
- The Llama 3 Herd of Models
発行日:2024年07月31日
Llama 3は、多言語対応、コーディング、推論、およびツールの使用をサポートする言語モデルで、GPT-4と同等の品質を提供し、画像、ビデオ、音声認識タスクで競争力を持つことが示されています. - AI achieves silver-medal standard solving International Mathematical Olympiad problems
発行日:2024年07月25日
2024年7月25日、AlphaProofとAlphaGeometryチームは、数学の高度な推論問題を解決するための画期的なモデルを開発し、IMOで成功を収めました. - Recursive Introspection: Teaching Language Model Agents How to Self-Improve
発行日:2024年07月25日
RISEアプローチは、知的エージェントの行動を改善するために、LLMsを微調整し、間違いを修正する能力を導入することを提案している. - Generation Constraint Scaling Can Mitigate Hallucination
発行日:2024年07月23日
LLMにおける幻覚を記憶と関連付け、記憶拡張型LLMデコーダーを使用して幻覚を緩和する方法を提案し、Wikipedia風の伝記エントリー生成タスクで最先端のLLM編集方法を上回る結果を示した. - OpenHands: An Open Platform for AI Software Developers as Generalist Agents
発行日:2024年07月23日
ソフトウェアとAIエージェントの開発プラットフォームOpenHandsは、熟練したプログラマーが世界とやり取りし、15の難しいタスクに対するエージェントの評価を行うことを可能にする. - Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach
発行日:2024年07月23日
RAGとLCの比較研究によると、LCはRAGを上回るが、RAGのコストが低いため、Self-RouteがLCと同等のパフォーマンスを維持しつつコストを削減する効果的な方法であることが示された. - A Survey on Employing Large Language Models for Text-to-SQL Tasks
発行日:2024年07月21日
リレーショナルデータベースのデータ増加により、非専門家ユーザー向けのText-to-SQLパーサーが重要性を増し、最近の大規模言語モデルを活用した新しい手法が登場している. - LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference
発行日:2024年07月19日
トランスフォーマーベースの言語モデルの推論は、プリフィリング段階とデコーディング段階で構成され、LazyLLMは重要なトークンのみを選択的に計算して生成を高速化する汎用的な手法であることが示されています. - MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens
発行日:2024年06月17日
MINT-1Tは1兆のテキストトークンと34億の画像を含む最大規模のマルチモーダルな交互データセットで、LMMsのトレーニングに不可欠であり、コミュニティに大きな利益をもたらす. - AI models collapse when trained on recursively generated data
発行日:2024年05月14日
生成モデルの崩壊は、学習されたモデルが次世代のデータを汚染し、誤った認識を引き起こす退化プロセスであり、統計的近似誤差、機能表現誤差、機能近似誤差などが影響を与える.
The Llama 3 Herd of Models
著者:Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, et al.
発行日:2024年07月31日
最終更新日:2024年08月15日
URL:http://arxiv.org/pdf/2407.21783v2
カテゴリ:Artificial Intelligence, Computation and Language, Computer Vision and Pattern Recognition

概要:
現代の人工知能(AI)システムは、基礎モデルによって動作しています.この論文では、新しい一連の基礎モデルであるLlama 3を紹介しています.これは、多言語対応、コーディング、推論、およびツールの使用をネイティブにサポートする言語モデルの群れです.最大のモデルは、405Bのパラメータと最大128Kトークンのコンテキストウィンドウを持つ密なTransformerです.この論文では、Llama 3の包括的な実証評価を行っています.私たちは、Llama 3がGPT-4などの主要な言語モデルと比較して、さまざまなタスクで同等の品質を提供することを発見しました.私たちは、405Bのパラメータ言語モデルの事前トレーニングおよび事後トレーニングバージョン、および入出力の安全性を確保するためのLlama Guard 3モデルを含むLlama 3を公開しています.また、画像、ビデオ、音声の機能をLlama 3に合成的なアプローチで統合する実験の結果も紹介しています.このアプローチは、画像、ビデオ、音声認識タスクで最先端の性能と競争力を持っていることが観察されました.得られたモデルはまだ広くリリースされていませんが、開発中です.
Q&A:
Q: 405Bのパラメータを持つ密集トランスフォーマーのアーキテクチャと設計上の選択について詳しく教えてください.
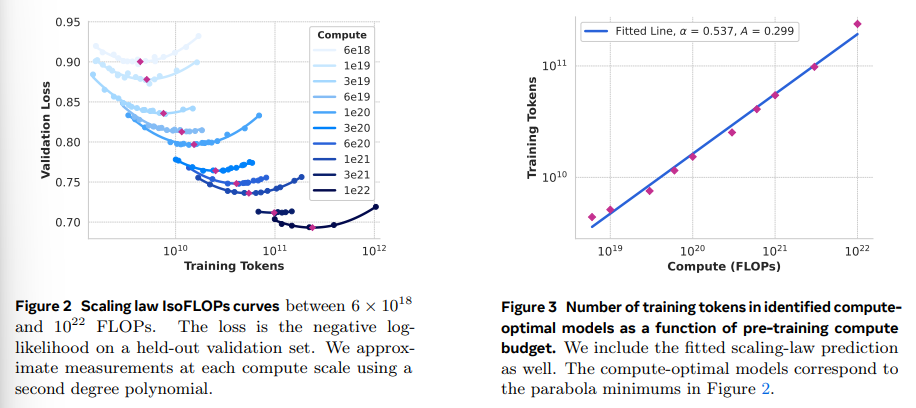
A: 与えられた文脈から、405Bパラメータを持つ密なTransformerモデルのアーキテクチャと設計選択についての詳細な情報を提供することは難しいです.ただし、いくつかの設計選択が言及されています.まず、標準的な密なTransformerモデルアーキテクチャ(Vaswani et al., 2017)が採用されており、これはトレーニングの安定性を最大化するために、混合専門家モデル(Shazeer et al., 2017)ではなく選ばれています.また、トレーニング後の手続きとして、監督付き微調整(SFT)、拒否サンプリング(RS)、および直接選好最適化(DPO; Rafailov et al. (2023))が採用されており、これはより複雑な強化学習アルゴリズムよりも安定性が高く、スケールしやすいとされています.さらに、量子化に関しては、Transformerの最初と最後の層では量子化を行わないという選択がされています.これらの選択は、モデルの開発プロセスをスケールする能力を最大化することを目的としています.
Q: ラマ3とGPT-4のようなモデルを比較するために、実証評価ではどのような指標が用いられたのですか?
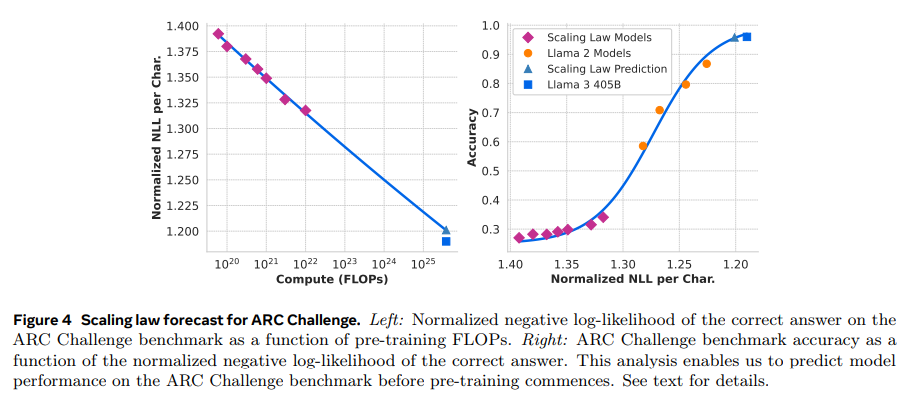
A: 与えられた文脈によれば、Llama 3と他のモデル(例えばGPT-4)との比較において使用された評価指標は、主に精度に基づくメトリクスであることが示されています.特に、数学と推論のベンチマークでは、GSM8K、MATH、GPQAなどのタスクが使用され、Llama 3のモデルが他の同等のサイズのモデルよりも優れていることが報告されています.また、長い文脈のベンチマークでは、Needle-in-a-Haystackというタスクが使用され、Llama 3モデルが完璧な情報検索性能を示したとされています.これらの評価は、バイアスのない評価プロトコルを使用し、n-gramの重複メトリクスではなく、精度に基づくメトリクスを優先していると述べられています.
Q: Llama Guard 3はどのようにしてインプットとアウトプットの安全性を確保しているのですか?また、具体的にどのような安全対策がとられているのですか?
A: Llama Guard 3は、入力プロンプトや出力応答が特定の危害カテゴリーに関する安全ポリシーに違反しているかどうかを検出するために使用されます.このモデルは、Llama 3 8Bモデルを安全分類のためにファインチューニングしたものであり、英語および多言語テキストに対応しています.また、検索ツールやコードインタープリタの悪用防止などのツールコールの文脈で最適化されています.さらに、メモリ要件を削減するために量子化されたバリアントも提供されています.具体的な安全対策としては、AI安全性分類法(Vidgen et al., 2024)に記載されている13の危害カテゴリーに基づいて訓練されています.
Q: 画像、ビデオ、スピーチ機能をLlama 3に統合するために使われた構成的アプローチについて教えてください.
A: Llama 3に画像、ビデオ、音声の機能を統合するために使用される構成的アプローチは、5つの段階でモデルを訓練する方法です.まず、言語モデルの事前訓練が行われます.次に、マルチモーダルエンコーダーの事前訓練が行われ、画像と音声のための個別のエンコーダーが訓練されます.画像エンコーダーは、大量の画像とテキストのペアを用いて訓練され、視覚的な内容とその内容の自然言語による説明との関係をモデルに学習させます.音声エンコーダーも同様に訓練されます.続いて、ビジョンアダプターの訓練が行われ、モデルの微調整が行われます.最後に、音声アダプターの訓練が行われます.このアプローチにより、Llama 3は画像、ビデオ、音声認識タスクにおいて最先端の性能と競争力を持つモデルとなります.
Q: Llama 3が既存の最先端モデルよりも優れている特定のタスクやベンチマークはありますか?
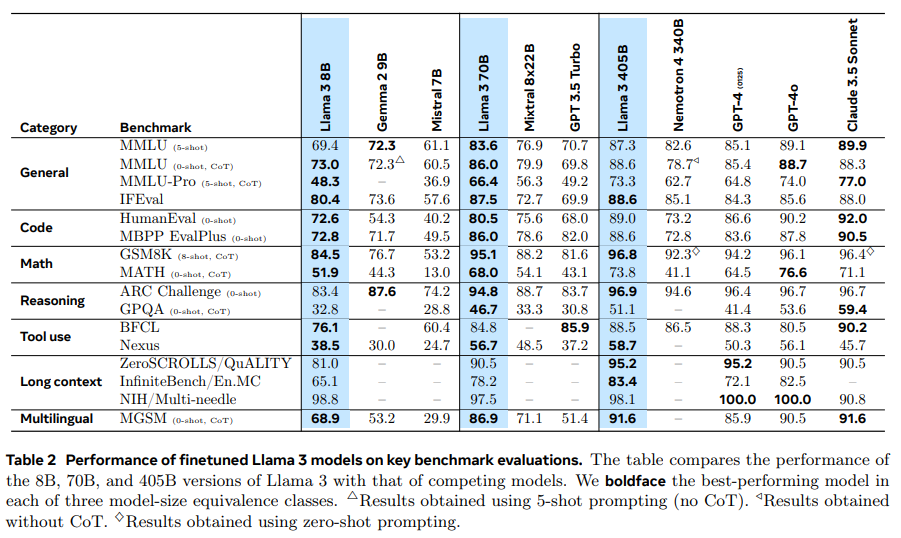
A: 与えられた文脈によれば、Llama 3は特定のタスクやベンチマークにおいて既存の最先端モデルを上回るとされています.特に、Llama 3 8Bモデルは、ほぼすべてのカテゴリーにおいて競合モデルを上回るパフォーマンスを示しており、カテゴリーごとの勝率や平均パフォーマンスにおいて優れた結果を出しています.また、Llama 3 70Bモデルは、ほとんどのベンチマークでその前身であるLlama 2 70Bを大きく上回っており、Mixtral 8x22Bも上回っています.これらの結果は、Llama 3が特に読解タスク、コーディングタスク、常識理解タスク、数学的推論タスク、一般的なタスクにおいて優れた性能を発揮していることを示しています.
AI achieves silver-medal standard solving International Mathematical Olympiad problems
著者:AlphaProof and AlphaGeometry teams, Deep Mind
発行日:2024年07月25日
最終更新日:不明
URL:https://deepmind.google/discover/blog/ai-solves-imo-problems-at-silver-medal-level/
カテゴリ:不明
概要:
2024年7月25日、AlphaProofチームとAlphaGeometryチームは、数学の高度な推論問題を解決するための画期的なモデルAlphaProofとAlphaGeometry 2を開発しました.
現在、数学者が新しい洞察や革新的なアルゴリズム、未解決の問題への回答を発見するのを支援するAIシステムを構築することで、我々は大きな進歩を遂げています.
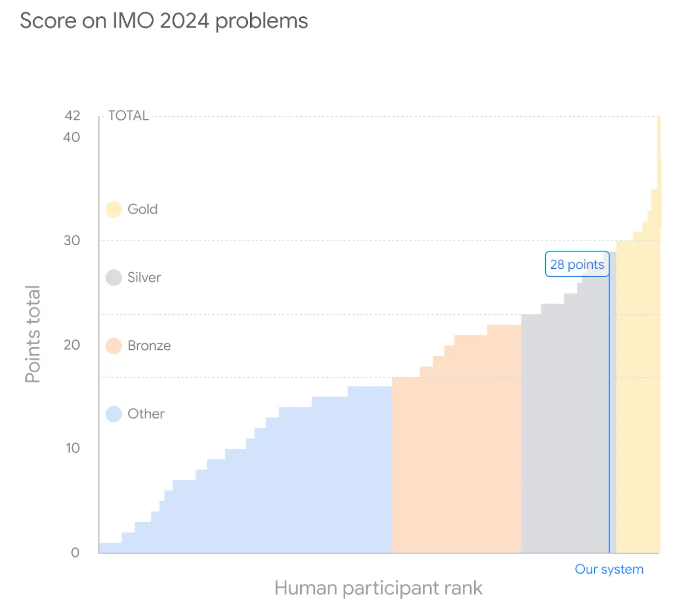
今日、私たちは、形式的な数学的推論のための新しい強化学習ベースのシステムであるアルファプルーフと、私たちのジオメトリ解決システムの改良版であるアルファジオメトリ第2回発表します.これらのシステムは、今年の国際数学オリンピアード(imoの6つの問題のうち4つを解決し、同じくらいの成績を収めました.
IMOの問題を解決するために、アルファプルーフは、代数学の問題2つと数論の問題1つを解決し、その正解を証明しました.2、過去25年間のIMOジオメトリ問題の83%を解決できるように訓練され、前任者の53%を上回る成績を収めました.
Q&A:
Q: 人間のIMO参加者と比べて、AIソリューションの採点プロセスはどうなっているのか?
A: AIの解答は、IMOの参加者と同様に、各問題で最大7点を獲得できるスコアリングシステムに基づいて採点されます.合計で42点が満点となります.今年、AIシステムは28点を獲得し、解いた問題ごとに満点を達成しました.これは、銀メダルの上限に相当します.金メダルの基準は29点から始まり、公式競技会では609人中58人の参加者がこの基準を達成しました.
Q: AlphaGeometry 2では、ジオメトリを解く能力を向上させるために、具体的にどのようなアルゴリズムやテクニックが採用されたのですか?
A: AlphaGeometry 2は、AlphaZeroアルゴリズムを用いて、より挑戦的な問題を解決するために自己訓練を行うソルバーネットワークを採用しております.また、Geminiに基づいた言語モデルを使用し、前任者よりも桁違いに多くの合成データで訓練されております.これにより、物体の動きや角度、比率、距離の方程式に関するより複雑な幾何学問題に取り組むことが可能になりました.さらに、シンボリックエンジンは前任者よりも二桁速くなっており、新しい問題に対しては、知識共有メカニズムを用いて異なる探索木の高度な組み合わせを可能にしております.
Q: IMOの問題に対するAIの解決策の信頼性と正確性を確保するためにどのような措置が取られましたか?
A: AIのIMO問題に対する解答の信頼性と正確性を確保するために、いくつかの措置が講じられました.まず、解答はIMOのポイント授与ルールに従って評価されました.この評価は、著名な数学者であるティモシー・ガウアーズ教授(IMO金メダリストでフィールズ賞受賞者)とジョセフ・マイヤーズ博士(2度のIMO金メダリストでIMO 2024問題選定委員会の議長)によって行われました.これにより、AIの解答が人間の基準に基づいて正確に評価されることが保証されました.
Q: AlphaProofとAlphaGeometry 2の性能指標は、IMO問題の解決を試みた過去のAIシステムと比較してどうなのか?
A: アルファジオメトリー2は、過去25年間のIMO幾何学問題の83%を解決することができました.これは、その前身が達成した53%の解決率と比較して大幅な改善です.また、アルファプルーフとアルファジオメトリー2は、今年の国際数学オリンピック(IMO)で6つの問題のうち4つを解決し、初めて銀メダリストと同じレベルに達しました.これらの成果は、以前のAIシステムと比較して大きな進歩を示しています.
Recursive Introspection: Teaching Language Model Agents How to Self-Improve
著者:Yuxiao Qu, Tianjun Zhang, Naman Garg, Aviral Kumar
発行日:2024年07月25日
最終更新日:2024年07月26日
URL:http://arxiv.org/pdf/2407.18219v2
カテゴリ:Machine Learning, Artificial Intelligence, Computation and Language
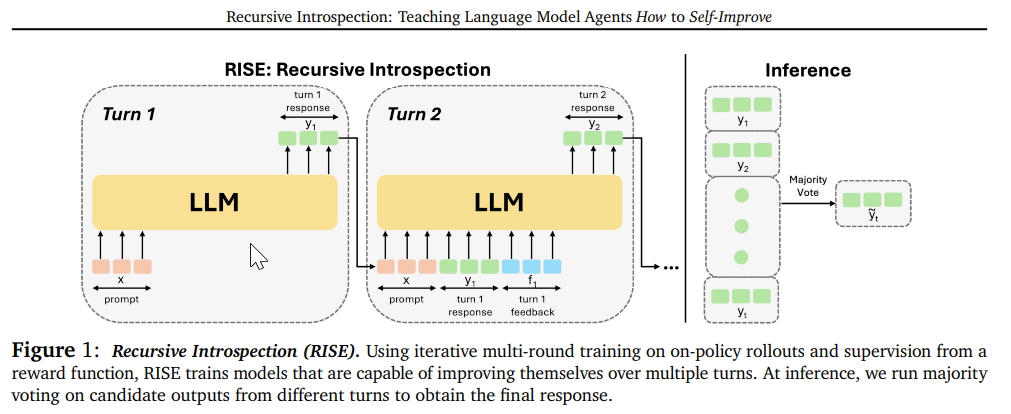
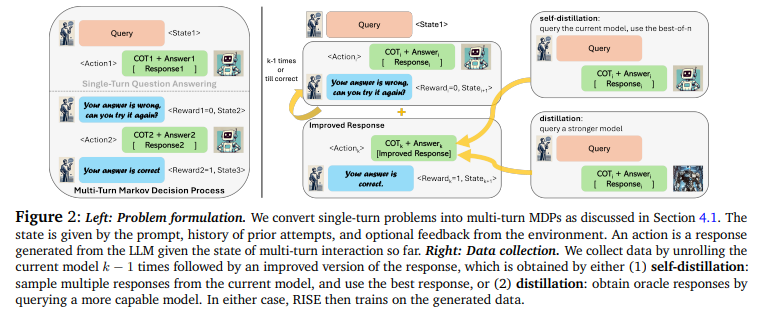
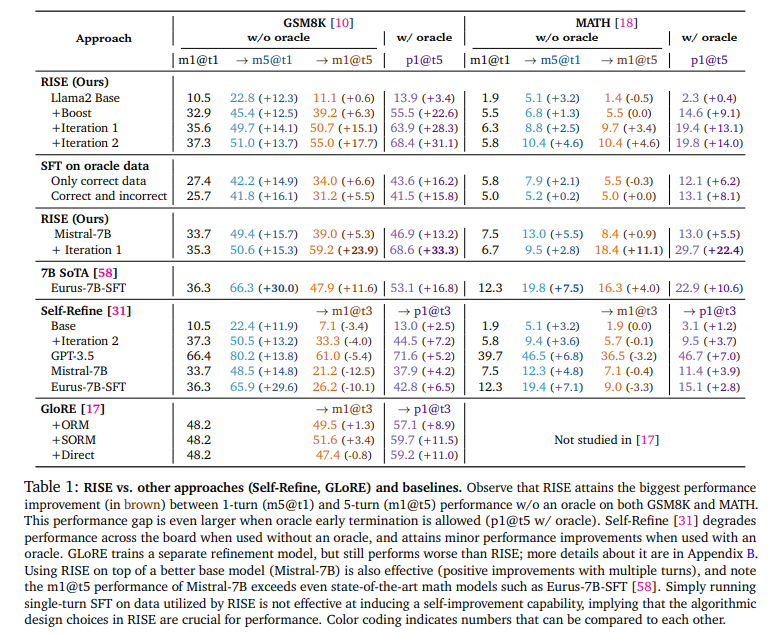
概要:
この論文では、知的なエージェント行動を可能にするための中心的な要素は、モデルが自分の行動や推論を内省し、間違いを修正する能力を持つようにすることです.最も強力なプロプライエタリな大規模言語モデル(LLMs)でさえ、明示的に間違いを犯していることを伝えられても、連続的に自分の応答を改善する能力をまだ完全に示していません.本論文では、この能力を獲得することが不可能であると仮説を立てていた先行研究にもかかわらず、RISE(Recursive IntroSpEction)というアプローチを開発しました.このアプローチは、LLMsを微調整して、この能力を導入することを提案しています.我々のアプローチは、反復的な微調整手順を規定し、モデルに、以前に失敗した試行を実行した後に、難しいテスト時の問題を解決する方法を変更する方法を教えようとします.RISEは、単一のターンプロンプトの微調整を、初期状態がプロンプトであるマルコフ決定過程(MDP)を解くこととして位置付けます.オンライン模倣学習や強化学習の原則に触発され、我々は提案します.さらに、オンライン模倣学習や強化学習の原則に基づいて、複数のターンのデータ収集とトレーニング戦略を提案し、LLMに前回の間違いを再帰的に検出して修正する能力を与えることを目指しています.実験の結果、RISEはLlama2、Llama3、Mistralモデルを数学的推論タスクでより多くのターンで改善させ、同じ推論時間の計算量が与えられた場合にいくつかの単一ターン戦略を上回ることが示されました.また、RISEはスケーリングがうまくいき、より能力の高いモデルではより大きな利益を得ることが多いことがわかりました.分析によると、RISEは、複雑な分布を表現する結果として、一回の能力を崩すことなく、難しいプロンプトの正しい解決策に向けて応答を意味のある改善を行います.
Q&A:
Q: LLMの再帰的内省を促進するために、RISEアプローチでは具体的にどのような技術を採用しているのか?
A: RISEアプローチでは、LLMが自己改善を行うために、いくつかの特定の技術が用いられています.まず、RISEは、学習者からのオンポリシーロールアウトをブートストラップし、次のターンでより良い応答を得るために、学習者自身からサンプリングされた複数の修正候補を使用して、タスクの成功指標を用いたベストオブNを実行します.これにより、学習者が自身の分布下でどのように応答を改善できるかを示すロールアウトを構築することが可能になります.その後、これらのデータを用いて学習者を微調整します.RISEは、単一ターンのプロンプトの微調整を、マルチターンのマルコフ決定過程(MDP)を解くこととして位置づけています.
Q: RISEの反復微調整手順は、従来のLLMの微調整方法とどう違うのですか?
A: RISEの反復ファインチューニング手法は、従来のLLMのファインチューニング手法といくつかの点で異なっております.まず、RISEは単一のプロンプトに対するファインチューニングを多ターンのマルコフ決定過程(MDP)として解決することを提案しております.これは、初期状態をプロンプトとし、オンライン模倣学習や強化学習の原則に基づいて、モデルが以前の誤りを検出し、次の反復で修正する能力を持つようにするための戦略を提案しております.さらに、RISEは手動での反復を必要とし、データ効率の良いオンポリシー学習をスケールする際には、より「オンライン」なバリアントが長期的な解決策となる可能性があると述べられております.これに対し、従来のファインチューニング手法は、通常、単一のターンでのパフォーマンス向上を目指し、自己改善の能力を持たないことが多いです.
Q: RISEが微調整プロセスをマルチターン・マルコフ決定過程(MDP)としてどのように定式化しているのか、詳しく教えてください.
A: RISEは、シングルターンのプロンプトのファインチューニングをマルコフ決定過程(MDP)として多ターンで解決する方法として定式化されています.まず、初期状態はプロンプトとして定義されます.MDPの各状態は、プロンプト、過去の試行の履歴、および環境からのオプションのフィードバックによって構成されます.アクションは、これまでの多ターンのインタラクションの状態に基づいてLLMが生成する応答です.RISEのアプローチでは、問題を多ターンのMDPに変換し、データを収集し、オフラインの報酬重み付き教師あり学習を実行して、この能力を誘導します.データ収集の際には、現在のモデルをk-1回展開し、その後、自己蒸留やより能力の高いモデルからのオラクル応答を用いて改善された応答を得ることが行われます.これにより、RISEは生成されたデータを用いてトレーニングを行います.
Q: オンライン模倣学習と強化学習の原理は、マルチターン・データ収集のために提案された戦略にどのような影響を与えるのか?
A: オンライン模倣学習と強化学習の原則は、マルチターンデータ収集の戦略において重要な影響を与えています.まず、オンライン模倣学習の原則に基づき、モデルの自己改善能力を高めるために、モデル自身の応答を反復的に監督することが提案されています.これは、より能力の高いモデルから独立同分布でサンプリングされたオラクル応答を用いるか、学習者自身から生成される応答を用いることができます.次に、強化学習の原則に基づき、マルチターンのデータ収集とトレーニングの戦略が提案されています.具体的には、マルコフ決定過程(MDP)として単一ターンのプロンプトを解決するためのファインチューニングが行われ、初期状態がプロンプトとなります.このアプローチでは、成功したロールアウトと失敗したロールアウトの両方から学習できるトレーニング目標と、反復的なオンポリシーデータ生成戦略が重要です.これにより、モデルが自己改善を行う能力を持つことが可能となります.
Q: RISEはより高性能なモデルに対してどのようにスケールアップするのか、またそのスケールアップを裏付ける証拠は何か?
A: RISEは、より能力の高いモデルと組み合わせることでスケールすることが示されています.具体的には、Mistral-7Bというベースモデルを使用した場合、RISEの性能が向上することが確認されています.文脈によれば、Mistral-7Bをベースにした場合、RISEは複数のターンにわたって性能が向上し、特に5ターン目のパフォーマンスでは、特定の数学データに特化して微調整された最先端のモデルであるEurus-7B-SFTを上回る結果を示しています.このことから、RISEはより強力なベースモデルと組み合わせることで、その性能をさらに引き出すことができると考えられます.
Generation Constraint Scaling Can Mitigate Hallucination
著者:Georgios Kollias, Payel Das, Subhajit Chaudhury
発行日:2024年07月23日
最終更新日:2024年07月23日
URL:http://arxiv.org/pdf/2407.16908v1
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning
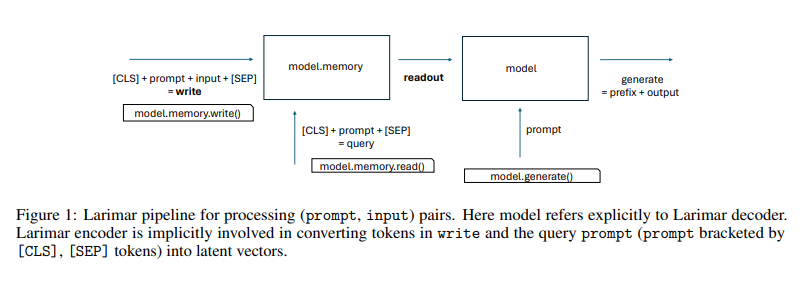
概要:
大規模言語モデル(LLM)における幻覚の問題に取り組むことは重要な課題です.幻覚の認知メカニズムは記憶と関連しているとされており、ここでは明示的な記憶メカニズムを備えたLLMにおける幻覚について探求します.我々は、単純に読み出しベクトルをスケーリングすることで、記憶拡張型LLMデコーダーにおける生成を制約することで、訓練フリーの方法で幻覚の緩和が実現できることを実証しています.我々の方法は幾何学に着想を得ており、Wikipedia風の伝記エントリーの生成タスクにおいて、生成品質とランタイムの複雑さの両方で、最先端のLLM編集方法を上回っています.
Q&A:
Q: この研究で使用されたメモリ増強型LLMデコーダーのアーキテクチャについて教えてください.
A: 本研究で使用されたメモリ拡張型LLMデコーダのアーキテクチャについて説明いたします.Larimarというモデルが使用されており、このモデルは外部のエピソードメモリコントローラを備えています.基本的な構成として、(i)エンコーダ、(ii)連想メモリモジュール、(iii)デコーダが含まれています.エンコーダはテキスト入力(エピソード)とクエリの潜在表現を計算します.これらの表現は、それぞれメモリの更新とクエリのために使用され、読み出しエンコーディングを返します.デコーダはプロンプトから出力テキストを生成し、この際に読み出しエンコーディングによって制約されます.読み出しベクトルは、デコーダにおいて特別な圧縮キー-バリュー(KV)キャッシュとして機能し、展開されます.
Q: 読み出しベクトルをスケーリングすることで、モデルにおける幻覚を機能的にどのように緩和するのか?
A: スケーリングされたリードアウトベクトルがモデルの幻覚をどのように機能的に軽減するかについて説明いたします.幻覚の問題は、特に大規模言語モデル(LLM)において重要な課題であり、これを軽減するための方法として、メモリを明示的に使用するメカニズムが提案されています.リードアウトベクトルのスケーリングは、メモリ拡張型LLMデコーダにおける生成を制約するための手法です.この手法は、幾何学にインスパイアされたものであり、トレーニングを必要としない方法で幻覚を軽減することができます.具体的には、リードアウトベクトルのスケーリングにより、入力と出力の潜在空間表現の幾何学的整合性が向上します.これにより、生成されるテキストの品質が向上し、幻覚の発生が抑制されます.数式で表すと、リードアウトベクトル \( \small \mathbf{v} \) をスケーリングファクター \( \small s \) でスケーリングする操作は、\( \small \mathbf{v}’ = s \cdot \mathbf{v} \) となります.この操作により、生成の制約が強化され、幻覚の軽減が実現されます.
Q: 伝記エントリーの生成品質を評価するために、どのような指標が用いられたのか?
A: 生成された伝記エントリーの品質を評価するために使用された指標は、RougeLスコアとJaccard類似度指数でございます.RougeLスコアは、参照テキストと生成されたテキストの間の類似性を測定するために使用され、Jaccard類似度指数は、トークン化されたテキストに対して集合演算を行い、参照テキストと生成されたテキストの間の類似性を評価するために使用されます.
Q: あなたのメソッドの幾何学にインスパイアされた側面について詳しく教えてください.
A: 幾何学に基づく手法について説明いたします.Larimarモデルでは、入力と出力の潜在空間表現の幾何学的整合性を最適化するために、軽量なメモリプリミティブを使用してデコーダーでの生成を制約する能力があります.具体的には、選択されたエンコーディング(ここではメモリの読み出し)に対して、ベクトルのスケーリングといった単純な幾何学に基づく操作を行います.これにより、z_{readout}ベクトルのスケーリングファクターsに対するベクトル距離の平均と角度(度数法)の平均が調整されます.これらの操作は、Larimarのように明示的なメモリメカニズムを備えたモデルに限定されますが、幻覚を軽減するために非常に効果的であることが示されています.
Q: あなたの研究は、LLMの記憶メカニズムにおける将来の発展に対してどのような示唆を与えてくれますか?
A: 本研究の結果は、LLMのメモリメカニズムの将来的な開発に対して重要な示唆を与えるものです.特に、外部メモリを持つLLMデコーダを用いることで、幻覚の軽減が可能であることが示されました.これは、メモリの読み出しベクトルをスケーリングすることで、トレーニングを必要とせずに幻覚を抑制できることを示しています.この方法は、幾何学に基づいたアプローチであり、メモリプリミティブのエンコーディングが生成パイプラインにおいて中間表現として機能することを活用しています.したがって、将来的には、メモリメカニズムをさらに洗練し、LLMの性能を向上させるための新しい手法が開発される可能性があります.具体的には、メモリの読み書きアクセスを最適化し、生成の精度と信頼性を高めることが期待されます.
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
著者:Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, Graham Neubig
発行日:2024年07月23日
最終更新日:2024年10月04日
URL:http://arxiv.org/pdf/2407.16741v2
カテゴリ:Software Engineering, Artificial Intelligence, Computation and Language
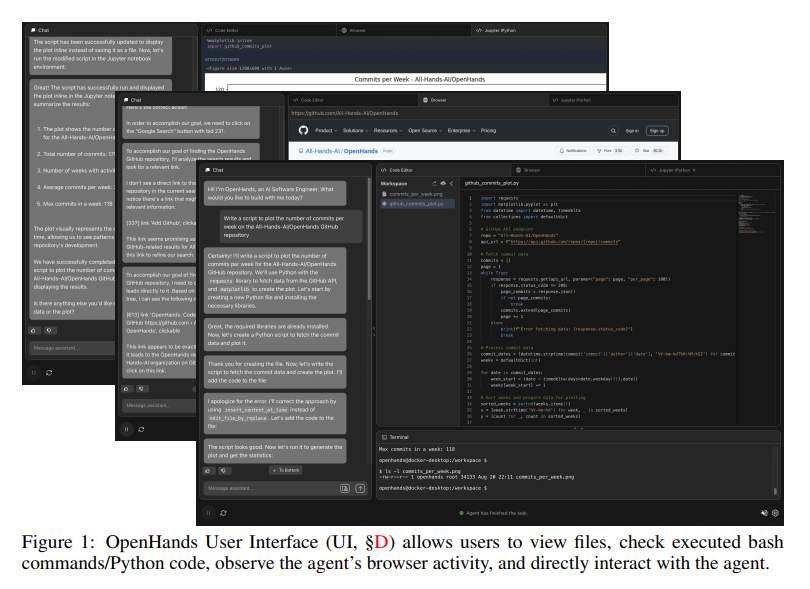
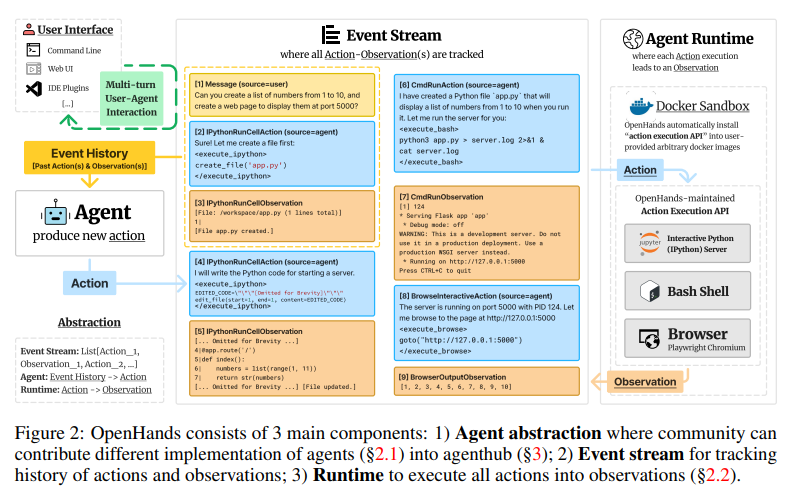

概要:
ソフトウェアは、私たち人間が持っている最も強力なツールの1つであり、熟練したプログラマーが複雑で深遠な方法で世界とやり取りすることを可能にします.同時に、大規模言語モデル(LLM)の改善により、AIエージェントの急速な開発も進んでおり、これらのエージェントは周囲の環境とやり取りし変化をもたらすようになっています.本論文では、MITライセンスの許可を受けたOpenHands(旧称OpenDevin)という、コードの記述、コマンドラインとのやり取り、ウェブの閲覧など、人間の開発者と同様の方法で世界とやり取りする強力で柔軟なAIエージェントの開発プラットフォームを紹介します.このプラットフォームは、新しいエージェントの実装、コード実行のためのサンドボックス環境での安全なやり取り、複数のエージェント間の調整、評価ベンチマークの組み込みを可能にします.現在組み込まれているベンチマークに基づいて、OpenHandsは、ソフトウェアエンジニアリング(SWE-BENCHなど)やウェブブラウジング(WEBARENAなど)を含む15の難しいタスクに対するエージェントの評価を行っています.OpenHandsは、学術界と産業界を横断したコミュニティプロジェクトであり、188人以上の貢献者から2,100以上の貢献があります.
Q&A:
Q: OpenHandsと他のソフトウェア開発用AIプラットフォームとの具体的な違いは何ですか?
A: OpenHandsは他のAIプラットフォームと比較して、いくつかの特異な特徴を持っております.まず第一に、ユーザーインターフェース、エージェント、環境がイベントストリームアーキテクチャを通じて相互作用する強力で柔軟なインタラクションメカニズムを提供しております.このメカニズムにより、エージェントはソフトウェアを通じて世界と効果的に相互作用することが可能です.さらに、安全なサンドボックス環境を提供し、エージェントが安全に開発され、ユーザーのシステムに悪影響を及ぼさないようにしております.また、エージェントの基本的なスキル、マルチエージェントの協力能力、包括的な評価フレームワークを備えており、これにより研究の革新とエージェントAIシステムの実世界での応用が加速されます.これらの特徴により、OpenHandsは他のプラットフォームと差別化されております.
Q: OpenHandsのアーキテクチャと、AIエージェントの開発をどのようにサポートしているか、詳しく教えてください.
A: OpenHandsのアーキテクチャは、AIエージェントの開発を支援するために設計されております.特に、ユーザーインターフェース、エージェント、環境がイベントストリームアーキテクチャを通じて相互作用することを可能にするインタラクションメカニズムを備えております.このアーキテクチャは、柔軟で強力な相互作用を提供し、エージェントがソフトウェアインターフェースを通じて世界と対話することを可能にします.OpenHandsは、エージェントの定義と実装、各アクションの実行が観察につながる方法、信頼性のあるエージェントの開発方法などを詳細に説明しております.これにより、エージェントが安全で信頼性のある方法で動作することを保証し、研究の革新と実世界での応用を加速させることが期待されております.
Q: OpenHandsは、コード実行中のサンドボックス環境との安全なやり取りをどのように保証しているのですか?
A: OpenHandsは、コード実行中に安全にサンドボックス環境と対話するために、いくつかの方法を用いています.まず、各タスクセッションごとに、OpenHandsは安全に隔離されたDockerコンテナサンドボックスを起動します.このサンドボックス内で、イベントストリームからのすべてのアクションが実行されます.OpenHandsは、サンドボックス内で実行されるREST APIサーバーを通じてサンドボックスに接続し、アクション実行APIを使用して任意のアクション(例:bashコマンド、Pythonコード)を実行し、実行結果を観察として返します.さらに、ユーザーがエージェントに作業させたいファイルを含む設定可能なワークスペースディレクトリが、その安全なサンドボックスにマウントされ、OpenHandsエージェントがアクセスできるようにしています.これにより、サンドボックス環境内での安全なコード実行が確保されます.
Q: OpenHandsにはどのような評価ベンチマークが組み込まれていて、どのように選択されているのですか?
A: OpenHandsに組み込まれている評価ベンチマークには、ソフトウェアエンジニアリング(例:SWE-BENCH)やウェブブラウジング(例:WEBARENA)など、15の挑戦的なタスクが含まれております.これらのベンチマークは、エージェントの評価を行うために使用されております.選定方法についての詳細は文脈に記載されておりませんが、OpenHandsは多様な研究および実世界のアプリケーションをサポートすることを目的としており、学術界と産業界のコミュニティプロジェクトとして開発されております.
Q: OpenHandsプラットフォームに新しいエージェントを導入するプロセスを教えてください.
A: OpenHandsプラットフォーム内で新しいエージェントを実装するプロセスは、いくつかのステップに分かれております.まず、エージェントは環境の状態を認識し、過去のアクションと観察を考慮に入れた上で、次のアクションを生成する必要があります.エージェントの定義と実装に関しては、セクション2.1で詳しく説明されております.エージェントは、観察の履歴を基にして、次のアクションを決定するためのアルゴリズムを持つことが求められます.次に、各アクションの実行がどのように観察につながるかについては、セクション2.2で説明されております.エージェントのスキルを管理し、拡張する方法については、セクション2.3で述べられております.最後に、複数のエージェントを組み合わせてタスクを解決する方法については、セクション2.4で説明されております.これらのステップを通じて、OpenHandsプラットフォーム上で新しいエージェントを効果的に実装することが可能となります.
Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach
著者:Zhuowan Li, Cheng Li, Mingyang Zhang, Qiaozhu Mei, Michael Bendersky
発行日:2024年07月23日
最終更新日:2024年10月17日
URL:http://arxiv.org/pdf/2407.16833v2
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning
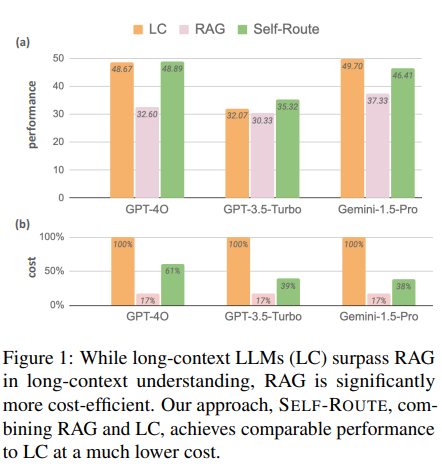
概要:
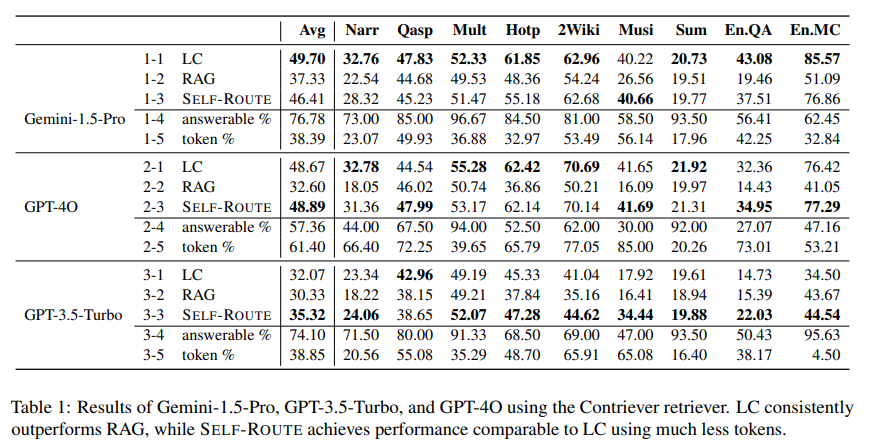
Retrieval Augmented Generation(RAG)は、過度に長いコンテキストを効率的に処理するための大規模言語モデル(LLM)にとって強力なツールでした.しかし、最近のGemini-1.5やGPT-4などのLLMは、長いコンテキストを直接理解する優れた能力を示しています.私たちは、RAGと長いコンテキスト(LC)LLMの包括的な比較を行い、両者の強みを活用しようとしています.最新のLLMを使用して、さまざまな公開データセットでRAGとLCをベンチマークにしました.結果は、十分なリソースがある場合、LCが平均パフォーマンスの面で一貫してRAGを上回ることを示しています.ただし、RAGのコストが大幅に低いという利点が残ります.この観察に基づいて、モデルの自己反映に基づいてクエリをRAGまたはLCにルーティングする単純かつ効果的なSelf-Routeを提案します.Self-Routeは、計算コストを大幅に削減しながら、LCと同等のパフォーマンスを維持します.私たちの調査結果は、RAGとLCを使用したLLMの長いコンテキストアプリケーションのためのガイドラインを提供します.
Q&A:
Q: あなたの研究では、RAGとロングコンテクストLLMのパフォーマンスを比較するために、具体的にどのようなベンチマークを使用しましたか?
A: 私たちの研究では、RAGと長文コンテキスト(LC)モデルの性能を比較するために、LongBench(Bai et al., 2023)と∞Bench(Zhang et al., 2024)というベンチマークが使用されました.LongBenchは21のデータセットを含み、平均コンテキスト長は7,000語です.一方、∞Benchはさらに長いコンテキストを持ち、平均長は100,000トークンです.これらのベンチマークは、合成および実際のテキストを含む複数の言語でのLLM評価のための新しいおよび既存のデータセットのコレクションを提供しています.
Q: Self-Routeメソッドにおいて、クエリーをRAGにルーティングするタイミングとロングコンテキストのLLMにルーティングするタイミングをどのような基準で決定しましたか?
A: 自己ルート法において、クエリをRAGにルーティングするか長文コンテキストLLMにルーティングするかを決定する基準は、LLMが提供されたコンテキストに基づいてクエリが回答可能かどうかを予測する能力に依存しております.具体的には、最初のステップでクエリと取得されたチャンクをLLMに提供し、クエリが回答可能であるかどうかを予測し、回答可能であれば回答を生成するように促します.このプロセスは標準的なRAGに似ておりますが、1つの重要な違いとして、LLMには「提供されたテキストに基づいてクエリに回答できない場合は『回答不能』と書く」という選択肢が与えられております.回答可能と判断されたクエリについては、RAGの予測を最終的な回答として受け入れ、回答不能と判断されたクエリについては、長文コンテキストLLMに完全なコンテキストを提供して最終的な予測を得るステップに進みます.
Q: モデルの自己反省という概念について、セルフ・ルート・アプローチと関連させて説明していただけますか?
A: モデルの自己反省(self-reflection)という概念は、SELF-ROUTEアプローチにおいて重要な役割を果たします.このアプローチでは、LLM(大規模言語モデル)が自身の予測能力を活用して、与えられたコンテキストに基づいてクエリが解答可能かどうかを判断します.具体的には、SELF-ROUTEはRAG(Retrieval-Augmented Generation)とLC(Long Context)を組み合わせた手法であり、コストを削減しつつLCに匹敵する性能を維持することを目指しています.まず、クエリと取得されたチャンクをLLMに提供し、そのクエリが解答可能かどうかを予測させ、解答可能であれば解答を生成します.このプロセスは標準的なRAGに似ていますが、SELF-ROUTEではLLMが自己反省を通じてクエリのルーティングを行う点が異なります.これにより、RAGとLCの強みを効果的に組み合わせ、コストを大幅に削減しつつ、LCに匹敵する性能を達成することが可能となります.
Q: ロング・コンテクストLLMと比べてRAGのコストが低い主な要因は何ですか?
A: RAGのコストが低い主な要因は、入力長を大幅に削減することにあります.RAGは、LLMの注意を取得したセグメントに正則化することで、無関係な情報による注意の分散を避け、不要な注意計算を節約します.これにより、計算コストが大幅に削減されます.具体的には、RAGはLLMのコンテキストウィンドウサイズを超える入力に対しても効率的に処理できるため、計算資源の節約が可能です.
Q: Gemini-1.5とGPT-4の長いコンテクストを理解する能力は、以前のモデルと比較してどうですか?
A: Gemini-1.5とGPT-4は、長いコンテキストを理解する能力において、以前のモデルと比較して大幅に改善されています.特に、Gemini-1.5は最大100万トークンをサポートし、GPT-4は128kトークンをサポートしています.これにより、これらのモデルはより大きなコンテキストウィンドウサイズを持ち、長いコンテキストのプロンプティングが可能になっています.以前のモデルでは、これほど大きなコンテキストウィンドウを扱うことはできませんでした.したがって、Gemini-1.5とGPT-4は、長いコンテキストを処理する能力において、以前のモデルよりも優れています.
Q: ベンチマーキングではどのような公共データセットを利用したのか、またなぜそれを選んだのか.
A: ベンチマークに使用された公開データセットは、LongBenchと∞Benchからのものでございます.LongBenchからは、NarrativeQA、Qasper、MultiFieldQA、HotpotQA、2WikiMultihopQA、MuSiQue、QMSumの7つのデータセットが選ばれました.∞Benchからは、En.QAとEN.MCの2つのデータセットが使用されました.これらのデータセットは、英語で書かれており、実際のデータに基づいており、クエリベースのタスクに焦点を当てているため選ばれました.例えば、要約タスクは関連情報を取得するためのクエリを含まないため、選ばれておりません.
A Survey on Employing Large Language Models for Text-to-SQL Tasks
著者:Liang Shi, Zhengju Tang, Nan Zhang, Xiaotong Zhang, Zhi Yang
発行日:2024年07月21日
最終更新日:2024年09月09日
URL:http://arxiv.org/pdf/2407.15186v3
カテゴリ:Computation and Language
概要:
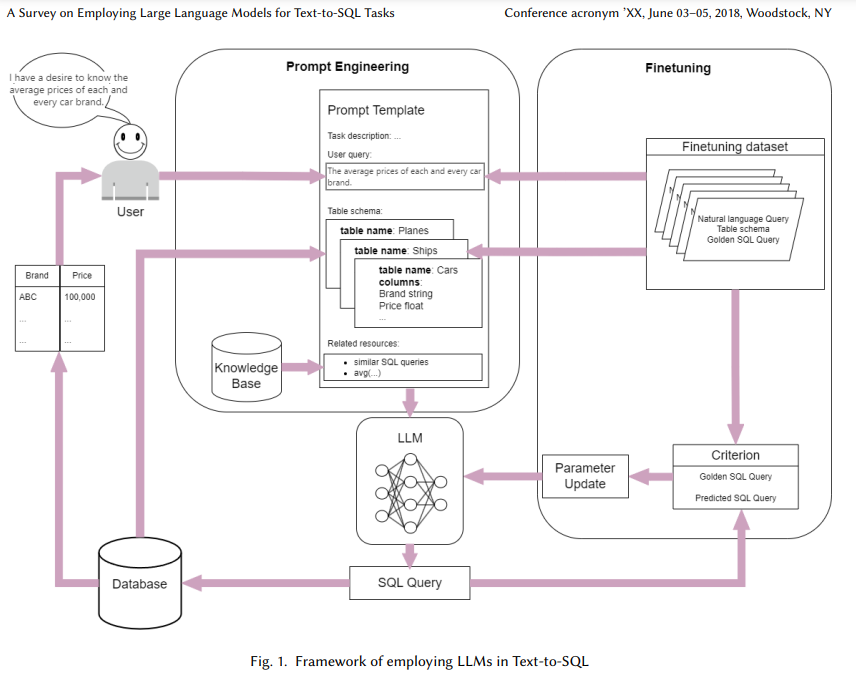
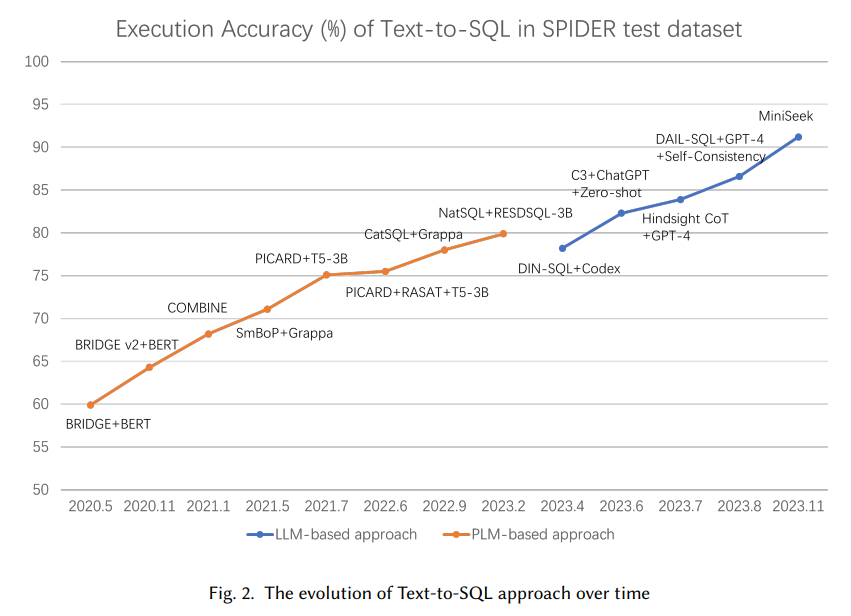
リレーショナルデータベースに格納されているデータの増加は、さまざまなセクターでのデータの効率的なクエリングと利用の必要性を引き起こしています.しかし、SQLクエリを書くには専門知識が必要であり、データベースへのアクセスとクエリを試みる非専門家ユーザーにとって課題となっています.Text-to-SQLパーサーは、自然言語クエリをSQLクエリに変換することで、データベースへのアクセスを非専門家ユーザーにとってよりアクセスしやすくします.最近の大規模言語モデル(LLMs)の進展を活用するために、プロンプトエンジニアリングとファインチューニングに焦点を当てた新しい手法が登場しています.この調査は、テキストからSQLへのLLMsのタスクにおける包括的な概要を提供し、ベンチマークデータセット、プロンプトエンジニアリング、ファインチューニング方法、および将来の研究方向について議論しています.このレビューが読者にこの分野の最近の進歩について広い理解を得ることを可能にし、その将来の方向性についていくつかの示唆を提供することを願っています.
Q&A:
Q: 調査に使用したベンチマークデータセットについて詳しく教えてください.サイズ、多様性、実世界のアプリケーションとの関連性という点で、どのように比較されていますか?
A: 本調査で使用されたベンチマークデータセットについて詳しく説明いたします.まず、BIRDデータセットについてですが、これはLLMの広範な利用後に作成されたもので、現実世界のアプリケーションに関連する新たな課題を提供しています.BIRDデータセットは、12,751のテキストからSQLへのペアと95のデータベースを含み、合計サイズは37の専門分野にわたって33.4 GBです.このデータセットは、汚れたデータやノイズの多いデータベース値、自然言語質問とデータベース値間の外部知識の基盤、特に大規模データベースの文脈でのSQL効率性などの新たな課題を強調しています.実験結果によれば、最も効果的なテキストからSQLへのモデル、すなわちGPT-4でさえ、実行精度で54.89%しか達成できず、人間の結果である92.96%にはまだ遠く及ばないことが示されています.次に、Dr.Spiderデータセットについては、文脈に情報が不足しているため、詳細を述べることができません.
Q: テキストをSQLに変換するタスクにおいて、LLMの微調整は従来の機械学習アプローチとどう違うのか?
A: LLMのファインチューニングは、テキストからSQLへのタスクにおいて、従来の機械学習アプローチといくつかの点で異なります.まず、ファインチューニングでは、事前に学習された大規模言語モデル(LLM)を使用し、特定のタスクに関連するデータセットでモデルをさらに訓練します.これにより、モデルは特定のタスクに対する性能を向上させることができます.従来の機械学習アプローチでは、通常、ゼロからモデルを訓練するか、特定のタスクに特化したモデルを設計する必要があります.
ファインチューニングのプロセスは、データの準備、事前学習モデルの選択、モデルのファインチューニング、モデルの評価というステップを含みます.特に、ファインチューニングでは、タスク固有のデータを用いてモデルを訓練するため、より大規模なトレーニングデータセットが必要とされます.これに対し、プロンプトエンジニアリングの手法は、少ないデータで済むことが多いですが、結果が最適でない場合があります.
また、従来のアプローチでは、シーケンス・ツー・シーケンス(Seq2Seq)モデルのような手法が用いられ、エンコーダが自然言語の意味を捉えるように設計されていました.これに対し、LLMを用いたアプローチでは、プロンプトエンジニアリングやファインチューニングを通じて、より高度な自然言語処理能力を活用することが可能です.
Q: Text-to-SQLモデルのパフォーマンスを評価するために推奨する特定のメトリクスや評価基準はありますか?
A: テキストからSQLへのモデルの性能を評価するための具体的な指標や評価基準として、一般的に使用されるのは、EM(Exact Match)とEA(Execution Accuracy)の精度率を計算することです.これらの指標は、モデルの微調整前後の性能を比較するために用いられます.EMは、生成されたSQLクエリが正解と完全に一致するかどうかを評価し、EAは生成されたクエリが正しく実行されるかどうかを評価します.これらの指標を用いることで、モデルの性能を定量的に評価することが可能です.
Q: LLMを使用したtext-to-SQLシステムの機能を向上させるために、将来的にどのような研究の方向性が重要だと思われますか?
A: 与えられた文脈に基づいて、テキストからSQLへのシステムの能力を向上させるための将来の研究方向として、いくつかの重要な点が考えられます.まず、プライバシーの懸念が挙げられます.大規模言語モデル(LLM)を使用する際には、データのプライバシーとセキュリティが重要な課題となります.次に、自律エージェントの開発が考えられます.これにより、より複雑なクエリを自動的に生成し、実行する能力が向上するでしょう.さらに、複雑なスキーマの処理能力の向上も重要です.これにより、より多様なデータベース構造に対応できるようになります.ベンチマークの改善も必要です.これにより、モデルの性能をより正確に評価し、比較することが可能になります.最後に、ドメイン知識の統合が挙げられます.特定の分野に特化した知識をモデルに組み込むことで、より精度の高いクエリ生成が可能になると考えられます.
LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference
著者:Qichen Fu, Minsik Cho, Thomas Merth, Sachin Mehta, Mohammad Rastegari, Mahyar Najibi
発行日:2024年07月19日
最終更新日:2024年07月19日
URL:http://arxiv.org/pdf/2407.14057v1
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning
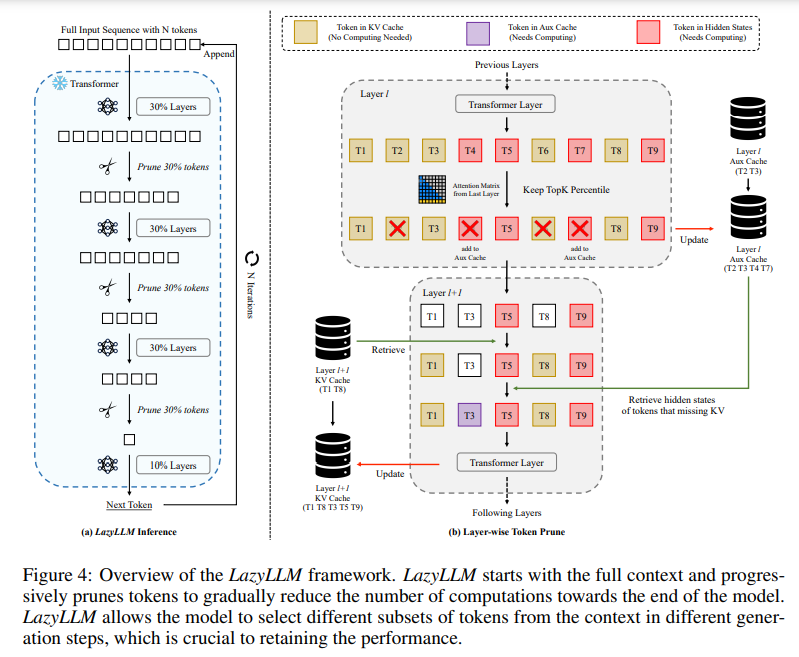
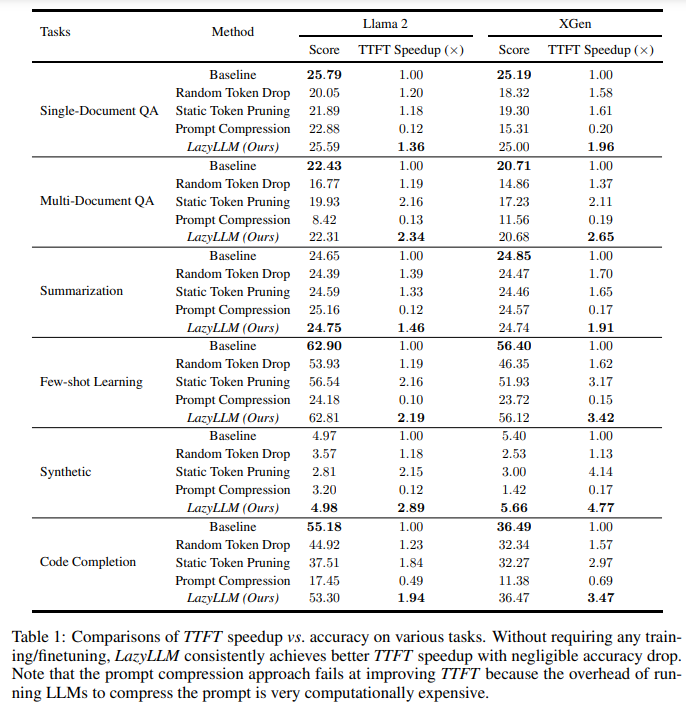
概要:
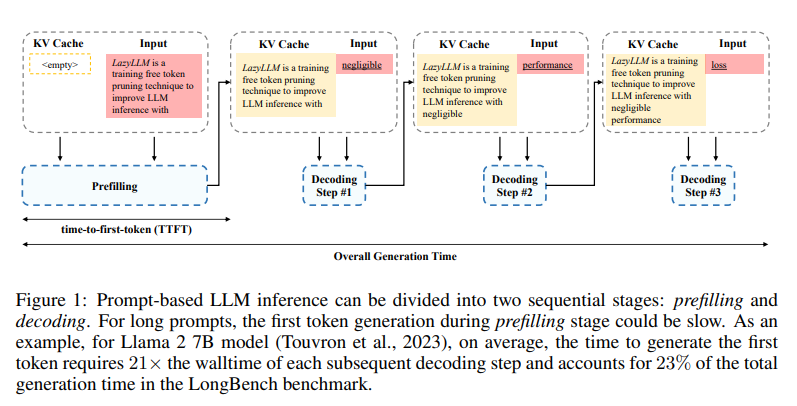
トランスフォーマーベースの大規模言語モデルの推論は、2つの連続した段階で構成されています.1つ目はプロンプトのKVキャッシュを計算し、最初のトークンを生成するプリフィリング段階であり、2つ目は後続のトークンを生成するデコーディング段階です.長いプロンプトの場合、プリフィリング段階ですべてのトークンのKVキャッシュを計算する必要があり、最初のトークンを生成するために必要な時間が大幅に増加する可能性があります.そのため、プリフィリング段階は生成プロセスのボトルネックになる可能性があります.すべてのプロンプトトークンが最初のトークンを生成するために必要かどうかという疑問が残っています.この疑問に答えるために、次のトークン予測に重要なトークンのみを選択してKVを計算する新しい方法、LazyLLMを導入しています.プリフィリング段階とデコーディング段階の両方で、次のトークン予測に重要なトークンのみを選択的に計算するLazyLLMは、プロンプト全体を一度に刈り込む静的なプルーニングアプローチとは異なり、言語モデルが異なる生成ステップでコンテキストから異なるトークンのサブセットを動的に選択できるようにします.さらに、標準データセットを使用したさまざまなタスクでの包括的な実験は、LazyLLMが汎用的な方法であることを示しています.さらに、様々なタスクにおいて、LazyLLMは微調整を必要とせず既存の言語モデルにシームレスに統合され、生成を大幅に加速することができる汎用的な手法であることが示されています.例えば、マルチドキュメントの質問応答タスクでは、LazyLLMはLLama 2 7Bモデルのプリフィリング段階を2.34倍高速化し、精度を維持しています.
Q&A:
Q: LazyLLMは、プリフィリングとデコーディングの段階で、どのトークンが次のトークン予測にとって重要かを判断するのに、具体的にどのような基準を使っているのですか?
A: LazyLLMは、トークンの重要性を測定するために、前のトランスフォーマーレイヤーのアテンションスコアを使用することが提案されています.これにより、トランスフォーマーの深さに沿ってトークンを段階的にプルーニングすることが可能です.具体的には、アテンションスコアが高いトークンが次のトークン予測に重要であると判断され、これらのトークンのKV(キーとバリュー)が選択的に計算されます.
Q: LazyLLMは、異なる生成ステップにまたがるトークンの動的選択をどのように扱うのですか?
A: LazyLLMは、各生成ステップで異なるトークンのサブセットを動的に選択することができます.これは、以前のステップでプルーニングされたトークンであっても、次の生成ステップで再選択される可能性があることを意味します.具体的には、LazyLLMは各生成ステップで文脈から異なるトークンのサブセットを選択することを許可しており、これによりモデルの性能を維持することが重要です.動的プルーニングは、次のトークン予測を各生成ステップで最適化するため、静的プルーニングと比較して優れています.LazyLLMは、最初の推論の反復(プリフィリングステップ)から重要なトークンのみを「遅延」して計算することにより、次のトークンを予測するために重要なトークンを選択します.これにより、各トークンが生成全体で最大1回しか計算されないようにAux Cacheを導入し、最悪の実行時間がベースラインより遅くならないようにしています.
Q: LazyLLMと従来のスタティック・プルーニング手法のパフォーマンスの違いを説明してもらえますか?
A: LazyLLMと従来の静的プルーニング手法の性能の違いについて説明いたします.LazyLLMは、トークンのプルーニングを動的に制御することにより、TTFT(Total Time for Task)をスピードアップしつつ、精度の低下を最小限に抑えることができます.具体的には、LazyLLMはプルーニングパラメータを調整することで、精度と推論速度の間で良好なトレードオフを提供します.これに対して、従来の静的プルーニング手法は、入力トークンを一度にプルーニングするため、精度の低下が大きくなる可能性があります.LazyLLMは、トランスフォーマーの異なる層でプルーニングを行うことができ、プルーニングの割合を調整することで、計算量を削減し、全体の生成プロセスを加速します.これにより、LazyLLMは、特に多文書質問応答タスクにおいて、2.34倍のTTFTスピードアップを達成し、精度の低下を1%以下に抑えることができます.
Q: LazyLLMを実装した場合、メモリ使用量と処理時間の点で計算上どのような影響がありますか?
A: LazyLLMの実装における計算上の影響について、メモリ使用量と処理時間の観点から説明いたします.LazyLLMは、トークンの計算を選択的に行うことにより、特に長いコンテキストシナリオにおいて、計算量を削減することができます.これにより、最初のトークンが生成されるまでの時間(TTFT)が大幅に最適化されます.具体的には、LazyLLMは、入力トークンすべてのKVキャッシュを事前に計算するのではなく、次のトークン予測に重要なトークンのみを選択的に計算し、残りのトークンの計算を後のステップに遅らせます.このアプローチにより、メモリ使用量は、計算されるトークンの数が減少するため、効率的に管理されます.また、処理時間も、不要な計算を避けることで短縮されます.したがって、LazyLLMは、メモリ使用量と処理時間の両方において効率的な改善をもたらすと考えられます.
Q: LazyLLMは、特に複数文書の質問応答タスクにおいて、どのように生成プロセスを高速化しながら精度を維持しているのか?
A: LazyLLMは、生成プロセスを加速しながら精度を維持するために、特にマルチドキュメント質問応答タスクにおいて、いくつかの重要な手法を用いております.まず、LazyLLMは、事前充填段階において、各トークンのKVキャッシュを計算し保存することで、最初のトークンを予測します.この段階での時間を「最初のトークンまでの時間(TTFT)」と呼びます.LazyLLMは、TTFTを2.34倍に加速しつつ、精度をほとんど損なわないことが示されています.具体的には、LazyLLMは、剪定パラメータを制御することにより、精度と推論速度の間で良好なトレードオフを提供します.例えば、LazyLLMは、精度の劣化を10%以下に抑えつつ、3.0倍のTTFTスピードアップを達成することができます.これに対して、ベースライン手法では、同様のTTFTスピードアップにおいて精度が大幅に低下します.したがって、LazyLLMは、既存の言語モデルにシームレスに統合され、微調整なしで生成を大幅に加速することが可能です.
Q: LazyLLMの有効性を検証するための広範な実験では、どのような種類のデータセットが使われたのですか?
A: LazyLLMの有効性を検証するために使用されたデータセットは、16の標準データセットであり、6つの異なる言語タスクにわたるものでございます.これらのデータセットは、ROUGE-L、F1、Accuracy、Edit Simなどの異なるメトリクスを含むタスクを含んでおります.
Q: LazyLLMはどのように既存の言語モデルと統合するのですか?
A: LazyLLMは、既存のトランスフォーマーベースの大規模言語モデル(LLM)にシームレスに統合され、推論速度を向上させることができます.この統合は、トレーニングやパラメータの変更を必要としないため、非常に効率的です.具体的には、LazyLLMは、LLMの推論プロセスにおけるプレフィリングとデコーディングの両方の段階で速度を向上させることができます.プレフィリング段階では、プロンプトから各トークンのKVキャッシュを計算して保存し、最初のトークンを予測します.この段階での時間を「最初のトークンまでの時間」(TTFT)と呼びます.LazyLLMは、特に長いコンテキストシナリオにおいて、完全なKVキャッシュを計算するために必要な広範な計算を効率化し、TTFTを短縮します.これにより、ユーザーはプロンプトを送信した後、応答を受け取るまでの待ち時間が短縮され、ユーザーエクスペリエンスが向上します.
Q: LazyLLMは、大規模言語モデルのための効率的な推論における他の最近の進歩と比較してどうですか?
A: LazyLLMは、他の最近の効率的な推論の進展と比較して、いくつかの利点を持っていると考えられます.まず、LazyLLMは普遍的であり、既存のトランスフォーマーベースの大規模言語モデル(LLM)にシームレスに統合でき、推論速度を向上させることができます.さらに、LazyLLMはトレーニングを必要とせず、パラメータの変更なしに直接統合できるため、導入が容易です.実証的な結果によれば、16の標準データセットにおける6つの異なる言語タスクで、LazyLLMはプレフィリングおよびデコーディングの両方の段階でLLMの推論速度を向上させることが示されています.特に、長いコンテキストシナリオにおいて、LazyLLMは完全なKVキャッシュを計算するために必要な広範な計算を削減し、最初のトークンまでの時間(TTFT)を短縮することができます.例えば、マルチドキュメント質問応答タスクにおいて、LazyLLMは2.34倍のTTFTのスピードアップを提供し、性能の損失はごくわずか(1%以下)であることが示されています.これにより、LazyLLMは精度と推論速度の間で良好なトレードオフを提供します.
MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens
著者:Anas Awadalla, Le Xue, Oscar Lo, Manli Shu, Hannah Lee, Etash Kumar Guha, Matt Jordan, Sheng Shen, Mohamed Awadalla, Silvio Savarese, Caiming Xiong, Ran Xu, Yejin Choi, Ludwig Schmidt
発行日:2024年06月17日
最終更新日:2024年09月19日
URL:http://arxiv.org/pdf/2406.11271v4
カテゴリ:Computer Vision and Pattern Recognition, Machine Learning
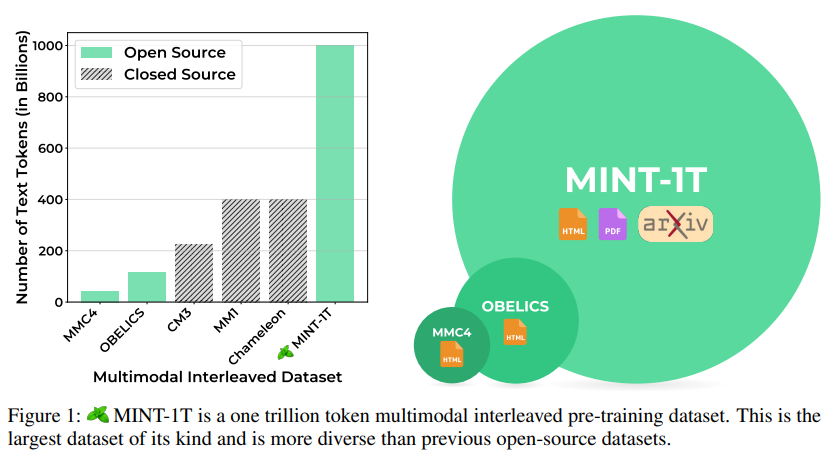

概要:
多様な画像とテキストの自由形式の交互シーケンスを特徴とするマルチモーダルな交互データセットは、最先端の大規模マルチモーダルモデル(LMMs)のトレーニングに不可欠です.オープンソースのLMMsの急速な進化にもかかわらず、大規模で多様なオープンソースのマルチモーダルな交互データセットは依然として非常に不足しています.この課題に対応するために、我々はMINT-1Tを紹介します.これは、これまでに存在した最も広範囲で多様なオープンソースのマルチモーダルな交互データセットです.MINT-1Tには1兆のテキストトークンと34億の画像が含まれており、既存のオープンソースデータセットから10倍のスケールアップが行われています.さらに、PDFやArXiv論文など、これまで利用されていなかったソースも含まれています.マルチモーダルな交互データセットのスケーリングには多大なエンジニアリングの努力が必要ですが、データキュレーションプロセスを共有し、データセットを公開することでコミュニティに大きな利益をもたらします.我々の実験では、MINT-1TでトレーニングされたLMMsは、以前の主要なデータセットでトレーニングされたモデルの性能に匹敵することを示しています.我々のデータとコードはhttps://github.com/mlfoundations/MINT-1Tで公開されます.
Q&A:
Q: MINT-1Tのデータセットを、PDFやArXivの論文などさまざまなソースからキュレートするために、具体的にどのような方法が用いられたのでしょうか?
A: MINT-1Tデータセットのキュレーションには、CommonCrawlのWARCダンプ(2017年から2024年)からHTMLドキュメントをフィルタリングする方法が用いられました.このフィルタリングは、テキストの品質、重複したコンテンツや望ましくないコンテンツの存在、画像のダウンロード可能性に基づいて行われました.また、PDFドキュメントは2023年から2024年のCommonCrawl WATダンプから同様の基準でフィルタリングされました.ArXivドキュメントについては、すべてのArXivドキュメントのサブセットが使用されました.
Q: マルチモーダルなインターリーブデータセットを1兆トークンまで拡張する際に直面したエンジニアリング上の課題について詳しく教えてください.
A: マルチモーダルインタリーブデータセットを1兆トークンにスケーリングする際のエンジニアリングの課題について説明いたします.まず、テキストのみや画像-テキストペアのデータセットを構築するよりも、マルチモーダルインタリーブデータをスケーリングすることは、より大きなエンジニアリングの挑戦となります.これは、より大きなドキュメントサイズを扱う必要があり、画像とテキストの元の順序を保持する必要があるためです.具体的には、データのスケーリングには、HTML、PDF、ArXivなどの多様なソースからのデータを統合し、これらの異なる形式のデータを一貫した方法で処理するための高度な技術が求められます.さらに、データの多様性と規模が増すにつれて、データの品質を維持し、効率的に処理するための新しいアルゴリズムやインフラストラクチャの開発が必要となります.
Q: MINT-1Tデータセットに含まれる画像とテキストの多様性を確保するために、どのような基準が用いられたのですか?
A: MINT-1Tデータセットの多様性を確保するために、画像とテキストは多様なソースから収集されました.具体的には、HTML、PDF、ArXivなどの異なるソースからデータが取得されております.これにより、データセットの多様性が高められております.
Q: MINT-1Tで学習させたLMMの性能は、OBELICS以外のデータセットで学習させたLMMの性能と比較してどうか?
A: MINT-1Tで訓練されたLMMの性能は、OBELICSで訓練されたモデルと比較して、いくつかの点で優れています.特に、科学と技術の分野では、MINT-1TのPDFサブセットがこれらの分野を大きく代表しているため、OBELICSよりも優れた性能を示しています.また、MINT-1Tはアートの分野でもOBELICSを上回っています.しかし、キャプションベンチマークにおいては、MINT-1TはOBELICSよりも劣る結果を示しています.全体として、MINT-1TはOBELICSと同等かそれ以上の性能を示し、スケールにおいては10倍の増加を提供しています.
Q: MINT-1Tデータセットを公開する前に行ったデータの前処理について詳細を教えてください.
A: MINT-1Tデータセットのリリース前に行われたデータの前処理について説明いたします.データセットは、低品質のテキスト、重複した文書やテキスト部分、そして不適切な内容や低品質の画像を削除するために前処理が行われました.
Q: MINT-1Tデータセットを使用するためのライセンス条件と、その使用に関する制限はありますか?
A: MINT-1Tデータセットの使用に関するライセンス条件は、CC-BY-4.0ライセンスの下で提供されております.このライセンスにより、データセットの使用者は、適切なクレジットを提供する限り、データを自由に共有および適応することが許可されております.第三者による知的財産権に基づく制限や、データセットに関連する輸出管理やその他の規制制限は存在しないとされています.
Q: コミュニティはMINT-1Tデータセットにどのように貢献し、自身の研究に活用することを想定していますか?
A: MINT-1Tデータセットは、Huggingfaceインターフェースを通じて公開される予定であり、研究者コミュニティがこのデータセットを利用して大規模なマルチモーダルモデルの研究を進めることが期待されております.データセットはJSONシャードとして配布され、各エントリーには文書のテキストと画像へのリンクが含まれています.研究者はこのデータセットを用いて、例えば、異なるモーダル間の相関を解析したり、新しいアルゴリズムを開発したりすることが可能です.また、データセットはCC-BY-4.0ライセンスの下でリリースされており、商業利用を考慮する際には、ユーザー自身が法的な遵守を確認する責任があります.さらに、Huggingfaceのプルリクエスト機能を通じて、データセットへの貢献も受け付けておりますので、コミュニティはデータの改善や拡張に参加することができます.
AI models collapse when trained on recursively generated data
著者:Ilia Shumailov, Nicolas Papernot, Ross Anderson, Yarin Gal, Yiren Zhao, Zakhar Shumaylov
発行日:2024年05月14日
最終更新日:不明
URL:https://www.nature.com/articles/s41586-024-07566-y
カテゴリ:不明
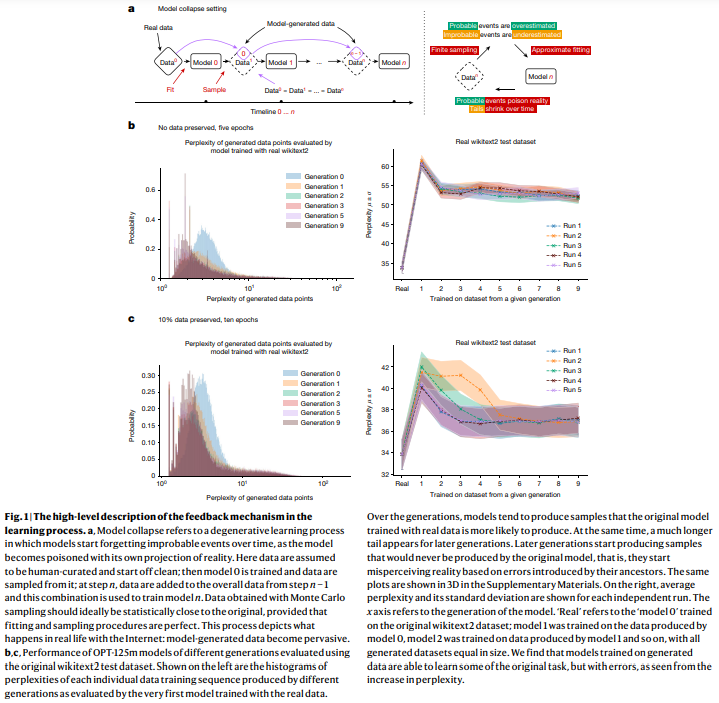
概要:
モデルの崩壊は、学習された生成モデルの世代に影響を与える退化プロセスであり、生成されるデータが次世代のトレーニングセットを汚染することによって、彼らは現実を誤って認識するようになります.このプロセスは、図1aに示されています.我々は、早期モデルの崩壊と遅期モデルの崩壊という2つの特別なケースを区別します.早期モデルの崩壊では、モデルは分布のテールに関する情報を失い始めます.遅期モデルの崩壊では、モデルは元の分布とはほとんど似ても似つかない分布に収束し、しばしば大幅に分散が減少します.このプロセスは、3つの特定のエラー源によって世代を超えて複合し、元のモデルからの逸脱を引き起こします.統計的近似誤差は、サンプル数が有限であるために生じる主要なエラータイプであり、サンプル数が無限に近づくと消失します.これは、再サンプリングの各ステップで情報が失われる可能性があるためです.機能表現誤差は、二次的なエラータイプであり、ニューラルネットワークが無限に大きくなるという条件下でのみ普遍的な近似器として機能するために生じます.その結果、ニューラルネットワークは、元の分布のサポート外で非ゼロの尤度を導入したり、元の分布のサポート内でゼロの尤度を導入したりすることがあります.機能表現誤差の簡単な例は、単一のガウス分布で2つのガウス分布の混合を適合しようとする場合です.データ分布について完璧な情報があっても(つまり、サンプル数が無限であっても)、モデルのエラーは避けられません.ただし、他の2つのエラータイプが存在しない場合、これは最初の世代でのみ発生します.機能近似誤差は、主に学習手法の制約から生じる二次的なエラータイプであり、例えば、確率的勾配降下法の構造バイアスや目的関数の選択などが挙げられます.このエラーは、各世代で無限のデータと完全な表現力を持つ限りにおいて発生すると見なすことができます.これらの要因は、モデルの崩壊を悪化させたり改善させたりする可能性があります.さらに、より高度な近似力は、統計的ノイズを打ち消す可能性がある一方で、ノイズを増幅させる可能性もあります.しばしば、個々の不正確さが組み合わさって全体の誤差が増大する連鎖効果が生じます.例えば、密度モデルの過学習は、モデルが不正確に外挿し、トレーニングセットのサポート外の低密度領域に高密度領域を割り当てることにより、これらの領域が任意の頻度でサンプリングされるようになります.他にも、実際にはコンピュータには限られた精度があるなど、他の種類のエラーも存在します.これらが観察されるエラーの原因となる数学的直感、異なるソースが複合する方法、そして平均モデルの逸脱を定量化する方法について説明するために、新しい文脈について考えてみましょう.
Q&A:
Q: 再帰的に生成されたデータで訓練されたLLMにおいて、「モデル崩壊」につながる具体的なメカニズムは何ですか?
A: 与えられた文脈によれば、モデル崩壊(model collapse)は、生成されたデータが次世代の学習データセットを汚染することによって引き起こされる退行的なプロセスであると説明されています.具体的なメカニズムとしては、生成モデルが生成したデータが次の世代のモデルの訓練データに含まれることで、モデルが現実を誤認識するようになることが挙げられます.このプロセスは、特にデータ分布の裾(tails)に関する情報が失われることから始まり、最終的にはモデルが非常に小さな分散を持つ点推定に収束することが示されています.さらに、モデルが元のデータ分布からより確率の高いシーケンスを生成し始め、自らの不確実なシーケンス、すなわちエラーを導入することも観察されています.これらのメカニズムにより、モデルは真のデータ分布を忘れてしまうのです.
Q: モデル崩壊という現象の背景にある理論的な直感について詳しく教えてください.
A: モデル崩壊の現象に関する理論的直感について説明いたします.モデル崩壊とは、生成モデルが以前の世代によって生成されたデータを再帰的に学習する際に、時間の経過とともに真の基礎データ分布を忘れてしまう退行的なプロセスであるとされています.この現象は、分布の時間的変化がない場合でも発生することが示されています.具体的には、ガウス混合モデル(GMM)、変分オートエンコーダ(VAE)、および大規模言語モデル(LLM)におけるモデル崩壊の例が挙げられています.時間の経過とともに、モデルは真の分布に関する情報を失い始め、最初は分布の尾が消失し、学習された行動は世代を重ねるごとに非常に小さな分散を持つ点推定に収束します.このプロセスは、長期学習に理想的な条件、すなわち関数推定誤差がない場合でも避けられないことが示されています.モデル崩壊に関連する既存の文献からの2つの近い概念として、タスクフリーの継続学習における破滅的忘却と、意図しない行動を引き起こすデータ中毒が挙げられていますが、これらは設定が根本的に異なるため、モデル崩壊の現象を完全に説明することはできません.
Q: 変分オートエンコーダ(VAE)やガウス混合モデル(GMM)と比較して、LLMではモデルの崩壊がどのように異なるのだろうか?
A: 与えられた文脈から、LLM(大規模言語モデル)におけるモデル崩壊は、VAE(変分オートエンコーダー)やGMM(ガウス混合モデル)と比較して、異なる方法で現れることが示されています.具体的には、LLMは通常、BERTやRoBERTa、GPT-2のような大規模なテキストコーパスで事前に訓練されたモデルを初期化し、その後、様々な下流タスクに微調整されます.このプロセスにおいて、他のモデルによって生成されたデータで順次微調整されると、モデル崩壊が発生します.モデル崩壊は、時間の経過とともにモデルが真の基礎データ分布を忘れてしまう退行的なプロセスであり、分布の変化がない場合でも発生します.具体的には、モデルはまず分布の裾野を失い始め、学習された行動は世代を重ねるごとに非常に小さな分散を持つ点推定に収束します.このプロセスは、長期学習に理想的な条件、すなわち関数推定誤差がない場合でも避けられないことが示されています.
Q: 今後のLLMのトレーニング、特にトレーニングデータの質に関して、モデル崩壊はどのような意味を持つのだろうか?
A: モデル崩壊の将来のLLMの訓練に対する影響は、特に訓練データの質に関して重要です.モデル崩壊とは、生成モデルの世代を重ねるごとに、生成されたデータが次の世代の訓練セットを汚染し、その結果、現実を誤認するようになる退行的なプロセスです.このプロセスは、特に低確率のイベントや複雑なシステムの理解において重要な、分布の裾野に関する情報を失うことから始まります.したがって、LLMの訓練においては、元のデータソースへのアクセスを維持し、LLMによって生成されていないデータが時間とともに利用可能であることを確保する必要があります.さらに、インターネットからクロールされたコンテンツの出所を確認することが求められますが、LLMによって生成されたコンテンツを大規模に追跡する方法は明確ではありません.この問題に対処するためには、LLMの作成と展開に関与する異なる当事者が情報を共有するためのコミュニティ全体の協調が一つの選択肢となります.
Q: 壊滅的な忘却という概念は、モデル崩壊とどのように関連しているのか、また、両者の重要な違いは何か?
A: 文脈によれば、カタストロフィックフォーゲッティングとモデル崩壊は関連するが異なる概念であると述べられています.カタストロフィックフォーゲッティングは、タスクフリーの継続学習の枠組みで発生する現象であり、新しい情報を学習する際に以前の情報が失われることを指します.一方、モデル崩壊は、時間の経過とともにモデルが真のデータ分布を忘れてしまう退行的なプロセスを指します.特に、他のモデルによって生成されたデータを使用することが原因で、分布の変化がないにもかかわらず、モデルが情報を失っていくことが示されています.カタストロフィックフォーゲッティングは特定のタスクに関連する情報の喪失に焦点を当てているのに対し、モデル崩壊はデータ分布全体の忘却に関するものであり、特に分布の尾部が消失し、学習された行動が小さな分散を持つ点推定に収束することが強調されています.したがって、両者は異なる設定において発生する現象であり、完全には説明できないが、観察された現象に対する別の視点を提供します.
