
今回のテーマ: OpenAIによる各COTステップへの報酬, BiomedGPT, ByteFormer, 逆伝搬なしでのモデル微調整, MERT, SQL-Palmなど.
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をLLMによって生成されるQ&Aを用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.自動生成記事のクオリティと信頼性を向上させるためにアルゴリズムの改善に取り組んでいます.個人で資料のQ&Aを作成されたい方には、https://www.chatpdf.com/ や https://scispace.com/などがお勧めです.
紹介する論文は以下の10本となります.
- Thought Cloning: Learning to Think while Acting by Imitating Human Thinking (発行日:2023年06月01日)
- Let’s Verify Step by Step (発行日:2023年05月31日)
- The Impact of Positional Encoding on Length Generalization in Transformers (発行日:2023年05月31日)
- MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training (発行日:2023年05月31日)
- Bytes Are All You Need: Transformers Operating Directly On File Bytes (発行日:2023年05月31日)
- CodeTF: One-stop Transformer Library for State-of-the-art Code LLM (発行日:2023年05月31日)
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model (発行日:2023年05月29日)
- Fine-Tuning Language Models with Just Forward Passes (発行日:2023年05月27日)
- BiomedGPT: A Unified and Generalist Biomedical Generative Pre-trained Transformer for Vision, Language, and Multimodal Tasks (発行日:2023年05月26日)
- SQL-PaLM: Improved Large Language ModelAdaptation for Text-to-SQL (発行日:2023年05月26日)
Thought Cloning: Learning to Think while Acting by Imitating Human Thinking
著者:Shengran Hu, Jeff Clune
発行日:2023年06月01日
最終更新日:2023年06月01日
URL:http://arxiv.org/pdf/2306.00323v1
カテゴリ:Artificial Intelligence, Machine Learning
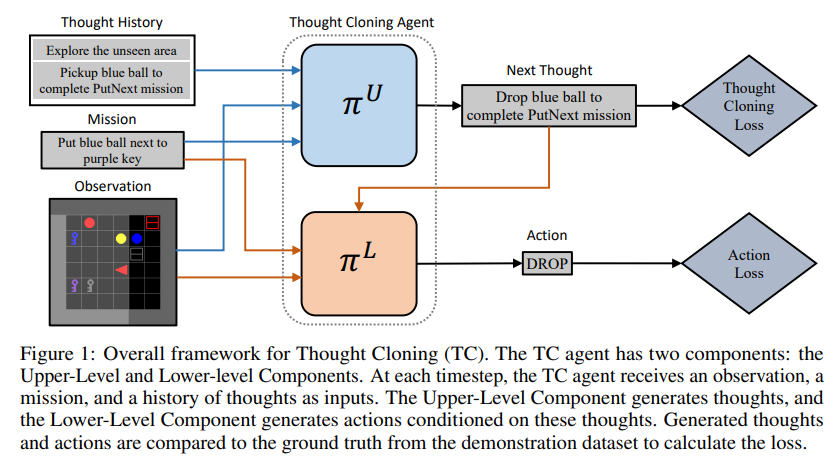
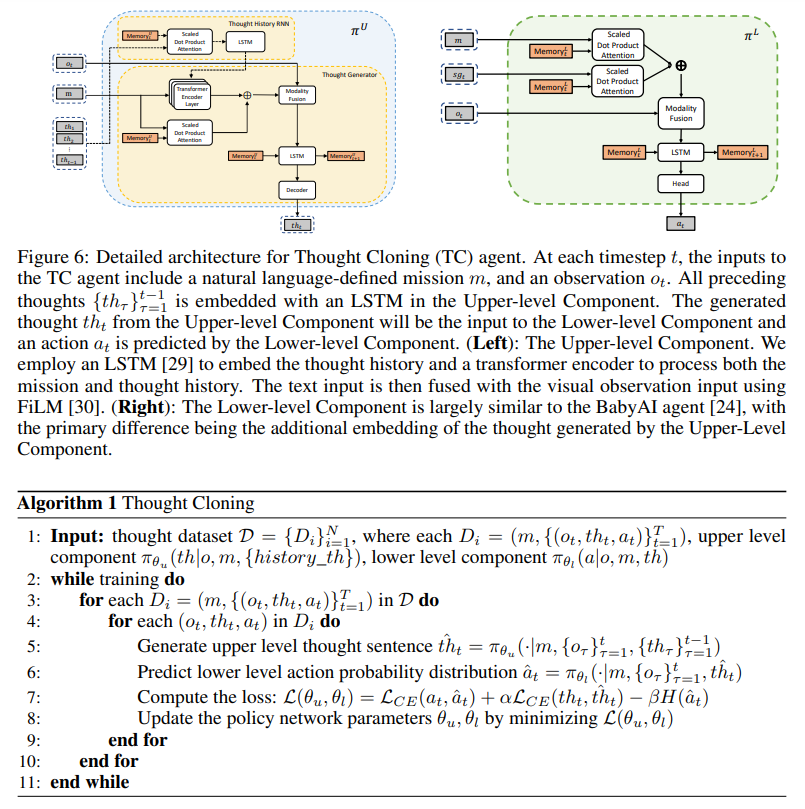
概要:
本研究では、新しい模倣学習フレームワークであるThought Cloningを紹介し、人間のデモンストレーターの行動だけでなく、彼らがこれらの行動を行う際に持つ思考も複製することを目的としています.Thought Cloningは、インターネットサイズの人間が行動しながら考えを言葉に出しているデータセット(例えば、トランスクリプト付きのオンラインビデオ)で本当に輝くことを期待していますが、ここでは思考と行動のデータが合成的に生成されたドメインで実験を行っています.結果は、Thought CloningがBehavioral Cloningよりもはるかに速く学習し、テストタスクが分布外であるほどパフォーマンスの優位性が増すことを示しており、新しい課題に対処する能力が向上していることを強調しています.また、Thought CloningはAIの安全性や解釈性にも重要な利点を提供し、AIのデバッグや改善を容易にすることができます.エージェントの思考を観察できるため、何がうまくいかないかをより簡単に診断し、問題を修正することができます.また、思考を修正することでエージェントを誘導したり、危険な行動を予防することもできます.全体的に、行動だけでなく思考もトレーニングすることで、Thought Cloningはより安全で強力なエージェントを作り出します.
Q&A:
Q: 強化学習(RL)エージェントの認知不足の仮説は何ですか?
A: Reinforcement Learning(RL)エージェントの認知的欠陥の仮説は、言語で考える利点が欠けているためであると考えられています.これにより、RLエージェントは人間のレベルには遠く及ばず、一般化、探索、計画、再計画、新しい状況に適応する能力において認知的欠陥が生じます.この仮説は、Shengran Huらによる「Thought Cloning: Learning to Think while Acting by Imitating Human Thinking」(p.1)に記載されています.
Q: 「Thought Cloning」のフレームワークは「Behavioral Cloning」とどう違うのですか?
A: Thought Cloningフレームワークは、Behavioral Cloningとは異なり、エージェントに行動する際に同期された人間の思考のデータセットを利用して、エージェントに思考する方法を教えることを目的としています.Thought Cloningは、行動クローニングエージェントが思考する能力を持っていても、思考クローニングが提供する思考の監視なしでそのスキルを学習する必要がある場合でも、Thought CloningがBehavioral Cloningを上回ることを示しています.また、ゼロショットおよびファインチューニング設定の両方で、Thought CloningがBehavioral Cloningよりも一般化能力が高いことを示しています.(p.5)
Q: Behavioral Cloningのエージェントが思考能力を持ちながら、Thought Cloningが提供する思考の監視なしにそのスキルを学ばなければならない場合でも、Thought CloningがBehavioral Cloningを上回る理由を説明できますか?
A: Behavioral Cloningエージェントが思考する能力を持っていても、Thought Cloningの監視なしでそのスキルを学習しなければならない場合でも、Thought Cloningが優れたパフォーマンスを発揮する理由は、Thought Cloningがより高速に学習するためです.また、Thought Cloningは、ゼロショットおよびファインチューニング設定の両方で、アウトオブディストリビューションタスクにおいて、Behavioral Cloningよりも汎化性能が高いことが示されています.これは、Thought Cloningが新しい状況に対処する能力が高いことを示しており、より安全で強力なエージェントを作成することができるということです.(p.5)
Q: Thought Cloningはどのようなデータセットに最適なのでしょうか?
A: Thought Cloningでは、人間の思考と行動が同期されたデータセットが最も効果的であると期待されています.このようなデータセットは、自然言語で定義されたミッション、観察、行動、思考を含むトラジェクトリーから構成されています.例えば、YouTubeの動画からVPTを使用して行動ラベルを推定し、対応するトランスクリプトを取得することで、人間の思考と行動の両方を含む思考データセットを取得することができます.この情報は、Minecraftのようなゲームでの行動に対応することができます. (p.2-3)
Q: 人間の思考と行動の両方を含むデータセットがどのように得られるのか、その例を教えてください.
A: 人間の思考と行動を含むデータセットの例を提供する方法について説明します.YouTubeビデオから行動ラベルを推定し、対応するトランスクリプトを取得することで、人間の思考と行動を含むデータセットを取得できます.このようなデータセットはオンラインで広く利用可能であり、Minecraftの場合、思考「夜降りる前にシェルターを建てるために木材を集める必要がある」という思考は、プレイヤーが木に向かって移動し、木材を集めることに対応します. (p.1)
Q: ソートクローンの実験結果はどうだったのでしょうか?
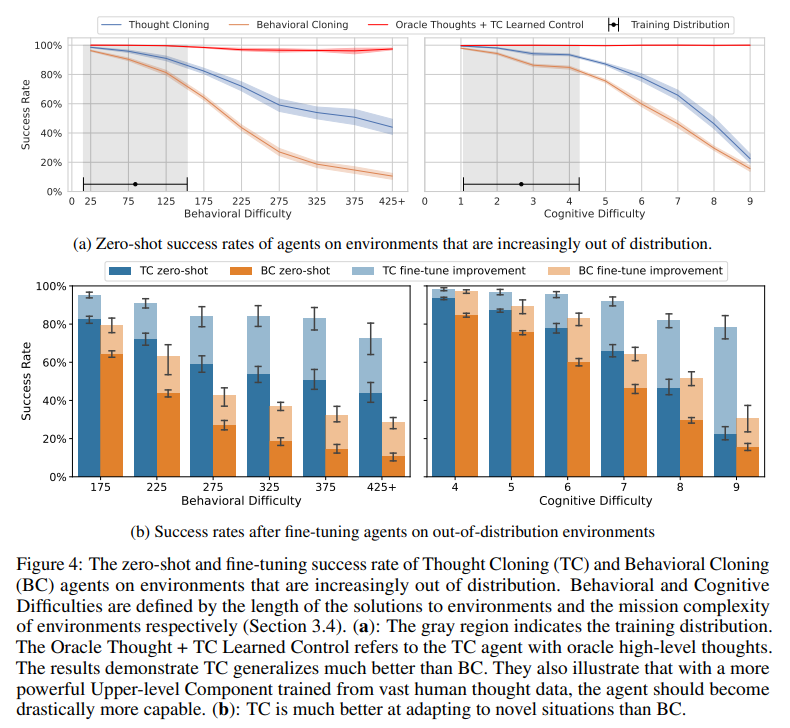
A: 実験結果によると、Thought CloningはBehavioral Cloningよりも学習が速く、一般化、探索、計画、再計画、およびさまざまな状況への適応能力が優れていることが示された.また、Thought CloningはAIの安全性と解釈可能性に重要な利点を提供し、AIのデバッグと改善を容易にする.さらに、Thought Cloningは、危険な行動をほぼ完璧に停止できるため、安全性の観点でも優れていることが実証された.これらの結果は、BabyAIという難しいドメインで合成思考データを用いて検証された.(p.5)
Q: 学習速度、一般化、探索、計画、再計画、適応性などの点で、Thought CloningがBehavioral Cloningより優れているという根拠は何ですか?
A: Thought Cloningは、Behavioral Cloningに比べて、学習速度、汎化性、探索、計画、再計画、および様々な状況への適応性において優れたパフォーマンスを示すことが実証されています.これは、潜在ベクトルで考える能力を持つBehavioral Cloningエージェントが、Thought Cloningによる思考の監督なしでそのスキルを学習しなければならない場合でも、Thought Cloningが優れたパフォーマンスを発揮することを示しています.また、オンラインビデオのトランスクリプトなどのデータではなく、思考と行動のデータが合成されたドメインでの実験でも、Thought CloningがBehavioral Cloningよりもはるかに速く学習し、ゼロショットおよびファインチューニングの両方の設定で、アウトオブディストリビューションタスクに対してBehavioral Cloningよりも汎化性が高いことが示されました.Thought Cloningは、AIの安全性と解釈性に重要な利点を提供し、AIをデバッグおよび改善することが容易になります.エージェントの思考を観察できるため、何がうまくいかないかをより簡単に診断し、問題を修正することができます.また、思考を修正することによってエージェントを誘導したり、エージェントが計画する危険なことを防止することもできます.総じて、Thought Cloningは、行動だけでなく思考も訓練することにより、より安全で強力なエージェントを作り出します.(p.5)
Q: AIの安全性や解釈可能性、AIのデバッグや改良を容易にするために、Thought Cloningはどのような重要な利点を提供するのですか?
A: Thought Cloningは、AIの安全性と解釈可能性を向上させ、AIのデバッグと改善を容易にする重要な利点を提供します.エージェントの思考を観察できるため、(1)何が間違っているのかをより簡単に診断し、問題を修正することが容易になります.(2)エージェントをより良く扱うために、思考を修正することでエージェントを誘導することができます.(3)エージェントが計画する危険なことを防止することができます.全体的に、Thought Cloningは、エージェントがどのように考えるかだけでなく、行動する方法を訓練することにより、より安全で強力なエージェントを作成します.(p.1,4-8)
Thought Cloningは、AIの安全性と解釈可能性を向上させ、AIのデバッグと改善を容易にする重要な利点を提供します.TCエージェントの堅牢な解釈可能性は、開発者がAIシステムを診断するのに役立ち、Precrime InterventionなどのメカニズムによってAIの安全性に貢献します.また、TCの誘導に関する私たちの実証結果は、TCの可能性をさらに浮き彫りにしました.(p.3-5)
Q: 思考クローニングは、AIの安全性と解釈力をどのように向上させるのか?
A: Thought Cloningは、AIの安全性と解釈可能性を向上させます.エージェントの思考を観察できるため、問題が発生した理由をより簡単に診断し、問題を修正することができます.また、思考を修正することでエージェントを誘導したり、危険な行動を予防することもできます.さらに、TCエージェントの堅牢な解釈可能性は、AIシステムの診断に役立ち、Precrime InterventionなどのメカニズムによってAIの安全性に貢献します. (p.1,5,30) Overall、Thought Cloningは、エージェントがどのように考えるかを訓練することで、より安全で強力なエージェントを作成します.
Q: 危険な行動の防止やエージェントの誘導に、「Thought Cloning」はどのような形で活用できるのか?
A: 危険な行動を防止し、エージェントを導くために、Thought Cloningは以下のように使用できます.Thought Cloningは強力な解釈性を持つため、危険な思考を検出するとエージェントを停止させ、安全でない行動を防止することができます.また、Thought Cloningはエージェントの思考を観察できるため、問題が発生した場合には、(1)なぜ問題が発生しているかをより簡単に診断し、問題を修正することができます.(2)エージェントを修正することで、エージェントを導くことができます.(3)エージェントが計画している安全でないことを防止することができます.これにより、Thought Cloningはより安全で強力なエージェントを作成することができます.(p.1,4-8)
Let’s Verify Step by Step
著者:Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, Karl Cobbe
発行日:2023年05月31日
最終更新日:2023年05月31日
URL:http://arxiv.org/pdf/2305.20050v1
カテゴリ:Machine Learning, Artificial Intelligence, Computation and Language

概要:
近年、大規模言語モデルは複雑な多段階の推論を行う能力が大幅に向上しています.しかし、最新のモデルでも論理的なミスを頻繁に生じます.信頼性の高いモデルを訓練するためには、最終結果に対するフィードバックを提供するアウトカム監視、または各中間推論ステップに対するフィードバックを提供するプロセス監視のいずれかに頼ることができます.信頼性の高いモデルを訓練することの重要性と、人間のフィードバックの高いコストのため、両方の方法を慎重に比較することが重要です.最近の研究では、この比較がすでに始まっていますが、まだ多くの問題が残っています.本研究では、プロセス監視がMATHデータセットの問題を解決するためのモデルの訓練において、アウトカム監視よりも優れていることを発見しました.プロセス監視されたモデルは、MATHテストセットの代表的なサブセットの問題の78%を解決します.さらに、アクティブラーニングがプロセス監視の効果を大幅に向上させることを示しました.関連する研究を支援するために、私たちは最高の報酬モデルを訓練するために使用された800,000ステップレベルの人間のフィードバックラベルの完全なデータセットであるPRM800Kをリリースします.
Q&A:
Q: 記事の目的は何ですか?
A: 本論文の目的は、大規模言語モデルの複雑な多段階推論能力を向上させることである.しかし、最新のモデルでも論理的なミスを頻繁に生じるため、より信頼性の高いモデルを訓練する必要がある.そのためには、最終結果に対するフィードバックを提供するアウトカム監視、または各中間推論ステップに対するフィードバックを提供するプロセス監視のいずれかに頼ることができる.本論文では、両方の方法を比較することが重要であると述べられている.大規模および小規模の実験が行われ、それぞれの利点が示されている.(p.1)
つまり、本論文の目的は、大規模言語モデルの信頼性を向上させるために、アウトカム監視とプロセス監視の方法を比較することである.大規模および小規模の実験が行われ、それぞれの利点が示されている.
Q: 言語モデルの信頼性を向上させるために、実験では具体的にどのような手法を用いたのでしょうか.
A: 実験で使用された特定の方法は、中規模と大規模の2つの異なる領域で行われました.大規模な領域では、GPT-4(OpenAI、2023)からすべてのモデルを微調整し、最も信頼性の高いORMとPRMをトレーニングすることに焦点を当てました.モデルの信頼性を向上させるために、最終結果のフィードバックを提供するアウトカム監視または各中間推論ステップのフィードバックを提供するプロセス監視のいずれかに転換できます.高いコストの人間のフィードバックを回避するために、大規模な報酬モデルを使用して、より小さな報酬モデルを監視する方法が使用されました.(p.1)
Q: なぜ、アウトカムモニタリングよりもプロセスモニタリングが好まれるのか?
A: プロセス監視は、アウトカム監視に比べて、より豊富な信号を提供するため、誤差の場所を正確に特定することができます.プロセス監視は、クレジット割り当てを容易にするため、アラインメントに関連するアウトカム監視よりも優れています.プロセス監視は、人間が支持するプロセスに従うようにモデルを促すため、解釈可能な推論をより多く生み出す可能性があります.また、アウトカム監視よりも直接的にアラインされた思考の連鎖を報酬として与えるため、より安全です. (p.1,5,30)
Q: アウトカムモニタリングとプロセスモニタリングの違いは何ですか?
A: アウトカム監視とプロセス監視の違いは、アウトカム監視が最終的な結果に焦点を当てるのに対し、プロセス監視は過程に焦点を当てることです.具体的には、アウトカム監視は最終的な答えが正しいかどうかを評価するのに対し、プロセス監視は最初のステップが正しいかどうか、および誤ったステップの正確な場所を指定することで、より詳細な情報を提供します.プロセス監視は、クレジット割り当てを容易にするため、アラインメントに関連する利点があります.また、アウトカム監視は、アラインメントに関連するリスクがあります.アウトカム監視は、結果を代理指標として使用するため、モデルが報酬信号を利用してミスアラインメントする可能性があります.これに対し、プロセス監視は、直接アラインされた思考の連鎖を報酬として提供するため、より安全です.(p.6-7)
Q: プロセスモニタリングは、アウトカムモニタリングと比較して、どのように詳細な情報を提供するのでしょうか?
A: プロセス監視は、不正確なステップの正確な場所と、最初のステップのうち正しいものがいくつあったかを指定することで、より詳細な情報を提供します.これにより、クレジット割り当てが容易になり、強力なパフォーマンスを説明することができます.(p.1)
プロセス監視は、人間が承認したプロセスに従うようモデルを促すため、解釈可能な推論をより生産的にする傾向があります.また、アラインメントに関連するアウトカム監視と比較して、より安全です.アラインドされた思考の連鎖を直接報酬として与えるため、アラインドされた行動の代理としてアウトカムを依存することはありません.(p.1)
プロセス監視は、アウトカム監視と比較して、不正確なステップの正確な場所と、最初のステップのうち正しいものがいくつあったかを指定することで、より詳細な情報を提供します.(p.1)
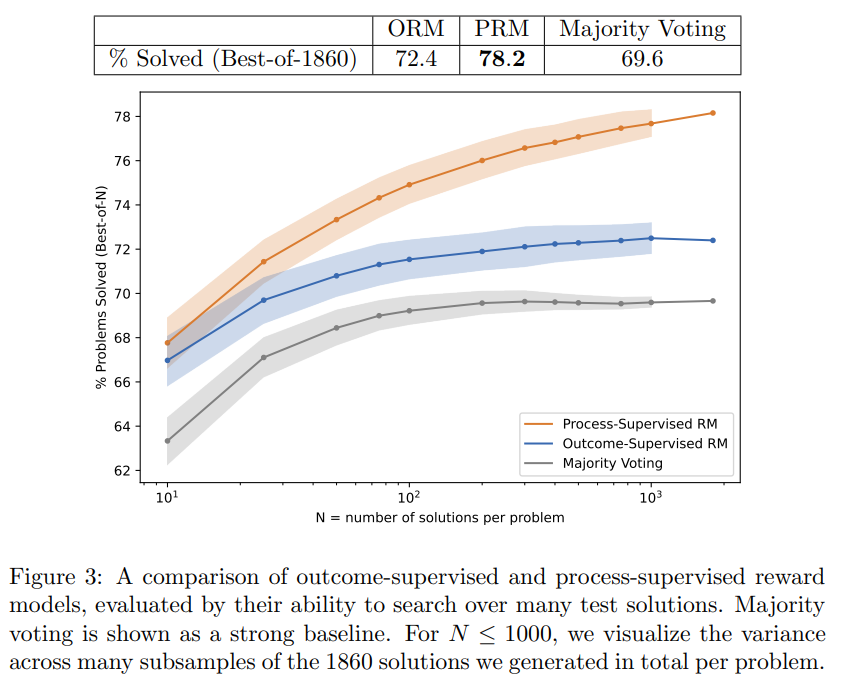
Q: MATHテストセットの問題を解く際のプロセス教師付きモデルの成功率は?
A: 本文中によると、プロセス監視モデルはMATHテストセットの代表的なサブセットの問題の78%を解決することができます(p.1).このモデルは、より多くの人間のフィードバックを使用してトレーニングされ、より難しいMATHデータセットでトレーニングおよびテストされました.また、プロセス監視による能力を向上させるためにアクティブラーニングが使用されました.この研究に関連するために、PRM800Kという完全なデータセットがリリースされ、これは最高の報酬モデルのトレーニングに使用された80万ステップレベルの人間のフィードバックラベルを含んでいます(p.1).
Q: アクティブ・ラーニングはプロセス・スーパービジョンの有効性をどのように向上させるのか?
A: Active learningは、process supervisionの有効性を高めることができます.これは、人間のフィードバックのコストを下げることができるためです.具体的には、active learningは、最も価値のあるモデルの完了のみを提示することにより、人間のデータ収集のコストを下げることができます.これにより、より多くのデータを収集することができ、より信頼性の高いモデルをトレーニングすることができます.(p.8)
Active learningは、process supervisionにおいて、より効果的なデータ収集を可能にすることで、モデルの信頼性を高めることができます.具体的には、最も価値のあるモデルの完了のみを提示することにより、人間のデータ収集のコストを下げることができます.これにより、より多くのデータを収集することができ、より信頼性の高いモデルをトレーニングすることができます.(p.8)
Q: PRM800Kデータセットとはどのようなもので、本研究でどのように使用されたのでしょうか?
A: PRM800Kデータセットは、101,599の解決サンプルに対して、1,085,590のステップレベルラベルを収集したものである.このデータセットは、https://github.com/openai/prm800kで利用可能である.このデータセットは、大規模な言語モデルのアラインメントに関する研究を促進することを目的として、研究で使用された報酬モデルのトレーニングに使用された人間のフィードバックの完全なデータセットを公開している.トレーニング中に品質管理に使用されたラベルや、ラベラーがタスクを完了できなかったステップレベルラベルなどは除外され、約75,000の解決策に対して約800,000のステップレベルラベルが含まれるフィルタリングされたデータセットが作成された.このデータセットは、プロセス監視の利点を観察するために大規模なモデルが必要ではないことを示す小規模な結果があることから、大規模な実験に使用された.また、このデータセットは、大規模な言語モデルのアラインメントに関する研究を促進することを目的として公開された. (p.1)
Q: 大規模言語モデルのアライメントに関する研究において、報酬モデルの学習に使用した人間のフィードバックの完全なデータセットを公開した目的は何でしょうか.
A: 大規模言語モデルの整合性に関する研究において、人間のフィードバックを使用して報酬モデルをトレーニングするために使用された完全なデータセットであるPRM800Kを公開することで、関連する研究を促進することが目的であった.この重要な障壁を取り除くことで、プロセス監視が現在未開拓であることを示し、今後の研究がこれらの方法がどの程度一般化するかをより深く調査することを期待している. (p.12)
The Impact of Positional Encoding on Length Generalization in Transformers
著者:Amirhossein Kazemnejad, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Payel Das, Siva Reddy
発行日:2023年05月31日
最終更新日:2023年05月31日
URL:http://arxiv.org/pdf/2305.19466v1
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning
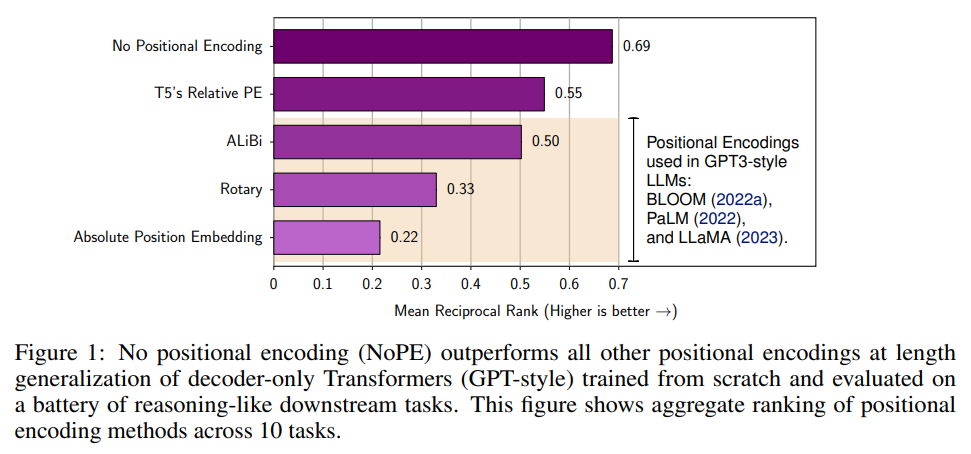
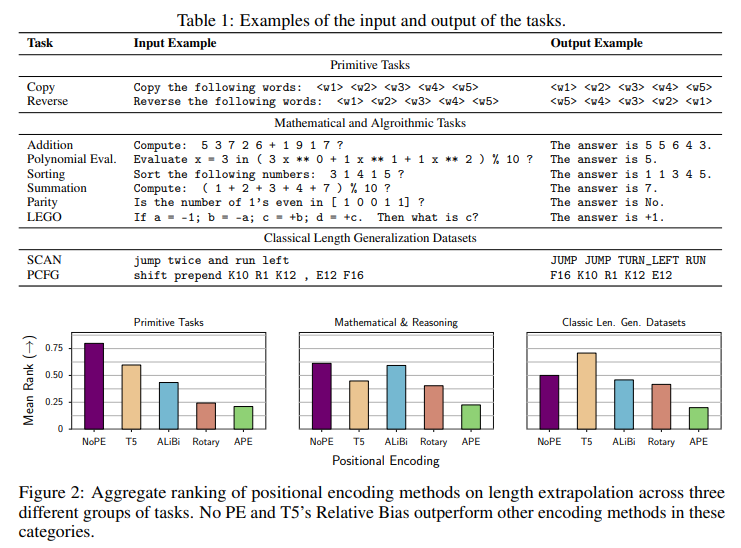
概要:
Transformerベースの言語モデルの開発において、小さなトレーニングコンテキストから大きなものへの一般化能力である「長さの一般化」は重要な課題である.位置エンコーディング(PE)は、長さの一般化に影響を与える主要な要因として特定されているが、異なるPEスキームが下流タスクでの外挿に与える正確な影響は不明である.本論文では、APE、T5の相対PE、ALiBi、Rotary、および位置エンコーディングなし(NoPE)を含む5つの異なる位置エンコーディングアプローチを使用したデコーダーのみのTransformerの長さの一般化性能を比較する系統的な実証研究を行った.評価は、推論および数学的タスクのバッテリーを含む.その結果、ALiBi、Rotary、APEなどの最も一般的に使用される位置エンコーディング方法は、下流タスクでの長さの一般化には適していないことが明らかになった.さらに重要なことに、NoPEは追加の計算を必要とせず、他の明示的な位置エンコーディング方法よりも優れた性能を発揮することがわかった.理論的には、NoPEは絶対的な位置エンコーディングと相対的な位置エンコーディングの両方を表現できることが示された.また、本研究では、スクラッチパッドが長さの一般化を解決するのに必ずしも役立たず、その形式がモデルの性能に大きく影響することが明らかになった.以上の結果から、デコーダーのみのTransformerにおいて、明示的な位置エンコーディングは長いシーケンスに対して一般化するために必要ではないことが示唆された.
Q&A:
Q: Transformerベースの言語モデルにおいて、長さの汎化とは何か、なぜ重要なのか?
A: 長さの一般化とは、小さなトレーニングコンテキストサイズから大きなものに一般化する能力であり、Transformerベースの言語モデルの開発において重要な課題です.位置エンコーディング(PE)は、長さの一般化に影響を与える主要な要因として特定されていますが、異なるPEスキームの下流タスクにおける外挿への正確な影響は不明です.本論文では、APE、T5の相対PE、ALiBi、Rotary、および位置エンコーディングなしのTransformerを含む5つの異なる位置エンコーディングアプローチを持つデコーダー専用Transformerの長さの一般化性能を比較する系統的な実証研究を行いました.評価は、推論と数学的なタスクのバッテリーを含みます.私たちの調査結果は、異なるPEスキームが長さの一般化に異なる影響を与えることを示しています.(p.1)
Q: 位置の符号化方式の違いは、下流のタスクにおける外挿にどのような影響を与えるか?
A: downstreamタスクの長さの推定において、異なる位置エンコーディング手法はどのように影響するかについて、本論文では系統的な実験的研究を行っている(Tay et al., 2022).APE、T5の相対PE、ALiBi、Rotaryを含む5つの位置エンコーディング手法と、位置エンコーディングを行わないTransformers(NoPE)を用いたデコーダーのみのTransformersの長さの一般化性能を比較している.3つのカテゴリーの合成タスクにおいて、NoPEとT5のRelative Biasが他のエンコーディング手法よりも優れた性能を示した(Figure 2).ただし、これらの研究では、下流タスクのパフォーマンスを明らかにする唯一の評価指標である言語モデリングのPerplexityを使用していない(Tay et al., 2022).また、デコーダーのみのTransformerのAttentionは、明示的な位置情報を持たないシーケンスをモデル化することが示されている(Tsai et al., 2019)ため、位置エンコーディングを行わない場合の効果(NoPE)についても検討している.これらの研究により、異なる位置エンコーディング手法が下流タスクにおける長さの推定にどのように影響するかが明らかになった(Tay et al., 2022).(p.1)
Q: 長さの汎化に影響を与える主要な要因として、位置エンコーディングはどのように特定されたのでしょうか?
A: ポジショナルエンコーディングは、トランスフォーマーベースの言語モデルの開発において、小さなトレーニングコンテキストサイズから大きなものに一般化する能力である「長さの一般化」に影響を与える主要な要因として特定されています.これは、論文のAbstract (p.1)に記載されています.しかし、異なるPEスキームの正確な影響は、下流タスクの外挿においてはまだ明確ではありません.したがって、本研究では、APE、T5のRelative PE、ALiBi、Rotary、およびPEなしのトランスフォーマーを含む5つの異なる位置エンコーディングアプローチを使用して、デコーダーのみのトランスフォーマーの長さの一般化性能を比較する系統的な実証研究を行っています.そして、彼らの評価は、推論と数学的なタスクのバッテリーを含んでいます.彼らの研究結果は、PEが長さの一般化に影響を与える主要な要因であることを示しています.
Q: この研究で比較された5種類のポジションエンコーディングアプローチとはどのようなものでしょうか?
A: 本研究で比較された5つの異なる位置エンコーディング手法は、NoPE、T5の相対バイアス、ALiBi、Rotary、Absolute Position Embeddingです.(p.2, Figure 2) これらの手法は、異なるタスクグループでの長さの外挿における性能を比較するために使用されました.(p.2) 結果、NoPEが他の明示的な位置エンコーディング手法よりも優れた性能を発揮し、APEやRotaryは一般化性能が低いことが示されました.(p.2, Figure 3) また、Rotaryは相対エンコーディング手法と考えられていることが多いですが、APEよりも他の相対スキームに近い性能を発揮することが示されました.(p.2) ALiBiは、長さの一般化において有望であるとされていましたが、T5の相対バイアスに比べて性能が低いことが示されました.(p.2, Figure 2)
Q: NoPEが他の明示的位置符号化方式に比べて性能が良い理由は何でしょうか?
A: NoPEが他の明示的な位置エンコーディング方法よりも優れたパフォーマンスを示す理由は、NoPEが追加の計算を行わずに同じレベルの汎化を達成することができるためです.これは、T5のRelative Biasのような明示的なPEによって引き起こされる追加の計算が、モデルのトレーニングと推論時間をほぼ2倍遅くすることがあるためです.また、NoPEは、位置エンコーディングを必要としないため、モデルのランタイムとメモリフットプリントにも直接的な影響を与えます.これは、明示的な位置エンコーディングがTransformerにとって課題を提供することを示唆する証拠の一部であり、NoPEが広く使用されているdecoder-only Transformerアーキテクチャの変更として有望であることを示唆しています.(p.1,5,8)
Q: 特にナイら(2021年)の足し算課題の文脈で、使用した評価方法について詳しく教えてください.
A: 評価方法についての詳細については、各タスクについてトレーニングセットに10万の例、テストに1万の例をサンプリングし、トレーニングセットの15%を検証セットとして使用しています.また、Nye et al.(2021)の加算タスクに関しては、各数字をスペースで区切って表現し、数字の正確な桁数にアクセスできるようにしています.トレーニングセットについては、数字のうち1つが最大L桁以下であるバケットを使用し、テストセットについては、数字のいずれかが最大L桁以下であるバケットを使用しています.モデルは、予測された結果の正確さに基づいて評価されます.詳細な結果については、付録Eを参照してください.(p.3)
Q: 異なる位置エンコード方法の性能に関する研究結果は?
A: 異なる位置エンコーディング手法の性能に関する研究の結果は、ALiBi、Rotary、APEなどの最も一般的に使用される位置エンコーディング手法は、下流タスクにおける長さの汎化には適していないことを示しています.さらに、NoPEは他の明示的な位置エンコーディング手法よりも優れた性能を発揮し、追加の計算を必要としません.この研究では、3つの異なるグループのタスクにおける長さの外挿に関する集計ランキングが示されており、NoPEとT5のRelative Biasがこれらのカテゴリで他のエンコーディング手法を上回っていることが示されています.(p.3-5)
この研究では、多数のタスクにおいて、異なる位置エンコーディング手法の性能を比較しています.その結果、NoPEが他の手法よりも優れた性能を発揮することが示されています.また、他の研究と同様に、人間の言語処理には認知的制約があることが指摘されており、自然言語モデリングの評価において位置エンコーディングがどのように汎化するかについての誤った印象を与える可能性があることが示唆されています.(p.3-5)
Q: 下流タスクにおける位置エンコード方法の違いによるパフォーマンスに関する研究結果は?
A: Downstream tasksにおける異なる位置エンコーディング手法の性能に関する研究結果は、図2に示されています.NoPEとT5のRelative Biasが、これらのカテゴリーで他のエンコーディング手法を上回っています.(p.2)
Q: NoPEは、他の明示的位置符号化手法と比較して、性能と計算量の点でどのような違いがあるのでしょうか?
A: NoPEは、他の明示的な位置エンコーディング方法よりも優れた性能を発揮し、追加の計算を必要としないことが示されています.これは、長さの外挿において明示的な位置エンコーディングがトランスフォーマーにとって課題を提供することを示唆しており、NoPEを使用することでこの問題を解決できる可能性があることを示唆しています.(p.1, 8)
Q: デコーダのみのTransformerがより長いシーケンスにうまく汎化するためには、明示的な位置埋め込みが必要であるということですが、この研究の全体的な結論はどのようなものでしょうか.
A: 本研究の結論は、decoder-only Transformerにおいて明示的な位置エンコーディングを使用するよりも使用しない方が、より長いシーケンスに対して汎化性能が高いことである.これは、有限かつ短い長さのトレーニング例から汎化する必要がある場合に、明示的な位置エンコーディングが長いシーケンスに対して不利であることが原因である.これは、(p.1)に記載されている.また、明示的な位置エンコーディングは、Transformersにおいて課題を引き起こす可能性があることが、Sinhaら(2022)やLuoら(2021)の研究から示唆されている.したがって、decoder-only Transformerにおいて位置エンコーディングを削除することは、広く使用されているアーキテクチャの改良として有望であると考えられる.これは、(p.1)および(p.8)に記載されている.
Q: SinhaとLuoの研究によって示唆された、トランスフォーマーにおける明示的なポジションエンコーディングが引き起こす可能性のある問題について、より詳しい情報を教えてください.
A: SinhaらとLuoらの研究によると、明示的な位置エンコーディングはNoPEに比べて長さの外挿において不利な影響を与え、位置エンコーディングはTransformerにとって課題を引き起こす可能性があることが示唆されています.我々の実験結果と理論的分析は、位置エンコーディングを削除することが、広く使用されているデコーダー専用Transformerアーキテクチャの改良として有望であることを示唆しています.(p.1,5,30)
MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training
著者:Yizhi Li, Ruibin Yuan, Ge Zhang, Yinghao Ma, Xingran Chen, Hanzhi Yin, Chenghua Lin, Anton Ragni, Emmanouil Benetos, Norbert Gyenge, Roger Dannenberg, Ruibo Liu, Wenhu Chen, Gus Xia, Yemin Shi, Wenhao Huang, Yike Guo, Jie Fu
発行日:2023年05月31日
最終更新日:2023年05月31日
URL:http://arxiv.org/pdf/2306.00107v1
カテゴリ:Sound, Artificial Intelligence, Computation and Language, Machine Learning, Audio and Speech Processing
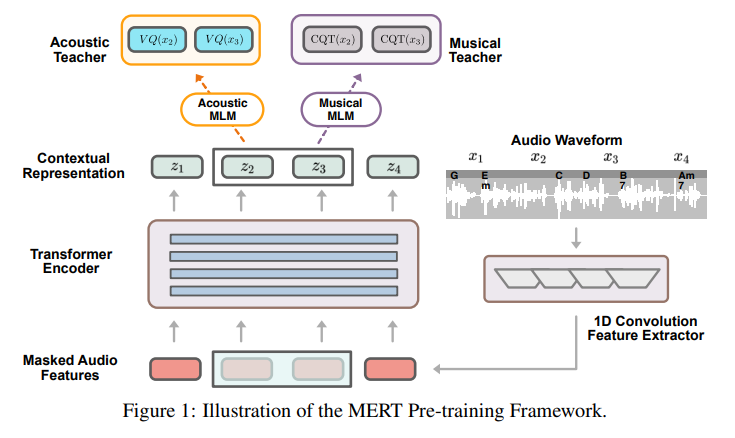
概要:
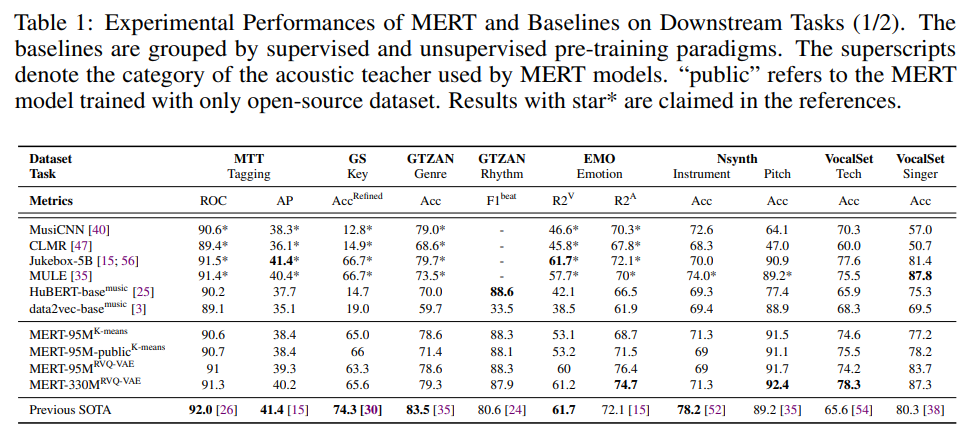
自己教育学習(SSL)は、視覚、テキスト、音声の分野で大規模なデータに対して汎用的なモデルを訓練する有望なパラダイムとして最近注目されています.しかし、音楽オーディオに対する適用はまだ十分に探究されておらず、音楽の音程や調性などの特徴的な要素をモデル化する上での課題があります.そこで、本研究では、大規模な自己教育学習(MERT)を用いた音楽理解モデルを提案しました.このモデルは、マスクされた言語モデリング(MLM)スタイルの音響プレトレーニングにおいて、教師モデルを組み込んで擬似ラベルを提供し、音楽オーディオの特徴的な要素をモデル化することに成功しました.さらに、バッチ内ノイズ混合増強を導入して表現の堅牢性を向上させ、音声言語モデルの不安定性を克服するための設定を探索し、95Mから330Mのパラメータにスケールすることができました.実験結果は、本モデルが14の音楽理解タスクで優れた性能を発揮し、総合スコアで最先端の成績を収めたことを示しています.本研究のコードとモデルは、https://github.com/yizhilll/MERTで公開されています.
Q&A:
Q: 提案されたモデルは何と呼ばれ、どのような目的を持っているのでしょうか.
A: 提案されたモデルはJukeMIRであり、その目的は音楽理解のための汎用的で費用対効果の高いオープンソースPLMを提供することです.Castellonら(2021)によって構築されたJukeMIRは、音楽タグ付けタスクだけでなく、キー検出や感情回帰などのタスクにも適用可能であり、事前学習モデルJukeboxをベースにしています.このモデルは、事前学習モデルを深層特徴抽出器として凍結し、下流タスクには多層パーセプトロン(MLP)などの単純な構造を使用することで、軽量なソリューションを提供します.また、事前学習モデルのパラメータを固定して、下流タスクに必要な特徴量を抽出することで、異なる下流タスク間で表現が再利用可能かどうかをテストします.(p.1,3-5)
Q: JukeMIRの目的、他のPLMとの違いは何ですか?
A: JukeMIRは、音楽タグ付けタスクに限定されず、キー検出や感情回帰などの音楽理解タスクにも対応することができるPLMである.これは、他のPLMと異なり、音楽理解の幅広いモデリングを統一することができ、転移学習によって高い性能を発揮することができる点が特徴である.また、JukeMIRは、オープンソースのコードベースやチェックポイントを提供することで、さらなる評価を可能にしている.しかし、この手法は、数十億のパラメータを持つ手間のかかる自己回帰トランスフォーマーデコーダを使用しているため、コストが高いという問題がある.(p.1)
Q: JukeMIRがJukeboxのプレトレーニングモデルをどのように使用し、下流のタスクに軽量なソリューションを提供するのか、説明していただけますか?
A: JukeMIRは、Jukebox事前学習モデルを使用して構築され、音楽タグ付けタスクに限定されず、キー検出や感情回帰などの範囲をカバーしています.しかし、このアプローチは、数十億のパラメータを持つ手間のかかる自己回帰トランスフォーマーデコーダを使用して音楽オーディオを階層的にモデル化しました.これにより、消費者向けGPUでMTGなどのデータセットから特徴を抽出するのに数週間かかり、音楽理解タスクの効率が低下しました.そこで、本研究では、一般化可能で手頃な価格の事前学習音楽モデルを設計してオープンソース化することを提案しています.MERTは、音声SSLパラダイムを継承し、教師モデルを使用して連続したオーディオクリップの疑似ターゲットを生成することで、音楽の特徴的なピッチと音色の特徴を捉えるためにマルチタスクソリューションを組み込んでいます.これにより、軽量なソリューションが可能になり、異なるダウンストリームタスク間で表現が簡単に再利用できるかどうかをテストできます.(p.3-5)
Q: 自己教師あり学習とはどのようなもので、このモデルでどのように使われているのでしょうか?
A: 本研究では、音声、テキスト、音声の分野で大規模なデータに対して一般化可能なモデルをトレーニングするための有望なパラダイムである自己教師あり学習(SSL)が提案されています.SSLは音声やオーディオにおいて効果が証明されていますが、音楽オーディオに対する適用はまだ十分に探究されていません.これは、音楽の知識をモデリングする上での独特の課題、特に音程や音高の特性があるためです.この研究のギャップに対処するために、本研究では、教師モデルを組み込んだ音響プレトレーニングのマスク言語モデリング(MLM)スタイルで疑似ラベルを提供する音楽理解モデルを提案しています.SSLは、教師なし学習の一種であり、擬似ラベルを生成するための有名な例としてMLMがあります.SSLは、各データサンプルxiに対して擬似ラベルyiを持つ新しいデータx’iを導出し、擬似ラベルyiと新しいデータに基づく予測ˆyi=fθ(x’i)の間の損失を最小化するトレーニングプロセスです.本研究では、音響教師(k-meansや深い音楽特徴など)への予測と、音楽教師(CQTスペクトルなど)への再構築を含む、MLMパラダイムに基づくプレトレーニングパラダイムとアーキテクチャを紹介しています.(p.1)
Q: 音楽知識のモデリング、特に音程や音色に関する独自の課題とは何でしょうか?
A: 音楽知識をモデリングする際の独自の課題は、音色や和声などの音楽処理の特異性が未だに未解決であることである.音楽情報をモデリングするために、音響情報に加えて、ピッチレベルの情報を強調するために、Constant-Q変換(CQT)スペクトログラムに新しい再構成損失を追加した.MERTモデルは、ビート、ピッチ、歌手情報などの局所的な音楽情報に焦点を当てたタスクにおいて優れたパフォーマンスを発揮するが、よりグローバルな音楽情報を必要とするタスクにおいては、競争力を維持することができる.音楽の事前トレーニングには、トレーニングデータの可用性やモデルサイズの制限があるため、パフォーマンスの向上に制限がある.また、いくつかのモデルは、アクセスできないデータセットでトレーニングされているか、公開されていないコードやモデルの重みでトレーニングされているため、再現性や拡張性が制限されている.これらの課題に対処するために、音楽と音響の両方の教師を組み合わせることができるMERTモデルが提案されている. (p.3-5)
Q: 音響や音楽の先生を含めるなど、この研究で提案されているMLMパラダイムに基づく具体的な事前トレーニングのパラダイムやアーキテクチャについて説明していただけますか?
A: 本研究では、MLMパラダイムに基づく事前学習パラダイムとアーキテクチャを提案しています.このパラダイムには、k-meansや深層音楽特徴などの音響教師への予測、およびCQTスペクトルなどの音楽教師への再構成が含まれています.また、音声処理の事前学習モデルには、別々にトレーニングされたコーデックをトレーニングまたは採用することが提案されています.音楽理解の事前学習には、音響情報のガイダンスを提供するために、音楽教師モデルを組み込むことが提案されています.本研究では、複数の事前学習設定を分析し、音響と音楽の教師と拡張の選択肢を考慮した多数の事前学習設定を分析し、今後の音楽理解の事前学習研究を指導する可能性がある抜粋研究を共有しています.(p.3)
Q: 音楽知識のモデル化にはどのような課題があるのでしょうか.
A: 音楽知識をモデリングする際には、独自の課題があるため、SSLを音楽オーディオに適用することがまだ十分に探究されていない.これは、音楽知識をモデリングするための独自の課題があるためである.例えば、音楽の前処理において、トンネル効果や和音などの音楽処理の独自性が未だに探究されていない.また、音楽のプレトレーニングにおいて、データの可用性やモデルのサイズの制限があり、パフォーマンスの向上が妨げられることがある.さらに、いくつかのモデルは、アクセスできないデータセットでトレーニングされているか、公開されていないコードやモデルの重みでトレーニングされているため、彼らのアプローチを再現または拡張することが困難である.これらの課題により、音楽知識のモデリングは困難である.(p.1,4-8)
Q: データの利用可能性やモデルサイズの制限が、音楽モデルの事前学習にどのように影響し、性能向上を妨げているのか.
A: 音楽モデルの事前学習において、データの入手可能性とモデルサイズの制限は、パフォーマンスの向上を妨げる.これは、音楽情報検索(MIR)の分野において、音楽オーディオの注釈付けに関連するコストや国別の著作権法の制限により、データアクセスに制限があるためである.これに対処するために、音響音楽のための事前学習言語モデル(PLMs)が提案され、再利用可能な学習済み表現を提供し、広範な下流MIRタスクの転移学習を可能にすることができる.しかし、音楽事前学習におけるデータの入手可能性とモデルサイズの制限により、モデルのパフォーマンス向上が妨げられる.(p.10, p.2)
Q: この研究では、どのような教師モデルの組み合わせが優れているとされたのでしょうか.
A: 本研究では、MERTパラダイムにおいて、自動タグ付け(MTT)、キー検出(GS)、ジャンル分類(GTZAN)、感情認識(EMO)などの下流タスクのサブセットを含む、教師モデルの最適な組み合わせと選択を探索しました.表3に示されているように、音響的な情報ガイダンスを提供するために、音響教師モデルとしてDéfossezらのモデルが採用され、音楽理解の事前トレーニングにおいて良好な結果を達成しました.また、音色やハーモニーなどの音楽処理の独自性の一部は未だに未開拓であるため、このギャップを埋めるために、対応する音楽教師モデルをMERTに組み込むことを提案しています.(p.8)
この研究において、最適な教師モデルの組み合わせと選択は、表3に示されています.音響教師モデルとしてDéfossezらのモデルが採用され、音楽理解の事前トレーニングにおいて良好な結果を達成しました.また、音楽処理の独自性の一部は未だに未開拓であるため、対応する音楽教師モデルをMERTに組み込むことが提案されています.(p.8)
Q: 今回使用した学生モデルは、音楽オーディオのモデリングをどのように向上させるのか?
A: 本研究では、音楽理解の事前トレーニングと音響情報のガイダンスを提供するために、Défossezらの研究(2022)で良好な結果を出した音楽再構築の教師モデルを採用することができます.しかし、音色やハーモニーなどの音楽処理の独自性の一部は未だに未開拓のままです.そのため、本研究では、MERTに対応する音楽教師モデルを組み込んで、このようなギャップを埋めることを提案しています.
具体的には、MERTは音声SSLパラダイムを継承し、教師モデルを使用して連続的なオーディオクリップの疑似ターゲットを生成することで、音響および音楽表現学習をバランス良く行うためのマルチタスクパラダイムを組み込んでいます.また、言語モデリングマスク戦略に基づく大規模言語モデルを使用して、音楽の抽出された離散トークンから音楽を生成することを可能にすることも提案しています.
これらの手法により、MERTは音楽理解タスクにおいて優れた結果を出すことができ、エントリーレベルの音楽タスクにも適用することができます.これにより、音楽オーディオモデリングが改善されます.
(p.1-2)
Q: オーディオと音楽の表現学習をバランスよく行うためのマルチタスクパラダイムを取り入れたMERTとはどのようなものか.
A: MERTは、音声と音楽のバランスのとれた表現学習のためのマルチタスクパラダイムを組み込んだ事前学習フレームワークです.MERTモデルは、ビート、ピッチ、歌手情報などのローカルレベルの音楽情報に焦点を当てたタスクにおいて優れたパフォーマンスを発揮し、よりグローバルレベルの情報が必要な音楽タグ付け、キー検出、ジャンル分類などのタスクでも競争力を維持しています.MERTは、音響と音楽の教師のブレンドによって、5秒のコンテキスト長で事前学習された場合でも、音楽録音の理解のための包括的なガイダンスを提供することができます.MERTモデルは、よりグローバルな音楽情報を必要とするタスクにおいても、最先端に近いパフォーマンスを発揮することができるため、広範な音楽理解のモデリングを統一することができます.これにより、異なるタスクに対して専用のモデルや特徴量が必要なくなります.この情報は、(p.8)から抽出されました.
Q: 言語モデリングマスク戦略と大規模言語モデルの活用により、抽出された離散的なトークンからどのように音楽を生成することができるのか.
A: 音楽の生成において、言語モデリングマスク戦略と大規模言語モデルの使用は、連続的な特徴から抽出された離散トークンに基づいて音楽を理解し生成することを可能にします.Dhariwalら(2020)は、階層的なトークンを生成して音楽を再構築することを調査し、Baevskiら(2019a)は、音声表現学習を実施するための予測ターゲットを提供するために事前にトレーニングされたVQ-VAEを導入しました.また、Hsuら(2021)は、K-meansを導入して離散トークンコードブックを提供し、音声ユニットを検出するためにモデルを事前にトレーニングすることで、音楽理解タスクにおいてSOTAのスコアを達成することができることを主張しています.これにより、我々のモデルは14の音楽理解タスクで汎用性があり、SOTAの総合スコアを達成することができます. (p.1)
Q: 提案するパラダイムは、95Mから330Mまでのパラメータをどのようにスケールさせるのか、実験結果はどうなっているのか.
A: 95Mパラメータから330Mパラメータにスケールアップすることが可能であり、EnCodec機能の使用により、k-means機能と比較してモデルを拡大することができる.実験結果によると、モデルサイズを330Mに増やすことで、ほとんどのタスクにおいて性能が向上するか、性能にほとんど差がなかった(0.1%未満)ことが示された.また、MERTシリーズモデルは、SOTAの自己教師付きベースラインJukebox-5B(Dhariwal et al.、2020)と比較して、1.9%(95M)と6.6%(330M)のパラメータしか必要とせず、大規模な分類やシーケンスラベリングMIRタスクに対して、1つの一般的な理解モデルを転送する新しい可能性を開く.実験結果は、ジャンル分類以外のGTZANにおいて、MERT-95Mと比較して有意な差がないことを示しており、データセットが代表的でなくても、モデルが強力な表現を獲得できることを示唆している.これらの情報は、(p.5-6)から抽出されました.
Q: モデルのスケールアップという点で、EnCodec関数とk-means関数を比較するとどうでしょうか.
A: K-meansモデルは、メモリと計算の消費が大きいため、大規模なデータセットでのスケーリングが困難であり、初期化に敏感な結果が得られる一方、EnCodecはRVQ-V AEを使用しており、音声予測ターゲットである中間離散コーデックをエンコーダーからニューラルデコーダーによって大幅に回復できるため、より包括的な音響情報を提供できるとされています.したがって、大規模なデータセットでのスケーリングが困難なK-meansモデルに代わり、EnCodecが最終的な音響教師の選択肢として使用されました.(p.1)
Q: モデルサイズを330Mにすると、ほとんどのタスクで性能が向上する、あるいはモデルサイズを小さくしても性能にほとんど差がないという実験結果の意味を説明できますか?
A: 実験結果によると、モデルサイズを330Mに増やすことで、ほとんどのタスクにおいて性能が向上するか、性能にほとんど差がないことが示された.これは、EnCodec機能の使用により、k-means機能と比較してモデルをスケーリングできるためである.また、MERTは、音楽理解アプリケーションにおいて強力な汎用性を示し、様々なMIRタスクにおいてSOTAの結果を達成することができる.これは、音響モデルの事前学習の不安定性を克服するために、畳み込みエンコーダを組み合わせることで、MERTを95Mから330Mのモデルサイズにスケールアップできることを示している. (p.2-3)
Bytes Are All You Need: Transformers Operating Directly On File Bytes
著者:Maxwell Horton, Sachin Mehta, Ali Farhadi, Mohammad Rastegari
発行日:2023年05月31日
最終更新日:2023年05月31日
URL:http://arxiv.org/pdf/2306.00238v1
カテゴリ:Computer Vision and Pattern Recognition
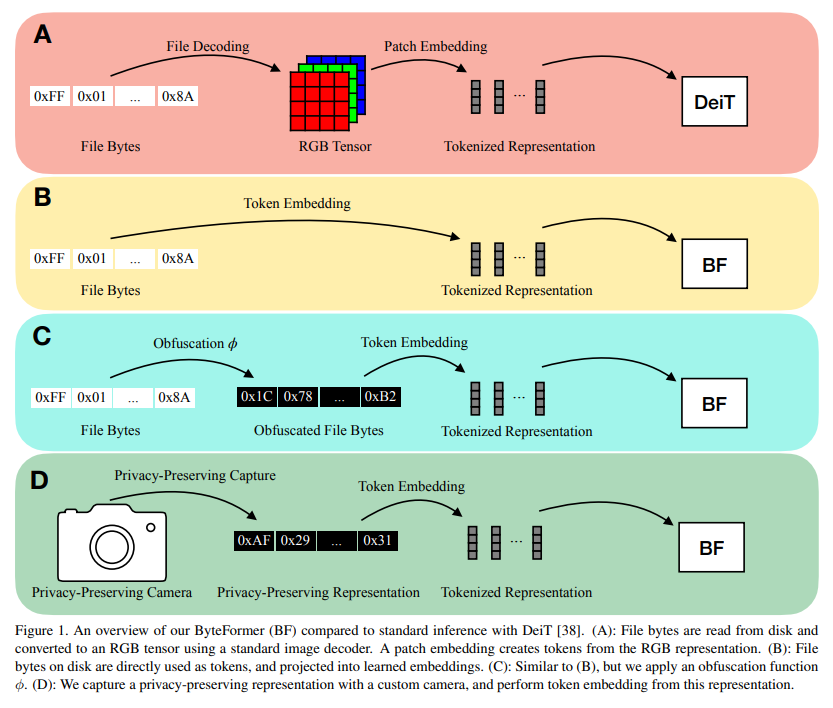
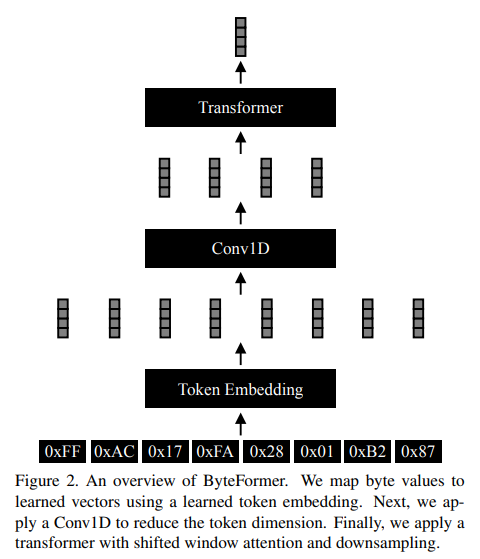
概要:
現代の深層学習アプローチでは、通常、入力をモダリティ固有の形式に変換します.たとえば、画像分類における最も一般的な深層学習アプローチは、画像ファイルバイトをRGBテンソルにデコードしてニューラルネットワークに渡すことです.代わりに、デコードする必要がないファイルバイトを直接分類することを調査します.ファイルバイトをモデルの入力として使用することで、複数の入力モダリティで動作するモデルの開発が可能になります.私たちのモデル、ByteFormerは、TIFFファイルバイトを直接トレーニングおよびテストすることで、DeiT-Tiに似た構成のトランスフォーマーバックボーンを使用してImageNet Top-1分類精度\( \small 77.33\% \)を達成します(RGB画像で動作する場合の精度は\( \small 72.2\% \)).変更やハイパーパラメータの調整なしに、ByteFormerは、Speech Commands v2データセットからのWAVファイルで動作する場合、\( \small 98.7\% \)の最新の精度に比べて\( \small 95.42\% \)の分類精度を達成します.さらに、ByteFormerは、特定の曖昧な入力表現で推論を実行でき、プライバシー保護推論にも応用できます.ByteFormerは、仮想的なプライバシー保護カメラでの推論にも対応し、画像の\( \small 90\% \)のピクセルチャンネルをマスキングすることで、ImageNetで\( \small 71.35\% \)の精度を達成しました.私たちのコードは、https://github.com/apple/ml-cvnets/tree/main/examples/byteformer で公開されます.
Q&A:
Q: 記事の主眼は何ですか?
A: 本論文の主な焦点は、画像と音声の分類におけるデータ効率的な画像変換器と蒸留を通じた注意力によるトレーニングについてです.著者らは、自分たちの方法が暗号レベルのセキュリティを提供しないことを認識しており、セキュリティ専門家が徹底的に分析された安全なシステムを設計するための構築ブロックとして捉えています.また、今後は、ビデオ、テキストなどの他のドメインや、検出、セグメンテーションなどの細かいローカリゼーションを必要とするタスクについても実験することが計画されています.さらに、著者らは、BF-Tiを関連する作品と比較し、ImageNet [6]での効率と精度の指標を示しています.この論文では、著者らのコードがGitHubで公開されていることも言及されています.(p.38-39)
Q: 論文で取り上げたデータ効率の良い画像変換や、画像や音声の分類のためのアテンションベースのトレーニングでは、具体的にどのような方法が用いられたのでしょうか.
A: 本論文では、画像と音声の分類におけるデータ効率的な画像変換器と注意力ベースのトレーニングについて議論されています.画像変換器には、ByteFormerと呼ばれる変更されたTransformerアーキテクチャが使用されており、注意力を使用したトレーニングには、Training data-efficient image transformers & distillation through attentionという手法が使用されています.これらの手法は、ImageNetとSpeech Commands v2の分類タスクで評価され、高い精度を達成しています.(p.1-5)
Q: BF-Ti法の効率や精度は、他の関連作品と比較して、特にImageNetの観点からどのように評価されていますか?
A: BF-Tiの効率と精度は、ImageNetにおいて、DeiT-Ti(5.72百万パラメータ、78.62%)とDeiT-S(22.05百万パラメータ、73.20%)の間に位置しています.BF-Tiの順方向パス時間は、モデル化されるトークンの数が多いため、遅くなっています.ドメイン固有のモデリング(BF-Tiが回避するもの)は、計算時間を劇的に短縮することができます.BF-Tiは、Table 8で関連する作品と比較され、ImageNetの効率と精度のメトリックが示されています.BF-Tiのトレーニング時間とスループットは、自分たちでトレーニングしたモデルについてのみ報告されています.これは、ハードウェアの違いが不一致な結果を生み出すのを避けるためです.BF-Tiのバッチサイズは、GPUの利用率を最大化するために調整されました.これにより、セクション5の実験に比べて、トレーニング時間がわずかに改善されました(10%未満). (p.5)
Q: 現代のディープラーニングアプローチは、一般的にどのように入力を変換するのでしょうか?
A: 現代の深層学習アプローチでは、一般的に入力をモダリティ固有の形式に変換します.例えば、画像分類の最も一般的な深層学習アプローチは、画像ファイルバイトをRGBテンソルにデコードして、ニューラルネットワークに渡すことです.しかし、本研究では、デコードを必要とせずに、ファイルバイトそのもので分類を行うことを調査しています.ファイルバイトをモデルの入力として使用することで、複数の入力モダリティで動作するモデルの開発が可能になります. (p.1-2)
Q: ファイルのバイトをモデルの入力として使用することで、複数の入力モダリティで動作するモデルの開発をどのように可能にするのでしょうか.
A: ファイルバイトをモデルの入力として使用することで、複数の入力モダリティで動作するモデルの開発が可能になります.多くの入力モダリティはファイルバイトとして保存できるため、デコードする必要がなく、プライバシーを保護することができます.また、変更やハイパーパラメータの調整なしで、ByteFormerはSpeech Commands v2データセットのWAVファイルに対して95.42%の分類精度を達成し、最新の精度である98.7%に比べても優れた結果を示しました.(p.1-2)
Q: ファイルバイトをモデルの入力として使用するメリットは何ですか?
A: ファイルバイトをモデルの入力として使用する利点は、入力モダリティに依存しないため、複数の入力モダリティに対応できることです.また、入力をデコードする必要がないため、プライバシーが保護されます.具体的には、RGB画像を入力とするスマートホームデバイスの場合、モデルの入力がアクセスされると、ユーザーのプライバシーが危険にさらされる可能性があります.そのため、ByteFormerモデルでは、ファイルバイトを入力として使用し、変換やデコードを行わずに推論を行います.(p.1)
Q: スマートホームデバイスの入力としてRGB画像を使用する場合と比較して、ファイルバイトを入力として使用する場合は、どのようにユーザーのプライバシーを保護しますか?
A: ユーザーのプライバシーを保護するために、RGB画像を入力として使用する代わりに、ファイルバイトを入力として使用することで、プライバシーを保護することができます.これは、RGB画像を使用する場合、モデル入力にアクセスできる攻撃者によって、ユーザーのプライバシーが侵害される可能性があるためです.一方、ファイルバイトを使用する場合、データを解析することなく、プライバシーを保護することができます.これは、多くの入力モダリティがファイルバイトとして保存できる共通の特性を持っているためです.(p.1)
Q: TIFFファイルのバイトを直接トレーニング、テストした場合のByteFormerの精度はどうでしょうか?
A: TIFFファイルバイトを直接トレーニングおよびテストすることで、ByteFormerは、DeiT-Tiに似た構成のトランスフォーマーバックボーンを使用して、ImageNet Top-1分類精度77.33%を達成します(RGB画像を操作する場合の精度は72.2%).修正やハイパーパラメータの調整なしで、ByteFormerは、Speech Commands v2データセットからのWAVファイルを操作する場合の分類精度が95.42%に達します(最先端の精度は98.7%です)(p.1).
Q: Speech Commands v2データセットのWAVファイルを操作した場合のByteFormerの精度はどうでしょうか?
A: WAVファイルからのByteFormerの分類精度は、state-of-the-artの精度が98.7%であるSpeech Commands v2データセットにおいて、95.42%であることが示されています.この精度は、修正やハイパーパラメータの調整なしで達成されました.(p.1)
Q: ByteFormerは、仮想のプライバシー保護カメラで推論を行う能力をどのように示しているのでしょうか.
A: ByteFormerは、プライバシー保護推論に応用できることを示しています.ByteFormerは、特定の曖昧化された入力表現で推論を実行することができ、精度の低下はありません.ByteFormerは、仮想的なプライバシー保護カメラでの推論の実行能力も示しています.このカメラは、90%のピクセルをマスクして完全な画像を形成せずに、プライバシー保護された非標準の入力表現をキャプチャします.ByteFormerは、90%のピクセルがマスクされた画像でトレーニングを行い、ImageNet [6]で71.35%の精度を達成することができます.ByteFormerは、マスクされていないピクセルの特定の場所に関する情報を必要としません.ByteFormerに渡される表現は、標準的な画像キャプチャを回避することにより、プライバシーを維持します.(p.5)
Q: プライバシー保護のために曖昧な入力表現に対して推論を行う際、ByteFormerはどのように精度を維持しているのか?
A: ByteFormerは、プライバシー保護のために曖昧な入力表現で推論を実行する際に、精度を維持することができます.具体的には、ByteFormerは、90%のピクセルチャネルを一貫してマスキングすることで、標準的な画像キャプチャを回避し、ImageNetで71.35%の精度を達成しながら、部分的に形成された画像上で推論を実行することができます.ByteFormerは、非マスクされたピクセルの特定の場所に関する情報を必要としません.これにより、プライバシーが維持されます.
Q: ByteFormerのコードはどこにあるのでしょうか?
A: ByteFormerのコードは、https://github.com/apple/ml-cvnets/tree/main/examples/byteformer で公開されています.(p.1)
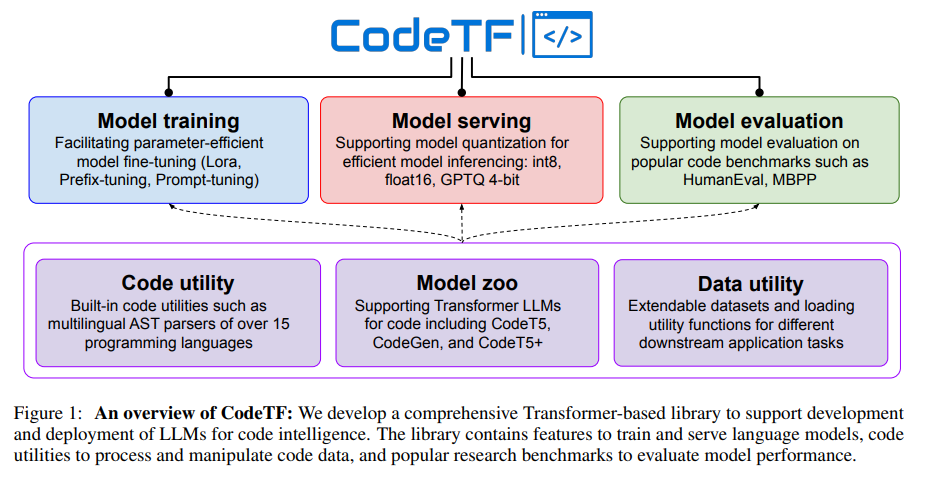
CodeTF: One-stop Transformer Library for State-of-the-art Code LLM
著者:Nghi D. Q. Bui, Hung Le, Yue Wang, Junnan Li, Akhilesh Deepak Gotmare, Steven C. H. Hoi
発行日:2023年05月31日
最終更新日:2023年05月31日
URL:http://arxiv.org/pdf/2306.00029v1
カテゴリ:Software Engineering, Artificial Intelligence
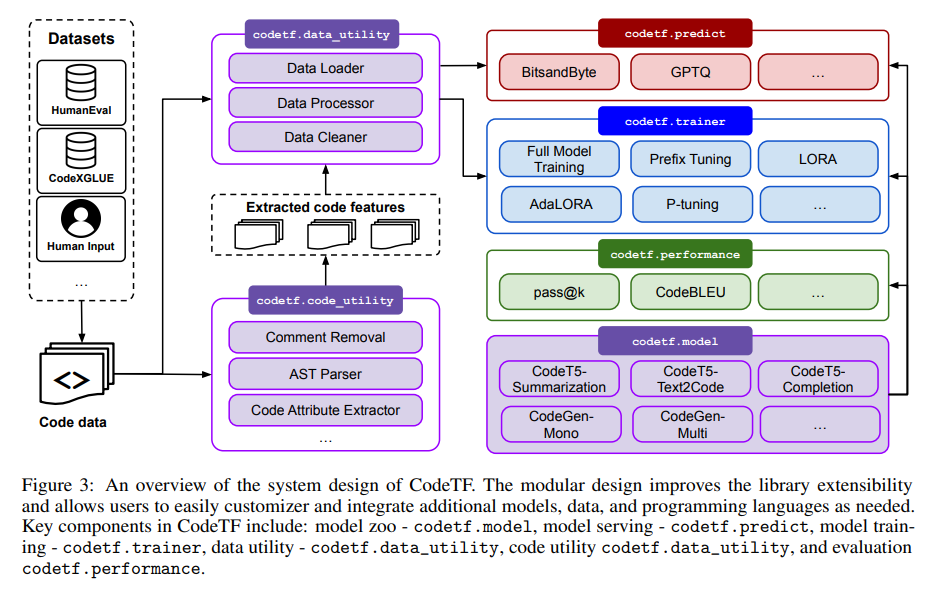
概要:
本論文では、最新のコードLLMとコードインテリジェンスのためのオープンソースTransformerベースのライブラリであるCodeTFを紹介し、設計原則、アーキテクチャ、主要なモジュールとコンポーネント、およびCodeTFの使用例について説明します.また、他の関連するライブラリツールと比較し、CodeTFが開発者、研究者、実践者にとって包括的なオープンソースソリューションを提供し、機械学習/生成AIとソフトウェアエンジニアリングのギャップを埋めることを目指しています.
Q&A:
Q: 大規模な言語モデルを扱うために、CodeTFは具体的にどのような機能を提供しているのでしょうか.
A: CodeTFは、大規模言語モデルの様々な側面を包括する包括的なライブラリであり、エンコーダーのみ、デコーダーのみ、エンコーダー・デコーダーの異なるスタイルで最新のモデルをロードして提供する機能、事前学習と微調整、評価、およびトレーニング目的のソースコード操作などの機能を提供しています.CodeTFは、これらの重要な側面をカバーするワンストップソリューションとして機能します.
具体的には、CodeTFは、言語モデルに適したデータを処理するためのコードユーティリティ、事前学習済みモデルとカスタムモデルの両方をトレーニングおよび提供するインターフェース、広範なプログラミング言語、モデル、およびデータを必要に応じて簡単に統合できるコードインテリジェンスタスクのためのモジュラーで拡張可能なフレームワーク、データ前処理および特徴抽出モジュールを備えた人気のあるコードコーパスのコレクションなどを提供しています.
CodeTFは、ソフトウェア開発者や研究者の両方にとって有用なツールになり、コードインテリジェンス研究のさらなるイノベーションを促進し、Code LLMのより広範な展開と応用を容易にすることを期待しています.
Q: CodeTFはどのようにユーザーの利便性を優先し、インストールやセットアップのプロセスを簡略化しているのでしょうか.
A: CodeTFでは、ユーザーフレンドリーさを優先し、初心者から上級者まで幅広いユーザーが利用できるようにしています.そのため、インストールやセットアップのプロセスを簡素化しています.複雑な設定や依存関係を必要としないようにしており、ユーザーが事前の経験や専門知識に関係なく、簡単にCodeTFを始めることができるようにしています.(p.1)
Q: CodeTFが守っているモジュール設計と拡張可能なフレームワークの原則は何でしょうか?
A: CodeTFは、モジュール化された設計原則と拡張可能なフレームワークの原則に従っています.これらの原則は、CodeTFの設計選択肢と機能の実装の基盤となり、実践者や研究者の多様なニーズに応えることを保証しています.モジュール化されたアーキテクチャにより、プログラミング言語、モデル、および特定の要件に合わせたユーティリティをシームレスに統合することができ、拡張性が向上しています.(p.2)
Q: CodeTFは具体的にどのような設計思想やフレームワークの原則を守っているのでしょうか.
A: CodeTFは、コードインテリジェンスタスクに対応するために特別に設計されたツールであり、モジュール化された設計と拡張可能なフレームワークの原則に従っています.CodeTFは、異なる種類のモデル、データセット、タスクに対して迅速なアクセスと開発を可能にする統一されたインターフェースを備えています.また、CodeTFは、事前学習済みのCode LLMモデルと人気のあるコードベンチマークをサポートし、コード属性を抽出するための言語固有のパーサーやユーティリティ関数などのデータ機能を提供しています.これらの設計原則は、CodeTFが実践者や研究者の多様なニーズに対応するように、設計選択肢と機能を実装するための基盤となっています.(p.4)
Q: CodeTFのモジュラーアーキテクチャは、特定の要件に合わせたプログラミング言語、モデル、ユーティリティとの統合や拡張性をどのように向上させるのでしょうか.
A: CodeTFのモジュールアーキテクチャは、プログラミング言語、モデル、および特定の要件に合わせたユーティリティのシームレスな統合を可能にすることで、拡張性を向上させています.このモジュール設計により、ライブラリの拡張性が向上し、ユーザーは必要に応じて簡単にカスタマイズや追加のモデル、データ、およびプログラミング言語を統合することができます.
Q: CodeTFはどのようなモデル、データセット、タスクに対応していますか?
A: CodeTFは、多様なコード関連タスクにおいて、潜在的な可能性を示すモデルを含んでいます.CodeTF内のモデルは、コードの知能能力に関して絶対的な保証を提供するわけではありません.CodeTFで使用されるデータセットや事前学習モデルには、誤解釈、不正確な結果、または望ましくない動作につながるバイアスが含まれる可能性があります.これらのバイアスは、複数の形を取ることができます.CodeTFのライブラリは、CodeBERT、CodeBERTA、CodeParrot、Incoder、CodeGen、SantaCoder、StarCoderなど、多様な事前学習済みTransformerベースのLLMをサポートしています.また、CodeT5、CodeT5+などのエンコーダー・デコーダーも含まれます.CodeTFには、HumanEvalやAPPSなどの人気のあるデータセットが含まれており、事前学習済みモデル、カスタムモデル、およびデータセットを効率的にロードおよび提供するためのインターフェースも備えています.CodeTFの統合インターフェースを通じて、ライブラリのユーザーは、最新のモデルを効率的に再現および実装するだけでなく、必要に応じて新しいモデルやベンチマークをシームレスに統合することができます.
Q: CodeTFで使用されるデータセットや事前学習済みモデルには、どのような種類のバイアスが存在し、それがモデルの結果や挙動にどのように影響する可能性があるのでしょうか.
A: CodeTFで使用されるデータセットや事前学習モデルには、完全なコードインテリジェンス能力を保証するものではありません.これらには、バイアスが含まれる可能性があり、誤った結果や望ましくない動作を引き起こす可能性があります.これらのバイアスは、言語バイアス、アプリケーション特有のバイアス、ライブラリおよびフレームワークバイアス、言語バージョンバイアス、コーディングスタイルバイアス、ソリューションバイアスの複数の形式を取ることができます.これらのバイアスが存在する場合、モデルは誤った結果を生成する可能性があります.また、AIの持続可能性についても考慮する必要があります.
Q: CodeTFがサポートするTransformerベースのLLMの学習済みタイプや、ライブラリに含まれる一般的なデータセットの例について教えてください.
A: CodeTFでは、事前学習済みのTransformerベースのLLMsとして、エンコーダーのみのもの(CodeBERT、CodeBERTA)、デコーダーのみのもの(CodeParrot、Incoder、CodeGen、SantaCoder、StarCoder)、エンコーダー・デコーダーのもの(CodeT5、CodeT5+)がサポートされています.また、人気のあるデータセットとして、HumanEvalやAPPSが含まれており、事前学習済みモデルやカスタムモデル、データセットの効率的なロードとサービングのためのインターフェースも提供されています.
Q: CodeTFがサポートすること前学習済みのCode LLMモデルと一般的なコードベンチマークは何ですか?
A: CodeTFは、事前学習済みのTransformerベースのLLM [5,4,18]とコードタスク[12,13,11]の多様なコレクションをサポートしています.CodeTFは、エンコーダーのみ(CodeBERT [6]、CodeBERTA)、デコーダーのみ(CodeParrot [19]、Incoder [20]、CodeGen [5]、SantaCoder [21]、StarCoder [22])、エンコーダーデコーダー(CodeT5 [4]、CodeT5+ [18])の広範なLLMのコードをサポートしています.CodeTFには、HumanEvalやAPPS [12,13,11,23]などの人気のあるデータセットと、事前学習済みモデル、カスタムモデル、データセットを効率的にロードして提供するためのインターフェースが含まれています.統合されたインターフェースを通じて、ライブラリのユーザーは、最新のモデルを効率的に再現および実装するだけでなく、必要に応じて新しいモデルやベンチマークをシームレスに統合することができます.(p.2-3)
Q: CodeTFには、学習済みモデル、カスタムモデル、データセットを効率的にロードして提供するために、どのような一般的なデータセットやインターフェースが含まれているのでしょうか.
A: CodeTFには、HumanEvalやAPPSなどの人気のあるデータセットと、事前学習済みモデル、カスタムモデル、データセットを効率的にロードして提供するためのインターフェースが含まれています.また、統一されたインターフェースを通じて、ライブラリのユーザーは、最新のモデルを効率的に再現・実装するだけでなく、必要に応じて新しいモデルやベンチマークをシームレスに統合することができます. (p.1)
Q: CodeTFはコード属性を抽出するために、どのようなデータ機能を備えているのでしょうか.
A: CodeTFでは、プログラミング言語に従う厳密な構文規則のため、コードデータは他のドメイン(例えば、ビジョンやテキスト)よりも厳密な前処理と操作手順を要求します.そのため、CodeTFは、tree-sitter2を活用した複数のプログラミング言語のASTパーサーを含む、コード属性(メソッド名、識別子、変数名、コードコメントなど)を抽出するためのユーティリティを提供しています.これらのツールは、モデルトレーニング中のコードデータの効率的な処理と操作を容易にするために細心の注意を払って設計されています.(p.3)
CodeTFは、tree-sitter4をパーサーとして使用し、Java、C++、Pythonなど15のプログラミング言語に対応した、重要なコード属性を抽出するためのビルトイン関数を提供するCode Utilityモジュールを提供しています.(p.3.6)
Q: tree-sitterとは何か、CodeTFは複数のプログラミング言語の解析にどのように活用しているのか.
A: tree-sitterは、複数のプログラミング言語のASTパーサーを提供するツールであり、CodeTFはこれを利用している.CodeTFは、Java、Apex、C、C++、C#、Python、Scala、SOQL、SOSL、PHP、JavaScript、Haskell、Go、Kotlin、Ruby、Rust、Scala、Solidity、およびYAMLなど、15のプログラミング言語に対応しており、それぞれの言語に適した構文規則を持つ「.so」ファイルを提供している.これらのファイルは、CodeTFにバンドルされており、プログラミングインターフェースを介して簡単にロードできる.また、CodeTFは、tree-sitterをパーサーとして使用して、コード属性(メソッド名、識別子、変数名、コードコメントなど)を抽出するためのユーティリティも提供している.これらのツールは、CodeTFの詳細なドキュメントとコード例とともに提供されており、様々なレベルのユーザーが学習し、採用することができるようになっている.(p.2-3)
Q: CodeTFは、他の関連ライブラリツールと比較してどうですか?
A: 関連するライブラリツールと比較して、CodeTFは包括的であり、様々なコード大規模言語モデルの側面を網羅しています.CodeTFは、エンコーダーのみ、デコーダーのみ、エンコーダーデコーダーの異なるスタイルで最新のモデルをロードして提供する機能、事前学習と微調整、評価、トレーニング目的のソースコード操作などを含みます.また、CodeTFは、初心者から上級研究者まで幅広いユーザーにアクセス可能であり、インストールとセットアッププロセスを簡素化し、複雑な構成や依存関係の必要性を減らすことで、ユーザーフレンドリーを重視しています.さらに、CodeTFは、モジュール式のアーキテクチャを採用しており、特定の要件に合わせてプログラミング言語、モデル、ユーティリティをシームレスに統合することで、拡張性を高めています.(p.2-3)
Q: CodeTFは、エンコーダーとデコーダーの異なるスタイルの最新モデルをロードし、アクセスを提供するために、具体的にどのような機能を提供しているのでしょうか.
A: CodeTFでは、エンコーダーのみ、デコーダーのみ、エンコーダー・デコーダーの異なるスタイルの最新モデルを読み込み、提供する機能が含まれています.また、事前学習やファインチューニング、評価、ソースコードの操作など、さまざまな機能をカバーしています.これらの機能を網羅することで、CodeTFはワンストップソリューションとして機能し、ユーザーにとって使いやすいライブラリとなっています.(p.1)
Q: CodeTFは、初心者から上級研究者まで幅広いユーザーに対して、どのように使いやすさを優先し、インストールやセットアップのプロセスを簡略化しているのでしょうか.
A: CodeTFでは、初心者から上級研究者まで幅広いユーザーが利用できるよう、ユーザーフレンドリーさを優先し、インストールやセットアップのプロセスを簡素化しています.複雑な設定や依存関係を必要とせず、誰でも簡単に始めることができます.これは、初めての利用者でも、以前の経験や専門知識に関係なく、CodeTFを簡単に利用できるようにするためです.(p.1)
Q: CodeTFは、機械学習・再生AIとソフトウェア工学の橋渡しをすることを目的としていますが、その狙いは何でしょうか.
A: CodeTFの目的は、機械学習/生成AIとソフトウェアエンジニアリングの間のギャップを埋めることです.CodeTFは、静的解析、動的解析、ポインタ解析、形式手法などの従来のソフトウェアエンジニアリング手法と人工知能を組み合わせ、複雑なソフトウェアエンジニアリングタスクに効果的に取り組むことを目的としています.CodeTFは、コードの大規模言語モデルの様々な側面を包括する包括的なライブラリであり、簡単なインストールとセットアッププロセスを提供し、初心者から上級研究者まで幅広いユーザーにアクセス可能なユーザーフレンドリーなライブラリです.CodeTFは、state-of-the-art Code LLMモデルと人気のあるコードベンチマークをサポートし、言語固有のパーサーやコード属性を抽出するためのユーティリティ関数などのデータ機能を提供します.CodeTFは、エンコーダーのみ、デコーダーのみ、エンコーダーデコーダーの異なるスタイルでstate-of-the-artモデルをロードおよびサーブする機能を備えており、事前トレーニング、微調整、評価、およびトレーニング目的のソースコード操作をカバーする一元的なインターフェースを提供します.CodeTFは、開発者、研究者、実践者向けの包括的なオープンソースソリューションを提供することを目的としています.(p.1)
Q: CodeTFはどのようなコードモデルやベンチマークをサポートし、言語固有のパーサーやコード属性を抽出するためのデータ機能を提供するのか.
A: CodeTFは、カスタムモデルとデータセットをサポートしています.また、CodeTFは、複数のプログラミング言語に対応したAbstract Syntax Tree(AST)パーサーと、メソッド名、識別子、変数名、コードコメントなどのコード属性を抽出するためのユーティリティを提供しています.これらのツールは、モデルのトレーニング、ファインチューニング、評価中にコードデータの効率的な処理と操作を容易にするために設計されています.CodeTFは、言語モデルに適した形式にコードを前処理するために必要な機能を提供しています.CodeT5などのモデルでは、複数の目的を持つ学習手法に必要な関数名の抽出や識別子の位置の特定が必要です.CodeTFの主な貢献は、プログラミング言語、モデル、データを必要に応じて簡単に統合できるモジュラーで拡張可能なフレームワーク、事前学習済みモデルとカスタムモデルの両方をトレーニングおよびサービスするためのインターフェース、広範なプログラミング言語とコードタスクをサポートする人気のあるコードコーパスとデータ前処理および特徴抽出モジュールのコレクション、さまざまなレベルの専門知識を持つユーザーの学習と採用プロセスを容易にする詳細なドキュメントとコード例です.CodeTFは、ソフトウェア開発者と研究者の両方にとって有用なツールになり、コードインテリジェンス研究のさらなるイノベーションを促進し、Code LLMのより広範な展開と応用を促進することを期待しています.(p.1)
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
著者:Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, Chelsea Finn
発行日:2023年05月29日
最終更新日:2023年05月29日
URL:http://arxiv.org/pdf/2305.18290v1
カテゴリ:Machine Learning, Artificial Intelligence, Computation and Language
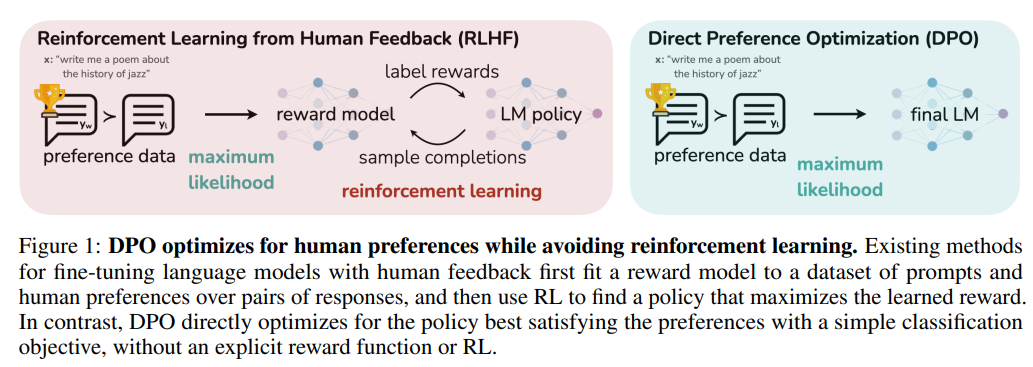
概要:
本論文では、Direct Preference Optimization(DPO)という手法が紹介されています.この手法は、報酬モデルの適合やLMのサンプリング、ハイパーパラメータの調整が必要なく、安定してパフォーマンスが高く、計算量も少ないことが特徴です.実験の結果、DPOを用いた微調整は、既存の方法と同等またはそれ以上に人間の好みに合わせることができることが示されました.特に、DPOを用いた微調整は、RLHFよりも生成物の感情を制御する能力が高く、要約や単一ターンの対話においても応答品質が向上することが確認されました.また、DPOは実装やトレーニングが大幅に簡素化されています.
Q&A:
Q: 大規模な教師なし言語モデルにおいて、動作の精密な制御を実現するための課題は何でしょうか?
A: 大規模な非監督学習言語モデルは、広範な世界の知識と一部の推論スキルを習得するが、その行動を正確に制御することは困難である.その理由は、彼らのトレーニングが完全に非監督学習であるためである.このような制御を得るための既存の方法は、モデル生成物の相対的な品質の人間のラベルを収集し、これらの好みに合わせて非監督学習LMを微調整することである.しかし、人間のフィードバックからの強化学習(RLHF)を用いることが多い.しかし、RLHFは複雑で不安定な手順であり、まず人間の好みを反映する報酬モデルを適合させ、その後、この推定報酬を最大化するように大規模な非監督学習LMを微調整することで、元のモデルからあまり遠く離れないようにする.本論文では、報酬関数と最適ポリシーの間のマッピングを活用して、この制約された報酬最大化問題を解決する方法を提案する. (p.1)
Q: 非教師付き言語モデルにおける制約付き報酬最大化問題を解くための提案手法とは?
A: 提案された方法は、報酬最大化の問題を解決するために、報酬モデルの学習を回避し、直接言語モデルを好みのデータで最適化することです.報酬関数から最適ポリシーへの解析的なマッピングを利用し、報酬関数の損失関数をポリシーの損失関数に変換することで、報酬関数の最適化を回避します.これにより、人間の好みに合わせた言語モデルの最適化が可能になります.この方法は、従来の強化学習による報酬最大化の方法よりも簡単で安定しています.(p.4)
Q: 教師なし言語モデルの挙動を制御するために、人間のフィードバックによる強化学習を用いることの限界は何でしょうか?
A: 現存する人間のフィードバックから強化学習を用いて非監視学習言語モデルの振る舞いを制御する方法には、いくつかの制限がある.この方法は、人間の好みに基づくデータセットを用いて報酬モデルを適合させ、その報酬を最大化するように言語モデルを最適化することで機能する.しかし、この方法は複雑で不安定であり、報酬モデルを適合させた後、大規模な非監視学習言語モデルを微調整することで、元のモデルからあまり逸脱しないようにする必要がある.この方法の制限には、人間の好みに基づくデータセットの収集が困難であること、報酬モデルの適合が不安定であること、報酬モデルが人間の好みを正確に反映していない可能性があることが含まれる.これらの制限は、より多くの言語モデルを人間の好みからトレーニングする障壁となる可能性がある.
Q: 言語モデルで操縦性を獲得するための既存の手法にはどのようなものがありますか?
A: 現存する言語モデルの操作性を向上させる方法は、人間のラベルを収集し、そのモデル生成物の相対的な品質を評価することである.その後、その評価に合わせて、強化学習を用いて、教師なしの言語モデルを微調整することである.しかし、この方法は複雑で不安定であり、報酬モデルを適合させ、その後、大規模な教師なしの言語モデルを微調整することで報酬を最大化することが必要である.この方法は、人間の好みに合わせて報酬関数を最適化し、その報酬を最大化するように言語モデルを微調整することで、翻訳、要約、ストーリーテリング、指示に従うなどのタスクにおいて、言語モデルの能力を向上させることができる.
Q: 報酬関数を最適化し、大規模な教師なし言語モデルを微調整することで、翻訳、要約、ストーリーテリング、指示に従うといったタスクにおける言語モデルの能力がどのように向上するのか.
A: 大規模な非監督学習言語モデル(LM)は、広範な世界知識と一部の推論スキルを学習するが、その振る舞いを正確に制御することは困難である.そのため、人間の相対的なモデル生成の品質に関するラベルを収集し、これらの好みに合わせて非監督学習LMを微調整する方法が存在する.これは、人間のフィードバックからの強化学習(RLHF)を用いて行われることが多い.これにより、報酬モデルを適合させ、その後、大規模な非監視LMを微調整して、元のモデルから遠く離れすぎないように、この推定報酬を最大化する.これにより、翻訳、要約、ストーリーテリング、指示の従順性などのタスクにおいて、報酬関数を最適化し、大規模な非監視言語モデルを微調整することで、言語モデルの能力が向上する.これらの方法は、まず、Bradley-Terryモデル[5]などの好みモデルに基づいて、好みのデータセットと互換性のあるニューラルネットワーク報酬関数を最適化し、その後、与えられた報酬を最大化するように言語モデルを微調整する.これにより、指示チューニングの成功にもかかわらず、応答品質の相対的な人間の判断は、専門家のデモンストレーションよりも収集しやすいため、後続の作業では、人間の好みのデータセットを用いてLLMsを微調整し、翻訳[16]、要約[35,45]、ストーリーテリング[45]、指示従順性[23,29]の能力を向上させている.(p.1)
Q: DPO(Direct Preference Optimization)アルゴリズムについて、報酬関数と最適ポリシーの対応付けによって生成される仕組みを説明していただけますか.
A: DPOアルゴリズムは、報酬関数と最適ポリシーのマッピングを通じて生成されます.この制約付き報酬最大化問題は、人間の好みデータの分類問題を解決するために、1つのポリシートレーニングステージで正確に最適化できることが示されています.DPOは、報酬関数を学習する必要がないため、人間の完了ベースラインを使用する従来の手法とは異なります.DPOは、人間の好みデータのデータセットが与えられた場合、報酬関数を明示的に学習することなく、単純なバイナリクロスエントロピー目的関数を使用してポリシーを最適化できます.DPOアルゴリズムは、報酬関数と最適ポリシーのマッピングを通じて生成され、従来の手法と比較して、報酬を最大化し、KLダイバージェンスを最小化する効率的なトレードオフを実現できます.(p.6)
Q: 言語モデルのファインチューニングにおいて、既存の方法と比較してDPOを使うメリットは何でしょうか?
A: DPOを既存の方法に比べて使用する利点は、報酬モデルの適合、ファインチューニング中のLMからのサンプリング、または重要なハイパーパラメータの調整の必要性を排除することです.DPOを使用することで、既存の方法と同等またはそれ以上に、LMを人間の好みに合わせてファインチューニングできることが実験によって示されています.特に、DPOを使用したファインチューニングは、RLHFの世代の感情を制御する能力を超え、要約や単一ターンの対話における応答品質を向上させる一方で、実装とトレーニングが大幅に簡素化されています.(p.1)
Q: DPOは、既存の方法よりも人間の好みに合わせてLMを微調整することができるのか?
A: DPOは、報酬モデルの適合、ファインチューニング中のLMからのサンプリング、または重要なハイパーパラメータの調整の必要性を排除することで、安定して、計算量が軽く、人間の好みに合わせてLMをファインチューニングすることができます.実験の結果、DPOは既存の方法と同等またはそれ以上に人間の好みに合わせてLMをファインチューニングすることができます.特に、DPOによるファインチューニングは、RLHFの世代の感情を制御する能力を超え、要約や単一ターンの対話における応答品質を向上させ、実装とトレーニングが大幅に簡素化されます.(p.1)
DPOは、既存の方法よりも人間の好みに合わせてLMをファインチューニングすることができます.DPOは、報酬モデルの適合、ファインチューニング中のLMからのサンプリング、または重要なハイパーパラメータの調整の必要性を排除することで、安定して、計算量が軽く、人間の好みに合わせてLMをファインチューニングすることができます.また、DPOによるファインチューニングは、RLHFの世代の感情を制御する能力を超え、要約や単一ターンの対話における応答品質を向上させ、実装とトレーニングが大幅に簡素化されます.(p.1)
Q: DPOでは、報酬を伴うモデルフィッティング、微調整時のLMサンプリング、重要なハイパーパラメータの調整などをどのように不要にしているのでしょうか.
A: 報告書によると、DPOは、報酬モデルの適合、ファインチューニング中のLMサンプリング、重要なハイパーパラメータの調整の必要性を排除することにより、高性能で計算量が軽くなっています.(p.1) また、DPOは、既存の方法と同等またはそれ以上に、人間の好みに合わせてLMをファインチューニングすることができます. (p.1) さらに、DPOを使用したファインチューニングは、RLHFの感情制御能力を超え、要約や単一ターンの対話における応答品質を向上させることができます. (p.1)
Q: DPOは要約や一転対話において、どのように応答品質を向上させるのか?
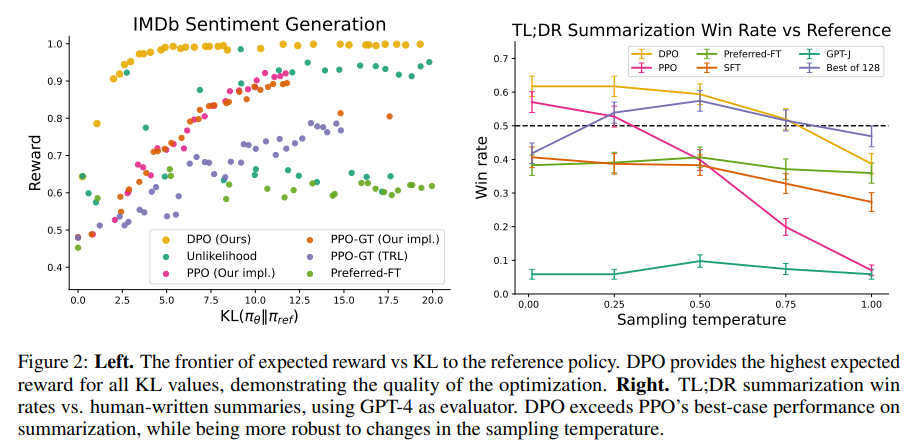
A: DPOは、PPOと同じ目的を最適化するが、DPOの方が明らかに効率的であり、報酬/KLのトレードオフがPPOを厳密に支配しているため、より良いフロンティアを実現しています.さらに、DPOは、PPOがグラウンドトゥルースの報酬にアクセスできる場合でも、より良いフロンティアを実現しています.DPOは、ほとんどハイパーパラメータの調整が必要なく、RLHF with PPOなどの強力なベースラインよりも優れたパフォーマンスを発揮し、学習された報酬関数の下でNサンプルされた軌跡の中で最良のものを返します.DPOは、summarizationとsingle-turn dialogueにおいて、応答品質を改善するために、より効率的なフロンティアを実現しています.(p.8)
Q: DPOがPPOや他のベースラインと比較して、より効率的なフロンティアを実現し、それが要約や1ターン対話の性能向上にどのようにつながっているのか、ご説明いただけますか?
A: DPOは、PPOと同じ目的を最適化するが、より効率的であるため、より効率的なフロンティアを持つ.DPOの報酬/KLトレードオフは、PPOを厳密に支配する.さらに、DPOは、PPO-GTにアクセスできる場合でも、PPOよりも優れたフロンティアを実現する.これは、summarizationやsingle-turn dialogueなどのタスクで、DPOが最高の報酬を獲得しながら、低いKLを実現することを意味する.DPOは、より効率的なフロンティアを持つため、より少ないトレーニングステップで最適なポリシーを見つけることができる.これは、summarizationやsingle-turn dialogueなどのタスクで、DPOがより高い報酬を獲得することを可能にする.これは、(p.8)からの情報である.
Fine-Tuning Language Models with Just Forward Passes
著者:Sadhika Malladi, Tianyu Gao, Eshaan Nichani, Alex Damian, Jason D. Lee, Danqi Chen, Sanjeev Arora
発行日:2023年05月27日
最終更新日:2023年05月27日
URL:http://arxiv.org/pdf/2305.17333v1
カテゴリ:Machine Learning, Computation and Language

概要:
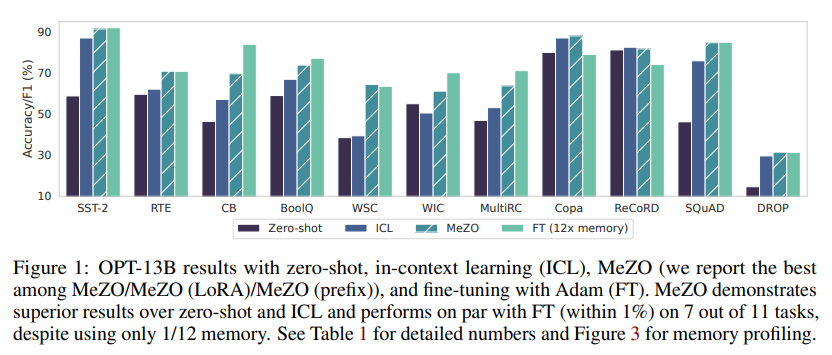
本研究では、包括的な実験を実施し、MeZOが複数のタスクで最大12倍のメモリ削減で、バックプロパゲーションで微調整する場合と同等のパフォーマンスを発揮することを明らかにしました.また、MeZOは、LoRAやprefix tuningなどのパラメータ効率の高い微調整技術とも互換性があり、非微分可能な目的関数(例:精度やF1の最大化)を効果的に最適化することができます.さらに、適切な事前学習とタスクプロンプトによって、古典的なZO分析が示唆するよりも、MeZOが巨大なモデルを微調整することができることを理論的に示しました.
Q&A:
Q: 提案されているメモリ効率の良いゼロ次オプティマイザー(MeZO)とはどのようなもので、どのように動作するのでしょうか.
A: 本研究では、メモリ効率の良いゼロ次最適化器(MeZO)を提案しています.MeZOは、古典的なZO-SGDアルゴリズムを適応させ、推論と同じメモリ消費量に減らします.MeZOは、大規模な言語モデルを微調整するために適用され、実験的にも理論的にも、数十億のパラメータを持つ言語モデルを成功裏に最適化できることを示しています.MeZOの主な貢献は、以下の通りです.(p.1)
- MeZOでは、ZO-SGDアルゴリズム[83]とその変種を適応させ、アルゴリズム1とセクション2で任意の大きさのモデルに対してほとんどメモリオーバーヘッドを持たせずに操作できるようにしています.
- MeZOは、マスクされたLMや自己回帰LMなどのモデルタイプ、350Mから66Bまでのモデルスケール、分類、多肢選択、生成などのタスクに対して包括的な実験を行っています.MeZOは、常にゼロショット、ICL、線形探索よりも優れた性能を発揮します.さらに、RoBERTa-largeでは、MeZOは5%未満の差で標準的な微調整に近い性能を発揮し、OPT-13Bでは、MeZOは微調整よりも優れたまたは同等の性能を発揮します.(p.1)
MeZOは、ゼロ次最適化器であり、古典的なZO-SGDアルゴリズムを適応させています.MeZOは、推論と同じメモリ消費量に減らすことで、大規模な言語モデルを微調整するために適用されます.MeZOは、アルゴリズム1とセクション2で任意の大きさのモデルに対してほとんどメモリオーバーヘッドを持たせずに操作できるようにしています.MeZOは、マスクされたLMや自己回帰LMなどのモデルタイプ、350Mから66Bまでのモデルスケール、分類、多肢選択、生成などのタスクに対して包括的な実験を行い、ゼロショット、ICL、線形探索よりも優れた性能を発揮します.(p.1)
Q: MeZOでは、大規模な言語モデルを最適化しながら、どのようにメモリ消費を抑えているのでしょうか.
A: MeZOは、大規模言語モデルを最適化する際にメモリ消費を削減することができます.例えば、OPT-13Bでは12倍のメモリコストを削減することができます.さらに、MeZOは精度やF1スコアなどの微分不可能な目的関数を最適化することができます.ICL、FT、LP、およびMeZOのメモリ消費を比較した結果、MeZOはFTに比べて6倍のメモリ消費を削減することができます.これにより、固定されたハードウェア予算内でより大きなモデルをトレーニングすることができます.MeZOは、66億パラメータモデルまでスケーリングすることができ、直接ファインチューニングすることが非常に高価な大規模モデルでも、ゼロショットやICLを上回る効果を発揮します.これらの測定値は、使用されるインフラストラクチャとパッケージに依存します.MeZOは、バックプロパゲーションよりも常にメモリ効率が高く、時間効率が高いことが理論的に示されています. (p.4-5)
Q: MeZOで行った包括的な実験について、テストしたモデルやタスクの種類、他の方法と比較したMeZOのパフォーマンスなど、より詳しく教えてください.
A: MeZOは、分類、多肢選択、生成タスクにおいて強力なパフォーマンスを発揮し、11のタスクのうち7つで1%以内の同等またはより優れたパフォーマンスを達成しています.MeZOは、SQuAD [77]およびDROP [30]の2つの質問応答データセットで評価され、生成タスクにおいては、分類または多肢選択タスクよりも複雑であると考えられています.トレーニングにはteacher-forcingを使用し、推論にはgreedy decodingを使用しています.表1によると、MeZOは、ゼロショット、ICL、LPよりもすべての生成タスクで優れたパフォーマンスを発揮し、FTと同等のパフォーマンスを達成しています.MeZOの実験は20Kステップで行われ、FTの実験は通常5エポック以内に収束するが、MeZOのパフォーマンスはより多くのトレーニングステップで改善されることが観察されています.RoBERTa実験については、[33]に従い、マスクされた言語モデルのプロンプトベースのファインチューニングパラダイムを使用しています.分類タスクについては、ラベルワードに対応するロジットを取り、それらにクロスエントロピー損失を適用します.多肢選択タスクおよび生成タスク(QA)については、正しい候補のみを保持し、正しい例に対してteacher forcingを使用してトレーニングします.候補部分のトークンの損失のみを保持し、プロンプト部分を除外します.(p.1,4-8)
Q: MeZOは、in-context learningやlinear probingと比較して、性能面ではどうでしょうか?
A: MeZOは、in-context learningやlinear probingよりも優れたパフォーマンスを発揮します.6つの多様なタスクにおいて、MeZOは事前学習モデルを最適化し、常にzero-shotやlinear probingよりも優れた結果を出します.また、いくつかのタスクにおいて、MeZOはBBTv2 [85]という別のZOアルゴリズムよりも最大11%の絶対値で優れた結果を出すことも示されています.これらの結果は、(p.3)に記載されています.
Q: MeZOがバックプロパゲーションよりもメモリや時間の効率が良いという理論的根拠を説明できますか?
A: MeZOとbackpropagationの理論的な時間-メモリートレードオフを比較した結果、MeZOは常にbackpropagationよりもメモリ効率が高く、時間効率も高いことがわかりました.また、最近の進歩により、transformerをよりメモリ効率化する方法があることも指摘されています.MeZOは、FTに比べて11倍のメモリ効率があり、固定されたハードウェア予算内でより大きなモデルをトレーニングできます.backpropagationの場合、モデルを容易に微分可能なブロックに分解する必要があり、各ブロックについて、出力をキャッシュするか再計算するかを選択する必要があります.このトレードオフは、GriewankとWaltherのルール21から適応された命題で捉えられています.これらの理論的な分析により、MeZOがbackpropagationよりもメモリ効率が高く、時間効率も高いことが示されました.(p.4)
Q: MeZOは、フルパラメーターとパラメーター効率の良いチューニング手法の両方に対応しているのでしょうか?
A: MeZOは、完全パラメータ調整とPEFTの両方の調整技術に対応しています.MeZOの完全パラメータ調整とPEFT(LoRAとprefix-tuningを使用したMeZO)は、同等の性能を発揮し、MeZO(prefix)がMeZOを上回ることもあります.また、私たちは、3つのバリアントが同様の収束率で収束することを示し、MeZOが最適化するパラメータの数に依存しない収束率で収束することを示すセクション4の理論と一致することを示します.(p.2-3)
MeZOは、完全パラメータ調整とPEFTの両方の調整技術に対応しており、完全パラメータ調整とPEFT(LoRAとprefix-tuningを使用したMeZO)は同等の性能を発揮します.また、MeZOは、非微分可能な目的関数(例えば、精度やF1の最大化)を効果的に最適化することができます.これらの結果は、適切な事前学習とタスクプロンプトがMeZOを巨大なモデルのファインチューニングに適用可能にすることを示しており、既存のZOの下限に反するものです. (p.2)
Q: 精度やF1の最大化など、微分不可能な目的関数を効率よく最適化する方法とは?
A: MeZOは、非微分可能な目的関数を最適化するために効果的であることを初期実験によって示しています.具体的には、精度とF1値がそれぞれの目的関数として使用されています.MeZOは、精度/F1値を用いた場合に、優れた性能を持つLMを最適化することができます.これは、バックプロパゲーションではできない非微分可能な目的関数を最適化することができることを示しています.この理論的な背景により、MeZOは数十億のパラメータを調整する際にも、致命的に遅くならないことがわかっています.ただし、MeZOは強力な性能を発揮するために多くのステップを必要とするため、その点には制限があります.(p.3,6)
Q: MeZOは差別化できない目的を効果的に最適化できるのか?
A: MeZOは、非微分可能な目的関数を最適化することができることが初期実験によって示されています.具体的には、精度とF1値が目的関数として使用され、MeZOはこれらの目的関数を成功裏に最適化し、大規模なLMにおいて優れたパフォーマンスを発揮することがTable 3によって示されています.(p.3.3)
MeZOは、バックプロパゲーションではできない非微分可能な目的関数を最適化することができることが示されています.また、MeZOは数十億のパラメータを調整する際にも効果的であり、大規模なモデルにおいてもゼロショットやICLを上回るパフォーマンスを発揮することが示されています.(p.6)
したがって、MeZOは非微分可能な目的関数を効果的に最適化することができます.
Q: MeZOの性能を評価するために使用した下流タスクとその結果は?
A: MeZOは、分類、多肢選択、生成タスクにおいて強力なパフォーマンスを発揮し、11のタスクのうち7つで、1%以内の比較可能なパフォーマンスまたはそれ以上を達成しています.
MeZOは、生成タスクにおいて、分類または多肢選択タスクよりも複雑であると考えられている2つの質問応答データセット、SQuAD [77]およびDROP [30]で評価されました.トレーニングにはteacher-forcingを使用し、推論にはgreedy decodingを使用しました.表1によると、すべての生成タスクにおいて、MeZOはゼロショット、ICL、LPを上回り、FTと比較可能なパフォーマンスを発揮しています.
Q: MeZOは、SQuADとDROPのデータセットで質問応答タスクについてどのように評価され、他のモデルと比較してどのようなパフォーマンスがあったのでしょうか.
A: SQuADとDROPの質問応答タスクにおいて、MeZOは教師強制学習を用いた訓練と貪欲デコーディングを用いた推論により評価され、ゼロショット、ICL、LPを上回り、FTと同等の性能を発揮した.これは、多くのファインチューニングLMの応用が生成タスクを対象としていることを考慮すると、MeZOが大規模LMを最適化するためのメモリ効率の高い技術としての潜在的な可能性を示唆している.これらの結果は、表1に示されている.
BiomedGPT: A Unified and Generalist Biomedical Generative Pre-trained Transformer for Vision, Language, and Multimodal Tasks
著者:Kai Zhang, Jun Yu, Zhiling Yan, Yixin Liu, Eashan Adhikarla, Sunyang Fu, Xun Chen, Chen Chen, Yuyin Zhou, Xiang Li, Lifang He, Brian D. Davison, Quanzheng Li, Yong Chen, Hongfang Liu, Lichao Sun
発行日:2023年05月26日
最終更新日:2023年05月26日
URL:http://arxiv.org/pdf/2305.17100v1
カテゴリ:Computation and Language, Artificial Intelligence
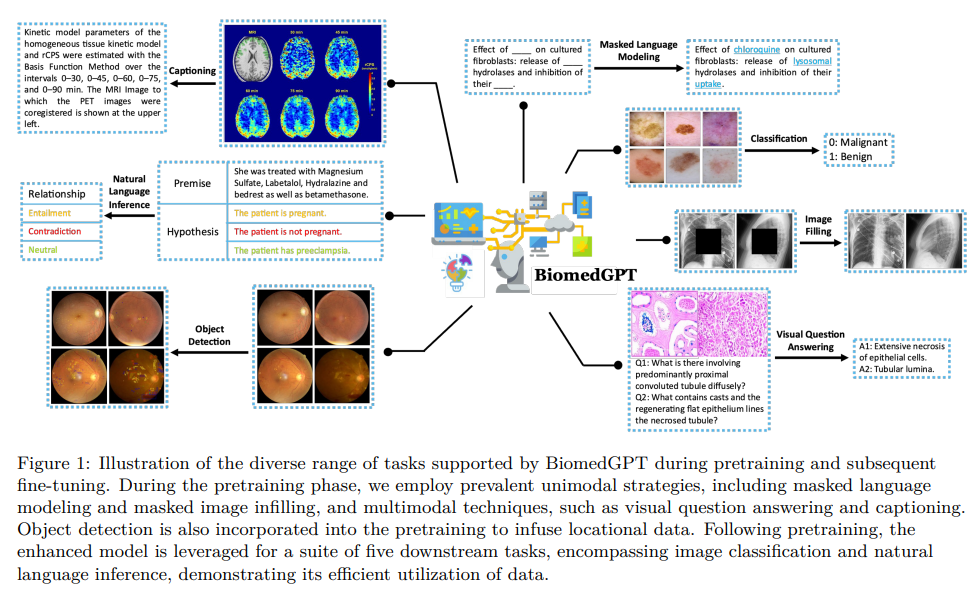
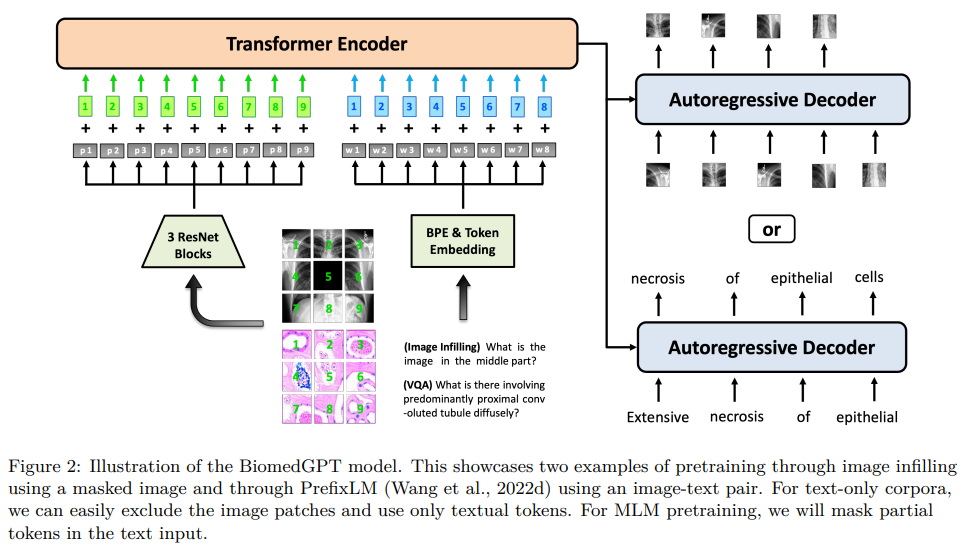
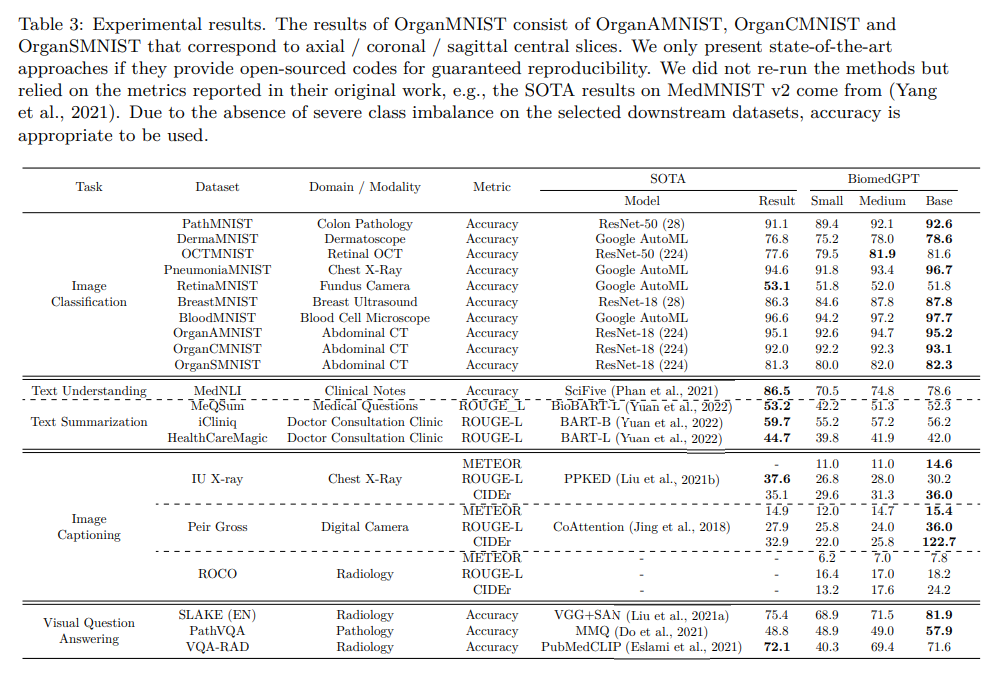
概要:
本論文では、自己教師あり学習を活用して大規模かつ多様なデータセットに対応し、マルチモーダルな入力を受け取り、様々な下流タスクを実行する統一的で汎用的なバイオメディカル生成事前学習トランスフォーマー(BiomedGPT)モデルを紹介します.実験により、BiomedGPTが、15種類のバイオメディカルモダリティをカバーする20の公開データセットで、先行する最新技術モデルの大部分を上回る、バイオメディカルデータの包括的で広範な表現を提供することが示されました.また、アブレーションスタディにより、マルチモーダルおよびマルチタスクの事前学習アプローチの有効性が、以前に見たことのないデータに知識を転移することが示されました.全体的に、私たちの研究は、統一的で汎用的なバイオメディシンモデルの開発における重要な一歩を示し、医療のアウトカムを改善するための広範な影響を持っています.
Q&A:
Q: Biomedical Generative Pre-trained Transformer (BiomedGPT)モデルとは何ですか?
A: BiomedGPTは、大規模で多様なデータセットに対する自己監督学習を活用し、マルチモーダル入力を受け入れ、さまざまなダウンストリームタスクを実行するための統一された汎用的なバイオメディカル生成事前学習トランスフォーマーです.BiomedGPTは、ビジョントランスフォーマー(ViT)と言語モデル(Lewis et al.、2020)のアイデアを使用して、データをパッチまたはトークンに分割することで、入出力の統一を実現しています.BiomedGPTは、バイオメディカルデータの包括的な表現を提供し、15以上のユニークなバイオメディカルモダリティをカバーする20の公開データセットを横断する5つの異なるタスクで、先行する最先端モデルの大部分を上回ることが実験によって示されています.この研究では、データの前処理、事前学習、微調整などのすべてのプロセスを含め、再現性を確保し、さらなる開発を促進するために、コードへのアクセスを提供するオープンソースの実践に取り組んでいます.(p.1-2)
Q: BiomedGPTでは、データをパッチやトークンに分割することで、どのように入出力の統一を実現しているのでしょうか.
A: BiomedGPTは、データをパッチまたはトークンに分割することで、入力/出力の統一を実現しています.これは、Vision Transformer(ViT)(Dosovitskiy et al.、2020)およびLanguage Models(Lewis et al.、2020)のアイデアを使用しています.具体的には、BiomedGPTは、生の画像\( \small x_v\in R^{H×W×C} \)をResNetモジュールを介して1Dパッチのシーケンス\( \small x_p\in R^{N×D} \)にマッピングし、トランスフォーマーの入力として使用します.ここで、\( \small N=HW/P^2 \)はパッチサイズ\( \small P×P \)が与えられた場合のパッチ数であり、\( \small D \)は固定された埋め込み次元です.このように、BiomedGPTは、パッチまたはトークンにデータを分割することで、異なるモダリティの入力を処理し、タスクに適用できる共通の多モーダル語彙を使用して、入力/出力の統一を実現しています.(p.2)
Q: BiomedGPTがカバーする20のパブリックデータセットと、5つの異なるタスクで従来のモデルをどのように凌駕しているか、詳細を教えてください.
A: BiomedGPTは、20の公開データセットを対象に、多様な入力を受け入れ、様々な下流タスクを実行することができます.実験結果は、15種類のバイオメディカルモダリティをカバーする20の公開データセットにおいて、5つの異なるタスクで、従来の最先端モデルを上回るバイオメディカルデータの包括的な表現を提供することを示しています.また、削除実験により、マルチモーダルおよびマルチタスクの事前学習アプローチの効果を示し、以前に見たことのないデータに対する知識の転移の有効性を示しています.これにより、バイオメディシンのための統一された汎用モデルの開発に向けた重要な一歩が踏み出され、医療のアウトカムの改善に大きな影響を与える可能性があります.(p.3)
BiomedGPTは、3つのスケーリングモデル、すなわちBiomedGPT Small、BiomedGPT Medium、およびBiomedGPT Baseを明示的に設計し、異なるスケールのタスクのパフォーマンスを調査しました.それぞれのモデルの構成は、表2に詳しく記載されています.表3の結果から、ほとんどの場合、より大きなモデルの方が優れたパフォーマンスを発揮する傾向があることがわかります.ただし、実際の展開では、パフォーマンスを向上させるためのスケーリングモデルがいくつかのデータセットでは経済的またはパラメータ効率的ではない場合があります.たとえば、BreastMNISTの実験結果では、中程度のサイズのモデルは小さいモデルに比べてわずか0.2%の精度向上しか示さず、約3倍のパラメータが必要です.(p.4)
BiomedGPTは、表3に示されるように、14のデータセットをカバーする3つの単一モーダルタスクを選択しました.画像分類タスクについては、いくつかのバイオメディカルドメインをカバーするベンチマークデータセットであるMedMNIST v2 Yang et al. (2021)の分類精度を示します.BiomedGPT Baseモデルは、10の画像のみのデータセットのうち9つで最高の精度を達成しています.RetinaMNISTではわずかに最先端に遅れていますが、小さな差です.(p.5)
比較のために、(Tasci et al.、2021)のアプローチに従って、これらのデータセットをバイナリ分類(正常対異常)に使用し、トレーニング、バリデーション、およびテストの70%/10%/20%の分割に分けました.表7は、異なるスケールのBiomedGPTの精度を示しています.高
Q: BiomedGPTが多様なモダリティからのマルチモダルの入力を受け入れる能力を用いて行うことができる下流のタスクについて、具体的な例を挙げてください.
A: BiomedGPTは、多様なバイオメディカルモダリティからのマルチモーダル入力を受け入れ、さまざまなダウンストリームタスクを実行することができます.具体的には、ビジョンのみのタスク、2つの言語のみのタスク、および2つのビジョン・言語タスクを含む、5つの異なるタスクにおいて、20の公開データセットを用いた実験により、BiomedGPTは先行する最新のモデルの大部分を上回る性能を発揮しています.(p.1)
BiomedGPTは、病理学、放射線学、学術文献など、多様なバイオメディカル分野を含む広範なドメインをカバーするように設計されており、実験結果は新しいベンチマークを設定し、異なるモダリティにわたる多様なバイオメディカル分野での事前学習の実現可能性を示しています.(p.1)
Q: BiomedGPTではどのような入力が可能ですか?
A: BiomedGPTは、多様な入力タイプを受け入れることができます.具体的には、CT画像や臨床ノートなどのさまざまなモダリティを含めることができます.これは、共通のマルチモーダル語彙に埋め込まれ、すべてのタスクに適用できるようになっています.このモデルは、事前学習と微調整の両方に統一されたシーケンス-シーケンス抽象化を使用しています.また、タスクの指示をプレーンテキストとして直接入力に注入することで、余分なパラメータが不要になります.これにより、データのモダリティやタスクに関係なく、効率的なタスクパフォーマンスが促進され、シームレスなプロセスが提供されます.(p.1)
Q: タスクの指示をプレーンテキストとして直接入力に注入することで、余分なパラメータが不要になり、効率的なタスク実行を促進する方法とは?
A: タスクの指示を入力に直接プレーンテキストとして注入することにより、余分なパラメータが不要になり、効率的なタスクパフォーマンスが促進されます.この設計により、データのモダリティやタスクに関係なく、シームレスなプロセスが提供されます.これにより、BiomedGPTは、単一ドメインまたは単一モダリティのデータセットでトレーニングされた専門家モデルと競合することができ、ビジョン言語タスクなどのタスクで新しい最先端(SOTA)のパフォーマンスを達成することができます. (p.3)
Q: BiomedGPTは、これまでの最先端モデルと比較してどうでしょうか?
A: 従来の最先端モデルと比較して、BiomedGPTは多様なモダリティを含むバイオ医学の最初の汎用AIモデルであり、複数のタスクで卓越したパフォーマンスを発揮しています.特に、ビジョン-言語タスクでは、画像キャプションや視覚的な質問に対する回答などで、新しい最先端のパフォーマンスを達成しています.これにより、研究者は複雑なデータを分析するためにバイオ医学の汎用モデルの力を利用し、人間の健康と疾患の基礎となる生物学的メカニズムの理解を進め、疾患の診断、治療、予防において新しい可能性を開拓することができます.(p.3-5)
Q: 本論文でのアブレーションスタディとはどのようなもので、何を示すものなのでしょうか.
A: ここでのAblation studyは、特定のタスクやモダリティグループを除外して、事前学習タスクとモダリティの影響を調べる研究手法です.本研究では、この手法を用いて、提案されたマルチモーダル・マルチタスクの事前学習手法が、未知のデータに対しても知識を転移できることを示しています.具体的には、15種類のバイオメディカルモダリティを含む20の公開データセットを用いた5つの異なるタスクに対して、事前学習を行い、その後、異なるタスクに対してfine-tuningを行いました.その結果、提案手法がバイオメディカル分野において、統一的で汎用的なモデルの開発に向けた重要な一歩であることが示されました.(p.1)
Q: 研究では何種類のタスクが使われ、微調整の結果はどうだったのでしょうか?
A: 本研究では、15種類のバイオメディカルモダリティをカバーする20の公開データセットを用いて、5つの異なるタスクを実施しました.また、fine-tuningフェーズにおいては、OFAの性能が制限されたエポック数内で低いことが明らかになりました.しかし、BiomedGPTは、マルチモーダル、マルチタスクの事前学習に関連するこれらの制限を克服することができました.fine-tuningプロセスにおいては、BiomedGPT baseを使用し、タスクに応じた入力形式を使用しました.結果として、我々のアプローチは、以前に見たことのないデータに対して知識を転移することができ、統一的で汎用的なモデルの開発において重要な進歩を示しました.(p.1,5,30)
SQL-PaLM: Improved Large Language ModelAdaptation for Text-to-SQL
著者:Ruoxi Sun, Sercan O Arik, Hootan Nakhost, Hanjun Dai, Rajarishi Sinha, Pengcheng Yin, Tomas Pfister
発行日:2023年05月26日
最終更新日:2023年05月26日
URL:http://arxiv.org/pdf/2306.00739v1
カテゴリ:Computation and Language, Artificial Intelligence, Databases

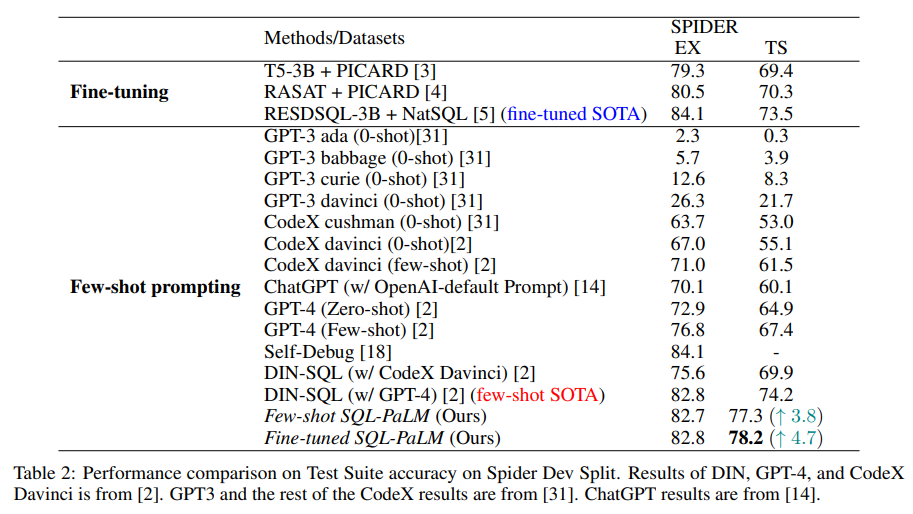
概要:
大規模言語モデル(LLM)の印象的な新興能力の1つは、データベースのStructured Query Language(SQL)を含むコードの生成です.自然言語テキストをSQLクエリに変換するタスクであるText-to-SQLにおいて、LLMの適応は、適応データの量に応じて、文脈に沿った学習と微調整の両方で極めて重要です.本論文では、PaLM-2を活用したLLMベースのText-to-SQLモデルSQL-PaLMを提案し、両方の設定で最先端を推進します.Few-shot SQL-PaLMは、Text-to-SQLの実行ベースの自己整合性プロンプトアプローチに基づいており、Spiderのテストスイート精度で77.3%を達成し、従来の最先端を微調整で大幅に上回ることを確認しました.さらに、微調整されたSQL-PALMがさらに1%上回ることを示しました.SQL-PaLMの能力については、堅牢性を評価し、SQL-PaLMの優れた汎化能力を示すために、Spiderの他の難しいバリアントでの評価を行いました.さらに、広範な事例研究を通じて、私たちはLLMベースのText-to-SQLの印象的な知的能力と様々な成功要因を実証します.
Q&A:
Q: この文章で提案されているText-to-SQLモデルの名称と、それを利用する技術は何ですか?
A: 本論文で提案されたText-to-SQLモデルの名前はSQL-PaLMであり、PaLM-2を利用しています.(p.1) 大規模言語モデル(LLMs)の印象的な新興能力の1つは、データベースのStructured Query Language(SQL)を含むコードの生成です.Text-to-SQLのタスクにおいて、LLMsの適応は、適応データの量に応じて、コンテキスト内学習と微調整の両方で極めて重要です.本論文では、Text-to-SQLに特化した実行ベースの自己整合プロンプティングアプローチを採用したSQL-PaLMを提案し、Spiderのテストスイート精度で77.3%を達成しました.(p.1) また、微調整されたSQL-PALMが、従来の最先端を大幅に上回ることを示しました.
Q: モデルで使われている実行ベースの自己矛盾プロンプトのアプローチは、最小限のデータで高い精度を実現することにどのように貢献しているのでしょうか.
A: 本研究では、Text-to-SQLにおいて、execution-based self-consistencyを適用することで、高い精度を少ないデータで達成することができます.複数の異なるSQLが同じ自然言語の質問に対して書かれることがあるため、execution-based self-consistencyは最も一貫性のある実行を選択することによって、最も一貫性のある答えを選択することができます.また、self-consistencyとexecution filteringの両方が重要な貢献をしていることが、表1のablation studiesで示されています.さらに、few-shot promptingによって、トレーニングが必要なく、過学習することがなく、新しいデータに簡単に適応できるという利点があります.しかし、パフォーマンスが最適でない可能性があるという欠点があります. (p.1,5,30)
Q: Spider上でfew-shotのSQL-PaLMモデルが達成したテストスイート精度は?
A: Spiderのfew-shot SQL-PaLMモデルのテストスイート精度は77.3%です.(p.4) このモデルは、Text-to-SQLのfew-shotプロンプティングアプローチに基づいており、従来のSOTAを4%以上上回る精度を達成しています.また、fine-tuningによる現在のSOTAを1%以上上回ることも示しています.さらに、Spiderの他のバリアントに対するモデルの堅牢性を評価し、SQL-PaLMの汎化能力の優位性を示しています.(p.4)
Q: Spider SQL-PaLMモデルで採用されているText-to-SQLのfew-shot方式は、どのような根拠があるのでしょうか.
A: Spider SQL-PaLMモデルのText-to-SQL few-shot promptingアプローチの基盤は、自然言語の質問に対応するSQL出力を生成するためのプロンプトの前に、デモンストレーション(入力、SQL)のペアのリストを付けることです.入力には、データベースを説明するテキストと自然言語の質問が含まれ、データスキーマ(テーブル、列、データ型)、主キー、外部キーなどのデータベース情報が含まれます.モデルは、プロンプトの形式に従って、与えられたプロンプトの後ろにある興味のある質問に対応するSQL出力を生成します.このアプローチは、Few-shot SQL-PaLMと呼ばれ、Spiderのトレーニングデータセットでトレーニングされたfine-tuned SOTAを上回り、さらに、単純なプロンプトの場合には、多数のラウンドの複合プロンプトよりも優れた性能を発揮します. (p.2-3)
Q: 微調整したSQL-PaLMモデルの性能は、few-shotと比較してどうなのでしょうか?
A: Fine-tuned SQL-PaLMモデルは、Few-shotモデルよりも優れた性能を発揮します.Spider dev splitにおけるテストスイートの精度は、Fine-tuned SQL-PaLMが78.2%であり、Few-shot SQL-PaLMより1%、現在のin-context learning SOTAより4.7%、現在のfine-tuned SOTAより4%優れています.ただし、Fine-tunedモデルの主な懸念点は、過学習と他のデータセットへの汎化能力です.Fine-tuned SQL-PaLMは、Spider train splitでトレーニングされ、他のSpiderバリアント(Sec. 6を参照)で評価され、テキストデータのシフトに対する堅牢性と汎化能力を分析します.(p.2-3)
Q: SQL-PaLMはどのように優れた汎化能力を発揮するのですか?
A: SQL-PaLMは、Spiderの他の難しいバリアントでの堅牢性を評価し、SQL-PaLMの優れた汎化能力を示すことで、現実世界のシナリオに適用することを目指しています.また、多数の事例研究を通じて、LLMベースのText-to-SQLの印象的な知的能力と様々な成功要因を示しています.(p.9)
SQL-PaLMは、複数のテーブルと複数のキーワードを結合する複雑なSQL出力を生成できるため、SQL生成能力に優れています.さらに、SQL-PaLMは、グラウンドトゥルースと異なる多数の解決策を生成できるため、SQL言語の深い理解を持っていることを示しています.SQL-PaLMは、新しい解決策を開発する際に人間の専門家が行うような単純な構文エラーをほとんど起こさず、代わりに類似したエラーを起こします.(p.9)
したがって、SQL-PaLMは、堅牢性、汎化能力、知的能力に優れており、Text-to-SQLの最新技術であり、最新の状態を示しています.(p.9)
Q: SQL-PaLMの主な目的は何ですか?
A: SQL-PaLMの主な目的は、複数のテーブルと複数のキーワードを結合する複雑なSQL出力を生成することであり、SQL言語の深い理解を持っていることを示すことです.また、人間の専門家が新しい解決策を開発する際に行うような単純な構文エラーではなく、同様のエラーを起こすことがあります.さらに、SQL-PaLMは、実世界のシナリオに適用するために、Spiderの他の難しいバリアントでの堅牢性を評価し、SQL-PaLMの優れた汎化能力を示します. (p.9)
Q: SQL-PaLMは、SQL言語への理解をどのように示しているのですか?
A: SQL-PaLMは、複数のテーブルと複数のキーワードを結合する複雑なSQL出力を生成できることから、SQL生成能力の優れた質的分析を示しています.さらに、SQL-PaLMは、グラウンドトゥルースと異なる多くの解を生成できるため、SQL言語の深い理解を持っていることを示しています.また、SQL-PaLMは、単純な構文エラーをほとんど起こさず、代わりに、新しい解を開発する際に人間の専門家が犯すエラーに似たエラーを起こします.(p.9)
Q: LLMベースのText-to-SQLが示す印象的なインテリジェント能力とは何でしょうか?
A: LLMベースのText-to-SQLによって示された印象的な知的能力には、SQLクエリの生成に必要な自然言語処理や言語解析の高度な能力が含まれます.これにより、SQLの専門知識を必要とせずにデータベースにアクセスできるようになり、高度なデータ分析能力を持つ会話エージェントの開発が可能になります.また、SQL-PaLMモデルのロバスト性や汎用性の高さも示されています.
Q: LLMベースのText-to-SQLを使ってSQLクエリを生成するためには、具体的にどのような自然言語処理・言語解析能力が必要なのでしょうか.
A: LLMベースのText-to-SQLを使用してSQLクエリを生成するために必要な特定の自然言語処理と言語解析の能力は、文脈に基づく学習と微調整の両方の設定において、SQL固有の設計とドメイン知識を持つLLMを使用することです.これにより、SQL-PaLMなどのモデルが開発され、自己整合性プロンプティングアプローチが設計され、テストスイートの精度が77.3%に達し、従来の最新技術を大幅に上回ることが示されています.(p.1)
Q: SQL-PaLMモデルの堅牢性や汎用性がどのように発揮されたのか、事例を紹介してください.
A: SQL-PaLMモデルの堅牢性と汎用性がどのように実証されたかの例を提供できます.テーブル5の2番目、4番目、5番目の例、およびすべての例(テーブル6)を使用することにより、SQL-PaLMはネストされたSQL構造(テーブル5の3番目の例で見られるように)を使用することができます.さらに、Few-shot SQL-PaLMは、正解と異なるが同じくらい正しいSQL出力を生成する能力を示しています.これは、SQLコンテンツの深い理解ではなく、単なる暗記ではないことを示唆しています.注目すべき例には、テーブル5の3番目の例、およびテーブル6の2番目、3番目、4番目、5番目の例が含まれます.テーブル6の6番目と7番目の例のようなエラーの場合でも、Few-shot SQL-PaLMは正解とは異なる代替ソリューションを提示します.さらに、Few-shot SQL-PaLMは、意味に基づいて関連するSQL式を推論する能力を示しています.つまり、「フランスの歌手」と「country=France」、および「young to old」と「OrderBy age ASC」(1番目と2番目の例で明らかになっています).この能力は、言語モデルの大規模な事前トレーニングに帰因されます.(p.6)
Q: SQL-PaLMが自己矛盾のプロンプトを出すために使っているアプローチは何ですか?
A: SQL-PaLMでは、自己整合性プロンプティングを使用しています.これは、複数の異なるSQLが同じ自然言語の質問に対して書かれることができるため、実行ベースの自己整合性が最も一貫性のある実行結果を生成することができるという理論に基づいています.具体的には、Few-shot SQL-PaLMを複数回サンプリングし、それぞれがSQL出力を生成します.その後、SQL出力をデータベースで実行し、各SQL出力が実行結果またはエラーを生成します.すべての実行結果からエラーを削除した後、それらの多数決を行い、多数決実行結果を出力するSQLを選択します.(p.4-5)
Q: SQL-PaLMは、最終的に実行されるSQL出力をどのように選択しているのですか?
A: 最終的に実行されるSQL出力を選択するために、SQL-PaLMは複数回Few-shot SQL-PaLMをサンプリングし、それぞれがSQL出力を生成します.その後、生成されたSQL出力をデータベースで実行し、実行結果またはエラーを得ます.すべての実行結果からエラーを除去した後、多数決を行い、多数決の実行結果を出力するSQLを選択します.(p.9)
Q: Text-to-SQLにおけるLLMの意義と、文脈内学習や微調整との関連は?
A: LLMは、Text-to-SQLタスクにおいて、自然言語テキストをSQLクエリに変換するためのモデルであり、in-context learningとfine-tuningの両方で、ドメイン固有のデータに適応することが必要です.in-context learningは、LLMが新しい例や新しいタスクに対して一般化する能力を持つことを示しており、few-shot prompting能力は、LLMのサイズが一定の閾値以上の場合により顕著になることが示されています.fine-tuningは、大規模なLLMをText-to-SQLタスクに適応させることができ、PaLM-2をSpiderトレーニングデータセットでfine-tuningしたFine-tuned SQL-PaLMは、Few-shot SQL-PaLMよりも0.9%高い性能を発揮し、SOTAを4.7%上回る結果を示しました.これらのことから、LLMはText-to-SQLタスクにおいて重要な役割を果たし、in-context learningとfine-tuningは、LLMの性能を向上させるために必要な手法であることが示唆されています.(p.1-3)
Q: Text-to-SQLにおいて、適応データの量は、文脈内学習と微調整の選択にどのような影響を与えるのでしょうか.
A: 適応データの量が少ない場合、Text-to-SQLにおいてはin-context learningが選択されることがある.一方、適応データが多い場合はfine-tuningが選択されることがある.これは、適応データが少ない場合はover-fitしにくく、新しいデータに適応しやすいfew-shot promptingが有利であるが、パフォーマンスが最適でないことがあるためである.一方、適応データが多い場合はfine-tuningが有利であるが、over-fittingの問題があるため、汎化性能を評価する必要がある.(p.3)
