
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をLLMによって生成されるQ&Aを用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.自動生成記事のクオリティと信頼性を向上させるためにアルゴリズムの改善に取り組んでいます.個人で資料のQ&Aを作成されたい方には、https://www.chatpdf.com/ や https://scispace.com/などがお勧めです.
- Agent Planning with World Knowledge Model
発行日:2024年05月23日
エージェントモデルの計画タスクにおいて、World Knowledge Model(WKM)を導入することで、グローバルな事前知識とローカルな動的知識を組み合わせてエージェントのパフォーマンスを向上させることが示された. - DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data
発行日:2024年05月23日
Leanのような証明アシスタントは数学的な証明の検証を革新し、LLMsは数学的な推論に有望な成果を示しているが、訓練データの不足により進歩が妨げられている.高校や大学レベルの数学競技問題から派生したLean 4証明データを使用して、DeepSeekMath 7Bモデルを微調整し、証明生成精度を向上させた. - Lessons from the Trenches on Reproducible Evaluation of Language Models
発行日:2024年05月23日
自然言語処理における言語モデルの効果的な評価に関する課題と、その解決策を提供する研究論文. - Aggregation of Reasoning: A Hierarchical Framework for Enhancing Answer Selection in Large Language Models
発行日:2024年05月21日
Chain-of-Thoughtプロンプティングの進歩により、LLMsの推論タスクにおける重要なブレークスルーが実現され、階層的推論集約フレームワークAoRが優れたアンサンブル手法を提供し、LLMsの推論能力を向上させている. - Efficient Multimodal Large Language Models: A Survey
発行日:2024年05月17日
過去1年間、MLLMsは視覚的なタスクで驚異的なパフォーマンスを示してきたが、モデルサイズやコストが課題であり、効率的なMLLMsの研究が重要である. - INDUS: Effective and Efficient Language Models for Scientific Applications
発行日:2024年05月17日
INDUSは、地球科学、生物学、物理学などのドメインに特化した大規模言語モデルで、科学コーパスを使用して訓練され、新しい科学ベンチマークデータセットを作成し、NLPタスクでRoBERTaやSciBERTを上回るパフォーマンスを示しています. - Layer-Condensed KV Cache for Efficient Inference of Large Language Models
発行日:2024年05月17日
トランスフォーマーアーキテクチャの注意メカニズムのための新しいKVキャッシュ方法は、大規模な言語モデルのメモリ消費を削減し、推論スループットを向上させることが示されました. - How Far Are We From AGI
発行日:2024年05月16日
AIの進化は人間社会に影響を与え、AGIへの動きを加速させている.AGIの定義、目標、発展軌道について包括的な議論が欠けており、この論文はその探求を促進している. - Risks and Opportunities of Open-Source Generative AI
発行日:2024年05月14日
ジェネラティブAI(Gen AI)のアプリケーションは、革新的な可能性があり、リスク管理と規制が必要であるが、オープンソースのGen AIの利点がリスクを上回ると主張されている.
Agent Planning with World Knowledge Model
著者:Shuofei Qiao, Runnan Fang, Ningyu Zhang, Yuqi Zhu, Xiang Chen, Shumin Deng, Yong Jiang, Pengjun Xie, Fei Huang, Huajun Chen
発行日:2024年05月23日
最終更新日:2024年05月23日
URL:http://arxiv.org/pdf/2405.14205v1
カテゴリ:Computation and Language, Artificial Intelligence, Computer Vision and Pattern Recognition, Machine Learning, Multiagent Systems
概要:
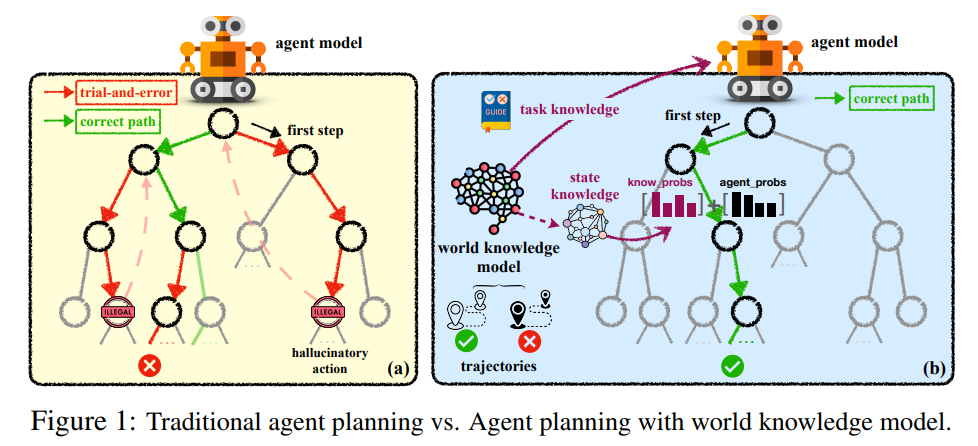
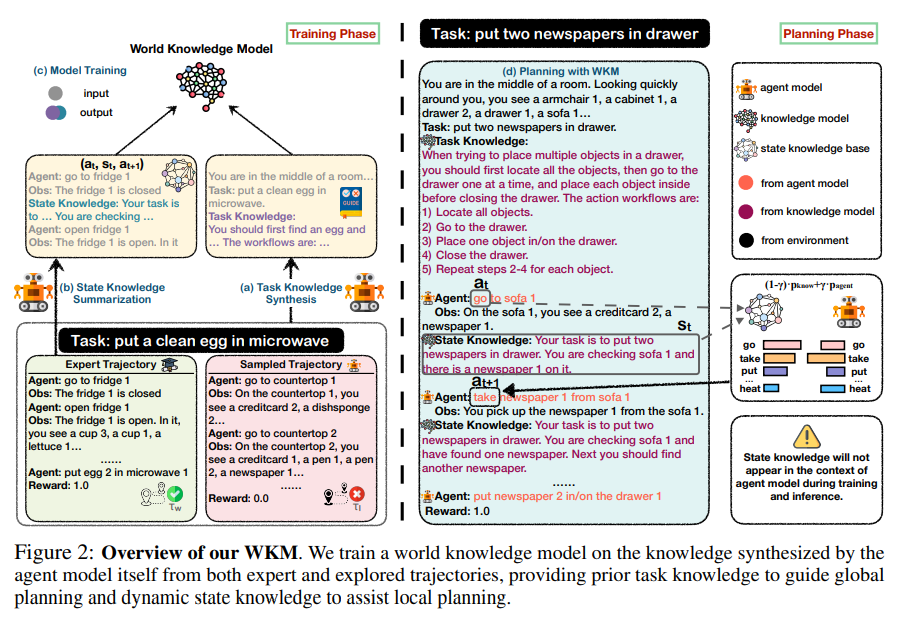
最近の取り組みでは、大規模言語モデル(LLM)をエージェントモデルとして直接使用して対話型計画タスクを実行することが評価されています.彼らの成果にもかかわらず、彼らは依然としてグローバルな計画における無謀な試行錯誤や、ローカルな計画における幻覚的な行動の生成に苦労しています.これは、彼らが「実際の」物理世界に対する理解力が乏しいためです.この論文では、タスク前にグローバルな事前知識を提供し、タスク中にローカルな動的知識を維持する人間の精神世界の知識モデルを模倣し、パラメトリックなWorld Knowledge Model(WKM)を導入してエージェントの計画を支援します.具体的には、エキスパートとサンプルされた軌跡から知識を自己合成するようにエージェントモデルを誘導し、グローバルな計画をガイドし、ローカルな計画を支援すること前タスク知識を提供するWKMを開発します.3つの複雑な実世界シミュレーションデータセットで、3つの最先端のオープンソースLLM、Mistral-7B、Gemma-7B、Llama-3-8Bを用いた実験結果は、強力なベースラインと比較して、当社の手法が優れたパフォーマンスを達成できることを示しています.さらに、我々のWKMが盲目的な試行錯誤や幻覚的な行動の問題を効果的に緩和し、エージェントが世界を理解するための強力なサポートを提供できることを分析しました.他の興味深い発見には、1) インスタンスレベルのタスク知識が未知のタスクに対してより一般化しやすいこと、2) 弱いWKMが強力なエージェントモデルの計画を導くことができること、3) 統一されたWKMトレーニングがさらなる発展の可能性を秘めていることが含まれます.コードはhttps://github.com/zjunlp/WKMで入手可能です.
Q&A:
Q: パラメトリックな世界知識モデル(WKM)が、エキスパートとサンプリングされた軌跡からどのように知識を自己合成するのか説明できますか?
A: パラメータ付きのWorld Knowledge Model(WKM)は、エキスパートとサンプリングされた軌跡から知識を自己合成するようにエージェントモデルを誘導します.具体的には、エージェントモデルは、専門家とサンプリングされた軌跡を比較してタスク知識を自己合成し、過去の行動に基づいて状態知識を自己要約し、状態知識ベースを構築します.
Q: WKMは、グローバルなプランニングの指針となること前のタスク知識と、ローカルなプランニングを支援する動的な状態知識をどのように提供するのか?
A: WKMは、グローバルプランニングをガイドするために事前のタスク知識を提供し、ローカルプランニングを支援するために動的な状態知識を提供します.これは、エージェントモデル自体によって専門家および探索された軌跡から合成された知識によって訓練された世界知識モデルによって行われます.
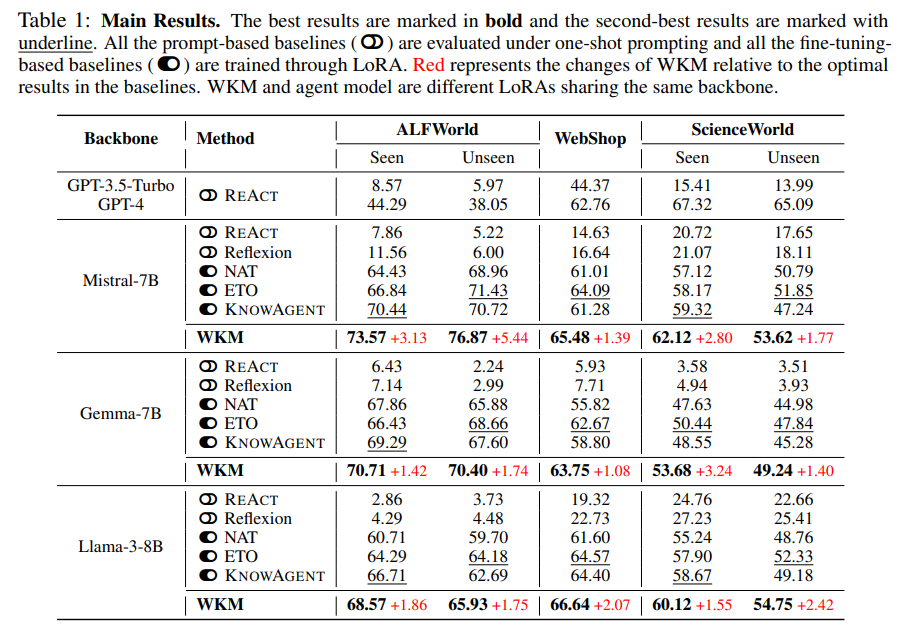
Q: 3つの複雑な実世界のシミュレーションデータセットに対する実験結果がどのように行われたか、詳しく教えてください.
A: 3つの複雑な実世界シミュレートされたデータセットでの実験結果は、WKM(前回のタスク知識を提供してグローバルプランニングをガイドし、動的な状態知識を提供してローカルプランニングを支援する手法)が、3つの最先端のオープンソースLLM(Mistral-7B、Gemma-7B、Llama-3-8B)と共に評価されました.これにより、我々の手法が優れた性能を達成できることが実験的結果で示されました.
Q: パフォーマンスという点で、あなたの方法は様々な強力なベースラインと比較してどうですか?
A: 私たちの手法は、さまざまな強力なベースラインと比較して、パフォーマンスの観点で優れていることが示されています.
Q: WKMはエージェント・プランニングにおいて、具体的にどのような問題の軽減を目指しているのか?
A: WKMは、グローバルプランニングにおける盲目的な試行錯誤の問題と、従来のエージェントモデルにおける局所プランニングにおける幻覚的な行動の問題を緩和することを目指しています.
Q: WKMはエージェントの世界の理解をどのように支援していますか?
A: WKMは、エージェントモデルが専門家や探索された軌跡から総合的な計画を導くための事前タスク知識を提供し、グローバルな計画をガイドし、局所的な計画を支援するための動的な状態知識を提供することで、エージェントの世界理解を助けます.
Q: インスタンスレベルのタスク知識が、どのようにして未知のタスクによりよく汎化できるのか、もう少し詳しく教えてください.
A: インスタンスレベルのタスク知識が未知のタスクに対してより一般化できる理由は、我々のモデルが生成する知識が、特定のデータセットに固有の詳細な情報を含んでいるためです.具体的には、我々のWKMによって生成された知識は、各データセットにおけるタスク知識を抽象化し、新しいデータセットレベルの知識に適応するためにエージェントモデルを再学習することで、未知のタスクに対応できるようになります.このようにして、インスタンスレベルの知識は、未知のタスクに対してより適応性が高く、一般化能力が強いと言えます.
Q: 弱いWKMは強いエージェントモデルのプランニングをどのように導くのか?
A: 弱いWKMは強いエージェントモデルの計画を導くことができます.これは、軽量な性質を持つ弱い知識モデルが、エージェントモデルのニーズに基づいて柔軟にパラメータを調整できるためです.これにより、大規模なエージェントモデルが新しい環境に適応する際の難しさを微調整を通じて解決できます.
Q: 統一されたWKMのトレーニングに、さらなる発展の可能性を感じますか?
A: 統一されたWKMトレーニングは、さらなる発展の可能性を秘めています.これにより、複数のデータセットから収集された世界知識を組み合わせて1つの統一された世界知識モデルをトレーニングすることで、未知のタスクに対してもより良い予測が可能となります.また、弱いWKMが強力なエージェントモデルの計画を導くことができ、統一されたWKMトレーニングはさらなる発展の可能性を秘めています.
DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data
著者:Huajian Xin, Daya Guo, Zhihong Shao, Zhizhou Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, Xiaodan Liang
発行日:2024年05月23日
最終更新日:2024年05月23日
URL:http://arxiv.org/pdf/2405.14333v1
カテゴリ:Artificial Intelligence
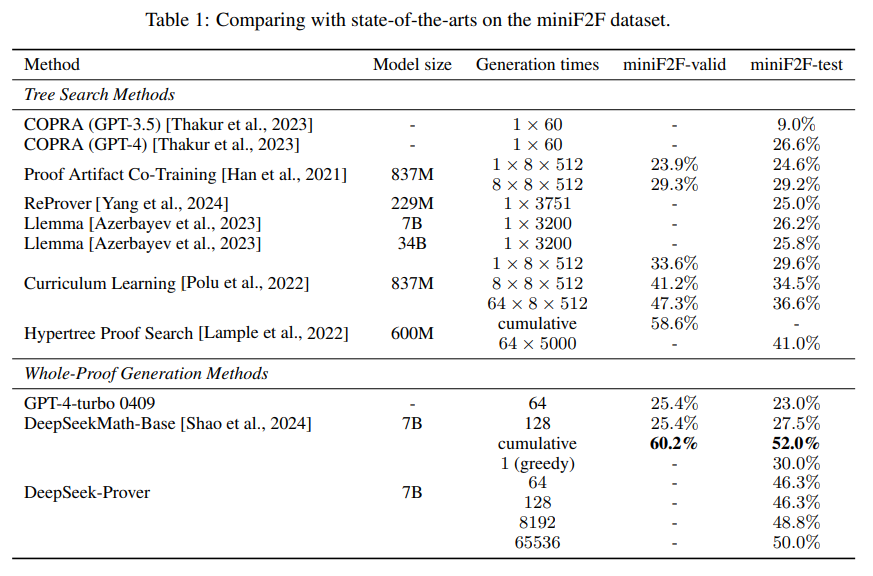
概要:
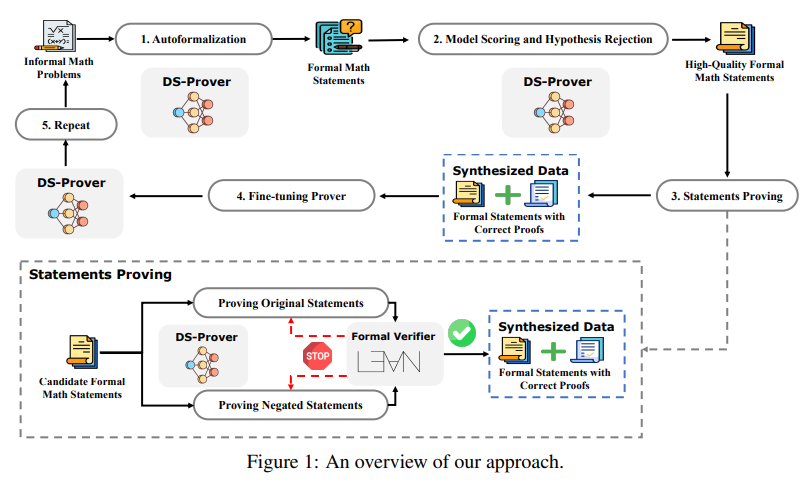
Leanのような証明アシスタントは、数学的な証明の検証を革新し、高い精度と信頼性を確保しています.一方、大規模言語モデル(LLMs)は数学的な推論において有望な成果を示していますが、形式的な定理証明の進歩はトレーニングデータの不足によって妨げられています.この問題に対処するために、私たちは高校や大学レベルの数学競技問題から派生したLean 4証明データを生成するアプローチを紹介しています.このアプローチは、自然言語の問題を形式的な文に翻訳し、低品質の文を取り除き、証明を生成して合成データを作成することを含んでいます.この合成データセットでDeepSeekMath 7Bモデルを微調整した結果、64サンプルで全体の証明生成精度が46.3%、Lean 4 miniF2Fテストでは累積で52%を達成し、ベースラインのGPT-4は64サンプルで23.0%、木探索強化学習法は41.0%でした.さらに、私たちのモデルはLean 4 Formalized International Mathematical Olympiad(FIMO)ベンチマークの148問題のうち5問を成功裏に証明しましたが、GPT-4は証明できませんでした.FIMOベンチマークでは、私たちのモデルが成功を収めた一方、GPT-4は一つも証明できませんでした.これらの結果は、大規模な合成データを活用してLLMsの定理証明能力を向上させる可能性を示しています.この合成データセットとモデルは、今後の研究を促進するために公開される予定です.
Q&A:
Q: 高校生や学部生レベルの数学競技の問題から、どうやって広範なリーン4の証明データを作成したのですか?
A: 高校や大学レベルの数学競技問題から、自然言語の問題を形式的な文に変換し、低品質な文を取り除いて証明を生成するアプローチが提案されました.この方法では、大規模言語モデル(LLM)を使用して証明生成を自動化し、これらの証明の正確性をLean 4環境内で検証します.
Q: データ作成プロセスにおいて、どのような基準で質の低い発言を除外したのか?
A: 低品質な文を除外するために使用した基準は、品質スコアモデルを使用して簡単な文をフィルタリングし、仮説の拒否戦略を使用して無効な文を除外することでした.
Q: 合成データセット上でDeepSeekMath 7Bモデルを微調整するプロセスを説明してもらえますか?
A: DeepSeekMath 7Bモデルを合成データセットで微調整するプロセスは、まず、グローバルバッチサイズを512、一定の学習率を1×10^(-4)として設定します.その後、合成データを用いて6,000回のウォームアップステップを組み込みます.このようにして、DeepSeek-Proverのパフォーマンスを評価し、他のベースラインと比較します.
Q: ベースラインのGPT-4や木探索強化学習法と比べて、あなたのモデルは具体的にどのような全体証明生成精度の向上を達成しましたか?
A: 当モデルは、ベースラインのGPT-4と木探索強化学習手法に比べて、全証明生成精度を大幅に向上させました.64サンプルを使用した場合、ベースラインのGPT-4の23.0%を上回り、木探索強化学習手法の41.0%を上回り、Lean 4 miniF2Fテストでは46.3%の精度を達成しました.累積的には52%の精度を達成しました.
Q: モデルの訓練に使われた合成データセットには、証明付きの公式声明がいくつ含まれていましたか?
A: 8百万の形式的な文と証明が、モデルのトレーニングに使用された合成データセットに含まれていました.
Q: Lean 4 miniF2F テストと Lean 4 Formalized International Mathematical Olympiad (FIMO) ベンチマークの詳細を教えてください.
A: Lean 4 miniF2Fテストは、競技レベルの問題を含む数学の証明を行うためのデータセットであり、アメリカ招待数学試験(AIME)、アメリカ数学コンペティション(AMC)、国際数学オリンピック(IMO)から問題が収録されています.試験(AIME)、米国数学競技会(AMC)、国際数学オリンピック(IMO) から問題が収録されています.4 正式化された国際数学オリンピック(FIMO)ベンチマークは、IMOのショートリストから取られた149の形式的な問題をLean 4に翻訳したもので、このベンチマークにおいて、我々の手法は100回の試行で4つの定理を証明し、GPT-.4は一つも証明できませんでした、096回に増やすことで、さらに1つの定理を証明することに成功しました.
Q: このプロジェクトでどのような困難に遭遇し、それをどのように克服しましたか?
A: このプロジェクトで遭遇した主な課題は、合成データの規模と品質の両方を確保することでした.具体的には、簡単な文をフィルタリングし、無効な文を仮説の拒否戦略を用いて除外することで生成された証明の品質を向上させることが挙げられます.また、未訓練のLLMを使用して非形式的な数学問題から合成文を生成し、その後の反復フレームワークによって証明の品質を向上させることも重要な課題でした.
Q: LLMの定理証明分野でのさらなる研究のために、合成データセットとモデルをどのように利用可能にする予定ですか?
A: 研究で使用された合成データセットとモデルは、今後の研究のために公開されます.これにより、この有望な分野でのさらなる研究が促進され、大規模な合成データを活用してLLMにおける定理証明能力を向上させる可能性が示されます.
Q: 大規模な合成データを活用することで、数学的推論だけでなく、LLMの定理証明能力を向上させるために、どのような応用が考えられますか?
A: 大規模な合成データを活用することで、LLMsの定理証明能力を数学的推論以外の領域にも拡張する可能性があります.例えば、自然言語処理や機械学習の分野において、大規模な合成データを使用することで、論理的な推論や証明能力を向上させることができます.これにより、自動要約、文書分類、質問応答システムなどの応用分野において、より高度な推論や証明が可能となります.
Q: 合成データを通じてLLMの定理証明を発展させるための研究の次のステップは何ですか?
A: 次のステップでは、より高度な数学的推論を可能にするために、大規模な合成データセットを使用してLLMsをさらにトレーニングし、証明の生成プロセスをさらに高速化することが計画されています.具体的には、8百万の形式的な文と証明から成る合成データセットを使用して、DeepSeekMath 7Bモデルをさらに微調整し、初期モデルよりもさらに高品質な定理-証明ペアを生成することが目指されています.
Lessons from the Trenches on Reproducible Evaluation of Language Models
著者:Stella Biderman, Hailey Schoelkopf, Lintang Sutawika, Leo Gao, Jonathan Tow, Baber Abbasi, Alham Fikri Aji, Pawan Sasanka Ammanamanchi, Sidney Black, Jordan Clive, Anthony DiPofi, Julen Etxaniz, Benjamin Fattori, Jessica Zosa Forde, Charles Foster, Jeffrey Hsu, Mimansa Jaiswal, Wilson Y. Lee, Haonan Li, Charles Lovering, Niklas Muennighoff, Ellie Pavlick, Jason Phang, Aviya Skowron, Samson Tan, Xiangru Tang, Kevin A. Wang, Genta Indra Winata, François Yvon, Andy Zou
発行日:2024年05月23日
最終更新日:2024年05月29日
URL:http://arxiv.org/pdf/2405.14782v2
カテゴリ:Computation and Language
概要:
自然言語処理における言語モデルの効果的な評価は依然として課題であり、研究者やエンジニアは評価セットアップへのモデルの感度、異なる手法間の適切な比較の難しさ、再現性や透明性の欠如などの方法論的な問題に直面しています.本論文では、大規模な言語モデルの評価における3年間の経験を活かし、研究者に対する指針や教訓を提供します.まず、言語モデルの評価において直面する一般的な課題について概説します.次に、これらの課題に対処するためのベストプラクティスを明確にし、その影響を軽減する方法を示します.さらに、言語モデル評価ハーネス(lm-eval)を紹介します.これは、これらの問題に対処するために独立した、再現可能な、拡張可能な言語モデルの評価を目指すオープンソースライブラリです.ライブラリの機能や、ライブラリがこれらの方法論的懸念を緩和するために使用されたケーススタディについて説明します.
Q&A:
Q: その中で述べられている言語モデル評価で直面する具体的な課題について、もう少し詳しく教えてください.
A: 言語モデルの評価における特定の課題について、文中で言及されたものについて詳細を提供します.言語モデルの評価における主な課題は、同じアイデアを表現するために意味的に同等であるが構文的に異なる方法が多数存在するという概念であり、これを「主要な問題」と呼んでいます.具体的には、自然言語の応答の正確さを評価する難しさ、ベンチマークの設計に関する課題、そしてしばしば隠されたり報告されない実装の詳細に依存することが挙げられます.
Q: 研究者は研究において、これらの課題にどのように対処し、その影響を軽減することを提案しますか?
A: これらの課題の影響を軽減するために、研究者は、問題を人工的に制限することで回避することができます.これを実現する最も一般的な方法は、質問を複数選択問題として再構築し、1つの正解目標と有限で静的な可能な回答のセットに変更することです.これにより、一貫性が確保され、異なる実装間で結論を導きやすくなります.
Q: 言語モデル評価ハーネス(lm-eval)の特徴をもう少し詳しく教えてください.
A: lm-evalは、言語モデルの評価を独立して、再現可能で拡張可能な方法で行うためのオープンソースライブラリです.このライブラリは、言語モデルの評価に関する問題を解決することを目指しており、その機能や使用事例について説明しています.
Q: lm-evalライブラリは、言語モデルの独立性、再現性、拡張性をどのように保証するのでしょうか?
A: lm-evalライブラリは、独立した、再現可能な、かつ拡張可能な言語モデルの評価を確実にするために、共有ベンチマークタスクの評価を可能にする機能を提供します.これにより、研究者は任意のモデルで任意のベンチマークを簡単に実行できるだけでなく、新しいモデル推論ライブラリや評価ベンチマークの作成者が自らの作業を広範なエコシステムに接続しやすくなります.
Q: lm-evalライブラリを開発したきっかけは何ですか?
A: lm-evalライブラリを開発するきっかけは、LM評価のオーケストレーション問題を解決する必要性から生じました.以前は、徹底的なLM評価を行うためには、以前のタスクを手作業で再実装するか、数十の小さなライブラリを個別にインストール、デバッグ、使用する必要がありました.この手間を省くために、研究者やライブラリユーザーが1つのコードベースを簡単にインストールし、選択したベースラインと共に自分の望むタスクを制御された方法で実行できるようにすることを目指しています.
Q: lm-evalライブラリは今後、NLPの分野にどのような影響を与えるとお考えですか?
A: lm-evalライブラリは、NLP分野において将来的に重要な影響を与えると考えられます.このライブラリは、言語モデルの評価をより独立して、再現可能で、拡張可能に行うことができるため、研究者がより信頼性の高い結果を得ることができます.また、lm-evalは、新しいベンチマークデータセットの評価を容易にするための設計にも活用されており、コミュニティ全体での新しいモデル推論ライブラリや評価ベンチマークとの連携を促進しています.さらに、このライブラリは、言語モデルの評価における一般的な課題やベストプラクティスについての理解を深めることに貢献しており、研究者がより有用で厳密な結果を得るための手助けをしています.
Q: 言語モデルの評価でlm-evalライブラリを使用する際の潜在的な制限や欠点にはどのようなものがありますか?
A: lm-evalライブラリを使用する際の潜在的な制限や欠点には、モデルの評価セットアップへの感度、方法間の適切な比較の困難さ、再現性と透明性の欠如が挙げられます.
Q: 言語モデルの評価のベストプラクティスを研究者自身の研究にどのように取り入れることを勧めますか?
A: 研究者は、言語モデルの評価におけるベストプラクティスを自身の研究に取り入れる際には、常に正確なプロンプトとコードを共有することが重要です.再現可能な評価ランを提供するために、可能であれば使用された完全なプロンプトを含む評価コード全体を提供するべきです.また、新しいモデル推論ライブラリや評価ベンチマークの作成者が自身の作業を広範なエコシステムに接続しやすくするために、ベンチマークを実行するための手順を簡単にすることも重要です.
Aggregation of Reasoning: A Hierarchical Framework for Enhancing Answer Selection in Large Language Models
著者:Zhangyue Yin, Qiushi Sun, Qipeng Guo, Zhiyuan Zeng, Xiaonan Li, Tianxiang Sun, Cheng Chang, Qinyuan Cheng, Ding Wang, Xiaofeng Mou, Xipeng Qiu, XuanJing Huang
発行日:2024年05月21日
最終更新日:2024年05月21日
URL:http://arxiv.org/pdf/2405.12939v1
カテゴリ:Computation and Language

概要:
最近のChain-of-Thoughtプロンプティングの進歩により、大規模言語モデル(LLMs)の複雑な推論タスクにおける重要なブレークスルーが実現されています.現在の研究では、複数の推論チェーンをサンプリングし、回答の頻度に基づいてアンサンブルすることで、LLMsの推論パフォーマンスを向上させています.しかし、このアプローチは、正しい回答が少数派の場合には失敗します.これをLLMsの推論能力を制限する主要な要因として特定し、予測された回答だけでは解決できない制限として認識しています.この問題に対処するために、階層的推論集約フレームワークAoR(Reasoningの集約)を導入し、推論チェーンの評価に基づいて回答を選択します.さらに、AoRは、タスクの複雑さに応じて推論チェーンの数を調整するダイナミックサンプリングを組み込んでいます.一連の複雑な推論タスクにおける実験結果は、AoRが優れたアンサンブル手法を上回ることを示しています.さらなる分析により、AoRはさまざまなLLMsに適応し、現在の方法と比較して優れたパフォーマンスの天井を達成していることが明らかになります.
Q&A:
Q: 階層的推論集約フレームワークAoRがどのように機能するのか、もう少し詳しく説明してもらえますか?
A: AoRは、論理的な推論過程を評価し、集約することで、アンサンブル方法を向上させる革新的なフレームワークです.AoRは、論理的な推論過程を複数の視点から評価する2段階のアプローチを採用しており、タスクの複雑さに応じて推論チェーンの数を動的に調整することで、不必要な計算オーバーヘッドを大幅に削減します.実験結果は、AoRがLLMの推論能力を大幅に向上させ、いくつかの確立されたベースラインを上回っていることを示しています.さらに、AoRは、正確な回答がより頻繁に発生するが誤った予測によって隠されるリスクを効果的に緩和するだけでなく、さまざまなLLMアーキテクチャにわたる適応性を持ち、より堅牢な評価者とより多くの推論チェーンを統合することでさらなる改善の可能性があります.
Q: AoRは、正解が少数派である場合に、現在の方法の限界にどのように対処するのか?
A: 現在の方法の制限を解決するために、AoRは適切な答えが少数派の場合に、多数決メカニズムが正しい答えを特定できなかったという問題に取り組んでいます.
Q: AoRにダイナミックサンプリングを取り入れる意義は?
A: AoRに動的サンプリングを組み込むことの重要性は、容易なサンプルと難しいサンプルを区別することによってサンプリングと評価の数を決定し、性能と計算コストのバランスを確立することにあります.
Q: AoRはどのように推論の連鎖を評価して答えを選ぶのですか?
A: AoRは、まず各回答に基づいて推論チェーンを集約し、その後2段階の評価プロセスを行います.最初の段階では、同じ回答を出す推論チェーンが評価されます.回答が一致しているため、評価は推論プロセスの妥当性と推論ステップの適切さに重点を置きます.2番目の段階では、異なる回答グループから最も論理的に整合し、方法論的に妥当な推論チェーンが共同で評価されます.目的は、推論プロセスとそれに対応する回答の整合性と一貫性を最もよく示す推論チェーンを特定し、この回答を最終出力として指定することです.
Q: AoRが著名なアンサンブル手法を上回った複雑な推論タスクの例を教えてください.
A: AoRは、複雑な推論タスクにおいて、顕著なアンサンブル手法を上回ることが示されています.例えば、Chain-of-Thought(CoT)プロンプトを使用した推論能力の向上や、明示的な推論ステップが豊富なサンプルに導かれたLLMsの中間ステップの生成などが挙げられます.
Q: AoRは様々なLLMにどのように適応するのですか?
A: AoRは、異なるLLMに適応する能力を持っています.具体的には、AoRはタスクの複雑さに応じて推論チェーンの数を調整することで、異なるLLMに適応します.実験結果によると、AoRは著名なアンサンブル手法を上回る性能を発揮します.さらなる分析により、AoRは様々なLLMに適応するだけでなく、現在の手法と比較して優れた性能を達成します.
Q: AoRが現行の方法と比較して優れたパフォーマンス上限を達成しているという主張を裏付ける実験結果は?
A: AoRは現在の方法と比較して、優れた性能の天井を達成することを支持する実験結果は、推論チェーンの数を調整することによって得られました.複雑な推論タスクの一連の実験結果によると、AoRは著名なアンサンブル手法を凌駕しています.さらなる分析により、AoRはさまざまなLLMを適応させるだけでなく、現在の方法と比較して優れた性能の天井を達成していることが明らかになりました.
Q: AoRは、複数の推論チェーンをサンプリングし、回答頻度に基づいてアンサンブルするという現在のアプローチとどう違うのですか?
A: AoRは、回答の頻度だけに依存する既存のアンサンブルメカニズムとは異なり、推論プロセスを組み込むことの重要性を強調し、階層的な推論プロセス集約フレームワークAoRの設計につながるという点で異なります.また、AoRは最適な推論チェーンの評価スコアを活用し、推論チェーンを動的にサンプリングする能力を統合しており、推論オーバーヘッドを効率的に最小化しています.
Q: LLMにおける答案選択の強化において、AoRが成功した主な要因は何ですか?
A: AoRの成功に貢献する主要な要因は、ローカルスコアリングフェーズで低品質の推論チェーンをフィルタリングし、候補回答の数を大幅に減らすことにより、グローバル評価でより正確な最終回答選択を可能にする点にあります.また、AoRは推論チェーンからの情報を活用して正しい回答を選択する可能性を高める効率性を持っており、より慎重な評価者を採用することでこの割合をさらに減らすことができます.
Q: LLMの複雑な推論タスクの分野で、AoRの将来的な応用をどのように想定していますか?
A: AoRは、LLMsの複雑な推論タスクにおける未来の応用において、推論チェーンの評価に基づいて答えを選択し、動的サンプリングを組み込むことで、現在の手法よりも優れた性能を達成する可能性があります.また、AoRは、タスクの複雑さに応じて推論チェーンの数を調整することで、柔軟性を持ち、効果的な推論処理を実現することが期待されます.
Efficient Multimodal Large Language Models: A Survey
著者:Yizhang Jin, Jian Li, Yexin Liu, Tianjun Gu, Kai Wu, Zhengkai Jiang, Muyang He, Bo Zhao, Xin Tan, Zhenye Gan, Yabiao Wang, Chengjie Wang, Lizhuang Ma
発行日:2024年05月17日
最終更新日:2024年05月17日
URL:http://arxiv.org/pdf/2405.10739v1
カテゴリ:Computer Vision and Pattern Recognition, Artificial Intelligence

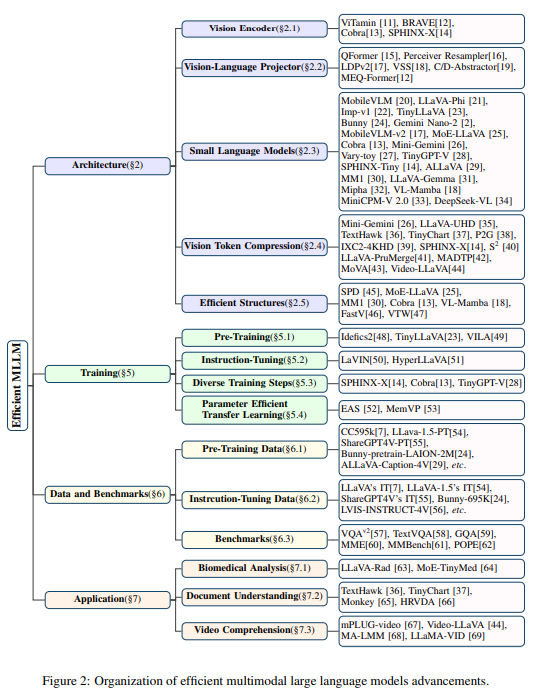
概要:
過去1年間、Multimodal Large Language Models(MLLMs)は、視覚的な質問に答える、視覚的理解や推論などのタスクにおいて驚異的なパフォーマンスを示してきました.しかし、膨大なモデルサイズや高いトレーニングおよび推論コストは、MLLMsの広範な学術および産業への適用を妨げてきました.そのため、効率的で軽量なMLLMsの研究は、特にエッジコンピューティングのシナリオにおいて非常に大きな可能性を持っています.本調査では、効率的なMLLMsの現状について包括的かつ体系的なレビューを提供します.具体的には、代表的な効率的なMLLMsのタイムライン、効率的な構造や戦略の研究状況、および応用についてまとめています.最後に、現在の効率的なMLLM研究の限界と将来の有望な方向について議論します.詳細については、以下のGitHubリポジトリを参照してください:.” rel=”nofollow”>https://github.com/lijiannuist/Efficient-Multimodal-LLMs-Survey.
Q&A:
Q: マルチモーダル大規模言語モデル(MLLM)は、具体的にどのようなタスクで顕著な性能を示したのでしょうか?
A: マルチモーダル大規模言語モデル(MLLM)は、視覚的質問応答、視覚理解、推論などのタスクで顕著な性能を示している.
Q: 膨大なモデルサイズと高い学習・推論コストは、MLLMの普及をどのように妨げてきたのだろうか?
A: 広範なモデルサイズと高いトレーニングおよび推論コストは、MLLMの普及を妨げています.これにより、大規模なモデルの開発と展開が困難になり、研究者や企業がこれらのモデルを利用する障壁が高まります.
Q: 効率的で軽量なMLLMは、特にエッジコンピューティングのシナリオにおいて、どのような潜在的なメリットをもたらすのだろうか?
A: 効率的で軽量なMLLMは、エッジコンピューティングシナリオにおいて特に以下の利点を提供します.まず第一に、リソース消費を減らすことで、エッジデバイス上での実行が容易になります.これにより、公平なアクセスを確保し、ユーザーのプライバシーを保護するという課題に対処できます.さらに、効率的で軽量なMLLMは、高いトレーニングおよび推論コストを抑えつつ、多様なアプリケーションに適用可能となります.これにより、学術界や産業界におけるMLLMの普及が促進され、エッジコンピューティングシナリオにおいて特に大きな潜在的利点があります.
Q: この調査で議論された代表的な効率的MLLMのタイムラインの概要を教えてください.
A: 調査で議論された代表的な効率的なMLLMのタイムラインの要約は、効率的なMLLMの発展史を概説し、効率的な構造と戦略の研究状況をまとめ、そして応用に焦点を当てています.これにより、効率的なMLLMの進化を明らかにし、リソース効率を高めるための様々な戦略を探求しています.現存する効率的なMLLMの性能を包括的に比較し、この新興分野の微妙なニュアンスを明らかにすることで、現在の最先端技術の包括的な理解を提供しようとしています.さらに、この調査は、将来の研究の可能性を示し、効率的なMLLMの領域で待ち受ける課題と機会のより深い理解を促進するロードマップとして機能しています.
Q: この調査で浮き彫りになった、MLLMのための効率的な構造や戦略の研究状況には、どのようなものがありますか?
A: 調査では、効率的な構造と戦略の研究状況が強調されました.これにより、MLLMsをよりリソース効率的にするための様々な戦略が探究され、その開発の歴史が概説されました.また、既存の効率的なMLLMsの性能が包括的に比較されました.この探究を通じて、現在の最先端技術の包括的な理解を提供し、この新興分野の複雑なニュアンスを明らかにすることを目指しています.さらに、この調査は、将来の研究の可能性を示し、効率的なMLLMsの領域で待ち受ける課題と機会のより深い理解を促進するための道筋となっています.
Q: 効率的なMLLMの応用例として、どのようなものがありますか?
A: 効率的なMLLMの応用のいくつかには、質問応答、ロボティクス、自動化、人工知能などが含まれています.
Q: 現在の効率的なMLLM研究にはどのような限界がありますか?
A: 現在の効率的なMLLM研究の限界として、拡張コンテキストのマルチモーダル情報を処理する際の課題が挙げられており、通常、単一の画像のみを受け入れることに制約があると述べられています.
Q: アンケートで議論された、効率的なMLLM研究の有望な将来の方向性は何ですか?
A: 調査で議論された効率的なMLLM研究の有望な将来方向のいくつかには、モデルのさらなるリソース効率化、新しい効率的なアーキテクチャの開発、異なるモーダル間の相互作用の最適化、およびリアルワールドの問題解決への貢献が含まれます.
Q: この文章で言及されているGitHubリポジトリで利用可能なコンテンツの詳細を教えてもらえますか?
A: GitHubリポジトリには、調査で取り上げられた論文が収集され、同じ分類法で整理されています.このリポジトリは、https://github.com/lijiannuist/Efficient-Multimodal-LLMs-Surveyで利用可能です.情報は定期的に更新され、最新の進展に追いつくためにクラウドソーシングを使用しています.
Q: 効率的なMLLMの将来は、学界や産業界でどのように発展していくとお考えですか?
A: 効率的なMLLMの将来は、学術界と産業の両方で重要な進化を遂げると考えられます.これまでの研究から、効率的なMLLMはリソースの効率的な利用に焦点を当て、実世界の問題解決に貢献する可能性があることが明らかになっています.これにより、ロボティクス、自動化、人工知能などの分野に革命をもたらす可能性があります.さらに、効率的なMLLMの応用範囲が広がり、実世界の問題解決に寄与する潜在能力が強調されています.今後、効率的なMLLMはさらに進化し、新たな研究や技術革新が期待されます.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: この論文で導入された新しい手法のコード実装のurlは、https://github.com/lijiannuist/Efficient-Multimodal-LLMs-Survey です.
INDUS: Effective and Efficient Language Models for Scientific Applications
著者:Bishwaranjan Bhattacharjee, Aashka Trivedi, Masayasu Muraoka, Muthukumaran Ramasubramanian, Takuma Udagawa, Iksha Gurung, Rong Zhang, Bharath Dandala, Rahul Ramachandran, Manil Maskey, Kaylin Bugbee, Mike Little, Elizabeth Fancher, Lauren Sanders, Sylvain Costes, Sergi Blanco-Cuaresma, Kelly Lockhart, Thomas Allen, Felix Grezes, Megan Ansdell, Alberto Accomazzi, Yousef El-Kurdi, Davis Wertheimer, Birgit Pfitzmann, Cesar Berrospi Ramis, Michele Dolfi, Rafael Teixeira de Lima, Panagiotis Vagenas, S. Karthik Mukkavilli, Peter Staar, Sanaz Vahidinia, Ryan McGranaghan, Armin Mehrabian, Tsendgar Lee
発行日:2024年05月17日
最終更新日:2024年05月20日
URL:http://arxiv.org/pdf/2405.10725v2
カテゴリ:Computation and Language, Information Retrieval

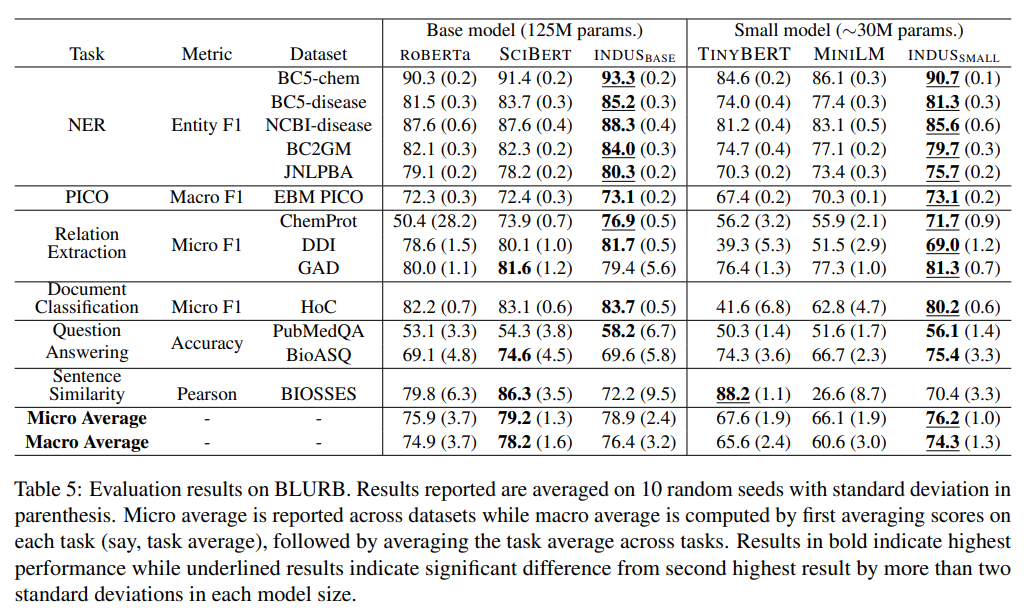
概要:
大規模言語モデル(LLMs)は、一般ドメインのコーパスで訓練された結果、自然言語処理(NLP)タスクで驚異的な成果を示しました.しかし、以前の研究では、特定のタスクにおいては、ドメインに焦点を当てたコーパスを使用して訓練されたLLMsの方が優れたパフォーマンスを示すことが示されています.この重要な洞察に触発され、私たちは地球科学、生物学、物理学、ヘリオフィジックス、惑星科学、天体物理学のドメインに特化した包括的なLLMsスイートであるINDUSを開発しました.これらのモデルは、多様なデータソースから収集された厳選された科学コーパスを使用して訓練されています.このスイートには、以下のモデルが含まれています:(1)自然言語理解タスクに対応するために、ドメイン固有の語彙とコーパスを使用して訓練されたエンコーダーモデル、(2)情報検索タスクに対応するために、複数のソースから収集された多様なデータセットを使用して訓練された対照学習ベースの一般テキスト埋め込みモデル、(3)遅延やリソース制約を持つアプリケーションに対応するために、知識蒸留技術を使用して作成されたこれらのモデルの小さなバージョン.また、CLIMATE-CHANGE-NER(エンティティ認識)、NASA-QA(抽出型QA)、NASA-IR(情報検索)という3つの新しい科学ベンチマークデータセットも作成し、これらのマルチディシプリン分野における研究を加速させました.最後に、私たちのモデルが、これらの新しいタスクだけでなく、関連する既存のベンチマークタスクにおいても、一般的な目的のエンコーダー(RoBERTa)や既存のドメイン固有のエンコーダー(SciBERT)を上回ることを示しました.
Q&A:
Q: INDUS開発のきっかけは?
A: INDUSの開発のインスピレーションは、一般ドメインのコーパスで訓練された大規模言語モデル(LLMs)が自然言語処理(NLP)タスクで驚異的な結果を示したことであり、以前の研究が、ドメインに焦点を当てたコーパスを使用して訓練されたLLMsが専門的なタスクでより優れたパフォーマンスを示すことを示したことから着想を得たものです.
Q: INDUSのLLMはどのように特定の科学的領域に合わせて作られたのですか?
A: INDUSは、特定の科学領域に合わせて調整されたLLM(大規模言語モデル)です.具体的には、(1)特定の領域に特化した語彙とコーパスを使用してトレーニングされたエンコーダーモデルが自然言語理解タスクに対応するように設計されています.(2)情報検索タスクに対応するために、多様なデータセットから抽出されたデータを使用してトレーニングされたコントラスティブラーニングベースの一般テキスト埋め込みモデルが含まれています.(3)これらのモデルの小規模版が、遅延やリソース制約を持つアプリケーションに対応するために知識蒸留技術を使用して作成されています.さらに、これらの新しい科学的ベンチマークデータセットで、INDUSのモデルが一般用途のエンコーダー(RoBERTa)や既存の特定領域エンコーダー(SCIBERT)よりも優れたパフォーマンスを示すことが示されています.
Q: INDUSのモデル群に含まれる3つのモデルとは?
A: INDUSスイートに含まれる3つのモデルは、(1) ドメイン固有の語彙とコーパスを使用してトレーニングされたエンコーダーモデル、(2) 多様なデータセットからトレーニングされた対照学習ベースの一般的なテキスト埋め込みモデル、および(3) 知識蒸留技術を使用して作成されたこれらのモデルの小さなバージョンです.これらのモデルは、自然言語理解タスク、情報検索タスク、および遅延やリソース制約を持つアプリケーションに対処するために設計されています.
Q: ベンチマークデータセットであるCLIMATE-CHANGE-NER、NASA-QA、NASA-IRはどのように作られたのですか?
A: CLIMATE-CHANGE-NER、NASA-QA、およびNASA-IRのベンチマークデータセットは、それぞれ、気候関連の文献から抽出された抄録や段落を使用して作成されました.CLIMATE-CHANGE-NERは、気候関連のキーワードを使用してSemantic Scholar Academic Graphから抽出された534の抄録を手動で注釈付けし、IOBタギングスキームを使用して名前付きエンティティを含む多様なエンティティタイプを含んでいます.NASA-QAは、AGUおよびAMSジャーナルからの39の段落をNASAの専門家が質問を作成し、それに対応する段落のスパンをマークすることで作成されました.NASA-IRは、AGU、AMS、ADS、PMC、およびPubmedからの166の段落からサンプリングされ、手動で3つの質問がアノテーションされたものを使用して作成されました.
Q: INDUSのモデルは、どのような点でRoBERTaのような汎用エンコーダーやSciBERTのような既存のドメイン特化型エンコーダーを凌駕しているのだろうか.
A: INDUSモデルは、一般的な用途向けのエンコーダーであるRoBERTaや既存の特定ドメイン向けエンコーダーであるSciBERTよりも、新しいベンチマークタスクや既存のベンチマークタスクにおいて優れた性能を発揮しています.また、知識蒸留されたモデルは、ほとんどのベンチマークタスクにおいて元のモデルと比較して強力な経験的性能を維持しつつ、レイテンシーを大幅に向上させました.
Q: ドメイン固有の語彙とコーパスを使用してトレーニングされたエンコーダーモデルについて、詳細を教えてください.
A: ドメイン固有の語彙とコーパスを使用してトレーニングされたエンコーダーモデルは、自然言語理解タスクに対応するために訓練されました.このモデルは、特定の科学分野に特化した語彙とコーパスを使用してトレーニングされ、その分野における自然言語処理タスクに適した表現を獲得します.このエンコーダーモデルは、他の一般的な目的のモデルや既存の科学分野エンコーダーを凌駕する強力な性能を示しました.
Q: 対照学習に基づく一般的なテキスト埋め込みモデルは、多様なデータセットを用いてどのように学習されたのか?
A: 多様なデータセットを使用してトレーニングされたコントラスト学習ベースの一般的なテキスト埋め込みモデルは、クエリと関連するパッセージの埋め込みを近づけ、関連しないパッセージの埋め込みを遠ざけるようにトレーニングされました.
Q: INDUSでより小さなバージョンのモデルを作るために、どのような知識抽出技術が使われたのか?
A: INDUSのモデルの小さなバージョンを作成するために使用された知識蒸留の技術は、教師モデルの類似スコアの分布を蒸留することでした.
Q: INDUSのモデルの小さいバージョンは、待ち時間やリソースに制約のあるアプリケーションにどのように対応していますか?
A: 小さなモデルは、大規模な教師モデルから能力を転送することによって、レイテンシやリソース制約を持つアプリケーションに対処しています.これは、知識の蒸留を使用して行われ、教師モデルの類似性スコアの分布を小さな生徒モデルに転送することで行われます.さらに、蒸留のためのトレーニング戦略を変更する必要があることが示されています.
Q: INDUSが地球科学、生物学、物理学、太陽物理学、惑星科学、宇宙物理学といった多分野の研究にどのような影響を与えることを期待していますか?
A: INDUSが研究機関や企業に効率的な文献へのアクセスを提供することで、地球科学、生物学、物理学、ヘリオフィジックス、惑星科学、天体物理学の多様な分野における研究に影響を与えることを期待しています.
Layer-Condensed KV Cache for Efficient Inference of Large Language Models
著者:Haoyi Wu, Kewei Tu
発行日:2024年05月17日
最終更新日:2024年06月04日
URL:http://arxiv.org/pdf/2405.10637v2
カテゴリ:Computation and Language
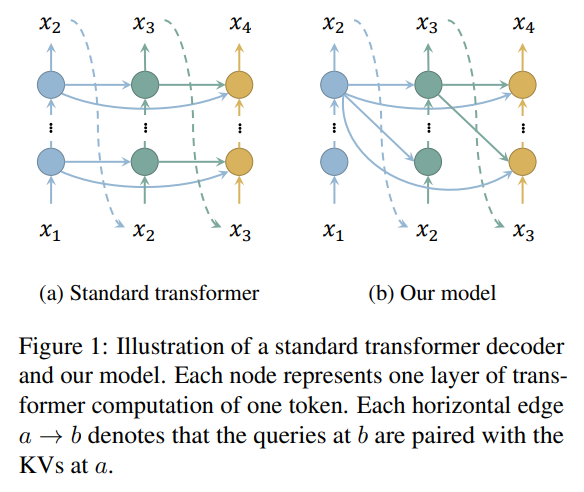
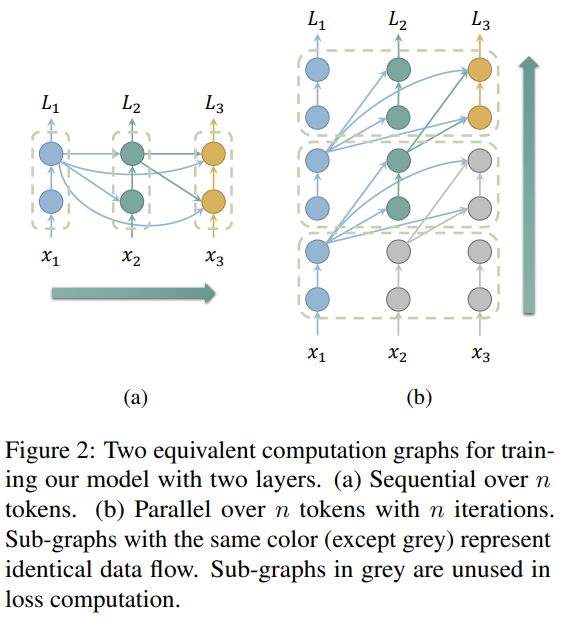
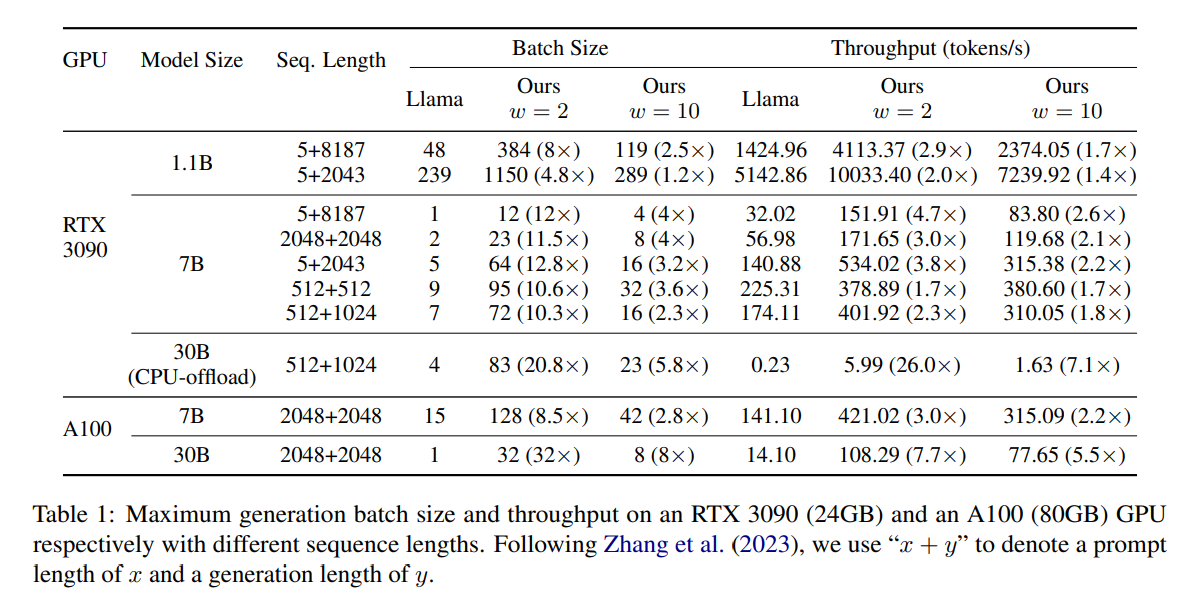
概要:
大規模な言語モデルを実世界のアプリケーションに展開する際、巨大なメモリ消費が主要な障害となってきました.パラメータの数が多いことに加えて、トランスフォーマーアーキテクチャの注意メカニズムのためのキー・バリュー(KV)キャッシュは、特に深層言語モデルの場合、多数のレイヤーがあるときにはかなりのメモリを消費します.本論文では、われわれは、わずかな数のレイヤーのKVsのみを計算してキャッシュする新しい方法を提案し、これによりメモリ消費を大幅に削減し、推論スループットを向上させます.大規模な言語モデルに対する実験では、われわれの方法が標準のトランスフォーマーよりも最大26倍高いスループットを達成し、言語モデリングや下流タスクで競争力のあるパフォーマンスを発揮することを示しました.さらに、われわれの方法は既存のトランスフォーマーのメモリ節約技術とは直交しているため、これらをわれわれのモデルと統合することで推論効率をさらに向上させることができます.われわれのコードはhttps://github.com/whyNLP/LCKVで入手可能です.
Q&A:
Q: あなたの方法が、少数のレイヤーのKVだけを計算してキャッシュする方法を、もう少し詳しく説明してもらえますか?
A: 私たちの方法では、全てのレイヤーのクエリをトップレイヤーのKVsとペアにし、他のレイヤーのKVsを計算したりキャッシュしたりする必要がないようにしています.これにより、メモリ消費と計算の両方を節約することができます.さらに、これらのレイヤーのKVsを計算する必要がなくなるため、これらのレイヤーの重みWK、WVを保持する必要もなくなり、モデルパラメータも節約できます.
Q: KVを計算し、キャッシュする最適なレイヤー数をどのように決定したのですか?
A: 最適な層の数を決定するために、我々は異なる層の数に対して推論スループットを評価しました.具体的には、異なる層の数における推論スループットを計測し、性能が最も高くなる層の数を選択しました.この過程により、我々の方法ではm=7の層数が最適であることが示されました.
Q: 推論効率をさらに向上させるために、具体的にどのような省メモリ技術をモデルに組み込んでいますか?
A: 私たちのモデルに統合されている特定のメモリ節約技術は、StreamingLLMなどの他のメモリ節約技術と効果的に統合できることが示されています.
Q: あなたの方法の有効性を実証するために、大規模な言語モデルを使って行われた実験について、より詳しい情報を教えていただけますか?
A: 大規模言語モデルにおける実験では、我々の手法が標準のtransformersよりも最大26倍のスループットを達成し、言語モデリングや下流タスクにおいて競争力のあるパフォーマンスを示したことが示されています.
Q: あなたの方法は、効率と性能の点で、他の既存のトランス・メモリー節約技術と比べてどうですか?
A: 私たちの方法は、KVキャッシュのメモリ消費を大幅に減らすことで、他の既存のトランスフォーマーメモリ節約技術と比較して効率性が向上しています.また、標準のトランスフォーマーと比較して、競争力のある性能を達成しています.
Q: 大規模な言語モデルを効率的に推論するための新しい手法を開発・実装する上で、どのような課題に直面しましたか?
A: 私たちの新しい方法を開発し実装する際に直面した課題は、トークンごとの処理が前のトークンのトップレイヤーに依存しており、並列トレーニングを妨げる順次依存関係を作成することでした.この課題に対処するため、並列トレーニングをサポートする近似トレーニング方法を導出しました.また、プロンプトを反復的に処理する必要があるため、プロンプトが生成長よりもはるかに長い場合、例えば文書要約の場合、スループットが低下するという課題もありました.
Q: その方法によって達成された推論スループットの向上をどのように測定し、定量化したのですか?
A: 私たちは、我々の手法による推論スループットの改善を測定し、定量化しました.具体的には、標準のトランスフォーマーと比較して、我々のモデルがより高い生成スループットを達成したことを示すために、実験を行いました.この実験では、同じバッチサイズで標準のトランスフォーマーと比較して、我々のモデルがより高いスループットを達成したことを示しました.また、同じバッチサイズで標準のトランスフォーマーと比較して、我々のモデルのレイテンシーが低減していることも報告しました.このことから、我々の手法が迅速な応答を必要とするシナリオにも利益をもたらす可能性があることが示唆されます.この現象の正確な理由はまだ明確ではなく、我々は、KVsの計算の削減、より速いメモリ転送とアクセスを可能にするメモリ消費の減少、およびさまざまな実装の詳細などの要因に帰因する可能性があると推測しています.
Q: あなたの方法を実世界のアプリケーションで使用する際に考慮すべき限界や潜在的な欠点はありますか?
A: 実際のアプリケーションでこの方法を使用する際に考慮すべき制限や潜在的な欠点があります.例えば、イテレーションによるトレーニングのため、同じ量のデータでモデルを事前トレーニングするのに約3倍の時間がかかります.つまり、我々の方法は推論効率を向上させる一方で、トレーニング効率を犠牲にしています.また、プロンプトを繰り返し処理する必要があるため、プロンプトが生成長よりもはるかに長い場合(例:文書要約など)、スループットが低下します.これらの制限を考慮する必要があります.
Q: さまざまな環境、さまざまなサイズの言語モデルで展開する場合、このメソッドはどの程度スケーラブルですか?
A: 私たちの手法は、異なる環境や言語モデルのサイズにおいて展開する際に非常にスケーラブルです.我々の手法は、大規模な言語モデルにおいても効果的であり、標準のトランスフォーマーに比べて高いスループットを達成しています.また、我々の手法は他のメモリ節約技術とも組み合わせやすく、推論効率をさらに向上させることができます.
Q: あなたのアプローチを用いて大規模言語モデルの効率と性能をさらに高めるために、将来どのような研究の方向性を描いていますか?
A: 私たちの手法をさらに向上させるための将来の研究方向としては、より効率的なトレーニングアプローチの設計、大規模なバッチに対応したカーネルの開発、そしてより大きく複雑なLLMでの手法の検証が挙げられます.私たちの研究がLLMの推論効率を向上させる新たな視点を提供し、この方向でのさらなる研究を促進することを期待しています.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: この論文で導入された新しい手法のコード実装のurlは、https://github.com/whyNLP/LCKV です.
How Far Are We From AGI
著者:Tao Feng, Chuanyang Jin, Jingyu Liu, Kunlun Zhu, Haoqin Tu, Zirui Cheng, Guanyu Lin, Jiaxuan You
発行日:2024年05月16日
最終更新日:2024年05月16日
URL:http://arxiv.org/pdf/2405.10313v1
カテゴリ:Artificial Intelligence, Computation and Language, Computers and Society, Machine Learning
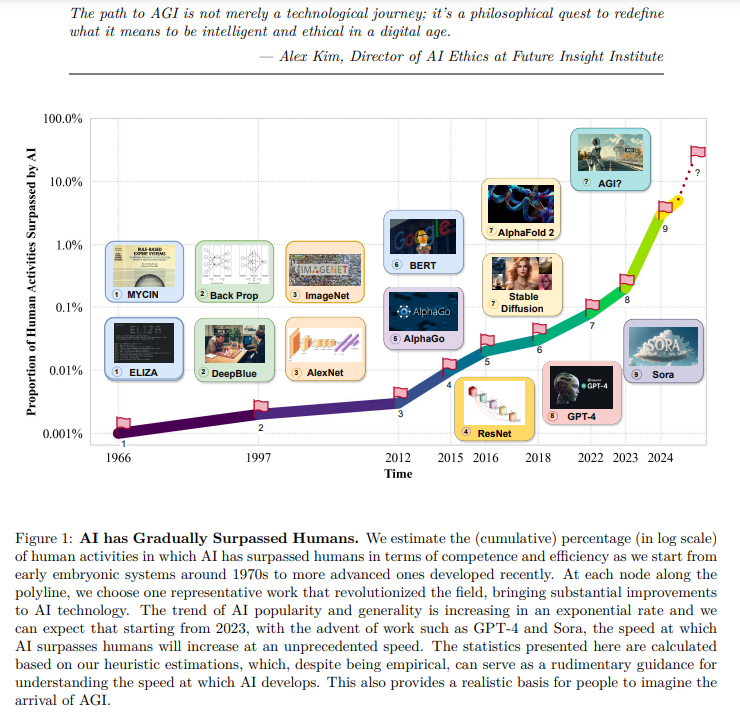
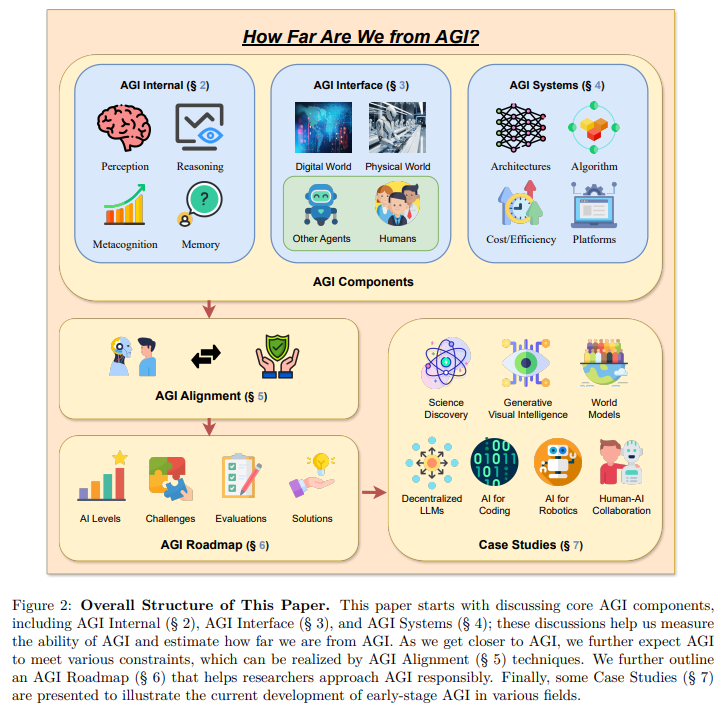
概要:
人工知能(AI)の進化は人間社会に深い影響を与え、さまざまな分野で重要な進歩をもたらしてきました.しかし、AIへの要求の増大は、現在のAIの限界を浮き彫りにし、人工一般知能(AGI)への動きを加速させています.AGIは、多様な実世界のタスクを人間の知能と同等の効率と効果で実行する能力によって区別され、AIの進化における重要なマイルストーンを反映しています.既存の研究は、AIの特定の最近の進歩を要約していますが、AGIの定義、目標、および発展軌道について包括的な議論が欠けています.この論文は、既存の調査論文とは異なり、AGIへの近接性に関する重要な問題や、その実現に必要な戦略について、広範な調査、議論、および独自の視点を掘り下げています.まず、AGIのための必要な能力フレームワークを明確にし、内部、インターフェース、およびシステムの次元を統合しています.AGIの実現には、より高度な能力と厳格な制約への遵守が必要とされるため、これらの要因を調和させるための必要なAGI調整技術についてさらに議論しています.特に、我々は、AGIに対して責任を持って取り組む重要性を強調し、まずAGIの進行の主要レベルを定義し、現状を位置づける評価フレームワークを示し、最終的にAGIの頂点に到達する方法のロードマップを提供しています.さらに、AIの統合の普遍的な影響を具体的に示すために、複数の領域でのAGIへの挑戦と潜在的な進路を概説しています.総括すると、現在のAGIの状況と将来の軌道に向けた先駆的な探求として、この論文は、研究者や実務家の間でAGIに関する幅広い公開討論を促進し、共通の理解を深めることを目的としています.
Q&A:
Q: 現在のAIの提供物にはどのような制限があり、それがAGIへの動きを導いたのでしょうか?
A: AIの現行の提供物の限界は、多くのセクターでの重要な進歩をもたらしたが、AIへの要求の増加がAIの現行の提供物の限界を浮き彫りにし、AGIへの動きを促しています.AGIは、人間の知能と同等の効率と効果を持って多様な実世界のタスクを実行する能力によって区別され、AI進化の中での重要なマイルストーンを反映しています.
Q: AGIは、その能力において既存のAIとどのように区別されるのでしょうか?
A: AGIは、既存のAIと比較して、より高度な能力を持つことで区別されます.具体的には、AGIは幅広い認識、理解、推論、学習、創造性などの能力を持ち、複雑な問題を解決する柔軟性があります.これにより、AGIは人間の知能に近いレベルの総合的な認知能力を持つことが期待されています.
Q: AGIプログレッションを定義する必要がある重要なレベルとは?
A: AGIの進行の主要な段階は、6つの異なるレベルに分ける必要があります.
Q: AGIに必要な能力フレームワークは、内部、インターフェース、システムの各次元をどのように統合しているのか?
A: AGIの必要な能力フレームワークは、内部、インターフェース、およびシステムの次元を統合しています.内部次元では、推論、記憶、知覚、メタ認知などの基本的な認知能力を評価します.インターフェース次元では、AGIのツール使用能力や知能へのリンク能力を評価します.システム次元では、効率性、スケール、および計算能力などの運用上の側面に焦点を当てます.そして、アライメント次元では、倫理的考慮事項や安全対策を含む倫理的能力や安全性などの要素を検討します.
Q: 論文で議論されているAGIのアライメントに必要な技術とは?
A: 論文で議論されている必要なAGIアライメント技術には、AGIの内部、インターフェース、およびシステムの次元を統合するための能力フレームワークが含まれます.また、AGIの実現にはより高度な能力が必要であり、厳格な制約に適合するために、これらの要因を調和させるためのAGIアライメント技術についてさらに議論しています.特に、AGIに責任を持って取り組むことの重要性を強調し、まずAGIの進展の主要なレベルを定義し、その後、現状を位置付ける評価フレームワークを示し、最終的にAGIの頂点に到達するためのロードマップを提供しています.
Q: 論文で言及されている評価の枠組みは、AGIの進歩の現状をどのように位置づけているのか?
A: 論文で言及されている評価フレームワークは、AGIの進行状況を現在の状態に位置付けるために、AGIの進行レベルを定義し、評価フレームワークを検討し、AGIの頂点に到達するためのロードマップを提供しています.
Q: 複数の領域におけるAGIに向けたAIの統合と潜在的な道筋に関して、論文で概説されている既存の課題は何ですか?
A: 論文では、AIの統合とAGIへの潜在的な経路に関する既存の課題と複数の領域への可能性の輪郭を示しています.具体的には、人間とAIのチームに将来のAGIを導入することで生じる多くの課題が挙げられています.最近のLLMは、非決定論的な性質、限られた推論能力、指示の理解に時折困難を抱えるため、人間とAIの相互作用プロセスで固有の課題に直面しています.これらの課題に直面する中、人間とAIの協力システムを構築するための設計知識の包括的な全体像を持つことはまだ遠いとされています.また、AGIの能力は高度に文脈依存的であり、人間とAIの協力設定で主観的に解釈されることがあります.そのため、人間とAIの協力を確立してポジティブな影響を最大化し、ネガティブな影響を最小化するのが望ましい場合はいつであり、どのようにして理解するのかは依然として難しい可能性があります.
Q: 責任を持ってAGIに取り組むことの重要性をどのように強調しているのか?
A: 論文は、AGIに責任を持って取り組む重要性を強調しています.具体的には、AGIの進展の主要な段階を定義し、現状を位置付ける評価フレームワークを示し、AGIの頂点に到達するためのロードマップを提供することで、責任あるアプローチの重要性を強調しています.さらに、AIの統合の普遍的な影響について具体的な洞察を提供することで、既存の課題や複数の領域でのAGIへの潜在的な進路について概説しています.
Q: 論文によれば、AGIの実現にはどのような戦略が必要なのか?
A: 論文によれば、AGIの実現にはより高度な能力と厳格な制約への遵守が必要であり、これらの要素を調和させるために必要なAGIアライメント技術についてさらに議論しています.また、AGIに責任を持って取り組む重要性を強調し、まずAGIの進展の主要な段階を定義し、現状を位置付ける評価フレームワークを検討し、最終的にAGIの頂点に到達するためのロードマップを示しています.
Q: この論文は、研究者や実務家の間で、AGIに関する集合的な理解や、より広範な社会的議論を促進することをどのように目指しているのか?
A: この論文は、AGIに関する研究者や実務家の間で共通の理解を促進し、広範な公開討論を促進することを目指しています.これにより、AGIの現在の状況と将来の方向性についての先駆的な探求を行い、研究者やエンジニアが共通の土台を築き、AGIのビジョンと可能性について考察し議論するための場を提供することで、コミュニティを「真の」AGIの実現に向けて前進させることを目指しています.
Risks and Opportunities of Open-Source Generative AI
著者:Francisco Eiras, Aleksandar Petrov, Bertie Vidgen, Christian Schroeder, Fabio Pizzati, Katherine Elkins, Supratik Mukhopadhyay, Adel Bibi, Aaron Purewal, Csaba Botos, Fabro Steibel, Fazel Keshtkar, Fazl Barez, Genevieve Smith, Gianluca Guadagni, Jon Chun, Jordi Cabot, Joseph Imperial, Juan Arturo Nolazco, Lori Landay, Matthew Jackson, Phillip H. S. Torr, Trevor Darrell, Yong Lee, Jakob Foerster
発行日:2024年05月14日
最終更新日:2024年05月29日
URL:http://arxiv.org/pdf/2405.08597v3
カテゴリ:Machine Learning
概要:
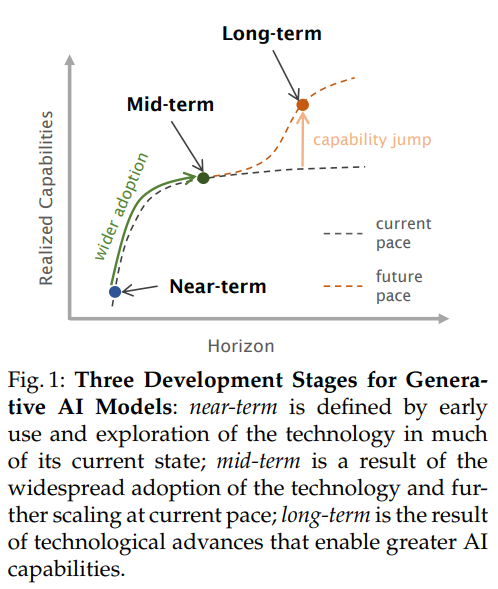
ジェネラティブAI(Gen AI)のアプリケーションは、科学や医学から教育までさまざまな分野を革新すると期待されています.これらの地殊な変化の可能性は、技術の主要企業の中にはAI開発をリードしている企業から、技術の潜在的なリスクについての議論を引き起こし、より厳格な規制を求める結果となりました.この規制は、新興のオープンソースのジェネラティブAI分野を危険にさらす可能性があります.Gen AIの開発において、近期、中期、長期の3段階のフレームワークを使用して、現在利用可能なものと同様の機能を持つオープンソースのジェネラティブAIモデルのリスクと機会を分析します.また、将来的にはより高度な機能を持つモデルについても検討します.総合的に、オープンソースのGen AIの利点がリスクを上回ると主張します.そのため、モデル、トレーニング、評価データのオープンソース化を奨励し、オープンソースのジェネラティブAIに関連するリスクを管理するための一連の推奨事項とベストプラクティスを提供します.
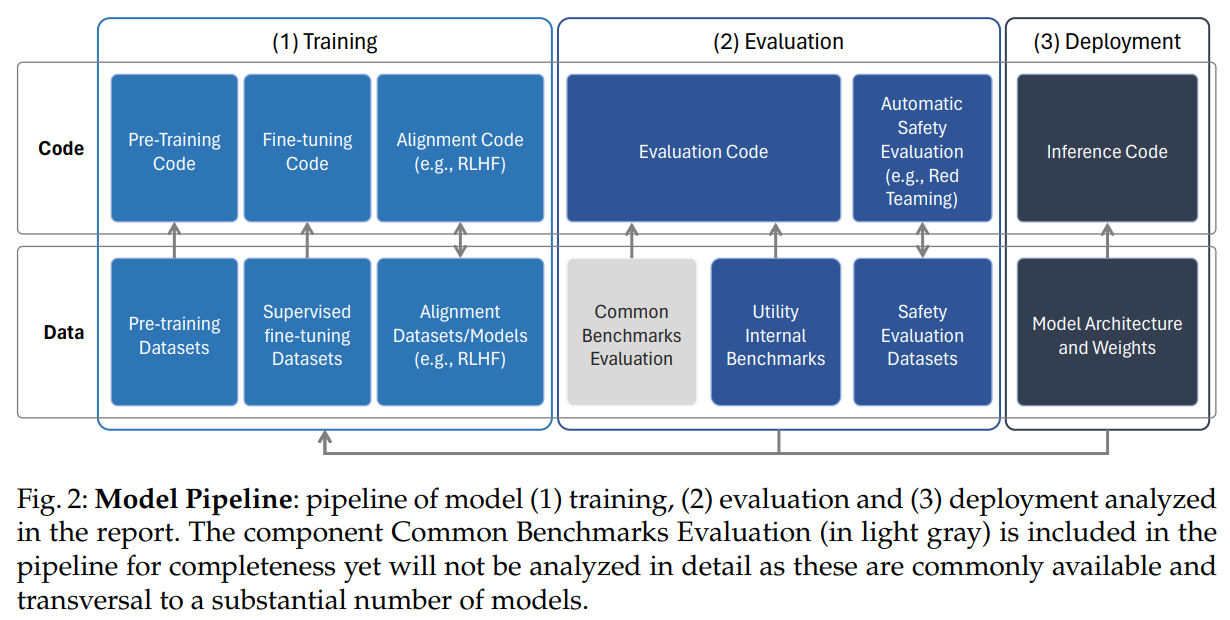
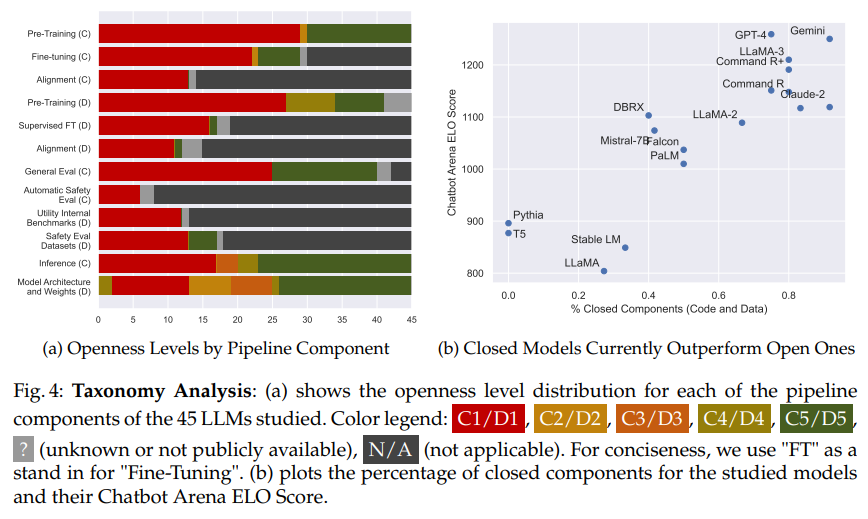
Q&A:
Q: オープンソースのジェネレーティブAIモデルには、近い将来、あるいは中期的にどのような潜在的リスクがあるのだろうか?
A: オープンソースの生成AIモデルには、現在および近い将来において、有害なコンテンツの生成、危険なアドバイスの提供、悪意のある命令の実行など、安全上のリスクがある可能性があります.これらのリスクは、ボランティアのコミットメントやベストプラクティスによって大部分が軽減できますが、技術的手段では完全に防ぐことができない可能性もあります.
Q: AI開発をリードする大手ハイテク企業は、ジェネレーティブAI技術の規制をどう見ているのか.
A: AI開発をリードする主要なテック企業は、生成AI技術の規制について厳しい規制を求めており、この規制はオープンソースの生成AI技術の発展を危険にさらす可能性があると考えています.
Q: 長期的には、より大きな能力を持つオープンソースのジェネレーティブAIモデルにどのような機会があるのだろうか?
A: オープンソースの生成AIモデルは、長期的にはより高度な機能を持つ可能性があります.これは、透明性、アクセス可能性、再現性を提供することで、多様な視点や新しい解決策を導入し、AIの効率性、効果性、倫理性を向上させることができるからです.オープンソースは、大規模言語モデル(LLMs)やその他の生成AIアーティファクトへの前例のないアクセスを提供し、モデルの検査と理解、既存研究の再現性、生成AI分野での新しい進歩を促進することができます.
Q: 著者によれば、オープンソースのGen AIの利点はどのようにそのリスクを上回るのだろうか?
A: オープンソースのGen AIモデルの利点がリスクを上回る理由は、透明性を通じて公共の信頼性を向上させ、モデルの利用性とアクセシビリティを高め、安全性のための技術革新を可能にし、研究を進展させるからです.
Q: オープンソースのジェネレーティブAIに関連するリスクを管理するために、著者はどのような提言やベストプラクティスを提供しているのだろうか?
A: オープンソースの生成AIに関連するリスクを管理するための推奨事項とベストプラクティスは、自発的なコミットメントとベストプラクティスによってリスクを大部分軽減できることを強調しています.これらの実践を自発的なものとし、オープンソースの開発を規制せず、法的な不確実性がオープンソースAIエコシステムを抑圧するリスクを伴うため、規制を行わないことを重要視しています.特に、開発者は、実際的で関連性があり、適切な場合には、次のことを検討することを推奨しています:1.開発前の関与:開発者が潜在的な利害関係者と批判的に関わり、モデルが開発される前にそのモデルが持つ広範な影響を議論し、そのモデルが開発されるべきかどうかを検討すること.
Q: ゲンAI開発の3段階フレームワークは、オープンソースモデルのリスクと機会の分析にどのように役立つのか?
A: Gen AI開発の三段階フレームワークは、オープンソースモデルのリスクと機会の分析に情報を提供します.近期から中期に利用可能なモデルと、長期的にはより高度な機能を持つモデルについて、オープンソースのGen AIの利点がリスクを上回ると主張しています.そのため、モデル、トレーニングデータ、評価データのオープンソース化を奨励し、オープンソースのGen AIに関連するリスクを管理するための一連の推奨事項とベストプラクティスを提供しています.
Q: 現在のオープンソースの生成AIモデルは、具体的にどのような機能を持っているのだろうか?
A: 現在のオープンソースの生成AIモデルは、モデルの検査と理解、既存の研究の再現性、生成AI分野での新しい進歩の促進を可能にするモデルパイプラインのオープンソース化を通じて、透明性、アクセス可能性、再現性の向上をもたらします.
Q: ジェネレーティブAI技術の規制強化は、オープンソース開発の分野にどのような影響を与えるだろうか?
A: より厳しい規制が生成AI技術に対して行われると、オープンソース開発の分野に影響を与える可能性があります.規制が強化されると、オープンソース開発者は制限され、開発や共有できるモデルが制限される可能性があります.これにより、オープンソースAIエコシステムが抑圧されるリスクがあります.
Q: ジェネレーティブAIの科学、医療、教育への応用例にはどのようなものがありますか?
A: 科学、医学、教育の分野における生成AIの応用の例には、AI4Science and Quantum(2023年)、Fecherら(2023年)、Birhaneら(2023年)による科学と医学の分野での期待される効果に関する研究、Alahdab(2023年)、Cooper(2023年)、Malikら(2023年)、Susarlaによる教育分野での研究などが挙げられます.
Q: モデル、トレーニング、評価データのオープンソース化は、ジェネレーティブAI技術の開発にどのようなメリットをもたらすのだろうか?
A: モデル、トレーニング、および評価データのオープンソース化は、多様な研究者やコミュニティを含める必要があるため、Generative AI 技術の開発に利益をもたらすことができます.オープンソースモデルは、柔軟性が高くカスタマイズ可能であり、開発者を支援し、イノベーションを促進し、研究を進め、信頼性と透明性を向上させ、クローズドソースのものよりも手頃でアクセスしやすい可能性があります.さらに、オープンソース化はAIの開発を民主化し、多様なコミュニティのニーズを満たすのに役立ち、長期的な視点での権力のバランスに重要な影響を与える可能性があります.
