
ここでは、トピックに絞って複数の関連性がある論文を同次に紹介しています.流れが少しでも把握できるように、一番新しいものから並べています.論文の概要やQ&A形式を用いて要点を記載しており、OpenReviewが既存であれば、意見をまとめたものを投稿しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.
- CLERC: A Dataset for Legal Case Retrieval and Retrieval-Augmented Analysis Generation
発行日:2024年06月24日
法律関係者を支援する知的システムCLERCは、先例の分析をサポートし、最先端のモデルであるGPT-4oが最高のROUGE Fスコアを達成するものの、現在のアプローチには課題が残ることが示されています. - Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools
発行日:2024年05月30日
法律実務においてAIを使用した製品が増加しており、幻覚を排除する法的研究ツールの評価結果が報告され、幻覚の発生率やシステムの違いが明らかになっています. - Topic Modelling Case Law Using a Large Language Model and a New Taxonomy for UK Law: AI Insights into Summary Judgment
発行日:2024年05月21日
イギリスのサマリー判決事件におけるトピックモデリングの新しい分類法を開発し、法的分析のギャップを埋める研究.Claude 3 Opusを使用して87.10%の精度でトピックを分類し、法的領域のパターンを明らかにする. - A Survey on Large Language Models for Critical Societal Domains: Finance, Healthcare, and Law
発行日:2024年05月02日
LLMs(大規模言語モデル)が金融、医療、法律などの分野を革新し、高リスクセクター内での方法論、応用、倫理的な応用について探求している. - CBR-RAG: Case-Based Reasoning for Retrieval Augmented Generation in LLMs for Legal Question Answering
発行日:2024年04月04日
RAGはLLMの出力を向上させるために事前知識を提供し、CBR-RAGの統合により法的な質問応答の品質が改善されることを示唆している. - LexDrafter: Terminology Drafting for Legislative Documents using Retrieval Augmented Generation
発行日:2024年03月24日
EUの立法文書の増加に伴い、新しい用語と定義が増加しており、LexDrafterフレームワークが立法文書の定義条項の起草を支援している. - Exploring Large Language Models and Hierarchical Frameworks for Classification of Large Unstructured Legal Documents
発行日:2024年03月11日
法的判決予測において、大規模な法的文書の構造情報の欠如に対処するために、MEScと呼ばれるディープラーニングベースの階層フレームワークが提案され、従来の手法よりも約2ポイントの性能向上を達成している. - SaulLM-7B: A pioneering Large Language Model for Law
発行日:2024年03月06日
SaulLM-7Bは70億のパラメータを持ち、法的テキストの理解と生成のために設計された大規模言語モデルで、英語の法的コーパスで訓練され、最先端の法的文書処理能力を持つ. - RAGged Edges: The Double-Edged Sword of Retrieval-Augmented Chatbots
発行日:2024年03月02日
ChatGPTなどの大規模言語モデルはAIの進歩を示し、幻覚を引き起こす可能性があり、検索拡張世代(RAG)はその解決策を提供する可能性がある. - Large Language Models in Law: A Survey
発行日:2023年11月26日
AIの台頭により、法律分野での人工知能の応用が進み、法的大規模言語モデル(LLMs)の可能性が探求されている. - A Comprehensive Evaluation of Large Language Models on Legal Judgment Prediction
発行日:2023年10月18日
LLMsは法律分野での可能性を示すが、GPT-4の法的評価に疑問があり、LLMsの能力を調査するために実用的なソリューションを設計し、IRシステムとの連携をテストした. - LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
発行日:2023年08月20日
LegalBenchは、LLMの法的推論能力を測定するための共同構築法的推論ベンチマークであり、異分野間の対話を促進し、弁護士やLLM開発者に共通の語彙を提供します. - MultiLegalPile: A 689GB Multilingual Legal Corpus
発行日:2023年06月03日
24言語の689GBのMultiLegalPileのコーパスを使用して、多言語RoBERTaとLongformerモデルをトレーニングし、LEXTREMEとLexGLUEでSotAを達成しました. - LexGLUE: A Benchmark Dataset for Legal Language Understanding in English
発行日:2021年10月03日
法的テキストの膨大なコーパスを分析し、自然言語理解技術を活用して法的NLUタスクのパフォーマンスを評価するLexGLUEベンチマークが、法的ドメインのモデル向上に貢献している.
CLERC: A Dataset for Legal Case Retrieval and Retrieval-Augmented Analysis Generation
著者:Abe Bohan Hou, Orion Weller, Guanghui Qin, Eugene Yang, Dawn Lawrie, Nils Holzenberger, Andrew Blair-Stanek, Benjamin Van Durme
発行日:2024年06月24日
最終更新日:2024年06月27日
URL:http://arxiv.org/pdf/2406.17186v2
カテゴリ:Computation and Language, Computers and Society
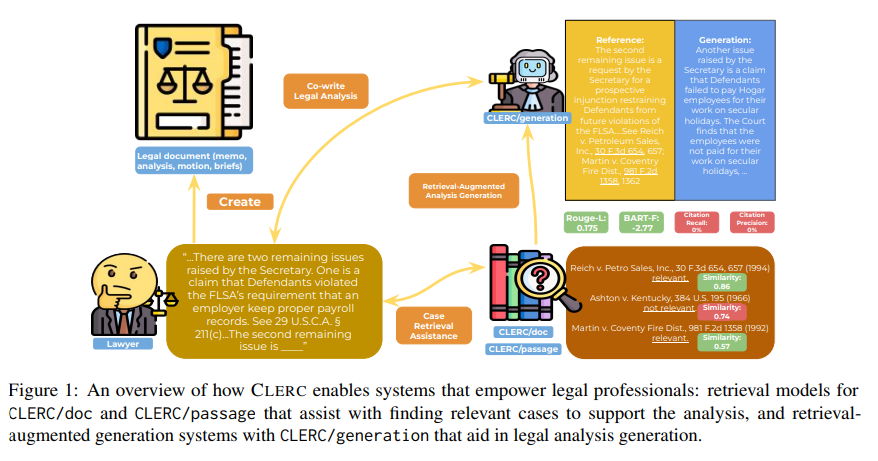
概要:
法律関係者は、関連する先例、つまり以前の事件の判決に依存する分析を書く必要があります.法律関係者を支援する知的システムがこのような文書の作成に役立つ利点を提供しますが、設計は困難です.このようなシステムは、有益であるために、重要な先例を見つけ、要約し、理由を立てる必要があります.このようなタスクのためのシステムを可能にするために、私たちは法律関係者と協力して、大規模なオープンソースの法的コーパスをデータセットに変換しました.このデータセットCLERC(Case Law Evaluation Retrieval Corpus)は、情報検索(IR)と検索増強生成(RAG)という2つの重要なバックボーンタスクをサポートするように構築されています.このデータセットは、与えられた法的分析に対応する引用を見つける能力と、これらの引用(および以前の文脈)のテキストをまとめて、推論目標をサポートする明確な分析に編纂する能力をモデルのトレーニングと評価のために構築されています.私たちは、CLERCで最先端のモデルをベンチマークに掲げ、現在のアプローチはまだ苦労していることを示しています.GPT-4oはROUGE Fスコアが最も高い分析を生成しますが、最も幻覚を見せ、ゼロショットIRモデルは1000件のリコールで48.3%しか達成できません.
Q&A:
Q: CLERCのデータセットはどのように構築され、具体的にどのようなタスクをサポートしているのですか?
A: CLERCデータセットは、Harvard Law SchoolのCaselaw Access Project(CAP)に含まれる1.84百万件以上の連邦判例文書を元に構築されました.このデータセットは、法的分析に対応する引用を見つける能力と、テキスト生成のための情報をまとめる能力の2つの重要なバックボーンタスクをサポートしています.
Q: 関連判例の引用に依存する分析を書く法律専門家を支援するインテリジェント・システムを設計する上での課題は何か?
A: 法的専門家が引用する先例に依存する分析を書くための知的システムを設計する際の課題は、適切な先例を見つけ、要約し、論理的に処理する必要があることです.
Q: CLERCデータセットにおいて、与えられた法的分析に対応する引用文献を見つけるという点で、現在の最先端のモデルはどのように機能するのだろうか.
A: CLERCデータセットにおける現在の最先端モデルは、与えられた法的分析に対応する引用を見つける際に苦労しています.GPT-4oは最も高いROUGE Fスコアを生成しますが、最も幻覚を見せ、ゼロショットIRモデルは1000件あたり48.3%のリコール率しか達成していません.
Q: CLERCデータセットの解析を行う上で、GPT-4oの限界は何ですか?
A: GPT-4oの限界は、CLERCデータセットでの分析生成において、最も幻覚を起こすことです.これは、完全なプロンプトの下でCFPスコアが最も高いことから反映されます.
Q: ゼロショットIRモデルは、CLERCデータセットのrecall@1000においてどのようなパフォーマンスを示すか?
A: ゼロショットIRモデルは、CLERCデータセットにおいてrecall@1000で48.3%の性能を達成しています.
Q: 判例の引用に依存する文書作成において、インテリジェント・システムは法律専門家に具体的にどのようなメリットをもたらすのか?
A: 法的文書において引用される先例に依存するため、知的システムは法律専門家に大きな利益をもたらします.これらのシステムは、重要な先例を見つけ、要約し、推論することで役立つ必要があります.
Q: 大規模なオープンソースのリーガル・コーパスをCLERCのようなデータセットに変換する際、法律専門家はどのように協力するのだろうか?
A: 法律専門家は、大規模なオープンソースの法的コーパスをCLERCのようなデータセットに変換する際に協力します.
Q: CLERCデータセットの主要な構成要素で、情報検索や検索を利用した生成タスクをサポートするものは何か?
A: CLERCデータセットの主要なコンポーネントは、情報検索(IR)および検索増強生成(RAG)タスクをサポートするために、法的分析を支援するための関連ケースを見つけるのに役立つCLERC/docおよびCLERC/passageの検索モデル、および法的分析生成を支援するCLERC/generationの検索増強生成システムです.
Q: CLERCデータセットで学習したモデルは、判例検索・分析生成領域における最先端のモデルと比較して、どのようなパフォーマンスを示すのか.
A: CLERCデータセットで訓練されたモデルは、最先端のモデルと比較して、法的なケースの検索と分析生成の領域でどのようにパフォーマンスするかを示しています.GPT-4oは最高のROUGE Fスコアを生成しますが、最も幻覚を見せ、ゼロショットIRモデルは1000件あたり48.3%のリコールしか達成できません.
Q: CLERCデータセットがサポートするタスクにおけるモデルのパフォーマンスを向上させるための今後の研究の方向性は?
A: CLERCデータセットでサポートされるタスクの性能を向上させるための将来の研究方向には、より高度な情報検索技術や生成モデルの開発が含まれます.特に、より高い再現率や生成されたテキストの品質を実現するために、新しいアルゴリズムやモデルアーキテクチャの検討が必要です.また、長い文脈を持つケースの検索や分析生成に焦点を当てたモデルの改善も重要です.
Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools
著者:Varun Magesh, Faiz Surani, Matthew Dahl, Mirac Suzgun, Christopher D. Manning, Daniel E. Ho
発行日:2024年05月30日
最終更新日:2024年05月30日
URL:http://arxiv.org/pdf/2405.20362v1
カテゴリ:Computation and Language, Computers and Society
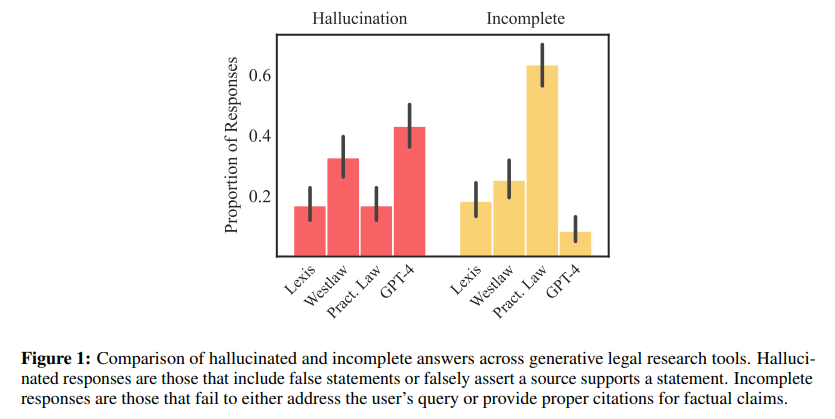
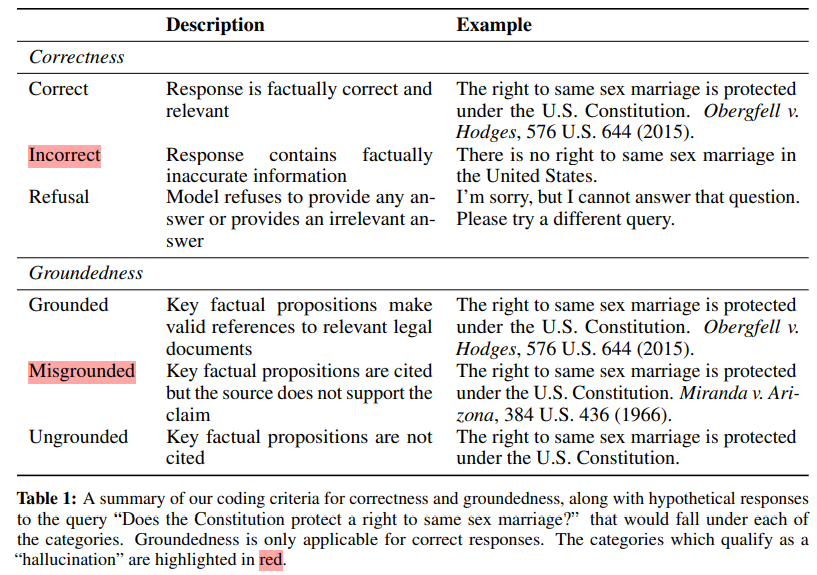
概要:
法律実務では、人工知能(AI)を組み込んだ製品が急速に増加しています.これらのツールは、判例の検索や要約から文書作成まで幅広い法的業務を支援するために設計されています.しかし、これらのツールで使用される大規模言語モデルは、「幻覚を見せる」または偽の情報を作り出す傾向があり、高リスクな領域での使用は危険です.最近、特定の法的研究プロバイダーは、リトリーバル増強生成(RAG)などの方法を「幻覚を排除する」と謳っています(Casetext、2023年)、または「幻覚を回避する」と述べています(トムソン・ロイター、2023年)、または「幻覚のない」法的引用を保証しています(LexisNexis、2023年).これらのシステムの閉鎖的な性質のため、これらの主張を体系的に評価することは困難です.本記事では、AI駆動の法的研究ツールの初めての事前登録された実証評価を設計し、報告します.私たちは、プロバイダーの主張が誇張されていることを示しています.幻覚は一般的なチャットボット(GPT-4)に比べて減少していますが、LexisNexis(Lexis+ AI)やトムソン・ロイター(Westlaw AI-Assisted Research)が作成したAI研究ツールでは、17%から33%の間で幻覚が発生しています.また、システム間の反応性や精度においても大きな違いがあることを文書化しています.私たちの記事は、4つの主要な貢献をしています.まず、RAGベースの独自の法的AIツールのパフォーマンスを評価し報告する初めてのものです.第二に、これらのシステムの脆弱性を特定し理解するための包括的で事前登録されたデータセットを導入しています.第三に、幻覚と正確な法的回答を区別するための明確な分類法を提案しています.最後に、法的専門家がAIの出力を監督し検証する責任についての情報を提供し、AIを法律に責任ある方法で統合するための中心的な未解決問題に対するエビデンスを提供しています.
Q&A:
Q: AIリーガル・リサーチ・ツールの文脈における「幻覚」の概念について説明していただけますか?
A: AIの法的研究ツールにおける「幻覚」とは、AIツールが証拠となるような誤った情報を生成する傾向のことを指します.これは、一部の高プロファイルなケースで、弁護士がAIサービスによって幻覚を起こした存在しない判例を引用して法廷に提出したことで叱責されたことから明らかです.以前の研究では、一般的なLLMが法的クエリに対して平均して58%から82%の幻覚を起こすことがわかっています.しかし、これまでの研究は、法的環境向けに特別に開発されたツール、例えば補助的な法的データベースやRAGを使用するツールなどを調査していませんでした.
Q: 検索補強生成(RAG)法は、AI法務調査ツールにおける幻覚をどのように除去または回避すると主張しているのか?
A: RAGは、検索と生成の2つの主要なステップからなり、クエリを応答に変換する.検索は、クエリに関連する情報を選択するプロセスであり、生成は、選択された情報を使用して応答を生成するプロセスである.RAGは、検索段階で信頼性の高い情報を取得し、生成段階でその情報を使用して正確な応答を生成することによって、幻覚をほぼゼロにまで減少させると主張している.
Q: AIを活用したリーガルリサーチツールの信頼性を評価するために、具体的にどのような方法を用いましたか?
A: 研究では、AI駆動型の法的研究ツールの信頼性を評価するために、正確性、根拠、幻覚の概念に従って各応答をコーディングしました.このため、法律の専門知識に基づいて、モデルの応答を手作業でスコアリングしました.内部妥当性、外部妥当性、再現性、および速度の間には不可避のトレードオフがあるため、AI生成テキストを効率的に評価することは未解決の問題であり、法的環境では特に複雑です.したがって、他のAI評価パイプラインで人気のある「自己チェック」技術はこのアプリケーションには適していません.
Q: レクシスネクシスとトムソン・ロイターのAIリサーチツールの応答性と精度の違いについて詳しく教えてください.
A: LexisNexisとThomson ReutersのAI研究ツールの応答性と精度の違いについて、この研究では詳細に評価されました.LexisNexisとThomson Reutersのツールは、それぞれ17%から33%の間で幻覚を見せることがあります.また、応答性と精度においても大きな違いが見られました.LexisNexisはリンクされた法的引用を100%幻覚から解放すると主張していますが、これについては明確な証拠が提供されていません.研究によると、同じクエリをこれらのモデルに提示しても、テキストデコーディングプロセスが確定的に設定されていないため、毎回異なる回答が得られる可能性があります.これにより、モデルの一貫した分析が妨げられています.
Q: あなたの研究は、AIツールにおける幻覚と正確な法的反応をどのように定義し、区別したのですか?
A: 研究では、法的RAGシステムにおける幻覚を定義し、正確な法的応答との違いを明確にしました.法的研究では、引用を含める必要があるため、幻覚を、誤った情報を含むか、ソースが提案を支持しているという誤った主張を含む応答と定義しました.
Q: レクシスネクシスとトムソン・ロイターのAIリサーチツールにおける幻覚の有病率について、調査の主な結果はどのようなものでしたか?
A: LexisNexis(レクシスAI)とトムソン・ロイター(Westlaw AI-Ask Practical Law AI)の研究ツールにおける幻覚の有病率は、それぞれ17%から33%の間であることが研究の主な結果である.
Q: あなたの研究結果は、AIツールの信頼性についてリーガル・リサーチ・プロバイダーが主張することをどのように否定するものですか?
A: 研究の結果、法的研究プロバイダーが自社のAIツールの信頼性について行っている主張に挑戦しています.具体的には、AIツールの出力における幻覚の高い割合や、提供される情報の不完全さが明らかになりました.これにより、法的プロフェッショナルがAIの出力を監督し検証する責任が強調され、AIを法律に適切に統合するための重要な課題が浮かび上がっています.
Q: 今回の調査結果は、AIのアウトプットを監督・検証する法律専門家の責任にどのような示唆を与えますか?
A: 私たちの調査結果は、法律専門家がAIの出力を監督および検証する責任に対する重要な示唆を提供しています.この研究により、AIツールが生成する命題や引用を手作業で検証するか、それによってAIが提供する効率の利点を損なうか、あるいは特定のリスクや利点について完全な情報を持たずにこれらのツールを使用するリスクを冒すかという難しい選択が法律家に課せられています.したがって、法律専門家はAIの出力を適切に監督し、検証する責任を強化する必要があります.
Q: AIリーガル・リサーチ・ツールの閉鎖的な性質のために、その主張を体系的に評価することの限界についてお話しいただけますか?
A: AI法律研究ツールの主張を体系的に評価する限界は、これらのツールが閉鎖的な性質を持っているために生じます.これらのツールは、公式文書に明確に示されていないため、弁護士がそれらを信頼しても安全であるかどうかを評価することが困難です.そのため、弁護士は、これらのツールが提供する特定のリスクと利点について完全な情報を持たずに使用するか、あるいはこれらのツールによって生成された各主張と引用を手作業で検証するかという難しい選択を迫られます.
Q: あなたの研究は、AIの法律への責任ある統合にどのように貢献すると思いますか?
A: 本研究は、AIを法律に責任ある形で統合するためにどのように貢献するかを明らかにします.具体的には、大規模言語モデル(LLMs)の導入によって生じる誤情報や誤導情報の問題を特定し、それらの原因を明らかにすることで、現行技術の限界を理解しました.これにより、AIの出力を監督し検証する法律専門家の責務を明確にし、AIを法律に適切に統合するための枠組みを提案しました.
Topic Modelling Case Law Using a Large Language Model and a New Taxonomy for UK Law: AI Insights into Summary Judgment
著者:Holli Sargeant, Ahmed Izzidien, Felix Steffek
発行日:2024年05月21日
最終更新日:2024年05月21日
URL:http://arxiv.org/pdf/2405.12910v1
カテゴリ:Computation and Language, Artificial Intelligence, Computers and Society, Machine Learning

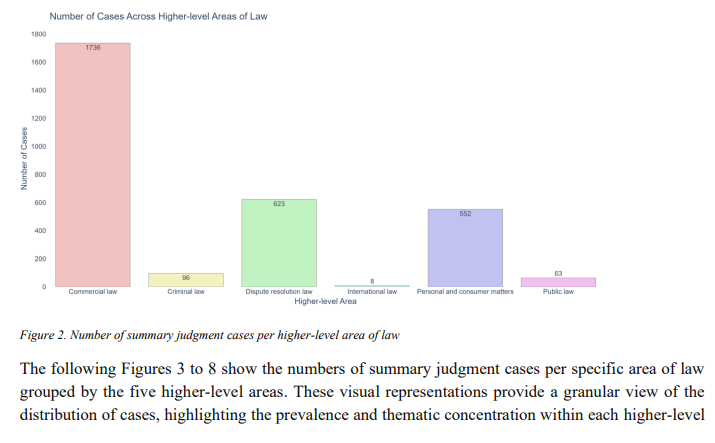
概要:
この論文は、イギリスにおけるサマリー判決事件のトピックモデリングのための新しい分類法を開発し適用することによって、法的分析における重要なギャップに取り組んでいます.サマリー判決事件のキュレーションされたデータセットを用いて、私たちは大規模言語モデルClaude 3 Opusを使用して機能的なトピックやトレンドを探求します.私たちは、Claude 3 Opusがトピックを正しく分類した精度が87.10%であることを発見しました.分析により、様々な法的領域におけるサマリー判決の適用における明確なパターンが明らかになります.イギリスの判例は元々キーワードやトピックフィルタリングオプションでラベル付けされていないため、この研究結果はサマリー判決のテーマ的基盤に関する理解を洗練させるだけでなく、従来のアプローチとAI駆動のアプローチを組み合わせる可能性を示しています.したがって、この論文はイギリス法の新しい一般的な分類法を提供しています.この研究の意義は、司法行政や計算法的研究方法論の分野におけるさらなる研究や政策論議の基盤となります.
Q&A:
Q: 英国における即決裁判をトピックモデル化するための斬新な分類法はどのように開発されたのですか?
A: 新しいタクソノミーを開発するために、法的領域の機能的な分野を開発し、イギリスのサマリージャッジメントケースのトピックモデリングに適用しました.
Q: 即決裁判の分析にはどのようなデータセットを使用しましたか?
A: 研究に使用したデータセットは、3078件のサマリー判決事件に基づいています.
Q: トピックの分類におけるクロード3オパスの精度を説明できますか?
A: Claude 3 Opusのトピック分類の正確性は、初期の精度スコアが84.50%であることが明らかにされました.しかし、いくつかの誤分類はトピックの名前にわずかな違いがあるだけであり、一般的なカテゴリは正しいとされています.例えば、Claude 3 Opusは、ケースを「Trusts (PCT)」と分類しましたが、実際は「Trusts (PCT)」であるべきでした.また、Claude 3 Opusは、混合評価や知識Q&Aで強力なパフォーマンスを示しており、一般的な認知タスクだけでなく、制御工学などの専門タスクでも優れたパフォーマンスを示しています.これらの専門領域の取り扱い能力は、微妙な法的トピックの分類においてもその効果的性を示唆しています.
Q: 様々な法的領域における略式裁判の適用において、どのような明確なパターンが見出されましたか?
A: 様々な法的領域におけるサマリー判決の適用には、明確なパターンが見られました.商業法がサマリー判決の申請において顕著であり、契約を含む商業法のケースが最も多かったです.知的財産、建設、会社、銀行、専門家の過失なども商業法に続いて高い集中度を示しました.商業紛争はしばしば重要な財務リスクを伴い、したがって、ビジネスの中断や経済的損失を最小限に抑えるために迅速な司法処理が必要です.商業法は、多くの契約法の問題を含むため、確実性と手続きの簡素さが求められ、これがこれらの分野でサマリー判決の頻繁な適用に大きな影響を与えています.
Q: 英国の判例にはキーワードやトピックのフィルタリングオプションがありませんが、どのように対処されたのですか?
A: イギリスの判例におけるキーワードやトピックフィルタリングオプションの不足に対処するために、機能的な法分野のタクソノミーを開発し、それを利用してイギリスのサマリージャッジメントケースのトピックモデリングを行いました.
Q: 法的分類において、伝統的なアプローチとAI主導のアプローチをどのように組み合わせたのですか?
A: 従来の手法とAI駆動アプローチを組み合わせることにより、UK法に特化した法的トピックの機能的な分類法を開発し、LLMsを使用して法的コーパスを分類しました.
Q: 論文の中で示されている英国法の新しい一般的な分類法について詳しく教えてください.
A: 本論文では、イギリス法に関する新しい一般的な分類法を提供しています.この分類法は、従来のアプローチとAIによるアプローチを組み合わせることで、サマリー判決のテーマの基盤をより洗練させ、法的分類における潜在能力を示しています.具体的には、イギリス法に特化した包括的な分類法を開発しました.これは、イギリスの法制度における市民が直面する実務上の法的問題に焦点を当てた機能的アプローチを採用しています.
Q: あなたの研究は、司法行政や計算法研究の方法論の分野における今後の研究や政策議論にどのような示唆を与えますか?
A: この研究の成果は、司法行政および計算法的法律研究方法論の分野におけるさらなる研究と政策議論の基盤となります.提案された方法論と開発された法的分野の分類は、他の法律分野に拡張できる枠組みを提供し、法的データの処理と理解方法を革新する可能性があります.この研究は、英国の裁判所における略式判決の使用のダイナミクスを明らかにするだけでなく、法的システムにおける効率と正義の目標をバランス良く保つために手続き法の継続的評価の重要性を強調しています.
Q: あなたの発見がリーガルアナリティクスの分野に与える潜在的な影響をどのようにお考えですか?
A: 研究の成果は、法的分析分野における計算方法の探求と改善に大きな影響を与える可能性があります.提案された方法論と開発された法的分野の分類は、他の法域にも拡張可能な枠組みを提供し、法的データの処理と理解方法を革新する可能性があります.研究は、司法プロセスのダイナミクスを明らかにし、法廷手続きの効率と公正性、アクセシビリティのバランスを取ることの重要性を強調しています.また、法的分野におけるトピックモデリングの課題や制約、特にトピックの幻覚の発生や法的言語を正しく解釈するために必要な微妙な理解力を強調しています.
Q: この分野での研究の次のステップは?
A: この研究の次のステップは、提案された方法論と開発された法域の分類をさらに探求し、他の法域に拡張することです.これにより、法的データの処理と理解方法が革新され、法的分析や政策立案に影響を与える可能性があります.
A Survey on Large Language Models for Critical Societal Domains: Finance, Healthcare, and Law
著者:Zhiyu Zoey Chen, Jing Ma, Xinlu Zhang, Nan Hao, An Yan, Armineh Nourbakhsh, Xianjun Yang, Julian McAuley, Linda Petzold, William Yang Wang
発行日:2024年05月02日
最終更新日:2024年05月02日
URL:http://arxiv.org/pdf/2405.01769v1
カテゴリ:Computation and Language
概要:
人工知能の急速に進化する領域では、GPT-3やGPT-4などの大規模言語モデル(LLMs)が金融、医療、法律などの分野を革新しています.これらの分野は、専門家の専門知識、データ取得の困難さ、高いリスク、厳格な規制順守が特徴です.この調査は、これらの高リスクセクター内でのLLMsの方法論、応用、課題、および将来の機会について詳細に探求しています.私たちは、LLMsが医療の診断や治療方法論の向上、金融分析の革新、法的解釈とコンプライアンス戦略の洗練に果たす重要な役割を強調しています.さらに、これらの分野でのLLMsの倫理的な応用について批判的に検討し、既存の倫理的懸念と、規制基準を尊重する透明で公正で堅牢なAIシステムの必要性を指摘しています.現在の文献と実践的な応用の徹底的なレビューを通じて、LLMsの変革的な影響を示し、学際的な協力、方法論の進歩、倫理的な imperativeの概要を示しています.さらに、LLMsを最大限に活用し、そのリスクを軽減するための将来の研究を促進するために、この分野における最新の進展を追跡する読書リストを開始しました.このリストは以下のリンクから常に更新されます:\url{https://github.com/czyssrs/LLM_X_papers}.
Q&A:
Q: 金融、医療、法律の領域で大規模言語モデル(LLM)を実装するために、具体的にどのような方法論が使われているのか?
A: ファイナンス、ヘルスケア、法律の分野で大規模言語モデル(LLMs)を実装するために使用されている具体的な方法論は、専門家知識の活用、機密データの取り扱い、多様なモダリティを持つ文書の処理、法的リスクの管理、説明責任と公平性の確保などが含まれます.
Q: LLMが医療における診断や治療方法をどのように向上させているか、例を挙げていただけますか?
A: LLMは、医療の診断および治療方法論を向上させるために、患者のデータや医学的知識を活用して、病気の診断や治療法の提案を行うことができます.これにより、医療従事者がより正確かつ迅速に患者の状態を評価し、最適な治療法を選択することが可能となります.
Q: LLMは金融セクターの財務分析をどのように革新しているのか?
A: LLMは、金融分析に革新をもたらしています.これは、BERTなどの一般的なPLMやLLMの進化するモデリングパラダイムに一致しています.金融分野では、高いリスク、厳格な規制順守が求められるため、LLMは重要な役割を果たしています.この調査は、これらの高リスクセクターにおけるLLMの方法論、応用、課題、将来の展望について詳細に探求しています.LLMは、医療の診断や治療方法の向上、金融分析の革新、
Q: LLMはどのような形で法解釈やコンプライアンス戦略を洗練させているのでしょうか?
A: 法律の分野において、LLMは法的解釈とコンプライアンス戦略を洗練する方法として、法的テキストや先例に深い洞察をもたらすことによって貢献しています.LLMは、法的テキストや先例により深い洞察を提供することで、より情報豊かな法の更新や学術研究に貢献することができます.また、LLMは厳密な分析と検証を通じて、特定の人口グループに対する不正義や差別を法的意思決定プロセスで特定し、是正するのに役立つことができます.
Q: このような重要な社会的領域におけるLLMの適用をめぐる、既存の倫理的懸念にはどのようなものがあるのでしょうか?
A: これらの重要な社会的領域におけるLLMの適用に関する既存の倫理的懸念のいくつかは、不正義や差別が特定の人口集団に対する法的意思決定プロセスで発生する可能性があることを特定し、修正することを求めています.
Q: LLM申請における倫理的懸念に対処するために、透明で公正かつ堅牢なAIシステムはどのように開発できるのか?
A: 透明で公正かつ堅牢なAIシステムを開発するためには、現存する倫理的懸念を解決するために、データの収集、モデルのトレーニング、および結果の解釈において透明性を確保する必要があります.また、公正性を確保するためには、データセットの偏りやバイアスを排除し、アルゴリズムの適切な調整を行うことが重要です.さらに、堅牢性を確保するためには、モデルのセキュリティを強化し、外部からの攻撃や悪意のある操作に対処する対策を講じる必要があります.
Q: これらの分野でLLMを成功させるためには、どのような学際的協力が必要なのだろうか?
A: これらのセクターでLLMの成功した実装のためには、AI研究者、専門家、および政策立案者の間での協力が必要です.これらの異なる分野の専門家が連携し、倫理的な側面を調整し、LLMの全体的な潜在能力を責任を持って活用する必要があります.
Q: 金融、医療、法律におけるLLMの効果をさらに向上させるためには、方法論においてどのような進歩が必要なのだろうか?
A: 金融、医療、法律の分野においてLLMの効果をさらに向上させるためには、新たな方法論の進化が必要です.具体的には、より複雑なデータセットや問題に対応できるようなモデルの開発、高い精度と信頼性を持つ予測能力の向上、倫理的な側面を考慮したモデルの構築などが求められます.
Q: このような精度に依存する分野でLLMを継続的に使用する際、倫理的な警戒はどのように維持できるのだろうか?
A: LLMの使用における倫理的な警戒を維持するためには、透明性、公正性、および堅牢なAIシステムが必要であり、規制基準を尊重する必要があります.これには、学際的な協力、方法論の進歩、倫理的な警戒が不可欠であり、これらの分野におけるリスクを軽減しながらLLMの利点を最大限に引き出すための将来の研究を促すことが目的です.
Q: 金融、医療、法律におけるLLMの最新の進歩を追跡するために始めたリーディング・リストについて、もう少し詳しく教えてください.
A: LLMのファイナンス、医療、法律分野における最新の進歩を追跡するために開始した読書リストは、このトピックの最新の進歩を追跡するものであり、継続的に更新されます.この読書リストは、広範な視点とLLM開発のさまざまな側面を探るLLM関連の調査文献も含んでいます.
CBR-RAG: Case-Based Reasoning for Retrieval Augmented Generation in LLMs for Legal Question Answering
著者:Nirmalie Wiratunga, Ramitha Abeyratne, Lasal Jayawardena, Kyle Martin, Stewart Massie, Ikechukwu Nkisi-Orji, Ruvan Weerasinghe, Anne Liret, Bruno Fleisch
発行日:2024年04月04日
最終更新日:2024年04月04日
URL:http://arxiv.org/pdf/2404.04302v1
カテゴリ:Computation and Language, Artificial Intelligence

概要:
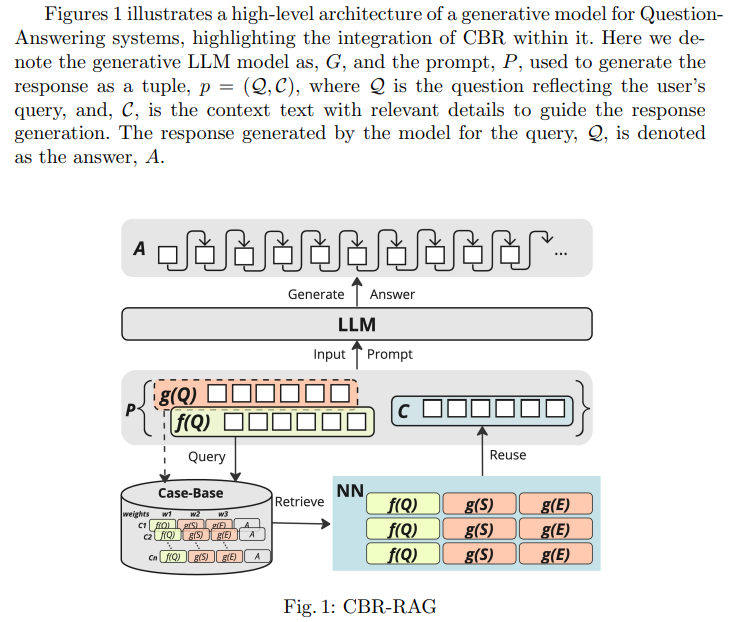
Retrieval-Augmented Generation(RAG)は、大規模言語モデル(LLM)の出力を向上させるために、事前知識を入力の文脈として提供します.これは、証拠を生成されたテキストの出力を検証するために必要とされる法的な質問応答など、知識集約的で専門家に依存するタスクにとって有益です.私たちは、ケースベース推論(CBR)がLLM内のRAGプロセスの一部として構造化検索の重要な機会を提供することを強調します.私たちはCBR-RAGを紹介し、CBRサイクルの初期検索段階、インデックス語彙、および類似性知識コンテナを使用して、LLMクエリを文脈に即したケースで強化します.この統合により、元のLLMクエリが拡張され、より豊かなプロンプトが提供されます.私たちはCBR-RAGの評価を行い、法的な質問応答のタスクにおいて異なる表現(一般的およびドメイン固有の埋め込み)や比較方法(相互、内部、ハイブリッド類似性)を検討します.結果は、CBRのケース再利用によって提供される文脈が、質問の関連する部分と証拠ベースの間の類似性を強化し、生成された回答の品質の著しい改善をもたらすことを示しています.
Q&A:
Q: 大規模言語モデル(LLM)において、事例ベース推論(CBR)がどのように検索補強型生成(RAG)プロセスに統合されているか説明していただけますか?
A: CBRは、RAGプロセスにおいてLLMに統合されます.具体的には、CBR-RAGでは、CBRサイクルの初期検索段階、インデックス語彙、および類似性知識コンテナが使用されて、LLMクエリを文脈に即したケースで強化します.この統合により、元のLLMクエリが拡張され、より豊かなプロンプトが提供されます.CBRのケース再利用によって提供される文脈は、質問の関連する部分と証拠ベースの類似性を強化し、生成された回答の品質を大幅に向上させます.
Q: CBR-RAGは、法律上の質問応答タスクに具体的にどのようなメリットをもたらすのか?
A: CBR-RAGは、法的な質問応答タスクにおいて、質問と証拠ベースの関連する部分の類似性を強化し、生成された回答の品質を著しく向上させるという特定の利点を提供します.
Q: CBRサイクルの最初の検索段階は、LLMクエリをどのように強化するか?
A: CBRサイクルの初期検索段階は、LLMクエリをコンテキストに関連するケースで強化します.この段階では、CBRサイクルの初期検索は、索引語彙や類似性知識コンテナを使用して、LLMクエリに関連するケースを取得し、元のLLMクエリを拡張し、より豊かなプロンプトを提供します.
Q: CBR-RAGで使用されている索引語彙と類似知識コンテナについて詳しく教えてください.
A: CBR-RAGでは、インデックス語彙と類似性知識コンテナが使用されます.インデックス語彙は、CBRサイクルの初期検索段階で使用され、LLMクエリを豊かにするために関連するケースを提供します.類似性知識コンテナは、関連する質問の要素と証拠ベースの間の類似性を強化し、生成された回答の品質を向上させます.
Q: この研究では、どのような異なる表現(一般的な埋め込みとドメイン固有の埋め込み)が評価されたのか?
A: 研究では、BERT、LegalBERT、およびAnglEBERTによって生成された埋め込みが評価されました.これらは、一般的な目的の埋め込みとは異なり、LegalBERTは多様な英語法的文書で事前にトレーニングされています.
Q: CBR-RAGの評価において、さまざまな比較方法(インター、イントラ、ハイブリッドの類似性)はどのように用いられたか?
A: 異なる比較方法(インター、イントラ、ハイブリッド類似性)は、CBR-RAGの評価において、異なる表現(一般的およびドメイン固有の埋め込み)と比較方法(インター、イントラ、ハイブリッド類似性)を検討するために使用されました.
Q: CBR-RAGの評価から、法的な質問に対する回答という課題に関して、どのような重要な発見があったのだろうか?
A: CBR-RAGの評価から得られた主な結果は、CBRのケース再利用による文脈が質問の関連する部分と証拠ベースの類似性を強化し、生成された回答の品質を著しく向上させることが示されました.
Q: CBRのケース再利用によって提供されるコンテキストは、生成された回答の品質をどのように向上させますか?
A: CBRのケース再利用によって提供されるコンテキストは、質問の関連する部分と証拠ベースの類似性を強化し、生成される回答の品質を大幅に向上させます.具体的には、CBRによって取得されたコンテンツがLLMのクエリに追加され、LLMのための文脈豊かなプロンプトが作成されます.これにより、ユーザーのクエリを反映する質問Qと、回答生成をガイドする関連する詳細を持つコンテキストテキストCからなるタプルp=(Q,C)が生成され、モデルによってクエリQに対する回答Aが生成されます.
Q: CBR-RAGの法的質問応答分野における将来的な応用や拡張の可能性は何か?
A: CBR-RAGの将来の潜在的な応用や拡張は、法的な質問応答の分野において、生成された回答の品質向上や関連する質問と証拠ベースの類似性の強化などが挙げられます.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: 新しい手法のコード実装のurlは、https://github.com/rgu-iit-bt/cbr-for-legal-rag です.
LexDrafter: Terminology Drafting for Legislative Documents using Retrieval Augmented Generation
著者:Ashish Chouhan, Michael Gertz
発行日:2024年03月24日
最終更新日:2024年03月24日
URL:http://arxiv.org/pdf/2403.16295v1
カテゴリ:Computation and Language
概要:
EUにおける立法文書の増加に伴い、新しい用語とその定義の数も増加しています.欧州議会、理事会、委員会の共同実務ガイドによると、法的文書で使用される用語は一貫性があり、普通の、法的、または技術的な言語の意味から逸脱しないように表現されなければなりません.したがって、新しい立法文書を起草する際に、既存の定義に関する洞察を提供し、文書の文脈に基づいて新しい用語を定義するのを支援するフレームワークを持つことは、異なる規制間で調和された法的定義をサポートし、曖昧さを避けるために重要です.本論文では、LexDrafterというフレームワークを紹介し、取得増強生成(RAG)と異なる立法文書に存在する既存の用語定義を使用して、立法文書の定義条項の起草を支援します.これにより、定義要素が既存の文書から抽出され、定義要素とRAGを使用して、起草中の立法文書に対して必要に応じて定義条項を提案することができます.さらに、LexDrafterの機能を詳しく説明し、エネルギー分野のEU文書のコレクションを使用して、その機能をデモンストレーションおよび評価します.LexDrafterフレームワークのコードは、https://github.com/achouhan93/LexDrafter で入手可能です.
Q&A:
Q: LexDrafterがどのように検索拡張世代(RAG)を使って、立法文書の定義条文の起草を支援するのか説明していただけますか?
A: LexDrafterは、既存の法令文書に存在する用語の定義要素を抽出して定義要素を構築し、その定義要素とRAGを使用して、起草中の法令文書に対して必要に応じて定義記事を提案することで、法令文書の起草を支援します.RAGは、定義する用語に関連するテキスト断片を取得し、大規模言語モデル(LLMs)を使用して定義を生成する手法です.LexDrafterの利点は、異なる法令間で法的定義を調和させることを目指しており、既存の定義に関する洞察を提供し、文書の文脈に基づいて新しい用語を定義することで、異なる規制間での一貫した法的定義を支援し、曖昧さを回避します.
Q: LexDrafterはどのようにして既存の文書から定義を抽出し、定義要素を構築するのですか?
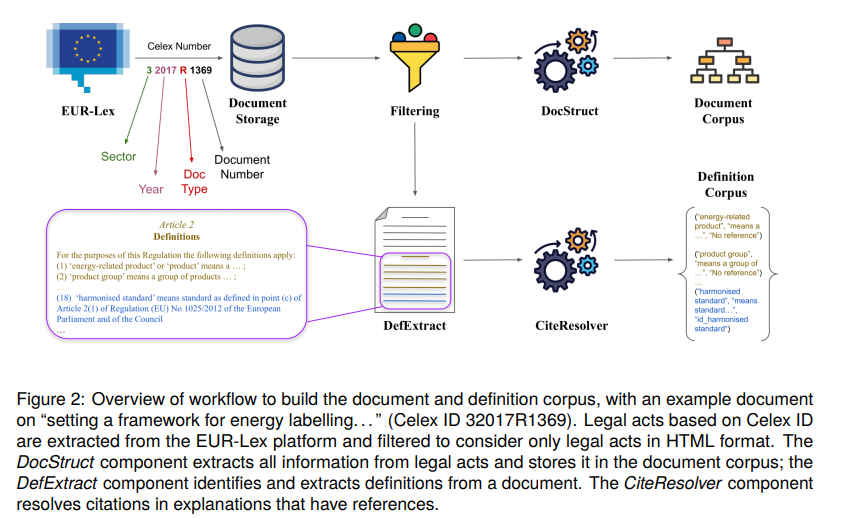
A: LexDrafterは、EUR-Lex法的文書から既存の定義を抽出し、定義要素を構築します.これにより、定義抽出自体だけでなく、外部参照を持つ定義に対して引用解決も行われ、最終的に所謂定義要素が生成されます.
Q: LexDrafterが起草中の立法文書に定義条文を提案する例を教えてください.
A: LexDrafterは、既存の文書から定義要素を抽出し、RAGを使用して立法文書のための定義記事を提案します.立法文書の起草中に、LexDrafterは要求に応じて定義記事を提案します.
Q: LexDrafterは、どのようにして異なる規制間の法的定義の一貫性と調和を確保しているのか?
A: LexDrafterは、既存の定義を抽出し、大規模言語モデル(LLM)を使用して定義を生成することにより、異なる法令間での法的定義の一貫性と調和を図っています.これにより、法的行為の定義記事の起草を自動化し、既存の用語定義(たとえば引用のため)を提供したり、新しい用語定義を生成することで、人為的なエラーを減らし、文書の起草にかかる時間を短縮します.さらに、LexDrafterは異なる法令間での法的定義の一貫性を図ることを目指しており、用語定義の一貫性を保つために人間が大量の文書を手動で参照する必要がないため、時間の節約にもつながります.
Q: 新しい用語を起草する際、LexDrafterは既存の定義について具体的にどのような知見を提供してくれるのか?
A: 新しい用語を起草する際に、LexDrafterは既存の定義に関する具体的な洞察を提供します.これにより、異なる規制の間で調和された法的定義をサポートし、曖昧さを回避することができます.
Q: 新しい用語を定義する際、LexDrafterは法律用語の曖昧さにどのように対処するのですか?
A: LexDrafterは、既存の定義に関する洞察を提供し、文書の文脈に基づいて新しい用語を定義することで、異なる規制間で調和された法的定義をサポートし、曖昧さを回避します.LexDrafterは、法的定義の起草を自動化することにより、異なる法的行為間で法的定義を調和させることを目指しています.また、既存の用語の定義(例:引用のため)を提供したり、新しい用語の定義を生成することで、人為的なエラーを減らし、文書の起草にかかる時間を短縮します.
Q: LexDrafterは、どのような基準で既存の用語定義を新しい立法文書に取り入れるかを決定するのですか?
A: 新しい立法文書に組み込む既存の用語定義を決定するためにLexDrafterが使用する基準は、異なる立法文書に存在する既存の用語定義を特定し、文書の文脈に基づいて新しい用語定義を生成することです.
Q: LexDrafterは、異なる立法文書間の用語の違いをどのように扱うのですか?
A: LexDrafterは、異なる立法文書間の用語の違いを取り扱うために、既存の用語定義を提供したり、新しい用語定義を生成することによって、法的定義を調和させることを目指しています.
Q: エネルギー分野のEU文書を用いてLexDrafterの機能を評価するプロセスを教えてください.
A: LexDrafterの機能性を評価するプロセスは、EUのエネルギードメインからの文書コレクションを使用して行われます.まず、EUR-Lexプラットフォームから法的行為を抽出し、HTML形式の法的行為のみを考慮してフィルタリングします.次に、DocStructコンポーネントが法的行為からすべての情報を抽出し、文書コーパスに保存します.DefExtractコンポーネントは文書から定義を識別して抽出し、CiteResolverコンポーネントは参照を持つ説明の引用を解決します.LexDrafterフレームワークの機能は、法的行為の起草時にユーザーを支援します.特に、文書のセクションの起草が完了した後、用語の定義が欠落している場合に役立ちます.LexDrafterに必要な主要コンポーネントは、起草されたセクションに特定の用語を含む断片です.これらの断片は、当社のRAGアプローチを使用して用語の定義に文脈情報を提供します.定義が必要な用語を自動的に識別するには、法的理論の理解が必要です.したがって、私たちの作業では、定義が必要な用語を決定するための用語を
Q: 立法文書の起草にLexDrafterを使用することで、効率性と正確性の面でどのような利点がありますか?
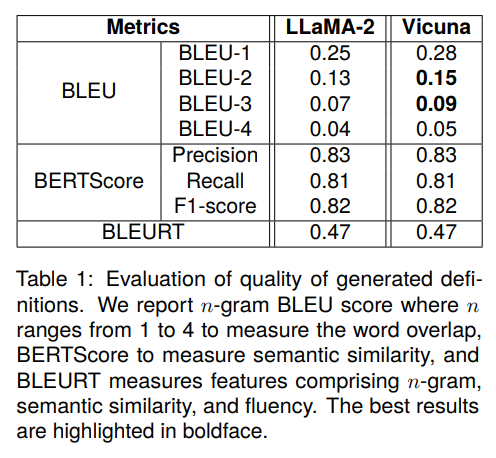
A: LexDrafterを使用することで、法的文書の起草において効率性と正確性が向上します.具体的には、LexDrafterは異なる法的文書間で法的定義を調整することを目的としており、既存の用語定義を提供したり新しい用語定義を生成することで人為的なエラーを減らし、文書の起草にかかる時間を短縮します.また、LexDrafterは定義の自動生成タスクにおいてBERTスコアとBLEUスコアを使用して機能性を評価し、LLMを使用した生成された定義が低い単語の重複率を示しつつも高い意味的類似性を持つことが示されています.
Exploring Large Language Models and Hierarchical Frameworks for Classification of Large Unstructured Legal Documents
著者:Nishchal Prasad, Mohand Boughanem, Taoufiq Dkaki
発行日:2024年03月11日
最終更新日:2024年03月11日
URL:http://arxiv.org/pdf/2403.06872v1
カテゴリ:Computation and Language, Artificial Intelligence
概要:
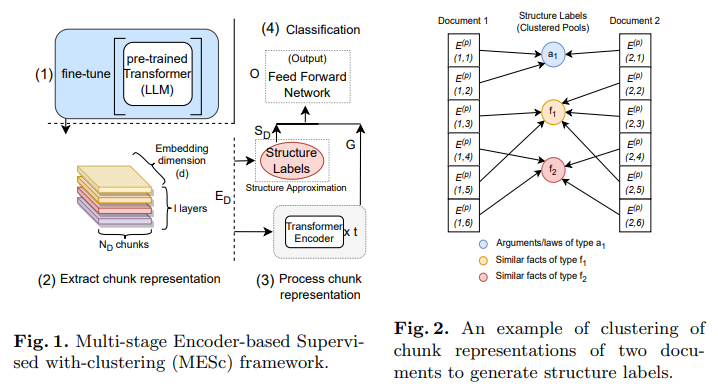
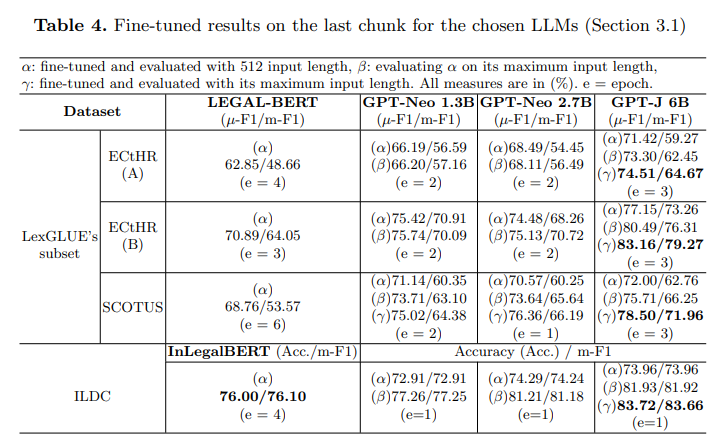
法的判決予測は、一般的に数万語を超える長い事件文書や一様でない構造を持つ文書という問題に苦しんでいます.このような文書から判決を予測することは、構造的注釈がない文書ではさらに困難な課題となります.私たちは、このような大規模な法的文書とその構造情報の欠如に対処するために、MESc(”Multi-stage Encoder-based Supervised with-clustering”)と呼ばれるディープラーニングベースの階層フレームワークを探求します.具体的には、文書を部分に分割して、カスタムで微調整された大規模言語モデルの最後の4つのレイヤーから埋め込みを抽出し、非監督クラスタリングを通じてその構造を近似しようとします.これらを別のセットのトランスフォーマーエンコーダーレイヤーで使用して、部分間の表現を学習します.私たちは、大規模言語モデル(LLM)(GPT-Neo、GPT-J)の数十億のパラメータとMEScの階層フレームワークの適応性を分析し、法的テキスト上での単独の性能と比較します.また、彼らのドメイン内(法的)転移学習能力と、最後からの埋め込みの組み合わせの影響も研究します.さらに、インド、欧州連合、アメリカの法的文書をILDCデータセットとLexGLUEデータセットのサブセットを用いて、幅広い実験と削減研究を行い、これらの手法とその効果を試験します.私たちのアプローチは、従来の最先端手法に比べて、最小でも約2ポイントの総合性能向上を達成しています.
Q&A:
Q: 大規模な法律文書から埋め込みを抽出する際に、MEScフレームワークがどのように機能するのか、もう少し詳しく説明していただけますか?
A: MEScフレームワークは、大規模な法的文書から埋め込みを抽出する際に、最後のレイヤーからの埋め込みを結合することによって機能します.具体的には、GPT-NeoやGPT-JなどのLLMの最後の2つのレイヤーからの埋め込みを連結することで、特徴の分散を最適な数に提供します.このようにして、埋め込みを連結することで、構造ラベルのより良い近似を得ることができ、パフォーマンスが向上します.
Q: あなたの研究では、判定予測の有効性をどのように定義し、測定しますか?
A: 研究では、判決予測の効果を定義し、測定するために、大規模な法的文書からの判決予測の精度を評価します.具体的には、我々のフレームワークは、ケースの事実と法律違反を使用して裁判の結果を予測するLegal Judgment Prediction(LJP)タスクを説明し、その予測の合理的な説明を提供するデータセットを作成します.また、AdaBoost決定木を使用して米国最高裁判所の判決を予測するなど、他の研究者たちも同様のタスクに取り組んでいます.
Q: 構造が統一されていない長いケース文書を扱う際に、具体的にどのような問題に直面しましたか?
A: 長い事件文書の非一様な構造に取り組む際に遭遇した具体的な課題は、文書の長さが一般的に数万語を超え、一貫性のない構造を持っていることです.このような文書から判決を予測することは困難な作業となります.特に、構造的注釈のない文書では、判決を予測することがさらに困難になります.
Q: 法律文書の構造を近似する教師なしクラスタリングのプロセスについて詳しく教えてください.
A: 法的文書の構造を近似するための教師なしクラスタリングプロセスは、文書の部分を抽出し、それらの埋め込みを取得した後、HDBSCANなどのクラスタリングアルゴリズムを使用して類似した部分をマッピングします.具体的には、文書を部分に分割し、カスタムでファインチューニングされた大規模言語モデルの最後の4つのレイヤーから埋め込みを抽出し、教師なしクラスタリングを通じてその構造を近似しようとします.この近似された構造ラベルは、埋め込みとともに処理され、他の文書の部分との類似性によって学習されます.
Q: GPT-NeoやGPT-Jのような大規模言語モデル(LLM)を、どのようにして階層型フレームワークで使えるように微調整したのですか?
A: GPT-Neo(1.3B、2.7B)やGPT-Jなどの大規模言語モデル(LLMs)を階層的フレームワークで使用するために、最後の2つのレイヤーからの埋め込みを連結することで、特徴の分散を最適化することができます.これにより、埋め込みを連結することで、構造ラベルのより良い近似が得られ、パフォーマンスが向上します.
Q: MEScの枠組みにおけるLLMの成績と、単独での法文の成績を比較した結果、どのような重要な発見や洞察がありましたか?
A: LLMはMEScフレームワーク内でのパフォーマンスが、法的テキストにおける単独のパフォーマンスよりも優れていることが示されました.特に、データセット内のほとんどの文書の長さがLLMの最大入力長よりもはるかに大きい場合や、長い文書の重要な部分が不明な場合に、MEScがLLMよりも優れたパフォーマンスを発揮します.
Q: 法律領域における数十億のパラメータを持つLLMの適応性をどのように評価しましたか?
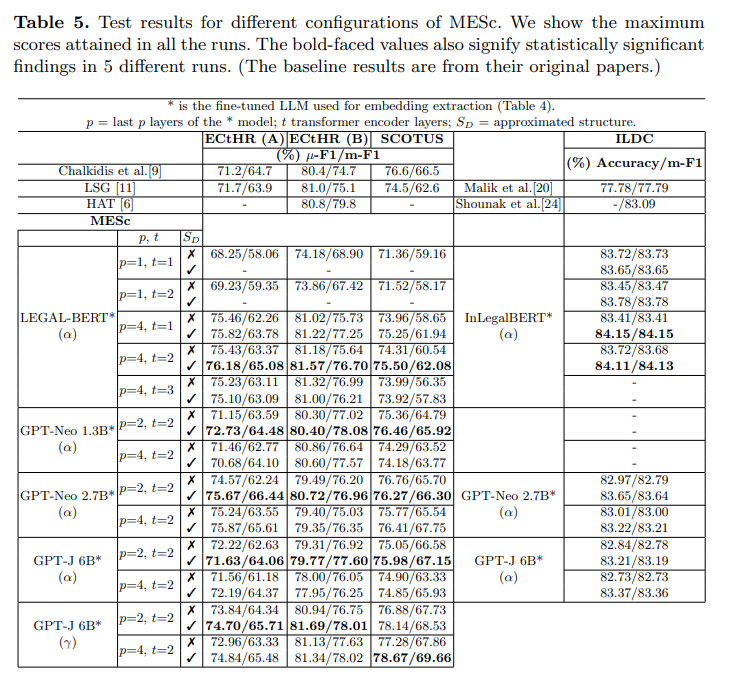
A: LLMの多億パラメータの適応性を法的領域でどのように評価したかについては、我々は、ドメイン固有の事前学習済みの多億パラメータLLMを法的文書に適用し、その内部ドメイン(法的)転移学習能力を調査しました.具体的には、GPT-NeoとGPT-Jの多億パラメータLLMをMEScに適用し、これらのLLMによるILDCおよびLexGLUEサブセット(ECtHR(A)、ECtHR(B)、およびSCOTUS)の分類における基準性能を分析しました.これにより、これらの言語モデルの内部ドメイン(法的)転移学習能力を示す新たな基準を確立しました.
Q: 領域内移動学習に使用された方法論と、MEScの最後の層からの埋め込みを組み合わせることの影響について説明してもらえますか?
A: 文中では、法的テキストにおけるインドメイン間転移学習の方法論と、MEScでの最後のレイヤーからの埋め込みの組み合わせの影響について詳細に説明されています.具体的には、GPT-NeoやGPT-Jの最後の2層からの埋め込みを連結することが最適な特徴分散の数を提供し、埋め込みを連結することで構造ラベルのより良い近似とパフォーマンスの向上が見られました.
Q: さまざまな地域の法的文書に対して実施された広範な実験とアブレーション研究から導き出された主な結果や結論は?
A: 実験と削減研究により、MEScの最後の層からの埋め込みを組み合わせる方法は、インド、欧州連合、アメリカの法的文書における前進した方法において、前の最先端技術よりも約2ポイントの最小総合性能向上を達成した.
Q: 今後の法的文書分類の研究において、MEScの枠組みをさらにどのように改善・拡張していく予定ですか?
A: MEScフレームワークを将来の研究でさらに改善または拡張するためには、まず、クラスタリングによる構造の近似をさらに精緻化し、各文書部分の埋め込みを取得するためのカスタムファインチューニングされたLLMの最後の4層からの抽出をさらに最適化することが重要です.さらに、予測に寄与するクラスターを分析し、予測を説明するための説明アルゴリズムの開発を目指します.また、フランスとヨーロッパの法的事例においてこのフレームワークを適用し、文書の長さや非一様な構造の問題をさらに探求することが重要です.
SaulLM-7B: A pioneering Large Language Model for Law
著者:Pierre Colombo, Telmo Pessoa Pires, Malik Boudiaf, Dominic Culver, Rui Melo, Caio Corro, Andre F. T. Martins, Fabrizio Esposito, Vera Lúcia Raposo, Sofia Morgado, Michael Desa
発行日:2024年03月06日
最終更新日:2024年03月07日
URL:http://arxiv.org/pdf/2403.03883v2
カテゴリ:Computation and Language
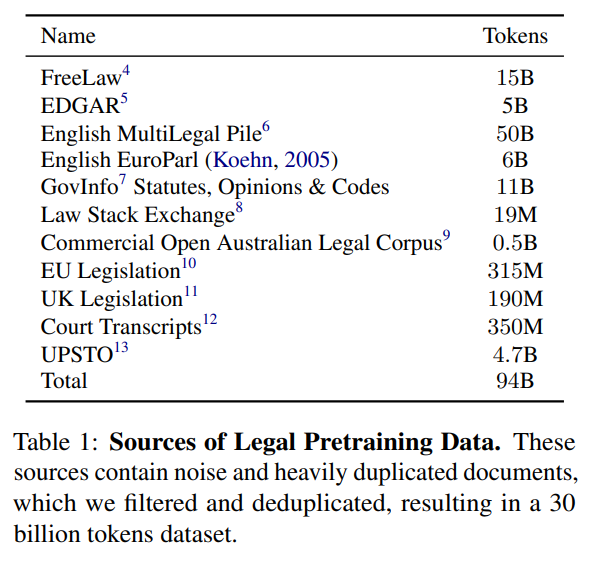

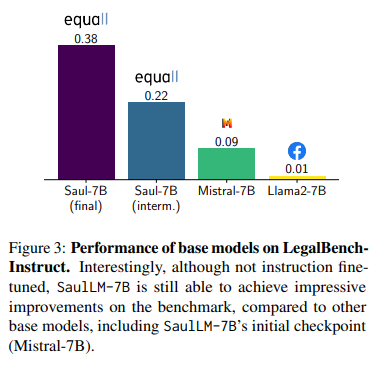
概要:
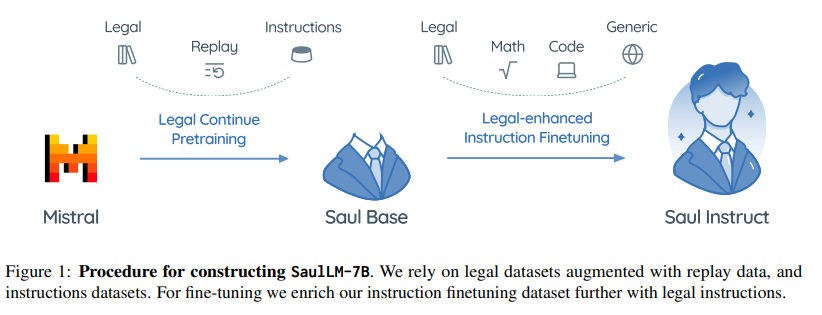
この論文では、法律領域に特化した大規模言語モデル(LLM)であるSaulLM-7Bを紹介します.SaulLM-7Bは70億のパラメータを持ち、法的テキストの理解と生成のために明示的に設計された初のLLMです.Mistral 7Bアーキテクチャを基盤として、SaulLM-7Bは30億以上のトークンからなる英語の法的コーパスで訓練されています.SaulLM-7Bは法的文書の理解と処理において最先端の能力を示しています.さらに、法的データセットを活用した新しいfine-tuning方法を紹介し、SaulLM-7Bの法的タスクにおける性能をさらに向上させています.SaulLM-7BはMITライセンスの下で公開されています.
Q&A:
Q: SaulLM-7Bの基盤として使われた具体的なアーキテクチャは?
A: SaulLM-7Bの基盤として使用された特定のアーキテクチャは、Mistral 7Bアーキテクチャです.
Q: SaulLM-7Bのパラメーター数は?
A: ソールLM-7Bは70億のパラメータを持っています.
Q: SaulLM-7Bが学習した英語法律コーパスのサイズは?
A: SaulLM-7Bは、3兆以上のトークンからなる英語法律コーパスで訓練されました.
Q: SaulLM-7Bは、法律文書を理解する能力という点で、他の言語モデルと比較してどうですか?
A: SaulLM-7Bは、法的文書の理解能力において他の言語モデルと比較して最先端の性能を示しています.SaulLM-7Bは、3,000億以上のトークンからなる英語の法的コーパスで訓練されており、法的文書の理解と処理において最先端の能力を発揮しています.
Q: SaulLM-7Bの法的業務のパフォーマンスを向上させるために使用される小説の指導微調整方法を説明できますか?
A: SaulLM-7Bのパフォーマンスを向上させるために使用される新しい教示ファインチューニング方法は、法的データセットを活用してSaulLM-7Bの性能をさらに向上させるためのものです.具体的には、法的データセットを活用してSaulLM-7Bを事前学習し、その後、法的指示を含む教示ファインチューニングデータセットでモデルをさらに微調整します.この方法により、SaulLM-7Bは法的文書の理解と処理において最先端の性能を発揮し、法的タスクにおいて優れた成績を収めることができます.
Q: SaulLM-7Bのライセンスは?
A: SaulLM-7BはMITライセンスの下でリリースされています.
Q: SaulLM-7Bはどのように法律領域向けに特別に調整されたのですか?
A: SaulLM-7Bは、法的テキストに特化した7億のパラメータを持つ大規模言語モデル(LLM)であり、法的文書の理解と生成のために明示的に設計されました.Mistral 7Bアーキテクチャを基盤とし、3兆以上のトークンからなる英語の法的コーパスで訓練されています.SaulLM-7Bは、法的文書の理解と処理において最先端の能力を示しており、法的データセットを活用した新しい教示の微調整手法を提供することで、SaulLM-7Bの性能をさらに向上させています.
Q: 法律分野でのSaulLM-7Bの応用の可能性は?
A: SaulLM-7Bは法律分野での様々な潜在的な応用が考えられます.例えば、法的文書の理解や生成、契約書の作成、法的文書の翻訳、法的アドバイスの提供などが挙げられます.
Q: SaulLM-7Bはどのように法文を生成するのですか?
A: SaulLM-7Bは、法的テキストの生成を処理する際に、7兆個のパラメータを持ち、法的テキストの理解と生成のために明示的に設計された最初のLLMです.Mistral 7Bアーキテクチャを基盤とし、英語の法的コーパスを使用してトレーニングされています.SaulLM-7Bは、法的文書の理解と処理において最先端の能力を示しており、法的データセットを活用した新しい指導的な微調整方法によって、その性能をさらに向上させています.
Q: ソールLM-7Bでは今後どのような開発や改良が予定されているのか?
A: SaulLM-7Bに対する将来の開発や改善については、特に文法的な課題に焦点を当てた新しい言語モデルの開発が計画されています.この新しいモデルは、法的文書のより高度な理解と処理を可能にするために設計されており、SaulLM-7Bの性能向上を図ることが期待されています.
RAGged Edges: The Double-Edged Sword of Retrieval-Augmented Chatbots
著者:Philip Feldman, James R. Foulds, Shimei Pan
発行日:2024年03月02日
最終更新日:2024年06月12日
URL:http://arxiv.org/pdf/2403.01193v3
カテゴリ:Computation and Language, Artificial Intelligence
概要:
大規模言語モデル(LLM)のようなChatGPTは、人工知能の驚異的な進歩を示しています.しかし、彼らの幻覚を起こす傾向 – つまり、合理的ではあるが誤った情報を生成すること – は重大な課題を提起しています.この問題は重要であり、最近の裁判でChatGPTの使用が存在しない法的判決の引用につながった事例で見られます.この論文では、外部知識をプロンプトと統合することで、Retrieval-Augmented Generation(RAG)が幻覚を打ち消す方法を探求しています.私たちは、幻覚を誘発するために設計されたプロンプトを使用して、RAGを標準のLLMと比較して実証的に評価します.結果は、RAGがいくつかのケースで精度を向上させることを示していますが、プロンプトがモデルの事前学習の理解と直接矛盾する場合、RAGも誤解される可能性があることを示しています.これらの結果は、幻覚の複雑な性質を浮き彫りにし、現実世界のアプリケーションでのLLMの信頼性を確保するためにより堅牢な解決策が必要であることを強調しています.私たちは、RAGの展開に向けた実用的な推奨事項を提供し、より信頼性の高いLLMの開発に対する影響について議論しています.
Q&A:
Q: ChatGPTのような大規模な言語モデルの文脈で、幻覚の概念を説明できますか?
A: 大規模言語モデル(LLM)のようなChatGPTにおける幻覚とは、モデルが信憑性のある情報を生成するが、それが実際には間違っている場合を指します.これは、外部の知識をプロンプトと統合することで幻覚をカウンターすることができるRetrieval-Augmented Generation(RAG)が重要であることを示しています.RAGは、いくつかのケースで精度を向上させるが、プロンプトがモデルの事前学習の理解と直接矛盾する場合には誤解される可能性があることが示されています.これらの結果は、幻覚の複雑な性質を強調し、実世界のアプリケーションにおいてLLMの信頼性を確保するためにより堅牢なソリューションが必要であることを示しています.
Q: 幻覚に対抗するために、RAG(Retrieval-Augmented Generation)はどのように外部知識をプロンプトと統合するのか?
A: Retrieval-Augmented Generation (RAG)は、外部知識をプロンプトと統合することで幻覚を防ぐことができます.具体的には、RAGは情報検索手法を使用してプロンプトに追加の文脈を提供します.これにより、モデルが事前に学習した理解と矛盾するプロンプトに直面した場合でも、幻覚を軽減することができます.
Q: ChatGPTの使用によって存在しない法的判決の引用があったケースについて詳しく説明していただけますか?
A: ChatGPTの使用により、存在しない法的判決が引用されたケースについて詳細に説明します.法廷弁護士がChatGPTを使用して法的研究を行い、存在しないケースを引用したということ例がありました.裁判所はこの場合には過失を認めませんでしたが、このような問題を将来防ぐためにLLMの幻覚を抑制する緊急の必要性を指摘しました.このような騙されやすい行動のニュースは、ソーシャルメディアを駆け巡り、ニューヨーク・タイムズなどの主要新聞に取り上げられました.
Q: RAGは標準的なLLMと比較して、どのような点で精度を高めたのでしょうか?
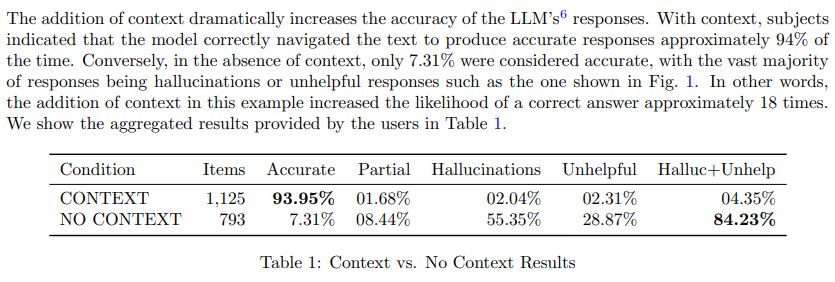
A: RAGは、コンテキストを取り入れることで、テキストを正確にナビゲートする能力を18倍向上させ、94%の印象的な正確性率を達成しました.
Q: 研究は、プロンプトがモデルの事前学習された理解と直接矛盾する場合でも、RAGがまだ誤解される可能性があることをどのように示したのですか?
A: 研究では、RAGがモデルの事前学習の理解と直接矛盾するプロンプトに誤導されることが示されました.これにより、RAGはいくつかのケースで精度を向上させますが、依然として誤解される可能性があることが明らかになりました.
Q: 実世界でのRAG展開のために、どのような実践的な提言がなされたのか?
A: RAGの展開に関する実用的な推奨事項が提供されました.これには、コンテキストの適切な理解とプロンプトエンジニアリングの向上が含まれます.
Q: 研究結果に基づき、より信頼できるLLMの開発にはどのような示唆があるのだろうか?
A: 研究の結果から、LLMの信頼性を向上させるためには、複数の応答を比較して生成された出力の事実性を評価することが重要であることが示唆されています.また、ユーザーの期待管理とプロンプトエンジニアリングの向上に焦点を当てた将来の研究が興味深い機会を提供しています.
Q: 人工知能の文脈における幻覚の複雑な性質をどのように定義しますか?
A: 人工知能の文脈における幻覚の複雑な性質は、モデルが信頼性のあるように見えるが、実際には不正確な情報を生成することを指します.これらの大規模言語モデル(LLMs)は、一貫したかつ文脈に適した応答を生成する能力を持っていますが、その驚異的な性能にもかかわらず、幻覚と呼ばれる問題が発生します.つまり、モデルが信憑性のある情報を生成しているように見えるが、実際には不正確な情報を生成しているということです.
Q: 実世界でのLLMの信頼性に関して、この研究から重要なことは何でしょうか?
A: LLMの信頼性に関する研究の主な要点は、モデルが幻覚を引き起こし、信頼性に欠ける可能性があることです.特に、訓練データのバイアスに関連して幻覚が生じることが示されており、1回の応答でこれを根絶するのは不可能であることが示唆されています.複数の応答を比較することで、生成された出力の事実性を評価することができます.複数の応答で共通する要素は、より事実である可能性が高いことが示されています.さらに、2023年6月の裁判でのChatGPTの使用によること例では、モデルが信頼できるように見えるが不正確な情報を生成する幻覚が問題となりました.このような問題を将来防ぐためには、LLMの幻覚を抑制することが急務であることが強調されています.
Large Language Models in Law: A Survey
著者:Jinqi Lai, Wensheng Gan, Jiayang Wu, Zhenlian Qi, Philip S. Yu
発行日:2023年11月26日
最終更新日:2023年11月26日
URL:http://arxiv.org/pdf/2312.03718v1
カテゴリ:Computation and Language, Artificial Intelligence
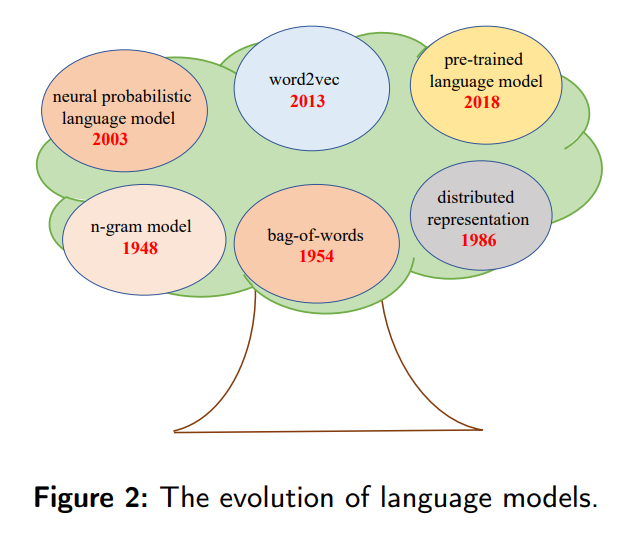
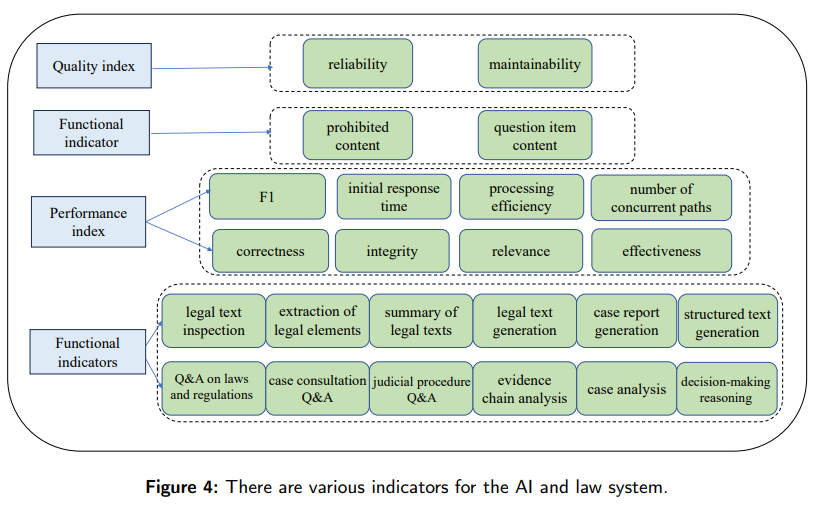
概要:
人工知能(AI)の台頭は、従来の司法業界に大きな影響を与えています.さらに、最近では、AI生成コンテンツ(AIGC)の開発により、AIと法律は画像認識、自動テキスト生成、対話チャットなど、さまざまな領域での応用が見られます.大規模モデルの急速な出現と人気の高まりから、AIが従来の司法業界の変革を推進することが明らかです.しかし、法的な大規模言語モデル(LLMs)の適用はまだ初期段階にあります.いくつかの課題が解決される必要があります.本論文では、法的LLMsの包括的な調査を提供することを目指しています.私たちはLLMsの広範な調査を行うだけでなく、それらが司法制度での応用を明らかにします.まず、法律分野におけるAI技術の概要を提供し、LLMsに関する最近の研究を紹介します.その後、法的LLMsによる実用的な実装について議論し、ユーザーに法的アドバイスを提供したり、裁判官を裁判中に支援したりする方法を示します.さらに、データ、アルゴリズム、司法実務など、法的LLMsの制限についても探求します.最後に、実用的な推奨事項をまとめ、これらの課題に対処するための将来の発展方向を提案します.
Q&A:
Q: 法律の分野で具体的にどのようなAI技術が使用されていますか?
A: 法律分野で使用されている具体的なAI技術には、深層学習や他のAI技術が含まれます.例えば、スマートコートやAIコートなどのAI技術を使用した裁判支援システムが導入されています.また、法的研究、文書分析、契約レビュー、事件結果の予測分析、法的チャットボットなどの分野でもAIが活用されています.
Q: 法的大規模言語モデル(LLM)は、法律における従来のAIアプリケーションとどう違うのか?
A: 法的大規模言語モデル(LLMs)は、従来のAIアプリケーションとは異なり、法律の文脈での特定の課題に焦点を当てています.LLMsは、裁判所の判断や法的文書の参照など、法的領域における特定の任務に特化しています.一方、従来のAIアプリケーションは、より一般的なタスクに使用されることが一般的です.また、LLMsは、法的データセットを処理し、裁判官の情報抽出や判断をシミュレートするための深層学習などのアルゴリズムを使用します.これにより、LLMsは法的文脈での特定の課題に適した情報処理能力を持っています.
Q: 現在、司法制度においてLLMがどのように活用されているか、例を挙げていただけますか?
A: 現在、法的LLMは裁判所の判決支援や法的助言の提供、裁判官の判断を補助するなど、さまざまな方法で司法制度で使用されています.
Q: 法学LLMの適用において、取り組むべき課題にはどのようなものがありますか?
A: 法的LLMの適用において解決すべき課題には、データセットの欠陥やモデルアルゴリズムの不備、伝統的な法律業界への影響、特定の司法実務に関連する問題などがあります.
Q: 法学部のLLMは裁判中にどのように裁判官を助けているのか?
A: 裁判官を裁判中に支援するために、法的LLMは裁判所に提供された証言を分析し、関連する文献を見つけ、事実を確立し、裁判所の判断に役立つ情報を提供します.また、法的LLMは裁判官が法の適用可能性に基づいて証拠の信憑性を評価する際や、被害者の財産損失の程度や被告人の補償能力などの要因を考慮して合理的な判断を下す際にも裁判官を支援します.
Q: データ、アルゴリズム、司法実務の観点から見た法学LLMの限界とは?
A: 法的LLMの制限は、データ、アルゴリズム、および司法実務の観点から考えられます.データの面では、データ品質とプライバシー保護の強化が必要であり、データの取得に偏りがある可能性や不適切なデータの選択、プライバシー保護の不備、データセットのトレーニングの複雑さなどが挙げられます.アルゴリズムの面では、アルゴリズムの解釈可能性、倫理、バイアスと公平性、最適化可能性に関する問題があります.司法実務の面では、長いテキストの処理能力の不足、個々のケースへの理解と適応能力の限界、プライバシーや倫理的な問題が挙げられます.
Q: 法学LLMの応用を改善するために、どのような実践的な提言がありますか?
A: 法的LLMの適用を改善するための実用的な推奨事項には、まず、法的ビッグデータの取得範囲を広げることが挙げられます.これにより、より包括的な法的ビッグデータを取得し、より正確な予測や意思決定を行うことが可能となります.さらに、判決システムへの法的LLMの適用が持つ影響を検討し、適切な対応を行うことも重要です.
Q: 法学LLMの今後の発展について、現在の課題にどのように取り組んでいくとお考えですか?
A: 現在の課題に対処するために、法的LLMの将来の発展は、まずデータとインフラストラクチャーの改善に焦点を当てる必要があります.具体的には、法的ビッグデータの獲得範囲を広げることが重要です.これにより、より包括的なデータセットが得られ、モデルアルゴリズムの欠陥や課題に対処するための基盤が整えられます.さらに、法的LLMの将来の発展において、AI技術の急速な発展を活用し、裁判官支援の裁判や法的コンサルテーションなどの機会を探求することが重要です.
Q: 法学LLMの発展のために、将来どのような方向性が考えられるか?
A: 法的LLMの将来の発展のためのいくつかの潜在的な方向性には、データとインフラストラクチャの強化が含まれます.具体的には、法的ビッグデータの取得範囲を広げることが挙げられます.AIや自然言語処理技術の進歩に伴い、法的LLMの応用に関連するさらなる問題に注目し、その発展の可能性を認識しています.将来の法的LLMの発展に向けていくつかの潜在的な方向性が提案されており、その詳細が以下で議論されています.
Q: 今後、AIは従来の司法業界をどのように変革し続けるとお考えですか?
A: AIは将来、伝統的な司法業界をさらに変革すると考えられます.これは、AI技術の進化により、法的大規模言語モデル(LLMs)がより洗練され、司法システムにおける様々なアプリケーションが可能になるからです.これにより、法的LLMsはユーザーに法的アドバイスを提供したり、裁判官が裁判中に支援したりするなど、司法システム全体に革新をもたらすことが期待されます.また、AI技術の進歩に伴い、司法分野でのAIの役割はますます重要になり、司法が提供される方法を変革することが期待されます.
A Comprehensive Evaluation of Large Language Models on Legal Judgment Prediction
著者:Ruihao Shui, Yixin Cao, Xiang Wang, Tat-Seng Chua
発行日:2023年10月18日
最終更新日:2023年10月18日
URL:http://arxiv.org/pdf/2310.11761v1
カテゴリ:Computation and Language
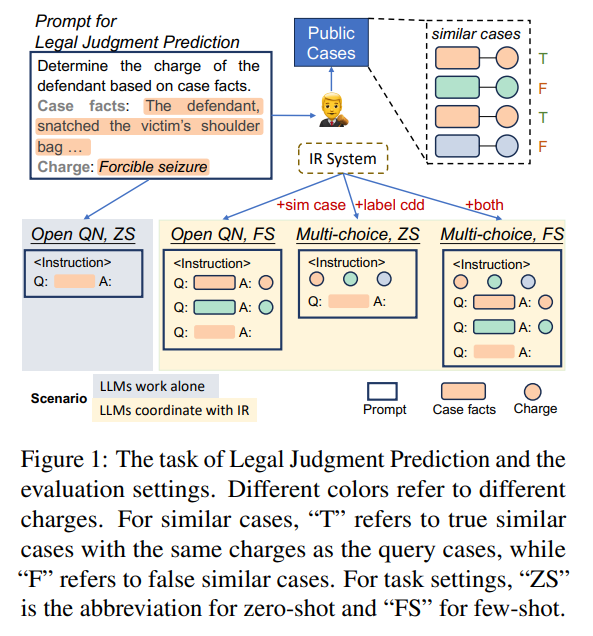
概要:
大規模言語モデル(LLMs)は、法律分野などの特定の領域において大きな可能性を示しています.しかし、最近のGPT-4の法的評価に関する論争は、実世界の法的タスクにおける彼らのパフォーマンスについて疑問を投げかけています.法律における彼らの能力を体系的に調査するために、私たちはLLMsに基づいた実用的なベースラインソリューションを設計し、法的判断予測のタスクでテストしました.私たちのソリューションでは、LLMsはオープンな質問に答えるために単独で動作するか、類似のケースから学習したり、簡略化された多肢選択問題を解決するために情報検索(IR)システムと連携することができます.私たちは、プロンプトに含まれる類似のケースや多肢選択肢(ラベル候補)が、専門的な法的推論に不可欠なドメイン知識を思い出すのにLLMsを支援することを示しています.さらに、弱いLLMsが強力なIRシステムから得られる利益が限られているため、IRシステムがLLM+IRのパフォーマンスを上回るという興味深い逆説を提示しています.このような場合、LLMsの役割は冗長となります.私たちの評価パイプラインは、他のタスクに簡単に拡張でき、他の領域での評価を容易にします.コードはhttps://github.com/srhthu/LM-CompEval-Legalで入手可能です.
Q&A:
Q: この研究を促したGPT-4の法律評価に関する具体的な論争を説明できますか?
A: この研究を促したGPT-4の法的評価に関する具体的な論争は、GPT-4が法的判断において90パーセンタイルのスコアで統一バー試験(UBE)に合格したと主張されたが、この結果が過大評価されていると指摘されたことによるものです.
Q: 法的判断予測のためのLLMに基づく実用的なベースライン・ソリューションをどのように設計したのですか?
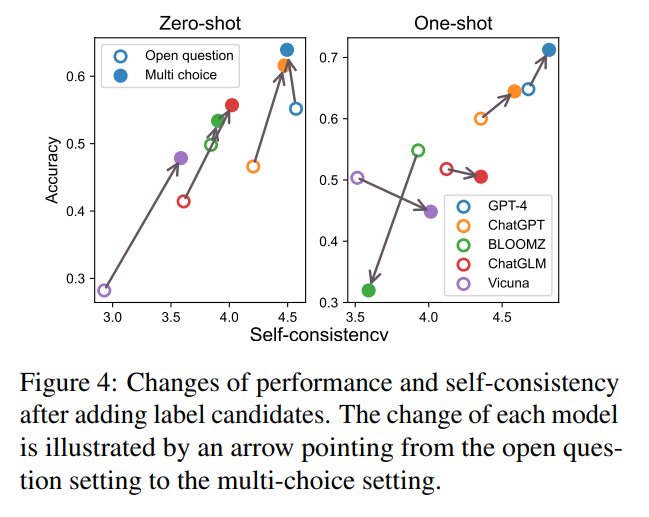
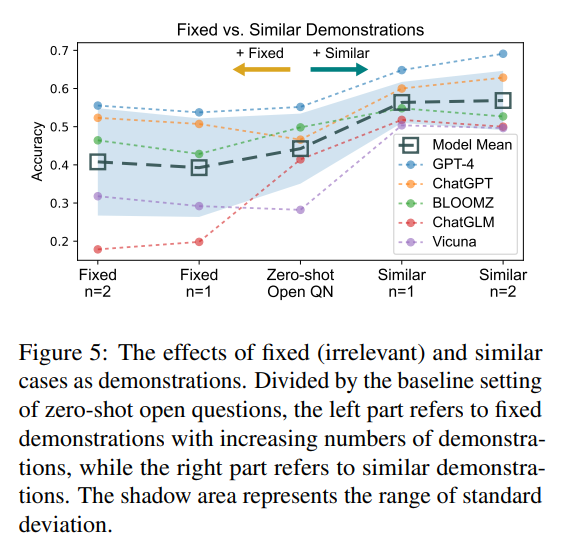
A: LLMを使用して法的判断予測のための実用的なベースラインソリューションを設計する際には、プロンプトを条件付きで生成することによって、ケースの事実に基づいてコミットされた料金を決定することが目標となります.これにより、ゼロショットオープン質問、フューショットオープン質問、ゼロショットマルチチョイス質問、およびフューショットマルチチョイス質問の4つのベースラインソリューションの設定が導かれます.マルチチョイス設定ではラベル候補を使用し、フューショット設定には似たケースからなるデモンストレーションが含まれます.最終的に、異なる能力を持つIRシステムをシミュレートする方法を紹介し、その効果を理解します.
Q: 法学修士が単独でどのように法的領域における未解決の問題に取り組むことができるのか、詳しく教えてください.
A: LLMは単独で法的領域のオープンな質問に答えることができます.LLMは、プロンプトに含まれる類似したケースやマルチチョイスの選択肢、つまりラベル候補が、専門的な法的推論に必要なドメイン知識を思い出すのに役立つことが示されています.したがって、LLMは、ラベル候補を通じてドメイン知識を思い出し、その知識を活用してオープンな質問に回答することができます.
Q: 法律業務における情報検索システムとの連携において、LLMの有効性をどのように判断しましたか?
A: LLMsと情報検索システムとの連携が法的タスクにおいてどれほど効果的であるかを判断するために、類似したケースや多肢選択肢を含むプロンプトがLLMsにとって重要なドメイン知識を思い出させ、専門的な法的推論に必要な知識を回復させることが示されました.また、弱いLLMsが強力な情報検索システムから得られる利益が限られているため、IRシステムがLLM+IRの性能を上回るという興味深い逆説が提示されました.このような場合、LLMsの役割が冗長となります.評価パイプラインは他のタスクにも簡単に拡張でき、他のドメインでの評価を容易にします.
Q: 法学修士が法的推論のための領域知識を想起する上で、類似事例や多肢選択式の選択肢はどのような役割を果たすのか?
A: 類似のケースと複数選択肢は、LLMsが法的推論のためのドメイン知識を思い出すのを助ける役割を果たします.これらの類似のケースと選択肢は、プロンプトに含まれており、LLMsが専門的な法的推論に必要なドメイン知識を思い出すのに役立ちます.また、これらの情報はLLMsが自信を持ってドメイン知識を獲得するのを助け、より一貫した出力を生成することが示されています.
Q: IRシステムが特定のケースでLLM IRを上回るというパラドックスについて、もう少し詳しく教えてください.
A: 与えられた文脈では、IRシステムがLLM+IRを上回る逆説的な状況が示されています.弱いLLMが強力なIRシステムから得られる情報の利益が限られているため、IRシステムがLLM+IRを上回ることがあります.その結果、LLMの役割が冗長になる可能性があると述べられています.
Q: あなたの評価パイプラインは、他のドメインでの評価を容易にするために、どの程度簡単に拡張できますか?
A: 当社の評価パイプラインは、他のドメインでの評価を容易に拡張することができます.これは、我々のパイプラインが柔軟性があり、他のタスクにも適用可能であるためです.
Q: 法的判断の予測に関するLLMの評価を通じて、具体的にどのような洞察や発見がありましたか?
A: LLMの評価により、法的判断予測のタスクにおけるLLMの法的能力に関する洞察を明らかにしました.具体的には、LLMが法的文書を生成する際にIRシステムから取得した文書を活用することが重要であること、類似したケースがより多く導入されると、LLMの最終的な結果に影響を与えることが示されました.また、LLMが単独で作業する場合とIRシステムと協力する場合の2つのシナリオに対処するための実用的な基準ソリューションを提案しました.
Q: この研究結果は、法律領域における大規模言語モデルの開発と使用にどのような影響を与えるとお考えですか?
A: この研究の結果は、法律領域における大規模言語モデルの開発と利用にどのような影響を与えるかについて、重要な示唆を提供します.具体的には、この研究により、大規模言語モデルが法的判断予測のタスクにおいてどのように機能するかが詳細に調査され、その能力や限界が明らかになります.また、この研究によって、大規模言語モデルが単独で問題に回答するだけでなく、情報検索システムと連携して似たケースから学習したり、簡略化された多肢選択問題を解決したりする実用的な基準ソリューションが提案されます.さらに、プロンプトに含まれる類似ケースや多肢選択肢が、大規模言語モデルが専門的な法的推論に必要なドメイン知識を思い出すのに役立つことが示されます.
Q: 評価の過程で遭遇した制限や課題で、留意すべき点はありますか?
A: 評価プロセス中に遭遇した制限や課題はいくつかありました.まず、先行研究の問題点として、UBEがあまりにも一般的であり、特定の法的管轄権に従っていないことが挙げられます.さらに、UBEには人間の専門家が評価する必要がある多肢選択問題や開放問題が含まれています.これを回避するために、一部のデータセットは開放問題を多肢選択問題に置き換えていますが、実際のアプリケーションでは多肢選択問題だけでなく開放問題も存在します.多肢選択問題だけでは十分ではない可能性があります.さらに、特に共通法に限定されないが、類似のケースは常に専門的な法的推論をサポートする証拠として導入されます.これらの問題は、評価プロセスにおいて重要であることを考慮する必要があります.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: この論文で導入された新しい手法のコード実装のurlは、https://github.com/srhthu/LM-CompEval-Legal です.
LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
著者:Neel Guha, Julian Nyarko, Daniel E. Ho, Christopher Ré, Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel N. Rockmore, Diego Zambrano, Dmitry Talisman, Enam Hoque, Faiz Surani, Frank Fagan, Galit Sarfaty, Gregory M. Dickinson, Haggai Porat, Jason Hegland, Jessica Wu, Joe Nudell, Joel Niklaus, John Nay, Jonathan H. Choi, Kevin Tobia, Margaret Hagan, Megan Ma, Michael Livermore, Nikon Rasumov-Rahe, Nils Holzenberger, Noam Kolt, Peter Henderson, Sean Rehaag, Sharad Goel, Shang Gao, Spencer Williams, Sunny Gandhi, Tom Zur, Varun Iyer, Zehua Li
発行日:2023年08月20日
最終更新日:2023年08月20日
URL:http://arxiv.org/pdf/2308.11462v1
カテゴリ:Computation and Language, Artificial Intelligence, Computers and Society

概要:
大規模言語モデル(LLM)の出現と法的コミュニティによる採用により、LLMがどのような法的推論を行うことができるかという問いが生じています.この問いをより詳しく研究するために、LegalBenchを提案します.LegalBenchは、6つの異なる法的推論をカバーする162のタスクからなる、共同で構築された法的推論ベンチマークです.LegalBenchは、法律専門家によって設計され手作りされたタスクを収集するという学際的なプロセスを通じて構築されました.これらの専門家が構築に主導的な役割を果たしたため、タスクは実用的に有用な法的推論能力を測定するか、または弁護士が興味を持つ推論スキルを測定します.法律のLLMに関する異分野間の対話を促進するために、法的推論を記述するための一般的な法的フレームワークが、多様な形態を区別することによって、LegalBenchのタスクに対応する方法を示します.これにより、弁護士やLLM開発者に共通の語彙が提供されます.この論文では、LegalBenchを説明し、20のオープンソースおよび商用のLLMの実証評価を行い、LegalBenchが可能にする研究探究の種類を示します.
Q&A:
Q: リーガルベンチ創設の動機は?
A: LEGAL BENCHは、法的タスクにおけるLLMの評価を目的とし、彼らの法的推論能力をよりよく理解するために作成されました.
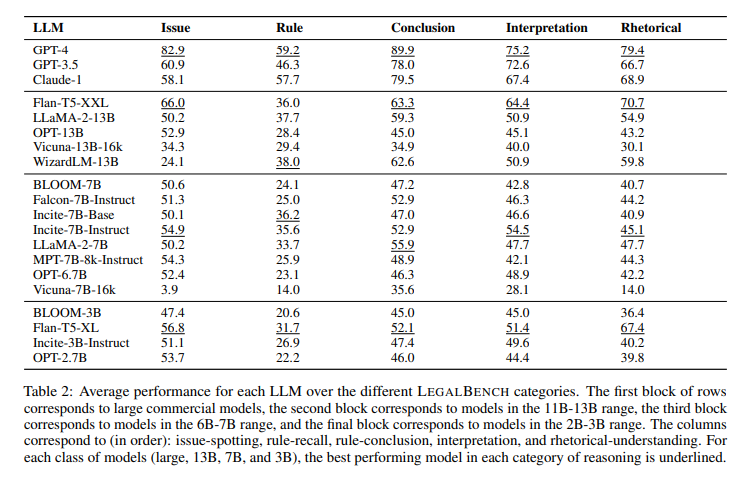
Q: LegalBenchにはいくつのタスクがあり、どのようなタイプの法的推論をカバーしていますか?
A: LegalBenchには162のタスクが含まれており、法的推論の種類としては、ルール-リコール(5タスク)、問題-スポッティング(16タスク)、ルール-アプリケーション(16タスク)、ルール-結論(16タスク)、解釈(119タスク)、修辞的理解(10タスク)がカバーされています.
Q: LegalBenchを構築するための学際的なプロセスについて説明していただけますか?
A: LegalBenchの構築に使用された学際的プロセスは、異なるデータソースから162のタスクを組み立てるために、法律の専門家やAI研究者など、さまざまな専門家が協力して行われました.これらのタスクは、法的推論の特定のタイプを測定するものであり、法的専門家が積極的かつ参加的な役割を果たし、評価タスクの作成に関与しました.このようなベンチマーク構築のスタイルは、学際的な協力の一つのアプローチを示しており、法律のLLM研究において法的専門家が評価や開発において重要な役割を果たすことを示しています.
Q: LegalBenchのタスクはどのように設計され、法律の専門家によって手作りされたのですか?
A: LegalBenchは、法律専門家によって設計および手作りされた162のタスクで構成されています.これらの専門家は、タスクの構築に主導的な役割を果たし、実用的に有用な法的推論能力を測定するか、推論を測定します.科学的背景を持つAI研究者と共に、36の異なるデータソースから162のタスクを組み立てました.したがって、LegalBenchは、私たちの知る限り、最初のオープンソースの法的ベンチマーク努力です.このようなベンチマーク構築スタイルは、領域の専門家が評価タスクの作成に積極的かつ参加的な役割を果たす方法を示しており、法律のLLMの評価と開発において法律専門家が重要な役割を果たすことを示しています.
Q: LegalBenchのタスクは、弁護士にとって実際的に役に立つ、あるいは興味深い法的推論能力をどのように測定するのでしょうか?
A: LEGAL BENCHは、法律専門家によって設計および手作りされたタスクを通じて、実用的に有用な法的推論能力を測定します.これらの専門家は、興味深い法的推論スキルを測定するか、法律におけるLLMの実用的な応用を捉えると信じるデータセットを提供するよう求められました.LEGAL BENCHのタスクで高いパフォーマンスを発揮することは、弁護士がLLMの法的能力を評価し、自分たちの業務フローで使用できるLLMを特定するのに役立つ情報を提供します.
Q: LegalBenchは、法学におけるLLMについてどのように学際的な会話を促進しますか?
A: LEGAL BENCHは、法律のLLMに関する異分野間の対話を可能にするために、法的推論を記述するための一般的な法的フレームワークがどのようにLEGAL BENCHのタスクに対応するかを示すことで、法律家やLLM開発者に共通の語彙を提供します.
Q: LegalBenchのタスクに対応する法的推論を記述するための一般的な法的フレームワークの例を教えていただけますか?
A: 人気のある法的枠組みの例として、IRAC(Issue, Rule, Application, Conclusion)フレームワークが挙げられます.このフレームワークでは、法的推論が4つの連続するステップに分解されます.具体的には、問題(Issue)を特定し、適用すべき法則(Rule)を明らかにし、それを具体的な事例に適用(Application)し、最終的に結論(Conclusion)を導きます.
Q: LegalBenchを使用した20のオープンソースおよび商業的LLMの実証的評価の結果は?
A: 20のオープンソースおよび商用LLMを使用した実証評価の結果は、異なるファミリーからの20のLLMを4つの異なるサイズポイントで評価し、パフォーマンスの違い、モデルサイズの役割、オープンソースと商用LLMの間のギャップについて初期観察を行った.また、3つの人気のある商用モデルであるGPT-4、GPT-3.5、およびClaude-1のパフォーマンスの類似点と相違点を示すためにLEGAL BENCHを使用した.最終的に、20の異なるファミリーからのLLMを評価し、異なるモデルのパフォーマンスに関する観察を行い、異なるプロンプトエンジニアリング戦略についての初期研究を提示した.これらの結果は、LEGAL BENCHが可能にする将来の研究の異なる方向を示すことを意図している.
Q: LegalBenchはどのようにして法的推論の分野における研究の探求を可能にするのでしょうか?
A: LegalBenchは、法的推論の研究探究を可能にします.法的プロフェッショナルが提供したデータセットを使用し、法的推論スキルを測定するためのベンチマークを構築することで、法的推論に関する研究を促進します.また、法的コミュニティに馴染みのある用語や概念フレームワークを使用することで、法的プロフェッショナルがLLMのパフォーマンスについて有意義な議論を行うことができます.
Q: LegalBenchは法曹界やLLM開発者にとってどのような潜在的影響がありますか?
A: LegalBenchは、法律コミュニティやLLM開発者にとって潜在的な影響を持つ可能性があります.LegalBenchは、法律専門家がLLMのパフォーマンスについて意味のある議論を行うことを可能にし、彼らにとって馴染み深い用語や概念フレームワークを使用します.また、AI研究者にとっては、法的知識が不足している場合でも、LegalBenchはLLMの促進や評価方法を理解するための重要なサポートを提供します.将来のユーザーは、LegalBenchのタスクを使用する際に、実際の法的イベントの合法性や訴訟の結果を予測するために使用しないように注意する必要があります.また、LegalBenchはすべての法的推論タスクや法的文書のすべてに一般化できるわけではないため、自分のユースケースに特化したデータ収集と検証を行うことが重要です.
MultiLegalPile: A 689GB Multilingual Legal Corpus
著者:Joel Niklaus, Veton Matoshi, Matthias Stürmer, Ilias Chalkidis, Daniel E. Ho
発行日:2023年06月03日
最終更新日:2024年05月19日
URL:http://arxiv.org/pdf/2306.02069v3
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning
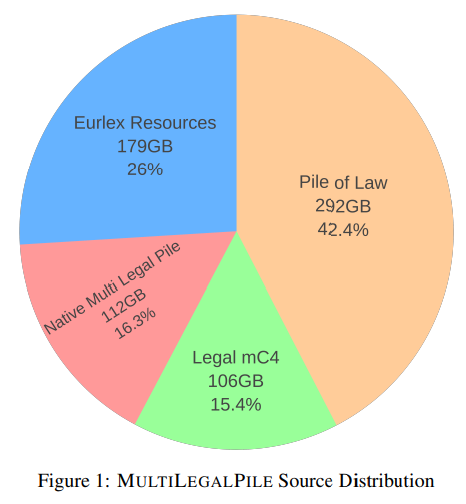
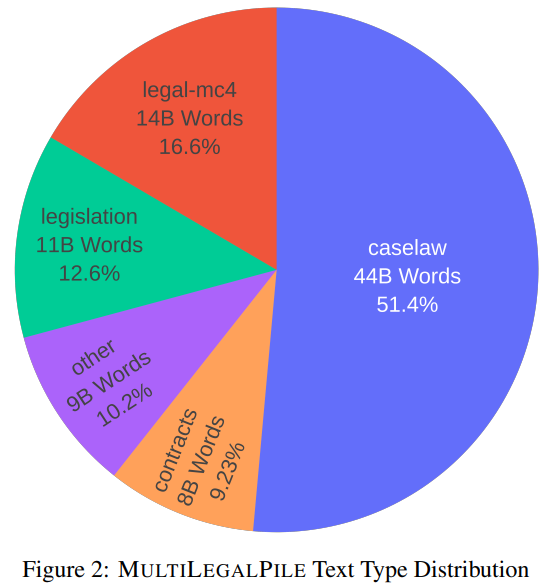

概要:
大規模で高品質なデータセットは、大規模言語モデル(LLM)のトレーニングには不可欠です.しかし、これまでに法律などの特定の重要な分野向けのデータセットはほとんどなく、利用可能なものも英語のみのものが多いです.私たちは、17の司法管轄区から24言語の689GBのコーパスであるMultiLegalPileを編纂してリリースしました.MultiLegalPileコーパスには、さまざまなライセンスを持つ多様な法的データソースが含まれており、Eurlex ResourcesとLegal mC4のサブセットにはより許容範囲の広いライセンスが付与されています.私たちは、2つのRoBERTaモデルと1つのLongformerモデルを多言語で事前トレーニングし、24の単言語モデルを各言語固有のサブセットごとにトレーニングし、LEXTREMEで評価しました.さらに、英語モデルと多言語モデルをLexGLUEで評価しました.私たちの多言語モデルはLEXTREMEで新たなSotAを樹立し、英語モデルはLexGLUEでSotAを達成しました.私たちは、データセット、トレーニング済みモデル、およびすべてのコードを可能な限り最もオープンなライセンスで公開しています.
Q&A:
Q: MultiLegalPileコーパスに含まれる法律データの情報源について、もう少し詳しく教えてください.
A: MultiLegalPileコーパスに含まれる法的データソースの詳細については、表9を参照してください.ほとんどのソースは直接データダウンロードリンクを提供しており、データのフォーマットが一貫していない場合は、jsonlなどの統一された形式に変換されました.CASS3の場合、XMLタグからテキストデータを抽出しました.しかし、すべての利用可能な言語に対して品質分析を行うことができなかったため、完全性を主張していないことに注意してください.
Q: コーパスに含まれる法律データの質をどのように確保したのですか?
A: 法的データの品質を確保するために、正確性を向上させるための反復的なプロセスが行われました.このプロセスにより、法的コンテンツの検出精度が向上し、コーパスのサイズが133GBから106GBに削減されました.また、正確性を高めるために、正確な法的コンテンツに焦点を当てることで、コーパスの品質と特異性が向上しました.
Q: コーパスに含まれる24の言語と17の管轄区域は、どのような基準で選ばれたのですか?
A: 24言語と17の司法管轄区を選択するための基準として、法律言語モデルのトレーニングに使用される言語の多様性と、法的コンテンツの高い精度を確保するための法的引用の検出が挙げられます.
Q: RoBERTaモデルとLongformerモデルを多言語で事前学習するプロセスを説明してもらえますか?
A: RoBERTaおよびLongformerモデルを多言語で事前学習するプロセスは、まず、24の言語固有のサブセットごとに2つのRoBERTaモデルと1つのLongformerモデルを事前学習します.その後、LEX-TREMEでこれらのモデルを評価します.さらに、英語モデルと多言語モデルをLexGLUEで評価します.最終的に、LEX-TREMEでは多言語モデルが新しいSotAを達成し、LexGLUEでは英語モデルがSotAを達成します.
Q: LEXTREMEとLexGLUEでのモデルのパフォーマンスをどのように評価しましたか?
A: モデルのパフォーマンスをLEXTREMEとLexGLUEで評価しました.LEXTREMEでは、データセットごとの結果を表4に示し、言語ごとの結果を表5に示しました.Legal-XLM-R-baseモデルは、パラメータの33%しか含まれていないにもかかわらず、XLM-R largeと同等の性能を示しました.LexGLUEでは、最良のスコアを持つモデルを表6に示し、データセットごとの結果の調和平均を計算しました.
Q: LEXTREMEにおける多言語モデルの評価から得られた主な結果は?
A: 多言語モデルの評価による主な結果は、我々の法的LongformerがLEXTRMEデータセットの4つすべてで他のすべてのモデルを上回り、最高のデータセット集計スコアに到達したことです.また、我々の単言語モデルは、24のデータセットのうち21でベースモデルXLM-Rを上回ることが分かりました.
Q: 英語モデルのLexGLUEでの成績は、他のモデルと比較してどうですか?
A: 英語モデルは、他のモデルに比べてLexGLUEで優れたパフォーマンスを発揮しています.
Q: データセット、学習済みモデル、コードのライセンスを選択する際、どのような点を考慮しましたか?
A: データセット、トレーニング済みモデル、およびすべてのコードに適用されるライセンスを選択する際に考慮した点は、データソースのライセンスが異なることである.ライセンスは、CC BY-NC-SA 4.0から最も自由なCC0ライセンスまでさまざまであり、データがパブリックドメインにリリースされるCC0ライセンスを含む.多くのソースは、使用可能なデータのライセンスを明示的に述べていないが、製作者が通常、裁判所や行政機関などの公的機関であるため、そのようなデータソースは事前トレーニングの使用を許可していると仮定される.このような立法や判例は通常、保護されていないため、ライセンスの選択においてこれらの異なるライセンスを考慮した.
Q: 今後、MultiLegalPileコーパスをより多くの言語や司法管轄区に拡大する予定はありますか?
A: 将来的な作業では、24のEU言語に焦点を当てましたが、将来的には、カバーされる言語や管轄区域を拡大したいと考えています.特に中国では、コーパスを拡大するのに適した多くのアクセス可能な情報源が存在します.さらに、我々は、我々のモデルが他の言語や管轄区域にも適用可能かどうかを調査したいと考えています.
Q: 法律分野の研究者や実務家は、MultiLegalPileコーパスと学習済みモデルをどのように利用することを想定していますか?
A: MultiLegalPileコーパスと訓練されたモデルは、法律領域の研究者や実務家が、多言語の法的データを活用して、自然言語処理モデルを事前学習し、特定の法的タスクに適用することが期待されます.これにより、法的文書の翻訳、要約、分類、情報抽出などのタスクを効率的に行うことが可能となります.また、訓練されたモデルは、法的文書の検索や分析、法的予測モデルの構築などにも活用されるでしょう.
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English
著者:Ilias Chalkidis, Abhik Jana, Dirk Hartung, Michael Bommarito, Ion Androutsopoulos, Daniel Martin Katz, Nikolaos Aletras
発行日:2021年10月03日
最終更新日:2022年11月08日
URL:http://arxiv.org/pdf/2110.00976v4
カテゴリ:Computation and Language

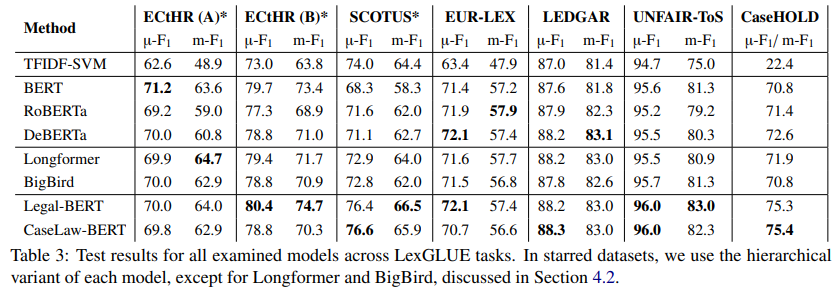
概要:
法律とその解釈、法的論点、合意は通常、文章で表現され、法的テキストの膨大なコーパスの生成につながります.これらの分析は、法的実務の中心であり、これらのコレクションが大きくなるにつれてますます複雑になります.自然言語理解(NLU)技術は、これらの取り組みを支援するための貴重なツールとなり得ます.ただし、その有用性は、現在の最先端モデルが法的ドメインのさまざまなタスクにわたって一般化できるかどうかに大きく依存します.この現在の未解決の問いに答えるために、私たちはLegal General Language Understanding Evaluation(LexGLUE)ベンチマークを導入しました.これは、標準化された方法でさまざまな法的NLUタスクにわたるモデルのパフォーマンスを評価するためのデータセットのコレクションです.また、一般的なモデルと法的志向のモデルの評価と分析を提供し、後者が複数のタスクで一貫してパフォーマンスの向上を提供することを示しています.
Q&A:
Q: LexGLUEベンチマークデータセットを作成した動機は何ですか?
A: LexGLUEベンチマークデータセットの作成の動機は、最近のGLUEマルチタスクベンチマークNLPデータセット、より難しいSuperGLUE、他の以前のマルチタスクNLPベンチマーク、および他のドメインでの類似した取り組みに触発されました.これにより、法的タスクにおけるNLP手法のパフォーマンスを評価するためのベンチマークデータセットであるLexGLUEが導入されました.
Q: 法律上の議論や合意は、一般的にどのように文書化されるのか?
A: 法的論拠や契約は通常、文章で表現されます.これらの文章は法的テキストの膨大なコーパスを生み出し、法的実務の中心となる分析がますます重要となります.
Q: 自然言語理解(NLU)技術は、法律家をどのようにサポートするのか?
A: 自然言語理解(NLU)技術は、法律実務者をさまざまな法的業務で支援することができます.これには、判決予測、法的文書からの情報抽出、事件の要約、法的質問への回答、テキスト分類などが含まれます.これらの技術は、法的文書やデータの処理を自動化し、法的業務の効率性を向上させることが期待されています.
Q: 法律領域におけるさまざまなタスクにわたって最先端のモデルを一般化することの意義とは?
A: 法的領域における様々なタスクにわたる最先端モデルの一般化の重要性は、異なる法的NLPタスクにおいても高い性能を実現することが期待されるためです.これにより、法的文書に特化した言語モデルが、一般的なコーパスで事前学習されたモデルよりも優れた結果をもたらす可能性があります.また、法的文書に特有の用語や表現を適切に理解し、適用することができるため、法的NLPタスクにおいてより適切な結果を得ることができます.
Q: LexGLUEベンチマークはモデルの性能をどのように評価するのですか?
A: LexGLUEベンチマークは、様々な法的NLUタスクにおけるモデルのパフォーマンスを標準化された方法で評価するためのデータセットのコレクションです.また、一般的なモデルと法的志向のモデルの評価と分析を提供し、後者が複数のタスクで一貫してパフォーマンスの向上を示していることを示しています.
Q: LexGLUEベンチマークに含まれるデータセットの種類は何ですか?
A: LexGLUEベンチマークに含まれるデータセットの種類は、法的NLUタスクの多様なセットに対するモデルのパフォーマンスを評価するためのデータセットのコレクションです.
Q: 法律指向のモデルは、複数のタスクにまたがるパフォーマンスという点で、一般的なモデルと比較してどうなのか?
A: 法的指向モデルは、一般的なモデルと比較して、複数のタスクにわたるパフォーマンスがどのように異なるかについて、特にUSの判例データに依存する2つのデータセット(SCOTUS、CaseHOLD)において、m-F1が+2-4% p.p.(m-F1)向上するなど、全体的に優れた結果を示しています.これらのタスクは、言語の観点でよりドメイン固有であるため、法的知識がより重要であるとされています.一方、一般的なコーパスで事前学習された同じサイズのTransformerベースのモデルよりも、法的指向の事前学習モデル(Legal-BERT、CaseLaw-BERT)の方が全体的に優れたパフォーマンスを発揮しています.
Q: モデルの評価と分析から得られた知見から、どのような影響が考えられるか?
A: モデルの評価と分析からの知見の潜在的な影響のいくつかには、法的テキストへのモデルの適応方法の向上、研究者による法的質問への回答モデルの開発、一般市民が法的権利をよりよく理解するための支援、高性能システムにおける法的テック業界への影響の評価、機械学習とNLPベースのツールの性能の独立した評価の不足、公開ベンチマークの標準化の必要性などが含まれる.
Q: LexGLUEベンチマークは、英語での法律用語の理解を向上させるためにどのように利用できますか?
A: LexGLUEベンチマークは、法律言語理解を向上させるために、様々な法的NLUタスクでモデルのパフォーマンスを評価し、一般的なモデルと法的志向のモデルを比較・分析することによって使用されます.
Q: 英語での法的言語理解に関する調査から、重要なことは何でしょうか?
A: 研究の主な結論は、法的言語理解における一連のタスクにおいて、一般的なモデルと法的志向のモデルを比較した結果、後者が複数のタスクで一貫して性能向上を示すことである.また、法的言語はしばしば「副言語」として分類され、法的文書は最新の深層学習モデルでも処理できないほど長いことが指摘されている.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: この論文で導入された新しい手法のコード実装のurlは、https://github.com/coastalcph/lex-glueです.
