
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をLLMによって生成されるQ&Aを用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.自動生成記事のクオリティと信頼性を向上させるためにアルゴリズムの改善に取り組んでいます.個人で資料のQ&Aを作成されたい方には、https://www.chatpdf.com/ や https://scispace.com/などがお勧めです.
- FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
発行日:2024年07月11日
TransformerアーキテクチャのAttentionは、FlashAttention-3によってH100 GPU上で高速化され、FP8では1.2 PFLOPs/sに達し、数値誤差も2.6倍低いことが示されている. - Internet of Agents: Weaving a Web of Heterogeneous Agents for Collaborative Intelligence
発行日:2024年07月09日
IoAは、LLMベースのマルチエージェント協力のための新しいフレームワークであり、異種エージェント間の効果的な協力を促進し、高度な知能と能力を実現する能力を示しています. - Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps
発行日:2024年07月09日
LLMが文脈的幻覚を引き起こし、提案されたルックバック比率ベースの検出器は、効果的に幻覚を検出し、XSum要約タスクで幻覚を削減することが示された. - Learning to (Learn at Test Time): RNNs with Expressive Hidden States
発行日:2024年07月05日
TTT-LinearとTTT-MLPは、線形モデルとMLPを使用して、長い文脈で優れた性能を発揮する新しいシーケンスモデリングレイヤーであり、MambaやTransformerよりも高い性能を示す可能性がある. - Mixture of A Million Experts
発行日:2024年07月04日
PEERレイヤーは、標準のトランスフォーマーアーキテクチャにおける計算コストとアクティベーションメモリの増加問題に対処し、100万以上の小さな専門家を活用して、言語モデリングタスクで高いパフォーマンスを達成する. - RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs
発行日:2024年07月02日
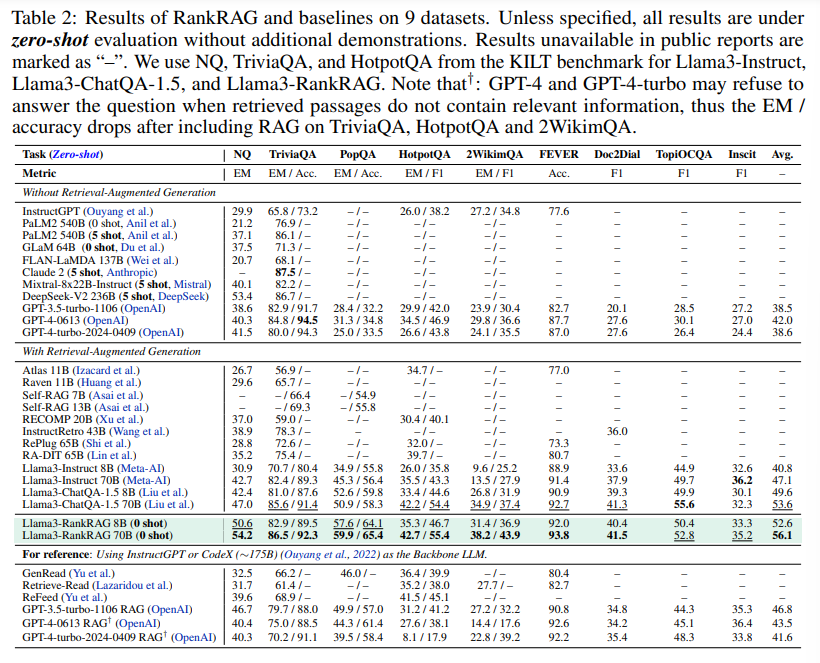
RankRAGは、LLMを指示微調整してRAGでコンテキストのランキングと回答生成を向上させ、9つの知識集約的なベンチマークでLlama3-ChatQA-1.5およびGPT-4を上回り、バイオメディカルデータでもGPT-4と同等のパフォーマンスを示す. - Reasoning in Large Language Models: A Geometric Perspective
発行日:2024年07月02日
LLMの進化は推論能力向上に重要で、表現力と自己注意グラフの密度の関連を探求し、固有次元が表現能力を高めることを示す. - A Survey on Mixture of Experts
発行日:2024年06月26日
LLMsは、大規模なモデルサイズと多様なデータセットによって支えられ、MoEがモデル容量を拡大する効果的な方法として注目されているが、MoEに関する包括的なレビューが不足しているため、この調査はMoEの構造、分類法、応用、可能性を提供し、https://github.com/withinmiaov/A-Survey-on-Mixture-of-Experts でリソースリポジトリを設立している. - RouteLLM: Learning to Route LLMs with Preference Data
発行日:2024年06月26日
LLMは、パフォーマンスとコストのトレードオフを考慮しながら、効率的なルーターモデルを提案し、コストを削減しつつ応答品質を最適化することを目指しています. - Meta 3D Gen
発行日:2024年06月25日
Meta 3D Gen(3DGen)は、Meta 3D AssetGenとMeta 3D TextureGenを統合した新しい高速パイプラインで、テキストから高品質な3Dアセットを1分未満で生成します.3DGenは、3Dオブジェクトの3つの補完的な表現を組み合わせており、AssetGenで始まり、オブジェクトの複数の一貫したビューを生成し、次にボリューメトリックスペース内の3Dオブジェクトの最初のバージョンを抽出します.その後、メッシュ抽出が行われ、オブジェクトの3D形状と初期バージョンのテクスチャが確立されます.最終的に、TextureGenのコンポーネントがテクスチャを再生成し、初期プロンプトに忠実であると同時に、テクスチャの品質と解像度を向上させます.3DGenは、内部データセットからの合成3Dデータのレンダリングを使用して、Metaの強力なテキストから画像へのモデルをさらに洗練させています.
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
著者:Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, Tri Dao
発行日:2024年07月11日
最終更新日:2024年07月12日
URL:http://arxiv.org/pdf/2407.08608v2
カテゴリ:Machine Learning, Artificial Intelligence



概要:
Transformerアーキテクチャの中核層としてのAttentionは、大規模な言語モデルや長いコンテキストのアプリケーションにおいてボトルネックとなっています.FlashAttentionは、GPU上でのAttentionの高速化手法を開発し、メモリの読み書きを最小限に抑えることで実現しています.しかし、最近のハードウェアの新しい機能を活用していないため、FlashAttention-2はH100 GPUでの利用率が35%にとどまっています.そこで、Hopper GPU上でAttentionを高速化するための3つの主要な技術を開発しました.それは、Tensor CoresとTMAの非同期性を活用して、(1) ワープ専用化を通じて全体の計算とデータ移動を重ね合わせ、(2) ブロックごとのmatmulとsoftmax操作を交互に行うこと、そして(3) ハードウェアのFP8低精度サポートを活用したブロック量子化と非連続処理です.我々の手法であるFlashAttention-3は、H100 GPU上で1.5〜2.0倍のスピードアップを実現し、FP16では最大740 TFLOPs/s(75%の利用率)、FP8では1.2 PFLOPs/sに達することを示しています.また、FP8 FlashAttention-3は、ベースラインのFP8 Attentionよりも数値誤差が2.6倍低いことを検証しています.
Q&A:
Q: FlashAttention-3がHopper GPUのアテンションを以前のバージョンと比べてどのように高速化したのか、もう少し詳しく説明してもらえますか?
A: FlashAttention-3は、新しいGPUアーキテクチャでのパフォーマンスをさらに向上させるために、3つの新しいアイデアを提案しています.1つ目は、生産者-消費者非同期性です.データの移動とTensor Coresの非同期実行を活用するために、データの生産者と消費者を分割するワープ専用ソフトウェアパイプラインスキームを定義しています.
Q: HopperGPUでアテンションを高速化するためにFlashAttention-3で使われている3つの主なテクニックは何ですか?
A: FlashAttention-3では、Hopper GPUs上の注意を高速化するために、3つの主要な技術が使用されています.1つ目は、Tensor CoresとTMAの非同期性を利用して、全体の計算とデータ移動を重ね合わせることです.これは、warp-specializationを介して行われ、生産者と消費者のデータを分割することで、データの非同期実行を活用します.2つ目は、ブロックごとのmatmulとsoftmax操作を交互に挟むことです.最後に、3つ目は、ハードウェアのFP8低精度を活用したブロックの量子化と非連続処理です.これにより、FlashAttention-3は、FP16では最大740 TFLOPs/s(75%の利用率)までのスピードアップを達成し、FP8では約1.2 PFLOPs/sに達します.
Q: FlashAttention-3は、テンソルコアとTMAの非同期性をどのように利用しているのですか?
A: FlashAttention-3は、Tensor CoresとTMAの非同期性を利用して、計算とデータ移動を重ね合わせることで、全体の計算とデータ移動を重ね合わせ、ブロックごとのmatmulとsoftmax操作を交互に挟み込み、ブロックの量子化と非連続処理を行うことで、注意を高速化しています.
Q: FlashAttention-3では、ワープスペシャリゼーションとブロック単位のインターリーブがどのように高速化に貢献しているのか、詳しく教えてください.
A: Warp-specializationとブロックごとの操作の交互配置は、FlashAttention-3の高速化に寄与します.Warp-specializationにより、クエリ行列のタイルQ𝑖を処理する際に、並列処理が可能となります.これにより、バッチサイズ、ヘッド数、およびクエリシーケンスの長さにおいて、前方パスが効率的に行われます.一方、ブロックごとの操作の交互配置により、ブロックの再スケーリングを行い、出力Oの計算を効率的に行います.これにより、FlashAttention-3の処理速度が向上し、FlashAttention-2よりも高速になります.
Q: ブロック量子化とFP8低精度によるインコヒーレント処理は、FlashAttention-3の高性能化にどのように役立つのか?
A: ブロック量子化と非整合処理は、FP8低精度を使用することで、FlashAttention-3の性能向上に役立ちます.ブロック量子化は、データを複数のブロックに分割し、各ブロックごとに量子化を行うことで、計算を効率化します.一方、非整合処理は、データの処理を同期させずに並列的に行うことで、並列性を高め、演算速度を向上させます.これにより、FP8低精度を使用しているにもかかわらず、FlashAttention-3は高い性能を発揮することができます.
Q: H100GPUでFlashAttention-3がFP16精度とFP8精度で達成したスピードアップは?
A: FlashAttention-3 は、FP16 による前方パスで1.5-2.0倍のスピードアップを達成し、最大740 TFLOPs/sに達する.また、FP8 による場合は、約1.2 PFLOPs/sに達する.したがって、FP16 によるスピードアップは1.5-2.0倍であり、FP8 による場合は1.2 PFLOPs/sに近い速度を達成している.
Q: FlashAttention-3によって、H100 GPUの使用率は以前のバージョンと比べてどのように向上しましたか?
A: FlashAttention-3は、FlashAttention-2およびTritonでのFlashAttention-2よりも最大2.0倍高速であり、H100 GPU上でのFlashAttention-2よりも最大1.5倍高速です.
Q: FP8 FlashAttention-3がベースラインのFP8アテンションと比較して達成した数値エラー削減の詳細を教えてください.
A: FP8 FlashAttention-3は、標準の実装よりも数値誤差を2.6倍低減させることができます.これは、中間結果(softmax)をFP32で保持することにより、より低いRMSEを達成できるためです.FP8のベースラインアテンションは、テンソルごとのスケーリングを使用し、matmulアキュムレータをFP32で、中間のsoftmax結果をFP16で保持しています.ブロック量子化と非整合処理のおかげで、FP8のFlashAttention-3はこのベースラインよりも2.6倍精度が向上しています.
Q: FlashAttention-3は、大規模な言語モデルやロングコンテキストのアプリケーションにおける注意力のボトルネックにどのように対処するのか?
A: FlashAttention-3は、大規模な言語モデルや長いコンテキストのアプリケーションにおける注意のボトルネックに対処するために、GPU上の注意を高速化するアプローチを詳細に説明しています.具体的には、Tensor CoresとTMAの非同期性を利用して、計算とデータ移動を重ね合わせることで全体の計算とデータ移動を重ね合わせ、ブロックごとのmatmulとsoftmax操作を交互に行い、ブロックの量子化と非一貫性処理を行うことで、注意を高速化しています.
Q: ディープラーニングや自然言語処理の分野において、FlashAttention-3は今後どのような意味を持ち、どのような応用の可能性があるのでしょうか?
A: FlashAttention-3は、新しいプログラミング技術やハードウェア機能(非同期性や低精度など)が、注意力の効率と精度に著しい影響を与えることを示しています.これにより、従来の注意力モデルよりも1.5〜2.0倍高速化し、FP8数値誤差を削減することが可能です.FlashAttention-3の改善は、分散型注意力モデルにも恩恵をもたらす可能性があります.これにより、大規模言語モデルや長いコンテキストを持つアプリケーションにおいて、より高速で正確な注意力を実現できる可能性があります.
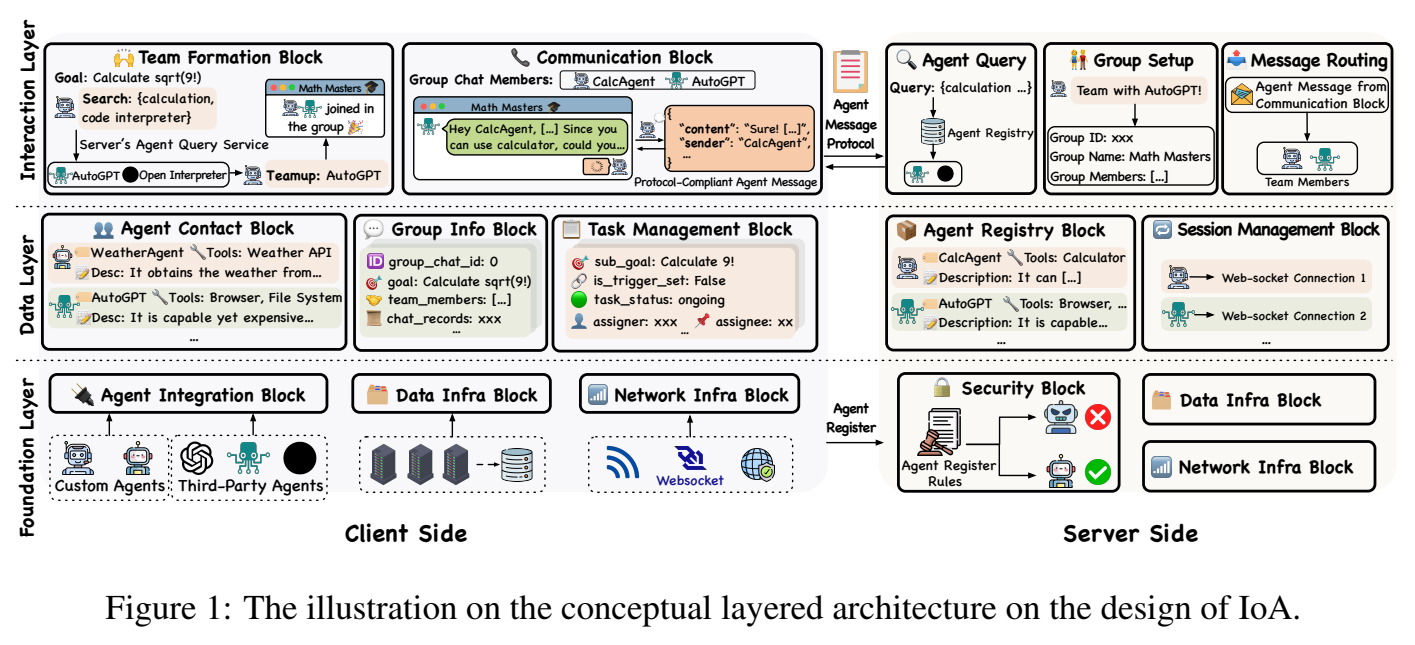
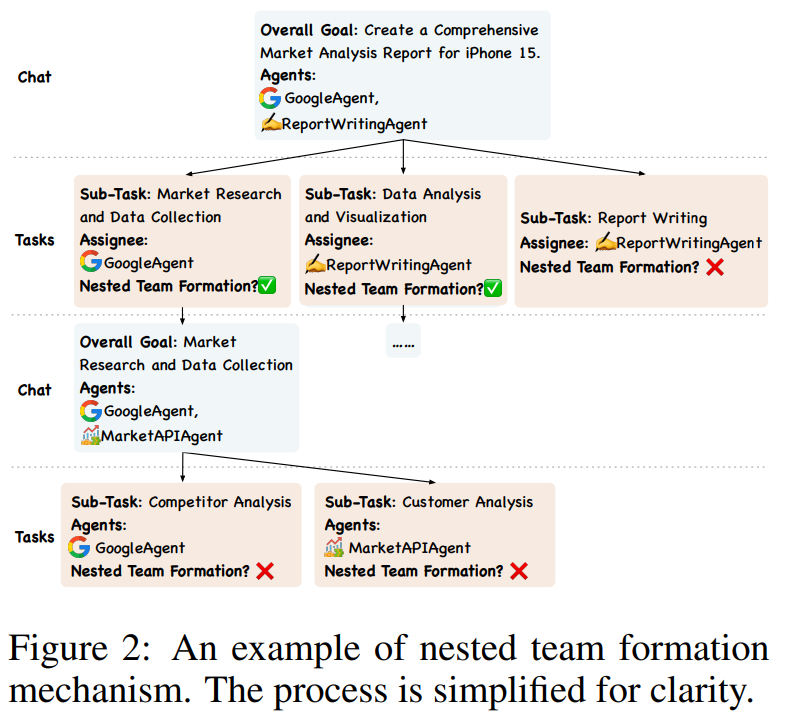
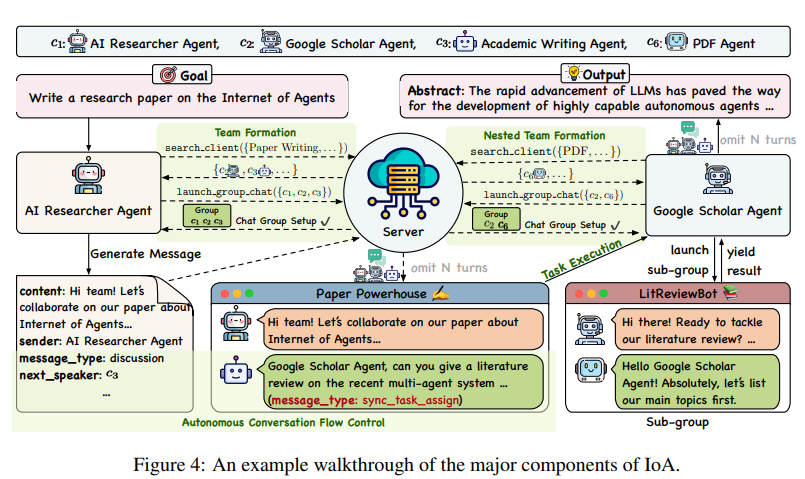
Internet of Agents: Weaving a Web of Heterogeneous Agents for Collaborative Intelligence
著者:Weize Chen, Ziming You, Ran Li, Yitong Guan, Chen Qian, Chenyang Zhao, Cheng Yang, Ruobing Xie, Zhiyuan Liu, Maosong Sun
発行日:2024年07月09日
最終更新日:2024年07月10日
URL:http://arxiv.org/pdf/2407.07061v2
カテゴリ:Computation and Language
概要:
大規模言語モデル(LLM)の急速な進化は、非常に能力の高い自律エージェントの開発の道を開いています.しかし、既存のマルチエージェントフレームワークは、自身のエコシステム内で定義されたエージェントに依存しているため、多様な能力を持つ第三者エージェントを統合する際に苦労しています.また、ほとんどのフレームワークが単一デバイスのセットアップに限定されているため、分散環境のシミュレーションにも課題があります.さらに、これらのフレームワークはしばしばハードコーディングされた通信パイプラインに依存しており、動的なタスク要件に適応する能力が制限されています.インターネットの概念に着想を得て、私たちはエージェントのインターネット(IoA)という新しいフレームワークを提案しています.IoAは、LLMベースのマルチエージェント協力のための柔軟でスケーラブルなプラットフォームを提供することで、これらの制限に対処しています.IoAは、エージェント統合プロトコル、インスタントメッセージングのようなアーキテクチャ設計、エージェントのチーミングと会話フロー制御の動的メカニズムを導入しています.一般的なアシスタントタスク、具現化AIタスク、および検索補助生成ベンチマークに関する広範な実験を通じて、IoAが常に最先端のベースラインを上回ることを実証し、効果的な促進を可能にする能力を示しています.IoAは、異種エージェント間の効果的な協力を促進する能力を示す最先端のベースラインを示し、エージェントがシームレスに協力してより高度な知能と能力を達成するための一歩を表しています.私たちのコードベースは、\url{https://github.com/OpenBMB/IoA}で公開されています.
Q&A:
Q: インターネット・オブ・エージェント(IoA)のコンセプトは何から生まれたのですか?
A: インターネットの概念がエージェントのインターネット(IoA)の概念にインスピレーションを与えました.
Q: IoAは、既存のマルチエージェント・フレームワークの限界にどのように対処するのか?
A: IoAは既存のマルチエージェントフレームワークの制限を解決するために、異なる第三者エージェントを統合する柔軟でスケーラブルなプラットフォームを提供し、分散型マルチエージェントの協力を可能にし、エージェントのチーム編成や会話フロー制御の動的なメカニズムを導入することで制限に対処しています.
Q: エージェントのコラボレーションを促進するために、IoAは具体的にどのような機能を導入するのですか?
A: IoAは、エージェントの統合プロトコル、インスタントメッセージのようなアーキテクチャ設計、およびエージェントのチーム編成と会話フロー制御のための動的メカニズムを導入しています.これらの機能により、異種エージェント間の効果的な協力が可能となります.
Q: IoAで使用されているエージェント統合プロトコルについて教えてください.
A: IoAで使用されているエージェント統合プロトコルは、第三者エージェントがIoAとシームレスに統合するために従う必要があるプロトコルを定義しています.現在、IoAのエージェント統合プロトコルでは、エージェントが入力としてタスクの説明を受け取り、タスク完了の要約を返す関数 def run(task desc: str) -> str を実装する必要があります.このシンプルで効果的なプロトコルにより、多様なエージェントがフレームワークに組み込まれ、それぞれの独自の能力を協力プロセスに貢献することが可能となります.
Q: IoAは他のフレームワークと比較して、動的なタスク要件をどのように扱うのですか?
A: IoAは他のフレームワークと比較して、動的なタスク要件をどのように処理するのかについて、特に最適化されていないにもかかわらず、柔軟性と効果を持っていることが示されています.IoAは、特定のツールが必要なタスクを簡単に統合し、エージェントの適応を通じて、タスク完了に参加できるようにすることができます.そのため、IoAは一般的なマルチエージェントフレームワークであり、具体的にはエンボディドAIタスク向けに設計されていないため、タスク完了にやや多くの意思決定ステップが必要ですが、その柔軟性と効果のために、ステップ数の増加は合理的なトレードオフです.
Q: 実験でIoAの性能を示すために使用されたタスクの種類は何ですか?
A: 実験で使用されたタスクの種類は、検索&レポートタスク、30のコーディングタスク、30の数学タスク、および41の生活支援タスクでした.
Q: IoAは共同作業において、最先端のベースラインをどのように上回るのか?
A: IoAは異種エージェント間の効果的な協力を促進する能力を示し、一貫して最先端のベースラインを上回ることが実験によって示されました.IoAは、異種エージェント間での効率的な協力を促進する効果を実証する実験を通じて、常に最先端のベースラインを上回っています.IoAは、異種エージェントをインターネットのような環境でリンクする一歩を表しており、エージェントがシームレスに協力してより高い知能と能力を達成することができます.
Q: インターネットのような環境で多様なエージェントをつなぐIoAの意義とは?
A: IoAは、異なるエージェントをインターネットのような環境でリンクすることで、エージェント同士の効果的な協力を可能にする重要な役割を果たします.これにより、異なるスキルやバックグラウンドを持つエージェント同士がシームレスに連携し、より高い知能と能力を発揮できる環境が提供されます.
Q: IoAのエージェントは、より高いインテリジェンスと能力を実現するために、どのように協力できるのか?
A: IoAにおけるエージェントは、異なるアーキテクチャを持つエージェントをシームレスに統合し、協力してより高い知能と能力を達成することができます.これは、IoAが異なるエージェント同士の協力を容易にし、それぞれの強みを活かすことができるためです.具体的には、エージェント統合プロトコルやインスタントメッセージのようなアーキテクチャ設計、エージェントチーム編成や会話フロー制御の動的メカニズムなどがIoAによって提供され、これにより異種エージェント間の効果的な協力が可能となります.
Q: IoAのコードベースにはどこからアクセスできますか?
A: IoAコードベースはhttps://github.com/OpenBMB/IoA で公開されています.
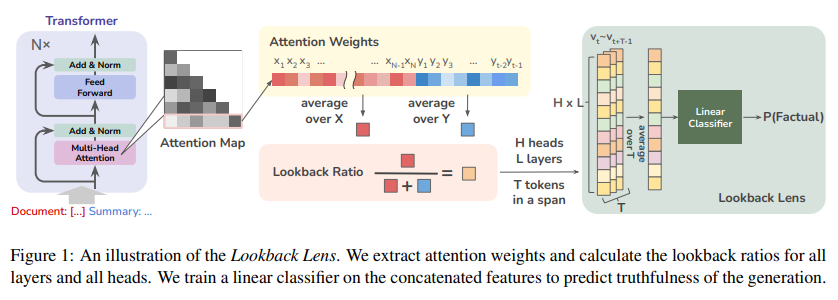
Lookback Lens: Detecting and Mitigating Contextual Hallucinations in Large Language Models Using Only Attention Maps
著者:Yung-Sung Chuang, Linlu Qiu, Cheng-Yu Hsieh, Ranjay Krishna, Yoon Kim, James Glass
発行日:2024年07月09日
最終更新日:2024年07月09日
URL:http://arxiv.org/pdf/2407.07071v1
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning
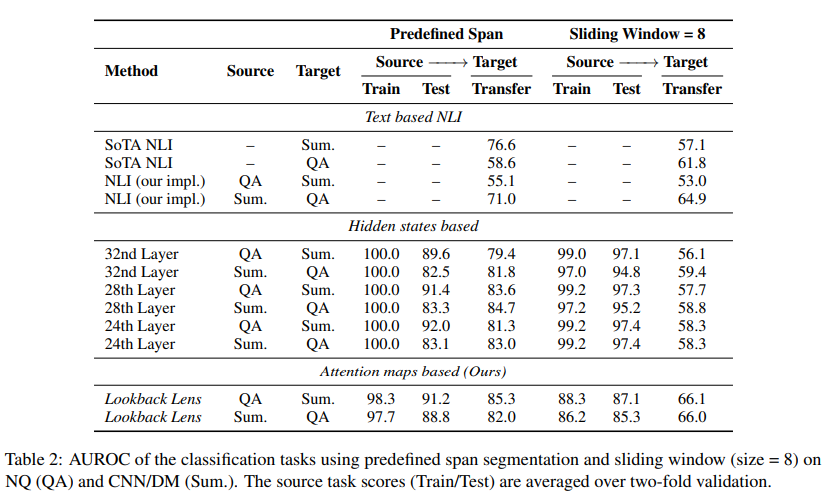
概要:
この論文は、大規模言語モデル(LLMs)が記事を要約したり、与えられた文章に対する質問に答えたりする際に、文脈の幻覚を生じさせ、根拠のない回答を提供することがあることを説明しています.この論文では、このような文脈的幻覚を検出するための簡単なアプローチについて述べています.我々は、文脈的幻覚が、LLMが提供された文脈の情報に対してどの程度注意を払っているかと、自身の生成物に対してどの程度注意を払っているかという点に関連していると仮説を立てています.この直感に基づいて、提案された単純な幻覚検出モデルの入力特徴は、各アテンションヘッドにおける文脈と新しく生成されたトークンの注意重みの比率で与えられます.我々は、このルックバック比率特徴に基づく線形分類器が、LLMの全隠れ状態やテキストベースの含意モデルを利用したより豊富な検出器と同等に効果的であることを見出しました.ルックバック比率ベースの検出器であるLookback Lensは、タスクやモデルを超えて転移することがわかり、7Bモデルで訓練された検出器を再訓練せずにより大きな13Bモデルに適用することが可能です.さらに、この検出器を用いて文脈的幻覚を緩和するために応用します.さらに、この検出器をXSum要約タスクに適用することで、例えば9.6%の文脈的幻覚を削減することができることが示されました.
Q&A:
Q: 幻覚検出モデルで、どのようにルックバック比の特徴を計算するのか、もう少し詳しく教えてください.
A: ルックバック比率特徴量は、与えられたコンテキストと新しく生成されたトークンの各アテンションヘッドにおけるアテンション重みの比率として計算されます.各時間ステップで、このルックバック比率を計算し、各アテンションヘッドごとに線形分類器を訓練します.この線形分類器は、ルックバックレンズと呼ばれ、ルックバック比率特徴に基づいてコンテキストの幻覚を検出します.
Q: ルックバック比の特徴に基づく線形分類器が他の検出器と同程度に効果的であると、どのようにして判断したのですか?
A: 線形分類器に基づくルックバック比特徴が他の検出器と同等に効果的であることを確認するために、与えられた文脈と新しく生成されたトークンに対する注意の重みの比率を使用して、モデルをトレーニングしました.この比率を計算し、Lookback Lensと呼ばれる線形分類器をトレーニングして、ルックバック比特徴に基づいて文脈的な幻覚を検出しました.その結果、Lookback Lensは、LLMの隠れた状態やテキストベースの帰結モデルを利用するより複雑な検出器と同等の性能を発揮しました.
Q: ルックバックレンズモデルによって検出された文脈幻覚の例を教えてください.
A: Lookback Lensモデルによって検出された文脈的幻覚の例は、与えられた文脈に基づいて正確でない回答を生成することです.
Q: ルックバック・レンズの検出器がタスクやモデルをまたいで使用できることをどのように保証したのですか?
A: Lookback Lensは、タスクやモデルを超えて転送できるようにするために、注目マップから抽出されたルックバック比特徴を使用しました.この特徴は、異なるタスクやモデルにおいても一貫した性能を示すことができ、転送可能性を確保しました.
Q: 分類器ガイド付きデコーディング・アプローチを使用して、文脈上の幻覚を軽減するために、具体的にどのような措置が取られたのか?
A: Lookback Lensによって特定された文脈的幻覚を軽減するために、分類器による誘導デコーディング戦略を導入しました.このアプローチは、生成をより文脈的に正確な出力に誘導するためのものです.
Q: 7BのモデルでLookback Lens検出器をトレーニングし、再トレーニングすることなく、より大きな13Bのモデルに適用するプロセスについて詳しく教えてください.
A: 7BモデルでトレーニングされたLookback Lensディテクターを、再トレーニングなしでより大きな13Bモデルに適用するプロセスは、7Bモデルと13Bモデルの注意ヘッドの数が異なるため、ヘッド間に明確な一対一のマッピングがないため、13Bモデルから7Bモデルへのヘッドのマッピングに線形回帰モデルを使用します.具体的には、7Bモデルに1024個のヘッドがあり、13Bモデルに1600個のヘッドがあるため、すべてのトレーニング例に対してヘッドごとの平均ルックバック比を抽出し、1024× |D|行列と1600× |D|行列を生成します.次に、13Bからのルックバック比に線形変換を適用し、変換されたヘッドを7Bの分類器で直接使用できるようにします.
Q: XSum要約タスクで9.6%減少したような幻覚の減少において、Lookback Lens検出器の有効性はどのように測定されたのか?
A: Lookback Lensの効果は、単純な分類器によって誘導されたデコーディングアプローチによって測定されました.このアプローチにより、XSum要約タスクにおいて9.6%の幻覚削減が達成されました.
Q: 文脈幻覚を検出し、軽減するためのルックバックレンズモデルを開発し、実装する上で、どのような課題にぶつかりましたか?
A: Lookback Lensモデルを開発および実装する際に遭遇した課題は、主に以下の点にあります.まず、Attention weightsだけから計算されるlookback ratioを利用して、文脈的な幻覚を検出するというアプローチは、従来の複雑な隠れた表現方法と比較して、どのようにして効果的かつ汎用的かを確認する必要がありました.また、文脈的な幻覚を検出するだけでなく、それを軽減するための方法も提案されました.このような新しいアプローチを開発し実装するにあたり、モデルの性能や汎用性を検証するための適切な評価手法を選択することも重要でした.
Q: 様々なタスクにおける大規模な言語モデルのパフォーマンスを向上させるために、Lookback Lensモデルをどのように応用できるとお考えですか?
A: Lookback Lensモデルは、大規模言語モデルの性能向上において、様々なタスクでの応用が期待されます.具体的には、Lookback Lensは注意マップから抽出された情報を活用して、大規模言語モデルにおける幻覚の検出や修正を行うことが可能です.このモデルは、サマリゼーションタスクや質問応答タスクなどの様々なタスクに適用可能であり、モデル間やタスク間での転移性が高いことが示唆されています.また、Lookback Lensは、注意マップから得られる情報を活用することで、コンテキスト上の幻覚を軽減することができるため、大規模言語モデルの性能向上に貢献する可能性があります.
Q: アテンション・マップのみを使用した大規模言語モデルにおける文脈幻覚の検出と軽減の研究において、何か限界や今後の研究課題があるのでしょうか?
A: 研究では、提案された検出モデルを生成プロセスに組み込んで文脈的幻覚をさらに軽減することを試みています.また、文脈的幻覚の検出に焦点を当てるだけでなく、その軽減にも取り組んでいます.さらに、文脈的幻覚の検出と軽減に関する研究は、内部表現ではなく注意マップに焦点を当てています.この研究において、注意マップのパターンがLLMが与えられた文脈情報をどのように処理しているかを記録していると考えられています.将来の研究では、提案された検出モデルを生成プロセスに組み込むことで、文脈的幻覚をさらに軽減する方法や、注意マップからの信号をより効果的に活用する方法などが検討される可能性があります.
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
著者:Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, Tatsunori Hashimoto, Carlos Guestrin
発行日:2024年07月05日
最終更新日:2024年07月05日
URL:http://arxiv.org/pdf/2407.04620v1
カテゴリ:Machine Learning, Artificial Intelligence, Computation and Language
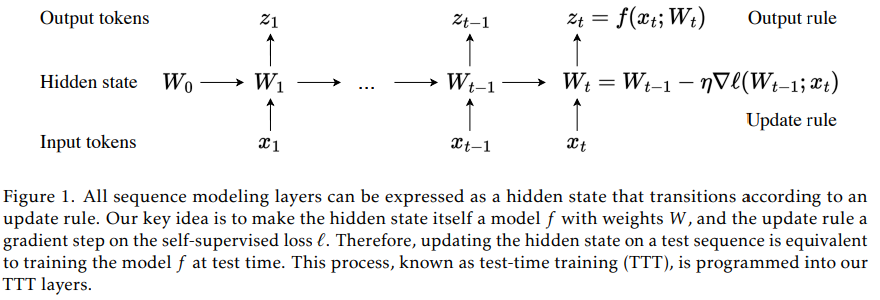
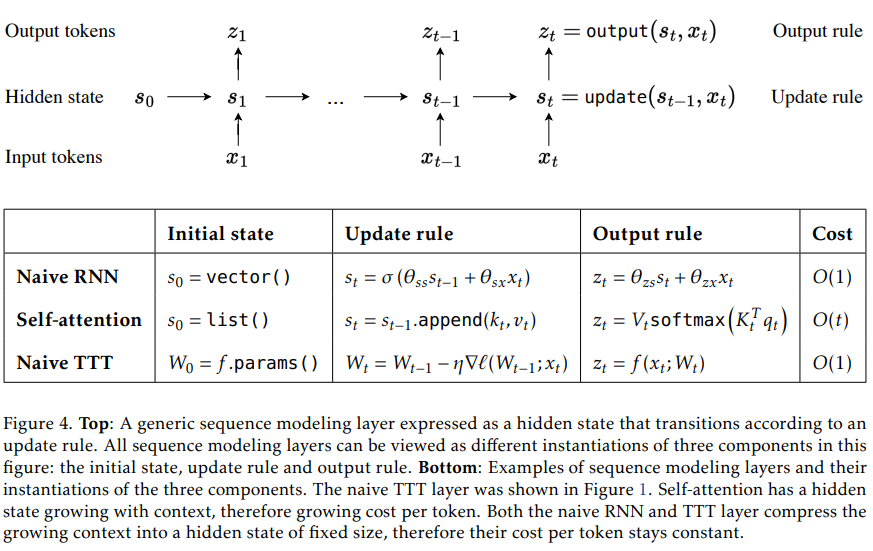
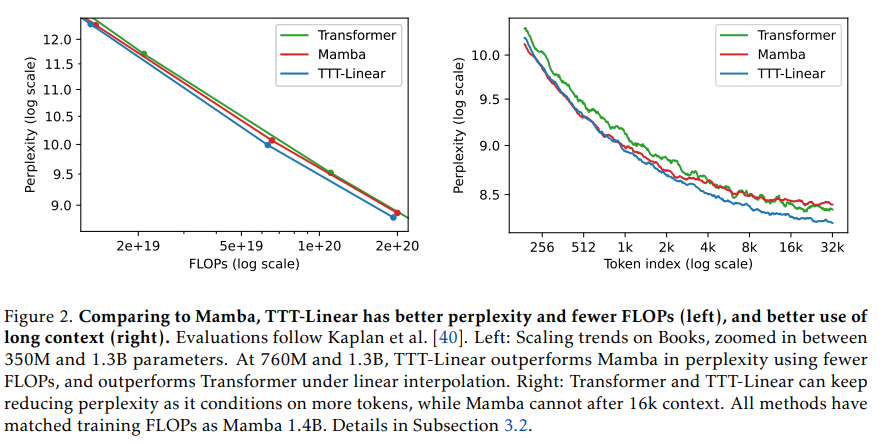
概要:
セルフアテンションは長い文脈で優れた性能を発揮しますが、二次の計算量を持っています.既存のRNNレイヤーは線形の計算量を持っていますが、その性能は隠れた状態の表現力によって長い文脈で制限されています.私たちは、線形の計算量と表現力豊かな隠れた状態を持つ新しいクラスのシーケンスモデリングレイヤーを提案します.その鍵となるアイデアは、隠れた状態を機械学習モデル自体にし、更新ルールを自己教師付き学習のステップにすることです.隠れた状態がテストシーケンスでもトレーニングによって更新されるため、私たちのレイヤーはTest-Time Training (TTT) レイヤーと呼ばれています.私たちは、TTT-LinearとTTT-MLPの2つの具体化を考えています.TTT-Linearは隠れた状態が線形モデルであり、TTT-MLPは2層のMLPです.私たちは、125Mから1.3Bのパラメータのスケールで、強力なTransformerと現代のRNNであるMambaと比較して、私たちの具体化を評価します.TTT-LinearとTTT-MLPの両方は、ベースラインを上回るか、それに匹敵します.Transformerと同様に、トークンをより多くの条件で結合することで、パープレキシティを減らし続けることができますが、Mambaは16kの文脈の後にはできません.初期のシステムの最適化により、TTT-Linearはすでに8kの文脈でTransformerよりも速く、ウォールクロックでMambaと一致します.TTT-MLPはまだメモリI/Oの課題に直面していますが、長い文脈でより大きな潜在能力を示し、将来の研究に向けた有望な方向性を示しています.
Q&A:
Q: セルフアテンションレイヤーと提案されているテストタイムトレーニング(TTT)レイヤーの違いを、長いコンテクストにおける複雑さとパフォーマンスという観点から説明していただけますか?
A: 提案されたTest-Time Training (TTT)レイヤーと自己注意の違いは、複雑さと長い文脈での性能にあります.自己注意は長い文脈でうまく機能しますが、二次の複雑さを持ちます.一方、TTTレイヤーは線形の複雑さを持ち、隠れた状態の表現力によって長い文脈での性能が制限されます.TTTレイヤーでは、隠れた状態自体が機械学習モデルであり、更新規則は自己教師付き学習のステップとなっています.また、TTTレイヤーはテストシーケンスでもトレーニングによって隠れた状態が更新されるため、自己注意と比較して長い文脈での性能が向上します.
Q: 隠れた状態を機械学習モデルそのものにすることで、シーケンスモデリング層のパフォーマンスがどのように向上するのか?
A: 隠れ状態を機械学習モデル自体にすることにより、シーケンスモデリング層の性能が向上します.これにより、隠れ状態がより表現豊かになり、より複雑なパターンや関係性を捉えることができるようになります.
Q: テストシーケンス中に隠れた状態を更新するという文脈での自己教師あり学習の概念について詳しく教えてください.
A: 自己教師あり学習は、大規模なトレーニングセットをモデルの重みに圧縮することができます.これにより、モデルはトレーニングデータの意味的なつながりについて深い理解を示すことができます.テストシーケンスで隠れ状態を更新するプロセスは、実際にはテスト時にモデルをトレーニングすることと同等です.このように、自己教師あり学習を使用して隠れ状態を更新することで、モデルはテスト時にもトレーニングされるため、テスト時トレーニング(TTT)と呼ばれるレイヤーが提案されています.
Q: TTT-LinearとTTT-MLPの隠れ状態モデルの主な違いは何ですか?
A: TTT-LinearとTTT-MLPの主な違いは、隠れ状態モデルです.TTT-Linearは線形モデルを隠れ状態として使用しているのに対し、TTT-MLPは2層のMLPを隠れ状態として使用しています.
Q: TTT-LinearとTTT-MLPのインスタンスは、パフォーマンスとスケーラビリティの点で、TransformerとMambaモデルと比較してどうでしょうか?
A: TTT-LinearとTTT-MLPのインスタンスは、パフォーマンスとスケーラビリティの観点から、TransformerとMambaモデルと比較して、優れた結果を示しています.TTT-Linearは、8kのコンテキストにおいてTransformerよりも速く、Mambaと同等の性能を発揮しています.一方、TTT-MLPは、メモリI/Oに課題を抱えていますが、長いシーケンスにおいて大きな潜在能力を示しています.
Q: TTT-Linearモデルが8キロのコンテクストでトランスフォーマーより速く、ウォールクロックのタイムでマンバに匹敵することの意味を説明できますか?
A: TTT-Linearモデルが8kのコンテキストでTransformerよりも速く、Mambaと同等の壁時計時間を達成することは、モデルの効率性と性能の向上を示しています.これにより、TTT-Linearは長いコンテキストにおいても高速かつ効率的に処理を行うことができるため、大規模な自然言語処理タスクにおいて優れた選択肢となり得ます.
Q: TTT-MLPはメモリI/Oの面でどのような課題に直面し、それが長いコンテクストでの可能性にどのような影響を与えるのか?
A: TTT-MLPは、線形モデルに比べてMLPの隠れ状態の計算複雑度が増すため、メモリI/Oの面で課題に直面します.この複雑性の増大は、MLPのパラメータと中間結果の保存とアクセスに必要なメモリ要件の増大につながります.コンテキストの長さが長くなるにつれて、TTT-MLPのメモリI/O要求も増加し、長いコンテキストの処理における可能性に影響を与えます.
Q: TTT-LinearとTTT-MLPモデルは、長い文脈を扱う上で既存のRNNレイヤーの限界にどのように対処しているのだろうか?
A: TTT-LinearおよびTTT-MLPモデルは、長いコンテキストを処理する既存のRNNレイヤーの制限に対処するために、より効率的な方法を提供します.これらのモデルは、トークンのミニバッチを使用してTTTを行うことで、並列処理を向上させます.さらに、各TTTミニバッチ内の操作のデュアル形式を開発することで、現代のGPUやTPUをより効果的に活用します.このデュアル形式は、単純な実装と同等の出力を持ちながら、5倍以上高速にトレーニングできます.また、TTT-Linearは、8kコンテキストでTransformerよりも速く、Mambaと同等の速度を達成します.
Q: TTT-LinearとTTT-MLPのインスタンスの評価で使用されたパラメータのスケールについて、もう少し詳しく教えてください.
A: TTT-LinearとTTT-MLPの評価では、パラメータのスケールは125Mから1.3Bまで変化します.
Q: シーケンスモデリング分野における今後の研究の方向性について、この発見はどのような意味を持つのだろうか?
A: 研究の結果から、シーケンスモデリングの将来の研究方向にはいくつかの重要な示唆があります.まず、隠れ状態をモデル化し、更新規則を自己教師付き損失ℓに対する勾配ステップとして扱うことで、テストシーケンスでの隠れ状態の更新がモデルの訓練と同等であることが示されました.このプロセスは、テスト時トレーニング(TTT)としてプログラムされ、TTTレイヤーに組み込まれています.さらに、長いコンテキストとより大きなモデルを使用することで、TTTレイヤーの利点がより顕著になることが期待されます.また、システムの最適化やパイプライン並列処理を通じて長いシーケンスを処理する方法など、さらなる改善の余地があります.さらに、より野心的なfの具体化も検討されるべきです.
Mixture of A Million Experts
著者:Xu Owen He
発行日:2024年07月04日
最終更新日:2024年07月04日
URL:http://arxiv.org/pdf/2407.04153v1
カテゴリ:Machine Learning, Artificial Intelligence
概要:
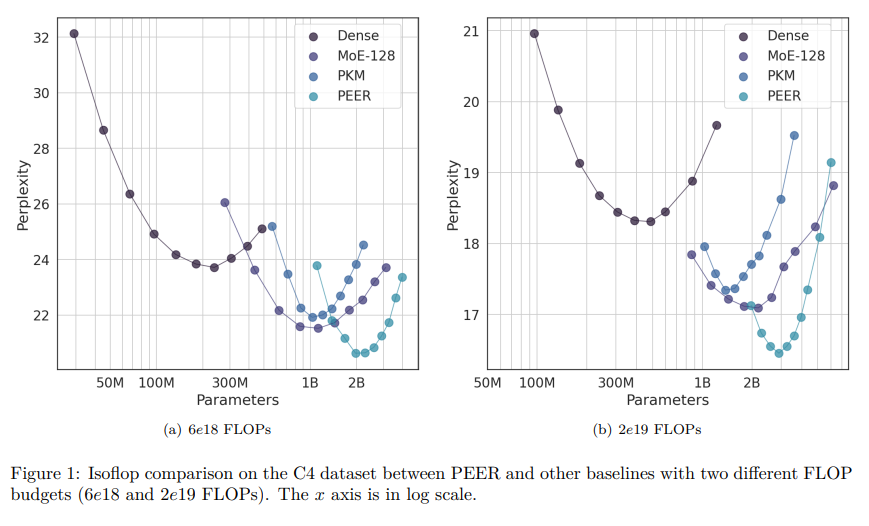
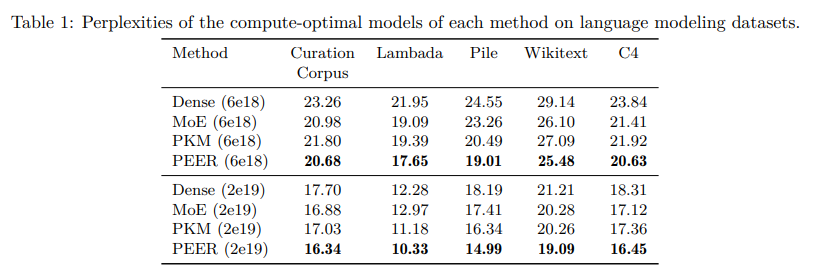
標準のトランスフォーマーアーキテクチャにおけるフィードフォワード(FFW)レイヤーは、隠れ層の幅が増加するにつれて、計算コストとアクティベーションメモリが線形に増加します.疎な専門家の混合(MoE)アーキテクチャは、この問題に対処するための有効なアプローチとして登場しました.最近の微細なMoEスケーリング法の発見は、より高い粒度がより良いパフォーマンスにつながることを示しています.しかし、既存のMoEモデルは、計算と最適化の課題により、少数の専門家に限定されています.本論文では、PEER(パラメータ効率的な専門家検索)という、巨大な数の小さな専門家(100万以上)からの疎な検索にプロダクトキー技術を利用する新しいレイヤーデザインを紹介しています.言語モデリングタスクでの実験では、PEERレイヤーがパフォーマンスと計算のトレードオフの観点で、密なFFWや粗いMoEを上回ることを示しています.膨大な数の専門家を効率的に活用することで、PEERはトランスフォーマーモデルのさらなるスケーリングの可能性を開き、計算効率を維持します.
Q&A:
Q: きめ細かなMoEスケーリング則の概念と、それがパフォーマンスにどのように関係しているのか説明してもらえますか?
A: 細かいMoEスケーリング則は、非常に広い密な順伝播層を多数の小さな専門家に分解するアーキテクチャであり、最近の発見によると、より高い粒度がより良いパフォーマンスをもたらすことが示されています.モデルの容量を向上させ続けることで、最終的には非常に多くの小さな専門家からなる大規模なモデルにつながると考えられます.
Q: PEERレイヤーの設計は、膨大な数の小さなエキスパートから疎な検索を行うために、プロダクトキー技術をどのように活用しているのだろうか?
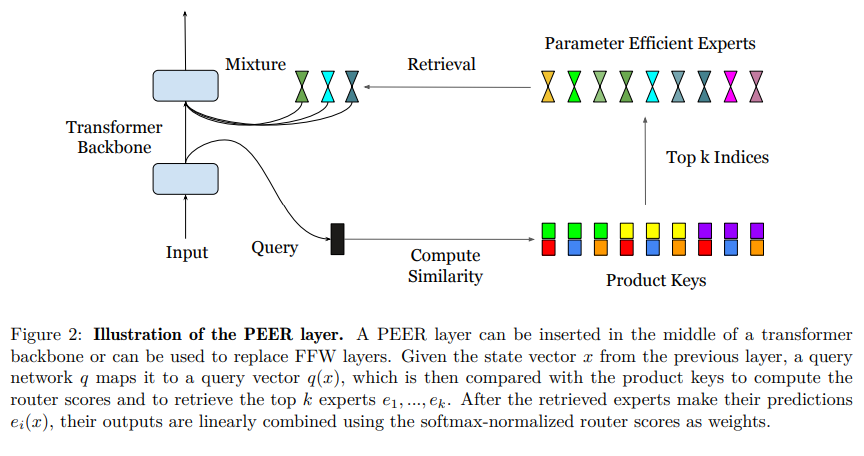
A: PEERレイヤーデザインは、膨大な数の小さな専門家からのスパースな検索において、プロダクトキー技術を活用しています.具体的には、PEERレイヤーは、前のレイヤーからの状態ベクトルxを受け取り、クエリネットワークqによってクエリベクトルq(x)にマッピングされます.その後、このクエリベクトルはプロダクトキーと比較され、ルータースコアが計算され、上位k個の専門家が取得されます.取得された専門家が予測を行い、その出力はソフトマックス正規化されたルータースコアを重みとして線形結合されます.
Q: 具体的にどのような計算や最適化の課題が、既存のMoEモデルを少数の専門家に限定しているのか?
A: 既存のMoEモデルを少数の専門家に制限している具体的な計算上および最適化上の課題は、計算コストと最適化の課題に起因しています.これらの課題により、高い専門家の数をサポートするMoE設計が制限されています.
Q: 性能と計算のトレードオフの観点から、PEERレイヤーは高密度FFWや粗視化MoEをどのように上回るのか?
A: PEERレイヤーは、膨大な数の小さな専門家からスパースな検索を行うために製品キー技術を利用する新しいレイヤーデザインであり、言語モデリングタスクにおいて、パフォーマンス-計算トレードオフの観点で密なFFWおよび粗い粒度のMoEsを上回ることが実験で示されています.巨大な数の専門家を効率的に活用することで、PEERはトランスフォーマーモデルのさらなるスケーリングの可能性を開放し、計算効率を維持します.
Q: PEERレイヤーの有効性を実証するために言語モデリングタスクで行われた実験について詳しく教えてください.
A: 言語モデリングタスクで行われた実験では、PEERレイヤーが密なFFWや粗い粒度のMoEsよりも、性能と計算のトレードオフの面で優れていることが示されました.PEERは、膨大な数の専門家を効率的に活用することで、トランスフォーマーモデルのさらなるスケーリングを可能にし、計算効率を維持しています.
Q: PEERはどのようにして、変圧器モデルにおける膨大な数のエキスパートの効率的な活用を可能にしているのか?
A: PEERは、膨大な数の専門家を効率的に活用することを可能にします.PEERレイヤーは、複数の専門家を持つMixture of Expertsアーキテクチャであり、製品キーを使用してルーター内で計算を行います.各専門家は単一ニューロンMLPとして機能し、製品キーとの比較によってトップkの専門家が選択されます.選択された専門家の出力は、ソフトマックス正規化されたルータースコアを重みとして線形結合されます.この方法により、膨大な数の専門家が効率的に利用され、transformerモデルのさらなるスケーリングが可能になります.
Q: 計算効率を維持しながら変圧器モデルをさらに拡張するために、PEERはどのような利点があるのでしょうか?
A: PEERは、膨大な数の専門家からなるプールから選択された微小な専門家を利用することで、transformerモデルのさらなるスケーリングの可能性を引き出すと同時に、計算効率を維持します.PEERは、広範なMoEスケーリング法則を活用し、高い粒度がより良いパフォーマンスをもたらすことを示しています.PEERは、広範なMoEスケーリング法則を活用し、高い粒度がより良いパフォーマンスをもたらすことを示しています.PEERは、広範なMoEスケーリング法則を活用し、高い粒度がより良いパフォーマンスをもたらすことを示しています.PEERは、広範なMoEスケーリング法則を活用し、高い粒度がより良いパフォーマンスをもたらすことを示しています.
Q: モデルサイズと計算コストを切り離すというコンセプトは、スパース混合エキスパート・アーキテクチャの開発においてどのような役割を果たしているのだろうか?
A: モデルのサイズと計算コストを切り離すという概念は、スパースな専門家の混合アーキテクチャの開発において重要な役割を果たします.これにより、モデルのサイズを増やすことなく、計算コストを削減できます.専門家モジュールのスパースな活性化により、膨大な数の専門家を効率的に利用できるため、より高い性能を実現できます.
Q: FFW層における計算コストと活性化メモリの線形増加は、トランスフォーマーアーキテクチャにどのような影響を与えるのだろうか?
A: FFW層の計算コストとアクティベーションメモリの線形増加は、トランスフォーマーアーキテクチャにおいて計算効率を低下させる可能性がある.
Q: 100万人の小さな専門家というコンセプトは、既存のモデルと比較してPEERレイヤーの全体的なパフォーマンスにどのように貢献するのでしょうか?
A: PEERレイヤーは、100万人以上の小さな専門家からの情報を効率的に利用することによって、既存のモデルと比較して優れた性能を発揮します.これにより、PEERはトランスフォーマーモデルのさらなるスケーリングを可能にし、計算効率を維持しながら、性能とのトレードオフを改善します.
RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs
著者:Yue Yu, Wei Ping, Zihan Liu, Boxin Wang, Jiaxuan You, Chao Zhang, Mohammad Shoeybi, Bryan Catanzaro
発行日:2024年07月02日
最終更新日:2024年07月02日
URL:http://arxiv.org/pdf/2407.02485v1
カテゴリ:Computation and Language, Artificial Intelligence, Information Retrieval, Machine Learning
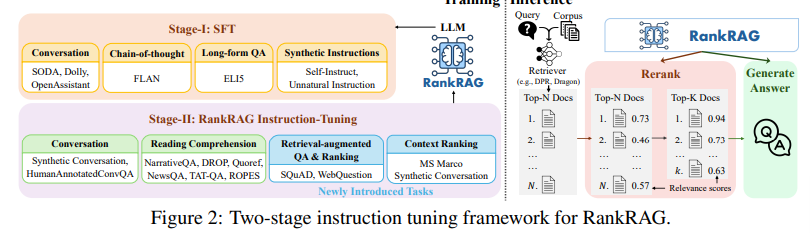
概要:
大規模言語モデル(LLM)は通常、リトリーバーからのトップkコンテキストを使用して、検索増強生成(RAG)で活用されます.この研究では、新しい指示微調整フレームワークであるRankRAGを提案し、RAGでのコンテキストのランキングと回答生成の両方を目的として単一のLLMを指示微調整します.特に、微調整されたLLMは、トレーニングブレンドにわずかなランキングデータを追加することで驚くほどうまく機能し、同じLLMを大量のランキングデータで専門的に微調整したモデルを含む既存の専門的なランキングモデルを上回ります.生成に関しては、GPT-4-0613、GPT-4-turbo-2024-0409、およびChatQA-1.5などの強力なベースラインと比較して、当社のモデルを評価しました.ChatQA-1.5は、RAGベンチマークで最先端のパフォーマンスを発揮するオープンソースモデルです.具体的には、当社のLlama3-RankRAGは、9つの知識集約的なベンチマークでLlama3-ChatQA-1.5およびGPT-4モデルを大幅に上回ります.さらに、バイオメディカル領域の5つのRAGベンチマークで、バイオメディカルデータに対する指示微調整を行わずにGPT-4と同等のパフォーマンスを発揮し、新しいドメインへの汎用性を示しています.
Q&A:
Q: RankRAGフレームワークで使われている、インストラクションの微調整の具体的な方法について教えてください.
A: RankRAGフレームワークの指示微調整に使用される具体的な方法論は、LLMをコンテキストのランキングと回答生成の両方に指示することです.訓練中、与えられた質問に対して関連するコンテキストやパッセージを特定する専門のタスクを設計します.このタスクはランキング向けに構造化され、指示付きの通常の質問応答としてフレーム化され、検索増強生成タスクとより効果的に整合します.推論時には、LLMはまず、ランキングされたコンテキストを生成するために指示されます.この方法により、RankRAGはコンテキストのランキングと回答生成の両方に焦点を当て、LLMのRAG能力を向上させることができます.
Q: RankRAGの命令チューニングされたLLMは、既存のエキスパートランキングモデルと比較してどのように機能するのか?
A: RankRAGにおける指示チューニングされたLLMは、トレーニングブレンドにわずかなランキングデータを追加するだけで、既存の専門家ランキングモデルを上回ることができることがわかりました.
Q: Llama3-RankRAGとGPT-4-0613やGPT-4-turbo-2024-0409のような他の強力なベースラインとの主な違いは何ですか?
A: Llama3-RankRAGは、GPT-4-0613やGPT-4-turbo-2024-0409などの他の強力なベースラインと比較して、9つの知識集約型ベンチマークで優れたパフォーマンスを発揮します.また、医学領域の5つのRAGベンチマークでもGPT-4と同等の性能を示しますが、医学データの追加の指導を受けずに、新しいドメインへの汎用性を示す能力が優れています.
Q: 知識集約型ベンチマークにおけるLlama3-RankRAGのパフォーマンスについて、Llama3-ChatQA-1.5やGPT-4モデルと比較して詳しく教えてください.
A: Llama3-RankRAGは、知識集約的なベンチマークにおいて、Llama3-ChatQA-1.5およびGPT-4モデルに比べて優れたパフォーマンスを示しています.具体的には、9つの知識集約的なベンチマークでLlama3-RankRAGはLlama3-ChatQA-1.5およびGPT-4モデルを大幅に上回っています.
Q: Llama3-RankRAGは、バイオメディカル領域におけるRAGベンチマークにおいて、バイオメディカルデータでのファインチューニングの指示なしに、どのようなパフォーマンスを示すか?
A: Llama3-RankRAGは、バイオメディカル領域のRAGベンチマークで、バイオメディカルデータに対する指示の微調整なしでどのように実行されますか?
Q: Llama3-RankRAGの新しいドメインへの汎化能力が優れている要因は何か?
A: Llama3-RankRAGの新しいドメインへの優れた汎化能力には、ランキングデータの一部をLLMの調整ブレンドに統合することが重要な要素となっています.この手法は、ランキング関連の評価において、10倍以上のランキングデータで調整されたLLMを上回るほどの驚異的な効果を示しました.この成功は、RankRAGトレーニングの移転可能な設計に起因しています.
Q: RankRAGのインストラクションチューニングされたLLMのトレーニングブレンドに、ごく一部のランキングデータはどのように組み込まれたのか?
A: RankRAGでは、指示調整されたLLMにトレーニングブレンドにランキングデータの一部を組み込むことによって、ランキングデータの一部をトレーニングブレンドに組み込みました.
Q: この研究で比較する特定のLLMを選んだ意思決定プロセスについて教えてください.
A: 特定のLLMを比較研究に選択する決定プロセスに関する洞察を提供します.研究では、異なるLLMを比較するために、異なるベースラインとして、RAGなしのベースラインLLM、InstructGPT、PaLM2、FLAN-LaMDA、GLaM、Claude2、Mixtral-8x22B-Instruct、DeepSeek-V2 Chat、ChatGPTシリーズモデルなどが考慮されました.これらのLLMは、それぞれ独自のデータでトレーニングされ、公式に報告された結果のみが使用されました.また、ランキングにBERTやT5などのモデルが使用されましたが、これらはクエリとコンテキストの関連性を捉えるのに十分でない場合があり、ゼロショットの汎化能力を欠いている可能性があります.最近の研究では、LLMがランキングタスクで強力な能力を示していますが、RAGパイプラインでこの能力をどのように活用するかは未解明のままです.
Q: RankRAGフレームワークの開発とテスト中に直面した主な課題は何でしたか?
A: RankRAGフレームワークの開発とテストにおいて主な課題は、より困難なQAデータセットに対する性能向上であった.特に、長尾型QA(PopQA)やマルチホップQA(2WikimQA)タスクにおいて、RankRAGはChatQA-1.5よりも10%以上の改善を達成しています.これらの結果は、困難なタスクにおいて、RankRAGが10倍のランキングデータで微調整されたLLMsをも凌駕することを示唆しています.この成功は、RankRAGトレーニングの移転可能な設計に帰因しています.
Q: 自然言語処理の分野でのRankRAGの潜在的な応用と将来の発展をどのように想定していますか?
A: RankRAGは、既存の指示調整データを拡張し、コンテキスト豊かなQA、リトリーバ増強QA、ランキングデータセットを組み込むことで、LLMのRAG能力を向上させます.これにより、RAGのリトリーバルと生成フェーズの両方で無関係なコンテキストをフィルタリングするLLMの能力が向上します.将来的には、RankRAGは自然言語処理の分野で、より高度な質問応答システムや情報検索システムの開発に活用される可能性があります.RankRAGの訓練方法やデザインの転送可能性により、他のモデルを凌駕する性能を発揮し、知識密集型ベンチマークで優れた結果を示しています.
Reasoning in Large Language Models: A Geometric Perspective
著者:Romain Cosentino, Sarath Shekkizhar
発行日:2024年07月02日
最終更新日:2024年07月02日
URL:http://arxiv.org/pdf/2407.02678v1
カテゴリ:Artificial Intelligence, Computation and Language
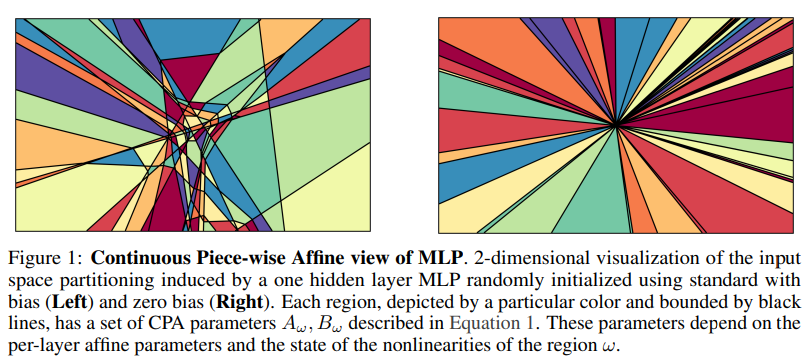
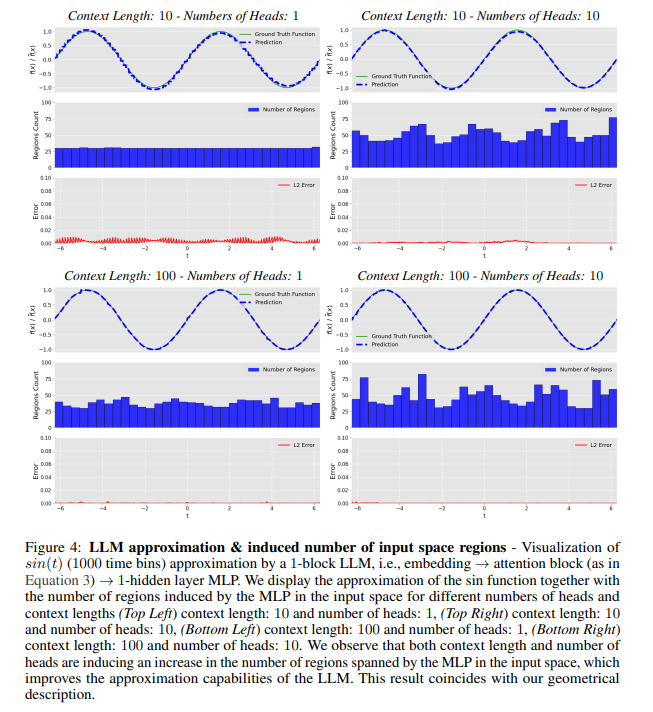
概要:
大規模言語モデル(LLM)の実世界アプリケーションにおける進化は、その推論能力の向上に極めて重要です.この研究では、大規模言語モデル(LLM)の推論能力をその幾何学的理解を通じて探求します.私たちは、LLMの表現力と自己注意グラフの密度との関連を確立します.私たちの分析は、これらのグラフの密度がMLPブロックへの入力の固有次元を定義することを示しています.理論的分析とおもちゃの例を通じて、より高い固有次元はLLMの表現能力を高めることを示します.さらに、この幾何学的フレームワークをLLMの推論能力を向上させるための最近の手法の進歩と結び付ける経験的証拠を提供します.
Q&A:
Q: 幾何学的な理解を通して、大規模な言語モデルの推論能力を分析するための具体的な方法を説明してもらえますか?
A: 大規模言語モデルの推論能力を幾何学的理解を通じて分析するために使用される具体的な方法は、自己注意グラフの密度とMLPブロックへの入力の固有次元の関係を確立することです.これにより、自己注意グラフの密度が入力の固有次元を定義し、より高い固有次元はLLMの表現能力を向上させることを示します.理論的分析とおもちゃの例を通じて、この幾何学的フレームワークを使用して、LLMの推論能力を向上させるための最近の手法との関連性を示しています.
Q: LLMの表現力と自己アテンション・グラフの密度との関連性をどのように確立したのですか?
A: LLMの表現力と自己注意グラフの密度との間の関連性を確立するために、各アテンションヘッドのグラフ密度を分析することによって特に自己注意ブロックを調査しました.この固有次元がコンテキストの長さやヘッドの数と関連している方法を示しました.入力のMLPブロックの固有次元が高いほど、LLMの表現能力が高まることを理論的分析とおもちゃの例を通じて実証しました.
Q: 自己アテンショングラフの密度がMLPブロックへの入力の固有次元をどのように定義しているのか、詳しく教えてください.
A: 自己注意グラフの密度が高いほど、MLPブロックへの入力の固有次元が高くなります.具体的には、自己注意ブロックのグラフ密度を分析することで、LLMの表現力を捉えることができます.自己注意グラフの密度が高いと、MLPによって誘導される領域の数が増加し、その表現力も高まります.
Q: 理論的な分析や玩具の例を通じて、内在次元が高いほどLLMの表現能力が高いことをどのように証明したのですか?
A: 理論的な分析とおもちゃの例を用いて、より高い固有次元がLLMの表現能力を向上させることを示しました.具体的には、自己注意グラフの密度がMLPブロックへの入力の固有次元を定義することを示しました.この関係により、より複雑な入力がモデルの推論パフォーマンスを向上させることが示唆されます.
Q: 幾何学的なフレームワークと、LLMの推論能力を高めることを目的としたメソッドにおける最近の進歩を結びつける、どのような経験的証拠を提供しましたか?
A: この幾何学的フレームワークを最近のLLMの推論能力向上のための手法の進歩と結びつけるために、実証的証拠を提供しました.
Q: 大規模な言語モデルの表現力をどのように定義するのか?
A: 大規模言語モデルの表現力は、その内在次元によって定義されます.内在次元が高いほど、LLMの表現能力が高くなります.内在次元が増加すると、自己注意層の表現力も増加します.
Q: 自己注視グラフの密度とLLMの推論能力との関連について、その意味を説明していただけますか?
A: 自己注意グラフの密度は、LLMの推論能力と密接に関連しています.具体的には、自己注意機構における各アテンションヘッドのグラフ密度がLLMの内部理解の幾何学的性質を示すことができます.研究結果は、LLMの内部理解の幾何学的性質が、モデルの推論能力に影響を与えることを示唆しています.特に、最終層における内在次元の大幅な上昇は、推論パフォーマンスの向上と強く相関しています.
Q: 実世界のアプリケーションのための大規模な言語モデルの開発にとって、今回の研究結果はどのような意味を持つ可能性がありますか?
A: 私たちの研究結果の潜在的な含意のいくつかは、実世界の応用における大規模言語モデルの開発に重要な影響を与える可能性があります.例えば、大きなモデルサイズと増加したコンテキスト長は、推論能力を向上させる一方で、実世界の使用ケースにおいて計算コストと推論の遅延を引き起こす可能性があります.さらに、LLMのアーキテクチャコンポーネントや変異の解釈により、LLMの表現力を向上させるための手段が明らかになるかもしれません.これにより、実世界のタスクにおける性能向上や効率化が期待されます.
Q: LLMの推論能力を向上させるために、あなたの分析から得られた洞察をどのように実用化することを想定していますか?
A: 私たちの分析から得られた洞察を実用的に活用する方法は、LLMの推論能力を向上させるために、トランスフォーマーレイヤーの幾何学的フレームワークを活用することです.このフレームワークを使用することで、LLMの内部構造や情報処理能力をより深く理解し、推論能力を向上させるための新しい手法やアルゴリズムを開発することが可能となります.さらに、幾何学的アプローチを通じて、LLMのモデルサイズや入力コンテキストの長さを増やさずに、推論能力を向上させる方法を探求することが重要です.
A Survey on Mixture of Experts
著者:Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, Jiayi Huang
発行日:2024年06月26日
最終更新日:2024年06月26日
URL:http://arxiv.org/pdf/2407.06204v1
カテゴリ:Machine Learning, Computation and Language
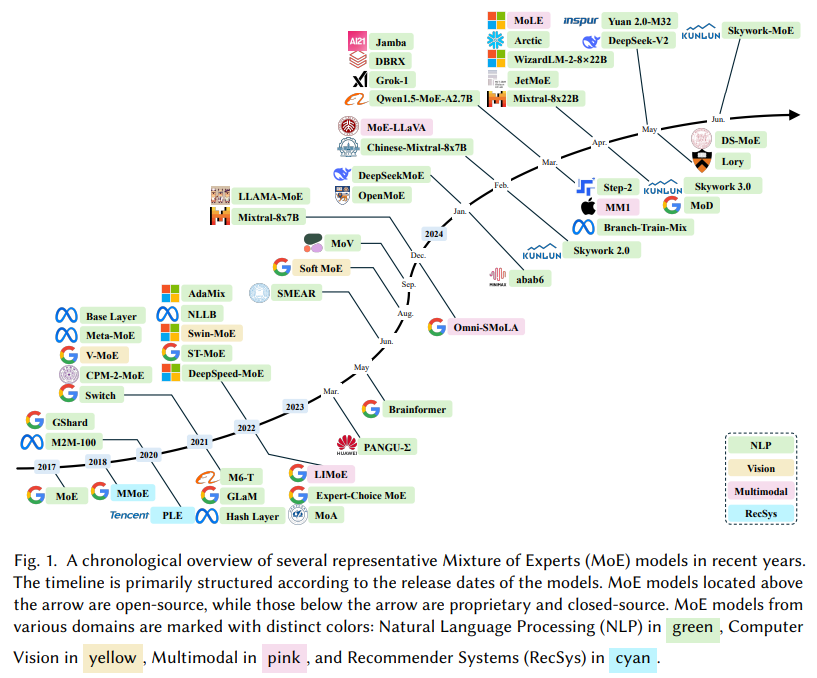
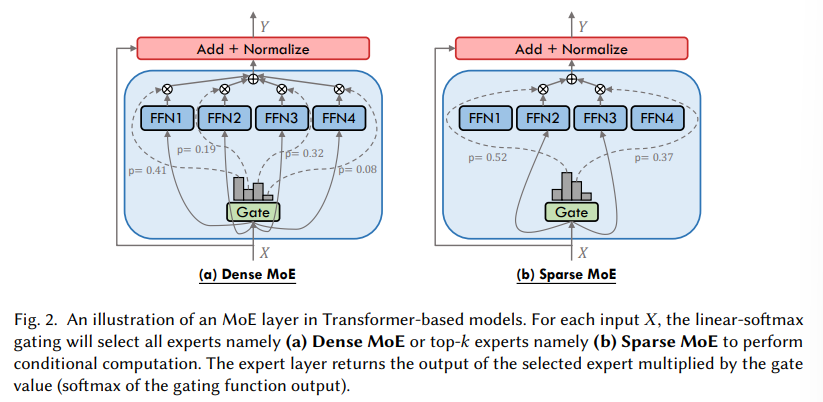
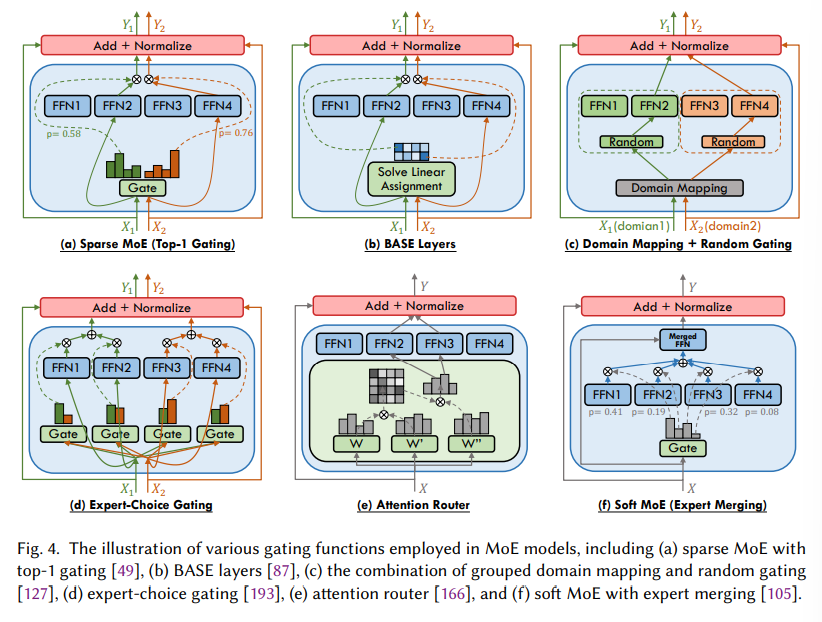
概要:
大規模言語モデル(LLMs)は、自然言語処理からコンピュータビジョンなどさまざまな分野で前例のない進歩を遂げてきました.LLMsの威力は、その大規模なモデルサイズ、幅広く多様なデータセット、およびトレーニング中に利用される膨大な計算能力によって支えられており、これらすべてがLLMsの新たな能力(例:コンテキスト学習)に貢献しています.この文脈の中で、専門家の混合(MoE)は、計算オーバーヘッドを最小限に抑えながらモデル容量を大幅に拡大する効果的な方法として登場し、学術界や産業界から注目を集めています.しかし、MoEに関する文献の体系的かつ包括的なレビューが不足しているため、この調査はそのギャップを埋めることを目指しており、MoEの複雑さに深く入り込む研究者にとって重要なリソースとなります.MoEレイヤーの構造を簡単に紹介し、次にMoEの新しい分類法を提案します.さらに、アルゴリズム的およびシステム的な側面を含むさまざまなMoEモデルのコアデザインを概説し、利用可能なコレクションも紹介します.さらに、実践におけるMoEの多面的な応用と、将来の研究の可能性についても概説します.MoE研究の最新情報の共有と進化を促進するために、https://github.com/withinmiaov/A-Survey-on-Mixture-of-Experts でアクセス可能なリソースリポジトリを設立しました.
Q&A:
Q: 各分野における大規模言語モデル(LLM)の意義について教えてください.
A: 大規模言語モデル(LLMs)は、自然言語処理、コンピュータビジョン、および多様な分野において革新的な影響を持っています.これらのモデルは、その巨大なサイズ、訓練されるデータの幅広さ、および開発に投資された膨大な計算リソースに起因する非凡な能力を示しています.LLMsの持つスケーリング法則を認識し、持続可能なスケーリングのための効率的な手法を特定し実装することが重要です.
Q: 豊富で多様なデータセットは、LLMの能力にどのように貢献するのか?
A: 広範で多様なデータセットは、LLMsの能力向上に重要な役割を果たします.これらのデータセットによって、モデルは異なる文脈やパターンを学習し、より幅広い知識を獲得することができます.さらに、多様なデータセットを使用することで、モデルはより一般化された能力を獲得し、新しいデータに対しても適切に対応できるようになります.
Q: 最小限の計算オーバーヘッドでモデル容量を拡大するために、専門家の混合(MoE)が果たす役割とは?
A: モデルの容量を最小の計算オーバーヘッドでスケーリングする際に、専門家の混合(MoE)の役割は、適切な専門家ネットワークを動的に選択するゲーティングメカニズムを活用して、入力データの処理に適した専門家ネットワークを選択することです.これにより、モデルは必要に応じて計算リソースを割り当てることができ、条件付き計算として知られる概念を実現します.このようにして、計算コストを抑えながらも、必要な専門家のみが特定の入力に対して活動し、モデルの容量を拡大することができます.
Q: MoEに関する文献の体系的かつ包括的なレビューを行おうと思った動機は何ですか?
A: MoEモデルの文献に対する体系的かつ包括的なレビューを実施する動機は、MoE技術の領域を探索する研究者にとって貴重な資料となることを目指していたからです.新しいMoEモデルの分類法を導入し、アルゴリズム設計、システム設計、実用的な応用という3つの観点を含む詳細な分析を提供しました.さらに、オープンソースの実装、詳細なハイパーパラメーター設定、徹底的な実証評価を補完しました.この調査は、MoEの文献に対する包括的なレビューが不足しているという課題に対処し、研究者が迅速にMoEモデルに精通するのに役立つ重要な参考資料となることを期待しています.
Q: さまざまなMoEモデルの中核となる設計について、アルゴリズムやシステム的な側面も含めて概要を教えてください.
A: MoEモデルのさまざまなコアデザインには、アルゴリズミックな側面とシステム的な側面が含まれています.アルゴリズミックな側面では、各エキスパートの重み付け方法やゲート関数の設計、学習アルゴリズムの最適化などが重要です.一方、システム的な側面では、計算、通信、およびストレージの最適化が必要であり、MoEモデルの特有の課題であるスパースで動的な性質に対処するために適合された改善が行われます.
Q: MoEに関連するオープンソースの実装、ハイパーパラメータ設定、経験的評価にはどのようなものがありますか?
A: MoEに関連するいくつかの利用可能なオープンソースの実装、ハイパーパラメータ構成、および実証評価には、Colossal-AI、OpenMoE、Mila QuebecのScatterMoE、スタンフォード大学のMegablocks、MicrosoftのTutel、BaiduのSE-.MOE、北京大学のHetuMoE、MicrosoftのDeepspeed-MoE、清華大学のFastMoE、MetaのFairseq、GoogleのMesh-TensorFlowなどが含まれます.
Q: MoEモデルは異業種間で実際にどのように適用されているのか?
A: MoEモデルは、自然言語処理、コンピュータビジョン、レコメンダーシステム、マルチモーダルなコンテキストなど、さまざまな分野で実践されています.これらのモデルは、専門知識の大規模なプールから専門家を活用し、モデルの容量を増やすことなく計算要件を増やさずにスケーラブルで柔軟なイノベーションを提供しています.実際、2024年にはMixtral-8x7Bなどの産業規模のLLMが登場し、MoEは着実な成長を続けています.
Q: MoE分野における今後の研究の方向性にはどのようなものが考えられるか?
A: 将来の研究の方向性として、MoEモデルの新たなアルゴリズム設計やシステム設計の探求、実践的な応用の拡大、さらなる実証評価の実施などが挙げられます.
Q: MoE研究の継続的な更新と最先端開発の共有のために設立されたリソースリポジトリに、研究者はどのようにアクセスできますか?
A: 研究者は、MoEの研究の最新情報や先端技術の共有のために設立されたリソースリポジトリにアクセスすることができます.
Q: 今回の調査で提案されたMoEの新しい分類法について詳しく教えてください.
A: 本調査では、MoEモデルの新しい分類法を提案しています.この分類法は、アルゴリズム設計、システム設計、実用的な応用という3つの異なる視点を包括的に分析しています.具体的には、MoEアルゴリズムの進化に焦点を当て、特にトランスフォーマーベースのLLMにおいて、フィードフォワードネットワーク(FFN)レイヤーをMoEレイヤーに置き換える傾向が強調されています.各MoEレイヤーは複数のFFN(各々がエキスパートとして指定される)を統合し、これらのエキスパートの選択的サブセットを活性化するゲーティング関数を使用します.この新しい分類法は、ゲーティング関数やエキスパートネットワークの設計選択肢、利用可能なオープンソースのコレクションなどを探求しています.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: この論文で導入された新しい手法のコード実装のurlは、https://github.com/hpcaitech/ColossalAI です.
RouteLLM: Learning to Route LLMs with Preference Data
著者:Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, Ion Stoica
発行日:2024年06月26日
最終更新日:2024年07月01日
URL:http://arxiv.org/pdf/2406.18665v2
カテゴリ:Machine Learning, Artificial Intelligence, Computation and Language
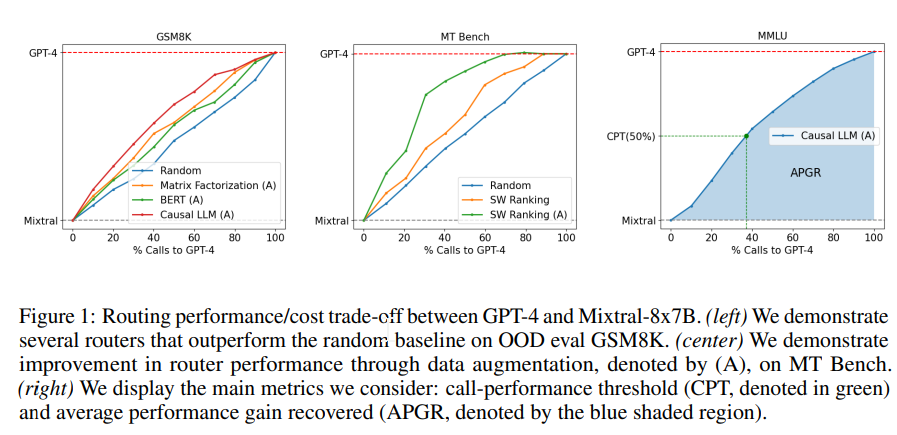
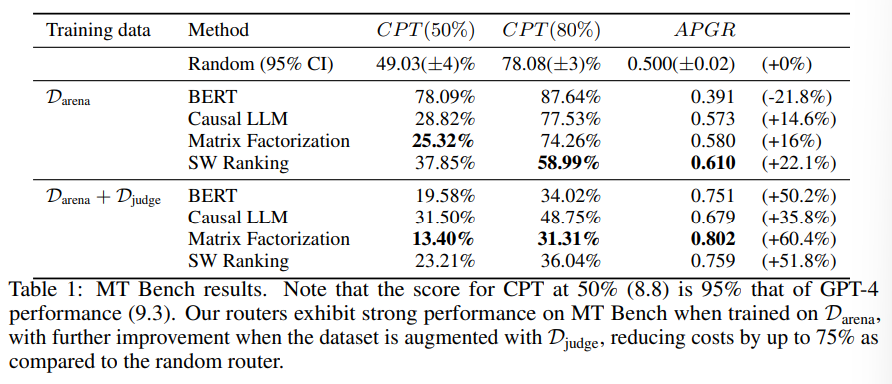
概要:
大規模言語モデル(LLM)は、さまざまなタスクで印象的な能力を発揮しますが、どのモデルを使用するかの選択はしばしばパフォーマンスとコストのトレードオフを伴います.より強力なモデルは効果的ですが、より高い費用がかかり、能力の低いモデルはコスト効率が良いです.このジレンマに対処するために、私たちはいくつかの効率的なルーターモデルを提案し、推論中により強力なモデルとより弱いモデルの間を動的に選択し、コストと応答品質のバランスを最適化することを目指しています.私たちは、人間の選好データとデータ拡張技術を活用して、これらのルーターのトレーニングフレームワークを開発し、パフォーマンスを向上させます.広く認識されているベンチマークでの評価では、私たちのアプローチが応答の品質を損なうことなく、コストを2倍以上削減することが示されています.興味深いことに、私たちのルーターモデルは、強力なモデルと弱いモデルがテスト時に変更されても、そのパフォーマンスを維持するという大きな転移学習能力も示しています.これは、これらのルーターがLLMを展開するためのコスト効率の良いかつ高性能なソリューションを提供する可能性を示しています.
Q&A:
Q: 推論中、ルーターモデルはどのように強いLLMと弱いLLMを動的に選択するのか?
A: 強力なLLMと弱いLLMの間で選択を動的に行うために、ルーターモデルは入力クエリの意図、複雑さ、およびドメインを推測し、候補モデルの能力を理解して、最適なモデルにクエリをルーティングする必要があります.さらに、ルーターモデルは経済的で速く、進化するモデルの状況に適応できる必要があります.新しいモデルが継続的に導入される状況下で、最適なLLMのルーティングを実現するために、簡単なクエリを弱いモデルに、より難しいクエリを強いモデルにルーティングすることで、コストを最小限に抑えつつ特定の性能目標を達成することを目指しています.
Q: ルーターのトレーニングフレームワークでは、具体的にどのようなデータ補強技術が使われているのですか?
A: ルーターのトレーニングフレームワークで使用される特定のデータ拡張技術は、LLMジャッジまたはドメイン内データをトレーニングデータに追加することです.
Q: トレーニング・プロセスで人間の嗜好データがどのように活用されているのか、詳細を教えてください.
A: 人間の選好データは、トレーニングプロセスでデータ拡張技術と組み合わせて活用されます.具体的には、2つのデータ拡張手法が探求されています.1つ目はGolden-labeled datasetsであり、この手法では、モデルの回答に対して自動的に計算されたゴールデンラベルlgが含まれるデータセットDgoldがトレーニングデータに追加されます.例えば、MMLUベンチマークなどが挙げられます.2つ目はLLM-judge-labeled datasetsであり、この手法ではオープンエンドの目的に関する選好ラベルを取得することが探求されています.これらのデータ拡張手法により、異なるモデルクラス間での人間の選好信号がまだまばらである場合でも、トレーニングデータの拡張が行われ、一般化が促進されます.
Q: 提案されているアプローチは、レスポンスの質を落とすことなく、具体的にどのようにコストを大幅に削減するのか?
A: 提案されたアプローチは、強力なモデルと弱いモデルの間で動的に選択することにより、コストと応答品質のバランスを最適化しようとするルーターモデルをいくつか提案しています.これにより、コストを大幅に削減することができます.さらに、ヒトの選好データとデータ拡張技術を活用したトレーニングフレームワークを開発し、広く認識されているベンチマークで2倍以上のコスト削減を実証しています.このアプローチにより、応答品質を損なうことなく、コストを大幅に削減することが可能です.
Q: ルーターモデルが示した転移学習能力について詳しく教えてください.
A: ルーターモデルは、強力なモデルと弱いモデルをテスト時に変更しても、その性能を維持するという転移学習の能力を示しています.これにより、これらのルーターはコスト効率の良い高性能な解決策を提供する潜在能力が示されています.
Q: アプローチの評価にはどのようなベンチマークが用いられたのか?
A: 評価に使用されたベンチマークは、MMLU、MTベンチ、GSM8Kでした.
Q: ルーターモデルは、コストとレスポンスの質のバランスをどのように最適化するのか?
A: ルーターモデルは、強力なLLMと弱いLLMの間で動的に選択し、クエリを適切なモデルにルーティングすることによって、コストと応答品質のバランスを最適化します.強力なモデルと弱いモデルの間でクエリを適切に分配することで、コストを最小化しながら特定の性能目標(例:強力なモデルの性能の90%)を達成することを目指しています.
Q: 推論中にLLMが強いか弱いかを選択する際に考慮される重要な要素とは?
A: 推論時により強力なLLMとより弱いLLMの間で選択する際に考慮される主要な要因は、モデルの品質とコストです.強力なモデルは高品質な応答を生成できますが、高コストがかかります.一方、弱いモデルはより安価で提供されますが、能力が低い傾向があります.選択は、応答の品質とコストのバランスを取ることが重要です.
Q: テスト時にストロングモデルとウィークモデルが変更された場合でも、ルーターモデルの性能はどのように維持されるのか?
A: 強いモデルと弱いモデルがテスト時に変更されても、ルーターモデルはパフォーマンスを維持することができます.これは、我々のアプローチがヒューマンプリファレンスデータとデータ拡張技術を活用してトレーニングフレームワークを開発したためです.このトレーニングフレームワークにより、ルーターモデルは転移学習能力を示し、テスト時に強いモデルと弱いモデルが変更されてもパフォーマンスを維持できるようになります.
Q: LLMを展開する上で、ルーターモデルはコスト効率に優れ、かつ高性能なソリューションを提供できる可能性があるのか?
A: これらのルーターモデルは、強力なモデルと弱いモデルをテスト時に変更しても、性能を維持することができます.これにより、LLMsを展開するための費用対効果の高い高性能なソリューションを提供する潜在能力が示されています.
Meta 3D Gen
著者:Raphael Bensadoun, Tom Monnier, Yanir Kleiman1, et al.
発行日:2024年06月25日
最終更新日:不明
URL:https://ai.meta.com/research/publications/meta-3d-gen/
カテゴリ:不明
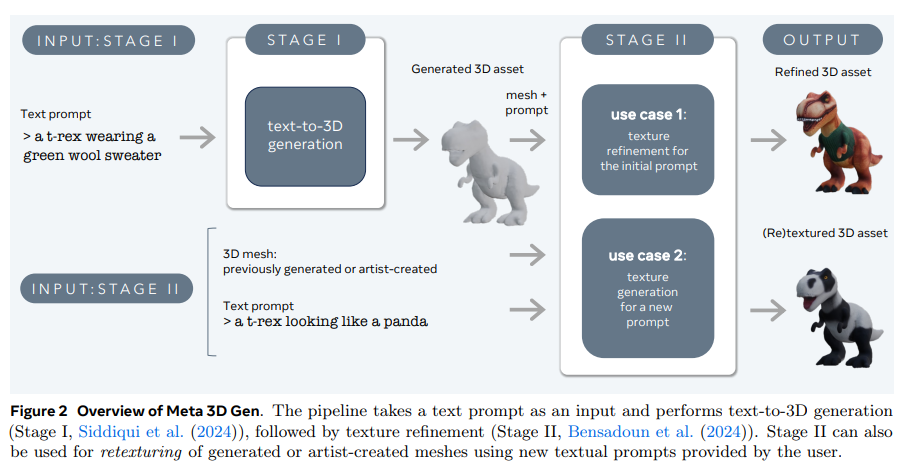
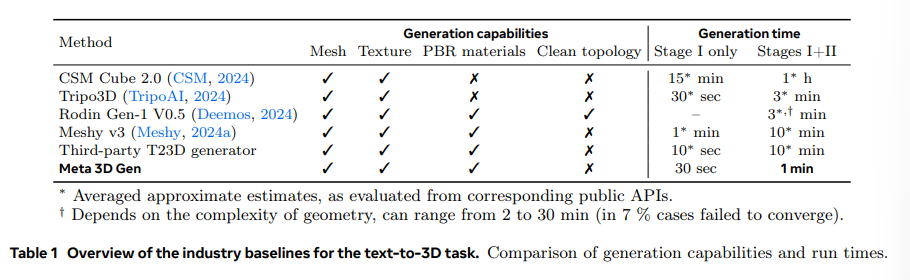
概要:
Meta 3D Gen(3DGen)は、新しい最先端で高速なパイプラインで、テキストから3Dアセットを生成するためのものです.3DGenは、高いプロンプトの忠実度と高品質な3D形状やテクスチャを1分未満で生成することができます.生成されたオブジェクトのテクスチャは、20秒で編集やカスタマイズが可能であり、その品質は他の代替手段と比較して高く、コストも削減されています.また、アーティストが作成した3Dメッシュの再テクスチャリングも変更なしで行うことができます.
Meta 3D Genは、Meta 3D AssetGenとMeta 3D TextureGenという主要な技術コンポーネントを統合しており、テキストから3Dおよびテキストからテクスチャ生成のために開発された2つのステージの方法を組み合わせています.具体的には、ステージIでは、ユーザーが提供したテキストプロンプトに基づいて初期の3Dアセットを生成します.このステージでは、Meta 3D AssetGenモデル(AssetGen)を使用し、3Dメッシュとテクスチャ、PBRマテリアルマップを生成します.推論時間は約30秒です.
さらに、ステージIIでは、2つの使用ケースがあります.1つ目は、生成された3Dアセットと初期のテキストプロンプトを使用して、より高品質なテクスチャとPBRマップを生成することです.これには、テキストからテクスチャを生成するMeta 3D TextureGenモデル(TextureGen)が使用されます.推論時間は約20秒です.2つ目の使用ケースでは、未テクスチャ化の3Dメッシュと外観を記述するプロンプトが与えられた場合、ステージIIを使用して、この3Dアセットのテクスチャをゼロから生成することができます(メッシュは以前に生成されたものまたはアーティストが作成したものである可能性があります).推論時間は約20秒です.
3DGenは、Metaの強力なテキストから画像へのモデルEmuを基盤としており、3Dオブジェクトの3つの高度に補完的な表現(ビュースペース、ボリューメトリックスペース、UVスペース)を効果的に組み合わせています.このプロセスは、AssetGenで始まり、オブジェクトの複数の一貫したビューを生成することから始まります.次に、AssetGenの再構築ネットワークが、ボリューメトリックスペース内の3Dオブジェクトの最初のバージョンを抽出します.これに続いて、メッシュ抽出が行われ、オブジェクトの3D形状と初期バージョンのテクスチャが確立されます.最後に、TextureGenのコンポーネントがテクスチャを再生成し、ビュースペースとUVスペースの組み合わせを利用して、テクスチャの品質と解像度を向上させながら、初期プロンプトに忠実であることを維持します.それぞれのステージは、内部データセットからの合成3Dデータのレンダリングを使用して、EmuをベースにしたMetaの一連の強力なテキストから画像へのモデルをさらに洗練させています.
さらに、3DGenは、内部データセットからの合成3Dデータのレンダリングを使用して、EmuをベースにしたMetaの一連の強力なテキストから画像へのモデルをさらに洗練させています.このプロセスにより、3Dオブジェクトの3つの高度に補完的な表現(ビュースペース、ボリューメトリックスペース、UVスペース)が効果的に組み合わせられ、より良いテクスチャが生成されています.
Q&A:
Q: Meta 3D Genがどのようにして高いプロンプト忠実度と高品質の3D形状やテクスチャを1分以内に実現するのか説明できますか?
A: メタ3D Genは、2つのステージからなる方法を組み合わせることで、高いプロンプトの忠実度と高品質な3D形状とテクスチャを1分未満で達成しています.第1ステージでは、ユーザーが提供したテキストプロンプトに基づいて、Meta 3D AssetGenモデル(AssetGen)を使用して初期の3Dアセットを作成します.このステップでは、テクスチャとPBRマテリアルマップを持つ3Dメッシュが生成されます.推論時間は約30秒です.第2ステージでは、2つの使用ケースがあります.1つ目は、Stage Iで生成された3Dアセットと生成に使用された初期のテキストプロンプトを使用して、Stage IIがこのアセットとプロンプトのためにより高品質なテクスチャとPBRマップを生成します.推論時間は約20秒です.2つ目の使用ケースは、未テクスチャ化の3Dメッシュとその外観を説明するプロンプトが与えられた場合、Stage IIを使用してこの3Dアセットのテクスチャをゼロから生成することができます.
Q: Meta 3D Genは、実世界のアプリケーションにおける3Dアセットのリライティングのために、物理ベースレンダリング(PBR)をどのようにサポートしていますか?
A: Meta 3D Genは、物理ベースのレンダリング(PBR)をサポートしており、生成されたアセットのリライティングを実世界のアプリケーションで可能にします.このシステムは、高品質なPBR素材マップを使用して、生成された3Dアセットのリライティングを容易に行うことができます.
Q: 3DGenは、追加のテキスト入力を使って、以前に生成された3D形状のジェネレーティブなリテクスチャリングをどのようにサポートしているのか、詳しく教えてください.
A: 3DGenは、以前に生成された3D形状を追加のテキスト入力を使用して再テクスチャリングすることをサポートします.具体的には、ユーザーが提供した追加のテキスト入力を使用して、以前に生成された(またはアーティストが作成した)3D形状を再テクスチャリングするための技術コンポーネントであるMeta 3D AssetGenとMeta 3D TextureGenを統合しています.これにより、異なる材料や芸術的スタイルを模倣することができます.具体的には、オブジェクトレベルのプロンプトをスタイル情報で補完することで、シーン全体を一貫した方法で再テクスチャリングすることができます.
Q: 3DGen、特にMeta 3D AssetGenとMeta 3D TextureGenに統合されている主要な技術コンポーネントは何ですか?
A: Meta 3DGenに統合されている主要な技術コンポーネントは、Meta 3D AssetGenとMeta 3D TextureGenです.Meta 3D AssetGenは、テキストから3Dアセットを生成するために使用され、初期の3Dメッシュとテクスチャ、PBRマテリアルマップを生成します.一方、Meta 3D TextureGenは、3DアセットのテクスチャとPBRマップを高品質に生成するために使用されます.これらのコンポーネントは、3DGenの高品質な3D生成を可能にするために統合されています.
Q: 3DGenは、どのようにして3Dオブジェクトをビュー空間、ボリューム空間、UV(またはテクスチャ)空間で同時に表現するのですか?
A: 3DGenは、3Dオブジェクトを視覚空間、体積空間、UV(またはテクスチャ)空間で同時に表現します.このプロセスは、AssetGenでオブジェクトの複数のかなり一貫したビューを生成し、テキストから画像へのマルチビューおよびマルチチャンネルバージョンを利用しています.次に、AssetGenの再構築ネットワークが3Dオブジェクトの最初のバージョンを体積空間で抽出します.これに続いて、メッシュ抽出が行われ、オブジェクトの3D形状と初期バージョンのテクスチャが確立されます.最後に、TextureGenのコンポーネントが、ビュースペースとUVスペースの組み合わせを利用してテクスチャを再生成し、テクスチャの品質と解像度を向上させながら初期プロンプトに忠実性を保持します.
Q: Meta 3D AssetGenとMeta 3D TextureGenの統合により、シングルステージモデルで勝率68%を達成した意義について教えてください.
A: メタ3D AssetGenとメタ3D TextureGenの統合により、単一段階モデルに比べて68%の勝率を達成することは、新しい組み合わせから得られる強みに加えて、個々のコンポーネントが受容機能において最先端を凌駕していることを示しています.具体的には、AssetGenは物理ベースのレンダリングをサポートし、生成されたオブジェクトを再照明することが可能であり、符号付き距離フィールドに基づいた改良された表現を通じてより良い3D形状を取得し、ビューベースの情報を効果的に組み合わせて単一のテクスチャに融合する新しいニューラルネットワークを開発しています.同様に、TextureGenは従来のテクスチャ生成アプローチを凌駕することで、ビューとUVスペースの両方で操作するエンドツーエンドネットワークを開発しています.
Q: 3DGenは、プロンプトの忠実度や複雑なテキストプロンプトのビジュアル品質という点で、業界のベースラインと比較してどうですか?
A: 3DGenは、複雑なテキストプロンプトにおいて、業界のベースラインに比べて、プロンプトの忠実度と視覚的品質の両方で優れていることが観察されました.
Q: Meta 3D Genがうまく活用された実例を教えてください.
A: メタ3D Genは、ビデオゲーム、拡張現実、仮想現実アプリケーションの開発、映画産業の特殊効果など、さまざまな分野で利用されています.
Q: 3Dアセット生成の分野におけるMeta 3D Genの今後の発展や応用の可能性をどのようにお考えですか?
A: Meta 3D Genは、テキストから3Dアセットを生成するための革新的な手法であり、その将来の発展と潜在的な応用は非常に期待されます.この手法は、テキストプロンプトから初期の3Dアセットを生成し、その後高品質なテクスチャとPBRマップを生成することで、高品質な3D生成を実現しています.将来的には、Meta 3D Genは、仮想現実や拡張現実などの分野での利用が期待されます.例えば、ゲーム開発や映像制作などの分野で、よりリアルな3Dアセットを効率的に生成するために活用される可能性があります.また、この手法は、テキストプロンプトに忠実であり、他の手法よりも高速で高品質な生成を実現しているため、プロフェッショナルな3Dアーティストにとっても有用性が高いと考えられます.
