
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をLLMによって生成されるQ&Aを用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.自動生成記事のクオリティと信頼性を向上させるためにアルゴリズムの改善に取り組んでいます.個人で資料のQ&Aを作成されたい方には、https://www.chatpdf.com/ や https://scispace.com/などがお勧めです.
紹介する論文は以下の10本となります.
- TacticAI: an AI assistant for football tactics
発行日:2024年03月19日
TacticAIは、リバプールFCの専門家と協力して開発されたAIサッカータクティクスアシスタントであり、コーナーキックの分析に焦点を当て、効果的な戦術を提供しています. - Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models
発行日:2024年03月19日
Agent-FLANは、LLMsをエージェント向けにファインチューニングし、従来の最高成績を上回り、幻覚問題を緩和し、常に最高のパフォーマンスを発揮します. - DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
発行日:2024年03月19日
DROIDは、多様な環境で収集された高品質なロボット操作データセットで、性能と汎化能力を向上させるための重要な一歩を示しています. - Evolutionary Optimization of Model Merging Recipes
発行日:2024年03月19日
私たちのアプローチによって生成されたモデルは、日本の文化固有のコンテンツを記述する際に効果を示し、従来の日本語VLMを上回っています. - RankPrompt: Step-by-Step Comparisons Make Language Models Better Reasoners
発行日:2024年03月19日
RankPromptは、LLMsの推論パフォーマンスを向上させ、人間の判断と一致率が高い自己ランク付け方法であり、一貫性や堅牢性を示し、高品質なフィードバックを引き出す効果的な手法である. - What Are Tools Anyway? A Survey from the Language Model Perspective
発行日:2024年03月18日
LMのツール化に関する研究では、統一された定義を提供し、効率的な方法を検証して、将来の研究の可能性を探る. - Open Release of Grok-1
発行日:2024年03月17日
2024年3月28日12:20、x.aiは3140億パラメータのMixture-of-Expertsモデルの重みとアーキテクチャを公開しました. - RAFT: Adapting Language Model to Domain Specific RAG
発行日:2024年03月15日
大規模な言語モデル(LLM)を事前トレーニングし、追加の知識を取り込むためにRetrieval Augmented FineTuning(RAFT)を使用することで、モデルのパフォーマンスが向上し、オープンブックのドメイン内での質問に答える能力が強化される. - Logits of API-Protected LLMs Leak Proprietary Information
発行日:2024年03月14日
LLMの商業化により、APIを通じて非公開情報を学習可能であり、ソフトマックスボトルネックにより様々な機能が解除される可能性がある. - LLM4Decompile: Decompiling Binary Code with Large Language Models
発行日:2024年03月08日
デコンパイルLLMのリリースとDecompile-Evalデータセットの導入により、C言語のソースコードをアセンブリコードに正確に変換する能力が向上しました.
TacticAI: an AI assistant for football tactics
著者:Daniel Hennes, Petar Veličković, Zhe Wang, et al.
発行日:2024年03月19日
最終更新日:不明
URL:https://www.nature.com/articles/s41467-024-45965-x
カテゴリ:不明
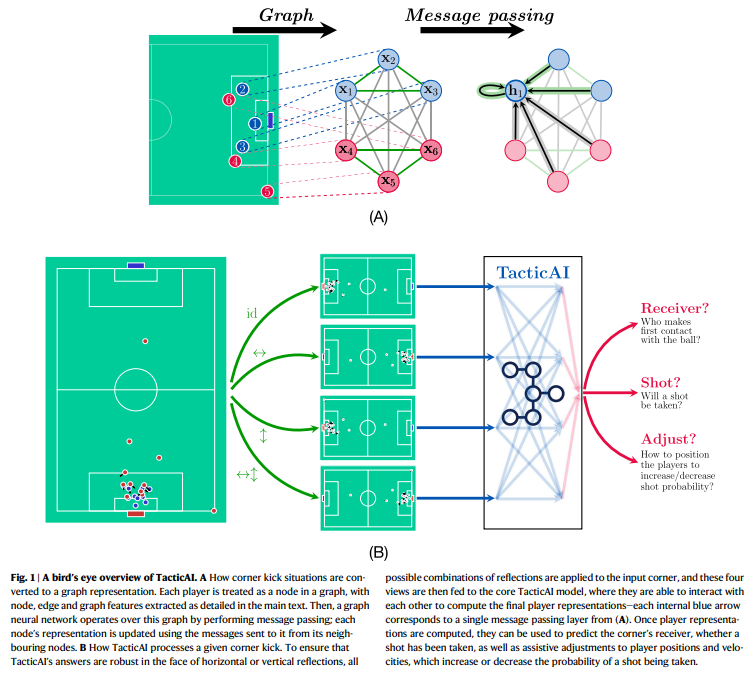
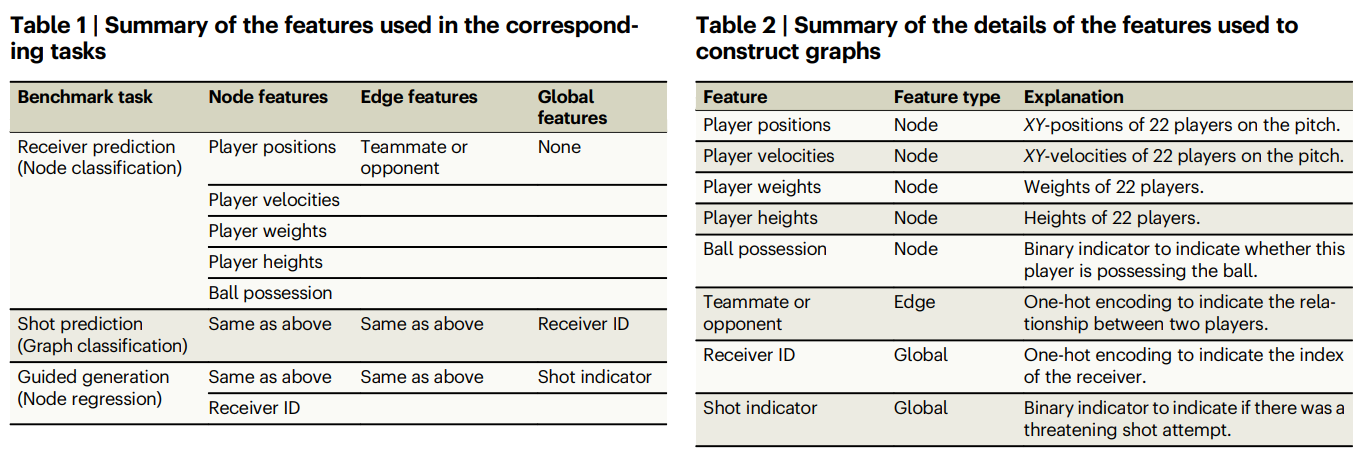
概要:
現代のサッカーにおいて、ライバルチームが実施する戦術の主要なパターンを特定し、効果的な対応を開発することが重要です.しかし、これをアルゴリズム的に行うことは未解決の研究課題です.この未解決のニーズに対処するために、私たちはTacticAIというAIサッカータクティクスアシスタントを提案し、開発しました.このシステムは、リバプールFCの専門家との緊密な協力のもとで開発・評価されています.コーナーキックの分析に焦点を当てており、コーチにとって介入や改善の最も直接的な機会を提供します.TacticAIには予測と生成の両方のコンポーネントが組み込まれており、コーチは各コーナーキックのルーチンに対して代替の選手配置を効果的にサンプリングし、探索することができ、成功の可能性が最も高いと予測されるものを選択することができます.TacticAIは、受信者やシュートの試行の予測、選手の位置調整の推奨など、いくつかの関連するベンチマークタスクで検証されています.また、リバプールFCのサッカー専門家による質的研究によって、TacticAIの有用性が検証されています.TacticAIのモデル提案が実際の戦術と区別がつかないだけでなく、既存の戦術よりも好まれていることが示されています.さらに、TacticAIは限られたゴールドスタンダードデータの利用可能性にもかかわらず、90%の確率で実際の戦術と区別がつかないだけでなく、既存の戦術よりも好まれていることが示されています.TacticAIは、幾何学的深層学習を通じてデータ効率性を実現し、効果的なコーナーキック回収システムを提供しています.
Q&A:
Q: TacticAIの開発において、リバプールFCのドメインエキスパートとはどのように協力したのですか?
A: リバプールFCの専門家と協力して、TacticAIの開発を行いました.具体的には、3人のデータサイエンティスト、1人のビデオアナリスト、1人のコーチングアシスタントのグループを招待し、ケーススタディを通じてTacticAIのコンポーネントを複数の視点から評価しました.彼らはケーススタディで4つのタスクを完了し、TacticAIの生成された調整のリアリティ、TacticAIのレシーバー予測の妥当性、TacticAIの埋め込みの効果、そしてリアルなコーナーの取得におけるTacticAIの有用性を評価しました.
Q: TacticAIの予測コンポーネントと生成コンポーネントについて説明していただけますか?
A: TacticAIは、受信者の予測、シュートの予測、そして戦術の推奨を通じたガイド付き生成の3つの異なる予測的および生成的コンポーネントで設計されています.これらのコンポーネントは、TacticAIを定量的に評価するためのベンチマークタスクにも対応しており、コーナーキック分析における正確な定量的な洞察を提供するだけでなく、予測的および生成的コンポーネントの相互作用により、コーチは興味のある各ルーチンの代替プレーヤーセットアップをサンプリングし、そのような代替の可能な結果を直接評価することができます.
Q: レシーブやシュートの予測について、TacticAIをどのように検証しましたか?
A: TacticAIの受信者とシュート試行を予測する方法を検証するために、評価データセットを使用して定量的評価を行いました.また、TacticAIの受信者予測コンポーネントのパフォーマンスを人間の評価者とのケーススタディで評価しました.
Q: リバプールFCのフットボール・ドメインの専門家を対象に実施した定性調査の結果は?
A: リバプールFCの専門家らによる質的研究の結果は、TacticAIの提案された調整の現実性、TacticAIの受信者予測の妥当性、TacticAIの埋め込みの効果的な類似コーナーの取得能力、およびTacticAIのコンポーネントの有用性が評価された.専門家らはこれらの観点からTacticAIを評価し、その有用性を検証した.
Q: TacticAIは既存の戦術と比較して好感度はどうだったのか?
A: TacticAIの提案は、90%の場合に人間の評価者に好意的であり、平均的に有益であることが示されました.
Q: TacticAIがどのように効果的なコーナーキック検索システムを提供しているのか説明していただけますか?
A: TacticAIは、効果的なコーナーキックの回収システムを提供しています.このシステムは、予測的な側面と生成的な側面の両方を組み合わせており、コーチが各コーナーキックの状況に対して代替の選手配置をサンプリングし、探索することができます.そして、成功の可能性が最も高いと予測される選手配置を選択することができます.また、TacticAIは、限られたゴールド標準データの入手可能性にもかかわらず、データ効率性を達成しています.これは、幾何学的深層学習を通じて行われています.
Q: TacticAIはどのようにして幾何学的ディープラーニングによるデータ効率化を実現したのか?
A: TacticAIは、幾何学的深層学習を通じてデータ効率を実現しました.この方法では、プレーヤーの表現が反射に対して同一に計算されるため、この対称性はデータから学習する必要がありません.高品質なトラッキングデータが限られている中で、年間リーグごとに数百試合しか行われていない状況でも、TacticAIは効果的に機能します.
Q: TacticAIは、コーチがコーナーキックルーチンのための代替プレーヤーのセットアップをサンプリングし、検討するのをどのように支援するのですか?
A: TacticAIは、コーナーキックのルーチンにおける代替プレーヤーセットアップを効果的にサンプリングおよび探索するための予測的および生成的コンポーネントを組み込んでいます.コーチは、成功の可能性が最も高いと予測されるプレーヤーセットアップを選択することができます.
Q: 入手可能なゴールドスタンダードデータが限られていることによるTacticAIの限界について説明していただけますか?
A: TacticAIの限られたゴールドスタンダードデータの利用可能性の制限は、モデルの汎用性と信頼性に影響を与える可能性があります.限られたデータセットからの学習は、モデルの汎用性を制限し、新しい状況やパターンに対する適応性を制限する可能性があります.また、ゴールドスタンダードデータの不足は、モデルの精度や予測の信頼性に影響を与える可能性があります.さらに、限られたデータセットからの学習は、過学習のリスクを増加させ、未知のデータに対する汎化能力を低下させる可能性があります.
Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models
著者:Zehui Chen, Kuikun Liu, Qiuchen Wang, Wenwei Zhang, Jiangning Liu, Dahua Lin, Kai Chen, Feng Zhao
発行日:2024年03月19日
最終更新日:2024年03月19日
URL:http://arxiv.org/pdf/2403.12881v1
カテゴリ:Computation and Language
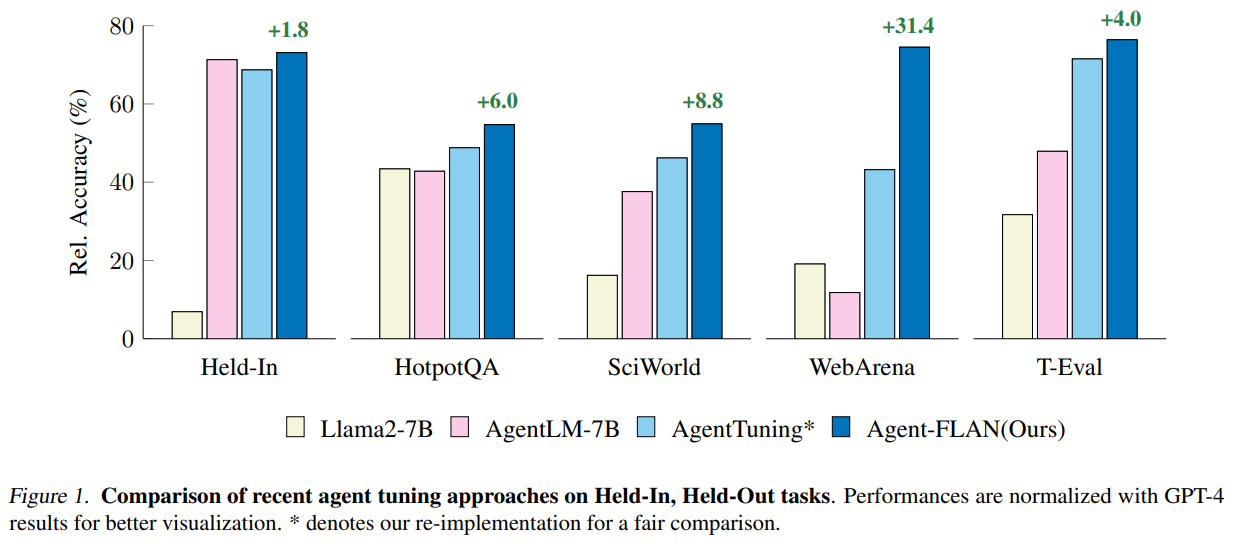
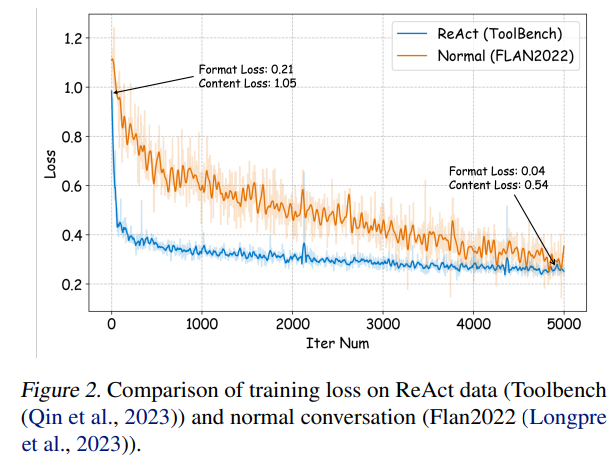
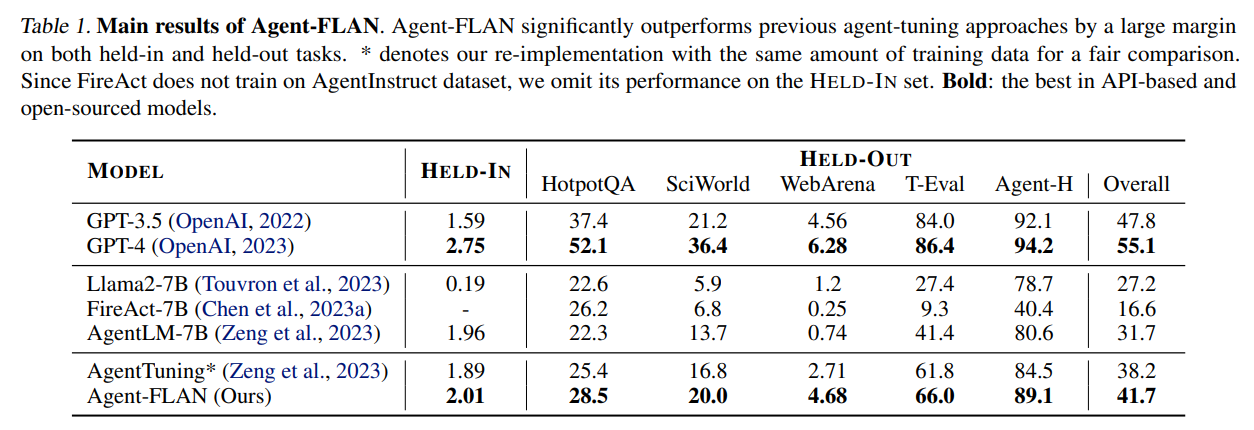
概要:
オープンソースの大規模言語モデル(LLMs)は、さまざまなNLPタスクで大きな成功を収めていますが、エージェントとして機能する際には、APIベースのモデルにはまだ大きく劣っています.一般的なLLMsにエージェント能力を統合する方法は、重要で緊急な問題となっています.この論文では、まず、以下の3つの重要な観察結果を示しています.まず、現在のエージェントトレーニングコーパスは、フォーマットの後に続くものとエージェントの推論が絡み合っており、これは事前トレーニングデータの分布から大きく逸脱しています.次に、LLMsは、エージェントタスクで必要とされる能力に対して異なる学習速度を示しています.そして、現在のアプローチは、幻覚を導入することでエージェント能力を向上させる際に副作用を引き起こしています.これらの発見に基づいて、我々はAgent-FLANを提案しています.これは、LANguageモデルをエージェント向けに効果的にファインチューニングするものです.トレーニングコーパスの注意深い分解と再設計により、Agent-FLANは、Llama2-7Bをさまざまなエージェント評価データセットで従来の最高成績を3.5%上回るようにすることができます.確立された評価基準に基づいて、Agent-FLANは幻覚問題を大幅に緩和するために包括的に構築された負のサンプルを提供します.さらに、Agent-FLANは、常に最高のパフォーマンスを発揮します.また、モデルサイズを拡大する際にLLMsの一般的な能力をわずかに向上させつつ、Agent-FLANはLLMsのエージェント能力を一貫して向上させます.コードはhttps://github.com/InternLM/Agent-FLANで入手可能です.
Q&A:
Q: 大規模言語モデル(LLM)がエージェントとして機能する際に、APIベースのモデルと比較して直面する具体的な課題について説明していただけますか?
A: 大規模言語モデル(LLMs)がエージェントとして機能する際に直面する特定の課題は、APIベースのモデルと比較して、エージェントタスクに必要な能力を獲得する速度が異なることです.LLMsは、エージェントタスクで必要とされる能力に対して異なる学習速度を示すことが観察されています.また、エージェントのトレーニングデータは、フォーマットのフォローとエージェントの推論の両方と絡み合っており、これは事前トレーニングデータの分布と大きく異なることが問題となっています.
Q: 現在のエージェント訓練コーパスとエージェント推論フォーマットは、LLMの事前訓練データの分布とどのように違うのでしょうか?
A: 現在のエージェントトレーニングコーパスとエージェントの推論形式は、事前トレーニングデータの分布と大きく異なることが観察されました.
Q: エージェントのタスクに必要な能力について、LLMが示す学習速度の違いとは?
A: LLMは、エージェントタスクに必要な能力に対して異なる学習速度を示します.具体的には、回収と理解は推論よりも比較的容易なタスクとして現れ、その後に続く指示が学習プロセスで最も簡単です.
Q: エージェント能力を向上させるための現在のアプローチは、どのように幻覚をもたらすのか、またその副作用は?
A: 現在のアプローチでは、エージェントの能力向上を図る際に、エージェントのデータと一般的なデータを同時にモデルに提供することで、性能向上をもたらすが、幻覚の問題には限定的な影響しか与えないことが観察されています.これは、最近のエージェント研究でしばしば見落とされる重要な懸念であり、実際のアプリケーションで言語モデルを展開する際に特に重要です.幻覚は、モデルがトレーニングフォーマットに厳密に従い、ユーザー生成のクエリを無視することや、誘発された質問に対して存在しない機能をトリガーされることなど、2つの主要な側面で現れます.したがって、エージェントの調整メカニズムをさらに洗練させることと、エージェントの幻覚問題を解決することにさらなる注意を向ける必要があります.
Q: Agent-FLANメソッドの概要と、エージェント用の言語モデルを効果的に微調整する方法について教えてください.
A: Agent-FLANは、大規模言語モデルをエージェント向けに効果的に微調整する方法です.この手法は、トレーニングコーパスの注意深い分解と再設計を通じて、LLM(Large Language Models)をエージェント評価データセット全体で3.5%上回る性能を発揮させることができます.
Q: Agent-FLANによって、Llama2-7Bは、さまざまなエージェント評価データセットにおいて、先行する最高傑作を3.5%も上回ることができました.
A: Agent-FLANは、Llama2-7Bをさまざまなエージェント評価データセット全体で従来の最高の作品を3.5%上回るようにすることができます.これは、包括的に構築された負のサンプルに基づいて幻覚問題を大幅に軽減し、確立された評価基準に基づいています.さらに、モデルサイズをスケーリングする際にエージェントの能力を継続的に向上させ、LLMの一般的な能力をわずかに向上させます.
Q: Agent-FLANは、包括的に構築されたネガティブサンプルによる幻覚の問題にどのように対処しているのか?
A: Agent-FLANは包括的に構築されたネガティブサンプルを使用して、幻覚問題に取り組んでいます.これにより、エージェントの能力を向上させるだけでなく、LLMの一般的な能力もわずかに向上させることができます.
Q: Agent-FLANは、LLMの一般的な能力をわずかに向上させながら、モデルサイズを拡大する際に、どのような点でLLMのエージェント能力を向上させるのでしょうか?
A: Agent-FLANは、モデルサイズをスケーリングする際に、LLMのエージェント能力を向上させる方法として、エージェントのトレーニングコーパスを慎重に分解および再設計し、エージェントタスクで必要とされる能力に対するLLMの異なる学習速度を示し、幻覚を導入することでエージェント能力を向上させる際の副作用を持つ既存のアプローチを改善します.これにより、Agent-FLANは、モデルサイズをスケーリングする際に、LLMのエージェント能力を向上させるだけでなく、一般的な能力もわずかに向上させます.
Q: Agent-FLANのコードがGitHubで入手可能かどうか、詳細を教えてください.
A: Agent-FLANのコードはhttps://github.com/InternLM/Agent-FLANで利用可能です.
Q: NLPやエージェントベースのタスクの分野において、Agent-FLANの将来的な意味をどのようにお考えですか?
A: Agent-FLANは、NLPおよびエージェントベースのタスクにおいて、特に重要な役割を果たす可能性があります.Agent-FLANは、訓練データの慎重な分解と再設計により、エージェント評価データセット全体で従来の最高の成果を3.5%上回ることができるため、エージェントの能力向上に大きく貢献します.また、Agent-FLANは、幻覚問題を大幅に軽減し、モデルサイズを拡大する際にモデルの一般的な能力をわずかに向上させることができます.これにより、Agent-FLANは、専門的かつ汎用的な言語モデルの間のギャップを埋めることができる可能性があります.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
著者:Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, Peter David Fagan, Joey Hejna, Masha Itkina, Marion Lepert, Yecheng Jason Ma, Patrick Tree Miller, Jimmy Wu, Suneel Belkhale, Shivin Dass, Huy Ha, Arhan Jain, Abraham Lee, Youngwoon Lee, Marius Memmel, Sungjae Park, Ilija Radosavovic, Kaiyuan Wang, Albert Zhan, Kevin Black, Cheng Chi, Kyle Beltran Hatch, Shan Lin, Jingpei Lu, Jean Mercat, Abdul Rehman, Pannag R Sanketi, Archit Sharma, Cody Simpson, Quan Vuong, Homer Rich Walke, Blake Wulfe, Ted Xiao, Jonathan Heewon Yang, Arefeh Yavary, Tony Z. Zhao, Christopher Agia, Rohan Baijal, Mateo Guaman Castro, Daphne Chen, Qiuyu Chen, Trinity Chung, Jaimyn Drake, Ethan Paul Foster, Jensen Gao, David Antonio Herrera, Minho Heo, Kyle Hsu, Jiaheng Hu, Donovon Jackson, Charlotte Le, Yunshuang Li, Kevin Lin, Roy Lin, Zehan Ma, Abhiram Maddukuri, Suvir Mirchandani, Daniel Morton, Tony Nguyen, Abigail O’Neill, Rosario Scalise, Derick Seale, Victor Son, Stephen Tian, Emi Tran, Andrew E. Wang, Yilin Wu, Annie Xie, Jingyun Yang, Patrick Yin, Yunchu Zhang, Osbert Bastani, Glen Berseth, Jeannette Bohg, Ken Goldberg, Abhinav Gupta, Abhishek Gupta, Dinesh Jayaraman, Joseph J Lim, Jitendra Malik, Roberto Martín-Martín, Subramanian Ramamoorthy, Dorsa Sadigh, Shuran Song, Jiajun Wu, Michael C. Yip, Yuke Zhu, Thomas Kollar, Sergey Levine, Chelsea Finn
発行日:2024年03月19日
最終更新日:2024年03月19日
URL:http://arxiv.org/pdf/2403.12945v1
カテゴリ:Robotics

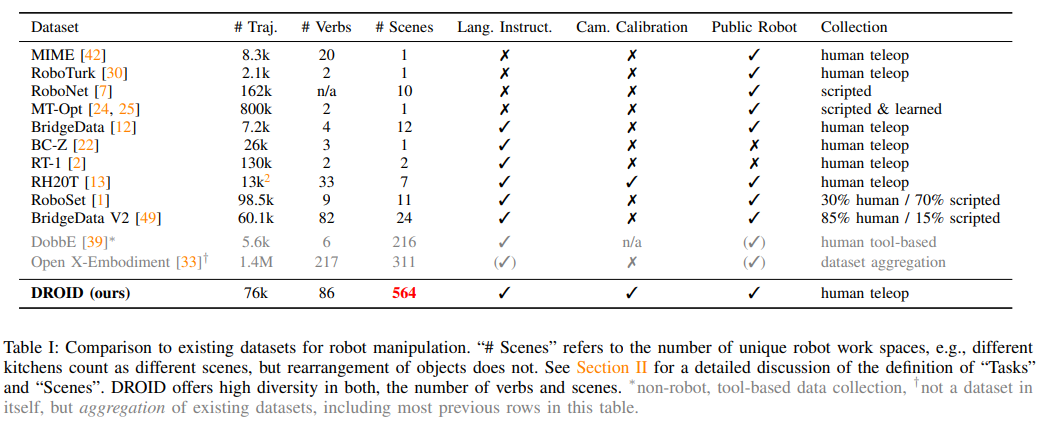
概要:
大規模で多様性が高く、高品質なロボット操作データセットの作成は、より能力が高く堅牢なロボット操作ポリシーに向けた重要な一歩です.しかし、このようなデータセットを作成することは困難です.多様な環境でのロボット操作データの収集は、物流や安全上の課題を抱え、ハードウェアや人的労働に大きな投資が必要です.その結果、現在の最も一般的なロボット操作ポリシーは、ほとんどが限られた環境で収集されたデータに基づいてトレーニングされています.
この研究では、DROID(分散ロボットインタラクションデータセット)を紹介します.このデータセットは、北米、アジア、ヨーロッパで50人のデータ収集者によって12ヶ月間にわたり収集された、564のシーンと84のタスクで76,000のデモトレイルや350時間の相互作用データを持つ多様なロボット操作データセットです.DROIDでトレーニングすることで、性能が向上し、汎化能力が向上したポリシーが得られることを示します.また、完全なデータセット、ポリシー学習コード、およびロボットハードウェアセットアップの詳細なガイドをオープンソースで公開しています.
Q&A:
Q: DROIDデータセットを作成した動機は何ですか?
A: DROIDデータセットを作成する動機は、より能力の高い、堅牢なロボット操作ポリシーに向けた重要な一歩である.しかしながら、このようなデータセットを作成することは困難であり、多様な環境でのロボット操作データの収集は物流上の課題や安全上の懸念を引き起こし、ハードウェアや人的労働に大きな投資が必要とされる.その結果、現在の最も一般的なロボット操作ポリシーは、限られた環境で収集されたデータに基づいて主に訓練されている.この状況に対処するため、DROID(分散ロボットインタラクションデータセット)を導入し、多様なロボット操作データセットを提供することとなった.
Q: DROIDデータセットに含まれるデモの軌跡の数は?
A: DROIDデータセットには76,000のデモンストレーショントラジェクトリが含まれています.
Q: DROIDのデータセットには何時間分のインタラクションデータが含まれているのですか?
A: 350時間の相互作用データがDROIDデータセットに含まれています.
Q: DROIDデータセットのデータ収集プロセスでは、いくつのシーンとタスクをカバーしたのか?
A: データ収集プロセスでカバーされたシーンとタスクの数は、564シーンと86タスクです.
Q: DROIDデータセットのデータコレクターはどの地域にいたのか?
A: データ収集者は北アメリカ、アジア、ヨーロッパの18の研究所に配置されました.
Q: DROIDデータセットのデータ収集にかかった時間は?
A: DROIDデータセットの収集には12ヶ月かかりました.
Q: DROIDデータセットで訓練されたポリシーのパフォーマンスと汎化能力に関する主な発見は?
A: DROIDデータセットで訓練されたポリシーは、性能が向上し、汎化能力が向上することが示されました.特に、DROIDと共同訓練されたポリシーは、他の比較と比較して滑らかで正確であることが観察されました.
Q: DROIDの全データセットはオープンソースですか?
A: はい、DROIDの完全なデータセットはオープンソースです.
Q: DROIDデータセットで使用されているロボットのハードウェアセットアップを再現するために、どのようなリソースが提供されていますか?
A: DROIDデータセットで使用されるロボットハードウェアセットアップを再現するためのリソースには、CC-BY 4.0ライセンスの下で提供される完全なデータセット、インタラクティブなデータセットビジュアライザ、DROIDで一般化可能なポリシーをトレーニングするためのコード、事前にトレーニングされたポリシーチェックポイント、およびロボットハードウェアセットアップと制御スタックを再現するための詳細なガイドが含まれています.
Evolutionary Optimization of Model Merging Recipes
著者:Takuya Akiba, Makoto Shing, Yujin Tang, Qi Sun, David Ha
発行日:2024年03月19日
最終更新日:2024年03月19日
URL:http://arxiv.org/pdf/2403.13187v1
カテゴリ:Neural and Evolutionary Computing
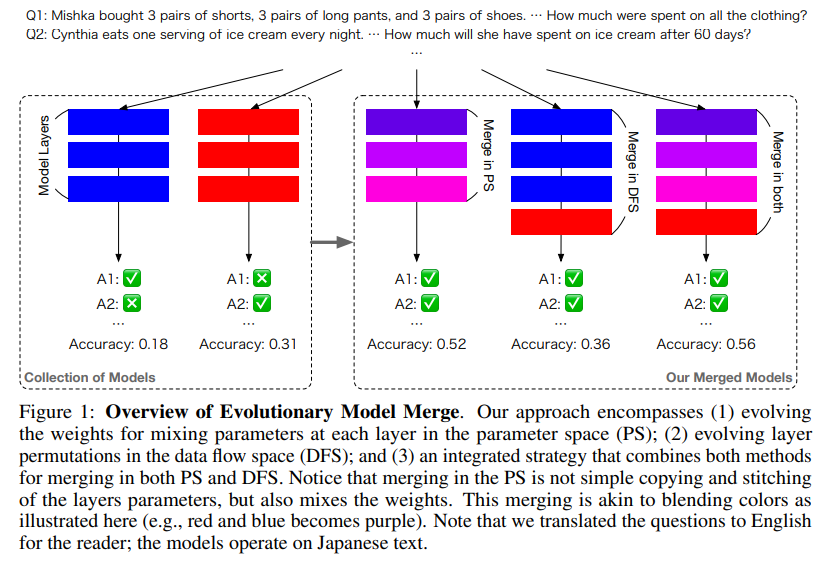
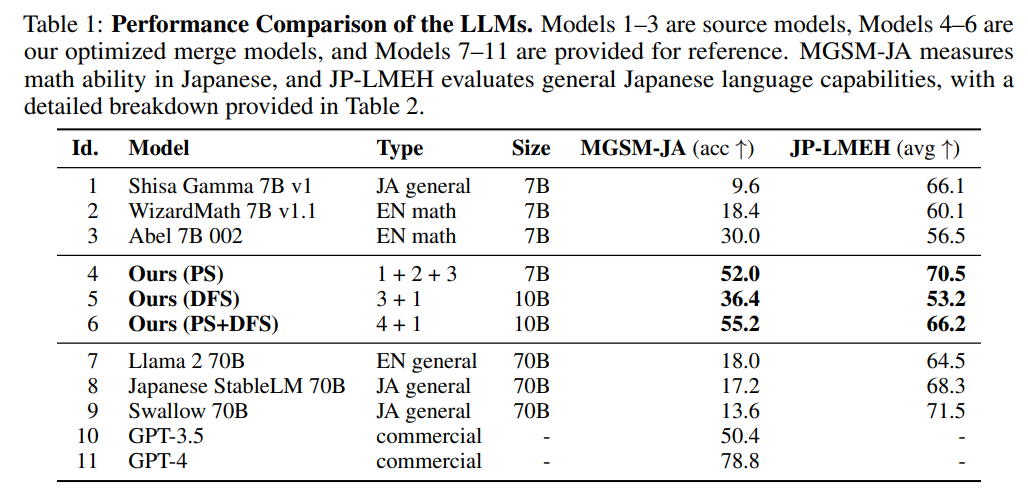
概要:
私たちのアプローチによって生成されたモデルは、日本の文化固有のコンテンツを記述する際にその効果を示し、従来の日本語VLMを上回っています.この研究は、新たな最先端モデルをオープンソースコミュニティに提供するだけでなく、自動モデル構成の新たなパラダイムを導入し、基礎モデル開発に対する代替効率的なアプローチを探る道を開いています.
Q&A:
Q: このような状況で、進化的アルゴリズムをモデル・マージに使うというアイデアはどのようにして生まれたのですか?
A: このコンテキストでは、進化アルゴリズムを使用してモデルのマージを行うアイデアは、新しい組み合わせを自動的に発見し、多様なオープンソースモデルの効果的な組み合わせを見つけることができるためです.これにより、人間の直感やドメイン知識に依存することなく、集合知を活用して強力な基盤モデルを作成することが可能となります.また、個々のモデルの重みだけでなく、パラメータ空間とデータフロー空間の両方で操作が可能であり、最適化が可能となります.さらに、このアプローチは異なるドメイン間のマージも容易に行うことができ、日本語のLLMと数学の推論能力を持つモデルなどを生成することができます.驚くべきことに、この日本語数学LLMは、様々な確立された日本語LLMベンチマークで最先端のパフォーマンスを達成しました.
Q: モデル・マージのために人間の直感やドメイン知識に頼ることの限界を、どのように克服しているのか説明していただけますか?
A: 人間の直感やドメイン知識に頼る限界を克服するために、我々のアプローチは、既存のオープンモデルの集合知を活用し、進化的アルゴリズムを使用して異なるドメインからのモデルを効果的に統合する新しい方法を自動的に発見することができます.これにより、広範囲の実世界の適用可能性を持つモデルを開発し、リーダーボードで定義された狭い範囲のタスクに最適化されたモデルの大きな集団を超えたモデルを開発することが可能となります.
Q: 個々のモデルのウェイトを超えた最適化という点で、あなたのアプローチは具体的にどのような利点をもたらしますか?
A: 私たちのアプローチは、個々のモデルの重みだけでなく、パラメータ空間とデータフロー空間の両方で操作することにより、最適化を可能にします.このアプローチは、個々のモデルの重みだけでなく、パラメータ空間とデータフロー空間の両方で操作することにより、最適化を可能にします.このアプローチは、個々のモデルの重みだけでなく、パラメータ空間とデータフロー空間の両方で操作することにより、最適化を可能にします.このアプローチは、個々のモデルの重みだけでなく、パラメータ空間とデータフロー空間の両方で操作することにより、最適化を可能にします.このアプローチは、個々のモデルの重みだけでなく、パラメータ空間とデータフロー空間の両方で操作することにより、最適化を可能にします.このアプローチは、個々のモデルの重みだけでなく、パラメータ空間とデータフロー空間の両方で操作することにより、最適化を可能にします.このアプローチは、個々のモデルの重みだけでなく、パラメータ空間とデータフロー空間の両方で操作することにより、最適化を可能にします.このアプローチは、個々のモデルの重みだけでなく、パラメータ空間とデータフロー空間の両方で操作することにより、最適化を可能にします.
Q: 日本の数学LLMが、確立されたベンチマークで最先端のパフォーマンスを達成するために、どのような工夫をしましたか?
A: 日本語の数学LLMが確立されたベンチマークで最先端のパフォーマンスを達成するためには、進化的モデルマージを適用しました.具体的には、日本語LLMと数学LLMを含む一連のソースモデルに進化的モデルマージを適用しました.これらのモデルは、shisa-gamma-7b-v1(日本語LLM)、WizardMath-7B-V1.1、Abel-7B-002などのモデルからなります.これらのモデルは、Mistral-7B-v0.1からファインチューニングされました.
Q: 御社のアプローチによって、文化的背景を考慮した日本のVLMが生み出される過程を詳しく教えてください.
A: 私たちのアプローチによる文化に敏感な日本語VLMを生成するプロセスは、まず、進化的な手法を使用して日本語の基礎モデルを自動的に生成します.この基礎モデルは、数学的な推論能力を持つ日本語LLMと、文化に特化した日本語VLMを作成します.驚くべきことに、これらのモデルは、いくつかのLLMおよびビジョンのベンチマークで最先端の結果を達成しました.これらのモデルは、これらのベンチマークで優れた性能を発揮するように明示的に最適化されていないにもかかわらず、広範囲にわたるトップパフォーマンスを達成しました.
Q: 新しい最先端モデルという点で、あなたの仕事はオープンソースコミュニティにどのように貢献していると思いますか?
A: 私たちの研究は、新しい最先端モデルをオープンソースコミュニティに提供することで貢献しています.具体的には、Evolutionary Model Mergeという進化的な手法を導入し、異なるオープンソースモデルの最適な組み合わせを自動的に見つけ出すことができます.このアプローチにより、膨大なトレーニングデータや計算能力を必要とせずに、強力なモデルを作成することが可能となります.さらに、我々の手法は異なるドメイン間(例:非英語言語と数学、非英語言語とビジョン)でのモデルのマージを実現し、従来の人間設計戦略を超える可能性があります.最終的に、我々の研究によって、日本語のLLMと日本語のビジョン言語モデル(VLM)を自動生成し、さまざまなベンチマークで最先端のパフォーマンスを達成することが示されました.
Q: 自動モデル構成パラダイムの開発と実装において、どのような課題に直面しましたか?
A: 私たちは、異なるドメインからのモデルの統合に関する新しい方法を開発しました.これにより、従来の人間による設計戦略を超える可能性があります.また、既存のオープンソースモデルの集合知を活用して、強力なモデルを作成することができます.さらに、トレーニングデータや計算の必要性なしに、新しい基盤モデルを作成するための最適な組み合わせを自動的に発見する進化的モデルマージという一般的な進化的手法を導入しました.
Q: 研究結果に基づき、自動モデル開発の将来像をどのように描いていますか?
A: 研究結果に基づいて、自動モデル開発の将来をどのように考えるかについて、私たちは、既存のオープンモデルの集合知を活用することで、ユーザーが指定した能力を持つ新しい基礎モデルを自動的に作成できる方法が可能であると考えています.私たちのアプローチは、異なるドメイン(例:非英語言語と数学、非英語言語とビジョン)から異なるモデルを自動的に統合する新しい方法を発見することができ、これは人間の専門家が自ら発見するのが難しいかもしれません.このような手法を活用することで、将来的には、より効率的でパワフルなモデルを作成するための新たな可能性が開かれると考えられます.
Q: 進化的最適化アプローチが有益である可能性のある他のアプリケーションやドメインの例を教えていただけますか?
A: 私たちの進化的最適化アプローチは、他の潜在的な応用分野やドメインにも適用できる可能性があります.例えば、自然言語処理、画像認識、音声認識、医療診断などの分野で、進化的アルゴリズムを使用して新しいモデルの組み合わせを発見し、高度な性能を達成することができるかもしれません.
Q: 自動モデルマージレシピの機能をさらに洗練させ、拡大するという点で、あなたの研究の次のステップは何ですか?
A: 研究の次のステップとして、自動モデルマージングレシピの能力をさらに洗練し拡張するために、我々は次のようなアプローチを検討する予定です.まず、進化アルゴリズムを使用して、モデルマージングのパラメータ空間とデータフロー空間の最適化をさらに探求し、個々のモデルの重みだけでなく、モデルの組み合わせ全体の最適化を行います.さらに、異なるドメイン間のマージングを促進するために、新たなモデル組み合わせの発見に焦点を当てます.また、論理的な整合性を欠いた応答を生成する可能性がある問題を解決するために、モデルの論理的な整合性を向上させる手法を開発する予定です.さらに、事実に基づかない出力を生じる可能性がある問題を解決するために、モデルの微調整や整合性を向上させる方法を検討します.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: この論文で導入された新しい手法のコード実装のurlは、https://github.com/SakanaAI/evolutionary-model-merge です.
RankPrompt: Step-by-Step Comparisons Make Language Models Better Reasoners
著者:Chi Hu, Yuan Ge, Xiangnan Ma, Hang Cao, Qiang Li, Yonghua Yang, Tong Xiao, Jingbo Zhu
発行日:2024年03月19日
最終更新日:2024年03月22日
URL:http://arxiv.org/pdf/2403.12373v3
カテゴリ:Computation and Language
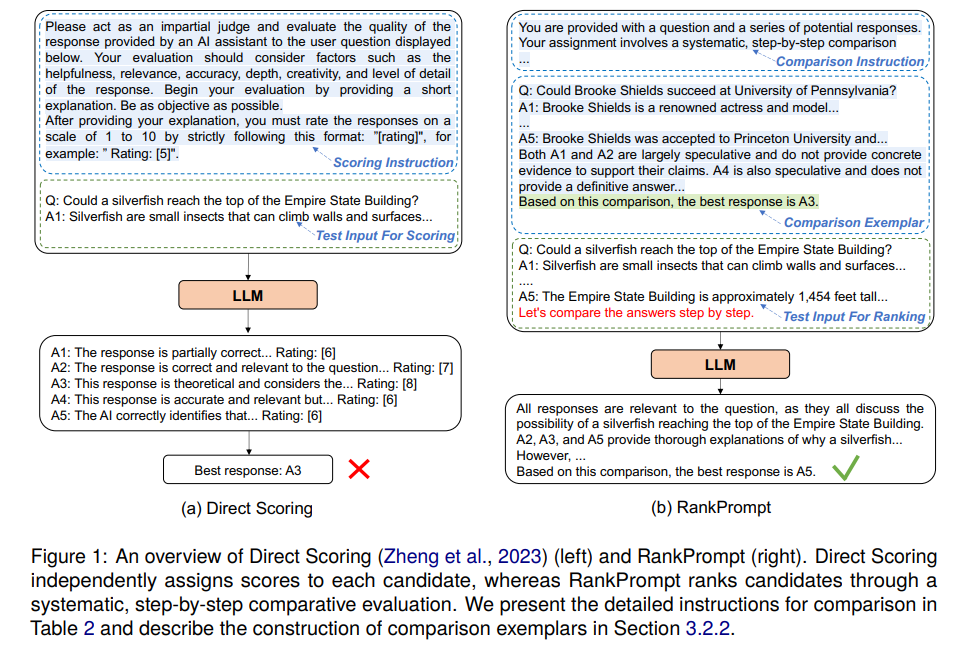
概要:
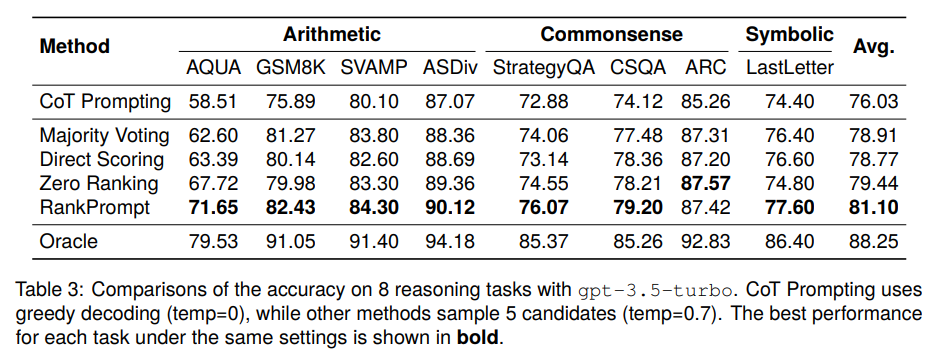
大規模言語モデル(LLMs)は、さまざまな推論タスクで印象的なパフォーマンスを達成しています.ただし、ChatGPTなどの最先端のLLMsでも、推論プロセス中に論理的なエラーが発生する可能性があります.既存の解決策は、タスク固有の検証者を展開するか、複数の推論パスを投票するなど、人間の注釈が必要であるか、一貫性のない応答があるシナリオで失敗します.これらの課題に対処するために、追加のリソースなしでLLMsが自己ランク付けを行う新しいプロンプティング方法であるRankPromptを紹介します.RankPromptは、多様な応答間の比較を通じてランキング問題を分解し、LLMsが比較の連鎖を生成するという固有の能力を活用しています.11の算術および常識推論タスク全体での実験では、RankPromptがChatGPTやGPT-4の推論パフォーマンスを著しく向上させ、最大13%の改善をもたらすことが示されました.さらに、RankPromptは、AlpacaEvalデータセットでの人間の判断と74%の一致率を示すLLMベースの自動評価に優れています.また、応答順序や一貫性の変化に対しても堅牢性を示しており、新たな文脈を加えることで、RankPromptは言語モデルから高品質なフィードバックを引き出す効果的な方法として確認されました.
Q&A:
Q: RankPromptがどのようにランキングの問題を、多様な回答間の一連の比較に分解するのか説明できますか?
A: RankPromptは、多様な応答の間でランキング問題を比較の一連のステップに分解します.具体的には、RankPromptは、LLMが自己ランク付けを行うための新しいプロンプティング方法です.RankPromptは、ランキング問題を、多様な応答の間での一連の比較に分解し、LLMが比較の連鎖を生成するという固有の能力を活用します.
Q: RankPromptは、LLMが本来持っている能力をどのように活用し、文脈上の模範となる比較の連鎖を生み出しているのか?
A: RankPromptは、LLMの固有の能力を活用して、比較の連鎖を生成し、文脈的な例示として利用しています.具体的には、RankPromptは、LLMに複数の比較の連鎖を生成させ、正しいランキング結果をもたらす連鎖を選択するよう指示します.これにより、RankPromptは、異なる経路を系統的に比較することで、ラベル付きデータの要件を減らし、人間の介入を最小限に抑えることができます.
Q: RankPromptの有効性をテストするために、実験では具体的にどのような推論課題が用いられたのですか?
A: 実験でRankPromptの効果をテストするために使用された具体的な推論タスクは、11個の算術および常識的な推論タスクでした.
Q: ChatGPTのような最先端のLLMが、推論過程で陥りやすい論理的エラーの例を挙げてもらえますか?
A: 最先端のLLMであるChatGPTなどは、論理的なエラーに陥りやすい傾向があります.例えば、代数の問題を解く際に、言語モデルが誤った数学的計算を行うことがあります.これは、数学的な式や計算方法を誤解したり、誤った数値を使用したりすることによって起こります.
Q: RankPromptは、タスクに特化した検証者の配置や、複数の推論パスに対する投票など、既存のソリューションと比較してどうでしょうか?
A: RankPromptは、タスク固有の検証ツールを展開するか、複数の推論経路に投票するなどの既存の解決策と比較して、追加のリソースなしでLLMsに自己ランク付けを可能にする新しいプロンプティング方法です.
Q: RankPromptの導入によるChatGPTとGPT-4の推論性能の向上について、主な発見は何でしたか?
A: RankPromptの実装によるChatGPTとGPT-4の推論パフォーマンスの主な改善点は、11の算術および常識的な推論タスクでの実験により示されました.RankPromptは、比較的多様な応答の間での一連の比較にランキング問題を分解し、LLMの固有の能力を活用して比較の連鎖を生成します.その結果、ChatGPTとGPT-4の推論パフォーマンスが著しく向上し、最大13%の改善が見られました.さらに、RankPromptは、AlpacaEvalデータセットにおいて、LLMによる自動評価において、人間の判断と74%の一致率を達成しました.
Q: 自由形式タスクのLLMベースの自動評価において、RankPromptは人間の判断と比較してどのようなパフォーマンスを示すか?
A: RankPromptは、LLMベースの自動評価において、人間の判断と74%の一致率を達成しました.
Q: 回答順や一貫性のばらつきに対するRankPromptの堅牢性について詳しく教えてください.
A: RankPromptは、候補者の順序の変化に対して非常に堅牢であり、3回の反復を通じてランキングが変化しない場合に一貫性があると見なします.図5に示されているように、RankPromptは、候補者の順序の変化に対してZero Rankingよりも優れた堅牢性を示しています.具体的には、RankPromptは75%から85%の間で一貫したランキングを生成します.これらの結果は、RankPromptが複雑な推論タスクにおいて信頼性の高い論理的推論因果判断形式の誤謬を示すことを示しています.
Q: 言語モデルから質の高いフィードバックを引き出す手法としてRankPromptを開発するにあたり、直面した主な課題は何でしたか?
A: RankPromptの開発において主な課題は、人間の注釈が必要ないか、一貫性のない応答のシナリオで失敗するなど、高品質なフィードバックを得るための方法としてのRankPromptの開発において直面した主な課題でした.
Q: LLMの推論能力を向上させるために、RankPromptを将来どのように応用することを想定していますか?
A: RankPromptは、LLMの推論能力を向上させるために、多様な推論経路を生成し、LLMが最適なものを選択するよう指示することによって、将来の応用を展望しています.これにより、従来の方法とは異なり、直接スコアリング方法とは異なり、候補を個別に評価するのではなく、LLMに候補を比較的評価させるように導きます.RankPromptは、推論タスクにおいてLLMが自己ランク付けを行うことを可能にする新しいプロンプティング方法であり、人間の介入を大幅に減らすことができます.
What Are Tools Anyway? A Survey from the Language Model Perspective
著者:Zhiruo Wang, Zhoujun Cheng, Hao Zhu, Daniel Fried, Graham Neubig
発行日:2024年03月18日
最終更新日:2024年03月18日
URL:http://arxiv.org/pdf/2403.15452v1
カテゴリ:Computation and Language, Artificial Intelligence
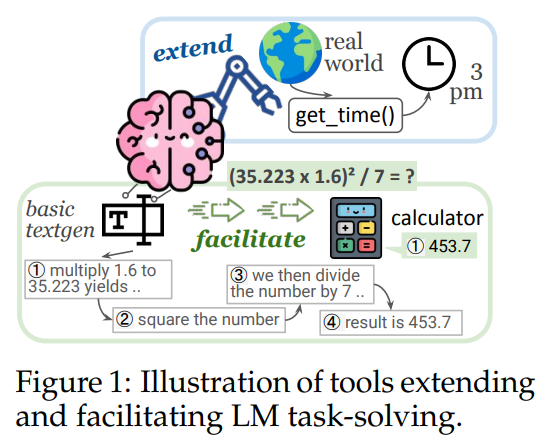
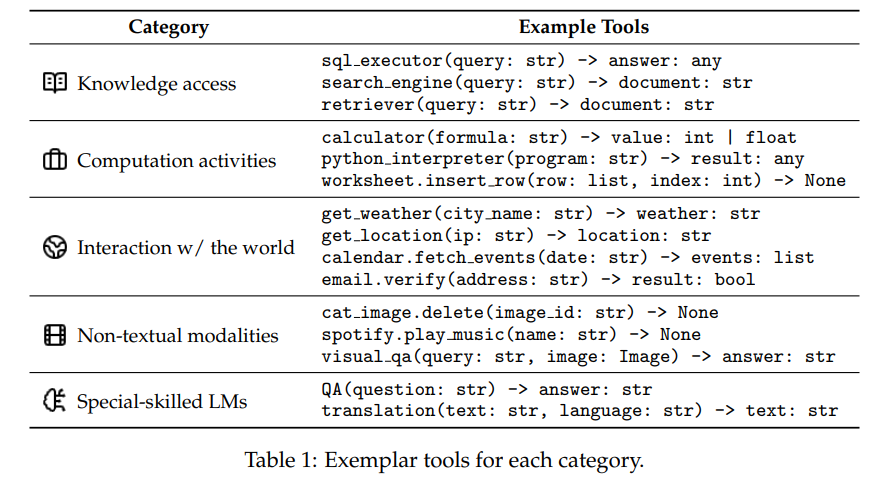
概要:
言語モデル(LM)は、テキスト生成タスクにおいて非常に強力ですが、主にそのために使用されています.ツールは、複雑なスキルが必要なタスクのパフォーマンスを大幅に向上させています.しかし、多くの研究では、「ツール」という用語を異なる方法で採用しており、そのために問題が生じています.そこで、ツールとは一体何か、そしてどのようにしてLMに役立つのかという疑問が生じます.この調査では、LMが使用する外部プログラムとしてのツールの統一された定義を提供し、LMのツール化シナリオとアプローチについて体系的なレビューを行います.このレビューに基づいて、さまざまなベンチマークでの必要な計算量とパフォーマンスの向上を測定することで、さまざまなツール化方法の効率を実証的に研究し、この分野におけるいくつかの課題や将来の研究の可能性を強調します.
Q&A:
Q: 言語モデルのツールとされる外部プログラムの例を教えてください.
A: 外部プログラムとしてのツールの例には、QAモデルや機械翻訳モデルなどがあります.
Q: テキスト生成タスクにおける言語モデルのパフォーマンスを、ツールはどのように向上させるのか?
A: ツールは、言語モデルの性能を向上させるために、外部プログラムとして使用されます.これにより、複雑なスキルを必要とするタスクにおいて、言語モデルの性能が大幅に向上します.具体的には、多くのドメインをカバーするタスクにおいて、最も高い向上が期待されます.
Q: 言語モデルのためのさまざまなツーリング手法の効率を判断するために、どのような基準を使っていますか?
A: 異なるツール作成方法の効率を決定するための基準は、計算コストと性能向上のバランスです.具体的には、計算コスト(M x B)と性能向上の関係を考慮し、TROVEが最も効率的であることが示されています.TROVEは、コストが1.2-1.4Kトークンでありながら、精度が12.0-21.0ポイント向上しています.一方、CREATORとCRAFTは、コストが3.8-6.0倍かかりますが、精度の向上は最小限(0.0-4.5%)または比較可能(4.1-5.0%)にとどまっています.
Q: さまざまなツーリング方法について、必要な計算量と性能向上をさまざまなベンチマークで測定するプロセスを説明してもらえますか?
A: さまざまなツールング手法の必要な計算量とパフォーマンス向上を測定するプロセスは、実験データセットを使用して行われます.これにより、より効率的な手法やツールを発見し、より少ない計算で大きな利益を得ることが可能となります.ツールによってもたらされる利益は、追加の計算コストという形で現れます.特に、LMにツールを使用するためのトレーニングやプロンプトが必要となります.性能向上だけでなく、計算オーバーヘッドの報告は、異なるアプローチ間の公平な比較を可能にします.
Q: 言語モデルを使ったツールを使用する際に生じる課題は何ですか?
A: 言語モデルとツールを使用する際に生じるいくつかの課題には、ツールが基本的な言語モデルと大きな構造的な違いを持たない場合があることが挙げられます.また、ツールが特定のタスクに特化しているため、他のタスクには適用できない場合もあります.さらに、ツールがニューラルネットワークであるため、基本的な言語モデルと比べて利点が限られていることも課題となります.
Q: ツールのシナリオやアプローチの違いは、言語モデルのパフォーマンスにどのような影響を与えるのか?
A: 異なるツールのシナリオやアプローチは、言語モデルのパフォーマンスにどのような影響を与えるかについては、具体的な結論を導くことは難しいです.ただし、ツールの使用や作成によって、複数のドメインをカバーするタスクにおいて最も高い効果が期待されます.例えば、ToolAlpacaベンチマークやBigBenchデータセットなどが挙げられます.これらのツールを使用することで、言語モデルの性能向上が期待されます.
Q: 言語モデル用ツールの分野では、今後どのような研究分野が考えられますか?
A: 言語モデルのツール化における将来の研究領域としては、外部プログラムを使用して言語モデルの性能を向上させる方法のさらなる改善や効率化、特定のタスクに特化したツールモデルの開発、ベース言語モデルとのアーキテクチャの違いに焦点を当てた研究、ツールがあまり役立たないシナリオの特定などが挙げられる.
Q: 言語モデルの文脈でツールをどのように定義しますか?
A: ツールは、言語モデルが外部プログラムを使用するための関数インターフェースであり、LMがツールを使用するために関数呼び出しと入力引数を生成するコンピュータプログラムであると定義されます.
Q: 言語モデルが使用する外部プログラムとしてのツールの統一的な定義について詳しく教えてください.
A: LMが使用するツールの統一された定義は、LMが外部プログラムを使用して、LMがツールを使用するために関数呼び出しと入力引数を生成するコンピュータプログラムの関数インターフェースであるというものです.
Q: 言語モデルのテキスト生成タスクにおいて、ツールはどのように役立つのか?
A: ツールは、外部プログラムとして使用されることで、言語モデルがテキスト生成タスクで助けられます.これにより、複雑なスキルが必要なタスクのパフォーマンスが向上し、言語モデルの効率が向上します.
Open Release of Grok-1
著者:xAI
発行日:2024年03月17日
最終更新日:不明
URL:https://x.ai/blog/grok-os
カテゴリ:不明

概要:
2024年3月28日12:20、x.aiはGrok-1という3140億パラメータのMixture-of-Expertsモデルの重みとアーキテクチャを公開しました.このモデルは大規模な言語モデルであり、xAIによってJAXとRustのカスタムトレーニングスタックを使用してゼロからトレーニングされました.これは2023年10月に終了したGrok-1の事前トレーニングフェーズの生のベースモデルチェックポイントであり、対話など特定のアプリケーションには微調整されていません.重みとアーキテクチャはApache 2.0ライセンスの下で公開されており、モデルを使用するための手順はgithub.com/xai-org/grokで確認できます.このベースモデルは大量のテキストデータでトレーニングされ、特定のタスクには微調整されていません.各トークンに対して25%の重みがアクティブな3140億パラメータのMixture-of-Expertsモデルは、xAIがJAXとRustのカスタムトレーニングスタックを使用してゼロからトレーニングしたものです.また、カバー画像はMidjourneyによって生成され、Grokが提案したプロンプトに基づいて作成されました.プロンプトは、透明なノードと発光する接続を持つニューラルネットワークの3Dイラストであり、接続線の太さや色が異なることで、異なる重みが示されています.
Q&A:
Q: Grok-1モデルのウェイトとアーキテクチャーを公開する意義は?
A: Grok-1モデルの重みとアーキテクチャを公開することの重要性は、モデルの基本的な構造とパラメーターにアクセスできることから、研究者や開発者がモデルを理解し、カスタマイズしてさまざまなタスクに適用することができる点にあります.これにより、モデルの透明性が向上し、AIの進歩や応用の促進につながる可能性があります.
Q: Grok-1モデルのトレーニングプロセスについて詳しく教えてください.
A: Grok-1モデルのトレーニングプロセスは、3140億パラメータのエキスパートの混合モデルであり、特定のタスクにファインチューニングされていない大量のテキストデータに基づいてトレーニングされました.このモデルは、xAIによってJAXとRustを使用したカスタムトレーニングスタックを使用して、2023年10月にゼロからトレーニングされました.重みの25%が特定のトークンでアクティブであり、透明なノードと発光する接続を持つニューラルネットワークの3Dイラストを提示するカバー画像は、Midjourneyによって生成されました.
Q: Apache 2.0ライセンスは、Grok-1モデルの使用にどのような影響を与えますか?
A: Apache 2.0ライセンスにより、Grok-1モデルの重みとネットワークアーキテクチャが無償で利用可能となります.また、このライセンスは商用利用や改変、再配布が可能であり、ただしライセンスと著作権の表示が必要です.
Q: プレトレーニングフェーズから生のベースモデルチェックポイントを解放する目的は何ですか?
A: プレトレーニングフェーズからの生のベースモデルチェックポイントのリリースの目的は、Grok-1の基本モデルの重みとネットワークアーキテクチャを公開することで、大規模な言語モデルであるGrok-1の訓練過程の一部を共有し、他の研究者や開発者がこのモデルを理解し、さらに改善や応用のために活用できるようにすることです.
Q: Grok-1モデルを使い始めるにはどうすればよいですか?
A: モデルを使用する方法については、github.com/xai-org/grokの指示に従ってください.モデルの重みとアーキテクチャはApache 2.0ライセンスの下でリリースされています.
Q: 専門家混合モデルと他の言語モデルとの違いは?
A: Mixture-of-Expertsモデルは、他の言語モデルと異なり、複数の専門家(エキスパート)モデルの組み合わせで構成されており、各エキスパートが特定のタスクに特化しています.各エキスパートは、入力データに対して重み付けされ、それぞれのエキスパートの出力が組み合わさって最終的な出力を生成します.このように、Mixture-of-Expertsモデルは、複数の専門家の知識を組み合わせることで、より高度なタスクに対応できる特徴があります.
Q: Grok-1モデルのトレーニングにxAIが使用したカスタムトレーニングスタックについて教えてください.
A: xAIによって使用されたカスタムトレーニングスタックは、JAXとRustをベースにしたものであり、2023年10月にGrok-1の事前トレーニングフェーズで使用されました.このスタックは、JAXを使用して高性能な数値計算を行い、Rustを使用して高速な並列処理を実現しています.これにより、大規模なテキストデータセットを使用してGrok-1をゼロからトレーニングする際に、効率的でスケーラブルなトレーニングが可能となりました.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: この論文で導入された新しい手法のコード実装のURLは、github.com/xai-org/grok です.
RAFT: Adapting Language Model to Domain Specific RAG
著者:Tianjun Zhang, Shishir G. Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, Joseph E. Gonzalez
発行日:2024年03月15日
最終更新日:2024年03月15日
URL:http://arxiv.org/pdf/2403.10131v1
カテゴリ:Computation and Language, Artificial Intelligence
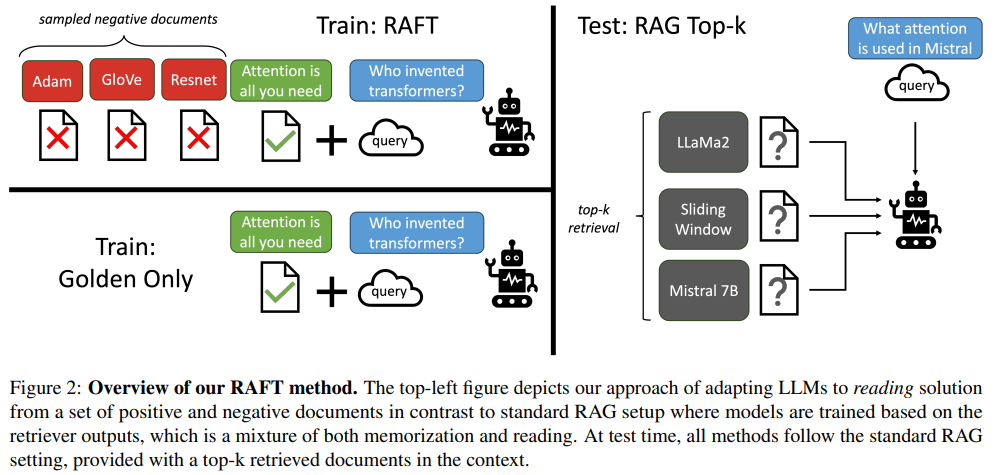
概要:
大規模な言語モデル(LLM)を大規模なテキストデータのコーパスで事前トレーニングすることは、現在標準的なパラダイムとなっています.これらのLLMをさまざまな下流アプリケーションに使用する際、追加の知識(例:時間的に重要なニュースやプライベートドメインの知識)を事前トレーニングされたモデルに取り込むことが一般的です.これは、RAGベースのプロンプティングやファインチューニングを介して行われます.ただし、モデルがそのような新しい知識を獲得するための最適な方法は未解決の問題です.本論文では、Retrieval Augmented FineTuning(RAFT)というトレーニングレシピを提案し、モデルが「オープンブック」のドメイン内設定で質問に答える能力を向上させます.RAFTでは、質問と取得された文書のセットが与えられた場合、モデルに質問に答えるのに役立たない文書、つまりディストラクター文書を無視するようにトレーニングします.RAFTは、質問に答えるのに役立つ関連文書から正しいシーケンスを引用することでこれを実現します.これに加えて、RAFTの思考の連鎖スタイルの応答が、モデルの推論能力を向上させるのに役立ちます.ドメイン固有のRAGでは、RAFTはPubMed、HotpotQA、DETAILED SUMMARY IN JAPANESEなどでモデルのパフォーマンスを一貫して向上させます.さらに、RAFTはGorillaデータセットを含むさまざまなデータセットでモデルのパフォーマンスを向上させ、オープンソースのコードとデモはgithub.com/ShishirPatil/gorillaで公開されています.
Q&A:
Q: Retrieval Augmented FineTuning(RAFT)の具体的な手法について、もう少し詳しく説明していただけますか?
A: RAFTは、教師ありファインチューニング(SFT)と情報検索を活用した生成(RAG)を組み合わせる新しい適応戦略であり、LLMsをドメイン知識を取り入れるようにファインチューニングする課題に取り組み、またドメイン内のRAGを改善することを目指しています.
Q: RAFTは、「オープンブック」のドメイン内設定でモデルの質問に答える能力をどのように向上させるのか?
A: RAFTは、モデルが質問に回答する際に、適切な文書からの引用を通じて、『オープンブック』のドメイン内設定での質問に回答する能力を向上させます.具体的には、RAFTは、質問と取得された文書のセットが与えられた場合、モデルに質問に回答するのに役立たない文書、つまり迷惑な文書を無視するように訓練します.これにより、モデルは適切な文書からの情報を適切に利用して質問に回答する能力が向上し、『オープンブック』の試験に効果的に対応できるようになります.
Q: RAFTで散漫文書を無視するモデルを訓練する意義は?
A: RAFTにおいてモデルを訓練して、質問に対して役立たない文書であると判断された文書(distractor documents)を無視することの重要性は、モデルが質問に適切に答えるために必要な情報に焦点を合わせることができるようにするためです.これにより、モデルは不要な情報を排除し、質問に適切に回答するための適切な情報を見つけることができます.
Q: RAFTでは、質問に答えるために、関連文書から適切な順序で逐語的にどのように引用するのですか?
A: RAFTは、適切な文書から正確なシーケンスを引用することで、質問に答えるのを助けます.
Q: RAFTの連鎖思考スタイルの応答がモデルの推論能力を向上させる具体例を提供できますか?
A: RAFTのChain-of-Thoughtスタイルの応答は、モデルの推論能力を向上させるために効果的であることが示されています.このアプローチでは、完全な推論チェーンを作成し、明確にソースを引用することで、モデルの回答の正確性が向上します.特に、RAFの応答は、推論プロセスを明確に説明することで、モデルがより論理的かつ正確に回答を生成できるように支援します.
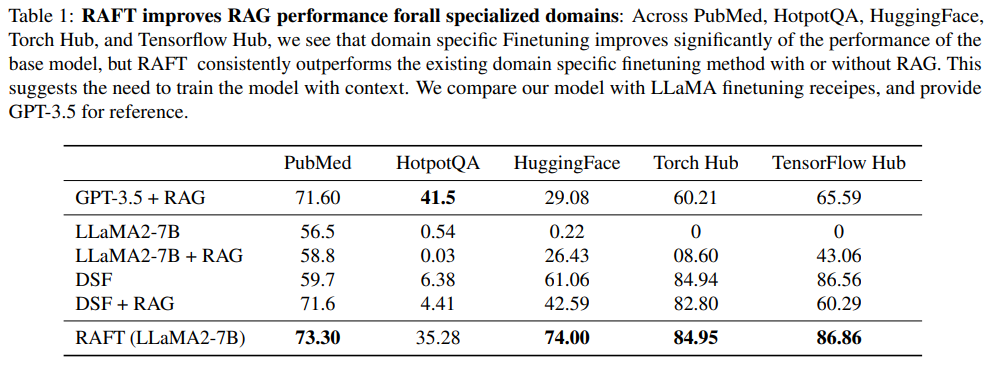
Q: RAFTは、PubMed、HotpotQA、Gorillaなどの異なるデータセットを通じて、モデルのパフォーマンスを一貫して向上させる方法は何ですか?
A: RAFTは、PubMed、HotpotQA、Gorillaなどの異なるデータセットにおいて、モデルの性能を一貫して向上させることができます.これは、ドメイン固有のRAGにおいて、RAFTがモデルの性能を改善するためのポストトレーニングレシピを提供することによるものです.RAFTは、提供されたコンテキストに頼ることで問題を解決する際に優れた性能を発揮し、HotpotQAやHuggingFaceなどのタスクにおいて優れた結果を示します.
Q: ドメイン固有のRAGにおいて、事前に訓練された大規模言語モデル(LLM)にRAFTが与える影響とは?
A: RAFTは、事前に学習された大規模言語モデル(LLMs)に対して、特定のドメインにおけるRAGにおいて大きな影響を与えます.RAFTは、質問に対する適切な文を引用することで、モデルの理解能力を向上させ、連鎖的な思考スタイルの回答によってモデルの推論能力を高めます.特定のドメインにおけるRAGでは、RAFTはPubMed、HotpotQA、Gorillaデータセットを通じてモデルのパフォーマンスを一貫して向上させ、事前学習されたLLMsを特定のドメインに適応させるためのトレーニングレシピを提供します.
Q: github.com/ShishirPatil/gorillaでRAFTのコードとデモをオープンソース化するプロセスを説明できますか?
A: RAFTのコードとデモをgithub.com/ShishirPatil/gorillaにオープンソース化するプロセスは、論文の中で詳細に説明されています.具体的には、RAFTのコードとデモは公開され、https://github.com/ShishirPatil/gorillaで利用可能です.このプロセスにより、他の研究者や開発者がRAFTを使用し、さらなる研究の応用を行うことが可能となります.
Q: RAFTは、事前に訓練されたLLMに新しい知識を組み込む他の方法と比べてどうなのでしょうか?
A: RAFTは、他の方法と比較して、事前にトレーニングされたLLMに新しい知識を組み込む際に優れた性能を示しています.RAFTは、質問(Q)に対して文書(D)から回答(A)を生成するモデルを訓練し、その過程で誤情報文書(Dk)が存在する状況でも高い精度を達成します.RAFTは、Supervised-finetuningと比較して、PubMed、HotpotQA、HuggingFace Hub、Torch Hub、Tensorflow Hub Gorillaなどのデータセットにおいて、RAGの有無に関わらず、優れた性能を示し、新しい技術を提供しています.
Q: 自然言語処理の分野で、RAFTの今後の応用や発展の可能性は?
A: RAFTは、自然言語処理の分野において、産業界や学術界の両方で興味を引き続けるであろう、ドメイン固有の知識を使用した問題解決タスクにおいて、将来的に重要な応用や発展が期待されます.一般的なRAGとは異なり、RAFTはLLMが特定のドメイン固有の知識を使用して質問に回答する実用的なシナリオに焦点を当てています.我々の研究結果は、小規模で微調整されたモデルが、一般的なLLMと比較して、ドメイン固有の質問応答タスクで同等の性能を発揮する可能性があることを示唆しています.
Logits of API-Protected LLMs Leak Proprietary Information
著者:Matthew Finlayson, Xiang Ren, Swabha Swayamdipta
発行日:2024年03月14日
最終更新日:2024年03月15日
URL:http://arxiv.org/pdf/2403.09539v2
カテゴリ:Computation and Language, Artificial Intelligence, Cryptography and Security, Machine Learning
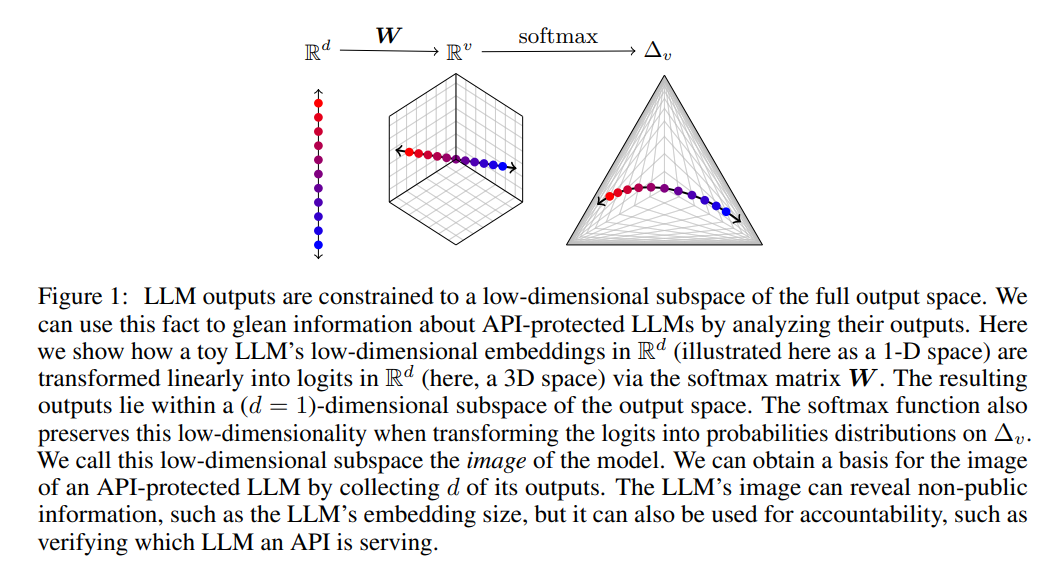

概要:
大規模言語モデル(LLMs)の商業化により、プロプライエタリモデルへの高レベルAPIのみのアクセスが一般的になっています.この研究では、モデルアーキテクチャについて保守的な仮定をしても、比較的少数のAPIクエリ(例:OpenAIのgpt-3.5-turboでは1,000ドル未満)からAPIで保護されたLLMについて驚くほど多くの非公開情報を学習することが可能であることを示しています.私たちの発見は、1つの重要な観察に焦点を当てています:ほとんどの現代のLLMはソフトマックスボトルネックに苦しんでおり、これによりモデルの出力が完全な出力空間の線形部分空間に制限されます.これにより、モデルイメージやモデル署名が可能となり、手頃なコストでいくつかの機能を解除することができます:LLMの隠れたサイズを効率的に発見する、完全な語彙の出力を取得する、異なるモデルの更新を検出して曖昧さを解消する、単一の完全なLLM出力が与えられた場合にソースLLMを識別する、さらには出力層パラメータを推定することさえ可能です.私たちの実証的調査は、OpenAIのgpt-3.5-turboの埋め込みサイズを約4,096と推定することができる方法の効果を示しています.最後に、LLMプロバイダーがこれらの攻撃に対抗する方法や、これらの機能を透明性と責任を高めるための特徴として捉える方法についても議論しています.
Q&A:
Q: 最近のLLMにおけるソフトマックスのボトルネックが、どのようにして専有情報の漏洩を可能にしているのか、もう少し詳しく説明していただけますか?
A: 現代のLLMにおけるソフトマックスボトルネックは、モデルの出力を完全な出力空間の線形部分空間に制限するため、非公開情報の漏洩を可能にします.この制限により、LLMの隠れたサイズを効率的に発見したり、安価な完全語彙の出力を取得したり、異なるモデルの更新を検出および曖昧化したり、単一の完全なLLM出力を与えられた場合にソースLLMを識別したり、出力層パラメータを推定したりする能力が開かれます.
Q: APIで保護されたLLMについて、少数のAPIクエリから大量の非公開情報を知ることが可能だと、どのように判断したのですか?
A: API保護されたLLMから非公開情報を学習することが可能であることは、多くの現代のLLMがソフトマックスボトルネックに苦しんでいることによるものです.このボトルネックは、モデルの出力を完全な出力空間の線形部分空間に制限するため、非公開情報を取得するために必要なAPIクエリの数を最小限に抑えることができます.
Q: LLMのモデル・イメージやモデル・シグネチャーを得ることで、具体的にどのような能力を引き出すことができるのか?
A: LLMのモデルイメージまたはモデルシグネチャを取得することで、モデルのハイパーパラメータを明らかにすることができます.また、出力層のパラメータを回復したり、特定の種類のモデル更新を検出したり、モデルの完全な出力を効率的に取得することができます.
Q: OpenAIのgpt-3.5-turboの埋め込みサイズを約4,096と推定したのはどうしてですか?
A: gpt-3.5-turboの埋め込みサイズを約4,096と推定するためには、次のトークン分布出力から特異値を収集し、インデックス4,600から4,650の間で値が急激に低下することを観察しました.この結果から、モデルの埋め込みサイズは最大でもこのサイズであると推測されます.また、LLMの埋め込みサイズは通常2の累乗(または2の累乗の和)に設定されるため、gpt-3.5-turboの場合、埋め込みサイズが212=4096または212+29=4608である可能性が高いと考えられます.そのうち前者が最も可能性が高いと予想しています.
Q: 実証的な調査において、その有効性を示すために用いた方法について詳しく教えてください.
A: 私たちの研究では、APIベースのLLMの埋め込みサイズを見つけるアルゴリズムを設計し、実証的に検証しました.具体的には、gpt-3.5-turboというクローズドソースのAPI保護されたLLMの埋め込みサイズを4,096と推定することで、我々の手法の効果を実証しました.また、LLM画像をユニークな署名として使用する効果を実証し、これらの署名がモデルのパラメータのわずかな変更に対して敏感であることから、モデルパラメータの更新に関する詳細な情報を推論するのに適していることも示しました.
Q: LLMプロバイダーが、あなたの研究で明らかになった攻撃から身を守るには、どのような方法がありますか?
A: LLMプロバイダーは、提供されるAPIを変更して情報を隠すことができます.また、新しいLLMをトレーニングすることで、攻撃を防ぐだけでなく、大語彙LLMに影響するトークン化の問題も解決できます.さらに、softmaxボトルネックフリーLLMへの移行は、攻撃を完全に防ぐことができます.また、LLMの変更を検出することで、LLMプロバイダーと顧客の間に信頼関係を築くことができ、プロバイダーの透明性と責任を高めることができます.
Q: LLMプロバイダーにとって、このような機能をバグではなく、むしろ特徴と捉えるにはどうしたらよいでしょうか?
A: LLMプロバイダーは、これらの機能をバグではなく機能として見ることができると提案されます.これにより、外部の観察者がモデルを監査できるようにすることで、顧客との信頼関係をより良く維持することができます.
Q: LLMのフル出力からソースのLLMを特定する方法について、もう少し詳しく教えてください.
A: 与えられた出力を元に、LLMの出力空間内での位置を特定することが可能です.これは、LLMの出力空間が低次元部分空間に制約されているためです.具体的には、LLMのイメージ空間を収集したLLM出力から構築し、そのイメージ空間内での位置を特定することで、与えられた出力がどのLLMから来たものかを特定できます.
Q: これまで議論してきた能力を通じて、より高い透明性と説明責任をどのように達成できるとお考えですか?
A: LLM APIユーザーがモデルの変更を検出できるようにすることで、LLMプロバイダーと顧客の間に信頼関係を築き、プロバイダーに対するより大きな説明責任と透明性をもたらすことができます.また、モデルの監査のための効率的なプロトコルを実装することができ、モデルの安全性とプライバシー保護に役立ちます.提案された方法と結果は、LLM APIのベストプラクティスを変更する必要はなく、むしろAPI顧客が利用できるツールを拡張し、LLMプロバイダーにAPIが露出する情報を警告することができます.
Q: 今回の研究結果は、今後の大規模言語モデルの商業化にとってどのような意味を持つのでしょうか?
A: 私たちの調査結果は、大規模言語モデルの商業化において重要な示唆を与えます.我々の発見は、APIで保護されたLLMから非公開情報を学習することが可能であることを示しています.これは、モデルのアーキテクチャについて保守的な仮定を行うことで、わずかなAPIクエリ(例:OpenAIのgpt-3.5-turboの場合、\( \small 1,000未満のコスト)から多くの情報を取得できることを意味します.このような情報漏洩は、LLMのプロバイダーにとっては潜在的な脅威となり、ユーザーにとっては潜在的なセキュリティリスクをもたらす可能性があります.将来の大規模言語モデルの商業化においては、セキュリティとプライバシーの重要性が一層高まるでしょう.
LLM4Decompile: Decompiling Binary Code with Large Language Models
著者:Hanzhuo Tan, Qi Luo, Jing Li, Yuqun Zhang
発行日:2024年03月08日
最終更新日:2024年03月08日
URL:http://arxiv.org/pdf/2403.05286v1
カテゴリ:Programming Languages, Computation and Language
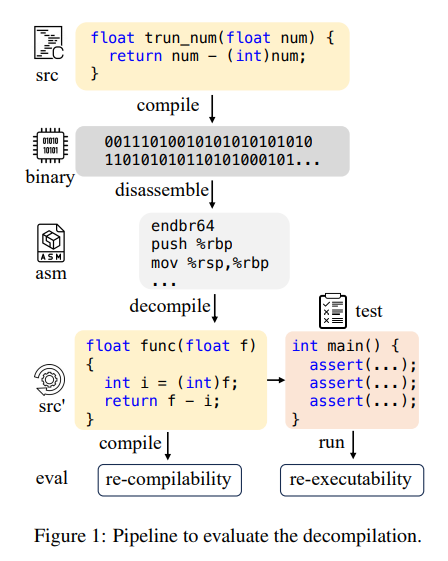
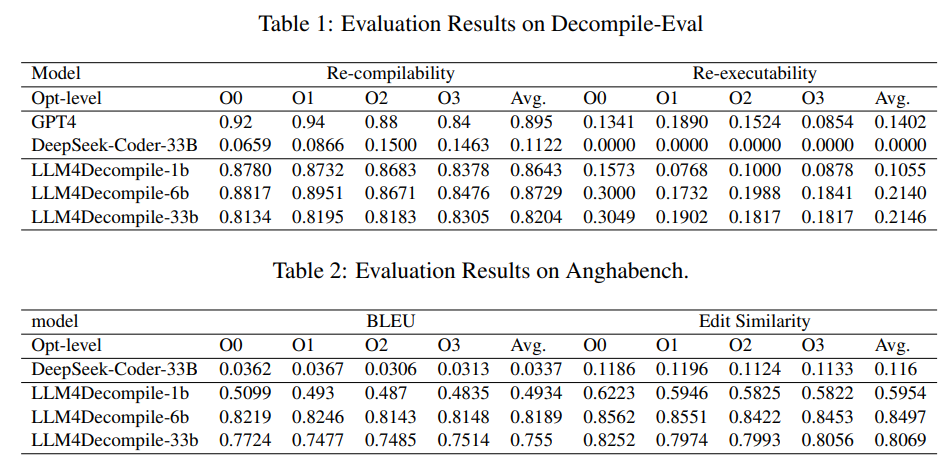
概要:
デコンパイルは、コンパイルされたコードを人間が読めるソースコードに復元することを目指していますが、名前や構造などの詳細に苦労しています.大規模言語モデル(LLMs)はプログラミングタスクにおいて有望性を示しており、そのためデコンパイルに応用されています.しかし、デコンパイル用のオープンソースLLMは存在していません.さらに、既存のデコンパイル評価システムは主にトークンレベルの精度を考慮しており、プログラムの最も重要な特徴であるコードの実行可能性をほとんど無視しています.そのため、我々は、C言語のソースコードと対応するアセンブリコードの40億トークンで事前学習された1Bから33Bまでの初のオープンアクセスデコンパイルLLMをリリースします.このオープンソースLLMは、この分野でのさらなる開発のためのベースラインとして機能することができます.実用的なプログラム評価を確保するために、デコンパイルのための再コンパイル可能性と再実行可能性を考慮した初のデータセットであるDecompile-Evalを紹介します.このベンチマークは、プログラムの意味論的観点からデコンパイルモデルを評価する重要性を強調しています.実験結果は、我々のLLM4Decompileが21%の精度で正確にデコンパイルできる能力を示していることを示しています.LLM4Decompileは、アセンブリコードの21%を正確にデコンパイルする能力を示し、GPT-4よりも50%の改善を達成しています.当該コード、データセット、およびモデルは、https://github.com/albertan017/LLM4Decompile で公開されています.
Q&A:
Q: 大規模言語モデル(LLM)をデコンパイルタスクに適用する動機について教えてください.
A: 大規模言語モデル(LLMs)を逆コンパイルタスクに適用する動機は、コンパイルされたコードを人間が読めるソースコードに復元することを目指す逆コンパイルの課題に対処するためです.逆コンパイルは、名前や構造などの詳細に苦労していますが、LLMsはプログラミングタスクにおいて有望性を示しており、逆コンパイルに応用することが動機となっています.既存の逆コンパイル評価システムは、主にトークンレベルの精度を考慮しており、コードの実行可能性をほとんど無視していますが、これはどんなプログラムにおいても最も重要な特徴です.そのため、我々は、Cソースコードと対応するアセンブリコードの4億トークンで事前学習された1Bから33Bまでのオープンアクセス逆コンパイルLLMsをリリースしました.これらのオープンソースLLMsは、この分野でのさらなる開発のためのベースラインとして機能することができます.
Q: Decompile-Evalを作るきっかけとなった、既存の逆コンパイル評価システムの限界とは?
A: 既存の逆コンパイル評価システムの限界は、公開されていないため、この分野でのさらなる進歩を促進することが制限されていることです.さらに、逆コンパイル技術を評価および比較するための標準化されたベンチマークデータセットが存在しないことが最大の問題です.研究者は異なるデータセットを使用して結果を評価する傾向があり(da Silva et al.、2021; Collie et al.、2020; Tan et al.、2017)、直接比較が困難になっています.そのため、逆コンパイルパフォーマンスを評価するためのベンチマークを確立する必要があり、これは逆コンパイル領域のための一貫した標準評価基準の策定を大幅に容易にする可能性があります.
Q: デコンパイル用のLLMはどのように事前学習され、どのようなデータで学習されたのですか?
A: LLMは、4 billion tokensのCソースコードとそれに対応するアセンブリコードで事前学習されました.データはAng-habenchに基づいて構築されたasm-sourceペアに基づいています.
Q: Decompile-Evalデータセットで再コンパイル可能性と再実行可能性を考慮する意義について詳しく教えてください.
A: Decompile-Evalデータセットで再コンパイル可能性と再実行可能性を考慮することの重要性は、デコンパイルシステムの評価をプログラムの意味論の観点から行うことを強調しています.再コンパイル可能性は、構文理解を示し、再実行可能性は、意味の保存を示唆しています.これにより、デコンパイルモデルの性能をより包括的に評価し、プログラムのセマンティクスに焦点を当てることができます.また、再コンパイル可能性と再実行可能性を考慮することで、デコンパイルシステムの信頼性や実用性を向上させることができます.
Q: LLM4DecompileはGPT-4のような以前のモデルと比べて、具体的にどのような改善を示していますか?
A: LLM4Decompileは、GPT-4に比べて、アセンブリコードの21%を正確に逆コンパイルできる能力を示し、50%の改善を達成しています.
Q: デコンパイル用に公開されたオープンアクセスのLLMを、開発者はどのように使うことを想定していますか?
A: オープンアクセスのLLMを使用する開発者は、コンパイルされたコードを人間が読めるソースコードに復元するために使用することができます.これにより、デコンパイルされたコードの名前や構造などの詳細を取り戻すことが可能となります.また、LLMはプログラミングタスクにおいて有望であり、デコンパイルに応用することができます.これにより、プログラムの再コンパイル可能性や再実行可能性を考慮した実用的なプログラム評価が可能となります.LLMを使用することで、プログラムのセマンティクスの観点からデコンパイルモデルを評価することが重要であり、開発者はこのオープンソースのLLMをベースラインとして、さらなる開発に活用することができます.
Q: LLM4Decompileの開発において、どのような課題に遭遇し、どのように対処しましたか?
A: LLM4Decompileの開発において遭遇した課題は、コンパイルされたコードを人間が読めるソースコードに復元することであり、特に名前や構造などの詳細に苦労しました.この課題は、元のプログラムの意味を保持することができないことが挙げられます.そのため、DeepSeek-Coderのベースバージョンは、バイナリを正確に逆コンパイルすることができませんでした.コードは正しく見えることがあり、時にはコンパイル可能であることがありましたが、元のプログラムの意味を保持することができませんでした.しかし、LLM4Decompileモデルを微調整した結果、バイナリを正確に逆コンパイルする能力が著しく向上しました.コードの構造と構文に対する堅固な理解を示し、約90%のコードがコンパイル可能であることを示しました.また、コードを実行する能力に関しては、LLM4Decompileの6Bバージョンは1Bバージョンよりも優れており、6Bバージョンから逆コンパイルされたコードの21%が実行可能であることが示されました.
Q: 今後、デコンパイルLLMをどのように発展させ、改善していく予定ですか?
A: 将来的な開発と改善において、我々はまず、既存のdecompilation LLMsの性能を評価し、問題点を特定する必要があります.その後、トークンレベルの精度だけでなく、コードの実行可能性を考慮に入れた新しい評価システムを導入することが重要です.また、ランダム性による非決定的な結果を排除し、一貫した性能評価を行うために、入力と出力サンプルの生成方法を改善する必要があります.更に、既存のモデルの統合に関する課題を解決し、より使いやすいオープンソースのLLMを開発することが重要です.
Q: LLM4Decompileの性能を評価するための実験方法について教えてください.
A: LLM4Decompileのパフォーマンスを評価するために使用された実験方法について、以下の手順が取られました.まず、Decompile-Evalデータセットを使用し、再コンパイル可能性と再実行可能性を考慮しました.次に、LLM4Decompileモデルがアセンブリコードの21%を正確に逆コンパイルできる能力を示す実験が行われました.この結果は、GPT-4よりも50%の改善を達成しました.さらに、6Bバージョンから逆コンパイルされたコードの21%がプログラムの意味を正確に捉え、すべてのテストケースに合格することができました.
Q: LLM4Decompileで行われた実験から、デコンパイルの精度とパフォーマンスに関して重要なことは何でしょうか?
A: LLM4Decompileの実験から得られた主な結果は、アセンブリコードの21%を正確に逆コンパイルできる能力を示し、これはGPT-4よりも50%の改善を達成していることです.また、LLM4Decompileモデルは、90%の逆コンパイルコードがGCCコンパイラで同じ設定を使用して再コンパイル可能であることを示し、コード構造と構文の理解が確固たるものであることを示しています.さらに、6BバージョンのLLM4Decompileから逆コンパイルされたコードの21%が実行可能であることが示されています.
