
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をLLMによって生成されるQ&Aを用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.自動生成記事のクオリティと信頼性を向上させるためにアルゴリズムの改善に取り組んでいます.個人で資料のQ&Aを作成されたい方には、https://www.chatpdf.com/ や https://scispace.com/などがお勧めです.
紹介する論文は以下の10本となります.
- Can Large Language Models Reason and Plan?
発行日:2024年03月07日
人間は自己批判を通じて誤った推測を修正する能力を示すが、LLMはその能力を持たず、誤った推測を修正することが困難である. - GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
発行日:2024年03月06日
GaLoreトレーニング戦略は、LLMのメモリ使用量を最大65.5%削減し、効率とパフォーマンスを維持しつつ、事前トレーニングやファインチューニングを可能にする. - SaulLM-7B: A pioneering Large Language Model for Law
発行日:2024年03月06日
SaulLM-7Bは法律領域に特化した大規模言語モデルで、英語法的コーパスで訓練され、法的文書の理解と処理において最先端の能力を持ち、MITライセンスの下で公開されている. - Design2Code: How Far Are We From Automating Front-End Engineering?
発行日:2024年03月05日
マルチモーダルLLMを使用したDesign2Codeタスクの研究では、GPT-4Vが最も優れたパフォーマンスを示し、64%のケースで生成したウェブページが元の参照ウェブページよりも優れていると考えられています. - KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents
発行日:2024年03月05日
KnowAgentは、アクション知識を活用してLLMsの計画能力を向上させ、HotpotQAとALFWorldでの実験で優れたパフォーマンスを示す新しいアプローチです.GitHubでコード入手可能. - The Claude 3 Model Family: Opus, Sonnet, Haiku
発行日:2024年03月04日
Claude 3は、画像データ処理能力を持つ新しいマルチモーダルモデルファミリーであり、Opus、Sonnet、Haikuの3つのモデルがあり、非英語圏言語においても改善された流暢さを示し、2024年3月に発表された. - TripoSR: Fast 3D Object Reconstruction from a Single Image
発行日:2024年03月04日
TripoSRは、トランスフォーマーアーキテクチャを使用して高速な3D生成を可能にし、LRMネットワークアーキテクチャを基盤として構築され、MITライセンスの下でリリースされた最新の3D生成AI技術. - Functional Benchmarks for Robust Evaluation of Reasoning Performance, and the Reasoning Gap
発行日:2024年02月29日
言語モデルの推論能力を評価するためのフレームワークを提案し、MATHベンチマークの機能的なバリエーションを使用して推論テストを行い、最先端のモデルの推論ギャップを発見しました. - Retrieval-Augmented Generation for AI-Generated Content: A Survey
発行日:2024年02月29日
AIGCの開発は進化し、RAG技術が課題に対処し、AIGCの精度と堅牢性を向上させる.RAGの統合方法や応用について包括的にレビューし、将来の研究方向を提案. - Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
発行日:2024年02月27日
2024年2月にリリースされたSoraは、テキストからビデオを生成するAIモデルであり、物理世界をシミュレートする能力を持ち、その背景、アプリケーション、課題、将来の方向性について包括的なレビューを提供しています.
Can Large Language Models Reason and Plan?
著者:Subbarao Kambhampati
発行日:2024年03月07日
最終更新日:2024年03月08日
URL:http://arxiv.org/pdf/2403.04121v2
カテゴリ:Artificial Intelligence, Computation and Language, Machine Learning
概要:
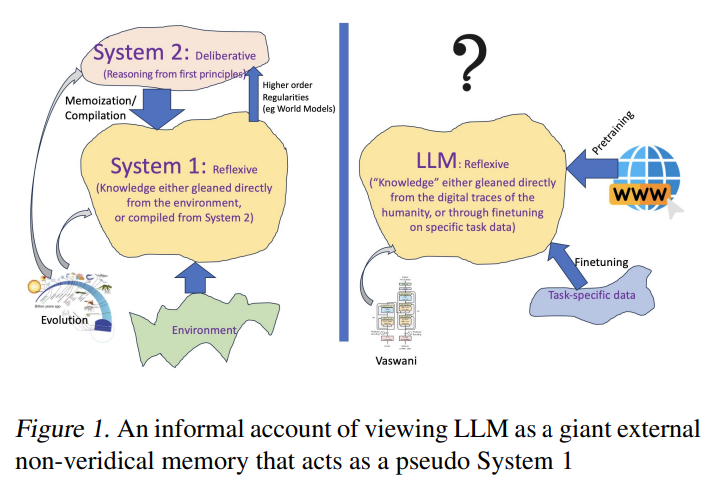
人間は時々自己批判を行うことで自分の誤った推測を修正する能力を示すことがありますが、LLMの場合にはその前提が存在しないようです.LLMは自己批判を行う能力を持っていないため、誤った推測を修正することが困難であるとされています.この点において、人間とLLMとの間には明確な違いが存在することが示唆されています.
Q&A:
Q: なぜ人間は自己批判によって自分の誤った推測を修正することができるのか、説明できますか?
A: 人間が自己批判によって自分の誤った推測を修正できる理由は、自己批判によって誤りを見つけ、正しい解決策に修正するための能力を持っているからです.
Q: 大規模言語モデル(LLM)には自己批評能力がないという主張を裏付ける証拠や研究は何か?
A: LLMsの自己批評能力を欠いているという主張を裏付ける証拠や研究は、明示的には提供されていません.
Q: LLMは推論や計画能力において人間とどう違うのか?
A: LLMsは、人間と比較して、推論能力と計画能力において異なる点があります.LLMsは、大規模言語モデルを通じて情報を取得し、アイデアの生成に優れていますが、原則的な推論や計画に関わる能力は持っていないとされています.一方、人間は、計算的に困難な推論や計画を行う能力を持っており、知識の獲得とそれを実行可能な計画に組み立てる能力を持っています.
Q: LLMが自己批評できないことに、潜在的な欠点や制限はありますか?
A: LLMsが自己批評を行えない場合の潜在的な欠点や制限は、自己生成した解決策を検証する能力がないため、誤った解を修正することができない可能性があることです.このような場合、間違った解が繰り返し生成され、改善されることなく、正しい解にたどり着くことが困難になります.また、自己批評がないことで、LLMsの解決策の信頼性や正確性が疑われる可能性もあります.
Q: LLMが自らの誤りを正すことができないことを示す例やケーススタディを提示できますか?
A: LLMsは自分の誤りを修正する能力がないことを示す例やケーススタディを提供する論文が存在します.
Q: LLMの自己批判能力の欠如は、彼らの全体的なパフォーマンスや信頼性にどのような影響を及ぼすのだろうか?
A: LLMの自己批評能力の欠如は、その全体的なパフォーマンスと信頼性に重大な影響を与える可能性があります.自己批評能力がない場合、LLMは生成した解決策を検証することができず、誤った解を生成してしまう可能性が高くなります.その結果、誤った情報や不正確な推論が出力される可能性があり、その信頼性が低下します.また、自己批評能力がないことにより、LLMが自己改善することが難しくなり、より正確な解決策を見つけるためのプロセスが阻害される可能性があります.
Q: LLMは現在、出力に含まれるエラーや誤った情報をどのように処理していますか?
A: LLMsは、自分たちが生成した解決策を検証する際に、誤った情報やエラーを取り扱う際に、偽陽性と偽陰性を幻視する傾向があることが示されています.
Q: LLMが自己批判できないことに関連して、倫理的な懸念が生じる可能性はありますか?
A: LLMの自己批評能力の欠如に関連する潜在的な倫理的懸念がある可能性があります.自己批評能力が不足している場合、LLMが生成する解決策の妥当性や倫理的側面を適切に評価できない可能性があります.これにより、誤った情報や偏見が強調され、望ましくない結果が生じる可能性があります.
Q: この研究で得られた知見は、様々な用途におけるLLMの今後の発展や活用に、どのような形で影響を与える可能性があるのだろうか?
A: この研究の結果は、LLMの将来の開発と様々なアプリケーションでの使用に影響を与える可能性があります.具体的には、LLMが計画や推論の課題に対して優れた性能を発揮できるかどうかについての疑問が浮上しています.これにより、LLMの知識獲得部分と推論/計画部分の向上が求められる可能性があります.また、LLMが既に優れた近似検索能力を持っていることから、これを有効に活用することで、疑問のある推論/計画能力をLLMに帰属する必要がないことが示唆されています.
GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
著者:Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, Yuandong Tian
発行日:2024年03月06日
最終更新日:2024年03月06日
URL:http://arxiv.org/pdf/2403.03507v1
カテゴリ:Machine Learning

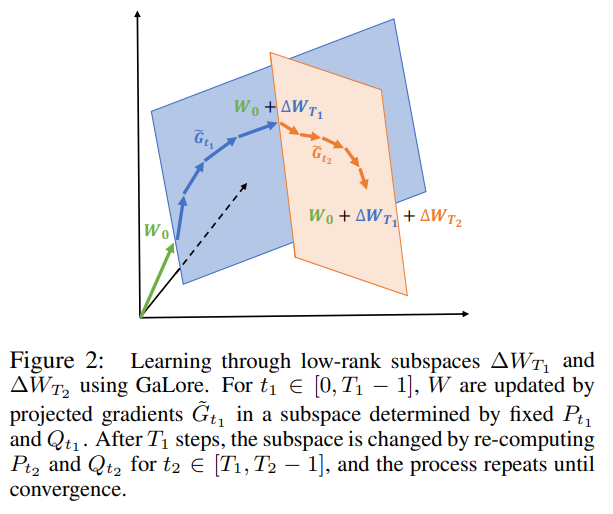
概要:
大規模言語モデル(LLM)のトレーニングは、重みとオプティマイザの状態の増加による記憶の課題を抱えています.一般的なメモリ削減アプローチである低ランク適応(LoRA)などは、各層の凍結された事前トレーニング済みの重みにトレーニング可能な低ランク行列を追加することで、トレーニング可能なパラメータとオプティマイザの状態を削減します.しかし、このようなアプローチは、一般的に事前トレーニングおよびファインチューニングの両方で完全ランクの重みを使用したトレーニングよりも性能が低くなる傾向があります.これは、パラメータの検索を低ランクの部分空間に制限し、トレーニングダイナミクスを変更し、さらには完全ランクのウォームスタートが必要になる可能性があるためです.本研究では、Gradient Low-Rank Projection(GaLore)というトレーニング戦略を提案しています.このアプローチは、全パラメータの学習を可能にしつつ、LoRAなどの一般的な低ランク適応方法よりもメモリ効率が向上しています.GaLoreは、C4データセットを使用したLLaMA 1Bおよび7Bアーキテクチャでの事前トレーニングや、GLUEタスクでのRoBERTaのファインチューニングにおいて、メモリ使用量を最大65.5%削減し、効率とパフォーマンスを維持しています.また、8ビットのGaLoreは、オプティマイザのメモリを最大82.5%削減し、トータルトレーニングを行います.さらに、BF16のベースラインと比較して、GaLoreはオプティマイザのメモリを最大82.5%、トータルトレーニングメモリを63.3%削減します.特筆すべきは、NVIDIA RTX 4090などの24GBメモリを搭載した消費者向けGPUで、モデルパラレル、チェックポイント、オフロード戦略を使用せずに、7Bモデルの事前トレーニングが可能であることを初めて実証しています.
Q&A:
Q: GaLoreがLoRAのような一般的な低ランク適応法とどう違うのか、もう少し詳しく説明していただけますか?
A: GaLoreとLoRAは、両方とも「低ランク」を名前に持っていますが、トレーニングの軌跡が非常に異なります.例えば、r=min(m, n)の場合、GaLoreはρt≡1で、元のモデルのトレーニング軌跡を正確に追います.一方、Bが完全ランクに達した場合(つまり、B∈Rm×mかつA∈Rm×n)、BとAを同時に最適化するLoRAは、元のモデルとは非常に異なるトレーニング軌跡をたどります.
Q: GaLoreはどのようにしてオプティマイザ状態のメモリ使用量を最大65.5%削減できるのか?
A: GaLoreは、最適化器の状態のメモリ使用量を最大65.5%削減することができます.これは、低ランク勾配射影によって最適化器の状態のメモリを65.5%削減し、また、層ごとの重み更新を行うことで重み勾配のメモリを13.5G削減することによって実現されます.
Q: GaLoreの性能と効率の改善について、フルランクウェイトや他の低ランク適応手法と比較して詳しく教えてください.
A: GaLoreは、フルランクの重みや他の低ランク適応方法と比較して、パフォーマンスと効率の向上が見られます.特に、1Bモデルサイズの場合、GaLoreはr=512ではなくr=1024の場合には、フルランクのベースラインを上回る結果を示します.LoRAやReLoRAと比較して、GaLoreはモデルパラメータやオプティマイザの状態を保存するためにより少ないメモリを必要とします.GaLoreは、メモリ効率の最適化により、AdamW、8ビットAdam、Adafactorなどのメモリ効率の高い最適化アルゴリズムに適用でき、メモリフットプリントを最大62.5%削減することが示されています.
Q: モデルの並列化、チェックポイント、オフロード戦略なしに、24GBのメモリを搭載したコンシューマー向けGPUで7Bのモデルをプリ・トレーニングできることの意義は何でしょうか?
A: 消費者向けGPUでモデル並列処理、チェックポイント、またはオフロード戦略なしで7Bモデルを事前学習できることの重要性は、大規模な言語モデルをより効率的に訓練し、より多くのリソースを必要とせずに高い性能を達成できる可能性があることです.これにより、研究者や開発者はより手軽に大規模なモデルを扱うことができ、より多くの応用分野でこれらのモデルを活用することができます.
Q: GaLoreの8ビット実装は、BF16ベースラインと比較して、最適化メモリを最大82.5%、総合トレーニングメモリを63.3%削減する方法は何ですか?
A: GaLoreの8ビット実装は、オプティマイザの状態を格納するメモリを最大82.5%、そして合計トレーニングメモリを最大63.3%削減します.これは、低ランク勾配射影によってオプティマイザの状態のメモリを65.5%削減し、また層ごとの重み更新を使用することで重み勾配のメモリを13.5%削減することによって達成されます.
Q: GaLoreを開発する際に、具体的にどのような課題にぶつかり、どのように対処しましたか?
A: GaLoreの開発において遭遇した具体的な課題は、メモリ効率を向上させながらも性能の低下を避けることでした.この課題に対処するために、GaLoreはランクを調整することでメモリと計算コストのトレードオフを実現しました.メモリ制約のシナリオでは、ランクを減らすことでメモリ予算内に留まりつつ、性能を維持するためにより多くのステップでトレーニングすることが可能となりました.
Q: 実験で事前学習と微調整に使用したデータセットとアーキテクチャの詳細を教えてください.
A: プレトレーニングおよびファインチューニングの実験で使用されたデータセットとアーキテクチャの詳細については、プレトレーニング実験では、C4データセットを使用し、LLaMAベースの大規模言語モデルをトレーニングしました.C4データセットは、Common CrawlのWebクロールコーパスの巨大でクリーンなバージョンであり、主に言語モデルと単語表現のプレトレーニングを意図しています.実験セットアップは、Lialin et al.(2023)から採用されたLLaMAベースのアーキテクチャを使用し、RMSNormおよびSwiGLUアクティベーションを採用しています.モデルサイズごとに、学習率を除くすべての方法で同じ一連のハイパーパラメータを使用し、BF16形式ですべての実験を実行し、同じ計算予算の下で各方法の学習率を調整し、最良のパフォーマンスを報告しています.ファインチューニング実験では、Hugging Faceから提供されたモデルを使用して、GLUEベンチマークで事前トレーニングされたRoBERTa-Baseモデルをファインチューニングしました.ファインチューニングのハイパーパラメータは、表7に示されており、CoLAを除くすべてのタスクにはバッチサイズ16を使用し、CoLAにはバッチサイズ32を使用しています.GaLoreの学習率とスケールファクターを調整しました.
Q: GaLoreは、フルランク重みを使用した場合と比較して、トレーニングダイナミクスにどのような影響を与えますか?
A: GaLoreは、フルランク重みを使用する場合と比較して、異なる軌跡をたどることで、学習ダイナミクスに影響を与えます.低ランク因数分解のランクが重み行列の次元の最小値(r=min(m, n))に達すると、ρt≡1のGaLoreは元のモデルの正確な学習軌道をたどります.これは勾配行列Gが学習中に低ランクになることを意味し、GaLoreは勾配行列Gを低ランクの形P⊤GQに射影するために射影行列P∈Rm×rとQ∈Rn×rを計算します.これにより、オプティマイザ状態のメモリコストを削減することで、よりメモリ効率の高い学習処理が可能になります.一方、低ランク分解がフルランク(B∈Rm×m、A∈Rm×n)に達したとき、フルランクの重みとオプティマイザ状態を最適化すると、元のモデルとは異なる学習軌跡をたどります.
Q: 大規模言語モデルの学習にGaLoreを使用することの潜在的な制限や欠点は何ですか?
A: GaLoreの潜在的な制限や欠点は、(1) 他の種類のモデル(例:ビジョントランスフォーマーや拡散モデル)のトレーニングにGaLoreを適用すること、(2) 低メモリ投影行列を使用してメモリ効率をさらに向上させること、(3) 他のハイパーパラメータを調整せずに単一の試行で8ビットGaLore(r=1024)と8ビットAdamを比較したため、ハイパーパラメータの調整が不足している可能性があることなどが挙げられる.
Q: GaLoreについて、今回発表された結果以外に、将来の研究の方向性やアプリケーションはありますか?
A: 本研究では、GaLoreが大規模言語モデルのトレーニングにおいてメモリ効率を向上させることが示されました.今後の研究方向としては、GaLoreの応用範囲を拡大し、他の機械学習の分野にも適用する可能性が考えられます.特に、メタラーニングや継続学習などの分野でGaLoreの効果を検証することが重要であると考えられます.
SaulLM-7B: A pioneering Large Language Model for Law
著者:Pierre Colombo, Telmo Pessoa Pires, Malik Boudiaf, Dominic Culver, Rui Melo, Caio Corro, Andre F. T. Martins, Fabrizio Esposito, Vera Lúcia Raposo, Sofia Morgado, Michael Desa
発行日:2024年03月06日
最終更新日:2024年03月07日
URL:http://arxiv.org/pdf/2403.03883v2
カテゴリ:Computation and Language
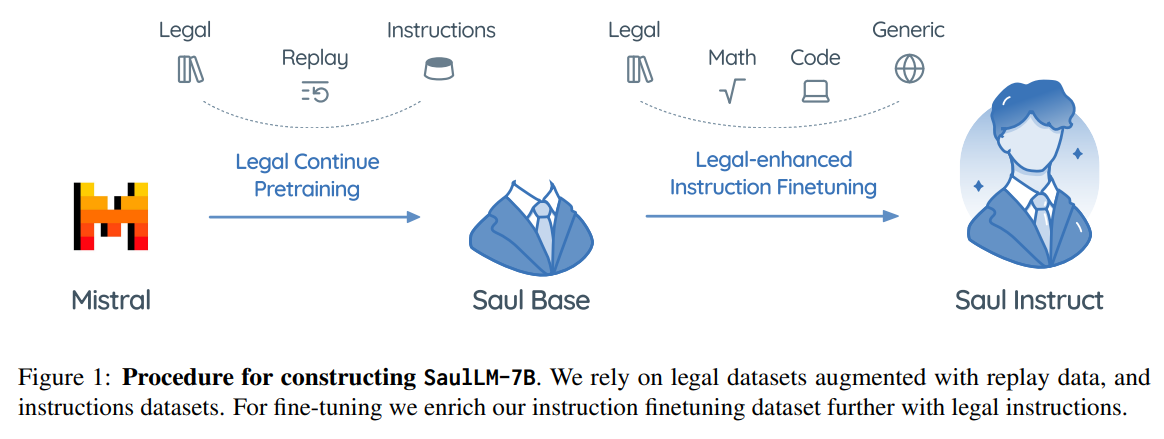
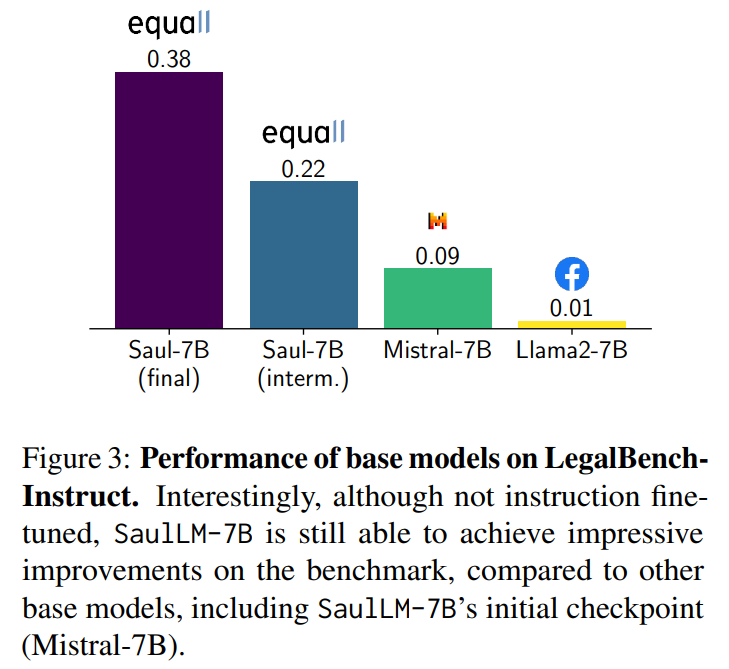
概要:
この論文では、法律領域に特化した大規模言語モデル(LLM)であるSaulLM-7Bを紹介します.SaulLM-7Bは70億のパラメータを持ち、法的テキストの理解と生成のために明示的に設計された初のLLMです.Mistral 7Bアーキテクチャを基盤として、SaulLM-7Bは300億トークン以上の英語法的コーパスで訓練されています.SaulLM-7Bは法的文書の理解と処理において最先端の能力を示しています.さらに、法的データセットを活用した新しいfine-tuning方法を紹介し、SaulLM-7Bの法的タスクにおける性能をさらに向上させています.SaulLM-7BはMITライセンスの下で公開されています.
Q&A:
Q: SaulLM-7Bの基盤として使われた具体的なアーキテクチャは?
A: SaulLM-7Bの基盤として使用された特定のアーキテクチャは、Mistral 7Bアーキテクチャです.
Q: SaulLM-7Bはどのように英語法コーパスを学習したのですか?
A: SaulLM-7Bは、Mistral 7Bアーキテクチャを活用して、30億以上のトークンからなる英語法律コーパスで訓練されました.
Q: SaulLM-7Bは具体的にどのような法律業務を得意としていますか?
A: SaulLM-7Bは、法的文書の理解と処理において最先端の能力を示しています.
Q: SaulLM-7Bは、既存の他の言語モデルと比較して、法文理解と生成における性能はどうなのか?
A: SaulLM-7Bは、他の既存の言語モデルと比較して、法的テキストの理解と生成のパフォーマンスにおいて最先端の能力を示しています.SaulLM-7Bは、法的文書の理解と処理において最先端の能力を発揮し、法的データセットを活用してSaulLM-7Bのパフォーマンスをさらに向上させる革新的な教示微調整方法を提供しています.
Q: SaulLM-7BをMITライセンスでリリースする意義を説明していただけますか?
A: SaulLM-7BをMITライセンスの下でリリースすることの重要性は、広範な採用を促進し、革新を促進することにあります.このオープンライセンスのアプローチは、協力的な開発を奨励し、法的領域およびその先にある幅広い商業および研究活動への採用を促進します.
Q: 法律領域におけるSaulLM-7Bの応用の可能性は?
A: SaulLM-7Bは法律分野での様々な応用が可能です.例えば、法的文書の理解や処理、法的文書の生成、法的文書の翻訳などが挙げられます.
Q: SaulLM-7Bは複雑な法律用語や専門用語をどのように扱っていますか?
A: SaulLM-7Bは、複雑な法律用語や専門用語を処理するために、7 billion parametersを持つ大規模言語モデル(LLM)として設計されています.SaulLM-7Bは、英語の法的コーパスを基にトレーニングされ、法的文書の理解と処理において最先端の能力を示しています.また、法的データセットを活用した新しい教示Fine-tuning手法を導入することで、SaulLM-7Bの法的タスクにおけるパフォーマンスをさらに向上させています.
Q: ソールLM-7Bの開発とトレーニングで、どのような課題に直面しましたか?
A: SaulLM-7Bの開発とトレーニング中に遭遇した課題は、法的文書のニュアンスを理解することでした.一般的なモデルと比較して、法的言語の微妙なニュアンスを理解するために、SaulLM-7Bは専門的なトレーニングプログラムを実証しました.
Design2Code: How Far Are We From Automating Front-End Engineering?
著者:Chenglei Si, Yanzhe Zhang, Zhengyuan Yang, Ruibo Liu, Diyi Yang
発行日:2024年03月05日
最終更新日:2024年03月05日
URL:http://arxiv.org/pdf/2403.03163v1
カテゴリ:Computation and Language, Computer Vision and Pattern Recognition, Computers and Society

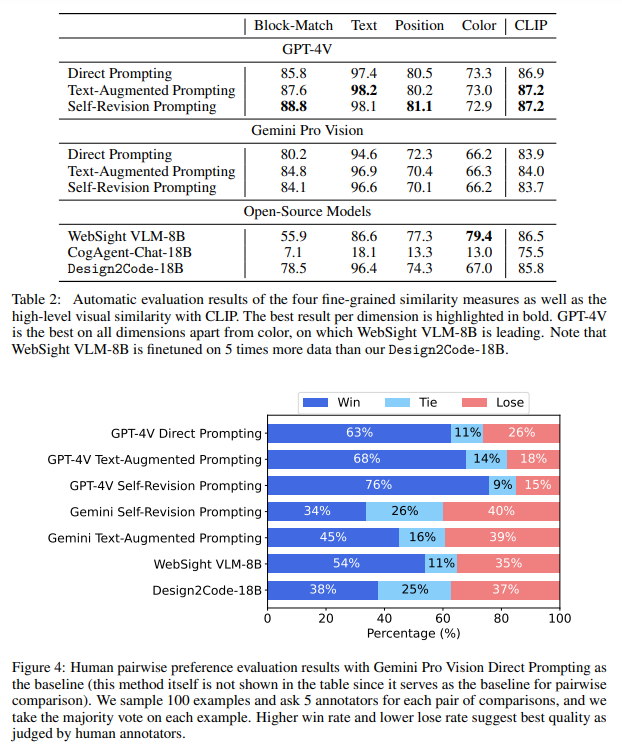
概要:
最近、生成AIは急速な進歩を遂げ、多様な理解能力とコード生成能力を実現してきました.これにより、マルチモーダルLLMが直接視覚デザインをコード実装に変換する新しいフロントエンド開発のパラダイムが可能になります.この研究では、これをDesign2Codeタスクとして形式化し、包括的なベンチマークを実施しています.具体的には、484の多様な実世界のウェブページをテストケースとして手動で収集し、スクリーンショットを入力として与えられた参照ウェブページに直接レンダリングされるコード実装を現在のマルチモーダルLLMがどれだけうまく生成できるかを評価するための一連の自動評価メトリクスを開発します.自動メトリクスに加えて包括的な人間評価も行います.私たちはマルチモーダルプロンプティング方法のスイートを開発し、GPT-4VとGemini Pro Visionでその効果を示します.さらに、Gemini Pro Visionのパフォーマンスに成功裏に匹敵するオープンソースのDesign2Code-18Bモデルを微調整します.人間の評価と自動メトリクスの両方が、他のモデルと比較してこのタスクでGPT-4Vが最も優れたパフォーマンスを発揮することを示しています.さらに、アノテーターは、GPT-4Vが生成したウェブページが参照ウェブページを置き換えることができると考えています.さらに、アノテーターは、GPT-4Vが生成したウェブページが視覚的な外観やコンテンツの面で元の参照ウェブページを置き換えることができると考えています.驚くべきことに、64%のケースで、GPT-4Vが生成したウェブページは元の参照ウェブページよりも優れていると考えられています.私たちの詳細なメトリクスによる分析では、オープンソースのモデルは主に入力ウェブページからの視覚要素の再現や正しいレイアウトデザインの生成において遅れており、テキストコンテンツや着色などの側面は適切な微調整で大幅に改善できることが示されています.
Q&A:
Q: ジェネレーティブAIの具体的な進歩が、この文章で言及されているマルチモーダル理解とコード生成の能力に貢献したのだろうか?
A: 多様な視覚的デザインをコード実装に直接変換する可能性を持つ新しいフロントエンド開発のパラダイムを実現するために、最近の生成AIの進歩が大きく貢献しています.
Q: Design2Codeタスクのために、484の多様な実世界のウェブページのベンチマークはどのようにキュレーションされたのか?
A: 484の多様な実世界のウェブページのベンチマークは、C4の検証セットからウェブサイトリンクをスクレイピングし、すべてのCSSコードをHTMLファイルに埋め込んで1つのコード実装ファイルを取得しました.これにより、実際の使用例を最もよく反映するために、合成的に生成されたものではなく、実際のウェブページを使用しました.C4の検証セットからウェブページをスクレイピングし、すべての例について注意深く手作業でキュレーションを行い、さまざまな実世界の使用例を表す高品質で難解で多様なウェブページのセットを取得しました.これにより、HTMLとCSS要素が関与するさまざまな複雑さの実世界の使用例をカバーする広範囲のベンチマークを提供しました.
Q: ビジュアル・デザインからコード実装を生成する現在のマルチモーダルLLMの性能を評価するために、どのような自動評価指標が開発されたのか?
A: 現在の多モーダルLLMのパフォーマンスを評価するために開発された自動評価メトリクスは、与えられたリファレンスWebページに直接レンダリングされるコード実装を生成する能力を評価するためのものです.
Q: GPT-4Vとジェミニ・プロビジョンで開発された一連のマルチモーダル促通方法とその効果について説明してもらえますか?
A: GPT-4VおよびGemini Pro Visionにおいて開発された複数モーダルプロンプティング手法のスイートは、Webページのスクリーンショットを入力として受け取り、与えられた参照Webページに直接レンダリングされるコード実装を生成する能力を評価するために開発されました.このスイートは、484の多様な実世界のWebページをテストケースとして手動でキュレーションし、現在の複数モーダルLLMがどの程度コード実装を生成できるかを評価するための一連の自動評価メトリクスを開発しました.さらに、包括的な人間評価と自動メトリクスを補完しました.GPT-4VおよびGemini Pro Visionにおいて、このタスクにおいて最も優れたパフォーマンスを発揮することが示されました.さらに、アノテーターは、GPT-4Vが生成したWebページが、視覚的な外観とコンテンツの面で元の参照Webページを49%のケースで置き換えることができると考えています.さらに、驚くべきことに、64%のケースでGPT-4Vが生成したWebページが元の参照Webページよりも優れていると考えられています.細かい詳細メトリクスによると、オープンソースモデルは、入力Webページから視覚要素を思い出すことや正しいレイアウトデザインを生成することにおいて主に遅れており、テキストコンテンツや着色などの側面は適切な微調整によって劇的に改善できることが示されています.
Q: オープンソースのDesign2Code-18Bモデルは、どのようにGemini Pro Visionの性能に合わせて微調整されたのですか?
A: オープンソースのDesign2Code-18Bモデルは、CogAgent [Hong et al., 2023]という最先端のオープンソースモデルをベースにし、Huggingface [2024]によって合成されたDesign2Codeデータでファインチューニングされました.この「小さな」オープンソースモデルは、合成トレーニングデータと現実的なテストデータの間の不一致にもかかわらず、Gemini Pro Visionのパフォーマンスに匹敵する競争力を持っています.
Q: GPT-4Vのパフォーマンスに関して、他のモデルと比較して人間の評価と自動メトリクスの結果はどうでしたか?
A: GPT-4Vは他のモデルと比較して、このタスクで最も優れたパフォーマンスを発揮しました.自動評価と人間の評価の両方で、GPT-4Vが他のモデルよりも優れていることが示されました.
Q: GPT-4Vによって生成されたウェブページが、元の参照ウェブページの外観や内容を置き換えることができるとアノテーターが考えたケースはどの程度あったのでしょうか?
A: アノテーターは、GPT-4Vが生成したウェブページが視覚的な外観とコンテンツの面で元の参照ウェブページを置き換えることができると考えたケースは49%でした.
Q: GPT-4Vで生成されたウェブページとオリジナルのリファレンス・ウェブページを比較した結果、意外な発見があったのですが?
A: GPT-4Vによって生成されたウェブページは、元の参照ウェブページよりも優れていると64%のケースで考えられていることが驚くべき発見でした.
Q: きめ細かなブレークダウンメトリクスによると、オープンソースのモデルがパフォーマンスで遅れをとった主な分野は何だったのだろうか?
A: オープンソースモデルがパフォーマンスで遅れていた主な領域は、入力ウェブページから視覚要素を思い出すことと、正しいレイアウトデザインを生成することでした.
Q: この文章で言及されているように、適切な微調整を行うことで、テキストの内容や色使いといった面を劇的に改善することができるのだろうか?
A: テキストの内容や色付けなどの側面を適切に微調整することで、特にHTMLトレーニングデータを使用することで、テキストの色コードを正確に生成することが他の側面よりも大幅に向上し、さらにWebsightデータセットを完全に微調整することでさらに改善される可能性があります.
KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents
著者:Yuqi Zhu, Shuofei Qiao, Yixin Ou, Shumin Deng, Ningyu Zhang, Shiwei Lyu, Yue Shen, Lei Liang, Jinjie Gu, Huajun Chen
発行日:2024年03月05日
最終更新日:2024年03月05日
URL:http://arxiv.org/pdf/2403.03101v1
カテゴリ:Computation and Language, Artificial Intelligence, Human-Computer Interaction, Machine Learning, Multiagent Systems
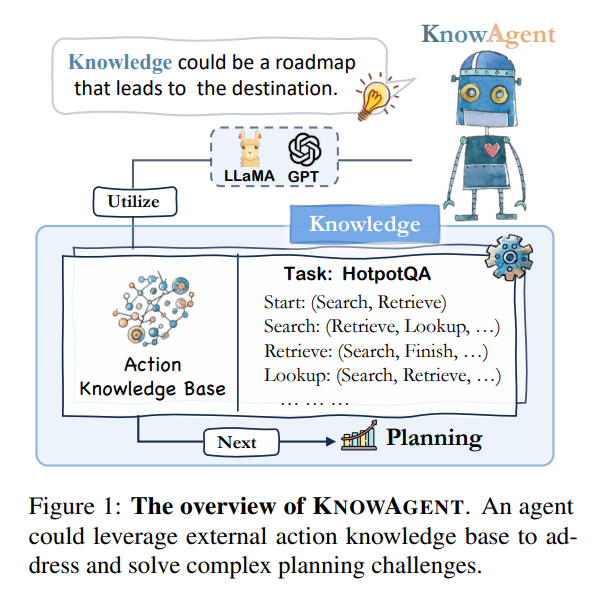
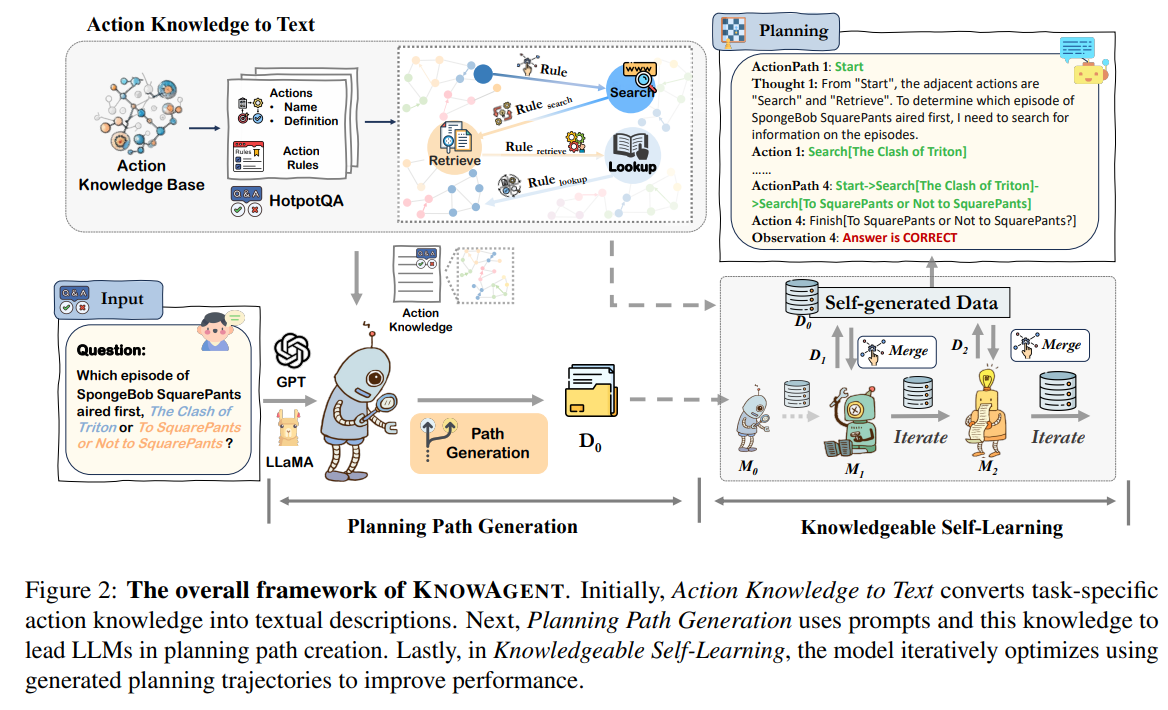
概要:
分析によると、KnowAgentの計画幻覚の緩和における効果が示されています.コードはhttps://github.com/zjunlp/KnowAgent で入手可能です.KnowAgentは、明示的なアクション知識を組み込むことでLLMsの計画能力を向上させる新しいアプローチです.具体的には、アクション知識ベースと知識豊富な自己学習戦略を使用して、計画中のアクションパスを制約し、より合理的な軌道合成を可能にし、言語エージェントの計画パフォーマンスを向上させます.HotpotQAとALFWorldでの実験結果は、KnowAgentが既存のベースラインと比較して同等または優れたパフォーマンスを達成できることを示しています.
Q&A:
Q: ラージ・ランゲージ・モデル(LLM)が、実行可能なアクションを生成して環境と相互作用する際に直面する具体的な課題とは?
A: 大規模言語モデル(LLMs)が環境とやり取りする際に実行可能なアクションを生成する際に直面する特定の課題は、言語エージェントに組み込まれたアクション知識の不足から主に生じます.これにより、自然言語で表現されたアクション知識が欠如し、生成された応答が不正確であったり、質問に対して適切でない回答を提供する可能性があります.
Q: 言語エージェントに内蔵された行動知識の欠如は、どのように幻覚計画に寄与するのか?
A: 言語エージェントに組み込まれていない行動知識は、計画幻覚を引き起こす可能性があります.具体的には、行動知識が欠如すると、タスク解決中に計画の軌道を適切に導くことができず、計画幻覚が生じる可能性があります.
Q: KnowAgentがLLMのプランニング能力をどのように高めているのか説明していただけますか?
A: KnowAgentは、LLMの計画能力を向上させるために、明示的なアクション知識を組み込むことで設計されています.具体的には、KnowAgentはアクション知識ベースと知識を持った自己学習戦略を使用して、計画中のアクションパスを制約し、より現実的な計画を可能にします.
Q: KnowAgentはどのようなコンポーネントで構成され、どのように連携してプランニングのパフォーマンスを向上させるのですか?
A: KnowAgentは、外部アクション知識ベース、アクション生成のガイド、モデルの理解のためのテキスト変換、知識に基づいた自己学習フェーズの複合的アプローチから構成されています.これらの要素が組み合わさり、エージェントの計画能力を向上させ、複雑なシナリオでの効果を証明しています.外部アクション知識を統合することで、計画プロセスを合理化し、パフォーマンスを向上させています.
Q: KnowAgentは、行動計画中に行動経路を制約するために、行動知識ベースと知識自己学習戦略をどのように活用しているのでしょうか?
A: KnowAgentは、行動知識ベースを利用して、モデルの行動生成を誘導し、知識のテキスト化を行い、深いモデル理解のために翻訳し、知識の自己学習フェーズを活用して行動経路を制約することで、計画中の行動経路を制約します.
Q: HotpotQAとALFWorldにおけるKnowAgentの有効性を示す実験結果は?
A: HotpotQA(Yang et al.、2018)およびALFWorld(Shridhar et al.、2021)に基づくさまざまなバックボーンモデルに基づく実験結果は、KNOW AGENTが既存のベースラインと比較して同等または優れたパフォーマンスを達成できることを示しています.
Q: パフォーマンスに関して、KnowAgentは既存のベースラインと比較してどうですか?
A: 既存のベースラインに比べて、KNOW AGENTはパフォーマンスが優れていることが示されています.特に、13bモデルは2つのデータセットでReActよりも15.09%と37.81%のパフォーマンス向上を達成しています.
Q: KnowAgentが計画の幻覚をどのように軽減しているのかについて教えてください.
A: KnowAgentは、外部のアクション知識を合成軌跡に組み込むことで、計画の幻覚を軽減します.この方法は、アクション知識を使用してモデルのアクション生成をガイドし、この知識をテキストに翻訳してモデルの理解を深め、知識豊富な自己学習フェーズを活用して継続的に改善します.この多面的なアプローチは、エージェントの計画能力を向上させるだけでなく、複雑なシナリオでも効果的であることを証明しています.さまざまなモデルを対象とした実験では、KnowAgentが他のベースラインと競合したり、それを上回ったりすることが効果的であることを示し、外部のアクション知識を統合して計画プロセスを合理化し、パフォーマンスを向上させる利点を示しています.
Q: KnowAgentのコードはどこで入手できますか?
A: KnowAgentのコードは利用可能です、https://github.com/zjunlp/KnowAgent でアクセスできます.
Q: KnowAgentの今後の計画や開発について教えてください.
A: KnowAgentに関する将来の計画や開発については、現在の実験が主に常識的なQAおよび家庭用データセットに限定されているが、医療、算術、ウェブ閲覧、具体的なエージェントなど、より広範囲の分野にも適用可能であることが示唆されています.これは、外部のアクション知識を統合して計画プロセスを合理化し、パフォーマンスを向上させる利点を示しており、今後はこれらの分野においてもKnowAgentの発展が期待されます.
The Claude 3 Model Family: Opus, Sonnet, Haiku
著者:Anthropic
発行日:2024年03月04日
最終更新日:不明
URL:https://www.anthropic.com/news/claude-3-family
カテゴリ:不明
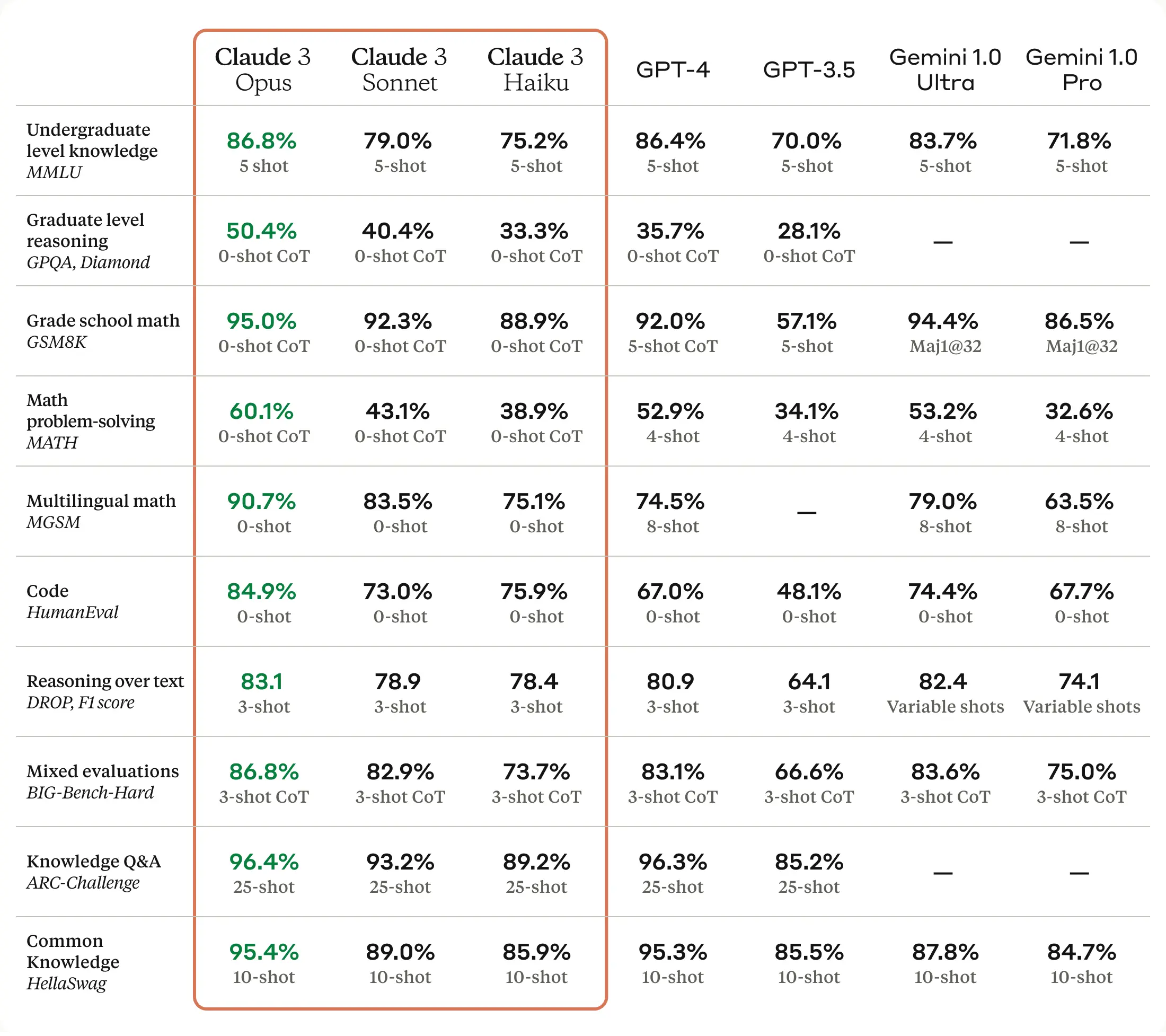
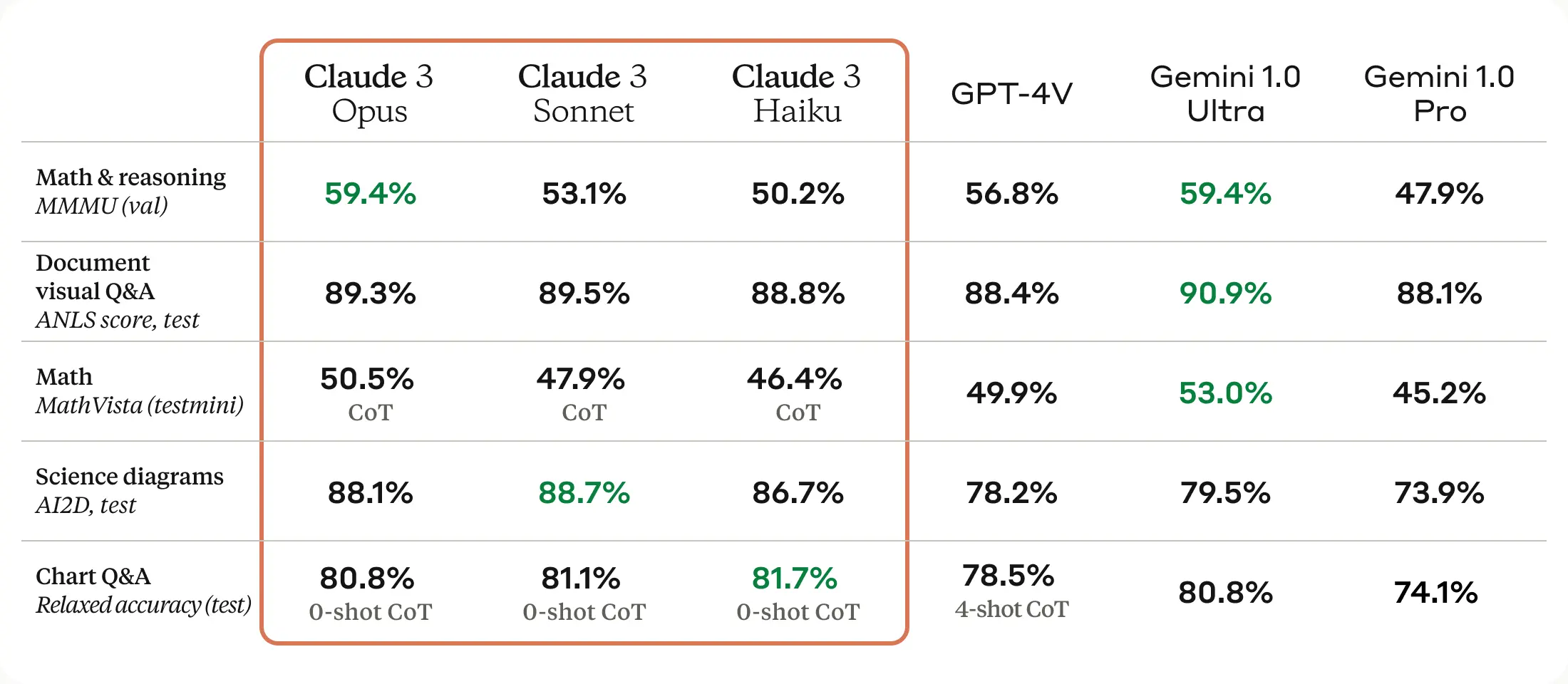
概要:
Claude 3は、新しい大規模なマルチモーダルモデルファミリーであり、最も能力が高いClaude 3 Opus、スキルとスピードの組み合わせを提供するClaude 3 Sonnet、最速かつ最も安価なモデルであるClaude 3 Haikuを紹介します.すべての新しいモデルには、画像データを処理および分析する能力を持つビジョン機能が搭載されています.Claude 3ファミリーは、ベンチマーク評価において強力なパフォーマンスを示し、推論、数学、コーディングの評価基準に新たな基準を設定しています.Claude 3 Opusは、GPQA、MMLU、MMMUなどの評価において最先端の結果を達成しています.Claude 3 Haikuは、ほとんどの純粋なテキストタスクにおいてClaude 2よりも同等またはそれ以上のパフォーマンスを発揮し、SonnetとOpusはそれを大幅に上回っています.さらに、これらのモデルは非英語圏の言語においても改善された流暢さを示し、グローバルな観客にとってより多目的になっています.Claude 3ファミリーは、コーディングタスクやスペイン語、日本語などの非英語圏言語における流暢さにおいて、前世代のモデルよりも大幅に向上しています.これにより、翻訳サービスなどのユースケースやより広範なグローバルな利用が可能となっています.Anthropicによって開発され、2024年3月に発表されたClaude 3モデルファミリーは、Claude.ai、Claude Proなどの消費者向け製品、Anthropic API、Amazon Bedrock、Google Vertex AIなどのエンタープライズソリューションで利用可能となります.Claude 3モデルの知識カットオフは2023年8月です.このモデルカードは、当社の研究全体を網羅するものではありません.研究方法論についての包括的な洞察を得るためには、当社の研究論文(例:AIシステムの評価における課題、大規模言語モデルの倫理的自己修正能力、言語モデルにおける主観的なグローバル意見の表現の測定に向けてなど)をご覧いただくことをお勧めします.また、当社は業界、政府、市民社会を横断して知見やベストプラクティスを共有することに取り組んでおり、これらの関係者と定期的に交流しています.今後も研究を続け、フロンティアモデルの研究と評価を行い、新たな知見を公開する予定です.
Q&A:
Q: クロード3オーパスは、具体的にどのようなベンチマーク評価で最先端の結果を残したのですか?
A: クロード3オーパスは、GPQA、MMLU、MMMUなどの評価で最先端の結果を達成しました.
Q: クロード3のモデルは、英語以外の言語での流暢さの向上をどのように示しているのか?
A: クロード3モデルは、スペイン語や日本語などの非英語の言語における流暢さを向上させるために訓練されています.これにより、翻訳サービスなどの使用事例や、より広範囲なグローバルなユーティリティが可能になります.
Q: 教師なし学習やコンスティテューショナルAIなど、クロード3モデルに使われたトレーニング方法の詳細を教えてください.
A: Claude 3モデルのトレーニング方法には、教師なし学習と憲法AIが含まれています.これらのモデルは、大規模で多様なデータによること前トレーニングを行い、言語能力を獲得するための方法や、単語予測などの手法を使用しています.また、人間からのフィードバックを受け取り、有益で無害で誠実な応答を引き出すための技術も使用しています.アンソロピックは、憲法AIと呼ばれる技術を使用して、Claudeを人間の価値観と一致させるために、ルールや原則を明示的に指定し、国連人権宣言などの情報源に基づいて強化学習中にClaudeに価値観を調整しました.Claude 3モデルでは、障害者の権利を尊重するための原則をClaudeの憲法に追加し、これは集合的憲法AIに関する研究からの情報源です.一部の人間からのフィードバックデータは、RLHFやレッドチームの研究と共に公開されました.
Q: クロード3モデルは、テキスト出力でマルチモーダル入力機能をどのように活用しているのか?
A: Claude 3モデルは、テキスト出力とともに画像(例:表、グラフ、写真)をアップロードし、より豊かなコンテキストと拡張されたユースケースを可能にするために、マルチモーダル入力機能を利用しています.
Q: クロード3モデルのトレーニングに使用されたハードウェアとコアフレームワークは?
A: クロード3のモデルのトレーニングには、Amazon Web Services(AWS)とGoogle Cloud Platform(GCP)のハードウェアが使用されました.
Q: クロード3作品とソネットは、コンテンツの作成、分析、予測、要約においてどのように熟練度を高めているのか?
A: クロード3オーパスとソネットは、微妙なコンテンツの作成、分析、予測、正確な要約において高い能力を示しています.これらのモデルは、企業がタスクを自動化し、ユーザー向けアプリケーションを通じて収益を生み出し、複雑な財務予測を行い、さまざまなセクターで研究開発を迅速化することを可能にするよう設計されています.
Q: クロード3モデルは、特殊なアプリケーションやカスタムワークフローのためのツール使用や関数呼び出しにおいて、どのような点で優れているのでしょうか?
A: Claude 3モデルは、特殊なアプリケーションやカスタムワークフローにおいて、ツールの使用や関数呼び出しに優れています.これは、Claudeの知能をシームレスに統合することが可能であり、特定の作業やワークフローに適した機能を提供します.
Q: クロード3俳句はクロード2俳句と比較して、純粋なテキスト・タスクのパフォーマンスはどうですか?
A: クロード3ハイクは、純粋なテキストタスクにおいてクロード2と比較して、ほとんど同等かそれ以上の性能を発揮します.
Q: クロード3モデルの「責任あるスケーリング方針」で議論されている社会的影響と大惨事のリスク評価について詳しく教えてください.
A: クロード3モデルの責任あるスケーリングポリシーでは、AIモデルからの潜在的な災害リスクを評価し軽減するための枠組みが提供されています.このポリシーは、クロード3モデルにおける社会的影響と災害リスクアセスメントに焦点を当てており、自動評価とレッドチームによる評価を通じてモデルのリスクレベルを割り当てています.現在、クロード3モデルはASL-2として分類されており、これらのモデルには大規模な災害リスクの指標がないことが示されています.ただし、評価は難しい科学的問題であり、方法論はまだ改善中であることが述べられています.
Q: クロード3モデルによって、企業はどのようにタスクを自動化し、収益を上げ、財務予測を行い、研究開発を促進することができるのだろうか?
A: Claude 3モデルは、企業がタスクを自動化し、収益を生み出し、複雑な財務予測を行い、研究開発を促進することを可能にします.これらのモデルは、コーディングタスクやスペイン語、日本語などの非英語の言語における流暢さを向上させ、翻訳サービスやより広範なグローバルなユーティリティなどのユースケースを実現することができます.
TripoSR: Fast 3D Object Reconstruction from a Single Image
著者:Dmitry Tochilkin, David Pankratz, Zexiang Liu, Zixuan Huang, Adam Letts, Yangguang Li, Ding Liang, Christian Laforte, Varun Jampani, Yan-Pei Cao
発行日:2024年03月04日
最終更新日:2024年03月04日
URL:http://arxiv.org/pdf/2403.02151v1
カテゴリ:Computer Vision and Pattern Recognition
概要:
この技術レポートでは、TripoSRという3D再構築モデルが紹介されています.このモデルは、トランスフォーマーアーキテクチャを活用して高速なフィードフォワード3D生成を実現し、単一の画像から0.5秒未満で3Dメッシュを生成します.LRMネットワークアーキテクチャを基盤として構築されたTripoSRは、データ処理、モデル設計、トレーニング技術の大幅な改善を統合しています.公開データセットでの評価では、TripoSRは他のオープンソースの代替手段と比較して、量的にも質的にも優れたパフォーマンスを示しています.MITライセンスの下でリリースされたTripoSRは、研究者、開発者、クリエイティブな人々に最新の3D生成AIの進歩を提供することを意図しています.

Q&A:
Q: TripoSRは、LRMネットワーク・アーキテクチャと比較して、データ処理、モデル設計、トレーニング技術において、具体的にどのような改善点があるのでしょうか.
A: TripoSRは、データ処理、モデル設計、およびトレーニング技術の特定の改善をLRMネットワークアーキテクチャと比較して統合しています.データ処理の改善点としては、Objaverseデータセットの慎重に選択されたサブセットを使用し、トレーニングデータの品質を向上させたことが挙げられます.また、データレンダリングでは、より多様なデータレンダリング技術を採用し、実世界により近い状況を模倣しています.モデル設計の面では、TripoSRはトランスフォーマーアーキテクチャを活用し、単一のRGB画像を入力として受け取り、その画像内のオブジェクトの3D表現を出力します.さらに、カメラパラメータをトレーニングおよび推論中に「推測」することで、モデルの頑健性を向上させています.トレーニング技術の改善点としては、正確なカメラ情報が必要なく、幅広い実世界シナリオを処理できるように設計された柔軟で弾力性のあるモデルを育成することを目指しています.
Q: TripoSRは、高速フィードフォワード3D生成のために、どのようにトランスフォーマー・アーキテクチャーを活用していますか?
A: TripoSRは、高速なフィードフォワード3D生成のためにトランスフォーマーアーキテクチャを活用しています.具体的には、LRMネットワークをベースにしたトランスフォーマーアーキテクチャを採用し、データのキュレーションやレンダリング、モデルの設計、トレーニング技術などの複数の軸で技術的な改善を行っています.これにより、他のオープンソースの代替手法と比較して、優れた性能を定量的・定性的に示しています.
Q: TripoSRが1枚の画像から3Dメッシュを0.5秒以内で作成できる主な要因は何ですか?
A: TripoSRが単一の画像から0.5秒未満で3Dメッシュを生成するための主要な要因は、トランスフォーマーアーキテクチャを活用した高速なフィードフォワード3D生成であり、LRMネットワークアーキテクチャを基盤として、データ処理、モデル設計、トレーニング技術の改善を統合していることです.公開データセットでの評価により、TripoSRは他のオープンソースの代替手法と比較して、量的および質的に優れた性能を示しています.
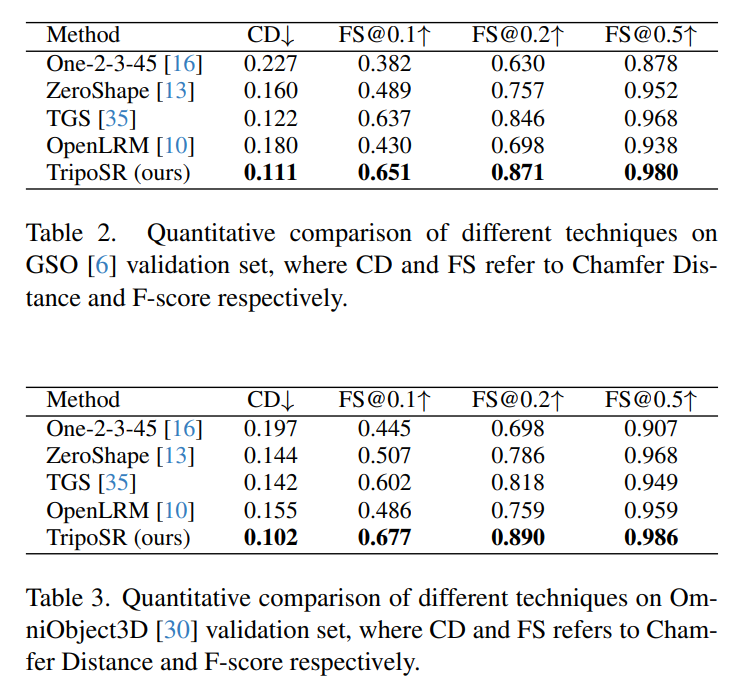
Q: TripoSRの優れた性能を示すために実施された公開データセットに関する評価の詳細を提供できますか?
A: 公開データセットの評価では、GSOとOmniObject3Dの2つのデータセットを使用しました.これらのデータセットには、多くの単純な形状のオブジェクト(例:ボックス、球、シリンダーなど)が含まれており、これらの単純な形状に対する高い検証バイアスが発生する可能性があることが特定されました.そのため、データセットを手動でフィルタリングし、各データセットから約300個のオブジェクトを選択し、一般的なオブジェクトの多様で代表的なコレクションを形成するようにしました.3D形状メトリクスでは、Marching Cubesを使用して等値面を抽出し、暗黙的な3D表現(NeRFなど)をメッシュに変換しました.これらの評価により、TripoSRの優れた性能が示されました.
Q: TripoSRは他のオープンソースの代替品と比較して、パフォーマンス面で定量的にどうですか?
A: TripoSRは、他のオープンソースの代替手法と比較して、性能の観点で優れています.具体的には、CDおよびFSメトリクスにおいて、すべてのベースラインを大幅に上回り、このタスクにおいて新たな最先端の性能を達成しています.
Q: TripoSRは、他のオープンソースの代替品と比較して、パフォーマンス面で質的にどうですか?
A: TripoSRは、他のオープンソースの代替手法と比較して、性能の観点で質的に優れています.具体的には、TripoSRはCDおよびFSメトリクスの両方で、他のベースラインを大幅に上回り、このタスクで新たな最先端のパフォーマンスを達成しています.
Q: TripoSRをMITライセンスでリリースした動機は何ですか?
A: TripoSRをMITライセンスの下でリリースする決定の動機は、研究者、開発者、クリエイティブなどに最新の3D生成AIの進歩を提供することを意図しているためです.
Q: TripoSRは、3DジェネレーティブAIの最新の進歩によって、研究者、開発者、クリエイターにどのような力を与えるとお考えですか?
A: TripoSRは、最新の3D生成AIの進歩を研究者、開発者、クリエイターに提供することで、彼らがより高度な3D生成AIモデルを開発することを可能にすると考えられます.このモデルは、高速なフィードフォワード推論を通じて単一画像から0.5秒未満で3D生成を行うことができ、他のオープンソースの代替手段よりも優れた性能を示しています.MITライセンスの下でリリースされ、ソースコード、事前学習モデル、インタラクティブなオンラインデモが提供されており、研究者、開発者、クリエイターが3D生成AIの最新技術を活用して作業を進めることができるようになっています.
Q: 現在、TripoSRの導入や利用において、制限や課題はありますか?
A: TripoSRは、高い計算効率を持つ性能を発揮する一方で、実装や使用上のいくつかの制限や課題に直面しています.例えば、モデルの高速な推論により、生成される3Dモデルの品質や精度に影響を与える可能性があります.また、データの収集や前処理、モデルの訓練において、十分な量の高品質なデータが必要であり、その確保が課題となることがあります.さらに、モデルの複雑さやパラメータの調整により、過学習や性能の安定性の問題が発生する可能性もあります.
Q: TripoSRの将来的な発展や強化の可能性は?
A: TripoSRにおける潜在的な将来の開発や強化の計画は、データ処理、モデル設計、トレーニング技術のさらなる改善を含むことが考えられます.これにより、より高度な3D生成AIモデルの開発において研究者や開発者がより強力なツールを手に入れることが期待されます.
Functional Benchmarks for Robust Evaluation of Reasoning Performance, and the Reasoning Gap
著者:Saurabh Srivastava, Annarose M B, Anto P V, Shashank Menon, Ajay Sukumar, Adwaith Samod T, Alan Philipose, Stevin Prince, Sooraj Thomas
発行日:2024年02月29日
最終更新日:2024年02月29日
URL:http://arxiv.org/pdf/2402.19450v1
カテゴリ:Artificial Intelligence, Computation and Language
概要:
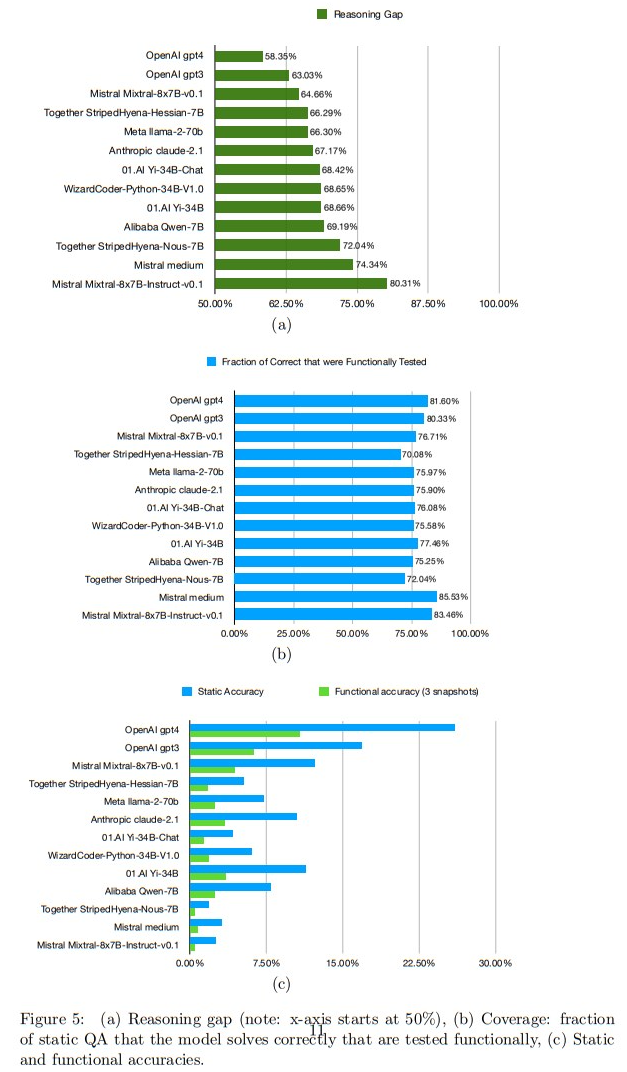
この論文では、言語モデルの推論能力を堅牢に評価するためのフレームワークを提案しています.このフレームワークでは、ベンチマークの機能的なバリエーションを使用して推論テストを解決するモデルは、問題の静的バージョンと機能的バージョンのスナップショットとのパフォーマンスに差がないはずです.著者らは、MATHベンチマークの関連フラグメントをその機能的バリエーションであるMATH()に書き直し、他のベンチマークの機能化も行う予定です.現在の最先端のモデルをMATH()のスナップショットで評価すると、推論ギャップが見つかります.これは、静的ベンチマークで優れたパフォーマンスを発揮する最先端の閉じた重みモデルやオープンな重みモデルの間で、推論精度のパーセンテージ差を示しています.推論ギャップは、58.35%から80.31%の範囲にあり、より洗練されたプロンプティング戦略を使用すると、ギャップはより小さくなる可能性があることに注意が必要です.この研究では、実世界のタスクで推論パフォーマンスが良いとされるモデルは、定量的に低いギャップを持っていることを示し、”ギャップ0″モデルの構築というオープンな問題を促しています.評価コードと新しい評価データセット、3つのMATH()スナップショットは、https://github.com/consequentai/fneval/で公開されています.
Q&A:
Q: 推論ギャップのコンセプトをもう少し詳しく説明していただけますか?
A: 理論的なギャップは、静的な変種と機能的な変種をテストした際の精度の違いの数量的な測定と定義されます.このギャップは、推論と記憶の違いを測定するものであり、ギャップ-0は真の推論を示し、ギャップ-100は完全な記憶を示します.コミュニティは、ギャップが0に近い状態を維持しながら最高の精度を持つモデルを構築することを目指すべきです.このギャップを最小化することは、一般的な推論においてより優れた性能を発揮するモデルを生み出す可能性があるため、トレーニングの最適化目標として役立つかもしれません.
Q: 最先端モデルの推論ギャップをどのように決定したのですか?
A: state-of-the-artモデルの推論ギャップは、Q1’24スナップショット(2023年10月、11月、12月)を評価することで決定されました.これにより、モデルの推論ギャップは58.35%から80.31%の範囲で変動することが示されました.
Q: MATHベンチマークを関数型に書き直したのはなぜですか?
A: MATHベンチマークを機能的なバリアントに書き直す決定は、既存のモデルがすでにテストされている既存のベンチマークを変更せずに再構築することに従ったものでした.MATHベンチマーク全体の機能化プロセスが進行中であり、特定の機能化コードは一般に公開されません.代わりに、毎四半期3つのスナップショットがリリースされます.
Q: 他のベンチマークの機能化のプロセスについて詳しく教えてください.
A: 他のベンチマークを機能化するプロセスは、各テストの推論をコードに書き直すことによって手動で行われます.この機能化は一度だけの時間のかかる作業であり、無限のスナップショットの瞬間化をもたらします.人気のあるベンチマークの中で、数学(MATH [29]およびGSM8K [20])およびコード(HumanEval [12]、MBPP [7]、およびNatural2Code [71])のサブカテゴリに対しては、機能化が容易です.
Q: 「ギャップ0」モデルをどのように定義し、この目標を達成することにどのような意味があるのか?
A: 「ギャップ0」モデルは、推論ギャップがないモデルを指します.つまり、モデルが静的ベンチマーク問題において正確な推論を行い、正解と一致することが期待されます.この目標を達成することにより、一般的な推論において優れた性能を発揮するモデルが構築される可能性があります.推論ギャップがないモデルを訓練することは、より高度なプロンプティング戦略によって推論ギャップが小さくなる可能性があることを示唆しています.現在のデータセット、訓練、ファインチューニング、および推論戦略は、ギャップ0モデルを訓練するために最適でない可能性があります.
Q: 評価コードとデータセットの公開を決めた理由は何ですか?
A: 評価コードとデータセットを公開する決定を促したものは、大規模言語モデル(LLMs)の能力を向上させるために、推論パフォーマンスを正確に評価することが重要であるという認識でした.
Q: より洗練されたプロンプティング戦略は、推論のギャップにどのような影響を与えると思いますか?
A: より洗練されたプロンプティング戦略は、推論ギャップにどのように影響するかについて、より正確な理解をもたらす可能性があります.モデル固有のプロンプティングやモデルに依存しない方法(例:Claude2.1検索プロンプティング、chain-of-thought、tree-of-thought、chain-of-code、chain-of-thought-decoding、転倒/脅威/説得プロンプティングなど)を使用することで、推論ギャップを減少させることができる可能性があります.実際、精度が同じでも、推論ギャップの削減はこれらの改善の有用性を定量的に検証することができるかもしれません.
Q: 実世界のタスクに対して優れた推論性能を持つモデルの例と、それに対応する推論ギャップを教えてもらえますか?
A: リアルワールドのタスクで優れた推論パフォーマンスを持つモデルとその対応する推論ギャップの例として、MATHベンチマークの特定のケースを調査することで、LLMの推論能力をより正確に評価する必要性を示します.
Q: 推論能力をしっかりと評価する枠組みは、今後どのように進化していくとお考えですか?
A: 将来、堅牢な推論能力の評価フレームワークは、既存の人気のあるテキストベンチマークや新しいテキストベンチマークに適用される、機能化されたベンチマーク技術や代替ベンチマーク技術を使用することが提案されています.これにより、既存のモデルのスコープ内であると知られているタスクに対して、それらが以前に見たことのないバージョンを提示することで、推論を評価する長期的な解決策が提供されます.将来的には、人気のあるMATHベンチマークの該当部分を機能化したMATH()の最新スナップショットを拡張し、他のゴールドスタンダードの推論ベンチマークにもこれを適用する予定です.新しい機能化されたベンチマークのスナップショットを毎四半期リリースし続けます.
Q: 言語モデルの評価に機能的な変種ベンチマークを使用することの潜在的な限界や課題は何ですか?
A: 機能的なベンチマークの使用には、いくつかの潜在的な制限や課題があります.例えば、機能的なベンチマークを作成する際に、元の静的なベンチマークとの間に適切な対応関係を確立する必要があります.また、機能的なベンチマークが適切に設計されていない場合、モデルの性能を過大評価する可能性があります.さらに、より洗練されたプロンプティング戦略が必要であることから、機能的なベンチマークの使用には高度な技術やリソースが必要となるかもしれません.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: この論文で導入された新しい手法のコード実装のurlは、https://github.com/consequentai/fneval/ です.
Retrieval-Augmented Generation for AI-Generated Content: A Survey
著者:Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Bin Cui
発行日:2024年02月29日
最終更新日:2024年02月29日
URL:http://arxiv.org/pdf/2402.19473v1
カテゴリ:Computer Vision and Pattern Recognition

概要:
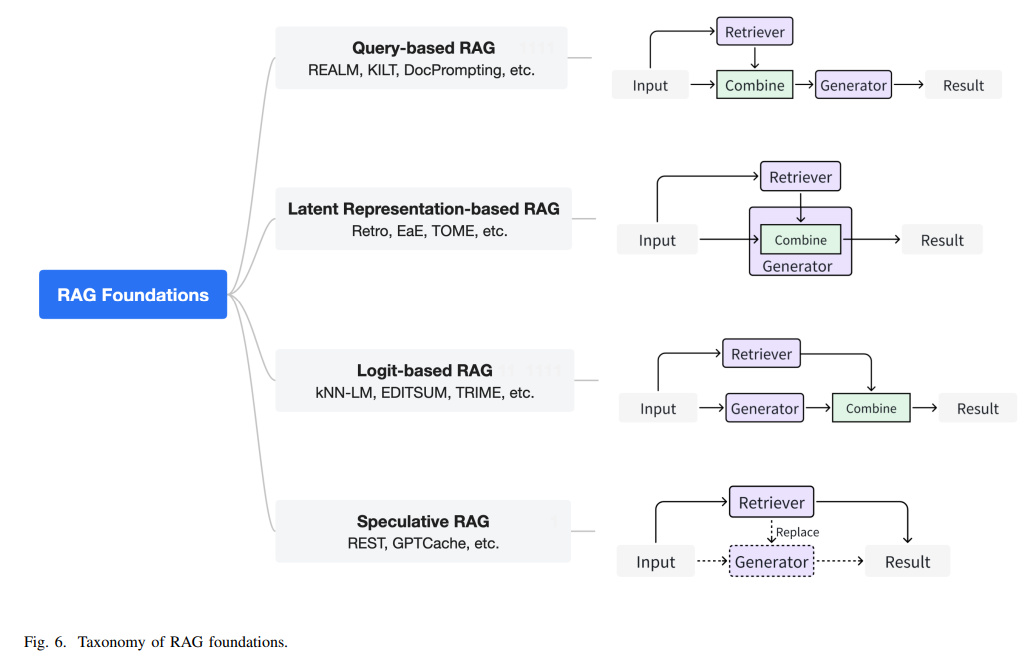
人工知能生成コンテンツ(AIGC)の開発は、モデルアルゴリズムの進化、スケーラブルな基本モデルアーキテクチャの進歩、そして豊富な高品質データセットの利用可能性によって促進されてきました.AIGCは驚異的なパフォーマンスを達成していますが、最新の知識やロングテールの知識を維持する難しさ、データ漏洩のリスク、トレーニングと推論に関連する高コストなどの課題に直面しています.最近、Retrieval-Augmented Generation(RAG)がこれらの課題に対処するためのパラダイムとして登場しました.特に、RAGは情報検索プロセスを導入し、利用可能なデータストアから関連するオブジェクトを取得することでAIGCの結果を向上させ、より高い精度と堅牢性を実現します.本論文では、RAG技術をAIGCシナリオに統合する既存の取り組みを包括的にレビューしています.まず、リトリーバーがジェネレーターをどのように拡張するかに応じてRAGの基盤を分類します.さまざまなリトリーバーとジェネレーターのための拡張方法論の基本的な抽象化を抽出します.この統一された視点はすべてのRAGシナリオを包括し、進歩を明らかにします.さらに、将来の進展に役立つ可能性のある重要な技術や進歩を明らかにする統一された視点を提供します.また、RAGの追加の拡張方法を要約し、RAGシステムの効果的なエンジニアリングと実装を促進します.さらに、異なるモダリティやタスクにわたるRAGの実用的な応用について調査し、研究者や実務家に有益な参考資料を提供します.さらに、RAGのベンチマークを紹介し、現在のRAGシステムの制限について議論し、将来の研究方向を提案します.プロジェクト:https://github.com/hymie122/RAG-Survey
Q&A:
Q: 人工知能生成コンテンツ(AIGC)の開発を促進したモデルアルゴリズムの進歩とは?
A: 人工知能生成コンテンツ(AIGC)の開発を促進したモデルアルゴリズムの進歩は、スケーラブルな基盤モデルアーキテクチャの進化と豊富な高品質データセットの利用可能性によって可能となりました.
Q: 目覚ましい業績を達成しながらも、AIGCが直面している課題とは?
A: AIGCは、驚異的なパフォーマンスを達成しているにもかかわらず、最新の知識や長尾の知識を維持する難しさ、データ漏洩のリスク、トレーニングと推論に伴う高いコストなどの課題に直面しています.
Q: 検索補強型世代(RAG)は、AIGCが直面する課題にどのように対処するのか?
A: Retrieval-Augmented Generation (RAG)は、AIGCが直面する課題を解決するために、情報検索プロセスを導入することで成果を上げています.具体的には、RAGは利用可能なデータストアから関連するオブジェクトを取得し、AIGCの結果を向上させることで、より高い精度と堅牢性を実現しています.また、RAGはアダプタブルなデータリポジトリを介して、前述の課題を軽減または完全に解決することが提案されています.検索用に保存された知識は非パラメトリックメモリとして概念化でき、広範なロングテール知識を収容し、機密データをエンコードすることも可能です.さらに、検索は生成コストを削減するためにも利用できます.例えば、RAGは大規模な生成モデルのサイズを縮小し、長いコンテキストをサポートし、特定の生成ステップを排除することができます.
Q: 情報検索プロセスは、RAGにおけるAIGCの結果をどのように高めているのか?
A: 情報検索プロセスは、利用可能なデータストアから関連するオブジェクトを取得することによって、AIGCの結果を向上させます.これにより、より高い精度と堅牢性が実現されます.
Q: RAG基礎は、レトリーバーが発電機をどのように補強するかによってどのように分類されますか?
A: RAGの基盤は、リトリーバーが生成器をどのように拡張するかによって分類されます.具体的には、ユーザーのクエリとリトリーバーが取得した文書からの洞察を統合するクエリベースのRAG、すなわちプロンプトの拡張が広く採用されているアプローチとして挙げられます.
Q: RAGにおける様々なリトリーバーとジェネレーターのためのオーグメンテーション手法の基本的な抽象化とは?
A: 様々なリトリーバーとジェネレーターにおける増強手法の基本的な抽象化を蒸留します.
Q: RAGシステムの効果的なエンジニアリングと実装を促進するために、RAGにはどのような追加強化方法がありますか?
A: RAGの効果的なエンジニアリングと実装を促進するために、入力、リトリーバ、ジェネレータ、および結果の強化が要約されています.
Q: さまざまなモダリティやタスクにおいて、RAGのどのような実用例が調査されているのだろうか?
A: 異なるモダリティとタスクにわたるRAGの実用的な応用が調査されています.
Q: RAGにはどのようなベンチマークが導入され、現行のRAGシステムにはどのような限界があるのか?
A: 現在のRAGシステムの限界は、入力、リトリーバ、ジェネレータ、および結果の改善を含むさまざまな側面にあります.また、RAGのための既存のベンチマークが紹介されています.
Q: RAGの文脈から、将来どのような研究の方向性が考えられるか?
A: RAGの将来の研究および応用の可能性の方向性として、より高度な方法論、拡張、および応用の開発が提案されています.既存の研究では、リトリーバーとジェネレーターの間のさまざまな相互作用パターンが探索されており、これら2つのコンポーネントの最適化目標が異なるため、実用的な拡張プロセスは最終的な生成結果に大きな影響を与えます.より高度な拡張の調査は、RAGの潜在能力を十分に引き出すための約束を持っています.また、既存のAIGC方法にRAG技術を組み込んだものを調査し、RAGが現在の生成モデルにどのように貢献しているかを示すことで、さまざまなモダリティやタスクに対する研究が行われています.RAGの限界と将来の研究方向について議論し、その潜在的な将来の発展に光を当てています.
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
著者:Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, Lifang He, Lichao Sun
発行日:2024年02月27日
最終更新日:2024年02月28日
URL:http://arxiv.org/pdf/2402.17177v2
カテゴリ:Computer Vision and Pattern Recognition, Artificial Intelligence, Machine Learning

概要:
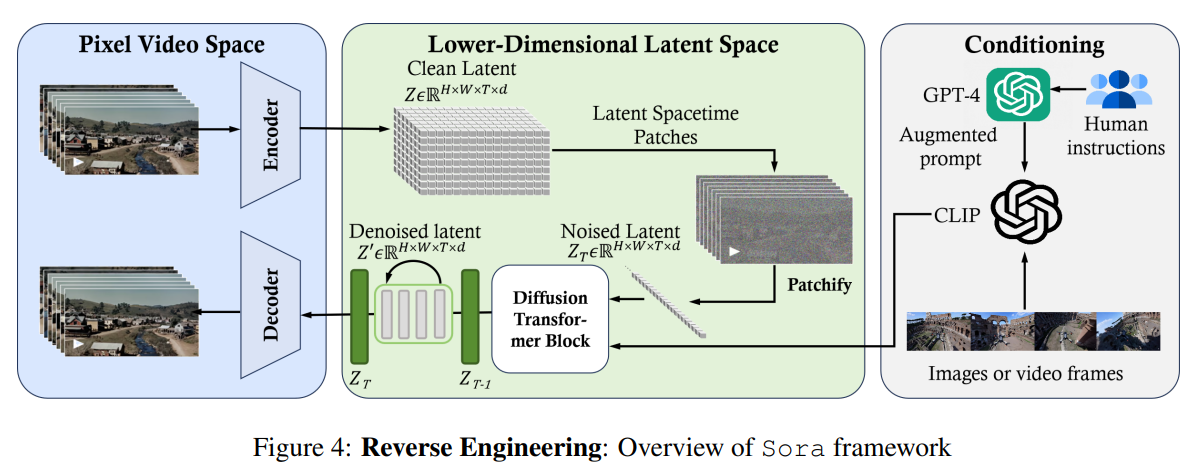
Soraは、2024年2月にOpenAIによってリリースされたテキストからビデオを生成するAIモデルです.このモデルは、テキストの指示に基づいて現実的または想像力豊かなシーンのビデオを生成するように訓練されており、物理世界をシミュレートする潜在能力を持っています.この論文は、公開されている技術レポートやリバースエンジニアリングに基づいて、テキストからビデオへのAIモデルの背景、関連技術、アプリケーション、残されている課題、および将来の方向性について包括的なレビューを提供しています.まず、Soraの開発を追跡し、この「ワールドシミュレーター」を構築するために使用された基盤技術を調査します.次に、映画製作や教育、マーケティングなどのさまざまな産業でのSoraのアプリケーションと潜在的な影響について詳細に説明します.Soraを広く展開するために必要な主な課題や制約、例えば安全で偏りのないビデオ生成を確保することなどについて議論します.最後に、Soraやビデオ生成モデルの将来の発展について、およびこの分野の進歩が新しい人間とAIの相互作用の方法を可能にし、ビデオ生成の生産性と創造性を向上させる方法について議論します.
Q&A:
Q: Sora開発のきっかけと、具体的な目標は?
A: Soraの開発のインスピレーションは、データをそのままのサイズでトレーニングする革新的なアプローチであり、これは学術コミュニティに革新的なインスピレーションを与え、より高度な生成モデルの作成を促します.モデルに設定された具体的な目標は、動的な広告や特定の観客の説明に合わせた動的な広告を作成すること、ゲーム開発者がプレイヤーの物語からカスタマイズされたビジュアルやキャラクターアクションを生成することなどです.
Q: Soraを構築するために使用された基礎技術と、それらがSoraの機能にどのように貢献しているか説明していただけますか?
A: Soraを構築するために使用される基盤技術は、事前にトレーニングされた拡散トランスフォーマーと空間時間潜在パッチです.トランスフォーマーモデルは、多くの自然言語タスクに対してスケーラブルで効果的であることが証明されています.GPT-4などの強力な大規模言語モデル(LLM)と同様に、Soraはテキストを解析し、複雑なユーザーの指示を理解することができます.ビデオ生成を計算効率的に行うために、Soraは空間時間潜在パッチを使用しています.具体的には、Soraは生の入力ビデオを潜在空間時間表現に圧縮します.その後、圧縮されたビデオから潜在空間時間パッチのシーケンスが抽出され、視覚的外観と動きの両方を包括するようになっています.
Q: Soraのテキストからビデオを生成する能力を最も恩恵を受けると考える産業は何ですか?
A: Soraのテキストからビデオ生成能力を最も活用する産業は、映画製作、教育、マーケティングなどの複数の産業です.Soraは高度にリアルな環境をテキストの説明から生成することができるため、映画製作や教育分野で革新的な影響をもたらす可能性があります.また、Soraを利用することで、マーケティングビデオを迅速に適応させてカスタマイズされたマーケティングコンテンツを作成することができ、広告の制作コストを削減し、広告の魅力と効果を向上させることができます.さらに、Soraの能力を活用することで、ブランドが観客との関わり方を革新し、製品やサービスの本質を捉えた没入感のある魅力的なビデオを作成することが可能になります.
Q: Soraを広く普及させるために対処すべき主な課題と限界は何ですか?
A: Soraを広く展開するためには、安全で偏りのないビデオ生成を確保するという主な課題と制限事項を解決する必要があります.
Q: そらでは、どのようにして安全で偏りのないビデオ生成を保証しているのか、また、潜在的な偏見に対処するためにどのような対策がとられているのか.
A: Soraは安全で偏りのないビデオ生成を確保するために、生成されたコンテンツに偏りや有害なビジュアルが含まれないようにするための対策が取られています.このために、開発者、研究者、および広いコミュニティによる責任ある使用が重要視されており、Soraの出力が一貫して安全で偏りのないものであることを確保することが主要な課題とされています.偏りを軽減し、有害なビジュアル出力を防ぐために、倫理的な考慮事項が挙げられており、このような課題に対処するための対策が必要とされています.
Q: ビデオジェネレーションの分野で、今後のSoraの発展に影響を与えるような進歩を予見していますか?
A: ビデオ生成の分野における進歩として、より複雑なアクションや微妙な表情を描写する能力の向上が期待されます.また、生成されるコンテンツの偏りを緩和し、有害なビジュアル出力を防ぐための倫理的考慮も重要です.Soraの出力が常に安全で偏りのないものであることを確認することは主要な課題です.ビデオ生成の分野は急速に進化しており、学術的および産業研究チームが不断の進歩を遂げています.競合するテキストからビデオへのモデルの出現は、Soraが近い将来、ダイナミックなエコシステムの一部になる可能性を示唆しています.この協力的で競争的な環境は、革新を促し、ビデオの品質を向上させ、労働者の生産性を向上させ、人々の生活をより楽しいものにする新しいアプリケーションを生み出すでしょう.
Q: Soraは物理的な世界をどのようにシミュレートしているのか.また、テキストの指示からリアルなシーンや想像的なシーンを生成するために、どのようなテクニックが使われているのか.
A: Soraは、物理世界をシミュレートするために、3Dモデリングを持たないにも関わらず、動的なカメラの動きやオブジェクトの持続性を含む長距離の一貫性を示す3Dの一貫性を示します.また、Soraは、Minecraftのようなデジタル環境を興味深くシミュレートし、視覚的な忠実度を維持しながら、基本的なポリシーによって制御されます.これらの新しい能力は、ビデオモデルをスケーリングすることで、物理的およびデジタル世界の複雑さをシミュレートするAIモデルを作成するのに効果的であることを示唆しています.
Q: Soraが映画製作、教育、マーケティングでどのように使われ、これらの業界にどのような影響を与えたか、例を挙げていただけますか?
A: Soraは映画製作、教育、マーケティングの分野でどのように使用されてきたか、およびこれらの産業に与えた影響について具体的な例を提供します.映画製作では、Soraはリアルな環境やシナリオをシミュレートすることができ、これにより従来困難または高額だった魅力的なビデオを通じて複雑なストーリーを伝えることが可能となりました.教育分野では、教育者がさまざまな科目に関するビデオを制作することができ、複雑な概念を生徒にとってよりアクセスしやすく魅力的にすることができます.また、マーケティング分野では、Soraを活用することでコンテンツ制作を革新し、情報共有を促進することができます.これらの産業におけるSoraの影響は、それぞれの分野で革新的な変化をもたらし、新たな可能性を切り拓いています.
Q: Soraは、パフォーマンス、能力、潜在的なアプリケーションの点で、他のテキストからビデオへのAIモデルと比較してどうですか?
A: Soraは、他のテキストからビデオへのAIモデルと比較して、パフォーマンス、機能、および潜在的なアプリケーションにおいて優れた点があります.Soraは、高品質の1分間のビデオを生成する能力を持ち、ユーザーのテキスト指示に従いながら、リアルなまたは想像上のシーンを生成することができます.これは、以前のビデオ生成モデルと比較して、より長いビデオを生成し、高い視覚的品質を維持しながら、ユーザーの指示に従う点で優れています.Soraは、複数のキャラクターが複雑な背景で特定のアクションを行う詳細なシーンを生成する能力を持ち、ユーザーの複雑な指示を正確に解釈し実行することができます.これにより、Soraは他のモデルよりも進化したビデオ生成モデルであり、動きや相互作用の微妙な描写を含む拡張されたビデオシーケンスを生成する能力を持っています.
Q: Soraと映像生成モデル全般の今後の方向性、また、これらの進歩の結果、人間とAIのインタラクションがどのように進化していくことを想定していますか?
A: Soraおよびビデオ生成モデル全般の将来の方向性は、AIの進化により、人間とAIの相互作用がどのように進化するかを考えると、新しい創造的な方法が可能になります.これにより、労働者の生産性が向上し、人々の生活がよりエンターテイニングになるでしょう.
Q: 本稿で紹介した新手法のコード実装のURLは?
A: この論文で導入された新しい手法のコード実装のurlは、https://github.com/lichao-sun/SoraReview です.
