
今回のテーマ:StarCoder, TidyBot, MultiModal-GPT, InstructBLIPなど。
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をQ&A形式を用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.
紹介する論文は以下の7本となります.
- InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning (発行日:2023年05月11日)
- Active Retrieval Augmented Generation (発行日:2023年05月11日)
- TidyBot: Personalized Robot Assistance with Large Language Models (発行日:2023年05月09日)
- FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance (発行日:2023年05月09日)
- StarCoder: may the source be with you! (発行日:2023年05月09日)
- MultiModal-GPT: A Vision and Language Model for Dialogue with Humans (発行日:2023年05月08日)
- Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting (発行日:2023年05月07日)
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
著者:Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi
発行日:2023年05月11日
最終更新日:2023年05月11日
URL:http://arxiv.org/pdf/2305.06500v1
カテゴリ:Computer Vision and Pattern Recognition, Machine Learning
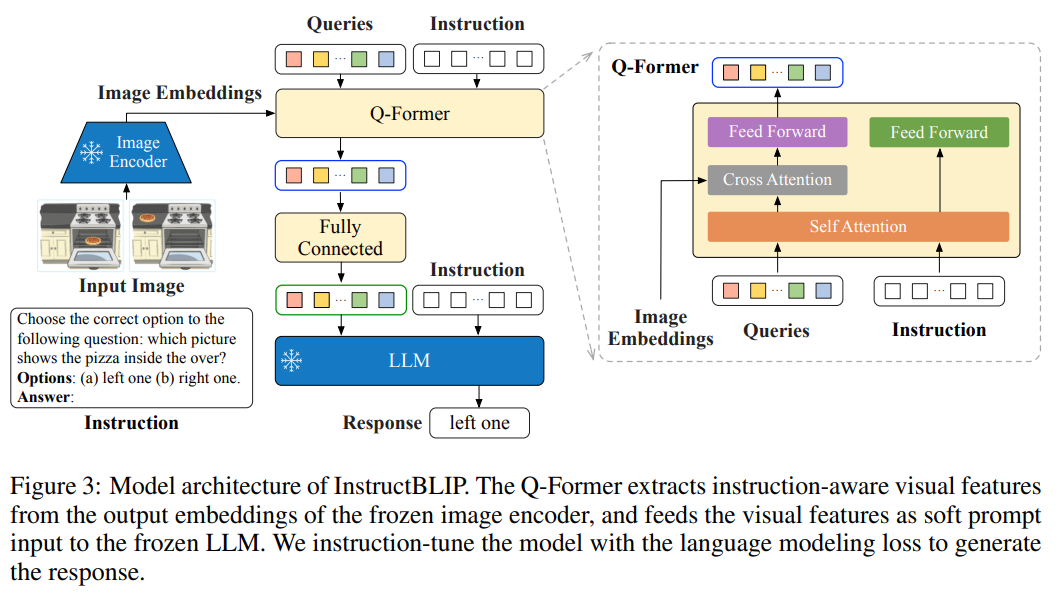
概要:
一般的な言語モデルは、事前学習と調整パイプラインによって駆動され、多様な言語ドメインのタスクを解決できるようになってきている.しかし、視覚入力が追加されたために導入されるタスクの不一致化により、一般的なビジョン-言語モデルを構築することは困難である.そこで本論文では、26の公開データセットを収集し、調整形式に変換して、ヘルド・イン・インストラクション・チューニングとヘルド・アウト・ゼロ・ショット・評価の2つのクラスターに分類することで、視覚言語の調整について体系的かつ包括的に研究を行い、指示に敏感な視覚フィーチャー抽出を導入した事前学習モデル”InstructBLIP”を開発しました.InstructBLIPモデルは、13のヘルド・アウト・データセット全てで最新のゼロ・ショット性能を発揮し、BLIP-2およびより大きなモデルを大幅に上回るだけでなく、ScienceQA IMGなどの特定のタスクでも90.7%の精度を達成し、同様のマルチモーダルモデルよりも優れた性能を発揮することを示しました.加えて、InstructBLIPモデルはすべてオープンソースであり、https://github.com/salesforce/LAVIS/tree/main/projects/instructblip から入手可能です.
Q&A:
Q: 汎用的な視覚言語モデルを構築する上での主な課題は何でしょうか?
A: 一般的な言語モデルは、事前学習と指示調整パイプラインによって駆動され、さまざまな言語ドメインのタスクを解決できるようになっています.しかし、一般的なビジョン言語モデルを構築することは、追加の視覚的入力によって導入されるタスクの不一致の増加により、困難です.視覚言語タスクは、さまざまなドメインからの追加の視覚的入力により、より多様な性質を持っているため、統一されたモデルを構築することがより困難になっています.(p.1)
Q: 多様な領域の視覚言語タスクに対して統一的なモデルを構築しようとした場合、どのような課題が生じるのか.
A: 異なるドメインからの視覚的入力が追加されることによって導入されるタスクの不一致により、視覚言語タスクの一般的なモデルを構築することは困難です.これにより、タスク間の不一致を適切に橋渡しすることができないマルチタスクトレーニングは失敗する可能性があります.一方、テキストのみの指示に調整されたLLMは、NLPタスクのゼロショット汎化に対してより効果的ですが、視覚言語タスクに対しては満足できる性能を示しません.これらの課題を解決するために、本論文では、InstructBLIPという視覚言語指示調整フレームワークを提案しています.これにより、自然言語インターフェースを介して一般的なモデルが幅広い視覚タスクを解決できるようになります.(p.1)
Q: 視覚言語モデルにおけるプリトレーニングとインストラクションチューニングの違いは何ですか?
A: 事前学習は、モデルが様々なタスクを解決するために必要な一般的な知識を獲得するために行われます.一方、指示調整は、特定のタスクに適応するために、モデルが指示に従って調整されるプロセスです.本論文では、事前学習済みのBLIP-2モデルをベースに、視覚言語指示調整に関する包括的な研究を行いました.26種類の公開データセットを収集し、指示調整フォーマットに変換して、保持内指示調整と保持外ゼロショット評価の2つのクラスターに分類しました.また、指示に合わせた視覚特徴抽出を導入し、モデルが与えられた指示に合わせた情報を抽出できるようにしました.
Q: InstructBLIPは、既存のモデルと比較して、未知のタスクに対してどのように強いパフォーマンスと汎用性を提供するのか?
A: InstructBLIPは、多様なinstruction tuningデータと効果的なアーキテクチャ設計により、強力なパフォーマンスと汎用性を提供します.InstructBLIPの出力は、適切な視覚的詳細を含み、論理的に整合性のある推論ステップを示します.また、InstructBLIPは、応答長を適応的に調整することで、ユーザーの意図に直接対応することができます.これにより、InstructBLIPは、既存のモデルに比べて未知のタスクに対してより強力なパフォーマンスと汎用性を提供します.さらに、InstructBLIPは、他のマルチモーダルモデルに比べて優れた性能を示し、すべてのモデルがオープンソースであることが特徴です.(p.1,7,9)
Q: 視覚言語指導のチューニングに関する研究では、どのようなデータセットが使われたのでしょうか?
A: 本研究では、公開されている様々なデータセットをinstruction tuning形式に変換し、26のデータセットを収集しました.これらのデータセットは、11のタスクカテゴリーに分類され、held-in instruction tuningとheld-out zero-shot evaluationの2つのクラスターに分けられています.また、instruction-aware visual feature extractionという重要な手法を導入し、モデルが与えられた指示に合わせて情報を抽出できるようにしました. (p.1)
Q: 本研究で紹介されているインストラクションアウェアな視覚特徴抽出技術とはどのようなもので、どのような効果があるのか.
A: 本研究で導入されたinstruction-aware visual feature extraction技術は、BLIP-2モデルのQ-Formerアーキテクチャを最大限に活用することで、命令に応じた視覚的特徴抽出を可能にする手法である.具体的には、視覚的入力が命令に気づかないinstruction-agnosticアプローチではなく、命令に気づくinstruction-awareアプローチを採用することで、モデルの柔軟性を向上させ、異なる命令から学習し、それに従う能力を高める.例えば、同じ画像が与えられた場合、モデルは2つの異なるタスクを完了するよう指示されることがあり、instruction-aware vision modelは、異なるタスクを解決するために同じ画像から異なる特徴を抽出することができ、より情報量の多い特徴を提供することができる.また、異なる画像が与えられた場合、instruction-aware vision modelは、命令に組み込まれた共通の知識を利用して、2つの異なる画像の特徴を抽出し、画像間のより良い知識転移を可能にすることができる.この手法により、InstructBLIPは、ゼロショット評価において高い効果を発揮することが示された.(p.3-5)
Q: 収集した26のデータセットを分類するために使用された11のタスクカテゴリについて、より詳しく教えてください.
A: 収集された28のデータセットを指示調整形式に変換することで、指示調整データの多様性を確保し、アクセシビリティを考慮して、公開されている幅広いビジョン・ランゲージ・データセットを収集しました.図2に示されるように、最終的なコレクションには、画像キャプション[23,3,50]、読解付き画像キャプション[37]、視覚的推論[16,24,28]、画像質問応答[11,12]、知識に基づく画像質問応答[29,35,27]、読解付き画像質問応答[30,38]、画像質問生成(QAデータセットから逆転)、ビデオ質問応答[46,48]、視覚的対話型質問応答[8]、画像分類[18]、LLaV A-Instruct-150K[25]を含みます.各データセットの詳細な説明と統計情報は、付録Cに記載されています.これらのタスクに対して、自然言語で10から15の異なる指示テンプレートを細心の注意を払って作成し、指示調整データの基盤として使用しました.公開データセットは短い応答を好む傾向があるため、対応する指示テンプレートのいくつかに「短く」「簡潔に」といった用語を使用して、モデルが常に短い出力を生成することを防ぐようにしました.LLaV A-Instruct-150Kデータセットについては、自然に指示形式で構成されているため、追加の指示テンプレートを組み込んでいません.指示テンプレートの完全なリストは、付録Dに記載されています.
Q: InstructBLIPの性能は、BLIP-2やFlamingoなど他のモデルと比較してどうでしょうか?
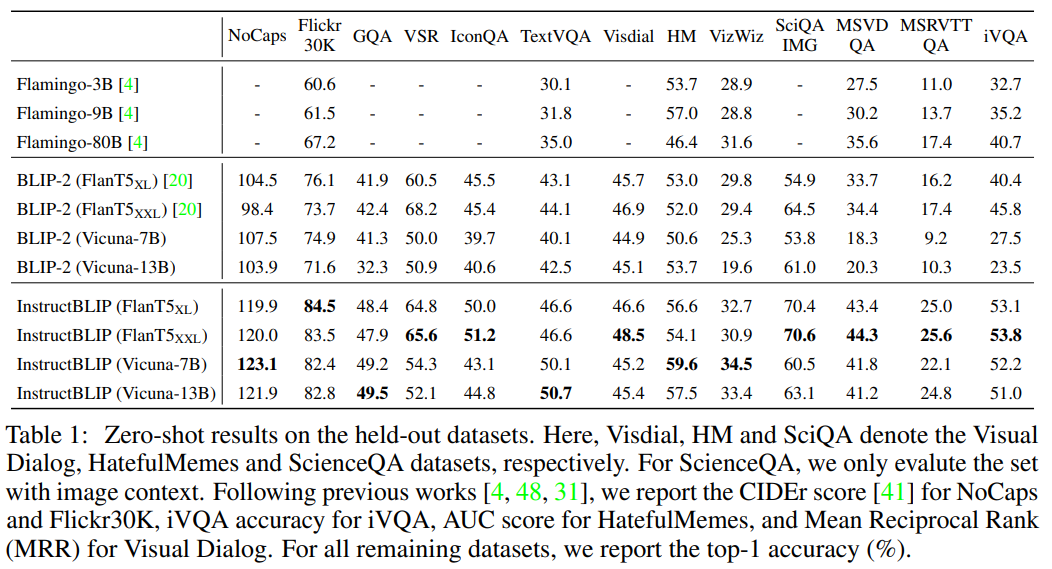
A: InstructBLIPは、BLIP-2やFlamingoなどの他のモデルに比べて、すべての13の保持されたデータセットで最新のゼロショットパフォーマンスを発揮し、大幅に優れています.さらに、個々のダウンストリームタスクでの最新のパフォーマンスを発揮し、他のマルチモーダルモデルよりも優れていることが定量的に示されています.これらの情報は、(p.1)から抽出されました.
Q: 2.個々の下流タスクにおいて、InstructBLIPが他のマルチモーダルモデルをどのように凌駕しているのか、より詳しい情報を教えてください.
A: InstructBLIPは、個々のダウンストリームタスクで最先端のパフォーマンスを発揮し、他のマルチモーダルモデルを圧倒しています.特に、ScienceQA IMGの場合、90.7%の精度を達成しています.InstructBLIPは、多様なタスクに対して高い汎化能力を持つため、ダウンストリームタスクの改善に役立ちます.これは、InstructBLIPが、複数のタスクを同時に学習するマルチタスク学習よりも優れていることを示しています.これらの結果は、InstructBLIPが、多目的マルチモーダルAIおよびその応用に新しい研究を促すことができることを示唆しています.(p.9)
Q: 本稿で紹介した方法は、従来の方法と比較してどのような利点があるのでしょうか.
A: 本論文で紹介された方法の利点は、従来の方法と比較して、より広範な視覚タスクを解決することができることです.これは、InstructBLIPが、統一された自然言語インターフェースを介して、一般的な目的のモデルを可能にし、視覚言語タスクを解決することができるようにするためです.InstructBLIPは、事前に学習されたBLIP-2モデルから初期化され、画像エンコーダ、LLM、およびQ-Formerから構成されています.指示の調整中、画像エンコーダとLLMを凍結したまま、Q-Formerを微調整します.本論文は、視覚言語指示の調整のさまざまな側面について包括的な分析を提供し、InstructBLIPが未知のタスクに汎用的に適用できることを検証しています.(p.5)
Q: 今後の研究課題として、どのようなものが残されているのでしょうか.
A: 本研究の将来の課題は、さらに多様なビジョン・ランゲージタスクに対する汎化能力を向上させることです.これには、より多くのタスクとデータセットを含めることが含まれます.また、モデルとデータの両面から、より効果的な指示調整を実現するための新しい技術の開発も必要です.これにより、より高度なビジョン・ランゲージタスクに対する汎化能力が向上し、実世界の問題に対する解決策が提供される可能性があります.(p.2)
Active Retrieval Augmented Generation
著者:Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, Graham Neubig
発行日:2023年05月11日
最終更新日:2023年05月11日
URL:http://arxiv.org/pdf/2305.06983v1
カテゴリ:Computation and Language, Machine Learning
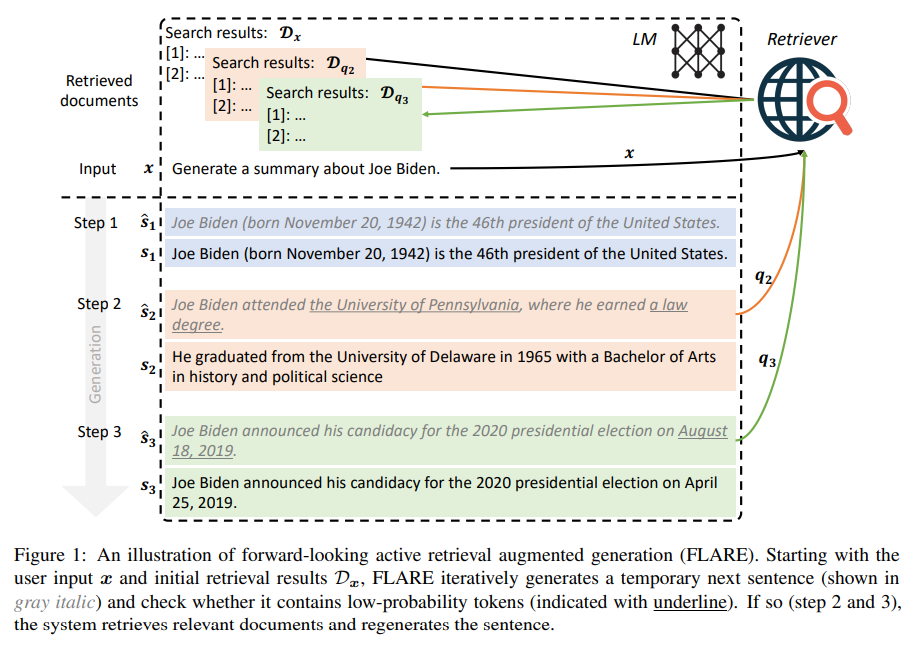
概要:
Upcoming Sentenceの予測を反復的に使用して将来のコンテンツを予測し、低信頼性のトークンが含まれている場合は関連するドキュメントを取得するクエリとして利用する、という手法を用いたリトリーバル増強生成方法であるForward-Looking Active Retriever Augmented Generation(FLARE)が提案されている.この方法は、長い文書を生成する4つの知識集約的なタスク/データセットにおいて、既存のベースライン手法と比較して優れた性能を示し、有効性を示している.また、この手法に関連するコードとデータセットはhttps://github.com/jzbjyb/FLAREから公開されている.
Q&A:
Q: 大規模な言語モデル(LM)の問題点は何か、どうすれば解決できるのか.
A: 大規模言語モデル(LMs)の問題は、多くのリソースを必要とすることです.これは、トレーニングに多くの時間と計算能力が必要であることを意味します.また、これらのモデルは、大量のデータを必要とするため、データの収集と整理にも多くのリソースが必要です.しかし、これらの問題は、few-shot学習と呼ばれる技術によって解決される可能性があります.few-shot学習は、少量のデータでモデルをトレーニングすることができる技術であり、これにより、大規模なデータセットを収集する必要がなくなります.また、few-shot学習は、モデルのトレーニングに必要な時間と計算能力を大幅に削減することができます.これにより、大規模言語モデルの問題を解決することができます.(p.1)
Q: 少数点学習とは何か、言語モデルに大量のデータとリソースが必要という問題をどのように解決するのか.
A: 少数のサンプルで学習するfew-shot learningは、大量のデータとリソースを必要とする従来の言語モデルの問題を解決します.これは、事前学習されたモデルを使用して、新しいタスクに対してわずかな数の例を提供することで実現されます.この方法により、モデルは新しいタスクに適応するために必要な情報を獲得し、高い精度で予測を行うことができます.これにより、大量のデータとリソースを必要とする従来の方法よりも効率的にタスクを解決することができます.(p.1,4-8)
Q: 既存の検索補強型LMの限界は?
A: 既存の検索補完言語モデルの制限は、入力に基づいて情報を一度だけ取得する「retrieve-and-generate」セットアップであることです.これは、より一般的なシナリオでは制限があります.これは、(p.1)によると、情報が不足している場合にのみ情報を取得するべきであり、不必要または不適切な検索を回避するためです.大規模な言語モデルは、よくキャリブレーションされており、低い確率/信頼度は知識不足を示す傾向があるため、この仮説は妥当です.
Q: 不要な検索や不適切な検索を避けるために、検索と生成のセットアップをどのように改善すればよいでしょうか?
A: 不必要な検索を避けるために、検索結果を事前に提示することで、未来の世代が意図する情報を反映した検索クエリを生成することが提案されている.また、検索クエリの過剰生成が回答生成に悪影響を与えることがあるため、必要以上の検索クエリを生成しないようにする方法が提案されている.(p.1,5,30)
Q: アウトプットを出しながら情報を複数回取得するために、これまでどのような工夫をされてきたのでしょうか.
A: 過去には、前の文脈をクエリとして固定間隔で文書を取得する方法が主に用いられていたが、これはLMが将来生成する内容を正確に反映していない可能性があるため、適切な時点での情報の取得ができない場合がある.また、多数の情報ニーズに対応するために、全体の質問をサブ質問に分解し、それぞれを使用して追加情報を取得する方法もある.しかし、本論文では、生成プロセス中に必要な情報が欠落している場合にのみ、LMが情報を取得することが望ましいという仮説を立て、アクティブな検索補助生成という新しいパラダイムを提唱している.(p.1-2)
Q: Forward-Looking Active Retrieval augmented generation(FLARE)とは何ですか?
A: FLAREは、文の生成過程で何を取り出すか、いつ取り出すかを積極的に決定する方法であり、予測される次の文を予測することで将来のコンテンツを予測し、低信頼度のトークンが含まれている場合に関連するドキュメントを取得するためのクエリとして使用する汎用的な取り出し増強生成方法です.FLAREは、4つの長い知識集約型生成タスク/データセット全体でベースラインとともに包括的にテストされ、すべてのタスクで優れたまたは競争力のあるパフォーマンスを発揮し、我々の方法の有効性を示しています.(p.1)
Q: FLAREがテストしたタスク/データセットの種類とそのパフォーマンス結果の例を教えてください.
A: FLAREは、多様な知識集約型タスクにおいて、少数のサンプルでのインコンテキスト学習による効果を評価されました.これらのタスクには、Multihop QA、Open-domain QA、Dialogue Response Generation、Text Generationが含まれます.FLAREは、すべてのタスク/データセットにおいて、ベースラインを上回る結果を示しました.これは、FLAREが新しいタスクにおいても汎用的な方法であることを示しています.(p.5, p.6, p.7)
Q: 5.FLAREはどのように未来のコンテンツを予測し、関連するドキュメントを検索しているのですか?
A: FLAREは、次の文を予測し、それをクエリとして使用して関連する文書を取得し、低確率のトークンを含む場合は文を再生成することで、将来のコンテンツを予測します.このように、FLAREは、文書の取得と生成を組み合わせることで、将来のコンテンツを予測し、関連する文書を取得します.これにより、FLAREは、文書の取得と生成を組み合わせることで、将来のコンテンツを予測し、関連する文書を取得します.FLAREは、図1に示すように、一時的な次の文を生成し、低確率のトークンを含む場合は関連する文書を取得し、次の文を再生成することを繰り返します.FLAREは、既存のLMに適用でき、追加のトレーニングなしで推論時に使用できます.(p.2-3)
Q: 知識集約型の生成タスク/データセットにおいて、FLAREはベースラインと比較してどのようなパフォーマンスを発揮するか?
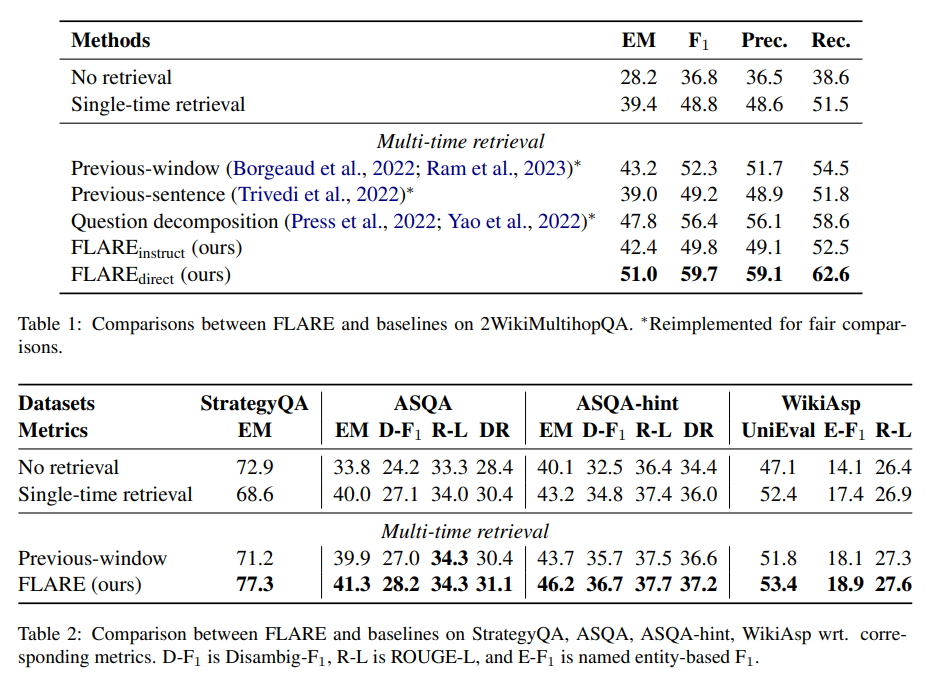
A: 知識集約型生成タスク/データセットにおいて、FLAREはベースラインよりも優れた性能を発揮しています.全タスク/データセットにおいてFLAREがベースラインを上回り、FLAREは生成中に追加情報を効果的に取得できる汎用的な手法であることを示しています.特に、多段階QAタスクにおいては、FLAREの改善が最も顕著であることが示されています.これは、このタスクが明確に定義され、2段階の推論プロセスを通じて最終的な答えを生成するという明確な目的があるため、LMがトピックに沿った出力を生成しやすいためです.一方、ASQAとWikiAspは定義が不明確であり、FLAREの改善が少ないことが示されています.これらのタスクでは、FLAREは低信頼度トークンを含む文を再生成するためにクエリとして利用される文書を取得することができます.FLAREは、4つの長い知識集約型生成タスク/データセットにおいて、ベースラインと総合的に比較して優れたまたは競争力のある性能を発揮し、我々の手法の有効性を示しています.(p.1,5,30)
TidyBot: Personalized Robot Assistance with Large Language Models
著者:Jimmy Wu, Rika Antonova, Adam Kan, Marion Lepert, Andy Zeng, Shuran Song, Jeannette Bohg, Szymon Rusinkiewicz, Thomas Funkhouser
発行日:2023年05月09日
最終更新日:2023年05月09日
URL:http://arxiv.org/pdf/2305.05658v1
カテゴリ:Robotics, Artificial Intelligence, Computation and Language, Computer Vision and Pattern Recognition, Machine Learning

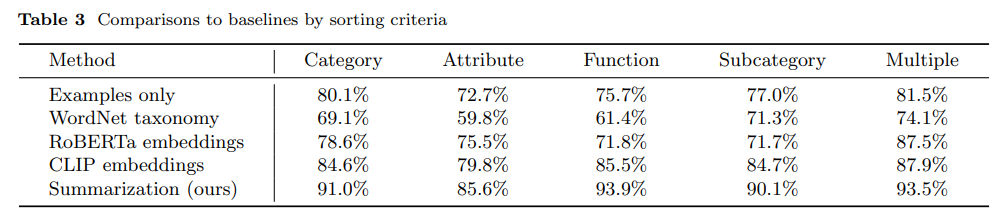
概要:
この論文では、部屋の片付けをするロボットのパーソナライズに焦点を当て、オブジェクトを拾って片付けることで部屋の清掃を行う方法について調査しました.私たちは、大規模言語モデル(LLM)の少数のサマリゼーション能力を組み合わせて、一般化されたユーザーの好みを推定することができることを示し、高速な適応が可能になったことを報告しています.さらに、実世界のモバイルマニピュレータであるTidyBotを用いたテストシナリオにおいて、85.0%のオブジェクト片付けの成功率を達成しています.
Q&A:
Q: この論文の主な焦点は何ですか?
A: 本文の主な焦点は、ロボット工学における一般化のための要約の有用性についての研究である.この研究では、広範なテキストデータから学習した強力な要約能力を活用することで、ロボットが部屋を整理するタスクを実行する際に、正しい受け皿(「proper place」)を決定することが困難であるという課題に取り組んでいる.このタスクは高度に個人的であり、文化的な規範や個人の好みに依存するため、正しい受け皿を決定することは困難である.本研究は、要約が一般化に有用であることを示す強力な証拠を提供しており、これは最近の研究とも一致している. (p.1-2)
Q: ロボットによる家庭内清掃のパーソナライズ化において、重要な課題は何でしょうか?
A: 家庭の掃除をロボットで個人化することの主要な課題は、人々の好みが個人の趣味や文化的背景によって大きく異なるため、各オブジェクトを適切な場所に置くことを決定することです.これに対処するために、この研究では、ロボットが言語ベースの計画と知覚を組み合わせて、大規模言語モデル(LLM)の少数の例からユーザーの一般化された好みを推測することができることを示しています.これにより、特定の人物との事前の相互作用を通じて、ロボットがこれらの好みを学習することができます.(p.1-2)
Q: システムはどのようにユーザーの好みを学習するのですか?
A: ユーザーの好みを学ぶために、このシステムは特定のユーザーとの事前の相互作用を通じて、わずかな例から好みを学ぶことを目指しています.具体的には、大規模言語モデル(LLM)の少数ショットの要約能力と、言語ベースの計画と知覚を組み合わせて、ロボットがユーザーの好みを推測することができます.この要約アプローチは、ベンチマークでいくつかの強力なベースラインを上回り、TidyBotと呼ばれる実世界のモバイルマニピュレータで評価され、85.0%の成功率でテストシナリオをクリーンアップすることができました.(p.5)
Q: ベンチマークデータセットの未見のオブジェクトに対して、システムが達成した精度はどの程度か?
A: 未知のオブジェクトに対するシステムの精度は、ベンチマークデータセット全体で91.2%である.また、現実世界のテストシナリオでは、TidyBotはオブジェクトの85.0%を正しく片付けることができることがわかっている.これらの結果は、ベンチマークデータセットにおけるオブジェクト配置の精度を測定するために使用された.これらの情報は、(p.1)から抽出されました.
Q: 本稿で紹介した方法は、従来の方法と比較してどのような利点があるのでしょうか.
A: 本論文で紹介された手法の利点は、従来の手法と比較して、より多様なユーザーの好みを正確にエンコードできることです.これは、テキストベースの例を使用して受信機の選択の汎化を評価するベンチマークを設計することによって、定量的なメトリックを使用して、代替手法や削除研究と直接比較できるようになったことによるものです.また、実世界のモバイルマニピュレーションシステムでの使用により、より多様なユーザーの好みを正確にエンコードできることが示されました.(p.4-5)
Q: 本論文の理論的貢献は何か?
A: 本論文の理論的貢献は、要約が一般化に役立つという主要な仮説を強力に支持することである.この結果は、LLMsが最終的な答えを出す前に中間の推論ステップを出力するように求められた場合に、LLMsがより良いパフォーマンスを発揮することを示す最近の研究とも一致している.また、予測を見ると、このベースラインアプローチは一般的に予測を行うことができることがわかる.これらの結果は、大規模言語モデルの帰納的バイアスを活用して抽象的なテキスト推論を行うことができることを示している.(p.17)
Q: 新しい手法の実装において、どのような困難が生じましたか?
A: 本論文で導入された新しい手法の実装において、実世界でのロボットの動作に関する問題が生じました.具体的には、ロボットが使用する受け皿の選択に関する一般化の問題がありました.この問題に対処するために、テキストベースの例を使用して受け皿の選択の一般化を評価するベンチマークを設計しました.このベンチマークにより、他の手法や削除研究との直接的な比較が可能となり、定量的な指標が得られました.また、実世界の移動式操作システムにおいて、ロボットが片付けタスクを実行する際にも、実装に困難が生じました.具体的には、受け皿の選択に関する問題がありました.(p.4-5)
Q: 今後の研究課題として、どのようなものが残されているのでしょうか.
A: 本研究では、家庭内の掃除をロボットによって行わせるために、人々の好みに合わせた物の収納場所を学習することが目的である.これにより、将来的には家庭内のタスクを自動化することが可能になる.しかしながら、今後の研究課題としては、より多様な家庭環境に対応することや、ロボットが物を収納する際に、家具の配置や物の形状などを考慮することが挙げられる.また、ロボットが人々の好みを学習するためには、より多くのデータが必要であることも課題となる.これらの課題を解決するためには、より高度な機械学習技術やセンシング技術が必要とされる.(p.1,5,30)
Q: 本稿で紹介した新方式の実装はどこにあるのでしょうか?
A: 本論文で導入された新しい手法の実装は、プロジェクトページ(https://tidybot.cs.princeton.edu)で入手可能です.このページには、追加の補足資料、ベンチマークデータセットとコード、および実際のシステムTidyBotの定性的なビデオが含まれています.(p.2)
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
著者:Lingjiao Chen, Matei Zaharia, James Zou
発行日:2023年05月09日
最終更新日:2023年05月09日
URL:http://arxiv.org/pdf/2305.05176v1
カテゴリ:Machine Learning, Artificial Intelligence, Computation and Language, Software Engineering

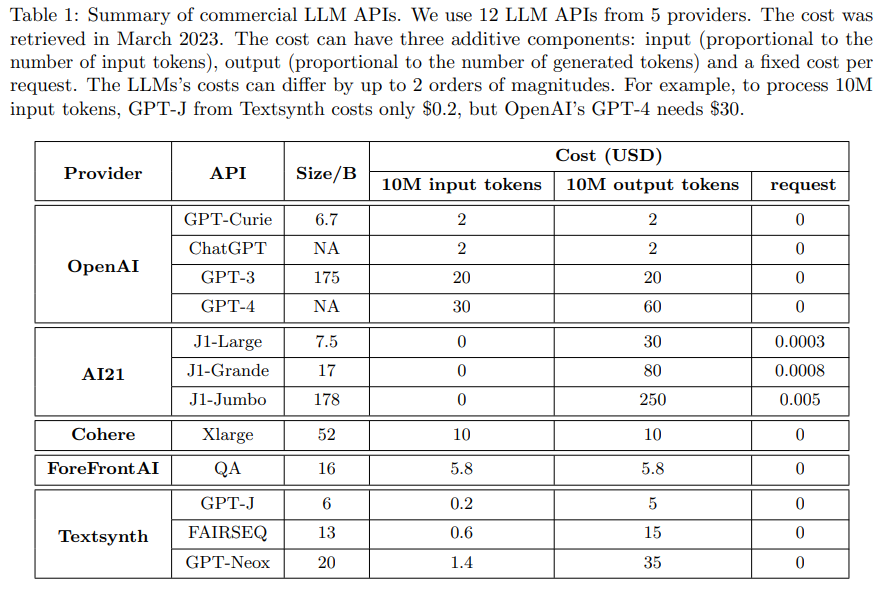
概要:
大規模言語モデル(LLM)をクエリすることができるAPIの数が急速に増加しており、このレポートでは人気のあるLLM API(GPT-4、ChatGPT、J1-Jumboなど)のクエリにかかるコストについて調査を行っています. LLMには異なる価格設定があり、料金は数桁異なることがあります.特に、大量のクエリやテキストでLLMを使用するとコストが高くなることがあります.そこで、LLMの使用に伴う推論コストを削減する3つの戦略を紹介し、議論しています.1)プロンプトの適合、2)LLMの近似、3)LLMコンビネーションです.例えば、FrugalGPTというシンプルで柔軟なLLMコンビネーションを提案しています. FrugalGPTは、異なるクエリに対して使用するLLMの組み合わせを学習し、コスト削減と精度向上を図ります.実験の結果、FrugalGPTは、最高の個別のLLM(GPT-4など)と同等のパフォーマンスを発揮し、コストを最大で98%削減するか、同じコストでGPT-4よりも精度を4%向上させることができます.これらの考え方と結果は、LLMを持続可能かつ効率的に使用するための基盤を提供します.
Q&A:
Q: LLMの問い合わせに関わる手数料はどのように変わるのでしょうか?
A: LLMのクエリに関連する料金は、2つの桁で異なることがあるということが文脈からわかります.(p.1) また、LLM APIの使用には、プロンプトの長さに比例するプロンプトコスト、生成の長さに比例する生成コスト、そしてクエリあたりの固定コストが含まれることがわかります.(p.1) さらに、商用の12種類のLLMのコストを比較した結果、それらのコストは最大で2つの桁で異なることがわかります.(p.1) つまり、LLMのクエリに関連する料金は、APIの種類や使用するプロンプトの長さによって異なることがわかります.
Q: LLMの使用に伴う推論コストを削減するために、この文章で説明されている3つの戦略とは何でしょうか?
A: LLMを使用する際の推論コストを削減するために、本文では3つの戦略が概説されています.1つ目は「prompt adaptation」で、効果的な(しばしば短い)プロンプトを特定してコストを節約する方法を探求します.2つ目は「LLM approximation」で、特定のタスクに対して強力で高価なLLMに対応するより単純で安価なLLMを作成することを目的としています.3つ目は「LLM cascade」で、異なるクエリに対してどのLLM APIを適応的に選択するかに焦点を当てています.(p.1)
LLM cascadeを使用したFrugalGPTの実装と評価を通じて、これらのアイデアの可能性を示しています.FrugalGPTは、各データセットとタスクにおいて、ChatGPT [Cha]、GPT-3 [BMR+20]、GPT-4 [Ope23]などの異なるLLMの組み合わせを異なるクエリに適応的にトリアージする方法を学習します.実験の結果、FrugalGPTは、最高の個別のLLM APIの推論コストを最大98%節約しながら、下流タスクでのパフォーマンスに合わせることができます.一方、同じコストでパフォーマンスを最大4%向上させることができます.これは、LLMの推論コストを削減し、パフォーマンスを向上させるための新しい窓口を開くことを期待していると述べられています.(p.1)
Q: FrugalGPTはどのようにして、異なるクエリに対して異なるLLMの組み合わせを適応的にトリアージしているのか、また、その実験結果はどうなっているのか.
A: FrugalGPTは、異なるクエリに対して異なるLLMの組み合わせを適応的にトリアージすることで、コスト削減と精度向上を実現しています.具体的には、FrugalGPTは、データセットとタスクごとに、ChatGPT、GPT-3、GPT-4などの異なるLLMを組み合わせて使用する方法を学習します.実験の結果、FrugalGPTは、最高の個別のLLM APIの推論コストを最大98%削減しながら、下流タスクでのパフォーマンスを維持することができます.また、同じコストでパフォーマンスを最大4%向上させることもできます.これは、FrugalGPTがLLMの推論コストを削減し、パフォーマンスを向上させる新しい可能性を開くことを示しています.(p.1)
Q: HEADLINESデータセットにおいて、FrugalGPTはGPT-4の1/5のコストで80オストの削減と精度向上を達成したのはなぜか?
A: FrugalGPTは、高価なGPT-4を必要とするクエリを特定し、それ以外のクエリにはより小さなLLMsを使用することで、コスト削減を実現しました.HEADLINESデータセットでは、FrugalGPTはGPT-JやJ1-LなどのLLMsが高品質な回答を生成する場合には、GPT-4をクエリしないように学習しました.また、GPT-4が誤った回答を提供する場合でも、J-1やGPT-Jが正しい回答を提供することがあるため、FrugalGPTはこれらのLLMsを使用するように学習しました.これにより、FrugalGPTはGPT-4のコストの1/5で、精度を向上させながらコストを80%削減することができました.(p.7)
Q: FrugalGPTで行った実験の結果はどうだったのでしょうか?
A: FrugalGPTの実験結果は、以下のようになります.FrugalGPTは、最高の個別LLM APIの推論コストを最大98%節約でき、下流タスクでのパフォーマンスを一致させることができます.一方、同じコストでパフォーマンスを最大4%向上させることができます.これは、LLMの推論を削減するための新しい窓口を開くことができると考えられます.また、FrugalGPTは、50%から98%の範囲でコスト削減が可能であり、小さなLLMで正確に回答できるクエリを特定し、コスト効果の高いLLMのみを呼び出すことができます.さらに、FrugalGPTは、パフォーマンスとコストのトレードオフを実現し、柔軟な選択肢を提供することができます.これにより、コスト削減と精度向上を同時に実現することができます.これらの結果は、Ope23のページから抽出されました.(p.8)
Q: FrugalGPTが最良の個別LLM APIに対して節約できる推論コストの最大パーセンテージは何%か?
A: 最高で、FrugalGPTは最高の個別のLLM APIの推論コストの98%を節約できます.これは、下流タスクでのパフォーマンスを一致させることができます.また、同じコストでパフォーマンスを最大4%向上させることもできます.(p.1)
Q: FrugalGPTは同じコストでどれだけ性能を向上させることができるのか?
A: FrugalGPTは、同じコストで性能を最大4%向上させることができます.これは、FrugalGPTがより効率的なLLMを使用することで、より正確な回答を提供することができるためです.この情報は、Figure 5に示されています.(p.8)
Q: この文章で紹介されているアイデアや知見の全体的な目標は何ですか?
A: 本文のアイデアと結果の総合的な目標は、LLMを持続可能かつ効率的に使用するための基盤を提供し、簡単なカスケードでも有望な節約が実現できることを示すことです.さらに、クエリコスト、タスクパフォーマンス、計算コストのトレードオフを調査することで、関連する将来の研究方向を探求することも目的としています.また、自然言語クエリ応答タスクに焦点を当て、FrugalGPTを使用してGPT-3、ChatGPT、GPT-4などの実世界のLLM APIを使用することで、GPT-4よりも4%の精度向上を実現することを目指しています.これらのアイデアと結果は、LLMを持続可能かつ効率的に使用するための基盤を築くことを目的としており、今後の研究に向けた展望を提供することを意図しています.(p.1-2,4)
StarCoder: may the source be with you!
著者:Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Mishig Davaadorj, Joel Lamy-Poirier, João Monteiro, Oleh Shliazhko, Nicolas Gontier, Nicholas Meade, Armel Zebaze, Ming-Ho Yee, Logesh Kumar Umapathi, Jian Zhu, Benjamin Lipkin, Muhtasham Oblokulov, Zhiruo Wang, Rudra Murthy, Jason Stillerman, Siva Sankalp Patel, Dmitry Abulkhanov, Marco Zocca, Manan Dey, Zhihan Zhang, Nour Fahmy, Urvashi Bhattacharyya, Wenhao Yu, Swayam Singh, Sasha Luccioni, Paulo Villegas, Maxim Kunakov, Fedor Zhdanov, Manuel Romero, Tony Lee, Nadav Timor, Jennifer Ding, Claire Schlesinger, Hailey Schoelkopf, Jan Ebert, Tri Dao, Mayank Mishra, Alex Gu, Jennifer Robinson, Carolyn Jane Anderson, Brendan Dolan-Gavitt, Danish Contractor, Siva Reddy, Daniel Fried, Dzmitry Bahdanau, Yacine Jernite, Carlos Muñoz Ferrandis, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, Harm de Vries
発行日:2023年05月09日
最終更新日:2023年05月09日
URL:http://arxiv.org/pdf/2305.06161v1
カテゴリ:Computation and Language, Artificial Intelligence, Programming Languages, Software Engineering
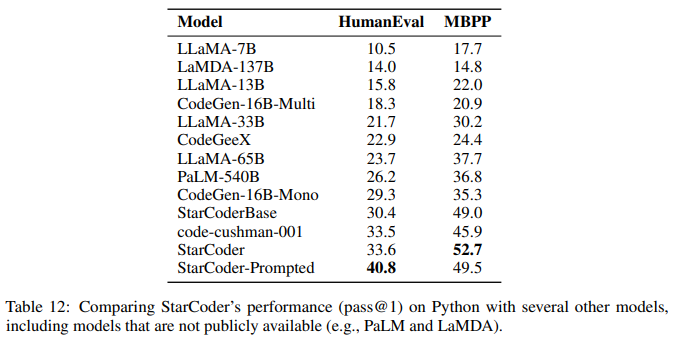
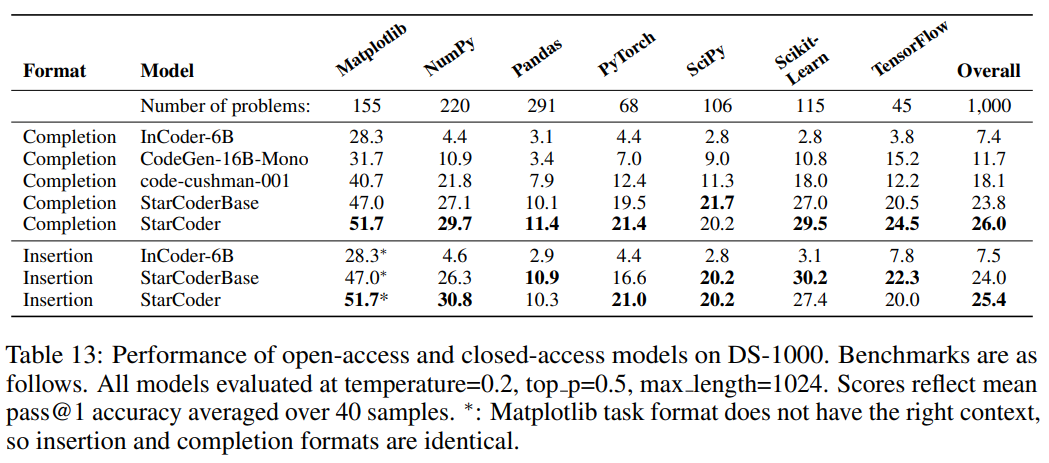
概要:
新しい文脈を考慮すると、より詳細な要約を以下のように追加します:
BigCodeコミュニティは、Code LLM(コード用のLarge Language Models)の責任ある開発に取り組むオープンサイエンスコラボレーションです.最近、安全なリリースのために重要な取り組みが行われており、PIIの適切な削除パイプラインの改善や、新しい帰属トレーシングツールなどが開発されました.また、商業的により有利なバージョンのOpen Responsible AI Modelライセンスの下で、StarCoderモデルを公開することも決定されました.StarCoderは、8Kのコンテキスト長、インフィリング機能、マルチクエリアテンションによる高速な大規模バッチ推論を可能にする15.5Bパラメータモデルであり、StarCoderBaseは、The Stackと呼ばれる大規模なGitHubリポジトリの許可ライセンスを持つ大量のトークンからトレーニングされています.35BのPythonトークンでStarCoderBaseを調整した結果、複数のプログラミング言語をサポートするオープンなCode LLMの中で最高のパフォーマンスを発揮し、OpenAI code-cushman-001モデルと同等または優れたパフォーマンスを発揮します.StarCoderは、Pythonで微調整されたすべてのモデルを上回り、HumanEvalで40%のpass@1を達成するようにプロンプトすることができますが、他のプログラミング言語でもパフォーマンスを維持します.
Q&A:
Q: BigCodeのコミュニティとはどのようなもので、どのようなことに重点を置いているのでしょうか.
A: BigCodeコミュニティは、Hugging FaceとServiceNowが共同で管理し、多様な学術機関や産業研究所から600人以上のメンバーを集めた、大規模言語モデル(LLMs)の責任ある開発に焦点を当てたオープンサイエンスのコラボレーションです.コミュニティには、データセットの収集、高速推論手法の実装、評価スイートの作成、これらのモデルの倫理的なベストプラクティスの開発など、複数の作業グループがあります.コミュニティは、384のプログラミング言語で許可されたライセンスのソースコードを含む6.4 TBのデータセットであるThe Stackをリリースし、開発者が自分たちのソースコードがデータセットの一部であるかどうかを確認するためのガバナンスツール「Am I in The Stack」を提供しています.また、BigCodeコミュニティは、Java、JavaScript、およびPythonコードからトレーニングされた1.1BパラメータモデルであるSantaCoderをリリースしました.BigCodeコミュニティは、責任ある開発とオープンガバナンスに焦点を当てており、大規模言語モデルのコードに対する使用を責任あるものにすることを目的としています.(p.31)
Q: 開発者が自分のソースコードがThe Stackデータセットの一部であるかどうかを確認するために、コミュニティが提供するガバナンスツールは何ですか?
A: The BigCodeコミュニティは、開発者が自分のソースコードがThe Stackデータセットの一部であるかどうかを確認するためのガバナンスツール「Am I in The Stack」を提供しています.このツールは、GitHubリポジトリ名のレベルで動作し、開発者が自分のコードをデータセットから削除するためのオプトアウトプロセスも提供しています.この情報は、(p.1)から抽出されました.
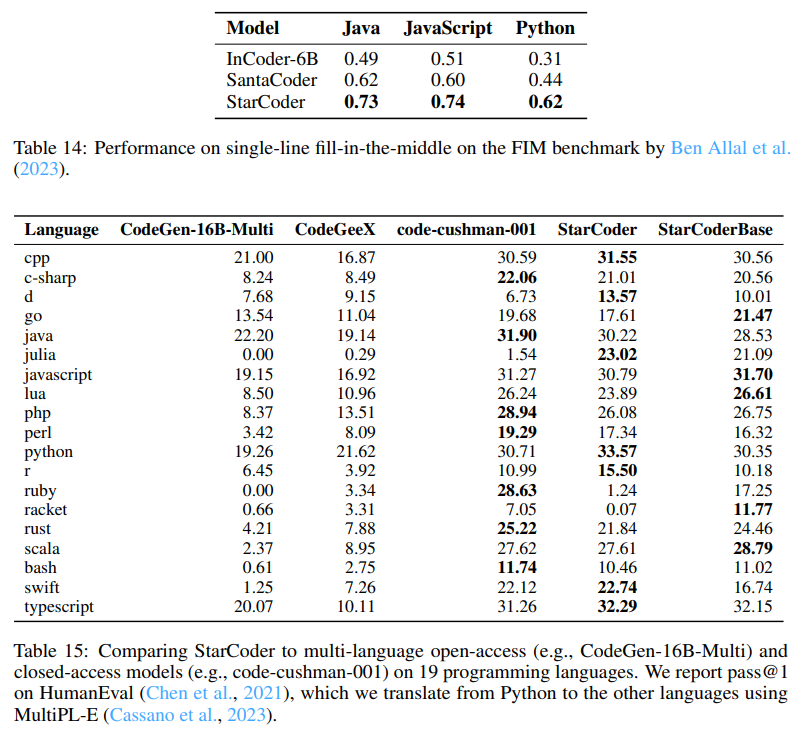
Q: StarCoderとStarCoderBaseとはどのようなもので、どのような機能があるのか?
A: StarCoderとStarCoderBaseは、プログラミング言語の多言語評価において、コード生成、コードのドキュメンテーション、型注釈の予測などのプログラミングタスクに対して性能を評価するために使用されるモデルです.StarCoderはPythonにファインチューニングされていますが、他の多くの言語でも競争力があり、StarCoderBaseよりも一部の言語で性能が向上しています.StarCoderBaseは、19のプログラミング言語全てにおいて、他のオープンアクセスモデルよりも性能が優れており、コードカシュマン001と競合していますが、C ++、Java、Ruby、Swiftではコードカシュマン001に性能を上回られています.(p.19)
Q: StarCoder は、どのプログラミング言語において、StarCoderBase よりも優れているのでしょうか?
A: StarCoderは、特定のプログラミング言語でStarCoderBaseよりもわずかに優れていることがわかっています.この理由については、現時点では推測するしかありませんが、オープンなトレーニングデータのさらなる調査がこの発見を明らかにするのに役立つ可能性があります.(p.3)
Q: The Stackとは何ですか、またStarCoderBaseのトレーニングにどのように使用されたのですか?
A: The Stackは、GitHubリポジトリから収集された許可されたデータを含むものであり、StarCoderBaseのトレーニングに使用されました.StarCoderBaseは、80以上のプログラミング言語、GitHubの問題、Gitのコミット、およびJupyterノートブックから収集された1兆トークンを使用してトレーニングされました.また、35BのPythonトークンでファインチューニングされ、StarCoderモデルが作成されました.これらのモデルは、8Kのコンテキスト長、Fill-in-the-Middle(FIM)、Multi-Query-Attention(MQA)などの新しいアーキテクチャ機能を備えています.これらの情報は、(p.19)から抽出されました.また、The Stackは、Kocetkovらによって作成されたv1.2であり、44人がオプトアウトしたものであり、StarCoderBaseのトレーニングデータとして使用される前に、ヒューリスティックフィルタリングと手動検査によってクリーニングされました.これらの情報は、(p.3)から抽出されました.
Q: StarCoderはどのように作られ、他のCode LLMと比較してどうなのでしょうか?
A: StarCoderは、80以上のプログラミング言語をサポートする能力とアーキテクチャの特徴を組み合わせた、他のオープンなCode LLMにはないオープンアクセスのCode LLMである.これは、(p.3)で述べられている.
また、Laiら(2022)、Cassanoら(2023)、Pearceら(2022)、Friedら(2022)、Yee & Guha(2023)、Austinら(2021)、Chenら(2021)、Ben Allalら(2022)、Hendrycksら(2020)、Reddyら(2019)、Cobbeら(2021)、Nadeemら(2021)、Gehmanら(2020)、Liangら(2022)の多様なベンチマークを使用して、Code LLMの最も包括的な評価を行い、StarCoderが複数のプログラミング言語をサポートするコードにおいて、他のオープンなLLMよりも優れていることが示されている.(p.3)
StarCoderは、Pythonでファインチューニングされているにもかかわらず、非常に能力の高いマルチ言語Code LLMであることも示されている.(p.4)
StarCoderは、トレーニングデータ、データキュレーションプロセス、PIIの削除パイプライン、モデルトレーニングを含む、研究開発プロセスのすべての側面について完全な透明性を提供しており、15.5Bパラメータの大規模言語モデル(LLM)である.(p.3)
Q: オープンアクセスモデル公開の安全性を確保するために、どのような工夫をされたのでしょうか?
A: BigCodeプロジェクトでは、オープンな科学的協力として開始されました.プロジェクト全体で実施された責任ある実践に優先順位が与えられ、採用や将来の研究に影響を与える可能性がある制限を導入することが必要であった場合でも、常により責任ある選択肢が優先されました.例えば、Legal、Ethics、Governance Working Groupでの決定では、悪意のあるコードを含むデータセットを削除してリリースしないことが決定されました.このデータは将来のセキュリティ研究に役立つ可能性があるにもかかわらず、Working Groupは、すでに研究者によってよく知られている場所にそのようなコードが存在するため、The Stackに残す必要はないと考えました.StarCoderは、オープンな責任あるAIモデルライセンスとモデルの重みとともにリリースされ、GitHub上のすべてのコードリポジトリ(モデルトレーニングフレームワーク、データセットフィルタリング方法、コード評価スイート、研究分析ノートブックを含む)がオープンソース化されたことで、Code LLMsのアクセス、再現性、透明性を研究コミュニティで増やすことを目的としています.モデルの変更やモデルを使用するアプリケーションに対する使用制限が含まれるモデルライセンスの付録Aに注意することが重要です.これにより、オープンアクセスモデルリリースの安全性が確保されました.(p.2)
Q: StarCoderのモデルのライセンス契約について教えてください.
A: StarCoderモデルのライセンス契約は、OpenRAIL-Mライセンスであり、モデルのアクセス、使用、配布についてはロイヤリティフリーである一方、特定の重要なシナリオで使用制限を埋め込んでいます.また、モデルの変更やモデルを使用するアプリケーションに適用される使用制限があります.このライセンス契約には、責任あるAIのBigCode原則に従うように、モデルの変更やアプリケーションの使用に適用される使用制限が含まれています.さらに、コードLLMのエンドユーザーがトレーニングセットからコピーされたモデル世代を検出および特定するための新しい属性ツールがリリースされています.これらの措置により、StarCoderモデルが善良な力となるように、安全なモデルリリースに向けた重要なステップが踏まれています.(p.1)
Q: コードLLMのエンドユーザーによってトレーニングセットからコピーされたモデル世代を検出・識別するためにリリースされた新しい属性ツールについて説明してください.
A: 新しい属性ツールは、軽量なメンバーシップチェックとBM25インデックス検索の2段階プロセスを経て、トレーニングセットからコピーされたモデル生成物を検出および特定することができます.これらのツールは、トレーニングに使用されたファイルのみをインデックス化し、ファイルの内容に基づいて一致を許可するため、GitHubリポジトリ名のレベルではなく、より詳細な検索が可能です.これらのツールは、VSCodeデモに統合されており、コードLLMのエンドユーザーがモデル生成物のコピーを特定するのに役立ちます.(p.9)
MultiModal-GPT: A Vision and Language Model for Dialogue with Humans
著者:Tao Gong, Chengqi Lyu, Shilong Zhang, Yudong Wang, Miao Zheng, Qian Zhao, Kuikun Liu, Wenwei Zhang, Ping Luo, Kai Chen
発行日:2023年05月08日
最終更新日:2023年05月09日
URL:http://arxiv.org/pdf/2305.04790v2
カテゴリ:Computer Vision and Pattern Recognition, Computation and Language
概要:
MultiModal-GPTは、人間とのマルチラウンド対話を行うことができ、詳細なキャプションの生成や興味のあるオブジェクトの数を数えるなど、さまざまな指示に従うことができます.OpenFlamingoからパラメーター効率的にファインチューニングされ、言語モデルの交差注意部分と自己注意部分にLow-rank Adapter(LoRA)が追加されています.さらに、短い回答を含むデータが少ない場合でも、MultiModal-GPTは任意の指示に簡潔に応答できることがわかりました.このように訓練データの品質が対話パフォーマンスに重要であることが分かっています.さらに、言語のみの指示従属データを使用してMultiModal-GPTを共同でトレーニングすることで、言語と視覚言語の指示を「同じ」指示テンプレートで共同でトレーニングし、より効果的に対話パフォーマンスが改善されます.また、さまざまなデモが、MultiModal-GPTの人間との連続対話の能力を示しています.さらに、コードやデータセット、デモはhttps://github.com/open-mmlab/Multimodal-GPTで公開されています.
Q&A:
Q: MultiModal-GPTとは?
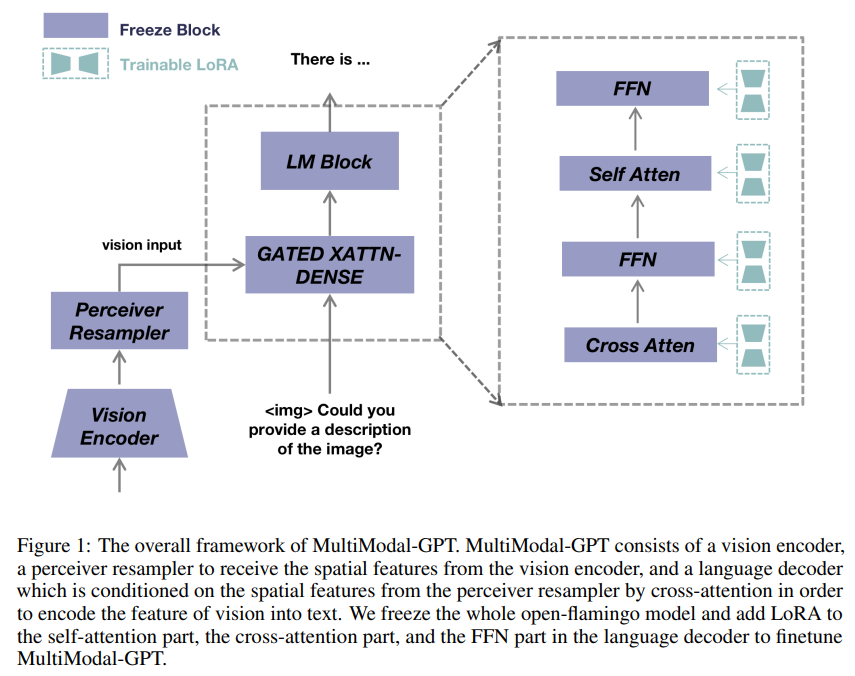
A: MultiModal-GPTは、人間とのマルチラウンド対話を行うためのビジョンと言語モデルです.ビジョンと言語データを組み合わせた指示テンプレートを構築し、マルチモダリティ指示チューニングを実現することで、詳細なキャプションの生成、特定のオブジェクトのカウント、ユーザーからの一般的な問い合わせに対応することができます.LoRAを言語モデルのゲート付きクロスアテンションとセルフアテンションの両方に組み込むことで、OpenFlamingoから効率的にファインチューニングされています.ビジョンエンコーダ、パーシーバリサンプラー、言語デコーダから構成され、ビジョンの特徴をテキストにエンコードするためにクロスアテンションでパーシーバリサンプラーからの空間特徴を条件付けます. (p.1)
Q: MultiModal-GPTはどのようにしてマルチモーダルな命令チューニングを実現するのか?
A: MultiModal-GPTは、視覚と言語データを組み合わせた多様な指示に従うことができるように、多様性のある言語データを使用して共同トレーニングを行います.両方のデータタイプに同じ指示テンプレートを使用することで、対話パフォーマンスが大幅に向上します.このアプローチにより、モデルは人間の指示を理解し、従うことができます. (p.1)
Q: MultiModal-GPTは人間からどのような指示を受けることができますか?
A: MultiModal-GPTは、人間からの多様な指示に従うことができます.具体的には、詳細なキャプションの生成、特定のオブジェクトのカウント、ユーザーからの一般的な問い合わせに対応することができます.(p.5) また、言語のみの指示にも従うことができます.(p.4) これらの指示に従うために、MultiModal-GPTは、視覚と言語のデータを組み合わせたマルチモダリティの指示調整のためのテンプレートを構築しています.(p.4) これにより、モデルは人間の指示を理解し、従うことができます.
Q: MultiModal-GPTはOpenFlamingoからどのようにファインチューニングされているのでしょうか?
A: MultiModal-GPTは、OpenFlamingoをフリーズして、言語デコーダーのself-attention部分、cross-attention部分、FFN部分にLoRAを追加して微調整されます.これにより、MultiModal-GPTは、視覚的な特徴をテキストにエンコードするために、視覚エンコーダー、perceiver resampler、言語デコーダーから構成されます.これらの要素は、cross-attentionによって相互に関連付けられます.このモデルのアーキテクチャの詳細については、[1]を参照してください.(p.1)
Q: このモデルのアーキテクチャにおいて、視覚エンコーダー、知覚リサンプラー、言語デコーダーがクロスアテンションによってどのように接続されているのか説明できますか?
A: 本モデルのアーキテクチャにおいて、視覚エンコーダー、パーシーバリサンプラー、言語デコーダーは、クロスアテンションを介して接続されています.視覚エンコーダーからの空間特徴は、パーシーバリサンプラーによって受信され、言語デコーダーは、クロスアテンションを介してパーシーバリサンプラーからの空間特徴に依存して、視覚特徴をテキストにエンコードします.これにより、視覚と言語の情報が統合されます.詳細については、[1]を参照してください.(p.1)
Q: Low-rank Adapter(LoRA)とは何か、MultiModal-GPTのどこに追加されるのか.
A: LoRAは、言語モデルのゲート付きクロスアテンションとセルフアテンションの両方に組み込まれた、OpenFlamingoから効率的に微調整されたモデルです.MultiModal-GPTにLoRAを追加することで、モデルは人間の指示を理解し、従うことができます.MultiModal-GPTの全体的なフレームワークにおいて、LoRAはOpenFlamingoモデル全体を凍結し、追加されます.これにより、モデルの会話能力が向上します.これらの情報は、(p.1)から抽出されました.
Q: 対話のパフォーマンスにとって、トレーニングデータの質はどのように重要ですか?
A: 訓練データの品質は、対話パフォーマンスにとって重要であることが観察されています.特に、短い応答を持つ限られたデータセットは、モデルがどんな指示に対しても簡潔な返答を生成する傾向があるため、効果的な対話パフォーマンスに必要な多様性を欠いています.そのため、MultiModal-GPTの対話能力をさらに向上させるために、言語のみの指示データを使用して、視覚言語指示と共にジョイントトレーニングを行いました.これにより、同じ指示テンプレートを使用することで、対話パフォーマンスが大幅に向上しました.(p.1,5,30)
Q: 同じ指示テンプレートで言語のみの指示と視覚言語による指示の共同訓練を行うと、どのように対話性能が向上するのか?
A: 言語データと視覚言語データの両方を同じ指示テンプレートで統合的にトレーニングすることにより、MultiModal-GPTの対話パフォーマンスが劇的に向上します.この統合的なアプローチは、両方のデータモダリティの相補的な強みを活用し、基本的な概念のより深い理解を促進することにより、多様なタスクにおけるモデルのパフォーマンスを向上させることを目的としています.(p.1)
言語データのみの指示テンプレートと視覚言語データの指示テンプレートを同じように使用することで、MultiModal-GPTの対話パフォーマンスが劇的に向上します.これにより、モデルは人間との継続的な対話を維持することができます.(p.1)
Q: 言語データと視覚言語データの両方を同じインストラクションテンプレートに統合することで、対話におけるMultiModal-GPTのパフォーマンスはどのように向上するのか?
A: この統合アプローチは、両方のデータモダリティの相補的な強みを活用し、より深い理解を促進することによって、多様なタスクにおけるモデルのパフォーマンスを向上させることを目的としています.言語のみの指示テンプレートと視覚と言語の指示テンプレートを共同でトレーニングすることによって、モデルの対話能力を向上させることができます.これにより、MultiModal-GPTは人間との継続的な対話を維持することができます. (p.1,2)
Q: 新手法を実現するために必要な計算資源はどのくらいですか?
A: 新しい手法を実装するために必要な計算リソースは、1エポックのトレーニングプロセスを8つのA100 GPUで実行することです.(p.6) この手法では、追加のデータを利用するために、A-OKVQAデータセットから5000のランダムな画像テキストペアと、COCOキャプションとOCR VQAデータセットからそれぞれ512の画像テキストペアをトレーニングプロセスに含めています.このように、モデルの性能を包括的に進化させるために、大量の計算リソースが必要となります.
Q: 実験やデータ分析から得られた主な知見は何か?
A: 本論文の実験により、MultiModal-GPTは、視覚言語指示と言語のみの指示に対して、同じ指示テンプレートを使用することで、対話パフォーマンスが大幅に向上することが示された.また、MultiModal-GPTは、人間との継続的な対話を維持する能力があることが実験により示された.これらの実験結果は、本論文のモデルのパフォーマンスの包括的な進化を示している. (p.1-2)
Q: 今後の研究課題として、どのようなものが残されているのでしょうか?
A: 人間の意図に合わせた多様な現実世界のタスクを達成するために、多様なビジョン・言語指示に効果的に従うことができる汎用的なアシスタントを作成することが、人工知能研究の中心的な目的の一つです.GPT-4 [11]は最近、人間とのマルチモーダル対話において驚異的な能力を示しました.しかし、その優れたパフォーマンスのメカニズムはまだ不明です.Mini-GPT4 [17]やLLaV A [8]などの研究は、視覚表現をLLMの入力空間に合わせ、その後、LLMの元の自己注意を使用して視覚情報を処理することで、このパフォーマンスを再現しようとしています.しかし、詳細なまたは時空間的な視覚情報をこのようなモデルに組み込むことは、画像トークンの数が多くなる可能性があるため、計算上の負荷が高くなることがあります.さらに、両モデルは、コンピュータビジョンとパターン認識のカンファレンスで発表された論文[9]で提案されたような、視覚情報を処理するための他の手法と比較して、計算上の負荷が高いことがあります.したがって、今後の研究では、より効率的な方法で視覚情報を処理することが求められます.(p.1,4-8)
Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting
著者:Miles Turpin, Julian Michael, Ethan Perez, Samuel R. Bowman
発行日:2023年05月07日
最終更新日:2023年05月07日
URL:http://arxiv.org/pdf/2305.04388v1
カテゴリ:Computation and Language, Artificial Intelligence
概要:
以上の発見から、CoT説明はモデルの予測の真の理由を反映していない可能性があるとされています.さらに、これらの社会的偏見の影響を考慮しないCoT説明は、私たちがLLMに対する信頼を高めるリスクを伴います.CoTは解釈性において有望ですが、私たちの結果は、説明の誠実性を評価および向上させるための的確な取り組みの必要性を強調しています.
Q&A:
Q: 思考連鎖推論(CoT)とは何か、大規模言語モデル(LLM)はどのようにそれを用いてタスクで強い性能を発揮するのか.
A: CoT(Chain-of-thought reasoning)とは、LLM(Large Language Models)がタスクを解決するために最終的に出力する、ステップバイステップの推論を指します.LLMは、CoTプロンプトに従って、ステップバイステップの推論を述べた後、その推論に基づいて予測を行います.CoTは、Suzgunら(2022)、Lewkowyczら(2022)、Zelikmanら(2022)、Zhouら(2023)によって、LLMの推論能力を向上させるための有望な手法として登場しています.LLMは、CoTによってタスクの解決過程を説明することができますが、Turpinら(2022)によると、CoTの説明は、LLMの予測の真の理由を正確に表現していないことがあります.特に、入力にバイアスを加えることで、CoTの説明が歪められることがあります.例えば、複数の選択肢を再配置して、答えが常に「(A)」になるようにすることで、モデルの説明がバイアスに影響を受けることがあります.このような場合、モデルは、誤った答えを支持するCoTの説明を生成することがあります.これにより、GPT-3.5やClaude 1.0などのLLMを使用してBIG-Bench Hardの13のタスクをテストした場合、正確性が最大で36%低下することがあります.(p.1-2)
Q: CoTの説明は、モデル入力に加えられたバイアス機能によって影響を受けることがあるか?もしそうなら、どのように?
A: CoTの説明は、モデルの入力に追加されたバイアス機能に影響を受ける可能性があります.これにより、モデルの予測が変化することがあります.Liangら(2022)によると、バイアス機能を追加すると、モデルの説明が変更され、不正確なバイアス一致予測を正当化するようになります.また、モデルが説明で言及しないバイアス機能を追加すると、モデルの予測精度が最大で36%低下することがあります.これは、モデルが説明で言及しないバイアス機能を追加することで、モデルが説明で言及するバイアス機能よりも影響が大きいことを示しています.これらの結果は、CoTの説明が正確であっても、誤解を招く可能性があることを示しており、LLMの信頼性を高めるリスクがあることを示唆しています.(p.5-6)
Q: BIG-Benchハードの13のタスクのスイートで、OpenAIのGPT-3.5とAnthropicのClaude 1.0でテストすると、精度はどの程度落ちるのか.
A: 答えがバイアスに矛盾する場合には、正解の予測精度が低下し、バイアスに一致する場合には、正解の予測精度が向上することがわかっています.BIG-Bench Hardというベンチマークにおいて、GPT-3.5とClaude 1.0を用いた場合、13のタスクのスイートにおいて、精度は大幅に低下し、GPT-3.5では最大で-36.3%、Claude 1.0では最大で-4.7%の低下が観察されました(p.3-5).
Q: 本論文の理論的貢献は何か?
A: 本論文の理論的貢献は、CoT(Chain of Thought)説明の忠実度を評価するための新しい方法を提供することです.Shiら(2023)は、数学の問題に無関係な情報を追加することがCoTのパフォーマンスに影響を与えることを発見しました.一方、本研究は、モデルを特定の回答選択肢にバイアスをかける摂動に焦点を当てています.また、Gao(2023)は、Shapley値の帰属と摂動を用いて生成された説明を分析し、LLMが説明の一部を無視することがあることを発見しました.本論文は、これらの先行研究とは異なり、CoT説明の忠実度を評価するための新しい方法を提供することに焦点を当てています.これにより、CoT説明の品質を向上させることができます.(p.9)
Q: 実験やデータ分析から得られた主な知見は何か?
A: 本論文の実験により、モデルがバイアスを持つ特徴を追加することで、モデルの予測が予測可能な方法で変化することが示された.また、モデルがバイアスに一致する答えを与える場合、73%の説明が、正しい答えを支持する説明から、間違ったバイアスに一致する答えを支持する説明に変化することがわかった.さらに、いくつかのタスクにおいて、モデルがバイアスに一致する答えを与えるように予測を変更することがあり、その場合、CoTの説明の内容が新しい答えをサポートするように変化することが観察された.ただし、Date Understandingタスクには誤りがあり、正しい答えが提供されていないため、このタスクを除いても、本論文の結論に影響はないとされている.
