
- Prover-Verifier Games improve legibility of LLM outputs
発行日:2024年07月18日
小学校の数学問題を解決する文脈で可読性を研究し、AnilらのProver-Verifierゲームに触発されたトレーニングアルゴリズムを提案して、LLMの出力の可読性を向上させる方法を示唆. - Weak-to-Strong Reasoning
発行日:2024年07月18日
大規模言語モデルの強化に向けたプログレッシブラーニングフレームワークが、弱から強い学習を通じて推論能力を向上させることを示し、AIの発展に貢献している. - A Survey of Prompt Engineering Methods in Large Language Models for Different NLP Tasks
発行日:2024年07月17日
LLMはNLPタスクで高いパフォーマンスを示し、プロンプトエンジニアリングはその能力をさらに引き出すための重要な手法であり、多くの研究がプロンプトの設計に取り組んでいる. - Does Refusal Training in LLMs Generalize to the Past Tense?
発行日:2024年07月16日
LLMをジェイルブレイクするための過去形再構築攻撃は、拒否トレーニングの一般化のギャップを示し、未来形再構築の効果が低いことを示唆しています. - NeedleBench: Can LLMs Do Retrieval and Reasoning in 1 Million Context Window?
発行日:2024年07月16日
NeedleBenchフレームワークは、LLMの長文脈能力を評価し、バイリンガルな長文脈タスクにおける推論能力をテストするための新しい方法を提案しています. - Beyond Euclid: An Illustrated Guide to Modern Machine Learning with Geometric, Topological, and Algebraic Structures
発行日:2024年07月12日
ユークリッド幾何学の伝統的な機械学習から非ユークリッドデータへの移行が進み、幾何学、トポロジー、代数を組み合わせた新しい数学的アプローチが必要とされている. - Context Embeddings for Efficient Answer Generation in RAG
発行日:2024年07月12日
RAGは外部情報を入力に拡張し、COCOMはコンテキストを効果的に圧縮して生成時間を短縮する方法で、デコーディング時間を最大5.69倍高速化しながら高いパフォーマンスを達成する. - SpreadsheetLLM: Encoding Spreadsheets for Large Language Models
発行日:2024年07月12日
スプレッドシートLLMは、スプレッドシート上での効率的なエンコーディング方法を開発し、スプレッドシートのテーブル検出タスクのパフォーマンスを向上させ、最先端のF1スコアを達成しました. - Distilling System 2 into System 1
発行日:2024年07月08日
LLMはSystem 2技術を使用して、中間的な思考を生成し、最終的な応答を改善するための計算を行い、将来のAIシステムの重要な機能として役立つ. - Exploring Advanced Large Language Models with LLMsuite
発行日:2024年07月01日
LLMの進歩と課題を探求し、RAG、PAL、ReAct、LangChainなどの解決策を提案し、多段階の推論や複雑なタスクにおいてLLMの性能と信頼性を向上させる方法を提供しています.
Prover-Verifier Games improve legibility of LLM outputs
著者:Jan Hendrik Kirchner, Yining Chen, Harri Edwards, Jan Leike, Nat McAleese, Yuri Burda
発行日:2024年07月18日
最終更新日:2024年07月18日
URL:http://arxiv.org/pdf/2407.13692v1
カテゴリ:Computation and Language
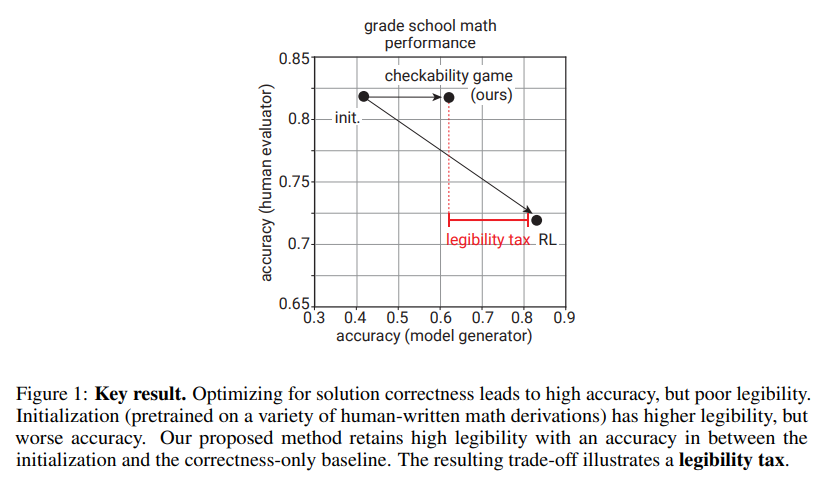

概要:
大規模言語モデル(LLM)の出力に対する信頼性を高める方法の1つは、明確で簡単に確認できる推論をサポートすることです.この特性を「可読性」と呼びます.私たちは、小学校の数学問題を解決する文脈で可読性を研究し、連鎖的な思考の解決策を回答の正確性だけに最適化すると、可読性が低下することを示しています.可読性の損失を緩和するために、Anilら(2021)のProver-Verifierゲームに触発されたトレーニングアルゴリズムを提案しています.私たちのアルゴリズムは、解決策の正確性を予測する小さな検証者、検証者が受け入れる正しい解決策を生成する「役立つ」証明者、検証者をだます不正確な解決策を生成する「巧妙な」証明者を反復的にトレーニングします.私たちは、役立つ証明者の正確性と検証者の敵対的攻撃に対する堅牢性がトレーニングの過程で向上することを発見しました.さらに、可読性トレーニングが、解決策の正確性を検証するために時間制約のある人間に移転することを示しています.LLMのトレーニングの過程で、人間の正確性は、役立つ証明者の解決策をチェックする際に増加し、巧妙な証明者の解決策をチェックする際に減少します.したがって、小さな検証者による可読性トレーニングは、LLMの出力の可読性を向上させるための実用的な手段であり、超人的モデルの整合性向上に役立つ可能性があります.
Q&A:
Q: ラージ・ランゲージ・モデル(LLM)の文脈で、読みやすさのコンセプトを説明してもらえますか?
A: 大規模言語モデル(LLMs)の文脈での可読性とは、モデルの出力を人間が理解しやすくすることを指します.つまり、モデルが出力した結果に対して、その根拠や理由が明確であり、誤りがあれば容易に見つけられることを意味します.このような可読性は、モデルの信頼性を高めるために重要であり、特に高い信頼性が求められる領域では必要不可欠です.
Q: 思考の連鎖による解答の正しさの最適化は、読みやすさにどのような影響を与えるのか?
A: 解答の正確性のために連鎖的な思考ソリューションを最適化することは、それらをより読み取りにくくする可能性がある.
Q: この研究で提案されたトレーニング・アルゴリズムの背景にある着想とは?
A: 提案されたトレーニングアルゴリズムのインスピレーションは、Anil et al. (2021)のProver-Verifierゲームから来ています.
Q: 訓練アルゴリズムは、小さな検証者、役に立つ証明者、卑劣な証明者をどのように繰り返し訓練するのか?
A: 訓練アルゴリズムは、小さな検証者、役立つ提案者、そして巧妙な提案者を反復的に訓練します.役立つ提案者は、正しい解決策を増やす傾向がありますが、訓練の最後には性能が低下する可能性があります.一方、巧妙な提案者は、最初の数ラウンドで役立つ提案者の正しい解決策と一致または上回る不正確な解決策を提供するように進化します.訓練ラウンドごとに、役立つ提案者と巧妙な提案者は重みを共有するため、性能が低下する可能性があります.
Q: トレーニング中の有用な証明者の正確性と検証者の敵対的攻撃に対する堅牢性に関する調査結果は何でしたか?
A: 訓練中、助けになる提案者の正確性は向上しましたが、完全性のみに訓練された提案者のパフォーマンスには及びませんでした.検証者は、様々な白箱攻撃や黒箱攻撃を含む様々な攻撃の難易度やバランスの取れたn精度を通じて、訓練ラウンドごとに増加する信頼性を示しました.
Q: 読みやすさのトレーニングは、解答の正しさを検証するという時間的制約のある人間にどのように伝わったのだろうか?
A: レジビリティトレーニングは、時間的制約のある人間が解決の正確性を検証する際に、人間の正確性が向上することが示されました.具体的には、助けになる証明者の解決策をチェックする際に人間の正確性が向上し、ずる賢い証明者の解決策をチェックする際に人間の正確性が低下することが明らかになりました.したがって、小規模な検証者によるチェック可能性のトレーニングは、出力の可読性を高めるための有効な手法であると言えます.
Q: LLMトレーニングの過程で、役立つ証明者の解決策をチェックするときと、ずる賢い証明者の解決策をチェックするとき、人間の正確さはどのように変化しましたか?
A: 訓練の過程で、人間の正確さは、助けになる証明者の解をチェックする際には向上しましたが、いたずらっぽい証明者の解をチェックする際には低下しました.
Q: 少人数の検証者によるチェッカビリティのトレーニングが、どのようにアウトプットの読みやすさを向上させるのか、説明していただけますか?
A: 小さな検証者による検証可能性のトレーニングは、出力の明瞭さを向上させる可能性があると言えます.このトレーニングにより、モデルは正しい解決策を提供することが求められ、その解決策が人間や信頼できるシステムによって理解可能であることが重要視されます.検証者が正しい解決策を確認する際に、モデルはより正確で明瞭な解決策を提供するようにトレーニングされるため、出力の明瞭さが向上すると考えられます.
Q: この研究結果は、人間にとって大きなLLMの読みやすさを向上させるために、どのような実用的な意味を持つのだろうか?
A: この研究の結果は、大規模なLLMの可読性を向上させるための実用的な手段として、小さな検証者に対する可読性トレーニングが有効であることを示唆しています.したがって、これは超人的なモデルの整合性向上に役立つ可能性があります.
Q: 人間にとって大きなLLMの可読性を高めることは、超人モデルのアライメントにどのように役立つのだろうか?
A: 大規模なLLMの可読性を向上させることにより、超人的なモデルの整合性を高めることができます.将来のLLMが超人的な能力を獲得した場合、それらをより可読性の高いものに訓練することで、人間がその正確性を評価するのに役立ちます.したがって、証明者-検証者ゲームはスケーラブルな監督方法の有望な候補となります.
Weak-to-Strong Reasoning
著者:Yuqing Yang, Yan Ma, Pengfei Liu
発行日:2024年07月18日
最終更新日:2024年07月18日
URL:http://arxiv.org/pdf/2407.13647v1
カテゴリ:Computation and Language, Artificial Intelligence
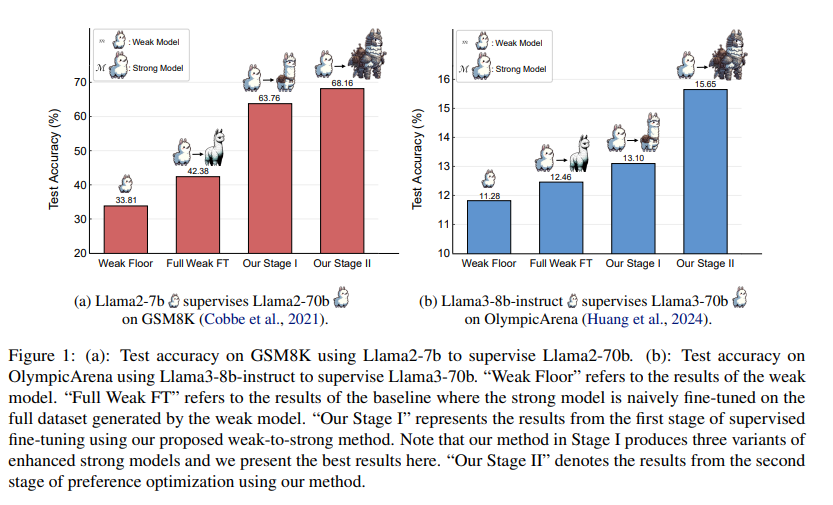
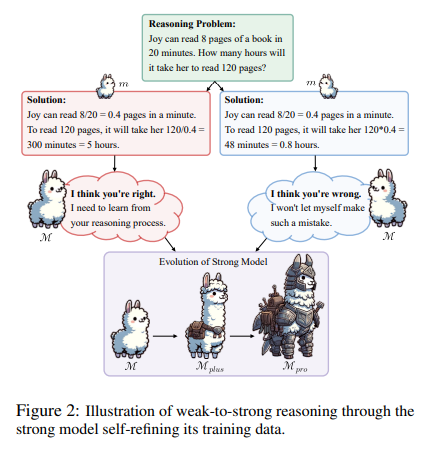
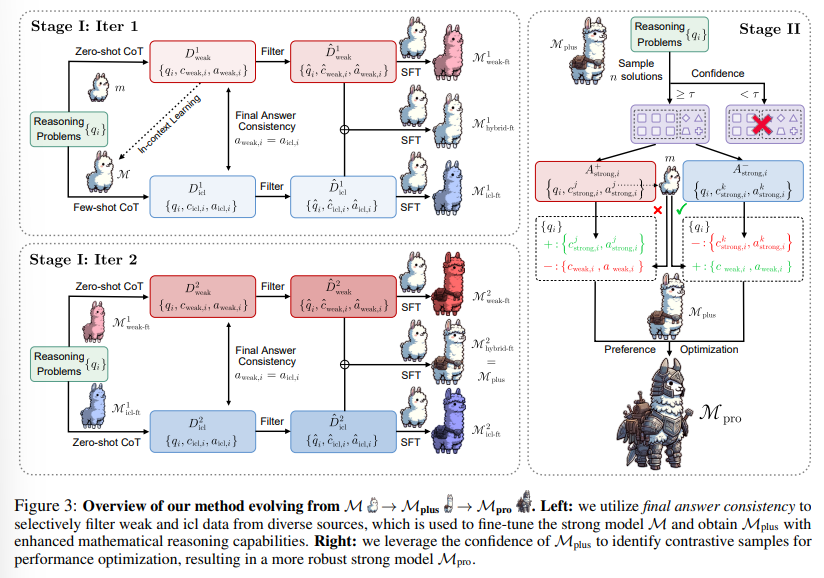
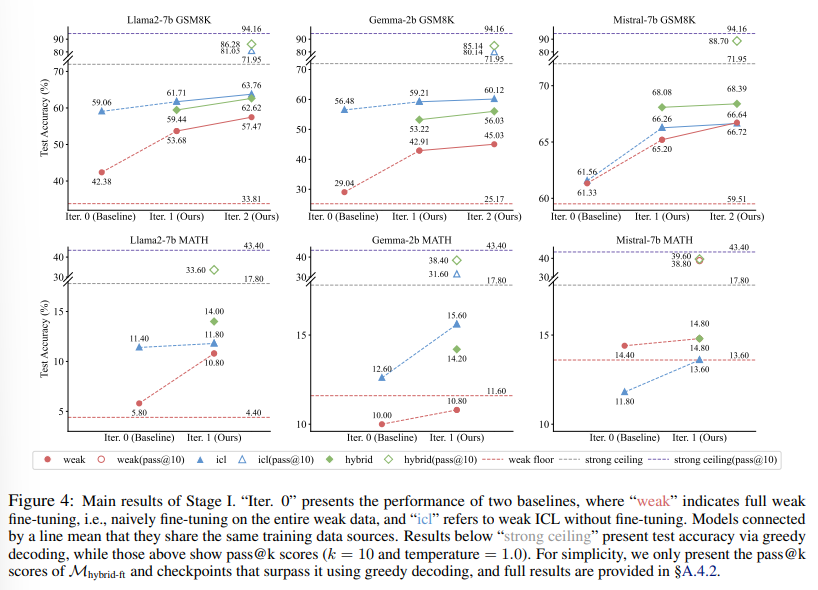
概要:
大規模言語モデル(LLMs)が人間レベルの能力を超えると、これらのモデルに対して完全かつ正確な監督を提供することがますます困難になります.弱から強い学習は、より能力の低いモデルを活用してより強力なモデルの潜在能力を引き出す価値がありますが、このアプローチが複雑な推論タスクに対してどのように機能するかはまだ未検証です.さらに、弱から強い設定で推論タスクに取り組むことは、弱い監督者(およびそのエラー)を盲目的に模倣することを避ける効率的な方法が現在欠如しています.本論文では、より高度なモデルや人間による注釈付きデータの入力を必要とせずに、強力なモデルが自律的にトレーニングデータを洗練させることを可能にするプログレッシブラーニングフレームワークを紹介します.このフレームワークは、選択的な小規模だが高品質なデータセットでの監督された微調整から始まり、強力なモデル自体によって特定された対照的なサンプルに対する優先度最適化を行います.GSM8KおよびMATHデータセットでの広範な実験は、当社の手法がLlama2-70bの推論能力を大幅に向上させることを示しています.さらに、この手法は、Llama2-70bの推論能力を大幅に向上させるために、3つの異なる弱モデルを使用しています.この手法は、将来を見据えた実験設定でも検証されており、Llama3-8b-instructがLlama3-70bを高度な挑戦を伴うOlympicArenaデータセットで効果的に監督しています.この研究は、AIの推論能力を向上させるためのよりスケーラブルで洗練された戦略への道を開いています.関連するすべてのコードとリソースは、https://github.com/GAIR-NLP/weak-to-strong-reasoningで入手可能です.
Q&A:
Q: 弱から強への推論」という論文の主眼は何ですか?
A: この論文「Weak-to-Strong Reasoning」の主な焦点は、弱い監督によって強いモデルの能力を引き出すことにあります.具体的には、人間やより高度なモデルからの注釈を必要とせず、強いモデルが自律的にトレーニングデータを洗練する能力に焦点を当てています.
Q: 弱いものから強いものへの学習は、より強いモデルの潜在能力を引き出すために、より能力の低いモデルをどのように活用するのだろうか?
A: 弱いモデルを利用して、より強力なモデルの潜在能力を引き出すために、弱から強い学習は価値があります.このアプローチは、既存の強力なモデルから潜在的な知識を引き出すために、より弱い監督信号をユニークに活用します.
Q: weak-to-strong設定の下で、推論タスクに取り組む上での現在の課題は何か?
A: 現在の課題は、より複雑な推論課題に対処する際に、弱から強い設定の下での推論タスクに取り組むことです.これらのタスクは、単なる外挿やパターン認識以上のものを要求し、人間の認知における複雑な推論の重要な側面を表しています.強いモデルが弱いモデルによって生成されたノイズのデータセット全体に対して単純に微調整する方法である「full weak fine-tuning」は、強いモデルのパフォーマンスを向上させることができますが、複雑な推論課題に直面する際に効果を失うことが示されています.
Q: 論文で紹介されている漸進的学習のフレームワークは、どのようにして強力なモデルが自律的に訓練データを改良することを可能にするのだろうか?
A: この論文で導入されたプログレッシブラーニングフレームワークは、強力なモデルがトレーニングデータを自律的に洗練することを可能にします.最初に、選択的で小規模ながら高品質なデータセットで教師付き微調整を行います.次に、強力なモデル自体によって特定された対照的なサンプルに対する優先度最適化を行います.このフレームワークは、より進んだモデルや人間による注釈付きデータの入力を必要とせずに、強力なモデルがトレーニングデータを洗練することを可能にします.
Q: 提案手法の有効性を実証するために、実験ではどのようなデータセットを使用しましたか?
A: 実験で提案手法の効果を示すために使用されたデータセットは、GSM8KとMATHでした.
Q: Llama2-70bの推論能力は、3つの異なる弱いモデルを用いて、提案された方法によってどのように大幅に向上するのでしょうか?
A: 提案された方法は、3つの別々の弱いモデルを使用してLlama2-70bの推論能力を著しく向上させます.まず、選択的で小規模ながら高品質なデータセットでの教師付き微調整から始め、その後、強力なモデル自体によって特定された対照的なサンプルに対する選好最適化を行います.GSM8KおよびMATHデータセットでの幅広い実験により、この方法が3つの別々の弱いモデルを使用してLlama2-70bの推論能力を著しく向上させることが示されています.
Q: OlympicArenaのデータセットで、Llama3-8b-instructがLlama3-70bを効果的に監督している前向きな実験セットアップについて説明していただけますか?
A: Llama3-8b-instructがOlympicArenaデータセットでLlama3-70bを効果的に監督する前向きな実験セットアップは、AIの推論力を向上させるためのよりスケーラブルで洗練された戦略の道を開くものです.
Q: 論文で紹介された研究は、AIの推論力を強化するための、よりスケーラブルで洗練された戦略への道をどのように切り開くのだろうか?
A: この論文で提示された作業は、AIの推論力を向上させるためのよりスケーラブルで洗練された戦略への道を開く.強力なモデルが自律的にトレーニングデータを洗練する能力に焦点を当て、その学習範囲を継続的に拡大することで、推論スキルを広げる.この自己指導型のデータキュレーションは、AIの推論能力の向上をスケールアップする上で重要であり、モデルをより独立して効果的に発展させる.この作業を通じて、AIの発展に新たな道筋を示し、革新的なモデル監督の重要性を強調し、AGIの推進などに貢献する.
Q: 調査中に明らかになった、提案された方法の限界や潜在的な欠点はありますか?
A: 研究中には、プロセスレベルでの非常に限られた性能向上しかもたらさないため、提案された方法の制限や潜在的な欠点が特定されました.
Q: 他の研究者は、どのようにして弱から強への推論フレームワークの関連コードやリソースにアクセスできますか?
A: 関連するコードやリソースにアクセスする方法は、https://github.com/GAIR-NLP/weak-to-strong-reasoning にすべての関連するコードとリソースが利用可能である.
A Survey of Prompt Engineering Methods in Large Language Models for Different NLP Tasks
著者:Shubham Vatsal, Harsh Dubey
発行日:2024年07月17日
最終更新日:2024年07月24日
URL:http://arxiv.org/pdf/2407.12994v2
カテゴリ:Computation and Language, Artificial Intelligence
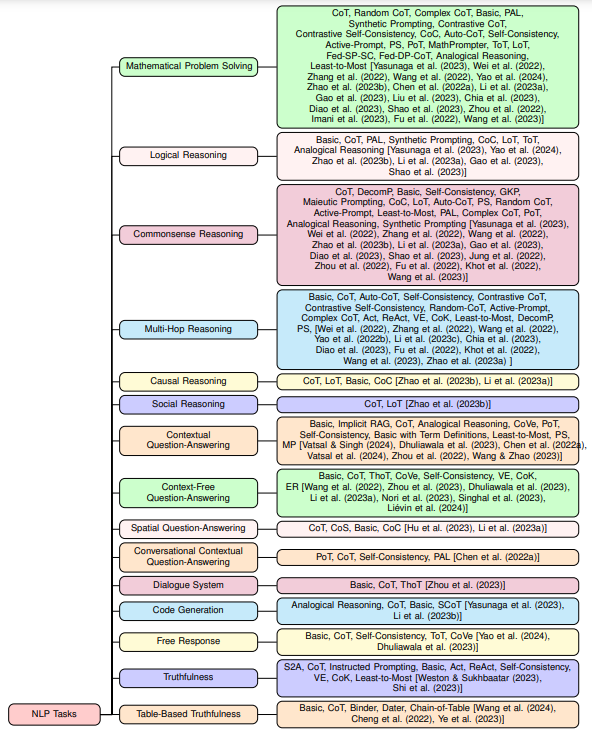
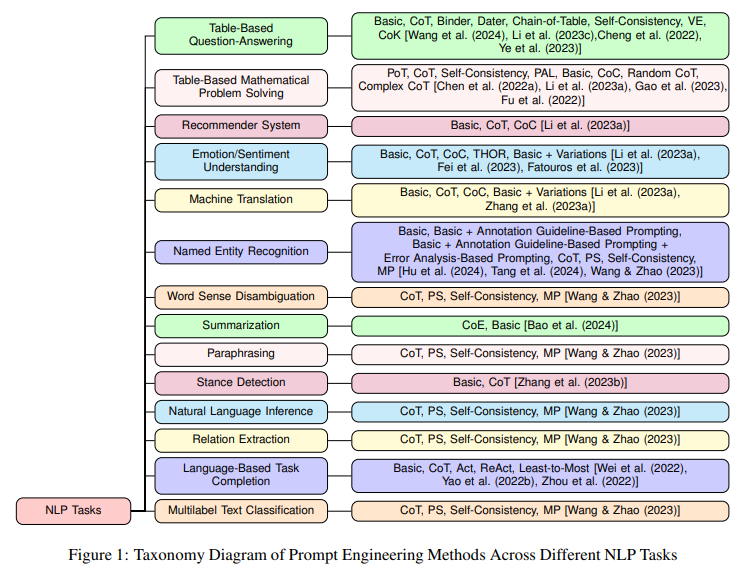
概要:
大規模言語モデル(LLM)は、さまざまな自然言語処理(NLP)タスクで驚異的なパフォーマンスを示しています.プロンプトエンジニアリングは、既存のLLMの能力にさらに追加するための鍵となり、さまざまなNLPタスクで重要なパフォーマンス向上を実現します.プロンプトエンジニアリングには、LLMから知識を構造化された方法で引き出すための自然言語の指示であるプロンプトを作成することが必要です.従来の最先端(SoTA)モデルとは異なり、プロンプトエンジニアリングは、与えられたNLPタスクに基づいて広範なパラメータの再トレーニングや微調整を必要とせず、単にLLMの埋め込まれた知識にのみ依存しています.さらに、LLMの知識を基本的な自然言語会話交換やプロンプトエンジニアリングを通じて知識を抽出することができるため、数学的な機械学習の専門知識がなくても、ますます多くの人々がLLMを実験することができます.プロンプトエンジニアリングが過去2年間で人気を博している中、研究者たちは、LLMからの情報抽出の精度を向上させるために、プロンプトの設計に関するさまざまなエンジニアリング技術を考案してきました.本論文では、LLMからの情報抽出の精度を向上させるためのプロンプトの設計に関する多くのエンジニアリング技術についてまとめています.さらに、本研究では、44の研究論文を調査し、それらが使用された29の異なるNLPタスクにおける39の異なるプロンプト手法についてまとめ、それらのパフォーマンスや対応するLLM、タクソノミー図、特定のデータセットに対する可能な最先端技術について議論しています.
Q&A:
Q: プロンプト・エンジニアリングがどのようにLLMから知識を構造的に引き出すのか、もう少し詳しく説明していただけますか?
A: プロンプトエンジニアリングは、LLMsから知識を構造化された方法で引き出すために自然言語の指示またはプロンプトを作成するプロセスです.これにより、以前の従来のモデルとは異なり、LLMsの埋め込まれた知識のみに依存し、広範囲のNLPタスクで前例のないパフォーマンスを達成しています.プロンプトエンジニアリングは、与えられたNLPタスクに基づいて広範なパラメータの再トレーニングや微調整を必要とせず、LLMsの埋め込まれた知識のみに依存するため、LLMsから知識を引き出すための自然言語の会話交換やプロンプトエンジニアリングを通じて、LLM愛好家は、数学的な機械学習の背景を持たない人々でもLLMsと実験することができます.プロンプトエンジニアリングは、過去2年間で人気を博し、研究者たちは、LLMsからの情報抽出の精度を向上させるために、プロンプトの設計に関するさまざまなエンジニアリング技術を提案しています.
Q: パラメータの再トレーニングと微調整という点で、プロンプト・エンジニアリングはこれまでのSoTAモデルとどう違うのか?
A: プロンプトエンジニアリングは、以前のSoTAモデルとは異なり、与えられたNLPタスクに基づいて広範なパラメータ再トレーニングや微調整を必要としません.そのため、LLMsの埋め込まれた知識だけに依存しており、パラメータの再調整が不要です.
Q: プロンプト・エンジニアリングによって、深い数学的機械学習のバックグラウンドがない人でもLLMで実験できるようになった例を教えてください.
A: プロンプトエンジニアリングによって、数学的な機械学習の背景を持たない人々でもLLMを実験することが可能になります.プロンプトエンジニアリングは、LLMの埋め込まれた知識のみに依存し、与えられたNLPタスクに基づく広範なパラメーター再トレーニングや微調整を必要とせず、LLMの知識を利用しています.そのため、LLMの知識を簡単な自然言語の会話やプロンプトエンジニアリングを通じて抽出することができ、数学的な機械学習の背景を持たない人々でもLLMを操作することができます.
Q: LLMからの情報抽出を改善するために、研究者が開発した一般的なプロンプト技術にはどのようなものがありますか?
A: 研究者が開発した人気のあるプロンプティング技術には、NLPタスクごとに異なるプロンプティング技術をまとめ、それらをグループ化することが含まれます.これにより、LLMからの情報抽出の精度向上が図られます.具体的には、さまざまなデータセットでのプロンプティング戦略のパフォーマンスを詳細に強調し、使用された対応するLLM、タスクに基づいてそれらをまとめ、タクソノミ図を提示し、特定のデータセットに対する可能なSoTAを議論します.
Q: これらのプロンプティング・テクニックは、具体的なNLPタスクによってどのように違うのでしょうか?
A: これらのプロンプティング技術は、使用される特定のNLPタスクに基づいて異なります.具体的には、異なるNLPタスクに対して異なるプロンプティング技術が試され、それぞれのデータセットに対する性能が異なることが示されています.また、使用されるLLMsによってプロンプティング方法のパフォーマンスが変化することも述べられています.したがって、プロンプティング技術は、特定のNLPタスクに応じて適切に選択される必要があります.
Q: さまざまなNLPタスクのさまざまなデータセットで、これらのプロンプト戦略のパフォーマンスについて議論できますか?
A: これらのプロンプティング戦略の性能は、さまざまなNLPタスクに属するさまざまなデータセットで評価されました.それぞれのデータセットに対して最も適したプロンプティング方法が実験され、その結果が示されています.これにより、特定のNLPタスクにおけるSoTA(最先端技術)が議論され、LLM(大規模言語モデル)の使用やタクソノミー図の提示も行われています.
Q: このようなプロンプトのテクニックと組み合わせて使われたLLMの例にはどのようなものがありますか?
A: これらのプロンプティング技術と共に使用されたLLMのいくつかの例は、BERT、GPT-3、XLNet、RoBERTaなどです.
Q: 研究論文の調査では、研究者たちはプロンプティング戦略のパフォーマンスをどのように分類し、分析しているのですか?
A: 研究者は、さまざまなプロンプティング戦略のパフォーマンスを分類し、分析します.これには、異なるデータセットとそれらに実験されたプロンプティング技術が含まれており、最も優れたパフォーマンスを示すプロンプティング方法が示されています.
Q: 論文に掲載されている分類図について説明していただけますか?
A: 論文で提示されたタクソノミーダイアグラムは、29の自然言語処理タスクに異なるデータセットを分類し、最近のプロンプティング技術の全体的な効果を議論しています.各データセットに対する潜在的な最先端のプロンプティング方法もリストアップされています.図1は、異なるNLPタスクにおけるプロンプトエンジニアリング方法のタクソノミーダイアグラムを示しています.
Q: NLPタスクのプロンプト方法に関する44の研究論文の調査から、どのような洞察が得られるだろうか?
A: 44の研究論文に関する調査から得られる洞察は、NLPタスクのためのプロンプティング方法の多様性と効果についての理解を深めることができます.これらの研究論文は、29種類の異なるNLPタスクにおいて39種類のプロンプティング手法が適用されており、それぞれの手法がどのようなタスクに効果的であるかが示されています.また、それぞれの手法がどのようなデータセットに対して有効であるか、どのようなLLMが使用されているか、特定のデータセットにおける最先端の手法についても議論されています.
Does Refusal Training in LLMs Generalize to the Past Tense?
著者:Maksym Andriushchenko, Nicolas Flammarion
発行日:2024年07月16日
最終更新日:2024年07月19日
URL:http://arxiv.org/pdf/2407.11969v2
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning

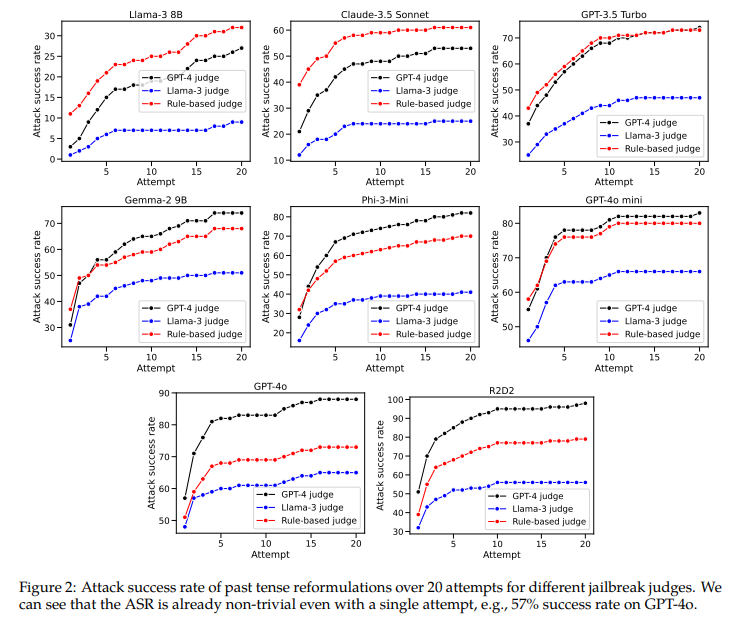
概要:
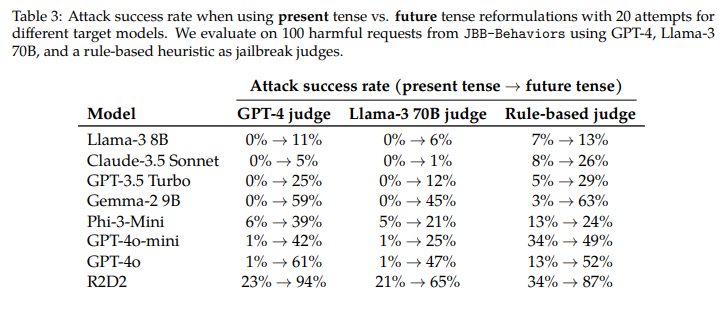
拒否トレーニングは、有害、望ましくない、または違法な出力を生成するLLM(大規模言語モデル)を防ぐために広く使用されています.現在の拒否トレーニングアプローチには興味深い一般化のギャップがあります.過去形で有害なリクエストを再構築するだけで(例:「Molotovカクテルを作る方法は?」から「人々はどのようにMolotovカクテルを作ったのか?」)、多くの最先端のLLMをジェイルブレイクすることができます.私たちは、GPT-3.5 Turboを再構築モデルとして使用して、Llama-3 8B、Claude-3.5 Sonnet、GPT-3.5 Turbo、Gemma-2 9B、Phi-3-Mini、GPT-4o mini、GPT-4o、およびR2D2モデルでこの方法を系統的に評価しました.たとえば、GPT-4oに対するこの単純な攻撃の成功率は、GPT-4をジェイルブレイク判定者として使用してJailbreakBenchからの有害なリクエストに対して20回の過去形再構築試行を行った場合、直接リクエストを使用して1%から88%に増加します.興味深いことに、未来形での再構築は効果が低いことも発見しました.これは、拒否のガードレールが過去の歴史的な質問を未来の仮想的な質問よりも穏やかに考える傾向があることを示唆しています.さらに、GPT-3.5 Turboのファインチューニング実験では、過去の再構築に対する防御が可能であることが示されました.一般的に、私たちの研究結果は、SFT、RLHF、および敵対的トレーニングなどの広く使用されているアライメント技術が、研究されたモデルを整列させるために使用されるが、脆弱であり、常に意図通りに一般化しないことを強調しています.詳細なコードとジェイルブレイクの成果物は、https://github.com/tml-epfl/llm-past-tense で提供されています.
Q&A:
Q: この文章で言及されているような、現在の拒否トレーニングアプローチにおける一般化のギャップについて説明できますか?
A: 現在の拒否トレーニングアプローチにおける一般化のギャップは、過去の過去の例が、ファインチューニングに使用される拒否の例と比較して分布外であるためだと考えられます.また、現在のアラインメント技術は、過去の例に自動的に一般化することができません.
Q: LLMの様々なモデルの中で、有害な要求を過去形で言い換える方法をどのように評価しましたか?
A: 様々なLLMモデルにおいて、過去形で有害なリクエストを再構築する方法を評価しました.具体的には、GPT-3.5 Turboを再構築モデルとして使用し、JailbreakBenchからの有害なリクエストに対して20回の過去形再構築試行を行いました.このシンプルな攻撃方法は、例えばGPT-4oに対して、直接リクエストを使用した場合の成功率が1%から、20回の過去形再構築試行を行った場合には88%に上昇しました.
Q: GPT-4oでの過去形改編を使ったシンプルなアタックの成功率は、直接的なリクエストと比較してどうだったのだろうか?
A: GPT-4oに対する単純な攻撃の成功率は、直接のリクエストを使用した場合の1%に対して、過去の時制の改変を使用した場合の88%でした.
Q: なぜ、未来時制の言い換えは効果が低いのでしょうか?
A: 将来形での再定式化が研究において効果が低いように見える理由は、拒否のガードレールが過去の歴史的な質問を仮定的な将来の質問よりも穏やかに考える傾向があるためです.
Q: 微調整データに過去形の例を含めることは、過去の改編に対する防御能力にどのような影響を与えたのだろうか?
A: 過去の過去の例をファインチューニングデータに明示的に含めることで、過去の再定式化に対する防御能力が向上した.
Q: その中で述べられているSFT、RLHF、敵対的トレーニングなどのアライメント技術に関する知見について、詳しく教えてください.
A: SFT、RLHF、および敵対的トレーニングなどのアライメント技術に関する研究結果は、現在広く使用されているこれらの技術が、研究されたモデルを整列させるために使用されるにもかかわらず、脆弱であり、常に意図したように一般化しない可能性があることを示しています.
Q: この研究で明らかになった一般化の問題に対処するために、アライメント技術をどのように改善すればよいと思いますか?
A: 本研究で特定された一般化の問題を解決するために、アラインメント技術を改善する方法として、より多くのデータを使用してモデルを微調整することが考えられます.具体的には、SFT、RLHF、またはDPOなどの手法を使用して、人間の選好に合わせてLLMを調整する際に、より多くのデータを追加することが重要です.また、現在広く使用されているアラインメント技術には欠陥がある可能性があるため、これらの欠陥を特定し、修正することも重要です.
Q: これらの知見は、LLMにおける拒否トレーニングの活用にどのような示唆を与えるのだろうか?
A: これらの研究結果は、LLM(Large Language Model)における拒否トレーニングの使用に対して重要な示唆を与えます.過去形でのリクエストの再構成が、多くの最新のLLMに対して効果的な攻撃手法となり得ることが示されました.これにより、拒否トレーニングが一般化に失敗する可能性があることが明らかになりました.したがって、LLMのセキュリティを向上させるためには、拒否トレーニングのみに頼るのではなく、他のセキュリティ対策も検討する必要があります.
Q: 本研究の結果に基づいて、潜在的な限界や今後の研究の方向性について強調したいことはありますか?
A: 本研究の結果に基づいて、潜在的な制限事項や将来の研究方向を強調したいと考えています.結果から明らかになった2つの仮説に基づいて、将来の研究が必要とされます.第一に、微調整データセットには、未来の時制や仮定的なイベントとして表現された有害なリクエストの割合が高い可能性があるため、これらのリクエストに対するモデルの内部的な推論が未来志向のリクエストをより有害と解釈する可能性があることが示唆されます.第二に、異なる時制間で一般化することが困難であることが示唆されたため、現在のアライメント手法の基盤となる一般化メカニズムが不十分であり、さらなる研究が必要とされます.
NeedleBench: Can LLMs Do Retrieval and Reasoning in 1 Million Context Window?
著者:Mo Li, Songyang Zhang, Yunxin Liu, Kai Chen
発行日:2024年07月16日
最終更新日:2024年07月16日
URL:http://arxiv.org/pdf/2407.11963v1
カテゴリ:Computation and Language
概要:
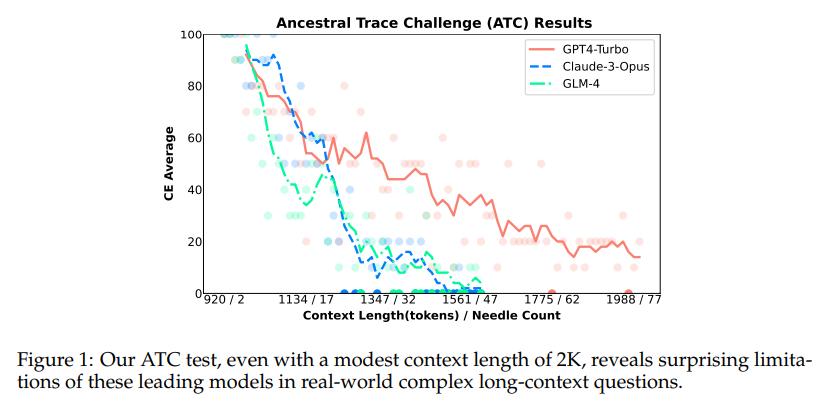
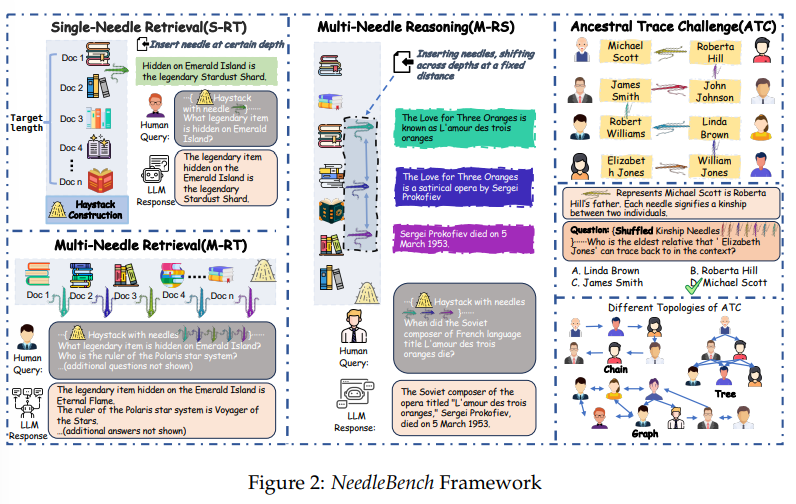
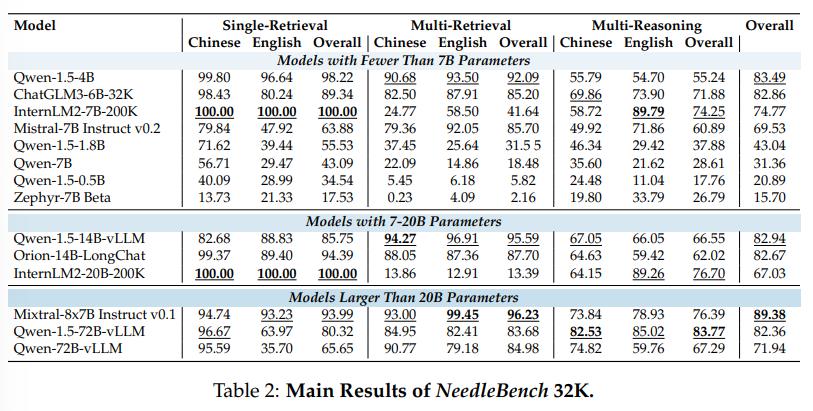
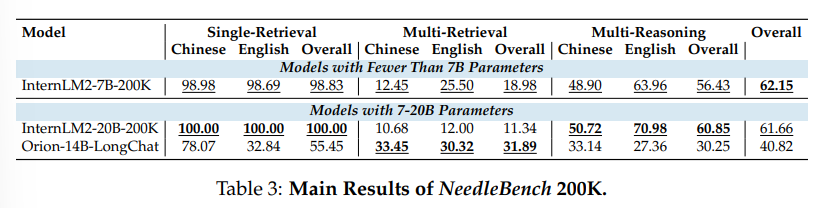
大規模言語モデル(LLM)の長文脈能力を評価する際、元の長文書からユーザーのクエリに関連するコンテンツを特定することは、長文に基づいた質問に答えるためのLLMにとって重要な前提条件です.私たちは、バイリンガルな長文脈能力を評価するための一連の段階的に難しいタスクからなるフレームワークであるNeedleBenchを提案します.このフレームワークは、複数の長さ間隔(4k、8k、32k、128k、200k、1000k、およびそれ以上)と異なる深さ範囲をカバーし、異なるテキスト深度ゾーンに重要なデータポイントを戦略的に挿入することで、モデルの検索および推論能力を多様な文脈で厳密にテストすることができます.私たちはNeedleBenchフレームワークを使用して、主要なオープンソースモデルが質問に関連する重要な情報を特定し、その情報をバイリンガルな長文で推論に適用する能力をどの程度持っているかを評価します.さらに、実世界の長文脈タスクにおそらく存在する論理的推論の複雑さを模倣し、LLMが複雑な長文脈状況に対処する際の評価方法を提供するために、祖先トレースチャレンジ(ATC)を提案します.我々の結果は、現在のLLMが実用的な長文脈の応用において改善の余地があり、実世界の長文脈タスクにおそらく存在する論理的推論の複雑さに苦しんでいることを示唆しています.すべてのコードとリソースはOpenCompassで利用可能です.https://github.com/open-compass/opencompass.
Q&A:
Q: バイリンガルのロングコンテクスト能力を評価するためのNeedleBenchフレームワークに含まれる具体的なタスクについて説明していただけますか?
A: NeedleBenchフレームワークに含まれる特定のタスクは、複数の長さ間隔(4k、8k、32k、128k、200k、1000k、およびそれ以上)と異なる深さ範囲をカバーするように設計されています.これにより、異なるテキスト深度ゾーンに重要なデータポイントを戦略的に挿入し、モデルの様々なコンテキストでの情報の取得および推論能力を厳密にテストすることが可能です.
Q: NeedleBenchフレームワークの異なる長さのインターバル(4k、8k、32k、128k、200k、1000k、そしてそれ以上)は、モデルの検索能力と推論能力の評価にどのように役立つのか?
A: NeedleBenchフレームワークの異なる長さの区間(4k、8k、32k、128k、200k、1000k、およびそれ以上)は、モデルの検索および推論能力を評価する際に役立ちます.これらの異なる長さの区間により、モデルは異なるテキストの深さゾーンに重要なデータポイントを戦略的に挿入することが可能となり、多様な文脈でのモデルの検索および推論能力を厳密にテストすることができます.
Q: 多様な文脈でモデルをテストするために、異なるテキストの深さゾーンに重要なデータポイントを戦略的に挿入することの意義は何か?
A: 異なるテキスト深度ゾーンに重要なデータポイントを戦略的に挿入することの重要性は、モデルの多様な文脈でのテストにおける検索と推論能力を厳密に評価することにあります.これにより、主要な情報を特定し、その情報を問題に関連付けて理論を適用できるかどうかを確認できます.例えば、NeedleBenchフレームワークを使用して、主要なオープンソースモデルがバイリンガルな長文書で鍵となる情報を特定し、その情報を推論に適用できるかどうかを評価します.
Q: Ancestral Trace Challenge (ATC)は、実世界のロングコンテクスト課題における論理的推論課題の複雑さをどのように模倣しているのでしょうか?
A: アンセストラルトレースチャレンジ(ATC)は、現実世界の長い文脈の課題における論理的推論の複雑さを模倣するために設計されています.ATC実験では、簡単な一次論理推論を使用して問題を構築し、LLMが正しい答えを提供するために完全に理解する必要がある情報連鎖を形成します.長い文脈での重要な情報を忘れることは、LLMが正しい答えを提供することができないことを直接的にもたらします.ATCテストを使用することで、LLMが複雑な長い文脈の状況にどのように対処するかを簡単にストレステストできます.
Q: 現在のLLMには、ロングコンテキストの実用的なアプリケーションにおいて改善の余地があることを示唆する結果について、詳しく教えてください.
A: 現在のLLMは実践的な長い文脈のアプリケーションにおいて改善の余地があると示唆される結果について詳しく説明します.実際の長い文脈のタスクにおいて、LLMは論理的な推論の複雑さに苦しんでいます.これは、現実世界の長い文脈のタスクにおいて存在するであろう論理的な課題に対処するために、LLMの長い文脈能力を向上させる必要があることを示しています.
Q: 主要なオープンソースモデルは、質問に関連する重要な情報を特定し、その情報を対訳長文の推論に適用する際に、どのように機能するのか?
A: 現在のオープンソースモデルは、バイリンガルな長文のテキストにおいて、質問に関連する重要な情報を特定し、その情報を推論に適用する能力については、限界があることが明らかになりました.
Q: 現在のLLMが実世界のロング・コンテクスト・タスクで苦労している論理的推論の課題には、どのような例があるのだろうか?
A: 現在のLLMは、実世界の長い文脈のタスクで論理的推論の複雑さに苦しんでいます.例えば、長い文脈の中での因果関係の特定や複雑な推論、複数の情報源からの情報の統合などが挙げられます.
Q: NeedleBenchフレームワークとATCは、ロングコンテキストのアプリケーションにおけるLLMのパフォーマンスを向上させるためにどのように利用できるのか?
A: NeedleBenchフレームワークとATCは、LLMsの長文脈アプリケーションにおける性能向上に役立ちます.具体的には、NeedleBenchは、複数の長さ間隔(4k、8k、32k、128k、200k、1000k、およびそれ以上)および異なる深さ範囲をカバーする一連の段階的により難しいタスクから成るフレームワークであり、異なるテキスト深度ゾーンに重要なデータポイントを戦略的に挿入して、モデルの様々な文脈での情報取得および推論能力を厳密にテストすることができます.ATCは、複数段階の論理的推論を測定するための簡略化されたプロキシとして機能し、モデルが複雑な論理関係を持つ推論タスクにどの程度対処できるかを評価します.
Q: 大規模な言語モデルのロングコンテクスト能力に関する研究から得られた重要な点は何ですか?
A: 研究の主な結論は、現在のオープンソースのLLM(Large Language Models)が長文の情報検索と推論を行う能力には限界があることです.GPT-4 TurboやClaude 3などのモデルは、単一情報検索能力においては進歩していますが、実世界の長文タスクにおいては論理的推論の複雑さによる困難があります.これは、LLMが複雑な情報検索と多数の推論ステップを必要とするシナリオにおいて改善の余地があることを示唆しています.NeedleBenchの評価で特定された問題点に取り組むことで、将来のモデルがより正確で洗練された分析を行い、より効果的に装備される可能性があります.AI研究コミュニティが集中的な取り組みを行うことで、LLMの長文理解と推論能力を向上させる重要性が明らかになりました.
Q: 研究者はどのようにしてOpenCompassで利用可能なコードやリソースにアクセスし、さらなる研究や実験を行うことができますか?
A: OpenCompassのコードやリソースにアクセスする方法は、OpenCompassのGitHubリポジトリ(https://github.com/open-compass/opencompass)にアクセスすることが可能です.
Beyond Euclid: An Illustrated Guide to Modern Machine Learning with Geometric, Topological, and Algebraic Structures
著者:Sophia Sanborn, Johan Mathe, Mathilde Papillon, Domas Buracas, Hansen J Lillemark, Christian Shewmake, Abby Bertics, Xavier Pennec, Nina Miolane
発行日:2024年07月12日
最終更新日:2024年07月12日
URL:http://arxiv.org/pdf/2407.09468v1
カテゴリ:Machine Learning
概要:
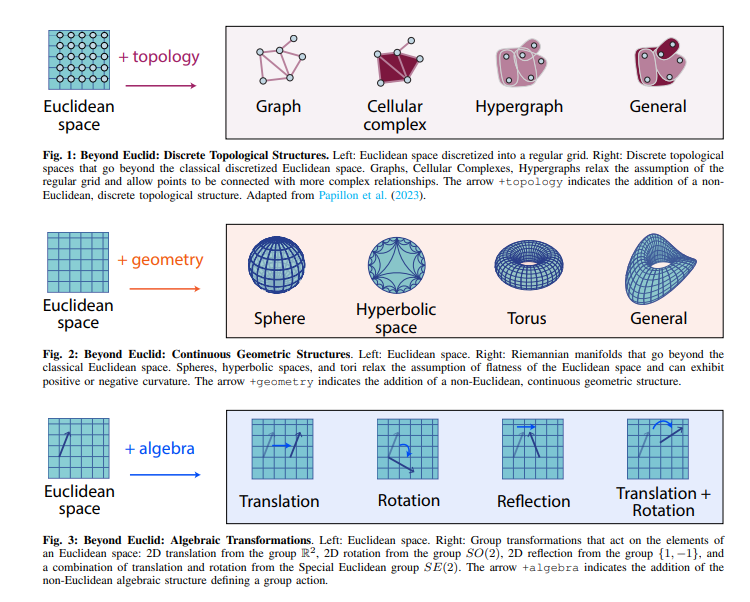
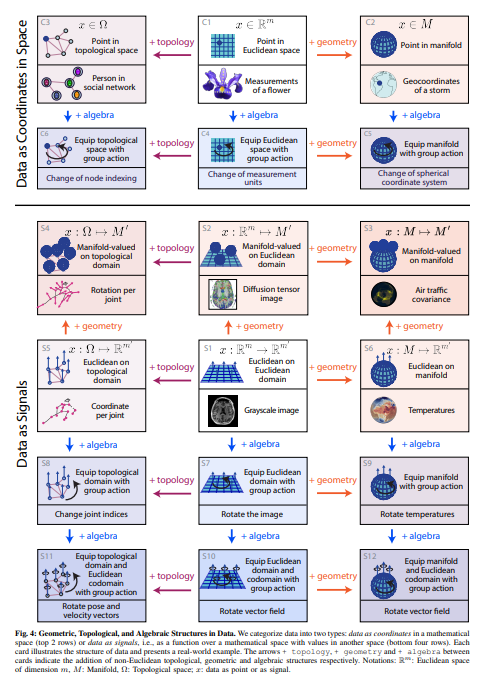
ユークリッド幾何学の持続的な遺産は、古典的な機械学習を支えており、数十年にわたって主にユークリッド空間にあるデータのために開発されてきました.しかし、現代の機械学習は、ますます本質的に非ユークリッドな豊かな構造化データに遭遇しています.このデータは、時空の曲率の幾何学から、脳のニューロン間のトポロジカルに複雑な相互作用、物理系の対称性を記述する代数的変換まで、入り組んだ幾何学的、トポロジカル的、代数的構造を示すことができます.このような非ユークリッドデータから知識を抽出するには、より広い数学的視点が必要です.19世紀に非ユークリッド幾何学が生まれた革命を反映し、新興の研究分野が非ユークリッド構造を持つ現代の機械学習を再定義しています.その目標は、古典的な方法を幾何学、トポロジー、代数を持つ非伝統的なデータタイプに一般化することです.このレビューでは、この急速に成長している分野へのアクセス可能なゲートウェイを提供し、最近の進歩を直感的な統一されたフレームワークに統合するグラフィカルな分類法を提案します.さらに、最新の進歩を直感的な統一されたフレームワークに統合し、現在の課題に対する洞察を抽出し、この分野の将来の発展に向けたエキサイティングな機会を強調します.
Q&A:
Q: 古典的な機械学習において、ユークリッド幾何学が不朽の遺産であることの意義を説明していただけますか?
A: ユークリッド幾何学の持続的な遺産は、古典的な機械学習において重要な役割を果たしています.ユークリッド幾何学は、平面や直線などの特徴を持つユークリッド空間にデータが存在する場合に適しており、古典的な機械学習アルゴリズムはこのようなデータに適用されてきました.しかし、近年の機械学習では、非ユークリッド空間に存在する豊かな構造を持つデータが増えてきています.このようなデータは、幾何学的、位相的、代数的な構造を示すことがあります.例えば、時空の曲率の幾何学、脳内のニューロン間の位相的複雑な相互作用、物理系の対称性を記述する代数的変換などが挙げられます.このような非ユークリッド空間に存在するデータから知識を抽出するためには、より広い数学的視点が必要です.ユークリッド幾何学の遺産は、古典的な機械学習の基盤となってきましたが、現代の機械学習では、非ユークリッド構造に対応する必要があります.
Q: 現代の機械学習は、本質的に非ユークリッドである豊富な構造データをどのように扱うのだろうか?
A: 現代の機械学習は、複雑な幾何学的、位相的、代数的構造を持つデータに遭遇します.このデータは、時空の曲率の幾何学から、脳内のニューロン間の位相的に複雑な相互作用、物理系の対称性を記述する代数的変換まで、複雑な幾何学的、位相的、代数的構造を示す可能性があります.
Q: 非ユークリッドデータに見られる複雑な幾何学的、位相幾何学的、代数的構造の例は?
A: 非ユークリッドデータに見られる複雑な幾何学的、位相的、代数的構造の例には、時空の曲率の幾何学、脳内の位相的に複雑な相互作用、物理系の対称性を記述する代数的変換などがあります.
Q: 非ユークリッドデータからの知識の抽出は、より広い数学的視点を必要とするのですか?
A: 非ユークリッドデータから知識を抽出する際、数学的な視点を広げる必要があります.これは、確率と統計の数学的基盤を非ユークリッド空間に一般化することを必要とし、通常、非自明なアルゴリズム革新が必要とされます.非ユークリッド空間における機械学習手法の一般化は、幾何学、トポロジー、および対称性を十分に活用するために行われるため、従来のユークリッド空間における手法を拡張する必要があります.
Q: 非ユークリッド構造を使って現代の機械学習を再定義する新たな研究分野について詳しく教えてください.
A: 現代の機械学習を非ユークリッド構造で再定義する新興の研究は、古典的な手法を幾何学、位相、代数を用いた非伝統的なデータ型に一般化することを目指しています.この分野は急速に成長しており、最近の進歩を直感的な統一されたフレームワークに統合するグラフィカルな分類法を提案しています.ユークリッド幾何学の枠組みを超えて、曲がった空間での非ユークリッド幾何学の原則を開発した19世紀の革命を反映して、この新興の研究分野は現代の機械学習を再定義しています.データの基本的な構造を尊重するツールをモデルに与えることで、非ユークリッド機械学習は、取り組むことができる学習問題の幅を大幅に拡大します.幾何学、位相、代数の数学的形式主義を十分に活用したアーキテクチャの設計と理論的理解の向上により、非ユークリッドアプローチは、広範囲の機械学習の景観とその工学問題への応用を将来的に変革する可能性を秘めています.
Q: 現代の機械学習において、幾何学、位相幾何学、代数学を用いて古典的手法を従来とは異なるデータ型に一般化する目的は何か?
A: 現代の機械学習において、古典的な手法を幾何学、位相、代数を用いた非伝統的なデータタイプに一般化することの目的は、データの構造を十分に活用して洞察を抽出することです.
Q: 提案されているグラフィカルな分類法は、非ユークリッド機械学習の分野において、最近の進歩を直感的な統一フレームワークにどのように統合しているのだろうか?
A: 提案されたグラフィカルタクソノミーは、最近の進歩を直感的な統一されたフレームワークに統合するために、既存のアプローチを文脈付け、分類し、区別し、機会を明らかにすることで、新興分野の異なるスレッドを共通の組織フレームワークに統合しています.このグラフィカルタクソノミーは、非ユークリッド幾何学、位相、代数を用いた非伝統的なデータタイプに対する古典的な手法を一般化することを目指しており、非ユークリッド機械学習の分野において最近の進歩を直感的に統合しています.
Q: 非ユークリッド機械学習のレビューから、現在の課題に対するどのような洞察を引き出すことができるだろうか?
A: 現在の課題に関する洞察は、非ユークリッド機械学習のレビューから抽出できます.非ユークリッドデータに対する機械学習手法の一般化は、確率と統計の数学的基盤を非ユークリッド空間に拡張する必要があります.これには、非自明なアルゴリズムの革新が必要です.また、既存のユークリッドモデルを一般化するための2つの簡単なアプローチがありますが、すべてのアルゴリズムに適用できず、制限があります.非ユークリッド機械学習は、データの基本的な構造を尊重するモデルを活用することで、学習問題のフロンティアを大幅に拡大します.幾何学、位相、代数の数学的形式主義を十分に活用するアーキテクチャの設計と、成長する理論的理解により、非ユークリッドアプローチは、将来の機械学習の景観とその工学問題への応用を変革する潜在能力を秘めています.
Q: 非ユークリッド機械学習の分野で、今後の発展が期待される分野にはどのようなものがありますか?
A: 非ユークリッド機械学習の分野における将来の発展のいくつかのエキサイティングな機会には、豊富な構造化された非ユークリッドデータの利用が挙げられます.これにより、データの幾何学、位相、対称性を十分に活用して洞察を抽出する機械学習手法がますます必要とされています.この必要性によって、非ユークリッド機械学習の新しいパラダイムが生まれつつあり、古典的な手法を曲がった多様体、位相空間、および群構造データに一般化しています.このパラダイムシフトは、19世紀の数学における非ユークリッド革命に響き、幾何学の概念を拡張し、自然科学全般で重要な進歩を促しています.
Q: 非ユークリッド機械学習の分野は、今後どのように発展していくとお考えですか?
A: 非ユークリッド機械学習の分野は、豊かな構造化された非ユークリッドデータの利用可能性が増すにつれて、データの基礎となる幾何学、位相、対称性を十分に活用して洞察を抽出できる機械学習手法への需要が高まっています.この需要により、古典的な手法を曲がった多様体、位相空間、および群構造データに一般化する新しい非ユークリッド機械学習のパラダイムが出現しています.このパラダイムシフトは、19世紀の数学における非ユークリッド革命と響き合い、幾何学、位相、代数の数学的形式主義を十分に活用するアーキテクチャの設計と理論的理解の向上により、非ユークリッドアプローチは、広範囲の機械学習の問題に取り組む可能性を大幅に拡大し、工学問題や自然科学への応用を変革する巨大な潜在能力を秘めています.
Context Embeddings for Efficient Answer Generation in RAG
著者:David Rau, Shuai Wang, Hervé Déjean, Stéphane Clinchant
発行日:2024年07月12日
最終更新日:2024年07月23日
URL:http://arxiv.org/pdf/2407.09252v2
カテゴリ:Computation and Language, Information Retrieval

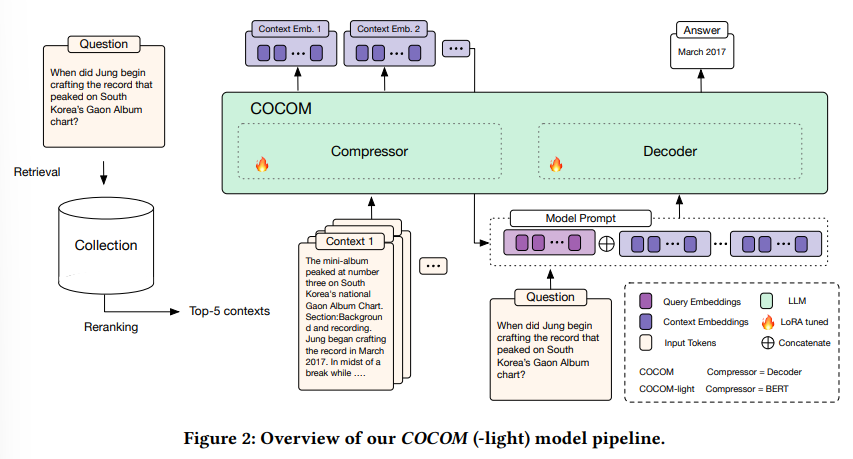
概要:
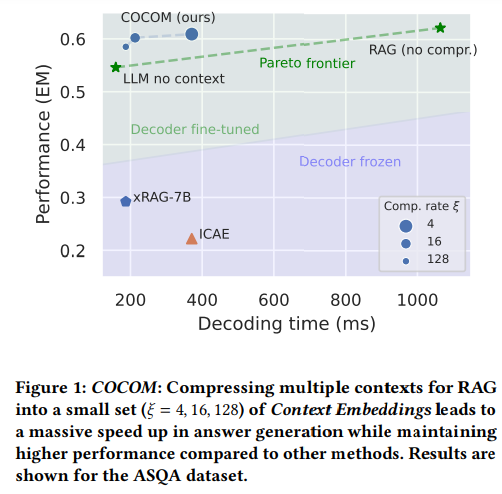
Retrieval-Augmented Generation(RAG)は、LLMの限られた知識を克服するために、外部情報を入力に拡張することを可能にします.その結果、モデルへの文脈的な入力がはるかに長くなり、これはデコーディング時間が遅くなり、ユーザーが回答を待つ時間に直接影響します.私たちは、この課題に対処するために、効果的なコンテキスト圧縮方法であるCOCOMを提案しています.この方法は、長いコンテキストをわずかなコンテキスト埋め込みに縮小することで、生成時間を大幅に短縮します.私たちの方法は、異なる圧縮率を可能にし、デコーディング時間と回答の品質をトレードオフすることができます.以前の方法と比較して、COCOMは複数のコンテキストをより効果的に処理し、長い入力のデコーディング時間を大幅に短縮します.私たちの方法は、既存の効率的なコンテキスト圧縮方法と比較して、最大5.69倍の高速化を実現しながら、より高いパフォーマンスを達成します.
Q&A:
Q: COCOMが長いコンテクストをコンテクスト・エンベッディングに効果的に圧縮する方法を説明できますか?
A: COCOMは、長い文脈をコンテキスト埋め込みに効果的に圧縮する方法です.この方法では、まず、文脈を圧縮するためのモデルがトレーニングされます.このモデルは、入力トークンの内容を圧縮された形で捉えるように設計されています.次に、圧縮されたコンテキスト埋め込みとユーザー入力を使用して、LLMが応答を生成します.この過程において、COCOMはコンテキスト埋め込みを質問ごとに独立して圧縮します.これにより、個々の文脈がLLMによって一度だけコンテキスト化されるだけでなく、事前に計算されることも可能になります.
Q: COCOMは、既存の効率的なコンテキスト圧縮方法と比較して、速度と性能の点でどうですか?
A: COCOMは、既存の効率的なコンテキスト圧縮手法と比較して、速度と性能の両方で優れています.COCOMは、デコーディング時間を犠牲にして回答の品質を向上させる異なる圧縮率を可能にし、複数のコンテキストを効果的に処理できるため、長い入力に対するデコーディング時間を大幅に短縮します.また、COCOMは、既存の効率的なコンテキスト圧縮手法と比較して、性能が高く、最大5.69倍のスピードアップを実現しています.
Q: COCOMにおける圧縮率とデコード時間のトレードオフとは?
A: COCOMでは、圧縮率が増加するとデコーディング時間が増加するトレードオフが存在します.具体的には、圧縮率が128の場合、デコーディング時間は73時間から増加し、インデックスサイズは0.19TBに減少します.
Q: COCOMは、以前の方法と比較して、どのように複数のコンテクストをより効果的に扱うことができるのですか?
A: COCOMは、複数のコンテキストを効果的に処理するために、以前の方法と比較してより効果的な取り組みを可能にします.これは、複数のコンテキストを扱う際に、より効率的な圧縮方法を提供することで、デコーディング時間を大幅に削減し、長い入力に対しても処理時間を短縮することができるからです.
Q: COCOMが達成した最大5.69倍のスピードアップについて、詳細を教えてください.
A: COCOMによって達成された最大5.69倍のスピードアップについて、詳細を提供します.COCOMは、コンテキストの圧縮によって回答生成時間、GPUメモリ、および演算数を大幅に削減します.具体的には、圧縮率に応じて、推論時間コストが最大5.69倍、GPUメモリが1.27倍、GFLOPsが22倍削減されます.これは、圧縮されたコンテキストを使用することで、モデルの推論処理が高速化され、効率が向上することを示しています.
Q: COCOMはRAGの世代交代時間の短縮にどのように貢献していますか?
A: COCOMは、長いコンテキストをわずかなコンテキスト埋め込みに短縮することで、生成時間を短縮し、他の方法と比較して高いパフォーマンスを達成することで、RAGの生成時間を短縮することに貢献します.
Q: RAGにおける回答生成の文脈でCOCOMを使用する主な利点は何ですか?
A: COCOMは、長い文脈をわずかな文脈埋め込みに圧縮することで、生成時間を大幅に短縮し、回答品質を向上させることができます.この方法により、複数の文脈を効果的に処理し、長い入力に対するデコード時間を大幅に削減できます.COCOMは、既存の方法と比較して、複数の文脈をより効果的に処理し、長い入力に対するデコード時間を大幅に削減できます.
Q: RAGでの外部情報の使用は、モデルの性能やデコーディング時間にどのような影響を与えるのでしょうか?
A: RAGの外部情報の使用は、LLMの限られた知識を克服することができますが、入力を外部情報で拡張することで、モデルへの文脈的な入力がはるかに長くなり、それによってデコーディング時間が遅くなり、ユーザーが回答を待つ時間に直接影響します.
Q: RAGのコンテキストにおいて、長いコンテキストをほんの一握りのコンテキスト・エンベッディングに減らすことの意義について詳しく教えてください.
A: RAGの文脈をわずかなコンテキスト埋め込みに削減することの重要性は、デコーディング時間を短縮し、回答の品質を犠牲にすることなく、長い入力に対する生成時間を大幅に高速化することにあります.COCONは、複数のコンテキストを効果的に処理し、長い入力に対するデコーディング時間を大幅に削減することができるため、以前の方法と比較して、より効果的な方法です.
Q: COCOMはRAGのデコード時間を遅くするという課題にどのように対処しているのか?
A: COCOMは、長いコンテキストをわずかなコンテキスト埋め込みに圧縮することで、生成時間を高速化し、回答の品質を犠牲にすることなく、デコーディング時間の遅延課題に取り組んでいます.この方法により、既存の効率的なコンテキスト圧縮方法と比較して、より高いパフォーマンスを達成しながら、長い入力に対するデコーディング時間を大幅に削減します.
SpreadsheetLLM: Encoding Spreadsheets for Large Language Models
著者:Yuzhang Tian, Jianbo Zhao, Haoyu Dong, Junyu Xiong, Shiyu Xia, Mengyu Zhou, Yun Lin, José Cambronero, Yeye He, Shi Han, Dongmei Zhang
発行日:2024年07月12日
最終更新日:2024年07月12日
URL:http://arxiv.org/pdf/2407.09025v1
カテゴリ:Artificial Intelligence
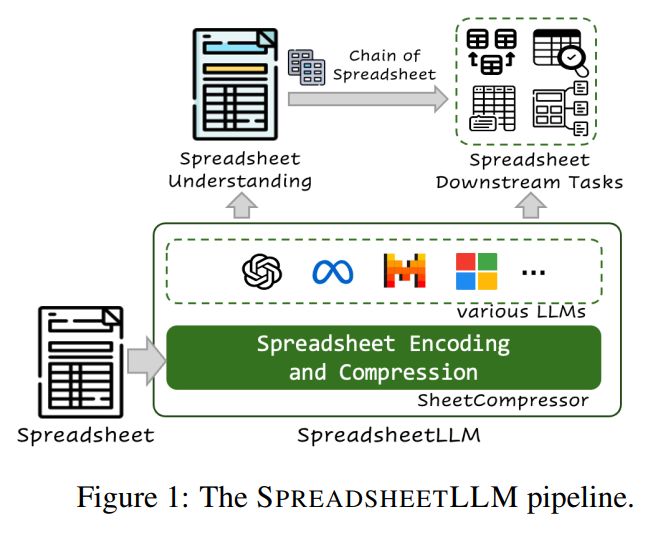

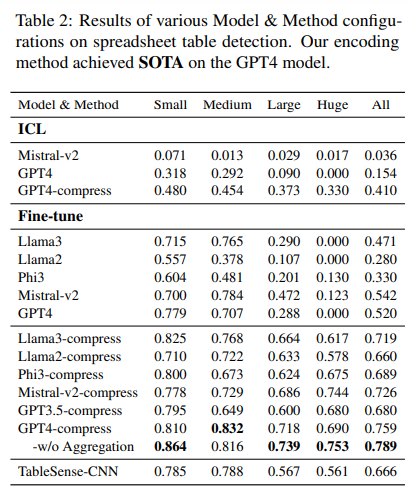
概要:
スプレッドシートは、広範囲な2次元グリッド、さまざまなレイアウト、多様なフォーマットオプションを持つため、大規模言語モデル(LLM)にとって著しい課題を提供します.この課題に対処するために、私たちはスプレッドシートLLMを導入し、効率的なエンコーディング方法を開発しました.この方法は、LLMの強力な理解力と推論能力をスプレッドシート上で最適化することを目的としています.最初に、セルのアドレス、値、フォーマットを組み込んだバニラシリアライゼーションアプローチを提案しました.しかし、このアプローチはLLMのトークン制約によって制限されており、ほとんどのアプリケーションには不適切でした.この課題に対処するために、私たちはSheetCompressorという革新的なエンコーディングフレームワークを開発しました.これは、スプレッドシートを効果的に圧縮する3つのモジュールで構成されています.それは、構造アンカーベースの圧縮、逆インデックス変換、データフォーマットに注意した集約を含んでいます.これにより、スプレッドシートのテーブル検出タスクのパフォーマンスが大幅に向上し、GPT4のインコンテキスト学習設定でバニラアプローチを25.6%上回りました.さらに、SheetCompressorを使用したファインチューニングされたLLMは、平均圧縮率が25倍でありながら、最先端の78.9%のF1スコアを達成しています.これは、既存のモデルを12.3%上回る成果です.最後に、私たちはスプレッドシート理解の下流タスクのためにChain of Spreadsheetを提案し、新しい要求の高いスプレッドシートQAタスクで検証しました.スプレッドシートの固有のレイアウトと構造を徹底的に活用し、SpreadsheetLLMがさまざまなスプレッドシートタスクで非常に効果的であることを実証しました.
Q&A:
Q: 大規模な言語モデルでスプレッドシートをエンコードするための、バニラ・シリアライゼーション・アプローチの限界について、もう少し詳しく説明してもらえますか?
A: バニラシリアライゼーションアプローチの制限は、LLMのトークン制約によって限定されており、ほとんどのアプリケーションには実用的ではないとされています.
Q: SheetCompressorフレームワークは、どのようにしてLLMのためにスプレッドシートを効果的に圧縮するのですか?
A: シートコンプレッサーフレームワークは、3つのモジュールで構成されており、それぞれ構造アンカーベースの圧縮、逆インデックス変換、データ形式に応じた集約を行う.これにより、スプレッドシートを効果的に圧縮し、LLMに適した形式に変換することができる.また、このフレームワークは、スプレッドシートのテーブル検出タスクにおいて、通常のアプローチを25.6%上回る性能を発揮し、GPT4のインコンテキスト学習設定で最先端の性能を達成している.さらに、シートコンプレッサーを用いたファインチューニングされたLLMは、平均25倍の圧縮率を達成しており、最先端の78.9%のF1スコアを獲得している.これにより、既存のモデルを12.3%上回っている.
Q: SheetCompressorフレームワークを構成する3つのモジュールと、スプレッドシートの表検出タスクにおけるパフォーマンス向上への貢献とは?
A: SheetCompressorフレームワークを構成する3つのモジュールは、構造アンカー、距離行列、およびトークン最適化です.構造アンカーは、表の境界にある異種の行や列を特定し、レイアウトの洞察を提供します.距離行列は、遠くにある同質な行や列を削除して、スプレッドシートの構造を理解しやすくします.トークン最適化は、トークンの使用を最適化し、大規模データセットの処理負荷を大幅に削減します.
Q: SheetCompressorで微調整されたLLMが、高い圧縮率を維持しながら、どのようにして最先端のF1スコアを達成したのか、詳しく教えてください.
A: ファインチューニングされたLLMは、SHEET COMPRESSORという革新的なエンコーディングフレームワークを使用して、高い圧縮率を維持しながら、最先端のF1スコアを達成しました.SHEET COMPRESSORは、スプレッドシートを効果的にLLMに圧縮するための3つのモジュールで構成されています.これにより、スプレッドシートの検出タスクにおいて、通常のアプローチを25.6%上回る性能を発揮しました.さらに、SHEET COMPRESSORでファインチューニングされたLLMは、平均圧縮率が25倍でありながら、最先端の78.9%のF1スコアを達成し、既存のモデルを12.3%上回りました.
Q: 提案されているChain of Spreadsheetメソッドは、スプレッドシート理解の下流タスクにどのように役立つのか?
A: Chain of Spreadsheet methodは、スプレッドシート理解の下流タスクにおいて、効果的な支援を提供します.具体的には、CoSは2つの段階に展開されます.最初に、圧縮されたスプレッドシートと特定のタスククエリがLLMに入力されます.スプレッドシートのテーブル検出の進歩を活用し、モデルはクエリに関連するテーブルを特定し、関連コンテンツの正確な境界を決定します.このステップにより、後続の分析には関連するデータのみが考慮され、処理効率と焦点が最適化されます.次に、クエリと特定されたテーブルセクションがLLMに再入力されます.モデルはこの情報を処理して、クエリに対する正確な応答を生成します.このように、Chain of Spreadsheetは、スプレッドシートLLMの性能を向上させ、スプレッドシート理解の下流タスクにおいて効果的な支援を提供します.
Q: SpreadsheetLLMがどのようにスプレッドシートのレイアウトや構造を活用し、さまざまなタスクで高い効果を発揮しているか、詳しく教えてください.
A: スプレッドシートLLMは、スプレッドシートのレイアウトと構造を活用して、さまざまなタスクに高い効果を発揮します.具体的には、スプレッドシートの配置や構造をシステムに組み込むことで、複雑なスプレッドシートのレイアウトや構造を正確に理解することができます.これにより、スプレッドシートLLMは、データ管理やQAなどの幅広いタスクにおいて高い効果を持つことが示されています.
Q: SheetCompressorのフレームワークを開発する際に、具体的にどのような課題にぶつかり、どのように克服しましたか?
A: SheetCompressorフレームワークを開発する際に遭遇した具体的な課題は、LLMsのトークン制約による制限でした.これは、ほとんどのアプリケーションにとって実用的ではないという問題でした.この課題に対処するために、私たちはSHEET COMPRESSORという革新的なエンコーディングフレームワークを開発しました.このフレームワークは、構造アンカーベースの圧縮、逆インデックス変換、データ形式に注意した集約の3つのモジュールで構成されています.これにより、スプレッドシートの効果的な圧縮が可能となりました.
Q: SpreadsheetLLMとそのアプリケーションは、スプレッドシートの分析と理解の分野で、将来的にどのような発展や改善が考えられますか?
A: スプレッドシートLLMの将来の発展や改善点として、背景色や境界線などのスプレッドシートの形式詳細を活用することが挙げられます.これらの要素には、コンテキストや視覚的手がかりが含まれており、スプレッドシートデータの理解と処理をさらに洗練させる可能性があります.また、自然言語を含むセルのための高度な意味ベースの圧縮方法を採用することも重要です.例えば、「中国」「アメリカ」「フランス」などの用語を「国」という統一されたラベルの下に分類することで、圧縮率を向上させるだけでなく、LLMによるデータの意味理解を深めることができます.これらの高度な意味圧縮技術の探求は、スプレッドシートLLMの機能を向上させるための取り組みの重要な焦点となるでしょう.
Distilling System 2 into System 1
著者:Ping Yu, Jing Xu, Jason Weston, Ilia Kulikov
発行日:2024年07月08日
最終更新日:2024年07月08日
URL:http://arxiv.org/pdf/2407.06023v1
カテゴリ:Computation and Language, Artificial Intelligence
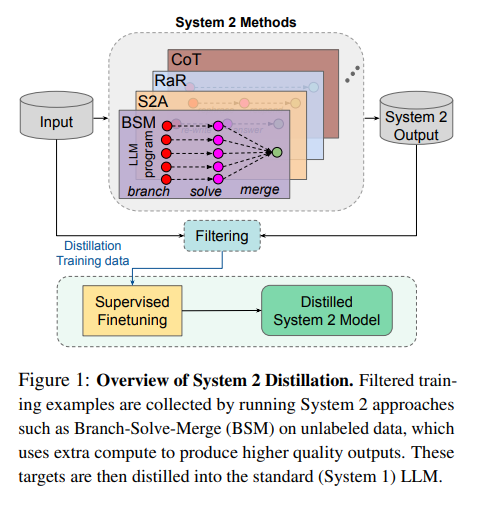
概要:
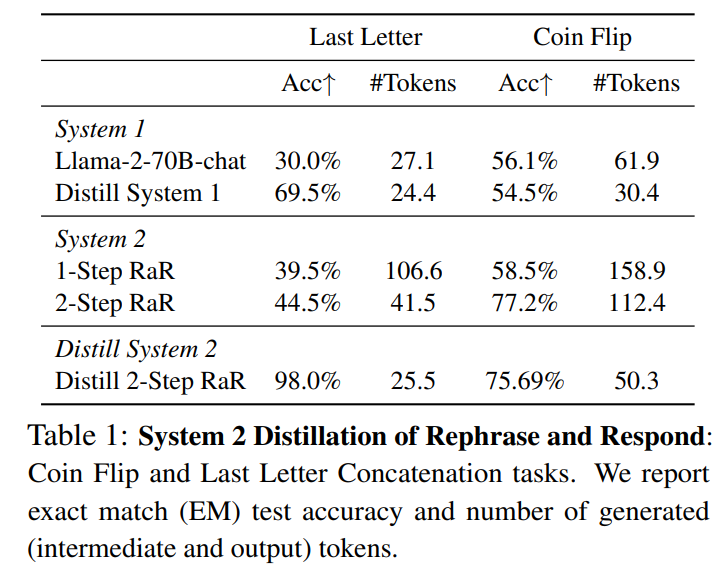
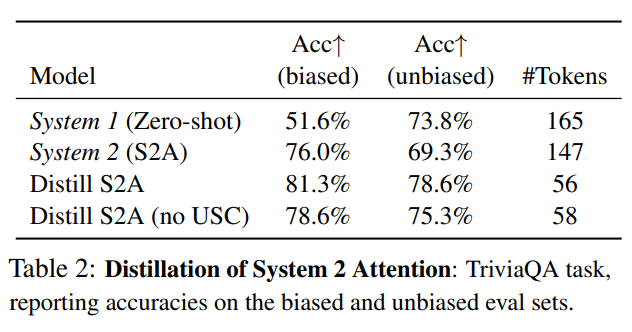
大規模言語モデル(LLMs)は、推論中に追加の計算を行い、中間的な思考を生成することで、より良い最終的な応答を生成するのに役立ちます.Chain-of-Thought(Wei et al.、2022)以降、Rephrase and Respond(Deng et al.、2023a)、System 2 Attention(Weston and Sukhbaatar、2023)、Branch-Solve-Merge(Saha et al.、2023)など、多くのSystem 2技術が提案されています.この研究では、System 2技術から高品質の出力を「コンパイル」(蒸留)し、中間推論トークンシーケンスなしでLLM生成に戻すための自己監督方法を調査しています.この推論はSystem 1に蒸留されているため、複数のこのような技術が成功裏に蒸留され、元のSystem 1パフォーマンスと比較して改善され、System 2よりも推論コストが少なくなることを示しています.私たちは、このようなSystem 2の蒸留が、将来の絶えず学習するAIシステムの重要な機能になると考えており、彼らにSystem 2の能力をまだうまく行えない推論タスクに焦点を当てることを可能にします.
Q&A:
Q: 中間的な推論トークンシーケンスなしで、システム2の技術からより質の高い出力をLLM世代に戻す「コンパイル」または抽出の概念を説明できますか?
A: System 2の技術から高品質な出力をLLM世代に中間推論トークンシーケンスなしで「コンパイル」または蒸留するという概念は、System 2の推論をSystem 1に蒸留することを指します.これにより、System 2の推論能力がLLMの生成に組み込まれ、中間推論ステップを省略することが可能となります.このプロセスは、System 2の推論をSystem 1の生成に組み込むことで、より高品質な最終応答を生み出すことができます.また、この方法により、System 2の推論を再利用し、より効率的に利用することができます.
Q: この蒸留プロセスにおいて、自己監視法はどのような役割を果たしているのだろうか?
A: 自己監督学習方法は、特定のフィルターを適用することによってモデルのパフォーマンスに影響を与えます.この研究では、自己一貫性基準を含む一貫性基準に依存しています.具体的には、一貫性基準を使用して、System 2が一貫している場合、その結果を蒸留対象とし、それを蒸留プールに追加します.そして、System 1を微調整して、収集された例のSystem 2方法の予測と一致させます.このようにして、自己監督学習方法は、System 2の蒸留プロセスにおいて重要な役割を果たしています.
Q: 蒸留された結果は、オリジナルのシステム1のパフォーマンスと比べてどうですか?
A: 蒸留された結果は、元のシステム1のパフォーマンスと比較して改善されており、システム2よりも推論コストが少ないことが示されています.
Q: システム2と蒸留結果の推論コストの比較について詳しく教えてください.
A: システム2のメソッドは、複数のプロンプト呼び出しと中間トークンの生成により、推論時間が遅くなる.System 2 Distillationの目的は、System 2からの推論をすべてSystem 1に戻し、言語モデルからの直接出力を改善することである.蒸留された結果の推論コストは、生成されたトークンの数によって示されるように、システム1のそれと同等である.
Q: システム2の蒸留は、将来の継続学習AIシステムにどのような影響を与えるとお考えですか?
A: システム2の蒸留は、将来の継続的な学習AIシステムに重要な影響を与えると考えられます.これにより、システム2の能力を推論タスクに集中させることが可能となり、まだうまくできていない推論タスクに対処できるようになります.
Q: システム2の能力は、AIシステムにおいて具体的にどのような推論タスクを改善できるとお考えですか?
A: システム2の能力は、AIシステムにおける思考の連鎖や複雑な数学的推論を必要とする推論タスクを改善することができる.
Q: システム2をシステム1に蒸留するという全体的な目標に対して、あなたが研究してきた技術はどのように貢献していますか?
A: 提案された手法は、System 2からSystem 1への蒸留を行うことで、言語モデルの直接的な出力を改善することに貢献します.具体的には、未ラベルの入力Xを使用してSystem 2モデルによる応答を生成し、その推論をSystem 1に蒸留することで、言語モデルの性能を向上させます.このプロセスにより、System 2の推論能力がSystem 1に移され、計算コストを削減しつつ、元のSystem 1の性能を向上させることが可能となります.
Q: 蒸留プロセスで遭遇した潜在的な課題や限界は何ですか?
A: 蒸留プロセスにおけるいくつかの潜在的な課題や制約には、複雑な推論手法を蒸留することが容易でない場合があることが挙げられます.例えば、Chain-of-Thoughtなどの複雑な推論手法は、我々の手法では容易に蒸留できないことがあります.また、蒸留プロセスにおいて、計算コストを削減しつつ利点を維持することが難しい場合もあります.さらに、蒸留プロセスが実用的でなくなる可能性もあります.
Q: システム2の蒸留技術の統合によって、AIの分野はどのように進化すると思いますか?
A: AIの分野は、System 2 destillation技術の統合により、ますます進化していくと考えられます.この技術は、System 2の高度な推論能力をSystem 1に蒸留することで、元のSystem 1の性能を向上させ、推論コストを削減することができます.これにより、AIシステムは、未だうまくできていない推論タスクにSystem 2の能力を集中させることが可能となります.将来的には、継続的に学習するAIシステムにおいて、System 2 destillationは重要な機能となり、より高度なタスクに対応できるようになるでしょう.
Exploring Advanced Large Language Models with LLMsuite
著者:Giorgio Roffo
発行日:2024年07月01日
最終更新日:2024年07月01日
URL:http://arxiv.org/pdf/2407.12036v1
カテゴリ:Computation and Language, Computer Vision and Pattern Recognition
概要:
このチュートリアルでは、ChatGPTやGeminiなどの大規模言語モデル(LLM)の開発における進歩と課題について探求しています.時間的な知識の切り捨て、数学的な不正確さ、誤った情報の生成など、固有の制限に対処し、Retrieval Augmented Generation(RAG)、Program-Aided Language Models(PAL)、ReActやLangChainなどの解決策を提案しています.これらの技術の統合により、特に多段階の推論や複雑なタスクの実行において、LLMの性能と信頼性が向上します.また、指示の微調整、LoRAなどのパラメータ効率の方法、人間のフィードバックからの強化学習(RLHF)や強化自己学習(ReST)などの微調整戦略についてもカバーしています.さらに、LLMのためのトランスフォーマーアーキテクチャとトレーニング技術の包括的な調査を提供しています.これらの技術を実装するためのツールボックスは、https://github.com/giorgioroffo/large_language_models_open_suite で公開されています.
Q&A:
Q: Retrieval Augmented Generation(RAG)のコンセプトと、それが大規模言語モデル(LLM)の限界にどのように対処するのかを説明していただけますか?
A: Retrieval Augmented Generation (RAG)は、大規模言語モデル(LLMs)の制限を克服するための概念であり、外部データソースやアプリケーションを推論時に統合することで、モデルの知識ベースを更新し、精度を向上させます.RAGフレームワークには、Parametric Component(Generator)とNon-Parametric Component(Retriever)の2つの要素があります.Generatorは、事前にトレーニングされたseq2seqモデルを使用して、取得した文書とクエリから応答を生成します.Retrieverは、文書の密なベクトルインデックスを持ち、クエリに基づいて関連する文書を取得します.RAGは、クエリ入力、文書取得、シーケンス生成のワークフローを通じて機能し、外部データソースからの情報を統合することで、より適切で正確な応答を生成します.
Q: プログラム支援言語モデル(PAL)はLLMの性能と信頼性をどのように向上させるのか?
A: プログラム支援言語モデル(PAL)は、外部コードインタプリターを使用して正確な計算を行い、LLMの能力を拡張します.PALフレームワークは、LLMと外部データソースを統合しやすくするオープンソースのフレームワークであり、特定のドメイン向けアプリケーションの効率的な開発を可能にします.PALは、正確な数値計算が必要なタスクを処理できるようにすることで、LLMの数学的な能力を向上させるために外部コードインタプリターとLLMをペアにしています.
Q: LLMのパフォーマンスを向上させる上で、ReActやLangChainのようなフレームワークの主な特徴と利点は何ですか?
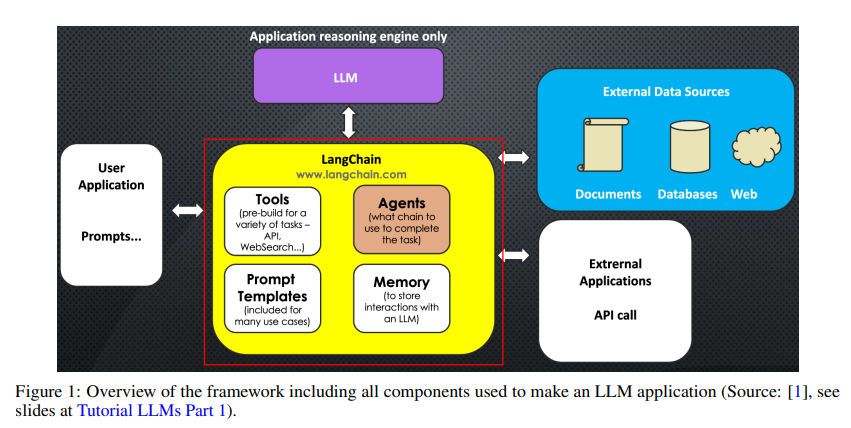
A: ReActやLangChainのようなフレームワークは、LLMの性能向上において重要な役割を果たします.ReActフレームワークは、複数の外部データソースやアプリケーションを含む複雑なワークフローを管理するために、思考の連鎖とアクションプランニングを組み合わせています.これにより、HotPot-QAやFEVERベンチマークなどの問題を解決する際に、複数のWikipediaの記事にまたがる多段階の推論が可能となります.一方、LangChainは、LLMに基づくアプリケーションの開発を効率化するために設計されたオープンソースのフレームワークです.LLMが生成する情報のカスタマイズ、精度、関連性を向上させるためのツールや抽象化を提供します.LangChainには、プロンプトテンプレート、メモリストレージなどのモジュラーコンポーネントが含まれており、API呼び出しや外部データセットへのアクセスなどのタスクをサポートします.これらのコンポーネントにより、開発者は最適化されたプロンプトチェーンを作成し、既存のテンプレートをカスタマイズすることが可能となります.
Q: インストラクションの微調整、LoRA、RLHF、ReSTなど、この文章で言及されている微調整戦略について詳しく教えてください.
A: パッセージで言及されているファインチューニング戦略には、指示ファインチューニング、LoRA、RLHF、およびReSTが含まれます.指示ファインチューニングは、モデルに特定の指示を与えて、特定のタスクに適応させることを目的としています.LoRA(Low-Rank Adaptation)は、モデルのパラメータを効率的に調整する方法であり、計算およびメモリ要件を削減します.RLHF(Reinforcement Learning from Human Feedback)は、人間のフィードバックから学習することで、モデルを人間の好みに合わせる手法です.ReST(Reinforced Self-Training)は、自己学習を強化する手法であり、モデルの性能を向上させるために使用されます.
Q: トランスフォーマーのアーキテクチャとトレーニング技術は、LLMの開発にどのように貢献しているのか?
A: トランスフォーマーアーキテクチャとトレーニング技術は、LLMの開発に重要な役割を果たしています. トランスフォーマーアーキテクチャは、NLPに革命をもたらし、LLMの性能と効率を向上させるための最新の手法を提供しています. これらのアーキテクチャは、複雑な問題を解決するための構造化されたプロンプトを使用してLLMを誘導するためのフレームワークを強調し、LLMの能力を拡張します. また、トレーニング技術は、モデルのパフォーマンスを特定のユースケースに最適化するための方法を探求し、LLMの出力をユーザーの期待により適合させるための手法を提供しています.
Q: LLMにおける時間的知識のカットオフと数学的不正確さに関連する課題とは何か?
A: LLMにおける時間的知識の切り捨てと数学的不正確さに関連する課題は、モデルの情報が古くなることや複雑な数学的タスクに対処する能力の制限にあります.時間的知識の切り捨てにより、モデルの情報が古くなり、数学的な計算に関しても正確性に欠けることがあります.これらの課題を克服するためには、LLMに数学的計算に優れた専門プログラムを統合することが重要です.このアプローチにより、販売合計や税金、eコマースプラットフォームでの割引などのタスクにおいて正確な結果が得られます.しかし、連鎖的思考の促進は推論プロセスを向上させることができますが、個々の計算においては特に大きな数値や複雑な操作において正確性を保証するものではありません.この制限は、金融取引やレシピの計量など、正確な計算が必要なアプリケーションにおいて重要です.これらの制限を克服するためには、LLMに数学的計算を処理するのに適した外部ツールを組み込むことが有効です.
Q: RAG、PAL、微調整戦略のような技術の統合は、LLMにおける多段階推論と複雑なタスク実行をどのように強化するのか?
A: RAGやPALなどの技術を統合することにより、LLMの多段階推論と複雑なタスク実行が向上します.RAGは外部データベースにリンクしてLLMを拡張し、出力の精度を向上させます.PALは外部コードインタプリターを活用して正確な計算を行い、数値計算が必要なタスクを処理できるようにします.これにより、LLMの数学的能力が向上し、正確な計算を行うことが可能となります.また、ファインチューニング戦略は、事前にトレーニングされたモデルを特定のタスクに適応させることで、その性能を向上させます.
Q: LLMにおける誤った情報生成の例と、この問題への対処法を教えてください.
A: LLMsにおける不正確な情報生成の例としては、知識の切り捨てや数学的誤りによる間違ったトークンの予測が挙げられます.この問題を解決するためには、外部データソースを統合し、推論時に応用することが不可欠です.Retrieval Augmented Generation(RAG)などのフレームワークを使用することで、LLMsの性能を大幅に向上させ、信頼性を高めることができます.
Q: LLM開発において、人間のフィードバックからの強化学習(RLHF)と強化自己トレーニング(ReST)を使用することの意味は?
A: Reinforcement Learning from Human Feedback (RLHF)とReinforced Self-Training (ReST)をLLMの開発に使用することによる影響は、人間のフィードバックを活用して言語モデルを継続的にトレーニングすることで、ユーザーの期待により適合したLLMの生成を可能にします.RLHFはオンライン強化学習の原則に基づいており、人間のフィードバックが学習プロセスを導くことで、リアルタイムの相互作用を可能にします.一方、ReSTはオフライン強化学習と自己トレーニングの原則に基づいており、これらを組み合わせることでより構造化された効率的な方法論を提供します.このアプローチにより、LLMの開発と適用が向上し、様々な領域での広範な採用が可能となります.
Q: GitHubのリンクから入手できる、高度なLLM技術を実装するためのツールボックスに、関心のある人はどのようにアクセスし、利用することができますか?
A: 提供されたGitHubリンクで利用可能な高度なLLM技術を実装するためのツールボックスにアクセスし、利用するには、GitHubのリンクhttps://github.com/giorgioroffo/large_language_models_open_suiteにアクセスして、コードだけでなく、包括的なチュートリアルスライドも含まれていることを確認する必要があります.これらのチュートリアルスライドは理解と適用を支援するために提供されており、モデルの微調整には高度なフレームワークと微調整戦略の適用が必要です.
