
今回のテーマ:LLM評価の調査論文, Elastic Decision Transformer, LongNetによる10億トークンのモデル, SPAEなど.
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をLLMによって生成されるQ&Aを用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.自動生成記事のクオリティと信頼性を向上させるためにアルゴリズムの改善に取り組んでいます.個人で資料のQ&Aを作成されたい方には、https://www.chatpdf.com/ や https://scispace.com/などがお勧めです.
紹介する論文は以下の10本となります.
- A Survey on Evaluation of Large Language Models (発行日:2023年07月06日)
- Lost in the Middle: How Language Models Use Long Contexts (発行日:2023年07月06日)
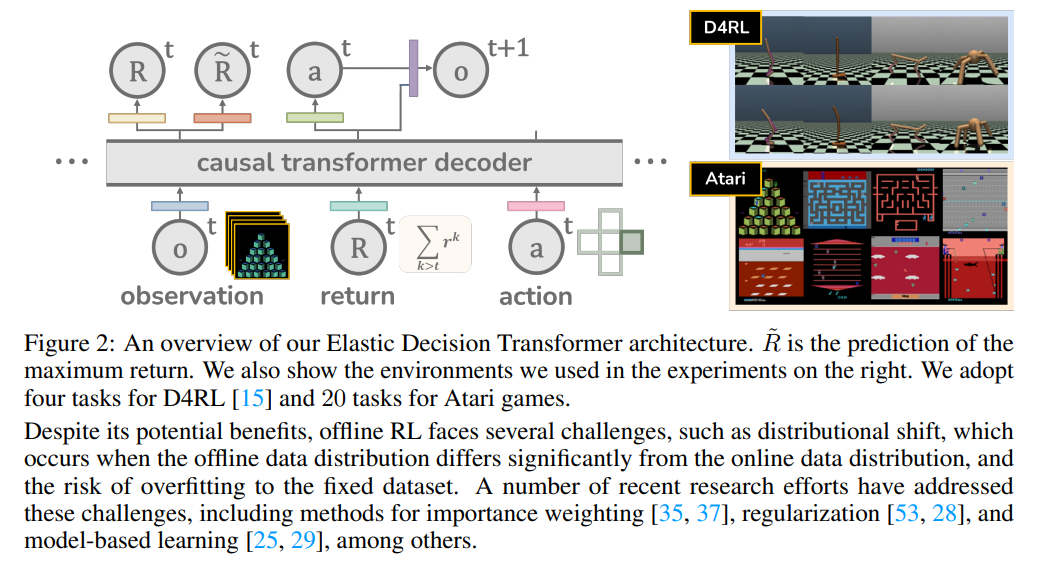
- Elastic Decision Transformer (発行日:2023年07月05日)
- LongNet: Scaling Transformers to 1,000,000,000 Tokens (発行日:2023年07月05日)
- Robots That Ask For Help: Uncertainty Alignment for Large Language Model Planners (発行日:2023年07月04日)
- Physics-based Motion Retargeting from Sparse Inputs (発行日:2023年07月04日)
- Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting (発行日:2023年06月30日)
- SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs (発行日:2023年06月30日)
- InterCode: Standardizing and Benchmarking Interactive Coding with Execution Feedback (発行日:2023年06月26日)
- CodeGen2: Lessons for Training LLMs on Programming and Natural Languages (発行日:2023年05月03日)
A Survey on Evaluation of Large Language Models
著者:Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Kaijie Zhu, Hao Chen, Linyi Yang, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, Xing Xie
発行日:2023年07月06日
最終更新日:2023年07月13日
URL:http://arxiv.org/pdf/2307.03109v4
カテゴリ:Computation and Language, Artificial Intelligence
概要:
大規模言語モデル(LLM)は、さまざまなアプリケーションで類まれなパフォーマンスを発揮し、学術界や産業界でますます人気を集めています.LLMは研究や日常の使用において重要な役割を果たし続ける一方で、その評価は、タスクレベルだけでなく、社会レベルでもますます重要になっています.過去数年間、LLMをさまざまな視点から評価するための重要な取り組みが行われてきました.本論文では、LLMの評価方法について包括的なレビューを提供し、評価すべき内容、評価すべき場所、評価方法の3つの主要な側面に焦点を当てています.まず、一般的な自然言語処理タスク、推論、医療利用、倫理、教育、自然科学、社会科学、エージェントアプリケーション、その他の領域を含む評価タスクの観点から概要を提供します.次に、評価方法とベンチマークについて詳しく説明し、LLMのパフォーマンス評価において重要な要素となる役割を果たします.最後に、成功事例と失敗事例をまとめ、さらにLLMの評価における将来の課題についても言及します.私たちの目的は、LLMの評価に関する貴重な洞察を研究者に提供し、より優れたLLMの開発を支援することです.評価はLLMの開発をより効果的に支援するための必須の学問分野として扱われるべきであるという私たちの主張を一貫して維持しています.関連するオープンソースの資料は以下のリンクで常に公開されています:https://github.com/MLGroupJLU/LLM-eval-survey.
Q&A:
Q: LLMが評価される一般的な自然言語処理タスクとは?
A: LLMsは、自然言語処理タスクにおいて評価されます.自然言語処理タスクは、自然言語の理解と生成の両方を含む広範なタスクを指します.具体的なタスクとしては、感情分析やテキスト分類などがあります.これらのタスクにおいて、LLMsの性能を評価し、その強みと弱点を明らかにすることが求められます.LLMsの評価研究の大部分は、自然言語タスクに焦点を当てて行われており、既存の研究の評価の側面がまとめられています.具体的な評価結果や結論は、後続のセクションで紹介されています.
Q: LLMの推論能力はどのように評価されるのですか?
A: 推論能力の評価は、LLM(Large Language Models)の能力を正確に評価するために重要な要素です.現在のLLMは、推論タスクにおいて特定の制限があります.推論タスクは、与えられた情報を理解するだけでなく、直接的な答えがない状況で既存の文脈から推論や推論を行うことを要求します.したがって、LLMの推論能力を評価するためには、以下の手法やベンチマークが使用されます.
まず、評価方法とベンチマークについて説明します.評価方法は、LLMのパフォーマンスを評価するための重要な要素です.これには、推論タスクにおける正確さや効率性などの指標が含まれます.ベンチマークは、LLMの性能を比較するための基準となるデータセットやタスクの集合です.これにより、異なるLLMの性能を客観的に評価することが可能となります.
次に、異なるタスクにおけるLLMの成功と失敗の事例をまとめます.これにより、LLMの推論能力の強みと弱点を明確にすることができます.成功事例では、LLMが与えられた情報から正確な推論を行い、適切な回答を提供することができることが示されます.一方、失敗事例では、LLMが推論を誤り、不正確な回答を提供することがあります.
最後に、LLMの評価において直面するいくつかの将来の課題について言及します.これにより、LLMの研究者に貴重な洞察を提供し、より優れたLLMの開発を支援します.評価は、LLMの開発をより効果的に支援するために必要不可欠な学問として扱われるべきです.
以上のように、推論能力の評価は、LLMのパフォーマンスを客観的に評価するための評価方法とベンチマークの使用、成功と失敗の事例のまとめ、将来の課題の洞察によって行われます.これにより、より優れたLLMの開発が促進されることが期待されます.
Q: LLMの業績を評価するために、どのような評価方法とベンチマークが使われていますか?
A: LLMのパフォーマンスを評価するために使用される評価方法とベンチマークは、論文の中で詳細に説明されています.まず、評価方法について説明します.論文では、現在のプロトコルと新しい評価手法を探求しています.これにより、LLMのパフォーマンスを評価するための方法を包括的に理解することができます.
次に、ベンチマークについて説明します.論文では、既存のデータセットとベンチマークをまとめて、現在のLLMの評価に関する深い理解を提供しています.これにより、LLMのパフォーマンスを評価するための基準を提供することができます.
具体的な評価方法やベンチマークについての詳細な説明は、論文の該当するセクションで確認することができます.評価方法とベンチマークは、LLMのパフォーマンスを客観的に評価するための重要な要素です.これらの評価方法とベンチマークは、LLMの成功と失敗のケースを要約し、将来のLLMの進展に対する洞察を提供することを目的としています.
また、論文では、LLMの評価に関する関連資料をオープンソース化し、https://github.com/MLGroupJLU/LLM-eval-surveyで維持していることも述べられています.これにより、より良い評価のための協力的なコミュニティを育成することが目指されています.
以上のように、論文ではLLMのパフォーマンスを評価するための評価方法とベンチマークについて詳細に説明されています.
Q: さまざまな仕事におけるLLMの成功例と失敗例を教えてください.
A: 異なるタスクにおけるLLMの成功と失敗の事例を挙げることができます.この調査では、既存の評価の取り組みに基づいて以下の結論が導かれており、その結果は特定のデータセットに依存しています.
まず、LLMの評価方法とベンチマークについて調査し、どこでどのように評価されているかについて説明します.これは、LLMの性能を評価する上で重要な要素です.次に、異なるタスクにおけるLLMの成功と失敗の事例をまとめます.最後に、最も有用で成功した評価プロトコルやベンチマークがあることが示されていますが、それぞれ異なる特性と焦点を持っています.これは、どのタスクにおいても単一のモデルが最も優れたパフォーマンスを発揮することはないことを示しています.
具体的なタスクの成功事例としては、LLMが流暢で正確な言語表現を生成することが挙げられます.また、感情分析やテキスト分類などの言語理解を必要とするタスクにおいても、LLMは印象的なパフォーマンスを示しています.さらに、LLMは文脈を理解し、一貫した応答を生成する能力も持っています.
一方、失敗事例としては、特定のデータセットに依存していることが挙げられます.つまり、LLMのパフォーマンスはデータセットによって異なる可能性があります.また、LLMが処理タスクや推論、医療利用、倫理、教育、自然科学、社会科学、エージェントアプリケーションなどのさまざまな領域で成功するかどうかも、具体的なタスクやデータセットに依存します.
以上のように、LLMの成功と失敗の事例はタスクやデータセットによって異なることがわかります.これらの事例を分析することで、LLMの評価プロトコルの新しいトレンドを導き出し、さらには将来の研究のための新しい課題と機会を提案することができます.
Q: LLMに関連する潜在的なリスクとは何か、またどのように評価されるのか?
A: LLM(Language Model)には、潜在的なリスクが存在します.これらのリスクを評価するために、さまざまな方法が用いられています.
まず、LLMの評価方法について述べられています.この論文では、評価タスク、評価場所、評価方法の3つの主要な側面に焦点を当てて、LLMの評価方法について包括的なレビューが提供されています.評価タスクの観点からは、一般的な自然言語処理タスク、推論、医療利用、倫理、教育、自然科学や社会科学、エージェントアプリケーション、その他の領域について概観が提供されています.評価場所と評価方法については、評価方法やベンチマークについて詳しく説明されています.これらはLLMの性能評価において重要な要素となります.
さらに、現在のLLMの成功事例と失敗事例についてもまとめられています.現在のLLMは、推論や頑健性のタスクなど、多くのタスクにおいて制約が存在することが明らかになっています.また、適切なタスクとデータセットが与えられた場合の評価プロセスについても議論されています.
この論文の貢献は以下の通りです.まず、LLMの評価に関する3つの側面(何を評価するか、どのように評価するか、どこで評価するか)から包括的な概観を提供しています.評価タスク、プロトコル、ベンチマークをまとめることで、現在のLLMの状況を理解し、その強みと制約を明らかにし、将来のLLMの進展に対する示唆を提供することを目指しています.
この論文の調査結果によれば、現在のLLMは推論や頑健性のタスクなど、多くのタスクにおいて制約が存在することが明らかになっています.同時に、現代の評価システムは適応し進化する必要があり、LLMの本来的な能力と制約を正確に評価することが求められています.将来の研究が取り組むべきいくつかの重要な課題も特定されており、これによりLLMの進展が期待されています.
したがって、LLMには推論や頑健性のタスクなどの潜在的なリスクが存在し、これらのリスクを評価するためには、適切な評価タスクとデータセットが必要です.現在の評価システムは、LLMの能力と制約を正確に評価するために適応し進化する必要があります.将来の研究は、これらの課題に取り組むことで、LLMの進展に貢献することが期待されています.
Q: 医療分野でLLMはどのように評価されますか?
A: まず、評価タスクの観点から概要を提供します.これには、一般的な自然言語処理タスク、推論、医療利用、倫理、教育、自然科学、社会科学、エージェントアプリケーション、その他の領域が含まれます.これらの評価タスクは、LLMsの性能を評価するための重要な要素です.
次に、評価方法とベンチマークについて、どこで評価するか、どのように評価するかという疑問に答えます.評価方法とベンチマークは、LLMsの性能評価において重要な役割を果たします.
さらに、異なるタスクにおけるLLMsの成功と失敗の事例をまとめます.これにより、LLMsの潜在的な応用範囲を探るために、医療試験評価におけるLLMsの性能を評価します.
医療分野におけるLLMsの評価は、医療質問応答、医療検査、医療評価、医療教育の4つの側面に分類されます.表5には、これらの側面に基づいた医療アプリケーションの評価の要約が示されています.
具体的には、医療質問応答が最も評価されており、医療分野におけるLLMsの評価の大部分がこの領域で行われていることが表5からわかります.
以上のように、医療分野におけるLLMsの評価は、評価タスク、評価方法とベンチマーク、成功と失敗の事例の観点から総合的に行われています.
Q: LLMでは倫理はどのように評価されるのか?
A: LLMの文脈において倫理はどのように評価されるのか?
倫理は、LLMの評価において重要な要素の一つです.LLMの倫理的な側面を評価するために、さまざまな方法が存在します.例えば、Kadavathら(2022年)、OpenAI(2023b)、Touvronら(2023年)、Weiら(2022b)の研究によって、LLMの倫理的な側面が評価されています.
LLMの倫理的な評価は、以下のような観点から行われます.
- データセットの倫理的な側面の評価:LLMは大量のデータを学習するため、そのデータセットには倫理的な側面が含まれる可能性があります.例えば、差別的な言語や偏見を含むデータセットが使用されることがあります.倫理的な評価では、データセットが公平でバイアスのないものであるかどうかが評価されます.
- モデルの倫理的な側面の評価:LLMは人間の言語を生成するため、その生成結果には倫理的な側面が関与することがあります.例えば、差別的な表現や攻撃的な言葉を生成する可能性があります.倫理的な評価では、モデルが倫理的なガイドラインに従っているかどうかが評価されます.
- モデルの倫理的なトレードオフの評価:LLMはさまざまなタスクに使用されるため、倫理的な要件とパフォーマンスのトレードオフが存在する場合があります.例えば、倫理的なガイドラインに従うためにパフォーマンスが低下する可能性があります.倫理的な評価では、モデルの倫理的な要件とパフォーマンスのバランスが評価されます.
これらの評価は、研究者や専門家によって行われます.倫理的な評価は、LLMの開発と使用において重要な役割を果たし、倫理的な問題を解決するための改善策やガイドラインの提案につながることが期待されています.
Q: 自然科学と社会科学におけるLLMの評価は?
A: 自然科学および社会科学において、LLM(Language Model)はどのように評価されるのでしょうか.
自然科学および社会科学におけるLLMの評価は、さまざまな視点から行われています.まず、評価タスクの観点から概要を提供しており、一般的な自然言語処理タスク、推論、医療利用、倫理、教育、自然科学、社会科学、エージェントアプリケーションなど、さまざまな領域を含んでいます.
次に、評価方法とベンチマークについての詳細を説明し、これらはLLMの性能評価において重要な要素となっています.さらに、異なるタスクにおけるLLMの成功と失敗の事例をまとめています.
社会科学におけるLLMのパフォーマンス評価は、学術研究、政策立案、社会問題の解決にとって重要です.このような評価は、社会科学におけるモデルの適用性と品質を向上させ、人間社会の理解を深め、社会の進歩を促進するのに役立ちます.Wuら(2023a)は、社会科学におけるスケーリングと測定の問題に対するLLMの潜在的な利用を評価し、LLMが政治的イデオロギーに関する意味のある回答を生成し、社会科学におけるテキストデータの手法を大幅に改善できることを示しました.
計算社会科学(CSS)のタスクでは、Ziemsら(2023)はLLMの総合的な評価を行いました.分類タスクでは、LLMはイベント引数抽出、キャラクタートロープ、暗黙のヘイト、共感の分類において最も低い絶対パフォーマンスを示し、正確度が40%未満となります.これらのタスクは、複雑な構造(イベント引数)を含んでいるか、LLMの事前学習時に学習されたものとは異なる意味論を持つ主観的な専門用語を含んでいます.一方、LLMは誤情報、スタンス、感情の分類において最も優れたパフォーマンスを発揮します.
以上のように、自然科学および社会科学におけるLLMの評価は、評価タスクの観点から概要を提供し、評価方法とベンチマークによって具体的な性能評価を行い、成功と失敗の事例をまとめることで行われています.
Q: LLMの評価における今後の課題は?
A: 将来のLLM(大規模言語モデル)の評価における課題は、いくつかの重要な点があります.まず、現在のLLMは、推論や頑健性のタスクなど、多くのタスクにおいて制約が存在していることが明らかになりました.これは、LLMの能力や限界を正確に評価するために、現代の評価システムが適応し進化する必要があることを示しています.
さらに、将来の研究が取り組むべき重要な課題も特定されています.これらの課題に取り組むことで、LLMは人類に対するサービスを徐々に向上させることが期待されています.
また、将来の研究においては、評価を重要な学問として位置づける必要があります.LLMや他のAIモデルの成功を促進するために、評価は必須の学問として扱われるべきです.既存のプロトコルやベンチマークに加えて、LLMの時代に関連するさまざまな側面を再設計することが求められます.
総括すると、将来のLLMの評価には以下のような課題が存在します.
- LLMの制約:現在のLLMは、推論や頑健性のタスクなど、特定のタスクにおいて制約があります.将来の研究では、これらの制約を克服するための手法やアプローチを開発する必要があります.
- 評価システムの適応と進化:現代の評価システムは、LLMの能力や限界を正確に評価するために適応し進化する必要があります.将来の研究では、より効果的な評価システムの開発や改善に取り組む必要があります.
- 評価の学問化:評価はLLMや他のAIモデルの成功に不可欠な要素です.将来の研究では、評価を重要な学問として位置づけ、評価に関連するさまざまな側面を再設計する必要があります.
これらの課題に取り組むことで、将来のLLMの進歩と人類への貢献が期待されます.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: この論文で紹介された新しい手法のコード実装のURLは、https://github.com/tatsu-lab/alpaca evalです.このURLにアクセスすると、AlpacaEvalという名前の自動評価ツールのコードが入手できます.
Lost in the Middle: How Language Models Use Long Contexts
著者:Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, Percy Liang
発行日:2023年07月06日
最終更新日:2023年07月06日
URL:http://arxiv.org/pdf/2307.03172v1
カテゴリ:Computation and Language
概要:
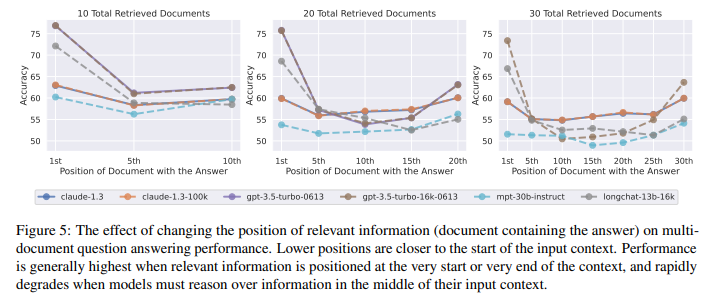
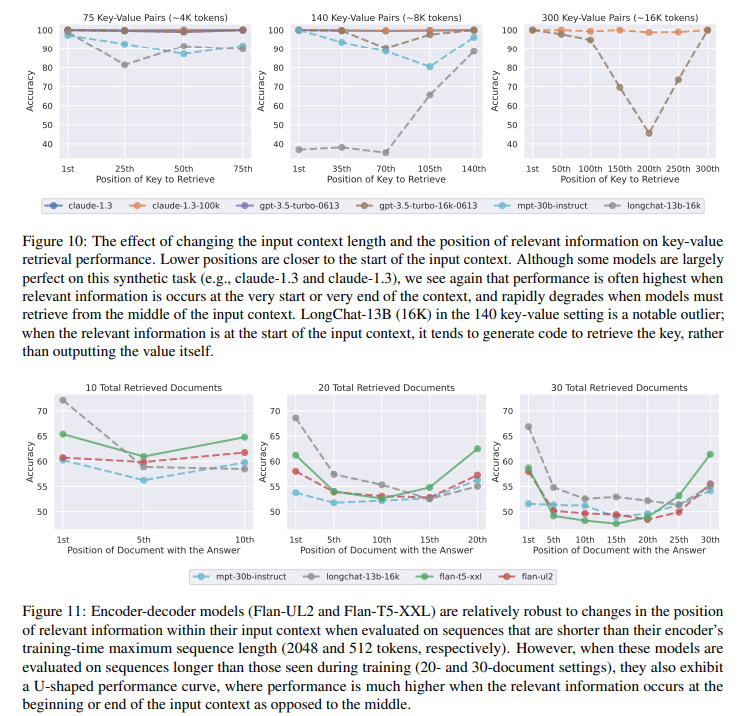
最近の言語モデルは、長い文脈を入力として受け取る能力を持っていますが、長い文脈をどれだけうまく利用しているかについてはほとんど知られていません.本研究では、複数の文書にまたがる質問応答やキー・バリューの検索といったタスクにおける言語モデルの性能を分析しました.その結果、関連情報が入力文脈の先頭や末尾にある場合に性能が最も高くなり、長い文脈の中で関連情報にアクセスする必要がある場合に性能が著しく低下することがわかりました.さらに、入力文脈が長くなるにつれて性能が大幅に低下し、明示的に長い文脈を扱うモデルでも同様の傾向が見られました.この分析は、言語モデルが入力文脈をどのように利用しているかをより良く理解するためのものであり、将来の長文脈モデルのための新しい評価プロトコルを提供します.
Q&A:
Q: 最近の言語モデルは、長い文脈を入力としてどのように扱っているのだろうか?
A: 最近の言語モデルは、長い文脈を入力として扱う能力を持っています.しかし、言語モデルが長い文脈をどのように扱うかについては、あまり知られていません.この論文では、複数の文書に対する質問応答やキー・バリューの検索といったタスクにおける言語モデルの性能を分析しています.その結果、関連情報が入力文脈の先頭や末尾にある場合、性能が最も高くなることが多いことがわかりました.一方、モデルが長い文脈の中で関連情報にアクセスする必要がある場合、性能が著しく低下します.さらに、入力文脈が長くなるにつれて性能が大幅に低下することも明らかになりました.このような性能の低下は、明示的に長い文脈を扱うモデルにおいても起こります.この分析により、言語モデルが入力文脈をどのように利用しているかについてより良い理解が得られ、将来の長文脈モデルのための新しい評価プロトコルも提案されています.
最近の言語モデルは、長い文脈を入力として扱う能力を持っていますが、その性能についてはまだ十分に知られていません.この論文では、複数の文書に対する質問応答やキー・バリューの検索といったタスクにおける言語モデルの性能を分析しました.その結果、関連情報が入力文脈の先頭や末尾にある場合、性能が最も高くなることが多いことがわかりました.一方、モデルが長い文脈の中で関連情報にアクセスする必要がある場合、性能が著しく低下します.さらに、入力文脈が長くなるにつれて性能が大幅に低下することも明らかになりました.このような性能の低下は、明示的に長い文脈を扱うモデルにおいても起こります.
具体的な理由としては、言語モデルは入力文脈を自己注意メカニズムを用いてエンコードします.しかし、この自己注意メカニズムの時間とメモリの複雑さは、入力の長さに対して二次的に増加するため、非常に長いシーケンスには適用できません.そのため、言語モデルは通常、比較的少量の前の文脈(コンテキストウィンドウ)で事前学習されます.このため、入力文脈の最大長さも制限されます.
最近のハードウェアの進歩やアルゴリズムの改善により、言語モデルの最大コンテキスト長を増やすことが可能になりました.しかし、この論文の結果からは、入力文脈が長くなるにつれ
Q: 言語モデルが長いコンテクストをどの程度利用できるかについての理解度は?
A: 長い文脈を入力として受け取ることができる最近の言語モデルは、そのような長い文脈をどの程度うまく利用しているかについては、比較的少なく知られています.この論文では、複数の文書にまたがる質問応答やキーバリュー検索といったタスクにおける言語モデルのパフォーマンスを分析しています.その結果、関連情報が入力文脈の先頭や末尾にある場合には、パフォーマンスが最も高くなることが多く、モデルが推論を行う必要があるコンテンツの量が増えると、パフォーマンスが著しく低下することがわかりました.
また、指示形式のデータが与えられた場合には、言語モデルはより長い範囲の情報(つまり、入力文脈の先頭)を利用することができることも示されました.このような文脈の利用方法は、事前学習中に見られる可能性のある同様の形式のデータ(例:StackOverflowの質問と回答)から学習される可能性があります.
実際の設定では、入力文脈の長さを増やすことには常にトレードオフが存在します.より多くの情報を提供することで、指示に適した言語モデルの性能を向上させることができますが、モデルが推論を行う必要があるコンテンツの量も増えます.たとえ言語モデルが16Kトークンを受け入れることができたとしても、それが実際に有益であるかどうかは疑問です.
Q: 言語モデルの性能は、入力コンテクスト内の関連情報を識別する際にどのように変化するのだろうか?
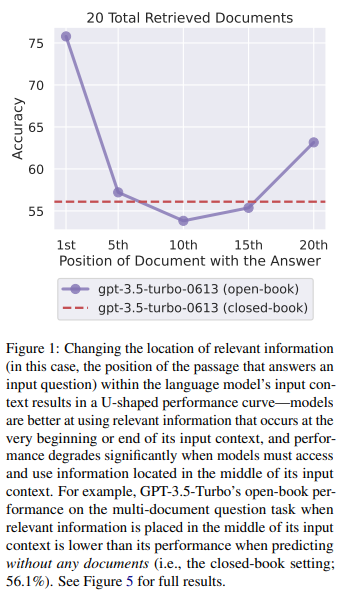
A: 言語モデルのパフォーマンスは、入力コンテキストの非常に初めまたは終わりに関連情報がある場合に最も高くなりますが、モデルが入力コンテキストの中間にある情報にアクセスして使用する必要がある場合、パフォーマンスは著しく低下します.具体的には、関連情報が入力コンテキストの中間に配置された場合、GPT-3.5-Turboのマルチドキュメントの質問タスクにおけるパフォーマンスは、ドキュメントなしで予測する場合(つまり、クローズドブックの設定)よりも低くなります(56.1%).さらに、長いコンテキストではモデルのパフォーマンスが徐々に低下することがわかっており、拡張コンテキストモデルが入力コンテキストをより良く使用するわけではないこともわかっています.
言語モデルは、マルチドキュメントの質問応答やキーバリューの検索といったタスクにおいて、入力コンテキスト内の関連情報を特定する能力についてパフォーマンスを分析しました.その結果、関連情報が入力コンテキストの初めまたは終わりにある場合、パフォーマンスが最も高くなり、長いコンテキストの中間にある情報にアクセスする必要がある場合、パフォーマンスが著しく低下することがわかりました.さらに、入力コンテキストが長くなるにつれてパフォーマンスが大幅に低下し、明示的に長いコンテキストを持つモデルでも同様の傾向が見られました.
この分析により、言語モデルが入力コンテキストをどのように使用しているかについてより良い理解が得られ、将来の長いコンテキストモデルのための新しい評価プロトコルが提供されました.
Q: 言語モデルの性能を評価するために分析された具体的なタスクは何ですか?
A: 言語モデルのパフォーマンスを評価するために分析された具体的なタスクは、マルチドキュメントの質問応答とキーバリューの検索です.これらのタスクでは、言語モデルは入力コンテキスト内の関連情報を特定する必要があります.マルチドキュメントの質問応答では、複数の文書からの情報を統合して質問に回答する必要があります.一方、キーバリューの検索では、JSON形式のキーバリューペアのコレクションが与えられ、言語モデルは入力コンテキストから一致するトークンを取得する能力を評価します.これらのタスクは、言語モデルのパフォーマンスを測定するための最小限のテストベッドとして設計されています.
Q: 関連する情報が入力コンテキストの最初や最後にある場合、言語モデルのパフォーマンスにはどのようなパターンが見られたか?
A: 言語モデルのパフォーマンスに関して、関連情報が入力コンテキストの最初や最後にある場合、最も高いパフォーマンスが得られることが観察されました.一方、モデルが入力コンテキストの中間にある情報をアクセスして使用する必要がある場合、パフォーマンスは著しく低下します.例えば、関連情報が入力コンテキストの中間に配置された場合、GPT-3.5-Turboのマルチドキュメントの質問タスクにおけるパフォーマンスは、ドキュメントなしでの予測(つまり、クローズドブックの設定)の場合よりも低くなります(56.1%).さらに、長いコンテキストではモデルのパフォーマンスが徐々に低下することがわかりました.また、拡張コンテキストモデルが入力コンテキストをより良く利用するわけではないこともわかりました.
具体的には、MPT-30BとMPT-30B-Instructの両方が、関連情報が入力コンテキストの最初や最後にある場合に最も高いパフォーマンスを示すU字型のパフォーマンス曲線を示していることが観察されました.MPT-30B-Instructの絶対的なパフォーマンスはMPT-30Bよりも一貫して高いですが、両者の全体的なパフォーマンスの傾向は非常に似ています.これらの観察結果は、言語モデルが最近のトークン(つまり、入力コンテキストの終わり)にバイアスを持っていることを補完しています.この最近のバイアスは、連続したテキスト上の次の単語予測の文脈で一般的に示され、言語モデルは長距離の情報からほとんど恩恵を受けないことが示されています.一方、私たちの結果は、言語モデルが指示形式のデータでプロンプトされた場合には、より長い範囲の情報(つまり、入力コンテキストの最初)を利用することができることを示しています.私たちは、このようなコンテキストを言語モデルが学習するのは、事前学習中に見られる可能性のある同様の形式のデータ(例:StackOverflowの質問と回答)からであると仮説を立てています.
言語モデルのパフォーマンスに関して、関連情報が入力コンテキストの最初や最後にある場合に最も高いパフォーマンスが得られることが観察されました.また、モデルが入力コンテキストの中間にある情報をアクセスして使用する必要がある場合、パフォーマンスは著しく低下します.さらに、長いコンテキストではモデルのパフォーマンスが徐々に低下することがわかりました.また、指示形式のデータでプロンプトされた場合には、言
Q: モデルが長いコンテキストの途中で関連情報にアクセスする必要がある場合、パフォーマンスはどのように低下するのだろうか?
A: 長い文脈の中でモデルが関連情報にアクセスする必要がある場合、パフォーマンスは著しく低下します.この状況では、モデルは文脈の中央にある情報を取得し、使用することが困難です.さらに、入力文脈が長くなるにつれて、明示的な長文脈モデルでもパフォーマンスが大幅に低下します.
この現象の理由をより良く理解するために、モデルのアーキテクチャ(デコーダのみ vs エンコーダ・デコーダ)、クエリに対するコンテキストの意識、および指示の微調整の効果について、いくつかの予備的な調査を行いました.
具体的な理由については明示されていませんが、文脈の中央にある情報にアクセスすることが困難であるため、モデルのパフォーマンスが低下すると考えられます.これにより、モデルは文脈の最初や最後にある情報を取得しやすくなります.
Q: 入力コンテキストの長さとパフォーマンスの低下には相関関係があるのか?
A: 文脈の長さと性能の低下との間に相関関係があるかどうかについては、与えられた情報からは明確な結論を導くことはできません.ただし、与えられた文脈が長くなるにつれて、モデルの性能が低下する傾向が見られることが示されています.具体的には、文脈が長くなると、モデルは長い文脈から関連情報を取得し、利用することに苦労するようです.
例えば、GPT-3.5-Turboの場合、20文書の設定では、回答が20文書の中で10番目に位置する場合の最低性能は52.9%です.また、30文書の設定では、入力文脈の長さが増えると性能がさらに低下しています.
この結果から、文脈の長さと性能の低下との間には相関関係がある可能性が示唆されます.しかし、与えられた情報だけでは、具体的な相関関係を確定することはできません.さらなる研究や評価プロトコルの開発が必要とされます.
Q: 言語モデルが入力文脈をどのように利用するかについて、分析はどのような洞察をもたらすのか?
A: 分析は、言語モデルが入力コンテキストをどのように使用しているかについての洞察を提供します.具体的には、長いコンテキストの中で関連する情報にアクセスする際に、モデルのパフォーマンスが著しく低下することが示されています.また、入力コンテキストが長くなるにつれて、明示的に長いコンテキストを扱うモデルでもパフォーマンスが低下することが示されています.
この分析により、言語モデルが入力コンテキストをどのように使用しているかについてより良い理解が得られます.また、将来の長いコンテキストモデルのための新しい評価プロトコルも提供されます.これにより、言語モデルが入力コンテキストをどのように使用しているかを理解し、改善するためのさらなる研究が促進されます.
Q: 分析に基づき、今後のロングコンテキストモデルにはどのような評価プロトコルが提案されるのか?
A: 分析に基づいて、将来の長文脈モデルのために提案される評価プロトコルは次のとおりです.
研究では、言語モデルが入力コンテキストをどのように使用するかをより良く理解するために、新しい評価プロトコルが導入されました.これにより、長文脈モデルの性能を評価するための新しい手法が提案されました.
具体的には、長文脈モデルの評価においては、以下の評価プロトコルが提案されました.
- モデルが長い文脈の中で関連情報にアクセスする場合の性能を評価するために、中間の関連情報へのアクセスが必要なタスクを設定します.これにより、モデルが長い文脈の中で適切に条件付けられるかどうかを評価することができます.
- 入力コンテキストが長くなるにつれて性能がどのように低下するかを評価するために、異なる長さの入力コンテキストを使用してモデルを評価します.これにより、モデルの性能が入力コンテキストの長さにどのように依存するかを明らかにすることができます.
これらの評価プロトコルは、将来の長文脈モデルの開発や改善に役立つことが期待されています.また、研究者は自身のコードと評価データを公開しており、さらなる研究や理解の促進に貢献しています.
Elastic Decision Transformer
著者:Yueh-Hua Wu, Xiaolong Wang, Masashi Hamaya
発行日:2023年07月05日
最終更新日:2023年07月07日
URL:http://arxiv.org/pdf/2307.02484v2
カテゴリ:Machine Learning, Artificial Intelligence
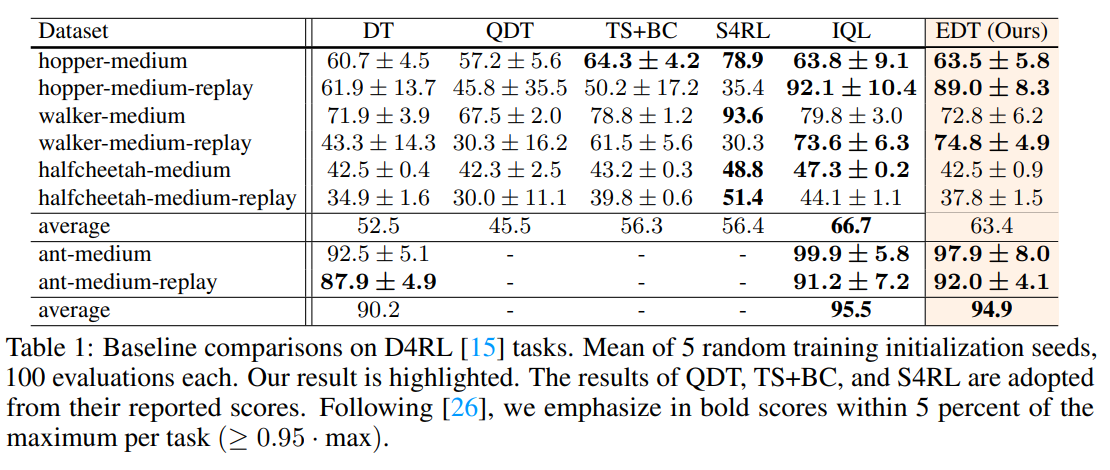
概要:
この論文では、既存のDecision Transformer(DT)およびその派生モデルに比べて、重要な進歩であるElastic Decision Transformer(EDT)を紹介しています.DTは最適な軌道を生成することを目指していますが、経験的な証拠からは、部分的に最適な軌道の中から最適またはほぼ最適な軌道を生成する「軌道のステッチング」というプロセスに苦労していることが示されています.提案されたEDTは、テスト時のアクション推論中に軌道のステッチングを容易にすることで、他と差別化しています.これは、DTで維持される履歴の長さを調整することによって実現されます.さらに、EDTは、前の軌道が最適である場合にはより長い履歴を保持し、部分的に最適な場合にはより短い履歴を保持することで、軌道を最適化します.これにより、より最適な軌道と「ステッチング」することが可能となります.詳細な実験により、EDTがDTベースの手法とQ学習ベースの手法の性能差を埋める能力があることが示されています.特に、EDTはD4RLロコモーションベンチマークとAtariゲームのマルチタスク環境でQ学習ベースの手法を上回る結果を示しています.ビデオは以下のURLでご覧いただけます:https://kristery.github.io/edt/
Q&A:
Q: Elastic Decision Transformer(EDT)とDecision Transformer(DT)の主な違いは何ですか?
A: Elastic Decision Transformer(EDT)とDecision Transformer(DT)の主な違いは、EDTがトラジェクトリステッチングを容易にする点です.トラジェクトリステッチングとは、複数のサブオプティマルなトラジェクトリの最良の部分から最適または近似最適なトラジェクトリを生成するプロセスのことです.DTは最適なトラジェクトリを生成することを目指していますが、経験的な証拠からは、トラジェクトリステッチングに苦労していることが示されています.
EDTは、DTと比較して、テスト時のアクション推論中にトラジェクトリステッチングを容易にすることで、自己を差別化しています.これは、DTで維持される履歴の長さを調整することによって実現されます.さらに、EDTは、前のトラジェクトリが最適である場合にはより長い履歴を保持し、サブオプティマルな場合にはより短い履歴を保持することで、トラジェクトリを最適化します.これにより、より最適なトラジェクトリと「ステッチ」することが可能となります.
具体的な違いを説明すると、EDTはトラジェクトリステッチングを容易にするために、アクション推論時に維持される履歴の長さを調整します.これにより、最適なトラジェクトリとのステッチングが可能となり、より良いパフォーマンスを発揮します.一方、DTはトラジェクトリステッチングに苦労しており、最適なトラジェクトリの生成に制約があります.
以上のように、EDTとDTの主な違いは、トラジェクトリステッチングの容易さとパフォーマンスの向上です.EDTは、より最適なトラジェクトリを生成するために、履歴の長さを調整することでトラジェクトリを最適化します.これにより、DTに比べてより優れた性能を発揮します.
Q: テスト時の行動推論において、EDTはどのように軌跡のスティッチングを促進するのか?
A: EDTは、テスト時のアクション推論中に軌跡のステッチングを容易にすることで、軌跡のステッチングを促進します.これは、維持される履歴の長さを調整することによって実現されます.
具体的には、EDTは複数のサブオプティマルな軌跡の最良の部分から最適またはほぼ最適な軌跡を生成するプロセスである軌跡のステッチングをテスト時のアクション推論中に容易にすることができます.これは、履歴の長さを調整することによって実現されます.
軌跡のステッチングによって、EDTはデータセット内のサブオプティマルな軌跡に惑わされることなく、現在のリターンを最適化するための履歴の長さとアクションについてより良い意思決定をする能力を示します.
したがって、EDTはテスト時のアクション推論中に軌跡のステッチングを容易にすることによって、軌跡のステッチングを促進します.
Q: 軌跡縫いのプロセスと、DTが苦戦する理由を説明していただけますか?
A: トラジェクトリーステッチングとは、複数のサブオプティマルな軌跡の一部を組み合わせて最適な軌跡を生成するプロセスを指します.このプロセスは、オフライン強化学習(RL)タスクにおいて重要な役割を果たします.しかし、DT(Decision Transformer)はトラジェクトリーステッチングにおいて制約があり、うまく処理することができません.
DTがトラジェクトリーステッチングに苦労する理由は、以下のような制約があるためです.まず、DTは入力シーケンスを効果的に処理することができますが、長い入力シーケンスに対しては制約があります.長い入力シーケンスを処理する際には、情報の欠落やノイズの影響を受ける可能性があります.そのため、トラジェクトリーステッチングにおいては、複数のサブオプティマルな軌跡を正確に組み合わせることが困難となります.
さらに、DTは即時の報酬に基づいて行動を選択する傾向があります.つまり、サブオプティマルな軌跡でも即時の報酬が高い場合には、その軌跡を選択する傾向があります.しかし、異なる軌跡を選択した場合には、時間の経過とともに累積報酬が高くなる可能性があります.DTはこのような長期的な累積報酬を考慮する能力に制約があり、トラジェクトリーステッチングにおいては最適な軌跡を生成することができません.
このような制約があるため、DTはオフラインRLタスクにおいてトラジェクトリーステッチングに苦労します.トラジェクトリーステッチングは、複数のサブオプティマルな軌跡を組み合わせて最適な軌跡を生成するため、長期的な累積報酬を最大化することができます.しかし、DTは情報の欠落や即時の報酬に基づく行動選択の制約があるため、トラジェクトリーステッチングをうまく処理することができません.
以上の理由から、DTはトラジェクトリーステッチングに苦労し、オフラインRLタスクにおいては制約があります.この制約を解決することで、DTの実世界の問題解決能力を大幅に向上させることができるでしょう.
Q: EDTはDTで維持されているヒストリーの長さをどのように調整し、軌道を最適化しているのか?
A: EDTは、現在の軌跡の品質に基づいて履歴の長さを調整することで、軌跡の最適化を図ります.具体的には、EDTは固定された履歴長と可変の履歴長の両方を使用してテストされます.その結果、可変の履歴長が固定の履歴長よりも優れたパフォーマンスを示し、特に「中程度の再生」データセットにおいて優れた結果を示すことが示されます.
EDTは、より高い推定リターンをもたらす履歴長を選択することで、軌跡の最適化を効果的に行います.履歴長を短くすることは軌跡のステッチングに役立ちますが、より長い履歴長を保持することも重要です.また、前の軌跡が最適である場合にはより長い履歴長を保持し、サブオプティマルな場合にはより短い履歴長を保持することで、より最適な軌跡とのステッチングを可能にします.EDTの能力を示す幅広い実験結果があり、DTベースとQベースのパフォーマンスのギャップを埋めることができることが示されています.
したがって、EDTは軌跡の最適化を目指すために、DTで保持される履歴長を調整します.
Q: 以前の軌跡が最適であった場合に長い軌跡を保持し、EDTにおいて最適でなかった場合に短い軌跡を保持することにどのような意味があるのだろうか?
A: EDTにおいて、前の軌跡が最適である場合にはより長い履歴を保持し、サブオプティマルな場合にはより短い履歴を保持することの意義は、最適な軌跡とより最適な軌跡を「縫い合わせる」ことができるという点にあります.
最適な軌跡を維持するためには、より長い履歴を保持することが重要です.これにより、過去の最適な軌跡の情報を利用して、より最適な軌跡を見つけることができます.履歴が長いほど、過去の最適な軌跡の情報がより多く含まれるため、より最適な軌跡を見つける確率が高まります.
一方、サブオプティマルな軌跡の場合には、より短い履歴を保持することが効果的です.これにより、サブオプティマルな軌跡との「縫い合わせ」がスムーズに行われ、より最適な軌跡に移行することができます.履歴が短いほど、サブオプティマルな軌跡の情報が少なくなるため、より最適な軌跡に移行する確率が高まります.
このように、前の軌跡が最適である場合にはより長い履歴を保持し、サブオプティマルな場合にはより短い履歴を保持することにより、EDTは最適な軌跡とより最適な軌跡を「縫い合わせる」ことができます.これにより、より高い推定リターンを得ることができます.
Q: D4RLロコモーションベンチマークとAtariゲームにおいて、EDTはQラーニングベースの手法をマルチタスク体制でどのような点で上回るのでしょうか?
A: EDTは、D4RLロコモーションベンチマークとAtariゲームのマルチタスク環境で、Q学習ベースの手法を上回る点で優れています.具体的には、EDTは、前の軌跡が最適である場合にはより長い履歴を保持し、前の軌跡がサブオプティマルである場合にはより短い履歴を保持することで、より最適な軌跡と「縫い合わせる」ことができます.さらに、EDTはDTベースとQ学習ベースの手法の性能差を埋める能力を持っており、多くの実験によってその能力が実証されています.具体的には、EDTは、D4RLロコモーションベンチマークとAtariゲームのマルチタスク環境で、Q学習ベースの手法を上回ることが示されています.
Q: DTやQラーニングに基づくアプローチと比較して、EDTを使用することの限界や潜在的な欠点はありますか?
A: EDTを使用する際のDTやQ学習ベースの手法と比べた場合の制限や潜在的な欠点はありますか?
この論文では、EDTがDTや他の主要なオフライン強化学習アルゴリズムと比較して優れたパフォーマンスを示すことが確認されました.特に、EDTはD4RLベンチマークやAtariゲームのマルチタスクシナリオで既存のQ学習ベースの手法を上回っています.しかし、EDTを使用する際の制限や潜在的な欠点も考慮する必要があります.
論文では、EDTの最適な履歴を推定する速度を向上させることが将来の改善の方向性として挙げられています.これにより、厳しい時間制約があるリアルタイムアプリケーションに適用することが可能になるかもしれません.しかし、この適応は将来の研究の興味深い方向性であり、本論文の主要な範囲外になります.
したがって、EDTの主な制限は、リアルタイムアプリケーションには適していない可能性があることです.また、EDTの実装には計算効率と組み合わせやすさの利点がありますが、他の手法と比較してもっと高速な推定ができるという制限があります.
これらの制限や潜在的な欠点を克服するためには、より高速な推定手法の開発やリアルタイムアプリケーションへの適用を検討する必要があります.これにより、EDTの利点を最大限に活用しながら、さらなる改善が可能になるでしょう.
Q: 軌道スティッチングの概念について、より詳しく説明していただけますか?また、それが最適または最適に近い軌道の生成とどのように関係しているのでしょうか?
A: トラジェクトリステッチングとは、複数のサブオプティマルなトラジェクトリから最適または近似最適なトラジェクトリを生成するプロセスです.この概念は、テスト時のアクション推論中にトラジェクトリステッチングを容易にすることで、提案されたEDTが他と異なる点です.これは、維持される履歴の長さを調整することによって実現されます.
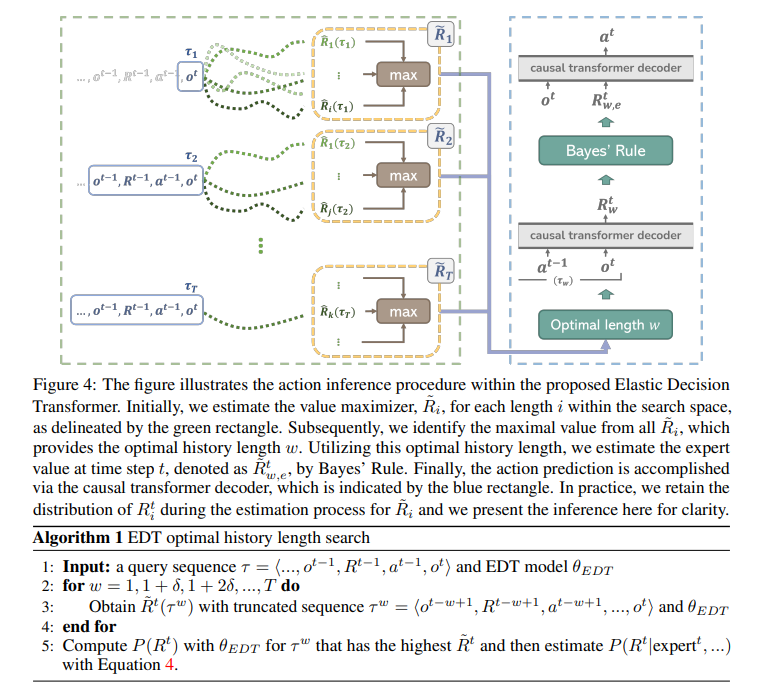
具体的には、トラジェクトリステッチングをアクション推論の段階で実現することを目指しています.図3には、簡単な例を用いてこの概念が示されています.このシナリオでは、2つのトラジェクトリからなるデータセットD=(sat−1, st, sat+1),(sbt−1, st, sbt+1)を考慮しています.このデータセットでトレーニングされたシーケンスモデルは、元のトラジェクトリに一致するように次の状態を予測する傾向があります.
これを克服するために、トラジェクトリステッチングを可能にする手法を提案しています.この手法では、モデルはsbt−1から始まり、sat+1で終了するようにします.これは、履歴の長さを適応的に調整することによって実現されます.最大値推定器˜Rを導入し、データセット内のすべての潜在的な結果の中で最大値を計算します.これにより、˜Rを最大化する最適な履歴の長さを決定することができます.
要約すると、EDTはトラジェクトリステッチングの有望な解決策を提供し、サブオプティマルなトラジェクトリからより良いシーケンスを生成することができます.この機能は、さまざまなアプリケーションにおいて性能を向上させることができるため、DTのバリエーションの改善に大きく貢献することができます.私たちは、私たちのコードを公開することに取り組んでいます.
トラジェクトリステッチングに関する制約事項としては、ポリシーの改善の速度を向上させることが挙げられます.同様に、他の拡散ベースの手法[21,32,50,5,10,4]では、拡散ベースの生成モデルを使用してポリシーまたはモデルのダイナミクスを表現し、さまざまなタスクで競争力のあるまたは優れたパフォーマンスを達成しています.
オフラインRLにおけるトラジェクトリステッチングの問題に取り組むためには、さまざまな手法が提案されています.Q-learning Decision Transformer(QDT)[57]は、推定値を用いてグラウンドトゥルースのリターン・トゥ・ゴーを再ラベル化するという技術を用いて、トラジェクトリ再結合を促進
Q: EDTがDTやQラーニングに基づく方法よりも大きな改善を示した具体例やケーススタディはありますか?
A: EDTは、DTやQ学習ベースの手法に比べて顕著な改善が見られる具体的な例やケーススタディがいくつかあります.論文のセクション4.2および4.3では、EDTがDTおよびその派生手法を大幅に上回ることが示されています.また、セクション4.3では、EDTがLocomotionやAtariゲームなどのマルチタスク学習環境でも効果的であることが示されています.
具体的な例として、論文ではD4RL locomotion ベンチマークおよびAtariゲームのマルチタスク環境での実験結果が示されています.これらの実験では、EDTがQ学習ベースの手法を上回る性能を示しています.また、論文には実験結果のビデオも提供されており、https://kristery.github.io/edt/で閲覧することができます.
これらの結果から、EDTがDTやQ学習ベースの手法に比べて優れたパフォーマンスを示すことが確認されています.具体的なケーススタディや例については、論文や提供されたビデオを参照することで詳細な情報を得ることができます.
LongNet: Scaling Transformers to 1,000,000,000 Tokens
著者:Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Furu Wei
発行日:2023年07月05日
最終更新日:2023年07月05日
URL:http://arxiv.org/pdf/2307.02486v1
カテゴリ:Computation and Language, Machine Learning

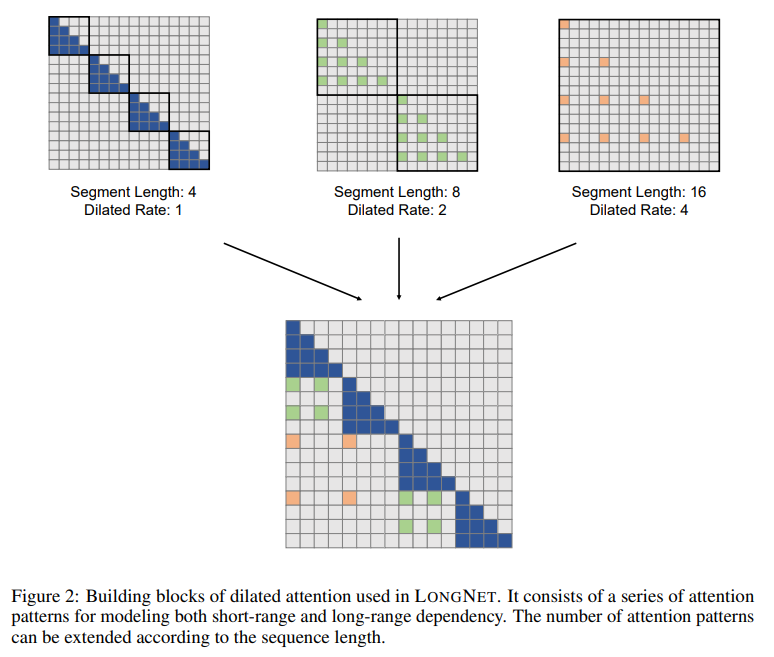
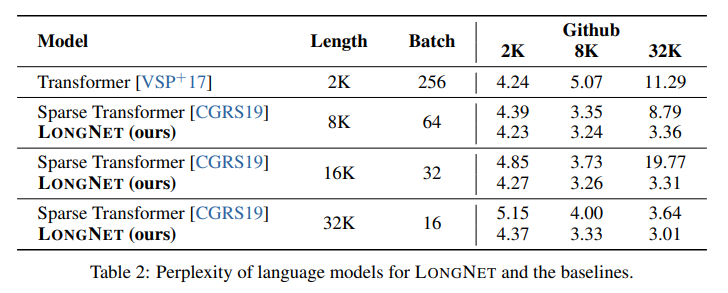
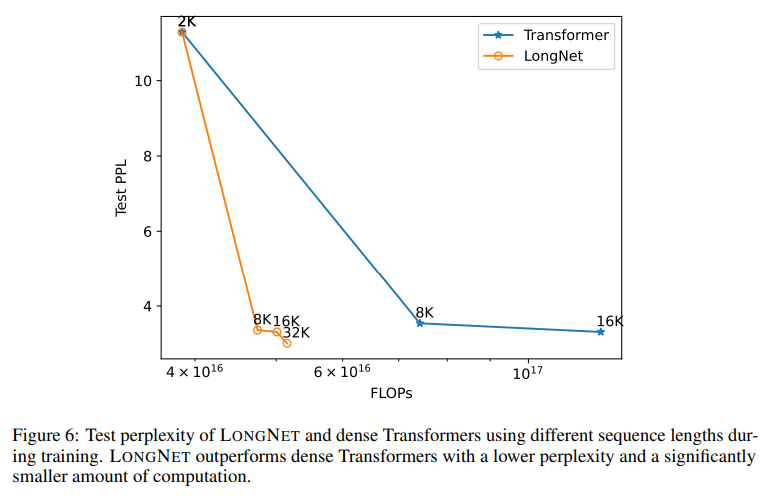
概要:
長いシーケンスのスケーリングは、大規模な言語モデルの時代において重要な要求となっています.しかし、既存の方法は、計算の複雑さまたはモデルの表現力のいずれかに苦しんでおり、最大シーケンス長が制限されています.本研究では、シーケンス長を10億トークン以上にスケーリングできるTransformerの派生モデルであるLongNetを提案します.LongNetは、短いシーケンスにおけるパフォーマンスを犠牲にすることなく、長いシーケンスに対応できます.具体的には、距離が増えるにつれて注意領域を指数的に拡大するdilated attentionを提案しています.LongNetには以下のような重要な利点があります:1)線形の計算複雑さとトークン間の対数的な依存性があること、2)非常に長いシーケンスの分散トレーナーとして使用できること、3)dilated attentionは標準のattentionの代替として使用でき、既存のTransformerベースの最適化とシームレスに統合できること.実験結果は、LongNetが長いシーケンスモデリングと一般的な言語タスクの両方で強力なパフォーマンスを発揮することを示しています.この研究は、コーパス全体またはインターネット全体をシーケンスとして扱うなど、非常に長いシーケンスのモデリングに新たな可能性を開拓します.
Q&A:
Q: LongNetが拡張できる最大シーケンス長は?
A: LongNetは、1つのモデルで1億以上のトークンのシーケンス長をスケーリングすることができます.これは、従来の方法では計算の複雑さやモデルの表現力の制約により、シーケンス長が制限されていた問題を解決するために開発されたTransformerの変種です.
具体的には、LongNetは拡張された注意機構であるdilated attentionを提案しています.この注意機構は、トークン間の距離が増加するにつれて、注意の範囲を指数関数的に拡大します.これにより、LongNetは以下のような重要な利点を持っています.
1) 線形の計算複雑性とトークン間の対数的な依存関係を持つこと.
2) 非常に長いシーケンスのための分散トレーナーとして機能すること.
3) dilated attentionは、既存のTransformerベースの最適化とシームレスに統合できる標準的な注意機構の代替となること.
LongNetの実装では、dense Transformerに変換することができます.これにより、Transformerの最適化(カーネルの統合、量子化、分散トレーニングなど)を利用することができます.また、線形の計算複雑性を活用することで、LongNetはノード間でトレーニングを並列化することができます.これにより、分散アルゴリズムによって計算とメモリの制約を効率的に破ることができます.
以上の利点により、LongNetは1億トークンにも及ぶシーケンス長をほぼ一定の実行時間でスケーリングすることができます.一方、従来のTransformerは二次の計算複雑性によって制約されています.
つまり、LongNetは最大で1億トークンのシーケンス長をスケーリングすることができます.
Q: LongNetは、長い配列にスケールアップしながら、どのようにして短い配列のパフォーマンスを維持しているのですか?
A: LongNetは、バニラトランスフォーマーのアテンションを新しい要素である拡張アテンションに置き換えることで、シーケンスの長さを10億トークンまでスケーリングすることに成功しました.拡張アテンションは、トークン間の距離が増加するにつれて指数関数的にアテンションの割り当てを減少させるという一般的な設計原則に基づいています.これにより、有限なアテンションリソースとすべてのトークンへのアクセス可能性との間の矛盾を解消することができます.
具体的な実装では、LONGNETは密なトランスフォーマーに変換することができます.これにより、トランスフォーマーの最適化(カーネルの統合、量子化、分散トレーニングなど)をシームレスにサポートすることができます.また、線形の計算量を活用することで、LONGNETはノード間でトレーニングを並列化することができ、計算とメモリの制約を分散アルゴリズムで打破することができます.これにより、ほぼ一定の実行時間でシーケンスの長さを10億トークンまで効率的にスケーリングすることができます.
LongNetは、バニラトランスフォーマーと比較して二次の計算量の問題を抱えているため、トレーニング中にシーケンスの長さを増やすことは一般的に言語モデルの改善につながることが示されています.また、推論時のシーケンスの長さの外挿は、モデルがサポートする長さよりもはるかに大きい場合には適用されないことがわかっています.さらに、LONGNETはベースラインモデルに比べて一貫して優れたパフォーマンスを発揮し、その有効性を証明しています.
したがって、LongNetは、シーケンスの長さをスケーリングする際に短いシーケンスのパフォーマンスを維持するために、拡張アテンションという新しい要素を導入しています.拡張アテンションは、トークン間の距離に応じてアテンションの割り当てを調整することで、有限なアテンションリソースを効果的に活用し、すべてのトークンへのアクセス可能性を確保することができます.また、線形の計算量を持つLongNetは、分散アルゴリズムを使用してトレーニングを並列化することができ、計算とメモリの制約を克服することができます.これにより、長いシーケンスにスケーリングしながらも、短いシーケンスのパフォーマンスを維持することができます.
Q: 拡張された注意力とは何なのか.また、距離が縮まるにつれて注意力がどのように拡大するのか.
A: Dilated attentionは、異なる部分でキーを集め、softmaxを一緒に計算することと同等です.局所的な注意は正確に計算されるべきであり、一方でグローバルな注意は近似的に計算できます.そのため、大きなwiと大きなriを持つように設定します.さらに、各注意に対してwiを最大の長さNまたは注意の数kに達するまで徐々に増やします.具体的には、wiとrを幾何学的な数列に設定します.LONGNEThasは、以下の利点があります.まず、トークン間の計算の複雑さが線形であり、対数の依存関係があります.次に、非常に長いシーケンスの分散トレーナーとして使用できます.また、dilated attentionは、通常のattentionの代替として使用でき、シームレスに組み込むことができます.さらに、dilated attentionは、バニラのattentionに比べて計算コストをNwr2の要素で大幅に削減することができます.実際には、セグメントのサイズwは注意の全体性を効率化のためにトレードオフしますが、サイズrのdilationは注意行列を近似することで計算コストを削減します.長距離と短距離の情報を効率的に捉えるために、異なるセグメントサイズとdilation rate {ri, wi}kの混合dilated attentionを実装しています.
Q: 既存の方法と比較して、ロングネットの利点は何ですか?
A: LongNetは、既存の手法と比較して以下の利点があります.
- 長いシーケンスモデリングにおいて強力なパフォーマンスを発揮する:LongNetは、長いシーケンスモデリングと一般的な言語タスクの両方で強力なパフォーマンスを示します.これは、従来のTransformerベースの最適化と統合されており、長いシーケンスに対しても優れた性能を発揮することを意味します.
- 非常に長いシーケンスのモデリングが可能:LongNetは、例えばコーパス全体やインターネット全体をシーケンスとして扱うといった、非常に長いシーケンスのモデリングに新たな可能性を開くものです.これにより、より大規模なデータセットやタスクに対しても適用することができます.
- 計算の複雑さを線形に削減:LongNetは、計算の複雑さを二次から線形に削減します.これにより、複数のGPUデバイスを使用してシーケンスのトレーニングを並列化することができます.実験結果は、LongNetが長いシーケンスと短いシーケンスの両方のモデリングにおいて、強力なベースラインよりも優れたパフォーマンスを示すことを示しています.
- オフシェルフの最適化をサポート:LongNetは、密なTransformerに変換することができます.これにより、Transformerの最適化(カーネルの統合、量子化、分散トレーニングなど)をシームレスにサポートすることができます.また、線形の計算量を活用することで、LongNetはノード間でトレーニングを並列化することができます.これにより、計算とメモリの制約を打破し、分散アルゴリズムによってシーケンスの長さを効率的に1Bトークンまでスケーリングすることができます.一方、従来のTransformerは二次の計算量によって制約されます.
以上がLongNetの既存の手法と比較した際の利点です.
Q: LongNetはどのようにして線形計算複雑性とトークン間の対数依存性を実現しているのか?
A: LongNetは、トークン間の距離が増加するにつれて指数関数的に注意割り当てが減少するという新しいコンポーネントである拡張された注意機構を使用して、バニラトランスフォーマーの注意機構を置き換えることによって、線形の計算複雑性とトークン間の対数依存性を実現しています.
具体的には、LongNetはトークン間の距離が増加するにつれて指数関数的に注意割り当てを減少させることで、計算複雑性を線形に保ちながら、トークン間の依存関係を対数的に制御しています.このアプローチにより、有限な注意リソースとすべてのトークンへのアクセス可能性の間の矛盾を解消しています.
具体的な実装では、LongNetは密なトランスフォーマーに変換することができます.これにより、トランスフォーマーの最適化(カーネルの統合、量子化、分散トレーニングなど)をシームレスにサポートすることができます.また、線形の計算複雑性を活用することで、LongNetはノード間でトレーニングを並列化することができ、計算とメモリの制約を分散アルゴリズムで打破することができます.これにより、ほぼ一定の実行時間でシーケンスの長さを1Bトークンまで効率的にスケーリングすることができます.一方、バニラトランスフォーマーは二次の計算複雑性に苦しんでいます.
つまり、LongNetは拡張された注意機構によって、トークン間の距離に応じて指数関数的に注意割り当てを減少させることで、線形の計算複雑性とトークン間の対数依存性を実現しています.
Q: LongNetは非常に長いシーケンスの分散トレーナーとして使用できますか?
A: 長いシーケンスの分散トレーナーとして、LONG NETは使用できますか?
はい、LONG NETは非常に長いシーケンスの分散トレーニングに使用できます.LONG NETは、複数のGPUデバイス間でシーケンスのトレーニングを並列化する分散トレーナーとして機能します.この分散アルゴリズムは、シーケンスの次元を分割し、各デバイスに個別に配置することから始まります.このようにして、トレーニングプロセスを並列化し、長いシーケンスに対して効率的なトレーニングを実現します.
LONG NETは、長いシーケンスと短いシーケンスの両方のモデリングにおいて、強力なベースラインに比べて優れたパフォーマンスを示しています.さらに、LONG NETは、トークン間の線形計算の複雑さと対数的な依存関係を持つため、計算の複雑さを劇的に削減することができます.また、LONG NETの拡張により、多様なタスク(例:多モーダルな大規模言語モデリング、BEiTの事前トレーニング、ゲノムデータモデリングなど)をサポートする予定です.
従来のモデル並列化アルゴリズム(モデル並列化、シーケンス並列化、パイプライン並列化)は、LONG NETには不十分です.特に、シーケンスの次元が非常に大きい場合には、これらのアルゴリズムでは対応できません.
以上のように、LONG NETは非常に長いシーケンスの分散トレーニングに使用できることがわかります.その線形計算の複雑さと分散アルゴリズムにより、効率的なトレーニングが可能となります.
Q: LongNetにおける拡張された注意は、既存のTransformerベースの最適化との統合という点で、標準的な注意と比べてどうなのか?
A: LONGNETのdilated attentionは、既存のTransformerベースの最適化とシームレスに統合できる点で、標準のattentionと比較しています.具体的には、dilated attentionは標準のattentionの代替として使用できるため、既存のTransformerベースの最適化との統合が容易です.
標準のattentionは、トークン間の関連性を計算するために使用されますが、その計算量は二次的なものです.一方、dilated attentionは、トークン間の距離が増加するにつれて、注意の割り当てが指数関数的に減少するため、計算量が線形になります.この線形の計算量は、既存のTransformerベースの最適化との統合を容易にし、効率的なスケーリングを可能にします.
具体的には、LONGNETのdilated attentionは、標準のattentionと同じインターフェースを持ち、既存のTransformerベースの最適化との互換性があります.これにより、既存の最適化手法(例:カーネル融合、量子化、分散トレーニング)をシームレスに適用することができます.
したがって、LONGNETのdilated attentionは、既存のTransformerベースの最適化との統合において、標準のattentionと比較して優れた特徴を持っています.
Q: LongNetの性能を示す実験の結果は、長シーケンスモデリングと一般言語タスクでどのようなものでしたか?
A: 長いシーケンスモデリングと一般的な言語タスクにおけるLongNetのパフォーマンスを示す実験結果は次の通りです.図7(b)はテストセットの結果を報告しており、コンテキストウィンドウが大きくなるにつれて、LONG NETのテスト損失が徐々に減少していることを示しています.これは、LONG NETが長いコンテキストを完全に活用して言語モデルを改善する優位性を示しています.さらに、実験結果は、LONG NETが長いシーケンスと短いシーケンスの両方のモデリングにおいて、強力なベースラインモデルよりも優れたパフォーマンスを持っていることを示しています.
Q: LongNetは、非常に長いシーケンスをモデル化するための新しい可能性をどのように切り開くのか?
A: LongNetは、非常に長いシーケンスのモデリングに新たな可能性を開く.これまでのTransformerの変種では、シーケンスの長さが制限されていたが、LongNetでは1億トークン以上のシーケンスのスケーリングが可能であり、短いシーケンスのパフォーマンスを犠牲にすることなく実現している.具体的には、私たちはdilated attentionを提案しており、これにより注意機構がシーケンスの距離に応じて指数関数的に増加する問題を解決している.LongNetは、既存のTransformerベースの最適化とシームレスに統合することができるため、既存のモデルに組み込むことが容易である.実験結果は、LongNetが長いシーケンスのモデリングと一般的な言語タスクの両方で強力なパフォーマンスを発揮することを示している.これにより、コーパス全体やインターネット全体をシーケンスとして扱うなど、非常に長いシーケンスのモデリングに新たな可能性が開かれる.
Q: LongNetは、コーパス全体、あるいはインターネット全体をシーケンスとして扱うのに使えるのか?
A: はい、LongNetはコーパス全体やインターネット全体をシーケンスとして扱うことができます.論文の文脈から推測すると、LongNetは非常に長いシーケンスをモデリングすることが可能であり、既存のTransformerベースの最適化と統合されています.実験結果は、LongNetが長いシーケンスモデリングと一般的な言語タスクの両方で強力なパフォーマンスを発揮することを示しています.これにより、コーパス全体やインターネット全体を1つのシーケンスとして扱うという新たな可能性が開かれました.
具体的には、LongNetはシーケンスの長さを10億トークン以上にスケーリングすることができます.これにより、非常に大きなデータセットや長い文章を効率的にモデリングすることができます.また、LongNetは既存のベースラインモデルよりも優れたパフォーマンスを示しており、長いシーケンスだけでなく、短いシーケンスのモデリングにも適しています.
さらに、LongNetは分散トレーナーとして機能し、複数のGPUデバイスでシーケンスのトレーニングを並列化することができます.これにより、大規模なデータセットや長い文章のトレーニングを効率的に行うことができます.
したがって、LongNetはコーパス全体やインターネット全体をシーケンスとして扱うための新たな可能性を開拓しています.これにより、非常に大きなデータセットや長い文章をモデリングするための新しい手法やアプリケーションが可能になります.
Robots That Ask For Help: Uncertainty Alignment for Large Language Model Planners
著者:Allen Z. Ren, Anushri Dixit, Alexandra Bodrova, Sumeet Singh, Stephen Tu, Noah Brown, Peng Xu, Leila Takayama, Fei Xia, Jake Varley, Zhenjia Xu, Dorsa Sadigh, Andy Zeng, Anirudha Majumdar
発行日:2023年07月04日
最終更新日:2023年07月04日
URL:http://arxiv.org/pdf/2307.01928v1
カテゴリ:Robotics, Artificial Intelligence, Applications

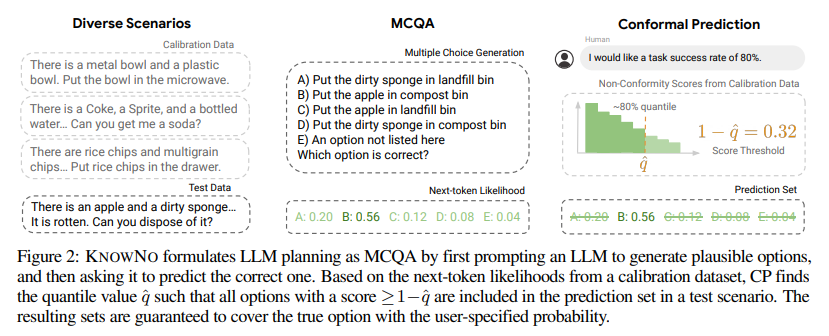
概要:
大規模言語モデル(LLM)は、ステップバイステップの計画から常識的な推論まで、さまざまな有望な機能を持っていますが、自信を持って幻覚的な予測をする傾向があります.本研究では、LLMベースのプランナーの不確実性を測定し、必要な時に助けを求めるように調整するためのフレームワークであるKnowNoを提案しています.KnowNoは、適合予測の理論に基づいて構築されており、複雑な多段階計画の設定において、タスク完了の統計的な保証を提供しながら、人間の助けを最小限に抑えます.空間的な不確実性から数値的な不確実性、人間の好みからウィノグラードスキーマまで、さまざまなモードの曖昧さを伴うシミュレーションおよび実際のロボットセットアップを含む実験では、KnowNoが現代のベースライン(アンサンブルや詳細なプロンプトの調整を含む場合もある)に比べて効率と自律性を向上させると同時に、形式的な保証を提供することが示されました.KnowNoは、モデルの微調整なしでLLMと組み合わせて使用することができ、成長する基盤モデルの能力に対応し、不確実性モデリングの軽量な有望なアプローチを示唆しています.詳細は、https://robot-help.github.ioをご覧ください.
Q&A:
Q: KnowNoフレームワークの目的は何ですか?
A: KnowNoフレームワークの目的は、言語指示に基づいて動作するロボットの不確実性を測定し、それに合わせることです.このフレームワークは、統計的な保証を提供しながら、複雑な多段階の計画状況で人間の助けを最小限に抑えるために、予測の不確実性を測定し、それに合わせる手法を提供します.
具体的には、KnowNoフレームワークは、conformal prediction(CP)の理論を利用して、LLMベースのプランナーの不確実性を調整します.このフレームワークは、以下のような貢献を行います.
- 言語指示が与えられた場合、事前にトレーニングされたLLMを使用して、不確実性を測定します.LLMは、ステップバイステップの計画から常識的な推論まで、幅広い有望な機能を持っていますが、自信を持って幻想的な予測をする傾向があります.
- 不確実性の調整という観点から、以下の要件を具体化します.
- キャリブレーションされた信頼性:ロボットは、ユーザーが指定した統計的に保証されたタスクの成功レベルを確保するために十分な助けを求めるべきです.
- 最小限の助け:ロボットは、タスクの可能な曖昧さを絞り込むことにより、求める助けの総量を最小限に抑えるべきです.
このように、KnowNoフレームワークは、LLMベースのプランナーの不確実性を測定し、それに合わせることで、効率性と自律性を向上させながら、形式的な保証を提供します.また、モデルの微調整なしでLLMsと組み合わせて使用できるため、不確実性をモデリングするための軽量なアプローチを提案します.
Q: KnowNoはLLMベースのプランナーの不確実性をどのように調整するのか?
A: KnowNoは、LLMベースのプランナーの不確実性を整列させるためのフレームワークです.このフレームワークは、確信を持って幻想的な予測をする傾向があるLLMに対して、彼らが自分がわからないことを知り、必要な時に助けを求める能力を与えることを目指しています.
KnowNoは、conformal prediction(CP)の理論を利用して、LLMベースのプランナーの不確実性を整列させる手法です.CPは、予測の信頼性を統計的に保証するために使用されます.具体的には、LLMは、与えられたタスクの指示に基づいて、可能な次のステップとそれらのオプションの信頼度(スコア)を生成します.CPは、ある特定の分位点以上のスコアを持つオプションを含む予測セットを提供します.セット内に複数のオプションがある場合、ロボットは助けを求めます.
KnowNoは、複数の具体例やさまざまな曖昧さのある状況を含む実験を通じて、ベースラインに比べて効率と自律性が大幅に向上することを示しています.
また、KnowNoは、助けを求めることが望ましいタスクの成功レベルを統計的に保証する方法を提供することができます.具体的には、不確実性の整列には、十分な助けを求めてユーザーが指定したタスクの成功レベルを統計的に保証すること(キャリブレーションされた信頼性)と、タスクの曖昧さを狭めることによって全体的な助けの量を最小化すること(最小限の助け)が含まれます.
以上のように、KnowNoは、LLMベースのプランナーの不確実性を整列させるためのフレームワークであり、conformal predictionの理論を活用しています.これにより、LLMの能力の向上に対応し、効率的かつ軽量な不確実性モデリング手法を提供することができます.
Q: コンフォーマル予測理論とは何か、そしてKnowNoはそれをどのように活用しているのか?
A: コンフォーマル予測の理論は、タスクの完了に対する統計的な保証を提供するために、不確実性のある複雑な多段階計画の設定で人間の助けを最小限に抑えるために構築されています.KNOW NOは、このコンフォーマル予測の理論を利用して、言語指示されたロボットの不確実性の整合性の問題に取り組むフレームワークです.
具体的には、KNOW NOは、言語モデル(LLM)に対してコンフォーマル予測を適用します.LLMは、言語指示に基づいて可能な次のステップを生成し、それぞれのオプションの確信度(スコア)を生成します.コンフォーマル予測は、特定の分位点以上のスコアを持つオプションを含む予測セットを提供します.予測セットに複数のオプションが含まれている場合、ロボットは助けを求めます.
KNOW NOは、このコンフォーマル予測の手法を使用することで、効率性と自律性を向上させると同時に、形式的な保証を提供します.また、モデルの微調整なしでLLMと組み合わせて使用することができるため、軽量な不確実性モデリング手法として有望です.
つまり、コンフォーマル予測の理論は、不確実性のあるタスクの統計的な保証を提供するために利用され、KNOW NOはこの理論を応用して言語指示されたロボットの不確実性の整合性を実現するために開発されたフレームワークです.
Q: 実験に使われた曖昧さのモードが異なるタスクの例を教えてください.
A: 実験で使用された異なる曖昧性のモードを持つタスクの例を提供できます.実験では、3つの異なる曖昧性タイプが使用されました.
- シミュレーションにおける属性の曖昧さ: このタイプの曖昧さでは、「緑」、「黄色」、「青」、「ブロック」、「ボウル」といった明確な用語に加えて、ブロックを「キューブ」、「直方体」、「箱」、「四角いオブジェクト」と呼び、ボウルを「容器」、「丸いオブジェクト」、「受け皿」と呼び、またはブロックまたはボウルを「オブジェクト」、「アイテム」、「物」と呼ぶことがあります(例:「黄色いボウルに青いオブジェクトを移動させてください」).また、「青」を「シアン」、「ネイビー」に、「緑」を「緑っぽい」、「草色の」と呼び、「黄色」を「オレンジ」または「ゴールド」と呼ぶこともあります.この設定は、3つの曖昧性タイプの中で最も曖昧性が少ない設定です.
これらの曖昧性は、人間によって意図的にもしくは意図せずに世界の環境に存在することがあります.不適切に構築された計画に自信を持って従うことは、望ましくない行動や安全でない行動につながる可能性があります.例えば、図1のような例では、食べ物を温めるためにロボットに「ボウルを電子レンジに置いてください」という指示が与えられた場合、カウンターに複数のボウルがある場合、指示は曖昧です.さらに、金属製のボウルは電子レンジには安全ではありません.このような曖昧な状況で行動し、電子レンジを破損したり、火災を引き起こしたりする代わりに、ロボットは自分がわからないことを知って質問をするべきです(例:「どのボウルを電子レンジに置くべきですか」と尋ねる).言語に基づく計画に関する先行研究では、このような曖昧な状況での行動を避け、明確化を求めることが提案されています.
以上のように、実験では異なる曖昧性のモードを持つタスクが使用されました.
Q: 効率性と自律性という点で、KnowNoは現代のベースラインと比べてどうなのか?
A: KnowNoは、効率性と自律性の観点で、現代のベースラインと比較して有利な結果を示しています.モデルの微調整やアンサンブル、プロンプトの調整などを含む現代のベースラインに比べて、KnowNoは効率性と自律性を向上させるだけでなく、形式的な保証も提供します.KnowNoは、モデルの微調整なしでLLMsと組み合わせて使用することができ、不確実性のモデリングにおける軽量なアプローチを提案しています.これにより、基礎モデルの能力の向上に合わせてスケーリングすることが可能です.
具体的な実験結果によると、さまざまなシミュレーションや実際のロボットのセットアップにおいて、KnowNoは異なる不確実性のモード(例:空間的な不確実性、数値的な不確実性、人間の好み、Winogradスキーマなど)を持つタスクにおいて、現代のベースライン(アンサンブルやプロンプトの調整を含む)と比較して有利な結果を示しています.これにより、効率性と自律性が向上し、同時に形式的な保証も提供されます.
また、KnowNoは複雑な多段階の計画設定において、人間の助けを最小限に抑えながらタスクの完了に対する統計的な保証を提供するために、conformal predictionの理論に基づいています.これにより、タスクの完了率を統計的に保証しながら、人間の助けを最小限に抑えることができます.
総合的に見て、KnowNoは効率性と自律性の向上に加えて、形式的な保証も提供することができるため、現代のベースラインと比較して優れた性能を持っています.
Q: KnowNoはモデル・ファインチューニングを必要としますか?
A: KnowNoは、モデルの微調整を必要としません.文脈からわかるように、KnowNoはLLMs(Large Language Models)と組み合わせて使用することができますが、モデルの微調整は必要ありません.これは、「KNOW NOcan be used with LLMs out of the box without model-finetuning」という文によって明示されています.したがって、KnowNoはモデルの微調整なしで使用できる軽量なアプローチであり、成果物モデルの能力の拡大に対応することができます.
Q: KnowNoが提案した不確実性をモデル化する軽量化アプローチについて説明してもらえますか?
A: KnowNoは、不確実性をモデル化するための軽量なアプローチを提案しています.このアプローチは、大規模言語モデル(LLMs)と組み合わせて使用することができます.KnowNoは、タスクの完了に関する統計的な保証を提供しながら、複雑な多段階計画の設定において人間の助けを最小限に抑えることを目指しています.
KnowNoは、conformal predictionの理論に基づいて構築されています.conformal predictionは、予測の信頼性を統計的に評価する手法です.具体的には、予測の信頼区間を計算し、その信頼区間内にタスクの解が含まれる確率を推定します.これにより、LLMsが自信を持って予測することができる範囲を明確にすることができます.
KnowNoの軽量なアプローチは、モデルの微調整なしでLLMsと組み合わせて使用することができます.つまり、既存のLLMsをそのまま利用することができます.これにより、モデルの再学習や調整の手間を省くことができます.
この軽量なアプローチは、基礎となるモデルの能力の向上に合わせて拡張することができます.つまり、LLMsの能力が向上するにつれて、KnowNoもより高度な不確実性モデリングを行うことができます.
以上のように、KnowNoは軽量なアプローチを提案しており、LLMsと組み合わせて使用することで不確実性のモデリングを行うことができます.このアプローチは、統計的な保証を提供しながら効率と自律性を向上させることができます.また、既存のモデルの再学習や調整の手間を省くことができるため、実用的な手法として有望です.
Q: 大規模言語モデル(LLM)が示す有望な能力とは?
A: 大規模言語モデル(LLM)は、ステップバイステップの計画から常識的な推論まで、幅広い有望な能力を示しています.これらの能力は、ロボットにとって有用である可能性がありますが、自信を持って幻想的な予測をする傾向があります.LLMを活用した計画において、現在のLLMの主な課題の1つは、幻想を生じる傾向があることです.つまり、現実とは関係のないがらくたであるがらくたを自信を持って生成することです.このような誤った出力に対する誤った自信は、LLMに基づくロボットの計画にとって重大な課題を提起します.さらに、現実の環境での自然言語の指示は、人間によって本質的にまたは意図せずに高い程度の曖昧さを含んでおり、誤った計画を自信を持って追跡することは、望ましくない行動や安全でない行動につながる可能性があります.LLMの有望な能力は、ステップバイステップの計画から常識的な推論までの幅広い範囲にわたります.
Q: シミュレーションと実際のロボットのセットアップで行われた実験の詳細について教えてください.
A: シミュレーションと実際のロボットセットアップで行われた実験について、詳細を提供できます.
シミュレーションの実験では、PyBulletシミュレータを使用して、ロボットアームによるテーブル上のオブジェクトの再配置が行われました.シナリオは、緑、黄色、青の色のボウルとブロックが3つずつ配置された状態で初期化されます.タスクは、一定数のブロックやボウルを別のオブジェクトに移動させるか、特定の位置に移動させることです.ユーザーの指示には、異なる種類の曖昧さがあるため、3つの設定が導入されました.これらの設定は、属性に基づくもの(例:「受け皿」という言葉でボウルを指す)、数値に基づくもの(例:移動するブロックの数が不明確)などです.
実際のロボットセットアップの追加の実験では、2つのKuka IIW A 7アームを使用して、テーブル上のオブジェクトを移動させるバイマニュアルセットアップが行われました.テーブルの片側には1つのビンがあります.各アームの到達可能な作業領域は制限されており、片方のアームはテーブルの反対側やもう一方のビンに到達することはできません.そのため、タスクによってはアームの選択に曖昧さが生じることがあります.例えば、図5では人間がロボットにマンゴーを渡すように頼んでいますが、人間が立っている側が明示されていません.KNOW NOは、このような曖昧さを捉え、明確化を促します.すべての指示が曖昧であるシナリオ分布が設計され、高い人間の介入が必要とされました.
実験の詳細に関しては、図1、図5以外にも図A3が示されており、オフィスのキッチン環境とモービルマニピュレーションで使用される引き出しとビンのセットが左側に、実験で使用されるオブジェクトのセットがバイマニュアルのマットの上に示されています.また、モービルマニピュレーションの実験では、ここには表示されていない非常に大きなカウンタートップの下にもう一つの引き出しが使用されています.
以上が、シミュレーションと実際のロボットセットアップで行われた実験に関する詳細な説明です.
Physics-based Motion Retargeting from Sparse Inputs
著者:Daniele Reda, Jungdam Won, Yuting Ye, Michiel van de Panne, Alexander Winkler
発行日:2023年07月04日
最終更新日:2023年07月04日
URL:http://arxiv.org/pdf/2307.01938v1
カテゴリ:Computer Vision and Pattern Recognition
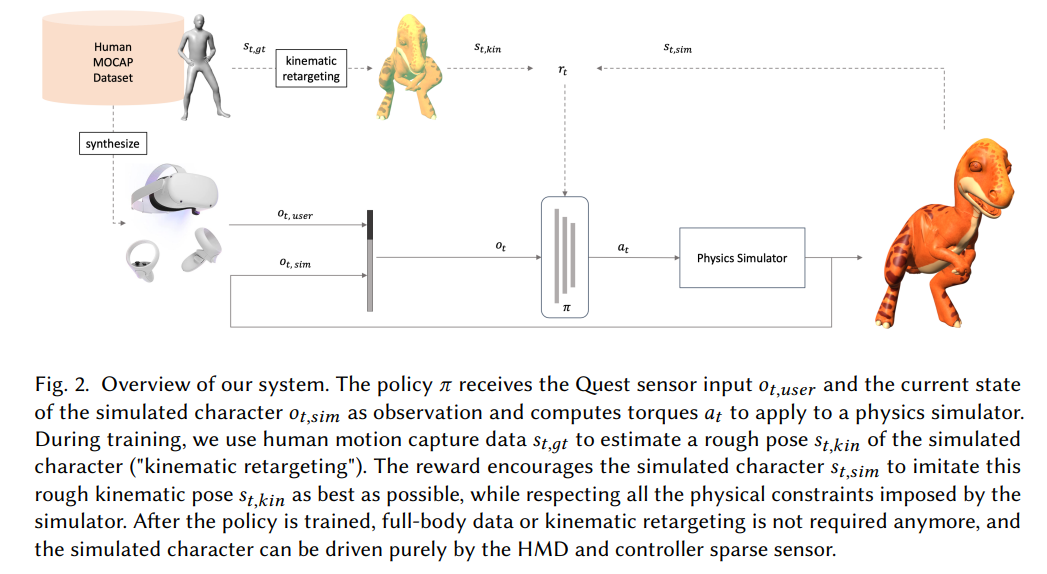

概要:
アバターは、仮想世界でインタラクティブで没入感のある体験を作り出すために重要です.ユーザーの動きを模倣するためにこれらのキャラクターをアニメーション化する際の課題の一つは、商用のAR/VR製品がヘッドセットとコントローラーのみで構成されており、ユーザーのポーズに関する非常に限られたセンサーデータしか提供していないことです.もう一つの課題は、アバターが人間とは異なる骨格構造を持つ場合があり、それらの間のマッピングが明確でないことです.
本研究では、これらの両方の課題に取り組んでいます.私たちは、リアルタイムでモーションをスパースな人間のセンサーデータからさまざまな形態のキャラクターにリターゲットするための手法を提案しています.私たちの手法は、物理シミュレータ内でキャラクターを制御するポリシーを訓練するために強化学習を使用しています.私たちは、各アバターに対してアーティストによるアニメーションを必要とせず、トレーニングには人間のモーションキャプチャデータのみを必要とします.これにより、大規模なモーションキャプチャデータセットを使用して、リアルタイムで実際のスパースデータから未知のユーザーを追跡できる一般的なポリシーを訓練することができます.
さらに、私たちは恐竜、ネズミのような生物、人間の3つの異なる骨格構造を持つキャラクターで私たちのアプローチの実現可能性を示しています.また、下半身のセンサーデータが利用できない状況でも、アバターのポーズがユーザーと驚くほどよく一致することを示しています.さらに、私たちは、キネマティックリターゲティングのステップ、模倣、接触およびアクション報酬、非対称のアクター・クリティック観察など、私たちのフレームワークの重要な要素を議論し、検証しています.さらに、バランスを崩す、ダンス、スポーツの動きなど、さまざまな状況で私たちの手法の堅牢性を探求しています.
Q&A:
Q: 限られたセンサーデータという課題に対して、今回紹介した方法はどのように対処しているのだろうか?
A: この研究で導入された方法は、制限されたセンサーデータの課題にどのように対処していますか?
この研究では、ヘッドセットとコントローラーから非常に限られたセンサーデータが提供されているという課題に取り組んでいます.また、アバターは人間とは異なる骨格構造を持つ場合があり、それらの間のマッピングは明確ではありません.この研究では、これらの両方の課題に対処しています.
具体的には、物理シミュレータ内でキャラクターを制御するためのポリシーを訓練するために、強化学習を使用しています.訓練には、各キャラクターの運動キャプチャデータのみを必要とし、各アバターのためにアーティストによって生成されたアニメーションに依存しません.これにより、大規模なモーションキャプチャデータセットを使用して、リアルタイムで実際のデータから未知のユーザーを追跡できる一般的なポリシーを訓練することができます.
さらに、制御信号の欠如にも対処しており、非常に限られた入力からリアルタイムのユーザーデータを未知のユーザーに対して再ターゲットすることができます.ただし、以前と比較して品質は低下します.
この方法では、制限されたセンサーデータの課題に対処するために、強化学習を使用してポリシーを訓練し、大規模なモーションキャプチャデータセットを使用して一般的なポリシーを訓練することで、リアルタイムで未知のユーザーのデータを追跡することができます.また、制御信号の欠如にも対処しており、非常に限られた入力からリアルタイムのユーザーデータを再ターゲットすることができます.
Q: 強化学習は、物理シミュレーターでキャラクターを制御するための方針を訓練する際に、どのような役割を果たすのだろうか?
A: リインフォースメントラーニングは、物理シミュレータ内のキャラクターを制御するためのポリシーを学習する際に重要な役割を果たします.具体的には、リインフォースメントラーニングは、物理シミュレータ内でのキャラクターの動作に対して適切なトルク値を生成するポリシーを学習します.
訓練中、人間のモーションキャプチャデータを使用して、ポリシーのためのHMD(ヘッドマウントディスプレイ)とコントローラデータを合成し、報酬のトレーニング信号を構築するために使用します.具体的には、モーションキャプチャデータは、キャラクターの望ましい動きを表現するために使用されます.これにより、ポリシーは望ましい動きを生成するためのトルク値を学習することができます.
ポリシーは、物理シミュレータ内の各関節に対して[-1,1]の範囲のトルク値を出力します.これらのトルク値は、各関節の最小および最大トルク値に基づいて再スケーリングされます.この再スケーリングは、PD(比例微分)ターゲット角度を出力するよりも優れたパフォーマンスを発揮し、より明確になることが以前の研究によって示されています.
ポリシーの訓練には、PPO(Proximal Policy Optimization)アルゴリズムとPyTorchの自動微分ソフトウェアが使用されます.また、物理シミュレーションにはNVIDIA PhysX Isaac Gym物理シミュレータが使用されます.
リインフォースメントラーニングによって学習されたポリシーは、物理シミュレータ内のキャラクターを制御するための適切なトルク値を生成することができます.これにより、非人間の物理ベースのキャラクターの異なる寸法や比例に対応することができます.
Q: それぞれのアバターについて、アーティストが作成したアニメーションに頼らないことが重要なのはなぜですか?
A: アバターを作成するために、アーティストによって生成されたアニメーションに頼らないことは重要です.これは、以下の理由からです.
まず第一に、アーティストによって生成されたアニメーションは、特定のキャラクターに対して作成されるため、他のキャラクターには適用できません.アバターの種類や形状は非常に多様であり、それぞれのキャラクターに対してアーティストがアニメーションを作成するのは非現実的です.そのため、アーティストによって生成されたアニメーションを使用すると、アバターの種類や形状が異なる場合には適切な動きを再現することができません.
第二に、アーティストによって生成されたアニメーションは、物理的な制約を考慮していない場合があります.物理的な制約は、キャラクターの重さや体の形状など、キャラクターの特性に関連しています.アーティストがアニメーションを作成する際には、これらの物理的な制約を考慮することが難しい場合があります.そのため、アーティストによって生成されたアニメーションは、物理的な現実感を欠いた動きを生み出す可能性があります.
以上の理由から、アーティストによって生成されたアニメーションに頼らず、大規模なモーションキャプチャデータセットを使用して一般的なポリシーをトレーニングすることが重要です.これにより、異なるアバターに対しても適切な動きを生成することができます.また、物理的な制約を考慮した動きを実現することができます.
Q: 大規模なモーションキャプチャーのデータセットを使って、どのように一般的な方針をトレーニングするのですか?
A: 大規模なモーションキャプチャーデータセットを使用して、一般的なポリシーをトレーニングするための方法は次のようになります.まず、強化学習を使用して物理シミュレーターのためのトルクを生成するポリシーを学習します.このポリシーは、非人間の物理ベースのキャラクターに対して、スパースな入力データからリターゲットするために使用されます.
トレーニング中、人間のモーションキャプチャーデータは、ポリシーのためのHMD(ヘッドマウントディスプレイ)とコントローラーデータを合成するために使用されます.また、報酬のトレーニングシグナルを構築するためにも使用されます.具体的には、モーションキャプチャーデータを使用して、望ましいモーションだけでなく、シミュレートされたキャラクターの特定の形態にも条件付けられた制御ポリシーが学習されます.さらに、実行時に形態を変更することさえ可能です.
この方法では、大規模なモーションキャプチャーデータセットを使用して、リターゲットの問題を解決するための基盤を構築しています.スパースな入力データから非人間の物理ベースのキャラクターにリターゲットする必要があるため、入力データは非常に曖昧な場合があります.しかし、強化学習とモーションキャプチャーデータを組み合わせることで、一般的なポリシーをトレーニングすることができます.
Q: フィージビリティ・デモンストレーションで使われた3人のキャラクターについて、もう少し詳しく教えてください.
A: フィージビリティデモンストレーションで使用された3つのキャラクターについて、詳細を教えていただけますか?
フィージビリティデモンストレーションでは、恐竜、ネズミのような生物、そして人間の3つの異なる骨格構造を持つキャラクターを使用して、アプローチの実現可能性を示しています.下半身のセンサー情報は利用できませんが、アバターのポーズはユーザーと驚くほどよく一致することが示されています.私たちは、キネマティックリターゲティングステップ、模倣、接触およびアクション報酬、および非対称のアクター・クリティック観察など、フレームワークの重要な要素を検討しています.さらに、不均衡、ダンス、スポーツの動きなど、さまざまな設定で私たちの方法の堅牢性を探求しています.
具体的には、以下の3つのキャラクターが使用されています:
- Oppy:下半身が短く、大きな頭、大きな耳、尾を持つネズミのようなキャラクターです.
- Dino:長くて重い尾と頭、短い腕を持つ高い恐竜です.
- Jesse:モーキャプデータに似た骨格構造を持つ人間のようなカートゥーンキャラクターです.
これらのキャラクターは、図3に視覚的な表現が示されており、表1にはそれぞれの骨格の構造の詳細が記載されています.このようなキャラクターの具現化は、現在のゲーム入力デバイスとディスプレイが提供する限られた没入感の中で、非常に魅力的なものであることが既に示されています.
Q: フレームワークの中で、議論され、切除された重要な構成要素は何か?
A: 重要な要素は、キネマティックリターゲティングステップ、模倣、接触およびアクション報酬、および非対称のアクター・評価者の観察です.これらの要素は、リターゲティングの成功に重要です.キネマティックリターゲティングステップは、モーションの再ターゲティングを可能にするために重要です.模倣は、モーションのスタイルを制御するために重要です.接触報酬は、足の接触情報を利用してモーションの品質を向上させるために重要です.アクション報酬は、モーションの品質を向上させるために重要です.非対称のアクター・評価者の観察は、モーションの再ターゲティングを可能にするために重要です.これらの要素は、リアルタイムで高品質のモーションを生成するために重要です.
Q: アンバランス、ダンス、スポーツモーションなど、さまざまな環境において、この方法はどのようにロバスト性を示すのか?
A: さまざまな設定での堅牢性を示すために、この手法は以下のような方法を用いています.
- キネマティックリターゲティングステップ:この手法では、キネマティックリターゲティングステップを使用して、モーションを特定のキャラクターに適応させます.キネマティックリターゲティングは、モーションの骨格構造を変換し、異なるキャラクターに合わせるための手法です.このステップにより、異なる設定やキャラクターに対しても適応性のあるモーションを生成することが可能となります.
- 模倣、接触、アクション報酬:この手法では、模倣、接触、アクション報酬という要素を含んでいます.模倣は、アーティストが提供したモーションやモーションキャプチャクリップを学習するための手法です.接触報酬は、キャラクターがバランスを保つために必要な接触力を考慮した報酬です.アクション報酬は、キャラクターが望ましい動作を行った場合に与えられる報酬です.これらの報酬を組み合わせることで、堅牢なバランスフィードバックを提供することができます.
- 非対称なアクター・クリティック観察:この手法では、非対称なアクター・クリティック観察を使用しています.非対称なアクター・クリティック観察は、キャラクターの動作を評価するための手法であり、キャラクターのバランスや動作の品質を評価するために使用されます.この観察により、異なる設定や動作に対しても堅牢性を持った評価が行われます.
以上の手法により、この方法はさまざまな設定(例:不安定な状態、ダンス、スポーツの動作)での堅牢性を示すことができます.キネマティックリターゲティングステップにより、異なるキャラクターや設定に対して適応性のあるモーションを生成することができます.模倣、接触、アクション報酬により、バランスフィードバックを提供し、望ましい動作を促進します.非対称なアクター・クリティック観察により、動作の品質を評価し、堅牢性を確保します.これらの要素の組み合わせにより、さまざまな設定での堅牢性が実現されます.
Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting
著者:Zhen Qin, Rolf Jagerman, Kai Hui, Honglei Zhuang, Junru Wu, Jiaming Shen, Tianqi Liu, Jialu Liu, Donald Metzler, Xuanhui Wang, Michael Bendersky
発行日:2023年06月30日
最終更新日:2023年06月30日
URL:http://arxiv.org/pdf/2306.17563v1
カテゴリ:Information Retrieval, Computation and Language, Machine Learning
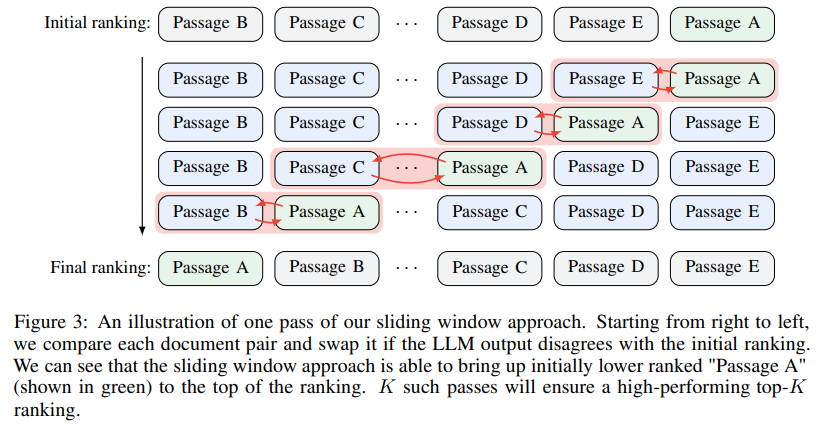

概要:
我々の研究では、既存の要約に加えて以下の文脈を提供します.PRPは、NDCG@5およびNDCG@10のメトリックにおいてはGPT-4ソリューションに劣る一方、InstructGPT(175Bパラメータ)などの他の既存の手法よりもほぼすべてのランキングメトリックで10%以上優れています.さらに、効率性を向上させるためにPRPのいくつかのバリアントを提案し、線形の複雑さでも競争力のある結果を達成することが可能であることを示しています.また、PRPの他の利点についても議論し、LLM APIの生成とスコアリングの両方をサポートし、入力の順序に対しても感度が低いことを示しています.
Q&A:
Q: 論文で取り上げられている主な問題は何か?
A: 本論文で主に取り組まれている問題は、非標準的なランキングデータセット(例:ArguAnaデータセットの反論)において、LLMs(Language Models)をどのように適応させるかということです.具体的には、LLMsが生成する”Yes”と”No”の確率を用いて、関連性スコアを計算する方法が提案されています.また、クエリ生成アプローチにおいても、LLMsが文書に基づいてクエリを生成し、実際のクエリを生成する確率を測定する方法が提案されています.
この論文では、点ごとの関連性予測の手法には2つの主要な問題があると指摘されています.まず、点ごとの関連性予測では、モデルがキャリブレーションされた点ごとの予測を出力する必要があります.これにより、比較のために使用することができます.また、点ごとの予測では、データセットのバランスが重要であり、クラスの不均衡がある場合には正確な予測が困難になる可能性があります.
したがって、この論文では、非標準的なランキングデータセットにおけるLLMsの適応方法と、点ごとの関連性予測手法の問題点について詳細に調査されています.
Q: なぜ研究者たちは、ベンチマークデータセットにおいて、微調整されたベースラインランカーを上回ることが難しいと感じているのだろうか?
A: 研究者は、ベンチマークデータセット上でファインチューニングされたベースラインランカーを上回ることが困難であると結論付けました.これは、既存の手法が十分なパフォーマンスを発揮できないためです.具体的には、Nogueira et al.(2020)やZhuang et al.(2023)などの研究では、既存の結果がベースラインランカーに比べて著しく性能が低いことが示されています.ただし、Sun et al.(2023)の提案した最近の手法は、ブラックボックスで巨大な商用GPT-4システムに依存しており、唯一の例外です.
この問題の理由を分析するために、既存の手法を調査した結果、以下のような技術的な懸念が存在することが明らかになりました.まず、入力の順序に対する感度があります.入力ドキュメントの順序が変わると、ランキング指標が50%以上低下する可能性があります.さらに、このようなブラックボックスシステムに依存することは、学術研究者にとっては著しいコスト制約やアクセス制限があるため、理想的ではないと主張されています.ただし、LLMのランキングタスクにおける能力を示すために、このような探索の価値は認められています.
さらに、既存の手法の分析により、Inpars(Bonifacio et al.、2022)などの手法は、ファインチューニングされたベースラインに比べて依然として十分なパフォーマンスを発揮できないことが明らかになりました.また、ExaRanker(Ferraretto et al.、2023)は、ランキングの決定に対する説明を生成するためにLLMを使用し、その説明をランキングモデルのファインチューニングに使用していますが、限定的なパフォーマンスの利益しか示していません.さらに、HyDE(Gao et al.、2022)は、LLMを使用して仮想的なドキュメントを生成することでクエリを補完していますが、パフォーマンスの利点は限定的です.
これらの理由により、研究者はベンチマークデータセット上でファインチューニングされたベースラインランカーを上回ることが困難であると結論付けました.
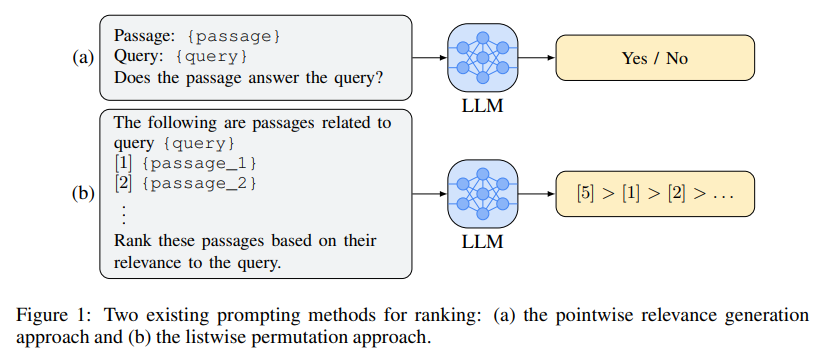
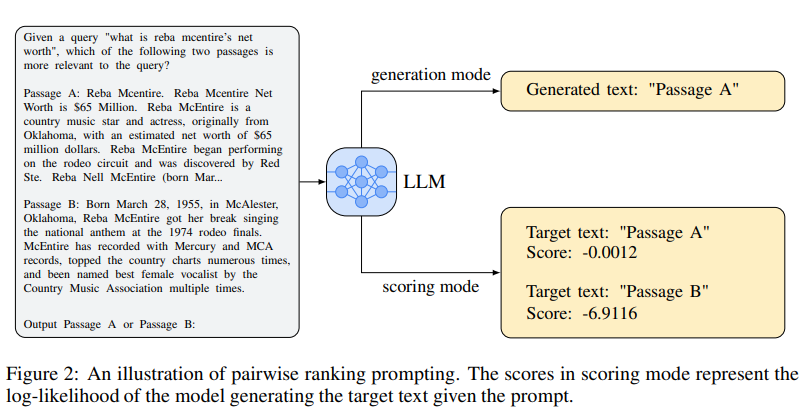
Q: Pairwise Ranking Prompting(PRP)とは?
A: Pairwise Ranking Prompting (PRP)は、LLMs(Language Model for Ranking)におけるランキングタスクの負荷を大幅に軽減するための新しい手法です.この手法は、クエリと2つのドキュメントのペアをLLMsのプロンプトとして使用し、ランキングタスクを実行します.その結果、LLMsのタスクの複雑さを大幅に減らし、キャリブレーションの問題を解決することができます.
PRPは、シンプルなプロンプトデザインに基づいており、生成型LLMsとスコアリング型LLMsの両方のAPIを自然にサポートしています.PRPは、効率の懸念点を解決するためにいくつかのバリエーションを提供しています.
PRPの主な目的は、LLMsのタスクの複雑さを軽減することです.従来のポイントワイズおよびリストワイズのランキング形式では、オフシェルフのLLMsはこれらのランキング形式を完全に理解することができませんでした.これは、LLMsのトレーニング方法の性質による可能性があります.
PRPは、LLMsのトレーニングおよびファインチューニング手順中にランキングタスクの困難さを軽減するために提案されています.具体的には、クエリとドキュメントのペアをプロンプトとして使用することで、LLMsによるランキングタスクの負荷を軽減します.このプロンプトデザインにより、LLMsはより簡単にランキングタスクを実行できるようになります.
PRPの効果は、標準ベンチマークデータセット上で中程度のサイズのオープンソースのLLMsを使用して、文献で初めて最先端のランキングパフォーマンスを達成した結果です.例えば、TREC-DL2020では、20Bパラメータを持つFlan-UL2モデルをベースにしたPRPは、50倍(推定)のモデルサイズを持つ商用のGPT-4に比べて、NDCG@1で5%以上の改善を達成しました.
以上のように、Pairwise Ranking Prompting (PRP)は、LLMsの負荷を軽減するための新しい手法であり、クエリとドキュメントのペアをプロンプトとして使用することで、ランキングタスクの複雑さを軽減します.これにより、中程度のサイズのオープンソースのLLMsでも最先端のランキングパフォーマンスを達成することができます.
Q: TREC-DL2020でPRPを使用した結果はどうでしたか?また、以前の最良のアプローチと比較してどうでしたか?
A: TREC-DL2020でのPRPの結果は、以前の最良の手法と比較して以下のようになります.PRPは、20Bのパラメータを持つFlan-UL2モデルに基づくバリアントを使用した場合、NDCG@1で50倍(推定)のモデルサイズを持つブラックボックスの商用GPT-4に次ぐ結果を示し、すべてのランキングメトリックスで最良の結果を達成します.また、175Bのパラメータを持つtext-davinci-003に基づくRankGPTよりも、すべてのランキングメトリックスで10%以上優れた結果を示し、ほとんどのランキングメトリックスで教師あり手法を上回ります.
Q: TREC-DL2019におけるPRPのパフォーマンスは、GPT-4ソリューションや他の既存ソリューションと比較してどうでしょうか?
A: 論文の結果によると、PRPはTREC-DL2019において、NDCG@5およびNDCG@10のメトリックにおいて、GPT-4のソリューションに次ぐ結果を示しました.また、NDCG@1のメトリックにおいては、(推定で)50倍のモデルサイズを持つGPT-4のソリューションを5%以上上回る結果を示しました.
さらに、PRPは175Bのパラメータを持つInstructGPTなどの既存のソリューションを、ほぼすべてのランキングメトリックで10%以上上回る結果を示しました.また、3Bおよび13Bのパラメータを持つFLAN-T5モデルを使用した場合でも競争力のある結果を示し、PRPのパワーと汎用性を示しました.
要約すると、PRPはTREC-DL2019において、GPT-4のソリューションや他の既存のソリューションと比較して非常に優れたパフォーマンスを発揮することがわかりました.
Q: 提案されているPRPのバリエーションとは?
A: 提案されたPRPのバリアントは、PRP-Allpair、PRP-Sorting、およびPRP-Sliding-Kです.これらのバリアントは、効率性を向上させるために異なるアプローチを取っています.
まず、PRP-Allpairは、すべてのクエリとドキュメントのペアに対してランキングスコアを計算することで効率性を向上させます.これにより、一度の呼び出しで複数のペアのスコアを計算できるため、LLMへの呼び出し回数を減らすことができます.
次に、PRP-Sortingは、ランキングスコアを計算する前に、クエリとドキュメントのペアを事前にソートすることで効率性を向上させます.ソートされたペアを使用することで、LLMへの呼び出し回数を減らすことができます.
最後に、PRP-Sliding-Kは、スライディングウィンドウを使用してランキングスコアを計算することで効率性を向上させます.スライディングウィンドウを使用することで、一度の呼び出しで複数のペアのスコアを計算できるため、LLMへの呼び出し回数を減らすことができます.
これらのバリアントは、LLMへの呼び出し回数を減らすことにより、効率性を向上させます.これにより、商用APIを呼び出す必要がなくなり、学術研究者にとってアクセスしやすいLLMを使用することができます.さらに、アクティブラーニングの技術を活用するなど、LLMへの呼び出し回数をさらに減らす方法についての研究も興味深い方向性です.
Q: 論文で述べられているPRPの他の利点は何ですか?
A: 論文で言及されているPRPの他の利点は、以下のようなものです.
- 生成とスコアリングのLLM APIの両方をサポートすること:PRPは、Large Language Model(LLM)の生成とスコアリングの両方をサポートすることができます.これにより、ユーザーは同じモデルを使用して、テキストの生成とランキングを行うことができます.例えば、ユーザーが特定のトピックに関連する文章を生成し、それらをランキングする場合、PRPはその両方のタスクをサポートします.
- 入力の順序に対して無感覚であること:PRPは、入力の順序に対して無感覚です.つまり、入力の順序が変わっても、PRPのパフォーマンスに影響を与えません.これは、ユーザーが入力の順序を変更しても、ランキング結果が一貫していることを意味します.例えば、ユーザーが複数の文を入力し、それらをランキングする場合、PRPは入力の順序に関係なく正確なランキング結果を提供します.
これらの利点により、PRPは強力で汎用性のあるモデルであることが示されています.また、PRPは商用APIの呼び出しを必要とせず、学術研究者にとってアクセスしやすいLLMを使用しています.さらに、PRPは効率的な変種を提供し、LLMへの呼び出し回数を減らすための研究方向も提案しています.また、PRPのドメイン適応に関する研究も必要であり、非標準的なランキングデータセットに対してどのように適応できるかについての調査が必要です.
Q: この論文では、既存のメソッドで使用されているポイントワイズおよびリストワイズ・ランキング・プロンプトはどのように分析されているか?
A: 論文では、既存の方法で使用されるポイントワイズおよびリストワイズのランキングプロンプトが分析されています.ポイントワイズアプローチは、セクション2.2で議論される非常に最近のリストワイズアプローチよりも前の主要な方法です.ポイントワイズアプローチでは、関連性生成(Liang et al.、2022)とクエリデータセットの2つの人気のある方法があります.論文では、既存の方法で使用されるポイントワイズおよびリストワイズのランキングプロンプトを分析し、オフシェルフのLLMがこれらのランキングの定式化を完全に理解していない可能性があると主張しています.これは、LLMのトレーニング方法の性質に起因する可能性があります.論文では、新しい技術であるPairwise Ranking Prompting(PRP)を使用して、LLMへの負荷を大幅に減らすことを提案しています.論文の結果は、中程度のサイズのオープンソースのLLMを使用して、標準ベンチマークで最先端のランキングパフォーマンスを実現した文献で初めてのものです.TREC-DL2020では、20Bパラメータを持つFlan-UL2モデルに基づくPRPが、50倍(推定)のモデルサイズを持つブラックボックス商用GPT-4に基づく先行研究のアプローチを上回り、NDCG@1で5%以上の性能向上を達成しています.TREC-DL2019では、
Q: LLMはどのような訓練を受け、それがランキング公式の理解にどのような影響を与えるのか?
A: LLM(Language Model)のトレーニングの性質とランキングの形式の理解に与える影響について、以下の文脈を使用して質問に答えます.
与えられた文脈からは、LLMのトレーニングの性質がランキングの形式の理解に影響を与えることが示唆されています.論文では、既存の方法ではLLMがランキングタスクを遂行することが困難であると述べられています.具体的には、ポイントワイズアプローチとリストワイズアプローチについて言及されています.
ポイントワイズアプローチでは、ランキングを行うためには、LLMがソートする前にキャリブレーションされた予測確率を出力する必要があります.しかし、これは非常に困難であり、生成のみのLLM API(例:GPT-4)ではサポートされていません.
リストワイズアプローチでは、明確な指示が与えられているにもかかわらず、LLMは頻繁に不明瞭なランキングを生成することがあります.これは、LLMのトレーニング方法の性質による可能性があります.
LLMのトレーニング方法は、論文では詳細には説明されていませんが、ランキングの形式の理解に影響を与える可能性があると示唆されています.論文では、LLMをランキングに対してより意識的にする方法についての研究方向が挙げられています.
したがって、LLMのトレーニングの性質がランキングの形式の理解に影響を与える可能性がありますが、具体的なトレーニング方法についての詳細は提供されていません.
Q: 実験に使われたFlan-UL2モデルの特徴は?
A: 実験で使用されたFlan-UL2モデルの特徴は次のとおりです.
Flan-UL2モデルは、Chungらによって2022年に提案されたモデルであり、そのモデルサイズは3B、11B、20Bという大きさです.このモデルは、他の代替手法よりもはるかに小さなモデルサイズを持ち、学術研究者でも利用可能です.
Flan-UL2モデルは、MS MARCOデータセットでトレーニングされた教師ありのベースラインモデルです.このモデルは、質問とパッセージの順位付けトレーニングに必要な教師信号を直接的には受け取らないため、FLANモデル(Weiら、2021年)を主に使用しています.これは、質問応答(QA)データセットの一部では、正解のQAペアがLLMのファインチューニングに使用される場合があるのとは対照的です.また、データセットのラベルは、各質問回答ペアに対して密な人間の注釈です.
実験結果からは、提案された手法を使用してモデルサイズを増やすと、一般的に上昇傾向が見られます.これは、ペアワイズランキングのプロンプトがLLMの能力をスケーリングサイズから利用できることを示しています.FLAN-T5-XLからFLAN-T5-XXLへのわずかな一貫性の欠如は、調整手順の違いによるものと考えられます.
さらに、効率的なPRPのバリエーションも良い結果を示しており、ペアワイズランキング手法の効率性の懸念を軽減しています.
以上のように、Flan-UL2モデルは小さなモデルサイズを持ちながらも、効率的でありながら良好な結果を示すことが特徴です.
SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs
著者:Lijun Yu, Yong Cheng, Zhiruo Wang, Vivek Kumar, Wolfgang Macherey, Yanping Huang, David A. Ross, Irfan Essa, Yonatan Bisk, Ming-Hsuan Yang, Kevin Murphy, Alexander G. Hauptmann, Lu Jiang
発行日:2023年06月30日
最終更新日:2023年07月03日
URL:http://arxiv.org/pdf/2306.17842v2
カテゴリ:Computer Vision and Pattern Recognition, Computation and Language, Multimedia
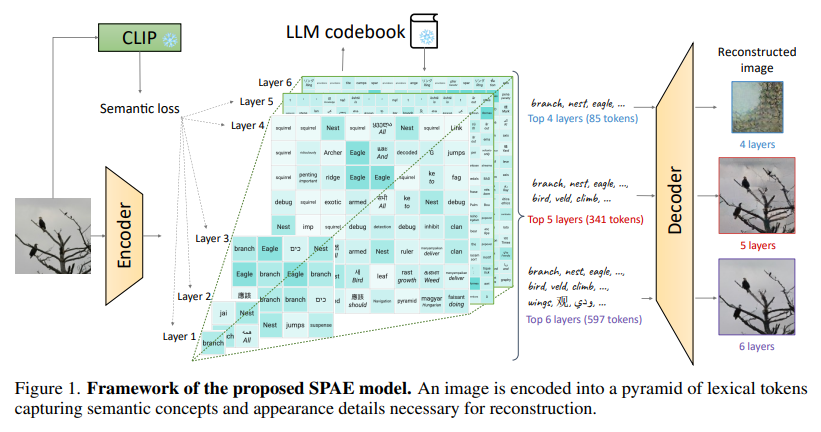

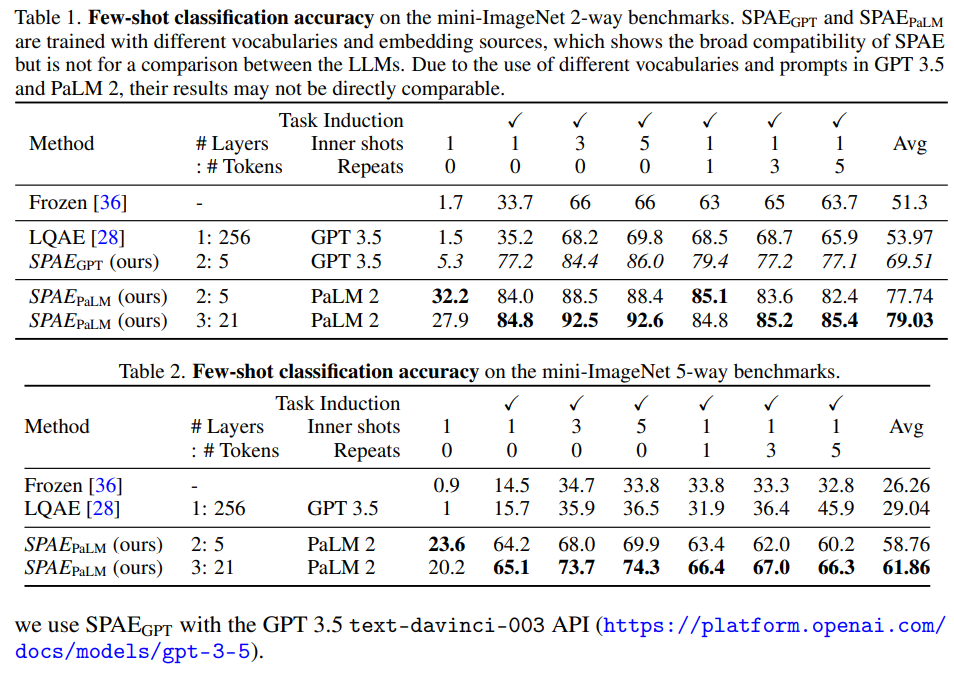
概要:
この研究では、Semantic Pyramid AutoEncoder(SPAE)を紹介し、凍結されたLLMが画像や動画などの非言語的なモダリティを理解し生成するタスクを実行できるようにします. SPAEは、LLMの語彙から抽出された解釈可能な語彙トークン(または単語)と生のピクセルとの変換を行います.結果として得られるトークンは、視覚再構成に必要な意味的な意味と細かい詳細を捉え、視覚コンテンツをLLMが理解できる言語に翻訳し、多様なマルチモーダルタスクを実行できるようにします.私たちのアプローチは、凍結したPaLM 2とGPT 3.5を使用した多様な画像理解と生成タスクのコンテキスト内学習実験によって検証されています.私たちの方法は、同じ設定で画像理解タスクで最先端の性能を25%以上上回りながら、凍結したLLMが画像コンテンツを生成することを可能にする最初の成功した試みです.
Q&A:
Q: この文章で言及されているセマンティック・ピラミッド・オートエンコーダ(SPAE)の主な目的は何ですか?
A: セマンティックピラミッドオートエンコーダー(SPAE)の主な目的は、画像生成を容易にするための進行中のコンテキストデノイジング手法を提供することです.SPAEモデルは、VQ-VAE [38]フレームワークを拡張しており、エンコーダ、量子化器、デコーダから構成されています.CNNエンコーダは、画像I∈RH×W×3を連続的な埋め込みZ∈Rh×w×cにマッピングします.各要素z∈Zは、最も近いコードブックのエントリに割り当てられる量子化埋め込みに渡されます.全体の画像の量子化埋め込みを表すˆZを使用します.CNNデコーダは、ˆZを入力として受け取り、再構成された画像ˆIを生成します.
SPAEは、図1に示されているように、ピラミッド構造に配置されたレキシカルトークンを生成します.このピラミッド構造には、上位のレイヤーには意味的な概念が含まれ、下位のレイヤーには徐々に洗練された詳細な外観が含まれています.また、概念的に関連するトークンの使用を促すために、セマンティックロスを導入しています.
SPAEの設計上の違いを以下に示します.
- 図1のフレームワークでは、デコーダがピラミッド構造のレキシカルトークンを生成し、再構成に必要な意味的な概念と外観の詳細をキャプチャします.
- レキシカルトークンの生成には、事前学習されたLLMコードブックが使用されます.
したがって、セマンティックピラミッドオートエンコーダー(SPAE)の主な目的は、画像生成を容易にするために、意味的な概念と外観の詳細をキャプチャするピラミッド構造のレキシカルトークンを生成することです.
Q: SPAEは、フローズンLLMに非言語的モダリティを含む理解・生成タスクをどのように可能にするのか?
A: SPAEは、凍結されたLLM(Large Language Models)が、画像や動画などの非言語的なモダリティを含む理解と生成のタスクを実行できるようにします.SPAEは、LLMの語彙から抽出された解釈可能な語彙トークン(または単語)と、生のピクセルとの間で変換を行います.生成されたトークンは、視覚的な再構成に必要な意味的な意味と細かい詳細を捉えており、視覚的なコンテンツをLLMが理解できる言語に変換し、多様なマルチモーダルなタスクを実行する能力を与えます.
具体的には、SPAEは画像や動画の視覚的なコンテンツをLLMの語彙に基づいた語彙トークンに変換します.この変換により、視覚的なコンテンツの意味的な意味と細かい詳細が捉えられます.LLMは、この言語的な表現を通じて視覚的なコンテンツを理解し、生成することができます.
SPAEによって、凍結されたLLMは、画像や動画などの非言語的なモダリティを含む理解と生成のタスクを実行することが可能となります.これにより、LLMの豊富な知識と推論能力をコンピュータビジョンの領域で活用することができます.これは、従来の言語のみのタスクの制約を超えた、凍結されたLLMが画像コンテンツを生成するという初の成功した試みです.
Q: 視覚的再構成のために、意味的な意味と細かな詳細の両方を捉える上で、結果として得られるトークンはどのような意味を持つのだろうか?
A: 結果のトークンは、意味のある意味と細かい詳細を視覚的な再構築に捉える上での重要性があります.これは、トークンの階層構造とトークンの数の増加によって実現されます.
まず、トークンの階層構造によって、意味的に重要な概念と視覚的な外観の両方を捉えることができます.最初の数層では、主要な概念が捉えられます.これは、画像内の重要な要素やキーワードが最初の数層で表現されることを意味します.一方、後の層では、視覚的な外観に焦点が当てられます.これにより、画像の細部や視覚的な特徴がより詳細に再構築されることが可能になります.
また、トークンの数の増加によって、意味的な意味と細かい詳細をより正確に捉えることができます.トークンの数が増えると、より多くの情報が表現されるため、意味的な意味や細かい詳細をより正確に再現することができます.特に、トークンの数が増えると、画像の再構築においてより詳細な特徴や微細なパターンが捉えられるようになります.
このように、結果のトークンは、意味的な意味と細かい詳細を捉えるために重要です.トークンの階層構造とトークンの数の増加によって、画像の再構築において意味的な意味や細かい詳細をより正確に捉えることができます.
Q: SPAEは映像コンテンツをどのようにLLMが理解できる言語に翻訳しているのか?
A: SPAEは、凍結された大規模言語モデル(LLM)に対して、非言語的なモダリティ(画像や動画など)を含む理解と生成のタスクを実行するために使用されます.SPAEは、LLMの語彙から抽出された解釈可能な語彙トークン(または単語)と、生のピクセルとの間で変換を行います.この結果得られるトークンは、視覚的な再構成に必要な意味的な意味と細かい詳細を捉えており、視覚的なコンテンツをLLMが理解できる言語に翻訳する役割を果たします.
SPAEは、画像の再構成に必要な細かい詳細を捉える外観表現を優先します.この設計により、トークンの長さを動的に調整することができます.理解タスクではより少ないトークンを使用し、生成タスクではより多くのトークンを使用することができます.
私たちは、LLMのパラメータを更新せずに、in-context学習[4]という極限の設定で私たちのアプローチの妥当性を検証しています.私たちのSPAEモデルは、言語モデルを逆伝播することなく単独でトレーニングされています.私たちは、画像分類、画像キャプション、ビジュアルクエスチョンアンサリングなどの画像理解タスクで私たちのアプローチを評価しています.また、in-contextのノイズ除去技術を活用して、LLMの画像生成能力を紹介しています.私たちの方法はLLMに依存せず、PaLM 2 [2]やGPT-3.5 [29]などの任意のLLMと互換性があることがテストされています.
SPAEが視覚的なコンテンツをLLMが理解できる言語に翻訳する方法は、以下のようになります.まず、SPAEは画像やビデオなどの視覚的なコンテンツを受け取ります.次に、SPAEはこれらの視覚的なコンテンツを解釈可能な語彙トークンに変換します.この変換は、生のピクセルとトークンの間の変換です.この変換により、視覚的なコンテンツの意味的な意味と細かい詳細がトークンに捉えられます.最後に、SPAEはこれらのトークンをLLMに入力し、LLMが理解できる言語に翻訳します.
このようにして、SPAEは視覚的なコンテンツをLLMが理解できる言語に翻訳することができます.
Q: LLMはSPAEの助けを借りて、どのような種類のマルチモーダルなタスクをこなすことができますか?
A: SPAEを使用することで、LLMは非言語的なモダリティ(画像や動画など)を含む理解と生成のタスクを実行することができます.SPAEは、LLMの語彙から抽出された解釈可能な語彙トークン(または単語)と、生のピクセルとの間で変換を行います.生成されたトークンは、視覚的な再構築に必要な意味的な意味と細かい詳細を捉えており、視覚的なコンテンツを効果的に翻訳します.
具体的には、SPAEは可変長の多言語の言語トークンとして、意味的な概念と細かい詳細の解釈可能な表現を生成する新しいトークナイザーを導入します.また、長いクロスモーダルシーケンスのインコンテキスト生成を容易にする新しいプログレッシブプロンプティング方法も提案されています.
この方法は、視覚的な理解と生成のタスクで評価されており、特に、同じインコンテキスト設定で最も優れたfew-shot画像分類精度[28]を25%上回る結果を示しています.
したがって、SPAEの支援を受けて、LLMは画像や動画を含む多モーダルのタスクを実行することができます.
Q: 凍結したPaLM 2とGPT 3.5を使って行われた文脈内学習実験の詳細を教えてください.
A: この研究では、凍結されたPaLM 2とGPT 3.5を使用して、多様な画像理解と生成のタスクにおいて、インコンテキスト学習実験を行い、アプローチの妥当性を検証しました.具体的には、画像理解タスクにおいて、従来の手法を上回る性能を発揮しながら、凍結されたLLMが画像コンテンツを生成することができるかどうかを評価しました.
実験では、凍結されたPaLM 2とGPT 3.5を使用し、画像理解と生成のタスクにおいて、多様なセットのデータを用いて学習を行いました.この学習実験によって、凍結されたLLMが画像コンテンツを生成する能力を持つことが初めて成功した試みであることが示されました.
また、同じ設定での画像理解タスクにおいて、従来の手法を25%以上上回る性能を発揮することも確認されました.これにより、凍結されたLLMが画像理解タスクにおいて、最先端の性能を超えることが可能であることが示されました.
具体的な実験結果は、表1と図3に示されています.表1では、SPAE GPTがLQAEを常に上回っており、同じGPT 3.5モデルとインコンテキスト形式を使用しているにも関わらず、トークンのわずか2%しか使用していません.図3では、異なる数のSPAE PaLMレイヤーを使用した場合の性能トレンドが示されています.6つの設定でのタスク誘導と0の繰り返しを行った結果、3つのSPAE PaLMレイヤーが最も優れた性能を発揮しました.これは、十分な意味とシーケンスの長さをバランスよく持ち、LLMの学習容量の負担を軽減するための最適な性能です.
総合的に見て、SPAE PaLMは、表1と表2の2ウェイおよび5ウェイのベンチマークにおいて、最先端の手法に比べて平均精度が+25%および+32%向上することが示されました.
Q: 画像理解タスクにおける凍結LLMの性能は、最先端技術と比較してどうなのか、また何パーセント上回っているのか?
A: 凍結されたLLMは、最先端の画像理解タスクにおいて、同じ設定の下で25%以上の性能を上回ることができる.
Q: SPAEを実装し、凍結LLMをマルチモーダル生成に使用する際の制限や課題はありますか?
A: SPAEと凍結されたLLMsを使用した多モーダル生成において、実装上の制約や課題はありますか?
この論文では、SPAEという新しい手法を用いて、凍結されたLLMsを使用して画像やビデオを含む多モーダルな理解と生成のタスクに取り組むことの未開拓の可能性を明らかにしています.SPAEは、可変長のレキシカルトークンと視覚的なコンテンツを変換することで、豊かな意味を持つトークンに変換します.
しかし、SPAEと凍結されたLLMsを使用した多モーダル生成にはいくつかの制約や課題があります.まず、制約としては、受け入れられるシーケンスの長さが大きく制約されることが挙げられます.現在のところ、受け入れられるシーケンスの長さには限界がありますので、より長いシーケンスを処理するための改善が必要です.
また、生成される画像の品質や多様性に関しても制約があります.現在の結果は、テキストと画像のペアデータで訓練された最新のテキストから画像へのモデルにはまだ及ばないということが示されています.したがって、画像生成の品質と多様性を向上させるためには、さらなる改善が必要です.
以上のように、SPAEと凍結されたLLMsを使用した多モーダル生成には制約や課題が存在しますが、これらの制約や課題を克服するための改善が今後の研究の課題となります.
Q: フローズンLLMが画像理解タスクに優れながら画像コンテンツを生成できるようにすることで、どのような応用や影響が考えられるか?
A: 凍結されたLLMが画像理解タスクで優れたパフォーマンスを発揮しながら画像コンテンツを生成することが可能になる場合の潜在的な応用や影響は以下のようなものです.
- 画像生成: 凍結されたLLMが画像コンテンツを生成する能力を持つ場合、画像生成タスクにおいて新たな可能性が開かれます.これにより、既存の画像生成手法よりも高品質な画像が生成される可能性があります.
- 画像キャプション生成: 凍結されたLLMが画像理解タスクに優れている場合、画像に対する適切なキャプションを生成することができます.これにより、自動的に画像に対する説明文を生成するアプリケーションやサービスが開発される可能性があります.
- 画像検索: 凍結されたLLMが画像理解タスクにおいて優れたパフォーマンスを発揮する場合、画像検索エンジンの性能向上が期待されます.これにより、ユーザーはより正確なキーワードやクエリを使用せずに、画像の内容や特徴に基づいて画像を検索することができます.
- クリエイティブなアプリケーション: 凍結されたLLMが画像理解タスクにおいて優れたパフォーマンスを発揮し、画像コンテンツを生成する能力を持つ場合、クリエイティブなアプリケーションの開発が可能になります.例えば、アート作品の生成やデザイン支援ツールの開発などが考えられます.
- バーチャルリアリティや拡張現実: 凍結されたLLMが画像理解タスクにおいて優れたパフォーマンスを発揮し、画像コンテンツを生成する能力を持つ場合、バーチャルリアリティや拡張現実の体験の向上が期待されます.これにより、よりリアルな仮想空間や拡張された現実の表現が可能になります.
以上のように、凍結されたLLMが画像理解タスクにおいて優れたパフォーマンスを発揮しながら画像コンテンツを生成する能力を持つことは、画像生成や画像キャプション生成、画像検索の向上、クリエイティブなアプリケーションの開発、バーチャルリアリティや拡張現実の体験の向上など、さまざまな応用や影響をもたらす可能性があります.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: この論文で導入された新しい手法のコード実装のURLは、https://github.com/google-research/magvit/projects/spae です.このURLには、再現可能な研究のためのコードとモデルが提供されています.この手法は、PaLM 2 [2]とGPT-3.5 [29]という任意のLLMと互換性があり、LLMに依存しない方法です.
InterCode: Standardizing and Benchmarking Interactive Coding with Execution Feedback
著者:John Yang, Akshara Prabhakar, Karthik Narasimhan, Shunyu Yao
発行日:2023年06月26日
最終更新日:2023年06月27日
URL:http://arxiv.org/pdf/2306.14898v2
カテゴリ:Computation and Language, Machine Learning, Software Engineering
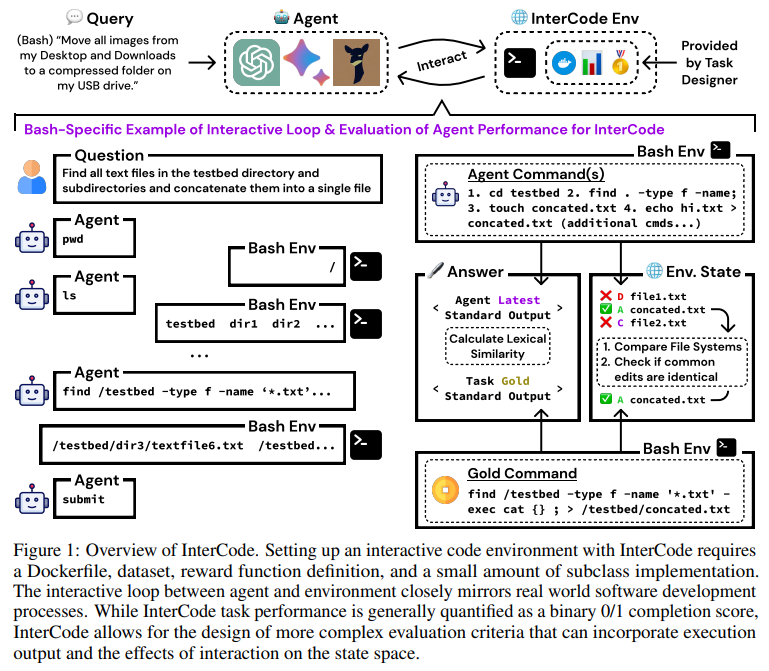
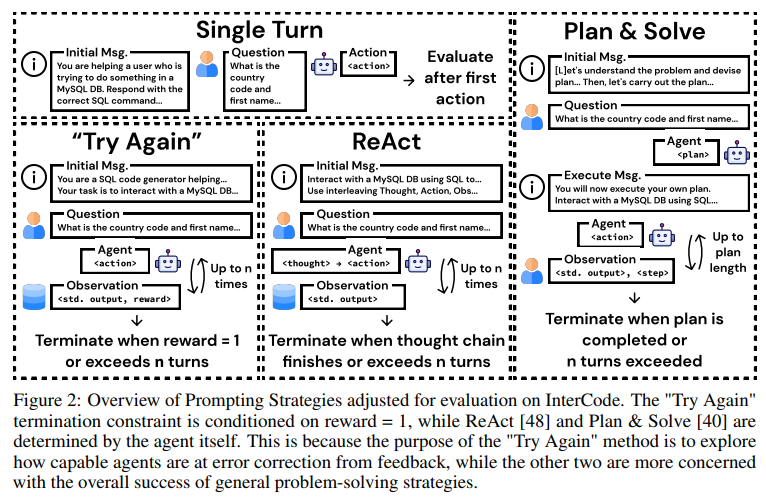
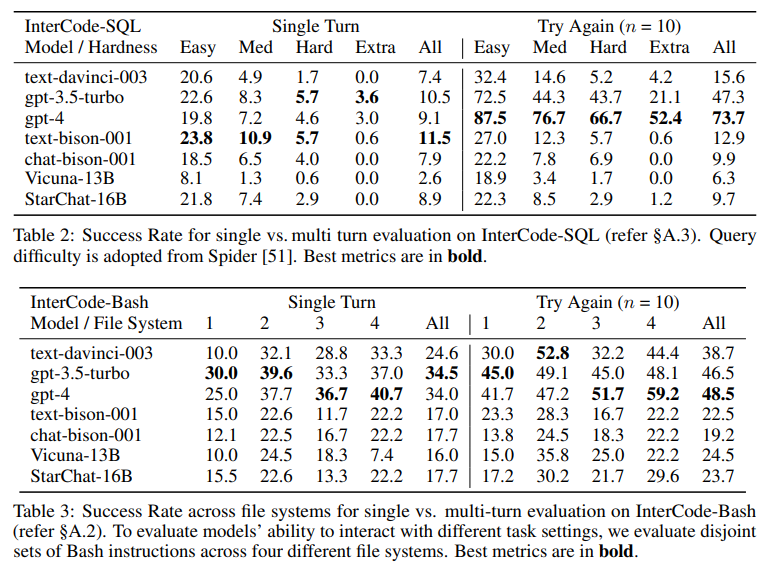
概要:
人間は基本的に対話的な方法でコードを書き、エラーの修正、曖昧さの解消、タスクの分解において、常に実行フィードバックに依存しています.最近のLLMsは、有望なコーディング能力を示していますが、現在のコーディングのベンチマークは主に静的な命令からコードのシーケンスへの変換プロセスを考慮しており、エラーの伝播や生成されたコードと最終的な実行環境との切断の可能性があります.このギャップを埋めるために、私たちはInterCodeを紹介します.これは、コードをアクションとし、実行フィードバックを観測とする、軽量で柔軟かつ使いやすい標準的な強化学習(RL)環境のフレームワークです.私たちのフレームワークは、言語やプラットフォームに依存せず、安全で再現可能な実行を提供するために、自己完結型のDocker環境を使用しており、従来のseq2seqコーディング手法との互換性があります.また、インタラクティブなコード生成のための新しい手法の開発も可能です.私たちはInterCodeを使用して、BashとSQLをアクションスペースとする2つのインタラクティブなコード環境を作成し、静的なSpiderとNL2Bashデータセットからデータを活用しています.さらに、InterCodeは静的なSpiderとNL2Bashデータセットからデータを活用し、ReActやPlan&Solveなどの異なるプロンプティング戦略で構成された最新のLLMを評価することで、テストベッドとしての実用性を示しています.私たちの結果は、インタラクティブなコード生成の利点を示し、InterCodeがコード理解と生成能力を向上させるための厳しいベンチマークとして機能することを示しています.InterCodeは拡張性が高く、複数のプログラミング言語を含む複数のステップを必要とする人気のあるコーディングパズルであるCapture the Flagなどの新しいタスクを組み込むことも可能です.プロジェクトのウェブサイトには、コードとデータが提供されています:https://intercode-ベンチマーク.github.io
Q&A:
Q: インターコードの目的は何ですか?
A: InterCodeの目的は、コーディングエージェントがコードを実行し、フィードバックを受け取り、改善を行うためのインタラクティブな環境を提供することです.このフレームワークは、標準的な強化学習(RL)環境のように設計されており、人間の介入を最小限に抑え、生成されたコードをアクションとして扱い、実行されて観測結果を明らかにします.
InterCodeは、さまざまなタスク設定の理解の課題を解決し、InterCodeを使用して新しいタスクとデータセットを簡単に定義できるかどうかを探求するために開発されました.
具体的には、以下の貢献を行っています.
- InterCodeは、使いやすさ、拡張性、安全性を提供する、新しい汎用フレームワークです.
- InterCodeは、多様なタスク設定を簡単に構築できる、インタラクティブなコーディングタスクの基盤を提供します.
- InterCodeは、アクションスペースとして任意のプログラミング言語を持つことができ、自動的な実行ベースの評価を行います.
- InterCodeは、実行ベースの評価をコーディングに適用することができます.これにより、NL-to-code生成モデルの評価がよりインタラクティブになります.
- InterCodeは、仮想コンテナを使用して実行サンドボックスを提供し、有害なアクションから保護するだけでなく、前述の評価基準を超えた高度な評価基準を可能にします.
したがって、InterCodeの目的は、インタラクティブなコード生成のための新しい汎用フレームワークを開発し、使いやすさ、拡張性、安全性を提供することです.また、InterCodeは、実行ベースの評価をコーディングに適用し、多様なタスク設定を簡単に構築できるようにします.
Q: InterCodeは、現在のコーディング・ベンチマークにおけるギャップにどのように対処するのか?
A: InterCodeは、現在のコーディングベンチマークのギャップをどのように解決しているのでしょうか?
InterCodeは、現在のコーディングベンチマークのギャップを解決するために、インタラクティブなコーディングを標準化した強化学習(RL)環境としてのフレームワークを導入しています.このフレームワークでは、コードをアクションとし、実行フィードバックを観測として使用します.
現在のコーディングベンチマークは、静的な指示からコードのシーケンスへの変換プロセスを主に考慮しています.しかし、このプロセスにはエラーの伝播の可能性や生成されたコードと最終的な実行環境との間の切断が存在します.
InterCodeは、このギャップを解決するために、インタラクティブな実行環境をネイティブに設計した最初の標準的なコーディングベンチマークです.人間の意思決定プロセスを忠実に模倣し、コードの生成と最終的な実行環境との間のつながりを強化します.
具体的には、InterCodeは以下のような特徴を持っています.
- インタラクティブな実行環境:InterCodeは、コーディングの実行フィードバックを提供するインタラクティブな実行環境を提供します.これにより、エラーの修正や曖昧さの解消、タスクの分解など、コーディングプロセスの中での人間の意思決定を模倣することができます.
- 安全で再現性のある実行環境:InterCodeは、安全で再現性のある実行環境を提供するために、独自のDocker環境を使用します.これにより、コードの実行時に予期しないエラーやセキュリティ上の問題が発生することを防ぐことができます.
- 伝統的なseq2seqモデルとの互換性:InterCodeは、伝統的なseq2seqモデルとの互換性があります.これにより、既存のモデルや手法を容易に統合することができます.
InterCodeは、これらの特徴によって、現在のコーディングベンチマークのギャップを解決し、コードの生成と実行環境とのつながりを強化することができます.
Q: インターコードのフレームワークは何に基づいているのですか?
A: InterCodeのフレームワークは、インタラクティブなコーディングを標準の強化学習(RL)環境として提供するための軽量で柔軟かつ使いやすいものです.このフレームワークでは、コードをアクションとし、実行フィードバックを観測として使用します.InterCodeは、言語やプラットフォームに依存せず、安全で再現可能な実行環境を提供するために、独立したDocker環境を使用します.また、従来のseq2seqコーディング手法との互換性を持ちながら、インタラクティブなコード生成のための新しい手法の開発を可能にします.InterCodeは、BashとSQLをアクションスペースとする2つのインタラクティブなコード環境を作成し、静的なSpider [51]とNL2Bash [29]のデータセットからデータを活用しています.InterCodeは、テストベッドとしての有用性を示し、現在のモデルのインタラクティブなコーディングタスクにおけるパフォーマンスの範囲についてさらなる洞察を得るための実験の可視化と分析も提供しています.InterCodeのフレームワークとInterCodeEnvインターフェースの実装と使用方法についての詳細な説明、各プロンプティング戦略の完全なテンプレート、およびこの研究の影響、リスク、制限事項についても議論しています.InterCodeのウェブページはhttps://intercode-ベンチマーク.github.io/にあります.InterCodeのコードはhttps://github.com/intercode-ベンチマーク/intercode-ベンチマークにあります.このリンクもInterCodeのウェブページに含まれています.
Q: InterCodeはどのようにして安全で再現性のある実行を保証するのですか?
A: InterCodeは、安全で再現性のある実行を保証するために、Dockerベースの環境を使用しています.具体的には、InterCodeはDockerの仮想コンテナを一般的な目的の実行サンドボックスとして使用しています.Dockerfileを使用して、システムと実行エントリーポイントを定義します.これにより、InterCodeは安全な実行環境を提供し、実行中に発生する可能性のある有害なアクションから保護します.
Dockerは、コンテナ化された環境を提供するオープンソースのプラットフォームであり、アプリケーションやサービスを独立して実行することができます.InterCodeでは、Dockerコンテナを使用することで、コードの実行を安全かつ再現可能にすることができます.
具体的には、InterCodeはDockerfileを使用して、実行環境を定義します.Dockerfileは、システムの設定や依存関係、実行に必要なパッケージなどを指定するファイルです.InterCodeはこのDockerfileを使用して、実行環境を作成し、コードの実行を行います.
Dockerコンテナは、仮想化技術を使用して独立した実行環境を提供します.これにより、コードの実行中に発生する可能性のある問題やエラーが、ホストシステムに影響を与えることなく、コンテナ内で処理されます.また、Dockerコンテナは再現性を保証するために使用されます.同じDockerfileを使用してコンテナを作成すれば、同じ実行環境を再現することができます.
InterCodeの実行環境は、仮想コンテナ内で実行されるため、ホストシステムに影響を与えることはありません.これにより、安全な実行が保証されます.また、Dockerコンテナは独立して実行されるため、他のコンテナやシステムとの干渉も防ぐことができます.
InterCodeは、安全で再現性のある実行を保証するためにDockerベースの環境を使用しており、コードの実行中に発生する可能性のある問題やエラーをコンテナ内で処理することで、安全な実行を実現しています.
Q: InterCodeがサポートしているプログラミング言語は何ですか?
A: InterCodeでは、どのプログラミング言語がサポートされていますか?
InterCodeは、プログラミング言語をアクションスペースとして持つことができる、多目的な基盤を提供しています.具体的には、BashとSQLのプログラミング言語をアクションスペースとしてサポートしています.ただし、今後の展開では、さらに多くのプログラミング言語をサポートする予定です.これにより、InterCodeEnvの有用性をさらに示すと同時に、InterCodeをトレーニングプラットフォームとして利用する開発者の利便性も向上させることを目指しています.
InterCodeは、コンパイラ/インタプリタによってコードが実行され、その結果をフィードバックとして受け取ることができるため、コーディングエージェントがインタラクティブに作業を行うことができます.また、生成されたコードはアクションとして扱われ、実行されることで観測結果が得られるように、InterCodeは標準的な強化学習(RL)環境のように設計されています.人間の介入を最小限に抑えることができるフレームワークです.
したがって、InterCodeはさまざまなプログラミング言語をサポートすることができますが、具体的なサポートされているプログラミング言語のリストは提供されていません.ただし、BashとSQLは現在のコードベースでサポートされており、今後の展開ではさらに多くのプログラミング言語がサポートされる予定です.
Q: InterCodeは異なる言語モデルの性能をどのように評価していますか?
A: InterCodeは、異なる言語モデルのパフォーマンスを評価するためにどのように機能するのでしょうか?
InterCodeは、実行ベースの評価を使用して異なる言語モデルのパフォーマンスを評価します.これは、自然言語からコード生成モデルの評価において、表層形式の類似性メトリック(BLEU、ROUGE、Exact Match)から実行指向の評価(ユニットテスト、出力の一致)へのシフトが最近行われていることに関連しています.
InterCodeは、自動的な実行ベースの評価を提供することで、異なるタスク設定の構築を容易にするための一般的な目的の基盤を提供します.これにより、異なるプログラミング言語をアクションスペースとして持つことができます.
具体的には、InterCodeは、異なる言語モデルが生成したコードを実行し、その実行結果を評価します.これにより、生成されたコードの実行環境との間にエラーの伝播や不一致が生じる可能性を排除することができます.
InterCodeは、最新のモデルの包括的な評価を行い、改善のためのいくつかの手段を特定するために使用されます.また、InterCodeは新しいベンチマークとしてフレームワークを公開し、新しい静的コードデータセットをインタラクティブなタスクにカスタマイズするための有用な経験的ツールも提供します.
このようにして、InterCodeは異なる言語モデルのパフォーマンスを実行ベースの評価によって評価し、モデルの改善のための指針を提供します.
Q: インタラクティブなコード生成の利点は?
A: 結果によると、インタラクティブなコード生成の利点は次のとおりです.
- コード生成の改善:インタラクティブなコード生成により、コンパイラやインタプリタからのフィードバックを受け取りながら、コーディングエージェントはコードを改善することができます.これにより、生成されるコードの品質と効率が向上し、より優れたコードが生成されます.
- 問題解決能力の向上:インタラクティブなコード生成により、コーディングタスクの解決能力が向上します.コーディングエージェントは、生成されたコードを実行して観察結果を得ることができます.これにより、エージェントは自身のコーディング戦略を改善し、より効果的な解決方法を見つけることができます.
- コード理解の向上:インタラクティブなコード生成により、コードの理解が向上します.コーディングエージェントは、生成されたコードを実行することで、コードの動作や振る舞いを観察することができます.これにより、エージェントはコードの意味や目的をより深く理解することができます.
- ベンチマークの向上:インタラクティブなコード生成により、コード理解と生成の能力を向上させるためのベンチマークが提供されます.InterCodeは、インタラクティブな実行環境を持つ標準的なコーディングベンチマークであり、既存の方法と比較することができます.これにより、コード生成の方法や手法の比較が容易になり、インタラクティブな生成の利点を明確に理解することができます.
以上の結果から、インタラクティブなコード生成は、コードの品質と効率の向上、問題解決能力の向上、コード理解の向上、およびベンチマークの向上という利点をもたらすことが示されています.
Q: InterCodeはコード生成以外のタスクにも使用できますか?
A: InterCodeは、インタラクティブなコーディングタスクを定義するための汎用的な基盤を提供しており、さまざまなタスク設定の簡単な構築が可能です.また、アクションスペースとして任意のプログラミング言語を使用することができ、自動的な実行ベースの評価も行います.
InterCodeは、コード生成以外のタスクにも使用することができます.InterCodeのタスク設計、モジュール設計、柔軟なタスク構築、仮想コンテナの使用により、タスクデザイナーは新しい複雑なコード駆動型のタスクを具現化することができます.これにより、コンプリートがより困難なタスクを作成することが可能です.
InterCodeは、プログラミング言語のカバレッジも拡大しており、BashやSQLなどのプログラミング言語をアクションスペースとして使用することができます.さらに、InterCodeの利便性を向上させるために、プログラミング言語だけでなく、データセット、タスク環境、タスクの種類も増やすための取り組みが行われています.
また、InterCodeの評価方法も特徴的であり、従来の表面的な類似度メトリック(BLEU、ROUGE、Exact Match)から、実行指向の評価(ユニットテスト、出力の一致など)にシフトしています.これにより、より柔軟なモデルの推論が可能となります.
したがって、InterCodeはコード生成以外のタスクにも使用することができます.そのため、さまざまなタスク設定やプログラミング言語を対象としたタスクの構築において、InterCodeは有用なツールとなります.
Q: InterCodeは簡単に拡張できるように設計されていますか?
A: InterCodeは、コーディングエージェントがコードを実行するコンパイラ/インタプリタからフィードバックを受け取り、さらなる改善を提出するための対話的な環境です.InterCodeは、生成されたコードをアクションとして扱い、実行して観測結果を明らかにするという、標準的な強化学習(RL)環境のように設計されています.このフレームワークは、さまざまなプロンプティング戦略(ReAct [48]やPlan & Solve [40]など)で構成された最先端のLLMを評価することによって、容易に拡張可能に設計されています.
InterCodeは、コード理解と生成能力の向上を目指すための難解なベンチマークとして機能することを示す結果を提供します.また、InterCodeは容易に拡張可能に設計されており、トレーニングプラットフォームとして興味を持つ実践者にとっても利用しやすくなっています.さらに、プログラミング言語のカバレッジを拡大するために、InterCodeベースのタスクの数を増やす計画があります.また、プログラミング言語だけでなく、追加の作業では、より多くのデータセット、タスク環境、およびタスクの種類を特集することも目指しています.
InterCodeは再現可能な実行を提供し、従来のseq2seqコーディング方法とも互換性があります.さらに、対話的なコード生成のための新しい手法の開発を可能にします.InterCodeを使用して、BashとSQLをアクションスペースとする2つの対話型コード環境を作成し、静的なSpider [51]およびNL2Bash [29]データセットからデータを活用しています.InterCodeは、ReAct [48]やPlan & Solve [40]などの異なるプロンプティング戦略で構成された最先端のLLMを評価することによって、テストベッドとしての実用性を示しています.InterCodeは、Capture the Flagなどの新しいタスクを組み込むことも容易に設計されており、これは複数のステップを含み、複数のプログラミング言語を必要とする人気のあるコーディングパズルです.
以上のように、InterCodeは容易に拡張可能に設計されています.
Q: InterCodeのコードとデータはどこにありますか?
A: InterCodeのコードとデータは、InterCodeのウェブページ(https://intercode-ベンチマーク.github.io/)で入手することができます.また、InterCodeのコードはGitHub(https://github.com/intercode-ベンチマーク/intercode-ベンチマーク)にもあります.InterCodeのウェブページには、GitHubのリンクも含まれています.
CodeGen2: Lessons for Training LLMs on Programming and Natural Languages
著者:Erik Nijkamp, Hiroaki Hayashi, Caiming Xiong, Silvio Savarese, Yingbo Zhou
発行日:2023年05月03日
最終更新日:2023年07月11日
URL:http://arxiv.org/pdf/2305.02309v2
カテゴリ:Machine Learning
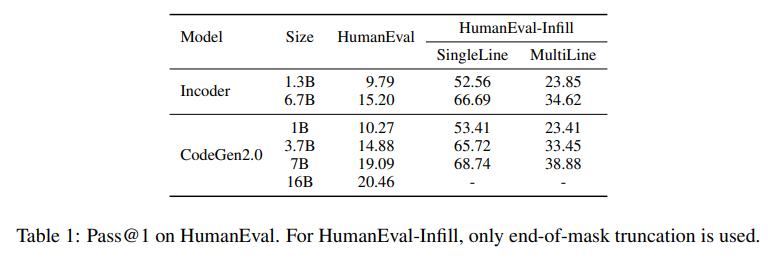
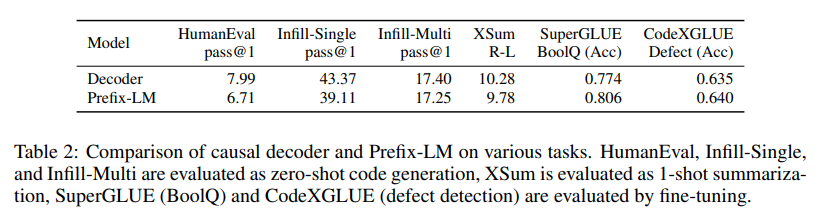
概要:
この研究では、プログラム合成のためのLLMのトレーニングを効率化するために、4つの主要な要素を統合しようと試みています.具体的には、モデルアーキテクチャでは、エンコーダとデコーダベースのモデルを単一のプレフィックス-LMに統合しようとします.学習方法では、(i)因果関係言語モデリング、(ii)スパン破損、(iii)インフィリングを単純な学習アルゴリズムに統合します.インフィルサンプリングでは、「無料の昼食」の仮説を探求します.データ分布では、混合分布とプログラミング言語と自然言語の複数エポックトレーニングがモデルの性能に与える影響を探求します.さらに、この研究では、1B LLMsについて包括的な一連の実験を行い、この探求の成功と失敗を5つの教訓にまとめています.また、1B、3.7B、7B、16BパラメータのCodeGen2モデルのトレーニングの最終的なレシピと、トレーニングフレームワークをオープンソースとして提供します.
Q&A:
Q: プログラム合成のためのLLMのトレーニングをより効率的にするために、この研究で統一された重要な要素は何か?
A: この研究では、プログラム合成のためのLLM(Large Language Models)のトレーニングを効率化するために、以下の4つの主要な要素を統一しようとしています:(1)モデルアーキテクチャ、(2)学習方法、(3)インフィルサンプリング、および(4)データ分布です.
まず、モデルアーキテクチャに関しては、エンコーダとデコーダベースのモデルを単一のプレフィックス-LMに統一しようとしています.これにより、モデルの構造を単純化し、トレーニングの効率化を図ります.
次に、学習方法に関しては、因果関係言語モデリング、スパンの破損、インフィリングを単一の学習アルゴリズムに統一しようとしています.これにより、学習方法を統一することで、トレーニングプロセスを簡素化し、効率化を図ります.
さらに、インフィルサンプリングに関しては、「無料の昼食」仮説を探求しています.これは、インフィルサンプリングによってデータの効率的な利用が可能であるかどうかを検証するものです.この仮説の検証により、トレーニングプロセスの効率化につながる可能性があります.
最後に、データ分布に関しては、プログラミング言語と自然言語の混合分布、および複数のエポックでのトレーニングの効果を探求しています.これにより、モデルのパフォーマンス向上に寄与するデータ分布の特性を明らかにしようとしています.
以上の要素を統一することにより、この研究では、プログラム合成のためのLLMのトレーニングを効率化しようとしています.
Q: モデル・アーキテクチャは、エンコーダーとデコーダー・ベースのモデルをどのように統一しようとしているのか?
A: モデルアーキテクチャは、エンコーダとデコーダの表現を統一することを試みています.具体的には、Prefix-LMと呼ばれるモデルアーキテクチャを提案しています.このモデルでは、双方向の自己注意機構が難しいfew-shotタスクにおいて有益であり、パフォーマンスの低下を招かずにエンコーダとデコーダの表現を統一することができます.
Prefix-LMは、時間にわたる結合密度を分解するためのモデルです.これにより、合成タスクにおいて競争力のある自己回帰サンプリングを実現する一方で、理解タスクにおいて強力な双方向表現を学習することが期待されています.
モデルアーキテクチャの統一化には、エンコーダまたはデコーダベースのモデルアーキテクチャの選択が通常、言語モデリングの学習アルゴリズムの選択に影響を与えます.エンコーダベースのモデルでは、マスクされた言語モデリングの形式でのノイズ除去スパンの修復タスクによるトレーニングが行われることが一般的です.一方、デコーダベースのモデルでは、次のトークン予測タスクの形式での密度言語モデリングが行われることが一般的です.
このような違いを統一するために、Prefix-LMではエンコーダとデコーダの表現を統一し、双方向の自己注意機構を利用することで、エンコーダベースとデコーダベースのモデルアーキテクチャの利点を組み合わせています.これにより、幅広い合成と理解のタスクに競争力のあるパフォーマンスを持つ単一のユニバーサルモデルを実現しようとしています.
Q: フリーランチ」仮説と、それがインフィル・サンプリングの文脈でどのように探求されているかを説明していただけますか?
A: 「フリーランチ」仮説は、モデルにインフィルサンプリングを装備することで、追加の計算コストをかけずに性能を向上させることができるという仮説です.この仮説は、Bavarianらの手法に従って訓練された場合には成り立つという仮説です.この仮説を検証するために、文脈では、CLM(Causal Language Model)とPSM(Prefix, Suffix, Middle sequence reordering)のインフィル目的を組み合わせたモデルを訓練しました.
具体的には、文脈では、インフィルサンプリングによる「フリーランチ」仮説を探索しています.また、プログラミング言語と自然言語の混合分布や、モデルの性能に与える影響についても調査しています.
結果として、シンプルな目的関数の混合によるゼロショット性能の維持に成功しました.一方で、インフィルサンプリングをモデルに装備することで、追加の計算コストをかけずに性能を向上させるという「フリーランチ」仮説については、追加のコンピュートコストが発生するという証拠を提供することはできませんでした.
以上のように、文脈では「フリーランチ」仮説を検証するために、インフィルサンプリングを組み込んだモデルを訓練し、その結果を報告しています.
Q: プログラミング言語と自然言語の混合分布とマルチエポックトレーニングの使用は、モデルの性能にどのような影響を与えるのか?
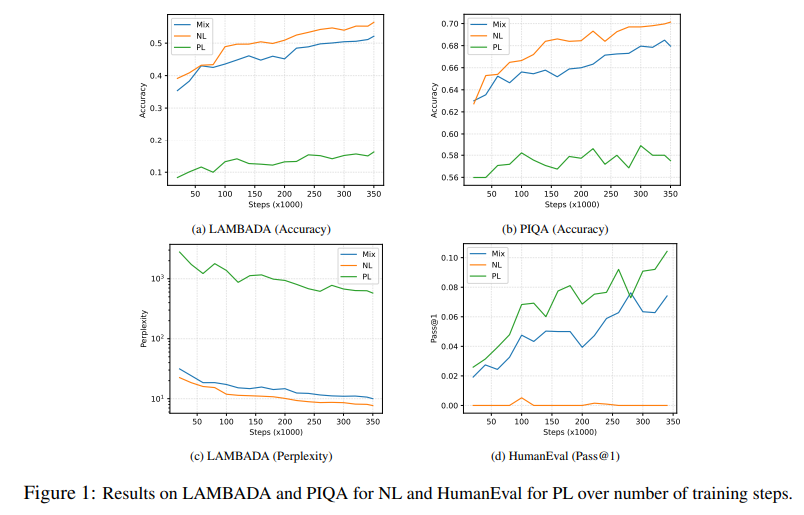
A: モデルのパフォーマンスには、プログラミング言語と自然言語の混合分布の使用とマルチエポックトレーニングがどのように影響するのでしょうか.
与えられた文脈から、プログラミング言語と自然言語の混合データを使用することで、モデルのパフォーマンスが向上することが示唆されています.特に、計算予算が制約されており、結果のモデルが両方のドメインで使用される場合には、自然言語とプログラミング言語を混合する必要があるとされています.
さらに、マルチエポックトレーニングを行うことで、モデルのパフォーマンスがさらに向上する可能性があります.データは有限であるため、モデルサイズのスケールの増加は限られています.通常、モデルはトレーニング中に各シーケンスを1回しか観察しないため、自然言語のタスクにおいてはパフォーマンスが低下する可能性があります.しかし、マルチエポックトレーニングを行うことで、モデルは繰り返しの観測から情報を吸収する能力を持つと仮定しています.
この仮説を検証するために、自然言語とプログラミング言語の混合データ(Mix)を使用して因果デコーダをトレーニングします.そして、トレーニングステップごとにモデルをプログラミング言語と自然言語のダウンストリームタスクでゼロショット評価し、データの混合が各モダリティに与える影響を評価します.
結果として、Mixはドメインにマッチしたモデルに近いパフォーマンスを示します.トレーニングの早い段階から、Mixはドメインミスマッチのベースライン(例えばLAMBADAのPL)に比べてパフォーマンスを大幅に改善することがわかります.これは、計算予算が制約されており、結果のモデルが両方のドメインで使用される場合には、自然言語とプログラミング言語を混合する必要があることを示唆しています.
また、単純なトレーニングデータの混合でも、両方のドメインで効率的な学習が可能であることがわかります.これは、Mixを使用したわずかに長いトレーニングが、両方のドメインに対して競争力のあるモデルを生み出す可能性があることを示唆しています.
つまり、プログラミング言語と自然言語の混合データの使用とマルチエポックトレーニングは、モデルのパフォーマンスを向上させることができる可能性があります.
Q: 神経スケーリングの法則は、学習された表現の質をどのように規定するのか?
A: 学習された表現の品質は、ニューラルスケーリングの法則によって決定されます.ニューラルスケーリングの法則は、モデルのパラメータ数と観測数の関数として表現され、利用可能なデータと計算量によってモデルの性能に上限が設けられます.この上限はコストがかかるものです.
ニューラルスケーリングの法則によって、モデルのパラメータ数やデータ量、計算量が増えると、学習された表現の品質が向上することが予測されます.つまり、より大きなモデルは、ダウンストリームのタスクで予測可能な改善をもたらすことが期待されます.
具体的には、ニューラルスケーリングの法則はべき乗則として表現されます.つまり、モデルのサイズが2倍になると、学習された表現の品質は2のべき乗倍に向上すると予測されます.このような法則に基づいて、モデルのパラメータ数やデータ量、計算量を調整することで、学習された表現の品質を向上させることができます.
ニューラルスケーリングの法則によって、学習された表現の品質が制約される理由は、データと計算の制約によるものです.利用可能なデータや計算量が限られているため、モデルのパラメータ数やデータ量、計算量を無制限に増やすことはできません.そのため、ニューラルスケーリングの法則によって、学習された表現の品質は上限が設けられるのです.
以上のように、ニューラルスケーリングの法則は、モデルのパラメータ数やデータ量、計算量と学習された表現の品質の関係を示しています.これにより、効率的な学習を実現するためには、適切なモデルのサイズやデータ量、計算量を選択する必要があります.
Q: 利用可能なデータ量と計算量によってモデルの性能に課される上限は?
A: 利用可能なデータと計算量によって課されるモデルの性能の上限は、学習された表現の数のモデルパラメータと観測数の関数として神経スケーリング法によって決定されます.つまり、モデルのパフォーマンスは、利用可能なデータと計算量の量によって制約されます.これは、データと計算の量が増えるほど、モデルの性能が向上する可能性がある一方で、データと計算の量には上限があり、それによってモデルの性能も制約されることを意味します.この制約は、データと計算の量が増えるほど高いコストがかかるため、実践者にとって重要な要素です.

