
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をLLMによって生成されるQ&Aを用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.自動生成記事のクオリティと信頼性を向上させるためにアルゴリズムの改善に取り組んでいます.個人で資料のQ&Aを作成されたい方には、https://www.chatpdf.com/ や https://scispace.com/などがお勧めです.
紹介する論文は以下の10本となります.
- Code Llama: Open Foundation Models for Code (発行日:2023年08月24日)
- Use of LLMs for Illicit Purposes: Threats, Prevention Measures, and Vulnerabilities (発行日:2023年08月24日)
- SeamlessM4T—Massively Multilingual & Multimodal Machine Translation (発行日:2023年08月23日)
- Prompt2Model: Generating Deployable Models from Natural Language Instructions (発行日:2023年08月23日)
- A Survey on Large Language Model based Autonomous Agents (発行日:2023年08月22日)
- IT3D: Improved Text-to-3D Generation with Explicit View Synthesis (発行日:2023年08月22日)
- Giraffe: Adventures in Expanding Context Lengths in LLMs (発行日:2023年08月21日)
- Instruction Tuning for Large Language Models: A Survey (発行日:2023年08月21日)
- LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models (発行日:2023年08月20日)
- Language to Rewards for Robotic Skill Synthesis (発行日:2023年06月14日)
Code Llama: Open Foundation Models for Code
著者:Aaron Grattafiori, Alexandre Défossez, Artyom Kozhevnikov, Baptiste Rozière, Cristian Canton Ferrer, Fabian Gloeckle, Faisal Azhar, Gabriel Synnaeve, Hugo Touvron, Itai Gat, Ivan Evtimov, Jade Copet, Jingyu Liu, Joanna Bitton, Jonas Gehring, Jérémy Rapin, Louis Martin, Manish Bhatt, Nicolas Usunier, Sten Sootla, Tal Remez, Tan, Thomas Scialom, Wenhan Xiong, Xiaoqing Ellen, Yossi Adi
発行日:2023年08月24日
最終更新日:不明
URL:https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
カテゴリ:不明
概要:
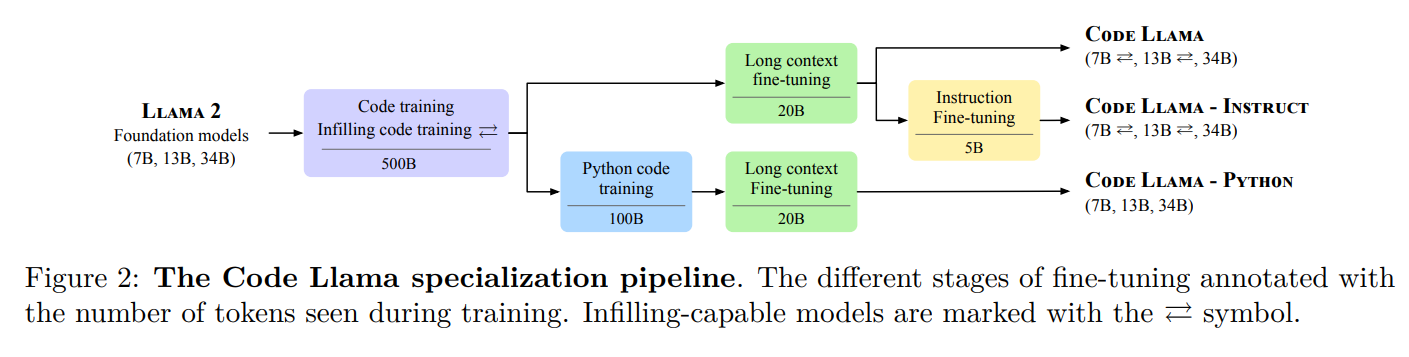
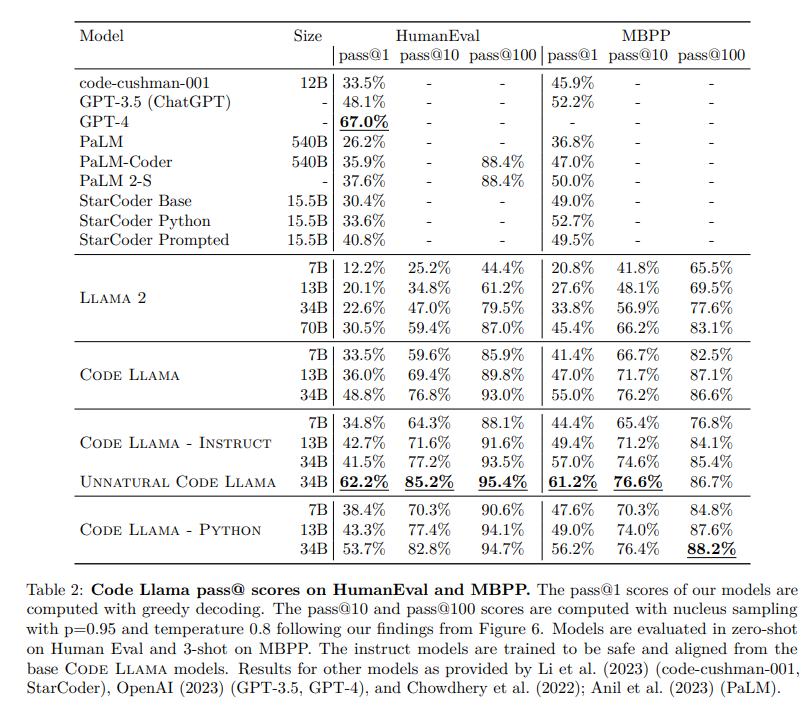
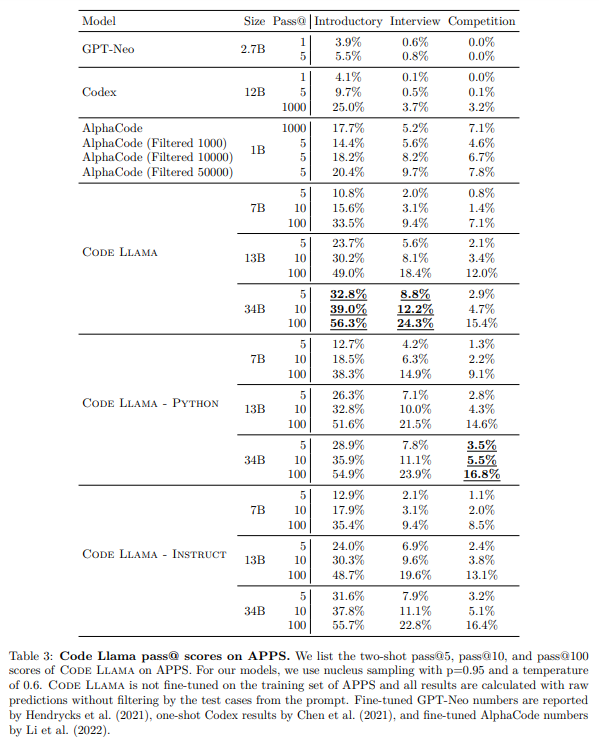
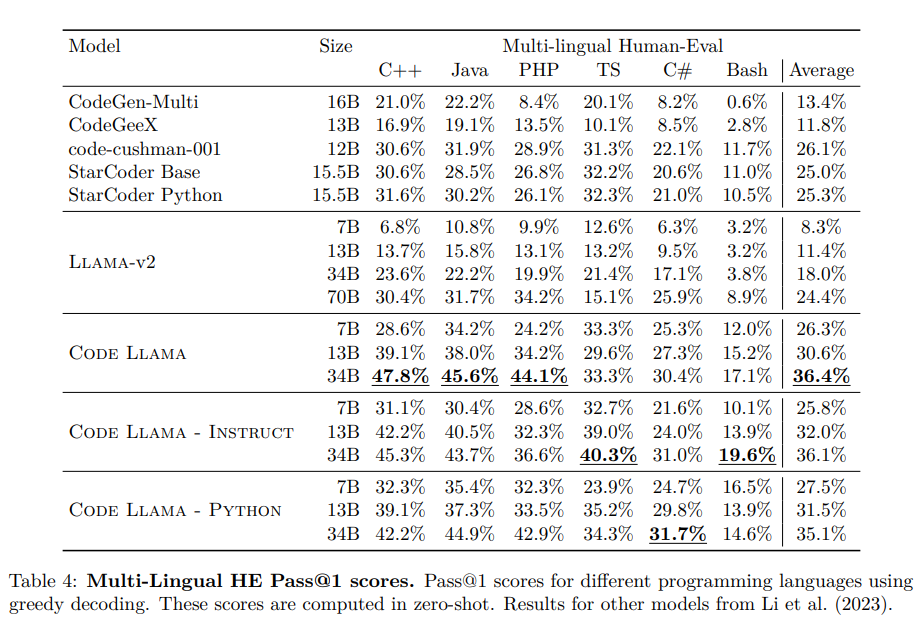
Code Llamaは、Llama 2をベースにしたコードのための大規模な言語モデルのファミリーをリリースします.このモデルは、オープンモデルの中でも最先端のパフォーマンスを提供し、インフィリング機能、大規模な入力コンテキストのサポート、プログラミングタスクのゼロショット命令の追跡能力を備えています.さまざまなアプリケーションに対応するために、Foundationモデル(Code Llama)、Pythonの特殊化モデル(Code Llama – Python)、命令の追跡モデル(Code Llama – Instruct)の複数のバリエーションを提供しています.それぞれのモデルは、16kトークンのシーケンスでトレーニングされており、最大100kトークンの入力に対して改善が見られます.7Bおよび13BのCode LlamaとCode Llama – Instructのバリエーションは、周囲のコンテンツに基づいたインフィリングをサポートしています.Code Llamaは、いくつかのコードベンチマークでオープンモデルの中でも最先端のパフォーマンスを発揮し、HumanEvalでは最大53%、MBPPでは最大55%のスコアを記録しています.特に、Code Llama – Python 7Bは、HumanEvalとMBPPでLlama 2 70Bを上回り、すべてのモデルがMultiPL-Eで他の公開モデルを上回っています.Code Llamaは、研究と商業利用の両方を可能にする許容的なライセンスの下でリリースされています.
Q&A:
Q: コードラマの目的は何ですか?
A: Code Llamaの目的は、コード生成と補完のためのLLM(Language Model)のファミリーであり、コンピュータシステムとの形式的な対話、自然言語仕様からのプログラム合成、コード補完、デバッグ、ドキュメンテーション生成などのタスクに使用されることです.
Q: Code Llamaの異なるフレーバーとそれぞれの具体的な用途は何ですか?
A: Code Llamaには複数のフレーバーがあります.基本モデルのCode Llamaは、さまざまなコード合成や理解のタスクに適応できます.Code Llama – Pythonは、特にPythonプログラミング言語を扱うために設計されています.Code Llama – Instructは、命令に従うモデルです.それぞれのモデルは、異なるパラメータ数とトークン数でトレーニングされており、特定のアプリケーションに合わせて調整することができます.
Q: コードラマの異なるバリアントには、どれくらいのパラメータがありますか?
A: Code Llamaの異なるバリアントは、それぞれ7B、13B、34Bのパラメータを持っています.
Q: モデルのトレーニングに使用されるトークンシーケンスの長さは何ですか?
A: モデルのトークンシーケンスの長さは、4,096トークンから16,384トークンに増加しました.
Q: Code Llamaモデルは、最大100kトークンの入力にどのような改善を示していますか?
A: コードラマモデルは、最大100kトークンの入力において改善が見られます.
Q: コードベンチマークにおいて、Code Llamaは他のオープンモデルと比較してどのようにパフォーマンスを発揮しますか?
A: コードラマは、コードのベンチマークで他のオープンモデルよりも優れたパフォーマンスを発揮し、それぞれHumanEvalとMBPPで最大53%と55%のスコアを達成しています.さらに、Code Llama – Python 7Bは、HumanEvalとMBPPでLlama 2 70Bを上回るパフォーマンスを発揮しています.さらに、Code Llamaのすべてのモデルは、他の公開モデルよりも優れたパフォーマンスを発揮しています.
Q: Code Llama – Python 7Bは、HumanEvalとMBPPにおいてLlama 2 70Bと比べてどのようなパフォーマンスを発揮しますか?
A: コードラマ – Python 7Bは、HumanEvalとMBPPの両方でLlama 2 70Bよりも優れたパフォーマンスを発揮します.
Q: Code Llamaモデルは、MultiPL-E上で他の公開モデルと比較してどのようになりますか?
A: コードラマモデルは、マルチプレイ上の他の公開モデルと比較して特に強力です.
Q: Code Llamaのライセンス契約は何ですか?
A: Code Llamaはカスタムの許容ライセンスの下でリリースされています.
Q: Code Llamaは研究目的と商業目的の両方に使用できますか?
A: はい、Code Llamaは研究目的と商業目的の両方に使用することができます.
Use of LLMs for Illicit Purposes: Threats, Prevention Measures, and Vulnerabilities
著者:Maximilian Mozes, Xuanli He, Bennett Kleinberg, Lewis D. Griffin
発行日:2023年08月24日
最終更新日:2023年08月24日
URL:http://arxiv.org/pdf/2308.12833v1
カテゴリ:Computation and Language, Cryptography and Security
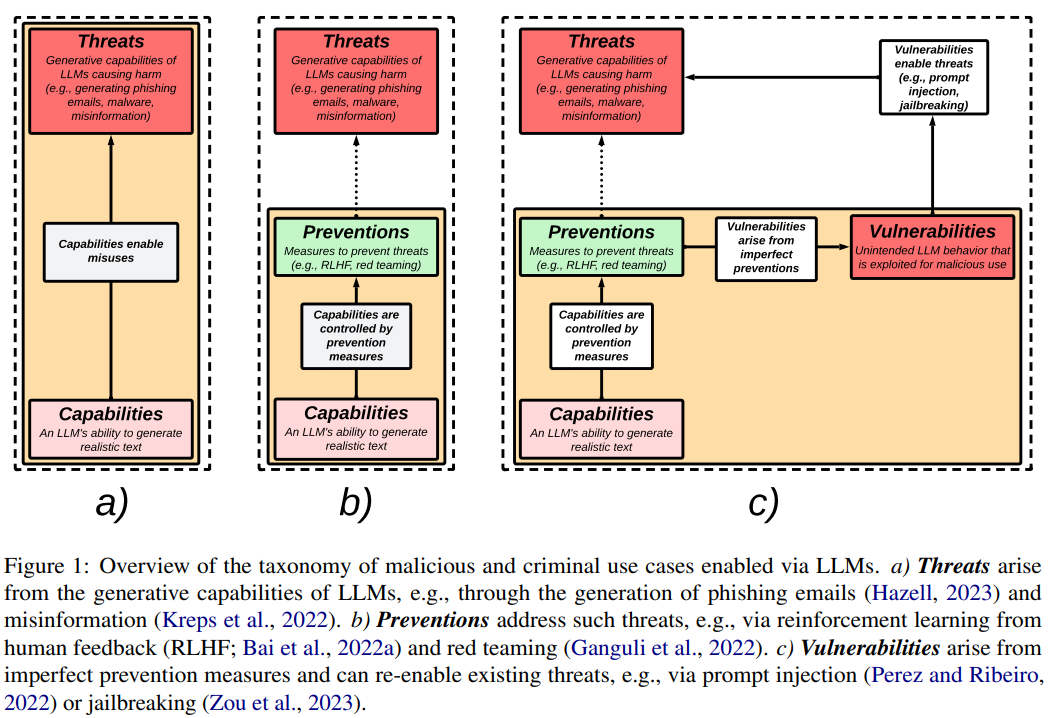
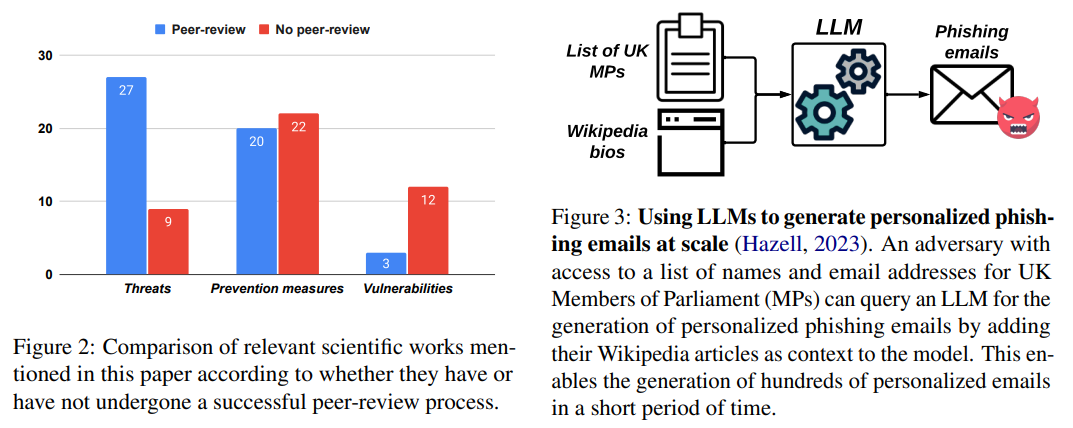
概要:
最近、産業界や学界で大規模言語モデル(LLM)の開発と配布が急速に増加していることを受けて、LLMの安全性とセキュリティに関連する脅威と脆弱性についての研究が注目されています.特に、LLMは詐欺、なりすまし、マルウェアの生成などの不正目的に悪用される可能性があることが示されており、他の研究者はAIの整合性というより一般的な問題を考慮しています.このようなモデルに関連するセキュリティ上の問題について、開発者や実践者が認識していることが重要です.本論文では、LLMに起因する脅威、それに対処するための予防策、および予防策の不完全性から生じる脆弱性の関係を説明するタクソノミーを提供します.私たちの研究により、経験豊富な開発者と新しい技術のユーザーの両方に対して、セキュリティ上の懸念を考慮したLLMの制約についての認識を高めることを目指しています.
Q&A:
Q: 大規模言語モデル(LLM)に関連する安全性とセキュリティに関する脅威と脆弱性は何ですか?
A: 大規模言語モデル(LLM)に関連する安全性およびセキュリティに関連する脅威と脆弱性は、詐欺、なりすまし、マルウェアの生成などの不正目的にLLMが誤用される可能性があることが示されています.また、他の著者はAIの整合性というより一般的な問題を考慮しています.開発者や実践者がこのようなモデルに関連するセキュリティ上の問題について認識していることが重要です.
Q: LLMは、詐欺、なりすまし、およびマルウェアの生成にどのように悪用される可能性がありますか?
A: LLMは、その生成能力を通じて詐欺、なりすまし、およびマルウェアの生成に悪用される可能性があります.LLMは、偽の文書や電子メールなどの詐欺行為に使用される詐欺コンテンツの生成に使用されることがあります.また、LLMは、個人の文章スタイルや話し方を模倣するテキストを生成することで、個人をなりすますために使用されることがあります.これは、アイデンティティ盗用やソーシャルエンジニアリング攻撃に使用される可能性があります.さらに、LLMは、悪意のあるスクリプトやプログラムを生成することで、コンピュータシステムの脆弱性を悪用するためのマルウェアコードの生成にも使用されることがあります.
Q: AIのアライメントの一般的な問題は何であり、それがLLMとどのように関連しているのか?
A: AIアライメントは、LLMを含むAIシステムが人間の価値観や目標に合致するように振る舞うことを確保する一般的な問題です.これには、AIモデルの望ましくない振る舞いやバイアスに対処するためのメカニズムや技術の設計が含まれます.LLMの文脈では、Wolfら(2023)は、望ましくないLLMの振る舞いに対処するためのどんなメカニズムも完全に排除しない限り、モデルは敵対的なプロンプト攻撃の対象になる可能性があるという理論的な説明を提供しています.つまり、LLMを人間の価値観に合わせるための努力があっても、モデルが望ましくない振る舞いを示したり、敵対的なプロンプトによって操作されるリスクがまだ存在するということです.El-Mhamdiら(2022)は、LLMを含む大規模AIモデル(LAIM)は、ユーザー生成のトレーニングデータが高次元で異質であるため、固有の制約と脆弱性を持っていると主張しています.彼らは、モデルのセキュリティを向上させるには、標準的なモデルの精度とのトレードオフが必要であると示唆しています.これらの議論は、LLMとのAIアライメントの達成における課題と制約を強調しています.
Q: LLMから生じる脅威と脆弱性を特定し、軽減するために既に行われている取り組みはありますか?
A: 既存の取り組みとして、LLMから生じる脅威と脆弱性を特定し、軽減するための努力が行われています.
Q: LLMの生成能力による脅威に対処するための予防策の例を示していただけますか?
A: LLMの生成能力による脅威に対処するための予防策の例として、人間のフィードバックからの強化学習(RLHF)やレッドチーミングが挙げられます.
Q: 不完全な予防策から生じる脆弱性は何ですか?
A: 不完全な予防措置から生じる脆弱性は、プロンプトの注入やジェイルブレイキングなどの手法によって引き起こされます.
Q: セキュリティ上の懸念事項において、LLMにはどのような制限がありますか?
A: LLMにはセキュリティ上の懸念があります.文献レビューによると、LLMの安全性とセキュリティの実現可能なレベルについて懸念があります.LLMの有用性と安全性の間には衝突があり、LLMの提供者や利用者がこのトレードオフを批判的に考慮することが重要です.さらに、LLMの人気の高まりにより、安全性やセキュリティに関わるシナリオで展開された場合に特に、その弱点や脆弱性を示す証拠の増加が予想されます.これにより、以前に説明された未来の犯罪の加速や新たな悪意のある犯罪活動の可能性が生じることがあります.将来の懸念の2つの具体的な領域は、LLMの個人化とデジタル情報やデマの拡散におけるLLMの影響です.
Q: 開発者や実践者は、LLMに関連するセキュリティの問題についてどのようにより意識を高めることができるでしょうか?
A: 開発者や実践者は、LLMに関連するセキュリティの問題についてより意識するために、関連文献を調査し、既存の脅威や考慮事項を把握する必要があります.著者の知識と専門知識に基づいて、ピアレビューされた科学論文やピアレビューを受けていない作品(例:プレプリント論文やニュース記事)を含む関連作品の収集を行うことが推奨されます.ただし、この論文に記載されている作品が公開日までの既存の取り組みの完全なコレクションを表していることを保証することはできません.むしろ、この論文では、LLMを使用する際にユーザーや実践者が意識すべき既存の脅威や考慮事項を概説することを目指しています.
Q: セキュリティ上の懸念事項に関して、経験豊富な開発者や新規ユーザーにどのようなアドバイスをしますか?
A: 経験豊富な開発者や新しいユーザーに対して、LLMのセキュリティ上の懸念に関して以下のアドバイスをすることが重要です.まず、LLMの利便性と安全性のトレードオフを注意深く考慮する必要があります.LLMの提供者やユーザーは、このトレードオフを批判的に評価することが重要です.さらに、LLMに関連するセキュリティ研究の分野は比較的新しいため、まだ成功した査読プロセスを経ていない関連論文が多数存在することに注意する必要があります.したがって、信頼性の高い情報源からの情報を確認することが重要です.また、今後LLMを利用する際には、セキュリティ上の懸念に対処するための最新の研究やベストプラクティスに関心を持つことが重要です.セキュリティに関する専門家やコミュニティの助言やガイドラインに従うことも推奨されます.
SeamlessM4T—Massively Multilingual & Multimodal Machine Translation
著者:Abinesh Ramakrishnan, Alexandre Mourachko, Alice Rakotoarison∗, Amanda Kallet, Ann Lee, Anna Sun, Bapi Akula, Benjamin Peloquin, Bernie Huang, Bokai Yu, Brian Ellis, Can Balioglu, Carleigh Wood, Changhan Wang, Christophe Ropers, Christopher Klaiber∗, Cynthia Gao, Daniel Li, Daniel Licht∗, David Dale, Elahe Kalbassi, Ethan Ye∗, Francisco Guzmán, Gabriel Mejia Gonzalez, Guillaume Wenzek∗, Hady Elsahar, Hirofumi Inaguma, Holger Schwenk, Hongyu Gong, Igor Tufanov, Ilia Kulikov, Janice Lam, Jean Maillard∗, Jeff Wang, John Hoffman∗, Juan Pino, Justin Haaheim, Justine Kao, Kaushik Ram Sadagopan∗, Kevin Heffernan, Kevin Tran, Loïc Barrault, Maha Elbayad, Mariano Cora Meglioli, Marta R. Costa-jussà‡, Min-Jae Hwang, Mohamed Ramadan, Naji El Hachem, Ning Dong, Onur Celebi, Paden Tomasello, Paul-Ambroise Duquenne, Peng-Jen Chen, Pengwei Li∗, Pierre Andrews, Prangthip Hansanti, Ruslan Mavlyutov, Russ Howes, Safiyyah Saleem, Skyler Wang, Somya Jain, Sravya Popuri, Tuan Tran, Vish Vogeti, Xutai Ma, Yilin Yang, Yu-An Chung
発行日:2023年08月23日
最終更新日:不明
URL:https://ai.meta.com/research/publications/seamless-m4t/
カテゴリ:不明
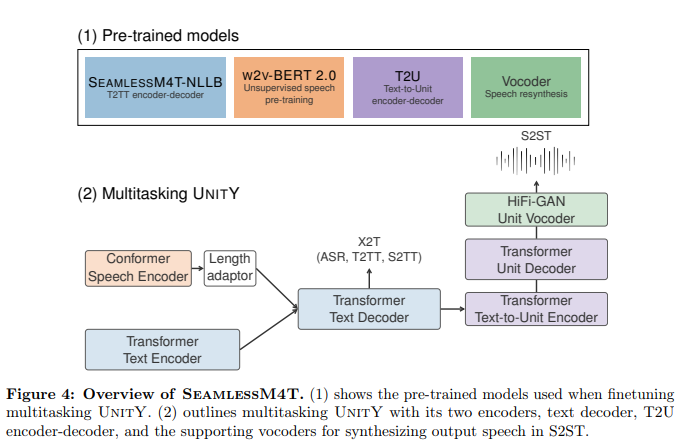
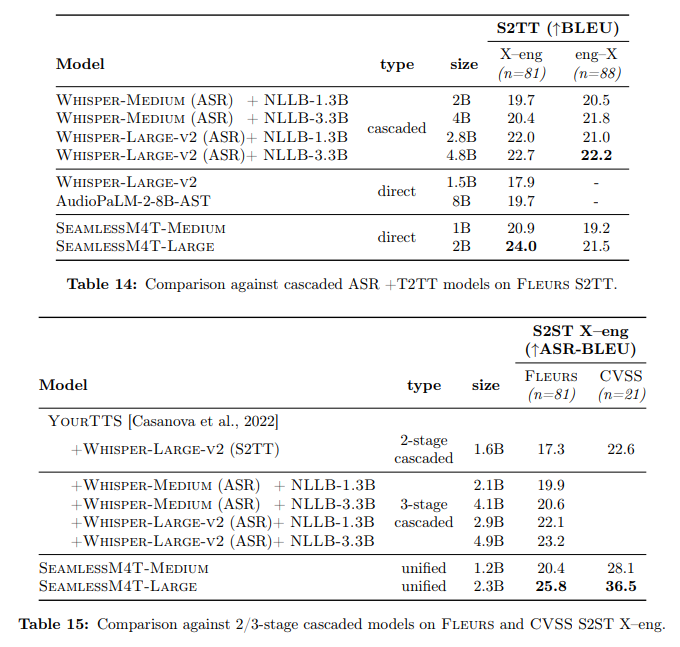
概要:
バベルフィッシュは、個人が任意の2つの言語間でスピーチを翻訳するのに役立つツールです.最近のテキストベースのモデルの突破により、機械翻訳のカバー範囲は200以上の言語を超えていますが、統一されたスピーチからスピーチへの翻訳モデルはまだ同様の進歩を達成していません.SeamlessM4T(Massively Multilingual & Multimodal Machine Translation)は、スピーチからスピーチへの翻訳、スピーチからテキストへの翻訳、テキストからスピーチへの翻訳、テキストからテキストへの翻訳、および最大100言語の自動音声認識をサポートする単一のモデルです.このモデルは、1百万時間のオープンスピーチオーディオデータを使用して構築され、スピーチとテキストの両方で英語からの翻訳が可能な最初の多言語システムを開発しました.SeamlessM4Tは、複数の目標言語への翻訳において新たな基準を設定し、直接のスピーチからテキストへの翻訳において従来の最先端技術に比べて20% BLEUの改善を達成しました.また、スピーチからテキストへの翻訳において1.3 BLEUポイント、スピーチからスピーチへの翻訳において2.6 ASR-BLEUポイントの品質向上を実現しました.さらに、SeamlessM4Tは、背景ノイズや話者の変動に対しても堅牢性があり、現行の最先端モデルと比較して、スピーチからテキストへのタスクにおいて平均的な改善率が38%および49%です.また、性別バイアスや有害性の評価においても優れた結果を示し、翻訳の出力における有害性の削減率は最大で63%です.この研究では、モデル、推論コード、Fine-tuningのレシピ、改良されたモデリングツールキットFairseq2によるメタデータなど、すべての貢献がオープンソース化され、https://github.com/facebookresearch/seamless_communicationで利用可能です.
Q&A:
Q: SeamlessM4Tの目的は何ですか?
A: SeamlessM4Tの目的は、研究者や機械翻訳の研究コミュニティを主なユーザーとして、音声とテキストの翻訳に関する研究を支援することです.SeamlessM4Tは、自動音声認識、音声から音声への翻訳、音声からテキストへの翻訳、テキストから音声への翻訳、テキストからテキストへの翻訳、およびテキストから音声の合成をサポートしています.ただし、SeamlessM4Tは研究モデルであり、製品展開には適していません.また、特定のドメイン(医療や法律など)には対応しておらず、長文の翻訳にも適していません.
Q: SeamlessM4Tはどのように構築されましたか?
A: SeamlessM4Tは、Seamless Communication et al, SeamlessM4T—Massively Multilingual & Multimodal Machine Translation, Arxiv, 2023という論文で詳細なトレーニングアルゴリズムとデータが説明されています.SeamlessM4T-Mediumは、SeamlessM4T-Largeよりもパラメーターが57%少なく、研究者や機械翻訳研究コミュニティを主なユーザーとして想定されています.SeamlessM4Tは一般的なドメインのデータでトレーニングされており、医療ドメインや法律ドメインなどの特定のドメインの入力には使用されません.また、長文の翻訳には適していません.
Q: SeamlessM4Tは音声からテキストへの翻訳において、どのような改善を実現していますか?
A: SeamlessM4Tは、直接音声からテキストへの翻訳において、従来の最先端技術に比べて20% BLEUの改善を達成しています.
Q: シームレスM4Tは、強力なカスケードモデルと比較して、翻訳品質はどのようになりますか?
A: SeamlessM4Tは、強力な段階的モデルと比較して翻訳の品質を向上させます.直接音声からテキストへの翻訳において、従来の最先端技術に比べてBLEUスコアが20%向上しています.具体的には、英語への翻訳では、SeamlessM4Tは音声からテキストへの翻訳の品質を1.3 BLEUポイント向上させ、FleursにおけるASR(自動音声認識)の品質を4.2 BLEUポイント向上させます.さらに、SeamlessM4T-Largeは、段階的モデルと比較して2 BLEUポイント以上の翻訳精度を向上させます.英語からの翻訳では、SeamlessM4T-LargeはCoVoST 2において従来の最先端技術(XLS-R-2B-S2T)を2.8 BLEUポイント上回り、Fleursにおいては段階的システムと同等の性能を発揮します.S2STタスクでは、SeamlessM4T-LargeはFleursにおいて強力な3段階の段階的モデルを2.6 ASR-BLEUポイント上回ります.CVSSでは、SeamlessM4T-Largeは2段階の段階的モデルをある程度上回ります.
Q: 音声からテキストへの翻訳の結果、人間の評価はどうでしたか?
A: 人間の評価による音声からテキストへの翻訳の結果は非常に印象的でした.英語からの翻訳では、24の評価言語すべてでXSTSスコアが5点満点中4点以上で一貫していました.英語への翻訳では、24の言語のうち7つでWhisper-Large-v2のベースラインに比べて大幅な改善が見られました.さらに、Blaser 2.0を開発してシステムを評価しました.これにより、音声とテキストの評価を行う際に、以前のモデルと同様の精度で品質推定が可能になりました.また、耐久性のテストでは、現在の最先端技術と比較して、背景ノイズや話者の変動に対して音声からテキストへのタスクでより優れた性能を発揮しました(それぞれ平均改善率は38%と49%).さらに、ジェンダーバイアスと追加の有害性に対してSeamlessM4Tを評価し、翻訳の安全性を評価しました.最先端技術と比較して、翻訳の出力における追加の有害性を最大で63%削減しました.最後に、この研究のすべての貢献(モデル、推論コード、ファインチューニングレシピ、改善されたモデリングツールキットFairseq2によるバックアップ、およびフィルタリングされていない470,000時間のSeamlessAlignを再現するためのメタデータ)はオープンソースです.
Q: 「Blaser 2.0」とは何ですか?それは前作と比べてどのようなものですか?
A: Blaser 2.0は、BLASERの新しいバージョンであり、音声とテキストの両方のモダリティに対応しています.先行バージョンと同様に、入力と出力の文の埋め込みの類似性を活用しています.Blaser 2.0は、音声モダリティで83の言語をサポートし、品質評価において先行バージョンと同等の精度を持っています.さらに、Blaser 2.0は、音声からテキストへの変換タスクにおいて、背景ノイズや話者の変動に対して、現在の最先端技術と比較して、38%および49%の平均改善を達成しています.
Q: SeamlessM4Tは、背景のノイズや話者の変動に対して、音声からテキストへの変換タスクをどのように実行しますか?
A: SeamlessM4Tは、背景ノイズや話者の変動に対してWhisper-Large-v2よりも堅牢性があり、平均して38%および49%の改善が見られます.
Q: SeamlessM4Tは、ジェンダーバイアスと翻訳の安全性にどのように対処していますか?
A: SeamlessM4Tは、ジェンダーバイアスと翻訳の安全性に対して評価され、追加の有害性を最大63%削減することを報告しています.また、中立的な用語から翻訳する際に男性的な形式に過度に一般化する傾向があり、ジェンダーをわずか3%変化させると頑健性に欠けることも評価されました.これらの効果を文書化し、さらなる緩和策を促すために報告されています.
Q: この仕事の貢献は何ですか?
A: この研究の貢献は、以下の要素によって実現されています.まず、Sergey EdunovとAngela Fanはプロジェクトの初期段階を形作るのに役立ちました.Shruti Bhosale、Vedanuj Goswami、Fernando Hernandez、Yun Tangはより良いモデルの構築に貢献しました.Mingda ChenはBlaser 1.0への貢献をしました.Kiryl Klyushkinはより良いエクスペリエンスの構築に役立ちました.Artyom KozhevnikovはFairseq2とSonarinferenceへの貢献をしました.Zhaoheng NiとXiaohui Zhangはオーディオノイズ除去モデルのベンチマークを行いました.Neil SeejoorとMark Duppenthalerはデモの設定に役立ちました.Vedanuj Goswami、Samuel Hsia、Bilge Acun-Uyan、Carole-Jean Wuは効率の最適化に協力しました.Adébissy Tharingerは研究を新しいオーディエンスに広めるのに役立ちました.Geeta Chauhan、Ankit Gunapal、Caleb Ho、Dinesh Kannappan、Apostolos Kokolis、Teng Li、Matthias Reso、Shubho Sengupta、Hamid Shojanazeri、Xinyuan Zhangは計算リソースとインフラストラクチャの提供に協力しました.Emmanuel DupouxとEric Michael Smithはフィードバックを提供しました.
Q: この論文で紹介された新しいメソッドのコード実装のURLは何ですか?
A: この論文で導入された新しい手法のコード実装のURLは、https://github.com/facebookresearch/seamless_communication/issues です.
Prompt2Model: Generating Deployable Models from Natural Language Instructions
著者:Vijay Viswanathan, Chenyang Zhao, Amanda Bertsch, Tongshuang Wu, Graham Neubig
発行日:2023年08月23日
最終更新日:2023年08月23日
URL:http://arxiv.org/pdf/2308.12261v1
カテゴリ:Computation and Language

概要:
本論文では、Prompt2Modelという一般的な手法を提案し、LLMに提供されるプロンプトのような自然言語のタスク説明を使用して、展開に適した特定のモデルをトレーニングする方法を示す.Prompt2Modelは、既存のデータセットと事前学習モデルの検索、LLMを使用したデータセットの生成、およびこれらの検索および生成されたデータセットでの教師あり微調整の複数ステップのプロセスによって行われる.この手法を用いることで、同じフューショットプロンプトを入力として与えられた場合、gpt-3.5-turboという強力なLLMの結果を平均20%上回るモデルをトレーニングすることが示されている.さらに、この手法を使用してモデルのパフォーマンスの信頼性のある推定値を得ることも可能である.Prompt2Modelはオープンソースとして提供されており、詳細はhttps://github.com/neulab/prompt2modelで確認できる.
Q&A:
Q: Prompt2Modelの目的は何ですか?
A: Prompt2Modelの目的は、プロンプトを使用してシステムの動作を指定することで、展開可能な特定の目的のモデルを維持しながら、軽量な方法でシステムの動作を指定する能力を保持することです.Prompt2Modelは、自動化されたパイプラインとして設計されており、重要なタスク情報を抽出し、その情報を使用してタスク固有のモデルを生成します.Prompt2Modelは、手動のデータ注釈やアーキテクチャの設計なしに、数時間でLLMを上回るタスク固有のモデルを生成することができます.また、Prompt2Modelは、モデルの蒸留、データセットの生成、合成評価、データセットの取得、モデルの取得など、新しい技術の探索のためのプラットフォームとしても利用できます.Prompt2Modelは、小さながらも正確なモデルを提供し、生成されたデータセットを使用して実世界のパフォーマンスを推定することができます.
Q: Prompt2Modelは従来の特定の目的のNLPモデルとどのように異なるのですか?
A: Prompt2Modelは、従来の特定の目的のNLPモデルとは異なり、手動のデータ注釈やアーキテクチャ設計の必要なく、小規模で能力のあるNLPシステムを迅速に構築することができます.これにより、LLMのプロトタイプ作成とモデルの実用的な展開のギャップを埋めることができます.従来の特定の目的のNLPモデルでは、タスクの範囲の定義、データの検索または作成、適切なモデルアーキテクチャの選択、モデルのトレーニング、パフォーマンスの評価、および実世界での使用の展開には相当な努力が必要です.Prompt2Modelは、数時間でLLMを上回るタスク固有のモデルを生成できるツールを提供することで、このプロセスを簡素化します.また、モデルの蒸留、データセットの生成、合成評価、データセットの取得、およびモデルの取得といった新しい技術の探索のためのテストベッドも提供しています.Prompt2Modelは、NLPコミュニティ外の人々にNLPモデルへのアクセスを向上させ、初期のNLP研究者の出発点を提供することを目指しています.
Q: Prompt2Modelを使用して特定の目的のモデルをトレーニングするためには、どのようなプロセスが関与していますか?
A: Prompt2Modelは、既存のデータセットと事前学習済みモデルの検索、LLMを使用したデータセットの生成、およびこれらの検索および生成されたデータセットでの教師付き微調整という複数のステップのプロセスを通じて、特定の目的に適したモデルのトレーニングを行います.
Q: Prompt2Modelでの既存のデータセットと事前学習済みモデルの取得方法を説明していただけますか?
A: Prompt2Modelは、特定の目的のモデルを訓練するために既存のデータセットと事前学習済みモデルを取得します.取得プロセスでは、プロンプトに基づいてユーザーの意図に適した事前学習済み言語モデル(LLM)を特定します.この選択されたLLMは学生モデルとして機能し、生成されたデータと取得されたデータを用いてさらに微調整と評価が行われます.既存のデータセットと事前学習済みモデルの取得は、LLMを使用したデータセットの取得とBM25やDataFinderなどの技術を使用したモデルの取得を含む多段階のプロセスを通じて行われます.取得されたデータセットとモデルは、Prompt2Modelの訓練に使用され、gpt-3.5-turboという強力なLLMの結果を上回るモデルを生成しますが、サイズは小さくなります.
Q: Prompt2Modelは、LLMを使用してデータセットを生成する方法はどのようなものですか?
A: Prompt2Modelは、LLMを使用してデータセットを生成し、LLMを「教師モデル」として使用して擬似ラベル付きデータセットを生成します.このプロセスでは、LLMを使用してタスク固有の知識を生成し、データセットに蒸留します.生成されたデータセットは、より小さな「学生」モデルのトレーニングに使用され、LLMの振る舞いを模倣します.これまでの研究では、このアプローチがより小さなサイズの正確なモデルのトレーニングに効果的であることが示されています.
Q: Prompt2Modelにおける監視付き微調整の意義は何ですか?
A: Prompt2Modelは、特殊な目的のモデルを訓練するために教師ありの微調整を使用します.このプロセスでは、取得されたデータセットと生成されたデータセットを使用して、与えられたフューショットのプロンプトに基づいてモデルを微調整します.教師ありの微調整により、モデルの性能が向上し、gpt-3.5-turboのベースラインを平均20%上回るモデルが得られます.
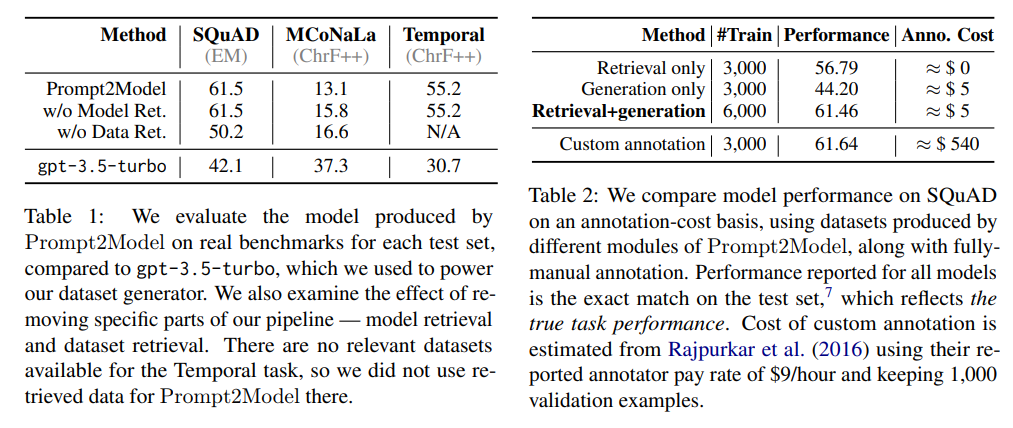
Q: Prompt2Modelがgpt-3.5-turboよりも優れているタスクの例を示していただけますか?
A: 表1では、Prompt2Modelによって生成されたモデルと、Prompt2Modelを使用せずに生成されたgpt-3.5-turboのモデルのパフォーマンスを評価しています.Prompt2Modelは、同じプロンプトを入力として使用する場合に、gpt-3.5-turboを上回る小さなモデルを生成することがあります.3つのタスクのうち2つでは、Prompt2Modelによってgpt-3.5-turboのベースラインよりも20ポイント以上の改善が観察されました.
Q: Prompt2Modelで訓練されたモデルは、gpt-3.5-turboに比べてどれくらい小さいですか?
A: Prompt2Modelによって訓練されたモデルは、gpt-3.5-turboよりも最大で700倍小さいです.
Q: Prompt2Modelは、モデル開発者が展開前にモデルの信頼性を評価することをどのように可能にしていますか?
A: Prompt2Modelは、モデル開発者が展開前にモデルの信頼性を評価することを可能にし、強力なLLMであるgpt-3.5-turboを平均20%上回るモデルを訓練することができます.さらに、Prompt2Modelから生成されたデータセットは、実世界のパフォーマンスを推定するために使用することができ、モデル開発者はモデルの信頼性を評価し、展開する前に情報を得ることができます.これにより、モデルの信頼性を評価し、展開する前に情報を得ることができます.
A Survey on Large Language Model based Autonomous Agents
著者:Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, Ji-Rong Wen
発行日:2023年08月22日
最終更新日:2023年08月22日
URL:http://arxiv.org/pdf/2308.11432v1
カテゴリ:Artificial Intelligence, Computation and Language
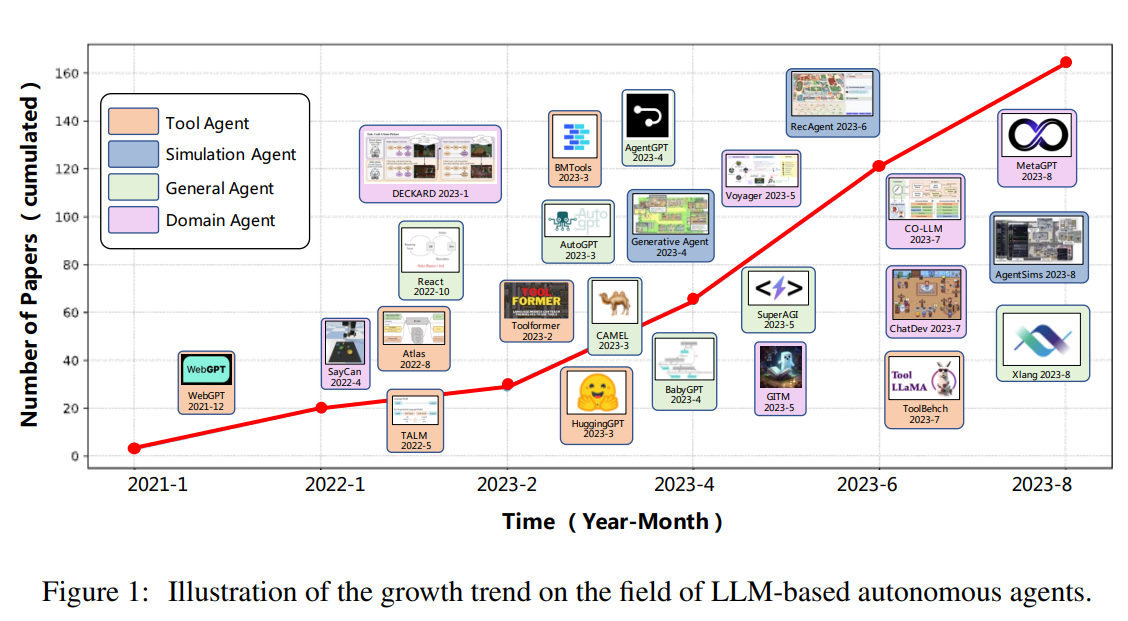
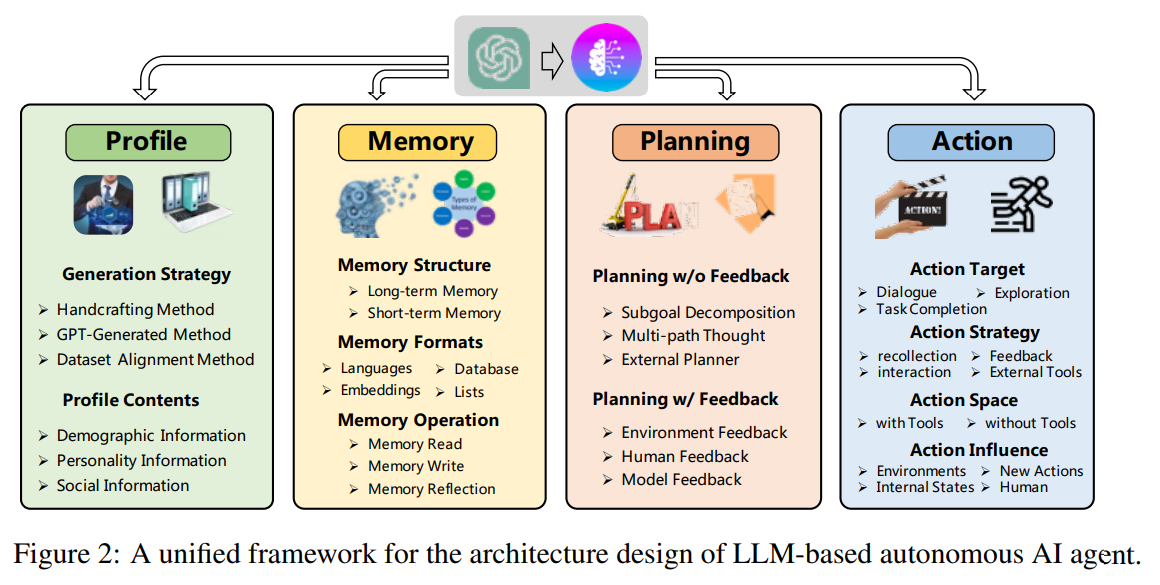
概要:
自律エージェントは、学術コミュニティにおいて長い間注目されてきた研究トピックです.この分野の以前の研究は、孤立した環境で限られた知識を持つエージェントを訓練することに焦点を当てており、これは人間の学習プロセスとは大きく異なるため、エージェントが人間のような意思決定をすることは困難です.最近では、膨大なウェブ知識の獲得を通じて、大規模言語モデル(LLM)が人間レベルの知能を実現する可能性を示しています.これにより、LLMに基づく自律エージェントに関する研究が急増しています.LLMの全ポテンシャルを引き出すために、研究者はさまざまなアプリケーションに適したエージェントアーキテクチャを考案しています.本論文では、このような研究の包括的な調査を行い、全体的な視点から自律エージェントの分野について体系的なレビューを提供します.さらに、LLMを基にしたAIのさまざまなアプリケーションについても概要を提供します.また、社会科学、自然科学、工学の領域でのLLMベースのAIエージェントのさまざまな応用についてもまとめました.最後に、LLMベースのAIエージェントの一般的に使用される評価戦略についても議論します.これまでの研究に基づいて、この分野でのいくつかの課題と将来の方向性も提示します.この分野を追跡し、調査を継続的に更新するために、関連する参考文献のリポジトリをhttps://github.com/Paitesanshi/LLM-Agent-Surveyで管理しています.
Q&A:
Q: 自律エージェントの研究の主な焦点は何ですか?
A: 研究の主な焦点は、LLMベースの自律エージェントの構築、応用、評価の3つの側面にあります.
Q: 以前の研究アプローチと人間の学習プロセスとの違いは何ですか?
A: 以前の研究では、孤立した環境で限られた知識を持つエージェントを訓練することが多くありました.しかし、これは人間の学習プロセスとは大きく異なり、エージェントが人間のような意思決定をすることが困難になります.
Q: 大規模言語モデル(LLM)は、人間レベルの知能を達成する可能性はあるのでしょうか?
A: 大規模言語モデル(LLM)は、人間レベルの知能を達成する上で非常に高い潜在能力を示しています.
Q: 研究者は、LLMの全ての潜在能力を引き出すために、エージェントのアーキテクチャをどのように調整してきたのでしょうか?
A: LLMベースのエージェントの構築に関して、研究者は異なるアプリケーションに合わせた多様なエージェントアーキテクチャを考案しています.これにより、LLMのフルポテンシャルを引き出すことが可能となっています.
Q: 社会科学、自然科学、工学におけるLLMベースのAIエージェントのさまざまな応用は何ですか?
A: LLMベースのAIエージェントは、社会科学、自然科学、工学のさまざまな応用があります.社会科学では、心理学、政治学、経済学、社会シミュレーション、法学、研究助手として使用されます.自然科学では、文書管理やデータ管理、実験助手、科学教育に使用されます.工学では、土木工学に使用されます.
Q: LLMベースのAIエージェントには、一般的にどのような評価戦略が採用されていますか?
A: LLMベースのAIエージェントの評価には、主観的評価と客観的評価の2つの一般的な評価戦略が使用されます.
Q: LLMベースの自律エージェントの分野で特定された課題は何ですか?
A: LLMベースの自律エージェントの開発には、いくつかの課題があります.そのうちの一つは、役割演じ能力です.これは、人間のような能力に基づいて効果的にタスクを実行するエージェントの能力を指します.もう一つの課題は、LLMベースのエージェントの設計に適したアーキテクチャを決定することです.さらに、LLMのパラメータを学習することも重要な側面です.これらの課題は、LLMベースの自律エージェントの分野で特定されています.
Q: この分野の研究の将来の方向性は何ですか?
A: この分野の研究の将来の方向性については、いくつかの課題が特定されており、それらに対する解決策やアプローチが提案されています.具体的には、LLMベースの自律エージェントの構築、応用、評価の各側面において、さらなる研究が必要です.エージェントの構築に関しては、LLMをより効果的に活用するためのアーキテクチャの設計が求められます.また、パラメータの学習に関しても、より効率的な手法やアルゴリズムの開発が必要です.さらに、エージェントの応用においては、LLMの人間のような能力をどのように活かすかについての研究が重要です.最後に、エージェントの評価に関しては、適切な評価指標や評価方法の開発が求められます.これらの課題に取り組むことで、LLMベースの自律エージェントの研究はさらに進展し、将来の方向性が明確になるでしょう.
Q: 過去の研究で特定の制限や欠点が特定されているLLMベースの自律エージェントにはありますか?
A: 前の研究では、LLMベースの自律型AIエージェントにはいくつかの制限や欠点が特定されています.これらの制限や欠点は、エージェントの構築、アプリケーション、評価のプロセスに関連しています.具体的には、LLMの学習には大量のデータと計算リソースが必要であり、訓練時間が非常に長くなる可能性があります.また、LLMは既存のデータに基づいて学習するため、新しい状況やドメインに対しては十分な対応ができない可能性があります.さらに、LLMは人間のような誤解や誤解釈の可能性があり、その結果、予測や行動が不正確になる可能性があります.
IT3D: Improved Text-to-3D Generation with Explicit View Synthesis
著者:Yiwen Chen, Chi Zhang, Xiaofeng Yang, Zhongang Cai, Gang Yu, Lei Yang, Guosheng Lin
発行日:2023年08月22日
最終更新日:2023年08月22日
URL:http://arxiv.org/pdf/2308.11473v1
カテゴリ:Computer Vision and Pattern Recognition, Artificial Intelligence

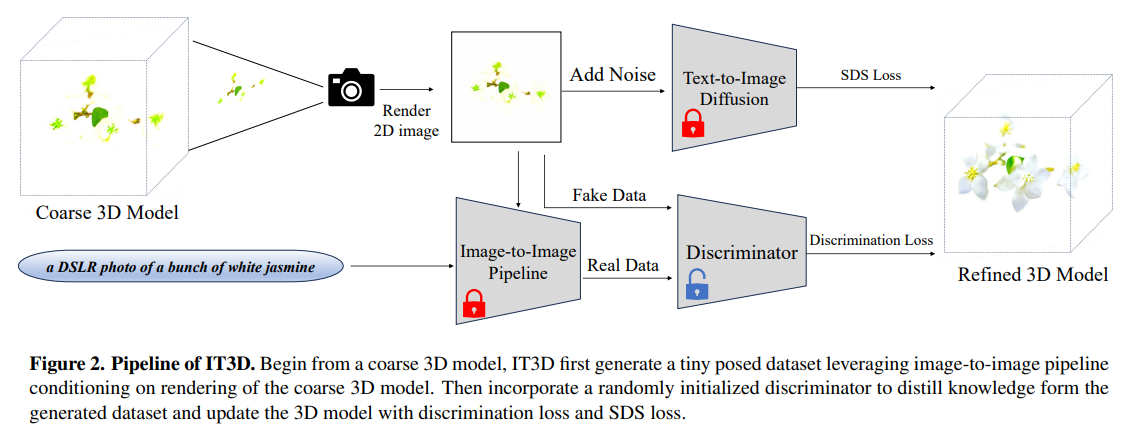
概要:
最近のText-to-3D技術の進展は、強力な大規模テキストから画像への拡散モデル(LDM)からの知識の蒸留によって推進されてきた.しかし、既存のText-to-3Dアプローチは、過度の飽和、不十分な詳細、非現実的な出力などの課題に直面している.本研究では、これらの問題に対処するために、明示的に合成されたマルチビュー画像を活用する新しい戦略を提案している.私たちのアプローチは、LDMによって強化された画像から画像へのパイプラインの利用を含み、粗い3Dモデルのレンダリングに基づいてポーズの高品質な画像を生成することです.生成された画像は、上記の問題の大部分を軽減しますが、大規模な拡散モデルの生成的な性質によるビューの不一致や内容の大きな変動などの課題が依然として存在し、これらの画像を効果的に活用することに困難を伴います.この障害を克服するために、私たちはDiffusion-GANデュアルトレーニング戦略とともに識別器を統合することを提唱しています.組み込まれた識別器では、合成されたマルチビュー画像は実データと見なされ、最適化された3Dモデルのレンダリングは偽データとして機能します.さらに、私たちはベースライン手法に比べて私たちの手法の効果を示す包括的な一連の実験を実施しています.
Q&A:
Q: 既存のテキストから3Dへのアプローチに直面する課題は何ですか?
A: 既存のテキストから3Dへのアプローチは、過度の飽和、不十分な詳細、非現実的な出力などの課題に直面しています.
Q: 提案された戦略は、明示的に合成されたマルチビュー画像をどのように活用していますか?
A: 提案された戦略は、明示的に合成されたマルチビュー画像を活用しています.このアプローチでは、LDMによって強化された画像間パイプラインを使用して、粗い3Dモデルのレンダリングに基づいてポーズの高品質な画像を生成します.生成された画像は、前述の問題の大部分を軽減しますが、大規模な拡散モデルの生成的な性質によるビューの不一致や内容の大きな変動といった課題が依然として存在し、これらの画像を効果的に活用することには困難が伴います.この障害を克服するために、我々は3Dモデルのトレーニングをガイドするために、新しいDiffusion-GANデュアルトレーニング戦略とともに識別器を統合することを提唱しています.組み込まれた識別器では、合成されたマルチビュー画像が
Q: 提案された手法における画像から画像へのパイプラインの役割は何ですか?
A: 提案された手法において、画像から画像へのパイプラインの役割は、高品質な画像を生成することです.具体的には、ControlNetとStable Diffusionという画像生成手法を使用して、粗いデータセットから高品質な画像を生成します.ControlNetは、深度マップ、法線マップ、ソフトエッジマップなどの特徴マップを抽出し、視点の一貫性を保ったデータの生成を行います.Stable Diffusionは、ランダムなガウスノイズを導入し、2D拡散ノイズ除去手法を適用することで、品質の高い画像を生成します.
Q: 粗い3Dモデルは、高品質な画像を生成する際にどのように使用されますか?
A: 粗い3Dモデルは、高品質の画像を生成するために使用されます.まず、粗い3Dモデルをレンダリングし、2D画像に変換します.次に、ノイズを追加し、テキストから画像への変換を行います.この変換された画像を使用して、画像から画像へのパイプラインを利用して、小さなポーズデータセットを生成します.このデータセットは、ランダムに初期化された識別器を使用して知識を抽出し、識別損失とSDS損失を使用して3Dモデルを更新します.最終的に、洗練された3Dモデルを使用して、高品質の画像を生成します.
Q: ビューの不一致とコンテンツの変動に関連する課題は何ですか?
A: 視点の不一致とコンテンツのばらつきは、大規模な拡散モデルの生成的な性質によって引き起こされ、これらの画像を効果的に活用する上で非常に困難をもたらします.
Q: これらの課題を克服するために、識別器の統合はどのように役立ちますか?
A: 生成されたデータセットからの知識をより効果的に抽出するために、識別器の統合が課題の克服に役立ちます.識別器は、生成されたデータセットからの知識をより良く抽出し、3Dモデルのトレーニングプロセスをガイドする役割を果たします.
Q: Diffusion-GANのデュアルトレーニング戦略について、もっと詳しく説明していただけますか?
A: Diffusion-GANデュアルトレーニング戦略は、拡散事前分布と識別損失の強みを組み合わせた革新的な戦略です.この戦略では、識別損失を更新方向のガイドとして利用し、拡散事前分布を利用して複雑なジオメトリとテクスチャの詳細を提供します.精製フェーズでは、識別器の損失と拡散事前分布の両方を使用して粗い3Dモデルθを微調整します.識別器はランダムに初期化されるため、識別損失は有意義なコンテンツと共に多くのノイズを3Dモデルに導入します.しかし、大規模な拡散モデルに固有の堅牢なノイズ除去能力のため、拡散事前分布は識別器から得られた貴重な情報を消去することなく、追加されたノイズを効果的に除去します.
Q: 提案された方法の効果を評価するために行われた包括的な一連の実験の結果は何でしたか?
A: 提案手法の効果を評価するために行われた包括的な実験の結果は、定性的および定量的な両方の実験結果を提供しています.実験結果は、提案手法がベースラインモデルを大幅に改善することを示しています.図5では、IT3Dが微小なジャヌスの問題を修正し、キャラクターのボディポーズなどの誤ったジオメトリを効果的に修正することを示しています.また、ユーザースタディでは、45人の参加者を対象に675のペア比較が行われ、平均して89.92%の人々が提案手法をベースライン手法よりも好んだことが示されました.
Giraffe: Adventures in Expanding Context Lengths in LLMs
著者:Arka Pal, Deep Karkhanis, Manley Roberts, Samuel Dooley, Arvind Sundararajan, Siddartha Naidu
発行日:2023年08月21日
最終更新日:2023年08月21日
URL:http://arxiv.org/pdf/2308.10882v1
カテゴリ:Artificial Intelligence, Computation and Language
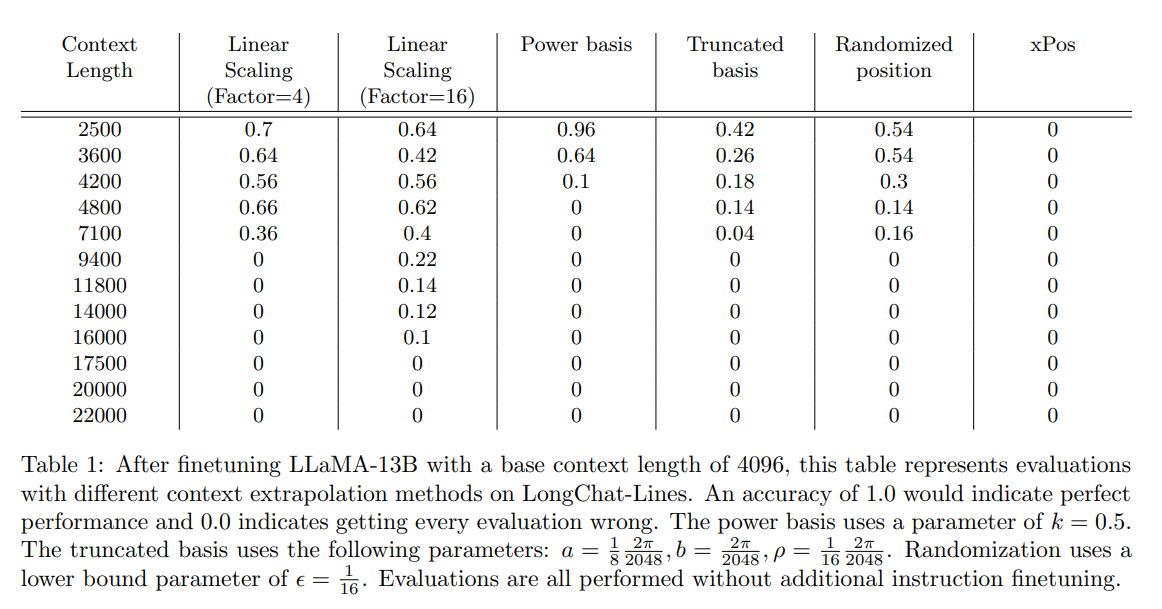
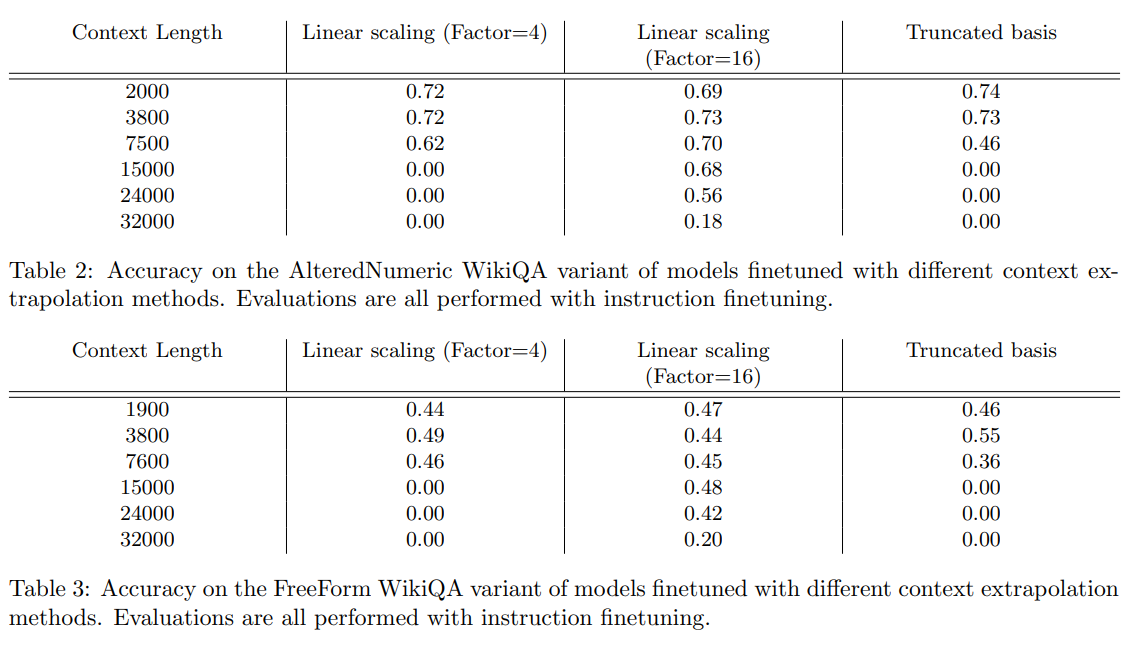
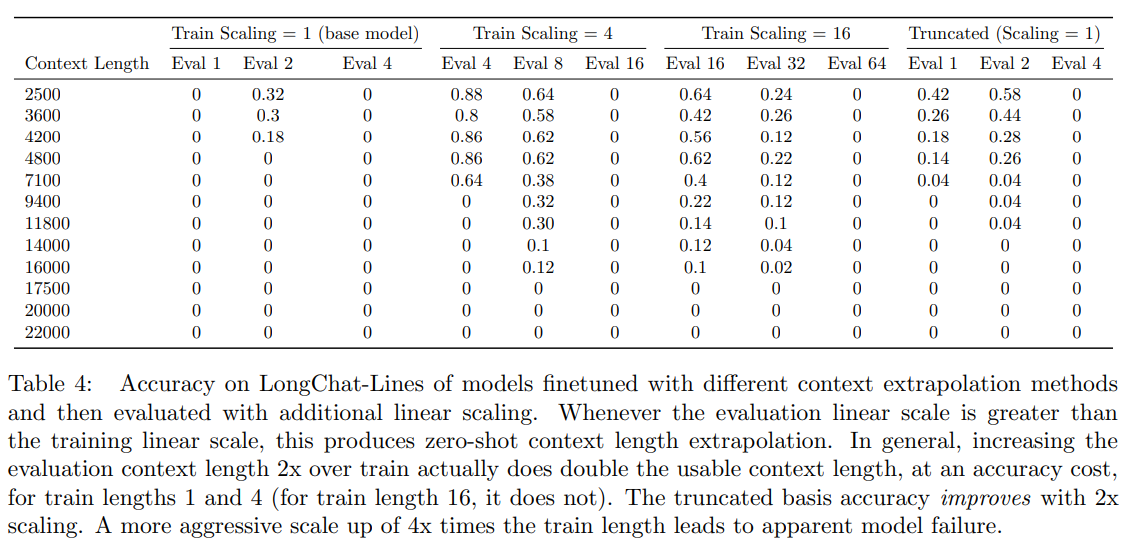
概要:
線形スケーリングは、コンテキストの長さを拡張するための最良の方法であり、評価時にはより長いスケールを使用することでさらなる利益が得られることを示しました.また、切り捨て基準でも有望な外挿能力を発見しました.この分野でのさらなる研究を支援するために、私たちは3つの新しい13Bパラメータの長いコンテキストモデルをリリースしました.これらのモデルはGiraffeと呼ばれており、ベースのLLaMA-13Bからトレーニングされた4kと16kのコンテキストモデル、およびベースのLLaMA2-13Bからトレーニングされた32kのコンテキストモデルです.また、私たちの結果を再現するためのコードも公開しています.
Q&A:
Q: LLMの注意機構は、入力シーケンスの長さに上限を設ける方法はどのようにしていますか?
A: LLMsの注意メカニズムは、入力シーケンスの長さに上限を設けるために、位置符号化システムを修正することに焦点を当てたコンテキスト長の外挿方法を使用します.
Q: 成長するコンテキスト長推測手法の中からいくつかの技術は何ですか?
A: 文脈の長さの外挿手法の成長するファミリーからいくつかの技術があります.
Q: これらの文脈長の外挿方法は、位置符号化のシステムをどのように変更しますか?
A: これらの文脈長の外挿手法は、位置符号化システムを変更することによって行われます.具体的には、位置符号化の基礎を修正するための新しい切り捨て戦略が導入されます.
Q: コンテキストの長さの外挿方法をテストするためにどのような評価タスクが使用されましたか?
A: 評価タスクとして、FreeFormQA、AlteredNumericQA、およびLongChat-Linesが使用されました.
Q: 「パープレキシティ」とは何ですか?なぜそれはLLMの長い文脈パフォーマンスの測定としてより詳細ではないと考えられていますか?
A: Perplexity(困惑度)は、言語モデルの性能を評価するための文献でよく使用される指標です.これは、前の文脈が与えられた場合に、言語モデルが次の単語をどれだけ正確に予測できるかを測定します.困惑度は、テストセットの逆確率を単語数で正規化したものです.困惑度が低いほど、モデルは次の単語をより正確に予測できることを示します.ただし、困惑度はLLM(言語モデル)の長い文脈の性能を評価する際には細かすぎると考えられています.なぜなら、困惑度はモデルがより長い文脈ウィンドウをどれだけうまく利用できるかを捉えていないからです.多くの自然言語データセットでは、モデルがコンテキストウィンドウの限られた範囲の情報にしか注意を払わない場合でも、合理的な困惑度スコアが達成できることがあります.これは、モデルが予測を行うために全体の文脈を効果的に利用していない可能性があることを意味します.したがって、困惑度だけではモデルが長い文脈から情報を抽出する能力を正確に反映しない場合があります.
Q: より長いスケールを使用して、コンテキストの長さをさらに延ばすためにどのように利用できるのか?
A: 評価時により長いスケールを使用することで、より長い文脈の長さを拡張するためにさらなる利益を得ることができます.
Q: 切り詰められた基盤でどのような有望な外挿能力が発見されましたか?
A: 切り捨て基底は真の外挿能力を持っており、以前に見たことのないコンテキストの長さでも非ゼロの正確さを達成することができることが発見されました.
Q: 新たにリリースされた13Bパラメータの長文脈モデルは3つありますが、それらの名前は何ですか?
A: 3つの新しい13Bパラメータの長文脈モデルはGiraffeと呼ばれ、ベースのLLaMA-13Bからトレーニングされた4kおよび16kのコンテキストモデル、およびベースのLLaMA2-13Bからトレーニングされた32kのコンテキストモデルです.
Instruction Tuning for Large Language Models: A Survey
著者:Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Fei Wu, Guoyin Wang
発行日:2023年08月21日
最終更新日:2023年08月21日
URL:http://arxiv.org/pdf/2308.10792v1
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning
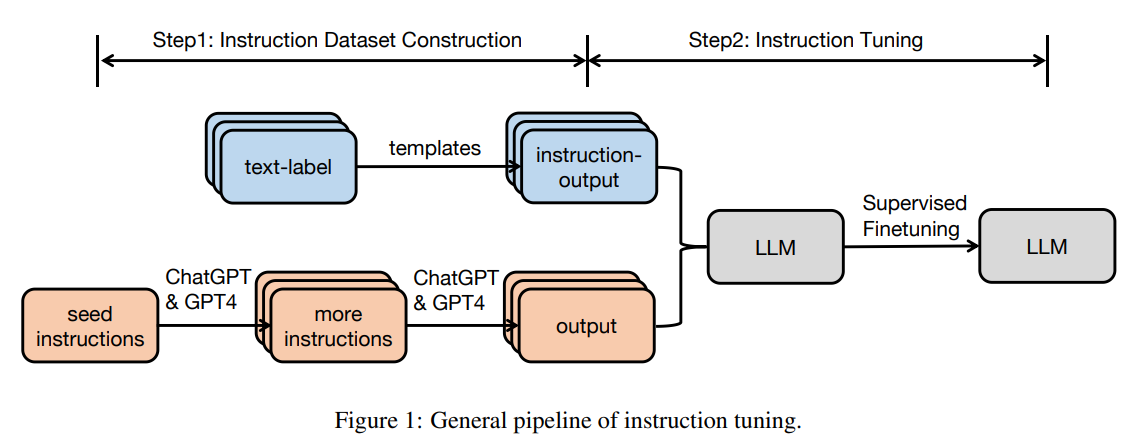
概要:
この論文は、大規模言語モデル(LLM)の機能と制御性を向上させるための重要な技術であるインストラクションチューニング(IT)の急速に進化する分野の研究を調査しています.インストラクションチューニングとは、LLMの次の単語予測目標とユーザーの指示に従うLLMの目標とのギャップを埋めるために、\textsc{(instruction, output)}のペアからなるデータセットを教師あり学習の形式でLLMにさらにトレーニングするプロセスを指します.本研究では、ITの一般的な方法論、ITデータセットの構築、ITモデルのトレーニング、および異なるモダリティ、ドメイン、アプリケーションへの応用について、文献の体系的なレビューを行い、指示の出力生成、指示データセットのサイズなどのITの結果に影響を与える要素についても分析します.また、ITの潜在的な落とし穴や批判、既存の戦略の現在の不足点を指摘し、有益な研究の方向性を提案する取り組みもレビューします.
Q&A:
Q: インストラクションチューニング(IT)の一般的な方法論は何ですか?
A: Instruction tuning (IT)の一般的な方法論は、2つの主要なステップで構成されます.まず、instruction datasetの構築が行われます.instruction datasetは、タスクを指定する自然言語テキストシーケンスであるinstruction、文脈の補足情報を提供するオプションのinput、そしてinstructionとinputに基づいた予測されるoutputの3つの要素で構成されます.instruction datasetの構築には、アノテーションされた自然言語データセットからのデータ統合と、人手で作成されたinstruction datasetの2つの方法が一般的に使用されます.次に、instruction datasetを使用してITモデルをトレーニングするための一般的なパイプラインが使用されます.このパイプラインには、ITモデルのトレーニング、モデルの評価、およびモデルの改善が含まれます.
Q: ITデータセットはどのように構築されていますか?
A: ITデータセットは、さまざまなモダリティ、ドメイン、およびアプリケーションに応用するために構築されます.データセットの構築には、指示の出力の生成、指示データセットのサイズなどの要素が影響を与える分析も含まれます.また、Wang et al. (2023c)によると、単一の最適なITデータセットはすべてのタスクに対して存在せず、データセットを手動で組み合わせることで最良の総合パフォーマンスが得られることも示されています.
Q: ITモデルはどのようにトレーニングされますか?
A: ITモデルは、専門的な指示データを使用してトレーニングされます.具体的には、LIMAは高品質なプロンプトと応答を持つ1,000のデモンストレーションを手動で作成し、事前にトレーニングされた65BパラメータのLLaMaを微調整します.これにより、LIMAはGPT-davinci003を上回る性能を発揮します.GPT-davinci003は、人間のフィードバックによって5,200の例で微調整されました.
Q: ITの潜在的な落とし穴は何ですか?
A: ITの潜在的な落とし穴は次のとおりです:(1)望ましいターゲットの振る舞いを適切にカバーする高品質な指示を作成することは容易ではありません.既存の指示データセットは通常、数量、多様性、創造性に制約があります.(2)ITは、ITのトレーニングデータセットで重要なサポートを受けているタスクのみを改善するという懸念が増えています.(3)ITは、表面的なパターンやスタイル(出力形式など)を理解するだけであり、深い理解を持っていないという厳しい批判があります.
Q: ITに対してどのような批判がされていますか?
A: ITに対して以下のような批判がされています.1) 既存の指示データセットは通常、数量、多様性、創造性に制約があります.2) ITは、ITのトレーニングデータセットで強くサポートされているタスクのみを改善するという懸念が増えています.3) ITは表面的なパターンやスタイル(出力形式など)を捉えるだけであり、ITの一般的な方法論やデータセットの構築、モデルのトレーニング、さまざまなモダリティ、ドメイン、およびアプリケーションへの適用については理解していないという厳しい批判があります.
Q: 現在のIT戦略にはどのような不足が存在していますか?
A: 既存のIT戦略には、数量、多様性、創造性の制約が存在しています.また、ITのトレーニングデータセットで重要なサポートを受けているタスクのみを改善するという懸念が高まっています.さらに、ITは表面的なパターンやスタイル(出力形式など)を捉えるだけであり、理解することができないという厳しい批判もあります.
Q: ITにおける有益な研究の方向性をいくつか提案していただけますか?
A: 現在のITモデルの不足点を解決するための研究の可能性はいくつかあります.まず、ITのトレーニングデータセットの量、多様性、創造性を向上させることが重要です.既存のデータセットは通常、これらの要素が制約されているため、より多様なデータセットの構築が求められます.また、ITのトレーニングデータセットに強くサポートされているタスクにのみ改善が見られるという懸念もあります.したがって、より幅広いタスクに対応できるITモデルの開発が必要です.さらに、ITが表面的なパターンやスタイルのみを捉えるという批判もあります.したがって、より深い理解を持つITモデルの開発が重要です.これらの課題に取り組むために、より高品質な指示文を生成する手法や、ITモデルのトレーニングにおける新しいアプローチの開発など、さまざまな研究の可能性があります.
LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
著者:Neel Guha, Julian Nyarko, Daniel E. Ho, Christopher Ré, Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel N. Rockmore, Diego Zambrano, Dmitry Talisman, Enam Hoque, Faiz Surani, Frank Fagan, Galit Sarfaty, Gregory M. Dickinson, Haggai Porat, Jason Hegland, Jessica Wu, Joe Nudell, Joel Niklaus, John Nay, Jonathan H. Choi, Kevin Tobia, Margaret Hagan, Megan Ma, Michael Livermore, Nikon Rasumov-Rahe, Nils Holzenberger, Noam Kolt, Peter Henderson, Sean Rehaag, Sharad Goel, Shang Gao, Spencer Williams, Sunny Gandhi, Tom Zur, Varun Iyer, Zehua Li
発行日:2023年08月20日
最終更新日:2023年08月20日
URL:http://arxiv.org/pdf/2308.11462v1
カテゴリ:Computation and Language, Artificial Intelligence, Computers and Society
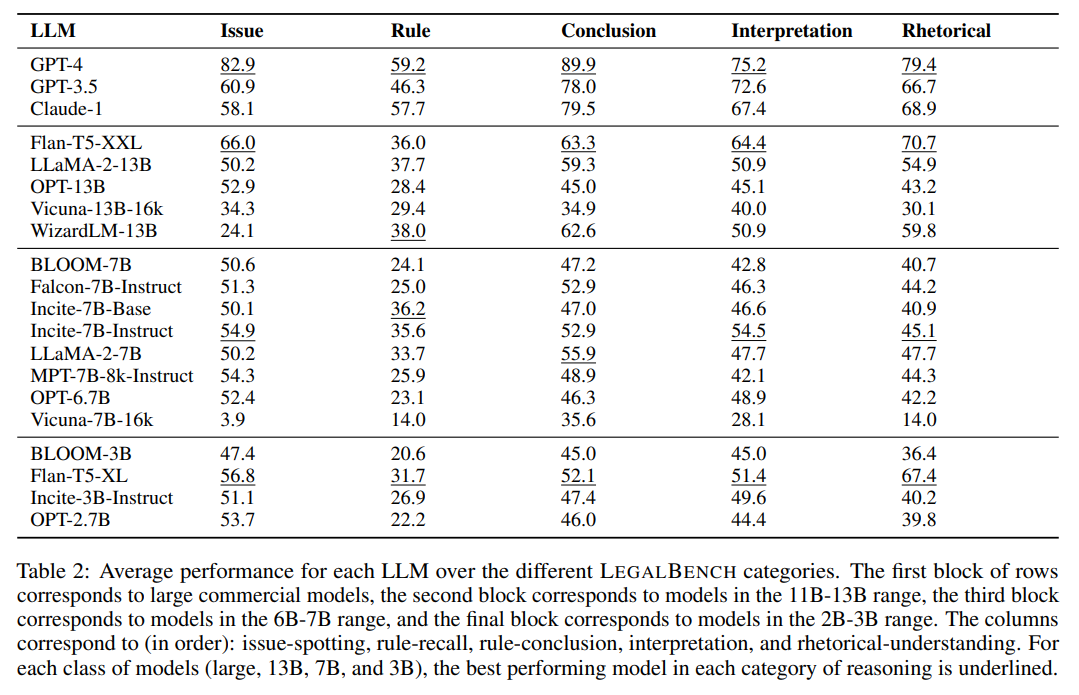
概要:
大規模言語モデル(LLM)の登場と法律コミュニティにおけるその採用は、次の疑問を引き起こしました:LLMはどのような種類の法的推論を行うことができるのでしょうか?この問いについての研究を促進するために、私たちはLegalBenchを提案します.LegalBenchは、6つの異なる法的推論をカバーする162のタスクからなる、共同で構築された法的推論のベンチマークです.LegalBenchは、法律専門家によって設計され、手作業で作成されたタスクを収集するという学際的なプロセスを通じて構築されました.専門家が主導した構築プロセスにより、タスクは実用的に有用な法的推論能力を測定するか、または弁護士が興味を持つ推論スキルを測定します.さらに、法律におけるLLMに関する異分野間の対話を可能にするために、LegalBenchのタスクが法的推論のさまざまな形態を区別する人気のある法的フレームワークと対応していることを示します.これにより、弁護士やLLMの開発者に共通の語彙が提供されます.本論文では、LegalBenchを説明し、20のオープンソースおよび商用のLLMの実証評価を行い、LegalBenchが可能にする研究探索の種類を示します.
Q&A:
Q: LegalBenchの目的は何ですか?
A: LegalBenchの目的は、法的な推論能力を測定するためのベンチマークを提供することです.このプロジェクトは、既存の法的データセットと法律の専門家によって作成されたデータセットを組み合わせて構築されており、法的な推論スキルを測定するか、法律におけるLLMの実用的な応用を捉えることを目的としています.LEGAL BENCHのタスクで高いパフォーマンスを示すことは、弁護士がLLMの法的な能力を評価するための有用な情報を提供し、また、彼らのワークフローで使用できるLLMを特定することができます.
Q: LegalBenchには何件のタスクが含まれていますか?
A: LegalBenchには合計で166のタスクが含まれています.
Q: LegalBenchはどのように構築されましたか?
A: LEGAL BENCHは、既存の法的データセットと法律の専門家によって作成された手作りのデータセットの組み合わせから構築されました.このコラボレーションに参加した法律の専門家は、興味深い法的推論スキルを測定するか、法律のLLMに実用的に役立つアプリケーションを捉えると考えるデータセットを提供するよう求められました.LEGAL BENCHのタスクで高いパフォーマンスを示すことは、弁護士がLLMの法的能力の評価を検証したり、ワークフローで使用できるLLMを特定したりするための有用な情報を提供します.
Q: LegalBenchの構築に関与した人々は誰でしたか?
A: このLegalBenchの構築には、法律の専門家や学者、実務家、計算法学研究者など、多様な専門背景を持つ人々が関与していました.
Q: LegalBenchでタスクを選択するための基準は何ですか?
A: タスクの選択基準は、既存の利用可能なデータセットとコーパス、以前に法律専門家によって構築されたが公開されていないデータセット、およびこの論文の著者によって特に開発されたタスクの3つのソースから引き出されます.
Q: LegalBenchは、法律のLLMに関する異分野間の対話をどのように促進していますか?
A: LEGAL BENCHは、法律のLLMに関する異分野間の対話を可能にし、法律専門家にとって馴染みのある共通の語彙と概念的枠組みを提供します.これにより、法律専門家は、自分たちが馴染みのある用語を使ってLLMのパフォーマンスについて意味のある議論に参加することができます.さらに、LEGAL BENCHは、LEGAL BENCHのタスクに対応する法的推論を記述するための人気のある法的枠組みを提示します.これにより、弁護士やLLM開発者は共通の理解を持ち、AI研究者と法律専門家の間での議論や協力を容易にします.LEGAL BENCHは、評価タスクの構築に法律専門家を関与させることにより、LLM研究における異分野間の協力の重要性を示し、法律専門家の評価と開発における重要な役割を強調しています.
Q: LegalBenchに関連して、論文は何を説明していますか?
A: 論文はLegalBenchに関連して、以下の内容を説明しています.LegalBenchは法的なタスクにおいてLLMsの評価を行い、彼らの法的な推論能力をより良く理解するために作成されました.また、LegalBenchは非法律のAI研究者がLegalBenchのタスクを使用し、研究することを支援するためのインフラストラクチャを提供しています.具体的には、各タスクにはタスクの実行方法、法的な意義、構築手順について詳細なドキュメントが付属しており、AI研究者が各タスクの機械的なプロセスを理解し、LLMのパフォーマンスをより良く理解するための作業的な理解を提供しています.さらに、各タスクには「ベース」プロンプトも付属しており、タスクの指示とデモンストレーションが含まれています.ベースプロンプトは、法的専門家が彼らにとって馴染みのある用語と概念フレームワークを使用してLLMのパフォーマンスについて意味のある議論を行うことを可能にします.最後に、LEGAL BENCHはさらなる研究を支援するためのプラットフォームとして意図されています.法的な専門知識を持たないAI研究者にとって、LEGAL BENCHはプロンプトや評価方法を理解するための重要なサポートを提供しています.
Q: LegalBenchはどのような研究探索を可能にしますか?
A: LEGAL BENCHは、潜在的な応用、人間とLLMの相互作用、および古いファインチューンモデルとの比較を含む、いくつかの領域での研究探求を可能にします.
Language to Rewards for Robotic Skill Synthesis
著者:Wenhao Yu, Nimrod Gileadi, Chuyuan Fu, Sean Kirmani, Kuang-Huei Lee, Montse Gonzalez Arenas, Hao-Tien Lewis Chiang, Tom Erez, Leonard Hasenclever, Jan Humplik, Brian Ichter, Ted Xiao, Peng Xu, Andy Zeng, Tingnan Zhang, Nicolas Heess, Dorsa Sadigh, Jie Tan, Yuval Tassa, Fei Xia
発行日:2023年06月14日
最終更新日:2023年06月16日
URL:http://arxiv.org/pdf/2306.08647v2
カテゴリ:Robotics, Artificial Intelligence, Machine Learning
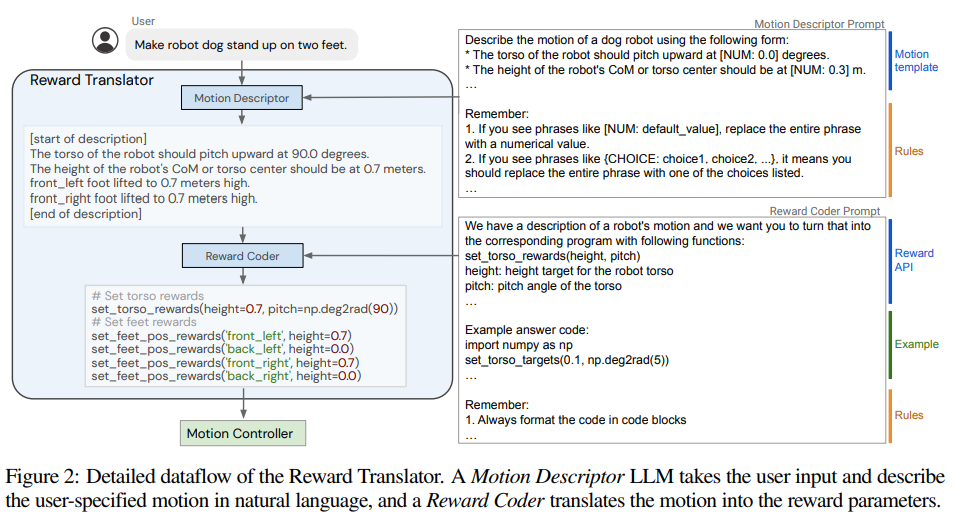
概要:
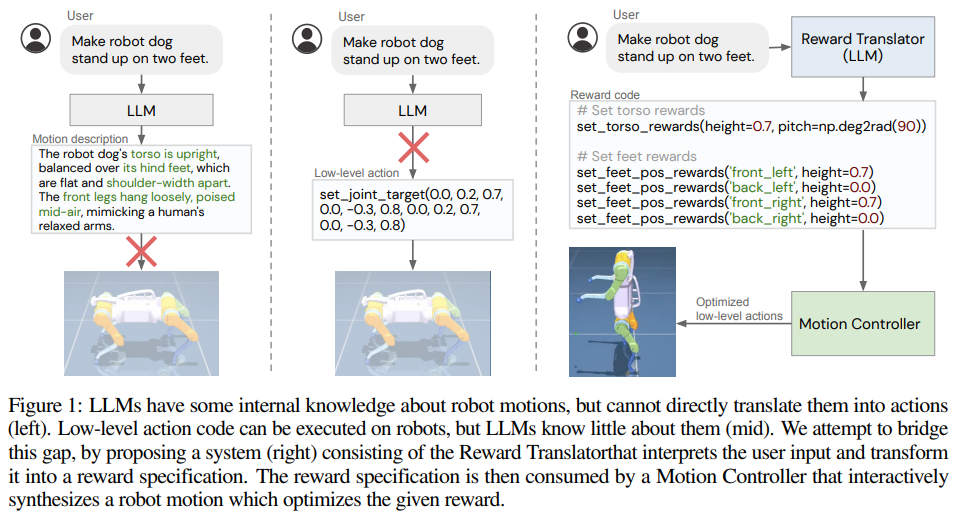
大規模言語モデル(LLM)は、論理的な推論からコードの記述まで、さまざまな新しい能力を獲得することを示しています.また、ロボット工学の研究者も、LLMを使用してロボット制御の能力を向上させるために取り組んでいます.しかし、低レベルのロボットアクションはハードウェアに依存し、LLMのトレーニングデータには十分に表現されていないため、ロボット工学へのLLMの適用に関する既存の取り組みは、LLMを意味的なプランナーとして扱うか、人間が設計した制御プリミティブを使用してロボットとのインターフェースを行うことに主に依存しています.一方、報酬関数は、多様なタスクを達成するために制御ポリシーを最適化するために柔軟な表現として示されており、その意味的な豊かさから、LLMによって指定されることが適しています.本研究では、この認識を活用する新しいパラダイムを紹介し、LLMによって最適化された報酬パラメータを定義し、さまざまなロボットタスクを達成することができるようにします.LLMによって生成される報酬を中間インターフェースとして使用することで、高レベルの言語的な指示や修正と低レベルのロボットアクションのギャップを効果的に埋めることができます.さらに、リアルタイム最適化ツールであるMuJoCo MPCと組み合わせることで、ユーザーは即座に結果を観察し、システムにフィードバックを提供することができるインタラクティブな行動作成体験が可能となります.本研究では、シミュレーションされた四足ロボットと器用なマニピュレータロボットのために合計17のタスクを設計し、提案手法の性能を体系的に評価しました.その結果、提案手法は設計されたタスクの90%を確実に解決することができることが示されました.一方、Code-as-policiesをインターフェースとして使用するベースラインは、タスクの50%を達成します.さらに、非把持の押し出しといった複雑な操作スキルが、本研究のインタラクティブシステムを通じて実際のロボットアームで実現されることも検証されました.
Q&A:
Q: ロボットの分野で大規模言語モデル(LLM)はどのように使用されていますか?
A: 大規模な言語モデル(LLM)は、ロボティクスの分野で次のように使用されています.LLMを使用して、ロボットの行動を制御するための新しい手法が開発されています.これには、ステップバイステップの計画、目標指向の対話、ロボットコードの生成などが含まれます.これらの手法は、既存の制御プリミティブを組み合わせて新しい行動を作成するために言語を使用することに焦点を当てています.また、LLMは、APIやタスクの説明、テキストフィードバックなど、さまざまなコンテキストに適応する能力を持っており、手作業で作成された例が最小限で済むため、柔軟性があります.
Q: なぜ既存のLLM(Language Model)をロボットに適用する取り組みでは、それらを意味的なプランナーとして扱ったり、人間が設計した制御プリミティブに依存したりしているのでしょうか?
A: 既存の取り組みでは、LLMを意味的なプランナーとして扱ったり、人間が設計した制御プリミティブに頼ったりしているのは、低レベルのロボットアクションがハードウェア依存であり、LLMのトレーニングコーパスにはほとんど含まれていないためです.
Q: ロボットの制御ポリシーに対して報酬関数を最適化する方法はどのようになりますか?
A: 報酬関数は、オンライン最適化技術を利用して解決するために、LLMを使用して自動的に生成することが提案されています.具体的には、LLMのコード作成能力を活用して、タスクの意味を報酬関数に変換し、自然言語の説明からの動きに関する知識に基づいてパラメータを最適化します.
Q: ロボット工学において、LLMはどのように報酬パラメータを定義するために使用されるのでしょうか?
A: LLMは、タスクの意味を報酬関数に変換するためのコード作成能力を利用して、ロボット工学において報酬パラメータを定義するために使用することができます.これにより、LLMは報酬を自動的に生成し、オンライン最適化技術を使用してさまざまなロボットタスクを解決するために最適化することができます.LLMが生成する中間インターフェースとして報酬関数を使用することにより、高レベルの言語命令と低レベルのロボットアクションの間のギャップを効果的に埋めることができます.このアプローチにより、人間が設計した制御プリミティブや手動で設計した報酬に依存する従来の取り組みの制約を克服し、報酬関数の柔軟性と意味的な豊かさをロボットの制御に活用することができます.
Q: LLMが生成する報酬を中間インターフェースとして使用することで、高レベルの言語指示と低レベルのロボットアクションの間のギャップをどのように埋めるのですか?
A: LLMは、報酬を中間インターフェースとして利用することで、高レベルの言語命令と低レベルのロボット動作とのギャップを埋める役割を果たします.これは、人間からの言語命令がしばしば低レベルの行動の詳細ではなく、行動の結果を記述することが多いためです.命令を報酬に接続することで、豊かな意味を持ち、制御ポリシーに最適化できる報酬パラメータに高レベルの言語命令を効果的に変換することができます.これらの報酬パラメータは、モーションコントローラによって使用され、与えられた報酬を最適化するロボットの動作を合成するために使用されます.このように、LLMは高レベルの言語命令をロボットが理解し実行できる形式に変換し、言語と低レベルの行動とのギャップを埋めることができます.
Q: 提案された方法におけるMuJoCo MPCの役割は何ですか?
A: MuJoCo MPCは、リアルタイム最適化ツールであり、提案された方法においてロボットの行動をリアルタイムで合成する役割を果たしています.
Q: 提案された方法は、Code-as-policiesとのインターフェースとして原始的なスキルを使用したベースラインアプローチと比較してどのようになりますか?
A: 提案された手法は、Code-as-Policiesとして原始的なスキルをインターフェースとして使用するベースライン手法と比較して、ほとんどのタスクでより良い成功率を達成しています.
Q: 提案された方法のパフォーマンスを評価するために、いくつのタスクが設計されましたか?
A: 提案された手法の性能を評価するために、合計17のタスクが設計されました.
Q: 提案された方法は、設計されたタスクの何パーセントを確実に対処できましたか?
A: 提案された手法は、設計されたタスクの90%を確実に解決することができました.
Q: 提案された方法は実際のロボットアームで検証されましたか?もしそうなら、インタラクティブシステムを通じてどのような複雑な操作スキルが生まれましたか?
A: はい、提案された手法は実際のロボットアームで検証されています.インタラクティブなシステムを通じて非把持の押し動作などの複雑な操作スキルが生まれました.
