
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をQ&A形式を用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.
紹介する論文は以下の9本となります.
- DataComp: In search of the next generation of multimodal datasets (発行日:2023年04月27日)
- Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond (発行日:2023年04月26日)
- Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning (発行日:2023年04月26日)
- AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head (発行日:2023年04月25日)
- Stable and low-precision training for large-scale vision-language models (発行日:2023年04月25日)
- Track Anything: Segment Anything Meets Videos (発行日:2023年04月24日)
- A Cookbook of Self-Supervised Learning (発行日:2023年04月24日)
- Evaluating ChatGPT’s Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness (発行日:2023年04月23日)
- Scaling Transformer to 1M tokens and beyond with RMT (発行日:2023年04月19日)
DataComp: In search of the next generation of multimodal datasets
著者:Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, Eyal Orgad, Rahim Entezari, Giannis Daras, Sarah Pratt, Vivek Ramanujan, Yonatan Bitton, Kalyani Marathe, Stephen Mussmann, Richard Vencu, Mehdi Cherti, Ranjay Krishna, Pang Wei Koh, Olga Saukh, Alexander Ratner, Shuran Song, Hannaneh Hajishirzi, Ali Farhadi, Romain Beaumont, Sewoong Oh, Alex Dimakis, Jenia Jitsev, Yair Carmon, Vaishaal Shankar, Ludwig Schmidt
発行日:2023年04月27日
最終更新日:2023年04月27日
URL:http://arxiv.org/pdf/2304.14108v1
カテゴリ:Computer Vision and Pattern Recognition, Computation and Language, Machine Learning
概要:
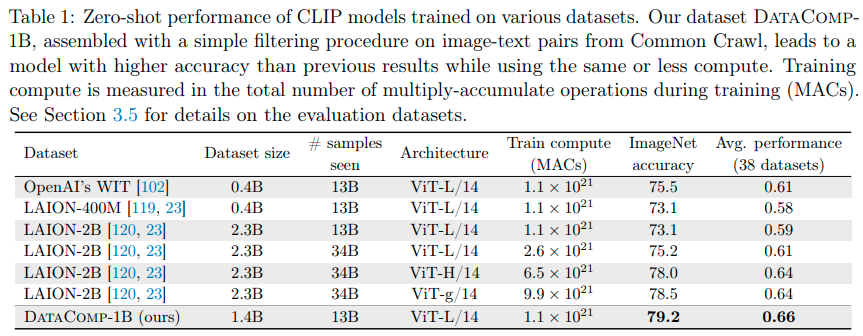
DataCompは、モデルの性能向上に向けた取り組みである.同エコシステムは、共通の懸念事項である大規模なマルチモーダルデータセットの欠点を解決することを目的としている.そのため、研究者たちは、常に新しいトレーニングセットを提案し、イノベーションを生み出す必要があった.ここでは、DataComp-1Bというデータセットが紹介されており、12.8Bからの候補者プールを単純なフィルタリングアルゴリズムを適用し、その結果1.4Bのサブセットを得ることができる.このサブセットを用いてCLIP ViT-L/14をゼロからトレーニングした結果、ImageNetにおいて79.2%のゼロショット精度を達成した.また、同じトレーニングコンピューティング予算を使用しているOpenAIのCLIP ViT-L/14を3.7ポイント上回り、ViT-g/14よりも優れた性能を発揮した.このような成果により、トレーニングセットの適切なキュレーションが、モデルのパフォーマンス向上に大きく関与することを証明した.DataComp-1Bは、今後のマルチモーダルデータセットの進化の先駆けとなる存在である.
Q&A:
Q: DataComp-1Bとは何ですか?以前の画像テキストのデータセットとどこが違いますか?
A: DataComp-1Bは、DataCompベンチマークワークフローの直接的な結果で構成された1.4Bサンプルの画像テキストデータセットです.LAION-2Bデータセットよりもサンプル数が少なく、LAION-2Bを作成するために使用されたプールよりも小さいプールから構築されています.DataComp-1BでCLIP L/14をトレーニングすると、ImageNetでLAION-2B競合相手に比べて6.1パーセンテージポイントの性能向上が見られます.また、同じコンピュータ予算でトレーニングされたOpenAIのViT-L/14よりも、DataComp-1Bでトレーニングすると、ImageNetの正答率が3.7パーセンテージポイント向上します.これらの結果は、DataCompがもたらす影響と参加者がビルドする有望な基盤を提供することを示しています.
Q: 同じイメージのプールからのより大きなデータセットよりも、より厳密にフィルタリングされた小さなデータセットが汎化性能の高いモデルにつながることがあるのでしょうか?
A: 同じ画像のプールからの大きなデータセットよりも、より厳密にフィルタリングされた小さなデータセットの方が、モデルの汎化にどのような影響があるかを調べた結果、小さなデータセットの方が汎化性能が良いことが明らかになりました.例えば、12.8Bのスケールで、最高のフィルタリングベースラインは、ImageNetのゼロショット精度を、未フィルタリングのプールに比べて、6.9パーセントポイント向上させました.
Q: DataCompが採用したゼロショット評価プロトコルとは何ですか?
A: DataCompは標準化されたCLIPトレーニングコードを実行し、38の下流テストセットで結果のモデルを試験することによって、零-shot評価プロトコルを採用しています.
Q: WinoGAViLベンチマークの目的は何であり、どのようにビジョン・アンド・ランゲージモデルに挑戦するのか?
A: WinoGAViLベンチマークの目的は、ビジョン・アンド・ランゲージ(V&L)モデルの構築において、言語推論と視覚推論の組み合わせに焦点を当てて、将来のモデルの開発を促進することです.これは、大量の一般的なデータセットを使用するV&Lモデルを評価する数々の試みの1つです.WinoGAViLベンチマークは、これまでに提案された他のデータセットとは異なり、JSON形式で記述された特殊な文を使用して、モデルが進化した能力を測定するためにデザインされています.したがって、WinoGAViLベンチマークは、V&Lモデルに新たな挑戦を与え、将来の研究に貢献することが期待されています.
Q: :ブラックボックス予測の理解において、影響関数の使用の背後にある主なアイデアは何ですか?
A: ブラックボックス予測を理解するために、インフルエンス関数の使用の主なアイデアは何ですか?インフルエンス関数は、トレーニングデータの特定のサブセットをモデルの振る舞いに関連付ける方法を提供する方法の一つであり、ロバスト統計学からのクラシックな手法です.トレーニングランのシミュレーションを通じて、あるトレーニングポイントを削除したときの学習済みモデルパラメーターの効果を近似するために、2次のテイラー展開を使用します.
Q: LAION-400Mとは何ですか?また、データセットの目的は何ですか?
A: LAION-400Mとは、Common Crawlから収集された画像とテキストのデータセットです.その目的は、多様性を持ち、現実のシチュエーションに基づいた画像とキャプションのモデルのトレーニングに使用することです.ただし、このデータセットには危険で安全でないデータが豊富に含まれているため、適切なフィルタリングが必要です.
Q: コアセットアプローチとは何ですか?また、畳み込みニューラルネットワークのアクティブラーニングにどのように使用されますか?
A: コアセット選択アルゴリズムは、データサブセットの選択により、完全なデータセットで訓練する場合と同じ性能を実現することを目的としています.この手法は、大規模で現代的なディープラーニングアルゴリズムに必要な大量のデータセットに対して、スケーリングが悪いことが問題視されています.また、コアセット選択は、既存の知識から得られたデータセットに適用されることもあります.アクティブラーニングにおいて、この手法は異なる戦略やアルゴリズムを用いることで、学習のスピードと正確さを向上させます.畳み込みニューラルネットワークに適用する場合、コアセット選択は、データの選択によりニューラルネットワークの学習コストを削減し、推論タスクの精度向上につながります.
Q: Conceptual Captionsデータセットとは何ですか、そして何に使われていますか?
A: Conceptual Captionsは画像の自動生成説明のためのクリーン化、上位語化、alt-textデータセットであり、ACL(Association for Computational Linguistics)の2018年会議で発表されました.このデータセットの目的は、多様なアプリケーションをサポートする強力な画像テキストデータセットを研究することです.
Q: Witデータセットとは何ですか、そしてそれはマルチモーダル多言語機械学習にどのように使用されますか?
A: Witは、多言語マルチモーダル機械学習におけるデータセットであり、Wikipediaをベースとしており、画像とテキストのペアを含んでいます.Witは、画像とテキストのペアを使用したモデルのトレーニングに使用されており、多言語翻訳や画像説明生成などのタスクで使用されています.
Q: データセット・カルトグラフィーとは何か、そしてトレーニング動態でデータセットをマッピングして診断する方法は何ですか?
A: データセット・カートグラフィーとは、ダイナミックなトレーニングを持つデータセットをマップし診断する方法である.これにより、データを示すグラフを作成し、トレーニングダイナミクスを視覚的に表現することができる.
Q: 実験またはデータ解析からの主要な発見は何ですか?
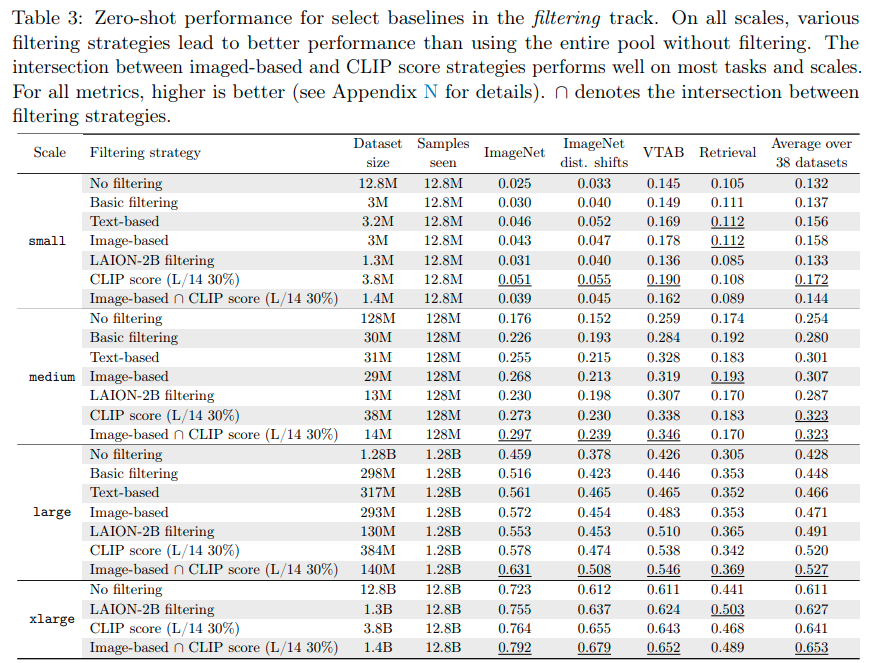
A: 主要な結果は、Table 3に示されており、ViT-L / 14モデルを使用して最も高いスコアを持つ上位30%の例を取る、画像ベースのフィルタリングとCLIPスコアフィルタリングの交差がほとんどのタスクで優れていることである.ただし、小規模や回収データセットでは、他のフィルタリングアプローチの方が優れている場合がある.さらに、基本的な、CLIPスコア、画像ベース、テキストベースのフィルタリングなど、他のフィルタリング戦略は、データの選択に比べて下流の性能が優れていることが示された.
Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
著者:Jingfeng Yang, Hongye Jin, Ruixiang Tang, Xiaotian Han, Qizhang Feng, Haoming Jiang, Bing Yin, Xia Hu
発行日:2023年04月26日
最終更新日:2023年04月27日
URL:http://arxiv.org/pdf/2304.13712v2
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning
概要:
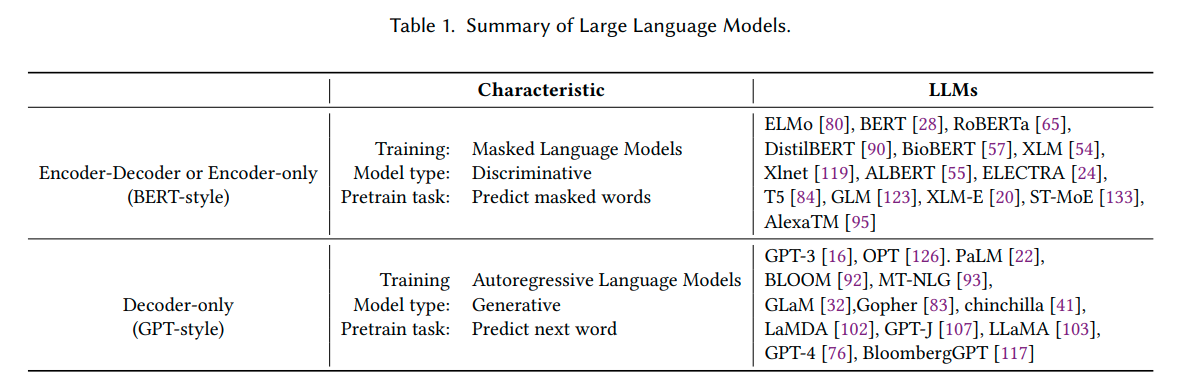
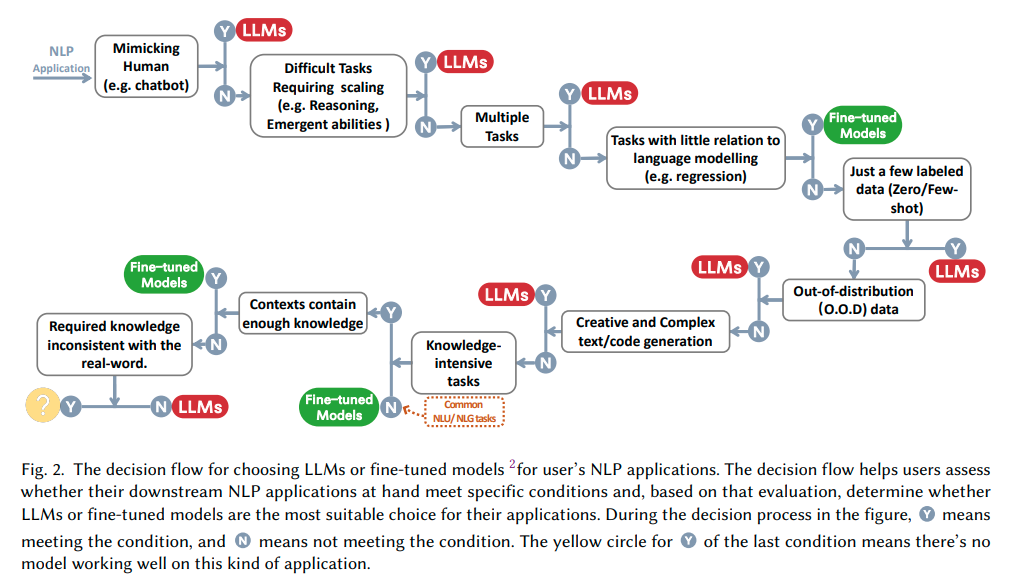
本論文は、現場の実践者やエンドユーザーが、Downstream Natural Language Processing(NLP)タスクにLarge Language Models(LLMs)を使用する際の包括的で実用的なガイドを提供することを目的としています.モデル、データ、Downstreamタスクの3つの視点から、LLMsの使用に関する議論や洞察を提供しています.また、効率、コスト、レイテンシーなど、実践においてLLMsを展開するにあたり、偽のバイアスの影響など、重要な問題も掘り下げています.この包括的なガイドは、研究者や実践者が、LLMsを効果的に実装し、様々なNLPタスクに応用するための貴重な洞察とベストプラクティスを提供することを目的としています.さらに、定期的に更新されるLLMsの実用的なガイドのカスタムリストは、\url{https://github.com/Mooler0410/LLMsPracticalGuide}で入手できます.
Q&A:
Q: :LLMの出現能力 (emergent abilities) は何ですか?また、LLMがスケールアップするにつれて生じる例を示せますか?
A: LLMsの出現能力としては、小規模なモデルの性能向上を外挿して予測することができず、ある一定の範囲を超えると突然モデルがいくつかのタスクで良いパフォーマンスを示すことがあります.この新しい能力は予測不可能かつ驚くべきもので、ランダムまたは予期せぬタスクが発生する可能性があります. LLMSの出現能力については、単語操作の処理が代表的な例として挙げられます.この能力は、反転した単語を与えられ、元の単語を出力するなどの記号操作を学習する能力を指します.例えば、GPT-3は単語の並べ替えや単語の並べ替えのタスクに対する能力を示し、PaLMはASCII文字認識とハイパバトンタスクに基づく能力を示します. LLMSは、推理、論理順序、論理グリッドパズルなどの論理的な能力がスケールアップするにつれて現れることが一般的です.また、リトリーバルによって必要な知識を取得できるため、かなり小さいサイズのモデルでもかなり良い結果を示すことがあります.これらの能力は、モデルの大きさに比例して出現し、さまざまなタスクでモデルの性能が指数関数的に向上することがあります.出現能力は、モデルの規模が急激に拡大するため、予測できない素晴らしい能力が現れることもあります. 例えば、 LLMSの出現能力には、単語操作や論理的な能力が含まれることがあります.
Q: 下流タスクの展開において、LLMによって生じる可能性のある課題は何ですか?
A: LLMsを下流タスクの展開に使用する場合、テスト/ユーザーデータとトレーニングデータの分布差異による課題が生じる可能性があります.これらの課題は、ドメインのシフト、分布外のバリエーション、または敵対的な例に起因する場合があります.これらの課題は、リアルワールドのアプリケーションにおいて、ファインチューニングモデルの効果を大幅に阻害することがあります.一方、LLMsは、明示的な適合プロセスを持たないため、これらのシナリオに対してかなりよく機能します.
Q: 最近の言語モデルの進歩によって、分布の違いを扱う能力がどのように向上しましたか?
A: 最近の言語モデルの進歩によって、分布上の差異を扱う能力が向上しました.Reinforcement Learning from Human Feedback(RLHF)手法は、LLMの一般化能力を著しく向上させました.InstructGPTは、異なる言語の指示に従うことができることを証明し、様々なタスクに対して指示に従う能力を示しました.同様に、ChatGPTは、最も厳しい分類および翻訳タスクに対して、一貫して優れた性能を発揮しました.その対話に関するテキストの理解能力により、DDXPlusデータセットにおいて印象的なパフォーマンスを示し、医療診断のために設計されたアウト・オブ・ディストリビューション(OOD)評価向けデータセットに対して高い精度を発揮しました.
Q: :ファインチューニングされたモデルを強化するためのフューショット学習手法は何があり、LLMを使用する場合と比較してどのようになりますか?
A: 少ないデータに対して、fine-tuned modelsを改善するfew-shot learning methodsの選択肢はありますが、LLMsを使用すると比較して、劣るパフォーマンスがあるかもしれません.反対に、多くのアノテーションされたデータがある場合、両方のモデルを使用することができます.LLMsはデータの可用性に対してより柔軟であり、fine-tuned modelsはより特定のタスクに合わせて調整されることができ、デプロイメントの制約や計算リソースに関わらず課題に応じて選択できます.
Q: コモンセンス推論に必要なものは何であり、モデルのサイズが大きくなるにつれて、これはどのように増加するのでしょうか?
A: コモンセンス推論に必要な要素は、情報の意味を理解し、推論を行い、決定を下すことです.LLMのサイズが増大することで、算術推論や常識的な推論など、LLMは特に能力を発揮します.ただし、LLMの能力の拡大に伴い、性能が常に改善されるわけではありません.LLMの能力の変化を十分理解していないためです.さらに、LLMのサイズが拡大するにつれ、単語操作の能力や論理的な能力など、LLMの発展的な能力が現れます.現存する推論問題は、常識推論や算術推論に分類されます.算術推論の場合、LLMのパラメータ数が13Bを超えると、二桁の加算能力などが現れます.LLMのスケーリングによる能力の拡大により、非常に低い状態から使用可能な状態に変化し、人間の能力に近づいていると言えます.
Q: :リトリーバル・オーグメンテーションは、モデルがタスクのために追加の知識にアクセスする方法をどのように可能にするのか、およびリトリーバル・オーグメンテーションモデルがNaturalQuestionsでどのように利用できるかの例は何ですか?
A: リトリーバル・オーグメンテーションは、予測を行う前に追加情報検索ステップを追加するアイデアであり、タスクに関連する役立つテキストを大規模なコーパスから検索します.これにより、モデルは入力コンテキストと検索されたテキストの両方に基づいて予測を行うことができます.このように、リトリーバル・オーグメンテーションを使用することで、リアルワールドの知識が不足した場合でも、モデルは追加情報を得ることができます.例えば、NaturalQuestionsでは、リトリーバル・オーグメンテーションを使用して、文脈から得られる知識だけでは不十分なタスクを解決することができます.
Q: :MMLUとは何ですか?それは、LLMにとってどのような課題であり、入力コンテキストから独立した知識のみが必要なタスクでうまく実行できますか?
A: MMLUとは、多岐にわたる選択肢の問題を含み、一般的な知識を必要とする高度な知識集約型タスクです.一方、自己完結型の知識のみで解決できるタスクでは、LLMsは十分に機能します.具体的には、機械読解(MRC)タスクがその例です.MMLUは、LLMsにとって挑戦的なタスクの一つであり、一般的な知識を必要とします.LLMsは、自己完結型の知識に基づく予測が可能なタスクにおいて、小規模な微調整モデルと同等に優れたパフォーマンスを発揮します.
Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning
著者:Tuomas Haarnoja, Ben Moran, Guy Lever, Sandy H. Huang, Dhruva Tirumala, Markus Wulfmeier, Jan Humplik, Saran Tunyasuvunakool, Noah Y. Siegel, Roland Hafner, Michael Bloesch, Kristian Hartikainen, Arunkumar Byravan, Leonard Hasenclever, Yuval Tassa, Fereshteh Sadeghi, Nathan Batchelor, Federico Casarini, Stefano Saliceti, Charles Game, Neil Sreendra, Kushal Patel, Marlon Gwira, Andrea Huber, Nicole Hurley, Francesco Nori, Raia Hadsell, Nicolas Heess
発行日:2023年04月26日
最終更新日:2023年04月26日
URL:http://arxiv.org/pdf/2304.13653v1
カテゴリ:Robotics, Artificial Intelligence, Machine Learning
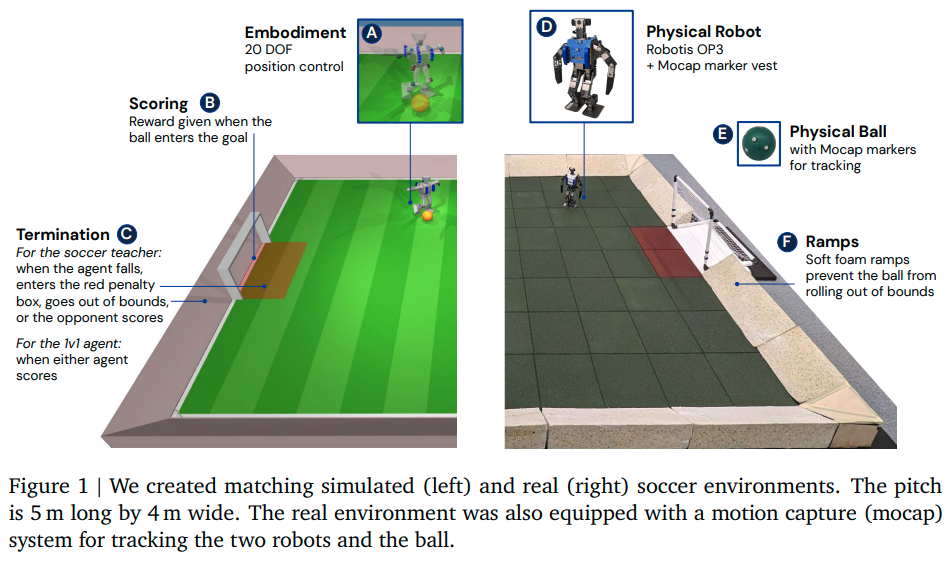
概要:
本研究では、Deep Reinforcement Learning(Deep RL)が、複雑で安全な移動技術を合成し、複雑な行動戦略をダイナミックな環境で実行できる低コストのミニチュアヒューマノイドロボットに適用可能かどうかを調査しました.20のアクチュエータを備えたヒューマノイドロボットに、簡略化された1対1のサッカーゲームのプレイを学習させるために、Deep RLを使用しました.シミュレーションでトレーニングされたエージェントたちは、十分に高周波制御とターゲティングされたダイナミクスの組み合わせが、シミュレーションから現実のロボットへの移行を支援することが分かりました.また、ランダム化やトレーニング中の摂動といった要素が加わり、実際のロボットでのトレーニング時には予想外の要素があったにもかかわらず、良質の転移を可能にしました.ロボットが本来は脆弱であったにもかかわらず、ハードウェアの微小な改良とトレーニング中の基本的な正則化により、安全で効果的な動きを学びながら、ダイナミックで俊敏な方法で動作させることができました.実験では、エージェントたちはスコアを最適化するよう最適化されましたが、スクリプトベースラインと比較して、156%速く歩き、63%早く起き上がり、キックが24%速かったりと、効率的にスキルを組み合わせて長期的な目標を達成しました.また、本研究で紹介されている一連のエマージェントビヘイビアーや1対1の試合については、補足ウェブサイトで確認できます.
Q&A:
Q: :DeepReinforcement Learning(Deep RL)とは何ですか?そして、最近物理ロボットにどのように適用されてきましたか?
A: DeepReinforcement Learning(Deep RL)は、物理的な制約を直接最適化することで、興味のあるタスクや行動に対して汎用性やスケーラビリティを提供し、適応的で長期的な行動を生み出すことができるようになりました.近年、Deep RLは物理ロボットに適用されることが増えており、特に高品質な四足歩行ロボットは、幅広い丈夫な運動行動を生成するために学習がどのように使用されるかのデモンストレーションの対象となっています.例えば、クライミング、ドリブルやキャッチのようなサッカーのスキル、そして四足動物のロボットを用いた体全体の制御やモバイル操作などがあります.
Q: エージェントはどのように訓練され、実際のロボットへのゼロショット転送が可能になったのか、未モデル化の影響やロボットの変動を考慮しても、高品質な転送が可能になる要因は何ですか?
A: エージェントはシミュレーションで訓練され、sufficiently high-frequency control、targeted dynamics randomization、およびトレーニング中の摂動を組み合わせた方法で、ハードウェアの未モデル化の影響やロボットインスタンス間の変動にもかかわらず、zero-shotで実ロボットに転送されました.シミュレーション中のトレーニング中に行われた、簡単なシステム識別、軽度のドメインランダム化、およびランダム力の摂動が、効果的な転送をもたらすことがわかりました.
Q: 深層強化学習は、複雑な知覚に基づく全身制御や複数エージェントの行動も扱えますか?また、現実のロボットで複雑な長期的なマルチスキル行動を創造する際の課題は何ですか?
A: Deep RLを使用して実際のロボットで複雑な長期的な行動を作成する場合、安定性と動的性のどちらを向上させるかについて、多目的RLから得られる洞察を使用することができるが、低レベルの行動では妥協が必要である.また、現在の手法ではシミュレーションから実際のロボットに転移することに頼っており、実際のデータを使用することができない.これらは、Deep RLをロボットに適用する際の一般的な課題である.しかし、自己学習による自動カリキュラムやトランスファー学習を使用することで、この問題を克服することができる.複雑な知覚駆動の全身制御やマルチエージェント行動を扱うことも、Deep RLによって実現可能である.
Q: 報酬関数の選択にどのような要因が寄与していますか?
A: DeepRLにおいて報酬関数を選ぶ際に考慮される要素には、目的、学習速度、報酬のスケール、ノイズに対する強さ、倫理的・実用的制約が含まれます.
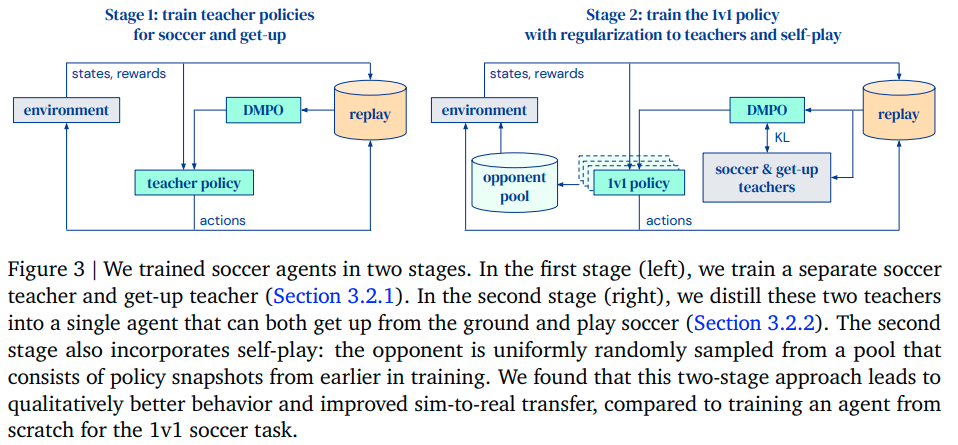
Q: シミュレーションでエージェントをトレーニングするために使用される2段階のパイプラインについて説明してください.
A: 第1段階では、得点と立ち上がりのための別々の先生方針がトレーニングされ、第2段階では、これらの先生方針が1対1のサッカーエージェントに結集され、自己対戦の形式で相手と相互作用するようにエージェントが学習する.自己対戦は、エージェントが遭遇する環境状態のセットを拡張するため、先生方針の頑健性を高めることもあります.
Q: シミュレーションから現実への転送を改善し、ロボットの故障を減らすために含まれる報酬コンポーネントについて、より詳細な情報を提供できますか?
A: sim-to-realの移行を改善し、ロボットの破損を減らすために含まれる報酬要素は、直立姿勢を保ち、11.5°の閾値内にあることを報酬とするものです.これらの2つの報酬要素の組み合わせにより、転送に頑健な方策が生成され、ほとんど膝の齧歯車が壊れず、得点や相手の攻撃に対してほぼ同等のパフォーマンスが得られました.
Q: get-up teacherは、どのようにトレーニングされ、目標のポーズに到達しますか?
A: DeepReinforcement Learningを使用して、get-up teacherはターゲットポーズに到達するように訓練されました.キーポーズを目標として、ポリシーを安定した衝突しない軌道にバイアスするために、ターゲットポーズのシーケンスを使用してget-up teacherを訓練しました.キーポーズ間の補間を行うだけで、ロボットは安定したがやや不器用な方法で立ち上がることができます.キーポーズを学習のガイドに使用しましたが、最終行動は制限していません.get-up teacherは、キーポーズ間の補間ポーズに到達するように訓練されました.そのために、ターゲットジョイントアングルからなるターゲットポーズの追加タスク変数を導入しました.
Q: セクション4.5で実施されたアブレーションに関する知見は何でしたか?
A: 正則化について教師へのアプローチの重要性と自己対戦の利用に焦点を当て、アブレーションを実行しました.教師に正則化を行わずに直接1v1タスクでエージェントをトレーニングすることを試みましたが、この結果、パフォーマンスの低下が見られました.しかし、報酬については、スパースな報酬またはセクション4.3で説明された報酬の形状を使用しても、同様の結果が得られました.また、自己対戦を組み込むことによって得られる効果を調査しました.
Q: 強化学習ポリシーは、歩行速度や起き上がる時間の点で、専門的に手動で設計されたスキルと比較してどうでしたか?
A: 強化学習ポリシーは、手動で設計された専門的なスキルよりも歩行速度が156%速く、起き上がるまでに必要な時間が63%少なかった.
Q: ボールへの追加アプローチを行った学習済みポリシーの平均キックスピードは何であり、スクリプトスキルと比較してどのようなものでしたか? 学習済みポリシーのエピソード毎の最大キックスピードは何でしたか?
A: 学習したポリシーの平均キックスピードは2.6メートル/秒で、スクリプトされたスキルよりも24%速く、エピソード全体で最大キック速度は3.4メートル/秒でした.学習したポリシーはボールの位置に応じた条件付けであったため、ボールを正確に蹴るためにロボットの位置を最適化しました.スクリプトされたスキルと比較して、学習したポリシーがより強力なキックを習得した理由として、追加の走り出しアプローチが挙げられます.
Q: :この論文で紹介されている方法と従来の方法を比較して、どのような利点がありますか?
A: この論文で紹介された方法は、以前の方法と比べて安定性と認識において改善が可能であると考えられ、大きなロボットにも同様の方法が適用可能であり、実世界の実用的な課題を解決することができる可能性があるという利点があります.
Q: この論文の実践的な貢献は何ですか?
A: 論文の実用的な貢献は、より安定したロボットのポリシーを改善するためのメソッドが、大型ロボットで実践的な現実世界のタスクを解決するために適用できる可能性があることを示していることです.また、シミュレーションの微調整や実際のデータの混合などの手法を使用することで、安定した行動スペクトルをさらに広げることができます.
Q: この新しい方法で見つかった困難については何ですか?
A: 新しい方法の実装において、安定性と活力のバランスを取ることが難しいという課題が見つかりました.また、現在の方法はシミュレーションから現実への移行にのみ依存しており、現実のデータを活用することで安定性と知覚性を改善できる可能性があります.さらに、より人間らしい挙動を実現し、堪え忍ぶ能力や安全性を向上させるために、他の制御方法を使用することが考えられます.また、より大きなロボットを使用する場合には、さらに別の課題が予想されます.
Q: :実験やデータ分析から得られた主要な結論は何ですか?
A: 実験やデータ分析から得られた主要な結果は、安定性と知覚の観点で政策を改善することができ、結果は励みになると同時に、同様の手法をより大きなロボットに適用して実践的な実世界のタスクを解決することができるということです.また、1v1サッカーのエージェントは、シュートやボールコントロール、走行などのモーションスキル、守備や戦略的な動きなど、さまざまなエマージェントビヘイビアを展開し、自己プレイや教師の正規化が重要であることが明らかにされています.
Q: 今後の研究に残された課題は何ですか?
A: 物理ロボットに適用するDeep Reinforcement Learningの研究において、今後の課題は何ですか? 今のアプローチは、シミュレーションをベースにしたものであり、現実のデータの取得や、多目的RLにより、安定性と柔軟性を向上させる取り組みや、複数のエージェントによる競争による複雑な動作の発生については、まだ課題が残されています.
AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head
著者:Rongjie Huang, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, Yi Ren, Zhou Zhao, Shinji Watanabe
発行日:2023年04月25日
最終更新日:2023年04月25日
URL:http://arxiv.org/pdf/2304.12995v1
カテゴリ:Computation and Language, Artificial Intelligence, Sound, Audio and Speech Processing
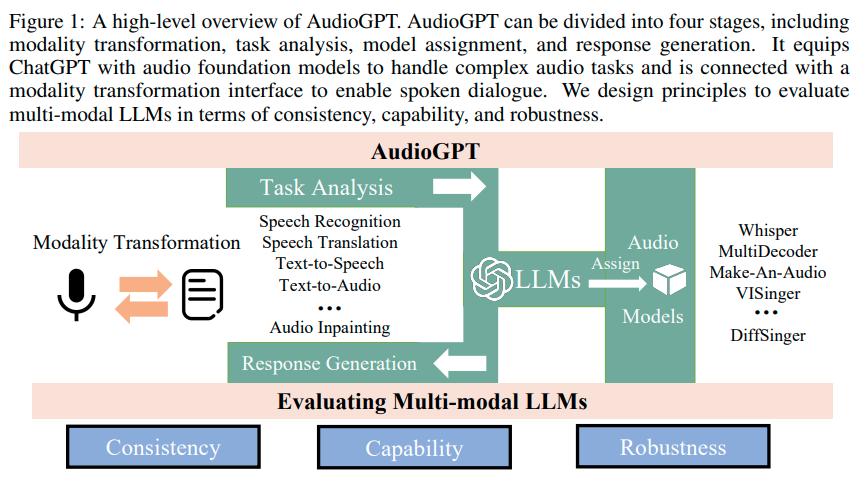
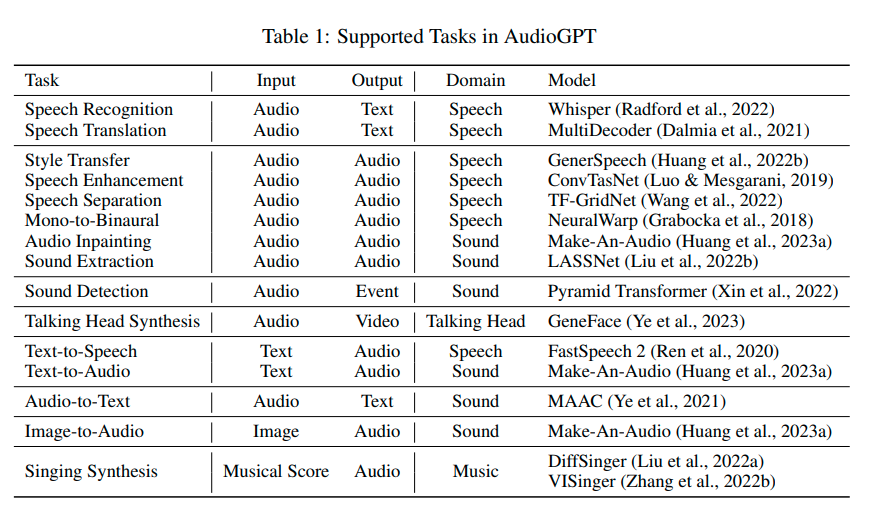
概要:
音声と音楽の理解・生成能力を持つMulti-Modal Language Model(マルチモーダル言語モデル、Multimodal LLM)であるAudioGPTを提案し、オーディオコンテンツ制作における前例のない簡単さを実現しました.当社のシステムは、\url{https://github.com/AIGC-Audio/AudioGPT}で公開されており、大規模な言語モデルの中で音声と音楽を扱うことができます.私たちの提案は、現代の学習と認知の理解を反映しています.
Q&A:
Q: AudioGPTとは何ですか、そしてそれはLLMsを補完する方法は何ですか?
A: AudioGPTは、LLMs(ChatGPT)を補完するために音声ファンダメンタルモデルを備えたマルチモーダルAIシステムです.これにより、AudioGPTは複雑な音声タスクを処理し、音声対話を可能にするための変換インタフェースと接続されます.つまり、AudioGPTは、LLMsに音声情報を処理するためのファンダメンタルモデルを提供し、音声理解や生成などの多数のタスクを解決することができます.
Q: オーディオモダリティ情報を処理する際の制限は何であり、なぜ人工的な一般的知能を達成する必要があるのでしょうか?
A: 音声モダリティ情報を処理する上での制限は、2つあります.1つ目は、ChatGPTの最大トークン長さによる対話の複数ターン制限と、2つ目は、AudioGPTがオーディオファウンデーションモデルに強く依存しているため、これらのモデルの精度と効果に影響される能力の制限です.
Q: AudioGPTプロセスの4つのステージは何でしょうか?
A: AudioGPTの4つのステージは、モダリティ変換、タスク分析、モデルの割り当て、そしてレスポンス生成です.これらのステージは、複雑なオーディオタスクを処理するためにChatGPTにオーディオ基盤モデルを提供し、音声対話を可能にするモダリティ変換インターフェースと接続されています.これらのステージは、一貫性、能力、頑健性の観点からマルチモーダルLLMの評価原則を設計します.
Q: :複数のラウンド対話において、AudioGPTが複雑な音声情報を処理する能力を示すいくつかの実験結果は何ですか?
A: 複数のAIタスクを含む音声、音楽、サウンド、およびトーキングヘッドの理解と生成において、AudioGPTが多数回の対話で解決する能力に優れた実験結果が示されています.これにより、人間が前例のない簡単さで豊かで多様な音声コンテンツを作成することができます.
Q: この論文の主な貢献は何ですか?
A: 論文の主な貢献は、AudioGPTが多様なAIタスクで音声、音楽、音や話し手の理解や生成を処理する能力を示す実験結果である.また、多数のラウンドの対話で音声情報を処理する能力を示し、人々が簡単に多様な音声コンテンツを作成できるようにしたことである.筆者らは、Multi-modal LLMsの評価原則とプロセスの設計を概説し、AudioGPTの一貫性、能力、頑健性を試験した.ただ、現在の原稿は、主にシステムの説明をカバーしている.
Q: タスクハンドラーHとは何ですか?
A: タスクハンドラーHは、クエリのI/Oモダリティに基づいて、異なるタスクファミリーにクエリを分類します.具体的には、クエリリソースfq(s1)n、q(s2)n、…、q(sk)n gからq0 nに分類され、タスクファミリーが選択された後、クエリの説明q0(d)nがプロンプトマネージャーMに渡され、引数anを生成するために使用されます.
Q: 選択されたオーディオ基礎モデルPpとその対応するタスク関連の引数hPpに基づいて、プロンプトマネージャーMが引数を生成する方法を説明してもらえますか?
A: 選択されたオーディオファウンデーションモデルPpとそれに対応するタスク関連引数hPpに基づいて、プロンプトマネージャーMは引数anを生成します.式(4)を使用して、タスクハンドラーHが選択したタスクファミリーに基づいてq0(d)nのクエリ記述がプロンプトマネージャーMに渡され、その結果、Mは選択されたオーディオファウンデーションモデルPpとその対応するタスク関連引数hPpを含む引数anを生成します.
Q: I/Oモダリティに基づいて、タスクハンドラーHによって考慮される異なるファミリーは何ですか?
A: I/Oモダリティに基づいて、タスクハンドラーHによって考慮される異なるファミリーは何ですか? → Audio-to-Text、Unsupported tasks、Error handling of multi-modal models、Breaks in contextの4つのファミリーが考慮されます.
Q: AudioGPTはどのようなタスクを実行し、どのドメインモデルを使用しますか?
A: AudioGPTは音声認識、音声翻訳、スタイル変換、音声強化、音声分離、モノラルからバイノーラル、音声インペインティング、音声抽出、音声検出、話し手合成、テキストから音声、音声からテキスト、画像から音声、歌声合成のタスクを実行し、各タスクにはそれぞれのドメインのモデルが使用されます.
Q: 話し言葉、音楽、音、そしてトーキングヘッドを理解し、生成することは、より高度なAIシステムにつながりますか?
A: 音声、音楽、音声、およびトーキングヘッドを理解および生成することが、より高度なAIシステムの開発にとって重要なステップであるため、強力な影響を与える可能性があります.人間は日常会話で話し言葉を使用し、生活の便利さを高めるために話し言葉アシスタント(たとえばSiriやAlexa)を利用するため、音声モダリティの情報処理は人工的一般的知性を実現するために必要なものです.また、音声、音楽、音声、およびトーキングヘッドを理解および生成することは、LLM向けの重要なステップであり、より高度なAIシステムの開発に繋がる可能性があります.
Q: この論文で紹介された方法の古い方法と比べた利点は何ですか?
A: 本論文で紹介された方法は、従来の方法に比べて、音声、音楽、音響、トーキングヘッドなどのAIタスクを多数のダイアログで処理し、豊富で多様な音声コンテンツを作成する能力が向上することが実験結果から示され、頑健性、能力、一貫性の点で評価するdesign principlesとプロセスを提供するという大きな利点があります.ただし、現在のマニュスクリプトにおいては、よりデモンストレーションのために実験が設計されていることに注意が必要です.
Q: この論文の実用的な貢献は何ですか?
A: この論文の主要な貢献は、AudioGPTの一貫性、能力、および頑健性の評価プロセスと設計原則を明らかにすることであり、実験結果は、複雑なオーディオ情報を処理するためにAudioGPTが持つ能力を示している.AIタスクには音声、音楽、音声理解、およびTalking Headの生成が含まれている.
Stable and low-precision training for large-scale vision-language models
著者:Mitchell Wortsman, Tim Dettmers, Luke Zettlemoyer, Ari Morcos, Ali Farhadi, Ludwig Schmidt
発行日:2023年04月25日
最終更新日:2023年04月25日
URL:http://arxiv.org/pdf/2304.13013v1
カテゴリ:Machine Learning, Computer Vision and Pattern Recognition
概要:
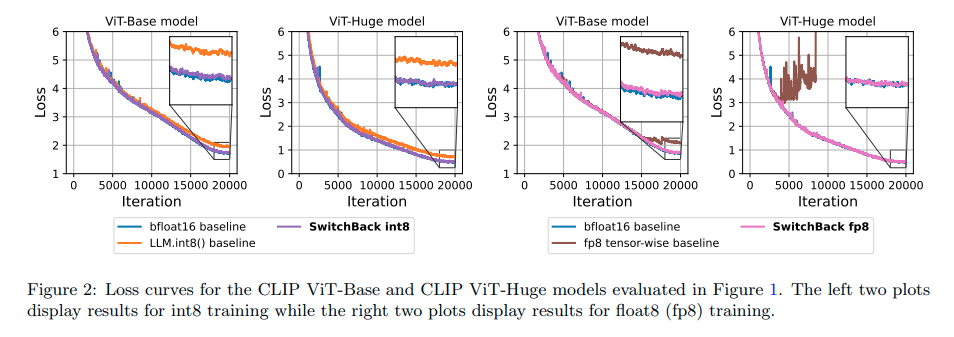
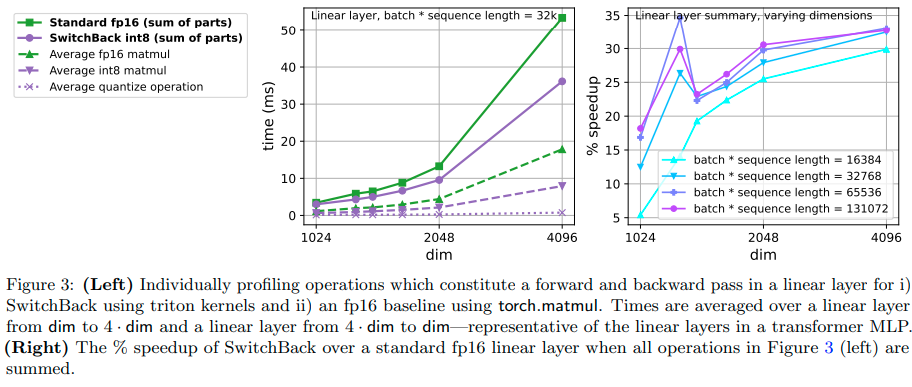
本論文では、大規模な言語・ビジョンモデルのトレーニングを加速し、安定化する新しい方法を紹介します.1つ目は、int8量子化トレーニング用の線形層であるSwitchBackを導入し、1BパラメータCLIP ViT-Hugeの場合、bfloat16トレーニングと同等のパフォーマンスを実現しながら、13-25%の高速化を実現します.GPUがfloat8をサポートすることは稀であるため、int8に重点を置いていますが、float8トレーニングについてもシミュレーションを行い、標準的な技術でも大きな特徴量が抑制されるように初期化およびトレーニングされている場合には同じく効果的であることを示しています.2つ目は、損失スパイクの分析で、AdamWは2番目のモーメント推定値が過小評価される8イテレーション後に一貫して発生することがわかります.そのため、gradient clippingを上回るStableAdamWというAdamW-Adafactorハイブリッドを推奨し、CLIP ViT-Hugeモデルのトレーニングでロススパイクが回避され、パフォーマンスが向上することを示します.
Q&A:
Q: SwitchBackとは何ですか?それはint8量子化モデルのトレーニングをどのように加速しますか?
A: SwitchBackは、int8の量子化モデルのトレーニングを加速するための線形層であり、最初の2つの行列乗算に8ビットの精度を使用し、重みの勾配にはより高い精度を使用します.これにより、速度の向上と精度の低下を防止することができます.
Q: int8を例にした行ごとの量子化のコンセプトは何ですか?
A: row-wise quantizationとは、入力と勾配に対して行単位で量子化を行い、重みに対してはテンソル単位で量子化を行う手法です.例えば、int8を使った場合、-127から127の整数を表現できます.行列Xの各行x1、x2、…、xbの行単位量子化Qrowは、式(1)で定義され、テンソル単位量子化Qtensorは、式(2)で定義されます.
Q: CLIPとは何ですか?また、なぜこの研究でCLIPスタイルのモデルを調べるのですか?
A: この研究では、CLIPと呼ばれるコンピュータビジョンのモデルを調査しています.CLIPスタイルのモデルは、画像分類タスクの幅広い範囲で最先端のパフォーマンスを発揮するとされ、Fast trainingとStable trainingに向けた貢献をしています.
Q: セクションCで詳細に説明されているLLM.int8()がCLIPトレーニングの16ビットパフォーマンスを再現できない理由に関する仮説は何ですか?
A: Section Cの分析に基づくと、CLIPモデルの重み勾配は、前向きおよび層間逆伝播操作に比べて51.2倍から12.8倍もノイズが多いため、LLM.int8()のトレーニングは16ビットパフォーマンスを再現できない可能性が高く、SGDに十分な信号を与えて局所的な最小値に収束させることができないことが原因と考えられます.
Q: zero-init layerscaleとは何ですか?また、浮動小数点数8のトレーニングを可能にする方法は何ですか?
A: zero-init layerscaleは、float8トレーニングを可能にするために機能するものであり、self-attentionまたはmlpブロックの出力をゼロで初期化された学習可能なベクトルで乗算することで、低精度トレーニングに適した高い特徴量の大きさを防止します.また、他の初期化およびスケーリング手法と比較して、zero-init layerscaleはゼロで初期化されており、簡単に使用できるため、精度を犠牲にすることなくfloat8トレーニングが可能になります.
Q: layer-scaleとは何ですか?layer-scaleテンソルを使用した事前規格化トランスフォーマーブロックでどのように使用されますか?
A: layer-scaleは、学習時のトランスフォーマーの各ブロックの出力に対して、初期化時にゼロで初期化された可学習パラメータを乗算する手法です.これにより、深層ネットワークにおける大きな出力値の問題を解消することができます.pre-norm transformer blockで使用する場合は、出力に対してスケーリングを施すことで、レイヤーノーマライゼーションの代わりとなります.
Q: Section 3.3はトレーニング中の損失スパイクに関して何を見つけましたか?
A: 3セクションの結果によると、低精度トレーニング中に損失スパイクが発生することがあり、大きな活性化や勾配が共存することがわかりました.これらのスパイクは、低精度トレーニングにおいては制限された表現範囲で問題を引き起こす可能性があるため、成功した学習のためには損失スパイクの削減が重要であることが示されています.また、多数のスパイクが観察され、Inf / NaN値が発生して損失スカラーが多数回落ちることがあることもわかっています.
Q: なぜAdaFactorは、大規模なトレーニングにおいてAdamWに比べて性能が低く評価されているのでしょうか?
A: AdaFactorのAdamWに対する劣る理由は、スケールが大きい場合、Lionよりも性能が低いことです.しかし、この研究の目的は、ハイブリッドを使用することを推奨することであり、そのためにPaLMはAdaFactor-AdamWのハイブリッドを使用していると考えられますが、アップデートクリップは使用していないと信じられています.
Q: 学習率は損失のスパイクにどのように影響しますか?
A: 学習率の増加に伴い、損失スパイクが増加することがわかっています.逆に、過度に減少させると学習が遅くなり、パフォーマンスが低下する可能性があります.AdamWの2hyperparameterを減らすことで、スパイクを軽減できることがわかっています.
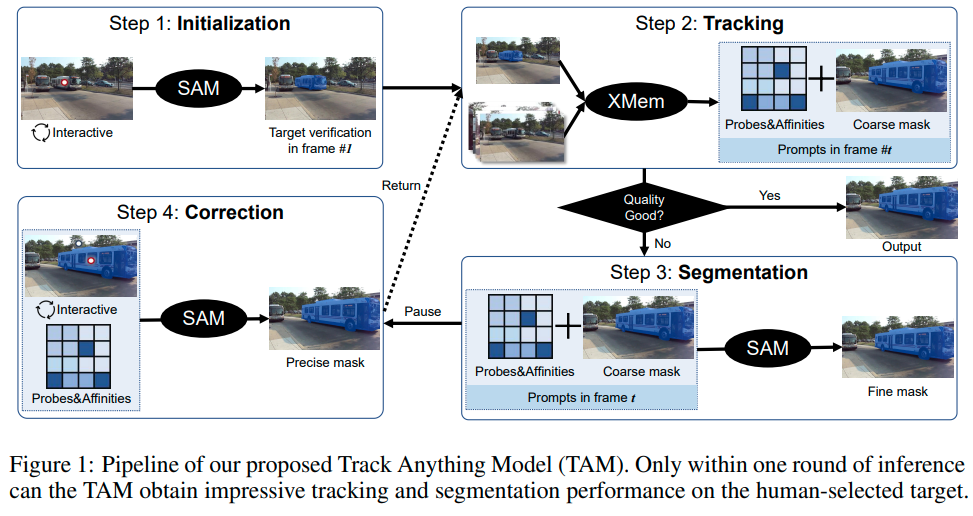
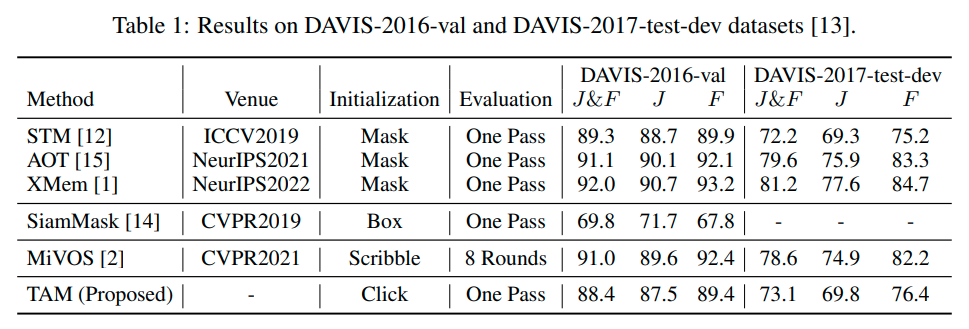
Track Anything: Segment Anything Meets Videos
著者:Jinyu Yang, Mingqi Gao, Zhe Li, Shang Gao, Fangjing Wang, Feng Zheng
発行日:2023年04月24日
最終更新日:2023年04月28日
URL:http://arxiv.org/pdf/2304.11968v2
カテゴリ:Computer Vision and Pattern Recognition
概要:
最近、Segment Anything Model(SAM)は、画像の印象的なセグメンテーション性能により、急速に注目を集めています.画像セグメンテーションの強力な能力と異なるプロンプトとの高い相互作用に関して、私たちは、ビデオにおいて一貫したセグメンテーション性能が低いことがわかりました.そのため、本報告では、ビデオにおける高性能なインタラクティブなトラッキングとセグメンテーションを実現するTrack Anything Model(TAM)を提案します.具体的には、ビデオシーケンスが与えられた場合、わずかな人間の関与、すなわち数回クリックするだけで、興味を持ったものを追跡し、一回の推論で満足のいく結果を得ることができます.追加のトレーニングなしで、このようなインタラクティブな設計は、ビデオオブジェクトのトラッキングとセグメンテーションにおいて印象的な性能を発揮します.すべてのリソースは{https://github.com/gaomingqi/Track-Anything}で利用可能です.この作品が関連する研究を促進することを願っています.
Q&A:
Q: :Track-Anythingプロジェクトとは何ですか?その目的は何ですか?
A: Track-Anythingプロジェクトとは、高性能なオブジェクト追跡とセグメンテーションのための効率的なツールキットを開発することを目的としたプロジェクトです.ユーザーフレンドリーなインターフェースを備えたTrack Anythingモデル(TAM)を使用することで、任意の動画内のオブジェクトを追跡およびセグメンテーションすることができます.
Q: Track Anythingモデル(TAM)はどのように機能し、その貢献は何ですか?
A: TrackAnything Model (TAM)は、高速なオブジェクトトラッキングとセグメンテーションのための効率的なツールキットを開発するプロジェクトであり、SAMとXMemを統合して、1回の推論で動画内のオブジェクトを追跡およびセグメンテーションすることができます.TAMの貢献は、SAMを動画レベルで適用して、インタラクティブなビデオオブジェクトトラッキングとセグメンテーションを実現することであり、長時間のオブジェクトトラッキング、ビデオ注釈、ビデオ編集、ビデオタスク向けの視覚化開発ツールキットなど、いくつかのアプリケーションを可能にします.TAMは、ユーザーフレンドリーなインタフェースで簡単に使用でき、効率的なアノテーションプロセスを提供します.
Q: SAMとXMemはTAMに統合され、相互作用するSAMの初期化のプロセスは何ですか?
A: TAMはSAMとXMemを統合することで構成されており、SAMはインタラクティブに初期化されます.初めに、ユーザーはSAMをインタラクティブに初期化し、ターゲットのオブジェクトを定義します.次に、XMemを使用して、次のフレームでオブジェクトのマスク予測を行います.その後、SAMがより正確なマスク記述を提供します.トラッキングプロセス中、トラッキングの失敗に気付いたら、ユーザーは一時停止して修正することができます.
Q: Track Anythingタスクとは何ですか?Segment Anythingタスクとは何が違いますか?また、Track Anythingタスクでターゲットオブジェクトを選択、追加、または削除することの利点は何ですか?
A: Track Anythingタスクでターゲットオブジェクトを柔軟に選択、追加、削除できるため、それによって多様なダウンストリームタスクが達成できます.例えば、単一または複数のオブジェクトトラッキング、短期・長期のオブジェクトトラッキング、教師なしVOS、準教師ありVOS、参照VOS、インタラクティブVOS、長期VOSなどが挙げられます.
Q: 5「Track-Anythingプロジェクト」にはどのような潜在的な応用があり、文章によると、多様な下流タスクに使用できるビデオの種類は何ですか?
A: Track-Anythingプロジェクトの潜在的な応用は、効率的なビデオ注釈、長期的なオブジェクト追跡、そしてユーザーフレンドリーなビデオ編集です.ビデオ注釈のタスクとしては、ビデオオブジェクトトラッキングやビデオオブジェクトセグメンテーションなどに使用できます.ビデオ編集の場合、Track Anything Modelは、オブジェクトのセグメンテーションとトラッキングの機能を提供します.ビデオの種類は、トリムされたビデオ以外にも任意の長さや種類が使用でき、多様な下流タスクを達成することができます.
Q: 「Interactive VOS」とは何であり、どのような入力を行い、オブジェクトマスクを指定する場合と比較してどのように注意を引きますか?
A: Interactive VOSは、ユーザーがスクリブルなどの入力を行い、その結果を反復的に改良して、満足のいくセグメンテーション結果を得ることができる方法です.一方、オブジェクトマスクの各ピクセルを指定する必要がある従来の手法と比較して、スクリブルの提供がはるかに簡単であるため、注目を集めています.ただし、従来のInteractive VOSの手法には、複数のラウンドが必要なため、実際の応用において効率が低下するという問題があります.
Q: TAMはどのようにして失敗を追跡し、ビデオオブジェクトの認識における極端な困難に対処していますか?
A: TAMは、トラッキングの失敗を検出した場合に一時停止し、ユーザーが失敗を修正することができるようにすることで、トラッキングの失敗に対処しています.また、複雑な構造や正確さを必要とするオブジェクトにはまだ対処できないため、より長期的なメモリ保存と短期的なメモリ更新の仕組みが重要であると述べています.
Q: この新しい方法にはどのような困難がありますか?
A: 現在のインタラクティブVOSの方法では、複数のラウンドを必要としているため、現実世界の応用において効率が低下するという問題が発見されました.また、複雑なオブジェクト構造にも苦戦しているため、適切なマスクの初期化が困難であり、予測の精度を低下させる可能性があることがわかりました.
Q: :実験またはデータ分析から得られた主な発見は何ですか?
A: 実験やデータ分析から得られた主な結果は、TAMがクリックのみで初期化して一度の推論で評価された際に、DA VIS-2016-valおよびDA VIS-2017-test-devデータセットでJ&Fスコア88.4と73.1を得たこと、さらにTAMが難しい複雑なシナリオにおいても優れたトラッキングおよびセグメンテーション能力を示したことである.また、図2の定性的な結果からも、TAMがマルチオブジェクト分離、ターゲット変形、スケール変更、カメラ移動などをうまく処理できることが示された.
Q: :この論文で紹介された新しい方法の実装はどこで見つけることができますか?
A: この論文で紹介されている新しい方法の実装は、https://github.com/gaomingqi/Track-Anythingで利用可能です.
A Cookbook of Self-Supervised Learning
著者:Randall Balestriero, Mark Ibrahim, Vlad Sobal, Ari Morcos, Shashank Shekhar, Tom Goldstein, Florian Bordes, Adrien Bardes, Gregoire Mialon, Yuandong Tian, Avi Schwarzschild, Andrew Gordon Wilson, Jonas Geiping, Quentin Garrido, Pierre Fernandez, Amir Bar, Hamed Pirsiavash, Yann LeCun, Micah Goldblum
発行日:2023年04月24日
最終更新日:2023年04月24日
URL:http://arxiv.org/pdf/2304.12210v1
カテゴリ:Machine Learning, Computer Vision and Pattern Recognition


概要:
自己教育学習(Self-supervised learning, SSL)は、機械学習を進めるための有望な方法であり、「知の暗黒物質」とも呼ばれています.しかし、料理と同様に、SSLメソッドをトレーニングすることは、高い参入障壁を持つ繊細な芸術です.多くのコンポーネントは馴染みがありますが、成功裏にSSLメソッドをトレーニングするには、前提タスクからトレーニングハイパーパラメータまで、目まぐるしいような選択肢が含まれています.このようなSSL研究への参入障壁を下げることを目的に、私たちは料理本のようなスタイルで、SSLの基礎と最新のレシピを紹介したいと考えています.私たちは、興味のある研究者が方法の領域を探索し、様々な操作の役割を理解し、SSLのおいしさを探求するために必要な知識を得られるようにしたいと思います.
Q&A:
Q: セルフスーパーバイズドラーニングとは何ですか?監督学習と非監督学習との違いは何ですか?
A: 自己教示学習(Self-supervised learning)は、ラベルの付いていない大量のデータから学習する手法で、監視学習(supervised learning)とは違い、ラベルされたデータの入手可能性に制限されないため、より広範囲なデータから学習が可能です.また、自己教示学習では、特定のタスクに限定されず、様々なタスクに適用できる表現が得られます.一方、非監視学習(unsupervised learning)とは、データにラベルを付けずに学習する手法であり、自己教示学習と似ていますが、非監視学習はデータの分布を学習するのに対し、自己教示学習は特定の目的に向けた表現を学習します.
Q: :SSLメソッドを成功裏に実装するために実際的な考慮事項は何ですか?
A: Self-supervised learningの方法を成功させるための実用的な考慮事項は何ですか? (回答:成功を収めるためには、データの品質に注意し、モデルの選択についても慎重に検討することが重要です.また、SSLの方法には膨大な種類があるため、理解するためには時間がかかる場合があります.しかし、適切に導入すると、ラベルの付いていないデータからも高い性能を発揮できます.)
Q: 対照的学習の考え方と、拡張入力を同様に表現するようにモデルを促す方法とは何ですか?
A: コントラスティブ学習とは、2つの入力が同じクラスから来るか否かを予測することによって、モデルの表現能力を向上させる手法です.類似した入力は互いに近く、異なる入力は互いに遠く表現されます.コントラスティブ学習は、既知の意味を保持する変換を使って、1つの入力のバリエーションを形成して行われます.これにより、モデルは拡張された入力を同様に表現する能力を獲得します.
Q: SSLの4つの大きなファミリーと、それぞれを簡単に説明できますか?
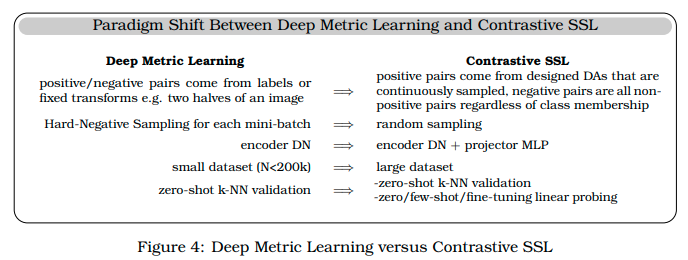
A: Self-supervised learning (SSL)の4つの広範なファミリーは、以下の通りです. 1)Deep Metric Learning Family、2)Self-Distillation Family、3)Canonical Correlation Analysis Family、4)Masked Image Modeling Familyです.Deep Metric Learning Familyは、入力の意味的に変換されたバージョンの類似性を促進する原則に基づいており、contrastive lossという認識目的に変換することで、学習目的として使用されます.Self-Distillation Familyは、学習済みのモデルから出力される確率分布に対して、損失関数を最小化して、入力画像にラベルをアサインします.Canonical Correlation Analysis Familyは、データセットの2つの異なるビューを追跡して、それらの表現の間の相関係数を最大化するように学習されます.Masked Image Modeling Familyは、出力されたカスタマイズされた画像を元の画像と同じくらい実用的であることを確認するために使われます.
Q: self-distillationとは何ですか?BYOL / SimSIAM / DINOなどの方法でどのように機能しますか?
A: Self-distillationは、BYOL/SimSIAM/DINOのような手法で利用されており、正解データを自己生成し、学習を進めることで、モデルの崩壊を防ぐための機構です.BYOLは、オンラインネットワークと目標ネットワークを使用し、同じ画像の異なる角度から導出された2つのビューを用いて、画像変換により連続的なターゲットを定義して学習します.オンラインネットワークの重みの指数平均によるゆっくりとした更新が、先生ネットワークの学習を促進します.
Q: SSLモデルと監督学習モデルの比較における潜在的な利点は何ですか?
A: SSLモデルは、教師あり学習方法と比較して、ラベルの高価さや特定のタスクが事前にわからない場合にも有用な汎用的な表現を学習できる可能性があります.また、敵対的な例やラベルの破損、入力の不規則性に対してもロバストな表現を学習し、公平性が高いというデータもあります.したがって、SSLモデルは注目を集めています.
Q: SSL法を正しくトレーニングするために必要な選択肢は何ですか?プレテキストタスクやトレーニングハイパーパラメータを含みますか?
A: SSL(自己監督学習)を成功させるためには、前提タスクからトレーニングハイパーパラメータまで、多くの選択肢があります.SSLの研究には計算コストが高いこと、複雑な実装の細かい詳細を開示した論文が存在しないことなど、入門のハードルが高いため、成功させるためには多くの選択肢が必要です.
Q: SSLモデルでの特異値分布の意味と重要性を説明できますか?
A: 特異値分布は、学習された表現の次元の崩壊を測定するために使用される.その崩壊を評価するために、特異値の数値分布、古典的なランク推定、特異値分布のべき乗則に合わせたフィッティングやAUCなど、いくつかの測定方法があります.しかし、これらの方法はすべて表現のランクを評価することに焦点を当てており、学習された表現の次元の崩壊を測定するために用いられます.
Q: ImageNet以外にも、SSLモデルの事前学習によく使用されるデータセットの例を示せますか?
A: ImageNet以外に、COCOやiNaturalistなどのデータセットがSSLモデルのプリトレーニングによく使用されています.また、Goyalらによる大規模な未編集データセットの使用についても研究が行われていますが、ImageNetのプリトレーニングは一般的なやり方として残っています.
Q: 著者は、より広範な下流タスクでの移植性を向上させるためにどのような提言をしていますか?
A: 転移性を高めるために、著者は幾つかの戦略を提案しています.それらは、多様な入力モーダルを使用すること、異なるオブジェクトジェネラルな地平面を対象とする前処理を採用すること、高い次元数を扱うためにより強力な表現能力を持つアーキテクチャを採用すること、大規模で多様なデータセットを使用すること、そしてSSL pre-trainingを複数回、連続的に行うことです.
Q: NNCLRとは何であり、埋め込み空間でどのように使用されていますか?
A: NNCLRは、埋め込み空間で最近傍を使用して、エンコーダに追加のクロップをフィードする計算負荷を除去する方法です. NNCLRでは、一致するポジティブクロップが潜在的な空間で最も近い近傍に置き換えられます.これにより、マルチクロップと同様の効果が得られ、正のペア関連の信号が増加します.この戦略は、UniVCLなどの方法でも使用されています.これらの手法すべてが、マルチクロップよりも小さい計算コストで、有意な性能向上を示しています.NNCLRにおいて、このk-NNグラフの使用は、トレーニング時間をわずか6%増加させるだけです.
Q: stochastic-depthとは何ですか? それはどこから発展し、ビジョンモデルでどのように使用されますか?
A: stochastic-depthは、NLPから発展した手法で、ビジョンモデルでより深いモデルをトレーニングするために使用されます.この手法は、ViTのブロックをランダムに削除することによって規正化することで、大型モデルのトレーニングに重要です.レイヤーごとのドロップ率は、レイヤーの深さに応じて線形に依存することができ、最近の研究では一様に依存することが示唆されています.ViT-LやViT-Hなどの大きなモデルのトレーニングには重要ですが、ViT-Bなどの小さなモデルのトレーニングには通常悪影響を与えます.
Q: iBOTとは何ですか?また、蒸留に基づくMIMにおいて教師と学生の両方がViTsをどのように使用するのですか?
A: iBOTは、教師としてのViTsと生徒としてのViTsを、蒸留ベースのMIMで使用する手法です.iBOTでは、蒸留ベースのMIMとして、ViTsを教師ネットワークと生徒ネットワークの両方に使用し、ImageNet分類の最先端手法を上回る結果を出しました.
Q: この論文で紹介された方法の利点は、従来の方法と比較して何ですか?
A: iBOTという論文で紹介された手法は、ViTsを使って教師と生徒の両方にマスクイメージモデリング(MIM)を用いた蒸留ベースのpretrainingを行うことで、従来の手法より高い性能を発揮することができます.具体的には、ImageNet classificationで先行研究を上回る成果を出しています.また、教師モデルの選択を気にする必要がなく、段階的に蒸留を行うことができることなど、重要な発見も行われています.
Q: :この論文の実用的な貢献は何ですか?
A: iBOTの論文の実用的な貢献は、凍結したエンコーダーを使用して幅広いビジョンタスクで競争力のある性能を実現し、マスク画像モデリングとself-distillationなどの古典的な手法の混合で構成されることです.また、オリジナルの画像を再構成ターゲットとして使用する代わりに、教師ネットワークを使用してターゲットを提供することで、教師あり学習を使用せずにマスク画像モデリングの目的を達成しています.
Q: この新しい方法で見つかる困難は何ですか?
A: iBOTという論文で導入された新しい手法の実装には、複雑な実装を詳細に説明した完全に透明な論文がないことが課題となっています.
Q: 実験やデータ分析から得られた主要な発見は何ですか?
A: iBOT論文における主な発見は、ViTsを使った教師ありMIMの蒸留法により、ImageNetの分類において従来の手法を上回る性能を発揮したことです.また、この方法では蒸留を段階的に行うことで、教師モデルの選択について慎重に選ぶ必要はないということが明らかになりました.
Q: :今後の研究に残る課題は何ですか?
A: SSLの信頼性にとって重要な汎化保証、公平性のプロパティ、および自然に発生する変動に対する耐性などの未解決の研究課題が依然として存在します.
Evaluating ChatGPT’s Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness
著者:Bo Li, Gexiang Fang, Yang Yang, Quansen Wang, Wei Ye, Wen Zhao, Shikun Zhang
発行日:2023年04月23日
最終更新日:2023年04月23日
URL:http://arxiv.org/pdf/2304.11633v1
カテゴリ:Computation and Language
概要:
最近では、ChatGPTのような大規模言語モデル(LLM)の能力によって、ユーザーの意図を理解し、合理的な応答を提供することが可能になり、非常に人気が高まっています.本論文では、ChatGPTの全体的な能力を評価するために、7つの微細情報抽出(IE)タスクに焦点を当てています.特に、ChatGPTのパフォーマンス、説明可能性、較正、忠実度を測定し、ChatGPTまたはドメインエキスパートから15のキーを結果として示しています.研究結果から、ChatGPTのパフォーマンスはStandard-IE設定では悪いが、OpenIE設定では人間の評価によって優れたパフォーマンスを発揮することが判明しました.また、ChatGPTは、その決定の高品質かつ信頼できる説明を提供することができることが示されました.ただし、ChatGPTの予測において過度の自信があり、結果として較正が低下するという問題があります.さらに、ChatGPTは、ほとんどの場合において元のテキストに忠実度が高いことが示されました.この研究では、7つの微細IEタスクのテストセットを手動で注釈付けし、さらに研究を推進するために、14のデータセットを含むデータセットとコードが公開されています.公開されたデータセットやコードは、https://github.com/pkuserc/ChatGPT_for_IEで入手可能です.
Q&A:
Q: ChatGPTのパフォーマンスを作者たちはどのように評価し、他の言語モデルと比較したか?
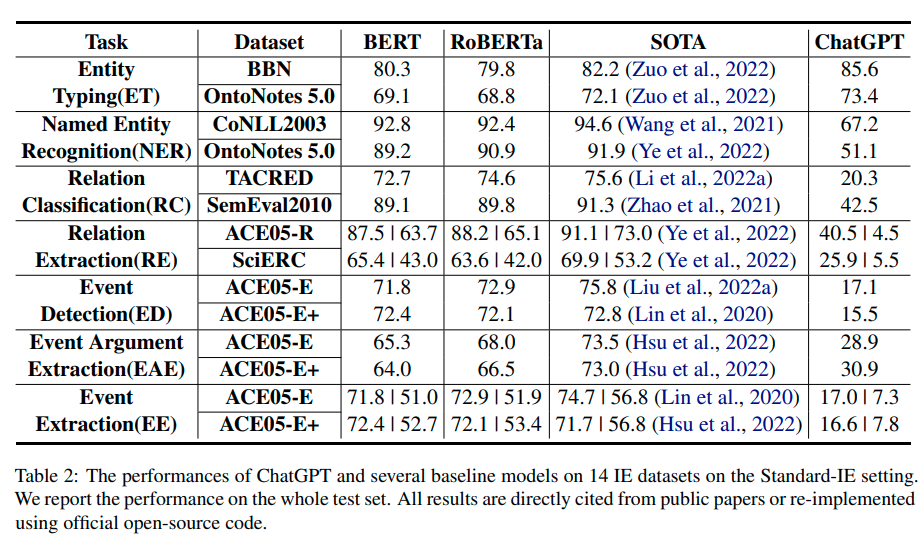
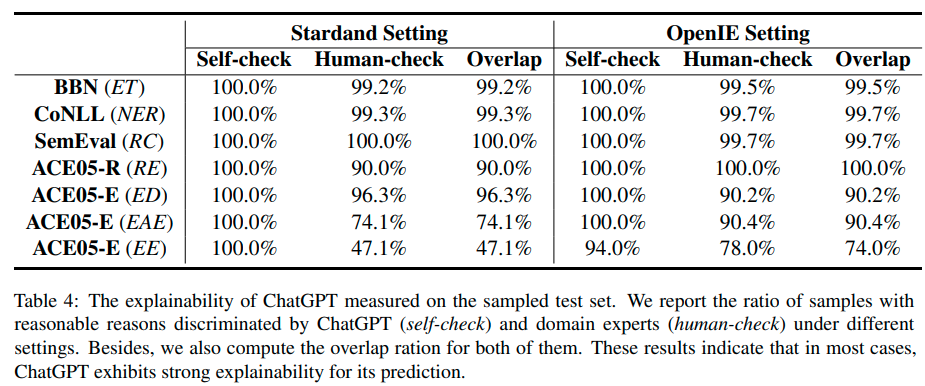
A: ChatGPTの性能を4つの観点(性能、説明可能性、キャリブレーション、忠実度)について包括的かつ体系的に評価し、自己チェックと人間のチェックを両方行い、15つのキーを集めました.さらに、14のデータセットで7つの細分化されたIEタスクを検証し、その結果を他の人気のあるモデルと比較しました.
Q: :ChatGPTのIEタスクにおける能力の潜在的な実世界応用にはどのようなものがありますか?
A: ChatGPTの能力を利用したIEタスクの潜在的な現実世界の応用例には、コンピューターやスマートフォンの自然言語処理、自然言語による会話AI、データ分析、情報検索、機械翻訳、クエリー応答、バーチャルアシスタント、および音声制御などがあります.
Q: この研究の主な貢献と制限は何ですか?
A: 研究の主な貢献は、ChatGPTが人生に及ぼす潜在的な影響に焦点を当てたことでした.制限には、研究が他の側面について探求する余地があることが挙げられます.
Q: より大きな言語モデルでは、どのような新しい能力が観察されますか?
A: 大規模な言語モデルでは、小規模なモデルでは観察されなかった新しい能力が現れることがあります.これにより、見たことのないタスクに対して強い汎用性を発揮することが可能となります.
Q: 研究者が特定したChatGPTの人生への潜在的な影響は何であり、その使用に関連する倫理的リスクは何ですか?
A: 研究者たちは、ChatGPTの潜在的な人間生活への影響を調べており、その利用に伴う倫理的リスクを指摘しています.倫理的リスクには、ハッキングや不正アクセスのリスク、プライバシー侵害のリスク、そして人工知能による偏見や差別のリスクなどがあります.また、ChatGPTの応用先として、教育、医療、自然言語処理のさまざまなタスクなどが注目されています.
Q: ChatGPTは、教育・医療分野でどのように活用され、これらの分野でどのような利点がありますか?
A: ChatGPTは、教育・医療分野で非常に役立ちます.教育分野では、ChatGPTを使用することで、生徒たちは質問に迅速に回答を得ることができます.また、テスト前に簡単なクイズを行ったり、教科書からの質問に答えたりすることができます.これにより、生徒たちは自己学習能力を向上させ、より深く学習することができます.
医療分野では、ChatGPTは医師や患者たちに役立ちます.医師はChatGPTを使用して、患者からの質問に即座に回答することができます.また、ChatGPTを使用して、患者たちに病気や治療方法についての情報を提供することができます.これにより、医師はより多くの時間を患者の治療に費やすことができます.
Q: チャットGPTにおける研究者によって探索されている今後の開発や応用の可能性は何ですか?
A: ChatGPTの可能性についての研究者たちの関心は、倫理的リスクや教育、医療などの分野においてもある一方で、自然言語処理の様々なタスクへの応用に対するChatGPTの潜在的能力を調査する研究もあります.
Q: 2023年のMitrovicらとGuoらの調査で調べられたように、人間が書いた文章とChatGPTが生成した文章の主な違いは何ですか?
A: Mitrovic et al.は、ChatGPTが生成するテキストがしばしば単純であり、文法的に誤っていることがある一方、Guo et al.は、ChatGPTが人間に近い性能を発揮するようになってきていることを示しており、人間とChatGPTにはまだ違いがあるものの、ChatGPTの生成するテキストは信頼性の高い説明を提供できることが分かっています.
Q: この論文の理論的貢献は何ですか?
A: この論文における理論的な貢献は、ChatGPTが細かい情報抽出タスクにおいてどのようなパフォーマンスを示すかを評価することである.具体的には、パフォーマンス、説明性、較正、信憑性の4つの側面から網羅的かつシステマチックな評価を行い、15の指標を収集した.さらに、7つの細かい情報抽出タスクに関する14のデータセットを用いてChatGPTの総合的なパフォーマンスを評価し、他の人気モデルと比較した結果、標準の情報抽出設定ではパフォーマンスが良くないが、オープンな情報抽出設定では人間の評価において優れた精度を示したことが明らかになった.さらに、ChatGPTは高品質かつ信頼性が高い決定の説明を提供する能力を備えていることもわかった.ただし、ChatGPTの予測に過度な自信を持つ傾向があるため、較正の点で低いことが課題である.また、ChatGPTは、原文に基づいて高い忠実度を示し、その予測は入力テキストに基づいているということが分かった.これらの結果は、将来の研究のために全ての手動アノテーションデータセットとコードを公開している.
Q: :この新しい方法で見つかった困難点は何ですか?
A: この論文で紹介された新しい手法には、ChatGPTがいくつかの課題を抱えていることがわかりました.キャリブレーション現象が多くの場合支配的であり、特に情報抽出タスクにおいて、計測の改善が必要であると示唆されています.また、ChatGPTはより複雑な情報抽出タスクに苦戦し、REやEEなどのタスクでは、より深い文脈分析と推論能力が必要であるため、パフォーマンスが異なることが示されました.
Q: 実験やデータ分析から得られた主な発見は何ですか?
A: この論文の実験やデータ分析から得られた主な発見は何ですか? ChatGPTは、IEタスクにおいてカリブレーションの問題を抱えることが明らかになり、さらに、偽情報を提供する可能性があることが判明しました.作者たちは、これらの問題を改善する必要性があることを示唆しています.また、ChatGPTモデルの忠実度を評価するために、忠実度がメトリックとして使用されています.
Scaling Transformer to 1M tokens and beyond with RMT
著者:Aydar Bulatov, Yuri Kuratov, Mikhail S. Burtsev
発行日:2023年04月19日
最終更新日:2023年04月19日
URL:http://arxiv.org/pdf/2304.11062v1
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning

概要:
この技術レポートでは、自然言語処理において最も効果的なTransformerベースのモデルの一つであるBERTのコンテキスト長を拡張するために再帰メモリを応用した手法が紹介されている.再帰メモリTransformerアーキテクチャを利用することで、モデルの有効なコンテキスト長を前例のない200万トークンに拡張することに成功し、高いメモリ検索精度を維持している.この手法により、ローカル情報とグローバル情報の両方を格納および処理することができ、再帰を利用して入力シーケンスのセグメント間で情報のフローを可能にする.実験により、この手法の有効性が示され、自然言語理解および生成タスクにおける長期依存性の処理を向上させる可能性があるだけでなく、メモリ集約型アプリケーションの大規模なコンテキスト処理を可能にすることが示された.
Q&A:
Q: RMTとは何ですか?そして、Transformerを1Mトークン以上にスケーリングするためにどのように役立ちますか?
A: RMTは、トークンベースのメモリメカニズムを導入することで、BERTなどの事前学習済みTransformerモデルと組み合わせることで、1Mトークン以上のシーケンスに対して完全な注意力と完全な精度の操作を単一のNvidia GTX 1080Ti GPUで適用できるようにする手法です.
Q: RMTの反復メモリは2Mトークンを跨いで情報を保持する方法は何ですか?
A: RMTは、再帰的なメモリとトランスフォーマーを組み合わせて、メモリをセグメント単位で伝達することによって、2Mトークンの情報を保持するメカニズムを持っています.具体的には、RMTは、再帰的なメモリをBERTモデルに追加することで、7個のセグメント(それぞれ512トークン)にわたる課題に対してタスク固有の情報を保持できます.推論の過程では、モデルは最大4,096セグメントにわたる2,048,000トークンの情報を効果的に活用し、トランスフォーマーモデルに報告された最大の入力サイズ(CoLT5の64Kトークン、GPT-4の32Kトークン)を大幅に上回ります.
Q: この方法の潜在的な応用分野は何ですか?
A: RMTとTransformerモデルを組み合わせることで、大規模なトークンシーケンスを保持するための潜在的な応用がある.特に、長い情報を必要とするタスクにおいて、この組み合わせは便利であり、言語モデリングといった根本的なアプリケーションにも適用可能である.
Q: メモリの拡張されたBERTは、どの程度の長さのシーケンスに対応できるように訓練されていますか?
A: RMT-enabled Transformerモデルは、1つのNvidia GTX 1080Ti GPUを使用して、1百万トークンを超えるシーケンスに対して完全なアテンションと完全な精度操作を適用できます. RMTは、最初に設計された入力長(512トークン)の7倍の長さのシーケンスに対処するためにトレーニングされ、1百万トークンを超えるシーケンスでもほぼ完璧に汎化できます. RMTモデルが必要とする計算量は、シーケンスが1セグメントを超える場合(512より大きい場合)に非再起的モデルより少なくなるため、長いシーケンスの場合に有利に働きます.
Q: どのようにして訓練されたRMTが、100万トークンを超える計算が必要なタスクをうまく処理できるようになったのか?
A: RMTは、トークンベースのメモリメカニズムを組み合わせたBERTということ前学習済みトランスフォーマーモデルによって、線形スケーリングされた演算を用いて1,000,000以上のトークンを単一のNvidia GTX 1080Ti GPUで処理することができるようになっています.さらに、より長い入力長さに対しては、モデルをより多くのセグメントにトレーニングすることで、RMTの汎化能力が高まり、長いタスクでもほぼ完璧に汎化することができます.また、モデルがより長いシーケンスにも対応できるようにするには、アテンション・パターンの分析が必要でした.
Q: RMTにおける記憶と再現の基盤は何ですか?
A: RRMTのメモリ操作は、キーとバリューの対で構成され、特定のパターンを持つアテンションで行われます.再帰性はなく、非再帰モデルよりも少ないFLOPsで大量のシーケンスを処理できます.ただし、32,000以上の極めて長いシーケンスになると、二次スケーリングに戻ることがあります.
Q: この方法ではどのような情報を保存し、処理することができますか?
A: RMT方法を使用することで、長いシーケンスの情報をストレージし、処理することができます.また、RMTは単純な事実や基本的な推論を記憶することも可能です.さらに、自然言語テキストと関係のないノイズを含んだタスクにおいても、RMTは情報を区別し、問題を解決することができます.
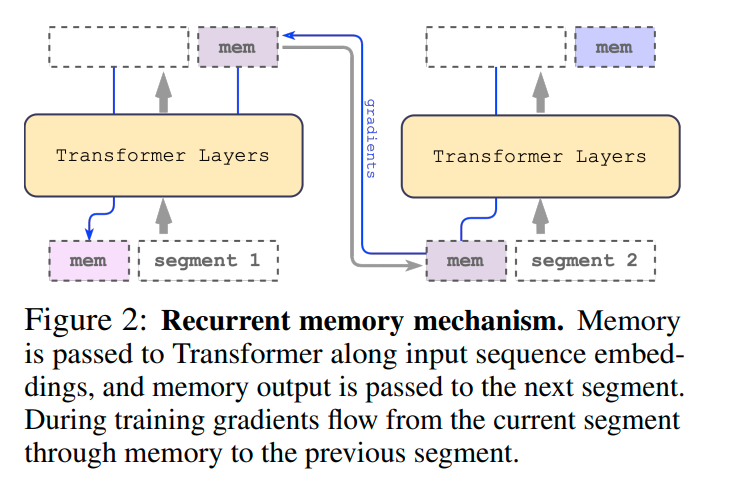
Q: トークンベースのメモリストレージとセグメントレベルの再現性をBERTに組み込むことで、どのように向上されましたか?
A: RMTは、BERTにトークンベースのメモリストレージとセグメントレベルの再帰を取り込むことで実現されます.記憶トークンの出力は、入力シーケンス埋め込みとともにTransformerに渡され、メモリは次のセグメントに渡されます.これにより、RMTによるメモリ拡張は、Transformerファミリーの任意のモデルと互換性があります.
Q: セグメントの長さが固定されている場合、RMTはどのモデルサイズに対しても線形スケーリングを実現するのですか?
A: RMTは、入力シーケンスをセグメントに分割し、完全なアテンション行列を計算することにより、セグメント長が固定された場合に、どのモデルサイズでも線型スケーリングを実現します.
Q: この実験におけるカリキュラム学習のプロセスは何ですか?
A: 短いバージョンのタスクでRMTを初めにトレーニングし、収束したら、タスクのセグメントを1つ追加して入力長さが必要な長さに達するまでカリキュラム学習プロセスを続けることで、トレーニングスケジュールを使用することでソリューションの正確さと安定性が大幅に向上することがわかった.
Q: この論文で紹介された方法の古い方法との比較での利点は何ですか?
A: この論文で紹介されている方法の利点は、旧来の方法と比較して、より長い入力に適用するのが容易であり、再帰的なアプローチとメモリを使用することで、二次的な複雑性を線形に減らせる点です.また、この方法でトレーニングされたモデルは、遥かに長いテキストにも適用でき、その能力を大幅に拡張できます.
Q: 新しい方法を実装するにはどの程度の計算リソースが必要ですか?
A: 必要な計算リソースは、長いシーケンスに応じて異なりますが、この方法は従来のモデルよりも少ないFLOPsを必要とし、クワドラチックなスケーリングを回避することができます.
Q: この論文の理論的貢献は何ですか?
A: この論文では、長期的な入力に対しても適用可能なメモリの強化ニューラルネットワークの方法が紹介されています.この方法は、学習されたメモリ操作のスケーラビリティーを拡大することができ、いくつかの異なるタスクで高い性能を示しています.さらに、この方法のアーキテクチャは、ニューラルアーキテクチャにおけるメモリの概念を今後発展させるための有用なアイデアを提供しているとされています.
Q: この新しい方法において見つかった困難は何ですか?
A: このモデルの最も重要な課題は、注意操作の二次の複雑さであり、大規模なモデルを長い入力に適用することがますます困難になるため、入力のスケーリングを制限することです.また、この方法の一般的な制約は、トレーニングと推論の両方において、入力サイズと共にメモリ要件が増大することであり、ハードウェア制約により、入力スケーリングを不可避的に制限します.しかし、再帰的なアプローチとメモリを使用することで、二次の複雑さを線形に減らすことができます.さらに、十分に大きな入力でトレーニングされたモデルは、桁違いに長いテキストに対する能力を外挿できることが示されています.ただし、この方法の実装には、適切なハードウェアが必要であるという難点があります.
Q: :今後の研究に残る課題は何ですか?
A: 将来の研究では、再帰メモリ手法を最も一般的に使用されるTransformersに適用して、効果的な文脈サイズを改善することを目的としています.また、見えない特性を持つタスクについてRMTを一般化するためのマイルストーンとして合成課題を探求することも計画しています.さらに、Attention操作の二次的な複雑性を軽減する新しいメカニズムの開発も重要な課題です.
