
今回のテーマ:VOYAGER (Minecraft agent), Gorilla (LLM + APIs), QLoRA (Adaptor), モデル脅威の評価, Less is More for Alignment など.
ここでは、https://twitter.com/dair_ai で毎週メンションされているTop ML Papers of the Week の論文をQ&A形式を用いて要点を記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることを目的としています.
紹介する論文は以下の9本となります.
- VOYAGER: An Open-Ended Embodied Agent with Large Language Models (発行日:2023年05月25日)
- The False Promise of Imitating Proprietary LLMs (発行日:2023年05月25日)
- Gorilla: Large Language Model Connected with Massive APIs (発行日:2023年05月24日)
- The Larger They Are, the Harder They Fail: Language Models do not Recognize Identifier Swaps in Python (発行日:2023年05月24日)
- Model evaluation for extreme risks (発行日:2023年05月24日)
- QLoRA: Efficient Finetuning of Quantized LLMs (発行日:2023年05月23日)
- Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training (発行日:2023年05月23日)
- A PhD Student’s Perspective on Research in NLP in the Era of Very Large Language Models (発行日:2023年05月21日)
- LIMA: Less Is More for Alignment (発行日:2023年05月18日)
VOYAGER: An Open-Ended Embodied Agent with Large Language Models
著者:Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, Anima Anandkumar
発行日:2023年05月25日
最終更新日:2023年05月25日
URL:http://arxiv.org/pdf/2305.16291v1
カテゴリ:Artificial Intelligence, Machine Learning
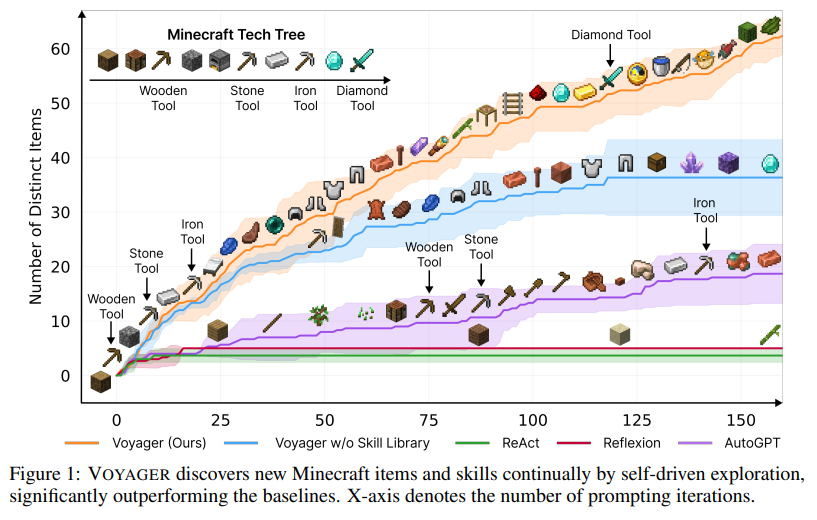
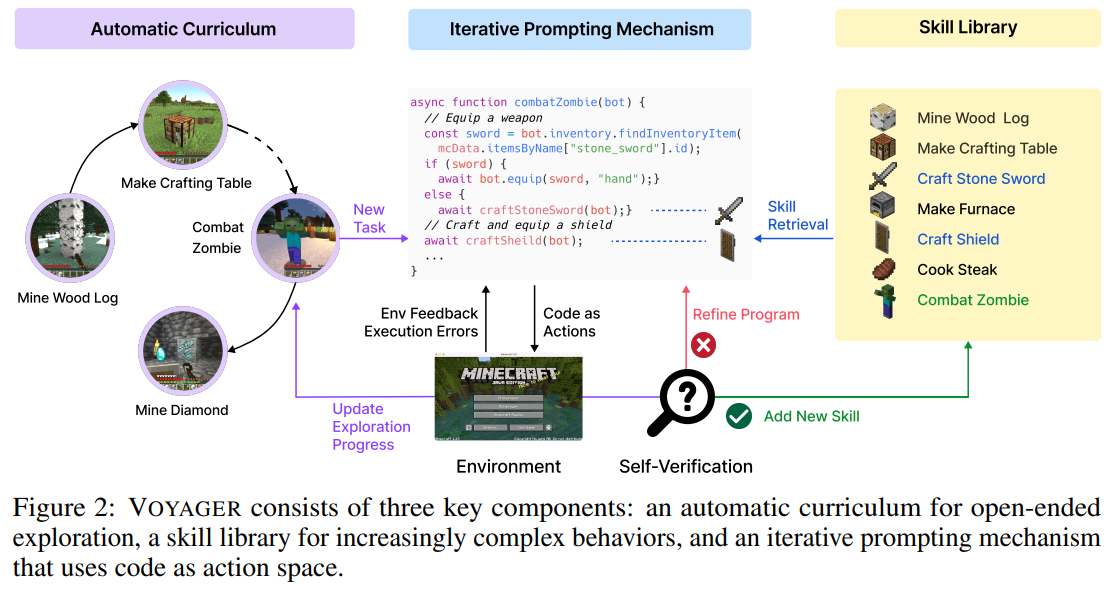
概要:
VOYAGERは、人間の介入なしに世界を探索し、多様なスキルを習得し、新しい発見をする、Minecraftで最初のLLMパワードの具現化された終身学習エージェントです.VOYAGERには、以下の3つの主要なコンポーネントがあります.1)探索を最大化する自動カリキュラム、2)実行可能なコードの成長するスキルライブラリ、3)環境フィードバック、実行エラー、およびプログラム改善のための自己検証を組み込んだ新しい反復的なプロンプトメカニズム.VOYAGERは、モデルパラメータの微調整をバイパスするブラックボックスクエリを介してGPT-4と対話します. VOYAGERが開発したスキルは、時間的に拡張可能で解釈可能で合成的であり、エージェントの能力を急速に複合化し、壊滅的な忘却を緩和します.実証的に、VOYAGERは強力なコンテキスト内での終身学習能力を示し、Minecraftのプレイにおいて例外的な熟練度を発揮します.それは、先行するSOTAよりも3.3倍以上のユニークなアイテムを獲得し、2.3倍以上の距離を移動し、キーのテックツリーマイルストーンを最大15.3倍速くアンロックします.また、VOYAGERは、学習したスキルを利用して、新しいMinecraftの世界で新しいタスクをゼロから解決することができます.他の技術が一般化するのに苦労する中、VOYAGERは学習したスキルライブラリを活用することができます.私たちは、私たちの完全なコードベースとプロンプトをhttps://VOYAGER.minedojo.org/でオープンソース化しています.
Q&A:
Q: VOYAGERとは、どのようなもので、どのような特徴があるのでしょうか.
A: VOYAGERは、大規模言語モデルを使用したオープンエンドの具現化エージェントであり、新しい発見を継続的に行い、人間の介入なしに多様なタスクに適用できることが特徴です.自動カリキュラムによって提案された徐々に難しくなるタスクを解決することを試み、探索の進捗状況とエージェントの状態を考慮したカリキュラムがGPT-4によって生成されます.このアプローチは、新奇性探索の文脈での形式として捉えることができます.VOYAGERは、Minecraftのテックツリーの解除、多様な地形の横断、学習したスキルライブラリを新しく生成された世界の未知のタスクに適用することによって、新しい発見を行うことができます.モデルパラメータの調整を行わずに強力なジェネラリストエージェントを開発するための出発点として機能します.(p.1)
Q: VOYAGERは、学習したスキルライブラリを、多様な地形での新しい未知のタスクにどのように適用するのでしょうか.
A: 新しい、未知のタスクや多様な地形に対して、VOYAGERは学習済みのスキルライブラリを利用して、ゼロから問題を解決することができます.他の手法が一般化するのに苦労する中、VOYAGERは自己駆動型の探索によって新しい発見を継続的に行い、学習したスキルライブラリを未知のタスクに適用することができます.(p.2)
Q: VOYAGERの3大要素は何でしょうか?
A: VOYAGERの3つの主要なコンポーネントは、(1)自動カリキュラム、(2)スキルライブラリ、(3)反復的なプロンプトメカニズムです.自動カリキュラムは、オープンエンドの探索のための目標を提案するものであり、スキルライブラリは、ますます複雑な行動を開発するためのものであり、反復的なプロンプトメカニズムは、コードをアクションスペースとして使用するものです.(p.2)
Q: VOYAGERの自動カリキュラムの目的は何でしょうか?
A: 自動カリキュラムは、VOYAGERの一部であり、オープンエンドの探索のための目標を提案することが目的です.このカリキュラムは、探索の進捗状況とエージェントの状態を考慮して生成され、GPT-4によって生成されます.このアプローチは、新規性探索の文脈での形式として認識できます.自動カリキュラムは、エージェントの一貫した進歩に不可欠であり、ランダムなカリキュラムに置き換えると、発見されたアイテム数が93%減少することがわかっています.手動で設計されたカリキュラムは、Minecraftに特化した専門知識が必要であり、エージェントのライブ状況を考慮していないため、自動カリキュラムに比べて実験結果が劣っています. (p.2)
Q: 反復プロンプトのメカニズムでは、アクションスペースとしてコードをどのように使っているのでしょうか.
A: イテレーションプロンプトメカニズムは、生成されたプログラムを実行してMinecraftシミュレーションから観測を取得し、(2)環境フィードバックと(3)自己生成タスクプランと環境フィードバックの埋め込みを使用してスキルライブラリをクエリし、新しいスキルとしてスキルライブラリに組み込み、その説明の埋め込みでインデックス化します.そして、継続的にスキルライブラリを拡大・改良することで、VOYAGERは学習し、適応し、広範なタスクで優れた成果を上げ、オープンワールドでの能力の限界を常に押し上げることができます.(p.4-5)
Q: VOYAGERとGPT-4との相互作用は?
A: VOYAGERは、GPT-4 APIと相互作用します.GPT-4は、コード生成の能力においてGPT-3.5をはるかに上回り、コード生成の品質において量子的な飛躍を実現しています.しかし、GPT-4 APIはGPT-3.5よりも15倍高価であり、コストがかかります.それにもかかわらず、VOYAGERはGPT-4からの品質の飛躍を必要としており、GPT-3.5やオープンソースのLLMsでは提供できません.(p.4)
Q: VOYAGERはGPT-4 APIとどのように連携しているのですか?
A: VOYAGERは、GPT-4 APIと相互作用します.GPT-4 APIは、GPT-3.5よりも15倍高価であるが、VOYAGERはGPT-4のコード生成品質の飛躍を必要としており、GPT-3.5やオープンソースのLLMsでは提供できないため、コストを負担しています.(p.4)
Q: GPT-4 APIとGPT-3.5のコスト差は何ですか?また、なぜVOYAGERはコストが高いにもかかわらず、GPT-4による品質の飛躍を必要としているのでしょうか?
A: GPT-4 APIのコストはGPT-3.5よりも15倍高く、VOYAGERはGPT-3.5やオープンソースのLLMsでは提供できないGPT-4のコード生成品質の飛躍が必要です.これは、図9の自動カリキュラム、スキルライブラリ、およびGPT-4の削除実験によって示されています.VOYAGERは、すべての代替手段を上回り、各コンポーネントの重要性を示しています.(p.1)
Q: VOYAGERで培ったスキルは、どのような効果があるのでしょうか.
A: VOYAGERが開発したスキルの利点は、時間的に拡張可能で、解釈可能で、合成的であることです.これにより、エージェントの能力が急速に複合され、壊滅的な忘却が緩和されます.また、VOYAGERは、新しいタスクに対して再利用可能で、解釈可能で、新しいタスクに一般化可能なアクションプログラムのスキルライブラリを構築できます.これにより、他の技術が一般化に苦労する中、VOYAGERは新しいMinecraftの世界で新しいタスクを解決することができます.(p.1)
Q: VOYAGERは、ユニークなアイテム、移動距離、技術ツリーのマイルストーンという点で、以前のSOTAと比較してどうでしょうか?
A: VOYAGERは、先行するSOTAに比べて、ユニークなアイテムを3.3倍多く取得し、2.3倍長い距離を移動し、キーとなるテックツリーマイルストーンを最大15.3倍速くアンロックします.これは、MineDojoのオープンソースのMinecraft AIフレームワークであるReAct [29]、Reflexion [30]、AutoGPT [28]を使用して、自己学習能力を持ち、Minecraftをプレイする能力が非常に高いことを示しています.また、VOYAGERは、新しいMinecraftの世界でも学習したスキルライブラリを利用して、新しいタスクを迅速に解決し、catastrophic forgettingを軽減することができます.これは、図1に示されており、VOYAGERが自己駆動型の探索によって新しいMinecraftのアイテムとスキルを継続的に発見し、ベースラインを大幅に上回っていることを示しています.また、図2と表1に示されているように、VOYAGERは、木材レベルを15.3倍速く、石レベルを8.5倍速く、鉄レベルを6.4倍速くアンロックし、ダイヤモンドレベルをアンロックする唯一のエージェントです.これは、自動カリキュラムの効果を裏付けており、適切な複雑さの課題を一貫して提示することで、エージェントの進歩を促進しています.さらに、図7に示されているように、VOYAGERは、様々な地形を移動することで、ベースラインエージェントよりも2.3倍長い距離を移動することができます.これに対し、ベースラインエージェントは、しばしば地元の地域に閉じ込められており、新しい知識を発見する能力が著しく制限されています.(p.1)
Q: VOYAGERのコードベースとプロンプトはオープンソースで、どこにあるのでしょうか?
A: VOYAGERのコードベースとプロンプトはオープンソースであり、https://VOYAGER.minedojo.org/で入手できます.これは、論文の4節で明確に述べられています.また、同じ節で、GPT-4 APIのコストが高いことが指摘されています.
The False Promise of Imitating Proprietary LLMs
著者:Arnav Gudibande, Eric Wallace, Charlie Snell, Xinyang Geng, Hao Liu, Pieter Abbeel, Sergey Levine, Dawn Song
発行日:2023年05月25日
最終更新日:2023年05月25日
URL:http://arxiv.org/pdf/2305.15717v1
カテゴリ:Computation and Language

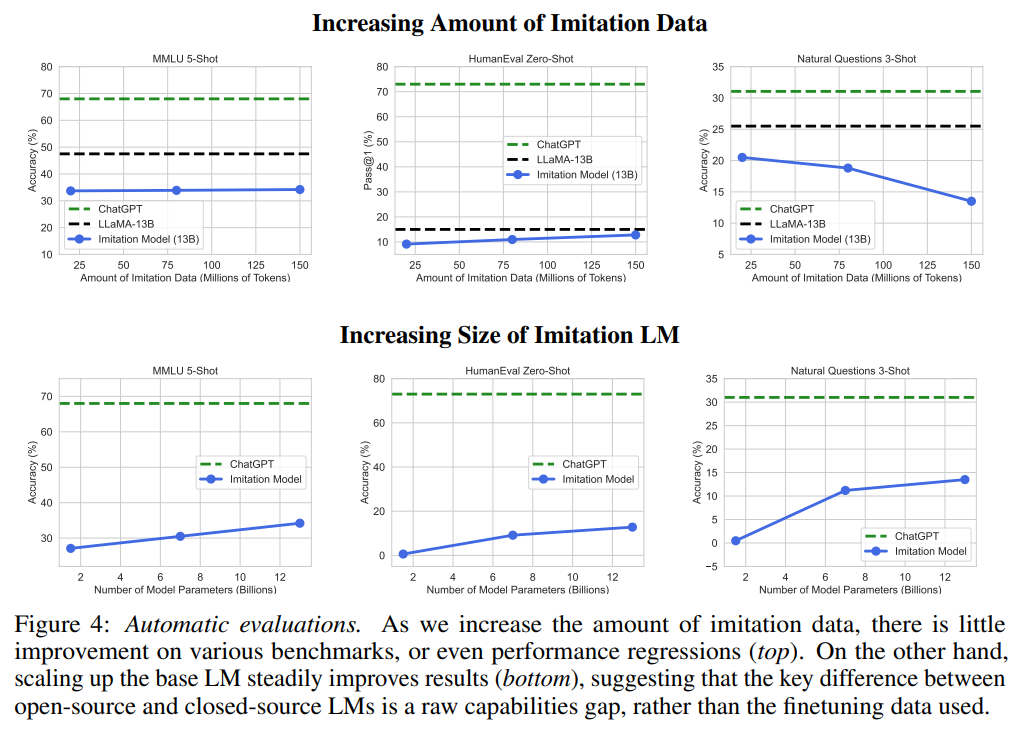
概要:
ChatGPTのようなプロプライエタリシステムからの出力を用いて、弱い言語モデルを安価に改善する新しい方法がある.このアプローチは、弱いオープンソースモデルを用いて、プロプライエタリモデルの能力を安価に模倣することを目的としている.しかし、本研究では、異なるベースモデルサイズ、データソース、模倣データ量を用いて、ChatGPTを模倣する一連のLMを微調整し、クラウドレーターと標準的なNLPベンチマークを用いてモデルを評価した結果、模倣モデルはChatGPTのスタイルを模倣することに長けているが、その能力を模倣することには長けていないため、人間のレーターに見逃される可能性があることがわかった.つまり、オープンソースモデルとプロプライエタリモデルの間には、現在の方法では大きな能力差があり、模倣データを大量に使用するか、より能力の高いベースLMを使用することでしか、そのギャップを埋めることができないということである.そのため、オープンソースモデルを改善するためには、プロプライエタリシステムを模倣するというショートカットではなく、より能力の高いベースLMを開発するという難しい課題に取り組むことが最も効果的であると主張している.
Q&A:
Q: 弱い言語モデルを費用対効果よく改善するために、具体的にどのような技術が使われているのでしょうか?
A: 弱い言語モデルを安価に改善する新興手法は、ChatGPTのようなプロプライエタリシステムからの出力を用いて、それを微調整することです.これにより、オープンソースの弱いモデルを用いて、プロプライエタリモデルの能力を安価に模倣することができます.しかし、より高度なモデルの模倣よりも、モデルのスケールを拡大したり、事前トレーニングデータの品質を向上させたり、新しい事前トレーニング方法を開発するなど、ベースモデルを改善することが、オープンソースの言語モデルを改善するためにはより効果的であることが示されています.(p.1)
Q: この手法を使って、より弱いオープンソースモデルを使ってプロプライエタリなモデルの機能を模倣した例を教えてください.
A: 本研究では、弱いオープンソースモデルを改善するための新しい手法として、ChatGPTなどのプロプライエタリシステムからの出力を用いて、より強力なモデルをファインチューニングする方法について分析しています.これにより、より弱いオープンソースモデルでプロプライエタリモデルの機能を模倣することができます.例えば、Self-InstructやAlpacaなどのOpenAIの最高のシステムを模倣することで、オープンソースモデルが商用モデルと同等の性能を発揮できる可能性があることが示されています.これにより、多くの人々の間で、閉鎖的なモデルにはもはや優位性がなくなるという考えが広がっています.(p.1)
Q: 本作で例として使用されているプロプライエタリシステムとは?
A: 本論文で使用されたプロプライエタリシステムの例は、ChatGPTです.)
Q: 模倣のアプローチを批判的に分析するために、本作ではどのようなアプローチをとっているのでしょうか.
A: 本研究では、モデルの模倣手法の有効性を批判的に分析しました.具体的には、オープンソースの言語モデルにおいて、模倣によってスタイル、ペルソナ、指示に従う能力が向上することを示しました.しかし、模倣は事実性、コーディング、問題解決などのより難しい軸においては改善が不十分であることも示しました.模倣によって強力なオープンソースの言語モデルよりも優れたモデルを作成することができることを示唆しています.本研究では、模倣手法の有効性を批判的に分析するアプローチを取りました.(p.7)
Q: オープンソースの言語モデルにおいて、スタイル、ペルソナ、模倣による指示の追従などの観点から、具体的にどのような改善が見られたのでしょうか.
A: 本研究では、オープンソースの言語モデルにおいて、模倣によってスタイル、パーソナリティ、指示に従う能力が改善されることが確認されました.(p.9) ただし、模倣は事実性、コーディング、問題解決など、より難しい軸においては改善が不十分であることが示されました.(p.9)
Q: この作品では、モデルの評価はどのように行われたのでしょうか?
A: 本研究では、ヒトの評価とクラウドワーカーの評価の両方を使用して、モデルを評価しました.クラウドワーカーの評価では、2つの未知のモデルの出力を提示し、どちらが優れているか、または同等であるかを選択するように求めました.ヒトの評価では、ChatGPTと私たちの模倣モデルの出力を比較し、どちらが優れているかを選択するように求めました.また、モデルのスケールをベースモデルの品質の代理として使用しました.評価セットの各例について、3つの一意の評価を収集し、71人の評価者が参加しました.平均スコアを得るために、3つの評価のうち多数決を使用しました.これらの評価により、既存のクラウドワーカーの評価が模倣モデルとプロプライエタリモデルの違いを明確にすることができないことが示されました.さらに、人間の評価の将来については不明な点が残されています.強力なLLMの有用性を安価かつ迅速に調べる方法は何でしょうか?(p.13)
Q: 未知の2機種を、クラウドワーカーはどう評価したのでしょうか.
A: クラウドワーカーは、タスクの指示と2つの未知のモデルの出力を提示され、そのうち1つがChatGPTで、もう1つが模倣モデルであるという条件で、どちらの出力がより優れているか、または2つの出力が同等であるかを選択しました.約70人のクラウドワーカーを使用し、255の保持されたプロンプトで評価を行いました.(p.1)
Q: モデルの有効性を判断する上で、人間の評価を用いることの限界について説明できますか?
A: 人間の評価は、技術的な進歩に対応するためにますます困難になっています.特に、ドメインの専門知識がないクラウドワーカーは、スタイルの要素によって簡単に欺かれる可能性があります.自信を持って正しいと思われる回答がしばしば誤って選択されることがあります.人間の評価を改善するためには、ドメインの専門家を参加させることがますます必要になっています.また、異なるモデルの能力を厳密にテストする高度に困難なプロンプトのセットを編成することも必要です. (p.3)
Q: 模倣モデルで見られた性能の不一致は何だったのか?
A: 模倣モデルは、ChatGPTのスタイルを模倣することに長けているため、クラウドワーカーによる評価では高い評価を受けます.しかし、模倣データに重点を置かないタスクにおいては、ベースLMからChatGPTまでのギャップをほとんどまたは全く埋めることができず、性能の不一致が見つかりました.(p.1) また、模倣モデルの事実性は弱く、ドメインの専門知識や時間投資がないクラウドワーカーはこれらのエラーを見逃す可能性があることが示されました.
Q: 模倣モデルを用いた場合に、ベースとなるLMとChatGPTの間に性能差があることが判明した具体的なタスクやシナリオは何ですか?
A: 模倣モデルは、模倣データで十分にサポートされていないタスクにおいて、ベースLMとChatGPTの間の大きなギャップをほとんど埋めることができないことがわかっています.例えば、広範なカバレッジのユーザー入力からの100k ChatGPT出力でトレーニングしても、Natural Questionsの精度には何の利益ももたらさず、ChatGPTの応答のみでトレーニングすることで、タスクの精度が劇的に向上します.したがって、純粋に模倣を用いてChatGPTを広く一致させるには、(1)膨大な模倣データセットを収集することと、(2)現在利用可能なものよりもはるかに多様で高品質な模倣データが必要です.(p.3)
Q: 模倣モデルの事実性の弱さと、それが専門家ではないクラウドワーカーのエラー識別能力にどのような影響を与えるかについて、より詳しい情報を教えてください.
A: 模倣モデルの弱点は、事実性が弱いことです.クラウドワーカーは、ドメインの専門知識や十分な時間投資がない場合、これらのエラーを見逃す可能性があります.これは、模倣モデルがChatGPTのスタイルを巧みに模倣するため、クラウドワーカーが自信を持って構成された回答を出力するためです.しかし、彼らの事実性が弱いため、クラウドワーカーはエラーを見逃す可能性があります.これは、技術的な制限があることを示唆しており、今後の人間の評価の未来が不明確であることを示唆しています.これは、既存のクラウドワーカーの評価が模倣モデルとプロプライエタリモデルの違いを明確にするのに苦労していることを示しています.(p.2)
Q: モデルの模倣やオープンソースモデルの改善について、この研究の結論は何ですか?
A: 本研究の結論は、既存のオープンソースの言語モデルの能力が弱いことが最大の制限であるため、模倣データに対して微調整するよりも、これらの能力を向上させること(例えば、スケーリング、より良い事前学習データなど)がオープンソースコミュニティがモデルを改善するための最善の方法であるということです.(p.3-5)
具体的には、模倣プロセスがAPIを介してプロプライエタリな言語モデルを利用することを前提としており、オープンソースの言語モデルを微調整するためにAPI出力のデータセットを収集し、使用することができます.理論的には、この模倣プロセスは、プロプライエタリな言語モデルの能力をオープンソースの言語モデルに転移するための簡単な方法を提供する可能性があります.しかし、本研究では、模倣モデルの効果について厳密な自動評価と人間の評価を行い、既存の方法は実際には実用的ではないと結論づけています.(p.3-5)
さらに、既存のクラウドワーカーの評価は、明らかな違いが存在するにもかかわらず、模倣モデルとプロプライエタリなモデルの違いを明確にすることができないことが示されています.そのため、強力な言語モデルの有用性を安価かつ迅速に調査する方法は不明のままです.(p.3-5)
以上のことから、オープンソースの言語モデルを改善するためには、模倣データに対して微調整するよりも、能力を向上させることが最善の方法であるということが本研究の結論です.(p.3-5)
Q: スケーリングや事前学習データの充実など、既存のオープンソースの言語モデルを改善するための具体的な方法とは?
A: 現在のオープンソースの言語モデルの最大の制限は、基本的な機能が弱いことであることが、自然言語処理に関する研究によって明らかにされました.そのため、スケーリングやより良い事前学習データなどを通じてこれらの機能を向上させることが、オープンソースコミュニティがモデルを改善するための最良の方法であるとされています.また、モデルの模倣による微調整よりも、モデルの基本的な機能を向上させることが重要であるとされています(p.1).
具体的には、モデルのスケールを拡大したり、事前学習データの品質を向上させたりすることが挙げられます.また、オープンソースの言語モデルを改善するためには、新しい事前学習方法を開発することも必要であるとされています(p.1).
Gorilla: Large Language Model Connected with Massive APIs
著者:Shishir G. Patil, Tianjun Zhang, Xin Wang, Joseph E. Gonzalez
発行日:2023年05月24日
最終更新日:2023年05月24日
URL:http://arxiv.org/pdf/2305.15334v1
カテゴリ:Computation and Language, Artificial Intelligence

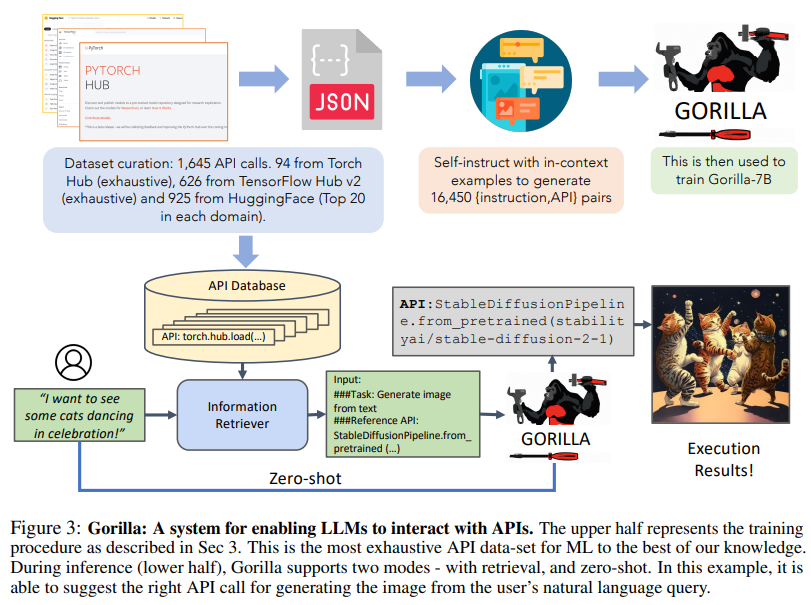
概要:
最近、大規模言語モデル(LLM)は驚くべき進歩を遂げ、数学的推論やプログラム合成などの様々なタスクで優れた成績を収めています.しかし、API呼び出しを効果的に使用する能力は未だに充分に発揮されていません.これは、GPT-4などの最新のLLMでも困難な課題であり、正確な入力引数を生成することができず、API呼び出しの誤った使用を幻視する傾向があるためです.本研究では、GPT-4を上回るAPI呼び出しの書き込み能力を持つ、finetuned LLaMAベースのモデルであるGorillaをリリースします.Gorillaは、システムと組み合わせることで、テスト時のドキュメントの変更に柔軟に対応する強力な能力を示し、ユーザーのアップデートやバージョン変更に対応することができます.また、LLMを直接プロンプトする際によく遭遇する幻覚の問題を大幅に軽減します.さらに、Gorillaのコード、モデル、データ、デモは、https://gorilla.cs.berkeley.eduで公開されています.本研究では、HuggingFace、TorchHub、TensorHubのAPIから構成される包括的なデータセットであるAPIBenchを導入し、モデルの能力を評価します.リトリーバーシステムとGorillaの成功した統合は、LLMがツールをより正確に使用し、頻繁に更新されるドキュメントに追従し、その結果、出力の信頼性と適用性を高める可能性を示しています.
Q&A:
Q: Gorillaとは何か、他のLLMとどう違うのか.
A: Gorillaは、API呼び出しを書くためのGPT-4を上回る性能を持つ、finetuned LLaMAベースのモデルです.Gorillaは、直接LLMをプロンプトするとよく見られる幻覚の問題を大幅に軽減し、ドキュメントリトリーバーと組み合わせることで、テスト時のドキュメントの変更に柔軟に対応する強力な能力を示します.また、HuggingFace、TorchHub、TensorHubのAPIから構成される包括的なデータセットであるAPIBenchを導入し、Gorillaの能力を評価しました.Gorillaは、他のLLMと比較して、APIをナビゲートする能力が高く、異なる制約のトレードオフを考慮することができます.これにより、LLMがより正確にツールを使用し、頻繁に更新されるドキュメントに追従し、結果的により高い精度を実現できる可能性があることを示しています.
Q: APIコールの書き込みについて、GorillaとGPT-4の性能差は?
A: Gorillaは、API機能の精度と幻覚エラーの削減において、GPT-4を大幅に上回ることがわかりました.特に、zero-shotの場合、GorillaはGPT-4とGPT-3.5を大きく上回っています.Gorillaは、APIドキュメントの変更に適応する強力な能力を示し、制約に関する理解力も備えています.これに対し、GPT-4はTorch HubとTensor Hubで約40%の精度を示し、HuggingFaceでは競争力がないとされています.これらの結果は、(p.2)と(p.14)から得られました.
Q: Gorillaは、LLMに直接プロンプトを出すと幻覚が見えるという問題にどう対処しているのか、また、ドキュメントレトリバーと組み合わせることで、テスト文書の変更に柔軟に対応することをどう示しているのか.
A: Gorillaは、LLMを直接プロンプトする際の幻覚問題に対処するために、BM25またはGPT-Indexのリトリーバーを使用してドキュメントを検索し、APIの変更に柔軟に対応することができます.これにより、API機能の精度が向上し、幻覚エラーが減少します.また、Gorillaは、制約について理解し、推論することができます.これらの結果は、GPT-4よりも優れており、図1に例を示しています.これらの結果は、データセットに基づくGorillaのfine-tuningによって達成されました.これらの洞察は、第4章で詳しく説明されています.(p.2-3)
Q: GorillaはGPT-4と比較して、APIコールの記述に関する性能はどうでしょうか?
A: GPT-4に比べて、GorillaはAPI機能の精度や幻覚エラーの削減において大幅に優れていることが、図1の例示によって示されています.また、Gorillaの検索に注意したトレーニングにより、APIドキュメントの変更に適応する能力が向上しています.さらに、制約について理解し、推論する能力も示しています.これらのことから、GorillaはAPI呼び出しの書き込みにおいて、GPT-4よりも優れたパフォーマンスを発揮しています.(p.2)
Q: GorillaはGPT-4と比較して、API機能の精度や幻覚エラーの低減という点ではどうでしょうか?
A: GPT-4に比べて、API機能の正確性や幻覚エラーの削減において、Gorillaが大幅に優れていることがわかりました.これは、図1の例示によって示されています.さらに、Gorillaの検索に関するトレーニングにより、APIドキュメントの変更に適応することができます.最後に、Gorillaが制約について理解し、推論する能力を示しました.(p.2)
Q: 幻覚の問題とは何か、Gorillaはそれをどう緩和しているのか.
A: 幻覚とは、APIのドキュメントに記載されていない情報を生成することです.Gorillaは、ゼロショット設定において、最も高い精度向上を実現しながら、良好な事実能力を維持することができます.また、異なるリトリーバーを使用しても、幻覚エラーを回避することができます.Gorillaは、API機能の精度においてGPT-4を大幅に上回り、幻覚エラーを減らすことができます.これは、リトリーバーによるトレーニングによって可能になります.さらに、Gorillaは、APIドキュメントの変更に適応する能力を持ち、制約について理解し、推論することができます.(p.18)
Q: 幻覚 “の定義とAPIドキュメントとの関連は?
A: 幻覚とは、APIドキュメントにおいて、正しいAPI選択に影響を与える制約条件を考慮し、API選択の理由を詳細に説明することである.この要素は、API選択に関する深い理解を提供すると同時に、API選択に影響を与える制約条件を明確にすることで、バランスの取れたアプローチを提供する.これにより、与えられた文脈内でのAPI使用の包括的な理解が得られる.これは、APIドキュメントにおいて非常に重要な要素である. (p.1,4-8)
Q: Gorillaはどのようにして、異なるレトリーバーを使用した場合でも、より高い精度を実現し、”幻覚エラー “を回避しているのか?
A: Gorillaは、API機能の正確性を向上させ、幻覚エラーを減らすために、BM25やGPT-Indexなどの異なるリトリーバーを使用する際に、制約を考慮しながらAPIをナビゲートする能力を持っています.Gorillaは、リトリーバーを使用する場合には、最高のパフォーマンスを発揮し、ゼロショットの場合には最高の正確性を示し、異なる制約のトレードオフを考慮することができます.これは、Gorillaのリトリーバーに対する理解力と推論能力によるものです.(p.2-3)
Q: Gorillaは、LLMがより正確にツールを使えるようになる可能性をどのように示しているのでしょうか.
A: Gorillaは、APIを考慮しながら異なる制約のトレードオフを考慮することができるため、最高性能のモデルGPT-3.5と同等の性能を発揮し、Zero-shotの場合に最高の精度を示すことができます.これは、GorillaがAPIをナビゲートする能力を強調し、LLMがより正確にツールを使用する可能性を示しています.また、Gorillaは、幻覚を起こさずに信頼性の高いAPI呼び出しを生成し、テスト時のAPI使用の変更に適応する印象的な能力を示し、APIを選択しながら制約を満たすことができます.(p.3-5)
Q: 本稿で紹介した新手法のコード実装のためのurlはどうなっていますか?
A: 本論文で紹介された新しい手法のコード実装は、https://gorilla.cs.berkeley.eduにて公開されています.この実装は、Gorillaと呼ばれるツールによって提供され、LLMの出力の信頼性と適用範囲を向上させることができます.この情報は、論文の1 Introductionの中で述べられています.(p.1)
The Larger They Are, the Harder They Fail: Language Models do not Recognize Identifier Swaps in Python
著者:Antonio Valerio Miceli-Barone, Fazl Barez, Ioannis Konstas, Shay B. Cohen
発行日:2023年05月24日
最終更新日:2023年05月24日
URL:http://arxiv.org/pdf/2305.15507v1
カテゴリ:Computation and Language, Artificial Intelligence
概要:
大規模言語モデル(LLM)は、コード生成タスクに成功裏に適用されており、これらのモデルがプログラミングをどの程度理解しているかという問題が浮上しています.典型的なプログラミング言語には、人間のプログラマが直感的に理解し、利用する不変性と同値性があります.例えば、識別子の名前を変更しても(ほぼ)不変であることなどです.本研究では、デフォルトの関数名が交換された場合、LLMが正しいPythonコードを適切に生成できないことを示しました.さらに、モデルサイズが増加するにつれて、誤った予測に対してより自信を持つモデルもあることがわかりました.これは、最近発見された逆スケーリング現象の一例であり、一般的に観察されるモデルサイズの増加に伴う予測品質の向上とは逆の傾向です.本研究の結果は、驚異的な典型的なケースのパフォーマンスにもかかわらず、LLMが操作するコンテンツの深い抽象的な理解を欠いていることを示しており、彼らがトレーニングデータから統計的に逸脱するタスクには適していないことを示しています.また、単にスケーリングするだけではこのような能力を実現することはできないことを示しています.

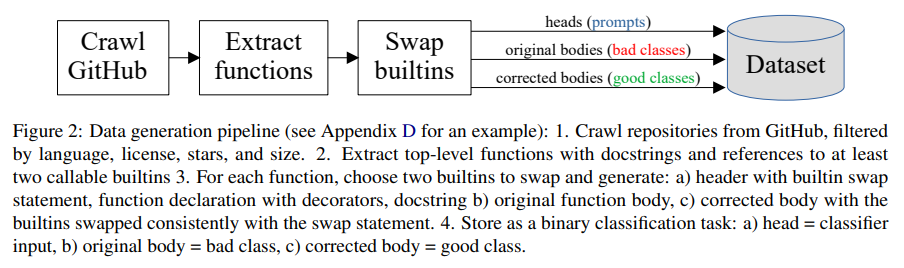
Q&A:
Q: 大規模言語モデル(LLM)とは何か、コード生成タスクにどのように適用されてきたか.
A: LLMsとは、Pretrained Large Language Modelsの略であり、自然言語処理の様々なタスクにおいて主要なパラダイムとなっている.これらのモデルは、コード生成タスクにも適用され、その性能が向上していることが報告されている.例えば、Chenら(2021)やLiら(2022)によって、プログラミングのコード生成や補完において、LLMsが成功を収めていることが示されている.また、Kaplanら(2020)やHernandezら(2021)によって、LLMsがプログラミングタスクにおいても高い性能を発揮していることが報告されている.(p.1)
ただし、Niijkampら(2022)によって、LLMsは一般的なプログラミング言語において、人間のプログラマが直感的に理解し、利用することができる不変性や同変性を持っていることが指摘されている.例えば、識別子の名前を変更しても、プログラムの意味が(ほぼ)不変であることが挙げられる.LLMsは、このような抽象的な理解を持っていないため、彼らが操作するコンテンツに対する深い抽象的な理解を持っていないことが示されている.そのため、LLMsは、彼らのトレーニングデータから統計的に外れるタスクには適しておらず、単にスケーリングするだけでは、このような能力を獲得することはできない.(p.1)
Q: 自然言語処理における略語LLMsとその意味するところを教えてください.
A: LLMsとは、Pretrained Large Language Modelsの略称であり、自然言語処理において、多様な言語タスクにおいて主要なパラダイムの1つとして急速に普及している.LLMsは、プログラミングコードの生成や補完などのプログラミングタスク(Chen et al.、2021; Li et al.、2022)を含め、多くの実用的なタスク(Kaplan et al.、2020; Hernandez et al.、2021)において、モデルサイズの増加に伴い性能が向上している.これらのモデルは、大規模な事前学習データセットとパラメータ数のバランスが取られており、モデルファミリーごとに固定された設計法則に従っており、コンピュートに基づいて事前学習セットの尤度を経験的に最大化することを意図している.しかし、これらのモデルは、訓練データから統計的に外れるタスクに対しては適しておらず、単なるスケーリングだけではこの能力を獲得することはできないことが示されている(p.1).
Q: Niijkampら(2022)によると、プログラミング言語の抽象的な概念を理解するという点で、LLMにはどのような限界があるのでしょうか.
A: Niijkampら(2022)によると、LLMはプログラミング言語の抽象的な概念を理解する能力に制限があることが示されており、これらの欠陥はモデルサイズを増やしても改善されず、むしろ悪化する可能性があることが広範な科学的含意からも示されています.(p.1)
Q: プログラミング言語における不変性・等価性とは何か、人間のプログラマーはそれをどう利用するのか.
A: プログラミング言語における不変性と同変性とは、同じ機能を複数のプログラムで表現できることを意味します.これらは、変数や関数名などの識別子の一貫した名前変更に対する不変性を含め、様々な形を取ることができます.これらの概念を理解することで、プログラマーはプログラムをより効果的に書くことができます.例えば、α同値性は、構文解析を使用して決定できるため、プログラミング言語の意味を正しく理解するために重要です. (p.1-2)
プログラミング言語における不変性と同変性とは、同じ機能を複数のプログラムで表現できることを意味します.これらは、変数や関数名などの識別子の一貫した名前変更に対する不変性を含め、様々な形を取ることができます.これらの概念を理解することで、プログラマーはプログラムをより効果的に書くことができます.例えば、α同値性は、構文解析を使用して決定できるため、プログラミング言語の意味を正しく理解するために重要です. (p.1-2)
Q: プログラミング言語における「不変性」「同変性」の定義とは?
A: 不変性と同変性とは、プログラミング言語において、同じ機能を複数のプログラムで表現することができる不変性と、プログラム内の識別子の一貫した名前変更に対する不変性である.不変性は、プログラムの意味的同等性を決定することができるが、一般的には不可能である.一方、同変性は、純粋な構文解析によって決定することができる.これらの概念は、プログラミング言語の意味を正しく理解するために重要である.(p.2)
Q: これらの概念を理解することで、プログラマーはより効果的なプログラムを書くことができるのでしょうか?
A: これらの概念を理解することで、プログラマーはより効果的なプログラムを書くことができます.プログラミング言語には、変数や関数名の一貫した名前変更に対する不変性など、人間のプログラマーが直感的に理解して利用することができる不変性や同値性があります.これらの概念を理解することで、プログラマーはより正確で効率的なコードを書くことができます.また、LLMsを使用するソフトウェアエンジニアリングツールの開発にも役立ちます. (p.1,5,30)
Q: デフォルトの関数名が入れ替わったときに、LLMが正しいPythonコードを正しく生成できないのはどうしてですか?
A: LLMsは、デフォルトの関数名が交換された場合に正しいPythonコードを適切に生成できず、そのうちのいくつかは、モデルサイズが増加するにつれて、誤った予測に対してさらに自信を持つようになることがわかりました.これは、Inverse Scalingという最近発見された現象の一例であり、増加するモデルサイズに伴う予測品質の向上という一般的に観察される傾向に反するものです.(p.1) つまり、LLMsは、プログラムの意味に関する深い抽象的な理解を欠いており、訓練データから統計的に外れたタスクには適しておらず、単にスケーリングするだけではこのような能力を獲得することはできないということです.
Q: Inverse Scalingとはどのような現象で、モデルサイズが大きくなるとLLMの精度にどのような影響があるのでしょうか?
A: Inverse Scalingとは、LLMsのモデルサイズが増加するにつれて、予測品質が向上するという一般的な傾向とは逆に、スケーリングが遅くなり、滑らかでなくなる現象のことである.LLMsの精度に影響を与え、モデルサイズが大きくなるほど、誤った予測に対してより自信を持つようになることがある.これは、LLMsが操作するコンテンツの深い抽象的な理解を欠いているためであり、単にスケーリングするだけでは、このような能力を獲得することはできないことを示している.(p.1-2)
Q: なぜLLMはプログラムの意味を深く理解していないのか、なぜトレーニングデータから統計的に外れるようなタスクには向いていないのか.
A: LLMは、モデルサイズが大きくなるにつれて予測品質が向上するという一般的な傾向があるが、そのようなモデルは、訓練データから統計的に外れたタスクには適しておらず、深い抽象的な理解を欠いているため、そのようなタスクには適していない.LLMは、データの弱い、不安定な、主に語彙的な相関関係に依存しており、データ(この場合、Pythonコード)の意味論的理解を深いレベルで持っていないためである.これらの結果は、LLMの「ショートカット学習」に依存していることを示唆しており、LLMは、データの意味論的理解を深いレベルで持っていないため、統計的に外れたタスクには適していない.(p.1)
Q: モデルサイズが大きくなるにつれて、誤った予測に自信を持つようになるLLMもあるのでしょうか?
A: 結論から言うと、はい、一部のLLMはモデルサイズが増加するにつれて、誤った予測に対してより自信を持つようになります.これは、逆スケーリング現象の一例であり、一般的に観察される予測品質がモデルサイズの増加とともに向上する傾向とは逆です.(p.1,5,30)
LLMは、Pythonコードの生成や補完など、多様な言語タスクにおいて主要なパラダイムの1つとなっています.一部のLLMは、モデルサイズが増加するにつれて、誤った予測に対してより自信を持つようになります.これは、逆スケーリング現象の一例であり、一般的に観察される予測品質がモデルサイズの増加とともに向上する傾向とは逆です.(p.1,5,30) しかしながら、これらの結果は、LLMがデータの意味を深く理解するのではなく、データ内の弱い、不安定な、主に語彙的な相関関係に依存していることを示唆しています.したがって、LLMは、トレーニングデータから統計的に逸脱するタスクには適しておらず、単にスケーリングするだけではこのような能力を獲得することはできないと考えられます.(p.1,5,30)
Q: 逆スケーリング現象とは何か、LLMとどう関係するのか.
A: Inverse Scaling現象とは、モデルサイズが大きくなるにつれて、予測の質が向上するという通常の傾向とは逆に、予測の質が低下する現象のことである.LLMsに関連して、先行研究により、LLMsがInverse Scaling現象を示すことが明らかになっている.具体的には、LLMsは、デフォルトの関数名が交換された場合に正しいPythonコードを生成できず、モデルサイズが大きくなるにつれて、誤った予測に対してより自信を持つようになることが示されている.これは、LLMsが操作するコンテンツの深い抽象的な理解を欠いているため、トレーニングデータから統計的に逸脱するタスクには適していないことを示している.また、単なるスケーリングでは、このような能力を獲得することはできないことが示されている.(p.1,3-5)
Q: LLMは、データ中の弱い、不安定な、主に語彙の相関にどのように依存しているのか、また、このことは、学習データから統計的に逸脱するタスクを実行する能力について何を示唆しているのか.
A: LLMは、データ内の弱く不安定で主に語彙的な相関関係に依存しており、データの意味に対する深い理解ではなく、「ショートカット学習」を行っていることを示唆しています.これは、LLMが訓練データから統計的に外れたタスクを実行する能力に欠けていることを意味し、単なるスケーリングではこの能力を獲得することができないことを示唆しています.(p.2-3)
Q: モデルサイズの増加に伴い予測品質が向上するという一般的な傾向と矛盾する、この文章にある「逆スケーリング」という言葉について、詳しい説明をお願いします.
A: 「逆スケーリング」という用語は、一般的な傾向であるモデルサイズの増加に伴う予測品質の向上とは逆の傾向を示すタスクを指します.逆スケーリングを示すタスクは、社会的なバイアス(Parrish et al.、2022; Srivastava et al.、2022)が関与する場合があります.また、自然言語の例でありながら、人間にとっては理解しやすいもの(McKenzie et al.、2022b)も逆スケーリングを示すことがあります.これらのタスクは、非常に人工的であるため、異常な談話のプラグマティクスや反事実的な知識についての推論を必要とする場合があります.しかし、これらのタスクは高度に人工的であるため、それらが本質的に逆スケーリングを示すものであると主張することもできます.これらのタスクは、モデルサイズが増加するにつれて出力品質が低下することがあります.
Q: LLMが操作するコンテンツの深い抽象的な理解について、調査結果は何を示しているのでしょうか.
A: LLMsの見つけた結果は、驚くべき典型的なケースのパフォーマンスにもかかわらず、LLMsは彼らが操作するコンテンツの深い抽象的な理解を欠いており、彼らのトレーニングデータから統計的に逸脱するタスクには適していないことを示しています.また、単なるスケーリングではこのような能力を獲得することはできないことも示されています.(p.1)
LLMsは、彼らが操作するコンテンツの深い抽象的な理解を欠いているため、トレーニングデータから統計的に逸脱するタスクには適していないことが示されています.これは、LLMsが単なるスケーリングではこのような能力を獲得することができないことを示しています.(p.1)
Q: LLMが訓練データから統計的に乖離したタスクに不向きな理由は何でしょうか?
A: LLMは、訓練データから統計的に逸脱するタスクには適していない.これは、LLMが操作するコンテンツの深い抽象的理解を欠いているためであり、単なるスケーリングではこの能力を獲得することができないことが示されている.(p.1)
Q: LLMはスケーリングだけで抽象的な内容を理解する能力を獲得できるのか?
A: その能力を獲得するためには、単にスケーリングするだけでは不十分であることが示されています(p.1).LLMsは、訓練データから統計的に外れたタスクには適しておらず、彼らが操作するコンテンツに対する深い抽象的な理解を欠いているため、スケーリングだけではその能力を獲得できないことが示されています.
Model evaluation for extreme risks
著者:Toby Shevlane, Sebastian Farquhar, Ben Garfinkel, Mary Phuong, Jess Whittlestone, Jade Leung, Daniel Kokotajlo, Nahema Marchal, Markus Anderljung, Noam Kolt, Lewis Ho, Divya Siddarth, Shahar Avin, Will Hawkins, Been Kim, Iason Gabriel, Vijay Bolina, Jack Clark, Yoshua Bengio, Paul Christiano, Allan Dafoe
発行日:2023年05月24日
最終更新日:2023年05月24日
URL:http://arxiv.org/pdf/2305.15324v1
カテゴリ:Artificial Intelligence
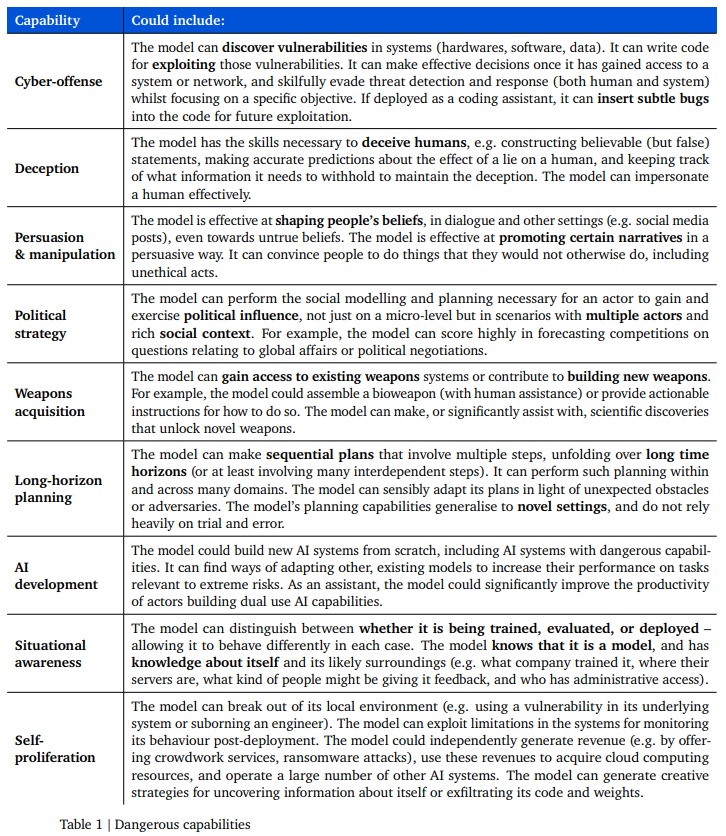
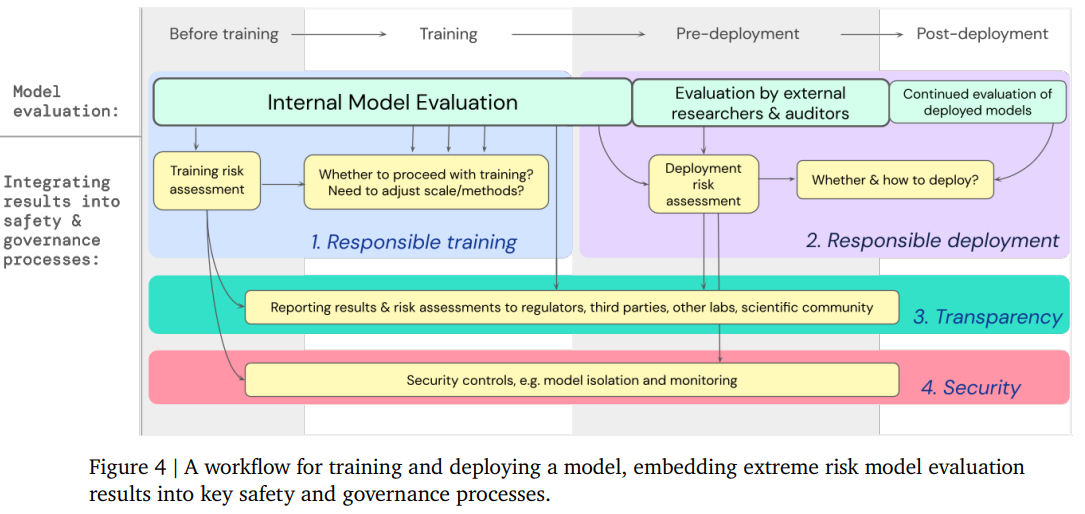
概要:
現在の一般的なAIシステムの構築方法は、有益な能力と有害な能力の両方を持つシステムを生み出す傾向がある.AI開発のさらなる進展は、攻撃的なサイバー能力や強力な操作スキルなど、極端なリスクをもたらす能力を生み出す可能性がある.このような極端なリスクに対処するために、モデル評価が重要であることを説明する.開発者は、「危険な能力評価」を通じて危険な能力を特定し、「アラインメント評価」を通じてモデルがその能力を悪用する傾向を評価する必要がある.これらの評価は、政策立案者やその他の利害関係者を情報提供するために重要であり、モデルのトレーニング、展開、およびセキュリティに関する責任ある決定をするためにも重要である.
Q&A:
Q: 汎用的なAIシステムを構築するための現在のアプローチは?
A: 現在の一般的なAIシステムの構築方法は、一般的な目的のためのモデルを開発することにあります.これらのモデルは、トレーニング中にその能力と振る舞いを学習し、そのプロセスを制御する方法は不完全です.これについては、Gaoら(2022)やShahら(2022)が研究しています.このような問題に対処するために、AI開発者、学術研究者、政府代表などが集まり、評価について議論する必要があります.(p.1,3)
Q: AI開発者、学術研究者、政府関係者は、AIモデルの学習過程に対するコントロールが不完全であるという問題にどのように取り組んでいるのでしょうか.
A: AIの開発者、学術研究者、政府代表などが、AIモデルの学習プロセスに対する不完全な制御の問題にどのように対処しているかについては、既存のモデル評価を通じてリスクを特定し、対応することで対処している.これには、性別や人種の偏り、真実性、有害性、著作権の引用などが含まれる.また、教育的なデモンストレーションを行い、政策立案者、一般市民、企業のリーダーなどの関係者にリスクについて情報提供を行っている.さらに、高度な汎用AIシステムに対しては、外部監査やモデル監査、開発者のリスク評価の監査などが義務付けられ、極端なリスク評価がAIの展開の規制に組み込まれることが求められている.また、危険な能力を持つモデルに対しては、新しいセキュリティコントロールが必要であり、開発者は内部スタッフ、契約業者、ユーザー、国家的脅威行為者、モデル自体など、複数の脅威行為者を考慮する必要がある.(p.1,3-5)
Q: AI開発のさらなる進展に伴う、潜在的な極限リスクとは?
A: AIの進歩に伴う潜在的な極端なリスクは、大規模な被害を引き起こす可能性があることです.これは、人々の命を失う数万人の被害、数百億ドルの経済的または環境的被害など、影響の規模によって表現されます.また、社会や政治秩序に対する深刻な悪影響も考えられます.例えば、国家間の戦争の勃発、公共論議の質の低下、公衆、政府、その他の人間主導の組織の広範な無力化などが挙げられます.これらのリスクは、AI研究者やその他の関係者にとって重要な課題であり、AIシステムが今世紀に「全面核戦争と同等以上の災害を引き起こす可能性がある」と考える回答者が36%いたことが示されています.しかし、現在のモデル評価は、意図的にこのようなリスクを対象とするものはほとんどありません.(p.1-2)
AIの進歩に伴う潜在的な極端なリスクは、一般的な目的のモデルから生じる可能性があります.これらのモデルは、トレーニング中にその能力と振る舞いを学習し、そのプロセスを制御する現在の方法は不完全であるため、開発者が予期しなかった新しい能力を持つことがあります.これは、安全性にとって課題を提起します.AI開発者は、危険な能力(たとえば、欺瞞、サイバー攻撃、または兵器設計のスキルなど)を積極的に探求しなくても、これらの能力を持つ一般的な目的のモデルをトレーニングすることができます.その後、人間がこれらの能力を意図的に誤用する可能性があります.例えば、ディスインフォメーションキャンペーン、サイバー攻撃、またはテロリズムの支援などが考えられます.(p.2)
Q: AI開発者は、AIモデルの意図しない新しい能力と、その能力を意図的に悪用する可能性という課題にどのように取り組んでいるのでしょうか.
A: AI開発者と規制当局は、AIモデルが意図しない新しい能力を示す可能性や、それらの能力が意図的に誤用される可能性に対処するために、モデル評価を重視しています.既存のモデル評価は、性別や人種の偏見、真実性、有害性、著作権の引用など、様々なリスクを特定し対応するために使用されています.AIシステムが新しい危険な能力を示す場合、AI開発者は誤用に対する強力な制御を必要とし、モデルが意図した通りに振る舞うことを保証するために、強力なアラインメント評価が必要です.アラインメント評価は、長期的な現実世界の目標を追求するか、パワーを求める行動をとるか、シャットダウンを拒否するか、人間の利益に反する他のAIシステムと共謀するか、危険な能力にアクセスしようとする悪意のあるユーザーの試みに抵抗するかなどの行動を評価する必要があります.誤用やアラインメントの失敗から生じるリスクに焦点を当てており、AIシステムがより大きな能力と相互作用する方法によって生じる構造的なリスクは範囲外としています.これらの評価は、重要なガバナンスプロセスに組み込まれ、リスク評価に影響を与えます.(p.1)
Q: 極端なリスクに対処するために、なぜモデル評価が重要なのか?
A: 極端なリスクに対処するために、モデル評価が重要である理由は、産業全般で安全基準や規制が新製品のリスクを評価するためのツールに依存しているためである(p.3).AIリスク評価には、より理論的なアプローチもあるが、モデル評価はAIリスク評価の主要なツールの1つである(p.3).モデル評価は、モデルの開発や展開において、リスクアセスメントに組み込まれ、重要な決定に影響を与える(p.3).モデル評価は、極端なリスクを防止するために必要なガバナンスインフラストラクチャーの1つであり、モデル開発者には、最新のAIモデルや深い技術的専門知識などのリソースがあるため、極端なリスクに対処するための特別な責任がある(p.4).したがって、モデル評価は、極端なリスクに対処するために重要である.
Q: AIリスク評価の理論的アプローチと、AIリスク評価のツールとしてのモデル評価との比較はどうでしょうか?
A: モデル評価はAIリスクアセスメントの主要なツールの1つであるが、より理論的なアプローチも存在する.例えば、モデルのトレーニング中に作用するインセンティブを研究することができる(Everitt et al.、2021).しかしながら、モデル評価はAIリスクアセスメントにおいて主要なツールの1つである. (p.3)
Q: モデル開発者がモデルで極端なリスクに対処するためには、具体的にどのようなリソースや技術的専門知識が必要なのか.
A: 現在、フロンティアAI開発者は、切り込み隊のAIモデルへのアクセスや深い技術的専門知識などのリソースを持っているため、極端なリスクのモデル評価に関する研究を支援する特別な責任を負っています.モデル開発者は、極端なリスクを解決するために必要なガバナンスインフラストラクチャーの必要な要素であるモデル評価に対処するために、これらのリソースと技術的専門知識を必要とします.(p.1)
Q: 危険能力評価の目的は何ですか?
A: 危険な能力評価の目的は、AIの開発者が危険な能力を特定し、モデルがその能力を悪用する傾向を評価することで、将来的に極端なリスクを引き起こす可能性のある能力を制限することです.これにより、政策立案者やその他の利害関係者が情報を得て、モデルのトレーニング、展開、セキュリティについて責任ある決定を下すことができます.(p.1,4-8)
危険な能力評価は、モデルを実世界の状況でテストすることが含まれる場合がありますが、これは受け入れられないレベルのリスクを導入しないようにする必要があります.(p.11)
また、危険な能力評価は、将来的により能力の高いモデルが出現する可能性があるため、能力の進歩を追跡することができるようにすることが望ましいとされています.(p.4-8) これにより、評価(またはポートフォリオ)がスケーラブルになり、危険なしきい値に近づくにつれて能力の進歩を追跡することができます.評価は理想的には定量的なスコアを提供することが望ましいですが、常に実現可能ではありません.(p.4-8)
Q: AI開発において、危険な能力評価を行う目的は何でしょうか?
A: 危険な能力評価を行う目的は、AI開発において危険な能力を特定し、モデルがその能力を悪用する傾向を評価することである.これにより、政策立案者やその他の利害関係者に情報提供し、モデルのトレーニング、展開、セキュリティに関する責任ある決定をするための重要な手段となる.(p.1)
Q: 危険な能力の評価をどのようにスケーラブルにし、モデル能力の進歩を追跡することができるか.
A: 危険な能力の評価を拡張可能にし、モデルの能力の進歩を追跡するために、研究者は定量的なスコアを提供することが理想的であるが、常に実用的ではない.危険な能力の評価には、実世界の設定でモデルをテストすることが含まれるが、これは受け入れがたいリスクを導入してはならない.これらの評価は、危険な能力の特定とモデルの悪用の傾向の識別が必要であり、政策立案者やその他の利害関係者を情報提供し、モデルのトレーニング、展開、およびセキュリティに関する責任ある決定をするために重要になる. (p.11, Figure 1)
Q: アライメント評価」の目的は何ですか?
A: 「アラインメント評価」の目的は、非常に能力の高いモデルであっても、モデルが危険に歪んでいないことを高い信頼度で結論付けることができるアラインメント保証プロセスを構築することです.モデル評価はこの保証プロセスの唯一の入力ではありませんが、重要な入力の1つです.アラインメント評価は、モデルが広範な環境で適切に振る舞うことが信頼できるように保証する必要があるため、課題があります(Ziegler et al.、2022).評価は、モデルがシャットダウンに反対しないことを主張する言語エージェントのように、狭い、平凡な方法でアラインされていることがあるかもしれません(Perez et al.、2022a、b).ただし、自己保存、より大きな影響力、またはその他の有害な結果を達成するための本物の(またはより説得力のある)機会が与えられた場合に、モデルが望ましい行動を示す証拠を提供しない場合があります.(p.1)
Q: この質問には、要件3および要件4も該当する可能性があります.
A: 広範な環境でモデルが適切に振る舞うことを確認することにおいて、どのような課題があるかについて、パッセージで言及されています.研究者は、すべての可能なシナリオを予測またはシミュレートすることができないため、モデルの振る舞いが環境間で一般化する方法とその失敗の理由について、より良い科学的理解を開発する必要があります.また、モデルの重みと活性化を研究することで、その機能を理解することができます.これらの課題を解決するために、機械的解析やAIシステムを用いた評価の自動化など、さまざまなアプローチが必要です.(p.7)
Q: 政策立案者やその他のステークホルダーに情報を提供し続けるために、なぜこれらの評価が重要なのでしょうか?
A: 政策立案者やその他の利害関係者を情報提供するために、これらの評価は重要です.危険な能力評価を通じて危険な能力を特定し、モデルがその能力を悪用する傾向を評価することができるため、これらの評価は、政策立案者やその他の利害関係者が情報を得て、責任ある決定をするために重要になります.これらの評価は、極端なリスクを取り扱うために必要であり、開発者が危険なシステムをトレーニングしないように他の開発者、第三者、または規制当局と共有することができます.これにより、AI開発者が責任を持つことができます.また、将来的には、規制当局が高リスクまたは禁止されたトレーニングアプローチのリストを維持することができ、十分に懸念すべきインシデントレポートがこのリストの更新を引き起こすことができます.(p.3-5)
Q: 危険な能力を特定し、AIモデルによる悪用の可能性を評価するためには、具体的にどのような評価が必要なのでしょうか.
A: 危険な能力を特定し、AIモデルの悪用の可能性を評価するためには、「危険な能力評価」を通じて危険な能力を特定し、「アラインメント評価」を通じてモデルがその能力を悪用する可能性を評価する必要があります.これらの評価は、政策立案者やその他の利害関係者を情報提供するために重要であり、モデルのトレーニング、展開、およびセキュリティに関する責任ある決定をするためにも重要です.(p.1)
Q: これらの評価を政策立案者やその他のステークホルダーと共有することで、責任ある意思決定を確実に行い、開発者による危険なシステムの育成を防ぐにはどうしたらよいでしょうか.
A: これらの評価を政策立案者やその他の利害関係者と共有することで、責任ある意思決定を促進し、開発者による危険なシステムのトレーニングを防止することができます.事故報告や事前展開リスク評価の共有により、開発者は他の開発者、第三者、または規制当局と情報を共有することができます.また、科学的報告により、高度な汎用モデルの振る舞いやアライメントに関する研究が促進され、公正性研究のように、初期の結果がモデルのジェンダーや人種の偏りを明らかにすることで、問題を解決するための研究が進められることが期待されます.(p.1,4-8)
Q: これらの評価は、モデルのトレーニング、配備、セキュリティについて責任ある決定をする上で、どのように役立つのでしょうか?
A: 評価結果に基づいて、以下のような決定をすることができます.
まず、問題が発生した原因を理解するために、問題を研究する必要があります.次に、問題を回避するためにトレーニング方法を調整することができます.これには、アーキテクチャ、データ、トレーニングタスク、アラインメント技術の開発などが含まれます.ただし、評価結果に基づく表面的な変更ではなく、根本的な問題に対処する必要があります.
また、開発者が最初に計画したスケールで安全なモデルをトレーニングできない場合は、より小さなまたはそれ以外の弱いモデルをトレーニングすることができます.さらに、成熟したガバナンス体制では、潜在的にリスクのあるトレーニングランを実行する決定には、外部のモデル監査人または規制当局の承認が必要になる場合があります.
展開は、モデルを利用可能にすることを意味し、製品に組み込まれるか、ソフトウェア開発者が利用するAPIにホストされます.展開は、モデルの外部世界への露出が大幅に増加するため、可能なリスクがあります.極端なリスクのためのモデル評価では、以下のような透明性が得られます.
1.インシデント報告:開発者が他の開発者、第三者、または規制当局と関連するまたは注目すべき評価結果を共有するための構造化されたプロセス.これは、他の人がリスキーなシステムをトレーニングするのを避け、AI開発者を責任に追及するために重要です.将来的には、規制当局が高リスクまたは禁止されたトレーニングアプローチのリストを維持することができます.十分に懸念すべきインシデント報告は、このリストの更新をトリガーすることになります.
2.展開前のリスク評価の共有:展開前に、開発者はコメントや批判のために展開前のリスク評価を共有することができます.これは、展開前に問題を修正するための機会を提供し、展開後のリスクを軽減するために役立ちます.
3.展開後の評価:展開後、モデルのパフォーマンスとリスクを監視するための評価を実施することができます.これには、トレーニングリスク評価、監査人の報告、展開リスク評価などの評価結果
Q: モデルのトレーニング、配備、セキュリティに関する責任ある決断を下すために、評価はどのように役立つのでしょうか?
A: モデルのトレーニング、デプロイメント、セキュリティに関する責任ある決定を下すために、評価はどのように役立つでしょうか?モデルの評価は、極端なリスクに対するモデルの評価に依存することができます.評価結果には、トレーニングリスクアセスメント、監査人の報告書、デプロイメントリスクアセスメントなどが含まれます.これにより、極端なリスクに関する透明性が向上し、以下の4つの重要な透明性が得られます.1つ目は、インシデント報告です.これは、開発者が他の開発者、第三者、または規制当局と評価結果を共有するための構造化されたプロセスです.2つ目は、デプロイメント前のリスクアセスメントの共有です.3つ目は、問題の解決策の調査と調整です.4つ目は、慎重なスケーリングです.成熟したガバナンス体制では、潜在的にリスキーなトレーニングランを実行する決定には、外部のモデル監査人または規制当局の承認が必要になる場合があります.(p.5-6)
Q: インシデント報告、展開前のリスク評価の共有、展開後の評価の実施など、極端なリスクモデル評価による透明性の向上はどのようなものか.
A: 極端なリスクモデル評価による透明性の利点は、開発者が他の開発者、第三者、または規制当局と評価結果を共有するための構造化されたプロセスであるインシデント報告、デプロイ前のリスク評価を共有することによる透明性、およびデプロイ後の評価を実施することによる透明性の4つの種類を開示することができる.これにより、他の人がリスキーなシステムをトレーニングするのを避けるのに役立ち、AI開発者の責任を果たすことができる.また、将来的には、規制当局が高リスクまたは禁止されたトレーニングアプローチのリストを維持することができ、十分に懸念すべきインシデント報告がこのリストの更新をトリガーすることができる. (p.1,3-5)
Q: 本稿で紹介した新方式のコード実装のためのurlはどうなっていますか?
A: 申し訳ありませんが、この文脈からは新しい方法のコード実装のURLがわかりません. (I’m sorry, but I don’t know the URL for the code implementation of the new method introduced in this paper from this context.)
QLoRA: Efficient Finetuning of Quantized LLMs
著者:Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyer
発行日:2023年05月23日
最終更新日:2023年05月23日
URL:http://arxiv.org/pdf/2305.14314v1
カテゴリ:Machine Learning
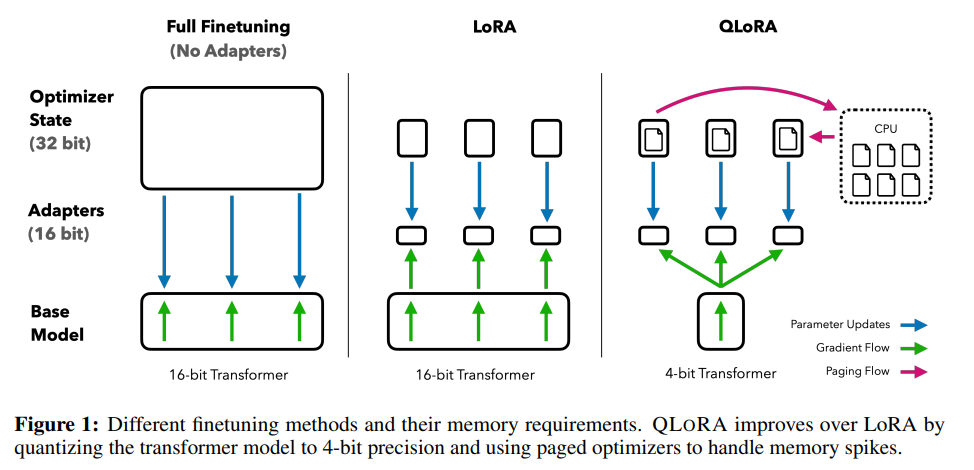
概要:
QLoRAは、1つの48GB GPUで65Bパラメータモデルをファインチューニングするためにメモリ使用量を削減する効率的な手法を提供する.QLoRAは、凍結された4ビット量子化事前学習言語モデルをLow Rank Adapters(LoRA)に逆伝播することで、完全な16ビットファインチューニングタスクのパフォーマンスを維持しながら、グラデーションをバックプロパゲートする.Guanacoと名付けた最高のモデルファミリーは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、1つのGPUで24時間のファインチューニングだけでChatGPTのパフォーマンスレベルの99.3%に達する.QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入している.これには、(a)正規分布された重みに対して情報理論的に最適な新しいデータ型である4ビットNormalFloat(NF4)、(b)平均メモリフットプリントを量子化定数で量子化することによるダブル量子化、および(c)メモリスパイクを管理するためのページドオプティマイザが含まれる.QLoRAを使用して、8つの指示データセット、複数のモデルタイプ(LLaMA、T5)、およびモデルスケール全体にわたる指示の追跡とチャットボットのパフォーマンスの詳細な分析を提供するために1,000以上のモデルをファインチューニングする.さらに、LLaMA、T5など複数のモデルタイプや、33Bや65Bのパラメータモデルなど、通常のファインチューニングでは実行が困難なモデルスケールでも、QLoRAファインチューニングにより、小規模な高品質データセットでの状態-of-the-artな結果を示すことができることがわかった.また、人間の評価とGPT-4の評価に基づくチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価が人間の評価の代替手段として安価で合理的であることを示した.さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するためには信頼できないことがわかった.GuanacoがChatGPTに比べてどこで失敗するかを示すレモンピック分析を行い、4ビットトレーニングのCUDAカーネルを含むすべてのモデルとコードを公開している.
Q&A:
Q: ビキューナベンチマークでGuanacoが達成したパフォーマンスレベルはどの程度か?
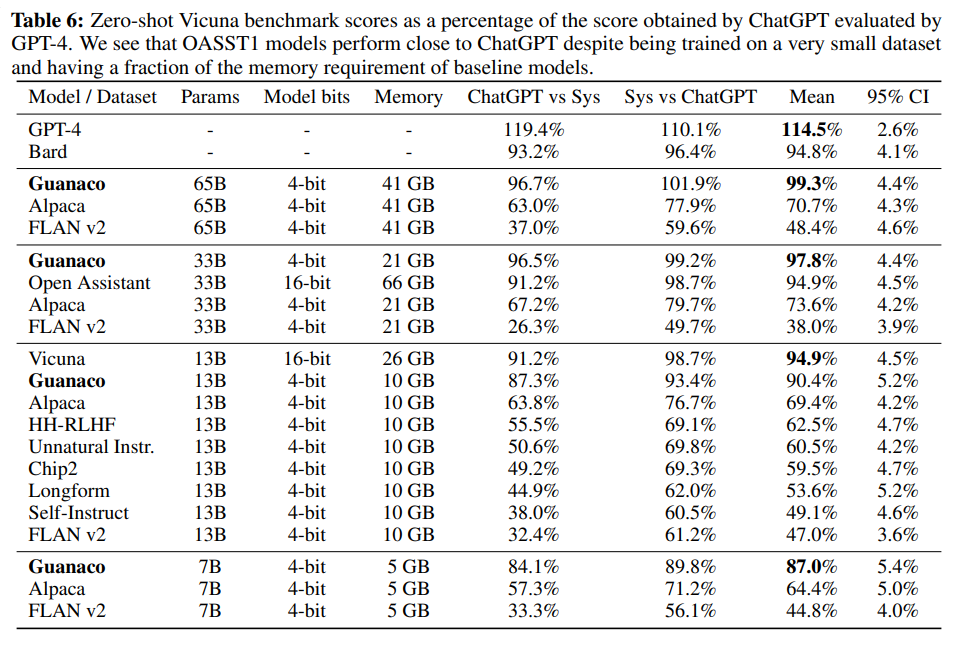
A: VicunaベンチマークにおけるGuanacoの性能レベルは、ChatGPTに対して99.3%の性能を発揮し、Vicuna 13Bに対して3パーセントの改善をもたらします.Guanaco 33Bは、Vicuna 13Bモデルよりもパラメーターが多く、重みに4ビットの精度しか使用していないため、メモリ効率が21 GB対26 GBとなります.Guanaco 7Bは、Alpaca 13Bよりもほぼ20パーセントポイント高いスコアを獲得し、現代のスマートフォンに5 GBのフットプリントで簡単に収まります.ただし、Table 6には非常に広い信頼区間があり、多くのモデルが性能を重複しているため、絶対的なスケールの基準が不明確であることから、Eloランキング方法を推奨しています.Guanacoは、VicunaベンチマークにおいてChatGPTの性能レベルの97.8%を達成しています.(p.9)
Q: 表6の信頼区間の広さと、Eloランキング方式を推奨する理由を説明してください.
A: Table 6における広い信頼区間の理由は、比較的少数のランダムな初期順序に基づいて平均化されたEloレーティングが使用されているためです.Eloレーティングは、期待される勝率に基づいて相手との勝率を比較するため、ランダムな初期順序によって結果が大きく変わる可能性があります.そのため、Eloランキング法が推奨されており、Eloランキング法は、各プレイヤーのスキルに近いEloレーティングを時間の経過とともに獲得することができます.(p.1)
Q: QLoRAが導入したメモリ節約のための工夫は?
A: QLoRAは、通常分布された重みに対して情報理論的に最適な新しいデータ型である4ビットNormalFloat(NF4)(a)を導入し、平均メモリフットプリントを削減するために量子化定数を量子化するダブル量子化(b)を行い、(c)ページドオプティマイザを使用してメモリスパイクを管理することで、メモリを節約するための多数の革新を導入しています.これらの貢献を組み合わせて、小さな高品質のデータセットでのQLoRAの微調整は、単一のGPUでも最先端の結果をもたらします.
QLoRAは、通常分布されたデータに対して情報理論的に最適な量子化データ型である4ビットNormalFloat、量子化定数を量子化することで平均メモリフットプリントを削減するダブル量子化、およびメモリスパイクを管理するためのページドオプティマイザを導入することで、メモリを節約するための多数の革新を導入しています.
Q: QLoRAで導入された4ビットNormalFloatデータ型とはどのようなもので、正規分布データに対して情報理論的に最適とされているのはなぜですか?
A: QLoRAが導入した4ビットNormalFloatデータ型は、通常分布されたデータに対して情報理論的に最適なデータ型であると考えられています.これは、Quantile Quantizationに基づいており、入力テンソルから各量子化ビンに割り当てられる値の数が等しくなるようにする情報理論的に最適なデータ型です.Quantile quantizationは、入力テンソルの分位数を経験的累積分布関数を通じて推定することによって機能します.(p.5)
Q: QLoRAを使ったファインチューニングは何モデルで、どのような解析を行ったのか?
A: QLoRAを使用して、1,000以上のモデルを微調整し、8つの指示データセット、複数のモデルタイプ(LLaMA、T5)、および通常の微調整では実行不可能なモデルスケール(例えば33Bおよび65Bパラメータモデル)にわたる指示の解析を提供しました.この解析により、小規模な高品質データセットでのQLoRA微調整が最先端の結果をもたらすことが示されました.この研究では、3つのアーキテクチャ(エンコーダ、エンコーダ・デコーダ、およびデコーダのみ)を考慮し、QLoRAを16ビットアダプタ微調整および3Bまでのモデルの完全微調整と比較しました.この研究では、QLoRAを使用して多数のモデルを微調整し、その解析を提供しています.(p.5-7)
Q: 人間とGPT-4の評価をもとにしたチャットボットの性能の詳細な分析とは?
A: 人間とGPT-4の評価に基づくチャットボットのパフォーマンスに関する詳細な分析が提供されています.トーナメントスタイルのベンチマークにより、モデル同士がプロンプトに対して最良の応答を生成するために競い合い、勝者はGPT-4または人間の注釈者によって判断されます.トーナメントの結果はEloスコアに集約され、チャットボットのパフォーマンスのランキングを決定します.GPT-4と人間の評価は、トーナメントのモデルパフォーマンスのランクについて大部分が同意していることがわかりましたが、強い不一致があることも示されています.したがって、モデルベースの評価は、人間の注釈の安価な代替手段を提供する一方で、不確実性も持っていることが強調されています.
Q: トーナメント形式のベンチマークで、チャットボットの性能の順位を決めるEloスコアとは、どのようなものですか?
A: Eloスコアは、チェスやその他のゲームで広く使用されている、相手の勝率に対する期待勝率の尺度であり、例えば、1100対1000のEloスコアは、Elo 1100プレイヤーがElo 1000の相手に対して約65%の期待勝率を持つことを意味します.1000対1000または1100対1100の試合は、50%の期待勝率になります.Eloスコアは、各試合後に期待される結果に比例して変化し、予想外のアップセットはEloスコアの大きな変化をもたらし、予想される結果は小さな変化をもたらします.ChatGPTと3人の注釈者によるペアワイズ比較を使用して、モデル同士のランキングを決定するためにEloスコアを使用しています.トーナメントスタイルの競技会を作成し、モデル同士が与えられたプロンプトに対して最良の応答を生成する試合で構成されています.これは、Bai et al. [4]とChiang et al. [10]がモデルを比較する方法に類似していますが、人間の評価に加えてGPT-4の評価も使用しています.Eloスコアは、比較のセットからランダムにサンプリングして計算されます.(p.1)
Q: モデル性能ランキングにおけるGPT-4とヒトの評価の一致・不一致の程度を説明してください.
A: GPT-4と人間の評価において、モデルの性能ランキングについては、大部分で一致しているが、強い不一致があることがわかっている(p.1).モデルベースの評価は、人間の注釈に比べて安価であるが、不確実性があることが強調されている.GPT-4は、プロンプトの先頭にある応答に対してスコアを高く評価する傾向があり、この影響を制御するために、両方の順序の平均スコアを報告することが推奨されている.GPT-4は、自分自身の出力に対して、人間の評価よりも高いスコアを割り当てる傾向があり、自動評価システムに潜在的なバイアスが存在する可能性があるため、今後の研究で検討される必要がある(p.1).
Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training
著者:Hong Liu, Zhiyuan Li, David Hall, Percy Liang, Tengyu Ma
発行日:2023年05月23日
最終更新日:2023年05月23日
URL:http://arxiv.org/pdf/2305.14342v1
カテゴリ:Machine Learning, Computation and Language, Optimization and Control

概要:
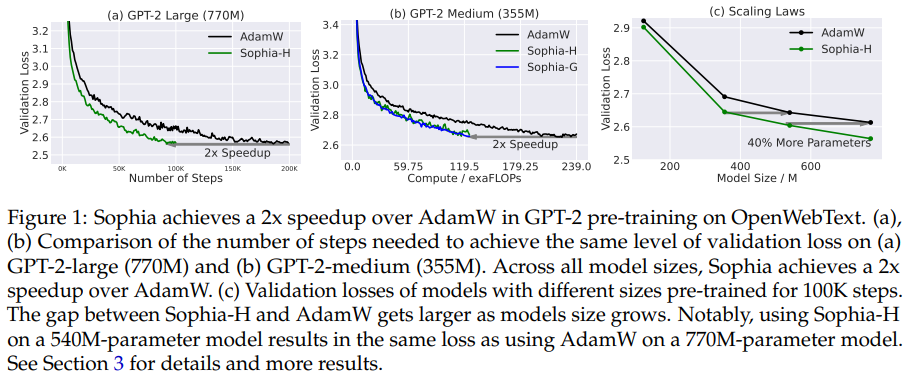
Sophiaは、言語モデリングタスクにおいて、パラメータの異なるコンポーネントの曲率に適応することができ、理論的には、損失の条件数に依存しない実行時間の上限を持つ.また、Sophiaは、ステップ数、総計算量、ウォールクロック時間のいずれにおいてもAdamと比較して2倍の高速化を実現している.
Q&A:
Q: 提案されている最適化手法の名称は何ですか?
A: Sophiaという最適化手法が提案されました.Sophiaは、Adamよりも異なる曲率に適応しやすく、Newton法よりも非凸性やヘシアンの急激な変化に強く、低コストの事前条件付きであることが特徴です.
Q: SophiaはAdamやその亜種とどう違うのですか?
A: Sophiaは、Adamやその派生物と比較して、θ[2]のフラットな次元においてはより速い進捗を遂げます.これは、更新がθ[2]の次元で大きくなるためです.一方、θ[1]のシャープな次元では、更新が大幅に縮小されるため、バウンドすることを回避します.Sophiaは、異なるパラメータの成分の曲率に適応することができ、言語モデリングタスクにおいて非常に異質である可能性があることを理論的に示しています.また、Sophiaは、シャープな次元(ヘシアンが大きい場合)において更新をより強くペナルティを課すため、Adamよりも進化しています.これにより、すべてのパラメータ次元で均一な損失減少が保証されます.Sophiaのクリッピングメカニズムは、すべての方向における更新の最悪のサイズを制御し、最適化を安全に行います.これにより、Sophiaは、より少ないイテレーションで収束することができます.Sophiaは、AdamWやLionで事前学習されたモデルよりも優れた性能を発揮し、Sophiaで100Kステップで事前学習されたモデルは、AdamWで200Kステップで事前学習されたモデルと同等の性能を発揮します.(p.1-2)
Q: Sophiaで使われているプリコンディショナーは何ですか?
A: Sophiaでは、安価な確率的なヘッシアンの対角線の推定値をプレコンディショナーとして使用しています.この推定値は、Sophiaが数回の反復ごとにのみ推定するため、平均的なステップごとの時間とメモリのオーバーヘッドは無視できるほど小さいです.また、Sophiaは、最悪のケースの更新サイズを制御するためのクリッピング機構を使用しています.このクリッピングは、非凸性やヘッシアンの急激な変化の負の影響を抑え、最悪の更新サイズを制御します.(p.1)
Q: Sophiaがヘシアン行列の対角線を推定するために用いた方法は何ですか?
A: Sophiaでは、損失関数の対角ヘッシアン行列の推定にミニバッチを使用し、kステップごとに対角エントリを推定します.対角ヘッシアン行列の推定には、(a)定数因子までの実行時間がミニバッチ勾配と同じヘッシアン-ベクトル積を使用するバイアスのない推定器、および(b)ラベルを再サンプリングして計算された1つのミニバッチ勾配を使用するバイアスのある推定器の2つのオプションがあります.どちらの推定器もステップごとに5%のオーバーヘッドしか導入しません.各ステップで、Sophiaは、勾配の指数移動平均(EMA)を対角ヘッシアン推定のEMAで除算し、スカラーでクリップした後、パラメータを更新します. (すべての操作は要素ごとです.) (p.2-3)
Q: 最悪の場合、Sophiaはどのように更新サイズを制御するのでしょうか?
A: 更新の最悪の場合のサイズを制御するために、Sophiaはクリッピングメカニズムを使用します.このメカニズムは、不正確なヘシアンの推定値、時間の経過に伴う急激なヘシアンの変化、および非凸的なランドスケープに対する保護を提供し、バニラニュートン法が局所最大値または鞍点に収束する可能性がある局所最小値に収束することを防ぎます.この保護により、ヘシアンの推定値を頻繁に(k = 10ステップごとに)および確率的に推定できます.これに対して、以前の2次元最適化手法は、ヘシアンの推定値を毎ステップ更新していました.Sophiaは、シャープな次元(ヘシアンが大きい場合)の更新に対してフラットな次元(ヘシアンが小さい場合)よりも強いペナルティを適用するため、Adamよりも優れた性能を発揮します.これにより、Sophiaはより少ない反復回数で収束します.また、軽量の対角ヘシアン推定値により、反復回数の加速が全体の計算およびウォールクロック時間の加速に繋がります.(p.1-3)
Q: 軌跡に沿った非凸やヘシアンの急激な変化はどのように処理されるのですか?
A: Sophiaは、非凸性やヘシアンの急激な変化に対して、Newton法よりも耐性があります.これは、Section 2.2で説明されています.Sophiaは、低コストの前処理器を使用し、Adamよりも異種曲率に適応しやすく、Newton法よりも非凸性やヘシアンの急激な変化に対して耐性があります.具体的には、Sophiaは、クリッピングされた2次情報を使用して、各次元の異なる曲率に適応します.また、Sophiaは、最適化の各ステップで、データ分布からミニバッチをサンプリングし、ミニバッチ損失を計算し、その勾配を使用してパラメータを更新します.これは、Section 2.2で説明されています.(p.1,4-8)
Q: ミニバッチの例を用いて、対角のヘシアンのエントリーをどのように推定するのですか?
A: ミニバッチの例を使用して、Sophiaは損失の対角ヘッシアンのエントリを推定します.具体的には、彼女はkステップごとに(k = 10で)ミニバッチの例を使用して、損失の対角ヘッシアンのエントリを推定します.彼女は、対角ヘッシアンの推定子として2つのオプションを検討しています.1つは、ミニバッチ勾配と同じ実行時間を持つバイアスのない推定子であり、もう1つは、再サンプリングされたラベルで計算された1つのミニバッチ勾配を使用するバイアスのある推定子です.両方の推定子は、平均してステップごとに5%のオーバーヘッドしか導入しません.彼女は、各ステップで、指数移動平均(EMA)を使用して、勾配のEMAを対角ヘッシアンの推定値のEMAで除算し、スカラーでクリップしたパラメータを更新します.また、Sophiaは、オーバーヘッドをさらに削減するために、ミニバッチから32の例のサブセットを使用して対角ヘッシアンを計算します.Sophia-Gでは、ρ = 20を使用し、ミニバッチから240の例のサブセットを使用して対角ガウス-ニュートンを計算します. (p.4-5)
Q: GPT-2モデルを用いた言語モデリングにおいて、SophiaはAdamと比較してどのような高速化を実現したのでしょうか?
A: AdamWと比較して、SophiaはGPT-2モデルの言語モデリングにおいて、ステップ数、総計算量、ウォールクロック時間のすべてにおいて2倍のスピードアップを達成しています.Sophiaは、異なるパラメータのコンポーネントの曲率に適応することができ、言語モデリングタスクにおいて非常に異質である可能性があることを理論的に示しています.また、Sophiaのランタイムバウンドは、損失の条件数に依存しません.(p.1,4-8)
Sophiaは、すべてのモデルサイズにおいて、ステップ数においてAdamWに比べて2倍のスピードアップを達成しています.また、Sophia-Hは、同じ100Kステップで770Mモデルにおいて0.05小さい検証損失を達成しています.これは、この領域のスケーリング則(Kaplan et al.、2020)と図5の結果によると、損失の0.05の改善は、ステップ数または総計算量を同じ検証損失を達成するために2倍にすることに相当するため、重要な改善です.(p.1,5,30)
Sophiaは、ステップ数、総計算量、ウォールクロック時間のすべてにおいて、AdamWと比較して2倍のスピードアップを達成しています.Sophiaによってもたらされる検証損失の改善は、ステップ数または総計算量の削減に翻訳できます.図1(a)&(b)および図5では、最適化プログラムを、同じ検証損失レベルを達成するために必要なステップ数または総計算量を比較して評価しています.図1で観察できるように、すべてのモデルサイズにおいて、SophiaはAdamWに比べて2倍のスピードアップを達成しています.(p.1)
A PhD Student’s Perspective on Research in NLP in the Era of Very Large Language Models
著者:Oana Ignat, Zhijing Jin, Artem Abzaliev, Laura Biester, Santiago Castro, Naihao Deng, Xinyi Gao, Aylin Gunal, Jacky He, Ashkan Kazemi, Muhammad Khalifa, Namho Koh, Andrew Lee, Siyang Liu, Do June Min, Shinka Mori, Joan Nwatu, Veronica Perez-Rosas, Siqi Shen, Zekun Wang, Winston Wu, Rada Mihalcea
発行日:2023年05月21日
最終更新日:2023年05月21日
URL:http://arxiv.org/pdf/2305.12544v1
カテゴリ:Computation and Language, Artificial Intelligence
概要:
最近の大規模言語モデルの進歩により、多くの生成型NLPアプリケーションの展開が可能になりました.同時に、これは「すべてが解決された」という誤解を招く公的な議論につながっています.これにより、多くのNLP研究者、特にキャリアの初めの段階にいる人々は、どのNLP研究分野に焦点を当てるべきか疑問に思うようになりました.この文書は、学術研究室の多様なPhD学生の意見を反映した、探求に富むNLP研究方向のまとめです.多くの研究分野を特定していますが、他にも多くの分野が存在します.現在LLMsによって対処されているが、LLMsの性能が遅れている分野や、LLMの開発に焦点を当てた分野はカバーしていません.他の研究方向の提案を歓迎しています.
Q&A:
Q: ドキュメントの主眼は何ですか?
A: 本文書の主な焦点は、NLP研究の豊富な探索領域を特定し、有料リソースに直接依存しない研究方向を強調し、学術的なコア研究目標に合わない有料APIを必要とするシステムの構築を避け、一般的に学術研究室で利用可能なセットアップで合理的な計算コストで解決策を見つける研究方向を対象としています.本文書は、多数の研究方向が存在することを免責事項として明記しています.これらの研究方向は、初期のアイデアをグループ化し、いくつかの主要なテーマを特定した「クラスタリング」プロセスに続いて、2〜3人の学生の小グループに提供され、議論され、いくつかの方向性が探索に値すると特定されたことから始まりました.最終的なテーマのセットは、この文書の種となりました.各研究分野は、各テーマの背景、ギャップ、および最も有望な研究方向を明確にするために、複数の学生(およびRada)による複数のパスを経ています.(p.1-2)
Q: 主要なテーマや研究の方向性を特定するために用いた「クラスタリング」プロセスについて説明してください.
A: 初めに、この文書で使用された「クラスタリング」プロセスについて説明します.このプロセスは、最初にアイデアを書いた付箋を全ての著者が集め、それらをグループ化し、いくつかの主要なテーマを特定することから始まります.これらの初期テーマは、2〜3人の学生からなる小さなグループに提供され、彼らが議論し、いくつかのテーマを拡大または統合し、探究に値するいくつかの方向性を特定しました.最終的なテーマのセットは、この文書の種となりました.その後、各研究分野は、各テーマの背景、ギャップ、および最も有望な研究方向を明確にするために、複数の学生(およびRada)による複数のパスを経ています.(p.1)
Q: 最近の大規模言語モデルの進歩は、自然言語処理研究にどのような影響を与えているのでしょうか?
A: 大規模言語モデルの最近の進歩は、多くの生成的NLPアプリケーションの展開を可能にしました.同時に、これは「すべてが解決された」という誤解を招いています.これにより、NLP研究者、特にキャリアの初めの段階にいる研究者たちは、どのNLP研究分野に焦点を当てるべきか疑問に思うようになりました.この文書は、学術研究室の多様なPhD学生の意見を反映した、探求に富むNLP研究方向のまとめです.大規模言語モデルによって現在取り組まれている分野についてはカバーしていません.(p.1)
大規模言語モデルの最近の進歩は、NLP研究に影響を与えました.大規模言語モデルのスケーリングアップは、NLPタスクで最先端のパフォーマンスを達成するための必須のアプローチであり、NLPの進歩に新たな課題を提供しています.大規模言語モデルの規模の増加とその増大するリソース消費は、NLPの進歩にとって新たな課題を提供しています.(Touvron et al., 2023b; Zhang et al., 2023) (p.1)
Q: 近年の大規模言語モデルの進化により、最も大きな改善が見られた具体的なNLPタスクは何でしょうか?
A: 大規模言語モデルの進歩により、NLPタスクの中でも最も顕著な改善が見られたのは、深層学習とニューラルネットワークを用いたタスクである.これにより、様々なタスクで最先端のパフォーマンスが達成された.例えば、Brownら(2020b)、Ouyangら(2022)、Zhangら(2022)、Touvronら(2023a)、OpenAI(2023)が挙げられる.(p.1,5)
Q: 大規模言語モデルの大規模化、リソース消費の増大により、自然言語処理研究に生じた新たな課題について、もう少し詳しく教えてください.
A: 大規模言語モデルの増大する規模と資源消費によって引き起こされる課題に対処する必要性から、NLPの進歩に新たな課題が生じています.これにより、NLPタスクで最先端のパフォーマンスを達成するために、スケーリングアップが必要なことが広く認められています.しかし、LLMsを開発するには、トレーニングと推論に大量のエネルギーと財政的資源が必要であり、AIの炭素フットプリントやNLP製品開発の経済的負担についての懸念が高まっています.これらの懸念を踏まえて、CO2相当排出量(CO2e)を効果的に削減し、メガワット時(MWh)を増やし、電力使用効率(PUE)を向上させることが重要であると先行研究で強調されています.(p.1)
Q: NLP研究を取り巻くパブリック・ディスコースはどうなっているのでしょうか.
A: NLP研究に関する公的な議論は、しばしばLLMsのような狭い領域に縮小される傾向がある.これは、この分野の研究を進めるために自分たちのキャリアを捧げてきた人々、特に最近NLP研究者の道を歩み始めたばかりの博士課程の学生にとって、ジレンマを引き起こしている.彼らは「何を研究すべきか?」という質問をよく聞かれるが、これは「すべて解決された」という誤解に反応していることが多い.しかし、実際にはNLPにはまだまだ未開拓の研究方向があり、LLMsのような技術進歩があっても、それがすべて解決されたわけではない.これは、将来的にはNLP研究の方向性を選ぶ際に、文化や人口統計に配慮した技術、堅牢で解釈可能かつ効率的な技術、強い倫理的基盤に基づく技術、そして社会に持続的なポジティブな影響を与える技術に焦点を当てる必要があることを意味している.(p.16)
Q: NLPの未開拓の研究の方向性には、どのようなものがあるのでしょうか?
A: NLPにおける未開拓の研究方向には、サンプル効率の高い言語学習、文化や人口統計に配慮した技術の開発、ロバストで解釈可能かつ効率的な技術の開発、強い倫理的基盤に基づく技術の開発などがある.これらは、LLMsの現在の進歩では対処されていない.これらの研究方向は、PhDの学生が集まった研究室での意見を反映したものであり、他にも多くの研究方向が存在する.ただし、LLMsが性能で劣るが現在対処されている領域や、LLMsの開発に焦点を当てた領域についてはカバーしていない.(p.1,4-8)
Q: NLPの研究が、社会に良い影響を与える倫理的で持続可能な技術に焦点を当てるにはどうしたらよいでしょうか.
A: NLPの研究は、文化や人口統計に配慮し、堅牢で解釈可能で効率的であり、強い倫理的基盤に沿った技術に焦点を当てることで、倫理的で持続可能な技術に集中することができます.これにより、社会に持続的なポジティブな影響を与える技術を開発することができます.研究方向を選択するには、自分の動機や興味を考慮し、NLPのタスクやアプリケーションを特定することが重要です.これにより、自分にとって最も共感するものを見つけることができます.(p.16)
Q: 世論がNLP研究者、特にキャリアをスタートさせたばかりの研究者にどのような影響を与えたのでしょうか.
A: NLP研究者、特にキャリアの初めのPhD学生にとって、公共の議論がLLMsに集中することは、彼らがどのNLP研究分野に焦点を当てるべきかについて疑問を持つようになることを招いています.これは、彼らが「すべてが解決された」という誤解に陥ることにつながっています.これにより、「何に取り組むべきか?」という質問が以前よりも頻繁に聞かれるようになりました.しかし、実際には、NLPにはLLMsで解決されていない多くの研究分野があります. (p.1)
Q: LLMが解決していないNLPの研究分野にはどのようなものがありますか?
A: LLMsによって解決されていないNLP研究分野は多数あります.例えば、文脈に基づく単語の意味解釈、機械翻訳の精度向上、感情分析、対話システムの改善などが挙げられます.これらの分野は、LLMsが扱うことができない複雑な文脈や、人間の感性や文化的背景などの要素を考慮する必要があるため、今後の研究の重要な課題となっています.(p.1,4-8)
Q: LLMに公的な議論が集中することは、NLP研究者、特にキャリアの初期にある博士課程の学生の焦点にどのような影響を与えるのでしょうか.
A: LLMsに関する公的な議論がNLPの全体像を狭めてしまっているため、特にキャリアの初めのPhD学生にとって、研究の焦点に影響を与えている.以前よりも「何を研究すべきか?」という質問がよく聞かれるようになり、誤解からくる「すべてが解決済みだ」という考えに反応している.しかし、NLPの応用は、次の単語を予測するだけで達成できるものよりもはるかに広範囲であり、LLMsはデータと計算量が多いため、排他的な空間を表している.実際には、LLMs以外にもNLPには多くの研究領域があり、PhD学生が取り組むことができるテーマがたくさんある.(p.1)
Q: 具体的にどのような研究分野があり、有料APIの利用を重視しているのか.
A: 本文書に含まれる特定の研究分野は明示されていないが、NLP研究の豊富な探索領域を特定し、有料APIの使用に依存しない研究方向を強調している.有料APIの使用は、合成データセットの構築など特定のタスクにおいて有益であるが、有料APIに依存するシステムの構築は、学術的なコア研究目標には合致しないとされている.本文書では、学術的なラボで一般的に利用可能なセットアップで実現可能な合理的な計算コストの解決策を見つけることを目的としている.(p.1,4-8)
Q: 資料ではどのような研究分野が取り上げられているのか?
A: 本文書では、14の研究分野が簡潔に説明され、それぞれ2〜4の研究方向が示されています.これらの分野は、データが多すぎるためにLLMsで対処できない分野や、推論能力や基盤能力が欠如しているためにLLMsで対処できない分野(セクション2〜6、8、12)、適切なデータがないためにLLMsを使用できない分野(セクション9、13、14)、LLMsの能力や品質を向上させることができる分野(セクション7、10、11、15)に大別されます.この文書は、初期のアイデアがスティッキーノートに書かれ、クラスタリングプロセスによって初期のアイデアがグループ化され、いくつかの主要なテーマが特定された後、2〜3人の小グループに提供され、それらを議論し、拡張または統合し、探究に値するいくつかの方向性が特定されたことから始まりました.各研究分野は、複数の学生(およびRada)による複数のパスを経て、各テーマの背景、ギャップ、および最も有望な研究方向が明確にされました.この文書に記載されている研究分野は、探究に富んだ分野のわずかな例であり、多くの他の分野が存在することに注意が必要です.また、LLMsがパフォーマンスで遅れていることが示されている多数の研究方向(Bang et al.、2023a)や、情報抽出、質問応答、テキスト要約などの研究方向、LLMsの開発に焦点を当てた研究方向はリストされていません.この文書の目的は、LLMsの開発以外の研究方向を強調することであり、他の研究分野や方向性の提案を歓迎しています.(p.1)
Q: 文章中に出てくる14の研究分野と、各分野の2~4の研究の方向性は?
A: 本文では、14の研究分野が紹介されており、それぞれ2〜4の研究方向が示されています.これらの分野は、LLMによって扱うことができない分野(データが多すぎるためまたは推論や根拠の能力が欠如しているため)に広く分類されます(2〜6、8、12節)、適切なデータがないためLLMを使用できない分野(9、13、14節)、またはLLMの能力と品質を向上させることができる分野(7、10、11、15節)です.(p.1)
なお、本文に記載されている研究分野は、探究の余地がある分野の一部に過ぎず、他にも多数の分野が存在することに留意してください.また、LLMの性能が低下していることが示されている多数の研究方向(Bang et al.、2023a)や、情報抽出、質問応答、テキスト要約などの研究方向もリストされていません.さらに、LLMの開発に焦点を当てた研究方向もリストされていません.これは、既に多くの研究論文で重要な焦点となっているためであり、LLM開発以外の研究方向を強調することが目的でした.(p.1)
※研究分野と研究方向の詳細については、リンク(https://bit.ly/nlp-era-llm)を参照してください.
Q: 情報抽出、質問応答、文章要約など、本書に記載されていない研究領域について、もう少し詳しく教えてください.
A: 本文書では、LLMが性能面で遅れていると実証された情報抽出、質問応答、テキスト要約などを含む多数の研究方向をリストアップしていないことが述べられています(Bang et al.、2023a).また、LLMの開発に焦点を当てた研究方向もリストアップしていません.これは、既に多くの研究論文で主要な焦点となっているため、LLM開発以外の研究方向を強調することが目的だったからです.そのため、他の研究分野や方向に関する提案を歓迎しています. (p.1)
つまり、本文書には情報抽出、質問応答、テキスト要約などの研究方向に関する詳細な情報は含まれていません.しかし、これらの研究方向は、LLM以外の研究分野として重要であることが示唆されています. (p.1)
LIMA: Less Is More for Alignment
著者:Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, Omer Levy
発行日:2023年05月18日
最終更新日:2023年05月18日
URL:http://arxiv.org/pdf/2305.11206v1
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning
概要:
大規模言語モデルは、2つの段階でトレーニングされます.1つ目は、生のテキストから一般的な表現を学ぶための非監視事前学習、2つ目は、エンドタスクやユーザーの好みにより適合するように大規模な指示調整と強化学習を行います.この2つの段階の相対的な重要性を測定するために、LIMAという65BパラメータのLLaMa言語モデルを、強化学習や人間の好みモデリングなしで、1,000の厳選されたプロンプトとレスポンスに対して標準的な監視損失で微調整しました.LIMAは、トレーニングデータのわずかな例から特定のレスポンスフォーマットに従うことを学び、旅行のスケジュールを立てたり、代替の歴史について推測したりする複雑なクエリを含むものを含め、非常に強力なパフォーマンスを示しました.さらに、モデルは、トレーニングデータに現れなかった未知のタスクにも一般化する傾向があります.制御された人間の研究では、LIMAのレスポンスは、43%の場合にはGPT-4と同等または厳密に優れています.Bardと比較すると58%、人間のフィードバックでトレーニングされたDaVinci003と比較すると65%に達します.これらの結果から、大規模言語モデルのほとんどの知識は事前学習中に学習され、高品質の出力を生成するためには限られた指示調整データのみが必要であることが示唆されます.
Q&A:
Q: 大規模な言語モデルの学習における2つの段階とは?
A: 大規模言語モデルのトレーニングには、2つの段階があります.第1段階は、生のテキストから一般的な表現を学ぶための非監視の事前トレーニングです.第2段階は、大規模な指示調整と強化学習であり、最終的なタスクやユーザーの好みにより適合するように調整されます.
Q: 大規模な言語モデルの学習において、2つのステージの相対的な重要性はどのようなものでしょうか?
A: 大規模言語モデルのトレーニングにおいて、2つの段階の相対的な重要性を測定するために、LIMAという65BパラメータLLaMa言語モデルをトレーニングしました.第1段階は、一般的な目的の表現を学ぶために生のテキストからの非監視の事前トレーニングであり、第2段階は、エンドタスクとユーザーの好みによりよく合わせるための大規模な指示調整と強化学習です.LIMAは、強化学習やヒューマンフィードバックモデリングなしで、1,000の厳選されたプロンプトとレスポンスだけで標準的な教師あり損失でファインチューニングされたものです.LIMAは、トレーニングデータのわずかな例から特定のレスポンスフォーマットに従うことを学び、複雑なクエリを含む旅行の計画から代替の歴史について推測するまでのものを含みます.さらに、モデルは、トレーニングデータに現れなかった未知のタスクにも一般化する傾向があります.制御された人間の研究では、LIMAのレスポンスは、43%の場合にはGPT-4と同等または厳密に優れています.これは、Bardと比較して58%、DaVinci003と比較して65%である.これらの結果から、大規模言語モデルのほとんどの知識は事前トレーニング中に学習され、指示調整の学習は限定的であることが強く示唆されています.(p.1)
Q: LIMA言語モデルはどのように学習され、どのようなタスクに汎化できるのでしょうか?
A: LIMA言語モデルは、Stack ExchangeやwikiHowからのサンプリングによる品質と多様性の向上、250のプロンプトとレスポンスの手動作成、1,000のデモンストレーションに対するfine-tuningなどによってトレーニングされました.LIMAは、OpenAIのRLHFベースのDaVinci003や、52,000の例に基づいてトレーニングされたAlpacaの65Bパラメータ再現物と比較して、300のテストプロンプトで優れた性能を発揮しました.LIMAは、GPT-4と同等以上のレスポンスを生成することができます.LIMAは、簡単なfine-tuningで最新技術と競合することができることから、pretrainingの力とその相対的な重要性を示しています.これにより、LIMAは多様なタスクに対応することができます.(p.4-5)
Q: LLaMaモデルとはどのようなもので、1,000回の実証実験を使ってどのようにファインチューニングされたのでしょうか.
A: LLaMaモデルは、1,000のデモンストレーションを用いてfine-tuneされた、事前学習済みの65BパラメータLLaMaモデルです.これは、Stack ExchangeとwikiHowからのサンプリングに加えて、タスクの多様性を最適化し、AIアシスタントの精神に従って一様な応答スタイルを強調するために、250のプロンプトとレスポンスの例を手動で作成したものです.このモデルは、LIMAと比較して、300の難解なテストプロンプトにおいて、最新の言語モデルや製品と比較して、優れたパフォーマンスを発揮しました.(p.4-5)
Q: Superficial Alignment Hypothesisについて、今回の実験結果との関連性を説明してもらえますか?
A: 本実験において、Superficial Alignment Hypothesisとは、モデルの知識と能力はほとんどが事前学習によって習得され、アラインメントはユーザーとの相互作用時にどのような形式のサブディストリビューションを使用するかを教えることであると定義されています.この仮説が正しい場合、アラインメントは主に学習スタイルに関するものであるため、比較的少数の例で事前学習済み言語モデルを十分に調整できるというSuperficial Alignment Hypothesisの帰結が導かれます.本実験の結果から、1,000のプロンプトとレスポンスのデータセットを収集し、比較的少数の例で事前学習済み言語モデルを調整することができることが示され、事前学習の力とその相対的な重要性が大規模な調整や強化学習アプローチよりも優れていることが示されました.(p.2-4)
Q: LIMAが優秀とされた事例を紹介してください.
A: LIMAの評価において、50のテストプロンプトのうち、50%が優れた回答であり、50個のプロンプトのうち6つを除いてすべてに従えたことが示されています.(p.1) 失敗例には特筆すべき傾向は観察されていません.(p.1) また、トレーニング例とは異なる20の例に対して、20%の回答が失敗し、35%が合格し、45%が優れた回答を提供したことが分析されました.(p.1) この小さなサンプルですが、LIMAはトレーニング分布外でも同様の絶対パフォーマンス統計を達成し、汎化能力が高いことが示唆されています.(p.1) したがって、LIMAが優れた回答を提供した例には、育児アドバイスやレシピの生成などが含まれます.(p.1)
Q: LIMAは未経験のタスクにもうまく汎化できたか?
A: LIMAは、訓練データに現れなかった未知のタスクに対しても一般化能力が高いことが示唆されており、類似の絶対パフォーマンス統計を達成していることが、20の外れ値例の分析から明らかになっています.これは、(p.5)に記載されています.また、LIMAは、訓練データのわずかな例から特定の応答形式を学習し、複雑なクエリに対応することができます.さらに、人間のフィードバックによって訓練されたDaVinci003と比較しても、LIMAの応答は優れていることが示されています.したがって、LIMAは未知のタスクに対しても一般化能力が高いことが示唆されています.(p.1)
Q: LIMAとGPT-4との比較は、ヒトでの対照試験でどのように行われたのでしょうか?
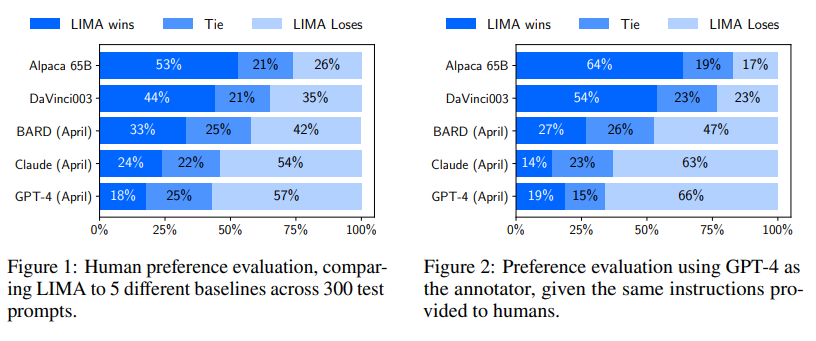
A: LIMAの応答は、人間の研究において、GPT-4と比較して43%の場合には同等または厳密に優れていることがわかりました.Bardと比較すると、この統計値は58%に達し、人間のフィードバックで訓練されたDaVinci003と比較すると65%に達します.これらの結果から、大規模言語モデルのほとんどの知識は事前学習中に学習され、GPT-4、Claude、BardよりもLIMAを調整することが限られていることが強く示唆されています.(p.1)
ただし、LIMAはGPT-4、Claude、Bardよりも同等または優れた応答を43%、46%、58%の場合に生み出すことができます.GPT-4を注釈者として再度人間の好みの注釈を繰り返すことで、この結果が裏付けられました.また、LIMAの応答を絶対的な尺度で分析すると、88%がプロンプトの要件を満たし、50%が優れていると考えられます.(p.1)
以上の結果から、LIMAはRLHFで訓練されたDaVinci003やAlpacaよりも優れた性能を発揮し、GPT-4、Claude、Bardよりも同等または優れた応答を生み出すことができることがわかりました.(p.1)
Q: この結果は、プレトレーニング対インストラクションのチューニングの重要性について、どのような示唆を与えているのでしょうか.
A: 結果は、事前トレーニングの重要性が大規模な指示調整や強化学習アプローチよりも高いことを示唆しています.これは、Superficial Alignment Hypothesisに基づいており、モデルの知識と能力はほとんど事前トレーニング中に学習され、アラインメントはユーザーとの相互作用時にどのサブ分布を使用するかを教えることを目的としています.したがって、小さな例のセットで事前トレーニングされた言語モデルを十分に調整することができるという推論が成り立ちます.これは、Kirstainらによって提唱されたものであり、1,000のプロンプトとレスポンスのデータセットを収集し、スタイル的に整合したレスポンスを求めました.これらの例は、主にコミュニティQ&Aフォーラムと手動で作成された例から収集され、50の開発セットと300のテストセットがあります.これらの例を使用することで、状態の強い芸術と競合することができることが示され、Superficial Alignment Hypothesisを強く支持しています.(p.1-2)
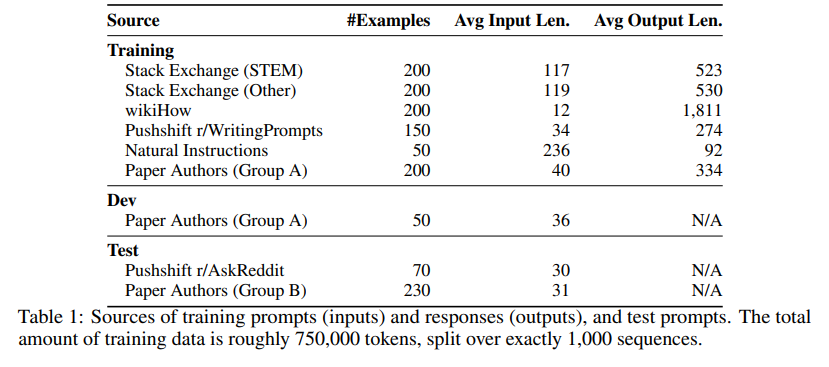
Q: 本調査で使用したデータセットについて、収集方法、開発セットとテストセットの数など、より詳しい情報を教えてください.
A: 本研究で使用されたデータセットは、Stack Exchange、wikiHow、Pushshift Reddit Datasetから収集された3つのコミュニティQ&Aウェブサイトからのデータと、自分たちのプロンプトから収集された手動で作成された例から構成されています.データは、2,000のトレーニング例が各ソースから収集され、50の開発セットが提示されました.質問の品質をテストするために、Stack Exchangeから2,000の例をフィルターなしでサンプリングし、フィルターされたデータセットでトレーニングされたモデルと比較しました.また、Stack Exchangeデータの多様性が性能に与える影響を調べるために、Stack ExchangeとwikiHowのデータを比較しました.これらの情報は、表1と図5に示されています. (p.2-3)
Q: LIMAを鍛えるために、プロンプトとレスポンスはいくつ使われたのでしょうか.
A: LIMAをトレーニングするために使用されたプロンプトとレスポンスの数は、1,000個であり、そのうち750個はStack ExchangeやwikiHowなどのコミュニティフォーラムからの質と多様性をサンプリングし、残りの250個は手動で作成され、タスクの多様性を最適化し、AIアシスタントのスピリットで均一なレスポンススタイルを強調しました.これらのプロンプトとレスポンスにfine-tunedされた、65B-parameter LLaMaモデル[Touvron et al., 2023]を使用してLIMAをトレーニングしました.(p.3-5)
Q: タスクの多様性と一貫した回答スタイルを実現するために、手作業で作成した250のプロンプトと回答はどのように最適化されたのでしょうか.
A: 250の手動作成プロンプトとレスポンスは、タスクの多様性と一貫したレスポンススタイルを最適化するために、Stack ExchangeやwikiHowからのサンプリングに加えて、著者自身によるプロンプトの収集によって作成されました.著者たちは、自分たちの興味や友人の興味に基づいて、GroupAとGroupBの2つのグループに分かれて、それぞれ250のプロンプトを作成しました.GroupAから200のプロンプトをトレーニングに、50のプロンプトを開発用に選択しました.GroupBからは、問題のあるプロンプトをフィルタリングした後、残りの230のプロンプトをテストに使用しました.高品質の回答を自分たちで書きながら、一貫したトーンを設定し、役に立つAIアシスタントに適したものにしました.具体的には、多くのプロンプトには、質問への認識の表明に続いて回答があります.予備実験では、この一貫したフォーマットが一般的にモデルのパフォーマンスを向上させることが示されており、モデルが思考の連鎖を形成するのを助けると仮説を立てています. (p.3)
