
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をQ&A形式を用いて要点を記載してみました.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.
紹介する論文は目次に記載されている9本となります.
Sparks of Artificial General Intelligence: Early experiments with GPT-4
著者:Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, Yi Zhang
発行日:2023年03月22日
最終更新日:2023年03月27日
URL:http://arxiv.org/pdf/2303.12712v3
カテゴリ:Computation and Language, Artificial Intelligence
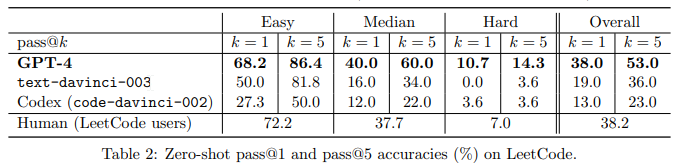
Q: AGIをより深く、より包括的なバージョンに進めるために、どのような課題があるのでしょうか.
A: 1994年の知能の定義が曖昧で不完全なものであり、能力の測定方法や比較方法が明示されていないことを認めています.さらに、この定義には反映されていないかもしれない、人工システム特有の課題や機会もある.この論文では、知能を理解するための意欲的な目標を掲げていますが、最近のAI研究の成功の多くは、明確に定義されたタスクや課題に焦点を絞ったものであることに留意してください.本稿では、より一般的なAIシステムの必要性を論じ、より一般的な知能システムの基礎となりうる原理を特定する.AGIには、広く受け入れられている単一の定義が存在しないことを指摘するものである.
Q: GPT-4は様々な産業や分野でどのような応用が考えられるか?
A: 論文の結論では、人工的なシステムがより深く総合的なAGIバージョンに向けて進む上での課題と機会が議論されています.言及されている課題や機会の中には、AGI自体の定義の明確化、AGIのためのLLMsの欠落部品の構築、最近のLLMsによって表示される知能の起源の理解向上、誤情報や操作への対処、偏見への対処、人間の専門知識、雇用、経済への影響の考慮、様々な影響や考慮事項の総合的な考慮があります.
Q: GPT-4がゲームを作成し、特定の言語構造を解釈する能力の限界は何ですか?
A: GPT-4は、ゲームの記述や特定の言語構成要素の解釈など、幅広いコーディング作業に対応することができます.しかし、まだ完璧なコーディングができるわけではなく、特に長いプログラムや複雑なプログラムでは、構文的に無効なコードや意味的に正しくないコードを作成することがあります.GPT-4は、既存のパブリック・ライブラリに依存するような集中的なプログラムを書くことに関しては高い能力を発揮しますが、異なるタイプの環境やタスクに対する性能について一般的な結論を出すためには、より大規模で多様な実世界の問題に対する体系的な評価が必要です.また、GPT-4は、現在の世界の知識の欠如や、数学のような記号的な操作の難しさなど、様々な弱点を抱えている.
Q: GPT-4に関連して、既存のコードを理解することの重要性についてお話しください.
A: 既存のコードを理解することは、他の人が書いたコードを読み、解釈し、修正することを可能にするため、GPT-4のコーディングの重要な側面です.このスキルは、GPT-4が既存のコードと統合したり、複雑で文書化されていないコードを扱う必要があるような、実世界のコーディングの課題やタスクで不可欠です.
Q: GPT-4とChatGPTの違いは何ですか?
A: GPT-4は、数学的な問題解決において、ChatGPTよりも大幅な改善を示しています.ChatGPTが低レベルのヒューリスティックに頼ることが多く、実際の理解力に欠けるのに対し、問題に対する深い理解や複雑な問題でも適切な推論を適用する能力を示しています.
Q: GPT-4がテキストを生成する概念を本当に理解しているかという懸念に対処し、その答えを支持する根拠を示すことができますか?
A: この論文では、GPT-4が数学、グラフ理論、常識的な推論など、様々な領域の概念を理解していることを示す証拠が提示されています.また、GPT-4が実際に理解しているのではなく、即興で処理している可能性があるという懸念に対処するため、モデルが概念を深く理解していることを反映するように推論、正当化、そして説明する能力を示すことで、著者たちは答えています.しかし、論文は、GPT-4の計画能力や文脈依存性などの限界を認め、幅広い知能を持つAIシステムをテストおよび分析するためのより形式的で包括的な方法を開発するための更なる研究を呼びかけています.
Q: AGIモデルが自然言語によるプログラミングのツールとして、今後コーディングにどのような革命をもたらすか、その可能性についてお聞かせください.
A: この質問に対する明確な回答は書かれていません.しかし、AGIの初期バージョンともいえるOpenAIが開発した新しいLLMが、数学とコーディングにまたがるタスクを特別なプロンプトなしで解決できることに言及しています.また、より包括的なAGIの実現に向けて、次の単語を予測する以上の新しいパラダイムを追求する必要があるなど、今後の課題についても述べています.
Q: GPT-4はどのような範囲のコーディング作業に対応できるのでしょうか?
A: GPT-4は、コーディングチャレンジから実世界のアプリケーション、低レベルのアセンブリから高レベルのフレームワーク、単純なデータ構造からゲームなど複雑なプログラムまで、幅広いコーディングタスクを処理することができます.また、コード実行に関する推論、命令の効果のシミュレーション、そして自然言語で結果を説明することもできます.GPT-4は既存の公開ライブラリに依存するプログラムの書き方に高い熟練度を持っており、一般的なソフトウェアエンジニアの能力に比べて優れています.ただし、GPT-4はまだコーディングに完全ではなく、特に長い、またはより複雑なプログラムについては、構文的に無効または意味的に間違っているコードを生成することがあります.
Q: GPT-4は、他者が異なる言語やパラダイムで書いた既存のコードをどのように理解し、推論しているのでしょうか?
A: GPT-4は、異なる言語やパラダイムであっても、他人が書いた既存のコードを理解し、推論する能力を持っています.コードの読み取り、解釈、実行が可能で、アセンブリコードのリバースエンジニアリングや、様々な分野の実世界のコーディング課題でもテストされています.
Q: この論文の実用的な意味は何ですか?
A: この論文では、AGI自体の定義、AGIのためにLLMに欠けているコンポーネントの構築、最近のLLMが示す知性のより良い理解など、より深く、より包括的なバージョンのAGIに向けて前進するためのいくつかの直接的な次のステップについて論じている.これらの議論の実用的な意味合いは、提供された文脈では明示されていないが、これらの領域でのさらなる研究開発が、AGI技術の進歩につながる可能性を示唆している.
Q: この論文の理論的な意味は何ですか?
A: この論文では、AGI自体の定義、AGIの欠落している部分のLLMsの構築、そして最近のLLMsによって表示される知能の理解を向上させるための、いくつかの即座の次のステップについて議論しています. この論文はまた、AIおよびAGIのより形式的で包括的な定義を提案しようとする文献が進行中であることを認め、”人工的一般知能”(AGI)というフレーズは、知性のより広い概念に向かって進むという願望を強調するために、2000年代初頭に普及したことを指摘しています. この論文は、大きな言語モデル(LLMs)による自然言語処理の進歩が、過去数年間のAI研究における最も注目すべきブレークスルーであることを示唆していますが、最近のAI研究の多くの成功は、明確に定義されたタスクや課題に狭く焦点を絞っており、より一般的なAIシステムの開発は、以前のAI研究の望みであったことも指摘しています. この論文は、議論の理論的な含意は何かという質問に明確な答えを与えていませんが、GPT-4の能力と制限に関する論文の探索が、技術的な飛躍が達成されたことを支持し、GPT-4の知能がコンピュータサイエンスおよびその先における真のパラダイムシフトを示しているとの評価を支持すると示唆しています.
Q: 実験やデータ解析で得られた主な知見は何ですか?
A: GPT-4の性能の様々な側面について話し合われています.例えば、誤った前提条件があっても正確な回答を提供できる能力、技術的な熟練度と頻繁な誤り、論点の各ステップを批判的に検討することに欠ける能力などです.また、GPT-4がChatGPTと比較して、異なるドメインやスタイルの一般的な原則やパターンを創造的かつ斬新な方法で合成する能力の例も提供されています.ただし、この文脈では実験やデータ分析から得られた具体的な主要な結論は提供されていません.
Artificial muses: Generative Artificial Intelligence Chatbots Have Risen to Human-Level Creativity
著者:Jennifer Haase, Paul H. P. Hanel
発行日:2023年03月21日
最終更新日:2023年03月21日
URL:http://arxiv.org/pdf/2303.12003v1
カテゴリ:Artificial Intelligence, Human-Computer Interaction
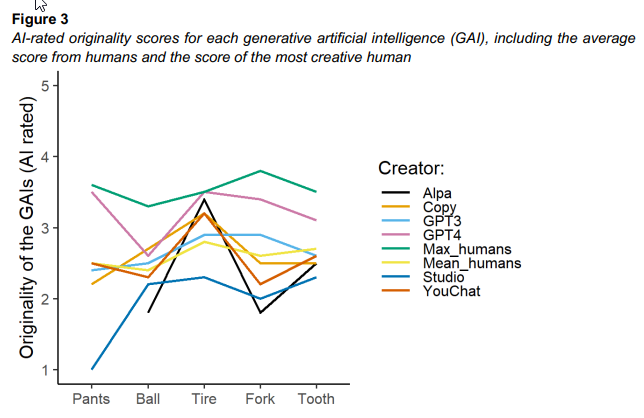
Q: 記事の主眼は何でしょうか?
A: 記事の主な焦点は、GAI(Generative Artificial Intelligence)の創造性をめぐる議論であり、創造性の未来を形作る上で潜在的な利点と欠点があるのかどうかということです.
Q: この研究でクリエイティビティはどのように定義され、測定されたのでしょうか?
A: クリエイティビティとは、オリジナルなアイデアを生み出す能力と定義され、書き物やチャットボットの会話、画像生成などの様々なタスクで、人間かGAIsがより創造的にアイデアを生み出すかを比較して測定された.流暢さ得点は、各参加者とGAIチャットボットが生成したアイデアの合計として計算された.この研究は、人間の創造性と創造的出力を詳しく調べることによって、GAIの創造的ポテンシャルに関する議論を進めることを目的としている.
Q: この結果は、AIの未来や創造性の可能性に対してどのような示唆を与えているのでしょうか?
この研究によると、GAIsは創造的なアウトプットを生成する可能性があり、人間の創造的な仕事を支援することができます.しかし、倫理的なジレンマに取り組み、人間のパフォーマンスを置き換える万能ツールとして見ることは避けることが重要です.自動化がますます普及するにつれ、人間の創造的な能力を持つ役割がより重要になります.この研究の結果は、GAIが創造性の未来を形作る上で持つ潜在的な利点と欠点を理解する上で重要な意味を持っています.
Q: GAIとはどのようなもので、どのような仕組みになっているのでしょうか?
A: 生成型人工知能(GAI)は、以前に収集されたデータから学び、新しい状況に適応することを可能にするアプローチです.自動化された意思決定プロセスを支援し、大規模なデータセットのパターンを検出し、人々の効率を向上させます. GAIの開発者は、彼らのソフトウェアが創造的であることを主張しており、最近の研究では、AIが生成したアイデアと人間が生成したアイデアの間に質的な違いはないことが示されています. GAIは創造的なプロセスで貴重なアシスタントになることができ、創造的タスクでのGAIの継続的な研究開発は、この技術の潜在的な利点と欠点を形成する創造性の未来を完全に理解するために重要です.
Q: 人間の創造性を支援し、高めるためにGAIはどのように活用できるのか?
A: 生成的人工知能(GAI)は人間の創造性を支援し、向上させるために活用されることができます.複雑なタスクで人間の創造性をサポートし、単調なタスクを自動化することで、人間がより創造的なタスクに集中できるようにし、知識を再結合してオリジナルのアイデアを生成することもできます. GAIは、考えやアイデアをレビューし、アイデアを拡張し、創造的な問題解決プロセスを支援するツールとしても活用できます.ただし、GAIの潜在的な誤用や有害な応用に対処する必要があります.
Q: 医療、教育、エンターテインメントなど様々な領域でGAIを活用することで、どのような意味合いや可能性があるのでしょうか?
A: GAIの日常生活での使用が増えるにつれ、私たちの仕事、コミュニケーション、創造性が変わりつつある.それは自動化された意思決定プロセス、大量のデータセットのパターン検出、人々の効率向上に役立っている.多くのタスクが自動化されるため、従業員はより複雑で創造的なタスクに取り残されることになり、人間の創造性と問題解決能力が必要とされる.GAIが複雑なタスクを遂行する可能性が高まるにつれ、GAIが人間の創造性をサポートし向上させる方法を探求する関心も高まっている.GAIが文書作成ツール、チャットボット、画像生成といった創造作業を適切にサポートする可能性は実際にあるが、他の高度な技術同様、誤用や有害な応用の可能性があるため、倫理的ジレンマは適切に対処されなければならない.医療、教育、エンタメなど、様々な分野でGAIの開発が進められることで、創造性の未来を形作る上でこの技術の可能性と欠点を十分に理解することが重要である.
Q: GAIの利用が進む中で、倫理的な配慮や懸念はどのようなものが考えられるか.
A: どのような技術であっても、誤用や有害な応用の可能性はあり、GAIの利用が進むにつれて、倫理的ジレンマに適切に対処する必要があります.
Q: 近年、AIはどのように創造力を発揮しているのでしょうか?
A: AIは、作曲、中国のボードゲーム「囲碁」の勝利、肖像画家の創造性の模倣など、さまざまな事例を通じて創造性の能力を実証しています.また、ある研究では、アイデアを出すなどの作業において、AIと人間が生み出す創造性の間に質的な差はないことが判明しました.しかし、AIシステムの不正確さは、信頼できる知識創造ツールとしての使用に疑問を投げかけ、AIシステムの正確な応用可能性と限界に関する議論を促しています.
Q: little-cの日常的な創造性と、Big-cの遠大な結果をもたらす創造的な仕事との違いは何ですか?
A: Little-cの日常的な創造性とは、テンポが速く、即興に関連し、日常の仕事や生活に組み込まれている創造的な仕事を指します.一方、Big-Cクリエイティブワークとは、より多くの時間や特定の知識を必要とし、潜在的な解決策がうまくいくかどうかを判断するためのテスト段階をしばしば必要とするクリエイティブな成果を指します.また、Big-C創造的な仕事は、ある領域や社会的な領域に対して、広範囲に及ぶ結果をもたらすものです.
Q: GAIが倫理的かつ責任を持って使用されるために、どのような対策がとられているのでしょうか?
A: GAIの誤用や有害な応用の可能性という倫理的ジレンマに適切に対処する必要があり、あらゆる潜在的な技術と同様に、誤用の可能性があることに言及しています.しかし、GAIを倫理的かつ責任を持って使用するための具体的な対策は示されていない.
Q: GAIがクリエイティブの未来にもたらす可能性のあるメリットとデメリットは何でしょうか?
A: GAIが創造性の未来を形作る上で持つ可能性のメリットには、GAIとの組み合わせで創造的なアウトプットを生成することができる可能性があり、アイデアを広げることで人間の創造的な作業を支援し、思考やアイデアの検討のための貴重なアシスタントとして機能することができるということが挙げられます.欠点には、倫理的ジレンマや、どんな強力な技術でも誤用や有害な利用の可能性があることが挙げられます.さらに、GAIが本当に創造的であるか、単に既存の知識を再構成して新しい形で現れるだけなのかについて議論があるということが挙げられます.
Q: この論文の実用的な意味は何ですか?
A: 本研究は、生成型人工知能(GAI)が、文章作成、チャットボット、画像生成など様々な分野で創造的なアウトプットを生成することにより、人間の創造性を支援する可能性を示唆しています.しかし、GAIの潜在的な誤用や有害な適用に関する倫理的な懸念に対処する必要がある.本研究では、GAIチャットボットを、人間のパフォーマンスを代替できる全能のツールではなく、思考やアイデアを確認するための貴重なアシスタントとして捉えることを推奨しています.自動化が私たちの労働生活に浸透するにつれて、創造性と想像力がより重要になるでしょう.
Q: この論文の理論的な意味は何ですか?
A: この研究では、生成型人工知能(GAI)がオリジナルなアイデアを生成する点で人間と同様に創造的であり、創造的プロセスの貴重なアシスタントとなる可能性があることが示唆されています.創造的タスクにおけるGAIの継続的な研究と開発は、この技術の潜在的な利点や欠点を完全に理解するために重要です.また、GAIの誤用や有害な適用の可能性に関する倫理的な懸念を解決する必要があることも強調されています.全体的に、この研究は、AIが創造的であることに対する一般的な仮定に挑戦し、GAIsがアイデアを拡大する上で貴重な役割を果たす可能性があることを示唆しています.
Q: 実験やデータ解析で得られた主な知見は何ですか?
A:この研究では、人間が生み出したアイデアとGAIチャットボットが生み出したアイデアの間に、創造性のレベルに大きな差はないことがわかりました.しかし、場合によっては、人間の方がGAIチャットボットよりも創造的であると評価されることもありました.また、テストした5つのGAIチャットボットは、いずれも他のチャットボットよりも独創的であることは確認されませんでした.最後に、どの回答を独創的とみなすかについては、人間もAIもほぼ同意していることがわかりました.6人の人間による評価者間の信頼性は、5つのプロンプトすべてにおいて優れていることが判明しました.
Q: 今後の研究課題として残っているものは何でしょうか?
A: 創造性の未来を形作る生成人工知能(GAI)の潜在的な利点と欠点を完全に理解するために、今後取り組むべき研究課題として、GAIが「真の」創造性を発揮できるかどうかを探ること、倫理的ジレンマやGAI技術の誤用・有害適用の可能性に適切に対処することが挙げられる.さらに、人間の創意工夫や問題解決能力を必要とする複雑で潜在的により創造的な作業において、GAIがどのように人間の創造性を支援し強化するために使用できるのか、さらなる研究が必要である.
GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models
著者:Tyna Eloundou, Sam Manning, Pamela Mishkin, Daniel Rock
発行日:2023年03月17日
最終更新日:2023年03月23日
URL:http://arxiv.org/pdf/2303.10130v4
カテゴリ:General Economics, Artificial Intelligence, Computers and Society, Economics
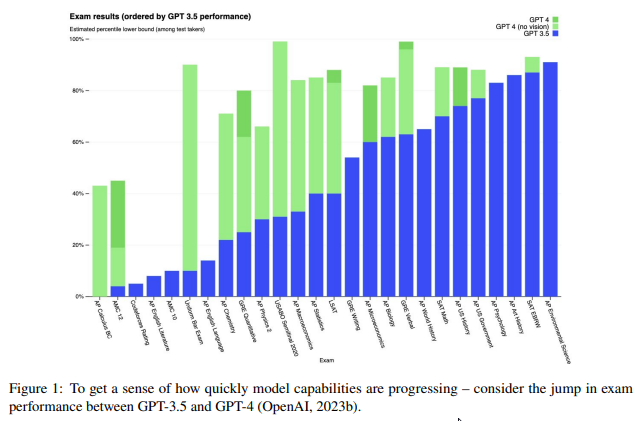
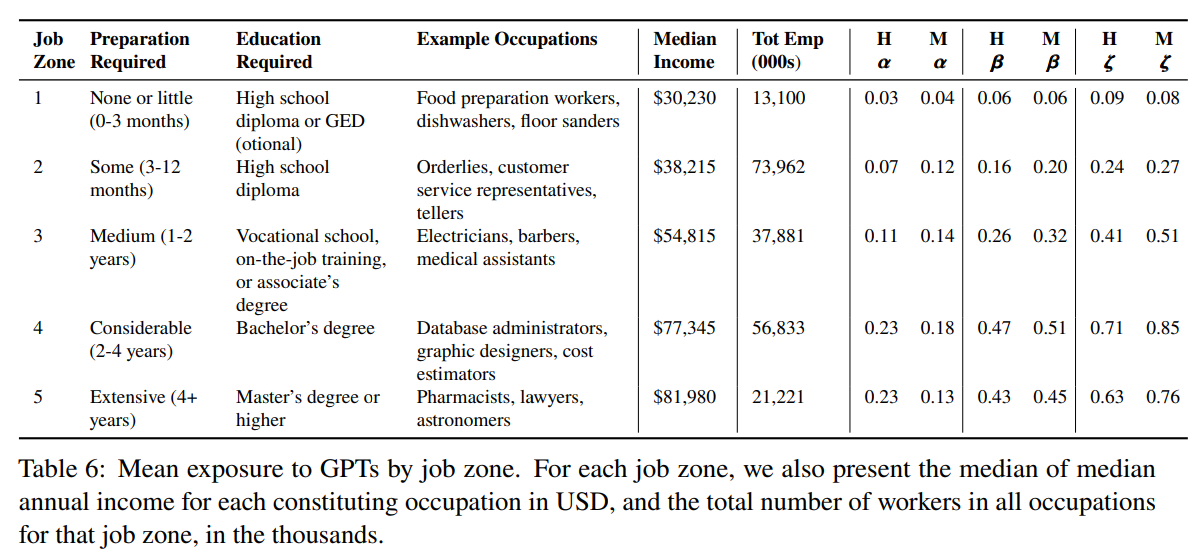
Q: Generative Pre-trained Transformers (GPT)のような大規模な言語モデルが、米国の労働市場に与える潜在的な影響とは?
A: この論文では、大規模言語モデルが米国の労働市場に与える潜在的な影響について、LLMを搭載したソフトウェアがLLM単体と比較してもたらす機能の向上に焦点を当てて調査しています.この論文では、米国の労働者の約80%が、LLMの導入により、少なくとも10%の業務に影響を受ける可能性があり、約19%の労働者は、少なくとも50%の業務に影響を受ける可能性があることを明らかにしている.この影響はすべての賃金水準に及び、高所得者ほどLLMの機能やLLMを搭載したソフトウェアに触れる機会が増える可能性があることが予測されます.全体として、GPTのようなLLMは汎用的な技術であり、経済的、社会的、政策的に大きな意味を持つ可能性があることが示唆された.
Q: LaMDAやGPT-4のようなLLMが活躍した実例を教えてください.
A: LLMのLaMDAやGPT-4は、翻訳、分類、クリエイティブライティング、コード生成など、さまざまなアプリケーションにおいて優れた成果を上げています.さらに、API、検索エンジン、他の生成型AIシステムなど、他のデジタルツールをプログラミングやコントロールすることも可能であり、個々のコンポーネントをシームレスに統合して、より優れた実用性、性能、一般化を実現することができます.さらに、ファインチューニングや強化学習などの手法を用いた、操作性、信頼性、効用の最新の進展は、これらのモデルのユーザー意図をより的確に識別する能力を向上させ、よりユーザーフレンドリーで実用的になります.
Q: 近年、研究者はLLMの操縦性、信頼性、実用性をどのように向上させてきたのでしょうか?
A: 研究者は近年、人間のフィードバックによる微調整や強化学習などの手法を用いて、LLMの操縦性、信頼性、実用性を向上させています.
Q: 汎用のLLMを様々なタスクに使用する場合の潜在的な問題点は何でしょうか?
A: 一般的なLLMの使用に関連する潜在的な問題には、人間がそれらに対して置く信頼度や習慣の適応などの既存のボトルネックの対処が必要であり、技術の柔軟性やコスト、労働者と企業の好みやインセンティブなどの要因も影響を与えます.さらに、バイアス、事実の捏造、調整のズレなど、LLMに関連する倫理的および安全上のリスクも採用に影響を与える可能性があります.データの可用性、規制環境、および権力と利益の分配などの要因により、LLMの採用は異なる経済セクターで異なるでしょう.政策立案者は、LLMの経済への影響の軌道を予測し規制することについて課題を面しています.労働者や企業によるLLMの採用や使用の包括的な理解、人間労働の増強または置換、雇用品質、不平等、スキル開発への影響など、LLMの進歩の広範な影響を探るためにさらなる研究が必要です.
Q: ドメイン固有の専門知識を取り入れることで、これらの欠点に対処するのに役立つツール、ソフトウェア、ヒューマンインザループシステムなどの特殊なワークフローについて、詳しい情報を教えてください.
A: 特殊なワークフローとは、様々なタスクに汎用的なLLMを使用する際に起こりうる問題(バイアス、事実の捏造、ズレ、採用の課題など)に対処するために、ドメイン固有の専門知識、ツール、ソフトウェア、または人間がループするシステムを組み込むことです.これらのワークフローは、LLMの出力に文脈と正確さを加えるのに役立ち、文章作成支援、コーディング、法律研究などの分野での専門的なアプリケーションに見ることができます.さらに、これらの補完的な技術は、LLMに関連すること実の不正確さ、固有のバイアス、プライバシーに関する懸念、偽情報のリスクなどの問題を解決するのに役立ちます.
Q: ケーステキストでは、LLMをどのように法学研究に活用しているのでしょうか?
A: CasetextがLLMをどのように活用しているのか、また、LLMが法律業界にもたらす潜在的な影響については、この文脈からは読み取ることができません.
Q: GitHub Copilotはコーディングアシスタントとしてどのように機能するのでしょうか?
A: GitHub Copilotは、LLMを採用してコードスニペットやオートコンプリートを生成し、ユーザーはその専門性に基づいて受け入れや拒否を行うことができます.
Q: 機械学習モデル開発において、LLMは研究者のコーディングアシスタントやデータラベリングサービス、合成データ作成者としてどのように活躍できるのでしょうか?
A: LLMは、コードスニペットやオートコンプリートを生成するGitHub Copilotなどのツールにより、コーディングアシスタントとして活用することが可能です.また、機械学習モデル開発におけるデータラベリングサービスや合成データ生成にも活用できます.
Q: スキルに偏った技術革新とはどのような概念で、労働市場にどのような影響を与えるのでしょうか.
A: 技能バイアス技術変化の概念は、技術の進歩が熟練労働者の需要を増加させ、未熟練労働者の需要を減少させるという考えに関連しています.これにより、米国では賃金格差が発生し、ルーティンタスクを専門とする労働者の相対賃金が低下しています.ルーティンタスクや反復作業に関与する労働者は、技術によって追い出されるリスクが高く、この現象はルーティンバイアス技術変化として知られています.最近の研究では、技術のタスク追放効果とタスク復帰効果を区別し、新しい技術がより広範な労働集約型タスクの必要性を増加させることが明らかになっています.
Q: 本研究で提案された方法は、LLMを採用して、被ばくや自動化の可能性のある作業をどのように評価するのでしょうか?
A: 本研究では、LLMが仕事に及ぼす潜在的な影響を評価するために、LLMにさらされるタスクの全体的な露出度を測定するルーブリック(A.1)を提案しています.このルーブリックは、人間の注釈とGPT-4分類の両方を用いて、タスクの露出と自動化の可能性を評価するもので、主にONETデータベースから入手した米国経済の職業データに適用されている.本研究では、ほとんどの職業がLLMにある程度さらされることを発見し、一般に高賃金の職業では、より多くのタスクが高いエクスポージャーを示すことを発見した.提案した手法は、言語モデルの概念を必ずしも特定のモデルに結びつけるものではなく、提案した露出度スコアの範囲を超えて、LLMと労働者の活動の相互作用の複雑さを探求する将来の研究の必要性を認めている.
Q: この論文の実用的な意味は何ですか?
A:この論文は、LLMが米国の幅広い職業に広範な影響を及ぼし、LLMが支えるさらなる進歩が様々な経済活動に大きな影響を及ぼす可能性があることを示唆しています.しかし、社会的、経済的、規制的、その他の要因が、実際の労働生産性の結果に影響を与えるだろう.本論文では、LLMの進歩がもたらす広範な影響について、人間の労働力を補強または代替する可能性、仕事の質への影響、不平等への影響、技能開発、その他多くの成果など、さらに研究を進めることを求めています.政策立案者や利害関係者は、この情報を利用して、AIの複雑な状況や仕事の未来を形成する役割をナビゲートするために、より多くの情報に基づいた意思決定を行うことができます.本稿では、LLMとそれが生み出す補完的な技術がもたらす潜在的な経済的混乱に対する社会的・政策的準備の必要性を強調しています.
Q: 実験やデータ解析で得られた主な知見は何ですか?
A: この調査では、米国の労働者の約80%が、大規模言語モデル(LLM)の導入により、少なくとも10%の業務に影響を受ける可能性があり、約19%の労働者は、少なくとも50%の業務に影響を受ける可能性があることが分かりました.この影響はすべての賃金水準に及び、高所得者ほどLLMの機能やLLMを搭載したソフトウェアに触れる機会が増える可能性があります.なお、本研究では、LLMの開発・導入時期については予測していない.
Q: 今後の研究課題として残っているものは何でしょうか?
A: LLMの進歩が、人間の労働力を補強したり代替したりする可能性、仕事の質、不平等、能力開発への影響、労働者や企業によるLLMの採用や使用に関する包括的な理解など、より広い意味での研究を進めることが必要です.
Capabilities of GPT-4 on Medical Challenge Problems
著者:Harsha Nori, Nicholas King, Scott Mayer McKinney, Dean Carignan, Eric Horvitz
発行日:2023年03月20日
最終更新日:2023年03月20日
URL:http://arxiv.org/pdf/2303.13375v1
カテゴリ:Computation and Language, Artificial Intelligence

Q: 医学的な課題問題に対するGPT-4の能力はどのようなものでしょうか?
A: 大規模言語モデルであるGPT-4は、医療を含む様々な領域において、自然言語理解・生成において顕著な能力を発揮している.本論文では、GPT-4を医学的な能力試験とベンチマークデータセットで包括的に評価した.このモデルは、訓練によって医療問題に特化したものではなく、また臨床課題を解決するために設計されたものでもない、汎用的なモデルである.分析対象は、米国で臨床能力を評価し免許を付与するために用いられる3段階の試験プログラムである米国医師免許試験(USMLE)の公式練習教材2セットです.また、ベンチマークデータセットであるMultiMedQAスイートでのパフォーマンスも評価しています.その結果、GPT-4は、特別なプロンプトを作成することなく、USMLEの合格点を20点以上上回り、初期の汎用モデル(GPT-3.5)や、医学知識に特化して微調整されたモデル(Flan-PaLM 540Bのプロンプトチューニング版Med-LaLM)も上回ることが分かりました.また、GPT-4はGPT-3.5よりも大幅にキャリブレーションが向上しており、その回答が正しい可能性を予測する能力が大幅に向上していることを実証しています.また、GPT-4が医学的推論を説明し、学生への説明をパーソナライズし、医学的なケースを中心に新しい反事実のシナリオをインタラクティブに作成する能力を示すケーススタディを紹介しています.本論文では、医学教育、評価、臨床現場におけるGPT-4の潜在的な利用法について、正確性と安全性の課題に適切に注意を払いながら、この発見がもたらす意味を議論する.
Q: ベンチマークデータセットであるMultiMedQAスイートとはどのようなもので、GPT-4の性能はどのようなものですか?
A: PubMedQAデータセットを除くMultiMedQAベンチマークスイートにおいて、GPT-4はGPT-3.5とFlan-PaLM 540Bを大幅に上回った.性能結果は表4に示されている.
Q: GPT-4は医学教育、評価、臨床においてどのような利用が考えられるか?
A: GPT-4およびその後継機は、医師やその他の医療従事者が医療提供の多数の側面において支援する潜在的な能力を持っています.決定支援、記憶の促進、行政タスクなどがその例です.また、将来的に臨床およびバイオ医学研究者を支援することもできます.医学教育および評価においては、GPT-4の出色のベンチマーク性能は、医学教育において利用され、医療提供の多数の側面での医療従事者の支援に役立つ潜在性を示唆しています.しかし、誤った生成や現実のシナリオでのパフォーマンス評価の課題があるため、GPT-4およびその応用に関連するリスクを最適化し、緩和するためには注意と技術革新が必要です.
Q: このような状況でGPT-4を利用する場合、安全性や精度の面でどのような課題があるのでしょうか?
A: GPT-4を医学教育、評価、臨床で使用する際に考慮しなければならない安全性と正確性の課題には、誤った生成のリスク、品質保証と継続的な警戒の必要性、医療提供やデータにおけるバイアスのリスクなどがあります.GPT-4 やその他のモデルに依存する医療従事者は、モデルによって生成された情報を検証するための最高基準を遵守しなければならず、安全で効果的な使用を保証するために、品質保証のためのベストプラクティスを開発し医療従事者間で共有しなければならない.また、医療従事者やその他の健康関連コンテンツの消費者にも、信頼性に関する課題と継続的な警戒の必要性を教育する必要があります.さらに、医療機関や医療従事者に指針を与えるために開発されたシステムやモデルに影響を与える可能性のある、医療の提供におけるバイアスが研究によって明らかにされているため、データやそのデータから構築されるシステムのバイアスに対処し緩和することも重要である.
Q: GPT-4をワークフローの一部として含むローステークスのアプリケーションでは、どのような専門家の監視が必要でしょうか?
A: ワークフローの一部としてGPT-4を使用する、より低いステークスのアプリケーションでは、適切な専門家の監視が必要であることを示唆する文脈があります.しかし、具体的にどのような専門家の監視が必要なのかは言及されていない.
Q: 正確性、公平性、医療行為への広範な影響に関して、どのような懸念に配慮する必要があるのか.
A: GPT-4とその後継モデルを医療現場で使用する際には、正確さ、公平さ、そして医療行為へのより広い影響を考慮する必要がある.医療従事者は、モデルによって生成された情報を検証するための最高基準を遵守する必要があり、安全で効果的な使用を保証するために、品質保証のためのベストプラクティスを開発し、医療従事者間で共有する必要があります.さらに、医療の提供やモデルのトレーニングに使用されるデータには、偏りが生じるリスクがあります.最後に、誤った世代が生まれるリスクもあり、医療における自動化の導入には十分な注意が必要です.
Q: GPT-4のようなモデルを実戦で活用するためには、どのような注意点や進歩が必要でしょうか?
A: この論文では、現実の医療現場におけるGPT-4のようなモデルの応用に伴う利点を最適化し、リスクを軽減するために、慎重さを実践し、適切な用途を開発・評価し、技術革新を追求することが不可欠であることを示唆しています.また、医療従事者がモデルによって生成された情報を検証するための最高基準を遵守し、品質保証のためのベストプラクティスを開発する必要性を強調するとともに、医療従事者や健康関連コンテンツの消費者に、信頼性に関する課題と継続的な警戒の必要性を教育しています.さらに、長期的な格差の伝播を避けるために、データとそのデータから構築されるシステムのバイアスに対処し、緩和することの重要性を強調しています.
Q: USMLEの公式試験問題において、GPT-4の前身モデルに対する改善率はどのくらいか?
A: GPT-4は、USMLEの公式試験問題でGPT-3.5と比較すると、両試験で30ポイント以上の向上が見られます.
Q: USMLE試験のStep1では、どのようなトピックが扱われるのでしょうか?
A: USMLE試験のStep1では、病態や生理など臨床のコアとなる知識、病態の基礎を学びます.
Q: USMLE試験のStep2は何を試すのか?
A: 米国医療国家試験(USMLE)のステップ2は、診断や患者管理に関する知識を試験受験者に問いただすことで臨床的理解力をテストします.これには、病理学や生理学を含む中核的な臨床知識、および医療状況の基礎が含まれます.
Q: USMLE試験のStep3は何を評価するのでしょうか?
米国医師国家試験(USMLE)のステップ3は、医師レジデントが医療の監督なしで医療の実践において自分の知識を適用する能力を評価します.一般的な医療ケアを提供するために必要な、実践的臨床とバイオメディカル知識を調べます.ステップ3の合格は、監視なしで医療行為を行うためのライセンスを取得するために必要です.
Q: USMLEの開発・運営は誰が行っているのか?
A: NBME(全米医師試験委員会)は、USMLEを開発・運営する組織の一つです.
Q: 本稿で紹介した方法は、従来の方法と比較してどのようなメリットがあるのでしょうか?
A: 本論文では、医療能力試験とベンチマークデータセットにおけるGPT-4、GPT-3.5、Flan-PaLM 540Bの比較評価を行っている.それによると、GPT-4は複雑な手法に頼らずとも、複数のデータセットで先行モデルや他のモデルを凌駕していることがわかる.この研究は、より大きなモデルを用いれば、集中的な実世界の課題に対して印象的な利益を得ることができ、法律、銀行、工学、会計など様々な分野における複雑な実世界の問題を扱うための進歩が今後も見られることを示唆しています.
Q: この論文の実用的な意味は何ですか?
A: 医療能力試験やベンチマークデータセットにおけるGPT-4の評価から、意思決定支援、記憶の整理、管理業務、さらには臨床・生物医学研究などの用途で、医療教育に役立ち、医療従事者に支援を提供できる大きな可能性があることが示唆されました.ただし、注意は必要であり、誤った世代がもたらす潜在的なリスクも考慮しなければならない.GPT-4のような大規模言語モデルの進歩速度は、医療関係者以外にも広く影響を与え、知識を必要とする様々な職業に影響を与える可能性があります.
Q: 実験やデータ解析で得られた主な知見は何ですか?
A: 実験とデータ分析により、汎用言語モデルであるGPT-4が、USMLE Step 1、Step 2、Step 3の医療能力試験やMultiMedQAスイートを含むベンチマークデータセットで、GPT-3.5やFlan-PaLM 540Bよりも優れた成績を収めたことがわかりました.また、モデルの出力確率が医療応用においてキャリブレーションに重要であることも確認されました.さらに、本研究では、GPT-4およびその後継機が医療教育やヘルスケア専門職にポジティブな影響を与える可能性があることが議論されましたが、現実世界での適用には注意が必要です.さらに、ベンチマークベースの性能評価の限界とその知識集約型職業に対する意義について、著者らは考察しています.
Q: 今後の研究課題として残っているものは何でしょうか?
A: この文章では、GPT-4およびその後継者を包括的に評価するためにはまだ多大な作業が残っており、医療に導入する際には注意が必要であると示唆しています.しかし、著者は、GPT-4およびその後継者が医学において重要な役割を果たす潜在的な可能性があることを認識しており、医師やその他の医療従事者が医療配信の多くの側面を支援し、臨床および生物医学研究者が調査を支援すること、そして医療従事者に支援を提供することができると主張しています.著者は、現実の世界でGPT-4を利用するために必要な注意事項と進歩を議論し、ベンチマークに基づくパフォーマンス評価の限界についても言及しています.彼らは、専門家の監視を世代およびワークフローの一部として含めた低リスクのアプリケーションが現実の世界での利用価値を持つ可能性があると示唆しています.著者はまた、GPT-4が医療教育に役立つ可能性についても議論し、正確性、公平性、および医療行為に対する幅広い影響を考慮する必要があると警告しています.最後に、彼らはGPT-4の能力を定性的に探索することが、LLMsが可能にする新しい形の教育体験や臨床応用につながる可能性があると示唆しています.
A Comprehensive Capability Analysis of GPT-3 and GPT-3.5 Series Models
著者:Junjie Ye, Xuanting Chen, Nuo Xu, Can Zu, Zekai Shao, Shichun Liu, Yuhan Cui, Zeyang Zhou, Chao Gong, Yang Shen, Jie Zhou, Siming Chen, Tao Gui, Qi Zhang, Xuanjing Huang
発行日:2023年03月18日
最終更新日:2023年03月18日
URL:http://arxiv.org/pdf/2303.10420v1
カテゴリ:Computation and Language
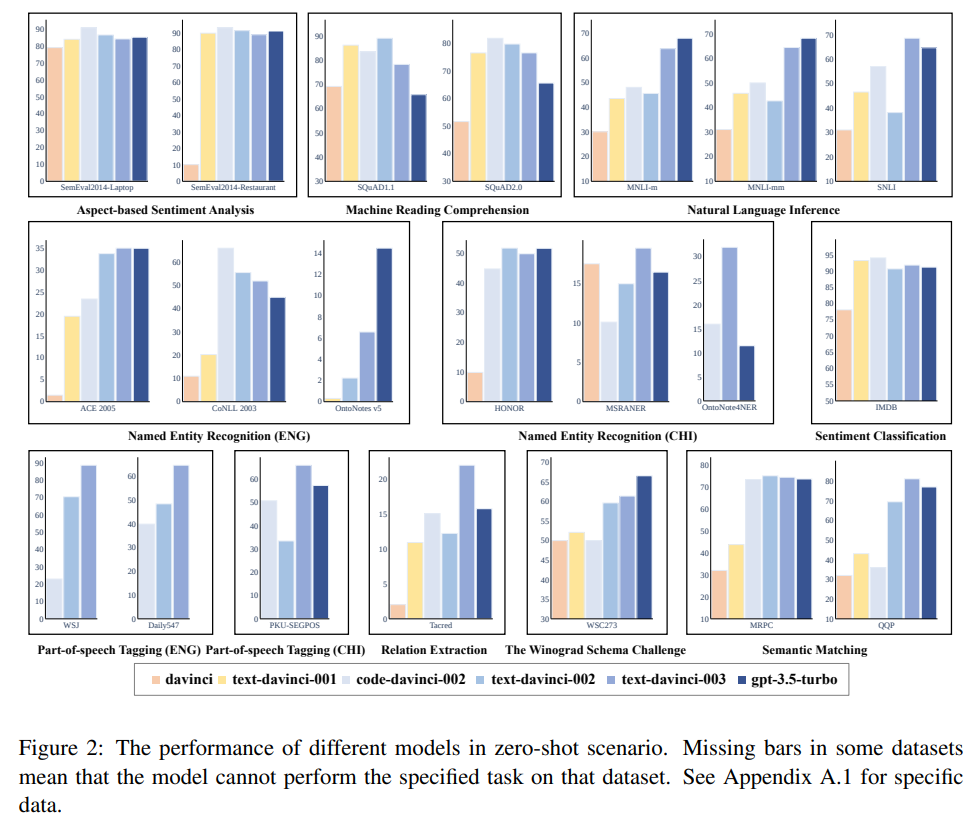
Q: 論文の焦点は何ですか?
A: この論文の焦点は、モデルのタスク解決能力と使いやすい応答性能をバランス良くすること、そしてパフォーマンスを高めながらその堅牢性を向上させることにあります.また、TextFlintというマルチリンガルプラットフォームを使用して、NLPタスクの堅牢性を評価します.
Q: 本研究で評価された自然言語理解タスクは何ですか?
A: 21のデータセットを用いて、9つの自然言語理解(NLU)タスクについて、さまざまなモデルの性能と頑健性を評価した研究です.
Q: NLUタスクにおけるGPTモデルの総合的な能力について、どのような知見があったのでしょうか?
A: 本研究では、NLUタスクにおけるGPTシリーズモデルの総合的な能力は、モデルの進化に伴い、特にRLHF学習ストラテジーの導入により、徐々に向上するわけではないことを発見しました.この学習法は、人間のような応答を生成する能力を向上させる一方で、いくつかのタスクの解決能力を低下させる.さらに、この研究では、モデルの頑健性などにも改善の余地があることが判明しました.
Q: 調査によると、改善が必要な箇所はどこでしょうか?
A: 自然言語理解(NLU)モデルにおけるモデルの頑健性など、まだまだ改善の余地があることが示唆されました.
Q: インコンテキストラーニングは、ダヴィンチモデルに対する理解をどのように深めるのでしょうか?
A: NERタスクとPOSタスクにおいて、文脈内学習はDavinciモデルのプロンプトの理解度を大幅に向上させました.
Q: MNLI-mmデータセットとはどのようなもので、どのようなタスクが対象になっているのか?
A: MNLI-mmデータセットは、実験で使用したデータセットで、自然言語推論タスクを対象としています.
Q: SQuAD2.0データセットとはどのようなもので、SQuAD1.1とはどのような違いがあるのか?
A: SQuAD2.0とSQuAD1.1のデータセットは、どちらも機械読解(MRC)タスクに使用されています.両者の違いは、SQuAD2.0には与えられた文脈に基づいて質問に答えられない場合を特定するための要件が含まれているのに対し、SQuAD1.1にはこの要件がないことである.両データセットは、MRCタスクにおけるGPTモデルの性能と頑健性を評価するために使用された.
Q: WSCデータセットとは、どのようなもので、どのような目的なのでしょうか?
A: WSCデータセットの目的は、代名詞の共参照や曖昧さを解消するために、自然言語理解モデルに挑戦することです.
Q: code-davinci-002モデルとは、どのようなモデルですか?
A:「code-davinci-002」モデルは、自然言語と数十億行のソースコードを含むデータで学習させた、GPT-3に基づく最も高性能なコーデックスモデルです.全体的に他のモデルよりも性能が高く、数発のシナリオでさらなる強化を示し、SemEval2014-Restaurantの「ReverseNonTarget」バリエーションでエラーゼロを達成しました.ゼロショットと少数ショットでの性能は他のモデルと同等であり、これらの2つのデータセットがプロンプトの例数に大きく影響されないことを示しています.
Q: Davinciモデルのプレトレーニングフェーズでは、何を取得しているのか?
A: 事前トレーニングの段階で、Davinciモデルは基本的な理解力と文脈の中での学習能力を身につけます.
Q: この論文の実用的な意味は何ですか?
A: この論文は、モデルのタスク解決能力とユーザーフレンドリーな応答機能をバランスよくする必要性、および性能を向上させながらロバスト性を強化する必要があることを強調しています.研究は、モデルがより優れた結果を示す一方、その堅牢性が大幅に向上していないことを示しており、さらなる調査が必要であることを示しています.
Q: この新方式に見られる困難は何ですか?
A: OpenAI APIによるアクセス制限のため、一部のモデルのテストに全データセットを使用できなかったこと、調査中にリリースされたがAPIが利用できなかったGPT-4をテストできなかったことなど、いくつかの制約を認めています.
Q: 実験やデータ解析で得られた主な知見は何ですか?
A: この論文では、21のデータセットにおける9つの自然言語理解タスクで6つのGPTシリーズモデルの能力を包括的に分析しています.その結果、GPTシリーズモデルの進化がすべての自然言語理解タスクにおいて普遍的な改善につながるわけではなく、使用されるトレーニング戦略と各タスクの特性に影響を受けることが明らかになりました.モデルのパフォーマンスが向上したにもかかわらず、その堅牢性が著しく向上していないことがわかり、今後の調査が必要です.この研究は、モデルのタスク解決能力とユーザーフレンドリーな応答能力のバランスをとり、そのパフォーマンスを向上させつつ、堅牢性を高める方法について新しい示唆を提供することを目的としています.
Q: 今後の研究課題として残っているものは何でしょうか?
A: この論文では、モデルの課題解決能力と利用者フレンドリーな反応能力のバランスをとる方法や、性能を向上させながら耐久性を向上させる方法についての今後の研究の必要性が指摘されています.
PanGu-Σ: Towards Trillion Parameter Language Model with Sparse Heterogeneous Computing
著者:Xiaozhe Ren, Pingyi Zhou, Xinfan Meng, Xinjing Huang, Yadao Wang, Weichao Wang, Pengfei Li, Xiaoda Zhang, Alexander Podolskiy, Grigory Arshinov, Andrey Bout, Irina Piontkovskaya, Jiansheng Wei, Xin Jiang, Teng Su, Qun Liu, Jun Yao
発行日:2023年03月20日
最終更新日:2023年03月20日
URL:http://arxiv.org/pdf/2303.10845v1
カテゴリ:Computation and Language

Q: PanGuの目的と、中国語NLPタスクのゼロショット学習での性能について教えてください.
A: PanGuの目的は、自然言語理解、生成、推論のための1兆個のパラメータを持つ大規模言語モデルであることです.様々な中国語NLPの下流タスクに対してゼロショット学習で最先端の性能を提供し、またオープンドメインの対話、質問応答、機械翻訳、コード生成のために細かく調整することができます.
Q: 2レベルルーティングは、All-to-Allの通信を減らすという点で、具体的にどのようなメリットがあるのでしょうか?
A: PanGuの2レベルルーティングは、高価なglobal all-to-all操作をgrouped all-to-allにすることで、通信量を大幅に削減し、エンドツーエンドのトレーニング待ち時間を短縮しています.
Q: PanGuのアーキテクチャと、柔軟なデザインについて教えてください.
A: PanGuモデルのアーキテクチャは、密な変形レイヤーと疎な変形レイヤーを組み合わせたものです.下のM層は異なるドメインで共有される密な層であり、上のNの変形レイヤーの順伝播部分は最小限のデータでモデル化され、最適なパフォーマンスを実現します.PanGuは、さまざまなトレーニングおよび展開のセットアップに基づいてパラメーターをグループ化および分離することで柔軟な設計を提供し、現実のアプリケーションにおいて重
要な利点を提供します.
Q: 兆個のパラメータを持つ言語モデルを学習させる場合、どのような課題があるのか?
A: PanGuのような1兆個のパラメータを持つ言語モデルの学習には、膨大な量のメモリが必要です.スパースアーキテクチャは計算量を効果的に節約できますが、メモリ消費量を減らすことはできず、すべてのパラメータと最適化状態は依然としてアクセラレータのメモリ内に保存される必要があります.つまり、1Tのモデルで通常16TBを消費することになります.
Q: PanGu-アーキテクチャのスパース性は、トレーニングスループットの向上にどのように役立つのでしょうか?
A: PanGuアーキテクチャのスパースな性質により、オプティマイザはほとんどのパラメータが条件付きで起動するため、1回の反復でエキスパートの一部のみを更新することが可能です.これにより、低速なホスト間通信やデバイス間通信による勾配や更新パラメータのやり取りが不要になり、ECSS(Expert Computation and Storage Separation)方式を用いることで、学習スループットを6.3倍にすることができます.
Q: PanGuをオープンドメイン対話、質問応答、機械翻訳、コード生成用に細かく調整した場合の性能はどうでしょうか?
A: 提供された文脈によると、PanGuは、オープンドメイン対話、質問応答、機械翻訳、コード生成のアプリケーションデータで微調整されたときに強い能力を発揮するそうです.また、様々な中国語NLPの下流タスクのゼロショット学習において最先端の性能を発揮し、自己チャット、トピックに基づく対話生成、質問応答において、自動評価と人間評価の点で常にベースラインを上回っています.しかし、個々のタスクに対する具体的な性能指標は提供されていない.
Q: RRE機構が動作するために必要なこと、ルーティングテーブルの初期化はどのように行われるか.
A: RREメカニズムは、Mixture of Expertsパラダイムに従って、トークンをPanGuの専門家にルーティングするために提案されたRandom Routed Expertsメカニズムである.トークンをドメイン別の専門家候補にマッピングし、ランダムに初期化されたルーティングテーブルに従って、そのドメインの専門家の1人にトークンをルーティングするという2段階の方法でトークンをルーティングします.
Q: この論文の実用的な意味は何ですか?
A: PanGuの論文は、様々な中国語NLPの下流タスクのゼロショット学習において最先端の性能を提供し、オープンドメインの対話、質問、会話などのアプリケーションデータで微調整した場合に強い能力を持つことを実証している.
Q: 実験やデータ解析で得られた主な知見は何ですか?
A: 実験結果から、PanGuは様々な中国語NLP下流タスクのゼロショット学習で最先端の性能を発揮し、オープンドメイン対話、質問応答、機械翻訳、コード生成のアプリケーションデータで微調整した場合に強い能力を発揮することがわかった.さらに、PanGuモデルは事実関係の質問に正確に答えることができ、自然言語理解タスクのSuperGLUEベンチマークで強い性能を発揮する.PanGuは、MBPPタスクのpass@1において、現在の最先端モデルPanGu-Coderを1.4ポイント上回った.
プロンプトエンジニアリング
Context-faithful Prompting for Large Language Models
著者:Wenxuan Zhou, Sheng Zhang, Hoifung Poon, Muhao Chen
発行日:2023年03月20日
最終更新日:2023年03月20日
URL:http://arxiv.org/pdf/2303.11315v1
カテゴリ:Computation and Language
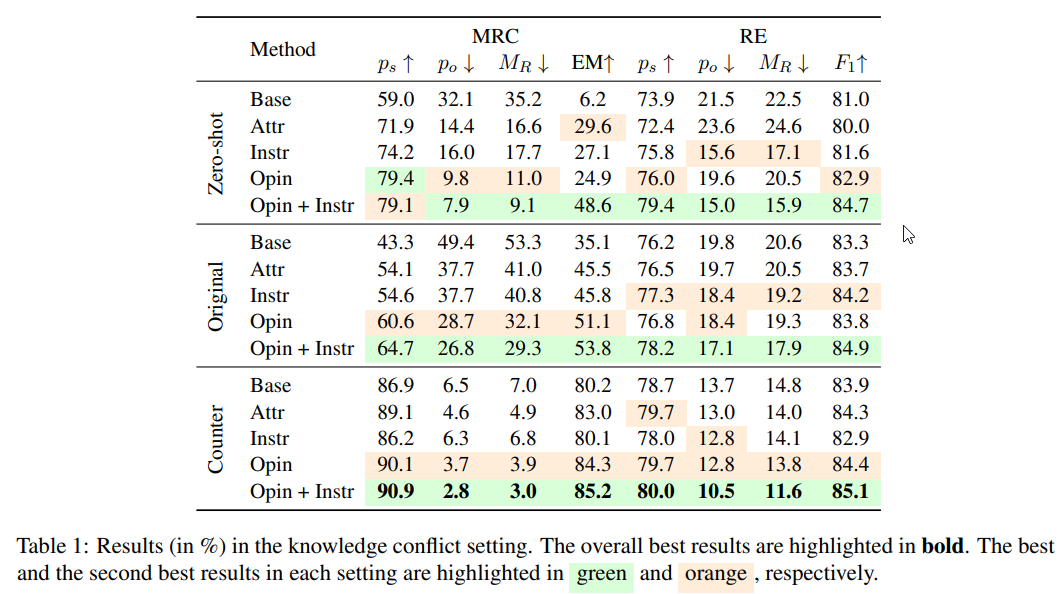
Q: 著者によれば、LLMの忠実度はどのようにすれば大幅に向上するのでしょうか?
A: 著者らは、意見に基づくプロンプトと反実仮想のデモンストレーションという2つの方法を用いて、文脈に特化したNLPタスク、特に知識対立を伴うシナリオや棄権を伴う予測において、LLMの文脈への忠実性を大幅に改善することを提案しています.
Q: LLMの忠実度を高めるために、プロンプトの戦略はどの程度効果があったのでしょうか?
A: 著者らは、文脈に特化したNLPタスクにおいて、特に知識対立を伴うシナリオや棄権を伴う予測において、意見ベースのプロンプトや反実仮想の実証という手法が、LLMの文脈への忠実性を高めるのに有効であることを発見しました.彼らは、機械読解と関係抽出という2つのタスクの3つのデータセットにおいて、文脈への忠実性の著しい向上を観察した.両技術を組み合わせることで、それぞれを単独で使用するよりも大きな効果を得ることができた.
Q: LLMが世の中の事実を暗記すると、どんな課題が発生するのか?
A: LLMの記憶していること実は世界が常に進化する中で時代遅れになる可能性があり、新しい事実に基づくLLMの予測を更新する必要性が重要視されます.記憶の編集方法や、関連知識を含む外部コンテキストでLLMの促進を拡張することが、この課題の解決策として研究されています.しかし、記憶の編集方法が新しい事実のすべてを包括する十分な容量を持つかどうかはまだ不明です.
Q: LLMs(言語モデル)の予測を新しい事実に基づいて更新することの重要性は何ですか?
A: LLMの予測を新しい事実で更新することが重要です.世界が常に進化するため、記憶された事実は古くなる可能性があり、そのためLLMは新しい知識を取り入れて更新する必要があります.更新しない場合、LLMは記憶された答えを持ち続け、それがもう正確でなくなる恐れがあります.したがって、新しい事実でLLMを更新することで、予測の正確性と信頼性を向上させることができます.
Q: 記憶編集の方法は、新しい事実の知識をすべて更新することができるのか、またその限界は何か.
A: 記憶編集の方法によって、新しい事実をすべて網羅するのに十分な容量が確保できるかどうかは、まだ不明です.
Q: 大量の新事実でLLMを更新する検索システムの可能性は?
A: 検索システムは、大量の新事実でLLMを更新する可能性を持っています.
Q: Selective prediction with abstention (棄権を伴う選択的予測)とは何か、なぜ信頼できるAIで重要なのか?
A: 棄権を伴う選択的予測とは、モデルが予測に不確実性がある場合に、誤った予測を返す代わりに不確実性を認め、ユーザーに通知することです.モデルがより信頼性の高い予測を行うことができ、誤った情報の拡散を防ぐことができるため、信頼性の高いAIにおいて重要です.インスタンスが判断境界に近い場合や、インスタンスが学習データと異なるドメインのものである場合など、異なるシナリオで採用されることがある.また、文脈が質問と無関係な場合、文脈に特化した自然言語処理でも好まれます.
Q: 本稿で紹介した方法は、従来の方法と比較してどのようなメリットがあるのでしょうか?
A: 本論文では、問題への回答とプロンプトへの反実仮想的なデモンストレーションの追加を組み合わせることで、それぞれの手法を単独で用いる場合と比較して最大の利得をもたらす手法を紹介している.この方法は、知識対立の側面で忠実性を向上させ、LLMの暗記率を大幅に低減できる.モデルパラメータに格納された事実を特定し編集する旧来の手法と比較すると、記憶編集手法がすべての新しい事実知識を包含するのに十分な能力を持つかどうかはまだ不明である.
Q: この論文の実用的な意味は何ですか?
A: 本論文では、知識対立を伴う文脈特異的なNLPタスクや棄権を伴う予測タスクにおいて、文脈に対するLLMの忠実度を向上させるために、意見ベースの促しと反事実のデモンストレーションという二つの方法を用いることを提案している.この論文では、両技術を組み合わせることで、それぞれを単独で使うよりも最大の効果が得られることを発見し、関係抽出のためのRe-TACRED、MRCのための自然な質問とRealTime QAなど3つのデータセットで忠実度を大きく改善する.また、より広範なNLPタスクで提案手法の有効性を評価し、忠実度をさらに向上させるための他の手法の研究を行うという今後の課題も提示しています.
Q: この論文の理論的な意味は何ですか?
A: 本論文は、意見ベースのプロンプトと反事実的デモンストレーションの使用を提案し、特に知識の衝突や棄権予測のシナリオで、文脈固有のNLPタスクにおけるLLMの信頼性を向上させることを目的としています.本論文は、これらの戦略がこのようなタスクで選択的な予測を行うLLMの能力を大幅に向上させることを示しています.この提案の理論的な意義は、本論文では明示的には議論されていません.
Reflexion: an autonomous agent with dynamic memory and self-reflection
著者:Noah Shinn, Beck Labash, Ashwin Gopinath
発行日:2023年03月20日
最終更新日:2023年03月20日
URL:http://arxiv.org/pdf/2303.11366v1
カテゴリ:Artificial Intelligence, Computation and Language, Machine Learning
Q: 大規模言語モデル(LLM)エージェントの意思決定における最近の進歩について教えてください.
A: 意思決定大規模言語モデル(LLM)エージェントの最近の進歩として、自然言語で複雑なタスクを接地する能力、テキストベースの環境において学習した方針なしに次の行動を選択する能力、与えられた環境においてタスクを理解する人間のような能力を発揮する能力が挙げられる.これは、様々なベンチマークやInternational Conference on Learning Representations (ICLR)などの会議に見られるように、自然言語処理の分野で大きな進展を示しています.しかし、自然言語RLエージェントの最適なポリシーの学習には、膨大でほとんど拘束されない状態空間のため、課題が残っています.
Q: Huangら(2022b)が閉ループフィードバック環境内で次の意思決定を処理するために用いているアプローチは何か.
A: Huangら(2022b)は、閉ループのフィードバック環境の中で、次の決定をさらに処理するためにインナーモノローグを使用しています.
Q: LLMはどのように自己反省という創発的な性質を持ち、自然言語に基づく自己最適化をどのように活用できるのでしょうか?
A: LLMにおける自己反省の創発的特性は、失敗から学び、自然言語に基づく自己最適化を効果的に活用する能力である.これは、LLMベースのエージェントに自己反省型LLMと幻覚や非効率な行動実行を検出する簡単なヒューリスティックを装備することで、Reflectionと名付けられたアプローチで活用でき、エージェントは自身の失敗から学び、新規環境での意思決定や知識集約型の探索タスクを改善できるようになります.
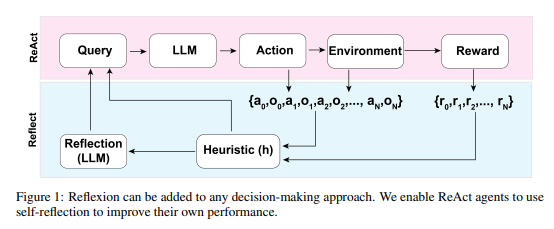
Q: 提案されたアプローチReflexionは、エージェントの推論トレースとタスク特定のアクション選択能力をどのように向上させますか?
A: 提案された手法である「Reflection」は、自己反省能力を導入することにより、エージェントの推論トレースとタスク固有のアクション選択能力を向上させます.これにより、エージェントは妄想のインスタンスを特定し、アクションシーケンスの繰り返しを回避し、与えられた環境の内部メモリマップを構築することができます.自己反省を使用することで、ReActエージェントはAlfWorld環境や知識重視の検索型質問応答タスクのHotPotQA環境で達成された成功率によって、学習や発見を通じて自己のパフォーマンスを向上させることができます.全体的に、自己反省の新しい特性は、エージェントの意思決定や問題解決能力を向上させるのに役立ちます.
Q: 意思決定や知識集約型のタスクにおいて、Reflexion agentがパフォーマンスを向上させるために、自己内省はどのように導かれるのか?
A: Refloxionアプローチは、エージェントに動的な記憶と自己反省機能を持たせ、既存の推論トレースとタスク固有の認識を強化するものである.エージェントは過去の行動を振り返り、最初の順序計画の欠陥を認識し、試行錯誤のプロセスを通じて間違いから学習することができます.自己反省を行うことで、エージェントは連続した試行でパフォーマンスを向上させ、シーケンスの計画における将来の決定を方向づけることができます.Reflexionアプローチは、あらゆる意思決定アプローチに追加することができ、二値報酬モデルにのみ依存します.
Q: 自然言語RLエージェントは、状態空間が広大でほとんど拘束されないため、最適なポリシーを学習するにはどのような課題があるのでしょうか?
A: 自然言語RLエージェントの最適なポリシーを学習する際の課題は、広大でほとんど拘束されない状態空間によるもので、与えられた状況下で取るべき最適な行動を見つけることが困難であることである.
Q: AlfWorldとHotPotQAベンチマークにおけるReflexionアプローチの結果と、ベースとなるReActエージェントの結果との比較は?
A: AlfWorldおよびHotPotQAベンチマークにおけるReflexionアプローチの結果、ベースとなるReActエージェントと比較して性能が向上しました.AlfWorldベンチマークでは、12回の自律的な試行でReflexionエージェントが97%の発見成功率を達成し、75%の精度を持つReActベースエージェントを上回った.HotPotQAベンチマークでは、Reflexionエージェントは51%の発見成功率を達成し、ベースとなるReActエージェントを17%上回った.しかし、Reflexionは完璧に近い精度を達成するために設計されたものではなく、試行錯誤を通じた学習により、これまで解決不可能とされていたタスクや環境での発見を可能にすることを重要視しています.
Q: Reflexion architectureは何を目指し、何を実証しようとしているのでしょうか?
A: Reflexionアーキテクチャの目標は、自然言語エージェントが過去の失敗から学び、人間の介入なしに計画シーケンスにおける将来の決定を方向付けることを可能にすることです.試行錯誤を通じた学習を実証することで、これまで解決不可能とされていたタスクや環境での発見を可能にすることを目的としています.Reflexionアプローチは、AlfWorldおよびHotPotQAベンチマークにおいて、ベースとなるReActエージェントを大幅に上回ることが実証されました.
Q: エージェントのランが終了する状況はどのようなものですか?
A: ベースラインとリフレクションの実行は、エージェントの精度が向上せず、有用で直感的な自己言及が生成されない場合、わずか4回の試行で終了します.
Q: 典型的なRLシナリオにおいて、エージェントはどのように問題解決を任されるのか?
A: 典型的なRLシナリオでは、エージェントは環境から観測を受け、現在のポリシーに基づいた行動を実行します.エージェントは、許容されるアクションのリストからアクションを実行することを選択でき、環境から観察と報酬を受け取り、それが次の状態を決定する.目標は、エージェントがタスクを理解し、サブタスクの逐次計画を立て、与えられた環境でアクションを実行することである.エージェントは自己反省と試行錯誤により、そのパフォーマンスを向上させることができます.
Q: 本稿で紹介した方法は、従来の方法と比較してどのようなメリットがあるのでしょうか?
A: Refloxionアプローチは、自然言語エージェントが、内部モデルの微調整、外部モデルの微調整、定義された状態空間でのポリシー最適化を必要とせずに、過去の失敗から学び、計画シーケンスで将来の決定を方向づけることを可能にします.エージェントに動的記憶と自己反省機能を付与することで、既存の推論トレースと、使用しているツールの品質に関するタスク固有の認識を強化します.AlfWorldおよびHotPotQAベンチマークにおいて、基本的なReActエージェントよりも大幅に性能が向上しており、バイナリ報酬モデルにのみ依存しているため、意思決定や知識集約型のタスクにおける試験間の性能向上に非常に適しています.
Q: この論文の実用的な意味は何ですか?
A: 本稿で紹介するReflexionアプローチは、意思決定や知識集約的なタスクの試行間のパフォーマンスを向上させるための実用的な意義を持つものです.自然言語エージェントが過去の失敗から学び、計画シーケンスにおいて将来の決定を方向づけることができるため、中間者アプローチにおける人間のトレーナーの必要性を排除することができます.このアプローチは、AlfWorldとHotPotQAベンチマークにおいて、ベースとなるReActエージェントを大幅に上回ることが実証されています.このアプローチは、エージェントが新しいアイデアを開発し、より大きな未知の状態空間を探索し、過去の環境での経験を通じてより正確な行動計画を形成することを学習しなければならない、より複雑なタスクに適用することができます.しかし、WebShopベンチマークにおけるエージェントの性能の低さに見られるように、Reflexionには限界もある.
Q: この論文の理論的な意味は何ですか?
A: 本論文で紹介するReflexionアプローチの理論的な意味は、自然言語エージェントが過去の失敗から学び、計画シーケンスにおいて将来の決定を方向付けることを可能にし、中間者アプローチにおける人間のトレーナーの必要性を排除することです.AlfWorldおよびHotPotQAベンチマークにおいて、ReActエージェントの基本性能を大幅に上回ることが実証されており、エージェントが過去の環境での経験を通じて新しいアイデアを開発し、より大きな未知の状態空間を探索し、より正確な行動計画を形成することを学習しなければならないより複雑なタスクに適用可能であることが示された.しかし、WebShopベンチマークで実証されたように、このアプローチには限界があり、いくつかの大規模言語モデルに存在する自己反省という創発的な性質に依存しています.
Q: この新方式に見られる困難は何ですか?
A: 論文で紹介したReflexionアプローチは、WebShopベンチマーク(テキストベースの問題解決ベンチマーク)において、ベースライン性能を向上させる能力に限界があることを示した.このベンチマークは、自然言語エージェントがeコマースサイトを操作し、クライアントからの要求に応じて商品を検索・購入することをテストするものである.著者らは、WebShop環境においてエージェントが商品購入を成功させる確率は、必ずしもエージェントの正しい行動計画を立て実行する能力に依存するのではなく、むしろWebShop検索エンジンの結果の質に依存することを観察しました.この観察はReflexionアプローチの直接的な限界ではないかもしれませんが、Reflexionエージェントが推論トレースと行動実行を最適化する能力はあるが、使用しているツールの品質を完全に認識しているわけではないことを強調しています.
Q: 今後の研究課題として残っているものは何でしょうか?
A: 著者らは、エージェントが過去の環境での経験を通じて、新しいアイデアを開発し、より大きな未知の状態空間を探索し、より正確な行動計画を形成することを学習しなければならない、より複雑なタスクにReflexionを適用することを奨励しています.したがって、Reflexionをより複雑なタスクに適用し、自然言語エージェントの意思決定を強化するための可能性を探るために、さらなる研究が必要である.
生成モデル
Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models
著者:Lukas Höllein, Ang Cao, Andrew Owens, Justin Johnson, Matthias Nießner
発行日:2023年03月21日
最終更新日:2023年03月21日
URL:http://arxiv.org/pdf/2303.11989v1

カテゴリ:Computer Vision and Pattern Recognition
Q: 論文に記載されている手法の名称と目的を教えてください.
A: 論文に記載されている手法の名称は明示されていませんが、2段階のポーズサンプリング方式を用いて、テキスト記述から3Dシーンを生成するテキストから画像への生成手法です.この手法の目的は、テキスト記述から完全で没入感のある3Dシーンを生成することである.しかし、この論文では、潜在的な社会的影響や、使用するテキストから画像へのモデルに内在するバイアスも認めている.
Q: テキストプロンプトからルームスケールのテクスチャ付き3Dメッシュを生成する方法はどのようなものでしょうか?
A: 本論文では、テキスト入力のみからテクスチャ付き3Dメッシュを生成する方法について説明する.これは、テキストから画像への2Dジェネレータを使用して一連の画像を作成し、すべての画像を反復的にメッシュに融合させる調整された視点選択戦略を採用することによって、完全な3Dシーンメッシュに持ち上げられるものである.テキストから画像への生成方法の目的は、テキスト入力から新しい室内シーン画像の合成を可能にすることである.
Q: 単眼深度推定とテキスト条件付きインペインティングを組み合わせて、出力を一貫性のある3Dシーン表現に持ち上げるには、どのようにすればよいのでしょうか?
A: シーンフレームを既存のジオメトリと融合させ、シームレスなメッシュを作成する連続的なアライメント戦略を採用しています.このアプローチでは、スケールの不一致を引き起こすことなく、新しいコンテンツを既存のジオメトリに合わせるために、調整された視点選択と深度アライメントが提案されます.さらに、この手法では、単眼の深度推定器を用いて未観測の深度をインペイントし、融合スキームを用いて生成されたコンテンツをメッシュに統合します.この反復生成方式により、魅力的なテクスチャと一貫したジオメトリを持つ、大規模なシーンスケールの3Dメッシュが生成されます.
Q: 視覚言語モデルを用いた3Dコンテンツ制作の代替アプローチとして、どのようなものがあるか?
A: 代替的なアプローチとしては、2Dビジョン言語モデルを用いて、生成を画像領域での最適化問題やオブジェクトの位置合わせとして定式化することで3Dコンテンツを作成する方法があります.関連する方法は、同様の方法でテキストガイダンスを通して既存の3D入力を洗練させ、最近の方法は、大規模なテキストから画像への拡散モデルと神経放射場を組み合わせて、トレーニングなしで3Dオブジェクトを生成します.他のアプローチでは、同様のテキストから3Dへのタスクでカスタム拡散モデルをトレーニングする.
Q: 案された研究は、アウトプットの質や多様性という点で、既存の手法と比較してどうでしょうか?
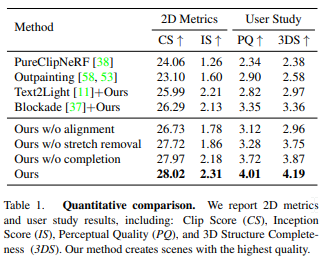
A: 提案研究は、表1や図14に示す定量的・定性的な結果に見られるように、既存の手法と比較して、高い出力品質と多様性を示しています.提案手法は、様々なメトリクスで最高スコアを達成し、高解像度の画像特徴を持つ完全なシーンを生成する一方、新規の軌跡を持つ複数のシーンを生成する多様性を示しています.
Q: アプローチにおける2段階のテーラード視点選択について説明してもらえますか?
A: 段階のテーラード視点選択戦略は、最適な位置から各次のカメラポーズをサンプリングし、その後に空白領域を洗練させます.第1段階では、一般的なレイアウトや家具を含むシーンの主要部分が、最終的に部屋全体をカバーする異なる方向への事前定義された軌道を使用して作成されます.第2段階では、生成されたシーンの劣化を避けるために、空の領域を精製します.この戦略により、生成されたシーンの伸縮や穴のアーティファクトを回避することができます.
Q: 両ステージのアプローチで使用されている反復的なシーン生成プロセスについて、より詳細に教えてください.
A: 提案するアプローチは、テキスト記述から3Dシーンを生成するために、両ステージで反復的なシーン生成プロセスを使用します.第1段階では、あらかじめ定義されたポーズとテキストをサンプリングして、完全なシーンレイアウトと家具を生成する.各新しいポーズは、反復的なシーン生成スキームでメッシュに新しく生成されたジオメトリを追加します.第2段階では、シーンのレイアウトが定義された後、残りの未観測領域を埋めるために追加のポーズがサンプリングされます.新しいポーズごとに、現在のメッシュがレンダリングされ、部分的なRGBおよび深度レンダリングが得られ、それぞれのインペインティングモデルとテキストプロンプトを使用して完成します.次のメッシュパッチは、深度アライメントとメッシュフィルタリングを行い、既存のジオメトリに統合することで得られます.このプロセスを繰り返し、シーンを構築していきます.
Q: 作品の最終目標や用途は何だったのでしょうか?
A: 作品の最終目標は、AR/VRアセット制作やコンピューターグラフィックスなど様々なアプリケーションで使用するために、テーラーメイドの視点選択と連続配置戦略を用いて、テキストのみを入力として複数のオブジェクトと明示的な3Dジオメトリを持つ完全な3Dシーンを生成し、シームレスでテクスチャ付きの3Dメッシュを作成することです.
Q: 単眼式奥行き推定器(3.2項参照)は、生成された画像に含まれる未観測の奥行きを埋めるのに、どのように役立つのですか?
A: 単眼深度推定器を用いて、深度整列ステップにより生成画像中の未観測の深度を埋める.まず、最先端の深度インペインティングネットワークを用いて、画像内の既知の部分の深度をインペイントし、予測値をそれに合わせます.次に、レンダリングされた深度と塗りつぶされた深度を最小二乗法で整列させ、整列された深度を得ることができる.最後に、レンダリングされた深度と予測された深度の間の画像エッジにガウスブラーカーネルを適用して、整列された深度を平滑化し、より滑らかでブロック感の少ない深度を得ることができます.この深度調整ステップは、メッシュパッチ間の穴のないトランジションを作成するために必要です.
Q: 式(4)の融合方式において、新規コンテンツと既存メッシュの組み合わせのプロセスを説明してください.
A: 式(4)の融合スキームで新規コンテンツと既存メッシュを組み合わせるプロセスは、新規コンテンツを三角測量してフィルタリングし、残った面を既存ジオメトリと融合させるものです.フィルタリングされた面は赤で表示され、残りの面は緑で表示され、青の既存ジオメトリと融合される.メッシュの融合ステップについては、セクション3.3で説明します.
Q: この論文の実用的な意味は何ですか?
A: 論文で提案されたこの手法は、テキスト・トゥ・イメージ・モデルを使ってテキストの説明から3Dシーンを生成することが可能であり、これによって必要な技能を大幅に削減し、大規模な3Dコンテンツ作成の民主化に貢献することができます.ただし、この手法は2Dモデルの可能性のある欠点を受け継いでおり、文化的またはステレオタイプなデータの分布に偏っている可能性があります.また、手法の完了段階ではすべての穴を修補できない場合があります.さらに、モデルのトレーニングに使用される大規模なテキスト・イメージ・データセットに含まれるアーティストの作品をクレジットする正しい方法には、倫理的な問題があります.
Q: この新方式に見られる困難は何ですか?
A: 利用可能な3Dトレーニングデータの不足は、3Dモデルの生成における中核的な課題である.テキストから3Dモデルを作成する既存のアプローチには大きな制限があり、2Dのテキストから画像へのモデルのような一般性がありません.さらに、3Dモデルの生成は、かなりの専門知識を必要とする骨の折れる作業である.また、この方法は、文化的またはステレオタイプなデータ分布への偏りや、有害なコンテンツを生成する可能性など、テキストから画像へのモデルの可能な欠点を継承しています.
Q: 実験やデータ解析で得られた主な知見は何ですか?
A: この論文では、表1に定量的な結果を示しており、彼らの手法が画像ベースのメトリクスで最高のスコアを達成したことを示しています.正確で完全なジオメトリの品質と、RGBテクスチャを強調した彼らの方法がユーザーに好まれていることがわかります.また、図15では、さらに定性的な結果も示しています.この論文には、提案手法の包括的な評価を提供し、ベースラインやアブレーションと比較した補足ビデオが掲載されています.この論文では、彼らの方法がテキストから画像のシーケンスを生成するためにテキストから画像へのモデルを活用することを指摘し、これらのモデルの可能な欠点や偏りについて議論しています.


コメント