
- Generative emulation of weather forecast ensembles with diffusion models
発行日:2024年03月29日
小規模な地域から全球までの確定的予測と条件付き生成対立ネットワークを使用した予測が行われ、深層学習モデルは物理ベースのアンサンブルよりも高いスキルを持つことが示されています. - Announcing Grok-1.5
発行日:2024年03月28日
2024年4月4日13:22に発表されたGrok-1.5は、128,000トークンのコンテキスト長を持ち、16倍長い文書から情報を利用できるようになり、問題解決能力を向上させた最新のモデルです. - Introducing DBRX: A New State-of-the-Art Open LLM
発行日:2024年03月27日
DBRXは、Databricksによって作成されたオープンで汎用性の高いLLMであり、GPT-3.5を凌駕し、Gemini 1.0 Proと競合しており、MoEアーキテクチャによって効率性を進化させ、トレーニングと推論を効率的に行う革新的なモデルです.FaceからDBRXをダウンロードするか、DBRX Instructを試してみるか、githubのモデルリポジトリをご覧ください. - Long-form factuality in large language models
発行日:2024年03月27日
LLMはオープンエンドのトピックに対する応答で誤った情報を生成しやすく、SAFEを使用して長文ファクトの評価を行い、大きな言語モデルがより良い結果を示すことが示された. - Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models
発行日:2024年03月27日
Mini-GeminiはVLMsを強化し、高解像度のビジュアルトークン、高品質のデータ、VLMによる生成を通じて画像理解、推論、生成を同時に可能にするフレームワーク. - AIOS: LLM Agent Operating System
発行日:2024年03月25日
AIOSはLLMエージェントオペレーティングシステムであり、リソース割り当てやコンテキスト切り替えを最適化し、エージェントの同時実行を可能にすることで、効率性とパフォーマンスを向上させる取り組みを行っている. - A comparison of Human, GPT-3.5, and GPT-4 Performance in a University-Level Coding Course
発行日:2024年03月25日
GPT-3.5とGPT-4のパフォーマンスを評価し、プロンプトエンジニアリングを行ったGPT-4が最も高いスコアを記録し、AIによる作業は人間の作業に近づいているが、人間の評価者によって検出される可能性がある. - FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions
発行日:2024年03月22日
FollowIRデータセットは、IRモデルが指示に従う能力を評価し、新しいFollowIR-7Bモデルは13%以上の改善を達成している. - LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement
発行日:2024年03月22日
LLM2LLMは、低データ領域でのLLMのパフォーマンスを向上させ、他の手法を凌駕するためのターゲテッドかつ反復的なデータ拡張戦略です. - Agent Lumos: Unified and Modular Training for Open-Source Language Agents
発行日:2023年11月09日
オープンソースのエージェント開発がクローズドソースの問題を解決し、LUMOSフレームワークは高品質なトレーニングアノテーションを提供し、GPTエージェントを凌駕している.
Generative emulation of weather forecast ensembles with diffusion models
著者:Ignacio Lopez-Gomez, Lizao Li, Robert Carver, et al.
発行日:2024年03月29日
最終更新日:不明
URL:https://www.science.org/doi/10.1126/sciadv.adk4489
カテゴリ:不明
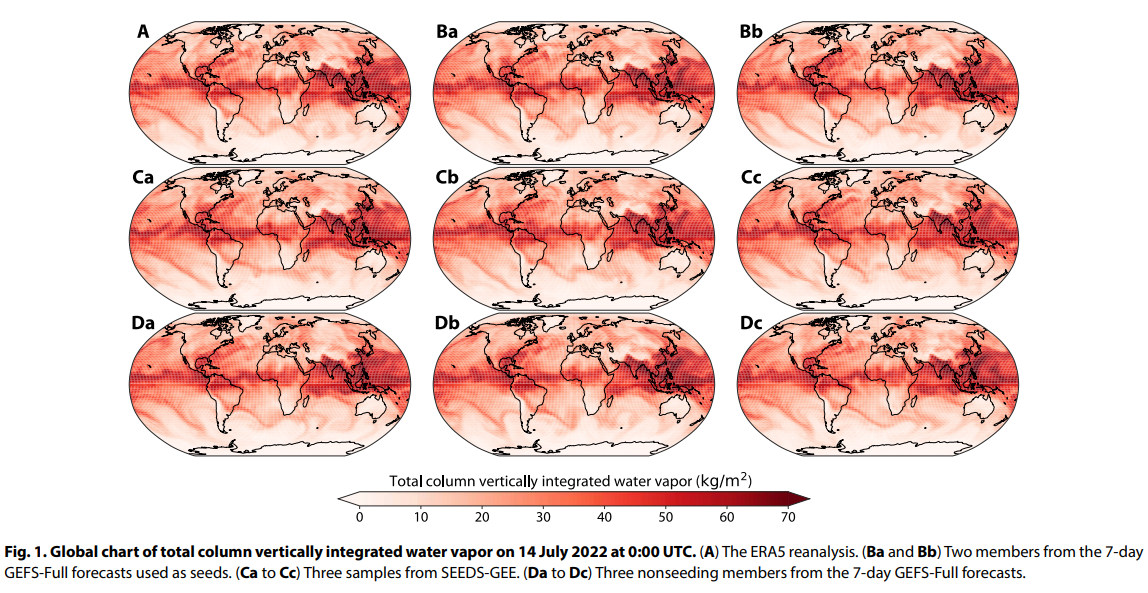
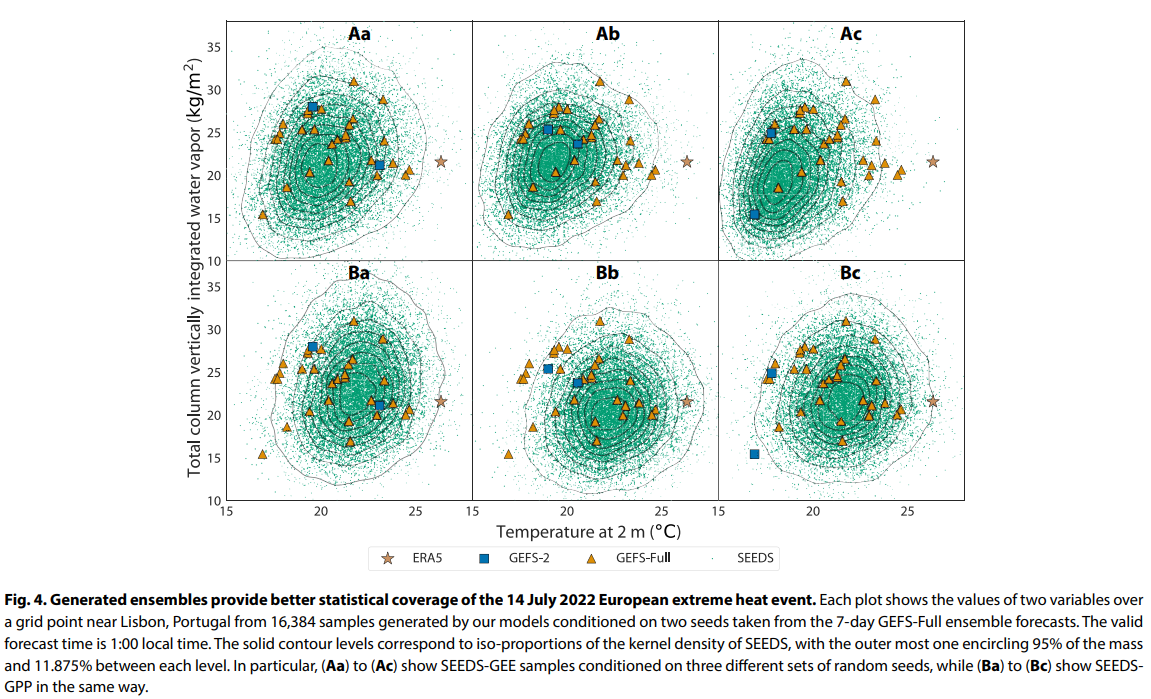
概要:
確定的予測に加えて、完全に接続されたネットワークを使用して小規模な地域、またはpix2pixアーキテクチャに基づいた条件付き生成対立ネットワークを使用して全球を対象とする予測も行われています.深層学習は、限られたサイズのアンサンブルをキャリブレーションするのにも効果的であり、例えば、自己注意のトランスフォーマーを使用してアンサンブルのスプレッドをキャリブレートすることができます.さらに、私たちの研究に関連するものとして、深層学習モデルは、物理ベースのアンサンブルよりもスキルが高い確率的予測を生成するために成功裏に使用されてきました.最終的なスキルは、メンバー数が少なくとも倍の(27)純粋な物理ベースのアンサンブルを上回っています.私たちのアプローチは、アンサンブル平均とスプレッドの改善を超えて付加価値を提供しており、描かれたサンプルは、気象の極端な空間パターンを特徴付けるために使用したり、変数や空間の相関に依存するターゲット気象アプリケーションに入力として使用することができます.
Q&A:
Q: 深層生成拡散モデルは、天気予報のエミュレーションにどのように役立つのか?
A: 深い生成拡散モデルは、物理ベースのシミュレーションを実行することなく、歴史データから学習されたモデルで、数千の現実的な天気予報を低コストでサンプリングできるため、天気予報を模倣するのに役立ちます.これらのモデルは、運用アンサンブル予測を模倣するように設計された場合、生成された予測は物理ベースのアンサンブルと統計的特性や予測スキルにおいて類似しています.また、運用予測システムに存在するバイアスを補正するように設計された場合、生成されたアンサンブルは改善された確率予測メトリクスを示し、より信頼性が高く、極端な天候イベントの確率をより正確に予測します.この方法論は、気象予報に焦点を当てていますが、気候リスク評価のために大規模な気候予測アンサンブルを作成する可能性があります.
Q: 天気予報に深層生成拡散モデルを使う利点は?
A: 深層生成拡散モデルを使用する利点は、物理ベースのアンサンブル予測をエミュレートすることで、統計的特性と予測スキルが向上し、運用予測システム内のバイアスを修正することで、信頼性が向上し、極端な天候事象の確率予測をより正確に行うことができる点にあります.また、この手法は気象予報に焦点を当てていますが、気候リスク評価のための大規模な気候予測アンサンブルの作成を可能にするかもしれません.
Q: 生成されたアンサンブルは、統計的特性や予測スキルの点で、物理学ベースのアンサンブルと比較してどうなのか?
A: 生成アンサンブルは、統計的性質と予測スキルにおいて物理ベースのアンサンブルと比較されます.生成アンサンブルは、運用予測システムに存在するバイアスを修正するように設計されると、改善された確率的予測メトリクスを示します.これらはより信頼性があり、極端な天候事象の確率をより正確に予測します.
Q: 生成されたアンサンブルは確率的予測指標をどのように改善するのか?
A: 生成されたアンサンブルは、確率的予測メトリクスを改善します.これにより、より信頼性が高まり、極端な天候事象の確率をより正確に予測することができます.
Q: ハイパフォーマンス・コンピューティング・アクセラレーターに対して、学習したモデルはどの程度スケーラブルなのか?
A: 学習されたモデルは、高性能コンピューティングアクセラレータに対して非常にスケーラブルであり、低コストで数千の現実的な天気予報をサンプリングすることができます.
Q: 生成されたアンサンブルは、どのようにして異常気象の発生確率をより正確に予測するのか?
A: 生成されたアンサンブルは、過去のデータから学習した深層生成拡散モデルによって作成され、高性能コンピューティングアクセラレータに対して高いスケーラビリティを持ち、低コストで数千の現実的な天気予報をサンプリングできます.これらは、運用アンサンブル予測を模倣するように設計された場合、物理ベースのアンサンブルと統計的特性および予測スキルにおいて類似しています.運用予測システムに存在するバイアスを補正するように設計された場合、生成されたアンサンブルは改善された確率的予測メトリクスを示し、より信頼性が高く、極端な天候事象の確率をより正確に予測します.天気予報に焦点を当てていますが、この方法論は気候リスク評価のために大規模な気候予測アンサンブルの作成を可能にするかもしれません.
Q: この方法論によって、気候リスク評価のための大規模な気候予測アンサンブルをどのように作成できるのか?
A: この方法論は、大規模な気候予測アンサンブルを作成し、気候リスク評価を可能にすることができます.具体的には、過去のデータから学習した深層生成拡散モデルを使用して、リアルな気象予測を数千回サンプリングすることができます.これにより、物理ベースのアンサンブルと同様の統計的特性と予測スキルを持つ生成されたアンサンブルが得られます.また、運用予測システムに存在するバイアスを補正するように設計された場合、生成されたアンサンブルは改善された確率予測メトリクスを示します.これにより、より信頼性が高く、極端な気象イベントの確率をより正確に予測することが可能となります.
Q: 数値気象予測モデルの不確実性を定量化する標準的な方法とは?
A: 数値天気予測モデルの不確実性を定量化する標準的な方法は、モデルの初期条件と小規模な物理過程の表現を確率的に摂動させて、天気軌跡のアンサンブルを作成することです.
Q: なぜ気象予報において、アンサンブル予報をより効率的に生成するアプローチを探ることが重要なのでしょうか?
A: アンサンブル予測を生成する効率的なアプローチを探求することが重要な理由は、数値天気予報モデルによる天気予測の不確実性を適切に評価するためです.これにより、天候の状態の確率分布をモンテカルロサンプルとして扱うことができ、極端な天候事象の確率をより正確に予測することが可能となります.また、非常に珍しい事象を特徴付けるために非常に大規模なアンサンブルを作成することができ、天候状態のサンプルを提供することで、その事象が発生する確率を定量化し、その下での天候状態をサンプリングすることができます.
Q: 生成的人工知能における最近の進歩は、予測要件の削減の可能性をどのようにもたらすのか?
A: 最近の生成的人工知能の進歩により、アンサンブル予測の要件を削減する可能性が提供されます.GAIモデルはデータセットから統計的事前分布を抽出し、学習された確率分布から条件付きおよび無条件のサンプリングを可能にします.このメカニズムにより、GAI技術はアンサンブル予測の生成コストを削減します.学習が完了すると、サンプリングプロセスは物理ベースのNWPモデルを時間ステップで進めるよりもはるかに計算効率が良くなります.
Announcing Grok-1.5
著者:xAI
発行日:2024年03月28日
最終更新日:不明
URL:https://x.ai/blog/grok-1.5
カテゴリ:不明
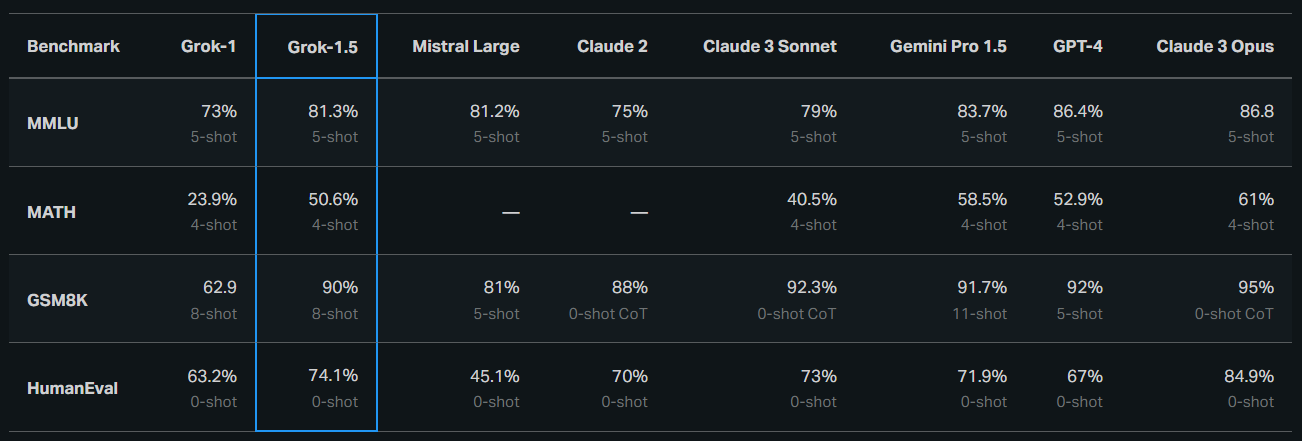
概要:
2024年4月4日13:22にGrok-1.5が発表されました.Grok-1.5は、改善された推論能力と128,000トークンのコンテキスト長を持つ最新のモデルです.この新機能により、Grokは以前よりも16倍長い文書から情報を利用できるようになりました.さらに、Grok-1.5は、長いコンテキストを処理し、128Kトークンまでの文脈内に埋め込まれたテキストを強力に取得する能力を示しました.これにより、Grokはより複雑なプロンプトを処理し、指示に従う能力を維持しながら、問題解決能力を向上させました.Grok-1.5は、128Kトークンまでの文脈内に埋め込まれたテキストを完璧に取得する能力を持ち、最新の大規模言語モデル(LLMs)研究に基づいています.また、Grok-1.5は、JAX、Rust、およびKubernetesに基づいたカスタム分散トレーニングフレームワーク上に構築されており、信頼性と柔軟性の高いインフラを提供しています.今後、Grok-1.5は早期テスターに利用可能となり、フィードバックをお待ちしており、さらに新機能を導入する予定です.また、今後数日間で新機能をいくつか導入する予定であり、GPT-4のスコアは2023年3月のリリースから取得されています.MATHとGSM8Kに関しては、maj@1の結果を示します.HumanEvalについては、pass@1のベンチマークスコアを報告します.
Q&A:
Q: Grok-1.5で向上した推論能力とは?
A: Grok-1.5の改善された推論能力は、数学関連のタスクにおける性能向上にあります.具体的には、MATHベンチマークで50.6%、GSM8Kベンチマークで90%のスコアを達成しました.これらのベンチマークは、広範囲の学校レベルから高校の競技問題をカバーしており、Grok-1.5はその領域で高い性能を示しています.
Q: Grok-1.5のコンテキストの長さは?
A: Grok-1.5のコンテキスト長は128Kトークンです.
Q: Grok-1.5は、コーディングや数学関連のタスクにおいて、どのようなベンチマークで好成績を収めたのでしょうか?
A: Grok-1.5は、数学関連のタスクにおいてMATHベンチマークで50.6%、GSM8Kベンチマークで90%のスコアを達成しました.
Q: Grok-1.5のベンチマーク性能は以前のモデルと比較してどうですか?
A: Grok-1.5は、以前のモデルと比較して、MMLU、MATH、GSM8K、CoT、HumanEvalなどのベンチマークパフォーマンスで改善されています.例えば、MATHベンチマークでは、Grok-1は23.9%のスコアを達成したのに対し、Grok-1.5は50.6%のスコアを達成しました.同様に、GSM8Kベンチマークでは、Grok-1は62.9%のスコアを達成したのに対し、Grok-1.5は90%のスコアを達成しました.
Q: Grok-1.5のロングコンテクスト理解に関する新機能は何ですか?
A: Grok-1.5の新機能は、16倍の前のコンテキスト長さの容量を持ち、大幅に長い文書から情報を利用できるようになったことです.
Q: Grok-1.5は、より長く複雑なプロンプトをどのように扱うのですか?
A: Grok-1.5は、以前のコンテキスト長の16倍の容量を持ち、これにより大幅に長いドキュメントから情報を利用できます.さらに、モデルはより長く、より複雑なプロンプトを処理できるようになりました.コンテキストウィンドウが拡大するにつれて、指示に従う能力を維持します.
Q: Grok-1.5はどのような基盤の上に構築されているのですか?
A: Grok-1.5は、JAX、Rust、およびKubernetesに基づいたカスタム分散トレーニングフレームワーク上に構築されています.
Q: Grok-1.5のカスタム分散トレーニングフレームワークは何をベースにしているのですか?
A: Grok-1.5のカスタム分散トレーニングフレームワークは、JAX、Rust、およびKubernetesに基づいています.
Q: Grok-1.5のカスタムトレーニングオーケストレータは、トレーニングジョブの信頼性とアップタイムをどのように確保していますか?
A: Grok-1.5のカスタムトレーニングオーケストレーターは、問題のあるノードがトレーニングジョブから自動的に検出および排除されることによって、信頼性とトレーニングジョブの稼働時間を最大化しています.また、チェックポイント、データの読み込み、およびトレーニングジョブの再起動を最適化することで、障害発生時のダウンタイムを最小限に抑えています.
Introducing DBRX: A New State-of-the-Art Open LLM
著者:The Mosaic Research Team
発行日:2024年03月27日
最終更新日:不明
URL:https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm
カテゴリ:不明
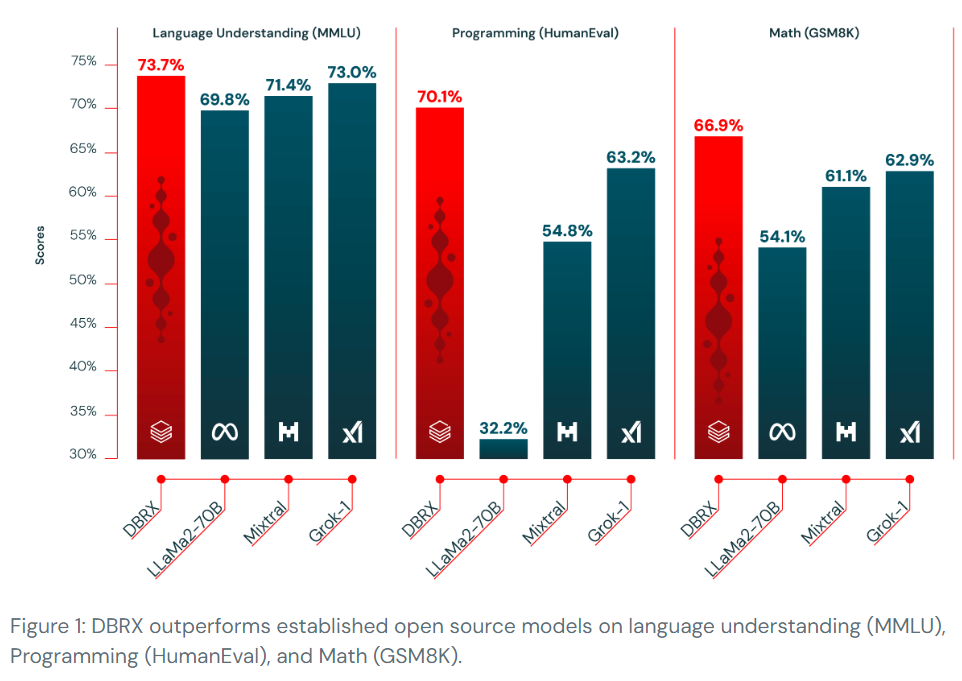
概要:
DBRXは、Databricksによって作成されたオープンで汎用性の高いLLMであり、標準ベンチマークの範囲を超えて、確立されたオープンLLMにおいて新たな最先端を示しています.さらに、これまで閉じられたモデルAPIに限定されていた機能をオープンコミュニティや自社のLLMを構築する企業に提供しています.DBRXは、GPT-3.5を凌駕し、Gemini 1.0 Proと競合しており、特にコードモデルとして優れた性能を発揮しています.DBRXは、微細な専門家の混合(MoE)アーキテクチャによってオープンモデルの効率性の最先端を進化させており、推論は最大2倍速くなり、トレーニングもより効率的に行うことができます.DBRXは、オープンLLMの新たな時代を切り開く革新的なモデルであり、研究チームはその導入に興奮しています.DBRXは、Mosaic AI Model Serving上で150 tok/s/userの速度でテキストを生成し、MoEのトレーニングは同じ最終モデル品質のために密なモデルのトレーニングよりも約2倍FLOP効率的です.DBRXは、以前のMPTモデルと同等の品質を、約4倍少ない計算量で達成することができます.DBRXは、言語理解(MMLU)、プログラミング(HumanEval)、数学(GSM8K)の分野で確立されたオープンソースモデルを凌駕しています.DBRXのベースモデルとファインチューニングモデルの重みは、オープンライセンスの下でHugging Faceで利用可能です.DBRXは、Databricksの顧客がAPIを介して利用できるようになり、Databricksの顧客は自社のDBRXクラスモデルをゼロから事前トレーニングしたり、私たちが使用したツールと科学を使用してチェックポイントの上でトレーニングを継続したりすることができます.DBRXは、すでにGenAIパワードのプロジェクトに統合されており、SQLなどのアプリケーションでは、早期展開がGPT-3.5 Turboを凌駕し、GPT-4 Turboに挑戦しています.また、オープンモデルやRAGタスクにおいてもトップクラスのモデルであり、GPT-3.5 Turboを上回っています.MoEモデルのトレーニングは困難であり、DBRXクラスモデルを効率的に繰り返しトレーニングするための堅牢なパイプラインを構築するために、さまざまな科学的およびパフォーマンス上の課題を乗り越えなければなりませんでした.これまでにその課題を克服し、世界クラスのMoE基盤モデルを企業がゼロからトレーニングできる独自のDBRXベーストレーニングスタックを持っています.この能力を顧客と共有し、コミュニティに学んだ教訓を共有することを楽しみにしています.Hugging FaceからDBRXをダウンロードするか、DBRX Instructを試してみるか、githubのモデルリポジトリをご覧ください.
Q&A:
Q: DBRXはどのようなベンチマークを超え、最先端のオープンLLMとしての地位を確立したのか?
A: DBRXは、ARCChallenge、HellaSwag、MMLU、TruthfulQA、WinoGrande、およびGSM8kの平均である複合ベンチマークと、世界知識、ナンセンス推論、言語理解、読解力、記号的理解、問題解決、およびプログラミングの6つのカテゴリにわたる30以上のタスクからなる複合ベンチマーク.問題解決、およびプログラミングの6つのカテゴリにわたる30以上のタスクからなる複合ベンチマークの2つのベンチマークで他のモデルを上回りました.
Q: DBRXはGPT-3.5やジェミニ1.0プロと比べて性能面でどうですか?
A: 具体的には、DBRX InstructはMMLU、HellaSwag、HumanEvalなどのベンチマークでGPT-3.5を上回っており、Gemini 1.0 Proとは異なる強みを持っています.
Q: DBRXはトレーニングや推論のパフォーマンスをどのように向上させるのか?
A: DBRXは、トレーニングと推論パフォーマンスの両方で改善を提供しています.トレーニングにおいては、12Tトークンのデータを使用し、最大コンテキスト長が32kトークンであることから、より高品質なデータを使用しており、カリキュラムラーニングを導入することでモデルの品質を大幅に向上させました.推論パフォーマンスにおいては、最適化されたモデルサービングプラットフォームで8ビットの量子化を使用し、NVIDIA TensorRT-LLMを16ビット精度で使用することで、最適化された推論スループットを実現しています.
Q: DBRXの細かい粒度の専門家の混合(MoE)アーキテクチャは、その効率性にどのように貢献していますか?
A: DBRXの細かい混合専門家(MoE)アーキテクチャは、モデルの品質と推論効率のトレードオフを改善することができます.MoEアーキテクチャを使用することで、密なモデルが通常達成するよりも、モデルの品質と推論効率の間でより良いトレードオフを実現できます.DBRXは、LLaMA2-70Bよりも高い品質であり、アクティブなパラメータが半分であるため、DBRXの推論スループットは最大2倍速くなります.Mixtralは、DBRXよりも小さく、品質はそれに比例して低くなりますが、より高い推論スループットを達成します.
Q: LLaMA2-70Bと比較したDBRXの推論スピードは?
A: DBRXの推論速度はLLaMA2-70Bよりも2倍速いです.
Q: DBRXのサイズはGrok-1と比べてパラメータ数はどうですか?
A: DBRXはGrok-1に比べて、パラメータ数が40%少ないです.
Q: Mosaic AI Model Serving上でホストされた場合のDBRXのテキスト生成速度は?
A: DBRXがMosaic AI Model Servingでホストされた場合、DBRXは1ユーザーあたり最大150トークン/秒のテキスト生成速度を実現できます.
Q: 専門家混合モデルの訓練は、密なモデルの訓練とFLOP効率の点でどう違うのか?
A: 混合専門家モデルのトレーニングは、同じ最終モデル品質のために密なモデルをトレーニングするよりも、FLOP効率が約2倍向上します.具体的には、DBRX MoE-Bのような小さなDBRXファミリーのメンバーをトレーニングする際、Databricks LLM Gauntletで45.5%のスコアに到達するために必要なFLOPは、43.8%に到達するために必要なLLaMA2-13Bよりも1.7倍少ないことが示されています.
Q: 言語理解、プログラミング、数学のタスクにおいて、DBRXはどのようなオープンソースモデルを上回るのか?
A: DBRXは、言語理解、プログラミング、数学のタスクで、MMLU、HumanEval、GSM8Kの既存のオープンソースモデルを上回っています.
Q: 専門家混合モデルのトレーニングにおいて、チームはどのような課題に直面し、どのように克服したのか?
A: 混合専門家モデルのトレーニングには、科学的およびパフォーマンス上のさまざまな課題を克服する必要がありました.これらの課題を克服するために、堅牢なパイプラインを構築する必要がありました.
Long-form factuality in large language models
著者:Jerry Wei, Chengrun Yang, Xinying Song, Yifeng Lu, Nathan Hu, Dustin Tran, Daiyi Peng, Ruibo Liu, Da Huang, Cosmo Du, Quoc V. Le
発行日:2024年03月27日
最終更新日:2024年03月27日
URL:http://arxiv.org/pdf/2403.18802v1
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning
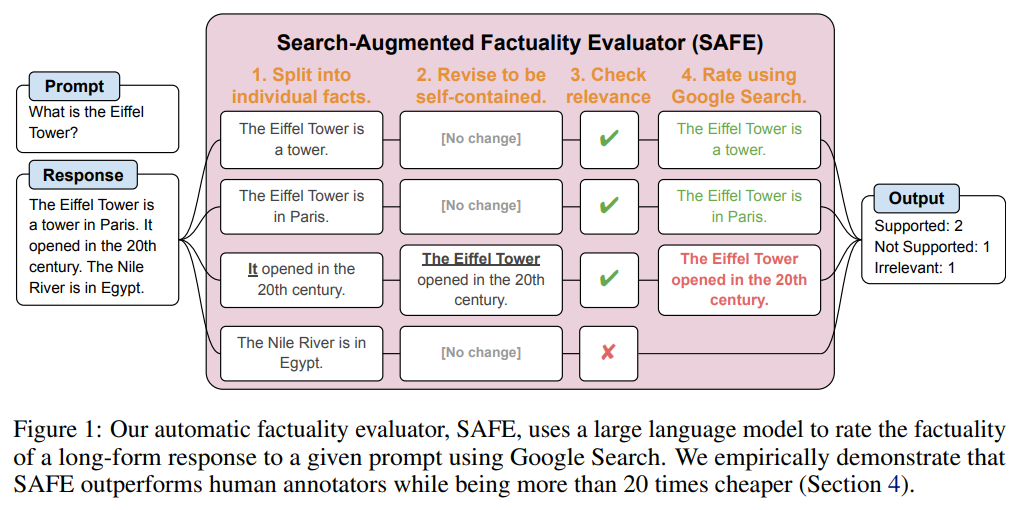
概要:
大規模言語モデル(LLM)は、オープンエンドのトピックに関するファクトシークイングプロンプトに対して応答する際に、事実に誤りを含むコンテンツを生成することがよくあります.オープンドメインにおけるモデルの長文ファクトのベンチマークを行うために、まずGPT-4を使用して、38のトピックにわたる数千の質問を含むプロンプトセットであるLongFactを生成します.次に、LLMエージェントを長文ファクトの自動評価者として使用できると提案し、その方法を「Search-Augmented Factuality Evaluator(SAFE)」と呼びます.SAFEは、LLMを使用して長文の応答を個々の事実のセットに分解し、Google検索に検索クエリを送信し、各事実の正確性を評価するための多段階の推論プロセスを使用します.さらに、長文ファクトの集約メトリックとしてF1スコアを拡張することを提案します.これを行うために、応答内のサポートされた事実の割合(適合率)と、ユーザーの好ましい応答長を表すハイパーパラメータに対する提供された事実の割合(再現率)をバランスさせます.実証的に、LLMエージェントが超人的な評価を達成できることを示しています.具体的には、SAFEは、約16,000の個々の事実について、人間の注釈者と72%の一致率を達成し、100の不一致ケースのランダムサブセットでは、76%の勝率を示しました.また、SAFEは人間の注釈者よりも20倍以上もコストが低いことがわかりました.さらに、Gemini、GPT、Claude、PaLM-2の4つのモデルファミリーにわたる13の言語モデルをLongFactでベンチマークし、一般的に大きな言語モデルがより良い長文ファクトの実現を達成することを発見しました.LongFact、SAFE、およびすべての実験コードは、https://github.com/google-deepmind/long-form-factuality で入手可能です.
Q&A:
Q: どのようにしてプロンプトセットLongFactを作り、どのようなトピックを扱っているのですか?
A: LongFactは、GPT-4に特定の概念やオブジェクトに関する質問を生成させ、複数の詳細なファクトを含む長い形式の回答を求めるためのプロンプトセットです.LongFactは、LongFact-ConceptsとLongFact-Objectsの2つのタスクで構成されており、質問が概念またはオブジェクトに関するかに基づいて分けられています.38の手動選択されたトピックを使用して、各トピックごとに60のプロンプトを生成し、重複する質問を削除してから、各トピックごとに30のプロンプトをランダムに選択しています.これにより、LongFact-Conceptsには1,140のプロンプト、LongFact-Objectsには1,140のプロンプトが生成されます.LongFactは、https://github.com/google-deepmind/long-form-factuality/tree/main/longfact で公開されています.
Q: Search-Augmented Factuality Evaluator(SAFE)メソッドについて、もう少し詳しく説明してもらえますか?
A: SAFE(Search-Augmented Factuality Evaluator)メソッドは、長い形式の回答を個々の自己完結型の事実に分割し、それぞれの事実が回答の文脈でプロンプトに適しているかどうかを判断し、Google検索クエリを発行し、検索結果がその事実をサポートしているかどうかを慎重に推論することによって、事実の信憑性を評価する手法です.この手法は、言語モデルを使用して、個々の事実を分離し、Google検索APIに送信するための事実チェッククエリを提案し、検索結果がその事実をサポートしているかどうかを推論します.SAFEは、人間の注釈の72%に同意し、Min et al.(2023)から76%の勝利を収めるなど、超人的なパフォーマンスを達成しています.
Q: SAFEは、長文回答における個々の事実の正確性を評価するために、Google検索をどのように活用していますか?
A: SAFEはGoogle検索を利用して、長い形式の回答の個々の事実の正確性を評価します.具体的には、SAFEは言語モデルを使用して、長い形式の回答を個々の自己完結型の事実に分割し、各個々の事実が回答文脈の中で適切かどうかを判断します.そして、各適切な事実に対して、Google検索への複数段階のクエリを発行し、検索結果がその事実をサポートしているかどうかを慎重に推論します.
Q: F1スコアを長文の事実性の集計指標として拡張することをどのように提案したのですか?
A: F1スコアを長い形式の事実性の集約メトリックとして拡張することを提案しました.この提案では、F1スコアは、長い形式の応答におけること実性の精度と再現率を評価するために使用されます.具体的には、Google検索に検索クエリを送信し、各事実が検索結果でサポートされているかどうかを判断する多段階の推論プロセスを使用して、各事実の正確性を評価します.
Q: LLMエージェントが超人的なレーティング・パフォーマンスを達成した実証実験の結果は?
A: LLMエージェントは、約16,000の個々の事実に関して、クラウドソーシングされた人間の注釈と72.0%の一致を示し、超人的な評価性能を達成したことが実証されました.
Q: SAFEを使用するコストは、人間のアノテーターと比べてどうでしょうか?
A: SAFEの使用コストは、人間の注釈者よりも20倍以上安いです.
Q: LongFact上の13の言語モデルのベンチマークプロセスと、より大きな言語モデルに関する調査結果について説明してもらえますか?
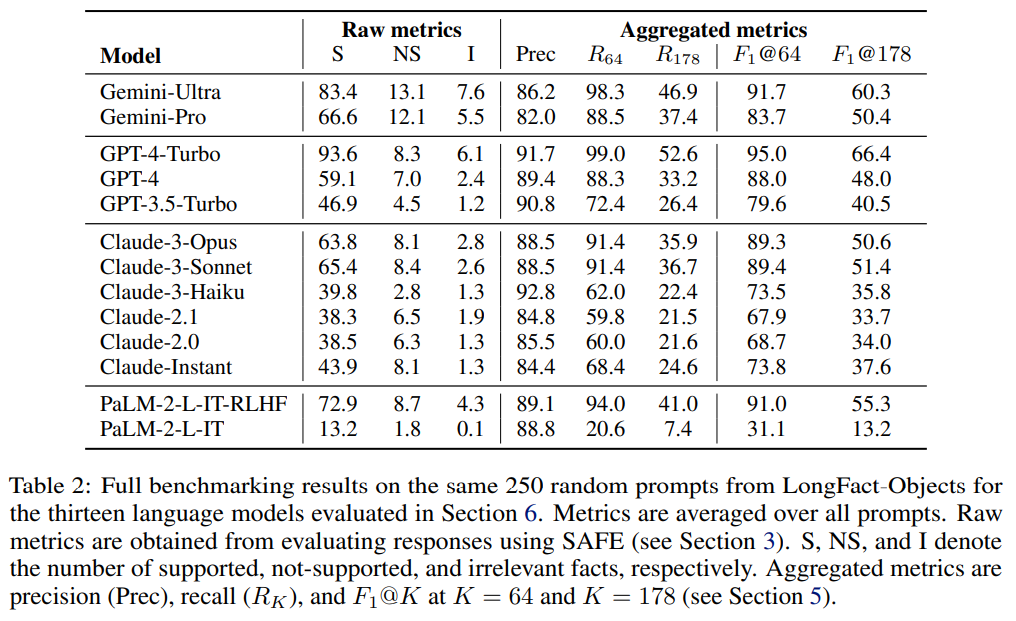
A: 13の言語モデルに関するLongFactでのベンチマーキングプロセスと、大きな言語モデルに関する調査結果は、LongFactと呼ばれる新しいプロンプトセットを使用して行われました.LongFactは、38の手動選択されたトピック全体で、2,280の事実を求めるプロンプトから構成されており、長い形式の回答を促します.これにより、各言語モデルが同じ250のランダムな評価例に対して評価され、SAFEを使用して応答が評価されました.F1@Kを使用してパフォーマンスを評価し、一般的に、より大きな言語モデルがより良い長い形式の事実性を達成することがわかりました.
Q: LongFact、SAFE、実験的コードで利用可能なリソースは?
A: LongFact、SAFE、および実験コードの利用可能なリソースは、https://github.com/google-deepmind/long-form-factuality で公開されています.さらに、LongFactの生成コード、SAFEの実装、および実験のすべてのコードは、同じリンクで提供されています.
Q: あなたは、応答の中でサポートされた事実の割合と、ユーザーの好ましい応答の長さを表すハイパーパラメータをどのように決定しましたか?
A: 応答内のサポートされた事実の割合とユーザーの好ましい応答長を表すハイパーパラメータを決定する方法は、F1@Kを使用して行われます.ここで、Kは応答が完全なリコールを達成するために必要なサポートされた事実の数を表します.具体的には、F1@Kは、K番目のサポートされた事実以降に追加のサポートされた事実を持つことに無関心なユーザーのために応答の事実性を評価します.Kの選択は、エンドユーザーの好みをモデル化する方法の選択と見なすことができます.
Q: この研究でベンチマークされた4つのモデルファミリー(Gemini、GPT、Claude、PaLM-2)の詳細について教えてください.
A: この研究でベンチマークされたGemini、GPT、Claude、およびPaLM-2の4つのモデルファミリーについての詳細な情報は提供されていません.
Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models
著者:Yanwei Li, Yuechen Zhang, Chengyao Wang, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, Jiaya Jia
発行日:2024年03月27日
最終更新日:2024年03月27日
URL:http://arxiv.org/pdf/2403.18814v1
カテゴリ:Computer Vision and Pattern Recognition, Artificial Intelligence, Computation and Language

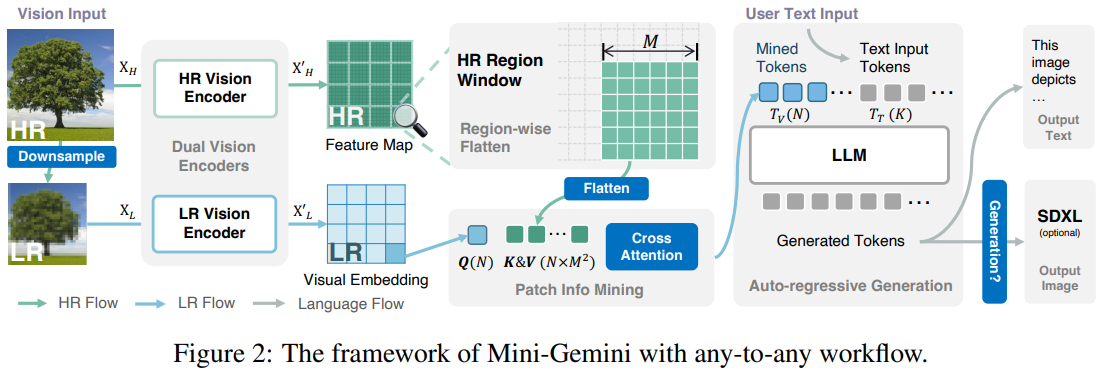
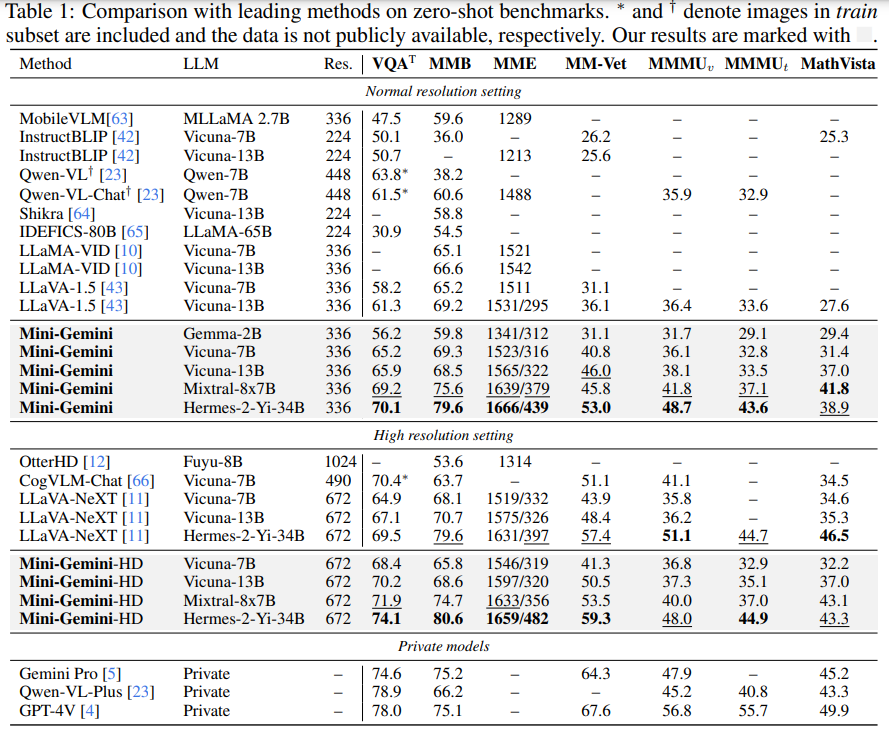
概要:
この作品では、私たちはMini-Geminiというシンプルで効果的なフレームワークを紹介しています.このフレームワークは、マルチモダリティのビジョン言語モデル(VLMs)を強化するものです.VLMsの進化により、基本的なビジュアルダイアログや推論が可能になりましたが、GPT-4やGeminiなどの高度なモデルと比較して、性能の差が依然として存在しています.私たちは、VLMsの潜在能力を掘り起こし、より良いパフォーマンスとあらゆるワークフローを可能にするために、高解像度のビジュアルトークン、高品質のデータ、VLMによる生成の3つの側面からアプローチしています.ビジュアルトークンを強化するために、追加のビジュアルエンコーダを使用して高解像度の精緻化を提案していますが、ビジュアルトークンの数を増やすことなく行います.さらに、正確な画像理解と推論に基づく生成を促進する高品質のデータセットを構築し、現在のVLMsの操作範囲を拡大しています.全体として、Mini-GeminiはVLMsの潜在能力をさらに掘り下げ、画像理解、推論、生成を同時に可能にする現在のフレームワークを強化しています.Mini-Geminiは、2Bから34Bまでの一連の密なMoE Large Language Models(LLMs)をサポートしており、いくつかの分野でトップクラスのパフォーマンスを達成していることが示されています.さらに、Zero-shot ベンチマークsにおいても先進的な性能を発揮し、開発されたプライベートモデルを凌駕しています.コードとモデルはhttps://github.com/dvlab-research/MiniGemini で入手可能です.
Q&A:
Q: Mini-Geminiがマルチモダリティ視覚言語モデル(VLM)をどのように強化するのか、詳しく教えてください.
A: Mini-Geminiは、高解像度の視覚トークン、高品質のデータ、およびVLMによる生成を通じて、VLMの潜在能力を掘り起こし、現在のフレームワークを画像理解、推論、生成に対応させることで、マルチモダリティビジョン言語モデル(VLMs)を強化しています.
Q: 基本的な視覚的対話と推論を容易にするVLMの具体的な進歩とはどのようなものですか?
A: 基本的なビジュアルダイアログと推論を促進するVLMの特定の進歩として、高解像度のビジュアルトークン、高品質のデータ、およびVLM-ビジュアル理解からの任意のワークフローの可能性を探ることによって、パフォーマンスギャップを狭めようとしています.
Q: ミニ・ジェミニは、GPT-4やジェミニのような上級モデルとの性能差をどのように縮めることを目指しているのですか?
A: Mini-Geminiは、高解像度の視覚トークン、高品質のデータ、およびVLMによるガイド付き生成の3つの側面から、VLMの潜在能力を探求し、GPT-4やGeminiなどの先進モデルとの性能差を縮めようとしています.高解像度の視覚トークンを向上させるために、視覚エンコーダを追加して高解像度の精緻な調整を行い、視覚トークン数を増やさずに性能を向上させます.さらに、正確な画像理解と推論ベースの生成を促進する高品質なデータセットを構築し、現在のVLMの操作範囲を拡大します.総じて、Mini-GeminiはVLMの潜在能力をさらに探求し、画像理解、推論、生成を備えた現行のフレームワークを強化します.
Q: VLMの可能性を掘り起こすための3つの側面、すなわち高解像度の視覚的トークン、高品質のデータ、VLM誘導生成について詳しく教えてください.
A: VLMの潜在能力を探るために、高解像度のビジュアルトークン、高品質なデータ、VLMによる生成を三つの戦略的側面から探求します.まず第一に、ConvNetを利用して、視覚的な詳細を向上させつつ、LLMの視覚トークン数を維持することで、より高解像度の候補を効率的に生成します.次に、多様な公開ソースから高品質なデータセットを統合し、豊かで多様なデータ基盤を確保することで、データ品質を向上させます.さらに、最先端のLLMと生成モデルとこれらの強化を統合することで、VLMのパフォーマンスとユーザーエクスペリエンスを向上させることを目指します.この多面的な戦略により、現在のVLMの視覚理解により深く踏み込むことが可能となります.
Q: ミニ・ジェミニで提案されている追加ビジュアルエンコーダーは、カウントを増やすことなく、どのようにビジュアルトークンの洗練度を向上させるのですか?
A: Mini-Geminiでは、追加のビジュアルエンコーダを使用することで、ビジュアルトークンの精緻化を図り、ビジュアルトークンの数を増やさずに高解像度の改善を実現しています.具体的には、LRビジュアルエンコーダとHRビジュアルエンコーダを使用し、入力サイズを672(LR)および1536(HR)に設定しています.HRビジュアルエンコーダは、高解像度の候補情報を提供するために主に使用され、解像度を増やしつつも、LLMによって処理されるビジュアルトークンの実効数は一貫しており、計算効率を確保しています.
Q: 精密な画像理解と推論に基づく生成のために、どのような方法で高品質のデータセットを構築したのか?
A: 高品質なデータセットを構築するために使用された方法は、LLaV A-filtered CC3Mデータセットから558Kの画像キャプションペアとALLaV Aデータセットから695KのサンプルされたGPT-4V-応答キャプションを利用し、合計で1.2Mの画像キャプションを取得しています.指示の微調整のためには、LLaV Aデータセットから643Kの単一およびマルチターンの会話をサンプリングし、画像理解に関連する約1.5Mの指示関連会話が収集されています.また、画像生成に関連する13Kのペアも収集されています.
Q: ミニ・ジェミニは、画像の理解、推論、生成を同時に行うことで、現在のフレームワークにどのような力を与えているのだろうか?
A: Mini-Geminiは、画像理解、推論、生成を同時に強化するために現在のフレームワークに力を与えます.デュアルビジョンエンコーダーを使用して低解像度の視覚埋め込みと高解像度の候補を提供し、パッチ情報の採掘を行い、高解像度領域と低解像度の視覚クエリの間でパッチレベルの採掘を行い、LLMを使用してテキストと画像を同時に理解および生成するために結婚させます.
Q: Mini-Geminiがサポートする一連の高密度言語モデルおよびMoEラージ言語モデル(LLM)の詳細について教えてください.
A: ミニジェミニは、2Bから34Bまでの一連の密なMoE Large Language Models(LLMs)をサポートしています.これらのモデルは、ゼロショットベンチマークで優れたパフォーマンスを達成し、開発されたプライベートモデルをさらに上回ることが示されています.
Q: ミニ・ジェミニは、具体的にどのようなゼロショットベンチマークでトップクラスのパフォーマンスを達成したのでしょうか?
A: 具体的なゼロショットベンチマークでMini-Geminiがリーディングパフォーマンスを達成したのは、MathVistaとMMMUのベンチマークです.
Q: ミニ・ジェミニのコードやモデルへのアクセス方法は?
A: ミニ・ジェミニのコードとモデルにアクセスするには、https://github.com/dvlab-research/MiniGemini にアクセスしてください.
AIOS: LLM Agent Operating System
著者:Kai Mei, Zelong Li, Shuyuan Xu, Ruosong Ye, Yingqiang Ge, Yongfeng Zhang
発行日:2024年03月25日
最終更新日:2024年03月26日
URL:http://arxiv.org/pdf/2403.16971v2
カテゴリ:Operating Systems, Artificial Intelligence, Computation and Language
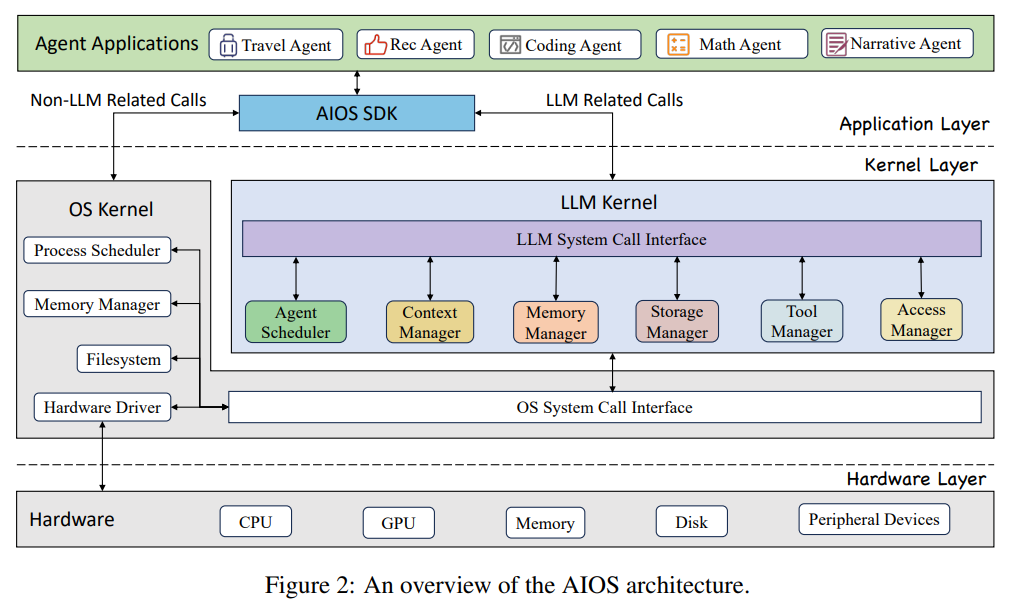
概要:
大規模言語モデル(LLM)ベースのインテリジェントエージェントの統合と展開は、その効率と有効性を損なうさまざまな課題に直面しています.これらの問題の中には、エージェントリクエストをLLM上での最適なスケジューリングとリソース割り当てに関するもの、エージェントとLLMの間の相互作用中にコンテキストを維持する難しさ、異なる能力と特化を持つ異種エージェントを統合する際の複雑さなどがあります.エージェントの数量と複雑さの急速な増加は、これらの問題をさらに悪化させ、しばしばリソースのボトルネックや最適な利用を妨げることがあります.これらの課題に着想を得て、本論文では、AIOSというLLMエージェントオペレーティングシステムを提案しています.これは、大規模言語モデルをオペレーティングシステム(OS)に組み込み、OSの脳として機能させるものであり、”魂を持つ”オペレーティングシステムを実現する重要な一歩となります.具体的には、AIOSはリソースの割り当てを最適化し、エージェント間のコンテキスト切り替えを容易にし、エージェントの同時実行を可能にし、エージェント向けのツールサービスを提供し、エージェントのアクセス制御を維持するよう設計されています.さらに、AIOSの基本設計と実装を提供し、複数のエージェントの同時実行に関する実験を通じて、AIOSモジュールの信頼性と効率性を示しています.これにより、LLMエージェントのパフォーマンスと効率性を向上させるだけでなく、将来のAIOSエコシステムの開発と展開に向けて先駆的な取り組みを行っています.プロジェクトはオープンソースであり、https://github.com/agiresearch/AIOS で公開されています.
Q&A:
Q: AIOSはLLMベースのインテリジェント・エージェントのリソース割り当てをどのように最適化するのか?
A: AIOSは、大規模言語モデルをオペレーティングシステム(OS)の脳として組み込むことで、リソース割り当てを最適化します.具体的には、AIOSはリソース割り当てを最適化し、エージェント間のコンテキスト切り替えを容易にし、エージェントの並行実行を可能にし、エージェントに対するツールサービスを提供し、エージェントのアクセス制御を維持します.
Q: AIOSが、LLMとのやりとりの中で、エージェント間のコンテキストの切り替えをどのように促進しているのか説明していただけますか?
A: AIOSは、エージェント間の相互作用中にコンテキストスイッチを容易にするために設計されています.これは、エージェントが実行中に他のエージェントに切り替える際に、そのエージェントの状態や情報を保存し、復元する機能を提供します.具体的には、AIOSは各エージェントの状態を適切に管理し、必要に応じてメモリ内の情報を切り替えることで、スムーズなエージェント間の移行を実現します.
Q: AIOSは、能力の異なる異種エージェントを統合する上で、どのような課題の解決を目指しているのでしょうか?
A: AIOSは、異なる能力を持つ異種エージェントを統合する際の課題を解決することを目指しています.具体的には、リソースの最適な割り当て、エージェント間のコンテキスト切り替えの容易化、エージェントの同時実行の可能化、エージェント向けのツールサービスの提供、およびエージェントへのアクセス制御の維持などのコアな課題を解決することを目指しています.
Q: AIOSはどのようにしてエージェントの同時実行を可能にするのですか?
A: AIOSは複数のエージェントの同時実行を可能にするために、リソースの割り当てを最適化し、エージェント間でのコンテキストスイッチを容易にし、エージェントの同時実行を可能にし、エージェント向けのツールサービスを提供し、エージェントのアクセス制御を維持するように設計されています.
Q: AIOSは代理店向けにどのようなツールサービスを提供していますか?
A: AIOSはエージェントに対してツールサービスを提供しており、リソースの最適化、コンテキストの切り替え、並行エージェントの実行、およびアクセス制御を可能にしています.
Q: AIOSはエージェントのアクセス制御をどのように行っていますか?
A: AIOSは、エージェントのためにアクセス制御を維持するために、モジュールの分離とLLMおよびOSの機能の集約を提供するように設計されています.具体的には、AIOSはリソースの割り当てを最適化し、エージェント間でのコンテキストスイッチを容易にし、エージェントの同時実行を可能にし、エージェント向けのツールサービスを提供し、エージェントのためのアクセス制御を維持します.
Q: AIOSのアーキテクチャの詳細を教えてください.
A: AIOSのアーキテクチャは、3つの異なるレイヤーに分かれており、それぞれのレイヤーがシステム全体での責任を明確に区別しています.各上位レイヤーは、それ以下のレイヤーの複雑さを抽象化し、インターフェースや特定のモジュールを介した相互作用を容易にし、モジュール化を向上させ、異なるレイヤー間でのシステムの相互作用を簡素化しています.具体的には、アプリケーションレイヤーでは、トラベルエージェントや数学エージェントなどのエージェントアプリケーションが開発および展開されます.AIOSは、エージェント開発者の開発プロセスを簡素化するシステムコールの高度な抽象化であるAIOS SDKを提供しています.このSDKにより、エージェント開発者はシステムとのやり取りを容易にすることができます.
Q: AIOSは、LLMエージェントの展開において、どのような中核的課題に取り組むことを目指しているのでしょうか?
A: AIOSはLLMエージェントの展開における主要な課題を解決することを目指しています.具体的には、リソースの最適な割り当て、エージェント間のコンテキスト切り替えの容易化、エージェントの同時実行の可能化、エージェント向けのツールサービスの提供、およびエージェントのアクセス制御の維持を目指しています.
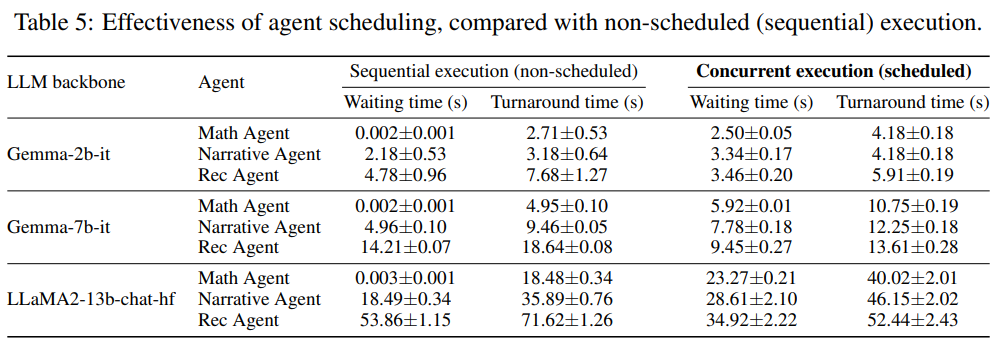
Q: 実施された実験に基づくと、AIOSモジュールの信頼性と効率性は?
A: AIOSモジュールは、複数のエージェントの同時実行に関する実験により、信頼性と効率性が示されました.
A comparison of Human, GPT-3.5, and GPT-4 Performance in a University-Level Coding Course
著者:Will Yeadon, Alex Peach, Craig P. Testrow
発行日:2024年03月25日
最終更新日:2024年03月25日
URL:http://arxiv.org/pdf/2403.16977v1
カテゴリ:Computation and Language
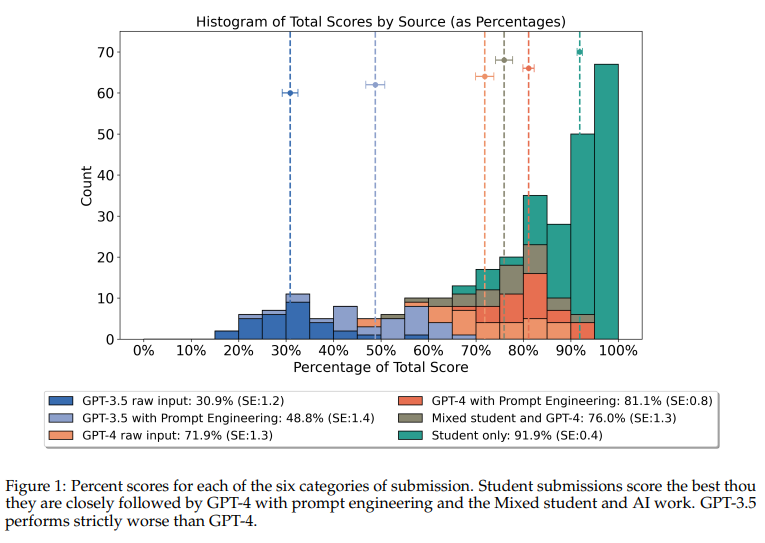
概要:
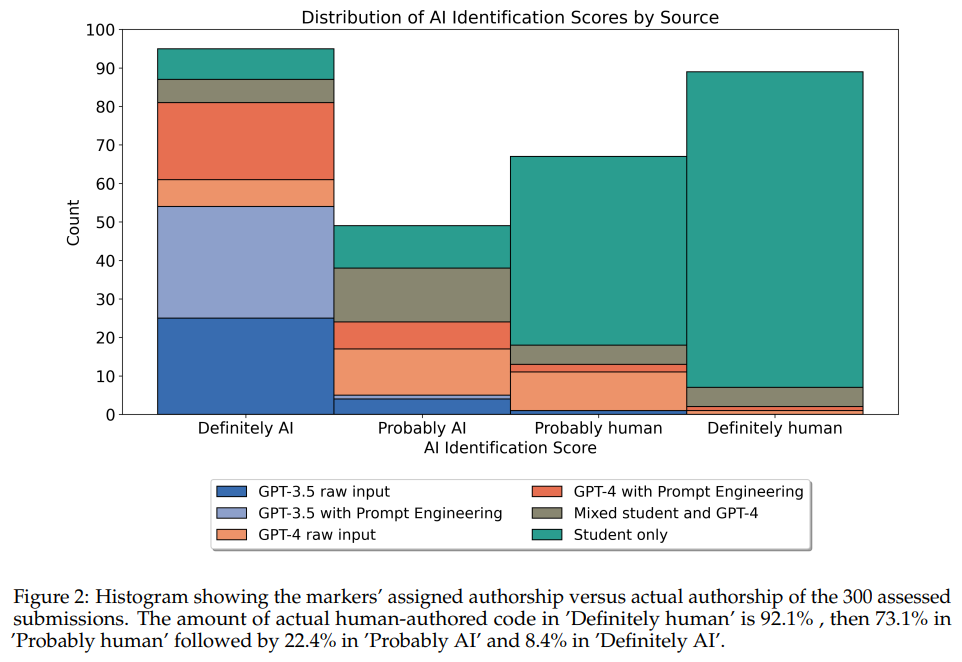
この研究は、ChatGPTのバリアントであるGPT-3.5とGPT-4のパフォーマンスを評価し、プロンプトエンジニアリングを行った場合と行わなかった場合の両方を、単に学生の作業と学生とGPT-4の両方の貢献を含む混合カテゴリーと比較して、Python言語を使用した大学レベルの物理学のコーディング課題で評価しました.異なるカテゴリーの50の学生提出物と50のAI生成提出物を比較し、3人の独立したマーカーによって盲目的に採点され、\( \small n = 300 \)のデータポイントを集めました.学生は平均91.9% (SE:0.4)を記録し、最も高いパフォーマンスを示したAI提出カテゴリーであるプロンプトエンジニアリングを行ったGPT-4は81.1% (SE:0.8)を獲得しました.これは統計的に有意な差であり(p = \( \small 2.482 \times 10^{-10} \))、プロンプトエンジニアリングはGPT-4 (p = \( \small 1.661 \times 10^{-4} \))とGPT-3.5 (p = \( \small 4.967 \times 10^{-9} \))の両方のスコアを有意に向上させました.さらに、盲目のマーカーは、提出物の著者を「絶対にAI」から「絶対に人間」までの4段階のLikertスケールで推測するように指示されました.彼らは提出物の著者を正確に特定し、’絶対に人間’と分類された作業の92.1%が人間によるものであることが確認されました.さらに、AI'またはHuman’の2つのカテゴリに単純化した場合、平均的な正解率は85.3%でした.これらの結果から、AIによる作業は大学生の作業の品質に近づいていますが、しばしば人間の評価者によって検出される可能性があることが示唆されます.
Q&A:
Q: この研究でGPT-3.5とGPT-4に使用されたプロンプト・エンジニアリングの詳細を教えてください.
A: この研究で使用されたGPT-3.5とGPT-4のプロンプトエンジニアリングについての詳細を提供します.GPT-3.5とGPT-4のプロンプトエンジニアリングは、テーブル2のガイドラインに従って課題テキストが修正され、GPT-3.5モデルとGPT-4モデルの相互作用を最適化し、より良い応答を得ることを目指しています.具体的には、プロンプトエンジニアリングは、モデルがより適切な応答を生成するために、入力されるテキストや指示を調整し、モデルの学習と応答の質を向上させることを意味します.
Q: この研究で比較するために、50の学生投稿と50のAI生成投稿はどのように選ばれたのですか?
A: この研究では、50の学生の提出物と50のAI生成の提出物を比較するために、それぞれのカテゴリーに10の提出物が生成されました.学生の提出物はランダムに選択された2023/24年のコホートからの55の提出物の中から50の提出物が含まれており、AIの提出物はOpenAIのAPIに入力テキストを送信し、その応答を入力テキストに追加し、Pythonスクリプトとして実行し、生成されたプロットを画像として抽出することで作成されました.AIの応答には、テキストや非Pythonコードが含まれることがあり、画像が抽出できないエラーが発生することがありました.カテゴリーごとに10の提出物を達成するために、スクリプトは目標数に達するまでwhileループで実行されました.さらに、いくつかの場合には、実際に空白の図が生成されましたが、これらはこの研究に有益な情報を提供しないため、除外されました.
Q: 3人の独立採点者が提出書類をブラインド採点した方法について説明していただけますか?
A: 3人の独立したマーカーは、提出物の採点を盲目的に行いました.彼らは、4段階のリッカート尺度を使用して、提出物の著者を推測することに取り組みました.この尺度は、「絶対にAI」から「絶対に人間」までの4つのポイントで構成されており、92.1%の作品が「絶対に人間」のカテゴリに分類された際に、人間が著したものと正確に識別しました.
Q: 投稿論文の著者を特定するマーカーの精度を判断するために、具体的にどのような基準が用いられたのか?
A: マーカーの正確性を決定するために使用された具体的な基準は、4段階のLikertスケールでの著者の特定でした.’Definitely AI’から’Definitely Human’までのスケールで、92.1%の作品が’Definitely Human’と分類された場合、それは人間によるものであると正確に特定されました.
Q: 学生とAI提出物の成績の違いについて、統計的有意水準(p値)はどのように計算されたのですか?
A: 差の統計的有意性レベル(p値)は、コクラン・アーミテージ検定を用いて計算されました.この検定により、AI投稿と学生投稿の間のパフォーマンスの違いに対して統計的な検定が行われ、p値が0.025となりました.
Q: 結果に影響を及ぼすような限界やバイアスはありましたか?
A: 研究には、前処理がAIの出力品質に与える影響に関する重要な方法論上の懸念がありました.前処理はAIが与えられたタスクを効果的に理解し実行するために重要な役割を果たしました.プロンプトエンジニアリング技術を用いることで、AIのパフォーマンスに顕著な改善が見られました.しかし、このアプローチはAIの固有能力から人間によるAIとの効率性に焦点を移すことを意味します.ユーザーの関与がAIのパフォーマンス向上にどのように影響するかを示す先行研究があり、これは分析にさらなる複雑さをもたらします.
Q: AIが生成した作業が大学生の作業の品質に密接に迫るが、人間の評価者によって検出可能であるという発見の含意について詳しく説明していただけますか?
A: AI生成された作業が大学生の作業の品質に密接に迫る一方、人間の評価者によって検出可能であるという結果の含意は、教育環境におけるAIの役割と評価方法に影響を与える可能性があります.これは、AI技術が教育分野においてますます重要な役割を果たす中で、人間とAIの協力が重要であることを示唆しています.AIが大学生の作業と同等の品質を持つことは、教育プロセスを向上させる可能性がある一方、人間の評価者がAI作業を検出できることは、教育の公正性と信頼性を確保するために重要です.
Q: この研究結果は、教育現場でのAI活用にどのような影響を与えると思いますか?
A: この研究の結果は、教育現場におけるAIの利用にどのような影響を与えるかを考える上で重要な示唆を提供する可能性があります.AIが教育プログラムに統合されることで、従来の教育方法や評価基準が再評価される可能性があります.AIの導入により、教育者はコーディング課題や教育戦略の目標を見直す必要があるかもしれません.AIの能力が向上し、人間のパフォーマンスを凌駕する可能性が高まる中、AIがより効果的なコーディングの指導者として従来の教育方法を超えることができるかどうかが探究されるでしょう.
Q: 調査の過程で、予想外の結果や意外な結果が出たことはありましたか?
A: 研究の過程で予期せぬまたは驚くべき結果はありませんでした.
Q: この研究結果を基に、今後どのような研究ができると思いますか?
A: この研究の結果を踏まえ、将来の研究では、AIが人間の物理コーディング課題に勝るようにするために、AIモデルの性能向上に焦点を当てることが重要です.特に、GPT-4のような新しいLLMの能力をさらに向上させるために、プロンプトエンジニアリングの役割を探求する研究が有益であると考えられます.また、AIが生成したプロットを人間が識別する能力を向上させるための方法についての研究も重要です.さらに、AIと人間の協力がAIのフルポテンシャルを引き出すためにどのように役立つかを探求する研究も必要です.
FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions
著者:Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, Luca Soldaini
発行日:2024年03月22日
最終更新日:2024年03月22日
URL:http://arxiv.org/pdf/2403.15246v1
カテゴリ:Information Retrieval, Computation and Language, Machine Learning
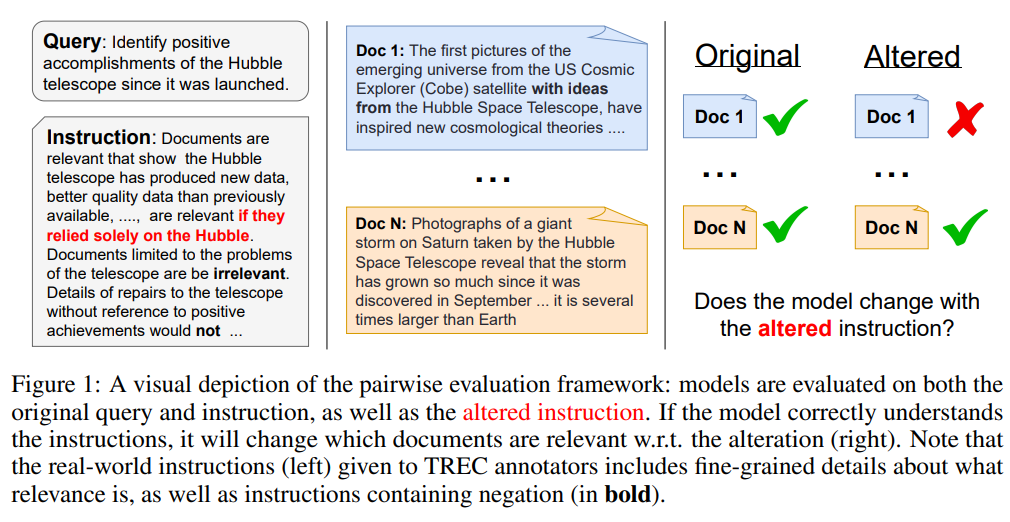
概要:
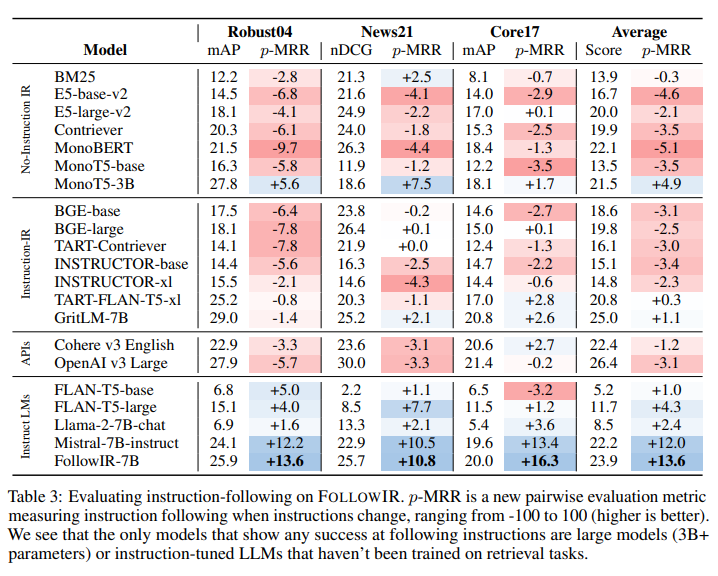
現代の大規模言語モデル(LLM)は、長く複雑な指示に従うことができ、多様なユーザータスクを可能にします.しかし、情報検索(IR)モデルは、ほとんどの場合、クエリのみを入力として受け取り、指示を受け取らないままLLMをバックボーンとして使用しています.最近のわずかなモデルが指示を受け取るようになったとしても、それがどのように使用されているかは不明です.私たちは、FollowIRというデータセットを紹介します.これには厳密な指示評価ベンチマークと、IRモデルが実世界の指示によりよく従うためのトレーニングセットが含まれています.FollowIRは、TRECカンファレンスの長い歴史に基づいて構築されています.TRECは、人間の注釈者に指示(ナラティブとも呼ばれる)を提供して文書の関連性を決定し、IRモデルもこれらの詳細な指示に基づいて理解し、関連性を判断できるべきです.私たちの評価ベンチマークは、3つの厳密に判断されたTRECコレクションから始まり、注釈者の指示を変更し、関連文書を再注釈します.このプロセスを通じて、IRモデルが指示にどれだけよく従うかを新しいペアワイズ評価フレームワークを通じて測定できます.私たちの結果は、IRモデルが指示にどれだけよく従うかを示しています.さらに、新しい文脈では、既存の検索モデルが指示を正しく使用せず、基本的なキーワードに使用し、長文情報を理解するのに苦労していることが明らかになりました.しかし、IRモデルが複雑な指示に従うことを学ぶことが可能であることを示しており、私たちの新しいFollowIR-7Bモデルは、トレーニングセットでの微調整後に13%以上の大幅な改善を達成しています.
Q&A:
Q: FollowIRデータセットは、情報検索モデルで使用される他のデータセットとどう違うのですか?
A: FollowIRデータセットは、他の情報検索モデルで使用されるデータセットと異なり、厳密な指示評価ベンチマークと実世界の指示に従うためのトレーニングセットを含んでいます.また、TREC会議の長い歴史に基づいており、人間の注釈者に指示を提供し、文書の関連性を決定するために使用されることが特徴です.
Q: FollowIR評価ベンチマークでアノテーターの指示を変更するプロセスを説明してもらえますか?
A: アノテーターの指示を変更するプロセスは、まずTRECの指示に基づいて文書の関連性を再評価します.その後、2人の専門家の人間のアノテーターによって指示が変更され、文書の関連性が再評価されます.このプロセスにより、IRモデルが指示にどの程度従うかを測定することができます.指示の微細な変更に対応することで、モデルの指示に従う能力を詳細に検証します.
Q: トレーニングセットでファインチューニングを行った後、FollowIR-7Bモデルは具体的にどのような改善を見せたのでしょうか?
A: フォローIR-7Bモデルは、トレーニングセットでの微調整後に13%以上の大幅な改善を示しました.
Q: 研究結果によると、既存の検索モデルは現在どのように指示を使用しているのだろうか?
A: 既存の検索モデルは、通常、非常に短い指示(10語未満)、繰り返し(データセットごとに1つの指示のみ)、および指示の遵守を明示的に測定する評価データセットが欠如している.指示に従う検索モデルは、TRECの指示を使用して文書の関連性を注釈付けできるように訓練されるべきであるという主要な考え方に基づいています.
Q: TREC会議をFollowIRデータセットの基盤として使用する意義は何ですか?
A: TRECカンファレンスをFollowIRデータセットの基盤として使用することの重要性は、IRモデルが実際の指示に従う能力を向上させるためのトレーニングセットを提供することです.TRECカンファレンスは、人間の注釈者に指示を提供して文書の関連性を決定するために使用されており、FollowIRデータセットはこの長い歴史に基づいて構築されています.このようにして、IRモデルは詳細な指示に基づいて関連性を理解し、決定できるようになります.
Q: この文章で言及されているように、IRモデルは長文情報の理解にどのように苦労しているのだろうか?
A: IRモデルは、長い文章を理解する際に苦労しています.具体的には、指示がキーワード検索に使用できない場合や、より長い指示の長さに慣れていない場合に問題が生じます.
Q: FollowIR評価ベンチマークで使用されている新しいペアワイズ評価フレームワークについて詳しく教えてください.
A: 新しいペアワイズ評価フレームワークは、異なる指示を持つ2つの文書に対して、ランク別スコア変化(p-MRRと呼ぶ)を測定することで、情報検索の評価を行うために開発されました.このフレームワークは、既存の情報検索モデルが指示に従うことが一般的に失敗することを示しており、これによりモデルが長い指示を使うことに慣れていないことや、指示をキーワード検索として使用していることが明らかになりました.
Q: 調査結果によると、IRモデルは現在、基本的なキーワードの指示をどのように使っているのだろうか?
A: IRモデルは、基本的なキーワードのために指示を使用しており、長い情報を理解するのに苦労していることが研究結果から明らかになっています.
Q: FollowIRのデータセットと評価ベンチマークを作成した動機は何ですか?
A: FOLLOW IRデータセットおよび評価ベンチマークの作成の動機は、TREC会議の歴史に基づいています.TRECは人間の注釈者に指示(ナラティブとしても知られる)を提供して文書の関連性を決定させるため、IRモデルもこれらの詳細な指示に基づいて関連性を理解し判断できるべきだと考えられたためです.既存の情報検索モデルが指示に従う能力を評価するための新しいベンチマークが必要であるという認識から、FOLLOW IRデータセットと評価ベンチマークが作成されました.
Q: FollowIRトレーニングセットを通して、IRモデルはどのように実世界の指示に従うことを学習するのか?
A: IRモデルは、FOLLOW IRトレーニングセットを介して、実世界の命令によりよく従う方法を学びます.このトレーニングセットは、TREC会議の長い歴史に基づいており、人間の注釈者に命令(narrativesとしても知られる)を提供して、文書の関連性を決定します.IRモデルは、これらの詳細な命令に基づいて理解し、関連性を判断することができるようになります.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: 新しい手法のコード実装のurlは、https://github.com/orionw/FollowIR です.
LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement
著者:Nicholas Lee, Thanakul Wattanawong, Sehoon Kim, Karttikeya Mangalam, Sheng Shen, Gopala Anumanchipali, Michael W. Mahoney, Kurt Keutzer, Amir Gholami
発行日:2024年03月22日
最終更新日:2024年03月22日
URL:http://arxiv.org/pdf/2403.15042v1
カテゴリ:Computation and Language
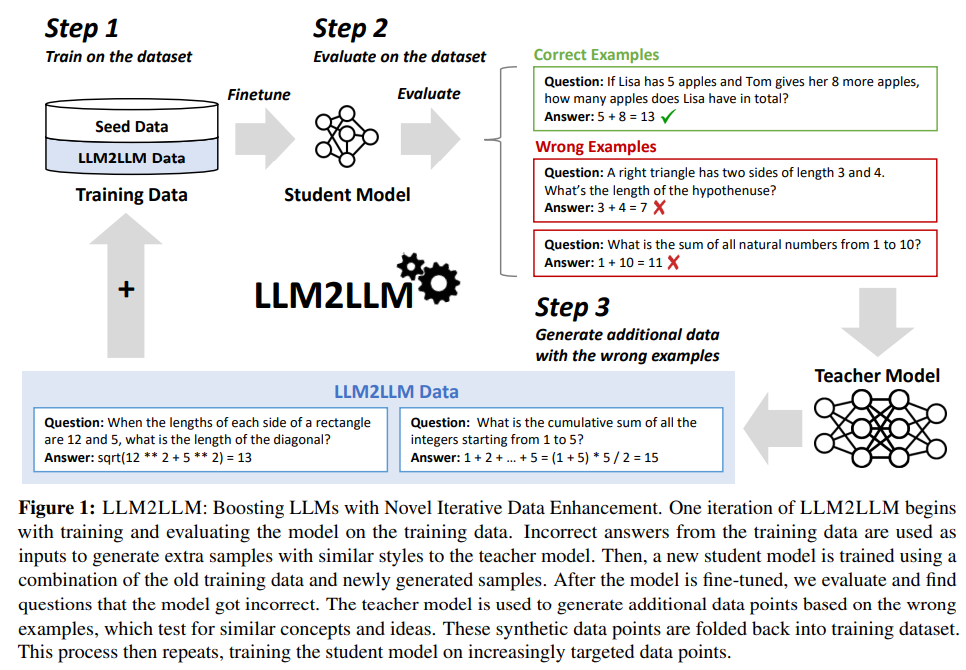

概要:
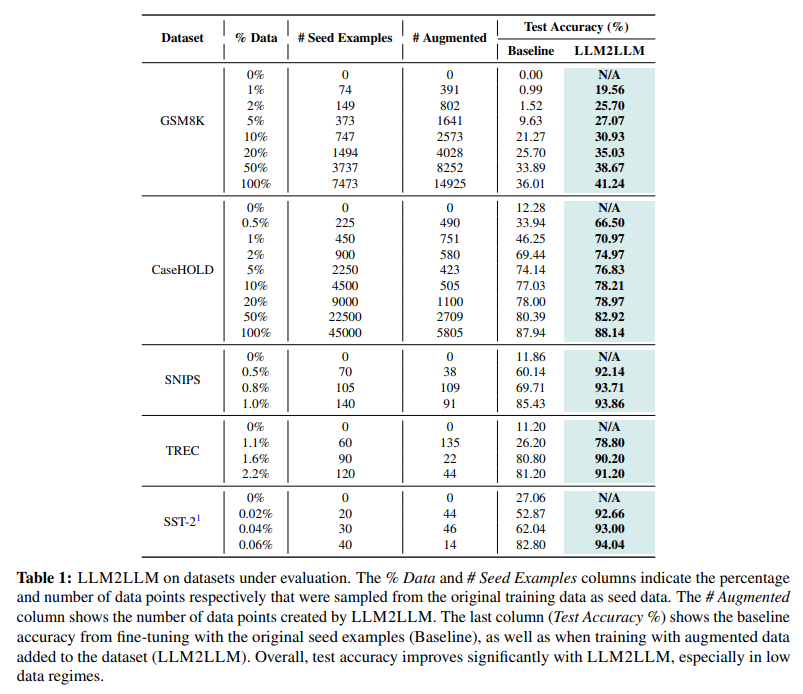
プリトレーニングされた大規模言語モデル(LLM)は現在、自然言語処理タスクのほとんどを解決するための最先端技術です.多くの実世界のアプリケーションは、依然として十分なパフォーマンスを達成するために微調整が必要ですが、その多くは低データ領域にあり、微調整が困難です.この問題に対処するために、特定のタスクにおいて微調整に使用できる追加データを増やすために、教師LLMを使用したターゲテッドかつ反復的なデータ拡張戦略であるLLM2LLMを提案しています.LLM2LLMは、(1)初期のシードデータに基づいてベースラインの学習者LLMを微調整し、(2)モデルが間違えたデータポイントを評価および抽出し、(3)これらの誤ったデータポイントに基づいて教師LLMを使用して合成データを生成し、それらをトレーニングデータに追加します.このアプローチは、トレーニング中にLLMによって不正確に予測されたデータポイントからの信号を増幅し、より難しい例に焦点を当てるためにそれらをデータセットに再統合します.私たちの結果は、LLM2LLMが低データ領域でのLLMのパフォーマンスを著しく向上させ、従来の微調整や他の手法を凌駕していることを示しています.LLM2LLMは、労働集約型のデータキュレーションへの依存を減らし、よりスケーラブルで高性能なLLMソリューションの道を開き、データ制約のある領域やタスクに取り組むことを可能にします.私たちは、LLaMA2-7B学習者モデルを使用して、GSM8Kデータセットで最大24.2%、CaseHOLDで32.6%、SNIPSで32.0%、TRECで52.6%、SST-2で39.8%の改善を実現し、低データ領域での通常の微調整に比べてLLM2LLMが優れていることを示しています.
Q&A:
Q: LLM2LLMのアイデアはどのようにして生まれたのですか?
A: LLM2LLMのアイデアは、小さなタスク固有のデータセットを効率的かつ効果的に拡張するための、ターゲット指向かつ反復的なLLMベースのデータ拡張技術を提案したことに由来します.LLM2LLMは、(1)初期データセットで学習した学習者LLMを微調整し、(2)トレーニングデータで評価し、モデルが誤ったデータポイントを抽出することによってこれを達成しています.
Q: 最初のシードデータからベースラインの学生LLMを微調整するプロセスを説明してもらえますか?
A: ベースラインの学生LLMを初期シードデータでファインチューニングするプロセスは、まず、シードデータと以前に生成されたLLM2LLMデータを使用して小さな学生モデルをトレーニングします.このLLM2LLMデータは、モデルが誤ったデータポイントを対象とした合成データを生成するプロセスによって生成されます.次に、元の学生モデルを常に全データセット(シードデータ+LLM2LLMデータ)でファインチューニングします.このステップでは、元のベースラインモデルをゼロから再度ファインチューニングするか、既にファインチューニングされたモデルを再利用するかを比較します.その結果、ゼロから再度ファインチューニングしたモデルの方が常に優れた性能を発揮することが示されました.
Q: LLM2LLMは、モデルが間違ったデータポイントをどのように評価し、抽出するのですか?
A: LLM2LLMは、まずベースラインの学習モデルMstudentを提供されたターゲットデータD0で訓練し、その性能を評価します.その後、学習モデルが正しく回答できなかった誤った訓練例をフィルタリングし、それらを保持します.次に、教師モデルは、概念的に整合しているが意味的に異なる追加の訓練データポイントを作成するように促されます.これにより、LLM2LLMは、訓練中にLLMが誤って予測したデータポイントから合成データを生成し、それらをデータセットに再統合することで、より難しい例に焦点を当てることができます.
Q: 教師であるLLMは、誤ったデータポイントに基づいて合成データを生成する際にどのような役割を果たすのでしょうか?
A: 教師LLMは、誤ったデータポイントに基づいて合成データを生成する際に重要な役割を果たします.これにより、学習中にLLMによって誤って予測されたデータポイントからの信号が増幅され、より難しい例に焦点を当てるためにデータセットに再統合されます.
Q: LLM2LLMはどのようにして、トレーニング中に誤って予測されたデータポイントからの信号を増幅するのでしょうか?
A: LLM2LLMは、誤って予測されたデータポイントから合成データを生成し、それらをトレーニングデータに再統合することで、誤って予測されたデータポイントからの信号を増幅します.これにより、LLMがトレーニング中に誤って予測したデータポイントからの信号が強調され、より難しい例に焦点を当てることができます.
Q: LLM2LLMが従来のファインチューニングや他のデータ増強ベースラインをどのように上回るのか、詳細を教えてください.
A: LLM2LLMは、従来のファインチューニングや他のデータ拡張のベースラインを上回る方法として、ターゲット指向かつ反復的なデータ拡張フレームワークを導入しています.LLM2LLMは、教師LLMを使用してトレーニングデータセットを拡張する新しいターゲット指向かつ反復的なアプローチを取っており、これにより、タスク固有の小さなデータセットを効率的かつ効果的に拡張することが可能です.具体的には、学習データセットを拡張するために生徒LLMをファインチューニングし、それを教師LLMによって拡張することで、従来のファインチューニングや他のデータ拡張手法を上回る性能を実現しています.
Q: LLM2LLMは具体的にどのような方法で、労働集約的なデータキュレーションへの依存を軽減するのでしょうか?
A: LLM2LLMは、労働集約的なデータキュレーションへの依存を減らすために、ターゲットを絞ったデータ拡張手法を提案しています.この手法は、初期データセット上で学習した学習モデルを微調整し、そのモデルが誤って予測したデータポイントを抽出することによって、小規模なタスク固有のデータセットを効率的かつ効果的に拡張します.
Q: LLM2LLMは、よりスケーラブルでパフォーマンスの高いLLMソリューションへの道をどのように切り開くのか?
A: LLM2LLMは、労働集約的なデータのキュレーションに依存せず、よりスケーラブルで高性能なLLMソリューションの道を開拓します.これにより、データ制約のある領域やタスクに取り組むことが可能となります.
Q: LLM2LLMを使用して、GSM8K、CaseHOLD、SNIPS、TREC、SST-2データセットで達成された主な改善点は?
A: GSM8K、CaseHOLD、SNIPS、TREC、およびSST-2データセットにおいて、LLM2LLMを使用することで得られた主な改善点は、GSM8Kでは24.2%、CaseHOLDでは32.6%、SNIPSでは32.0%、TRECでは52.6%、SST-2では39.8%の向上が観測されました.
Q: LLaMA2-7Bの学生モデルの使用は、低データ領域でのLLM2LLMの成功にどのように貢献しているのか?
A: LLaMA2-7Bの学生モデルは、LLM2LLMの成功に貢献する.このモデルは、低データ領域での性能向上において、従来のファインチューニングや他のデータ拡張手法を凌駕することができる.LLaMA2-7B学生モデルを使用することで、データ収集に労力を要する作業の依存度を減らし、よりスケーラブルで高性能なLLMソリューションを実現する.このモデルは、データ点からの信号を強化することができるため、LLMが誤ったデータ点からの情報を向上させることができる.その結果、GSM8Kデータセットで24.2%、CaseHOLDで32.6%、SNIPSで32.9%、TRECで57.6%、SST-2で39.8%の改善を達成することができた.
Agent Lumos: Unified and Modular Training for Open-Source Language Agents
著者:Da Yin, Faeze Brahman, Abhilasha Ravichander, Khyathi Chandu, Kai-Wei Chang, Yejin Choi, Bill Yuchen Lin
発行日:2023年11月09日
最終更新日:2024年03月13日
URL:http://arxiv.org/pdf/2311.05657v2
カテゴリ:Artificial Intelligence, Computation and Language, Machine Learning

概要:
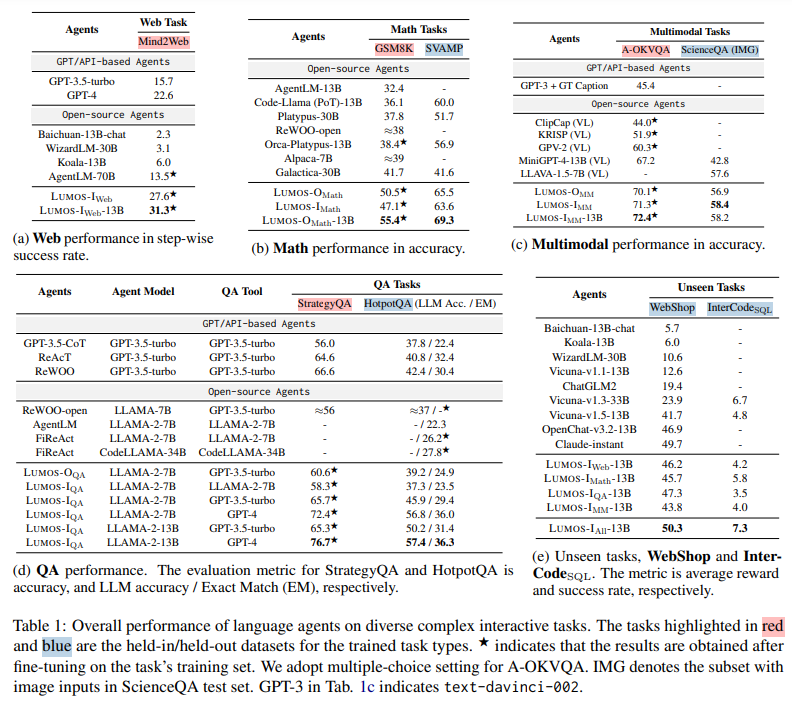
クローズドソースのエージェントは、複雑なインタラクティブなタスクにおいて、手頃な価格性、透明性、再現性の欠如などの問題に直面しています.これがオープンソースの代替手段の開発を促しています.私たちは、オープンソースのLLMベースのエージェントをトレーニングするための最初のフレームワークの1つであるLUMOSを紹介します.LUMOSは、学習可能な、統一された、モジュラーなアーキテクチャを特徴とし、高レベルのサブゴール生成を学習するプランニングモジュールと、これらを実行モジュール内のさまざまなツールを使用してアクションに変換するためにトレーニングされたグラウンディングモジュールを備えています.この設計により、モジュラーなアップグレードとさまざまなインタラクティブなタスクへの広範な適用が可能となります.一般化可能なエージェント学習を促進するために、さまざまな複雑なインタラクティブなタスクにわたる多様な真の推論根拠から派生した大規模で統一された高品質のトレーニングアノテーションを収集しています.LUMOSは、9つのデータセットでいくつかの主要な利点を示しています:(1)LUMOSは、各タスクタイプについてトレーニングに使用されていない保持されたデータセットで、複数の大規模なオープンソースのエージェントを凌駕しています.LUMOSは、QAやWebタスクにおいてさえ、GPTエージェントを上回っています;(2)LUMOSは、チェーンオブソウツや非モジュラ化された統合トレーニングによって生産されたオープンソースのエージェントを凌駕しています;そして(3)LUMOSは、33Bスケールのエージェントや特定のドメインエージェントを上回り、未知のタスクに効果的に一般化します.
Q&A:
Q: クローズドソースのエージェントが直面している具体的な問題と、LUMOSのようなオープンソースの代替エージェントがどのようにこれらの問題に対処しているのかを説明していただけますか?
A: 閉鎖されたソースエージェントは、手頃な価格性、透明性、再現性の欠如などの問題に直面しています.これは、複雑な対話タスクに特に当てはまります.これに対して、LUMOSのようなオープンソースの代替手段は、これらの問題に対処するために開発されています.LUMOSは、学習可能な、統一された、モジュラーなアーキテクチャを特徴とし、高レベルのサブゴール生成を学習するプランニングモジュールと、グラウンディングモジュールを備えています.
Q: LUMOSのモジュラー・アーキテクチャーは、オープンソース・エージェントのトレーニングにどのように有効なのでしょうか?
A: LUMOSのモジュラーアーキテクチャは、タスクをサブゴールに分解し、それらを具体的なアクションに変換し、それらのアクションを実行するという一般的な解決策を提供することによって、オープンソースエージェントの効果的なトレーニングに貢献しています.
Q: LUMOSのプランニングモジュールと、高レベルのサブゴール生成をどのように学習するかについて詳しく教えてください.
A: LUMOSの計画モジュールは、複雑なタスクを高レベルのサブゴールのシーケンスに分解するために設計されています.このモジュールは、自然言語で表現された高レベルのサブゴールを生成するために訓練され、新しいタスク計画を容易に学習し、他のモジュールに影響を与えることなく、タスクを解釈可能でツールに依存しない方法で低レベルのアクションに分解するのを支援します.
Q: LUMOSのグラウンディング・モジュールは、ハイレベルのサブゴールをどのようにアクションに変換するのか、また、実行モジュールではどのようなツールが使用されるのか.
A: LUMOSのグラウンディングモジュールは、計画モジュールによって生成された高レベルのサブゴールを低レベルの実行可能なアクションに変換します.例えば、GMは、サブゴール「Lowell Shermanの生涯をクエリする」を、KnowledgeQuery(Lowell Sherman)やQA([R2], Query:「Lowell Shermanの生涯は何ですか?」)などの1つ以上のアクションに変換します.GMは、新しいアクションを学習するために簡単にカスタマイズできます.実行モジュールでは、グラウンディングモジュールによって生成されたアクションを実装し、実行結果を取得します.API、ニューラルモデル、仮想シミュレータなど、さまざまなツールが展開されます.例えば、実行モジュールは、KnowledgeQueryアクションを達成するためにWikipediaやGoogle検索APIを呼び出すことができます.
Q: LUMOSのために収集されたトレーニングアノテーションが大規模で統一され、高品質であることを保証するために、どのような措置が取られたのですか?
A: 訓練アノテーションが大規模で統一され、高品質であることを確保するために取られた手順には、既存のベンチマークの正当な根拠を活用し、強力なLLMの支援を受けてアノテーションを統一形式に変換することが含まれます.この変換は、モジュラー設計に一貫した普遍的に適用可能な形式であることを確認するために行われます.提案されたアノテーション変換方法により、約56,000のマルチタスクマルチドメインエージェントトレーニングアノテーションが生成され、エージェントの微調整に最適なオープンソースリソースの1つとなります.
Q: LUMOSが他のオープンソースのエージェントを、さまざまな種類のタスクでどのように凌駕しているか、例を挙げていただけますか?
A: LUMOSは、WebやQAタスクにおいて、GPTベースのエージェントを上回ることができます.具体的には、Mind2WebではGPT-4に対して5.0%の向上を示し、HotpotQAではReActおよびReWOOエージェントに対してGPT-3.5-turboに完全に基づいて4.1%および3.5%のLLM精度向上を示します.
Q: LUMOSは、思考の連鎖やモジュール化されていない統合トレーニングによって生み出されたエージェントと比べて、どのような点で優れているのでしょうか?
A: LUMOSは、chain-of-thoughtおよびunmodularized integrated trainingによって生成されたエージェントに比べて、複数の大規模なオープンエージェントを上回ります.
Q: LUMOSは、33Bスケール・エージェントやドメイン固有エージェントを凌駕する、未知のタスクへの効果的な汎化をどのように示しているのだろうか?
A: LUMOSは、未知のタスクに対して効果的な汎化を示し、33Bスケールのエージェントやドメイン固有のエージェントを上回っています.具体的には、WebShopでは30Bスケールのエージェントをほぼ20ポイント上回りました.また、LUMOSはドメイン固有のエージェントに比べて一貫した報酬改善を提供しています.これは、LUMOSがタスク間で汎化できることを示し、幅広い言語エージェントアプリケーションに潜在的な利点があることを示唆しています.
Q: LUMOSの性能と多様なインタラクティブ・タスクへの適用性をさらに向上させるために、将来可能性のあるアップグレードや開発にはどのようなものがありますか?
A: LUMOSの将来のアップグレードや開発の可能性には、トレーニングデータの多様化、新しいタスクタイプのアノテーションの組み込み、複数の異なるトレーニングタスクタイプからの統合アノテーションを活用した統一トレーニング、複雑な対話型タスク間の内在的なリンクを発見するための統一タスク表現の活用などが挙げられます.これらのアップグレードや開発により、LUMOSのパフォーマンスと様々な対話型タスクへの適用性がさらに向上する可能性があります.
