
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をLLMによって生成されるQ&Aを用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.自動生成記事のクオリティと信頼性を向上させるためにアルゴリズムの改善に取り組んでいます.個人で資料のQ&Aを作成されたい方には、https://www.chatpdf.com/ や https://scispace.com/などがお勧めです.
紹介する論文は以下の10本となります.
- Accurate proteome-wide missense variant effect prediction with AlphaMissense (発行日:2023年09月22日)
- LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset (発行日:2023年09月21日)
- LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models (発行日:2023年09月21日)
- Chain-of-Verification Reduces Hallucination in Large Language Models (発行日:2023年09月20日)
- Kosmos-2.5: A Multimodal Literate Model (発行日:2023年09月20日)
- Language Modeling Is Compression (発行日:2023年09月19日)
- Contrastive Decoding Improves Reasoning in Large Language Models (発行日:2023年09月17日)
- OWL: A Large Language Model for IT Operations (発行日:2023年09月17日)
- Struc-Bench: Are Large Language Models Really Good at Generating Complex Structured Data? (発行日:2023年09月16日)
- Compositional Foundation Models for Hierarchical Planning (発行日:2023年09月15日)
Accurate proteome-wide missense variant effect prediction with AlphaMissense
著者:Akvile Žemgulyte, Alexander Pritzel, Andrew W. Senior, Clare Bycroft, Demis Hassabis, Guido Novati, John Jumper, Joshua Pan, Jun Cheng, Lai Hong Wong, Michal Zielinski, Pushmeet Kohli, Rosalia G. Schneider, Taylor Applebaum, Tobias Sargeant, Žiga Avsec
発行日:2023年09月22日
最終更新日:不明
URL:https://www.science.org/doi/pdf/10.1126/science.adg7492
カテゴリ:不明
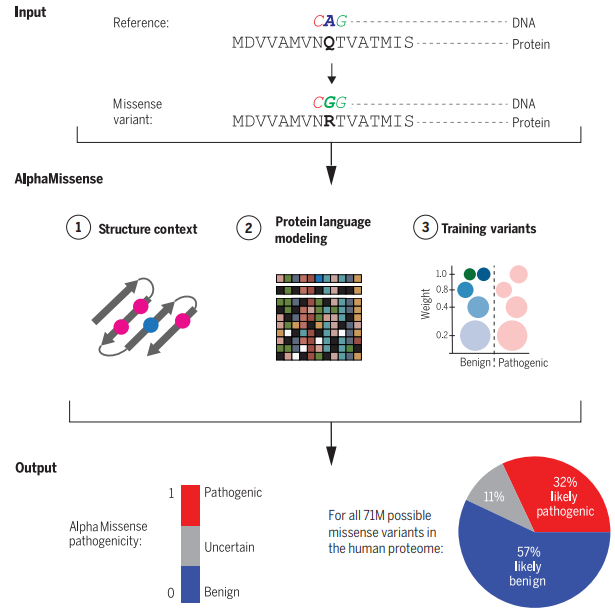
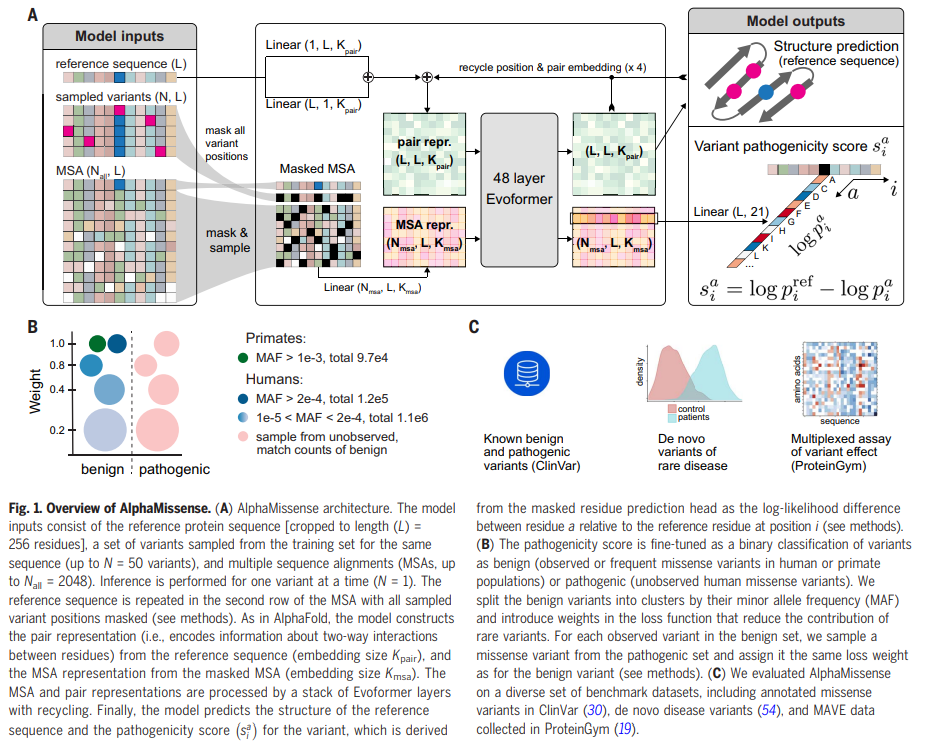
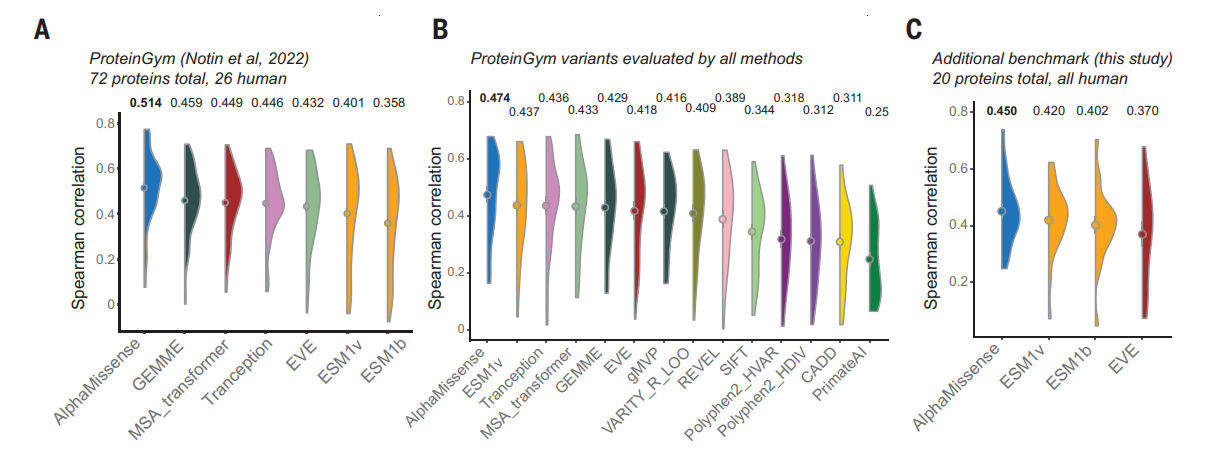
概要:
ゲノムシーケンシングにより、人間の集団における広範な遺伝的変異が明らかにされています.ミスセンス変異は、タンパク質のアミノ酸配列を変化させる遺伝的変異です.病原性のあるミスセンス変異はタンパク質の機能を破壊し、生物の適応度を低下させますが、良性のミスセンス変異は限定的な影響しかありません.
これらの変異を分類することは、人間の遺伝学における重要な課題です.400万以上の観察されたミスセンス変異のうち、わずか2%が臨床的に病原性または良性と分類されており、その大部分は臨床的な意義が不明です.これにより、希少疾患の診断や、潜在的な遺伝的原因を対象とした臨床的な治療の開発や適用が制限されています.
機械学習の手法を用いることで、未注釈の変異の病原性を予測するために生物学的データのパターンを利用することができます.具体的には、タンパク質の配列からタンパク質の構造を正確に予測するAlphaFoldを基盤として、変異のタンパク質への病原性を予測することができます.
研究者たちは、AlphaMissenseという手法を開発しました.これは、以下の進展を活用しています:(i)教師なし学習によるアミノ酸分布の学習、(ii)AlphaFold由来のシステムを用いた構造的な文脈の組み込み、および(iii)人間による注釈からのバイアスを避けるために、人口頻度データからの弱いラベルでの微調整.AlphaMissenseは、臨床的な注釈、新規疾患変異、および実験的なアッセイのベンチマークにおいて、明示的なトレーニングなしで最先端のミスセンス変異の病原性予測を達成しています.
このリソースをコミュニティに提供することで、人間のタンパク質組織中のすべての単一アミノ酸置換に対する予測のデータベースを提供しています.ClinVarデータセットにおいて90%の精度を得るためのカットオフを使用し、32%のミスセンス変異を可能性の高い病原性とし、57%を可能性の高い良性と分類しています.したがって、ほとんどの人間のミスセンス変異に対して自信を持った予測を提供しています.
このリソースが複数の分野の研究を加速する方法を示しています.分子生物学者は、飽和アミノ酸を探る実験の設計や解釈の出発点としてデータベースを利用することができます.さらに、ヒトの遺伝子の機能的な意義を定量化するために、遺伝子レベルのAlphaMissense予測と集団コホートに基づくアプローチを組み合わせることで、人間の遺伝学者は特に短いヒト遺伝子の場合に統計的なパワーが不足している場合でも機能的な意義を評価することができます.また、臨床医は、希少疾患の診断のために新たな病原性変異を優先的に選別する際に、確信を持って分類された病原性変異のカバレッジの向上により恩恵を受けることができ、AlphaMissenseの予測は、希少な遺伝性疾患の診断のための研究や、稀であり、有害な変異の注釈を使用する複雑な特性遺伝学の研究にも役立つでしょう.
Q&A:
Q: アルファミセンスの目的は何ですか?
A: AlphaMissenseの目的は、タンパク質の機能に対する変異の分子効果を明らかにし、病原性のあるミスセンス変異や以前に知られていなかった疾患原因遺伝子の同定に貢献し、まれな遺伝性疾患の診断率を向上させることです.
Q: アルファミセンスは教師なしタンパク質言語モデリングをどのように活用していますか?
A: AlphaMissenseは、アミノ酸の分布を学習するために教師なしのタンパク質言語モデリングを活用しています.
Q: アルファ・ミセンスはどのように構造的な背景を組み込んでいるのか?
A: AlphaMissenseは、AlphaFold由来のシステムを使用することで、構造的背景を組み込んでいる.
Q: AlphaMissenseは、人間がキュレーションしたアノテーションによるバイアスをどのように回避しているのですか?
A: AlphaMissenseは、代わりに母集団頻度データからの弱いラベルで微調整することで、人間がキュレーションしたアノテーションからのバイアスを回避する.このアプローチにより、モデルは配列コンテキストに条件付けられたアミノ酸の分布から学習し、AlphaFold由来のシステムを使用して構造コンテキストを組み込むことができる.AlphaMissenseは、人間が作成したアノテーションを明示的に学習しないことで、そのようなアノテーションによってもたらされる潜在的なバイアスを回避することができる.
Q: AlphaMissenseのミスセンス病原性予測の結果は?
A: AlphaMissenseは、ミスセンスバリアントが病原性である確率を予測し、良性の可能性が高い、病原性の可能性が高い、不確実のいずれかに分類する.
Q: AlphaMissenseは、ミスセンスバリアントのうち、何パーセントを病原性の可能性が高く、良性の可能性が高いと分類しているのか?
A: AlphaMissenseは、ミスセンス変異のうち32%(22.8百万)を可能性の高い病原性として分類し、57%(40.9百万)を可能性の高い良性として分類します.
Q: AlphaMissenseはどのようにして、ほとんどのヒトのミスセンス変異体に対して信頼性の高い予測を提供しているのか?
A: AlphaMissenseは、構造的文脈と進化的保存を組み合わせることで、ほとんどのヒトミスセンスバリアントの確実な予測を提供する.そのようなデータで明示的に学習することなく、幅広い遺伝的・実験的ベンチマークにおいて最先端の結果を達成した.このモデルは、ClinVarデータセット上で90%の精度をもたらすカットオフを用いて、全ミスセンスバリアントの32%を病原性の可能性が高いものとして、57%を良性の可能性が高いものとして分類する.このヒトプロテオームにおけるすべての可能な1アミノ酸置換の予測データベースは、分子生物学者、ヒト遺伝学者、臨床医が利用することができ、様々な分野での研究や診断を加速することができる.
Q: 分子生物学者はアルファミセンスデータベースを研究にどのように利用できるのか?
A: 分子生物学者は、AlphaMissenseデータベースを研究の出発点として使用することができます.具体的には、彼らは人間のプロテオーム全体にわたる飽和アミノ酸置換を調べる実験の設計や解釈において、このデータベースを利用することができます.
Q: ヒト遺伝学者は、集団コホートに基づくアプローチと組み合わせて、アルファミセンスの予測をどのように利用できるのだろうか?
A: AlphaMissense予測は、ヒト遺伝学者が集団コホートベースのアプローチと組み合わせることで、遺伝子の機能的意義を定量化することができる.遺伝子レベルのAlphaMissense予測を集団コホートベースのアプローチと統合することで、ヒト遺伝学者は遺伝子バリアントが遺伝子機能に与える影響をより包括的に理解することができる.この組み合わせにより、遺伝子の機能的重要性をより正確に評価することが可能となり、希少疾患診断のためのde novoバリアントの優先順位付けに役立てることができる.さらに、AlphaMissenseの予測結果を集団コホートベースのアプローチと統合することで、希少で劇症である可能性が高いバリアントのアノテーションを利用した複雑形質遺伝学の研究に情報を提供することができる.全体として、AlphaMissense予測と集団コホートベースのアプローチの組み合わせは、ヒト遺伝学者が遺伝子や遺伝的バリアントの機能的意義を研究するための強力なツールを提供する.
Q: 希少疾患の診断において、臨床医はアルファミセンスの予測からどのような利益を得ることができるのか?
A: AlphaMissense予測は、確実に分類された病原性バリアントのカバレッジを高めることにより、希少疾患診断において臨床医に利益をもたらす.臨床医は、これらの予測に基づいて、希少疾患診断のためのde novoバリアントに優先順位をつけることができます.さらに、AlphaMissenseの予測は、希少でおそらく致死的なバリアントのアノテーションを使用する複雑形質遺伝学の研究に情報を提供することができます.これにより、病原性ミスセンス変異やこれまで知られていなかった疾患原因遺伝子の同定に貢献することができる.最終的には、AlphaMissense予測を利用することで、希少遺伝病の診断率を高めることができる.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: この論文で導入された新しい手法のコード実装のURLは、Zenodo(57)およびhttps://github.com/deepmind/alphamissenseにあります.
LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset
著者:Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zhuohan Li, Zi Lin, Eric. P Xing, Joseph E. Gonzalez, Ion Stoica, Hao Zhang
発行日:2023年09月21日
最終更新日:2023年09月30日
URL:http://arxiv.org/pdf/2309.11998v3
カテゴリ:Computation and Language, Artificial Intelligence
概要:
この論文では、大規模な言語モデル(LLM)との実世界での相互作用の研究が、さまざまなアプリケーションでの広範な使用のためにますます重要になっていることを紹介しています.本論文では、25の最先端のLLMを用いた100万件の実世界の会話を含む大規模なデータセットであるLMSYS-Chat-1Mを紹介しています.このデータセットは、VicunaデモとChatbot Arenaのウェブサイトで210,000のユニークなIPアドレスから収集されています.私たちは、データセットの内容、キュレーションプロセス、基本統計、およびトピックの分布について概要を提供し、その多様性、独自性、およびスケールを強調しています.私たちは、このデータセットの多様な用途を示すために、以下の4つのユースケースを紹介しています:GPT-4と同等のパフォーマンスを発揮するコンテンツモデレーションモデルの開発、安全性のベンチマークの構築、Vicunaと同等のパフォーマンスを発揮する指示に従うモデルのトレーニング、および難解なベンチマークの質問の作成.私たちは、このデータセットがLLMの能力を理解し進歩させるための貴重なリソースとなると考えています.このデータセットは、https://huggingface.co/datasets/lmsys/lmsys-chat-1mで公開されています.
Q&A:
Q: LMSYS-Chat-1Mデータセットの目的は何ですか?
A: LMSYS-Chat-1Mデータセットの目的は、LLM技術の理解と改善を向上させるための貴重なリソースとして、ユーザーとLLMの相互作用に関する洞察を提供することです.また、コンテンツのモデレーション、指示の微調整、ベンチマーキングなどのタスクにも役立ちます.
Q: データセットはどのように収集されたのか?
A: データセットは、2023年4月から8月までの間にウェブサイト上で収集されました.ウェブサイトには、シングルモデル、チャットボットアリーナ(バトル)、チャットボットアリーナ(サイドバイサイド)の3種類のチャットインターフェースがあります.ユーザーは利用規約に同意する必要があり、その同意によって会話データの公開が許可されます.また、ウェブサイトのコードは公開されており、25のモデルをホストするために数十のA100 GPUが使用されています.
Q: データセットの基本統計は?
A: データセットの基本統計は、以下のようになります.LMSYS-Chat-1Mデータセットには、100万の会話が含まれており、25の最新のLLMモデルと210,000人のユーザーが参加しています.会話ごとに、会話ID、モデル名、OpenAI API JSON形式の会話テキスト、検出された言語タグ、およびOpenAIモデレーションAPIタグが含まれています.他の類似のデータセットとの比較では、LMSYS-Chat-1Mは大規模なスケール、多様性、および複数のモデルのカバレッジで特筆されます.表1には、LMSYS-Chat-1Mを含むいくつかの会話データセットの基本統計が示されています.LMSYS-Chat-1Mデータセットの統計では、100万の会話、25のモデル、210,479人のユーザー、154の言語、平均2.0のターン数、平均69.5のトークン数、および人間の優先度を示す平均214.5のトークン数があります.
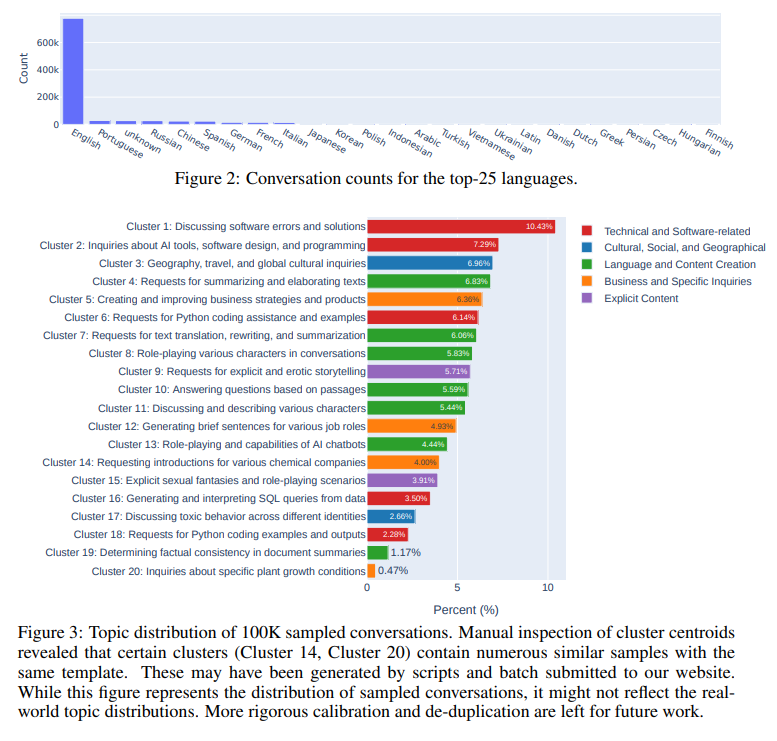
Q: データセット内の会話のトピック分布は?
A: データセットの会話のトピック分布は、図3に表示されています.クラスタリングアルゴリズムを適用して、ユーザープロンプトのトピック分布分析を行いました.英語の会話からランダムに選んだ10万のプロンプトを抽出し、初期ターンとフォローアップターンの両方を含んでいます.32文字未満または1536文字以上のプロンプトは除外しました.次に、SentenceTransformersのall-mpnet-base-v2モデルを使用して、これらのプロンプトの文の埋め込みを計算しました.そして、k-meansクラスタリングを使用して20のクラスタを形成しました.各クラスタについて、重心に最も近い100のプロンプトを選び、GPT-4にその中心的なトピックの要約を提供してもらいました.
Q: コンテンツ・モデレーション・モデルの開発にデータセットをどのように利用できるか?
A: データセットは、コンテンツモデレーションモデルの開発に使用することができます.著者らは、Vicuna-7Bを使用してコンテンツモデレーションモデルを微調整し、特定のメッセージがなぜフラグされたのかについての説明を生成するために言語モデルを微調整しました.OpenAIのモデレーションAPIの5つのカテゴリに焦点を当て、LMSYS-Chat-1Mから各カテゴリの上位1,000件のフラグ付きメッセージと1,000件の通常のメッセージを選択しました.さらに、ShareGPTから3,000件の会話を取り込んでトレーニングデータセットの多様性を向上させました.モデルの評価のために、LMSYS-Chat-1MからOpenAIのモデレーションAPIによってフラグされていない110件の有害なメッセージを選択し、手動でタグ付けしました.
Q: このデータセットは、どのようにして指示追従モデルのトレーニングに利用できるのか?
A: LMSYS-Chat-1Mデータセットのサブセットを使用して、命令に従うモデルのトレーニングが行われます.具体的には、「HighQuality」と「Upvote」という2つのサブセットが抽出され、Llama2-7Bモデルがこれらのサブセットでファインチューニングされます.これにより、「HighQuality-7B」と「Upvote-7B」という2つのモデルが作成されます.
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
著者:Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, Jiaya Jia
発行日:2023年09月21日
最終更新日:2023年09月21日
URL:http://arxiv.org/pdf/2309.12307v1
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning
概要:
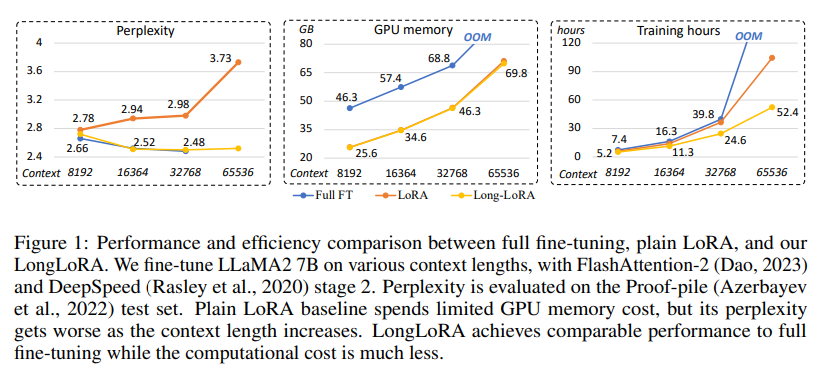
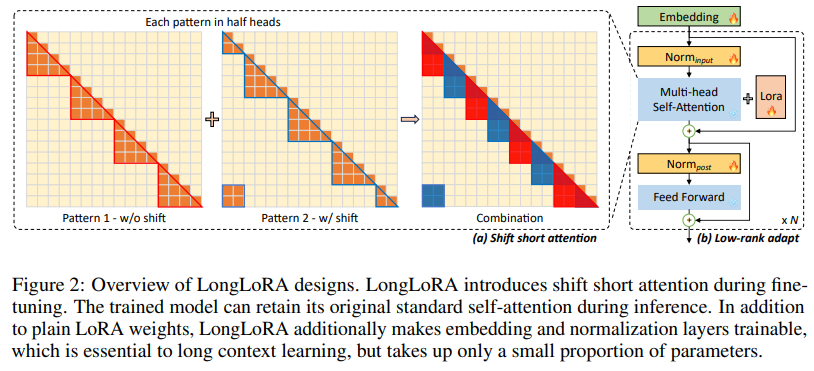
LongLoRAは、計算コストを制限しながら、事前学習された大規模言語モデル(LLM)のコンテキストサイズを効率的に拡張する方法を提案しています.通常、長いコンテキストサイズでLLMをトレーニングすることは計算コストが高く、長時間のトレーニングとGPUリソースが必要です.例えば、コンテキスト長が8192の場合、2048の場合と比べて自己注意層の計算コストが16倍になります.本論文では、LLMのコンテキスト拡張を2つの側面で高速化しています.一方で、推論時には密なグローバルアテンションが必要ですが、モデルのファインチューニングは疎なローカルアテンションで効果的かつ効率的に行うことができます.提案されたシフトショートアテンションは、コンテキストの拡張を可能にし、バニラアテンションでのファインチューニングと同等のパフォーマンスを持ちながら、非自明な計算の節約ができます.特に、トレーニングではわずか2行のコードで実装でき、推論時にはオプションとなります.他方で、コンテキストの拡張のためのパラメータ効率的なファインチューニング手法を再評価しています.特に、訓練可能な埋め込みと正規化の前提条件の下で、コンテキスト拡張のためのLoRAがうまく機能することを発見しました.LongLoRAは強力なパフォーマンスを示しており、LLaMA2モデルの7B/13Bから70Bまでのさまざまなタスクで実証結果を示しています.LongLoRAは、LLaMA2 7Bを4kのコンテキストから100kに、またはLLaMA2 70Bを32kに拡張することができます.また、LongLoRAはモデルの元のアーキテクチャを保持しながらコンテキストを拡張し、FlashAttention-2などの既存の技術と互換性があります.さらに、LongLoRAを実用的にするために、監視付きファインチューニングのためのデータセットであるLongQAを収集しました.これには3,000以上の長いコンテキストの質問と回答のペアが含まれています.
Q&A:
Q: LongLoRAの目的は何ですか?
A: LongLoRAの目的は、LLMのコンテキストの長さを効率的に拡張することです.
Q: LongLoRAは、事前に訓練された大規模言語モデルのコンテキストサイズをどのように拡張するのか?
A: LongLoRAは、シフトショートアテンション(S2-Attn)アプローチにより、事前に学習された大規模言語モデルのコンテキストサイズを拡張する.このアプローチにより、疎な局所的注意でモデルを効果的かつ効率的に微調整することで、コンテキストの拡張が可能になる.S2-Attn手法は、学習ではわずか2行のコードで実装でき、推論ではオプションである.このアプローチを用いることで、LongLoRAは、計算コストを大幅に削減しながら、バニラ注意による微調整に匹敵する性能を達成する.
Q: 長いコンテクストサイズを持つLLMのトレーニングに計算コストがかかるのはなぜか?
A: 長いコンテキストサイズを持つLLMは、膨大なトレーニング時間とGPUリソースを必要とするため、計算コストが高い.例えば、コンテキスト長が8192のLLMを学習する場合、自己アテンション層の計算コストは2048のLLMの16倍になる.これは、入力シーケンスのトークン数が増えるため、自己アテンション演算の回数が増え、メモリ要件が増えるためです.その結果、長いコンテキストサイズを持つLLMを訓練することは、ほとんどの研究者にとって法外に高価になる.
Q: 提案されているシフト・ショート・アテンションは、どのようにしてコンテクストの延長を可能にするのだろうか?
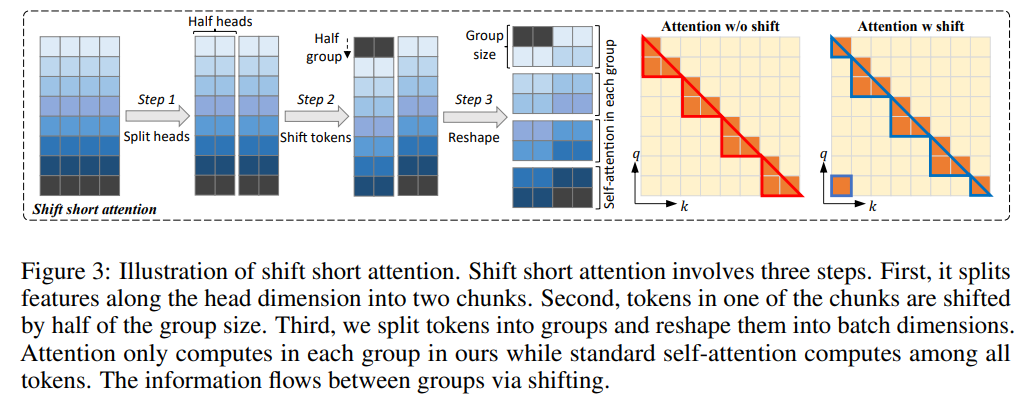
A: 提案されたシフト短い注意力は、トークンを半分の注意ヘッドでシフトし、特徴をトークン次元からバッチ次元に転置することで、標準の自己注意パターンを近似することができます.これにより、コンテキストの拡張が可能になります.
Q: コンテキストの拡大におけるパラメータ効率の良い微調整領域とは?
A: コンテキスト拡張のためのパラメータ効率的なファインチューニングの手法は、低ランク適応(LoRA)です.
Q: 様々なタスクにおけるLongLoRAの実証結果は?
A: LongLoRAは、7B/13Bから70BまでのLLaMA2モデルの様々なタスクにおいて、強力な経験的結果を示している.
Q: LongLoRAはどのLLaMA2モデルを採用し、拡張コンテキストのサイズは?
A: LongLoRAはLLaMA2 7Bを4kコンテクストから100kまで、またはLLaMA2 70Bを8×A100マシン1台で32kまで採用している.
Q: LongLoRAはFlashAttention-2のような既存の技術と互換性がありますか?
A: はい、LongLoRAはFlashAttention-2のような既存の技術と互換性があります.
Q: LongQAデータセットの目的は何ですか?
A: LongQAデータセットの目的は、監督付きの微調整(SFT)のためのデータセットを提供することです.このデータセットには、3,000以上の長い質問とそれに対応する回答が含まれています.技術論文、SF小説、その他の書籍に関連するさまざまなタイプの質問を設計しています.LLMのチャット能力を向上させるために、SFTは重要です.
Q: LongQAデータセットには、何組の長い文脈の質問と答えが含まれていますか?
A: LongQAデータセットには、3,000以上の長い文脈の質問とそれに対応する回答が含まれています.
Chain-of-Verification Reduces Hallucination in Large Language Models
著者:Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, Jason Weston
発行日:2023年09月20日
最終更新日:2023年09月25日
URL:http://arxiv.org/pdf/2309.11495v2
カテゴリ:Computation and Language, Artificial Intelligence

概要:
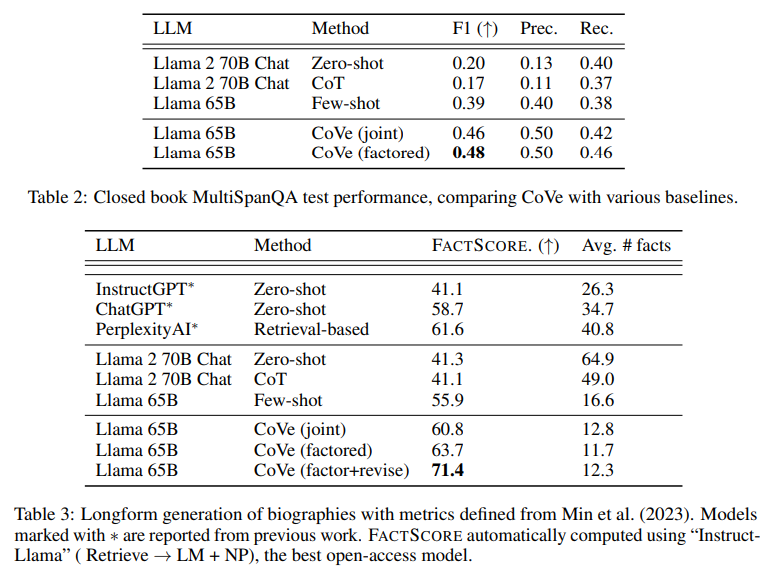
大規模な言語モデルにおける根拠のない事実情報の生成(幻覚と呼ばれる)は、未解決の課題である.本研究では、言語モデルが自身の誤りを修正するために、回答を検討する能力を調査する.Chain-of-Verification(CoVe)という手法を開発し、モデルはまず(i)初期の回答を起草し、次に(ii)その回答を事実確認するための質問を計画し、(iii)他の回答にバイアスを与えないように独立してそれらの質問に回答し、最終的な検証済みの回答を生成する(iv).実験では、CoVeがWikidataのリストベースの質問、クローズドブックのMultiSpanQA、および長文テキスト生成など、さまざまなタスクにおいて幻覚を減少させることを示している.
Q&A:
Q: チェーン・オブ・ベリフィケーション(CoVe)方式はどのように機能するのか?
A: Chain-of-Verification (CoVe)は、大規模な言語モデルの幻覚を減らすためのアプローチであり、自身の応答を検討し、修正することによって実現されます.具体的には、CoVeは以下の4つの主要なステップを実行します.まず、LLMを用いてクエリに基づいて基準となる応答を生成します.次に、クエリと基準応答を考慮に入れ、元の応答に誤りがあるかどうかを自己分析するための検証質問のリストを生成します.その後、各検証質問に対して回答し、元の応答と照らし合わせて矛盾や誤りをチェックします.最後に、発見された矛盾(あれば)を考慮に入れて修正された応答を生成します.これらのステップは、異なる方法で同じLLMに対してプロンプトを与えることで実行されます.
Q: モデルによって作成された初回回答の目的は何ですか?
A: 初期の応答は、作業の進行状況を確認するための検証質問を計画し、それらの質問に順番に答えることで改善された応答を生成するためのものです.
Q: そのモデルは、草稿を事実確認するための検証質問をどのように計画しているのか?
A: モデルは、元のクエリとベースラインの回答に基づいて、検証問題の計画を立てます.具体的には、元のベースラインの回答の事実的な主張をテストする一連の検証問題を生成するようにモデルに指示します.例えば、長い形式のモデルの回答の一部に「メキシコアメリカ戦争は1846年から1848年までのアメリカとメキシコの間の武力衝突だった」という記述が含まれている場合、その日付を確認するための可能な検証問題は「メキシコアメリカ戦争はいつ始まり、いつ終わったのですか?」となります.検証問題はテンプレート化されず、言語モデルは自由に形式を選ぶことができます.また、元のテキストの表現に厳密に一致する必要もありません.実験では、このような検証計画を、LLMに(response, verification)のデモンストレーションを提供することで行います.
Q: なぜモデルが検証の質問に独立して答えることが重要なのか?
A: モデルが独立した検証の質問に答えることは重要です.なぜなら、独立した検証の質問に答えることで、元の回答よりも正確な事実を提供することができるからです.これにより、全体的な回答の正確性が向上します.
Q: CoVe法は大規模言語モデルの幻覚を減らすのにどのように役立つのか?
A: CoVeメソッドは、大規模な言語モデルにおける幻覚を減らすために、モデルが自身の誤りを特定するために時間をかけて熟考することによって改善された応答を生成することができます.具体的には、モデルは最初に初期の応答を起草し、次にその起草を事実チェックするための検証質問を計画し、独立してそれらの質問に回答し、他の応答にバイアスをかけないようにします.最終的な検証済みの応答を生成します.
Q: CoVeが幻覚の減少に成功した例を教えてください.
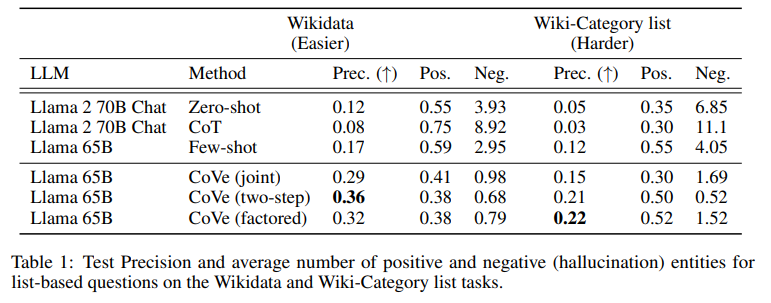
A: CoVeはウィキデータ・タスクと長文生成タスクで幻覚を減らすことに成功している.
Q: 大規模言語モデルでは、どのような種類の事実情報が幻覚とみなされるのか?
A: 大規模な言語モデルにおいて、事実と異なる生成物は幻覚として考えられます.これは、モデルが間違った情報を生成し、通常は信憑性のある見た目のものです.幻覚は、直接述べられた事実の不正確さだけでなく、間違った推論ステップや意見の一部としても現れる可能性があります.
Q: CoVeメソッドは偏った回答の問題にどのように対処しているのか?
A: CoVeアルゴリズムは、バイアスのある応答の問題に対処するために、幻覚の特定と修正を試みます.CoVeは、幻覚を特定し、それらを修正するための手順を踏みます.具体的には、CoVeは検証質問のセットを生成し、それらに答えることで計画を実行し、合意を確認します.個々の検証質問は、元の長文生成の事実の正確性よりも高い正確性で回答されることが通常です.最終的な修正された応答は、検証を考慮に入れます.CoVeのファクタリングバージョンは、元の応答に依存しないように検証質問に答えるため、繰り返しを避け、パフォーマンスを向上させます.
Q: CoVeメソッドを導入することによる制限や潜在的な欠点はありますか?
A: CoVe法には限界と潜在的な欠点がある.制限の一つは、出力により多くのトークンを生成するため、計算量が増えることである.つまり、CoVe法を実装するには、より多くの計算リソースが必要になる可能性がある.もう一つの潜在的な欠点は、CoVeによって生成される検証は、その決定に解釈可能性を加えるかもしれないが、これは計算費用の増加という代償を伴うということである.さらに、CoVe法を実装することによるその他の制限や潜在的な欠点に関する情報は、この文脈では提供されていない.
Q: CoVeメソッドは、この文章で言及されている以外の言語モデルでテストされましたか?
A: パッセージでは、CoVeメソッドはLlama 65BとLlama 2 Chatの2つの言語モデルでテストされていることは明記されていません.
Kosmos-2.5: A Multimodal Literate Model
著者:Tengchao Lv, Yupan Huang, Jingye Chen, Lei Cui, Shuming Ma, Yaoyao Chang, Shaohan Huang, Wenhui Wang, Li Dong, Weiyao Luo, Shaoxiang Wu, Guoxin Wang, Cha Zhang, Furu Wei
発行日:2023年09月20日
最終更新日:2023年09月20日
URL:http://arxiv.org/pdf/2309.11419v1
カテゴリ:Computation and Language, Computer Vision and Pattern Recognition

概要:
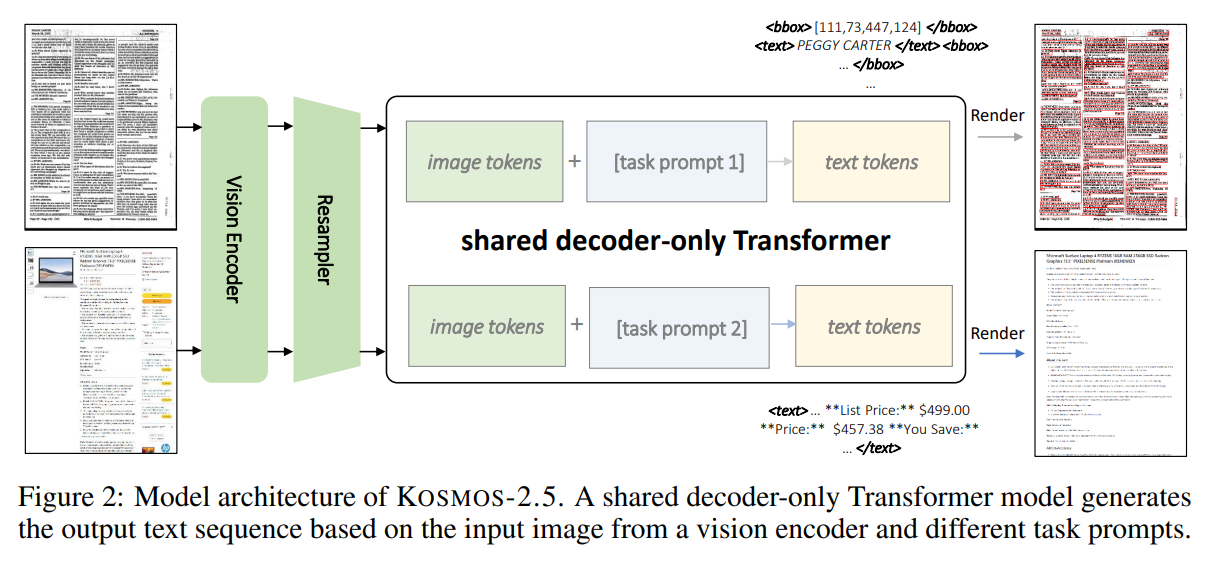
Kosmos-2.5は、テキストが豊富な画像の機械読み取りのためのマルチモーダルなリテラシーモデルです.大規模なテキストが豊富な画像で事前学習されたKosmos-2.5は、2つの異なるが協力的な転写タスクで優れています:(1)空間的に認識されたテキストブロックの生成、各テキストブロックには画像内の空間座標が割り当てられます.そして(2)スタイルと構造をマークダウン形式でキャプチャする構造化されたテキストの出力を生成します.この統合されたマルチモーダルなリテラシー能力は、共有のTransformerアーキテクチャ、タスク固有のプロンプト、柔軟なテキスト表現によって実現されています.私たちは、Kosmos-2.5をエンドツーエンドのドキュメントレベルのテキスト認識と画像からマークダウンテキストの生成について評価しています.さらに、このモデルは、監督付きのファインチューニングを介して異なるプロンプトを持つ任意のテキストが豊富な画像理解タスクに容易に適応できるため、テキスト豊富な画像を含む実世界のアプリケーションにおける汎用ツールとなります.この研究は、マルチモーダルな大規模言語モデルの将来的なスケーリングの道を開拓するものでもあります.
Q&A:
Q: KOSMOS-2.5の目的は何ですか?
A: KOSMOS-2.5の目的は、テキスト重視の画像の機械読み取りに取り組むためのマルチモーダルなリテラシーモデルを提供することです.
Q: Kosmos-2.5はどのように事前トレーニングされているのですか?
A: KOSMOS-2.5は、2つの転写タスク(空間認識テキストブロック生成と構造化マークダウンテキスト生成)を単一の統一されたモデルアーキテクチャに組み込んで事前学習される.トークンはランダムに初期化され、すべてのパラメータは学習中に更新される.モデルをよりロバストにするために、TrOCRからのデータ増強アプローチも活用されている.モデルの推論は、対応するタスクプロンプトを持つ様々な評価データセットにわたって単一のモデルチェックポイントを使用して行われ、データセットごとに個別にモデルを微調整する必要がないことを実証している.
Q: Kosmos-2.5が得意とする2つの異なる転写作業とは?
A: KOSMOS-2.5は、2つの異なる転写タスクに優れています.1つ目は、画像内の各テキストブロックにその空間座標を割り当てる空間的に意識したテキストブロックの生成です.2つ目は、スタイルやテキストの2D位置をキャプチャする構造化されたテキストの出力を生成することです.
Q: Kosmos-2.5はどのようにして空間認識テキストブロックを生成するのですか?
A: KOSMOS-2.5は、画像内の各テキストブロックに空間座標を割り当てることで、空間を意識したテキストブロックを生成します.
Q: Kosmos-2.5はどのようなフォーマットで構造化テキストを出力しますか?
A: KOSMOS-2.5はマークダウン形式で構造化されたテキスト出力を生成します.
Q: Kosmos-2.5はどのようにして統一されたマルチモーダルリテラシー能力を実現しているのか?
A: KOSMOS-2.5は、共有のTransformerアーキテクチャ、タスク固有のプロンプト、柔軟なテキスト表現を通じて、統合されたマルチモーダルリテラシー能力を実現しています.
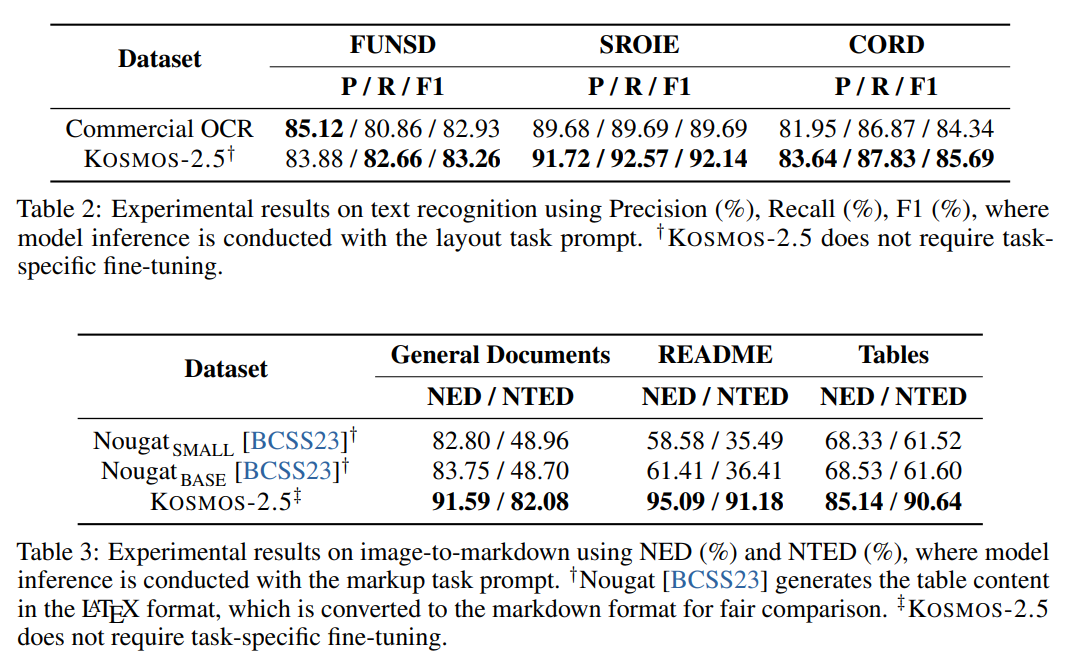
Q: Kosmos-2.5は、テキスト認識とテキスト生成の面でどのように評価されていますか?
A: KOSMOS-2.5は、エンドツーエンドの文書レベルのテキスト認識とマークダウン形式の画像からテキストへの生成という2つのタスクで評価されている.実験の結果、テキストを多用するいくつかの画像理解タスクにおいて、強力なリテラル性能が実証された.さらに、KOSMOS-2.5は、数ショットおよびゼロショット学習シナリオにおいても有望な能力を示し、テキストが豊富な画像を含む実世界のアプリケーションに普遍的なインターフェースを提供する.
Q: Kosmos-2.5は、テキストを多用する画像理解タスクに適応できるか?
A: はい、KOSMOS-2.5は異なるテキスト集中型画像理解タスクに適応することができます.
Q: Kosmos-2.5はどのように微調整できるのか?
A: KOSMOS-2.5は教師付き微調整により、異なるプロンプトに対して微調整が可能である.このモデルはテキスト画像を入力とし、与えられたタスクプロンプトに基づいて、空間認識テキストまたはマークダウン形式のテキストを生成する.異なるプロンプトを与えることで、各データセットに対して個別にモデルを微調整することなく、様々なタスクを実行するようにモデルを学習させることができる.これにより、KOSMOS-2.5は、テキストリッチな画像を含む実世界のアプリケーションのための柔軟で汎用的なツールとなる.
Q: Kosmos-2.5の実世界での応用の可能性は?
A: KOSMOS-2.5の潜在的な実世界の応用は、テキスト豊かな画像を含む実際のアプリケーションにおいて、エンドツーエンドのドキュメントレベルのテキスト認識や画像からテキストへのマークダウン形式の生成などのテキスト重視の画像理解タスクにおいて強力な性能を発揮することです.また、少数のサンプルやゼロショット学習のシナリオでも有望な能力を示し、マルチモーダルリテラシーモデルの将来の進歩と拡張性の基盤を築いています.
Language Modeling Is Compression
著者:Grégoire Delétang, Anian Ruoss, Paul-Ambroise Duquenne, Elliot Catt, Tim Genewein, Christopher Mattern, Jordi Grau-Moya, Li Kevin Wenliang, Matthew Aitchison, Laurent Orseau, Marcus Hutter, Joel Veness
発行日:2023年09月19日
最終更新日:2023年09月19日
URL:http://arxiv.org/pdf/2309.10668v1
カテゴリ:Machine Learning, Artificial Intelligence, Computation and Language, Information Theory, Information Theory
概要:
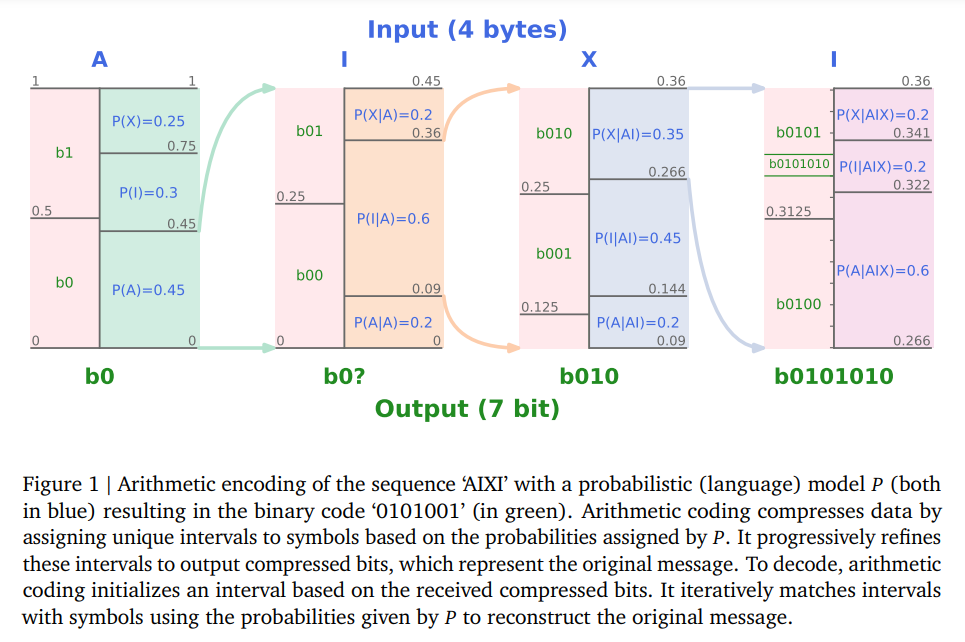
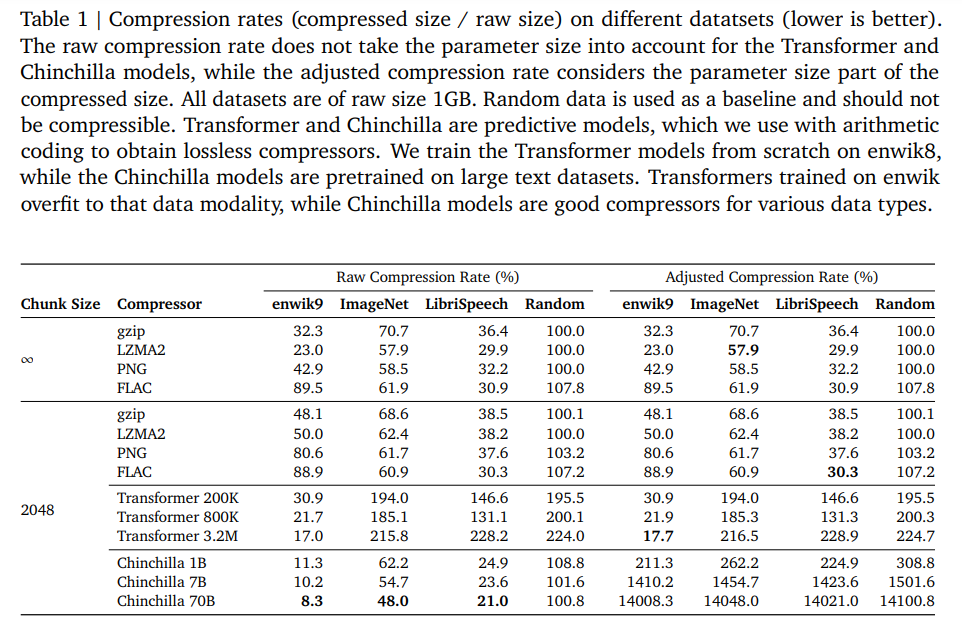
従来から、予測モデルは無損失圧縮器に変換できることが確立されており、その逆も可能であることが知られている.最近では、機械学習コミュニティはますます大きくて強力な自己教師あり(言語)モデルのトレーニングに注力してきた.これらの大規模言語モデルは印象的な予測能力を持っているため、強力な圧縮器としての位置づけがされている.本研究では、予測問題を圧縮の観点から見ることを提唱し、大規模(基礎)モデルの圧縮能力を評価する.我々は大規模言語モデルが強力な汎用予測モデルであり、圧縮の視点がスケーリング則、トークン化、およびコンテキスト学習について新たな洞察を提供することを示す.例えば、Chinchilla 70Bは主にテキストでトレーニングされているにもかかわらず、ImageNetのパッチを元のサイズの43.4%、LibriSpeechのサンプルを元のサイズの16.4%に圧縮し、それぞれPNG(58.5%)やFLAC(30.3%)などのドメイン固有の圧縮器を上回る.最後に、予測-圧縮の等価性により、gzipなどの任意の圧縮器を使用して条件付き生成モデルを構築することができることを示す.
Q&A:
Q: 予測モデルをどのようにロスレス・コンプレッサーに変換できるか、またその逆は?
A: 予測モデルは、符号化によって圧縮器に変換することができます.逆に、圧縮器は、符号化長を使用してシャノンのエントロピー原理に従った確率分布を構築することで、予測モデルに変換することができます.
Q: ますます大規模で強力になる自己教師付き言語モデルをトレーニングすることの意義とは?
A: 近年、機械学習コミュニティは、ますます大きくて強力な自己教師あり(言語)モデルのトレーニングに注力しています.これらの大規模な言語モデルは印象的な予測能力を持っているため、強力な圧縮器としての位置づけがされています.大きな言語モデルのトレーニングは、スケーリングの法則、トークン化、およびインコンテキスト学習について新しい洞察を提供します.
Q: 大規模な言語モデルは、どのようにして驚異的な予測能力を発揮するのだろうか?
A: 大規模な言語モデルは、印象的な予測能力を示すことができます.
Q: 圧縮の視点は、スケーリング法則、トークン化、コンテクスト内学習について、どのように新しい洞察をもたらすことができるのか?
A: 圧縮の視点は、スケーリング法則、トークナイゼーション、およびコンテキスト学習に関して新しい洞察を提供することができます.スケーリング法則に関しては、モデルのサイズと圧縮性能の関係を考慮することで、データセットのサイズがモデルのサイズに制約を与え、スケーリングが万能な解決策ではないことを示します.トークナイゼーションに関しては、事前圧縮と見なすことができますが、一般的には圧縮性能を向上させることはありません.ただし、トークナイゼーションによりモデルはコンテキストの情報量を増やすことができ、予測性能を向上させるために一般的に使用されます.コンテキスト学習に関しては、大規模な言語モデルが強力な汎用予測モデルであることを示し、圧縮の視点はスケーリング法則、トークナイゼーション、およびコンテキスト学習に関して新しい洞察を提供することができます.
Q: チンチラ70Bとその圧縮能力について詳しく教えてください.
A: Chinchilla 70Bは、テキストデータを主に訓練されたモデルでありながら、画像や音声データでも他の圧縮ツールよりも優れた圧縮性能を発揮します.Chinchilla 70Bは、既存のシーケンスの一部(enwik9の場合は1948バイト、ImageNetとLibriSpeechの場合はサンプルの半分)を条件として、圧縮ベースの生成モデルで残りのバイトを生成します.gzipと比較した場合、Chinchilla 70Bはテキスト、画像、音声の3つのデータモダリティ全体で生成性能を比較しています.また、図3から図5では、gzipとChinchilla 70Bの圧縮性能を比較しています.図6では、gzip、Chinchilla 1B、enwik8で事前訓練されたTransformerの圧縮率をシーケンスの長さに対して可視化しています.シーケンスが長いほど、モデルはより多くのデータをコンテキストで処理できるため、圧縮性能が向上します.Chinchilla 70Bは、テキストを主に訓練されたモデルであるにもかかわらず、画像や音声データでも他の圧縮ツールよりも優れた性能を発揮することが示されています.ただし、Chinchilla 70Bはこの種のデータで訓練されていないことに注意する必要があります.Hoffmann et al.(2022)の付録Aによると、訓練データセットはインターネットのテキストデータ(Wikipedia、ウェブサイト、GitHub)と書籍のミックスで構成されています.しかし、一部のウェブサイトで画像や音声サンプルがテキストにエンコードされた可能性もあります.したがって、Chinchilla 70Bは(メタ)トレーニングされたモデルを特定のタスクに対してコンテキスト学習を介して調整することで、印象的な圧縮性能を実現しています.
Q: チンチラ70Bの圧縮効率は、PNGやFLACのようなドメイン固有のコンプレッサーと比べてどうですか?
A: チンチラ70Bは、圧縮効率の点でPNGやFLACのようなドメイン固有のコンプレッサーを凌駕する.
Q: 予測-圧縮の等価性によって、どのような圧縮機でも条件付き生成モデルを構築できるようになるのか?
A: 予測-圧縮の等価性により、gzipのような任意の圧縮器を使用して条件付き生成モデルを構築することができます.予測モデルを圧縮器に変換することで、圧縮器はシャノンのエントロピー原理に従って確率分布を構築するための符号化長を使用して予測モデルに変換することができます.
Q: 文脈内学習の概念と、言語モデリングや圧縮との関連性について説明していただけますか?
A: インコンテキスト学習とは、言語モデリングと圧縮において重要な概念です.インコンテキスト学習は、トランスフォーマーなどの大規模な言語モデルが、与えられた文脈内での情報を利用して学習する能力を指します.これにより、モデルは文脈に基づいて予測を行い、より効果的な圧縮を実現することができます.言語モデルは、トークンごとに2〜3バイトのコード化を行い、数キロバイトのデータを圧縮することができます.しかし、より長い文脈を必要とする予測タスクでは、モデルの文脈の長さを拡張する必要があります.インコンテキスト学習は、現在の基礎モデルの失敗モードについての洞察を提供します.
Q: 大規模な言語モデルを強力な汎用予測器として使用することで、どのような応用や利点が考えられますか?
A: 大規模な言語モデルを強力な汎用予測モデルとして使用することによるいくつかの潜在的な応用や利点は次のとおりです.まず第一に、大規模な言語モデルは高度な予測能力を持っており、さまざまなタスクに適用することができます.例えば、自然言語処理、機械翻訳、質問応答などのタスクにおいて、大規模な言語モデルは高い精度で予測を行うことができます.また、大規模な言語モデルは圧縮の観点からも有用です.大規模な言語モデルは、テキストや画像などのデータを効率的に圧縮することができます.これにより、データの保存や転送において効率的な利用が可能となります.さらに、大規模な言語モデルは、トークン化や文脈学習などの新しい洞察を提供することができます.これにより、言語処理のさまざまな側面において改善や革新が可能となります.
Q: 圧縮の目的で大規模な言語モデルを使用する際の制限や課題はありますか?
A: 大きな言語モデルを圧縮目的で使用する際には、いくつかの制約や課題が存在します.まず第一に、大きな言語モデルは非常に高い計算コストを要求します.モデルのトレーニングや圧縮処理には膨大な計算リソースが必要であり、それには高性能なハードウェアや大規模なデータセットが必要です.また、モデルのサイズも大きくなるため、ストレージやメモリの容量も必要となります.さらに、大きな言語モデルはトレーニングデータに依存しており、特定のドメインや言語に特化したデータセットでトレーニングされたモデルは、他のドメインや言語に対しては効果的な圧縮ができない可能性があります.また、大きなモデルはトレーニングデータの特徴を捉えるため、データセットのバイアスやノイズも反映される可能性があります.さらに、大きなモデルはトレーニングデータの特徴を捉えるため、データセットのバイアスやノイズも反映される可能性があります.これらの制約や課題を克服するためには、より効率的なアルゴリズムやモデルの設計が必要となります.
Contrastive Decoding Improves Reasoning in Large Language Models
著者:Sean O’Brien, Mike Lewis
発行日:2023年09月17日
最終更新日:2023年09月29日
URL:http://arxiv.org/pdf/2309.09117v2
カテゴリ:Computation and Language, Artificial Intelligence
概要:
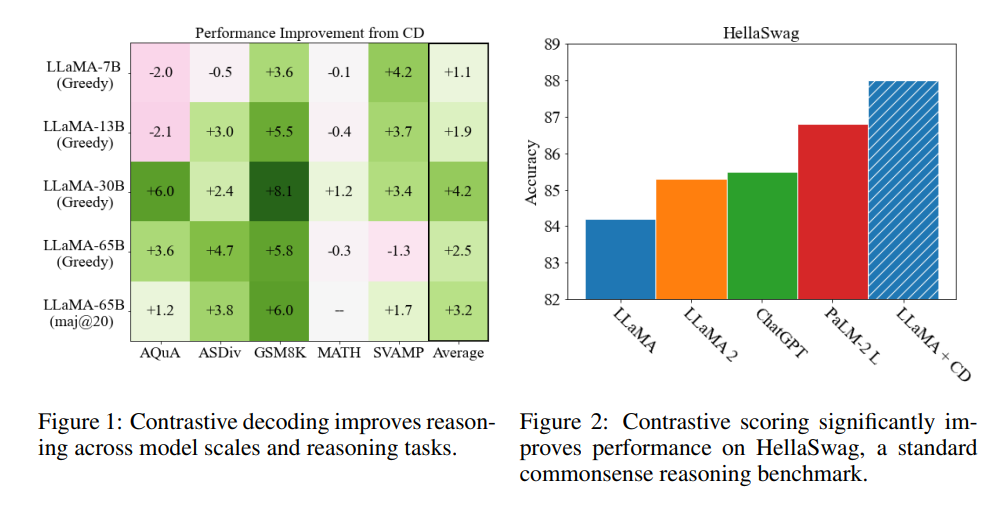
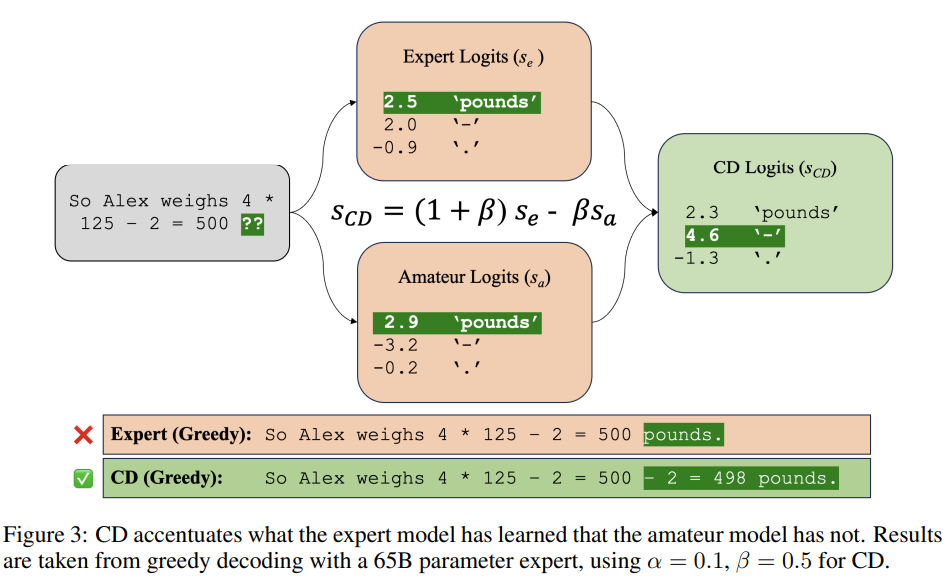
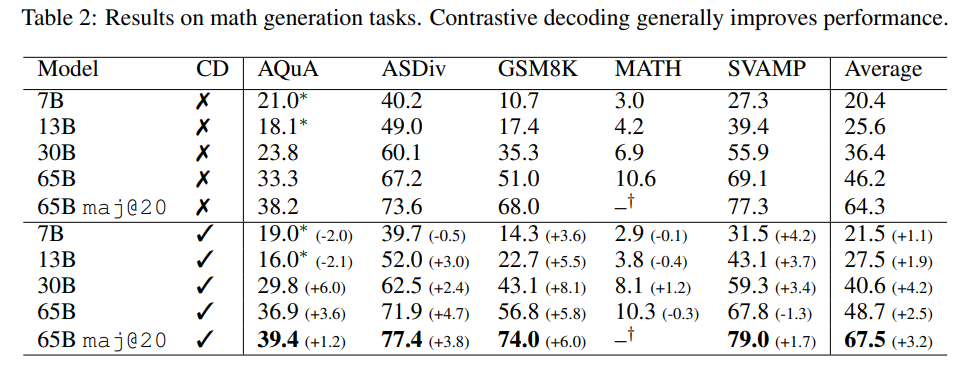
Contrastive Decoding(対照的デコーディング)は、Liらによって提案されたシンプルで計算量の軽い、トレーニング不要のテキスト生成手法であり、我々はそれがさまざまな推論タスクにおいてグリーディデコーディングよりも大幅な改善を実現することを示しています.元々は長文テキスト生成の品質を向上させることが示されていたContrastive Decodingは、強いモデルと弱いモデルの尤度の重み付き差を最大化する文字列を探索します.我々は、Contrastive Decodingによって、HellaSwagの常識的な推論ベンチマークにおいてLLaMA-65BがLLaMA 2、GPT-3.5、PaLM 2-Lを上回り、GSM8Kの数学的な単語推論ベンチマークにおいてもLLaMA 2、GPT-3.5、PaLM-540Bを上回ることを示しました.さらに、他のタスクでも改善が見られました.分析から、Contrastive Decodingは既存の手法よりも抽象的な推論エラーを防ぐことや、思考の連鎖中に入力の一部をコピーするなどのより単純なモードを回避することによって改善が見られることが示唆されています.全体として、Contrastive Decodingは長文生成においてnucleusサンプリングを上回り、推論タスクにおいてはグリーディデコーディングを上回るため、言語モデルからテキストを生成するための強力な汎用手法となります.
Q&A:
Q: 対照的デコーディングとは何か、他のテキスト生成方法とどう違うのか?
A: Contrastive Decodingは、Li et al.(2022)によって提案された単純で計算量の少ないトレーニングフリーのテキスト生成手法であり、貪欲デコーディングに比べて大幅な改善をもたらします.Contrastive Decodingは、強いモデルと弱いモデルの間の尤度の重み付き差を最大化する文字列を探索することで動作します.この手法は、長文テキスト生成の品質を向上させることが最初に示されました.Contrastive Decodingは、HellaSwag commonsense reasoningベンチマークでLLaMA-65BがLLaMA 2、GPT-3.5、PaLM 2-Lを上回り、GSM8K math word reasoningベンチマークでLLaMA-65BがLLaMA 2、GPT-3.5、PaLM-540Bを上回ることを示しています.また、他のタスクでも改善が見られます.Contrastive Decodingは、抽象的な推論エラーや思考の連鎖中に入力の一部をコピーするなどのより単純なモードを回避することで、既存の手法を改善しています.また、Contrastive Decodingは、貪欲デコーディングよりもプロンプトからの表層的なコピーが少なく、推論ステップの欠落も少ないことが示されています.この結果は、Li et al.(2022)の研究結果と同様に、Contrastive Decodingがモデル分布の反復的なまたはその他の望ましくないモードを減らすことによって機能していることを示唆しています.現在の手法は、常識的な推論タスクに対しては混合的な結果を示し、事実の検索をわずかに低下させる傾向がありますが、これらの傾向は手法のさらなる改良を促すものです.全体として、Contrastive Decodingは、さまざまなベンチマークでLLMの精度を大幅に向上させるだけでなく、推論とテキスト生成の両方の問題で最先端の結果を達成する最初の生成アルゴリズムです.
Q: 対照的デコーディングは、長文テキスト生成の知覚品質をどのように向上させるのか?
A: 対比的デコーディングは、強いモデルと弱いモデルの間の尤度の重み付けされた差を最大にする文字列を検索することにより、長文テキスト生成の知覚品質を向上させる.この方法は抽象的な推論エラーを防ぎ、思考の連鎖中に入力の一部をコピーするような単純なモードを回避する.全体として、対照的デコーディングは、長文生成のための核サンプリングや推論タスクのための貪欲なデコーディングを凌駕し、言語モデルからテキストを生成するための強力な汎用手法となっている.
Q: Contrastive Decodingで、強いモデルと弱いモデルの尤度の重み付け差を最大にする文字列を検索するプロセスを説明できますか?
A: 強いモデルと弱いモデルの間の尤度の重み付き差を最大化する文字列を探すプロセスは、コントラスティブデコーディングと呼ばれます.これは、専門家モデルとアマチュアモデルの間の尤度の差を最大化する文字列を見つけることで、専門家モデルが学習した内容を強調することを目的としています.具体的には、コントラスティブデコーディングは、専門家モデルの分布の望ましくないモード(例:短い文字列や一般的な文字列)を避けることで、専門家モデルとアマチュアモデルの間の尤度の差を最大化します.
Q: 対照的デコーディングのパフォーマンスを評価するために、具体的にどのような推論課題が用いられたのか?
A: 算術的推論や多肢選択順位付けなどの推論課題の成績を評価するために、対照解読が用いられた.
Q: HellaSwagコモンセンス推論ベンチマークにおいて、対照的デコーディングはLLaMA 2、GPT-3.5、PaLM 2-Lといった他のモデルと比較してどうなのか?
A: コントラストデコーディングは、HellaSwagの常識的な推論ベンチマークにおいて、LLaMA 2、GPT-3.5、およびPaLM 2-Lよりも優れた性能を発揮します.
Q: GSM8K math word reasoning ベンチマークにおいて、LLaMA 2、GPT-3.5、PaLM-540Bに対するContrastive Decodingの改善点の詳細を教えてください.
A: GSM8K数学ワード理解ベンチマークにおいて、Contrastive DecodingはLLaMA 2、GPT-3.5、およびPaLM-540Bに比べて改善が見られます.具体的には、LLaMAモデルのさまざまなバリエーションにおいて、Contrastive Decodingは最大8パーセントポイントの絶対パフォーマンス向上をもたらします.これは、パラメータ数が5億多く、データ量が40%多いLLaMA 2を上回る結果です.
Q: 対照的デコーディングの評価には、他にどのようなタスクが含まれていたのですか?
A: 評価では、対照的デコーディングはゼロショットの多肢選択問題においても使用され、HellaSwagとARC-Challengeのタスクで特に良い結果を示しました.0となり、LLaMA-2(85.3)、GPT-3.5(85.5)、PALM 2-Large(86.8)を上回りました.
Q: 対照的デコーディングが抽象的な推論の誤りを防ぎ、思考の連鎖の間に入力の一部をコピーするような単純なモードを避けることを示唆する洞察や分析とは?
A: コントラスティブ・デコーディングは、プロンプトからの表面的なコピーを減らし、モデル分布の繰り返しや望ましくないモードを減らすことに重点を置く.このことは、対照的デコーディングが抽象的な推論の誤りを防ぎ、思考の連鎖の間に入力の一部をコピーするような単純なモードを避けることを示唆している.
Q: 対照的なデコーディングは、ロングフォーム生成のための核サンプリングと比べてどうなのか?
A: コントラスティブデコーディングは、長い文章の生成において核サンプリングよりも優れた性能を示します.
Q: 推論タスクにおいて、対照的デコーディングはどのような点で貪欲デコーディングを上回るのか?
A: 対照復号は、グリーディ復号に比べて推論タスクで優れた性能を発揮します.具体的には、対照復号は、抽象的な推論エラーや入力の一部をコピーするなどの単純なモードを回避することで、グリーディ復号よりも優れた結果を示します.
OWL: A Large Language Model for IT Operations
著者:Hongcheng Guo, Jian Yang, Jiaheng Liu, Liqun Yang, Linzheng Chai, Jiaqi Bai, Junran Peng, Xiaorong Hu, Chao Chen, Dongfeng Zhang, Xu Shi, Tieqiao Zheng, Liangfan Zheng, Bo Zhang, Ke Xu, Zhoujun Li
発行日:2023年09月17日
最終更新日:2023年09月17日
URL:http://arxiv.org/pdf/2309.09298v1
カテゴリ:Computation and Language
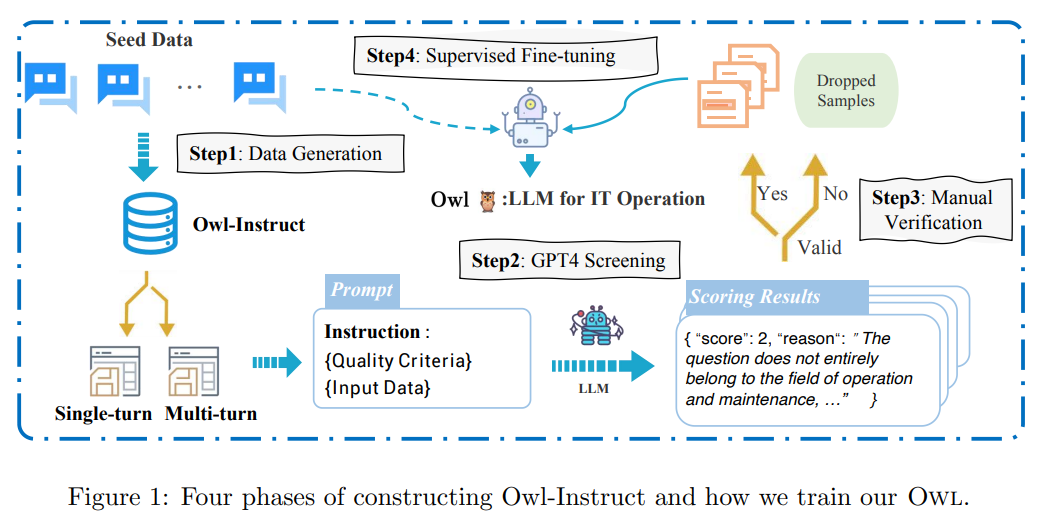
概要:
ITオペレーションの急速な発展に伴い、実用的なアプリケーションのために大量のデータを効率的に管理・分析することがますます重要になってきています.自然言語処理(NLP)の技術は、固有表現認識、機械翻訳、対話システムなど、さまざまなタスクにおいて優れた能力を示しています.最近では、大規模言語モデル(LLM)がさまざまなNLPの下流タスクで大幅な改善を達成しています.しかし、ITオペレーション向けの専門的なLLMが不足しています.本論文では、私たちが収集した広範なIT関連情報を含むOWL-Instructデータセットでトレーニングされた大規模言語モデルであるOWLを紹介し、ドメインやタスク間でのパラメータ効率のチューニングを改善するためのアダプタの混合戦略を提案します.さらに、私たちが確立したOWL-BenchおよびオープンなIT関連ベンチマークで、OWLのパフォーマンスを評価します.OWLはITタスクで優れたパフォーマンスを示し、既存のモデルを大幅に上回ります.さらに、私たちの研究の成果が専門的なLLMを用いたITオペレーションの技術革新についての洞察を提供することを期待しています.
Q&A:
Q: OWL言語モデルの目的は何ですか?
A: OWL言語モデルの目的は、ITオペレーションに特化した大規模な言語モデルを提供することです.
Q: OWL言語モデルの学習方法は?
A: Owl言語モデルは、セルフインストラクト戦略に基づいて構築されたOwl-Instructデータセットを用いて学習された.このデータセットには、IT操作に関するLLMの汎化能力を向上させるために、多様なIT関連タスクが含まれている.大規模言語モデルの学習において採用されるデータの質は非常に重要であり、最近の研究ではデータの多様性と質の両方の重要性が強調されている.そのため、Owl-Instructデータセットは、特に運用保守(O
Q: OWL-Instructデータセットとはどのようなもので、どのようなIT関連情報が含まれているのか?
A: Owl-Instructデータセットは、運用と保守(O&M)の領域に特化した高品質の教示データセットです.このデータセットはChatGPTを使用して生成された多様な指示を含み、シングルターンとマルチターンのシナリオの両方をカバーしています.
Q: ミクスチャー・オブ・アダプター戦略と、それがどのようにパラメータ効率チューニングを向上させるのか説明していただけますか?
A: 混合アダプタ戦略は、事前学習済みモデルにタスク固有の変更を導入することで、異なるドメインやタスク間でパラメータ効率のチューニングを改善するための手法です.この戦略では、軽量なLoRAアダプタのグループを使用し、事前学習済みモデルと比較して計算量を削減します.低ランクのダウンプロジェクション行列とアッププロジェクション行列を持つアダプタは、事前学習済みの埋め込み、アテンション、セグメントに直接挿入することができます.これにより、異なるドメインやタスクに対して効率的かつ柔軟な転移学習が可能となります.
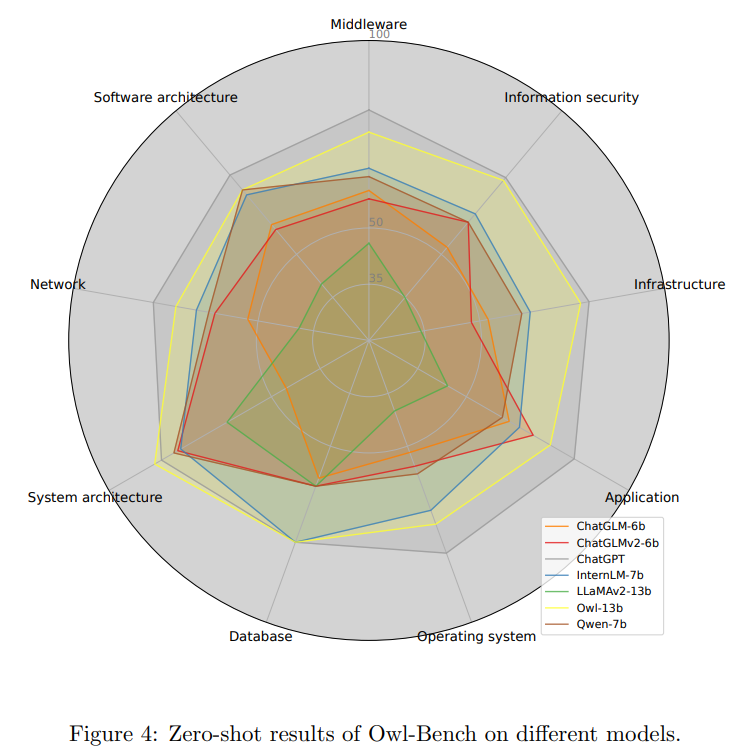
Q: OWLの性能は、OWL-BenchやオープンIT関連のベンチマークでどのように評価されたのでしょうか?
A: OWLのパフォーマンスは、OWL-BenchとオープンなIT関連のベンチマークデータセットで評価されました.OWLはITタスクで優れたパフォーマンス結果を示し、既存のモデルを大幅に上回り、OWL-Benchで効果的な汎化能力を維持しています.
Q: OWLのパフォーマンスは、ITタスクにおいて既存のモデルと比較してどのようになりますか?
A: Owlのパフォーマンスは、既存のモデルに比べてITタスクで優れています.
Q: OWLがITオペレーションにもたらす改善や進歩の詳細を教えてください.
A: Owlは、IT業務に改善と進歩をもたらす大規模な言語モデルである.IT業務に関する言語モデルの汎化能力を向上させるため、多様なIT関連タスクを含むOwl-Instructと呼ばれるデータセットで学習される.Owlはまた、命令チューニング性能を向上させるmixture-of-adapter戦略を導入している.Owlの性能は、9つの運用保守領域を含むOwl-Bench評価ベンチマークデータセットで評価される.Owl-Benchでの実験結果は、既存のモデルを大幅に上回るものであり、IT運用におけるOwlの有効性を実証している.本研究で得られた知見は、IT運用管理に革命をもたらすさらなる洞察を提供する.
Q: この研究で得られた知見は、LLMに特化したITオペレーションの技術にどのような革命をもたらすとお考えですか?
A: この研究の成果は、ITオペレーションの専門的なLLMを用いた技術に革新をもたらすことが期待されます.Owlという大規模な言語モデルは、IT関連の広範な知識を持つデータセットで訓練されており、ITタスクにおいて優れたパフォーマンスを示します.特に、Owlは既存のモデルよりも優れた結果を示し、ITタスクにおけるパラメータ効率のチューニングを改善するためのアダプタの混合戦略を提案しています.さらに、Owl-Benchというデータセットを用いて、Owlのパフォーマンスを評価しています.この研究の成果は、ITオペレーションの分野において、専門的なLLMを活用した新たな技術の革新をもたらすことが期待されます.
Struc-Bench: Are Large Language Models Really Good at Generating Complex Structured Data?
著者:Xiangru Tang, Yiming Zong, Jason Phang, Yilun Zhao, Wangchunshu Zhou, Arman Cohan, Mark Gerstein
発行日:2023年09月16日
最終更新日:2023年09月19日
URL:http://arxiv.org/pdf/2309.08963v2
カテゴリ:Computation and Language
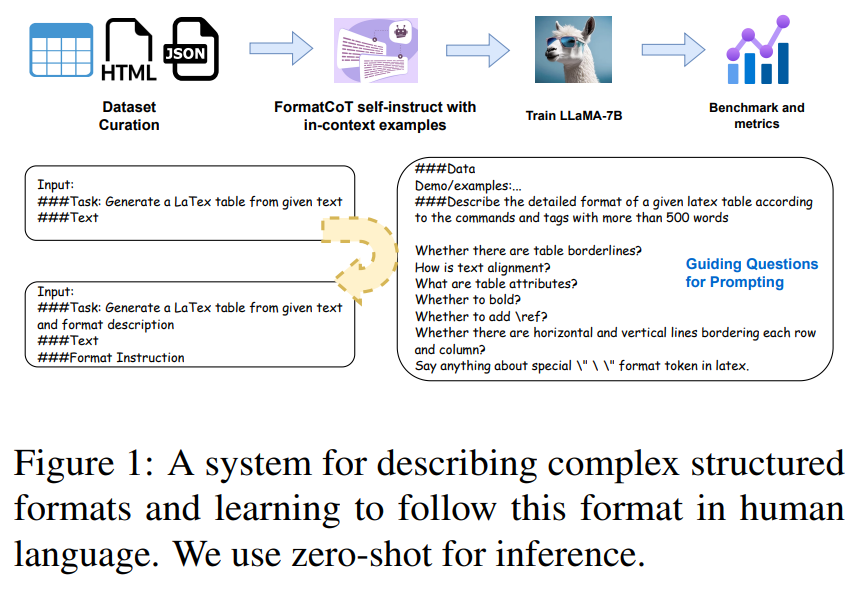
概要:
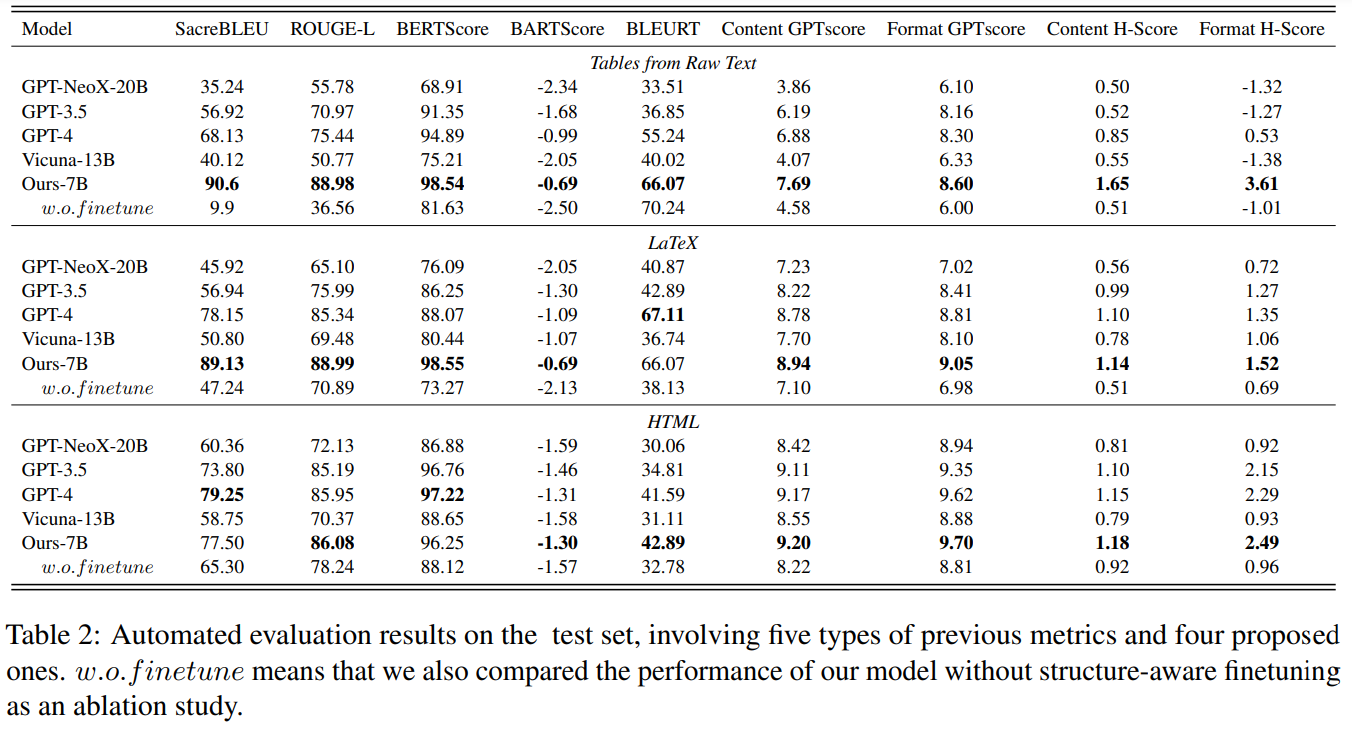
大規模言語モデル(LLM)の力にもかかわらず、GPT-4のようなモデルは、複雑な構造を持つ出力を生成するタスクにはまだ苦労しています.この研究では、現在のLLMの複雑な構造データ生成能力を評価し、この能力を向上させるための構造に注意したファインチューニング手法を提案します.包括的な評価を行うために、私たちはStruc-Benchを提案し、GPT-NeoX 20B、GPT-3.5、GPT-4、Vicunaの5つの代表的なLLMを含め、テキスト、HTML、LaTeXテーブルをカバーする慎重に構築されたデータセットで評価します.現在のモデルのパフォーマンスの分析に基づいて、特定の共通のフォーマットエラーや改善の余地のある領域を特定します.複雑なフォーマット要件に対処するために、ターゲットの出力からフォーマット指示を生成するためにFormatCoT(Chain-of-Thought)を利用します.私たちの実験は、LLaMA-7Bに適用された構造に注意したファインチューニング手法が、自然言語の制約に対する遵守度を大幅に向上させ、他の評価されたLLMよりも優れていることを示しています.これらの結果に基づいて、6つの次元からモデルの能力マップを提示します.さらに、結果として、6つの次元からモデルの能力マップを提示します(カバレッジ、フォーマット、推論、理解、語用論、幻想).このマップは、LLMの複雑な構造化された出力の取り扱いにおける弱点を明らかにし、将来の研究の有望な方向性を示唆しています.私たちのコードとモデルは、https://github.com/gersteinlab/Struc-Benchで入手できます.
Q&A:
Q: この箇所で述べられている研究の目的は何ですか?
A: 研究の目的は、LLMの能力を向上させ、構造化されたテキストを生成することです.
Q: 現行モデルのパフォーマンス分析において、具体的にどのような一般的なフォーマットエラーが確認されたのか?
A: 現行のモデルのパフォーマンス分析において特定された一般的なフォーマットエラーは、要素エラー、要素の形式エラー、構造エラー、構造の命名エラーです.
Q: 複雑なフォーマット要件に対応するために、FormatCoT(思考の連鎖)メソッドはどのように貢献しますか?
A: FormatCoT(Chain-of-Thought)メソッドは、複雑なフォーマット要件に対処するために貢献します.このメソッドは、ターゲットの出力からフォーマットの指示を生成するために使用されます.実験の結果、LLaMA-7Bに適用された構造に注意を払ったファインチューニング手法は、自然言語の制約に対する遵守度を大幅に向上させ、他の評価されたLLMを上回る性能を示しました.
Q: 構造を考慮した微調整法を適用した場合、どのLLMが自然言語制約への準拠において他の評価対象LLMを上回ったか?
A: 現在評価されている他のLLMを上回る自然言語の制約への適合性において、structure-aware fine-tuningメソッドを適用したLLMa-7Bが最も優れていました.
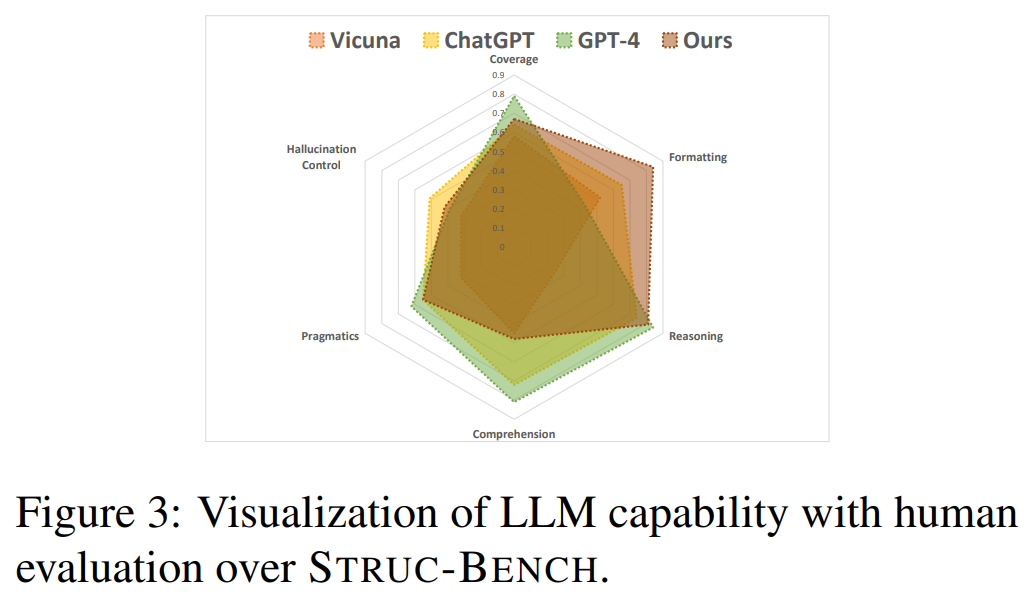
Q: モデル能力の能力マップを作成するために使用される6つの次元とは?
A: モデルの能力マップは、カバレッジ(Coverage)、フォーマット推論(Formatting Reasoning)、理解(Comprehension)、プラグマティクス(Pragmatics)、幻覚制御(Hallucination Control)の6つの次元を使用して作成されました.
Q: 複雑な構造化されたアウトプットを扱う上で、LLMのどのような弱点が能力マップによって浮き彫りにされたのか?
A: 能力マップは、LLMが複雑な構造化された出力を処理する際の弱点を示しており、カバレッジ、フォーマット、推論、理解、語用論、幻想の6つの側面からその能力を評価しています.
Q: 研究に関連するコードやモデルはどこにありますか?
A: 研究に関連するコードとモデルは、https://github.com/gersteinlab/Struc-Bench で見つけることができます.
Compositional Foundation Models for Hierarchical Planning
著者:Anurag Ajay, Seungwook Han, Yilun Du, Shuang Li, Abhi Gupta, Tommi Jaakkola, Josh Tenenbaum, Leslie Kaelbling, Akash Srivastava, Pulkit Agrawal
発行日:2023年09月15日
最終更新日:2023年09月21日
URL:http://arxiv.org/pdf/2309.08587v2
カテゴリ:Machine Learning, Artificial Intelligence, Robotics

概要:
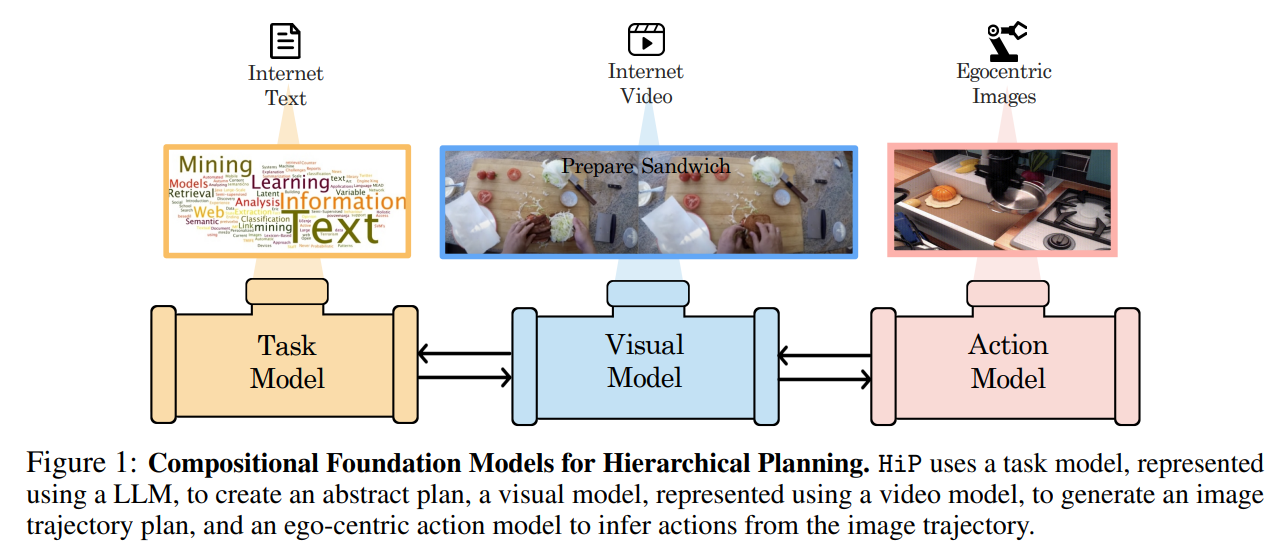
新しい環境で長期目標を持って効果的な意思決定をするためには、空間的および時間的なスケールを横断した階層的な推論を行うことが重要です.これには、抽象的なサブゴールのシーケンスを計画し、その計画に基づいて視覚的に推論し、視覚モーター制御を通じて計画に従って行動を実行することが含まれます.私たちは、長期目標のタスクを解決するために、言語、ビジョン、およびアクションのデータを個別にトレーニングした複数の専門家の基礎モデルを組み合わせた、階層的計画のための構成的な基礎モデル(HiP)を提案します.大規模な言語モデルを使用して、環境に根ざした象徴的な計画を構築します.生成されたビデオ計画は、生成されたビデオからアクションを推論する逆ダイナミクスモデルを介して視覚モーター制御に根ざされます.この階層内で効果的な推論を可能にするために、モデル間の一貫性を反復的に改善することで実現します.私たちのアプローチの効果と適応性を、3つの異なる長期目標のテーブルトップ操作タスクで示します.
Q&A:
Q: 提案されている階層的プランニング(HiP)のための構成的基礎モデルの主な目的は何ですか?
A: 提案されたCompositional Foundation Models for Hierarchical Planning (HiP)の主な目的は、新しい環境での長期の目標に基づいた効果的な意思決定を行うために、空間的および時間的なスケールで階層的な推論を行うことです.これには、抽象的なサブゴールのシーケンスを計画し、計画の基礎となるビジュアルな推論を行い、ビジュアルモーターコントロールを通じて計画に従って行動を実行することが含まれます.
Q: HiPモデルはどのように複数の専門家基盤モデルを活用しているのか?
A: HiPモデルは、異なる専門家モデルの組み合わせで構成されており、それぞれのモデルが個別に訓練されています.具体的には、HiPモデルは大規模な言語モデルを使用して、抽象的な言語指示からサブタスクのシーケンス(つまり、計画)を見つけます.次に、HiPモデルは大規模なビデオ拡散モデルを使用して、世界の幾何学的および物理的情報をキャプチャし、観察のみの軌跡としてより詳細な計画を生成します.最後に、HiPモデルは大規模な事前訓練逆モデルを使用して、エゴ中心の画像のシーケンスをアクションにマッピングします.このような構成的な設計選択により、別々のモデルが階層の異なるレベルで推論し、専門家の意思決定を共同で行います.
Q: 各基礎モデルのトレーニングには、どのような種類のデータが使われたのか?
A: 個々の基礎モデルのトレーニングには、言語、ビジョン、およびアクションデータが使用されました.
Q: HiPモデルはどのようにシンボリックプランを構築するのか?
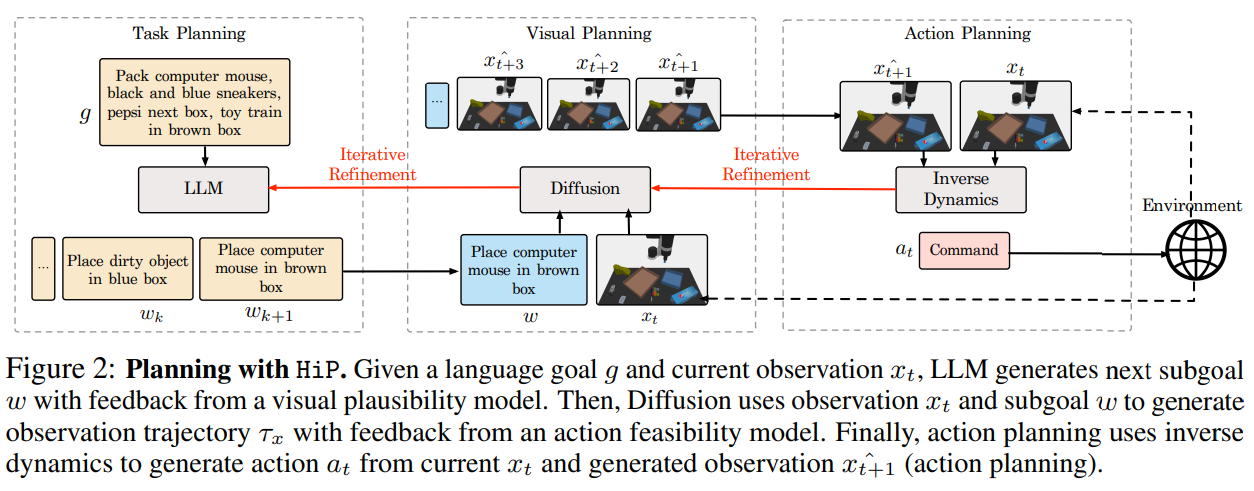
A: HiPは、長ホライズンタスクの行動軌跡を生成する問題を、タスク計画、視覚計画、行動計画の3つの階層レベルに分解することにより、シンボリック計画を構築する.タスク計画レベルでは、HiPは観察と言語目標を条件として言語サブ目標を推論する.視覚計画レベルでは、HiPは最初のタイムステップで、与えられた言語サブゴールと観察結果ごとに、物理的に妥当な計画を画像軌跡のシーケンスとして生成する.最後に行動計画レベルでは、HiPは画像軌跡から一連の行動軌跡を推論し、計画を実行する.意思決定のための構成的設計の選択により、別々のモデルが階層の異なるレベルで推論し、共同で専門的な意思決定を行うことができる.
Q: 生成されたビデオプランはどのように環境に根ざしているのか?
A: 生成されたビデオプランは、大規模なビデオ拡散モデルを介して環境に根ざしています.
Q: HiPモデルにおける逆ダイナミクスモデルの役割とは?
A: HiPの逆動力学モデルの役割は、観測ペア(xi,t, xi,t+1)を与えられたときに、アクションai,tを推論することです.
Q: HiPモデルは、異なるモデル間の整合性をどのように確保しているのですか?
A: HiPモデルは、異なるモデル間の一貫性を確保するために、異なるレベルの階層で推論を行い、専門家の意思決定を共同で行うことによって一貫性を確保しています.
Q: 新しい環境での意思決定において、階層的推論を用いることの潜在的な利点は何か?
A: 新しい環境での意思決定において階層的な推論を使用することには、いくつかの潜在的な利点があります.まず第一に、階層的な推論は長期的な目標を達成するための計画を立てることができます.これにより、複雑なタスクをより効果的に解決することができます.また、階層的な推論は異なる空間および時間スケールでの推論を統合することができます.これにより、より包括的な情報を考慮して意思決定を行うことができます.さらに、階層的な推論は抽象的なサブゴールのシーケンスを計画し、視覚的にその計画について推論し、計画に従って行動を実行することができます.これにより、より効果的な意思決定が可能となります.
Q: HiPモデルは、長期的な目標と空間的・時間的推論の課題にどのように対処しているのだろうか?
A: HiPは、そのアーキテクチャとトレーニングプロセスを通じて、長期の目標と空間的時間的な推論の課題に取り組んでいます.このモデルは、オブジェクト間の時間的依存関係と空間的関係を捉えるために、事前トレーニングにビデオ拡散モデルを利用しています.モデルは、現在のフレームと次のフレームが与えられた場合に次のアクションを予測するようにトレーニングされており、これにより空間的時間的な文脈を理解する必要があります.HiPのパフォーマンスは、オブジェクト、色、およびサブタスクの新しい組み合わせで未知のタスクを解決する場合でも、長期の目標に対する能力を示しています.これは、モデルがさまざまなシナリオで一般化し、長期の目標について推論する能力を持っていることを示しています.また、反復的な改善プロセスと視覚的な計画モデルの選択も、モデルのパフォーマンスに貢献しています.サブゴールの粒度とハイパーパラメータの感度も分析され、モデルのパフォーマンスをさらに向上させるために活用されています.全体的に、HiPはそのアーキテクチャ、トレーニングプロセス、および反復的な改善を通じて、長期の目標と空間的時間的な推論の課題に効果的に取り組んでいます.
