
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をLLMによって生成されるQ&Aを用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.自動生成記事のクオリティと信頼性を向上させるためにアルゴリズムの改善に取り組んでいます.個人で資料のQ&Aを作成されたい方には、https://www.chatpdf.com/ や https://scispace.com/などがお勧めです.
- DrEureka: Language Model Guided Sim-To-Real Transfer
発行日:2024年06月04日
シミュレーションで学習したポリシーを実世界に転送するために、大規模言語モデル(LLM)を使用して自動化および加速化する方法を提案し、新しいロボットタスクを解決する能力を示唆している. - DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
発行日:2024年05月07日
DeepSeek-V2は、経済的なトレーニングと効率的な推論を特徴とする強力なMoE言語モデルで、DeepSeek 67Bと比較して大幅に強力なパフォーマンスを達成し、トレーニングコストを42.5%節約し、KVキャッシュを93.3%削減し、最大生成スループットを5.76倍に向上させます. - Granite Code Models: A Family of Open Foundation Models for Code Intelligence
発行日:2024年05月07日
コードLLMsはソフトウェア開発を革新し、Granite Codeモデルファミリーは企業向けに最適化された高性能なコード生成タスク向けのモデルです. - xLSTM: Extended Long Short-Term Memory
発行日:2024年05月07日
LSTMは深層学習で成功を収めたが、Transformer技術の登場により、新たな時代が訪れ、xLSTMの指数ゲーティングと変更されたメモリ構造により、パフォーマンスとスケーリングの両方で優れた結果を示す. - AlphaMath Almost Zero: process Supervision without process
発行日:2024年05月06日
MCTSフレームワークを使用して、プロセスの注釈をバイパスし、数学的推論能力を向上させる革新的なアプローチを紹介. - Is Sora a World Simulator? A Comprehensive Survey on General World Models and Beyond
発行日:2024年05月06日
Soraモデルを含む世界モデルは、AGIの重要な経路であり、ビデオ生成や自律走行などの様々なアプリケーションに利用され、高度なリアルな視覚コンテンツの合成を容易にする. - MAmmoTH2: Scaling Instructions from the Web
発行日:2024年05月06日
指示チューニングは、LLMの推論能力を向上させるために、大規模な指示データを収集し、MAmmoTH2モデルを構築することでパフォーマンスを向上させる新しいパラダイムを提案しています. - Is Flash Attention Stable?
発行日:2024年05月05日
大規模な機械学習モデルのトレーニングにおいて、数値の逸脱が不安定性の原因として浮上し、Flash Attentionの最適化において数値の逸脱が低いことが示された. - CLLMs: Consistency Large Language Models
発行日:2024年02月28日
JacobiデコーディングはLLM推論の効率を向上させる可能性があるが、従来のARデコーディングと比較してスピードアップが少ないため、新しいアプローチが開発され、生成速度を維持しながら生成品質を向上させることが示された.
DrEureka: Language Model Guided Sim-To-Real Transfer
著者:Yecheng Jason Ma, William Liang, Hung-Ju Wang, Sam Wang, Yuke Zhu, Linxi Fan, Osbert Bastani, Dinesh Jayaraman
発行日:2024年06月04日
最終更新日:2024年06月04日
URL:http://arxiv.org/pdf/2406.01967v1
カテゴリ:Robotics, Artificial Intelligence, Machine Learning
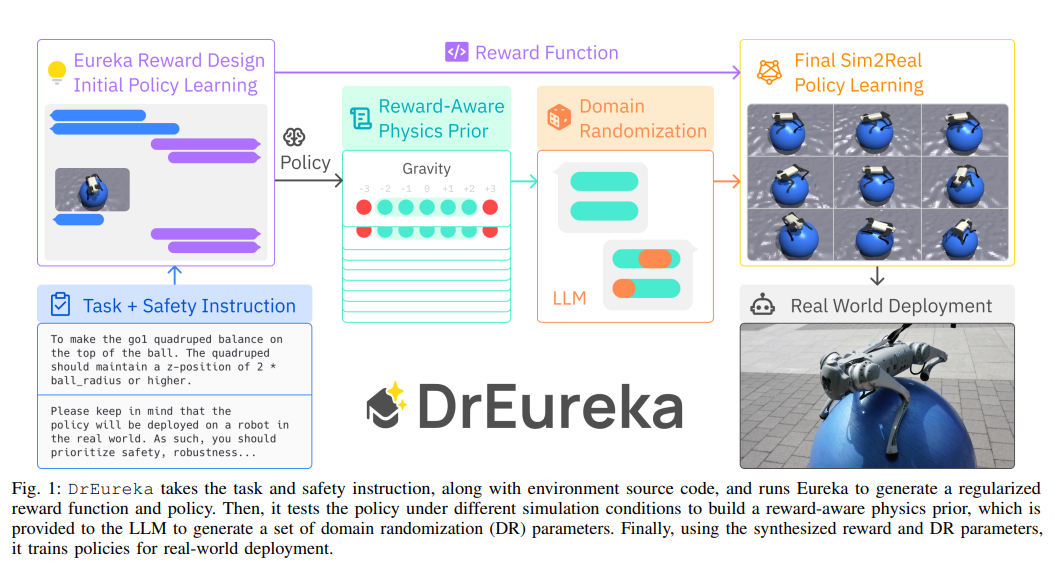

概要:
シミュレーションで学習したポリシーを実世界に転送することは、ロボットスキルを大規模に獲得するための有望な戦略です.しかし、シミュレーションから実世界へのアプローチは、通常、タスクの報酬関数やシミュレーションの物理パラメータの手動設計と調整に依存しており、プロセスが遅く、人間の労力が必要です.本論文では、大規模言語モデル(LLM)を使用して、シミュレーションから実世界への設計を自動化および加速化することを検討しています.私たちのLLMによるシミュレーションから実世界へのアプローチ、DrEurekaは、対象タスクの物理シミュレーションのみを必要とし、適切な報酬関数やドメインランダム化分布を自動的に構築して実世界への転送をサポートします.まず、私たちのアプローチが四足歩行や器用な操作タスクにおいて既存の人間設計のものと競合するシミュレーションから実世界への設定を発見できることを示します.そして、私たちのアプローチが、四足バランスやヨガボールの上を歩くなどの新しいロボットタスクを解決する能力を持っていることを紹介します.
Q&A:
Q: DrEurekaはLarge Language Models (LLM)を使って、どのようにシムツーリアル設計を自動化し、高速化しているのでしょうか?
A: DrEurekaは、大規模言語モデル(LLMs)を使用して、シミュレーションから実世界への設計を自動化および加速化します.具体的には、DrEurekaは、対象タスクの物理シミュレーションのみを必要とし、実世界への転送をサポートする適切な報酬関数とドメインランダム化分布を自動的に構築します.これにより、人間が設計したものと競合するシミュレーションから実世界への設定を発見できます.
Q: DrEurekaが、実世界での移籍に適した報酬関数や領域ランダム化分布をどのように構築しているのか説明してもらえますか?
A: DrEurekaは、タスクと安全指示、環境ソースコードを取り、Eurekaを実行して正則化された報酬関数とポリシーを生成します.次に、異なるシミュレーション条件下でポリシーをテストして報酬に敏感な物理事前知識を構築し、それをLLMに提供してドメインランダム化(DR)パラメータのセットを生成します.最後に、合成された報酬とDRパラメータを使用して、実世界展開のためのポリシーを訓練します.これにより、DrEurekaは実世界への転送を容易にするために適切な報酬関数とドメインランダム化分布を構築します.
Q: DrEurekaでテストされた具体的なタスクはどのようなもので、人間が設計した既存のコンフィギュレーションと比べてどうでしたか?
A: DrEurekaは前進運動タスクでテストされ、前進速度と全回転の両方でHuman-Designedの構成を上回ることができた.DrEurekaの平均および最良のポリシーは、総回転の点でHuman-Designedを上回った.DrEurekaとHuman-Designedのパフォーマンスの違いは、DrEurekaが生成したDRパラメータと報酬関数の違いに起因すると考えられる.DrEurekaは、人間が設計したものに匹敵するSim-to-Realトレーニング構成を提供することができ、手動の既存のSim2Realパイプラインとの競争力を示した.
Q: DrEurekaは、四足歩行のバランスやヨガボールの上を歩くなど、斬新なロボットのタスクでどのようなパフォーマンスを見せてくれるのだろうか?
A: DrEurekaは、四つん這いでヨガボールの上をバランスを取りながら歩くという新しいロボットタスクにおいて、高いパフォーマンスを発揮します.このタスクは、サーカスでよく見られる難しいものであり、DrEurekaによって訓練されたポリシーは、実際のヨガボールの上で様々な屋内外の地形で数分間バランスを保つことができます.また、ヨガボールを蹴ったり、ボールを空気を抜いた状態で操作したりするなどの乱れを導入しても、ポリシーはこれらの課題を成功裏に乗り越え、多様な運用条件においてその適応性と堅牢性を示しています.
Q: DrEurekaは、手作業による設計とチューニングに頼る従来のシム・ツー・リアルのアプローチと比べて、どのような利点がありますか?
A: DrEurekaは、人間による設計と調整に依存する従来のシミュレーションからリアルなアプローチに比べて、より優れた性能を提供します.具体的には、DrEurekaは、シミュレーションでの状態情報を使用して現実世界のセンサーを使用する学習ポリシーを監督することで、人間が設計したものよりも優れた回転方針を提供します.また、DrEurekaは、異なるDRパラメータや報酬関数によって生成されるため、人間が設計したものとの性能の違いはこれらの要因に帰せられます.さらに、DrEurekaは、3つのランダムシードを使用してポリシーをトレーニングし、試行とシード間の平均値および標準偏差を報告することで、信頼性の高い結果を提供します.
Q: シミュレーションで学んだ方針をDrEurekaを使って現実の世界に移すプロセスについて詳しく教えてください.
A: シミュレーションで学習したポリシーを実世界に転送するプロセスは、DrEurekaによって行われます.DrEurekaは、シミュレーション環境で学習されたポリシーを実世界のセンサー情報を使用して監視するための特権状態情報を受け取ります.このプロセスでは、DrEurekaが異なるDRパラメータと報酬関数を生成し、それに基づいてポリシーをトレーニングします.トレーニングされたポリシーは、シミュレーションで生成された報酬関数とDRパラメータに基づいて、実世界でのタスクに適応されます.このプロセスにより、DrEurekaはシミュレーションから実世界へのポリシー転送を実現し、新しいタスクにおいても有用な設計を自律的に達成することが示されています.
Q: DrEurekaは、シムからリアルへの移籍において、時間がかかり、人手を要するプロセスにどのように対処していますか?
A: DrEurekaは、物理シミュレーションのみを必要とし、適切な報酬関数とドメインランダム化分布を自動的に構築するため、シミュレーションから実世界への転送をサポートすることで、遅くて人間労働集約的なプロセスに対処しています.
Q: DrEurekaが効果的に機能するために必要な物理シミュレーションの重要な要素は何ですか?
A: DrEurekaが効果的に機能するためには、物理シミュレーションの主要な要素は、正規化された報酬関数とポリシーを生成するEurekaを実行し、さまざまなシミュレーション条件下でポリシーをテストして報酬に敏感な物理事前知識を構築し、それをLMMに提供してドメインランダム化(DR)パラメータのセットを生成し、合成された報酬とDRパラメータを使用して、実世界展開のためのポリシーをトレーニングすることです.
Q: DrEurekaは、手作業による設計を繰り返すことなく、どのようにして実戦への移籍を成功させているのでしょうか?
A: DrEurekaは、人間による手作業設計なしに成功した実世界への転送を確実にするために、シミュレーションから実世界への転送を行うためのパイプラインを構築します.このパイプラインは、ドメインランダム化を使用して、シミュレーション内で学習されたポリシーを実世界の環境変動に対して堅牢にすることができます.また、DrEurekaは、シミュレーション内で学習されたポリシーを実世界の環境に適応させるために、異なるドメインランダム化の設定や報酬関数を生成します.これにより、DrEurekaは人間の介入なしで、実世界での成功を確実にします.
Q: ロボットのスキル習得にDrEurekaを大規模に使用することで、どのような応用や影響が考えられますか?
A: DrEurekaを使用することによるロボットのスキル獲得の潜在的な応用や影響は、大規模なスケールでのロボット学習研究の加速化が期待されます.具体的には、DrEurekaは大規模言語モデルを使用してシミュレーションから実世界への強化学習を導く新しい技術であり、人間の監督なしに効果的な報酬関数やドメインランダム化構成を自動生成することができます.これにより、ロボットが新しい難しいタスクを習得する際に、人間が設計する難しい側面を自動化することが可能となります.
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
著者:DeepSeek-AI
発行日:2024年05月07日
最終更新日:2024年05月08日
URL:http://arxiv.org/pdf/2405.04434v2
カテゴリ:Computation and Language, Artificial Intelligence
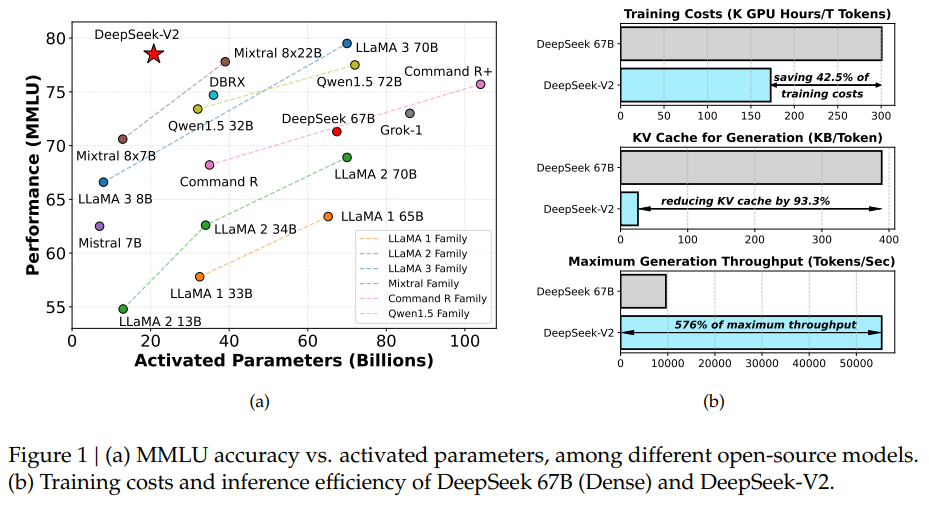
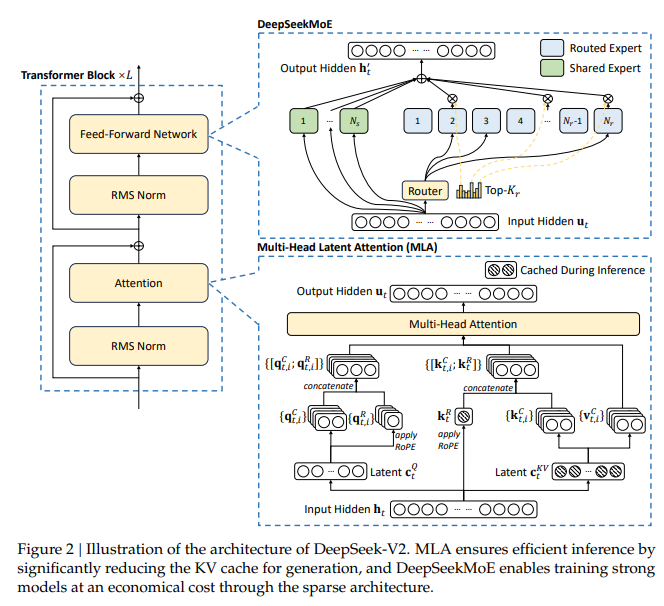

概要:
DeepSeek-V2は、経済的なトレーニングと効率的な推論を特徴とする強力なMixture-of-Experts(MoE)言語モデルを提供しています.総パラメータ数は236Bで、各トークンに対して21Bがアクティブ化されており、128Kトークンのコンテキスト長をサポートしています.DeepSeek-V2は、Multi-head Latent Attention(MLA)やDeepSeekMoEなどの革新的なアーキテクチャを採用しています.MLAは、Key-Value(KV)キャッシュを潜在ベクトルに大幅に圧縮することで効率的な推論を保証し、DeepSeekMoEはスパースな計算を通じて経済的なコストで強力なモデルをトレーニングすることを可能にします.DeepSeek 67Bと比較して、DeepSeek-V2は大幅に強力なパフォーマンスを達成し、同時にトレーニングコストを42.5%節約し、KVキャッシュを93.3%削減し、最大生成スループットを5.76倍に向上させます.我々は、8.1Tトークンからなる高品質かつ多元ソースのコーパスでDeepSeek-V2を事前トレーニングし、さらにSupervised Fine-Tuning(SFT)とReinforcement Learning(RL)を実施してその潜在能力を十分に引き出します.評価結果は、アクティブ化されたパラメータがわずか21Bであっても、DeepSeek-V2およびそのチャットバージョンはオープンソースモデルの中でもトップクラスのパフォーマンスを達成していることを示しています.
Q&A:
Q: DeepSeek-V2の効率に貢献している、マルチヘッド潜在的注意(MLA)やDeepSeekMoEなどのアーキテクチャにおける具体的な革新について説明してもらえますか?
A: DeepSeek-V2の効率性に貢献するMLA(Multi-head Latent Attention)とDeepSeekMoEの具体的な革新について説明します.MLAは、低ランクのキー値共通圧縮を利用して、推論時のキー値キャッシュのボトルネックを排除し、効率的な推論をサポートします.これにより、推論の効率が向上し、モデルの性能が向上します.一方、DeepSeekMoEは、高性能なMoEアーキテクチャであり、経済的なコストで強力なモデルのトレーニングを可能にします.これにより、モデルのトレーニングが効率的に行われ、モデルの性能が向上します.
Q: DeepSeek-V2は、DeepSeek 67Bと比較して大幅に強化されたパフォーマンスを達成しながら、トレーニングコストを削減し、KVキャッシュを削減できるのはなぜですか?
A: DeepSeek-V2は、DeepSeek 67Bと比較して、トレーニングコストを節約し、KVキャッシュを削減しながら、著しく強力なパフォーマンスを達成します.これは、DeepSeek-V2が高品質で多元ソースのコーパスを使って事前学習され、さらに監督されたファインチューニング(SFT)と強化学習(RL)を行い、その潜在能力を十分に引き出すことによるものです.MLA(Hooper et al.、2024; Zhao et al.、2023)による最適化と、各要素を平均6ビットに圧縮するための技術を使用することで、DeepSeek-V2は実際に展開されたDeepSeek 67Bよりもはるかに少ないKVキャッシュを必要とし、より大きなバッチサイズを処理できます.さらに、DeepSeek-V2の生成スループットは、DeepSeek 67Bの最大生成スループットの5.76倍を超える50Kトークン/秒を達成し、プロンプト入力スループットは100Kトークン/秒を超えます.
Q: DeepSeek-V2 の 128K トークンのコンテキスト長の意味は何ですか?
A: DeepSeek-V2のコンテキスト長が128Kトークンであることの重要性は、モデルが効率的な推論を保証し、大規模なキー・値(KV)キャッシュを潜在ベクトルに効果的に圧縮するMLA(Multi-head Latent Attention)アーキテクチャを採用しているためです.また、DeepSeekMoEを使用することで、経済的なコストで強力なモデルをトレーニングできる点も重要です.
Q: 8.1Tのトークンで構成される高品質なマルチソースコーパスにDeepSeek-V2をプリトレーニングするプロセスについて詳しく教えてください.
A: DeepSeek-V2は、8.1Tトークンからなる高品質で多元ソースのコーパスを用いて事前学習を行います.まず、DeepSeek-V2はフルの事前学習コーパスで事前学習されます.次に、数学、コード、執筆、推論、安全性などさまざまなドメインを含む150万の会話セッションを収集し、DeepSeek-V2 Chat(SFT)の監督されたファインチューニング(SFT)を行います.最後に、このモデルは高品質で多元ソースのコーパスで事前学習され、監督されたファインチューニング(SFT)と強化学習(RL)が行われ、その潜在能力が完全に引き出されます.
Q: Supervised Fine-Tuning(SFT)と強化学習(RL)は、DeepSeek-V2の可能性をどのようにさらに引き出すのでしょうか?
A: DeepSeek-V2の潜在能力をさらに引き出すために、監督されたファインチューニング(SFT)と強化学習(RL)が行われます.SFTでは、モデルの事前学習時に設定されたパラメータを微調整し、モデルの性能を向上させます.一方、RLでは、DeepSeek-V2の潜在能力を最大限に引き出すために、人間の好みに合わせてモデルを調整します.RLのトレーニングコストを節約するために、Group Relative Policy Optimization(GRPO)アルゴリズムが採用され、批評家モデルを省略します.
Q: 有効化されたパラメータが21Bしかないことが、DeepSeek-V2およびそのチャット・バージョンのパフォーマンスに与える影響は?
A: 21Bのアクティブ化されたパラメーターのみを持つことにより、DeepSeek-V2およびそのチャットバージョンのパフォーマンスがトップレベルに向上します.
Q: DeepSeek-V2は、スパース計算によって、どのように経済的なコストで強力なモデルをトレーニングできるのですか?
A: DeepSeek-V2は、スパースな計算を通じて経済的なコストで強力なモデルのトレーニングを可能にします.具体的には、DeepSeekMoEアーキテクチャを採用しており、これは通常のMoEアーキテクチャ(例:GShard)よりも優れた利点を示しています.このアーキテクチャにより、経済的なコストで強力なモデルをトレーニングすることができます.さらに、トレーニング中に専門家並列処理を採用することで、通信オーバーヘッドを制御し、負荷バランスを確保するための補助的なメカニズムも考案されています.これらの2つの技術を組み合わせることで、DeepSeek-V2は強力なパフォーマンス、経済的なトレーニングコスト、効率的な推論スループットを同時に実現しています.
Q: パラメータ、学習コスト、推論効率の点で、DeepSeek-V2 と DeepSeek 67B の主な違いは何ですか?
A: DeepSeek-V2とDeepSeek 67Bの主な違いは、DeepSeek-V2が21Bのアクティブなパラメータを持ち、DeepSeek 67Bよりも少ないパラメータを活性化することです.そのため、DeepSeek-V2のトレーニングコストは理論的にはDeepSeek 67Bよりも経済的であり、実際のトレーニングではGPU時間を42.5%節約できることが示されています.また、DeepSeek-V2は推論効率を向上させるためにパラメータをFP8の精度に変換し、KVキャッシュの量子化も行っています.
Q: DeepSeek-V2でのキー・バリュー(KV)キャッシュの潜在ベクトルへの圧縮の詳細を教えてください.
A: DeepSeek-V2では、KVキャッシュの各要素を平均6ビットに圧縮するために、MLAと最適化手法が使用されました.これにより、DeepSeek 67Bよりもはるかに少ないKVキャッシュが必要となり、より大きなバッチサイズを処理できるようになりました.
Q: DeepSeek-V2は、最大世代スループットを従来モデルの5.76倍にまで高めているが?
A: DeepSeek-V2は、前のモデルと比較して、最大生成スループットを5.76倍に向上させるために、MLA(Multi-Level Attention)とKVキャッシュの最適化を利用しています.具体的には、DeepSeek-V2は、各要素を平均6ビットに圧縮するためにKVキャッシュ内の要素をさらに圧縮するために、Hooperら(2024年)やZhaoら(2023年)の研究に基づいて、新しい技術を導入しています.
Granite Code Models: A Family of Open Foundation Models for Code Intelligence
著者:Mayank Mishra, Matt Stallone, Gaoyuan Zhang, Yikang Shen, Aditya Prasad, Adriana Meza Soria, Michele Merler, Parameswaran Selvam, Saptha Surendran, Shivdeep Singh, Manish Sethi, Xuan-Hong Dang, Pengyuan Li, Kun-Lung Wu, Syed Zawad, Andrew Coleman, Matthew White, Mark Lewis, Raju Pavuluri, Yan Koyfman, Boris Lublinsky, Maximilien de Bayser, Ibrahim Abdelaziz, Kinjal Basu, Mayank Agarwal, Yi Zhou, Chris Johnson, Aanchal Goyal, Hima Patel, Yousaf Shah, Petros Zerfos, Heiko Ludwig, Asim Munawar, Maxwell Crouse, Pavan Kapanipathi, Shweta Salaria, Bob Calio, Sophia Wen, Seetharami Seelam, Brian Belgodere, Carlos Fonseca, Amith Singhee, Nirmit Desai, David D. Cox, Ruchir Puri, Rameswar Panda
発行日:2024年05月07日
最終更新日:2024年05月07日
URL:http://arxiv.org/pdf/2405.04324v1
カテゴリ:Artificial Intelligence, Computation and Language, Software Engineering
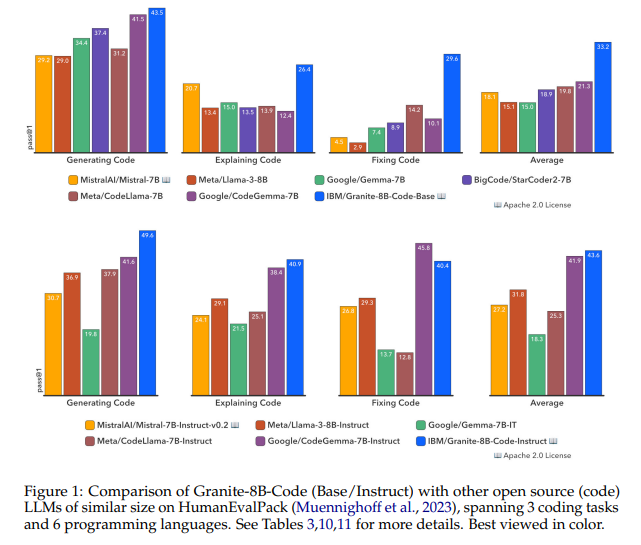
概要:
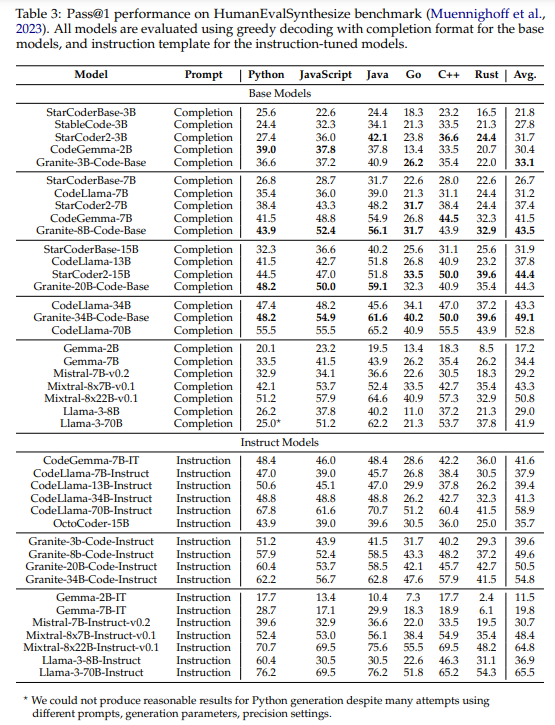
大規模言語モデル(LLMs)はコードにトレーニングされ、ソフトウェア開発プロセスを革新しています.コードLLMsは、人間のプログラマーの生産性を向上させるためにソフトウェア開発環境に統合されるようになり、LLMベースのエージェントは複雑なタスクを自律的に処理する可能性を示し始めています.コードLLMsの完全な潜在能力を実現するには、コード生成、バグ修正、コードの説明と文書化、リポジトリの維持など、さまざまな能力が必要です.この研究では、116のプログラミング言語で書かれたコードでトレーニングされたコード生成タスク向けのGraniteシリーズのデコーダー専用コードモデルを紹介します.Granite Codeモデルファミリーは、3から34億のパラメータを持つモデルで構成されており、複雑なアプリケーションの近代化タスクからデバイス上のメモリ制約のあるユースケースまでのアプリケーションに適しています.包括的なタスクセットでの評価では、Granite Codeモデルは利用可能なオープンソースのコードLLMsの中で常に最先端のパフォーマンスに達しています.Granite Codeモデルファミリーは、企業向けソフトウェア開発に最適化されており、さまざまなコーディングタスク(コード生成、修正、説明など)に対応し、汎用性の高いコードモデルとして機能します.また、Granite Codeモデルは、研究および商用利用の両方のためにApache 2.0ライセンスの下でリリースされています.
Q&A:
Q: グラナイト・コード・モデルは、コード生成タスクに対して具体的にどのような機能を持っているのか?
A: Granite Codeモデルは、コード生成タスクにおいてコードLLMの機能を持っています.具体的には、コード生成、バグ修正、コードの説明、リポジトリのメンテナンスなどの幅広い機能を持っており、企業のソフトウェア開発ワークフローに最適化されています.
Q: グラナイト・コード・モデルのトレーニングには、いくつのプログラミング言語が使われたのですか?
A: Granite Codeモデルをトレーニングするために使用されたプログラミング言語は116言語です.
Q: グラニット・コード・ファミリーのモデルのパラメータの範囲は?
A: Granite Codeファミリーのモデルのパラメータの範囲は、3から34億までです.
Q: グラニット・コード・モデルのパフォーマンスは、他のオープンソース・コードLLMと比較してどうでしたか?
A: Granite Codeモデルの性能は、さまざまな人気のあるプログラミング言語でのコード生成、説明、およびバグ修正のさまざまなコード関連タスク全体の平均性能において、最近リリースされたCodeGemma、StarCoder2、およびLlama3モデルの性能を上回るか、あるいは一致していることが示されました.
Q: Granite Codeのモデルは、企業のソフトウェア開発ワークフローにどのように最適化されたのか?
A: Granite Codeモデルは、企業のソフトウェア開発ワークフローに最適化されました.これにより、さまざまなコーディングタスク(コード生成、修正、説明など)で優れたパフォーマンスを発揮し、多目的な「オールラウンド」コードモデルとなっています.
Q: グラナイト・コード・モデルが得意とするコーディング作業の例(コード生成、修正、説明など)を教えてください.
A: Granite Codeモデルは、コード生成、修正、説明などのコーディングタスクに優れています.
Q: Granite Codeのモデルはどのライセンスでリリースされていますか?
A: Granite CodeモデルはApache 2.0ライセンスの下でリリースされています.
Q: グラナイト・コード・モデルは、人間のプログラマーの生産性向上にどのように貢献するのか?
A: Granite Codeモデルは、プログラマーの生産性向上に貢献しています.これらのモデルは、コード生成、修正、説明などのさまざまなコーディングタスクで高いパフォーマンスを発揮し、企業ソフトウェア開発ワークフロー向けに最適化されています.さらに、Granite Codeモデルは、自然言語の指示によるコーディングタスクにおいても強力なパフォーマンスを示し、複雑な問題やタスクの解決において推論能力が重要であることを示しています.
Q: グラナイト・コードのモデルは、複雑なタスクを自律的に処理するためにどのような可能性を秘めているのだろうか?
A: Granite Codeモデルは、複雑なタスクを自律的に処理する潜在能力を持っています.コードLLMの完全な潜在能力を実現するには、コード生成、バグ修正、コードの説明と文書化、リポジトリのメンテナンスなど、幅広い能力が必要です.Granite Codeモデルファミリーは、3から34億のパラメータを持つモデルで構成され、複雑なアプリケーションの近代化タスクからデバイス上のメモリ制約のあるユースケースまでのアプリケーションに適しています.包括的なタスクセットでの評価により、Granite Codeモデルは利用可能なオープンソースのコードLLMの中で常に最先端のパフォーマンスに達しています.Granite Codeモデルファミリーは、企業向けソフトウェア開発ワークフローに最適化されており、コード生成、修正、説明などのさまざまなコーディングタスクで優れたパフォーマンスを発揮し、多目的なコードモデルとなっています.
Q: グラナイト・コード・モデルは、ソフトウェア開発プロセスにおけるリポジトリ管理の必要性にどのように対処しているのだろうか?
A: Granite Codeモデルは、コードの生成、バグ修正、コードの説明および文書化、リポジトリのメンテナンスなど、さまざまなコーディングタスクに対応するために最適化されています.これにより、ソフトウェア開発プロセスにおけるリポジトリの維持ニーズを効果的に解決することができます.
xLSTM: Extended Long Short-Term Memory
著者:Maximilian Beck, Korbinian Pöppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael Kopp, Günter Klambauer, Johannes Brandstetter, Sepp Hochreiter
発行日:2024年05月07日
最終更新日:2024年05月07日
URL:http://arxiv.org/pdf/2405.04517v1
カテゴリ:Machine Learning, Artificial Intelligence, Machine Learning
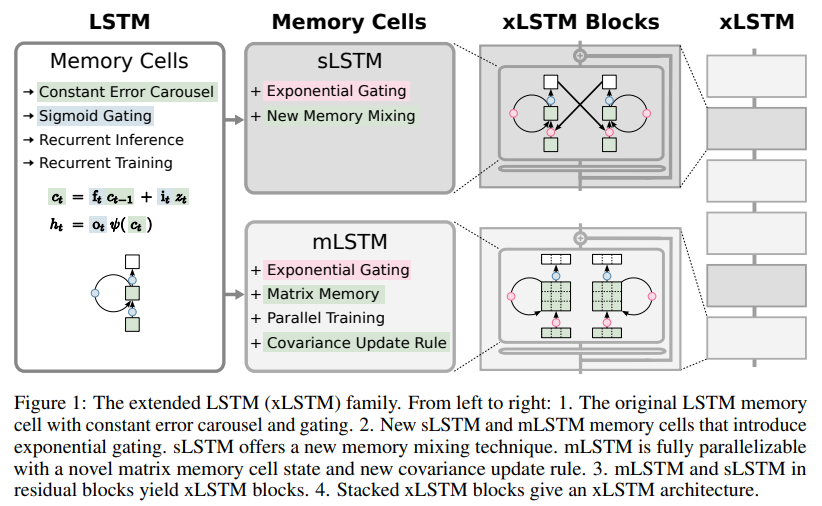
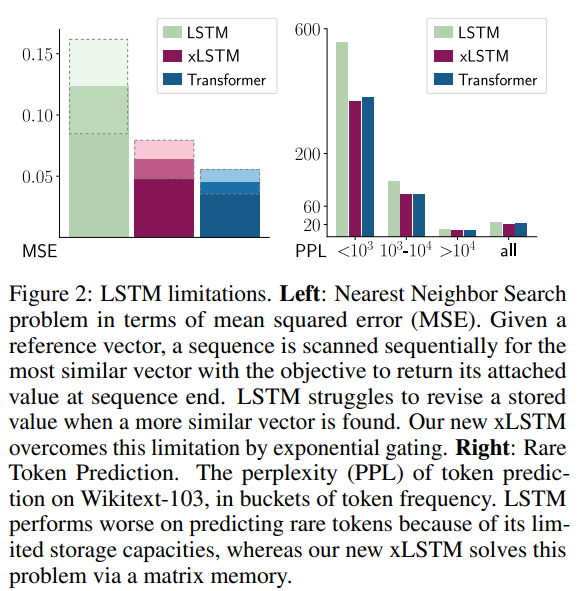
概要:
1990年代に、長期短期記憶(LSTM)の中心的なアイデアとして、常にエラーカルーセルとゲーティングが導入されました.それ以来、LSTMは時代の試練に耐え、多くの深層学習の成功に貢献し、特に最初の大規模言語モデル(LLM)を構成しました.しかし、Transformer技術の登場により、その中心に並列化可能なセルフアテンションがある新しい時代の幕開けが訪れ、LSTMをスケールで凌駕しました.今、私たちは単純な質問を提起します.LSTMを数十億のパラメータにスケーリングし、現代のLLMからの最新の技術を活用しつつ、LSTMの既知の制限を緩和することで、言語モデリングでどれだけ進展できるのでしょうか?まず、適切な正規化と安定化技術を用いた指数ゲーティングを紹介します.次に、LSTMメモリ構造を変更し、(i)スカラーメモリ、スカラーアップデート、新しいメモリミキシングを持つsLSTM、(ii)行列メモリと共分散アップデートルールを持つ完全に並列化可能なmLSTMを得ます.これらのLSTMの拡張機能を残差ブロックバックボーンに統合することで、xLSTMブロックが得られ、それらはxLSTMアーキテクチャに残差的に積み重ねられます.指数ゲーティングと変更されたメモリ構造により、xLSTMの能力が向上し、最先端のTransformerやState Space Modelsと比較して、パフォーマンスとスケーリングの両方で有利な結果を示すことができます.
Q&A:
Q: 1990年代に導入されたLong Short-Term Memory(LSTM)の中心的な考え方とは?
A: 1990年代に導入されたLong Short-Term Memory(LSTM)の中心的なアイデアは、定数エラーカルーセルとゲーティングです.これらのアイデアは、再帰ニューラルネットワークの勾配消失問題を克服するために導入されました.
Q: LSTMはディープラーニングの成功例、特に大規模言語モデル(LLM)の開発にどのように貢献してきたのでしょうか?
A: LSTMは、1990年代に導入された定数エラーカルーセルとゲーティングを中心としたアイデアであり、多くの深層学習の成功事例に貢献し、特に最初の大規模言語モデル(LLMs)を構成しました.しかし、Transformer技術の台頭により、LSTMを規模化した場合にどのような言語モデリングの進展が得られるかという疑問が提起されました.
Q: スケールでLSTMを凌駕する、新時代の幕開けを告げるテクノロジーとは?
A: 並列化可能な自己注意を核とするトランスフォーマー・テクノロジーは、スケールにおいてLSTMを凌駕し、新時代の幕開けを告げた.
Q: LSTMを数十億のパラメータに拡張し、LLMの最新技術を活用することで、言語モデリングはどこまで進化するのだろうか?
A: LSTMを数十億のパラメータにスケーリングし、LLMからの現代の技術を活用することで、言語モデリングをどれだけ進展させることができるかについては、現在の技術であるTransformersやState Space Modelsと同等以上の進展が可能であることが示されています.xLSTMは、新しいメモリ構造と指数ゲーティングによってLSTMを強化したモデルであり、言語モデリングにおいて、TransformersやState Space Modelsなどの最先端の手法と比較して有利な結果を示しています.スケーリングの法則からは、より大きなxLSTMモデルが、Transformer技術を用いて構築された現在の大規模言語モデルと真剣な競合相手となる可能性があることが示されています.xLSTMは、強化学習や時系列予測、物理システムのモデリングなど、他の深層学習分野にも大きな影響を与える可能性があります.
Q: xLSTMアーキテクチャでは、LSTMのメモリ構造にどのような変更が加えられているのですか?
A: xLSTMアーキテクチャでは、LSTMのメモリ構造に対して主に2つの変更が加えられています.1つ目は、新しいsLSTMが導入され、スカラーメモリ、スカラーアップデート、およびメモリ混合を持つことです.2つ目は、新しいmLSTMが導入され、行列メモリと共分散(外積)アップデートルールを持つことで、完全に並列化可能となっています.両方のsLSTMとmLSTMは指数ゲーティングを通じてLSTMを強化しています.
Q: エクスポネンシャル・ゲーティングと改良されたメモリ構造は、トランスフォーマーやステート・スペース・モデルと比較して、xLSTMの能力をどのように向上させるのか?
A: 指数ゲーティングと修正されたメモリ構造は、xLSTMの能力を向上させるために使用されます.これにより、xLSTMは、TransformersやState Space Modelsと比較して、パフォーマンスとスケーリングの両方で有利な結果をもたらします.指数ゲーティングは、適切な正規化と安定化技術を用いて導入され、メモリ構造が変更されます.これにより、新しいメモリ混合技術を導入したスカラーメモリとスカラーアップデートを持つsLSTM(scalar LSTM)や、行列メモリと共分散更新ルールを持つ完全に並列化可能なmLSTM(matrix LSTM)などの新しいメモリセルが得られます.これらのLSTMの拡張機能を残差ブロックのバックボーンに統合することで、xLSTMブロックが得られ、それらが残差的に積み重ねられてxLSTMアーキテクチャが構築されます.
Q: メモリ構造と更新ルールの点で、sLSTMとmLSTMにはどのような違いがありますか?
A: sLSTMとmLSTMの違いは、メモリ構造と更新規則にあります.sLSTMはスカラーメモリとスカラーアップデート、メモリミキシングを持ち、mLSTMは行列メモリと共分散(外積)更新規則を持ち、完全に並列化可能です.mLSTMはメモリミキシングを放棄し、つまり隠れ-隠れ再帰接続を持たない一方、sLSTMは複数のメモリセルに拡張でき、セル間でメモリミキシングを特徴としています.さらに、sLSTMは複数のヘッドを持つことができますが、ヘッド間ではメモリミキシングを行わず、各ヘッド内のセル間でのみメモリミキシングを行います.sLSTMのヘッドの導入と指数ゲーティングにより、新しいメモリミキシングの方法が確立されました.一方、mLSTMにおいて、複数のヘッドと複数のセルは同等です.
Q: xLSTMブロックはどのように残余ブロック・バックボーンに統合されるのか?
A: xLSTMブロックは、残差ブロックバックボーンに統合されます.これは、過去の情報を非線形的に要約し、高次元空間にマッピングすることで、異なる過去や文脈をよりよく分離するために行われます.このプロセスは、過去の情報を元の空間で非線形的に要約し、次に高次元空間に線形的にマッピングし、非線形活性化関数を適用することで行われます.
Q: xLSTMアーキテクチャーは、最先端のモデルと比較して、パフォーマンスとスケーリングの点でどのように機能するのだろうか?
A: xLSTMアーキテクチャは、性能とスケーリングの観点から、State-of-the-artモデルと比較して優れたパフォーマンスを示しています.xLSTMは、言語モデリングにおいて、TransformersやState Space Modelsなどの最新技術と比較して有利な結果を出しています.また、スケーリングの法則からも、xLSTMモデルが大規模な言語モデルとして、Transformer技術を用いた現行の大規模言語モデルと真剣な競合相手となる可能性があることが示されています.
Q: xLSTMアーキテクチャで緩和されるLSTMの既知の限界とは?
A: xLSTMアーキテクチャで軽減されるLSTMの既知の制限事項には、以下のものが含まれます. (i) 類似したベクトルが見つかった場合に、格納された値を修正することにLSTMが苦労すること.xLSTMは指数ゲーティングによってこの制限を解消します. (ii) 情報をスカラーセル状態に圧縮する必要があるため、記憶容量が限られていること.xLSTMは行列メモリによってこの問題を解決します. (iii) メモリの混合による並列化の不足、つまり、1つの時間ステップから次の時間ステップへの隠れた状態間の隠れた-隠れた接続が逐次処理を強制すること.
AlphaMath Almost Zero: process Supervision without process
著者:Guoxin Chen, Minpeng Liao, Chengxi Li, Kai Fan
発行日:2024年05月06日
最終更新日:2024年05月23日
URL:http://arxiv.org/pdf/2405.03553v2
カテゴリ:Computation and Language, Artificial Intelligence
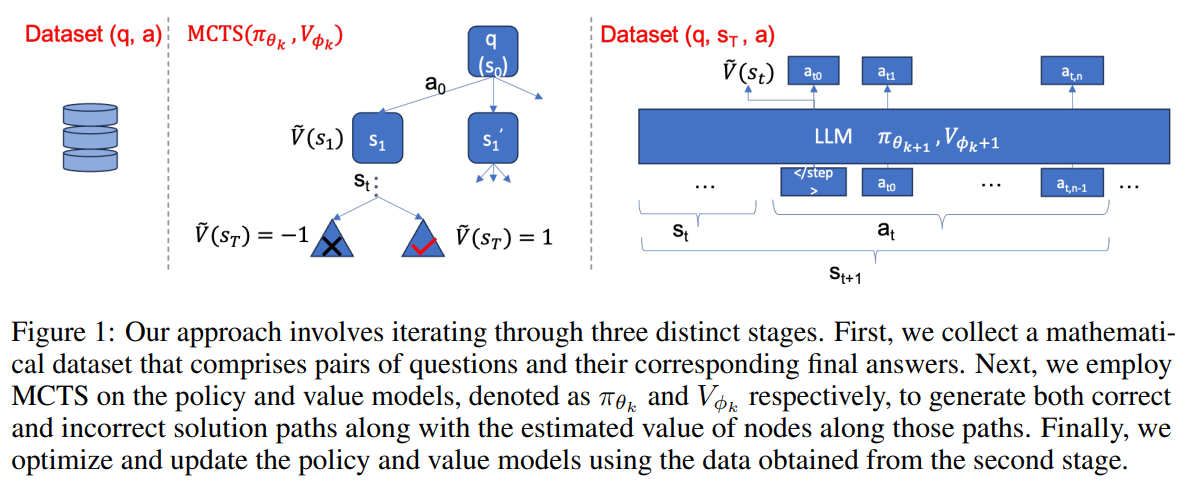

概要:
最近の大規模言語モデル(LLM)の進歩により、数学的推論能力が大幅に向上しました.しかし、これらのモデルは依然として、複数の推論ステップを必要とする複雑な問題に苦しんでおり、しばしば論理的または数値的なエラーが発生しています.数値的な間違いはコードインタープリタを統合することで大部分が解決できますが、中間ステップでの論理的なエラーを特定することはより困難です.さらに、これらのステップをトレーニングするために手動で注釈を付けることは、専門の注釈付け者の専門知識が必要であり、コストと労力がかかります.本研究では、Monte Carlo Tree Search(MCTS)フレームワークを活用して、プロセスの注釈(人間またはGPTから)をバイパスする革新的なアプローチを紹介しています.この技術は、プロセスの監督とステップレベルの評価信号の両方を自動的に生成します.さらに、価値モデルがポリシーモデル(つまりLLM)を支援するように設計された、より効果的な推論経路をナビゲートするために、我々の方法は、ポリシーとバリューモデルを反復的にトレーニングし、十分に事前トレーニングされたLLMの能力を活用して、その数学的推論能力を徐々に向上させます.さらに、効率的な推論戦略であるステップレベルのビームサーチを提案し、バリューモデルがポリシーモデル(つまりLLM)を支援するように設計されています.実験結果は、ドメイン内外のデータセットの両方で、GPT-4や人間によるプロセス監督なしでも、我々のAlphaMathフレームワークが従来の最先端の手法と比較して同等または優れた結果を達成していることを示しています.
Q&A:
Q: モンテカルロ・ツリー・サーチ(MCTS)フレームワークは、プロセス注釈の必要性をどのように回避するのですか?
A: モンテカルロ木探索(MCTS)フレームワークは、研究でのプロセス注釈の必要性を回避する革新的なアプローチを導入します.この技術は、プロセスの監督とステップレベルの評価信号を自動的に生成します.我々の方法は、ポリシーと値のモデルを反復的にトレーニングし、事前にトレーニングされたLLMの機能を活用して数学的推論能力を徐々に向上させます.さらに、ステップレベルのビームサーチという効率的な推論戦略を提案し、値のモデルがポリシーモデル(つまりLLM)を支援するように作成され、以前の確率だけに頼るのではなく、より効果的な推論経路をたどるのを助けます.
Q: あなたの手法では、政策モデルと価値モデルがどのように反復学習されるのか説明できますか?
A: ポリシーモデルとバリューモデルは、従来の方法とは異なり、別々にトレーニングされます.この研究では、バリューモデルをポリシーモデルに統合するために、線形層を追加します.最も既存のLLMがデコードのみのアーキテクチャに従っているため、最後のトークンを利用して、全体の推論ステップの表現として使用します.そして、この方法では、ポリシーモデルとバリューモデルを反復的にトレーニングし、事前にトレーニングされたLLMの機能を活用して、数学的推論スキルを徐々に向上させます.
Q: ステップレベルのビーム探索戦略は、あなたのフレームワークの推論経路をどのように改善するのですか?
A: ステップレベルビームサーチ戦略は、価値モデルがポリシーモデルを助けることで、より効果的な解決経路を見つけるのに役立ちます.これにより、事前確率だけに頼るのではなく、LLMの推論能力が大幅に向上します.
Q: よく訓練されたLLMの具体的な能力は、あなたの研究において数学的推論能力を高めるために活用されていますか?
A: よく事前学習されたLLMの特定の能力は、適切な刺激を必要とするが、すでに正しい推論を生成するために必要な数学的知識を持っているという仮説です.具体的には、適切なプロンプトや検索戦略などの刺激を受けることで、LLMは数学的推論能力を向上させることができます.
Q: ドメイン内データセットとドメイン外データセットでの実験結果は、御社のAlphaMathフレームワークの有効性をどのように裏付けていますか?
A: 実験結果は、従来の最先端の手法に比べて、GPT-4や人間による注釈付きプロセスの監督なしで、AlphaMathフレームワークが同等以上の結果を達成することを示しています.これにより、AlphaMathは、事前確率だけに頼るのではなく、より効果的な推論経路を閉じることができることが示されています.
Q: 人間やGPTの注釈なしにプロセス監視を行う革新的なアプローチを開発する上で、どのような課題に直面しましたか?
A: 私たちの革新的なアプローチを開発する際に直面した課題は、人間やGPTの注釈なしでのプロセス監督でした.数値的な誤りはコードインタプリタを統合することで大部分が解決できますが、中間ステップの論理的なエラーを特定することはより困難です.さらに、これらのステップを訓練するために手動で注釈を付けることは、専門家の注釈付けが必要であり、高価で労力を要するという課題がありました.
Q: 数学的推論における大規模言語モデルにとって、中間ステップ内の論理エラーはどのような課題となるのだろうか?
A: 大規模言語モデルにおいて、中間ステップでの論理的なエラーは数値的なエラーとは異なり、より認識が難しい問題を引き起こします.これは、モデルが問題の詳細を無視し、誤った問題解決アプローチを取る可能性があるためです.このような論理的エラーは、問題の本質を理解する上で重要であり、モデルが正しい解決策を見つける障害となります.
Q: 複雑な問題における数値の間違いに対処するためにコード・インタープリターを統合するプロセスについて詳しく教えてください.
A: 数値の間違いは、コードインタプリタを統合することで主に解決できます.コードインタプリタは、数値計算の過程で発生するエラーを特定し修正するのに役立ちます.これにより、数値的なミスを効果的に取り除くことができます.
Q: モンテカルロ・ツリー・サーチのフレームワークを研究に使おうと思ったきっかけは何ですか?
A: 研究でMonte Carlo Tree Searchフレームワークを使用する動機は、探索と活用のバランスをより効果的に取るためでした.LLMとMCTSを統合することで、高品質なプロセス監督ソリューションを生成することが可能となりました.また、価値モデルをLLMに組み込むことで、報酬の推定のための時間を節約し、ソリューション生成の効率を向上させました.
Q: AlphaMathのフレームワークは、これまでの最先端の手法と比較して、どのような結果やパフォーマンスを示しているのでしょうか?
A: AlphaMathフレームワークは、以前の最先端の手法と比較して、結果とパフォーマンスの両方で同等または優れた成績を収めています.実験結果は、GPT-4や人間によるアノテーションプロセスの監督なしでも、AlphaMathフレームワークが以前の最先端の手法に比べて同等または優れた結果を達成していることを示しています.
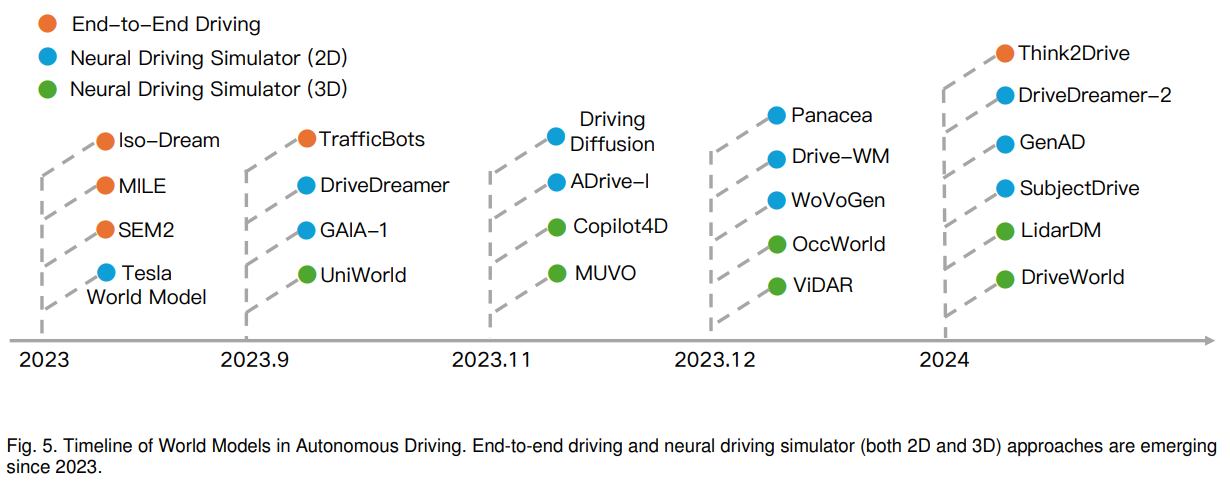
Is Sora a World Simulator? A Comprehensive Survey on General World Models and Beyond
著者:Zheng Zhu, Xiaofeng Wang, Wangbo Zhao, Chen Min, Nianchen Deng, Min Dou, Yuqi Wang, Botian Shi, Kai Wang, Chi Zhang, Yang You, Zhaoxiang Zhang, Dawei Zhao, Liang Xiao, Jian Zhao, Jiwen Lu, Guan Huang
発行日:2024年05月06日
最終更新日:2024年05月06日
URL:http://arxiv.org/pdf/2405.03520v1
カテゴリ:Computer Vision and Pattern Recognition
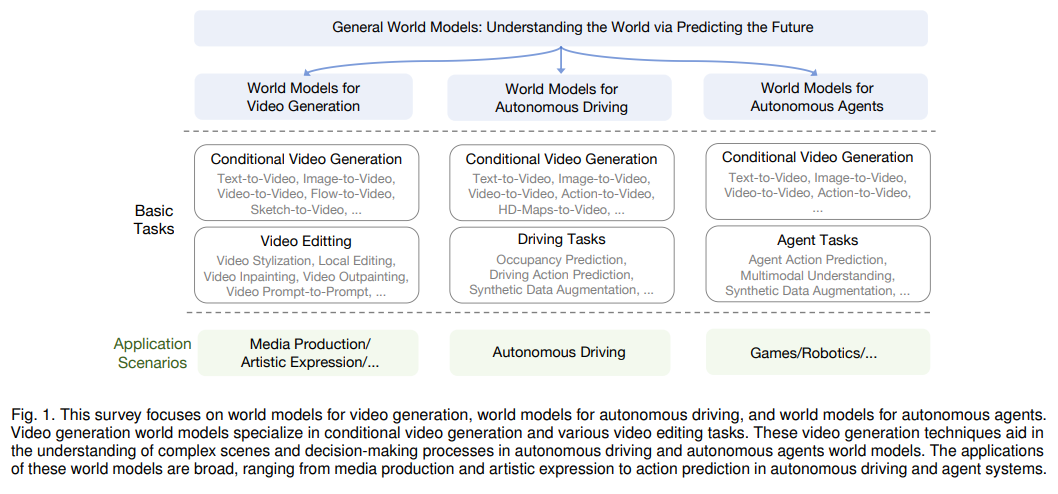
概要:
一般的な世界モデルは、人工一般知能(AGI)を達成するための重要な経路を表し、仮想環境から意思決定システムまでさまざまなアプリケーションの基盤として機能します.最近、Soraモデルの登場により、その優れたシミュレーション能力が注目されており、物理法則の初期理解を示しています.この調査では、世界モデルの最新の進歩について包括的に探求します.私たちの分析は、ビデオ生成における生成手法の最前線を航行し、世界モデルが高度にリアルな視覚コンテンツの合成を容易にする重要な構築物として立ち位置していることを示します.さらに、自律走行世界モデルの新興分野を検討し、交通や都市の移動を再構築する上で不可欠な役割を細かく明らかにします.さらに、動的な環境コンテキスト内での知的な相互作用を可能にするために、自律エージェント内で展開される世界モデルに固有の複雑さに深く入り込みます.最後に、世界モデルの課題や限界、そして将来の可能性について議論します.この調査が研究コミュニティにとって基礎的な参考資料となり、継続的なイノベーションを促すインスピレーションとなることを願っています.この調査は定期的に以下のリンクで更新されます:.” rel=”nofollow”>https://github.com/GigaAI-research/General-World-Models-Survey.
Q&A:
Q: 物理法則のシミュレーションという点で、Soraモデルの具体的な能力について詳しく教えてください.
A: Soraモデルは、物理法則をシミュレートする際に特定の観察が必要であり、物理学に基づいたシミュレーターと組み合わせることが有益であると示唆されています.これらのシミュレーターはSoraのリアリティのレベルには達しないかもしれませんが、物理的な特性を正確に追求します.Soraは運動のモデリングにおいて改善されていますが、流体や複雑な物理現象を正確にシミュレートすることには苦労しています.
Q: 世界モデルは人工知能(AGI)の発展にどのように貢献するのか?
A: 世界モデルは、人工知能(AGI)の開発において重要な役割を果たします.これらのモデルは、世界を生成的なプロセスを通じて理解しようとします.特に、Soraモデルの導入により、その驚異的なシミュレーション能力が注目されています.これらのモデルは、さまざまなモダリティにわたる理解と予測能力を豊かにするために、より多くの意味的な特徴を学習することに焦点を当てています.
Q: そらモデルのような世界モデルがうまく実装されたアプリケーションの例を教えてください.
A: 世界モデル、特にSoraモデルなどの世界モデルが成功裏に実装されている例として、ビデオ生成、自律走行、自律エージェントの運用などが挙げられます.これらのアプリケーションでは、世界モデルが物理原理の理解やシミュレーション能力を活用して、高度な意思決定システムや没入型仮想環境の構築に貢献しています.
Q: 映像生成におけるジェネレーティブな方法論は、リアルな映像コンテンツを生み出すために、どのように世界モデルを活用しているのだろうか?
A: ビデオ生成の世界モデルは、条件付きビデオ生成とさまざまなビデオ編集タスクに特化しています.これらのビデオ生成技術は、自律走行や自律エージェントの世界モデルにおける複雑なシーンの理解や意思決定プロセスを支援します.これらの世界モデルの応用は幅広く、メディア制作や芸術表現から自律走行やエージェントシステムにおけるアクション予測まで多岐にわたります.
Q: 交通と都市のモビリティを再構築する上で、自律走行の世界モデルはどのような役割を果たすのか?
A: 自動運転ワールドモデルは、交通と都市の移動を再構築する上で重要な役割を果たしています.これらのモデルは、安全で効率的な道路上のナビゲーションを実現することで、交通システムの安全性と効率性を向上させるだけでなく、都市計画とデザインの新たな可能性を開くことができます.
Q: 自律型エージェントがダイナミックな環境コンテクストの中でインテリジェントなインタラクションを可能にする上で、ワールドモデルの重要性を説明できますか?
A: 自律エージェントにおける世界モデルの重要性は、動的な環境コンテキスト内で知的な相互作用を可能にする点にあります.これにより、エージェントは環境のダイナミクスを正確に理解し、適切な行動を取ることができます.世界モデルは、物理世界の複雑さだけでなく、デジタル環境の微妙なニュアンスもシミュレートする能力を持っており、これによってエージェントは環境変化に適応し、効果的に行動することが可能となります.
Q: あなたの研究で明らかになった、世界モデルに関する課題や限界は何ですか?
A: 研究において特定された世界モデルに関連するいくつかの課題と制限には、因果推論、3Dワールドシミュレーターの欠如、および実世界の複雑な状況や相互作用の正確なモデリングが含まれます.
Q: 人工知能の分野において、世界モデルは今後どのように進化していくとお考えですか?
A: 人工知能の分野における世界モデルの将来の方向性は、物理法則の初期理解を示すだけでなく、世界モデルの有望な進歩を強調しています.我々はAI駆動の革新の最前線に立っており、世界モデルの領域にさらに深く入り込み、その複雑さを解明し、現在の開発段階を評価し、将来的に辿る可能性のある軌道を熟考することが重要です.世界モデルは、世界の理解を深めるために未来を予測します.この予測能力は、ビデオ生成、自律走行、自律エージェントの開発という3つの主要な方向性において、世界モデルの発展の中心的な方向性を表しています.
Q: 一般的な世界モデルに関する調査はどのくらいの頻度で更新される予定ですか?また、今後の更新ではどのような新情報が期待できますか?
A: 調査は定期的に更新される予定であり、将来の更新では世界モデルに関する新しい情報が提供される予定です.これには、ビデオ生成や自律走行などの応用分野における世界モデルのさらなる探求や、自律エージェント内で展開される世界モデルの複雑さに関する詳細な情報が含まれるでしょう.
Q: 人工知能分野の研究者は、自らの研究やイノベーションの基礎資料として、この調査をどのように活用できるのだろうか.
A: この調査は、研究者が人工知能の分野で自らの研究と革新に基礎として活用することができます.最近の世界モデル研究の包括的な調査を提供し、哲学的視点や詳細な議論を含んでいます.また、ビデオ生成、自律走行、自律エージェントの世界モデルに関する文献に深く踏み込み、それらがメディア制作、芸術表現、エンドツーエンドの運転、ゲーム、ロボットなどでの応用を明らかにしています.既存の課題を評価することで、新参者がこの分野に足を踏み入れる際に貴重な示唆を提供し、確立された研究者の間で批判的思考と議論を刺激することが期待されます.
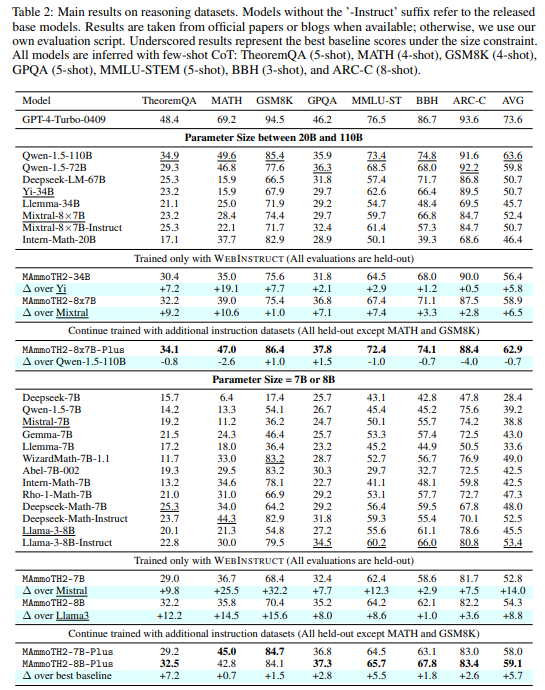
MAmmoTH2: Scaling Instructions from the Web
著者:Xiang Yue, Tuney Zheng, Ge Zhang, Wenhu Chen
発行日:2024年05月06日
最終更新日:2024年05月23日
URL:http://arxiv.org/pdf/2405.03548v4
カテゴリ:Computation and Language
概要:
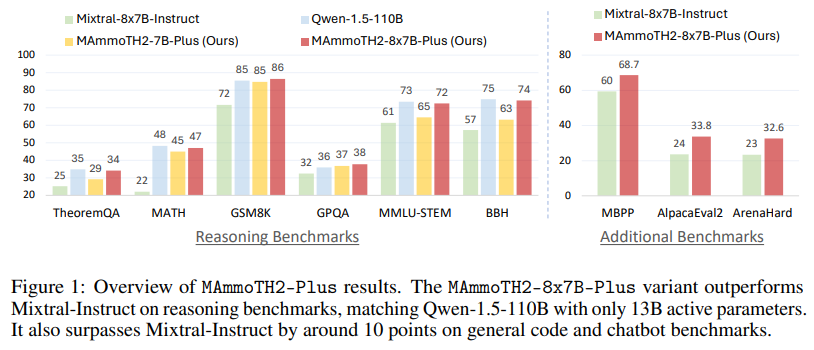
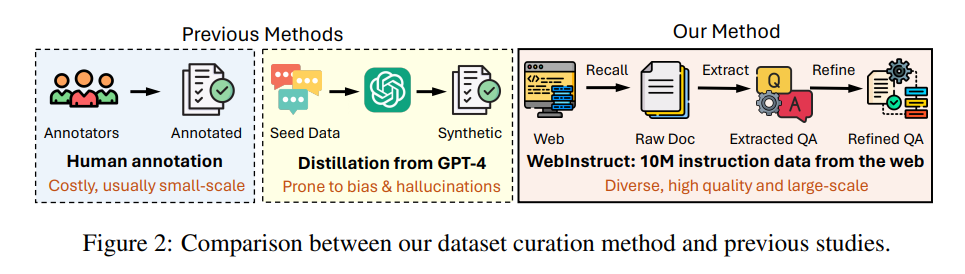
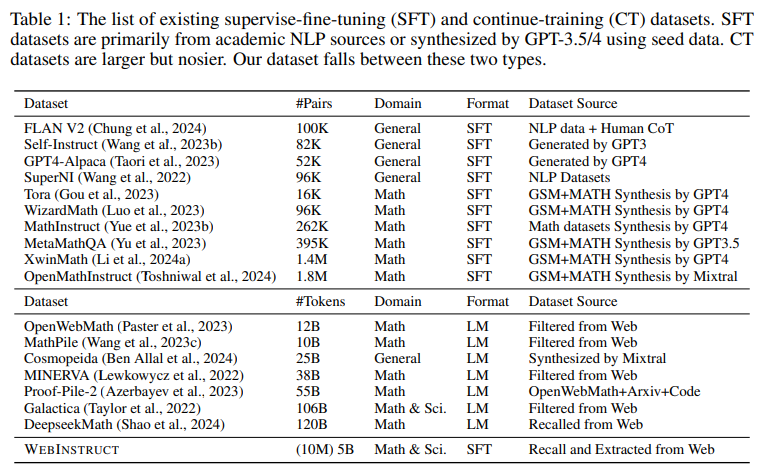
指示チューニングは、大規模言語モデル(LLM)の推論能力を向上させることができますが、データの品質とスケーラビリティが重要な要素です.指示チューニングデータの多くは、人間のクラウドソーシングやGPT-4の蒸留から得られています.私たちは、事前トレーニングウェブコーパスから1000万の自然に存在する指示データを効率的に収集し、LLMの推論を強化するためのパラダイムを提案しています.私たちのアプローチは、(1)関連する文書を呼び出し、(2)指示-応答ペアを抽出し、(3)抽出されたペアをオープンソースのLLMを使用して洗練することを含みます.このデータセットでベースLLMを微調整し、MAmmoTH2モデルを構築することで、推論ベンチマークでのパフォーマンスを大幅に向上させます.特に、MAmmoTH2-7B(Mistral)のパフォーマンスは、MATHで11%から36.7%、GSM8Kで36%から68.4%に向上しました.さらに、公開されている指示チューニングデータセットでMAmmoTH2をさらにトレーニングすることで、MAmmoTH2-Plusを実現し、いくつかの推論およびチャットボットのベンチマークで最先端のパフォーマンスを達成します.私たちの研究は、高品質の大規模な指示データを、高コストの人間の注釈やGPT-4の蒸留なしで収集する方法を示し、より良い指示チューニングデータを構築するための新しいパラダイムを提供しています.
Q&A:
Q: 事前学習用のWebコーパスから、自然に存在する1,000万件のインストラクションデータをどのように効率的に採取したのですか?
A: 10億の自然に存在する指示データを事前トレーニングウェブコーパスから効率的に収穫するために、リコール、抽出、および精製の3段階のパイプラインを開発しました.
Q: 関連文書を呼び出すプロセスを説明していただけますか?
A: 文書を再呼び出すプロセスは、まず多様なシードデータセットを作成し、それを使用してfastTextモデルをトレーニングします.その後、Common Crawlから文書を再呼び出すためにこのモデルを使用します.GPT-4を使用して、呼び出された文書をそのルートによってトリミングします.1000以上の文書が残されます.次に、約600Kのドメインを抽出します.GPT-3.5によって、これらのドメインをスキャンし、指示データを含む可能性があるものを自動的に選択します.約50KのドメインがGPT-3.5によって正のサンプルとしてラベル付けされます.最初のラウンドで再呼び出されたすべての文書は、Q-Aペアの抽出と改良には使用されません.次に、選択されたドメインからの文書を正の例としてサンプリングし、選択されていないドメインと一般的なCommon Crawlからの文書を負の例として使用して改良されたfastText分類器を再トレーニングします.新しくトレーニングされたfastText分類器を使用して文書を再呼び出します.新しくトレーニングされたfastTextモデルを使用して40Bトークンを再呼び出しました.最終的に、GPT-4に再呼び出されたドメインをふるいにかけさせ、望ましいウェブサイトから主に発信された18Mの生の文書を取得します.
Q: ウェブコーパスからどのように指示と応答のペアを抽出したのか?
A: 指示-応答ペアは、ウェブコーパスから3段階のパイプラインを使用して抽出されました.最初に、多様なシードデータセットを作成し、それを使用してfastTextモデルをトレーニングし、Common Crawlから文書を呼び出しました.次に、オープンソースのLLMを使用してこれらの文書からQ-Aペアを抽出し、候補となるQ-Aペアを約500万個生成しました.最後に、Mixtral-8×7BとQwen-72Bを使用してこれらの候補Q-Aペアを洗練し、関連のないコンテンツを削除し、形式を修正し、欠落している説明を追加しました.この洗練作業は、抽出されたQ-Aペアの品質を維持するために重要であり、最終的にはこれらのステップを通じて合計1000万の指示-応答ペアを収穫しました.
Q: 抽出されたペアを絞り込むために、どのようなオープンソースのLLMが使われたのか?
A: 抽出されたペアを洗練するために、Mixtral-8 ×7BとQwen-72Bが使用されました.
Q: 収穫されたデータセットでベースLLMを微調整することで、推論ベンチマークのパフォーマンスはどのように向上したのか?
A: 収穫されたデータセットをベースLLMsに微調整することで、推論ベンチマークの性能が向上しました.具体的には、収穫されたデータセットを使用して、強力なLLMを使用してコーパスをフィルタリングし、クリーニングして、指示チューニングペアを抽出しました.このようにして、ベースLLMsはより高品質な指示応答ペアに微調整され、推論能力が向上しました.
Q: MATHおよびGSM8KベンチマークにおけるMAmmoTH2-7B(Mistral)の性能向上について、詳細を教えてください.
A: MAmmoTH2-7B(Mistral)のMATHおよびGSM8Kベンチマークでの性能向上について、MAmmoTH2-7BはMATHベンチマークでの性能を平均14ポイント向上させ、GSM8Kベンチマークでの性能を向上させました.特に、WEBINSTRUCTでのトレーニング後、Mistral-7BのMATHの精度は11.2%から36.7%に向上しました.これにより、MAmmoTH2-7Bは強力な汎化能力を示しました.
Q: MAmmoTH2-Plusとはどのようなもので、推論やチャットボットのベンチマークでどのように最先端の性能を達成しているのか?
A: MAmmoTH2-Plusは、大規模で高品質な指示データを収集する方法を示し、高い性能を達成します.これは、人間の注釈やGPT-4の蒸留を必要とせずに、新しいパラダイムを提供し、より良い指示チューニングデータを構築する方法を示しています.MAmmoTH2-Plusは、複数の推論およびチャットボットのベンチマークで最先端のパフォーマンスを達成します.
Q: あなたの研究は、より良いインストラクション・チューニング・データを構築するための新しいパラダイムをどのように示していますか?
A: 私たちの研究は、高品質な指示データを費用対効果の高い人間の注釈やGPT-4の蒸留なしで収集する新しいパラダイムを提供しています.私たちのアプローチは、事前トレーニングウェブコーパスから1000万の自然に存在する指示データを効率的に収集し、LLMの推論を向上させるものです.この方法により、いくつかの推論およびチャットボットのベンチマークで最先端のパフォーマンスを達成したMAmmoTH2-Plusを含むMAmmoTH2をさらにトレーニングすることが可能となります.私たちの研究は、高品質な指示データを構築するための新しいパラダイムを提供しています.
Q: ウェブコーパスから大規模で質の高い指導データを採取する上で、どのような課題に直面しましたか?
A: 大規模で高品質な指示データをウェブコーパスから収集する際に直面した課題は、指示データがコーパス全体に分散しているため、その発見が非常に困難であることでした.このような指示データは多様で高品質であるが、ウェブ全体に散在しているため、収集することが特に困難でした.
Q: あなたのアプローチは、大規模言語モデルのインストラクション・チューニングの分野にどのような影響を与える可能性があるとお考えですか?
A: 私たちのアプローチは、大規模言語モデルのための指示チューニング分野における潜在的な影響を大きく変える可能性があります.私たちの提案では、既存の指示データをウェブから収集し、LLMの推論能力を向上させることができます.これにより、データの質とスケーラビリティが向上し、指示チューニングの効率が向上します.また、我々のアプローチは、人間のクラウドソーシングやGPT-4の蒸留からのデータ収集に比べて、より多くの自然に存在する指示データを収穫することができます.これにより、指示チューニングの領域全体に革新的な変化をもたらす可能性があります.
Is Flash Attention Stable?
著者:Alicia Golden, Samuel Hsia, Fei Sun, Bilge Acun, Basil Hosmer, Yejin Lee, Zachary DeVito, Jeff Johnson, Gu-Yeon Wei, David Brooks, Carole-Jean Wu
発行日:2024年05月05日
最終更新日:2024年05月05日
URL:http://arxiv.org/pdf/2405.02803v1
カテゴリ:Machine Learning, Distributed, Parallel, and Cluster Computing
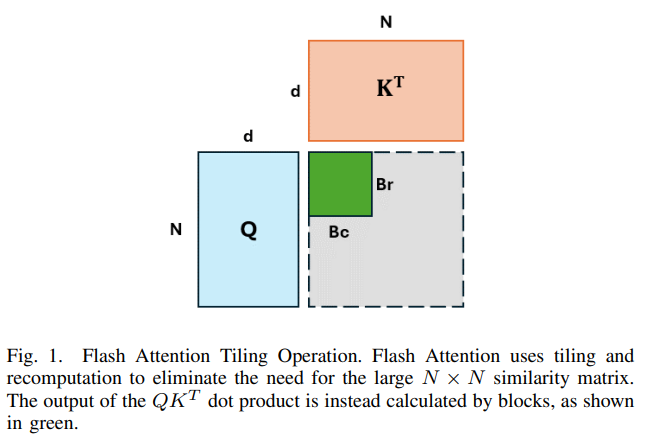
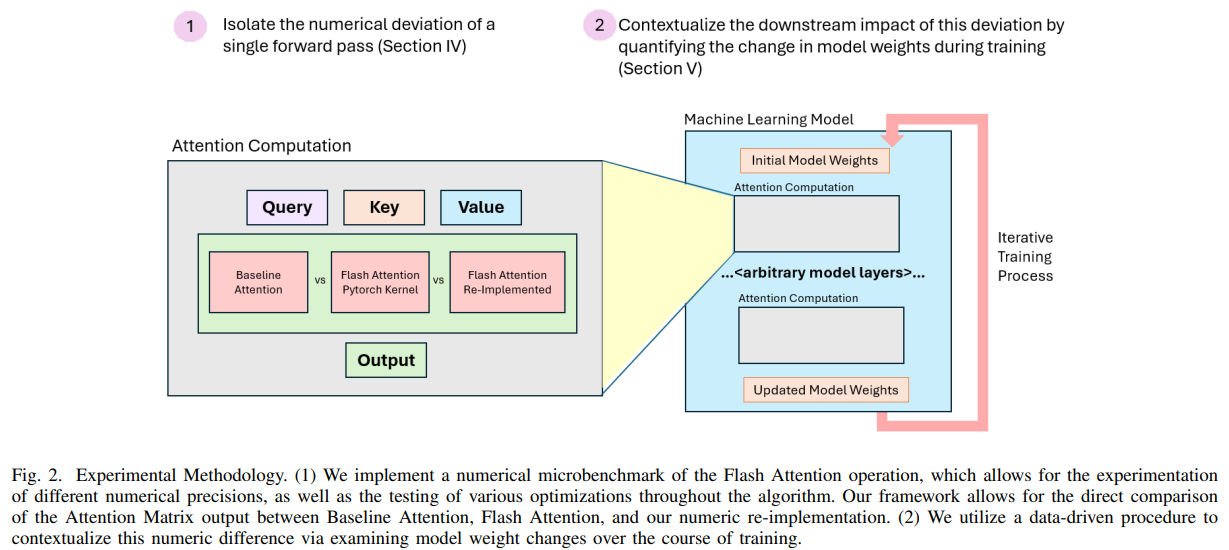
概要:
大規模な機械学習モデルのトレーニングは、現在のワークロードのサイズと複雑さの両方を考慮すると、独自のシステム上の課題を抱えています.最近、最先端の生成AIモデルをトレーニングしている多くの組織が、トレーニング中の不安定性の事例を報告しており、これはしばしば損失の急上昇として現れます.数値の逸脱がこのトレーニングの不安定性の潜在的な原因として浮上しており、ただし、トレーニングランのコストがかかるため、これを定量化することは特に困難です.この研究では、数値の逸脱の影響を理解するための原則に基づいたアプローチを開発し、下流の影響を定量化するのが難しい場合に観察を文脈に置くためのプロキシを構築します.ケーススタディとして、広く採用されているFlash Attentionの最適化を分析するために、このフレームワークを適用します.単独のフォワードパス中に測定した際、Flash AttentionはBF16でBaseline Attentionと比較して数値の逸脱がおおよそ1桁多いことがわかります.さらに、新たな文脈として、数値の逸脱がトレーニング中のモデルの重みにどのように影響するかを調査した結果、Flash Attentionにおける数値の逸脱は、低精度トレーニングよりも2〜5倍程度少ないことが明らかになりました.次に、Wasserstein距離に基づいたデータ駆動型の分析を使用して、この数値の逸脱がモデルの重みにどのように影響するかの上限を提供します.
Q&A:
Q: 数値偏差の概念と、それがトレーニングの不安定性に与える潜在的な影響について、もう少し詳しく説明してもらえますか?
A: 数値の逸脱とは、最適化手法とその対応するベースラインとの間の数値的な差異を指します.この逸脱が訓練中に徐々に誤差を蓄積し、訓練の過程で損失スパイクを引き起こす可能性があり、モデル状態のリセットを必要とすることがあります.訓練の確率的性質から、ある程度の数値の逸脱は許容される可能性がありますが、訓練が不安定になる閾値を決定することは困難です.
Q: この作品では、数値偏差の影響を理解するための原則的なアプローチをどのように開発したのですか?
A: この研究では、数値の偏差の影響を理解するための原則に基づいたアプローチを開発しました.具体的には、数値の偏差を測定するためのプロキシを開発し、下流の影響を定量化することが難しい場合に観測値を文脈に置く手法を構築しました.Flash Attentionをケーススタディとして検討し、数値の偏差を定量化するための進展を遂げました.私たちは、この方法論を共有することで、他の人々が同様の方法で将来の研究課題を調査することができるようにし、この訓練の不安定性という難しい問題を調査することを奨励します.
Q: 数値偏差の影響を定量化する際、観測結果を文脈に当てはめるために、具体的にどのようなプロキシを構築しましたか?
A: 観測値をコンテキストに置くために構築した具体的なプロキシは、数値偏差の影響を定量化する際に使用されます.これにより、数値偏差の影響をモデルの重みの観点で制限するためのプロキシが開発されました.
Q: BF16でベースライン・アテンションと比較してフラッシュ・アテンションの最適化を分析したケーススタディの結果について詳しく教えてください.
A: フラッシュアテンション最適化を分析したケーススタディでは、BF16においてベースラインアテンションと比較して、フラッシュアテンションは数値的な偏差が約10倍大きいことが明らかになりました.数値精度が変化するにつれて、BF16からFP64に変換すると、フラッシュアテンションとベースラインアテンションの数値的な偏差が減少することが示されました.
Q: 孤立したフォワードパス中のフラッシュ・アテンションの数値偏差はどのように測定したのですか?
A: フラッシュアテンションの数値的な逸脱を孤立したフォワードパス中にどのように測定しましたか?フラッシュアテンションの数値的な逸脱を測定するために、ワッサーシュタイン距離に基づいたデータ駆動型分析を使用しました.この分析により、数値的な逸脱がモデルの重みに与える影響の上限を提供し、フラッシュアテンションに存在する数値的な逸脱が低精度トレーニングよりも2〜5倍程度重要でないことがわかりました.
Q: 特にワッサーシュタイン距離など、どのようなデータドリブン分析テクニックを使って、トレーニング中のモデルの重みに対する数値偏差の影響について上限を出したのですか?
A: ワッサシュタイン距離を用いて、数値のずれがモデルの重みに与える影響の上限を提供しました.この数値のずれがトレーニング中のモデルの重みにどのように影響するかを評価するためにデータ駆動型の分析を行いました.
Q: フラッシュ・アテンションの数値偏差が、低精度トレーニングの2~5分の1であることを発見した意義について説明していただけますか?
A: フラッシュアテンションの数値的な逸脱が低精度トレーニングよりも2〜5倍少ないことの重要性は、モデルの重みの変動がより制御され、安定していることを示しています.これは、モデルの重みがトレーニング中にどれだけ変化するかを示す重要な指標であり、数値的な逸脱が少ないほど、モデルの予測性や信頼性が向上し、モデルの性能が安定する可能性が高まります.
Q: これらの発見は、大規模な機械学習モデルにおけるトレーニングの不安定性の理解にどのように貢献するのだろうか?
A: これらの研究結果は、大規模な機械学習モデルにおけるトレーニングの不安定性の理解に貢献しています.数値の偏差が最適化と対応するベースラインの間に生じることで、エラーが徐々に蓄積され、トレーニングの過程で損失スパイクが発生し、リセットが必要となる可能性があることが示唆されています.また、損失スパイクがトレーニング中に最大20回発生することが報告されており、これらの中断はトレーニングプロセスに中断を引き起こし、トレーニングを停止して再開する必要があるため、コストがかかります.これらの研究結果は、アルゴリズムの観点からトレーニングの安定性を高めるための可能な緩和策が検討されてきましたが、この不安定性の根本的な原因はまだ明確ではありません.モデルトレーニングの確率的性質と、そのような効果が大規模なスケールでのみ現れることが多いことが、これらの不安定性の本質を完全に理解するための独自の課題を提供しています.さらに、これらの大規模なモデルを繰り返しトレーニングして寄与要因を分離することは、データセンターの計算のコストと高い需要からしばしば実現不可能です.
Q: これらの結果は、最先端のジェネレーティブAIモデルをトレーニングする組織にとって、どのような意味を持つのだろうか?
A: これらの結果は、最先端の生成AIモデルを訓練している組織にとって重要な示唆を与える.数値の偏差が訓練の不安定性の原因となる可能性があるため、数値の安定性を確保することが重要である.また、訓練中の損失スパイクが問題となることから、数値の偏差を正確に理解し、その影響を評価することが必要である.
Q: この研究から派生する将来の研究の方向性や実用化の可能性はありますか?
A: この研究からは、将来の研究方向や実用的な応用が生まれる可能性があります.例えば、数値偏差の影響を理解し、その下流効果を文脈に置くためのプロキシを開発することが挙げられます.さらに、ハードウェアの信頼性やトレーニングの不安定性、システムのオーバーヘッドなどに関する関係を調査し、データセンター向けの低炭素で省電力なインフラ設計に持続可能性の影響を考慮することも重要です.
CLLMs: Consistency Large Language Models
著者:Siqi Kou, Lanxiang Hu, Zhezhi He, Zhijie Deng, Hao Zhang
発行日:2024年02月28日
最終更新日:2024年06月13日
URL:http://arxiv.org/pdf/2403.00835v4
カテゴリ:Computation and Language, Artificial Intelligence
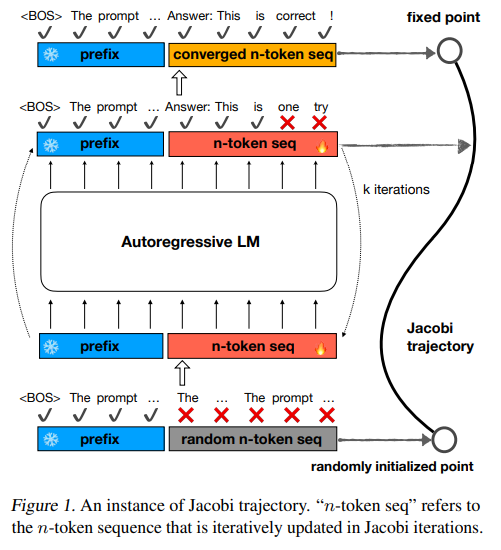

概要:
パラレルデコーディング方法であるJacobiデコーディングなどは、LLM推論の効率を向上させる可能性があります.これは、LLMデコーディングプロセスの直列性を破り、並列化可能な計算に変換するからです.しかし、実際には、Jacobiデコーディングは、1つの固定小数点反復ステップで1つ以上のトークンを正確に予測することが少ないため、従来の自己回帰(AR)デコーディングと比較してほとんどスピードアップを達成しません.この問題に対処するために、私たちは、Jacobi軌道上の任意の状態から固定点までの収束を高速に実現する新しいアプローチを開発しました.これは、入力として任意の状態を与えられた場合でも、ターゲットLLMを常に固定点を予測するように洗練することによって達成されます.広範な実験により、私たちの方法の効果が示され、ドメイン固有およびオープンドメインのベンチマークの両方で、生成速度を維持しながら生成品質を向上させることが示されました.
Q&A:
Q: ヤコビ復号がどのようにLLM復号の逐次的な性質を破り、並列化可能な計算に変換するのか、もう少し詳しく説明していただけますか?
A: Jacobi decodingは、LLMの逐次的なデコーディングプロセスを破り、並列化可能な計算に変換します.具体的には、Jacobi decodingは、非線形方程式のシステムを解くことでLLMの推論プロセスを再構築します.これにより、各トークンyiについて、f(yi,y<i,x) = 0を満たすような非線形方程式を解くことで、逐次的な処理を回避し、同時に複数のトークンを予測することが可能となります.Jacobi fix-point iteration methodを用いて、ランダムに初期化されたnトークンシーケンスy(0)から始めて、並列で解を見つけることができます.
Q: ヤコビデコーディングで正確な予測を達成するために、具体的にどのような課題に遭遇し、どのように対処したのですか?
A: Jacobiデコーディングでは、1つの固定小数点反復ステップで1つ以上のトークンを正確に予測することが稀であるという特定の課題に直面しました.この問題に対処するために、Jacobi軌道上の任意の状態から固定点に速やかに収束する新しいアプローチを開発しました.これは、Jacobi軌道上の固定点を一貫して予測するようにターゲットLLMを改良することで達成されます.
Q: ヤコビ軌跡上の固定点を予測するという点で、あなたの新しいアプローチは従来の自己回帰復号法とどう違うのですか?
A: 新しいアプローチは、ジャコビ軌道上の固定点を予測する際に、従来の自己回帰デコーディング手法とは異なります.具体的には、ジャコビデコーディングは、1つの固定小数点反復ステップで1つ以上のトークンを正確に予測することができないため、通常の自己回帰デコーディングよりも高速な収束を実現することを目指しています.
Q: どのような状態を入力として与えても一貫して固定点を予測できるように、ターゲットLLMをどのように改良したのか、もう少し詳しく教えてください.
A: ターゲットLLMを改良するために、Jacobi軌道上の任意の状態から固定点を一貫して予測するようにしました.これは、局所的な一貫性損失を導入することで達成されます.具体的には、隣接する状態(y(j), y(j+1))が同じ出力を生成するように要求されます.
Q: 広範な実験から、あなたの方法の有効性を示す重要な発見は何でしたか?
A: 私たちの広範な実験からの主な結果は、一貫性のあるグローバル損失と一貫性のあるローカル損失を使用してCLLMの効果を示すことでした.表6は、グローバル損失がCLLMのトレーニングにおいてより効果的であることを示しています.
Q: その方法によって達成された発電速度の向上をどのように測定し、数値化したのですか?
A: 我々は、ジャコビ復号化を用いた壁時計世代スループットとベースラインAR復号化の比率としてスピードアップを測定しました.
Q: あなたの実験では、ドメイン固有のベンチマークとオープンドメインのベンチマークの両方で、生成の品質がどのように保たれたのか、詳しく教えてください.
A: 実験では、ジャコビ軌跡データセットの品質が高いことが重要であることが観察されました.したがって、データのクリーニングが不可欠であり、セクション3.2.1で議論されています.データセットのサイズも重要であり、セクション4.3で説明され、表4に示されています.たとえば、Code-Search-Net Pythonデータセットの10%のみを使用して生成されたジャコビ軌跡は、表2で示されているように2.9倍の高速化を実現できます.ただし、ShareGPTのようなオープンドメインのデータセットの場合、より多くのデータが効率向上に必要です.したがって、ジャコビ軌跡データセットの品質と量が、特定およびオープンドメインのベンチマークで生成品質を維持するために重要であることが示されました.
Q: あなたの実験で観察された発電速度の2.4倍から3.4倍向上には、主にどのような要因があったのですか?
A: 実験で観察された生成速度の2.4倍から3.4倍の改善に貢献した主な要因は、高品質のJacobi軌道データセットと、データのクリーニングが重要であることです.
Q: 効率的なLLM推論が重要な実世界のシナリオにおいて、あなたのアプローチをどのように実用化することを想定していますか?
A: 私たちのアプローチは、効率的なLLM推論が重要な実世界のシナリオにおいて、高速化と精度の両方を実現することができます.Jacobiデコーディングを使用することで、特定のドメインのベンチマークやオープンドメインのベンチマークで高速化を達成し、精度の損失を最小限に抑えることができます.また、追加のトレーニングを必要としないため、システム内で2つの異なるモデルを管理する複雑さを軽減します.さらに、他の効率的なLLM推論技術とシームレスに統合することで、より大きな高速化を実現できます.
Q: 今回の調査結果を踏まえて、限界やさらなる研究の余地があると思われる点はありますか?
A: 研究の結果、CLLMを使用して生成速度を向上させる際には、高品質なJacobi軌道データセットが重要であることが明らかになりました.そのため、データのクリーニングが不可欠であり、データセットのサイズも一定の役割を果たします.また、特定の領域では10%のデータセットでも効率的な速度向上が可能である一方、ShareGPTのようなオープンドメインのデータセットでは、より多くのデータが必要とされます.さらなる研究が必要である可能性があります.
