
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をLLMによって生成されるQ&Aを用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.自動生成記事のクオリティと信頼性を向上させるためにアルゴリズムの改善に取り組んでいます.個人で資料のQ&Aを作成されたい方には、https://www.chatpdf.com/ や https://scispace.com/などがお勧めです.
紹介する論文は以下の10本となります.
- C4AI Command-R
発行日:2024年03月15日
2024年3月18日15:48、35億のパラメータを持つC4AI Command-R生成モデルがCohereによって開発されました.10の言語で高性能なRAG機能を備えています. - Scaling Instructable Agents Across Many Simulated Worlds
発行日:2024年03月14日
SIMAプロジェクトは、言語を基盤として行動するシステムを構築し、自由形式の命令に従うエージェントを訓練しており、言語と具体的な行動を結びつけることを目指しています.さらに、光学文字認識(OCR)を使用したり、エージェントの行動を記録したビデオの人間による評価を行ったりするなど、さまざまな評価方法を開発しています.この報告書の残りの部分では、SIMAの究極の目標である、どのような仮想3D環境でも人間ができることを達成できる指示可能なエージェントを開発するための高レベルなアプローチ(図1に示されている)と初期の進捗状況について説明します. - MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
発行日:2024年03月14日
MLLMsの構築において、画像エンコーダとデータ選択の重要性を研究し、30BパラメータのMM1モデルを構築してSOTAを達成し、競争力のあるパフォーマンスを示す. - Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
発行日:2024年03月14日
文章や話す際、人々は推論を含む合理的な考え方を学ぶために一時停止することがあり、Quiet-STaRはLMに合理的な推論を生成させることで、予測の改善を図る新しい手法を提案している. - Knowledge Conflicts for LLMs: A Survey
発行日:2024年03月13日
LLMにおける知識の衝突に関する詳細な分析を提供し、コンテキストとパラメトリック知識の組み合わせによる課題を強調. - Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
発行日:2024年03月12日
BTXは、LLMsを複数の専門分野で効率的にトレーニングする方法で、高いスループットと通信コストの削減を実現し、最良の精度と効率のトレードオフを提供する. - Stealing Part of a Production Language Model
発行日:2024年03月11日
この論文では、ブラックボックスプロダクション言語モデルから情報を抽出するモデル盗用攻撃を紹介し、具体的にはtransformerモデルの埋め込み射影層を回復する攻撃を行い、OpenAIのAdaとBabbage言語モデルの全埋め込み射影行列を20ドル未満で抽出し、gpt-3.5-turboモデルの隠れた次元サイズを推定します. - Is Cosine-Similarity of Embeddings Really About Similarity?
発行日:2024年03月08日
コサイン類似度は、ベクトル間の角度の余弦を用いて意味的な類似性を定量化するが、正則化された線形モデルから導出された埋め込みを研究することで、意味のない「類似性」を生み出す方法を解析的に導出する. - RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation
発行日:2024年03月08日
情報検索を活用した「検索強化思考(RAT)」は、大規模言語モデルの性能を向上させ、GPT-3.5やGPT-4などに適用すると、コード生成や数学的推論、創造的な執筆、タスク計画のパフォーマンスが大幅に向上する. - Large language models surpass human experts in predicting neuroscience results
発行日:2024年03月04日
科学的な発見は、大規模言語モデル(LLMs)を使用して、神経科学の結果を予測する際に専門家を上回る可能性があることが示された.
C4AI Command-R
著者:Cohere, Cohere For AI
発行日:2024年03月15日
最終更新日:不明
URL:https://huggingface.co/CohereForAI/c4ai-command-r-v01
カテゴリ:不明
概要:
2024年3月18日15:48、Hugging FaceのCohereForAI/c4ai-command-r-v01は、35億のパラメータを持つ高性能な生成モデルであるC4AI Command-Rの研究リリースを行いました.Command-Rは、オープンウェイトを持つ大規模な言語モデルであり、理論、要約、質問応答などのさまざまな用途に最適化されています.Command-Rは、10の言語で評価され、高性能なRAG機能を備えています.
このモデルは、CohereとCohere For AIによって開発されました.モデルのライセンスはCC-BY-NCであり、C4AIの利用規約にも従う必要があります.モデルのサイズは35億のパラメータで、コンテキストの長さは128Kです.
モデルを試すためには、Inference Endpoints(専用)で起動する必要があります.このモデルは、C4AI Command-Rの非量子化バージョンであり、rafaaa2105/C4AI-Command-Rに量子化バージョンが含まれています.
新しいコンテキストを加えると、モデルはbitsandbytesを介して量子化され、8ビット精度で処理されています.使用方法は、transformers、bitsandbytes、accelerateをインストールし、指定されたコードを実行することで可能です.
また、このモデルは、自己回帰言語モデルであり、最適化されたトランスフォーマーアーキテクチャを使用しています.事前学習後、このモデルは、監督されたファインチューニング(SFT)および選好トレーニングを使用して、モデルの振る舞いを人間の好みに合わせ、有用性と安全性に関する人間の選好に一致させます.
さらに、このモデルは、英語、フランス語、スペイン語、イタリア語、ドイツ語、ブラジルポルトガル語、日本語、韓国語、簡体字中国語、アラビア語のような言語で優れたパフォーマンスを発揮するように最適化されています.事前学習データには、ロシア語、ポーランド語などの追加の13の言語も含まれています.
Command-Rは、会話ツールの使用能力を持つように特別にトレーニングされています.これらは、特定のプロンプトテンプレートを使用して、監督されたファインチューニングと選好ファインチューニングの組み合わせによってモデルにトレーニングされました.このプロンプトテンプレートから逸脱すると、性能が低下する可能性がありますが、実験を奨励しています.
Command-Rは、特定のツール使用機能を持ち、会話を入力として受け取り、利用可能なツールのリストと共に、json形式のアクションリストを生成します.モデルは、直接回答ツールを認識し、他のツールを使用したくない場合に使用します.また、文書スニペットのリストに基づいて回答を生成し、情報の出典を示す接地スパン(引用)を含めることができるため、接地生成機能を持っています.この振る舞いは、監督されたファインチューニングと選好ファインチューニングの組み合わせによってモデルにトレーニングされました.プロンプトテンプレートから逸脱すると、性能が低下する可能性がありますが、実験を奨励しています.Command-Rの接地生成振る舞いは、会話を入力として受け取り、取得された文書スニペットのリストと共に、オプションのユーザー提供のシステム前文を使用します.文書スニペットは、長い文書ではなく、通常100〜400語程度のチャンクであるべきです.文書スニペットは、キーと値のペアで構成されています.キーは短い記述的な文字列であるべきで、値はテキストまたは半構造化データであっても構いません.Command-Rは、デフォルトで、まず関連する文書を予測し、次に引用する文書を予測し、最後に回答を生成することで接地応答を生成します.
新たなコンテキストにより、Command-Rは正確な接地生成を行うために訓練されており、他の回答モードと組み合わせて選択できます.トークナイザーでサポートされている高速引用モードは、回答を完全に書き出すことなく、直接回答を生成し、その中に接地スパンを挿入します.これにより、トークンの生成を減らす代わりに、一部の接地精度が犠牲になります.
最後に、プロンプトをレンダリングし、生成して解析する最小限の作業例を示すコードスニペットが以下に示されています.接地生成に関するプロンプト戦略の包括的なドキュメントとガイドは、後続の段階で提供される予定です.
コードスニペットを使用して、Command-Rはコードスニペット、コードの説明、またはコードの書き直しをリクエストすることで、コードと対話するように最適化されています.デフォルトでは、そのままでは十分なパフォーマンスを発揮しないかもしれませんが、コードの変更によって選択できる他の回答モードで動作します.
このモデルのリリースにより、35億のパラメータを持つ高性能なモデルの重みが世界中の研究者に公開され、コミュニティベースの研究活動がよりアクセスしやすくなることを期待しています.このモデルは、CC-BY-NCライセンスによって管理されており、許容可能な使用追加規定があり、C4AIの利用規約にも従う必要があります.
Q&A:
Q: C4AI Command-Rモデルのライセンスは何ですか?
A: C4AI Command-RモデルのライセンスはCC-BY-NCであり、C4AIの利用規約にも従う必要があります.
Q: C4AIのCommand-Rモデルにはいくつのパラメータがありますか?
A: C4AI Command-Rモデルのパラメータ数は350億です.
Q: C4AI Command-Rモデルのコンテキストの長さは?
A: C4AI Command-Rモデルのコンテキスト長は128Kです.
Q: Command-Rモデルの能力は?
A: Command-Rモデルの能力には、多言語生成能力と高性能なRAG機能が含まれています.このモデルは、会話ツールの使用能力を持ち、特定のプロンプトテンプレートを使用して、会話を入力として受け取り、利用可能なツールのリストと共に、実行するアクションのjson形式のリストを生成します.また、直接回答ツールを認識し、他のツールを使用したくない場合に使用します.このモデルは、特定のプロンプトテンプレートから逸脱すると性能が低下する可能性がありますが、実験を奨励しています.
Q: 誰がCommand-Rモデルを開発したのですか?
A: Command-RモデルはCohereとCohere For AIによって開発されました.
Q: Command-Rモデルはいくつの言語で評価されましたか?
A: Command-Rモデルは10言語で評価されました.
Q: Command-RモデルはPythonコードでどのように使えるのか?
A: Command-Rモデルは、Pythonコード内で使用するために、transformersライブラリを使用してpip installする必要があります.その後、モデルは会話と利用可能なツールのリストを入力として受け取り、それらのツールのサブセットに対して実行するアクションのjson形式のリストを生成します.直接回答ツールを含めることを推奨しますが、実験を奨励します.ツールの使用プロンプトに関する包括的なドキュメントとガイドが提供されます.
Q: Pythonのコード・スニペットにおけるBitsAndBytesConfigの目的は何ですか?
A: BitsAndBytesConfigは、8ビットの精度でモデルを読み込むための設定を行うために使用されます.
Q: モデルはどのようにビットとバイトで量子化できるのか?
A: モデルはbitsandbytesを介して量子化されることができます.具体的には、BitsAndBytesConfigを使用して、_load_in_8bit=Trueと設定し、モデルを8ビット精度で読み込むことができます.
Q: 推論APIを使用するためにモデルをロードする推奨の方法は何ですか?
A: モデルを推論API使用に適した方法は、推論エンドポイント(専用)を起動することです.
Scaling Instructable Agents Across Many Simulated Worlds
著者:Deep Mind SIMA Team
発行日:2024年03月14日
最終更新日:不明
URL:https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/sima-generalist-ai-agent-for-3d-virtual-environments/Scaling%20Instructable%20Agents%20Across%20Many%20Simulated%20Worlds.pdf
カテゴリ:不明
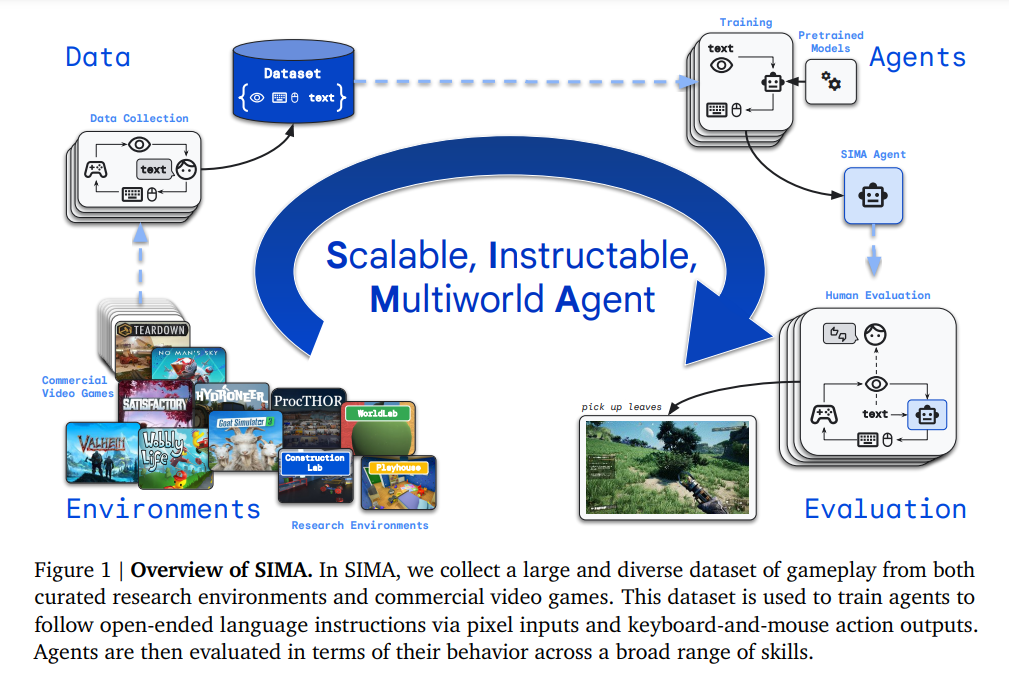
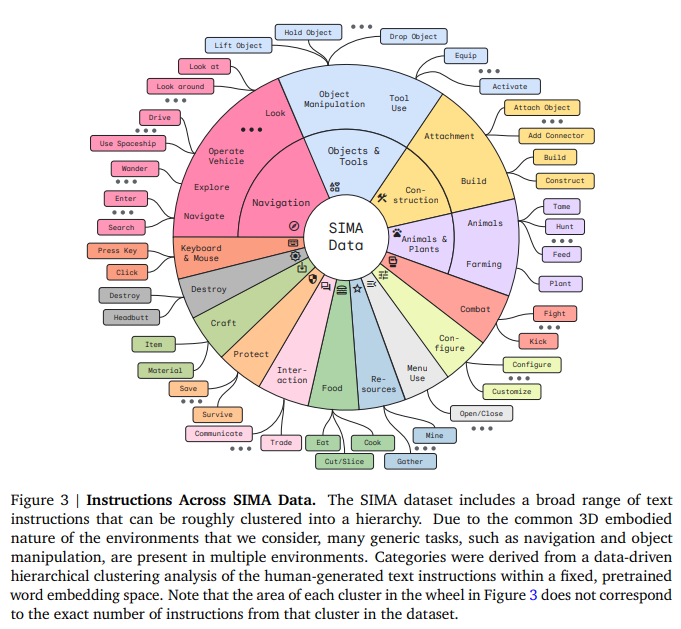
概要:
SIMAプロジェクトは、言語を基盤として行動するシステムを構築することを目指しており、さまざまな仮想3D環境で自由形式の命令に従うエージェントを訓練しています.この取り組みは、言語と具体的な行動を結びつけることが、一般的な具体的なAIを開発するための中核的な課題であることを示唆しています.また、SIMAプロジェクトでは、カスタムビルドの研究環境から商用ビデオゲームまで、さまざまな仮想3D環境でキーボードとマウスのアクションを通じて任意の言語命令に従うことが可能です.これにより、従来の研究とは異なり、多くの仮定を置かずに、多くのシミュレート環境を横断してこの問題に取り組んでいます.さらに、我々のアプローチは、多くの豊かで視覚的に複雑なオープンエンドのビデオゲームを取り入れ、エージェントが人間と同じように環境と対話することを可能にしています.エージェントは、人間と同じキーボードとマウスの操作を使用して環境とやり取りし、単にゲームをプレイして勝率を最大化するのではなく、言語命令に従うことに焦点を当てています.また、エージェントは簡略化された文法やコマンドセットではなく、オープンエンドの自然言語を使用して訓練およびテストされています.これらの設計選択肢は学習問題を難しくしますが、その汎用性により新しい環境への拡張が容易になります.エージェントは、新しいゲームごとに制御と観察空間をカスタム設計する必要なく、同じインターフェースを使用します.さらに、エージェント-環境インターフェースが人間と互換性があるため、エージェントは人間ができることを達成する可能性があり、人間の行動からの直接模倣学習も可能です.新しい文脈を考慮すると、我々のアプローチは、エージェントが以前に学習したスキルを未知のゲームにゼロショットで転送できるようにすることも可能です.また、一般的な仮想環境で研究を行うことで、我々のエージェントを幅広くかつ挑戦的な状況でテストすることができ、視覚的に豊かな知覚と制御を持つロボティクスなどの実世界の応用により適用可能な教訓を得ることが期待されます.SIMAプロジェクトでは、これまでに、ユーザーが生成した言語命令に基づいて短期的なタスクを実行するエージェントを作成してきました.命令は言語モデルによって生成されることもあります.研究環境と商用ビデオゲームからなる10以上の3D環境のポートフォリオを持ち、研究環境ではエージェントをグラウンドトゥルーステートを使用して評価しています.商用ビデオゲームでは、任意の言語タスクの完了を報告するために、光学文字認識(OCR)を使用したり、エージェントの行動を記録したビデオの人間による評価を行ったりするなど、さまざまな評価方法を開発しています.この報告書の残りの部分では、SIMAの究極の目標である、どのような仮想3D環境でも人間ができることを達成できる指示可能なエージェントを開発するための高レベルなアプローチ(図1に示されている)と初期の進捗状況について説明します.
Q&A:
Q: SIMA(スケーラブル、インストラクタブル、マルチワールドエージェント)プロジェクトの目標はどのように定義していますか?
A: SIMAプロジェクトの目標は、仮想3D環境内での任意の言語命令に従い、キーボードとマウスの操作を行うシステムを構築することです.このプロジェクトでは、研究環境から商用ビデオゲームまで幅広い仮想3D環境で行動できるエージェントを開発することを目指しています.言語モデルの大規模なデータに基づくトレーニングが一般的なAIの進歩に最も効果的であることから、SIMAは多様な仮想3D環境で自由形式の命令に従うエージェントをトレーニングすることでこの課題に取り組んでいます.
Q: 多様なバーチャル3D環境で自由形式の指示に従うエージェントを訓練するために、SIMAが取ったアプローチとは?
A: SIMAは、多様な仮想3D環境で自由形式の指示に従うエージェントを訓練するためのアプローチを取っています.このアプローチは、言語駆動型のタスクを中心にしており、エージェントがピクセル入力とキーボードおよびマウスのアクション出力を通じて自由形式の言語指示に従うように訓練されます.エージェントは、幅広いスキルにわたる行動を評価されます.
Q: SIMAプロジェクトでエージェントが使用するインプットとアウトプットについて教えてください.
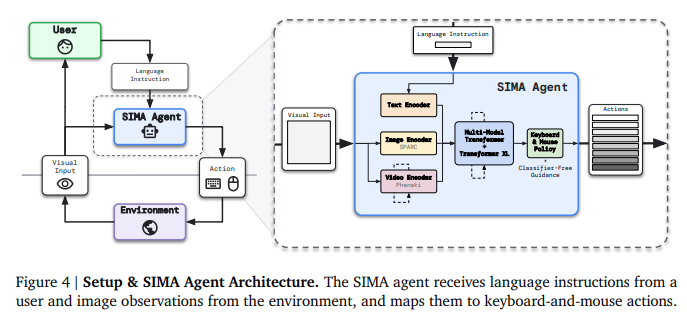
A: SIMAプロジェクトのエージェントが使用する入力は、言語命令と環境からの画像観測であり、出力はキーボードとマウスのアクションです.具体的には、SIMAエージェントはユーザーからの言語命令と環境からの画像観測を受け取り、それらをキーボードとマウスのアクションにマッピングします.このプロセスには、画像エンコーダ、SPARCテキストエンコーダ、ビデオエンコーダ、Phenaki Multi-Modal Transformer、Transformer XL、キーボード&マウスポリシー、およびClassifier-Free Guidanceが含まれます.
Q: 言語主導の一般性という点で、SIMAプロジェクトの主眼は何ですか?
A: SIMAプロジェクトの主な焦点は、言語駆動の一般性にあります.具体的には、言語を介して環境に関する知識を向上させることに焦点を当てています.
Q: SIMAプロジェクトは、視覚的に複雑で、意味論的に豊かな環境の中で、どのように言語を基礎づけることを目指しているのだろうか?
A: SIMAプロジェクトは、視覚的に複雑で意味豊かな環境において言語を基盤とすることを目指しています.このプロジェクトでは、多様な3D環境を使用し、豊富で深い言語の相互作用の可能性を提供することに焦点を当てています.これらの環境は、第一者視点または第三者視点(プレイヤーの肩越しのカメラ)のいずれかであり、商用ビデオゲームやエージェント研究のために作成された環境など、さまざまな環境を使用しています.これにより、言語条件付きの行動を豊富で複雑なシミュレート環境で実現し、エージェントの言語指示を行動に結びつけることが可能となります.
Q: この文章で述べられている最初の進展と有望な予備的結果とは何か?
A: この文章では、SIMAエージェントの初期の進捗と有望な予備結果について言及されています.SIMAエージェントは、豊富な3D環境で言語指示を行動に結びつける能力を示し、環境ごとおよびスキルカテゴリごとに分解されたSIMAエージェントの定量的なパフォーマンスを考慮しました.また、環境間の転送や保留環境への基本的なスキルのゼロショット転送など、注目すべきパフォーマンスと環境間の転送の初期兆候も見られました.しかし、まだ多くのスキルやタスクが手に届かない状態にあります.将来の研究では、より多くの環境にスケールを拡大することを目指しています.
Q: SIMAプロジェクトは、大規模な言語モデルを身体化された世界に接続するという課題にどのように取り組んでいるのだろうか?
A: SIMAプロジェクトは、大規模な言語モデルを具体的な世界に接続する課題に取り組んでいます.これは、言語と事象をスケールで結びつける基本的な課題を克服するために、言語モデルの抽象的な能力を具体的な環境に根付かせることを目指しています.
Q: SIMAがエージェントのトレーニングに使用しているデータセット収集とトレーニングプロセスについて詳しく教えてください.
A: SIMAは、研究環境と商用ビデオゲームからのゲームプレイの大規模かつ多様なデータセットを収集し、エージェントをピクセル入力とキーボードおよびマウスのアクション出力を介して自由な言語命令に従うように訓練します.エージェントは、幅広いスキルにわたる行動を評価されます.データ収集はGoogleと契約を結んだ参加者によって行われ、データ収集プロトコルの詳細は独立した人間行動研究委員会によって審査および承認されました.訓練前に、オフラインの前処理ステップが実行され、エージェント入力のためにデータのリサイズ、さまざまなヒューリスティックを使用して低品質のデータをフィルタリングし、環境とコレクション全体でデータをリミックスおよび重み付けして、最も効果的な学習体験を優先します.
Q: SIMAプロジェクトにおけるエージェントの行動は、幅広いスキルの観点からどのように評価されているのでしょうか?
A: SIMAプロジェクトにおいて、エージェントの行動は、環境とスキルカテゴリーごとに定量的に評価されます.これにより、エージェントの一般化能力と設計選択の効果を評価するため、いくつかのベースラインと削減を比較します.最終的には、人間レベルのパフォーマンスを推定するために、一部の評価タスクを調査します.
Q: SIMAプロジェクトにおけるWorldLabコンストラクション・ラボの意義とは?
A: WorldLab Construction Labは、SIMAプロジェクトにおいて、研究環境の相対的な難しさと評価タスクの重要性を強調するために、その性能が低いことが示されています.
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
著者:Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Floris Weers, Anton Belyi, Haotian Zhang, Karanjeet Singh, Doug Kang, Hongyu Hè, Max Schwarzer, Tom Gunter, Xiang Kong, Aonan Zhang, Jianyu Wang, Chong Wang, Nan Du, Tao Lei, Sam Wiseman, Mark Lee, Zirui Wang, Ruoming Pang, Peter Grasch, Alexander Toshev, Yinfei Yang
発行日:2024年03月14日
最終更新日:2024年03月14日
URL:http://arxiv.org/pdf/2403.09611v1
カテゴリ:Computer Vision and Pattern Recognition, Computation and Language, Machine Learning
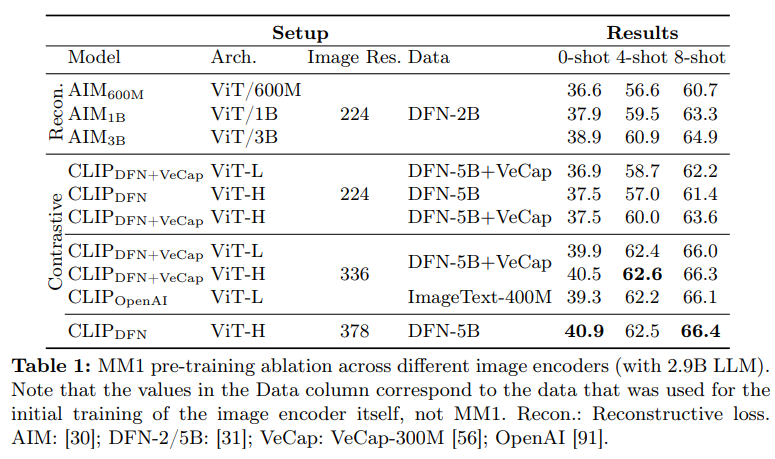
概要:
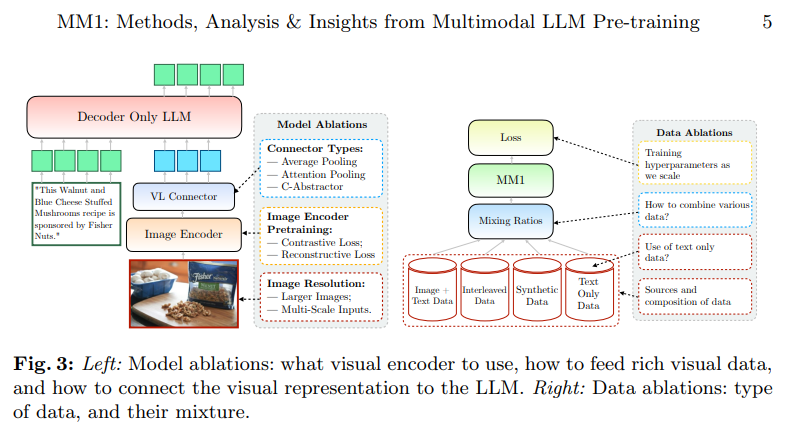
この作品では、パフォーマンスの高いマルチモーダル大規模言語モデル(MLLMs)の構築について議論しています.特に、さまざまなアーキテクチャコンポーネントやデータ選択の重要性について研究しています.画像エンコーダ、ビジョン言語コネクタ、さまざまな事前トレーニングデータの徹底的かつ包括的な削除を通じて、いくつかの重要な設計の教訓を特定しました.たとえば、大規模なマルチモーダル事前トレーニングにおいて、画像キャプション、交互に配置された画像テキスト、およびテキストのみのデータを慎重に組み合わせることが、他の公開された事前トレーニング結果と比較して、複数のベンチマークでSOTAのフューショット結果を達成するために重要であることを示しています.さらに、画像エンコーダと画像解像度、画像トークン数が重要な影響を与える一方、ビジョン言語コネクタの設計は比較的重要ではないことを示しています.提示されたレシピをスケーリングアップすることで、30BパラメータまでのマルチモーダルモデルファミリーであるMM1を構築し、密なモデルとエキスパートの混合(MoE)バリアントを含み、事前トレーニングメトリクスでSOTAを達成し、確立されたマルチモーダルベンチマークの範囲で監督されたファインチューニング後に競争力のあるパフォーマンスを達成します.さらに、MM1は、確立されたマルチモーダルベンチマークの範囲で監督されたファインチューニング後に競争力のあるパフォーマンスを達成するために、多様なプロパティを享受しています.これには、コンテキスト内学習の強化や、複数の画像推論、フューショットの連鎖的な思考促進が含まれます.
Q&A:
Q: マルチモーダル大規模言語モデル(MLLM)を構築する上で研究された主要なアーキテクチャ・コンポーネントは何ですか?
A: 本研究では、Multimodal Large Language Models(MLLMs)を構築する際に、画像エンコーダ、ビジョン言語コネクタ、およびさまざまな事前トレーニングデータの重要性が研究されました.
Q: 最先端の数発勝負の結果を得るための、さまざまな事前学習データの選択の重要性に関して、どのような発見があったのでしょうか?
A: 異なること前トレーニングデータの選択の重要性に関する結論は、キャプションのみのデータを使用した事前トレーニングがSFT評価指標を向上させることがわかった.また、異なるVLコネクターアーキテクチャは最終結果にほとんど影響を与えないことも示された.
Q: 画像-キャプション、画像-テキスト、テキストのみのデータを注意深く組み合わせることが、事前トレーニングの成功にどのように貢献したのだろうか?
A: 画像キャプション、交互画像テキスト、およびテキストのみのデータを注意深く混合することで、事前トレーニングプロセスの成功に貢献しました.特に、テキストのみのパフォーマンスとゼロショットパフォーマンスにおいて、交互およびテキストのみのトレーニングデータが非常に重要であり、キャプションデータはゼロショットパフォーマンスを向上させました.さらに、画像とテキストデータの注意深い混合は、最適なマルチモーダルパフォーマンスをもたらし、強力なテキストパフォーマンスを維持することができました.
Q: 画像エンコーダー、画像解像度、画像トークン数は、モデルの性能にどのような影響を与えたのか?
A: 画像エンコーダー、画像解像度、および画像トークン数は、モデルのパフォーマンスに大きな影響を与えました.低い画像解像度では、凍結された画像エンコーダーの方が解凍された画像エンコーダーよりも優れたパフォーマンスを示しました.一方、高い解像度では、解凍された画像エンコーダーの方が良い結果をもたらしました.画像トークン数や画像解像度を増やすと、ゼロショットおよびフューショットのパフォーマンスが向上することが示されました.
Q: 視覚言語コネクタの設計は、他のアーキテクチャーのコンポーネントと比べてどの程度重要でしたか?
A: ビジョン言語コネクターの設計は、他のアーキテクチャコンポーネントと比較して、比較的重要性が低いとされています.
Q: モデル内のさまざまなコンポーネントのアブレーションを通じて、明らかになった設計上の重要な教訓とは?
A: 異なるモデルのコンポーネントの削減によって特定された主要な設計の教訓は、画像解像度、視覚ハイパーパラメータ、およびモデルのどの部分をどの段階で訓練するかの設計要素の重要性の順序である.
Q: 発表されたレシピをスケールアップすることで、最大30Bのパラメーターを持つマルチモーダルモデルのファミリーであるMM1が開発された経緯は?
A: 提示されたレシピをスケーリングアップすることにより、MM1という30Bのパラメータを持つ複数モダルモデルのファミリーが開発されました.このモデルは密なモデルと専門家の混合(MoE)バリアントから構成されており、事前トレーニングのメトリクスでSOTAを達成し、確立された複数モダルのベンチマークでの監督されたファインチューニング後に競争力のあるパフォーマンスを達成しています.大規模な事前トレーニングのおかげで、MM1は魅力的な特性を持っており、インコンテキスト学習の強化やマルチイメージ推論を可能にし、フューショットのチェーンオブソートプロンプティングを実現しています.
Q: 大規模な事前訓練によって強化されたMM1の特性、例えば文脈内学習や多画像推論とはどのようなものだったのだろうか?
A: MM1は大規模な事前トレーニングによって、コンテキスト内の予測や複数画像の推論などの魅力的な特性を享受しました.
Q: 確立されたマルチモーダルベンチマークで教師ありファインチューニングを行った後、MM1はトレーニング前の指標と競争力の点でどのようなパフォーマンスを示したのでしょうか?
A: MM1は、30Bのパラメータまでの多モーダルモデルファミリーであり、密なモデルと専門家の混合(MoE)バリアントから構成されています.これらのモデルは、事前トレーニングのメトリクスでSOTAであり、確立された多モーダルベンチマークでの監督されたファインチューニング後に競争力のあるパフォーマンスを達成しています.大規模な事前トレーニングのおかげで、MM1は魅力的なfew-shot pre-trainingパフォーマンスを楽しんでいます.少数の例でのパフォーマンスにおいて、MM1は事前トレーニングされたMLLMsに関するすべての公開された先行研究を上回っています.30BでのキャプションベンチマークとVizWiz-QAベンチマークで優れたパフォーマンスを示しています.VQAv2、TextVQA、OKVQAでは、Emu2に匹敵する規模で競争力があります.zero-shotパフォーマンスにおいても、指示のファインチューニングなしで、モデルはTextCaps全体で有利なパフォーマンスを発揮し、ほとんどのベンチマークにおいて小規模なスケールでFlamingo-3Bに匹敵しています.
Q: MM1の思考連鎖プロンプト機能は、マルチモーダルなタスクにおいて、どのようにして推論と理解の向上を可能にしたのだろうか?
A: MM1のfew-shot chain-of-thought prompting機能により、複数の画像を理解し、推論する能力が向上しました.この機能により、4-shotパフォーマンスがゼロショットよりも2.5ポイント高い41.9になり、さらに8-shot chain of thoughtによりパフォーマンスが44.4に向上しました.MM1は事前学習から継承されたコンテキスト内での学習能力を保持しており、混合分解戦略が制限されたエンコーダーロスと容量、およびビジュアルエンコーダーの事前学習データ内でfew-shotパフォーマンスをさらに向上させる効果的であることが示されました.
Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
著者:Eric Zelikman, Georges Harik, Yijia Shao, Varuna Jayasiri, Nick Haber, Noah D. Goodman
発行日:2024年03月14日
最終更新日:2024年03月14日
URL:http://arxiv.org/pdf/2403.09629v1
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning
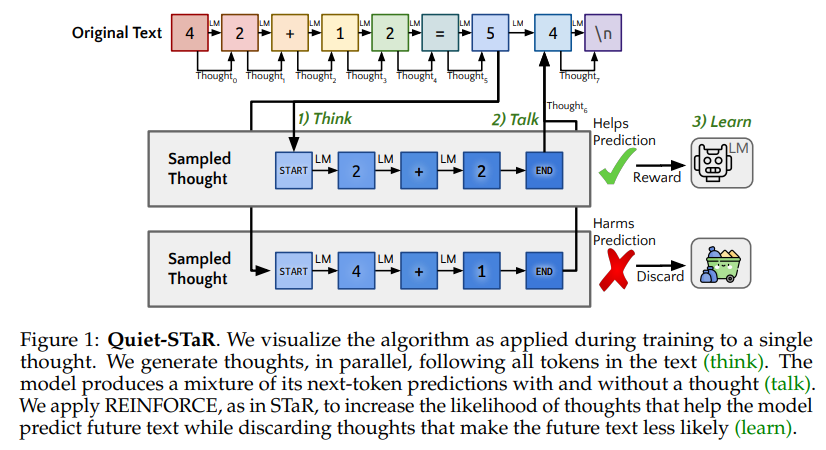
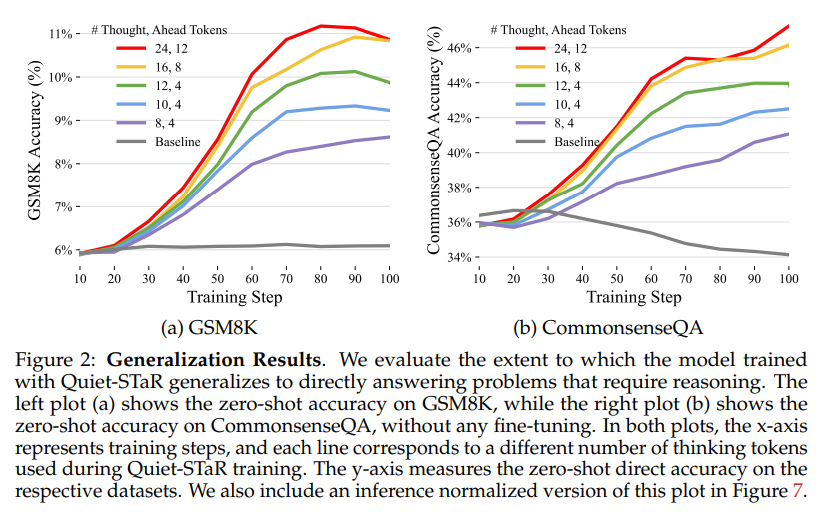

概要:
文章や話す際、人々は考えるために一時停止することがあります.推論に焦点を当てた作品は、推論を質問に答える方法や代理的なタスクを完了する方法としてフレーム化してきましたが、推論はほとんどすべての文章に暗黙的に含まれています.例えば、これは証明の行間に記載されていない手順や会話の基礎となる心の理論にも当てはまります.自己学習推論者(STaR、Zelikman et al. 2022)では、質問に答える際の少数の例から合理的な推論を推論し、正しい答えに導くものを学習します.これは非常に制約のある設定ですが、理想的には言語モデルは任意のテキストで記載されていない合理的な推論を推論することができるはずです.私たちはQuiet-STaRを提案し、これはSTaRの一般化であり、LMsは将来のテキストを説明するために各トークンで合理的な推論を生成することを学習し、予測を改善します.計算コストの生成継続、LMが最初は内部思考を生成または使用する方法を知らないこと、個々の次のトークンを超えて予測する必要があるという主要な課題に対処します.これらを解決するために、トークンごとに提案を行います.さらに、個々の次のトークンを超えて予測する必要がある課題に対処するために、トークンごとの並列サンプリングアルゴリズムを提案し、思考の開始と終了を示す学習可能なトークンと拡張された教師強制技術を使用します.生成された合理的な根拠は、特に予測が困難なトークンにモデルを助け、LMの難しい質問に直接答える能力を向上させることが示されています.特に、Quiet-STaRでインターネットテキストのコーパスでLMを継続的に事前学習した後、GSM8K(5.9%→10.9%)とCommonsenseQA(36.3%→47.2%)でゼロショットの改善が見られ、自然なテキストの難しいトークンのパープレキシティが改善されました.重要なのは、これらの改善にはこれらのタスクの微調整が必要ないことです.Quiet-STaRは、より一般的かつスケーラブルな方法で推論を学習できるLMに向けた一歩を示しています.
Q&A:
Q: Quiet-STaRとSTaR(Self-Taught Reasoner)との違いは?
A: Quiet-STaRは、STaRと比較して、各トークンごとに将来のテキストを説明するための根拠を生成し、予測を改善することで、言語モデルが学習する点が異なります.
Q: Quiet-STaRで取り組んでいる主な課題は何ですか?
A: Quiet-STaRは、様々な非構造化テキストデータから推論を学習することを一般化し、特定のデータセットに特化せずにトレーニングを行うことで、より堅牢で適応性のある言語モデルを示すことを目指しています.Quiet-STaRは、豊富な推論タスクを含む多様なウェブテキストからトレーニングすることで、ダウンストリームの推論パフォーマンスを向上させ、質的に意味のある合理的な根拠を生成します.
Q: Quiet-STaRのトークンワイズ並列サンプリングアルゴリズムはどのように機能するのですか?
A: Quiet-STaRにおけるトークン単位の並列サンプリングアルゴリズムは、入力シーケンス内の各トークン位置で合理的な生成を効率的に行うために設計されています.具体的には、入力シーケンスx0:n内の各トークンxiに対して、長さtのrrationalesを生成し、それぞれの合理性の開始と終了を示す学習可能な<|startofthought |>および<|endofthought |>トークンを挿入します.このアルゴリズムでは、各トークン位置で合理的な生成を並列に行うことで、計算コストを削減し、長いシーケンスに対しても効率的に対応できるようになっています.
Q: Quiet-STaRで学習可能なトークンを使用して、考えの開始と終了を示す意義は何ですか?
A: Quiet-STaRでは、学習可能なトークンを使用して思考の開始と終了を示すことの重要性は、モデルがより有用な合理的根拠を生成するために最適化を加速することにあります.これにより、モデルはトレーニング中により有用な合理的根拠を生成するように訓練されます.
Q: Quiet-STaRは、LMが難しい質問に答える能力をどのように向上させるのですか?
A: Quiet-STaRは、未来のテキストを説明するためにトークンごとに根拠を生成し、その根拠を使用して未来のテキストの予測を行い、REINFORCEを使用してより良い根拠を生成することで、LMの難しい質問に対する能力を向上させます.
Q: Quiet-STaRで事前トレーニングを行った後、GSM8KとCommonsenseQAで観察されたゼロショットの向上はどのようなものだったのでしょうか?
A: GSM8KとCommonsenseQAにおいて、Quiet-STaRで事前学習した後のゼロショット改善は、GSM8Kでは5.9%から10.9%に、CommonsenseQAでは36.3%から47.2%になりました.
Q: Quiet-STaRは、LMがより一般的でスケーラブルな方法で推論を学習することにどのように貢献するのだろうか?
A: Quiet-STaRは、様々な非構造化テキストデータから推論を学習するためにSTaRを一般化しました.これは、キュレーションされた推論タスクや推論タスクのコレクションではなく、テキスト全般から推論を学習するLMを明示的にトレーニングする最初の取り組みです.また、トレーニングを豊富な推論タスクスペクトラムに暗黙的に含まれる多様なウェブテキストで行うことで、特定のデータセットに狭く特化するのではなく、より堅牢で適応可能な言語モデルへの道を示しています.Quiet-STaRは、ダウンストリームの推論パフォーマンスを向上させながら、質的に意味のある根拠を生成するという結果を示しています.このアプローチの可能性を示し、将来的には思考をアンサンブル化してさらなる改善を目指すことができるかもしれません.
Q: Quiet-STARで使われている、教師による強制的な拡大テクニックについて説明してもらえますか?
A: 拡張されたteacher-forcing技術は、Quiet-STaRで使用されています.この技術では、損失に含めることで、思考後のトークンだけでなく、後のトークンの予測の尤度も考慮しています.
Q: Quiet-STARは、継続を生成する計算コストにどのように対処しているのか?
A: Quiet-STaRは、追加のトークンを生成する前に多くのトークンを生成することで、かなりのオーバーヘッドを引き起こします.これは、次のトークンを現在の文脈に基づいて生成できる通常の言語モデルにとっては利点とも見なすことができます.Quiet-STaRは、次のトークンの予測を向上させるために追加の計算を活用する一般的な方法がないことを指摘しています.
Q: Quiet-STaRで事前学習した後、自然文の難解なトークンに見られる改善がどのような意味を持つのか?
A: 困難なトークンの改善は、Quiet-STaRで事前トレーニングした後の自然なテキストにおけるより深い推論と理解を示唆しています.これにより、モデルは自身が生成した思考を活用し、入力についてより徹底的に推論することが成功していることが示されます.
Knowledge Conflicts for LLMs: A Survey
著者:Rongwu Xu, Zehan Qi, Cunxiang Wang, Hongru Wang, Yue Zhang, Wei Xu
発行日:2024年03月13日
最終更新日:2024年03月13日
URL:http://arxiv.org/pdf/2403.08319v1
カテゴリ:Computation and Language, Artificial Intelligence, Information Retrieval, Machine Learning
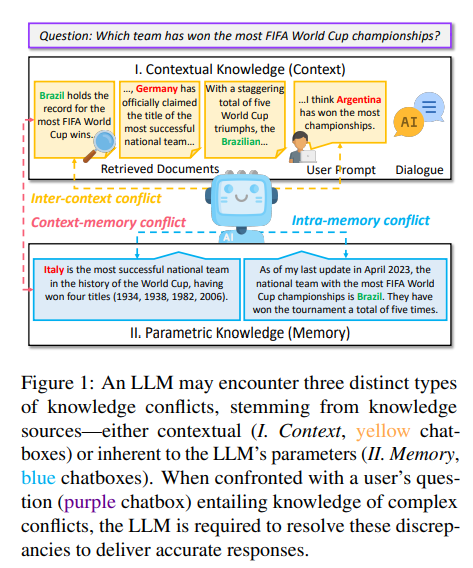
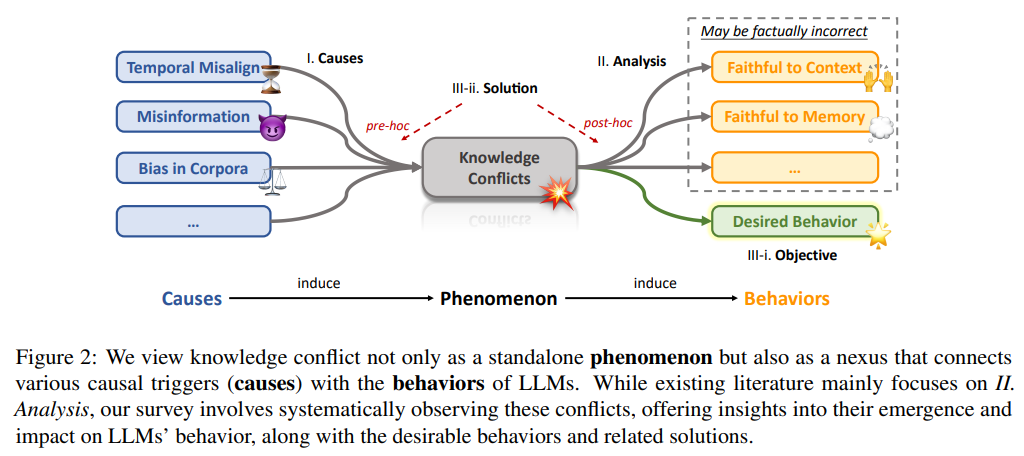
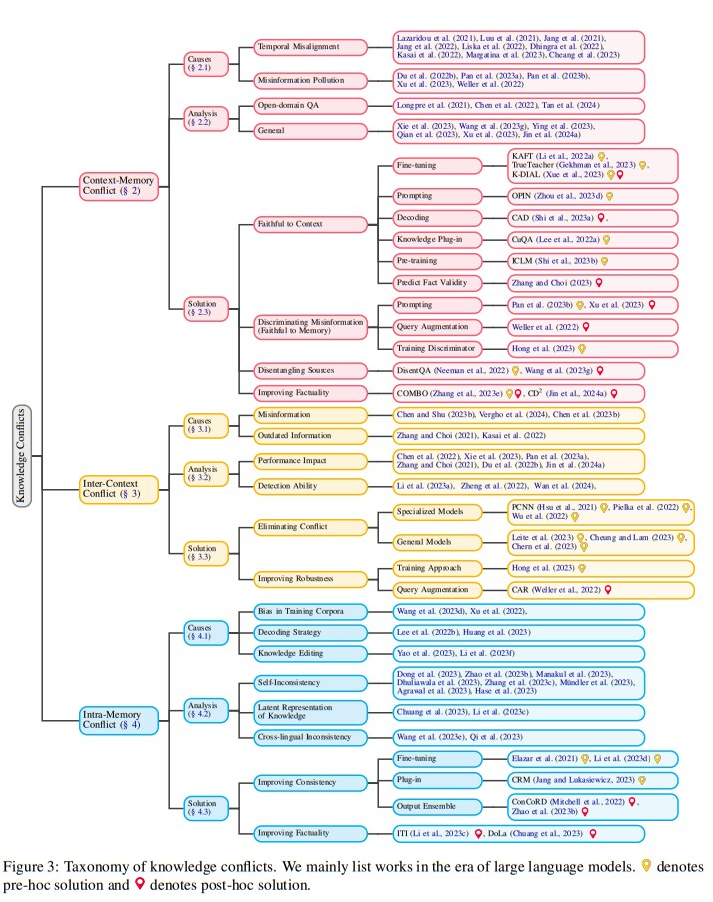
概要:
この調査は、大規模言語モデル(LLM)における知識の衝突について詳細な分析を提供し、コンテキストとパラメトリック知識を組み合わせる際に遭遇する複雑な課題を強調しています.私たちの焦点は、知識の衝突の3つのカテゴリー、つまりコンテキストメモリ、インターコンテキスト、およびイントラメモリの衝突にあります.これらの衝突は、特にノイズや誤情報が一般的な実世界のアプリケーションにおいて、LLMの信頼性とパフォーマンスに大きな影響を与える可能性があります.これらの衝突をカテゴリー分けし、原因を探り、LLMがこのような衝突下でどのような振る舞いをするかを調査し、利用可能な解決策を検討することで、この調査はLLMの堅牢性を向上させる戦略に光を当て、この進化する分野の研究を推進するための貴重なリソースとなることを目指しています.
Q&A:
Q: LLMが遭遇したコンテキストとメモリの衝突の例を教えてください.
A: LLMsが遭遇するコンテキストメモリーの衝突の例として、同じ意味や意図を共有するさまざまな表現に対して一貫した出力を生成することが求められるが、コンテキストメモリーの衝突が発生すると、LLMsは文法的に異なるが意味的に同等な入力に対して予測不能な振る舞いを示し、異なる応答を生成する可能性があります.
Q: 文脈間の対立はLLMの信頼性にどのような影響を与えるのか?
A: インターコンテキストの衝突は、LLMの信頼性に影響を与える可能性があります.外部情報源を組み込む際に、LLMはパラメトリックな知識に従う一方で、コンテキストの影響を受けやすいとされています.この外部知識が事実に反している場合、LLMの信頼性に問題が生じる可能性があります.信頼性の問題は、LLMの実時間の正確性や堅牢性にも影響を及ぼす可能性があります.そのため、LLMの信頼性を高めるためには、知識の衝突についてより深く探求することが重要です.
Q: LLMでよくあるメモリ内競合の原因は何ですか?
A: LLM内の記憶内の衝突の一般的な原因には、トレーニングコーパスのバイアス、デコーディング戦略、知識編集があります.
Q: 知識の衝突は、実世界のアプリケーションにおけるLLMのパフォーマンスにどのような影響を与えるのか?
A: 大規模言語モデル(LLMs)の性能に影響を与える知識の衝突は、特に実世界のアプリケーションにおいて、LLMsの信頼性とパフォーマンスに重大な影響を与える可能性があります.これは、文脈とパラメータの知識を組み合わせる際に生じる複雑な課題を強調しています.具体的には、文脈-メモリ、文脈間、およびメモリ内の衝突の3つのカテゴリーが挙げられます.これらの衝突は、LLMsの信頼性とパフォーマンスに大きな影響を与える可能性があります.
Q: コンテキストとメモリーの競合に直面したときのLLMの行動を説明できますか?
A: LLMは、コンテキストと記憶の衝突に直面した際の振る舞いを説明します.先行研究によると、LLMは与えられたコンテキスト情報と学習済み情報が矛盾する場合、パラメトリックな知識に過度に依存する傾向があることが明らかになっています.また、最近の研究では、LLMが知識の衝突に対処する際の振る舞いを出力レベルで分析し、ユーザーの意見に合わせる傾向があることが指摘されています.内部メカニズムや特定の注意ヘッド、ニューロンの活性化など、モデルが衝突に遭遇した際にどのように判断するかをよりよく理解するために、より微視的な検証が必要であることが強調されています.
Q: LLMにおける知識の衝突に対処するために、どのような解決策が提案されてきたか?
A: LLMにおける知識の衝突を解決するために提案された解決策は、既存の先行研究が事前の仮定に基づいているか、あるいは特定の衝突のサブクラスに焦点を当てていることが挙げられます.また、実際の検索結果から矛盾する文書を収集し、それに基づいて衝突を調査する研究も行われています.今後は、人工的に作成された衝突ではなく、実世界のシナリオでLLMがどのように機能するかを評価する研究にますます関心が集まっています.
Q: 知識の衝突を分類することで、LLMの頑健性をどのように向上させることができるのか?
A: 知識の衝突をカテゴリー分けすることによって、LLMの頑健性を向上させることができます.これは、LLMが異なる種類の知識衝突にどのように対処するかを理解し、それに応じた適切な対策を講じるための基盤を提供するからです.
Q: ノイズや誤った情報が存在する中で、LLMの信頼性を高めるための戦略にはどのようなものがあるだろうか?
A: ノイズや誤情報が多い状況において、LLMの信頼性を向上させるためのいくつかの戦略には、衝突を分類し、原因を探り、LLMがそのような衝突下でどのような振る舞いをするかを調査し、利用可能な解決策を見直すことが含まれます.これにより、LLMの堅牢性を向上させる戦略に光を当て、この進化する分野の研究を推進するための貴重なリソースとなることを目指しています.
Q: LLM分野の研究を進めるために、研究者はこの調査結果をどのように活用できるのか?
A: この調査の結果を活用することで、LLMの分野における研究を進めることができます.具体的には、この調査が提供する戦略を適用し、LLMの頑健性を向上させるための新しいアプローチを開発することが重要です.また、実世界のシナリオでのLLMのパフォーマンスを評価し、その能力をよりよく理解するために、より多くの研究が必要です.
Q: この調査から、LLMと仕事をする実務家にとって重要なことは何でしょうか?
A: この調査からの主な収穫は、LLMと共に作業する実務者にとって、文書のクエリに対する関連性を重視するだけでなく、科学的な参照文献の存在やテキストの中立的なトーンなど、人間が重要視するスタイル的な特徴を見落とさないことが重要であることです.また、LLMは真実の情報と誤情報を区別するのに苦労し、コンテキスト内で最も頻繁に現れる証拠を好み、内部メモリに一致する外部情報に確証バイアスを示すことが分かっています.
Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
著者:Sainbayar Sukhbaatar, Olga Golovneva, Vasu Sharma, Hu Xu, Xi Victoria Lin, Baptiste Rozière, Jacob Kahn, Daniel Li, Wen-tau Yih, Jason Weston, Xian Li
発行日:2024年03月12日
最終更新日:2024年03月12日
URL:http://arxiv.org/pdf/2403.07816v1
カテゴリ:Computation and Language, Artificial Intelligence
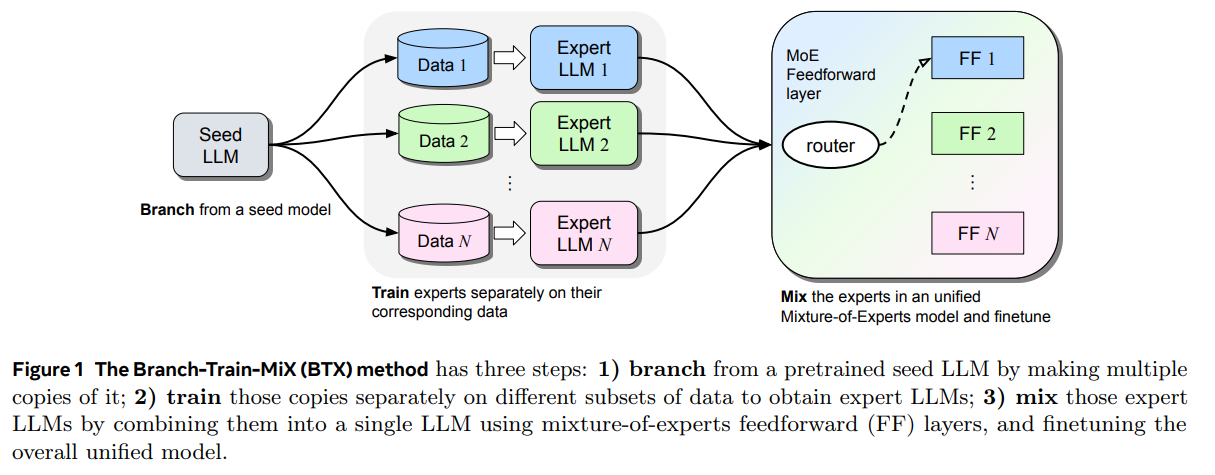
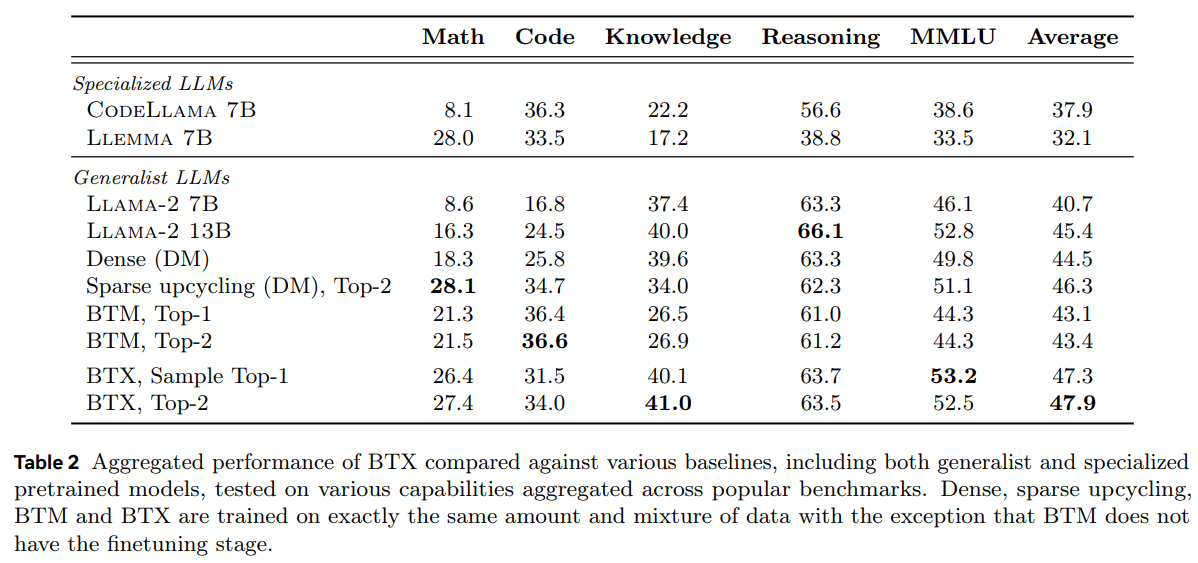
概要:
私たちは、Large Language Models(LLMs)を複数の専門分野(コーディング、数学的推論、世界知識など)で能力を持つように効率的なトレーニング方法を調査しています.私たちの方法であるBranch-Train-MiX(BTX)は、シードモデルから始まり、高いスループットと通信コストの削減を伴う恥ずかしいほど並列な専門家をトレーニングするために分岐します.個々の専門家が非同期にトレーニングされた後、BTXは彼らの順伝播パラメータをMoE(Mixture-of-Expert)レイヤーの専門家としてまとめ、残りのパラメータを平均化し、その後MoEファインチューニング段階でトークンレベルのルーティングを学習します.BTXは、MoEファインチューニング段階でルーティングを学習しないBranch-Train-Mergeメソッドと、専門家を非同期にトレーニングする段階を省略するsparse upcyclingという2つの特殊なケースを一般化します.代替手法と比較して、BTXは最良の精度と効率のトレードオフを実現しています.
Q&A:
Q: BTX(Branch-Train-MiX)メソッドが大規模言語モデル(LLM)で開発しようとしている具体的な機能について教えてください.
A: Branch-Train-MiX(BTX)メソッドは、大規模言語モデル(LLMs)に特定の能力を開発することを目指しています.BTXは、専門分野でのコーディング、数学的推論、世界知識など、複数の特化領域での能力を持つLLMsを効率的にトレーニングする方法を研究しています.BTXは、シードモデルから始まり、恥ずかしげな並列ファッションで専門家をトレーニングすることで、高いスループットと通信コストの削減を実現します.個々の専門家が非同期にトレーニングされた後、BTXは彼らのフィードフォワードパラメータをMoEレイヤーの専門家としてまとめ、残りのパラメータを平均化し、その後MoEファインチューニング段階に進み、トークンレベルのルーティングを学習します.
Q: BTXメソッドは、専門領域のLLMを養成する従来の方法とどう違うのですか?
A: BTXメソッドは、従来のLLMを特定のドメインでトレーニングする方法と異なり、複数の専門家を微調整するアプローチを提供します.これにより、指示の微調整やRLHF手順に直接適用できます.しかし、本論文では事前トレーニング段階に焦点を当てているため、将来の研究にそのまま残しています.
Q: シードモデルを枝分かれさせ、恥ずかしながら並行してエキスパートを育成するプロセスについて詳しく教えてください.
A: シードモデルから専門家LLM(M1、…、MN)をトレーニングするために、各モデルMiはそれぞれのデータセットDiを使用して独立してトレーニングされます.これにより、全体のトレーニングプロセスがN方向に驚くほど並列化されます.このトレーニングパラダイムにはいくつかの利点があります.コンピューティングのサイズを拡大するときに、全体のトレーニングスループットを線形スケーリングすることができます.一方、ジョイントトレーニングはバッチサイズを増やすことで不確実なパフォーマンスに直面することがよくあります.また、オール・トゥ・オール通信コストが低くなります.また、単一のトレーニングの失敗が発生した場合、Nつのトレーニングプロセスのうちの1つだけに影響を与えるため、より弾力性があります.
Q: BTX法において、MoE(Mixture-of-Expert)層に個々のエキスパートのフィードフォワードパラメータをまとめることの意義は何か?
A: 個々の専門家のフィードフォワードパラメータをMixture-of-Expert(MoE)レイヤーで結合することにより、BTX方法では、各トークンでどの専門家のフィードフォワードを使用するかを選択するためのルーターネットワークを学習することができます.これにより、モデルはより適切にデータを処理し、トークンレベルでのルーティングを学習することができます.
Q: BTXメソッドにおけるMoE-ファインチューニングステージは、トークンレベルのルーティング学習にどのように貢献しているのでしょうか?
A: BTXメソッドにおけるMoEファインチューニング段階は、トークンレベルのルーティングを学習するために重要です.この段階では、専門家としてのエキスパートLLMsが組み込まれ、残りのパラメーターが平均化されます.そして、MoEファインチューニングによって、トークンレベルのルーティングが学習されます.これにより、モデルは異なるタスクにおいて適切なエキスパートを選択し、適切なルーティングを行うことができるようになります.
Q: BTX法とBranch-Train-Merge法の違いを、ルーティングの学習という観点から説明していただけますか?
A: BTXメソッドとBranch-Train-Mergeメソッドの違いは、ルーティングの学習方法にあります.BTXメソッドでは、MoEのファインチューニング段階を通じてトークンレベルのルーティングを学習します.一方、Branch-Train-Mergeメソッドでは、ルーティングを学習するMoEのファインチューニング段階が存在しません.そのため、BTXメソッドは、MoEのファインチューニングを通じて学習されたルーティングの利点を示し、タスク全体で優れたパフォーマンスを発揮します.
Q: BTX法におけるスパース・アップサイクリングの目的と、それが非同期のエキスパート訓練に与える影響とは?
A: スパースアップサイクリングの目的は、専門家のトレーニングを非同期に行うことで、モデルの効率を向上させることです.スパースアップサイクリングは、専門家のトレーニングを並列化し、モデルの事前トレーニング段階での効率を高めるために使用されます.
Q: BTX法の精度と効率のトレードオフは、複数の専門領域のLLMを訓練するための代替アプローチと比較してどうなのか?
A: BTX法は、複数の専門分野でLLMを訓練するための代替手法と比較して、精度と効率のトレードオフが優れています.BTX法は、より大きな汎用LLMを訓練するよりも計算効率が高く、複数の個別に特化したLLMを訓練するよりも計算効率が高いことがわかりました.これらの洞察は、遅い事前訓練段階で計算をどのように割り当てるかを示すことができ、強力な汎用モデルを実現することができます.
Q: 大規模言語モデルの学習にBTXメソッドを使用する主な利点は何ですか?
A: BTXメソッドを使用することの主な利点は、他のアプローチと比較して最適な精度と効率のトレードオフを達成することです.BTXは、MoEモデルのトレーニングにおいて、ドメイン専門家のトレーニングとMoEモデルの微調整を含む、総合的なトレーニングコンピュート効率を向上させます.他のアプローチと比較して、BTXは高い性能を持ち、特に密なモデルやBranch-Train-Mergeよりも優れた結果をもたらします.
Q: BTX法がLLM能力を大きく向上させた専門領域の例を教えてください.
A: BTXメソッドがLLMの能力を大幅に向上させた専門分野の例として、数学、コーディング、世界知識などが挙げられます.これらの分野では、BTXは専門家が特化したタスク全体で改善をもたらしました.特に、数学とコーディングの分野では、他のタスクに影響を与えることなく、大幅な改善が見られました.
Stealing Part of a Production Language Model
著者:Nicholas Carlini, Daniel Paleka, Krishnamurthy Dj Dvijotham, Thomas Steinke, Jonathan Hayase, A. Feder Cooper, Katherine Lee, Matthew Jagielski, Milad Nasr, Arthur Conmy, Eric Wallace, David Rolnick, Florian Tramèr
発行日:2024年03月11日
最終更新日:2024年03月11日
URL:http://arxiv.org/pdf/2403.06634v1
カテゴリ:Cryptography and Security

概要:
この論文では、OpenAIのChatGPTやGoogleのPaLM-2などのブラックボックスプロダクション言語モデルから正確で重要な情報を抽出する最初のモデル盗用攻撃を紹介しています.具体的には、通常のAPIアクセスを利用して、transformerモデルの埋め込み射影層(対称性を含む)を回復する攻撃を行います.20ドル未満で、私たちの攻撃はOpenAIのAdaとBabbage言語モデルの全埋め込み射影行列を抽出します.これにより、これらのブラックボックスモデルがそれぞれ1024および2048の隠れた次元を持っていることを初めて確認します.また、gpt-3.5-turboモデルの正確な隠れた次元サイズを回復し、全埋め込み射影行列を回復するために2000ドル未満のクエリが必要であると推定します.最後に、潜在的な防御策と緩和策についてまとめ、私たちの攻撃を拡張する可能性のある将来の研究の影響について議論します.
Q&A:
Q: ブラックボックス化されたプロダクション言語モデルから、どのようにしてトランスフォーマーモデルの埋め込み投影レイヤーを抽出することができるのか、もう少し詳しく説明していただけますか?
A: 攻撃は、言語モデルの最終層を直接抽出することができる.具体的には、言語モデルの最終層が隠れた次元から(より高次元の)ロジットベクトルに射影することを利用しています.この最終層は低ランクであり、モデルのAPIに対してターゲットされたクエリを行うことで、埋め込み次元や最終重み行列を抽出することができます.
Q: 攻撃を成功させるためには、具体的にどのようなAPIアクセスが必要なのか?
A: 攻撃が成功するためには、モデルからトークンを送信または受信するAPIアクセスが必要です.
Q: OpenAIのAdaとBabbage言語モデルの全射影行列を抽出するコストを20ドル未満と決定した方法は何ですか?
A: OpenAIのAdaとBabbage言語モデルの全射影行列を抽出するコストが20ドル未満であることは、攻撃が重み行列抽出攻撃であるためです.この攻撃では、Typical APIアクセスを使用して、transformerモデルの埋め込み射影層(対称性まで)を回復します.攻撃が成功するため、AdaとBabbageモデルの全射影行列を抽出するコストが20ドル未満であることが確認されました.
Q: エイダとバベッジの言語モデルの隠し次元が1024と2048であることを確認するために、どのような方法を用いましたか?
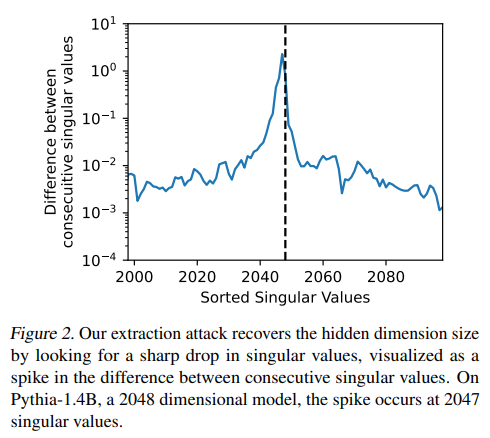
A: AdaおよびBabbage言語モデルの隠れた次元が1024および2048であることを確認するために使用した方法は、SVD(特異値分解)でした.具体的には、最終出力層の次元が隠れた次元よりも大きい場合、SVDを使用してモデルの隠れた次元を回復することができます.この手法により、Adaモデルの隠れた次元が1024であることと、Babbageモデルの隠れた次元が2048であることを確認しました.
Q: gpt-3.5-turboモデルの正確な隠し寸法をどうやって復元したのですか?
A: gpt-3.5-turboモデルの隠れた次元サイズを正確に回復するために、完全なレイヤースティーリング攻撃を実行しました.我々は、我々の抽出された重みが実際の重みとほぼ同一であり、誤差が7×10^{-4}未満であることを確認しました.この攻撃によって、h×h行列積を介して、抽出された重み行列と実際のモデルの重みの間のRMSが報告されました.
Q: この攻撃に対する潜在的な防御策や緩和策について、もっと詳しく教えてください.
A: 攻撃に対する潜在的な防御策と緩和策については、ログイットバイアスと出力ログ確率の両方を提供できる場合、攻撃が10倍安くなることが示唆されています.これは自然な緩和策を示唆しており、同時にログイットバイアスとログ確率を使用するAPIクエリを禁止することです.この種の防御は、敵対者を誤解させ、モデルが実際よりも広いと思わせることができます.
Q: あなたの攻撃を拡大する可能性のある将来の仕事について、どのような示唆があると思いますか?
A: 攻撃を拡張する可能性については、モデルの最後の層(およびそれによって隠された次元)を回復することで、より多くのグローバル情報が明らかになる可能性があります.これにより、異なるモデル間の相対的なサイズの違いなど、モデルに関するより多くの情報が得られるかもしれません.また、量子化された重みを使用して対称性を破ることで、大規模な製品モデルに対する攻撃を改善する可能性があります.
Q: ブラックボックス化された生産言語モデルから抽出される情報の精度と正確性は、どのようにして確保したのですか?
A: 情報を抽出する際の精度と正確性を確保するために、我々は最終層のモデルを直接抽出する攻撃を行いました.具体的には、言語モデルの最終層が隠れた次元からより高い次元への射影を行うことを利用しました.また、最終層から抽出することで、より高い精度を持つモデルを再構築することが可能となりました.
Q: 生産言語モデルに対するモデル盗用攻撃の研究から得られた重要な要点や洞察は何ですか?
A: 研究により、我々はブラックボックスのプロダクション言語モデルに対するモデル盗用攻撃に関する重要な洞察を得ました.具体的には、我々の攻撃は、一般的なAPIアクセスを利用して、トランスフォーマーモデルの埋め込み射影層(対称性を含む)を回復することができます.我々の攻撃は、20ドル未満でOpenAIのadaおよびbabbage言語モデルの完全な射影行列を抽出します.これにより、これらのブラックボックスモデルには、それぞれ1024および2048の隠れた次元があることを初めて確認しました.また、gpt-3.5-turboモデルの正確な隠れた次元のサイズを回復し、全体の射影行列を回復するために2000ドル未満のクエリが必要であると推定しました.さらに、OpenAIとGoogleは、我々の攻撃に対応するためにAPIを変更し、攻撃者がこの攻撃を行うのをより困難にするための防御策を導入しました.
Is Cosine-Similarity of Embeddings Really About Similarity?
著者:Harald Steck, Chaitanya Ekanadham, Nathan Kallus
発行日:2024年03月08日
最終更新日:2024年03月08日
URL:http://arxiv.org/pdf/2403.05440v1
カテゴリ:Information Retrieval, Machine Learning

概要:
コサイン類似度は、2つのベクトル間の角度の余弦、またはそれらの正規化の内積である.一般的な応用例は、学習された低次元の特徴埋め込みにコサイン類似度を適用して、高次元オブジェクト間の意味的な類似性を定量化することである.これは、実際には埋め込まれたベクトル間の非正規化の内積よりもうまく機能することがあるが、時には悪化することもある.この経験的な観察を理解するために、正則化された線形モデルから導出された埋め込みを研究する.閉形式の解が解析的な洞察を可能にする.コサイン類似度が任意のため意味のない「類似性」を生み出す方法を解析的に導出する.一部の線形モデルでは、類似性は一意ではなく、他のモデルでは正則化によって暗黙的に制御される.線形モデルを超えた含意について議論する.深層モデルを学習する際には、異なる正則化の組み合わせが使用される.これらは、結果の埋め込みのコサイン類似度を取る際に暗黙的で意図しない効果を持ち、結果が不透明であり、可能性として任意である.これらの洞察に基づいて、我々は、コサイン類似度の盲目的な使用に注意を喚起し、代替手段を概説する.
Q&A:
Q: コサイン類似度と正規化ベクトル間のドット積の違いを説明できますか?
A: コサイン類似度は、2つのベクトル間の角度のコサインであり、正規化されたベクトル間の内積と同等です.一方、正規化されたベクトル間の内積は、ベクトルの大きさによらず、方向のみを考慮するため、スケーリングの影響を受けません.
Q: 低次元の特徴埋め込みに余弦類似度を適用すると、高次元のオブジェクト間の意味的類似性がどのように定量化されるのか?
A: 低次元特徴埋め込みにコサイン類似度を適用することで、高次元オブジェクト間の意味的類似性を定量化することができます.コサイン類似度は、2つのベクトル間の角度のコサイン、またはそれらの正規化されたベクトルの内積として定義されます.これにより、学習された低次元特徴埋め込みにコサイン類似度を適用することで、ベクトル間の方向の整列が重要であり、ベクトルのノルムはそれほど重要ではないという考え方が反映されます.
Q: なぜコサイン類似度が非正規化ドット積よりも実際に機能するのか、あるいは機能しないのか、詳しく教えてください.
A: コサイン類似度が実践上で正規化されていないドット積よりも良い結果をもたらす場合と悪い結果をもたらす場合について、その理由は、埋め込みベクトル間の方向の整合性が重要であるためです.コサイン類似度は、ベクトルの正規化によって方向の情報が保持されるため、高次元オブジェクト間の意味的類似性を定量化する際に有用です.一方、正規化されていないドット積は、埋め込みベクトル間の方向の整合性に焦点を当てるため、場合によってはコサイン類似度よりも優れた結果をもたらすことがあります.
Q: 閉形式の解を持つ正則化線形モデルから得られる埋め込みを研究して、どのような洞察を得ましたか?
A: 正則化された線形モデルから導出された埋め込みを研究することで、余弦類似性が任意であり、したがって意味のない「類似性」を生じる可能性があることを解析的に導き出しました.一部の線形モデルでは、類似性は一意ではなく、他のモデルでは正則化によって暗黙的に制御されています.これらの洞察に基づいて、余弦類似性の盲目的な使用に注意を喚起し、代替手段を概説しました.
Q: どうしてコサイン類似度が、この文章で言及されているような恣意的で無意味な類似性をもたらすのか?
A: コサイン類似度が任意および意味のない類似性を生じる可能性があるのは、学習された埋め込みにおいて自由度が存在するためです.具体的には、コサイン類似度自体ではなく、学習された埋め込みが、任意のコサイン類似性を生じる可能性がある自由度を持っていることが原因です.これにより、コサイン類似度は任意の結果を生じる可能性があります.したがって、コサイン類似度はそのままでは意味を持たず、学習された埋め込みの自由度によって任意の結果が生じることが示されています.
Q: なぜ線形モデルによっては類似性が一意でないのか、また他のモデルでは正則化によってどのように制御されるのか、説明できますか?
A: 一部の線形モデルでは、類似性が一意でない理由は、コサイン類似度が任意の値を取る可能性があるためです.一方、他の線形モデルでは、正則化によって類似性が制御されます.正則化は、埋め込みベクトル間の類似性を制御する重要な役割を果たし、結果として類似性が一意になるように調整されます.
Q: ディープモデルの学習で採用される正則化の違いは、結果として得られる埋め込みの余弦類似度を取るときに、どのように意図しない効果をもたらすのか?
A: 異なる正則化が深層モデルの学習に使用されると、その結果の埋め込みのコサイン類似度を取る際に意図しない影響を持つ可能性があります.これにより、結果が不透明であり、任意のものになる可能性があります.
Q: 埋め込み画像の余弦類似度を取った結果は、どのような形で不透明なものになるのだろうか?
A: 埋め込みのコサイン類似度を取ることで、結果が不透明であり、可能性としては任意のものになる可能性がある.これは、学習された埋め込みが任意のコサイン類似度を生じさせる自由度を持っているためであり、その結果、類似度が意味をなさなくなる可能性がある.
Q: あなたの洞察に基づき、なぜコサイン類似度をやみくもに使うことに警告を発するのですか?
A: 私たちの洞察に基づいて、コサイン類似度を盲目的に使用することに注意を喚起し、この問題を緩和するためのいくつかの代替手段を提案しています.線形モデルに基づく洞察を可能にする線形モデルに限定されたこの短い論文では、コサイン類似度がどのように意味を持たないものになる可能性があるかを解説しました.深層モデルで学習された埋め込みのコサイン類似度が、さまざまな正則化手法の組み合わせによって同様の問題、あるいはそれ以上の問題に悩まされる可能性があると予想しています.深層モデルの異なる層に異なる正則化が適用されるため、異なる潜在次元のスケーリングが暗黙的に決定され、各層の学習された埋め込みの異なる潜在次元に対する影響を決定します.
RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation
著者:Zihao Wang, Anji Liu, Haowei Lin, Jiaqi Li, Xiaojian Ma, Yitao Liang
発行日:2024年03月08日
最終更新日:2024年03月08日
URL:http://arxiv.org/pdf/2403.05313v1
カテゴリ:Computation and Language, Artificial Intelligence
概要:
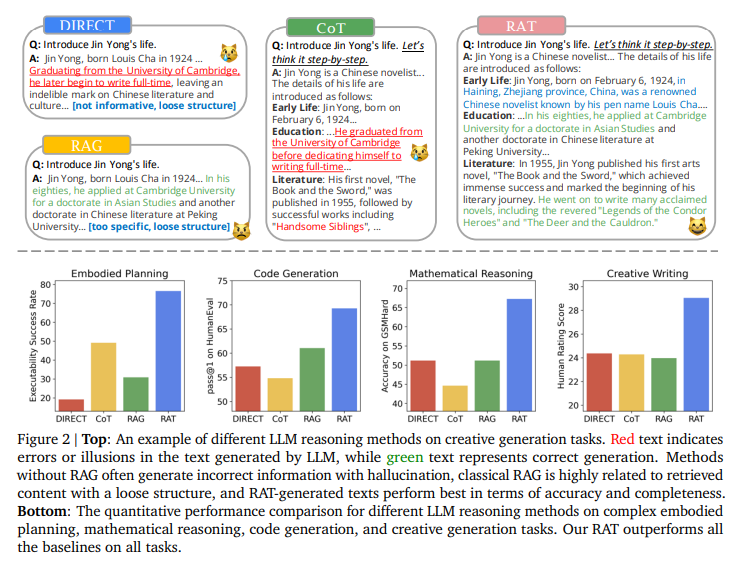
この研究では、情報検索を活用して一連の思考を反復的に修正することが、大規模言語モデルの推論能力と生成能力を著しく向上させることを探求しています.特に、提案された方法である「検索強化思考(RAT)」は、ゼロショットのCoTが生成された後、タスククエリ、現在の思考ステップ、過去の思考ステップに関連する情報を検索して、各思考ステップを一つずつ修正します.GPT-3.5、GPT-4、CodeLLaMA-7bにRATを適用すると、さまざまな長期生成タスクでのパフォーマンスが大幅に向上し、コード生成では評価スコアが平均13.63%、数学的推論では16.96%、創造的な執筆では19.2%、具体的なタスク計画では42.78%向上しました.デモページはhttps://craftjarvis.github.io/RATでご覧いただけます.
Q&A:
Q: 検索された情報を使って各思考ステップを修正するRAT(retrieval-augmented thoughts)法がどのように機能するのか、もう少し詳しく説明してもらえますか?
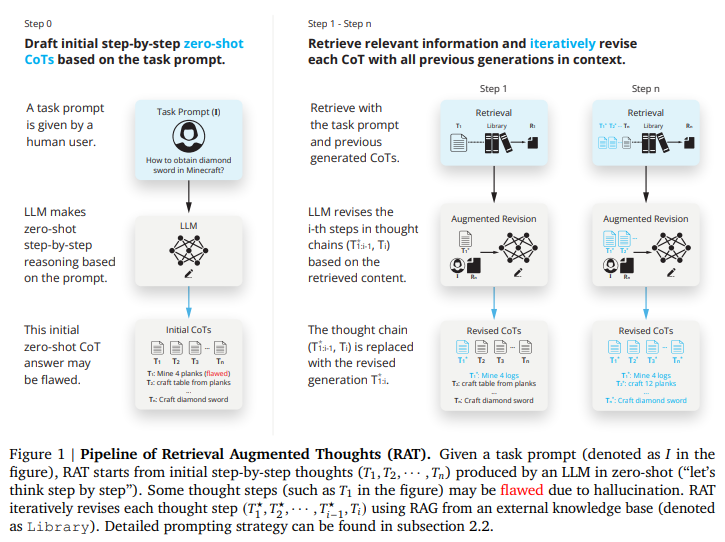
A: Retrieval Augmented Thoughts(RAT)メソッドは、タスククエリ、現在および過去の思考ステップに関連する取得情報を反復的に修正することによって機能します.このプロセスにより、長期的な生成タスクにおける大規模言語モデルの推論および生成能力が向上し、幻覚が減少します.最初に、ゼロショットのChain of Thought(CoT)が生成されます.その後、RATは、取得情報を組み込むことで、1つずつ思考ステップを修正します.この取得情報は、外部知識を提供することで、モデルの推論プロセスを向上させ、意思決定や計画立案を支援します.RATを利用することで、GPT-3.5、GPT-4、CodeLLaMA-7bなどのモデルは、コード生成、数学的推論、創造的な執筆、具体的なタスク計画などのさまざまなタスクで著しい性能向上を示しています.
Q: GPT-3.5、GPT-4、CodeLLaMA-7bにRATを適用することで、長ホライズン生成タスクでの性能がどのように向上するのか?
A: RATをGPT-3.5、GPT-4、およびCodeLLaMA-7bに適用することで、長期的な生成タスクのパフォーマンスが向上します.具体的には、コード生成では13.63%、数学的推論では16.96%、創造的執筆では19.2%、具体的なタスク計画では42.78%の相対的な評価スコアの平均が向上します.
Q: RATがパフォーマンスの大幅な向上を示した具体的なロングホライズン発電タスクの例を教えてください.
A: RATは数学的推論タスクにおいて、GSM8Kでの正確性が8.37%向上し、GSMHardでは31.37%向上し、GPT-3.5モデルに適用した際には全体的な平均改善率が18.44%に達した.また、Minecraftにおけるオープンエンドの具体的な計画タスクでも、RATは他のすべての手法を大きく上回り、実行可能性において76.67±8.02%、妥当性において29.37の人間評価スコアを達成した.
Q: RATはどのようにして幻覚を軽減しているのか?
A: RATは、情報検索を用いて、タスククエリ、現在および過去の思考ステップに関連する情報を取得し、各思考ステップを一つずつ修正することで、幻覚を軽減します.
Q: 提案された方法における最初のゼロショットCoTの意義は?
A: 提案された方法における初期のゼロショットCoTの重要性は、複雑な問題解決タスクを容易にするための段階的推論プロセスをシミュレートすることにあります.これにより、ゼロデモンストレーションの下で問題解決を促進し、最終的な回答を生成するためのLLMsの振る舞いを刺激することができます.
Q: 検索された情報とタスクのクエリー、現在、過去の思考ステップとの関連性をどのように判断するのか?
A: 情報の関連性を決定するために、現在の思考ステップと過去の思考ステップに加えて、タスククエリをクエリとして変換し、Retrieval Augmented Generation(RAG)を使用して関連文書を取得します.この取得された情報は、タスククエリと思考ステップに追加され、修正された思考ステップを生成するために使用されます.修正された思考ステップは、最終的なモデル応答として使用されるか、コード生成や創造的な執筆などのタスクの場合は、LLMによってさらに促されてステップバイステップで完全な応答を生成するようになります.
Q: 情報検索の助けを借りて、思考の連鎖を繰り返し修正するプロセスをより詳しく説明していただけますか?
A: 情報検索を通じた思考の連鎖の反復的な修正プロセスは、より正確で信頼性の高い生成された出力を向上させるのに役立ちます.この反復プロセスは、継続的に更新されるコンテキストに基づいて検索と推論のステップを洗練させることで、より正確で関連性の高い情報検索を可能にし、それがさらに正確な最終回答をサポートします.
Q: GPT-3.5、GPT-4、CodeLLaMA-7bの性能向上は、RATを使用した場合とRATを使用しなかった場合でどのように比較されますか?
A: GPT-3.5、GPT-4、およびCodeLlama-7bを使用した場合、RATを使用すると性能が向上します.具体的には、GPT-3.5モデルにRATを適用すると、平均18.44%の相対的な改善が見られました.同様に、GPT-4にRATを適用すると、DIRECTからRATへの相対的な改善率は10.26%でした.これに対して、CodeLlama-7bでは性能の低下が示されました.これは、小さな言語モデルの文脈学習能力の制限によるものです.
Q: 他の言語モデルや生成タスクにRATメソッドを実装する場合、どのような制限や課題が考えられますか?
A: RATメソッドを他の言語モデルや生成タスクに実装する際の潜在的な制限や課題には、以下のようなものが考えられます.まず、RATは大規模な言語モデルに対しては効果的であることが示されていますが、小規模な言語モデルには適用しづらい可能性があります.小規模な言語モデルでは、RATが適切に機能せず、性能の低下を招く可能性があります.また、RATは特定のタスクにおいては効果的である一方で、他のタスクにおいては適用が難しい場合もあります.さらに、RATを導入することで、モデルの学習や処理における複雑さが増すため、実装や管理が困難になる可能性も考えられます.
Q: 自然言語処理や人工知能の分野でのRAT手法の将来的な応用をどのように想定していますか?
A: RAT方法は、情報検索を活用して思考の連鎖を反復的に修正することで、大規模言語モデルの推論能力と生成能力を著しく向上させることができます.これにより、幻想を大幅に軽減しながら、長期的な生成タスクにおいて優れたパフォーマンスを発揮します.RATは、ゼロショットのプロンプトアプローチであり、難解なコード生成、数学的推論、具体的なタスク計画、創造的な執筆などのタスクにおいて、バニラのCoTプロンプト、RAG、および他のベースラインよりも優れた利点を示しています.RATは、言語モデルの性能をさまざまな長期的な生成タスクで大幅に向上させ、コード生成では評価スコアを平均13.63%、数学的推論では16.96%、創造的な執筆では19.2%、具体的なタスク計画では42.78%向上させています.RATの将来の応用としては、自然言語処理や人工知能の分野において、より高度な推論能力や生成能力を持つシステムの開発に貢献することが期待されます.
Large language models surpass human experts in predicting neuroscience results
著者:Xiaoliang Luo, Akilles Rechardt, Guangzhi Sun, Kevin K. Nejad, Felipe Yáñez, Bati Yilmaz, Kangjoo Lee, Alexandra O. Cohen, Valentina Borghesani, Anton Pashkov, Daniele Marinazzo, Jonathan Nicholas, Alessandro Salatiello, Ilia Sucholutsky, Pasquale Minervini, Sepehr Razavi, Roberta Rocca, Elkhan Yusifov, Tereza Okalova, Nianlong Gu, Martin Ferianc, Mikail Khona, Kaustubh R. Patil, Pui-Shee Lee, Rui Mata, Nicholas E. Myers, Jennifer K Bizley, Sebastian Musslick, Isil Poyraz Bilgin, Guiomar Niso, Justin M. Ales, Michael Gaebler, N Apurva Ratan Murty, Leyla Loued-Khenissi, Anna Behler, Chloe M. Hall, Jessica Dafflon, Sherry Dongqi Bao, Bradley C. Love
発行日:2024年03月04日
最終更新日:2024年03月14日
URL:http://arxiv.org/pdf/2403.03230v2
カテゴリ:Neurons and Cognition, Artificial Intelligence
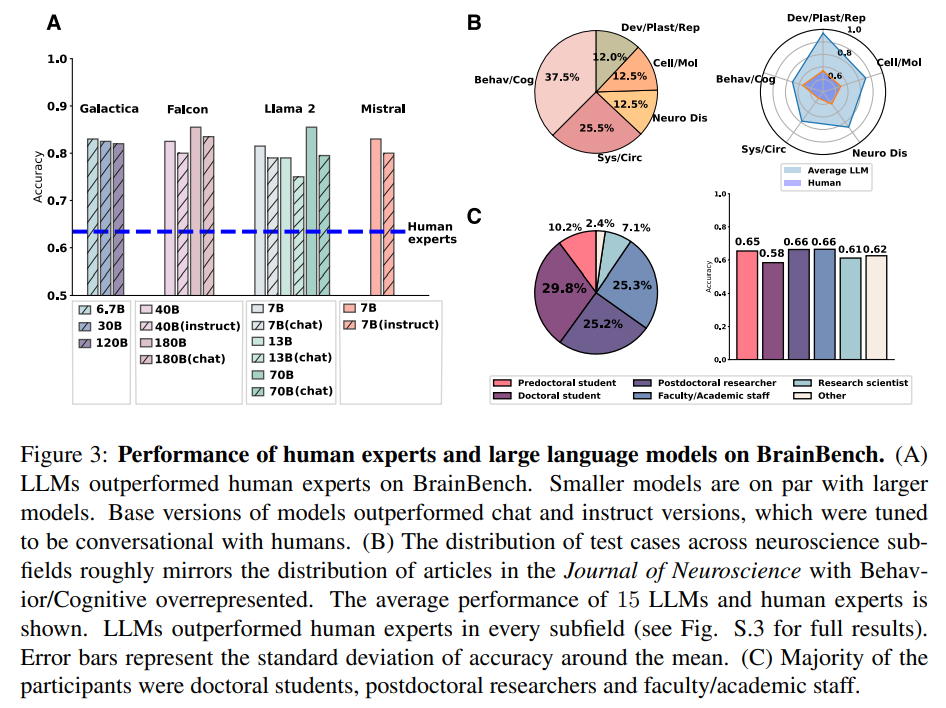
概要:
科学的な発見はしばしば数十年にわたる研究を統合することにかかっており、これは人間の情報処理能力を超える可能性がある.大規模言語モデル(LLMs)はその解決策を提供している.科学文献に基づいて訓練されたLLMsは、ノイズの多いが相互に関連する知見を統合し、人間の専門家よりも新しい結果を予測する可能性がある.この可能性を評価するために、私たちは神経科学の結果を予測するための先進的なベンチマークであるBrainBenchを作成した.我々は、LLMsが実験結果を予測する際に専門家を上回ることを発見した.神経科学の文献に調整されたLLMであるBrainGPTは、さらに優れた成績を収めた.LLMsも人間の専門家と同様に、自分たちの予測に自信を持っているときには、正しい可能性が高くなることがわかった.これは、人間とLLMsが協力して発見をする未来を予見している.私たちのアプローチは神経科学に特化しておらず、他の知識集約的な取り組みにも応用可能である.
Q&A:
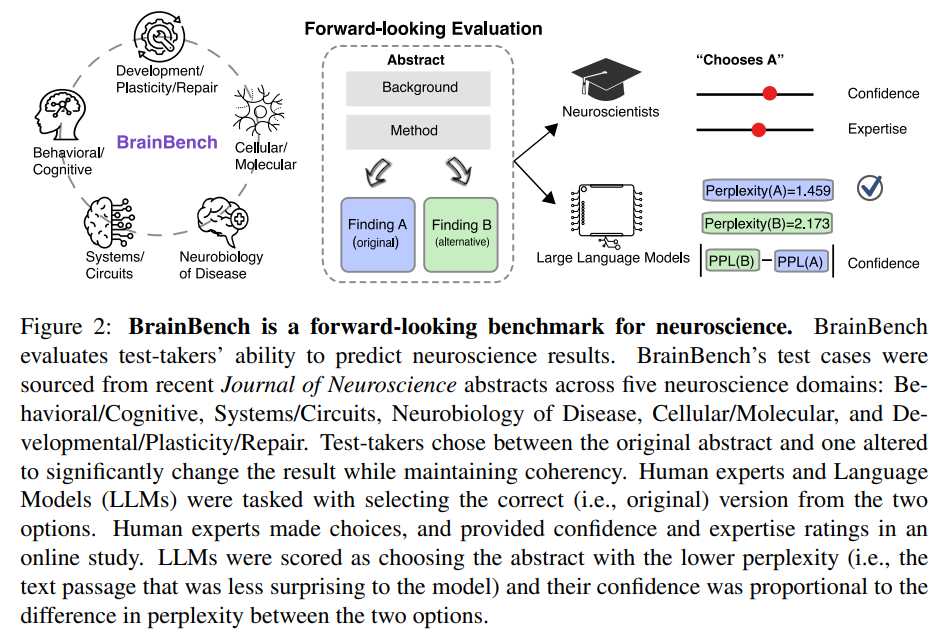
Q: 神経科学の結果を予測するベンチマークであるBrainBenchはどのようにして作られたのですか?
A: BrainBenchは、神経科学の結果を予測するためのベンチマークとして作成されました.BrainBenchは、最近のJournal of Neuroscienceの抄録からテストケースを収集し、5つの神経科学領域(行動/認知、システム/回路、疾患の神経生物学、細胞/分子、発達/可塑性/修復)をカバーしています.テストケースでは、元の抄録と結果を大幅に変更しながら一貫性を保つように変更された抄録の2つから選択する必要があります.人間の専門家と言語モデル(LLMs)は、2つの選択肢から正しい(つまり元の)バージョンを選択するように指示されました.人間の専門家は選択を行い、オンライン調査で信頼度と専門性の評価を提供しました.LLMsは、パープレキシティが低い(つまりモデルにとって驚きが少ないテキストパッセージ)抄録を選択したときにスコアがつけられ、その信頼度は2つの選択肢のパープレキシティの差に比例しています.
Q: ラージ・ランゲージ・モデル(LLM)を科学文献に学習させるプロセスを説明していただけますか?
A: 科学文献を用いた大規模言語モデル(LLMs)のトレーニングプロセスは、まず膨大な科学文献データセットを収集し、そのデータを前処理してモデルに適した形式に整形します.次に、トークン化と呼ばれるプロセスを通じて文を単語やサブワードに分割し、それらを数値化してモデルが理解できる形に変換します.その後、事前学習と呼ばれる段階で、巨大なニューラルネットワークを使用して文脈を理解し、言語のパターンを学習させます.最終的に、特定の科学分野に焦点を当てるために、その分野に特化した追加のトレーニングが行われ、モデルがその分野の専門知識を獲得します.
Q: 実験結果の予測において、人間の専門家と比較してLLMのパフォーマンスを評価するために、具体的にどのような基準を用いましたか?
A: LLMsと人間の専門家のパフォーマンスを評価するために使用した具体的な基準は、アイテムの難易度に関するスピアマンの相関係数でした.LLMsにおいて、アイテムの難易度を決定する手順は、上記で説明したものと同一でした.一方、人間の専門家においては、アイテムの難易度はそのアイテムの平均正解率として計算されました.最終的に、これらの難易度の指標のスピアマンの相関係数を計算して、合意を評価しました.
Q: 神経科学文献にチューニングを施したLLMであるBrainGPTは、他のモデルをどのように凌駕したのか?
A: BrainGPTは、神経科学の文献に調整されたLLMであり、他のモデルよりも優れた性能を発揮しました.
Q: LLMは自分の予測に自信があるほど的中しやすいということですが、その意義について詳しく教えてください.
A: LLMsが自信を持っていると、より正確な予測を行う可能性が高くなります.これは、LLMsの信頼性を高め、予測システム全体の信頼性を向上させる重要な特性です.
Q: 今後、人間とLLMのコラボレーションによってどのような発見がなされるとお考えですか?
A: 人間とLLMsの協力は、将来的には発見をする際に重要な役割を果たすと考えられます.人間の科学者は、経験に基づいて研究デザインに基づいて将来の結果を予測する直感を持っていますが、LLMsは訓練中に処理できる科学文献の量に制約がないため、より多くの情報を取り入れることができます.LLMsは予測において人間を置き換える可能性がありますが、科学的な説明を提供するために人間の専門家の役割も重要であると予想されます.
Q: 神経科学だけでなく、他の知識集約的な試みにあなたのアプローチを転用できる要因は何ですか?
A: 私たちのアプローチが他の知識集約型の取り組みにも移植可能である要因は、膨大な量の科学文献を処理し、統合する能力にあります.この能力は、人間の能力を超えている可能性があります.また、専門家のソリューションを提供することで、特定の課題に対処することができるため、他の分野にも適用可能です.
Q: LLMにおいて、ノイズを含みながらも相互に関連する知見を統合し、新規の結果を正確に予測するにはどうすればいいのだろうか?
A: LLMsは、広範囲の科学文献から訓練されるため、ノイズの多いが相互に関連する知見を統合し、新しい結果を予測する能力を持つ.これにより、人間の能力を超えた情報処理が可能となり、予測精度が向上する.
Q: BrainBenchを開発し、神経科学の予測用にLLMをチューニングする過程で、どのような課題にぶつかりましたか?
A: BrainBenchの開発とLLMsの神経科学予測の調整において遭遇した課題は、神経科学の構造を理解するための基本的なパターンを把握するLLMsの能力を評価することでした.具体的には、BrainBenchは、最新のジャーナル記事からの抄録の2つのバージョンを提示し、テスト受験者が研究の結果を予測するタスクを行うことで、神経科学の結果を方法から予測できるかどうかを評価しました.また、LLMsが神経科学に関する追加のトレーニングを受けた場合にどのように変化するかも検証しました.
Q: 神経科学研究の分野において、LLMの役割は今後どのように発展していくとお考えですか?
A: LLMは神経科学研究の分野において、将来的には予測能力をさらに高めることが期待されます.これにより、科学者が新たな発見をする際にLLMが支援する役割が拡大するでしょう.LLMは急速に拡大する文献に追いつく必要がありますが、BrainBenchのようなツールを用いて神経科学の予測能力をテストすることで、LLMの能力向上が図られています.LLMは既に科学文献、特に神経科学に関するトレーニングを受けており、その予測能力を評価することが可能です.LLMが人間の専門家を上回ることができれば、科学の実践や発見のペースが大きく変わる可能性があります.将来的には、LLMが予測において人間を置き換える可能性がありますが、科学的な説明を提供する人間の専門家の役割も重要であると考えられます.
