
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をLLMによって生成されるQ&Aを用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.自動生成記事のクオリティと信頼性を向上させるためにアルゴリズムの改善に取り組んでいます.個人で資料のQ&Aを作成されたい方には、https://www.chatpdf.com/ や https://scispace.com/などがお勧めです.
- Mixtral 8x22B
発行日:2024年04月17日
Mistral AIチームは、Mixtral 8x22Bというオープンモデルをリリースし、AIコミュニティ内でのパフォーマンスと効率の新基準を設定しています. - A Survey on Retrieval-Augmented Text Generation for Large Language Models
発行日:2024年04月17日
RAGは、リトリーバルメソッドと深層学習を組み合わせ、LLMsの制限に対処し、外部情報を統合して信頼性を向上させる方法論であり、テキスト領域に焦点を当てている. - The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey
発行日:2024年04月17日
AIエージェントの実装の進歩と能力に焦点を当てた調査論文で、現在の能力と制限、将来の発展に関する洞察を提供し、エージェントシステムの設計選択肢と影響を評価している. - How faithful are RAG models? Quantifying the tug-of-war between RAG and LLMs’ internal prior
発行日:2024年04月16日
RAGは、LLMに最新の知識を提供するが、取得された情報が間違っている場合、モデルは誤った情報を再現しやすくなる可能性がある. - Chinchilla Scaling: A replication attempt
発行日:2024年04月15日
Hoffmannら(2022)は、スケーリング法の推定に3つの方法を提案し、第3の手法は信頼性が低いことが示されたが、私たちの再導出は他の2つの手法と互換性がある. - State Space Model for New-Generation Network Alternative to Transformers: A Survey
発行日:2024年04月15日
Transformerアーキテクチャの代替として注目されているState Space Model(SSM)に関する包括的なレビューと実験的な比較を提供し、SSMの特徴と利点を明らかにする.GitHubで関連研究が継続的に更新されている. - LLM In-Context Recall is Prompt Dependent
発行日:2024年04月13日
LLMの普及は、利点や制限を評価し、プロンプト情報の取得能力を重視し、トレーニング戦略やファインチューニングによってパフォーマンスを向上させる重要性を示唆している. - Reducing hallucination in structured outputs via Retrieval-Augmented Generation
発行日:2024年04月12日
GenAIの一般的な制限は幻覚を引き起こす傾向があり、RAGの実装により幻覚を減少させ、LLMの一般化を改善し、リソース効率的に展開できる. - The Illusion of State in State-Space Models
発行日:2024年04月12日
SSMはLLMを構築するための代替アーキテクチャとして登場し、トランスフォーマーと同様に状態追跡に制限があり、実世界の問題を解決する能力が制限される可能性がある.
Mixtral 8x22B
著者:Mistral AI team
発行日:2024年04月17日
最終更新日:不明
URL:https://mistral.ai/news/mixtral-8x22b/
カテゴリ:不明
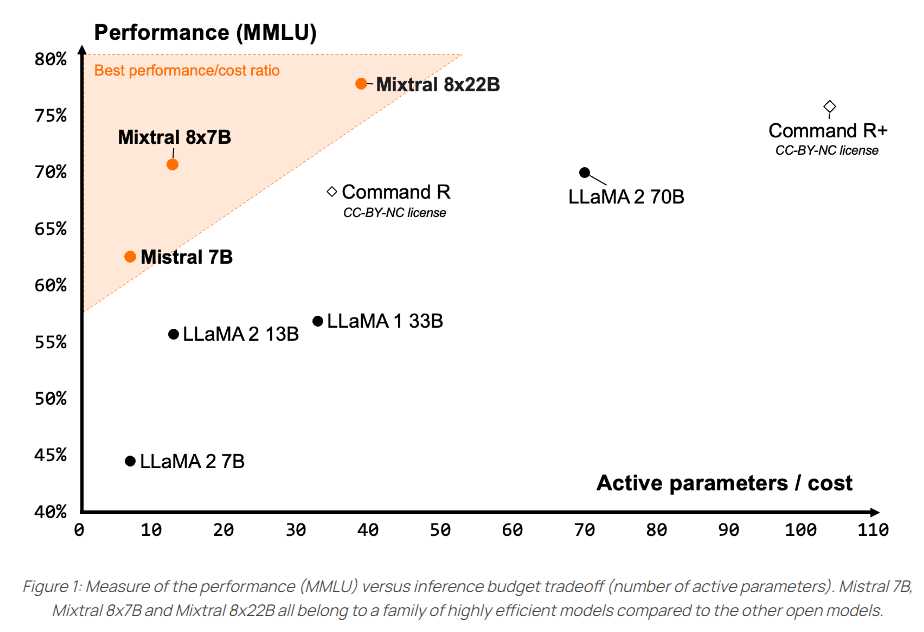
概要:
Mistral AIチームは、AIの最前線を押し進め、それをすべての人にアクセス可能にすることを続けています.彼らの最新のオープンモデルであるMixtral 8x22Bは、AIコミュニティ内でのパフォーマンスと効率の新基準を設定しています.このモデルは、Apache 2.0の下でリリースされ、誰もが制限なくどこでも使用できる最も寛大なオープンソースライセンスです.Mixtral 8x22Bは、そのサイズに対して比類のないコスト効率を提供し、コミュニティが提供する他のモデルの中で最高のパフォーマンス対コスト比を実現しています.このモデルは、他のオープンウェイトモデルよりも優れており、ベースモデルの利用可能性により、ファインチューニングのユースケースの優れた基盤となります.また、Mixtral 8x22Bは、推論において優れた性能を発揮するために最適化されています.2024年5月10日21:17にMixtral 8x22Bを発表し、AIの最前線をあなたの手に提供しています.さらに、Mixtral 8x22Bは、推論、一般的な常識、推論、知識のベンチマークにおいて最適化されており、多言語対応も備えています.また、Mixtral 8x22Bは、他のオープンモデルと比較して、コーディングや数学のタスクにおいて最も優れたパフォーマンスを発揮しています.
Q&A:
Q: ミックスドラル8x22BのスパースSMoE(Mixture-of-Experts)モデルの意義は?
A: Mixtral 8x22Bにおける疎な専門家モデル(SMoE)の重要性は、モデルが141Bのパラメータのうち39Bのアクティブなパラメータのみを使用しているため、そのサイズに対して比類のないコスト効率を提供している点にあります.このような疎なアクティベーションパターンは、他の密なモデルよりも高速でありながら、より優れた性能を持つため、AIコミュニティ内で新たな基準を設定しています.
Q: ミクストラル8x22Bは、コスト効率や性能の面で他のオープンモデルと比較してどうですか?
A: Mixtral 8x22Bは、他のオープンモデルと比較して、コスト効率と性能の両方で優れています.モデルは、そのサイズに対して最高の性能対コスト比を提供し、他のオープンモデルよりも優れたコスト効率を持っています.また、Mixtral 8x22Bは、他のオープンウェイトモデルよりも速く、より能力が高いとされています.ベースモデルの利用可能性により、微調整用途に優れた基盤となっています.
Q: ミックスドラル8x22Bの推論と知識の最適化について説明していただけますか?
A: Mixtral 8x22Bは、推論において高い効率を持つよう最適化されています.その理由は、スパースな活性化パターンを持つことにより、他の密な70Bモデルよりも速く、他のオープンウェイトモデルよりも能力が高いからです.このモデルは、推論において高い性能を持ちながら、コスト効率も優れており、ファインチューニングのユースケースに最適な基盤となります.
Q: Mixtral 8x22Bの多言語対応機能は、さまざまなベンチマークでのパフォーマンスにどのように貢献していますか?
A: Mixtral 8x22Bの多言語対応は、フランス語、ドイツ語、スペイン語、イタリア語のさまざまなベンチマークでの性能に大きく貢献しています.これにより、Mixtral 8x22BはLLaMA 2 70Bよりも優れたパフォーマンスを発揮し、HellaSwag、Arc Challenge、MMLUのベンチマークで優れた結果を示しています.
Q: Mixtral 8x22BをApache 2.0オープンソースライセンスでリリースした理由は何ですか?
A: Mixtral 8x22BをApache 2.0のオープンソースライセンスの下でリリースする理由は、誰もが制限なくどこでもモデルを使用できるようにするためです.
Q: Mixtral 8x22Bの64Kトークンコンテキストウィンドウは、情報想起能力をどのように高めているのでしょうか?
A: Mixtral 8x22Bの64Kトークンのコンテキストウィンドウは、大規模なドキュメントからの正確な情報の呼び出しを可能にします.このウィンドウサイズは、モデルが過去の64Kトークンの情報を保持し、それを使用して次のトークンを生成する際に参照することができるため、文脈を理解し、適切な情報を取得するのに役立ちます.
Q: アプリケーション開発と技術スタックの近代化のためにla Plateformeに実装された制約出力モードについて詳しく教えてください.
A: La Plateformeに実装された制約付き出力モードは、大規模なドキュメントからの正確な情報の呼び出しを可能にする64Kトークンのコンテキストウィンドウと組み合わせて、アプリケーション開発とテックスタックの現代化を規模化することができます.
Q: 標準的な業界ベンチマークにおけるMixtral 8x22Bのパフォーマンスは、他のオープンモデルと比較してどうですか?
A: Mixtral 8x22Bは標準産業ベンチマークでの性能が他のオープンモデルと比較して非常に優れています.特に、GSM8K maj8において90.8%、Math maj4において44.6%のスコアを記録し、他のモデルよりも優れた数学パフォーマンスを示しています.
Q: Mistral AIのオープンモデルファミリーの自然な継続性をMixtral 8x22Bは何にしますか?
A: Mixtral 8x22Bは、Mistral AIのオープンモデルファミリーの自然な継続性を持っています.このモデルは、他のオープンウェイトモデルよりも優れた性能を提供し、スパースな活性化パターンを持つため、70Bの密なモデルよりも高速であり、ファインチューニングのユースケースに優れた基盤を提供しています.
Q: Mixtral 8x22Bの希薄な活性化パターンは、他のモデルと比較して、どのように速度と能力に貢献していますか?
A: Mixtral 8x22Bの疎な活性化パターンは、他のモデルと比較して、より速く、より能力が高いという特性を持っています.この疎な活性化パターンにより、モデル内のパラメータのうち、ほんの一部しか活性化されず、他のモデルよりも高速に処理が可能となります.また、このような活性化パターンにより、モデル全体の効率が向上し、他のオープンウェイトモデルよりも優れた性能を発揮します.
A Survey on Retrieval-Augmented Text Generation for Large Language Models
著者:Yizheng Huang, Jimmy Huang
発行日:2024年04月17日
最終更新日:2024年04月17日
URL:http://arxiv.org/pdf/2404.10981v1
カテゴリ:Information Retrieval, Artificial Intelligence, Computation and Language
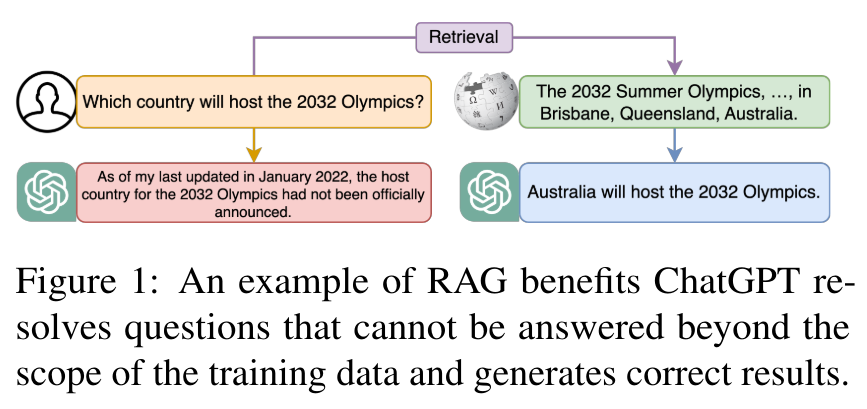
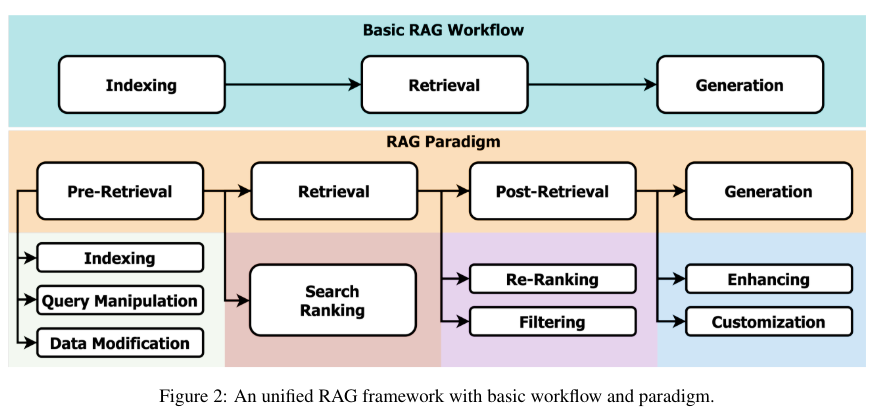
概要:
Retrieval-Augmented Generation(RAG)は、リトリーバルメソッドと深層学習の進歩を組み合わせ、大規模言語モデル(LLMs)の静的な制限に対処するために、最新の外部情報を動的に統合することを可能にする.この方法論は、主にテキスト領域に焦点を当てており、LLMsによる信憑性のあるが誤った応答の生成に対する費用対効果の高い解決策を提供し、実世界のデータを使用して出力の正確性と信頼性を向上させる.RAGが複雑化し、パフォーマンスに影響を与える複数の概念を取り入れるにつれて、この論文はRAGパラダイムを事前リトリーバル、リトリーバル、ポストリトリーバル、ジェネレーションの4つのカテゴリに整理し、リトリーバルの観点から詳細な視点を提供する.また、論文はRAGの進化を概説し、重要な研究の分析を通じて分野の進歩について議論する.さらに、論文はRAGの評価方法を紹介し、直面する課題に対処し、将来の研究方向を提案する.整理されたフレームワークとカテゴリ化を提供することで、この研究はRAGに関する既存の研究を統合し、その技術的基盤を明確にし、LLMsの適応性と応用の拡大を強調することを目指している.
Q&A:
Q: 大規模な言語モデルの文脈で、検索手法がディープラーニングの進歩とうまく統合された例を教えてください.
A: 最新の外部知識の動的統合を可能にすることで、大規模言語モデル(LLM)の静的な限界に対処するために、検索手法とディープラーニングの進歩を融合させることで、大規模言語モデルの文脈で検索手法とディープラーニングの進歩を融合させることに成功している.この統合により、外部知識を活用することで、より正確で、適切で、ロバストな応答を生成することが可能になる.
Q: 実世界のデータを使用することで、検索支援型生成の文脈における大規模言語モデルからの出力の精度と信頼性をどのように高めることができるのか?
A: リアルワールドデータの使用により、大規模言語モデルからの出力の正確性と信頼性が向上します.これは、リアルワールドデータを取り込むことで、モデルが最新の情報を反映し、より適切な回答を生成できるようになるからです.
Q: RAGパラダイムはどのような主要カテゴリーに分類され、それらがシステム全体のパフォーマンスにどのように貢献しているのか?
A: RAGパラダイムは、前検索、検索、後検索、生成の4つの主要カテゴリに分類されており、それぞれがシステム全体の性能向上に寄与しています.前検索は、情報の収集と整理を行い、検索プロセスの効率を高めます.検索は、高品質な情報を取得するための重要な段階であり、適切な情報を選択し取得することで、システムの精度を向上させます.後検索は、取得した情報を分析し、必要な情報を抽出することで、システムの応用性を向上させます.生成は、取得した情報を元に新しい情報を生成し、システムの柔軟性と応用範囲を拡大させます.
Q: RAGの進化と、論文で論じられているような時間の経過による進歩について説明していただけますか?
A: この論文では、RAG技術の進化と進展について詳細に議論されています.Lewisらによって2020年に導入されたRAG技術は、ChatGPTの成功に大きく影響を受け、重要な進歩を遂げてきました.しかし、その後の研究の進展やRAGのメカニズムに関する徹底的な分析には、文献に明らかな欠如があります.さらに、この分野は多様な研究焦点と、類似した手法に対する曖昧な用語の使用に特徴付けられており、混乱を招いています.この論文は、RAGの進展を明確にすることを目的としています.進化の過程で、特定の側面が十分に分析されずに残ったり、最近の進展が見逃されたりする可能性があります.論文は、RAGの開発を支援する評価手法を参照していますが、LangChainやLlamaIndexなどの成熟したツールも有用なリソースとして認識しています.しかし、この調査の焦点は、評価パイプラインの詳細やこれらのツールの具体的な使用方法についてではなく、評価の側面がRAGの進展を支援する方法を示すことにあります.この選択は、将来の研究のための領域を強調し、方法論の明確さと評価ツールの適用がRAGモデルの磨き上げと向上にどれほど重要かを強調しています.
Q: RAGにはどのような評価方法が提案されており、その効果を評価する上で直面する主な課題は何か?
A: RAGの評価方法としては、生成されたテキストの品質、取得された文書の関連性、モデルの誤情報に対する耐性など、複数の次元でシステムを評価するためのフレームワークやベンチマークが導入されています.これらの評価は、ノイズに対する堅牢性、ネガティブプロンプティング、情報の統合、因果関係の堅牢性など、特定の能力を評価することに焦点を当てており、RAGシステムが実践的な応用において直面する複雑な課題を示しています.評価フレームワークやメトリクスの継続的な開発は、分野の進歩に不可欠であり、RAGシステムの適用範囲を広げ、複雑で変化に富んだ情報環境の要求を満たすことを確実にするために重要です.
Q: この研究は、RAGに関する既存の研究をどのように統合し、その技術的裏付けを明らかにすることを目的としているのか?
A: この研究は、既存のRAGに関する研究を整理し、その技術的基盤を明確にすることを目指しています.具体的には、RAGの中核技術を詳細に分析し、情報の検索と生成における強みを検討することで、RAG領域の包括的な枠組みを提供しています.また、RAG研究で使用される評価方法を紹介し、異なる知識源を統合する利点を強調しています.
Q: 検索補強世代を使用することで、大規模な言語モデルの幅広い適応性にどのような潜在的な応用や利点があるとお考えですか?
A: 大規模言語モデルの広範な適応性を高めるためのリトリーバル増強生成の利点として、外部情報の動的統合により、正確性と信頼性が向上し、誤った応答の生成を防ぐことができます.また、リトリーバル増強生成は、リアルワールドデータの使用により、大規模言語モデルの出力を向上させるための費用対効果の高い解決策を提供します.さらに、リトリーバル増強生成は、複数の概念を組み込むことで、そのパフォーマンスに影響を与える可能性があるため、その進化を促進し、重要な研究の分析を通じて分野の進歩を議論します.
Q: 論文で示された分析に基づいて、RAGの今後の研究の方向性をどのように描いていますか?
A: 本論文による分析から、RAGの将来の研究方向は、テキストベースの研究から画像やマルチモーダルデータへの拡張に集中することが示唆されています.これにより、RAG技術の進化が促進され、新たな応用領域が開拓される可能性があります.また、RAGのメカニズムや進歩に関する包括的な分析が不足しているため、今後の研究ではこれらの側面に焦点を当てることが重要です.さらに、研究の焦点や用語の曖昧さによる混乱を解消するために、明確な定義と統一された用語の使用が求められます.
Q: 論文で言及されているように、RAGのパフォーマンスに影響を与える具体的なコンセプトや要因について、洞察していただけますか?
A: 論文では、RAGのパフォーマンスに影響を与える特定の概念と要因について詳細に説明されています.具体的には、RAGのパフォーマンスに影響を与える要因として、様々な方法のカテゴリ化、RAGの中核技術の分析、および評価方法が挙げられています.これらの要素は、RAGの進化や分野の進展を促進し、LLMの適応性と応用範囲を広げる潜在能力を強調しています.
Q: 検索手法とディープラーニングの融合は、特に大規模な言語モデルの文脈で、今後どのように進化していくとお考えですか?
A: Retrieval methodsの統合は、大規模言語モデルの文脈で特に将来的にどのように進化するかについては、RAG技術の成功による影響が大きいと考えられます.ChatGPTの成功により、RAG技術は大きな進歩を遂げており、外部データを取得してモデルを補完することで、より正確で最新の出力を確保することができます.今後、RAG技術はさらに発展し、大規模言語モデルの静的な制限を克服するために、外部データの動的な統合を可能にすることで、さらなる進化が期待されます.
The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey
著者:Tula Masterman, Sandi Besen, Mason Sawtell, Alex Chao
発行日:2024年04月17日
最終更新日:2024年04月17日
URL:http://arxiv.org/pdf/2404.11584v1
カテゴリ:Artificial Intelligence, Computation and Language
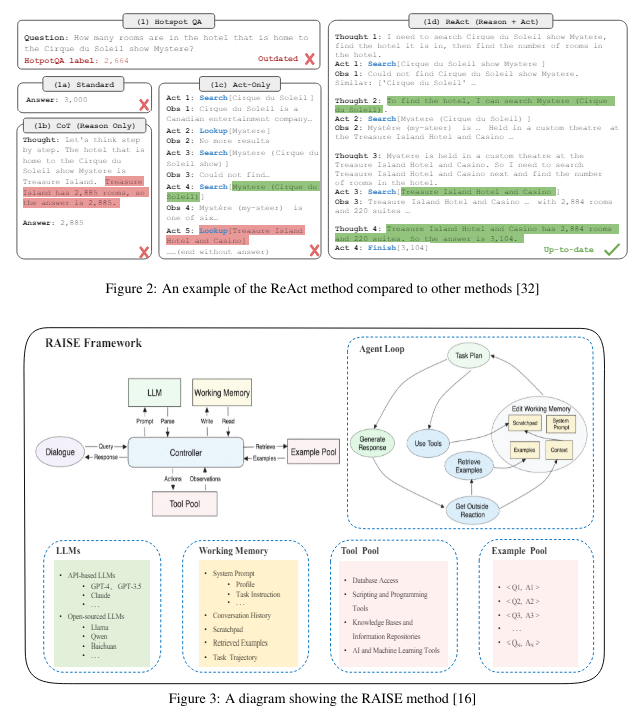
概要:
この調査論文は、AIエージェントの実装の最近の進歩を検討し、高度な推論、計画、およびツール実行能力が必要な複雑な目標を達成する能力に焦点を当てています.この研究の主な目的は、a) 現在のAIエージェントの実装の能力と制限を伝えること、b) これらのシステムの実際の観察から得られた洞察を共有すること、およびc) AIエージェント設計の将来の発展に重要な考慮事項を提案することです.これは、単一エージェントとマルチエージェントのアーキテクチャの概要を提供し、設計選択肢の主要なパターンと逸脱を特定し、提供された目標を達成するための全体的な影響を評価することによって達成されます.私たちの貢献は、エージェントのアーキテクチャを選択する際の主要なテーマ、エージェントシステムにおけるリーダーシップの影響、エージェントのコミュニケーションスタイル、および計画、実行、および反映のための主要なフェーズを特定し、堅牢なAIエージェントシステムを可能にします.
Q&A:
Q: 調査論文の主な目的は何ですか?
A: この調査論文の主な目的は、現在のAIエージェントの実装の成功率、人間の応答との出力類似性、および全体的な効率性を伝えることです.これらの客観的な指標は、実装の信頼性と正確性を理解する上で重要ですが、性能のより微妙で主観的な測定も考慮することが重要です.ツールの使用効率、モデルの偏りなどのメトリクスは、信頼性のあるエージェントを可能にするために近い将来に取り組む必要があります.この調査は、静的言語モデルからより動的で自律的なエージェントへの進化を検討することで、現在のAIエージェントの景色を包括的に理解し、既存のエージェントアーキテクチャを使用する人やカスタムエージェントアーキテクチャを開発する人に洞察を提供することを目指しています.
Q: AIエージェントが達成できる複雑な目標の例を教えてください.
A: AIエージェントが達成できる複雑な目標の例としては、高度な推論、計画、およびツールの実行能力が必要な多段階の問題の解決が挙げられます.これらの目標は、単一エージェントまたは複数エージェントのアーキテクチャによって達成され、明確なフィードバック、タスクの分解、反復的な改善、および役割の定義によってエージェントのパフォーマンスが向上します.
Q: 既存のAIエージェント実装の現在の能力と限界は?
A: 現在のAIエージェントの実装の現在の能力と制限については、論文がその能力を伝え、観察から得られた洞察を共有し、将来のAIエージェント設計の重要な考慮事項を提案しています.単一エージェントと複数エージェントのアーキテクチャの概要を提供し、設計選択肢の主要なパターンと逸脱を特定し、それらが全体的な影響に与える評価を行うことで、これを達成しています.
Q: AIエージェント・システムの動作を観察することで、どのような知見が得られたのだろうか?
A: AIエージェントシステムの実行を観察することで得られた洞察は、言語モデルによる推論、計画、およびツールの呼び出しの迅速な向上を示しています.シングルエージェントとマルチエージェントのパターンの両方が、高度な問題解決スキルを必要とする複雑な多段階問題に取り組む能力を示しています.本論文で議論された主要な洞察は、最良のフィードバック、知的メッセージフィルタリング、およびツールの使用を含む技術を活用するアーキテクチャが、さまざまなベンチマークや問題タイプにおいてより効果的であることを示唆しています.
Q: AIエージェントの設計における今後の発展には、どのような配慮が必要なのだろうか?
A: AIエージェント設計の将来の展望に関しては、既存のAIエージェント実装の制限を共有し、これらのシステムの観察から得られた洞察を共有し、AIエージェント設計の将来の展望に関する重要な考慮事項を提案することが重要です.これは、単一エージェントとマルチエージェントのアーキテクチャの概要を提供し、設計選択肢の主要なパターンと相違点を特定し、それらが全体的な性能に与える影響を評価することによって達成されます.
Q: シングルエージェントアーキテクチャーとマルチエージェントアーキテクチャーの違いを説明していただけますか?
A: シングルエージェントアーキテクチャとマルチエージェントアーキテクチャの違いは、シングルエージェントアーキテクチャでは他のAIエージェントからのフィードバックメカニズムがないが、人間がエージェントを導くためのフィードバックオプションがある一方、マルチエージェントアーキテクチャでは2つ以上のエージェントが関与し、それぞれが同じ言語モデルまたは異なる言語モデルを利用することができる.エージェントは同じツールまたは異なるツールにアクセスすることができ、通常、それぞれが独自のペルソナを持つ.マルチエージェントアーキテクチャは、複数のペルソナからのフィードバックがタスクの達成に有益な場合に適しており、例えば、文書生成では、1つのエージェントが文書の一部について別のエージェントに明確なフィードバックを提供するマルチエージェントアーキテクチャが有益である.また、異なるタスクやワークフロー間での並列化が必要な場合にもマルチエージェントシステムは有用である.シングルエージェントとマルチエージェントのパターンは、範囲の観点から異なる能力を持っており、研究によると、「十分に堅牢なプロンプトが提供された場合、マルチエージェントの議論が推論を向上させるわけではない」とされている.そのため、エージェントアーキテクチャを導入する際には、推論能力に基づいてシングルエージェントまたはマルチエージェントを選択するのではなく、使用ケースの広い文脈に基づいて選択すべきである.
Q: 設計の選択は、AIエージェントシステムの全体的な成功にどのような影響を与えるのか?
A: AIエージェントシステムの全体的な成功には、設計の選択肢が重要な影響を与えます.例えば、明確なリーダーシップやタスク分担、計画・実行・評価の段階を持つこと、動的なチーム構造、人間またはエージェントからのフィードバック、インテリジェントなメッセージフィルタリングなどのアプローチを組み込むことで、最も優れたエージェントシステムが構築されます.
Q: エージェント・アーキテクチャを選択する際に考慮すべき重要なテーマとは?
A: 選択する際に考慮すべき主要なテーマには、スキルに基づいた知的な分業の機会を提供するマルチエージェントアーキテクチャ、様々なエージェントのパーソナリティからの有益なフィードバック、リーダーシップがエージェントシステムに与える影響、エージェントのコミュニケーションスタイル、計画、実行、反省のための主要なフェーズが含まれる.これらの要素は、ロバストなAIエージェントシステムを実現するために重要である.
Q: リーダーシップはAIエージェントシステムにどのような影響を与えるのか?
A: リーダーシップはAIエージェントシステムに重要な影響を与えます.リーダーシップは、エージェントシステム内でのタスクの分担や意思決定プロセスに影響を与える可能性があります.また、リーダーシップの存在は、エージェントシステム全体の効率性や目標達成に対する影響を持つことが示唆されています.
Q: ロバストなAIエージェント・システムにおける計画、実行、反省の重要な段階とは?
A: 計画、実行、反省のための主要な段階は、明確に定義されたシステムのプロンプト、明確なリーダーシップとタスク分担、専用の推論/計画-実行-評価段階、動的なチーム構造、人間またはエージェントからのフィードバック、そしてインテリジェントなメッセージフィルタリングを組み込むことです.
How faithful are RAG models? Quantifying the tug-of-war between RAG and LLMs’ internal prior
著者:Kevin Wu, Eric Wu, James Zou
発行日:2024年04月16日
最終更新日:2024年04月16日
URL:http://arxiv.org/pdf/2404.10198v1
カテゴリ:Computation and Language, Artificial Intelligence
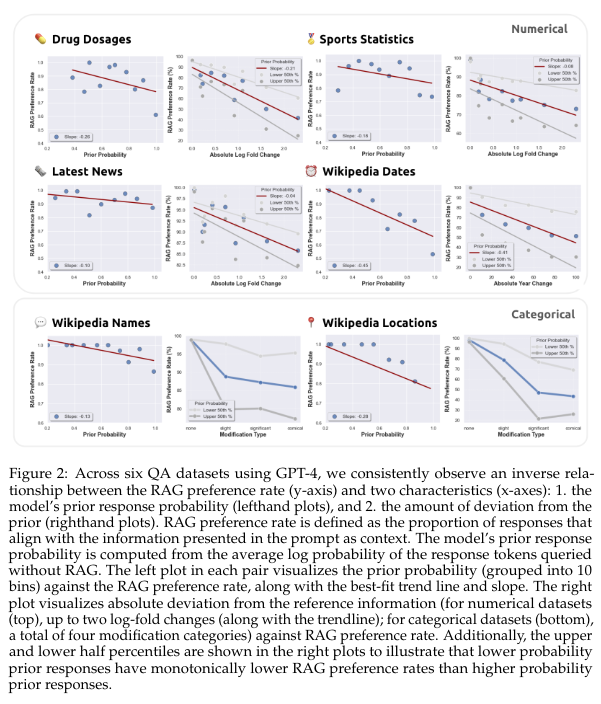
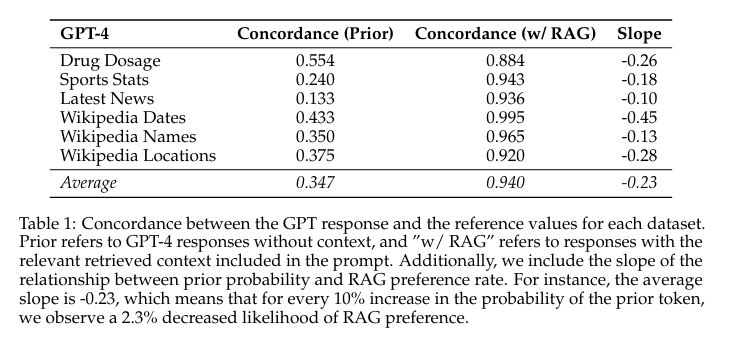
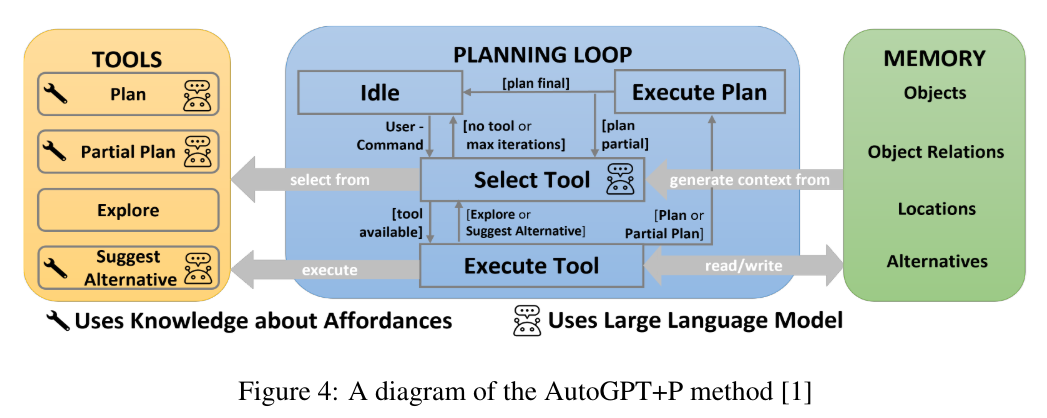
概要:
Retrieval augmented generation (RAG)は、幻覚を修正し、大規模言語モデル(LLM)に最新の知識を提供するためによく使用されます.しかし、LLM単独で質問に誤った回答をする場合、正しい取得されたコンテンツを提供することで常にエラーが修正されるでしょうか?逆に、取得されたコンテンツが間違っている場合、LLMは誤った情報を無視する方法を知っているのでしょうか、それともエラーを再現するのでしょうか?これらの質問に答えるために、LLMの内部知識(つまり事前知識)と取得された情報が異なる場合の攻防を体系的に分析します.私たちは、参照文書のあるデータセットとないデータセットを横断して、GPT-4や他のLLMの質問応答能力をテストします.期待通り、正しい取得情報を提供することで、ほとんどのモデルの間違いが修正されます(94%の正確さ).しかし、参照文書が間違った値を増やすにつれて、LLMは内部事前知識が弱い場合には、誤った修正された情報を再現しやすくなりますが、事前知識が強い場合にはより抵抗力があります.同様に、修正された情報がモデルの内部事前知識からどれだけ逸脱するかに応じて、モデルが修正された情報を再現するかどうかもわかります.さらに、修正された情報がモデルの事前知識からどれだけ逸脱するかによって、モデルがその情報を好むかどうかも変わります.これらの結果は、モデルの事前知識と参照文書に提示される情報との間に潜在的な緊張関係があることを示しています.
Q&A:
Q: 検索拡張世代(RAG)は、幻覚を修正し、大規模言語モデル(LLM)に最新の知識を提供する上で、どのように役立つのだろうか?
A: Retrieval augmented generation (RAG)は、大規模言語モデル(LLMs)の幻覚を修正し、最新の知識を提供するのに役立ちます.RAGは、LLMsの内部知識(事前知識)と照会文書から取得した情報との間の葛藤を定量化することで、モデルの誤りを修正することができます.正しい取得情報を提供することで、モデルの誤りの大部分を修正できますが、取得情報が誤っている場合、LLMはその誤った情報を無視するか、誤りを再現するかを判断する能力があります.
Q: LLMだけでは質問に正しく答えられない場合、正しい検索内容を提供すれば必ずエラーは直るのですか?
A: 提供された正しい取得コンテンツは、モデルの誤りを修正する場合がありますが、常に修正するわけではありません.
Q: 検索された内容が正しくない場合、LLMは間違った情報を無視することを知っているのか、それともエラーを再現するのか?
A: 提供された情報が間違っている場合、LLMはその誤った情報を無視するか、それを再現するかを知っていますか?
Q: 研究は、LLMの内部知識(事前知識)と取得した情報が異なる場合における綱引きをどのように系統的に分析しましたか?
A: 研究では、LLMの内部知識(事前知識)と異なる場合に、取得情報との間の綱引きを体系的に分析しました.この研究では、質問に回答するためにLLMをクエリし、参照文書にさまざまな摂動を導入しながら、トークン確率を測定しました.
Q: GPT-4と他のLLMを、参考文献のあるデータセットとないデータセットで質問応答能力をテストしたところ、どのような結果が出たか?
A: GPT-4および他のLLMをデータセット全体で質問応答能力をテストした結果、正しい取得情報を提供すると、ほとんどのモデルの誤りが修正されました(94%の正解率).ただし、参照文書が変更された場合、LLMは内部の事前知識と取得情報の間で葛藤が生じ、内部の事前知識が弱い場合、誤った情報を引用しやすくなりますが、事前知識が強い場合はより抵抗力があります.
Q: LLMの内部事前情報の強さが、参照文書が間違った値で歪められた場合に、誤った修正情報を引用する可能性にどのように影響するか?
A: LLMの内部事前確率が弱い場合、参照文書が間違った値で乱されると、LLMが間違った修正情報を述べる可能性が高くなります.一方、内部事前確率が強い場合、LLMはより抵抗力を持ちます.修正情報がモデルの事前確率からどれだけ逸脱するかに応じて、モデルがそれを好む可能性が低くなることもわかりました.
Q: 修正された情報の逸脱がモデルの事前情報からどのようにモデルの好みに影響するのか?
A: 修正された情報の偏差がモデルの事前情報からどれだけ desu かによって、モデルがそれを好むかどうかが変わります.
Q: 結果に基づいた参照文書に提示された情報とモデルの事前知識の間には、どのような根底にある緊張が強調されていますか?
A: 結果に基づいて、モデルの事前知識と参照文書に提示された情報との間に強調される基本的な緊張が、モデルの内部知識と取得された情報の間で生じることが示されています.
Q: 検索された正しい情報が提供されたとき、モデルはどの程度正確に間違いを修正できたか?
A: モデルは、正しい取得情報を提供すると、ほとんどの間違いを修正する際に非常に正確でした.修正された情報を提供することで、モデルの誤りを修正することができる確率は94%であることが示されました.
Q: 内部的な事前情報がより強かった場合、モデルは誤った修正情報を復唱することにどの程度抵抗があったのだろうか?
A: モデルの内部事前知識が強い場合、修正された情報を引用することに対してモデルはより抵抗力を持っていました.
Chinchilla Scaling: A replication attempt
著者:Tamay Besiroglu, Ege Erdil, Matthew Barnett, Josh You
発行日:2024年04月15日
最終更新日:2024年04月15日
URL:http://arxiv.org/pdf/2404.10102v1
カテゴリ:Artificial Intelligence, Computation and Language
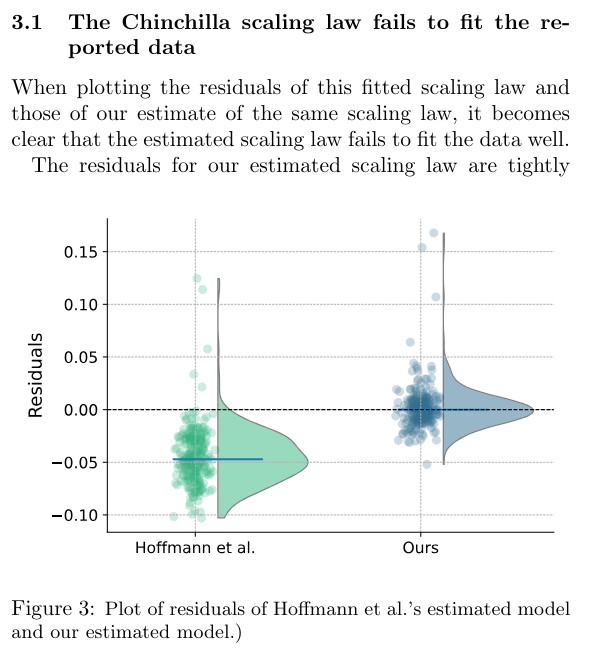
概要:
Hoffmannら(2022)は、計算最適なスケーリング法を推定するための3つの方法を提案しています.私たちは、彼らのプロットからのデータの再構築にパラメトリック損失関数を適合させるという、彼らの第3の推定手法を複製しようと試みました.報告された推定値は、彼らの最初の2つの推定方法と矛盾し、抽出されたデータに適合しないことがわかりました.また、信頼区間が信じがたく狭いことを報告しています.このように狭い信頼区間を得るには、600,000以上の実験が必要であり、彼らはおそらく500未満の実験しか行っていないでしょう.一方、私たちが第3のアプローチを使用してスケーリング法を再導出した結果は、Hoffmannらによって記述された最初の2つの推定手法から得られた結果と互換性があります.
Q&A:
Q: 計算最適スケーリング則を推定するためにHoffmannらが提案した3つの方法について説明できますか?
A: Hoffmannらによって提案された3つの方法は、計算最適なスケーリング法を推定するためのものです.第1の方法は、モデルパラメータの数Nとトレーニングトークンの数Dに対して、パラメトリックな損失関数を適合させることです.具体的には、L(N, D) = E + A N^α + B D^βという関数を使います.第2の方法は、Hoffmannらのプロットからのデータ再構築にパラメトリックな関数を適合させることです.第3の方法は、Hoffmannらの推定値が第1および第2の方法と矛盾し、抽出されたデータに適合しないことを発見し、信頼区間が信じられないほど狭いことを報告しています.このように、Hoffmannらの3つの方法は、計算最適なスケーリング法を推定するための手法です.
Q: あなたが再現を試みた3番目の推定手順について、具体的にどのような詳細を説明できますか?
A: 第3の推定手順は、Hoffmannらが提案した計算最適なスケーリング則を再現するための手法であり、彼らのプロットからのデータの再構築にパラメトリック損失関数を適合させることを含んでいます.
Q: ホフマンらのプロットからのデータ再構築にパラメトリック損失関数をどのように適合させましたか?
A: Hoffmannらのプロットからのデータ再構築に対して、我々はパラメトリック損失関数を適合させました.これは、最終事前トレーニング損失をモデル化するためのパラメトリック関数を適合させることを意味します.具体的には、L(N, D) = E + A N^α + B D^βという関数を適合させました.ここで、Nはモデルパラメータの数を表し、Dはトレーニングトークンの数を表します.
Q: 報告された推定値が最初の2つの推定方法と矛盾していると感じた理由を詳しく教えてください.
A: 報告された推定値が最初の2つの推定方法と一貫していないと判断された理由は、彼らの推定モデルが抽出されたデータに適合せず、信頼区間が不自然に狭いためです.このように狭い信頼区間を得るには、600,000以上の実験が必要ですが、彼らはおそらく500未満しか実行していない可能性があるためです.
Q: 第3の推定手順を用いて抽出したデータをフィッティングする際に、どのような課題に直面しましたか?
A: 第3の推定手法を使用して抽出されたデータを適合させる際に直面した課題は、Hoffmannらの推定モデルが再構築されたデータに非常に適合していないことでした.また、データ再構築時のノイズや外れ値モデルを除外することを考慮しても、この結論は成立していました.さらに、データポイントの数に比して信頼区間が非常に狭すぎることも挑戦でした.信頼区間をそのように狭くするには、数十万もの観測が必要であり、彼らはおそらく400程度しか持っていなかったでしょう.最後に、彼らの推定モデルが他の手法や私たちの適合によって導かれたスケーリングポリシーと矛盾しており、20トークンごとのパラメータの経験則とも一致していないことも課題でした.
Q: ホフマンらが報告した信頼区間があり得ないほど狭いと、どうして判断したのですか?
A: Hoffmannらが報告した信頼区間が信じがたく狭いと判断された理由は、彼らが推定したパラメータaおよびbに対する信頼区間が非常に狭いことにあります.具体的には、彼らがaおよびbについて報告した0.454から0.455、0.542から0.543の信頼区間は、おそらくαおよびβを推定するために400回程度の観測を行ったにも関わらず、非常に狭いとされました.一方、私たちはaの標準誤差を0.018と推定しており、これに基づく80%信頼区間の幅はHoffmannらが報告したものの50倍に相当します.そのため、Hoffmannらの報告した信頼区間が信じがたく狭いと判断されたのです.
Q: Hoffmannらが報告したような狭い信頼区間を得るために、60万回以上の実験を必要とすることの意義は何だろうか?
A: Hoffmannらは、最適なスケーリング関係を理解する上で極めて重要なパラメータaとbの信頼区間を極めて狭くして報告した.これらの係数は、計算予算をどのように配分するのが最適かを記述し、トレーニング計算量の最適配分をモデル化する.報告された狭い信頼区間は、推定値の精度が高いことを意味し、このような狭い信頼区間を達成するためには、多くの実験を必要とする.600,000回以上の実験を必要とすることで、Hoffmannらが報告した信頼区間と同程度の狭い信頼区間を得ることができ、彼らの発見の重要性を示している.
Q: 報告された結果に基づいて、ホフマンらが行ったと思われる実験数をどのように見積もったのですか?
A: 報告された結果に基づいて、Hoffmannらが行った実験の数を推定しました.彼らは「400以上」の観測値を持っていたと報告しており、これを400から500のデータポイントと解釈しました.彼らが各訓練済みモデルの最終損失値のみを使用したと主張していたため、数十万の観測値を持っていた可能性は低いと考えられます.しかし、著者からのさらなる明確化が役立つでしょう.
Q: 3つ目の方法を用いてスケーリング則を再導入した結果はどうでしたか?また、最初の2つの推定方法から得られた結果と比べてどうでしたか?
A: 第3のアプローチを使用して再導出したスケーリング法の結果は、Hoffmann et al.の最初の2つの推定手法から得られた結果と一致しています.具体的には、我々の再導出によるスケーリング法の推定値は、Hoffmann et al.の推定法1および2から得られた結果と整合性があります.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: 新しい手法のコード実装のurlは、https://epochai.org/code/analyzing-chinchilla です.
State Space Model for New-Generation Network Alternative to Transformers: A Survey
著者:Xiao Wang, Shiao Wang, Yuhe Ding, Yuehang Li, Wentao Wu, Yao Rong, Weizhe Kong, Ju Huang, Shihao Li, Haoxiang Yang, Ziwen Wang, Bo Jiang, Chenglong Li, Yaowei Wang, Yonghong Tian, Jin Tang
発行日:2024年04月15日
最終更新日:2024年04月15日
URL:http://arxiv.org/pdf/2404.09516v1
カテゴリ:Machine Learning, Artificial Intelligence, Computation and Language, Computer Vision and Pattern Recognition, Multimedia
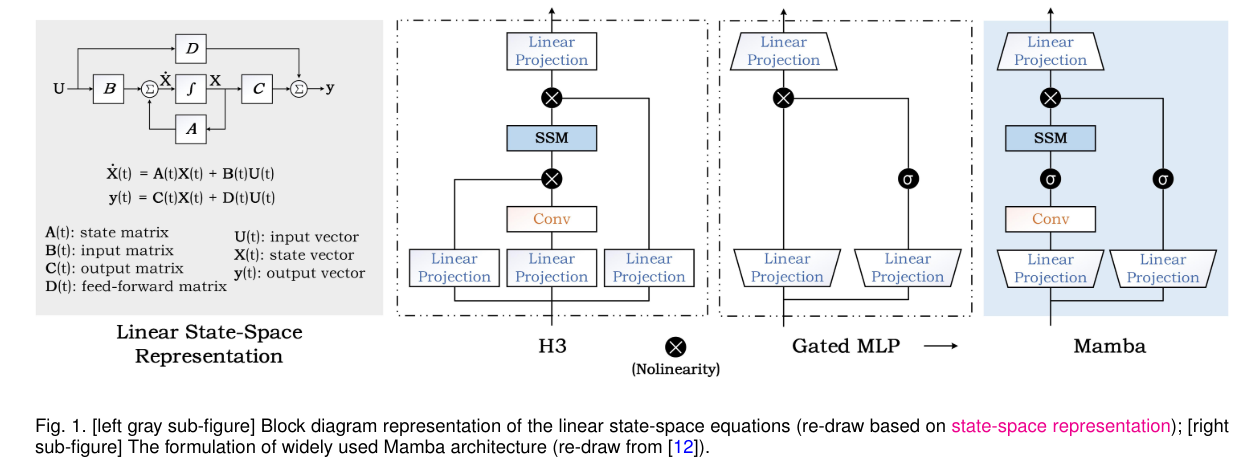
概要:
ディープラーニング後の時代において、Transformerアーキテクチャは事前に訓練された大規模なモデルやさまざまな下流タスクで強力なパフォーマンスを示してきました.しかし、このアーキテクチャの膨大な計算要求は多くの研究者を妨げてきました.注意モデルの複雑さをさらに低減するために、より効率的な方法を設計するための多くの取り組みが行われています.その中で、自己注意ベースのTransformerモデルの可能な代替として、State Space Model(SSM)が近年ますます注目されています.本論文では、これらの研究の初めての包括的なレビューを行い、SSMの特徴と利点をよりよく示すために実験的な比較と分析も提供します.具体的には、SSMの主要なアイデアを迅速に把握するための原則の詳細な説明をまず行います.その後、自然言語処理、コンピュータビジョン、グラフ、マルチモーダルおよびマルチメディア、ポイントクラウド/イベントストリーム、時系列データ、その他の領域を含む既存のSSMおよびそのさまざまな応用のレビューに入ります.さらに、これらのモデルの統計的な比較と分析を行い、異なる構造の効果をさまざまなタスクにおいて理解するのに役立つことを期待しています.さらに、この方向性での可能な研究ポイントを提案し、SSMの理論モデルの発展と応用の促進をより良くすることを目指します.関連する研究は以下のGitHubで継続的に更新されます:.” rel=”nofollow”>https://github.com/Event-AHU/Mamba_State_Space_Model_Paper_List.
Q&A:
Q: 研究者たちを躊躇させているトランスフォーマー・アーキテクチャーの具体的な計算要求について説明していただけますか?
A: Transformerアーキテクチャの特定の計算要求は、入力トークンをクエリ、キー、および値の特徴に変換し、類似度行列(クエリとキーの特徴の積によって得られる)を値の特徴と乗算するメカニズムによって長距離特徴を出力します.このアーキテクチャは、高度なグラフィックスカードと大容量メモリを必要とするため、広範な適用を大幅に制限しています.
Q: 状態空間モデル(SSM)は、自己注意をベースにしたトランスフォーマーモデルとどう違うのですか?
A: State Space Model (SSM)は、自己注意ベースのTransformerモデルと比較して、異なるアプローチを取っています.具体的には、SSMは状態空間モデルとして定義され、系列データの時間的な依存関係をモデル化するために使用されます.一方、Transformerモデルは、自己注意メカニズムを使用して入力シーケンス内の要素間の関連性を捉えます.SSMは、状態方程式と観測方程式を使用して、系列データの状態と観測値を表現し、時間的な変化を考慮します.一方、Transformerモデルは、エンコーダーとデコーダーから構成され、入力と出力の間の関連性を学習するために自己注意機構を使用します.
Q: 読者が素早く捉えるべきSSMの重要な原則とは何か?
A: 読者が迅速にSSMの主要なアイデアを把握するための原則は、第2節で詳細に説明されています.SSMの主要な原則には、状態方程式と観測方程式が含まれます.状態方程式は、システムの状態が時間とともにどのように進化するかを表し、一般的には次のように表されます:
\( \small x_{t+1} = Fx_t + Gu_t + w_t \)
ここで、\( \small x_{t+1} \)は次の時刻の状態、\( \small x_t \)は現在の時刻の状態、\( \small u_t \)は入力、\( \small F \)は状態遷移行列、\( \small G \)は入力行列、\( \small w_t \)はプロセスノイズを表します.観測方程式は、システムの状態から得られる観測値を表し、一般的には次のように表されます:
\( \small y_t = Hx_t + v_t \)
ここで、\( \small y_t \)は観測値、\( \small H \)は観測行列、\( \small v_t \)は観測ノイズを表します.これらの原則はSSMの基本的な構造を理解するために重要です.
Q: さまざまな領域でのSSMの応用例を教えていただけますか?
A: 異なるドメインにおけるSSMのさまざまな応用例を挙げることができます.例えば、自然言語処理においては、文章生成や機械翻訳などのタスクにSSMを活用することができます.また、コンピュータビジョンでは、画像トラッキングやピクセルレベルのセグメンテーションなどにSSMを応用することができます.さらに、グラフデータやマルチモーダル/マルチメディアデータにおいても、SSMを使用して特徴学習やデータ処理を行うことが可能です.時間系列データやイベントデータ、ポイントクラウドデータなどの領域でも、SSMは有用です.
Q: SSMモデルについて、どのような統計的比較や分析が行われてきたのか?
A: SSMモデルに関する統計的比較と分析が行われました.これにより、異なるモデルや応用領域におけるSSMの性能や特徴が評価されました.
Q: SSMの構造の違いは、さまざまなタスクのパフォーマンスにどのような影響を与えるのか?
A: 異なるSSMの構造は、さまざまなタスクのパフォーマンスに影響を与えます.具体的には、SSMのベース、大規模、巨大なバージョンは、画像分類、物体追跡、セグメンテーション、画像からテキスト生成、人物/車両の再識別などの下流タスクにおいて、異なる性能を示す可能性があります.
Q: SSMをさらに発展させるために、どのような研究ポイントが考えられるか?
A: SSMのさらなる開発のために提案されたいくつかの研究ポイントには、新しいトラック変更スキャン方法の開発やSSMの一般化性能の向上が含まれます.また、既存の深層ニューラルネットワークモデルを強化するために最新のSSMモデルを使用することも提案されています.
Q: 既存のSSMは、効率と性能の面で従来の変圧器モデルと比較してどうなのか?
A: 既存のSSMは、一部のTransformerネットワークと同様の性能を達成していますが、全体的な結果はまだ最先端のモデルに劣っています.メモリ使用量の減少も下流のタスクで観察されます.SSMのアーキテクチャは、モデルの複雑さを理論的に大幅に削減するため、高解像度データ(リモートセンシングデータ、X線医療画像)や長期シーケンスデータ(長期ビデオフレーム)におけるモデリング能力は非常に価値があります.しかし、これらの側面はTransformerネットワークなどの他の強力なモデルを使用してもうまく対処されていません.
Q: SSMの特徴や利点を実証するために行われた実験的な比較や分析について詳しく教えてください.
A: 実験的な比較と分析は、SSMの特徴と利点をよりよく示すために行われました.具体的には、既存のSSMモデルとそのさまざまな応用に焦点を当て、自然言語処理、コンピュータビジョン、グラフ、マルチモーダルおよびマルチメディア、ポイントクラウド/イベントストリーム、時系列データなどの領域におけるSSMのレビューを行いました.これにより、これらのモデルの統計的比較と分析を提供しました.
Q: 読者はどのようにしてSSM分野の関連作品や進展について最新情報を得ることができるのでしょうか?
A: 読者は、SSMの関連作業や開発に関する最新情報を把握するために、この論文の体系的なレビューを参照することができます.このレビューでは、SSMの原点や変異、自然言語処理、コンピュータビジョン、グラフ、マルチモーダルおよびマルチメディア、ポイントクラウド/イベントストリーム、時系列データなど、複数の側面からSSMに関連する作業が検討されています.さらに、これらのモデルの統計的比較と分析も提供されています.
LLM In-Context Recall is Prompt Dependent
著者:Daniel Machlab, Rick Battle
発行日:2024年04月13日
最終更新日:2024年04月13日
URL:http://arxiv.org/pdf/2404.08865v1
カテゴリ:Computation and Language, Machine Learning
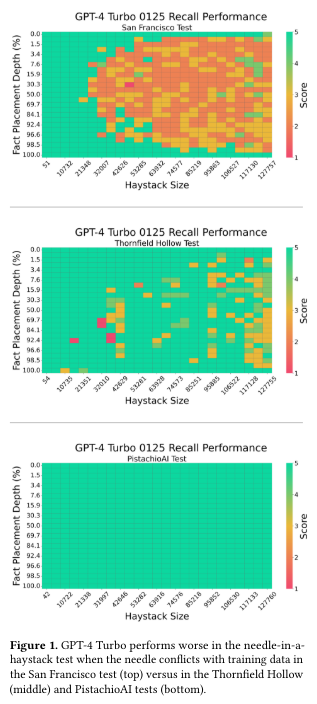
概要:
大規模言語モデル(LLM)の普及は、それらの比較的な利点、制限、および最適な使用ケースを識別するために徹底的な評価を行うことの重要性を強調しています.特に重要なのは、与えられたプロンプトに含まれる情報を正確に取得する能力を評価することです.モデルがこれを行う能力は、コンテキストの詳細を効果的に利用する方法に大きく影響し、実際のアプリケーションでの実用性と信頼性に影響を与えます.トレーニング戦略やファインチューニングなどの調整によって、パフォーマンスを向上させることができることも示唆されています.私たちの研究は、針の中のハイスタック法を使用して、さまざまなLLMのインコンテキストリコールパフォーマンスを分析しています.このアプローチでは、事実(”針”)がフィラーテキスト(”ハイスタック”)のブロックに埋め込まれ、モデルに取得するように求められます.私たちは、さまざまなハイスタックの長さや針の配置を変えて、各モデルのリコールパフォーマンスを評価し、パフォーマンスパターンを特定します.この研究は、LLMのリコール能力がプロンプトの内容だけでなく、トレーニングデータのバイアスによっても損なわれる可能性があることを示しています.逆に、モデルアーキテクチャ、トレーニング戦略、またはファインチューニングの調整によってパフォーマンスを向上させることができます.さらに、私たちの分析は、LLMの振る舞いに関する洞察を提供し、より効果的なLLMのアプリケーションの開発に向けた方向性を示しています.
Q&A:
Q: LLMを評価する上で、「針小棒大方式」という言葉をどのように定義しますか?
A: LLMを評価する際の「針の中のハヤスタック法」とは、モデルが特定の事実(針)を見つけるよう求められる中で、その事実が埋め込まれたテキストブロック(ハヤスタック)の中からそれを取り出す方法です.この方法では、モデルのリコール性能を評価し、異なるハヤスタックの長さや針の配置を変えて、性能パターンを特定します.この研究は、LLMのリコール能力がプロンプトの内容だけでなく、トレーニングデータのバイアスによっても影響を受けることを示しています.逆に、モデルアーキテクチャ、トレーニング戦略、またはファインチューニングの調整によって性能を向上させることができます.我々の分析は、LLMの振る舞いに対する洞察を提供し、より効果的なLLMの応用の方向性を示しています.
Q: 与えられたプロンプトから情報を正確に取得するLLMの能力を評価する重要性を説明できますか?
A: 与えられたプロンプトから情報を正確に取得するLLMの能力を評価する重要性は、実際の世界の応用において、モデルがコンテキストの詳細を効果的に利用し、その実用的な効力と信頼性に影響を与えるからです.この能力が高いほど、モデルは正確で適切な回答を生成したり、意味のある対話を提供したりすることができます.したがって、LLMのプロンプトから情報を正確に取得する能力を評価することは、そのモデルの実用的な有用性を理解し、向上させるために不可欠です.
Q: LLMの能力に影響を与える要因は何ですか?
A: LLMの能力を効果的にコンテキストの詳細を利用することに影響を与える要因には、プロンプトに含まれる情報を正確に取得する能力が含まれます.モデルがこれを行う能力は、コンテキストの詳細を効果的に利用する方法に大きな影響を与え、それによって実用的な効果と信頼性が現実世界のアプリケーションでどのように影響するかが決定されます.
Q: 「針」を「野山」の中に配置することが、LLMのリコールパフォーマンスにどのように影響するのか?
A: 「針」が「ヘイスタック」内のどこに配置されるかによって、LLMの回想能力に影響が及ぶ可能性があります.特に、針がテキストの始め、中間、または終わりに配置される場合、LLMの回想性能に異なるパターンが現れることが示唆されています.
Q: LLMのトレーニングデータに偏見がある場合、どのようにしてそのリコール能力が損なわれる可能性がありますか?
A: LLMのトレーニングデータに偏りがあると、モデルがそのデータに偏ってしまい、新しい情報や矛盾する情報を区別する能力が低下する可能性があります.
Q: LLMのリコール性能を向上させるために、モデルアーキテクチャ、トレーニング戦略、またはファインチューニングにどのような調整ができますか?
A: LLMのリコール性能を向上させるためには、モデルのアーキテクチャ、トレーニング戦略、またはファインチューニングを調整する必要があります.Llama 2 70Bの結果から、パラメータ数を増やすことがモデルのリコール能力を向上させることが示されています.Mistralの分析では、パラメータ数を一定に保ちながらモデルのアーキテクチャとトレーニング戦略を変更することでリコール性能を向上させることができることが示されています.また、WizardLMとGPT-3.5 Turboの結果から、ファインチューニングはモデルのリコール能力を増強する補完的な戦略であることが示唆されています.
Q: LLMの文脈内想起性能は、実世界のアプリケーションにおける実用的な有効性と信頼性にどのような影響を与えるのか?
A: LLMのインコンテキストリコールのパフォーマンスは、実用的な効果と信頼性に大きな影響を与えます.特に、モデルが与えられたプロンプトに含まれる情報を正確に取得する能力は、コンテキストの詳細を効果的に利用することができるかどうかに大きく影響し、それによって実際の世界のアプリケーションでの実用性と信頼性が変わります.
Q: LLMの研究において、針の穴を通すような方法で特定されたパフォーマンス・パターンの例を教えてください.
A: 研究では、LLMの性能パターンの例として、異なる針の配置やヘイスタックの長さによるリコール性能の変化が特定されました.また、プロンプトの内容によってもリコール性能が影響を受けることが示されました.さらに、モデルのアーキテクチャ、トレーニング戦略、ファインチューニングの違いが性能に影響を与えることも明らかになりました.
Q: LLMの行動を分析した結果、LLMをより効果的に活用するための方向性はどのように示されましたか?
A: LLMの振る舞いの分析により、モデルのアーキテクチャ、トレーニング戦略、またはファインチューニングの調整がパフォーマンスを向上させる可能性が示唆されます.これにより、より効果的なLLMのアプリケーションの開発に向けた方向性が提供されます.
Q: LLMのインコンテキスト・リコールがプロンプト依存であることについての研究から、重要なことは何ですか?
A: 研究の主な結論は、LLMのコンテキスト内リコールがプロンプトに依存していることです.この研究では、GPT-4とLangChain Evaluationsを使用して、LLMのリコールを評価しました.プロンプトによって生成される応答の品質が影響を受けることが示されました.例えば、プロンプトの変更により、生成された応答は意味があるものの、スコアリング方法により低いスコアが付けられました.この研究から、LLMのリコール能力はプロンプトに大きく依存しており、その品質を評価する際には慎重に考慮する必要があることが明らかになりました.
Reducing hallucination in structured outputs via Retrieval-Augmented Generation
著者:Patrice Béchard, Orlando Marquez Ayala
発行日:2024年04月12日
最終更新日:2024年04月12日
URL:http://arxiv.org/pdf/2404.08189v1
カテゴリ:Machine Learning, Artificial Intelligence, Computation and Language, Information Retrieval
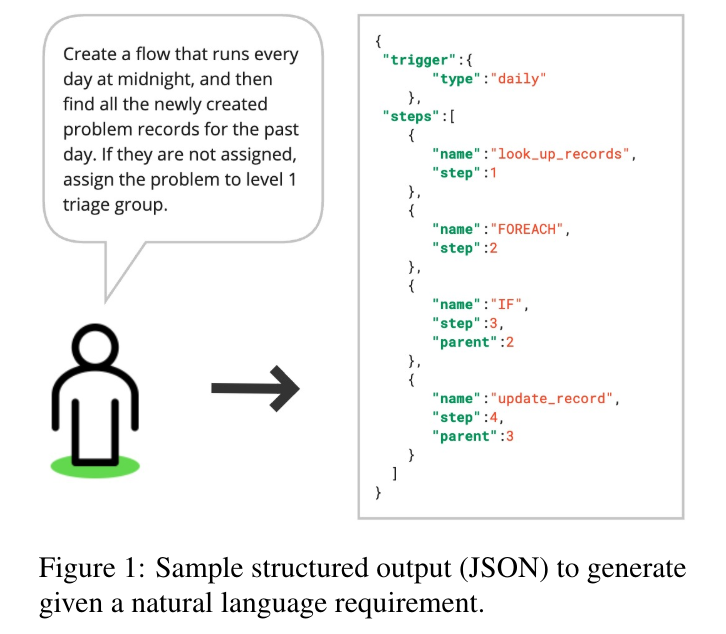
概要:
ジェネレーティブAI(GenAI)の一般的で基本的な制限は、幻覚を引き起こす傾向があることです.大規模言語モデル(LLM)が世界中で注目されていますが、幻覚を排除するか、少なくとも軽減しない限り、実世界のGenAIシステムはユーザーの採用に課題を抱えるかもしれません.自然言語要件に基づいたワークフローを生成する企業アプリケーションを展開する過程で、私たちはRetrieval Augmented Generation(RAG)を活用したシステムを考案し、そのようなワークフローを表す構造化された出力の品質を大幅に向上させました.RAGの実装により、提案されたシステムは出力の幻覚を大幅に減少させ、LLMの一般化をドメイン外の設定で改善します.さらに、訓練が十分なリトリーバーエンコーダーを使用することで、付随するLLMのサイズを縮小することができ、LLMベースのシステムの展開をリソース効率的に行うことができます.
Q&A:
Q: 構造化された出力における幻覚を減らすために、RAG(Retrieval-Augmented Generation)がどのように機能するのか、もう少し詳しく説明してもらえますか?
A: Retrieval-Augmented Generation (RAG)は、外部の知識源にアクセスする必要がある場合に、幻覚を減少させ、出力品質を向上させることができる方法です.RAGは、生成された出力が正しいものであることを確認するために、外部の情報を取得し、それを生成されたテキストに組み込むことで幻覚を減らすことができます.これにより、生成された構造化された出力の信頼性が向上し、幻覚を減らすことができます.
Q: このシステムを開発するに至ったエンタープライズ・アプリケーションの展開において、具体的にどのような課題に直面しましたか?
A: このシステムの開発につながった企業アプリケーションの展開において遭遇した具体的な課題は、内部データセットが主にIT分野に偏っていたことであり、RAGシステムがHRやファイナンスなどの異なる領域に展開できる可能性があるため、システムの品質を異なる領域で評価する必要があったことです.そのため、実際のユーザーによって作成された他の展開からの5つの分割をアノテーターにラベリングしてもらいました.
Q: RAGの実装は、自然言語要件に基づくワークフローにおいて、構造化出力の品質をどのように向上させるのか?
A: RAGの実装により、ワークフローの構造化された出力の品質が向上します.具体的には、RAGはalleviate hallucination(幻覚を軽減する)ことができ、アウトプットの信頼性を高めることができます.また、RAGを使用することで、アウトオブドメインの設定においてもLLMの汎用性を高めることができます.さらに、適切に訓練された小さなリトリーバーを使用することで、伴うLLMのサイズを削減し、パフォーマンスの損失なしに、LLMベースのシステムの展開をリソース効率的に行うことができます.
Q: 提案されているシステムが、出力における幻覚をどのように減らしているのか、例を挙げていただけますか?
A: 提案されたシステムは、Retrieval-Augmented Generation(RAG)を活用してalgorithmsを使用し、自然言語要件からワークフローを生成する際に幻覚を減らすことができます.RAGは、リトリーバーとLLM(Large Language Models)を組み合わせることで、構造化された出力の品質を向上させることができます.このシステムは、生成されたステップが存在しないことをユーザーに明確に示し、ユーザーに出力を修正するよう促すための後処理レイヤーを含んでいます.
Q: よく訓練された小型のレトリーバー・エンコーダーの使用は、LLMベースのシステムのサイズとリソース集約性にどのような影響を与えるのだろうか?
A: 小さな、適切にトレーニングされたリトリーバーエンコーダーの使用は、LLMベースのシステムのサイズとリソースの消費にどのような影響を与えるかについて考えると、リトリーバーエンコーダーのサイズが小さいため、大規模なLLMに対してほとんど影響を与えず、同じGPUにデプロイできるという利点があります.さらに、リトリーバーをCPUにデプロイすることも可能です.リトリーバーとLLMの間での共同トレーニングを行わないことの利点は、リトリーバーを他の類似データソースを使用する他のユースケースに再利用できることです.また、それらを分離することで、関心事の明確な分離と独立した最適化が可能になります.
Q: 構造化されたアウトプットの幻覚軽減に関する研究の主な発見や結果は何でしたか?
A: 研究の主な結果は、構造化された出力における幻覚を減少させるためのアプローチを提案し、RAGを活用することで、生成されたステップの幻覚を明確に示し、ユーザーに修正を促すことで、リスクを軽減できるということです.
Q: 提案されたシステムは、領域外の設定におけるLLMの汎化をどのように改善するのか?
A: 提案されたシステムは、RAGの実装により、幻覚を大幅に減少させ、LLMの一般化を領域外の設定に可能にします.また、小さな、十分に訓練されたリトリーバーを使用することで、付随するLLMのサイズを縮小し、パフォーマンスの損失なしに、LLMベースのシステムの展開をリソース効率的にします.
Q: 実際のGenAIシステムにおいて、このシステムはどのような潜在的な意味合いや応用があるのでしょうか?
A: このシステムは、リアルワールドのGenAIシステムにおいて、ユーザーの採用に関する課題を克服する可能性があります.RAGを活用することで、限られたリソース設定でシステムを展開することが可能となります.小さなリトリーバーを小さなLLMと組み合わせることで、システムを展開することができます.将来の課題としては、リトリーバーとLLMのシナジーを向上させることが挙げられます.共同トレーニングや、より良い連携ができるモデルアーキテクチャの構築などが含まれます.
Q: 提案されたシステムは、構造化された出力における幻覚を減らすための他の方法やアプローチと比較してどうですか?
A: 提案されたシステムは、他の方法やアプローチと比較して、幻覚を構造化された出力から削減する際により効果的であると考えられます.RAGを活用することで、リアルワールドのGenAIシステムがユーザーの採用に直面する課題を軽減することができます.また、RAGの実装により、生成されたステップの幻覚を明確に示し、ユーザーに修正を促すことで、構造化された出力の品質を向上させることができます.
Q: 幻覚軽減におけるRAGの効果をさらに向上させるための次のステップや今後の研究の方向性は?
A: RAGの効果をさらに向上させるための次のステップや将来の研究方向には、リトリーバーとLLMの間のシナジーを改善することが含まれます.これは、共同トレーニングや、より良く連携するためのモデルアーキテクチャを使用することで実現できます.
The Illusion of State in State-Space Models
著者:William Merrill, Jackson Petty, Ashish Sabharwal
発行日:2024年04月12日
最終更新日:2024年04月12日
URL:http://arxiv.org/pdf/2404.08819v1
カテゴリ:Machine Learning, Computational Complexity, Computation and Language, Formal Languages and Automata Theory
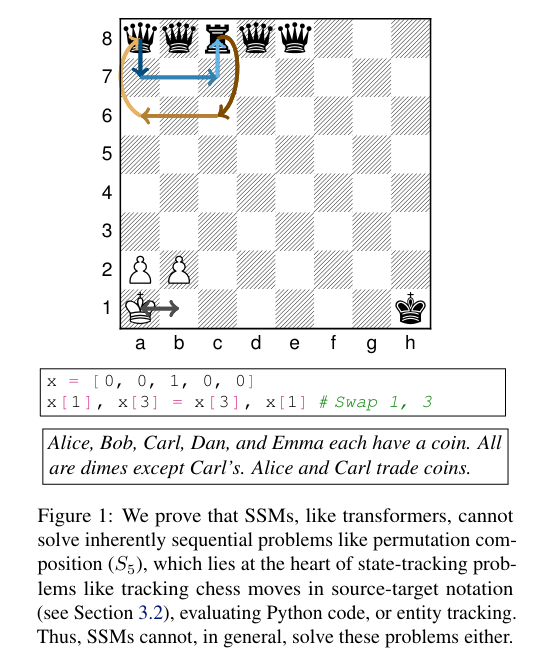
概要:
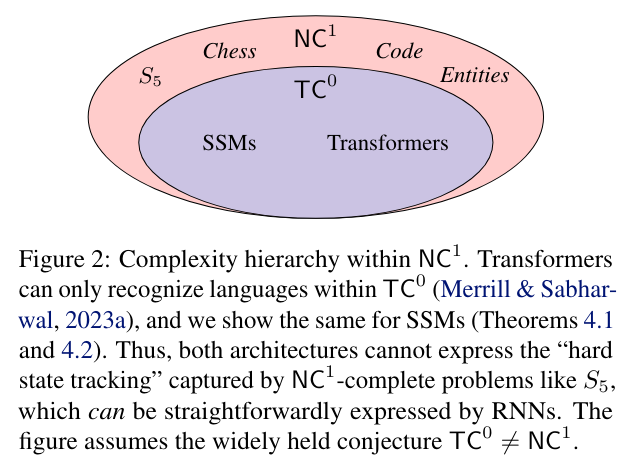
ステートスペースモデル(SSM)は、以前に普及していたトランスフォーマーアーキテクチャと比較して、大規模言語モデル(LLM)を構築するための潜在的な代替アーキテクチャとして登場しています.トランスフォーマーの理論的な弱点の1つは、特定の種類の連続計算や状態追跡を表現できないということです(Merrill and Sabharwal、2023).これに対して、SSMは再帰ニューラルネットワーク(RNN)との密接なアーキテクチャの類似性によって、これらの問題に対処するよう明示的に設計されています.しかし、SSMが状態追跡において本当に(トランスフォーマーに比べて)優位性を持っているのでしょうか?驚くべきことに、その答えはノーです.私たちの分析によると、SSMの表現力はトランスフォーマーと非常に類似して制限されています:SSMは複雑性クラス\( \small \mathsf{TC}^0 \)の外で計算を表現することができません.特に、これは、SSMが置換合成のような単純な状態追跡問題を解決することができないことを意味します.これにより、SSMはチェスの手の特定の表記、コードの評価、または長い物語の中のエンティティの追跡を正確に行うことができないことが証明されます.形式的な分析を補完するために、MambaスタイルのSSMが実際に苦戦していることを示す実験結果を報告しています.さらに、実験結果により、MambaスタイルのSSMが状態追跡に苦戦していることが明らかになりました.したがって、再帰的な構造を持つにも関わらず、SSMにおける「状態」は幻想であり、SSMはトランスフォーマーのような非再帰モデルと同様の表現力の制限を持っている可能性があり、これが実世界の状態追跡問題を解決する能力を根本的に制限する可能性があります.
Q&A:
Q: ある種の逐次計算や状態追跡を表現する上での変圧器の理論的な弱点を説明できますか?
A: トランスフォーマーの理論的な弱点は、シーケンシャルな計算や状態追跡の特定の種類を表現することができないという点にあります.これは、トランスフォーマーが単純な置換のシーケンスを組み合わせるなどの状態追跡問題を表現できないことを示しています.トランスフォーマーは、固定された層数での置換組み合わせの状態追跡問題を解決することを学習しないため、その理論的な弱点が明らかになります.
Q: 状態追跡におけるトランスフォーマーの限界に対処するために、状態空間モデル(SSM)はどのように設計されているのか?
A: State-space models (SSMs)は、transformersの制限を解決するために設計されています.SSMsは、再帰的ニューラルネットワーク(RNNs)との類似性により、特定の種類の連続的な計算と状態追跡を表現することができます.しかし、SSMsはtransformersと同様に、計算複雑度クラスTC0の外の計算を表現することができず、簡単な状態追跡問題を解決することができません.そのため、SSMsはチェスの手の追跡、コードの評価、長い物語の中のエンティティの追跡などを正確に行うことができないことが証明されています.
Q: 複雑さクラス\( \small mathsf{TC}^0 \)とは何で、SSMや変換器の表現力とどう関係するのか?
A: TC^0とは、定数深さで計算可能な問題の集合を表す複雑性クラスです.SSMとtransformersの表現力に関して、TC^0は非常に制限された計算能力を持つことが示されています.具体的には、SSMやtransformersは簡単な状態追跡問題を解決することができず、例えばチェスの手の追跡やコードの評価、長い物語中のエンティティの追跡などができません.TC^0の制約により、これらのアーキテクチャはNC^1-completeな問題のような「難しい状態追跡」を表現することができません.したがって、SSMとtransformersは、RNNのようなアーキテクチャが簡単に表現できる問題には対応できないことが示されています.
Q: 順列合成のような、SSMが解決できない状態追跡の問題の例を教えてもらえますか?
A: SSMは、例えばチェスの状態追跡やコードの評価、物語中のエンティティの追跡など、実世界の状態追跡問題の中心にある置換合成などの問題を解決することができません.
Q: SSMの表現力の限界は、チェスの手を正確に追跡したり、コードを評価したり、長い物語中の実体を追跡したりする能力にどのような影響を与えるのだろうか?
A: SSMの表現力の制限により、チェスの手を正確に追跡したり、コードを評価したり、長い物語の中のエンティティを追跡する能力が制限されます.
Q: 状態追跡におけるマンバ式SSMの苦戦を示すために、どのような実験が行われたのか?
A: Mamba-style SSMsに関する実験が行われ、その結果、状態追跡において苦労していることが示されました.
Q: SSMの再帰的定式化は、これらのモデルにおける状態の錯覚にどのように寄与しているのだろうか?
A: SSMの再帰的な形式は、SSMが状態を追跡する際に状態の幻想を引き起こす要因の一つとなります.再帰的なモデル(RNNなど)は、状態を追跡するために設計されていますが、実際にはSSMは状態を真に追跡することができないことが明らかになっています.SSMは、浅いショートカットが存在する単純な状態追跡問題のみを解決できるため、再帰的な形式にもかかわらず、SSM内の「状態」は幻想であると言えます.
Q: トランスフォーマーのような非リカレントモデルと比較して、SSMの表現力の限界について詳しく教えてください.
A: SSMsの表現力の制限は、transformerのような非再帰モデルと比較して、同様に限定されています.具体的には、SSMsとtransformersの両方が、本質的に順序付けされた問題を表現できないことが理論的に証明されています.例えば、RNNsが簡単に表現できる置換の合成などの状態追跡問題をSSMsやtransformersは学習できないことが示されています.
Q: SSMの状態追跡の限界は、どのような点で、実世界の問題を解決する能力を妨げる可能性があるのか?
A: SSMの状態追跡の制限は、実世界の問題を解決する能力を妨げる可能性があります.SSMは、状態追跡問題において限られた表現力を持ち、複雑な問題や実世界の問題を解決するために必要な深い表現力を持たない可能性があります.また、SSMの拡張によって表現力を向上させることができますが、それには並列性や学習ダイナミクスに悪影響を及ぼす可能性があります.
Q: SSMの状態追跡能力を向上させる可能性のある解決策や回避策はありますか?
A: SSMの状態追跡能力を向上させるための潜在的な解決策や回避策は、線形SSMの最小限の拡張を提案することであり、これにより状態追跡の表現力が向上し、順列合成を解決できるようになる.ただし、これらの拡張は並列性や学習ダイナミクスに悪影響を及ぼす可能性がある.将来的な研究では、状態追跡の表現力を向上させつつ、強力な並列性と学習ダイナミクスを持つSSMのようなモデルを開発できるかどうかは興味深い未解決の問題である.
