキー値ブロックを次のホストに同時に送信し、前のホストから必要なキー値ブロックを受信することで効率的に調整します.これにより、効率的な計算と通信が可能になり、個々のデバイスによって課されるメモリ制約を軽減します.
Q: リング・アテンションは、長いシーケンスを複数のデバイスにどのように分配するのですか?
A: リング・アテンションは、自己アテンションのブロック単位の計算を利用して、長いシーケンスを複数のデバイスに分散させる.
Q: キー・バリュー・ブロックの通信とブロックワイズ・アテンションの計算をオーバーラップさせる利点は?
A: キー値ブロックの通信とブロックごとの注意の計算を重ね合わせることによる利点は、通信のオーバーヘッドを削減し、計算時間を節約することです.これにより、システムは必要なキー値ブロックを待つ必要がなくなり、計算と通信を同時に行うことができます.
Q: リング・アテンションは、以前の記憶効率の良いトランスフォーマーと比較して、どのように長いシーケンスのトレーニングと推論を可能にするのか?
A: リング・アテンションは、自己アテンションのブロック単位の計算を活用し、キー・バリュー・ブロックの通信とブロック単位のアテンションの計算をオーバーラップさせながら、長いシーケンスを複数のデバイスに分散させることで、従来のメモリ効率の高いTransformerと比較して、より長いシーケンスのトレーニングと推論を可能にします.これにより、個々のデバイスによって課されるメモリ制約が効果的に排除され、従来のメモリ効率の高いTransformersのものよりデバイス数の倍まで長いシーケンスの学習と推論が可能になる.言い換えれば、リングアテンションは、シーケンスの長さがデバイスの数に比例してスケーリングできるため、ほぼ無限のコンテキストサイズを可能にする.
Q: リング・アテンションが有効な、長時間のシーケンスや長期的な依存関係を含むタスクの例を教えてください.
A: リング・アテンションは、言語モデリングなど、長いシーケンスが関係するタスクにおいて有益である.リング・アテンションは、メモリ効率の高い従来のトランスフォーマーよりも、最大でデバイス数倍長いシーケンスの学習と推論を可能にする.これにより、個々のデバイスによって課されるメモリ制約が効果的に排除され、大きなシーケンス入力サイズが可能になり、パフォーマンスが向上する.
Q: リング・アテンションは、どのようにしてより大きなシーケンス入力サイズを可能にするのですか?
A: リング・アテンションは、個々のデバイスによって課されるメモリ制約を排除することで、より大きなシーケンス入力サイズを可能にします.これにより、従来のメモリ効率の高いTransformerのシーケンスよりも、デバイス数倍長いシーケンスの学習と推論が可能になる.これは、Transformerのコンテキスト長をデバイス数に比例してスケーリングすることにより達成され、実質的に無限に近いコンテキストサイズを実現する.
Q: リング・アテンションが言語モデリングタスクのパフォーマンスをどのように向上させるのか、説明していただけますか?
A: リング・アテンションは、トランスフォーマーのメモリ要件を削減することで、言語モデリングタスクのパフォーマンスを向上させ、アテンションに近似することなく、より長いシーケンスのトレーニングを可能にします.これは、個々のデバイスによって課されるメモリの制約を排除し、デバイスの数に比例してスケールする長さのシーケンスのトレーニングと推論を可能にします.これは本質的に無限に近いコンテキストサイズを実現する.リング・アテンションが大きなシーケンス入力サイズを可能にし、パフォーマンスを向上させる有効性は、言語モデリングタスクに関する広範な実験を通じて実証されている.
