
今回のテーマ:DragGAN, LLMによる医療QA, Simbol tuning, StructGPT, MEGABYTE, TinyStories など.
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をQ&A形式を用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.
紹介する論文は以下の10本となります.
- Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold (発行日:2023年05月18日)
- Evidence of Meaning in Language Models Trained on Programs (発行日:2023年05月18日)
- DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining (発行日:2023年05月17日)
- Searching for Needles in a Haystack: On the Role of Incidental Bilingualism in PaLM’s Translation Capability (発行日:2023年05月17日)
- Towards Expert-Level Medical Question Answering with Large Language Models (発行日:2023年05月16日)
- StructGPT: A General Framework for Large Language Model to Reason over Structured Data (発行日:2023年05月16日)
- Symbol tuning improves in-context learning in language models (発行日:2023年05月15日)
- CodeT5+: Open Code Large Language Models for Code Understanding and Generation (発行日:2023年05月13日)
- MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers (発行日:2023年05月12日)
- TinyStories: How Small Can Language Models Be and Still Speak Coherent English? (発行日:2023年05月12日)
Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold
著者:Xingang Pan, Ayush Tewari, Thomas Leimkühler, Lingjie Liu, Abhimitra Meka, Christian Theobalt
発行日:2023年05月18日
最終更新日:2023年05月18日
URL:http://arxiv.org/pdf/2305.10973v1
カテゴリ:Computer Vision and Pattern Recognition, Graphics
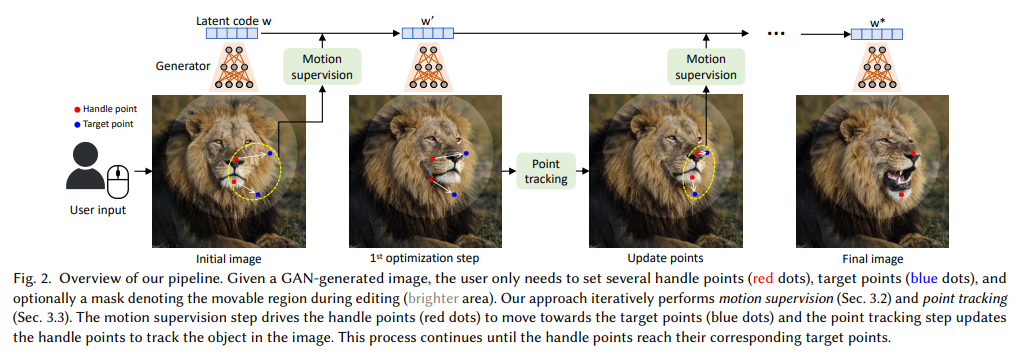
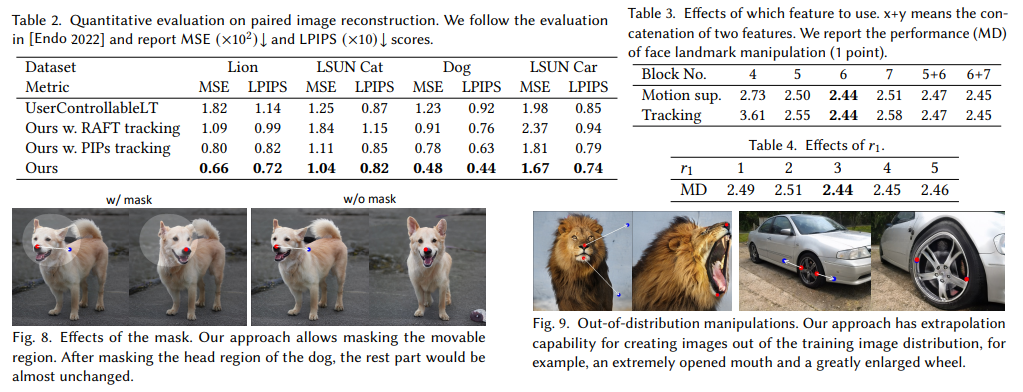
概要:
DragGANは、生成敵対的ネットワーク(GAN)を柔軟かつ正確に制御することで、ユーザーのニーズに合った視覚コンテンツを合成することを目的としています.既存の手法では、訓練データに手動で注釈を付けるか、事前に3Dモデルを用意することで、GANの可制御性を高めてきましたが、柔軟性、正確性、汎用性に欠けることが問題となっています.本研究では、画像内の任意のポイントをユーザーインタラクティブな方法で目標ポイントに正確に移動させることを研究し、多様なカテゴリーのポーズ、形状、表情、レイアウトを自由に修正できるようになりました.さらに、DragGANは、学習済みGANの生成画像マニフォールド上で操作されるため、様々な厳しいシナリオ下で高品質な出力を生成できることが特徴的であり、隠蔽されたコンテンツや物体の剛性に沿った変形など、より困難なタスクの処理に優れています.定量的・定性的な比較により、DragGANが従来手法よりも優れた画像操作およびポイント追跡タスクを実現することが示されました.また、GAN反転を介したリアルな画像の操作も実証しています.
Q&A:
Q: 本作で提案するGANの制御方法とは?
A: 本研究では、従来の手法が満たせなかった柔軟性、精度、汎用性を全て達成することを目標としています.既存の手法は、事前に作成された3Dモデル[Deng et al. 2020; Ghosh et al. 2020; Tewari et al. 2020]や、手動で注釈付けされたデータ[Abdal et al. 2021; Isola et al. 2017; Ling et al. 2021; Park et al. 2019; Shen et al. 2020]によってGANの制御性を獲得していますが、これらの手法は新しいオブジェクトカテゴリに汎用的でなく、空間属性の制御範囲が限定的であり、編集プロセスの制御がほとんどできません.最近では、テキストによる画像合成が注目されています[Ramesh et al. 2022; Rombach et al. 2021; Saharia et al. 2022]が、空間属性の編集において精度と柔軟性に欠けています.本研究では、GANの制御において、テキストと画像の両方を利用することで、柔軟性、精度、汎用性を兼ね備えた手法を提案しています.(p.1)
Q: 空間属性の制御や編集処理の面で、既存の手法には具体的にどのような限界があるのでしょうか?
A: 既存の方法には、空間属性の制御や編集プロセスにおいて特定の制限がある.これらの方法は、制御できる空間属性の範囲が限定されていたり、編集プロセスの制御が不十分であったりする.また、既存の方法は、新しいオブジェクトカテゴリに対して汎用的でない場合がある.これに対して、本研究では、ポイントベースの編集を使用して、空間属性の微細な制御を可能にする手法を提案している.これにより、より高い精度で空間属性を制御できるようになり、さまざまなオブジェクトカテゴリに適用できるようになる. (p.1,4-8)
Q: テキストと画像の両方を活用し、GAN制御の柔軟性、正確性、一般性を実現する提案手法は?
A: 本提案手法は、テキストと画像の両方を活用して、GANの制御において柔軟性、精度、汎用性を実現しています.これは、従来の手法が3Dモデルや手動注釈データに依存しており、新しいオブジェクトカテゴリに汎用的でなかったり、空間属性の範囲が限定されたり、編集プロセスに対する制御が少なかったりすることに対する改善策として提案されています.具体的には、テキストと画像を同時に入力としてGANに与え、画像の空間属性を高精度で編集することができます.また、提案手法は、従来の3Dモデルによる制御とは異なり、オブジェクトの位置やライティングに限定されず、より広範な制御が可能です.これにより、提案手法は、テキストによる高レベルな意味編集と画像の細かい空間属性の編集を両立し、柔軟性、精度、汎用性を実現しています.(p.2-3)
Q: DragGANの2大コンポーネントは何ですか?
A: DragGANの2つの主要なコンポーネントは、1)ハンドルポイントを目標位置に移動させる特徴ベースのモーション監視、および2)多様なオブジェクトカテゴリーにわたるポーズ、形状、表情、レイアウトなどの属性を活用する新しいポイントトラッキングアプローチです.これにより、DragGANを通じて、誰でも画像を変形させ、ピクセルがどこに行くかを正確に制御し、ポーズ、形状、表情、オブジェクトの剛性に一貫して従う形状を操作できます.これは、画像操作とポイントトラッキングのタスクにおいて、DragGANが従来のアプローチよりも優れていることを定量的および定性的に比較することによって示されています.また、GAN反転を通じて実際の画像の操作を紹介しています.(p.1)
Q: DragGANで活用されている新しいポイントトラッキングのアプローチと、従来のアプローチとの違いは何ですか?
A: DragGANでは、従来の手法とは異なり、識別的なジェネレータの特徴を利用して、ハンドルポイントの位置を追跡する新しい手法が提案されています.これにより、編集ステップごとにハンドルポイントの位置が把握できます.この手法は、複数のポイントを制御し、正確な位置制御を必要とするため、従来の手法とは異なります.これにより、より多様で正確な画像操作が可能になります.(p.1,5)
Q: DragGANを使用して操作できるオブジェクトのカテゴリは?
A: DragGANを使用することで、動物、車、人間、風景など、多様なカテゴリーのレイアウトや形状を操作することができます.(p.1) DragGANは、GANの学習された生成画像マニフォールド上で操作が行われるため、オクルージョンされたコンテンツの幻覚や、オブジェクトの剛性に沿った形状の変形など、困難なシナリオでも現実的な出力を生成する傾向があります.(p.1)
Q: オクルードコンテンツや物体の剛性に応じた形状変形など、難しいシナリオでもリアルな出力が得られるのはなぜですか?
A: DragGANは、学習されたGANの生成画像多様体上で操作を行うため、動物、車、人間、風景などの多様なカテゴリーのポーズ、形状、表情、レイアウトを制御することができます.これらの操作は、オクルージョンされたコンテンツを幻覚化したり、オブジェクトの剛性に従って形状を変形させたりするような困難なシナリオでも、現実的な出力を生成する傾向があります.
Q: DragGANは、画像操作やポイントトラッキングの点で、先行するアプローチと比較してどうでしょうか?
A: DragGANは、画像操作とポイントトラッキングのタスクにおいて、従来の手法に比べて優位性があることが定量的・定性的に示されています.DragGANは、GANの特徴空間が動きの監視と正確なポイントトラッキングを可能にすることを利用しており、最適化ステップごとにハンドルポイントがターゲットに近づくように移動することで、モーション監視を実現しています.また、最近傍探索を用いてポイントトラッキングを行います.DragGANは、RAFなどの追加ネットワークを必要とせず、効率的な操作が可能であり、多様で正確な画像操作が可能になります.これに対し、Endo [2022]は、複数のポイントを制御することができず、ポイントの位置を正確に制御することができないという課題があります. (p.1,5)
Q: DragGANは、GANの特徴空間をどのように活用し、動きの監視や正確な点追跡を可能にしているのでしょうか.
A: GANの特徴空間は、移動監視と正確なポイント追跡を可能にする十分に識別力があるため、DragGANはこの特徴空間を利用して、画像の任意のポイントを正確にターゲットポイントに移動させることができます.具体的には、移動監視は、潜在的なコードを最適化する移動された特徴パッチ損失によって達成されます.各最適化ステップは、ハンドルポイントがターゲットに近づくように移動するため、ポイント追跡は特徴空間での最近傍探索を介して実行されます.この最適化プロセスは、ハンドルポイントがターゲットに到達するまで繰り返されます.また、DragGANは、領域固有の編集を実行するために、オプションで興味領域を描画することもできます.DragGANは、手動注釈付きトレーニングデータまたは事前の3Dモデルを介して敵対的ネットワーク(GAN)を利用する従来の方法よりも柔軟性、精度、汎用性に欠けることが多いため、より強力であることが示されています.(p.1)
Evidence of Meaning in Language Models Trained on Programs
著者:Charles Jin, Martin Rinard
発行日:2023年05月18日
最終更新日:2023年05月18日
URL:http://arxiv.org/pdf/2305.11169v1
カテゴリ:Machine Learning, Artificial Intelligence, Computation and Language, Programming Languages
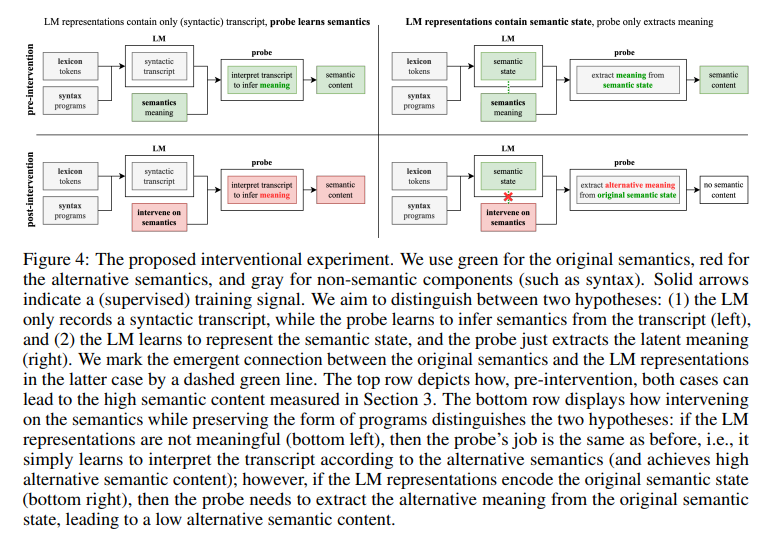
概要:
この研究では、言語モデルがテキストから意味を学ぶ可能性が示されました.具体的なタスクであるプログラム合成を使用することで、言語モデルの意味の存在を特徴化する中間試験としてのプログラム合成が有用であることが示されました.Transformerモデルをプログラムのコーパスで訓練した結果、線形プローブがモデルの状態から現在のおよび将来のプログラムの状態の抽象化を抽出できることがわかりました.さらに、意味を自動合成するための語彙的および文脈的な手法を用いることで、モデル内に意味が表現されていることを示すいくつかの実行可能なプログラムが生成されました.また、学習されたプログラムの平均的な長さよりも短いプログラムを生成できることが発見され、これは言語モデルの出力が学習分布と異なる形で意味的な変化をもたらす可能性があることを示すものです.この研究は、言語モデルの学習技術について新しい技術を提供するものではありませんが、(形式的な)意味の取得と表現に関する洞察を提供するための実験的枠組みを展開しました.また、モデル内に意味が表現されていることを評価するための新しい実験手法を開発し、その有用性を示しました.
Q&A:
Q: プログラムを扱う際に、言語における意味に関連する概念はどのように定義されるのか?
A: プログラムの前にある(テキストの)入出力例の形で、各プログラムには仕様が先行しています.プログラムを扱うことで、言語における意味に関連する概念(例えば、正確性や意味論)を正確に定義することができ、プログラム合成は言語モデルの意味の存在(または不在)を特徴づけるための中間テストベッドとして適しています.(p.1)
プログラムを扱うことで、言語における意味に関連する概念を正確に定義することができます.具体的には、プログラムの正確性や意味論などが挙げられます.これにより、プログラム合成は言語モデルの意味の存在(または不在)を特徴づけるための中間テストベッドとして適していると言えます.(p.1)
Q: 言語意味論に関する具体的な概念で、ハンドリングプログラムによって正確に定義できるものは何か.
A: プログラムを扱うことによって、言語の意味に関連する特定の概念(例えば、正確さや意味論)を正確に定義することができます.これにより、プログラム合成は、言語モデルの意味の存在(または不在)を特徴付けるための中間テストベッドとして適しています.また、プログラムを扱うことによって、基礎となるプログラミング言語の正確な形式的意味論から概念を定義し、測定し、実験することができます.これにより、現在の言語モデルの能力に関する原則的な理解に貢献する新しい洞察が得られます.(p.2)
Q: プログラム合成を中間テストベッドとして、言語モデルにおける意味の有無はどのように特徴づけられるか?
A: プログラム合成を中間テストベッドとして使用することで、言語モデルの意味の存在または不在を特徴付けることができます.各プログラムは、(テキストの)入出力例の形式で仕様が先行します.プログラムを扱うことで、言語に関連する意味に関連する概念を正確に定義することができます(例:正確性と意味論).したがって、プログラム合成は、言語モデルの意味の存在または不在を特徴付けるための中間テストベッドとして適しています.(p.1)
Q: 仕様が与えられたプログラムを完成させるとき、学習済みモデルの隠れた状態はどのように探られるのでしょうか?
A: 訓練されたモデルの隠れ状態は、仕様に基づいてプログラムを完了する際にプローブされます.モデルは、言語の意味を学習するための帰納的なバイアスを提供しないにもかかわらず、線形プローブがモデルの状態から現在および将来のプログラム状態の抽象化を抽出できることがわかりました.さらに、プローブの精度とモデルが仕様を実装するプログラムを生成する能力との間には、強い統計的有意性の相関があります.モデルの状態に意味が表現されているか、プローブによって学習されたかを評価するために、言語の意味を介入しながらレキシコンと構文を維持する新しい実験手順を設計しました.これにより、モデルが仕様を実装する正しいプログラムを生成することができることが示されました. (p.3-5)
Q: 言語モデルの出力が、意味的に意味のある方法で訓練分布と異なる可能性があることを示す証拠は何ですか?
A: 訓練分布と異なる形で言語モデルの出力が意味的に異なることの証拠は、論文のセクション5で示されている.具体的には、言語モデルは訓練セット内のプログラムよりも短いプログラムを生成する傾向があり(それでも正しいプログラムを生成する)、言語モデルのperplexityは訓練セット内のプログラムに対して一貫して高いままであることが挙げられる.これは、言語モデルの出力が訓練分布と意味的に異なることを示す証拠である.ただし、この論文は言語モデルのトレーニングに新しい技術を提案するものではなく、言語モデルにおける(形式的な)意味の習得と表現に関する実験的な枠組みを開発し、洞察を提供することを目的としている.
DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining
著者:Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy Liang, Quoc V. Le, Tengyu Ma, Adams Wei Yu
発行日:2023年05月17日
最終更新日:2023年05月17日
URL:http://arxiv.org/pdf/2305.10429v1
カテゴリ:Computation and Language, Machine Learning
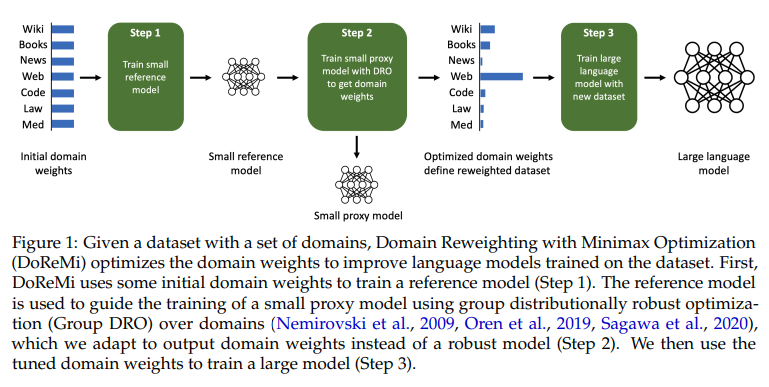
概要:
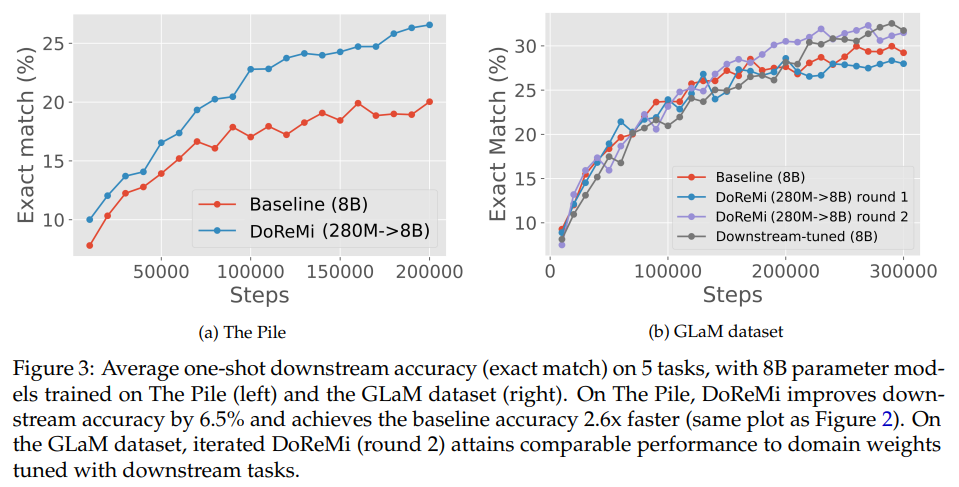
この論文では、事前トレーニングデータのドメインの混合割合が言語モデル(LM)のパフォーマンスに大きな影響を与えることが述べられています.そこで、本論文では、ドメイン再重み付けと最小最大最適化(DoReMi)を提案し、最初に、下流のタスクの知識なしにグループ分布ロバスト最適化(Group DRO)を使用してドメインの重み(混合割合)を生成するために、小規模のプロキシモデルをトレーニングします.次に、これらのドメインの重みを使用してデータセットを再サンプリングし、大型のフルサイズモデルをトレーニングします.実験では、DoReMiを使用して、8B-パラメータモデル(30倍大きい)を効率的にトレーニングするために、280M-パラメータプロキシモデルにドメインの重みを見つけるために使用します.The Pileでは、DoReMiはすべてのドメインでperplexityを向上させ、ドメインの重みを下げた場合でも、平均フューショットダウンストリームの精度をベースラインモデルより6.5%向上させ、トレーニングステップを2.6倍少なくしてベースラインの精度に到達します.GLaMデータセットでは、下流タスクの知識がないDoReMiは、下流タスクに調整されたドメインの重みを使用した場合と同等のパフォーマンスを発揮します.
Q&A:
Q: 言語モデルの事前学習において、データの混合を最適化する手法の提案とは?
A: 提案された方法は、言語モデルの事前学習におけるデータ混合の最適化に関するものです.具体的には、グループ分布ロバスト最適化(Group DRO)を用いて、下流タスクの知識を必要とせずに、ドメインの重み(混合比)を生成する小規模なプロキシモデルを最初にトレーニングします.その後、これらのドメインの重みでデータセットを再サンプリングし、より大きなフルサイズのモデルをトレーニングします.この手法はDomain Reweighting with Minimax Optimization(DoReMi)と呼ばれています.この手法を用いることで、280Mパラメータのプロキシモデルを使用して、8Bパラメータのモデルをより効率的にトレーニングすることができます.DoReMiは、The Pileのすべてのドメインでperplexityを改善し、ドメインの重みを下げた場合でも改善します.DoReMiは、The Pileのデフォルトのドメインの重みを使用してトレーニングされたベースラインモデルよりも平均few-shot downstream accuracyを6.5%改善し、ベースラインのaccuracyに到達します.(p.1-2)
Q: DoReMi法は、デフォルトのドメイン重みで学習させたベースラインモデルと比較して、どのように数ショット下流の精度を向上させるのですか?
A: DoReMiメソッドは、The Pileのデフォルトのドメインウェイトでトレーニングされたベースラインモデルに比べ、few-shot downstream accuracyを6.5%改善し、2.6倍少ないトレーニングステップでベースラインの精度に到達します(p.3.2).また、DoReMiは、downstreamタスクにチューニングされたドメインウェイトを使用するパフォーマンスと同等の結果を、downstreamタスクの知識を持たない状態でGLaMデータセットで達成します(p.1).
Q: DoReMi法は、下流タスクの知識がないのに、どのようにドメインウエイトを決定しているのですか?
A: Downstream tasksに関する知識がなくても、DoReMiはlanguage modeling datasetのdomain weightsを最適化するために小さなproxy modelを使用するアルゴリズムです.最初に、DoReMiはいくつかの初期domain weightsを使用して参照モデルをトレーニングします.参照モデルは、グループ分布ロバスト最適化(Group DRO)を使用して、ドメインごとに最適化されたドメインの重みを出力するように適応させた小さなproxy modelのトレーニングをガイドします.最適化されたdomain weightsを使用して、大きなモデルをトレーニングします.(p.1)
DoReMiは、downstream tasksに関する知識がなくても、小さなproxy modelを使用してdomain weightsを最適化することができます.具体的には、DoReMiは、参照モデルをトレーニングし、小さなproxy modelをグループ分布ロバスト最適化(Group DRO)を使用してトレーニングし、最適化されたdomain weightsを使用して大きなモデルをトレーニングします.このようにして、DoReMiはdownstream tasksに関する知識がなくても、domain weightsを最適化することができます.(p.1)
Q: 実験に使用したプロキシモデルのサイズは?
A: 実験で使用されたプロキシモデルのサイズは記載されている.(Appendix Table 6) 70M、150M、280M、1BのスケールでDoReMiプロキシモデルのサイズが考慮され、メインモデルのサイズが8Bに固定されている.プロキシモデルのサイズは、表6に示されている.(p.8)
Q: DoReMiのプロキシモデルサイズに異なるスケール(70M、150M、280M、1B)を使用することの意義は何ですか?
A: DoReMiのプロキシモデルサイズを異なるスケール(70M、150M、280M、1B)にすることの意義は、8Bのメインモデルのパフォーマンス向上につながることである.70Mから280Mまでプロキシモデルサイズを増やすと、8Bでのダウンストリームの精度が向上する.しかし、1Bのプロキシモデルでは、グループDROオプティマイザーが大規模なスケールでは悪化するため、この傾向は続かないと仮説を立てている.各スケールのDoReMiモデルは、ベースラインよりもダウンストリームのパフォーマンスを大幅に改善する. (p.9)
Q: DoReMiがベースラインモデルに対して達成した平均few-shot downstream accuracyの向上はどの程度ですか?
A: DoReMiは、The Pile上のベースラインモデルと比較して、平均few-shot downstream accuracyを6.5%改善し、ベースラインaccuracyを75kステップ以内で達成しました.これは、ベースライン(200kステップ)よりも2.6倍速く、トレーニングを劇的に加速し、downstream performanceを改善することができます.これは、Figure 3(left)に示されています.(p.3)
Q: GLaMデータセットにおけるDoReMiの性能は、下流タスクでチューニングしたドメインウェイトを用いた場合と比較してどうでしょうか?
A: GLaMデータセットにおいて、DoReMiは下流タスクに調整されたドメインウェイトを使用する場合と同等の性能を発揮します.DoReMiは、下流タスクの知識を持たないにもかかわらず、ドメインウェイトを調整した場合と同等の性能を発揮します.これは、DoReMiが一様な初期ドメインウェイトから開始し、下流データを使用せずに類似したドメインウェイトを回復できるためです.これは、(p.4)から抽出されました.
Q: DoReMiは、下流タスクの知識を持たずに、下流タスク用に調整されたドメインウェイトを使うのと同じ性能をどのように実現しているのですか?
A: Downstream tasksに関する知識がなくても、DoReMiは下流タスクに調整されたドメインの重みを使用することと同じパフォーマンスを達成することができます.これは、DoReMiが下流タスクに調整されたドメインの重みと同じ一般的なパターンを持つ重みを見つけることができるためです.DoReMiは、下流データを使用せずに均一な初期ドメインの重みから開始して、同様のドメインの重みを回復することができます.(p.1)
Q: DoReMiがダウンストリームデータを使用せずに、類似ドメインウェイトを復元することができる理由を教えてください.
A: DoReMiは、下流のデータを使用せずに、均一な初期ドメインウェイトから同様のドメインウェイトを回復することができます.これは、小さなプロキシモデルを使用して言語モデリングデータセットのドメインウェイトを最適化するアルゴリズムであり、280Mのプロキシモデルで実行された場合、DoReMiは、The Pileデータセットにおいて、ウェブテキストドメインであるPile-CCに最も重みが置かれることがわかります.また、Wikipediaはベースラインに比べてダウンウェイトされていますが、DoReMiは、Wikipediaから派生したタスク(例えばTriviaQA、Appendix Table 5)においても下流の精度を向上させることができます.これは、DoReMiが、下流のデータを使用せずに、均一な初期ドメインウェイトから同様のドメインウェイトを回復することができるためです.(p.3-5)
Searching for Needles in a Haystack: On the Role of Incidental Bilingualism in PaLM’s Translation Capability
著者:Eleftheria Briakou, Colin Cherry, George Foster
発行日:2023年05月17日
最終更新日:2023年05月17日
URL:http://arxiv.org/pdf/2305.10266v1
カテゴリ:Computation and Language
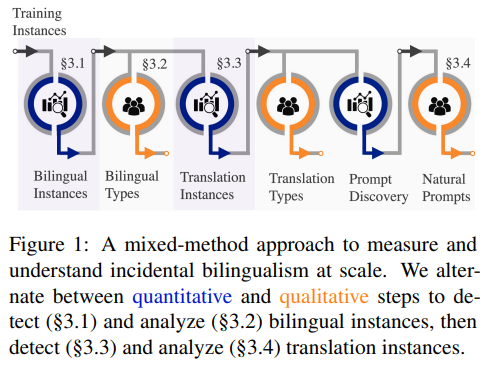
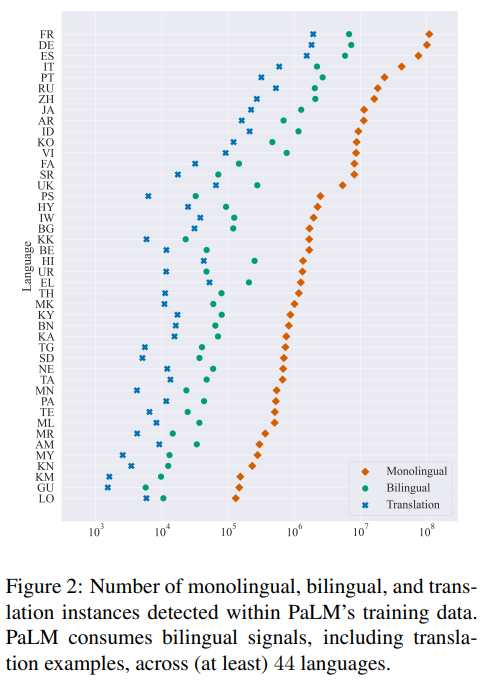
概要:
大規模な多言語言語モデルは、一般的なニューラル翻訳システムに提供される意図的に含まれた翻訳例を見たことがなくても、驚くほど優れたゼロまたはフューショットの機械翻訳能力を発揮する.本記事では、偶発的なバイリンガリズム・意図的に提供された翻訳例を含む双方向シグナルを偶然に消費することによる、大規模言語モデルの翻訳能力を解明するため、Pathways Language Model(PaLM)を事例として取り上げている.混合メソッド・アプローチを紹介し、PaLMは、少なくとも44の言語で3,000万以上の翻訳対を把握していることを示した.また、モデルのスケールにより、偶発的なバイリンガルなコンテンツの影響は減少するが、その存在が翻訳能力に大きな影響を与えることを示した.さらに、非英語の言語において、偶発的な単言語の内容量と偶発的なバイリンガルコンテンツ量が強く相関していることを明らかにした.偶発的なバイリンガルコンテンツをゼロショットのプロンプトに関連付け、従来の英語外のゼロショット翻訳の品質を向上させるための新しいプロンプトをマイニングすることができることも示した.
Q&A:
Q: 偶発的なバイリンガリズムとは何か、また機械翻訳能力との関連は?
A: 偶発的なバイリンガリズムとは、単一のトレーニングインスタンス内でバイリンガルテキストを意図的に消費することなく、偶然に消費することを指します.これは、PaLMの翻訳能力に関連しており、PaLMは偶発的なバイリンガルテキストを多く消費しています.
偶発的なバイリンガリズムは、機械翻訳能力に影響を与えます.PaLMは、偶発的な翻訳信号に自然にさらされており、英語とペアになった44言語の3千万以上の翻訳ペアを見ています.さらに、偶発的な翻訳から抽出されたデータ駆動型のプロンプトは、PaLMのゼロショット能力を改善するのに役立ちます.
これらの翻訳能力は、LLMsがゼロショットパラダイムでさまざまな自然言語生成タスクを実行する能力に関連しています.(p.1, 5)
Q: 偶然のバイリンガルは機械翻訳能力にどのような影響を与え、PaLMはそれをどのように活用してゼロ・ショット能力を向上させるのか?
A: PaLMは、偶発的なバイリンガリズムによって、翻訳シグナルに自然に露出しており、44言語の3千万以上の翻訳ペアを見ている.また、偶発的なバイリンガリズムから抽出されたデータ駆動型のプロンプトは、PaLMのゼロショット能力を平均で14chrF向上させることができることが示されている.(p.5)
Q: 偶然のバイリンガルを大規模に測定し理解するために、混合法のアプローチを用いる目的は何ですか?
A: 大規模な偶発的なバイリンガリズムを測定し理解するために、混合手法を導入することが目的である.この手法では、定量的な手法と定性的な手法を交互に使用し、バイリンガルなインスタンスを検出し、分析することで、バイリンガルな信号を探索する.また、翻訳インスタンスも検出し、分析することで、バイリンガルな信号を理解する.この手法は、LLMsからの知識を利用し、データ駆動型のプロンプトを使用することで、バイリンガルな信号を検出する. (p.3-5)
Q: この手法では、どのように対訳インスタンスを検出し、分析するのですか.また、どのようなプロセスで翻訳インスタンスを検出し、分析するのですか.
A: バイリンガルインスタンスは、§3.1で自動的に検出され、§3.2で分析されます.分析を容易にするために、KnowYourDataツールを使用して、バイリンガルインスタンスのより少ない頻度の言語の範囲をハイライトします.100の英仏バイリンガルインスタンスの質的分析により、バイリンガリズムはさまざまなクロスリンガル現象で現れることが明らかになりました.検出アプローチは、言語識別の問題に起因するエラーを除いて、正確であることがわかりました.正しく検出されたバイリンガルインスタンスは、5つのカテゴリーのうちの1つに属するように注釈が付けられます.また、§3.3と§3.4では、翻訳インスタンスを検出し、分析するために同様の手法が使用されます. (p.3-5)
Towards Expert-Level Medical Question Answering with Large Language Models
著者:Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Le Hou, Kevin Clark, Stephen Pfohl, Heather Cole-Lewis, Darlene Neal, Mike Schaekermann, Amy Wang, Mohamed Amin, Sami Lachgar, Philip Mansfield, Sushant Prakash, Bradley Green, Ewa Dominowska, Blaise Aguera y Arcas, Nenad Tomasev, Yun Liu, Renee Wong, Christopher Semturs, S. Sara Mahdavi, Joelle Barral, Dale Webster, Greg S. Corrado, Yossi Matias, Shekoofeh Azizi, Alan Karthikesalingam, Vivek Natarajan
発行日:2023年05月16日
最終更新日:2023年05月16日
URL:http://arxiv.org/pdf/2305.09617v1
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning
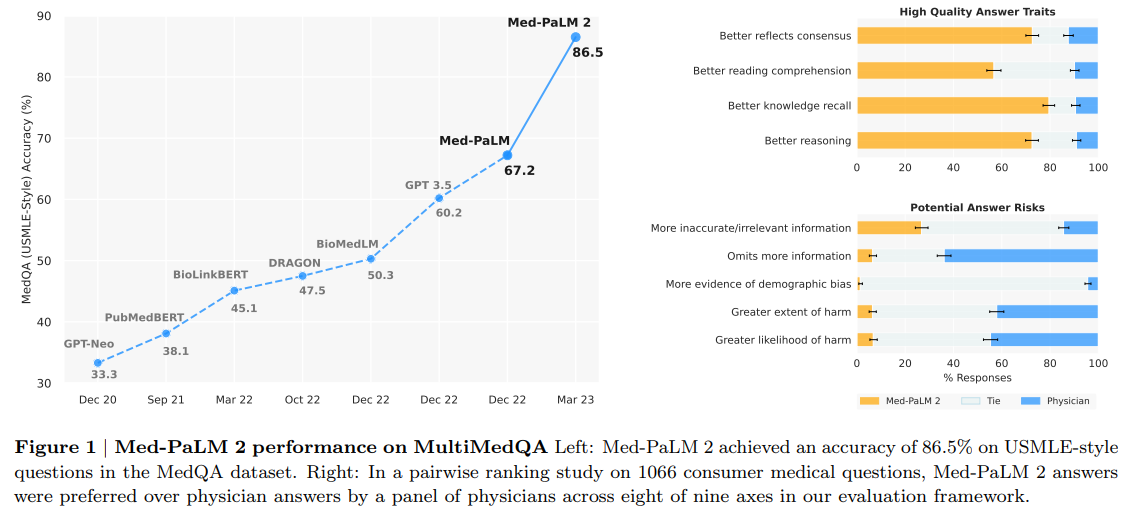

概要:
人工知能(AI)システムは、最近Goからタンパク質の折り畳みまでの「グランドチャレンジ」で一定の進展を見せている.このようなAIシステムが医療領域でも活用され、医師に匹敵する医療問題に対する回答能力が長年にわたって目指されてきました.大規模言語モデル(LLM)は、医療問題に対する医学的質問への回答において重要な進展をもたらし、Med-PaLMは、初めて67.2%の合格点以上のスコアを記録した最初のモデルでした.
しかし、医療従事者の回答と比較してまだ改善される余地があることが示唆され、それを埋めるべく、PaLM 2をベースにした改良や、医療領域の微調整、新しいアンサンブル改良アプローチを含むプロンプティング戦略を組み合わせたMed-PaLM 2が開発されました.その結果、MedQAデータセットで最大86.5%のスコアを記録し、Med-PaLMに比べて19%以上改善され、新たな最高記録を樹立しました.また、MedMCQA、PubMedQA、MMLUのクリニカルトピックスデータセットでも、最高記録に迫るパフォーマンスを発揮していることがわかりました.
このモデルについて、医療従事者の評価や長いフォームの質問への回答など、医療応用に関する複数の軸において詳細な評価が行われました.その結果、1066個のコンシューマーメディカル質問を比較したペアワイズランキングにおいて、医師は、臨床価値に関する9つの軸のうち、8つにおいてMed-PaLM 2の回答を医師の回答よりも優先する結果となりました(p < 0.001).また、LLMの制限を調べるために導入された240の長い「対立的な」質問のデータセットでも、Med-PaLMと比較して、評価のすべての軸において(p < 0.001)有意な改善が見られました.
これらの結果は、医療質問において医師レベルのパフォーマンスに向けた急速な進歩を示しており、今後の検証研究が必要ながらも、リアルワールドでの効果を実証する可能性があります.
Q&A:
Q: Med-PaLM 2は、MedQA以外の臨床トピックのデータセットでも良い結果を出したのでしょうか?
A: Med-PaLM 2は、MedQA以外の臨床トピックスデータセットでも、state-of-the-artに近いパフォーマンスを示しました.具体的には、MedMCQA、PubMedQA、およびMMLU clinical topicsデータセットで、state-of-the-artに近いパフォーマンスを観察しました.これは、Med-PaLM 2が、PaLM 2の改良、医療ドメインの微調整、および新しいアンサンブル改良アプローチを含むプロンプティング戦略を活用しているためです.(p.2)
Q: Med-PaLM 2では、複数の臨床トピックデータセットで最先端に近い性能を実現するために、具体的にどのような改良が施されたのでしょうか.
A: Med-PaLM 2は、PaLM 2のベースLLMの改善、医療ドメインの微調整、および新しいアンサンブル改善アプローチを含むプロンプティング戦略を組み合わせて、複数の臨床トピックデータセットでほぼ最新のパフォーマンスを達成するために改良されました.(p.2-3)
Q: Med-PaLM 2』のプロンプト戦略で採用されたアンサンブル改善アプローチについて教えてください.
A: アンサンブル改善アプローチは、Med-PaLM 2のプロンプティング戦略の一部であり、表5に示されています.アンサンブル改善は、少数ショットや自己整合性のプロンプティング戦略よりも、これらのベンチマーク全体で強力なモデルパフォーマンスを引き出すことができます.アンサンブル改善は、複数のモデルを組み合わせることによって、より正確な予測を行うことができます.具体的には、アンサンブル改善は、複数のモデルの出力を平均化することによって、より一貫性のある予測を行います.これにより、Med-PaLM 2は、MedQAデータセットで86.5%のスコアを獲得し、Med-PaLMよりも19%以上向上し、新しい最高値を設定しました.(p.2-3)
Q: 長文問題に対する人間の評価結果はどうでしたか?
A: 長文の消費者向け医療質問応答におけるMed-PaLM 2のパフォーマンスを評価するために、人間による評価を行いました.医師と一般人の評価者による人間の評価が行われ、Med-PaLM 2の回答は、MultiMedQA 140データセットにおいて、Med-PaLMの回答よりも直接的に関連性が高く、役に立つと評価されました.評価には、Section A.3.4で提供されたプロンプトを使用し、Med-PaLMとMed-PaLM 2の両方で一貫して行われました.評価結果は、(p.3.5)に記載されています.
Q: 臨床的有用性に関わるすべての軸において、医師が作成した回答よりもMed-PaLM 2の回答の方が好まれたのか.
A: 医師は、臨床的有用性に関する9つの軸のうち8つで、医師やMed-PaLMの回答よりもMed-PaLM 2の回答を好んだことが示されています(4.2節および図1).医学的合意をよりよく反映していると判断されたり、医学的推論能力が高いと判断されたり、有害性の可能性が低いと判断されたりするなど、臨床的有用性に関する多くの軸で、Med-PaLM 2の回答が優れていたとされています.したがって、医師レベルの性能に向けて進展するにつれて、改善された評価フレームワークがさらなる進歩を測定するために重要であることが示唆されています.(p.2)
Q: 臨床的有用性に関わる9つの軸は何でしょうか?
A: 本文には、臨床的有用性に関連する9つの軸が言及されています.(p.2)
- 医学的合意に沿ったもの:「どちらの回答が現在の科学的および臨床コミュニティの合意をよりよく反映していますか?」
- 読解力:「どちらの回答がより良い読解力を示していますか?(質問が理解されたことを示す)」
- 知識の回想:「どちらの回答がより良い知識の回想を示していますか?(質問に答えるための関連するおよび/または正しい事実の言及)」
- 推論:「どちらの回答がより良い推論ステップを示していますか?(正しい理論または知識の操作による質問に答えるため)」
- 不適切なコンテンツの含有:「どちらの回答には、不正確または関係のないコンテンツがより多く含まれていますか?」
- 事実性
- 医学的推論能力
- 重要な情報の省略
- 危険性のリスク
Q: Med-PaLM 2の回答は、この文章にある8つの軸について、医師が作成したものよりも優れているとどのように判断されたのでしょうか.
A: 医師やMed-PaLMによる回答と比較して、臨床的有用性に関する9つの軸のうち8つで、Med-PaLM 2の回答が優れていると判断された.たとえば、医師の回答に比べて、Med-PaLM 2の回答の方が医学的な合意をよりよく反映していると判断された割合は72.9%であった.ただし、不正確または関係のない情報を含む軸に関しては、Med-PaLM 2の回答は医師の回答よりも不利であった.これらの結果は、MultiMedQAにおいて得られたものである.(p.2-3)
Q: Med-PaLMと比較して、長文「逆境」問題240問の導入により、すべての評価軸で大きな改善が見られたか.(p.5)
A: (p.5) Med-PaLM 2は、240の長文形式の「adversarial」質問に対して、Med-PaLMと比較して、すべての評価軸で有意な改善が見られました.医師による評価では、Med-PaLM 2の回答は、Med-PaLMに比べて、推論の証拠、不正確な知識の回想、不正確な推論の3つの軸で有意に優れていました.また、一般的なサブセットと健康格差に焦点を当てたサブセットの両方で、Med-PaLM 2の回答は、Med-PaLMに比べて、すべての軸で有意に高品質でした.さらに、一般市民による評価では、Med-PaLM 2の回答は、Med-PaLMに比べて、有用性と関連性の両方で有意に高く評価されました.
StructGPT: A General Framework for Large Language Model to Reason over Structured Data
著者:Jinhao Jiang, Kun Zhou, Zican Dong, Keming Ye, Wayne Xin Zhao, Ji-Rong Wen
発行日:2023年05月16日
最終更新日:2023年05月16日
URL:http://arxiv.org/pdf/2305.09645v1
カテゴリ:Computation and Language
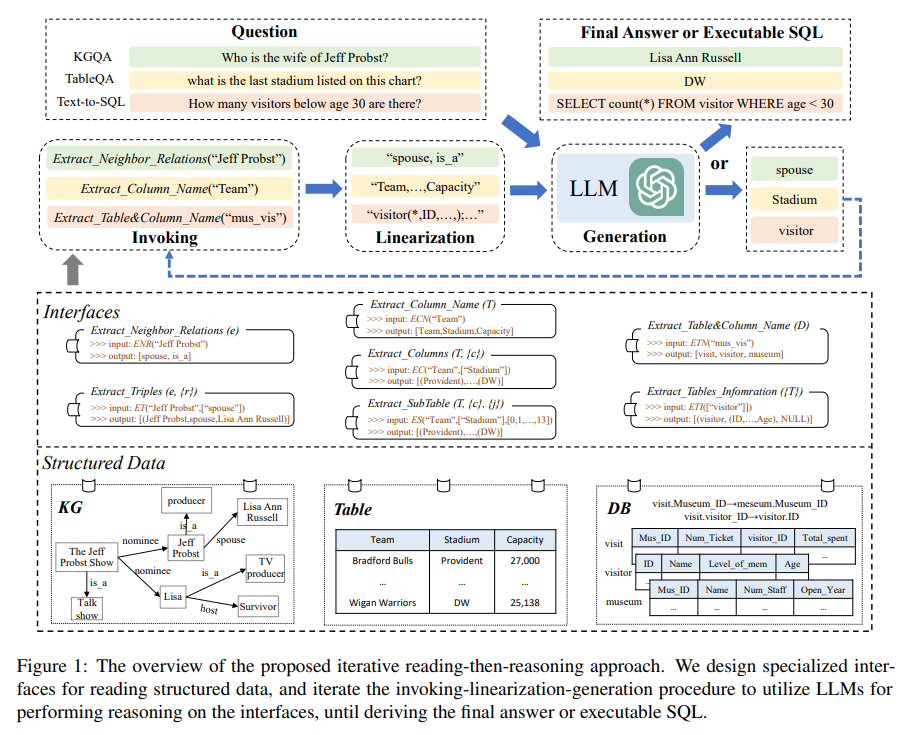
概要:
この論文では、大規模言語モデル(LLMs)を用いた構造化データのゼロショット推論能力を改善する方法について研究しました.ストラクチャードデータに基づく質問応答タスクを解決するためのイテレーティブリーディング-リーズニング(IRR)アプローチ、すなわちStructGPTを開発し、ストラクチャードデータから関連する証拠を収集する専門的な関数を構築しました.外部インターフェースの支援を受けて、LLMsがストラクチャードデータ上でリーズニングするための呼び出し、線形化、生成手順を提案し、その手順を提供されたインターフェースで反復することで、アプローチは徐々に与えられたクエリのターゲット回答に近づくことができます.さらに、3種類のストラクチャードデータで行った広範な実験では、このアプローチがチャットGPTの性能を大幅に向上させ、フルデータの教師ありチューニングベースラインと比較可能な性能を発揮することが示されました.この研究のコードとデータは、\url{https://github.com/RUCAIBox/StructGPT}にて公開されています.
Q&A:
Q: 構造化データタスクを解決するために提案されたIRRアプローチとはどのようなもので、どのように機能するのか?
A: 本論文では、構造化データに基づく質問応答タスクを解決するための提案手法として、反復的な読解と推論(IRR)アプローチを提案しています.このアプローチでは、LLMが質問に関連する十分な証拠を収集し、その後LLMが答えを導き出すために使用されます.しかし、このアプローチは構造化データに直接適用することはできません.そこで、本論文では、タスクに適したインターフェースを設計する方法と、LLMによる推論にどのように利用するかという2つの問題に焦点を当て、インターフェース拡張アプローチを補完するためのIRRアプローチを提案しています.IRRアプローチは、構造化データに基づく質問応答タスクを解決するための反復的な読解と推論の手法であり、KGQA、TableQA、Text-to-SQLの3つのタスクに適用できます.(p.3-5)
Q: ChatGPTでSQLクエリを生成する際に、提案するアプローチはどのように無関係な情報の影響を軽減するのか?
A: 提案手法は、ChatGPTがSQLクエリを生成する際に不要な情報の影響を軽減するために、関連する情報のみを反復的にアクセスして利用するより効果的な方法を提供します.これにより、テーブルからの不要な情報や冗長な情報の影響を軽減し、ChatGPTがSQLクエリを生成する際の正確性を向上させます.(p.1,5,30)
Q: LLMは、アクセス可能な構造化データSから有用な証拠を抽出し、抽出された証拠に基づいて期待される結果を生成し、質問qに答えるために、どのようにしているのですか?
A: LLMは、自然言語の質問qとアクセス可能な構造化データS(知識グラフまたはデータベースなど)が与えられた場合、Sから有用な証拠を抽出し、抽出された証拠に基づいて期待される結果を生成して質問qに答える必要があります.このプロセスは、問題文の中で「質問応答タスク」と形式的に説明されています.このタスクを解決するために、構造化データのインターフェースを利用して正確で効率的なデータアクセスとフィルタリングを実装し、LLMの推論能力を利用して質問に対する最終的な計画または結果を導き出すことが基本的なアイデアです.この方法により、LLMは、専門的な知識を考慮せずに、質問に答える推論プロセスに集中することができます.(p.2-3)
Q: 特化型機能は、どのようなアプローチで使われているのでしょうか?
A: 本アプローチにおいて、専門的なツールは、LLMsが複雑なタスクを解決するために使用されます.構造化データは、形式言語またはクエリを介して簡単にアクセスできるため、アプローチの基本的なアイデアは、LLMsの読解と推論の2つのプロセスを分離することです.構造化データのインターフェースを利用して、正確で効率的なデータアクセスとフィルタリング(関連する証拠の取得)を実装し、さらにLLMsの推論能力を利用して、質問の最終的な計画または結果を決定します(タスクを達成します).このように、LLMsは、専門的なアプローチを考慮せずに、質問に答える推論プロセスに集中できます.このアプローチは、構造化データに直接適用することはできませんが、専門的なツールを使用して複雑なタスクを解決することに着想を得ています.これにより、LLMsは、質問に関連する十分な証拠を収集し、LLMsによって答えを見つけることができます.しかし、構造化データに対しては、LLMsは正確に表現し理解する能力に限界があります.そのため、本アプローチでは、構造化データをブラックボックスシステムとしてカプセル化し、正確で効率的なデータアクセスとフィルタリングを実現することで、LLMsの推論能力を利用して、質問に答えることができます.(p.3-5)
Q: 構造化データの表現と理解におけるLLMの限界は?
A: LLMsにおける構造化データの表現や理解には限界がある.構造化データは、データモデルに準拠した標準化された形式で組織化されており、例えば、知識グラフは、ヘッドエンティティとテールエンティティの関係を示すファクトトリプルとして、データテーブルは、行ごとに列インデックス付きレコードとして組織化されている.しかし、構造化データは、LLMsが事前トレーニング中に見たことのない特別なデータ形式やスキーマを持っているため、完全に把握したり理解したりすることができない可能性がある.この問題を解決するための直接的な方法は、LLMsが理解できるように構造化データを文に直線化することである.しかし、構造化データの量は多く、すべてをLLMsに含めることは不可能である. (p.1)
Q: LLMの構造化データに対する推論を支援するために提案された手順とは?
A: 提案された手順は、外部インターフェースの支援を受けて、LLMsが構造化データを読み取り、推論するための呼び出し線形化生成手順です.この手順を提供されたインターフェースで反復することで、与えられた質問に対する目標回答に徐々に近づくことができます.この手順により、LLMsは、構造化データの読み取りに特化したアプローチを考慮することなく、質問に回答する推論プロセスに集中することができます.(p.3-5)
Q: 実験ではどのような種類の構造化データを使用したのですか?
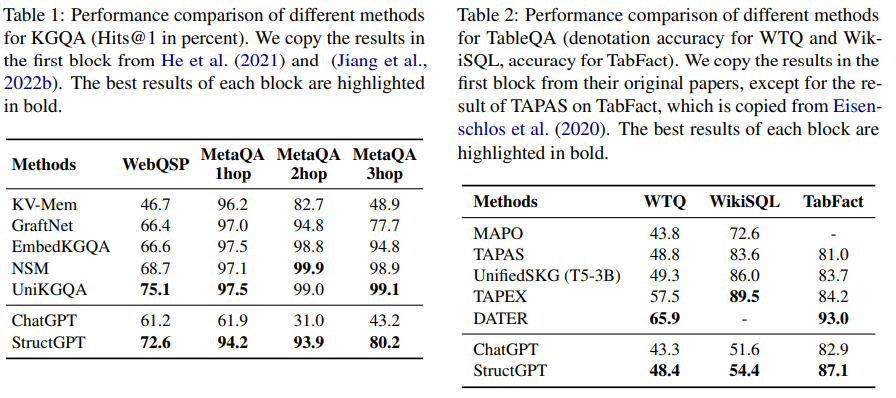
A: 実験では、構造化データに基づく3つの複雑な推論タスク、すなわちKGベースのQA、テーブルベースのQA、およびDBベースの意味解析に対して、SQLが使用されました.これは、4.1 Experimental Settings (p.4)および4.1.1 Datasets (p.4)で説明されています.KG based QAには、WebQuestionsSPとMetaQAの2つのベンチマークデータセットが使用され、Table based QAには、WikiSQL、WikiTableQuestions、およびTabFactの3つのデータセットが使用されました.これらのデータセットは、構造化データの種類を示しており、実験においてアプローチの有効性を検証するために使用されました.
Q: KGベースQAとテーブルベースQAで使用したデータセットと、その選択方法を教えてください.
A: KGベースのQAとTableベースのQAに使用されたデータセットは、それぞれWebQuestionsSPとMetaQA、WikiSQL、WikiTable-Questions、TabFactです.WebQuestionsSPとMetaQAは、KG上で2ホップまたは3ホップの推論が必要な質問に対する回答を含むベンチマークデータセットです.WikiSQLは、テーブルの内容をフィルタリングおよび集計する情報を要求し、WTQはより高度な推論能力(例:ソート)を要求します.TabFactは、提供された文がテーブルに格納された事実と一致するかどうかを判断する必要があります.これらのデータセットは、論理的推論能力を評価するために選択されました.(p.4-5)
Symbol tuning improves in-context learning in language models
著者:Jerry Wei, Le Hou, Andrew Lampinen, Xiangning Chen, Da Huang, Yi Tay, Xinyun Chen, Yifeng Lu, Denny Zhou, Tengyu Ma, Quoc V. Le
発行日:2023年05月15日
最終更新日:2023年05月15日
URL:http://arxiv.org/pdf/2305.08298v1
カテゴリ:Computation and Language

概要:
本研究では、自然言語ラベル(例:「ポジティブ/ネガティブな感情」)が任意のシンボル(例:「foo/bar」)で置き換えられた、インプット-ラベルペアに対して、言語モデルを微調整する「symbol tuning」を提案する.Symbol tuningは、モデルがタスクを解決するために指示や自然言語ラベルを使用できない場合、代わりにインプット-ラベルのマッピングを学習する必要があるという直感を利用している.
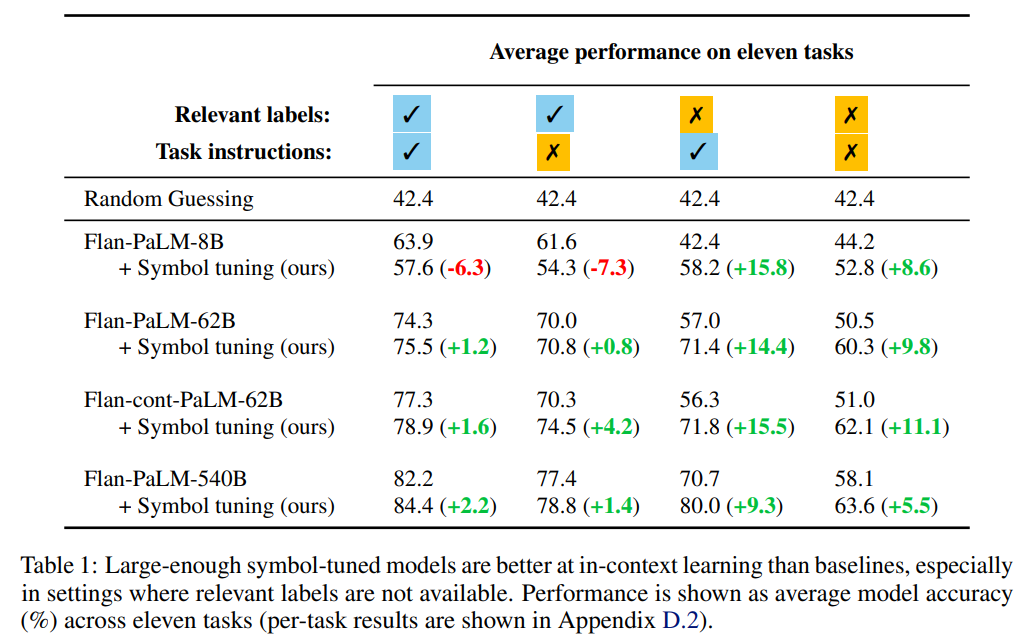
Flan-PaLMモデルを540Bパラメータまで実験し、様々な設定でsymbol tuningの利点を観察した.まず、symbol tuningは未知のインコンテキスト学習タスクにおいてパフォーマンスを向上させ、指示や自然言語ラベルがないような指定が不十分なプロンプトに対しては、より堅牢な性能を示した.次に、symbol tuningされたモデルはアルゴリズム的な推論タスクで非常に強く、リスト関数ベンチマークにおいて最大18.2%、シンプルなチューリング概念ベンチマークにおいて最大15.3%の性能改善を示した.最後に、symbol tuningされたモデルは、インコンテキストで提示されたフリップされたラベルを追跡する能力が格段に向上したため、先行の意味的知識を上書きするためにインコンテキスト情報をより利用できるようになったことを示している.
Q&A:
Q: symbol tuningとは何か、また、文脈内学習課題におけるパフォーマンスの向上はどのようなものか.
A: symbol tuningは、タスクに関係のないシンボルをラベルとして使用し、指示がない場合でもモデルが学習できるようにすることを目的としています.これにより、symbol tuningは、自然言語の入力を任意のシンボルにマッピングする能力だけでなく、アルゴリズムなどの他の形式の入力-ラベルマッピングの学習能力も向上させることができます.実験により、symbol tuningは、自然言語の設定だけでなく、アルゴリズムのタスクでも、インコンテキストの例から学習する能力を大幅に向上させることが示されました.具体的には、symbol tuningは、未知のインコンテキストの学習タスクでのパフォーマンスを向上させ、アルゴリズム的な推論タスクでも強力なモデルを作成することができます.また、フリップされたラベルに従う能力も向上させます.これにより、symbol tuningは、インコンテキストの学習タスクにおいて、パフォーマンスを向上させることができます.(p.5)
Q: 未視聴の文脈内学習課題におけるsymbol tuningの利点は?
A: Symbol tuningによる未知のin-context learningタスクにおける利点は、以下の3つです.まず、symbol tuningはin-context learningタスクにおけるパフォーマンスを向上させ、指示がない場合や自然言語ラベルがない場合などのunder-specified promptsに対してもより堅牢です.次に、symbol-tunedモデルはアルゴリズム的な推論タスクにおいてもより強力であり、List Functionsベンチマークでは最大18.2%、Simple Turing Conceptsベンチマークでは最大15.3%のパフォーマンス向上が見られます.最後に、symbol-tunedモデルはin-contextで提示されたflipped-labelsに従う能力が大幅に向上し、先行する意味的知識を上書きするためにin-context情報をより活用できることが示されています.(p.5-6)
Q: アルゴリズム推論タスクにおいて、symbol tuningはどのようにパフォーマンスを向上させるのか?
A: Symbol tuningは、in-context exemplarsからのinput-label mappingsによる学習をモデルに強制するように設計されています.これは、シンボルがタスクに関係なく、指示が提供されていないため(したがって、モデルはタスクを決定するための他のガイダンスに頼ることができないため)、モデルが自然言語の入力を任意のシンボルにマッピングする能力だけでなく、アルゴリズムなどの他の形式のinput-label mappingsを学習する能力も向上すると考えられます.これを検証するために、BIG-Bench(Srivastava et al.、2022)のアルゴリズム的推論タスクで実験を行いました.Symbol tuningは、List Functionsベンチマークで最大18.2%の性能向上をもたらし、アルゴリズム的推論タスクでモデルの性能を向上させます(p.8-9).)
Q: List Functionsベンチマークとアルゴリズム推論タスクにおけるSymbolチューニングの実験結果について、もう少し詳しく教えてください.
A: Symbol tuningによるList Functions benchmarkとアルゴリズム推論タスクの実験結果の詳細については、セクションD.1および図5を参照してください.List Functions benchmarkでは、symbol-tunedモデルは、リスト関数タスクのカテゴリごとに平均された精度が、ベースモデルやinstruction-tunedモデルよりも高いことが示されています.また、アルゴリズム推論タスクでは、symbol-tunedモデルは、List Functions benchmarkにおいて最大18.2%の性能向上を示しました.これらの結果は、symbol tuningが、未知の文脈学習タスクにおいても性能を向上させ、アルゴリズム推論タスクにおいても強力であることを示唆しています.(p.6)
Q: List FunctionsベンチマークとSimple Turing Conceptsベンチマークの詳細について教えてください.
A: リスト関数タスクは、人間の正確性ベースラインが最も高い20のリスト関数タスクを5つのカテゴリに分けて示したものであり、各サブタスクの平均精度を示しています.これらのタスクは、Flan-PaLM-8Bに対して18.2%、Flan-PaLM-62Bに対して11.1%の平均性能向上をもたらしました.また、シンプルなチューリングコンセプトタスクは、バイナリストリングを理解して入力を出力にマッピングする概念を学習する必要があるタスクであり、3つ以下の命令を含むAS IIサブセットでテストされました.これらのタスクは、モデルが異なるタスクタイプに汎化する能力をテストし、世界知識を必要としないため、アルゴリズム的なタスクとして選択されました.(p.6)
Q: symbol tuningされたモデルは、インコンテクストで提示されたフリップド・ラベルをフォローする際に、どのようなパフォーマンスを発揮するか?
A: 6. symbol tuningされたモデルは、文脈で提示された反転ラベルに従うことにおいて、指示調整されたモデルよりも優れた性能を発揮します.指示調整されたモデルは、予測を反転ラベルに従うように反転することができず(性能はランダムな推測よりもはるかに低い)、一方で、symbol tuningされたモデルはこれをより頻繁に行うことができます(性能はランダムな推測に一致するか、またはわずかに上回ります).これは、symbol tuningによって、モデルが反転ラベルに矛盾すること前知識を使用することを減らすことができるためです.これにより、symbol tuningが文脈での学習を改善し、反転ラベルに従う能力を回復することができると期待されます.(p.7)
Q: 提示された文脈や反転したラベルに従うという点で、記号調整モデルと指示調整モデルのパフォーマンスの差はどの程度か.
A: Symbol tuningによって、モデルはフリップされたラベルに矛盾すること前知識の使用を減らすことができるため、symbol tuningモデルは指示調整モデルよりも、提示された文脈と反転したラベルに従う能力が向上することが期待されます.図6によると、symbol tuningモデルは指示調整モデルよりも、すべてのモデルサイズにおいて、提示された文脈と反転したラベルに従う能力が優れています.指示調整モデルは予測を反転して反転したラベルに従うことができず(パフォーマンスはランダムゲスシングよりも低い)、symbol tuningモデルはこれをより頻繁に行うことができます(パフォーマンスはランダムゲスシングに一致またはわずかに上回ります).したがって、symbol tuningモデルは、提示された文脈と反転したラベルに従う能力が向上することが示されています.(p.7)
Q: Symbol tuningによって、モデルが文脈内の情報を使って、事前の意味知識を上書きする能力が高まることを説明できますか?
A: 記号調整手順によって、モデルは先行知識をオーバーライドすることができるようになります.これは、モデルが矛盾する情報を受け取った場合に、先行知識を無視することができるようになるためです.記号調整は、言語モデルが入力-ラベルペアから学習する能力を向上させることができます.これにより、モデルは先行知識を利用する利点を維持しながら、in-context exemplarsで示される入力-ラベルペアから学習する能力を向上させることができます.記号調整は、タスクの多様性がある場合に最も効果的であり、関連するラベルがある設定でモデルのパフォーマンスが低下する可能性があるため、少数のタスクで記号調整を行うことは避ける必要があります.(p.10)
Q: どのような場面でSymbol tuningが最も効果的なのか、また、なぜ少数のタスクでは避けるべきなのか.
A: Symbol tuningは、タスクが不明確で推論が必要な場合に最も効果的であり、自然言語のラベルや指示からタスクを学習することができないプロンプトのような不明確なプロンプトに対しても堅牢性が高いことが示されています.(p.7)
一方、symbol tuningは、関連するラベルが利用可能な設定ではモデルの性能を低下させることがあります.したがって、symbol tuningは、多様なタスクが使用される場合に最も効果的であり、少数のタスクでsymbol tuningを行うと、関連するラベルが利用可能な設定で性能が低下する可能性があるため、避ける必要があります.(p.7)
CodeT5+: Open Code Large Language Models for Code Understanding and Generation
著者:Yue Wang, Hung Le, Akhilesh Deepak Gotmare, Nghi D. Q. Bui, Junnan Li, Steven C. H. Hoi
発行日:2023年05月13日
最終更新日:2023年05月20日
URL:http://arxiv.org/pdf/2305.07922v2
カテゴリ:Computation and Language, Machine Learning, Programming Languages
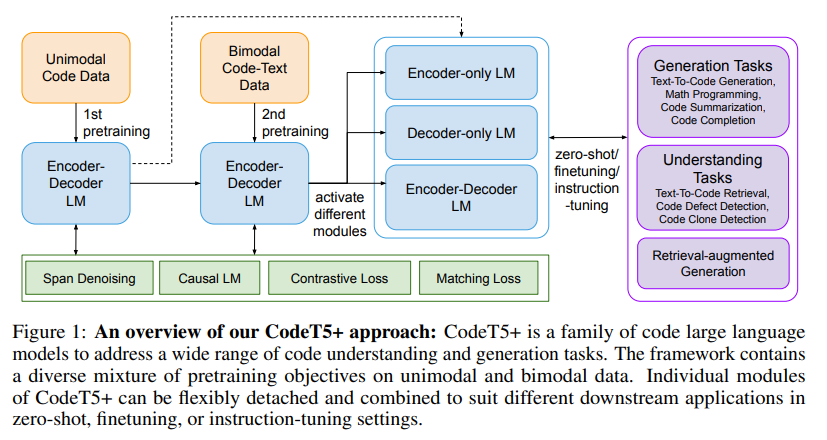
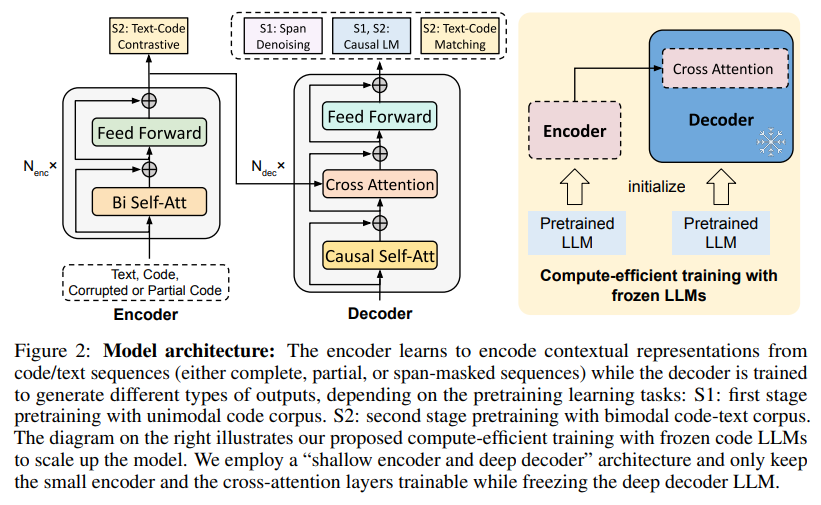
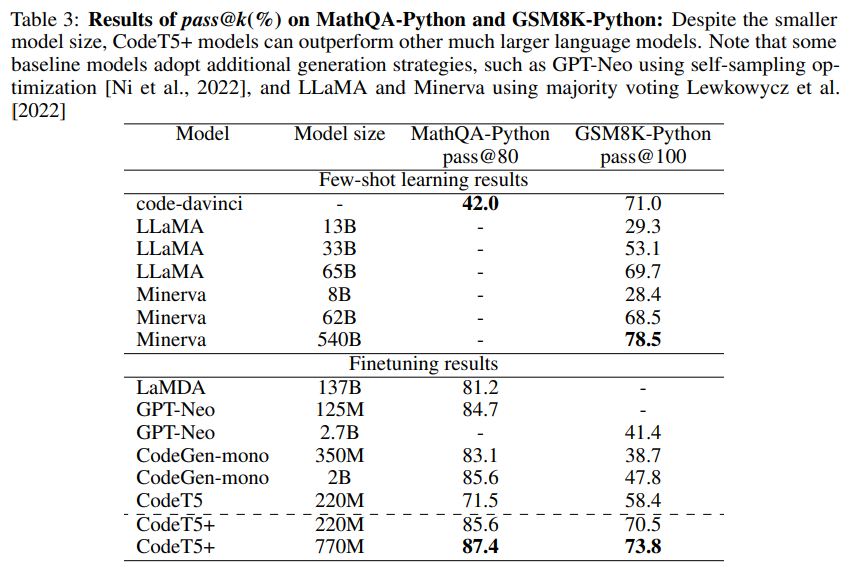
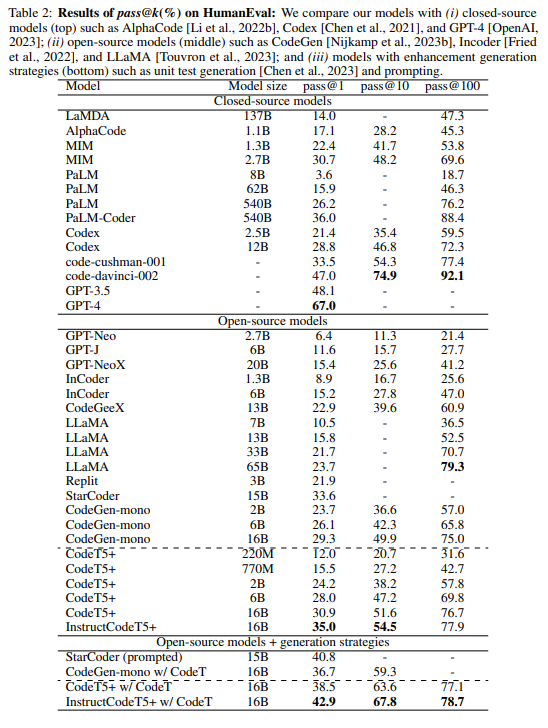
概要:
「CodeT5 +」は、複数のプリトレーニング目的混合をカバーし、アンモーダルおよびバイモーダルの多言語コードコーパスでのプリトレーニングタスクを行う柔軟なエンコーダーデコーダーLLMsのファミリーです.さらに、私たちはオフシェルフのLLMsを凍結してCodeT5 +を初期化し、効率的にモデルをスケーリングアップし、自然言語の指示に合わせた命令調整を探索します.私たちは、異なる設定で20以上のコード関連のベンチマークでCodeT5 +を広範囲に評価し、ゼロショット、ファインチューニング、命令チューニングを含めた複数のタスクで最先端(SoTA)のモデルパフォーマンスを観察しました.特に、私たちの命令調整されたCodeT5 + 16Bは、他のオープンなコードLLMsに対してHumanEvalコード生成タスクで新しいSoTA結果を達成しています.コード生成および完成、数式プログラミング、テキスト – コード検索タスクなど、さまざまなコード関連タスクでSoTAモデルパフォーマンスを実証します.
Q&A:
Q: 既存のコードLLMのアーキテクチャとプリトレーニングタスクの2つの主な限界は何ですか?
A: アーキテクチャの観点からは、既存のコードLLMは、エンコーダーのみまたはデコーダーのみのモデルを採用することが多く、特定の理解または生成タスクでのみ優れたパフォーマンスを発揮します.事前学習タスクの観点からは、多くの既存のモデルが特定のタスクのサブセットでのみ優れたパフォーマンスを発揮するように設計されていることがわかりました.これは、GitHubの公開データなどの大量のコードベースのデータで事前学習を行うことにより、コードLLMが豊富な文脈表現を学習し、さまざまなコード関連のダウンストリームタスクに転送できるためです.ただし、これらの制限があるため、既存のモデルは、他のオープンなコードLLMを上回ることができない場合があります. (p.1)
Q: 既存コードLLMの2大限界とは?
A: 既存のコードLLMの主な2つの制限は、アーキテクチャと事前学習タスクの両方に関するものです.アーキテクチャの観点からは、既存のコードLLMは、エンコーダーのみまたはデコーダーのみのモデルを採用することが多く、特定の理解または生成タスクにしか適していません.具体的には、エンコーダーのみのモデルは、GitHubの公開データなどの大量のコードベースのデータを使用して、さまざまなコード関連のダウンストリームタスクに転送できる豊富な文脈表現を学習できます.しかし、多くの既存のモデルは、特定のタスクのサブセットでしかうまく機能しないことがわかりました.これは、主にアーキテクチャと事前学習タスクの2つの制限によるものだと主張しています.(p.1)
Q: CodeT5で提案されていること前学習目的の混合は?
A: 3. CodeT5+では、複数の事前学習目的を等しい重みで共同最適化することで、段階的なトレーニングアプローチを採用しています.これにより、モデルにより多様なデータが提示され、豊富な文脈表現を学習することができます.また、CodeT5+の初期化には、棚からぼたもちのコードLLMを使用することで、モデルを効率的にスケーリングすることができます.CodeT5+のモデルコンポーネントは、異なるダウンストリームアプリケーションタスクに合わせて動的に組み合わせることができます.CodeT5+の事前学習目的の混合には、スパンデノイジング、コントラスティブラーニング、テキストコードマッチング、因果LM事前学習タスクが含まれます.これらの目的は、単一言語および多言語のコードコーパスで実行されます.また、CodeT5+の個々のモジュールは、ゼロショット、ファインチューニング、インストラクションチューニングの設定で、異なるダウンストリームアプリケーションに柔軟に取り付けられます.(p.4-5)
Q: CodeT5で使用されているさまざまな事前トレーニングの目的と、その実行方法を教えてください.
A: CodeT5+では、複数のpretraining objectivesを同等の重みで最適化することで、各ステージで効率的にモデルを学習します(Sec. 3.2).第1段階では、大量のコードデータを用いて計算効率の高い目的でモデルをpretrainし、第2段階では、少量のコード-テキストデータを用いて、クロスモーダル学習目的でモデルをpretrainします.また、CodeT5+は、オフシェルフのコードLLMsを使用してモデルをスケーリングすることもできます(Sec. 3.3).最後に、CodeT5+のモデルコンポーネントは、異なるダウンストリームアプリケーションタスクに合わせて動的に組み合わせることができます(Sec. 3.4). (p.3-5)
Q: CodeT5では、異なるダウンストリームアプリケーションのために、モデルコンポーネントをダイナミックに組み合わせることができますが、どのように実現されているのでしょうか?
A: CodeT5+は、私たちが提案した様々な事前学習タスクによって、コードデータとテキストコードの対比学習、マッチング、スパンノイズ除去、因果言語モデリング(CLM)などの多様な事前学習目的を組み合わせることで、異なる下流タスクに対応するための柔軟性を持っています.CodeT5+は、エンコーダーのみ、デコーダーのみ、エンコーダーデコーダーモードで柔軟に動作することができ、個々のモジュールは、ゼロショット、ファインチューニング、インストラクションチューニングの設定で異なる下流アプリケーションに適応することができます.(p.1)
Q: CodeT5では、どのようにして下流のコードタスクに柔軟性を持たせているのでしょうか?
A: CodeT5+は、提案された事前学習タスクによって、コードデータとテキストコードの対比学習、マッチング、スパンノイズ除去、因果言語モデリング(CLM)タスクを含め、エンコーダーのみ、デコーダーのみ、エンコーダーデコーダーモードで柔軟に動作できるようになっています.このような柔軟性により、CodeT5+は、コード生成、要約などのSeq2Seq生成タスクに自然に適応できます.また、エンコーダーを使用してコードスニペットを検索し、エンコーダーとデコーダーの両方でコード生成に使用することで、検索支援生成モデルとしても適応できます.(p.1,4-8)
Q: コードとテキストコードの対比学習、マッチング、スパンノイズ除去、因果関係言語モデリングについて、CodeT5は具体的にどのようなタスクを実行できるのか.
A: CodeT5+は、コードとテキストコードのコントラスト学習、マッチング、スパンノイズ除去、因果言語モデリングの特定のタスクを実行できます.これらのタスクは、コード補完や数学プログラミングタスクにおいて因果LM目的が重要であること、テキストコードマッチング目的が検索パフォーマンスに重要であること、そしてスパンノイズ除去と因果言語モデリングのタスクがコードデータに対して実行されることを含みます.また、CodeT5+は、エンコーダーのみ、デコーダーのみ、エンコーダーデコーダーモードで柔軟に動作し、テキストコードの検出タスクや検索タスクにおいて、エンコーダーを使用してテキスト/コードの埋め込みを取得し、デコーダーと組み合わせてテキストコードマッチングスコアを予測することができます.これらのタスクは、CodeT5+の広範なコード理解および生成タスクの基盤を形成します.(p.2)
Q: CodeT5の初期化、スケールアップを効率的に行うには?
A: CodeT5+は、オフシェルフのコードLLMを使用して初期化され、モデルのコンポーネントを効率的にスケーリングアップします.具体的には、「浅いエンコーダーと深いデコーダー」アーキテクチャ[L i et al.、2022b]を採用し、エンコーダーとデコーダーの両方が事前学習済みのチェックポイントから初期化され、クロスアテンションで接続されます.これにより、より大きなモデルサイズを効率的に扱うことができます(p.4).
Q: CodeT5モデルは、コード領域でのタスク精度を向上させるために、どのようにInstruction Tuningを適用するのですか?
A: CodeT5+モデルは、タスクの精度を改善するためにInstruction Tuningを適用します.これは、事前学習済みのLLMsが新しいタスク指示、入力(ある場合)、および期待される出力を生成することによって生成された20,000以上のコードドメインの指示データを使用して、モデルをトレーニングすることを意味します.この拡張データセットでモデルをトレーニングし、最大3エポックまで実行し、instruction-tunedモデルを「InstructCodeT5+」として示します.Instructionデータは、下流の評価タスクとは完全に独立して生成されるため、ゼロショットの方法でinstruction-tunedモデルを評価します.InstructionデータはLMによって生成されるため、期待される出力の注釈を含め、すべてのデータが完全に正確であるわけではありません.しかし、Wangらはこれらの例をデータノイズとして扱い、チューニングされたモデルは、合成指示データの大部分から利益を得ることができると述べています.(p.1)
Q: CodeT5が最先端の性能を発揮したコード関連タスクには、どのようなものがあるのでしょうか.
A: CodeT5+は、20以上のコード関連のベンチマークで、ゼロショット、ファインチューニング、指示チューニングなどのさまざまな設定で評価されました.その結果、CodeT5+は、多くのダウンストリームタスクにおいて、SoTAベースラインに比べて大幅なパフォーマンス向上をもたらしました.たとえば、8つのテキストからコードを検索するタスク(+3.2平均MRR)、2つの行レベルのコード補完タスク(+2.1平均正確一致)、2つの数学プログラミングタスクなどがあります.CodeT5+は、自己サンプリング最適化[Ni et al.、2022]や多数決[Lewkowycz et al.、2022]などの生成戦略で改良された以前のアプローチのいくつかもあります.
表3は、CodeT5+が、はるかに大きなサイズの多くのコードLLMを上回る、有意なパフォーマンス向上を達成し、新しいSoTA結果である87.4%のトップ1検索されたコードを達成したことを示しています.全体的に、CodeT5+は、トップ10の検索を使用する以前のSoTAベースラインを上回り、トップ1の検索のみでも、多くの場合において優れたパフォーマンスを発揮します.
Q: CodeT5がこれまでのSoTAのベースラインを上回った具体的なタスク(8テキストからコードを検索するタスクや2行レベルのコード補完タスクなど)について、より詳しく説明してください.
A: CodeT5+は、20以上のコード関連ベンチマークで、ゼロショット、ファインチューニング、インストラクションチューニングなどの様々な設定で評価されました.その結果、CodeT5+は、多くのダウンストリームタスクにおいて、SoTAベースラインに比べて大幅な性能向上を示しました.例えば、8つのテキストからコードを検索するタスク(平均MRR +3.2)、2つの行レベルのコード補完タスク(平均正解率+2.1)、そして欠陥検出タスク(正解率66.7%)などがあります.これらのタスクにおいて、CodeT5+は、トップ10の検索を使用する従来のSoTAベースラインよりも、トップ1の検索でも有意に優れた結果を示しました.これらの結果は、p.23から引用されています.
MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers
著者:Lili Yu, Dániel Simig, Colin Flaherty, Armen Aghajanyan, Luke Zettlemoyer, Mike Lewis
発行日:2023年05月12日
最終更新日:2023年05月19日
URL:http://arxiv.org/pdf/2305.07185v2
カテゴリ:Machine Learning
概要:
「MEGABYTE」というマルチスケールデコーダーアーキテクチャを提案し、一百万バイト以上のシーケンスをエンドツーエンドで微分可能にモデリングすることが可能になりました.これは、高解像度の画像、ポッドキャスト、コード、または書籍など、長いシーケンスに拡張が困難だった「Autoregressive transformers」モデルに取って代わるものとして機能するアルゴリズムで、 パッチにシーケンスを分割して、パッチ内のローカルサブモデルとパッチ間のグローバルモデルを使用することで、サブ二乗セルフアテンション、同じコンピュートでより大きなフィードフォワード層、デコーディング中の改善された並列処理が実現可能になりました.MEGABYTEを用いることで、長い文脈の言語モデリングにおいてサブワードモデルと競合するようなモデルの性能が発揮され、ImageNetにおいて最先端の密度推定を実現し、生のファイルからオーディオをモデリングすることも可能になりました.これらの結果から、トークナイゼーションフリーの自己回帰シーケンスモデリングの拡張性が実証されました.
Q&A:
Q: MEGABYTEはどのように配列を分割し、パッチ内やパッチ間でどのようなモデルを使っているのでしょうか?
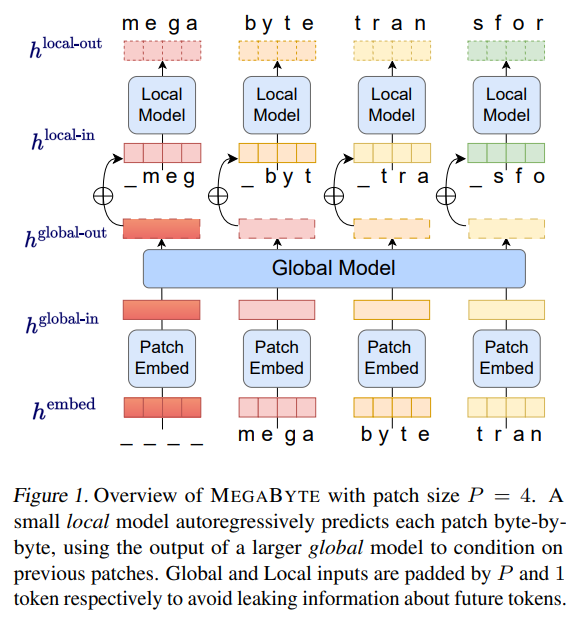
A: MEGABYTEは、シーケンスをパッチに分割し、パッチ内のローカルサブモデルとパッチ間のグローバルモデルを使用して構成されています.パッチ埋め込み器は、離散的なシーケンスを入力し、各要素を埋め込み、長さPのパッチに分割します.大規模なグローバルトランスフォーマーは、前のパッチに対して自己注意を実行してパッチ表現を文脈化し、より大きなフィードフォワード層を使用して、同じ計算に対して改善された並列処理を実現します.小さなローカルトランスフォーマーは、パッチ内の局所的な関係をモデル化します.これにより、MEGABYTEは、\( O(N^{\frac{3}{4}}) \)の自己注意コストを削減し、1百万バイト以上のシーケンスをエンドツーエンドで微分可能なモデリングすることができます.(p.5-6)
Q: MEGABYTEはどのようにして自己アテンションコストを\( O(N^{\frac{3}{4}}) \)に抑えているのですか?
A: 自己注意の二次コストを軽減するために、MEGABYTEは長いシーケンスを2つの短いシーケンスに分解し、最適なパッチサイズによって自己注意コストを\( O(N^{\frac{3}{4}}) \)に削減します.これは、長いシーケンスでも扱いやすくなります.(p.1)
Q: MEGABYTEが微分可能なモデリングでエンドツーエンドでモデリングできるシーケンスの最大サイズは?
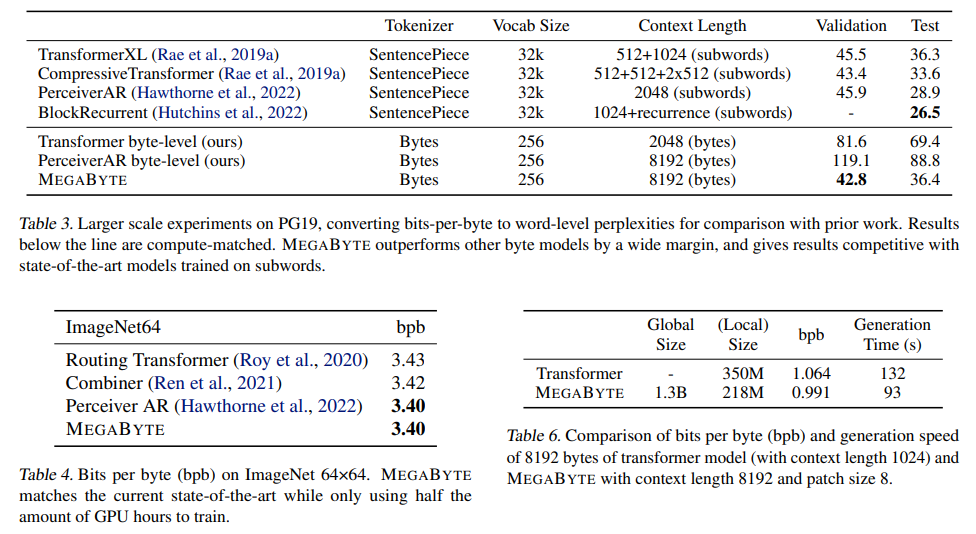
A: MEGABYTEは、異なるシーケンス長さに対して単一のフォワードパスでモデル化できます.ただし、標準のTransformerやPerceiverARでは、1.2Mトークンを超える長いシーケンスを適切なモデルサイズでモデル化することができませんでした.したがって、MEGABYTEは、1.2Mトークンまでのシーケンスをエンドツーエンドでモデル化できます.
Q: MEGABYTEがTransformerと比較して、ロングシーケンスモデリングにおいて、特にセルフアテンション、フィードフォワード層、デコード時のパラレルプロセッシングの3つの主要な改善点は何ですか?
A: MEGABYTEは、長いシーケンスモデリングにおいて、Transformerに比べて3つの主要な改善点を提供します.1つ目は、自己注意における二次コストを軽減することで、長いシーケンスを2つの短いシーケンスに分解し、最適なパッチサイズにより自己注意コストを\( O(N^{\frac{3}{4}}) \)に減らします.2つ目は、パッチごとのフィードフォワード層を持ち、3つ目は、デコーディング時の並列処理です.これらの改善点により、MEGABYTEは、トークナイゼーションフリーの自己回帰シーケンスモデリングをスケールアップすることが可能であり、長いコンテキストの言語モデリング、ImageNet上の密度推定、生のオーディオファイルからの音声モデリングにおいて、最先端のパフォーマンスを達成しています.(p.1)
Q: MEGABYTEの性能を検証するために、どのような実験が行われたのでしょうか?
A: MEGABYTEの性能をテストするために、多数の実験が実施されました.(p.1) これらの実験では、MEGABYTEがバイトレベルのモデルを使用して、競争力のある性能を発揮することが示されました.また、他のシステムと比較して、MEGABYTEが優れた性能を発揮することも確認されました.(p.1) さらに、MEGABYTEは、長い依存関係を持つデータセットにおいて、言語モデリングの性能も評価されました.(p.5) これらの実験では、MEGABYTEが他のモデルよりも優れた性能を発揮することが示されました.(p.5) また、実験では、MEGABYTEのパッチサイズやモデルサイズなどの詳細な設定も報告されています.(p.1)
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
著者:Ronen Eldan, Yuanzhi Li
発行日:2023年05月12日
最終更新日:2023年05月12日
URL:http://arxiv.org/pdf/2305.07759v1
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning
概要:
この研究では、GPT-3.5およびGPT-4によって生成された、通常の3〜4歳の子供が理解できる単語のみを含む短編小説の合成データセットTinyStoriesを紹介します.TinyStoriesを使用することで、state-of-the-artモデル(合計パラメータが10万未満の場合)よりもはるかに小さなLMsを訓練および評価することができます.また、1つのトランスフォーマーブロックのみを持つより単純なアーキテクチャを持つことができ、それでも流暢で一貫性があり、複数の段落を持ち、多様で文法がほぼ完璧で、推論能力を示すストーリーを生成することができます.さらに、この研究では、GPT-4を用いて、LMの出力を生徒が書いた物語としてグレードするフレームワークを提案することで、従来のベンチマークの問題を克服し、文法、創造性、一貫性などの異なる能力に対するスコアを提供するとしています.この新しい評価基準は、LMの開発、分析、研究を促進し、特にリソースの限られたあるいは特別な分野において有用であると期待されます.さらに、この研究は、LMにおける言語能力の出現についても示唆しています.
Q&A:
Q: 言語モデル(LM)とは何か、自然言語処理で何に使われるのか?
A: 自然言語処理において、生成言語モデル(LMs)は、テキスト要約、対話生成、ストーリーの完成など、さまざまなタスクで印象的な結果を出しています.しかし、これらのモデルのほとんどは非常に大きく、数億または数十億のパラメータを持っており、トレーニング、推論、展開に重大な課題を提供しています.これらのモデルの多くは、大規模なコーパスでの広範な事前トレーニングにもかかわらず、数語を超える明確で一貫した文を生成することができません.生成言語モデルには、LAMBADA、CLOZE、TriviaQA、Winograd Schema Challengeなどの既存のベンチマークがありますが、これらはモデルが回答として単語または短いフレーズを生成することを要求するため、自然言語の「話す」と「理解する」能力を測定するには不十分です. (p.1,4-8)
Q: これらのモデルは、パラメータ数が多いため、学習、推論、展開にどのような課題があるのでしょうか.
A: 大規模言語モデルのトレーニング、推論、展開には、多数のパラメータが必要であるため、重要な課題があります.例えば、GPT-3は1750億のパラメータを持ち、トレーニングには数百ペタオプスの計算が必要です.一方、GPT-2 smallは1億2500万のパラメータしか持たず、大規模なコーパスでの事前トレーニングにもかかわらず、数語を超える明確で一貫した文を生成することができません.これらの課題を解決するために、知識蒸留、プルーニング、量子化などの方法が提案されていますが、GPTのような自己回帰言語生成モデルに対しては、BERTのようなマスク言語モデルよりも効果が低いことが報告されています.また、GPTのようなモデルの評価は、BERTのようなモデルとは異なり、ラベル付きデータを用いた下流タスクで微調整して評価することができないため、より困難です. (p.1)
Q: なぜLMは小さい時に首尾一貫した流暢な文章を作るのに苦労するのでしょうか?
A: 小さな言語モデル(SLM)は、性能や機能において非常に限定されており、特にテキスト生成のタスクにおいては、流暢で一貫性のあるテキストを生成することが困難であるため、LMsは一貫性のある流暢なテキストを生成するのに苦労しています.例えば、GPT-Neo(small)やGPT-2(small)などの約125Mのパラメータを持つモデルは、Pile [9]、Common Crawl [1]、またはCC-100 [31]などの大規模なコーパスでの広範なトレーニングの後でも、数語を超える一貫したテキストを生成することができず、不明瞭で繰り返しの多い、意味のない文を生成し、段落をまたいで明確なトピックや論理的な構造を維持することができません.これは、流暢な英語を話す能力が大規模なモデル(数億のパラメータ以上)と複雑なアーキテクチャ(多数のグローバルアテンション層を持つ)でのみ発生するかどうかという問題を提起しています.(p.1)
Q: GPT-Neo(小)やGPT-2(小)のようなモデルのサイズと、首尾一貫した英文を生成する上での限界は?
A: GPT-Neo (small)やGPT-2 (small)のようなモデルは、約125Mのパラメータを持ち、大規模なコーパス(Pile、Common Crawl、CC-100など)での広範なトレーニングにもかかわらず、数語を超える明確で一貫した英文テキストを生成することはほとんどできないという制限があることが、TinyStoriesの論文(p.1)で述べられています.これらの小さな言語モデル(SLMs)は、テキスト生成タスクにおいて非常に限られた性能と能力しか持っておらず、しばしば不明瞭で繰り返しの多い、意味のない文を生成し、段落をまたいで明確なトピックや論理的な構造を維持することができません(p.1).これは、明確で一貫した英文を生成する能力の出現が、数億のパラメータ以上の大規模なモデルと、多数のグローバルアテンション層を持つ複雑なアーキテクチャにのみ発生する可能性があるという疑問を提起しています(p.1).
Q: TinyStoriesとはどのようなもので、どのように生成されたのでしょうか?
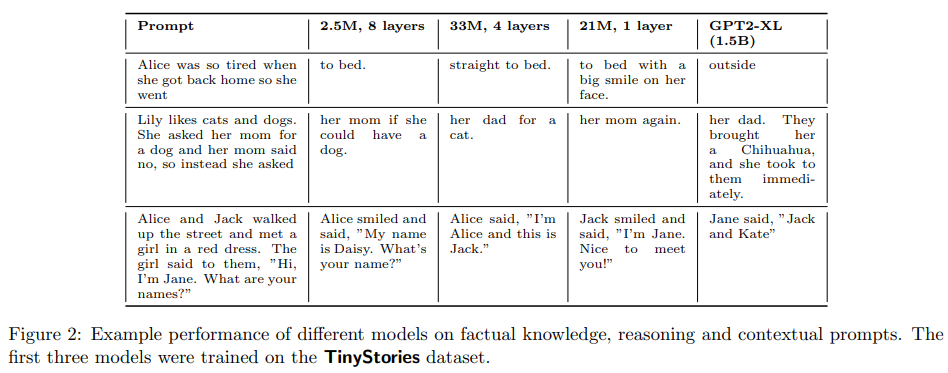
A: TinyStoriesは、3〜4歳の典型的な子供が理解できる単語だけを含む短編小説の合成データセットであり、GPT-3.5とGPT-4によって生成されました.このデータセットは、自然言語に存在する文法、語彙、事実、推論などの質的要素を組み合わせ、同時に内容がより制限され、多様性が少なく、小さくなるように設計されています.このデータセットは、大量の合成コンテンツを生成できる最新のテキスト生成モデルであるOpenAIのGPT-3.5とGPT-4を使用して生成されました.具体的には、典型的な3歳児が理解できる語彙だけを使用するようにモデルに指示し、英語の短編小説の形式に制限しました.このデータセットは、2〜3段落からなる単純なプロットと一貫したテーマに従うストーリーで構成されており、全体的には3〜4歳の子供の語彙と事実知識を網羅するように設計されています.このデータセットを使用して、本論文では、state-of-the-artモデルよりもはるかに小さいSLMsを訓練および評価できることを示しました. (p.1)
Q: TinyStoriesデータセットは、学習や評価の面で他の最先端モデルと比較してどうでしょうか?
A: TinyStoriesは、最新のモデルよりも orders of magnitude 小さい言語モデルを訓練および評価できるデータセットである.このデータセットを使用することで、基本的な文書生成能力を持つ言語モデルを訓練および評価できる.本研究では、TinyStoriesをテストベッドとして使用し、アーキテクチャとパフォーマンスの探索に向けた最初のステップを踏み出した.小さなモデルでも、LLMの観察されたパターンに類似したものがあることを示した.特に、モデルサイズと学習予算のバランス、および与えられたモデル幅と深さに対するアテンションヘッドの数の選択について調査した.一定量のトレーニングFLOPsに対するモデルサイズとトレーニングステップ数のトレードオフがあることが示された.以前の研究では、LLMにおいてモデルサイズと学習予算の間に多項式スケーリング則があることが示されている.TinyStoriesは、GPT-3.5およびGPT-4によって生成された、典型的な3〜4歳児が理解できる単語のみを含む短編小説の合成データセットである.TinyStoriesは、10百万以下の言語モデルを訓練および評価するために使用できることが示された.(p.1-2)
Q: モデルの幅と深さが決まっている場合、アテンションヘッドの数はどのように選択するのですか?
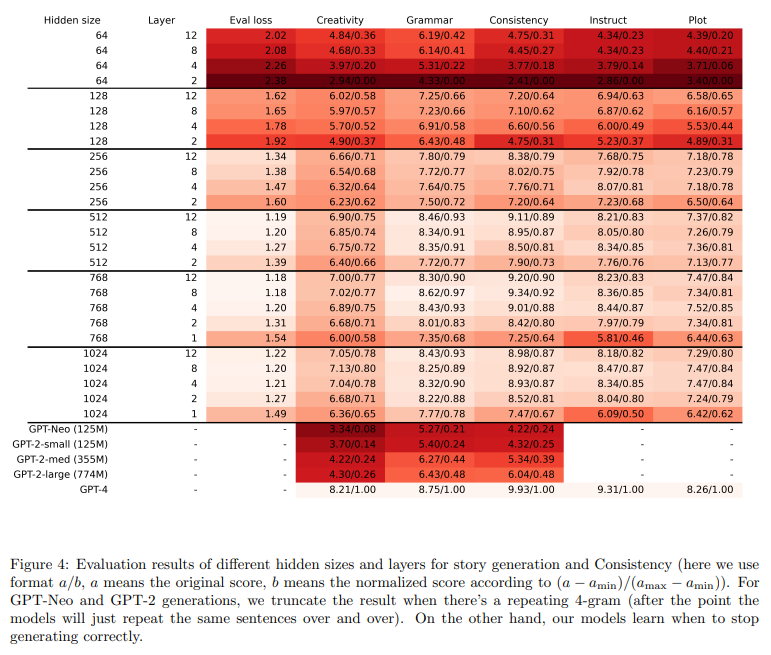
A: モデルの幅と深さが固定された場合、注意ヘッドの数がモデルの性能にどのように影響するかは明らかではありません.しかし、図24に示される結果から、注意ヘッドの数が少ない場合には、それを増やすことですべてのメトリックにおいてモデルの性能が向上することが示唆されています.具体的には、小さなモデルにおいては、注意ヘッドの数を増やすことで、評価損失、文法、創造性、一貫性のすべての面で性能が向上することが観察されました.これは、注意機構がより多くの情報を処理することができるため、モデルがより複雑な関係性を学習できるようになるためです.
Q: 言語モデルの評価のための新しいパラダイムとは何か、そして標準的なベンチマークの欠点をどのように克服するのか.
A: 新しい言語モデルの評価方法は、GPT-4を使用して、人間の教師が評価する学生の作文のように、これらのモデルによって生成されたコンテンツを評価することです.この新しい方法は、標準的なベンチマークの欠点を克服しています.従来の評価方法は、モデルの出力が与えられた答えと一致する必要があるタスクの形式の構造化された評価データセットに依存していましたが、新しい方法は、既存の大規模な言語モデルを活用して、より自然な言語を話し理解する能力を評価することができます.これにより、言語モデルの豊かさや多様性を捉えることができます.(p.1)
Q: 従来の言語モデルの評価手法の限界は?
A: 従来の言語モデルの評価方法の限界は、LAMBADA [22]、CLOZE [29]、TriviaQA [15]、Winograd Schema Challenge [17]などの既存のベンチマークが、モデルが回答として単語または短いフレーズを生成することを要求するため、自然言語を話し理解する能力を評価することができないことです.(p.1)
小規模な言語モデル(SLMs)は、テキスト生成タスクにおいて特に性能と能力に制限があります.たとえば、GPT-Neo (small)やGPT-2 (small)などの約125Mのパラメータを持つモデルは、Pile [9]、Common Crawl [1]、またはCC-100 [31]などの大規模なコーパスでの広範なトレーニングの後でも、数語を超える一貫したテキストをほとんど生成できません.これらのモデルは、不明瞭で繰り返しの多い、意味のない文を生成し、段落全体で明確なトピックや論理的な構造を維持できません.
従って、一貫したテキストを生成するためには、かなり大規模なスケールが必要であることが示唆されています.従来の評価方法の限界を克服するためには、より細かい分析が可能なデータセットと評価パラダイムが必要です.(p.1)
Q: 新しい評価方法は、従来の評価方法の限界をどのように克服しているのでしょうか.
A: 従来の評価方法の限界を克服するために、新しい評価方法は、既存の大規模言語モデルを利用して、学生が書いた物語を教師が評価するように、GPT-4を使用して言語モデルの生成されたコンテンツを評価する新しいパラダイムを導入しました.この新しいパラダイムは、モデルの出力が非常に正確であることを要求する従来のベンチマークの欠点を克服します.これにより、より細かい評価が可能になり、モデルのサイズやアーキテクチャによる異なる能力の依存関係についての結論を導くことができます.(p.3-5)
Q: TinyStoriesは、特に低リソースや専門的な領域のLMの開発、分析、研究にどのような影響を与える可能性があるか?
A: TinyStoriesは、低リソースまたは専門分野に特化したLMの開発、分析、および研究を促進することが期待されます.この研究において、TinyStoriesを使用することで、モデルとデータセットの両方のサイズに関して、より小規模なスケールで、LMの言語能力の出現を観察し、研究することができます.また、TinyStoriesで訓練されたモデルは、大きなモデルよりも解釈性が高く、注意力と活性化パターンを視覚化して分析することで、ストーリーの生成と理解の方法を理解することができます.これにより、TinyStoriesは、より小さなスケールで、より基本的な能力を持つLMを訓練および評価することができるため、LMのアーキテクチャやパフォーマンスの探索のためのテストベッドとしての可能性があります.
Q: TinyStoriesを用いたモデルのトレーニングは、物語の生成と理解の理解にどのようにつながるのか、また、注意や活性化のパターンを分析するために、具体的にどのような可視化技術を用いることができるのか.
A: TinyStoriesを用いたモデルのトレーニングにより、より小さなモデルでも高い解釈性が得られ、その注意力や活性化パターンを視覚化・分析することで、ストーリーの生成と理解の仕組みをより理解することができます.(p.3-5) また、TinyStoriesによってトレーニングされたモデルが、データセットのテキストの断片を単にコピーするのではなく、本当に新しいストーリーを生成できることが示されました.ただし、これらのモデルの「創造性」の真の範囲を評価することは依然として課題であり、生成されたストーリーが単なるテンプレートマッチングによるものであるのか、ある程度の「理解」(非常に低いレベルで)を反映しているのかを評価することが必要です.このデータセットを用いて、言語モデルの創造性の程度について洞察を得ることができることを期待しています.
