
これまで (~2023年) のプロンプトエンジニアリングに関連する論文から、幾つか選定してキーポイントをリスト化してみました.ここで、紹介する論文は以下の6本となります.
- ReAct: Synergizing Reasoning and Acting in Language Models
- LangChainライブラリにチャットエージェントして導入されている手法.
- Language Models Are Greedy Reasoners: A Systematic Formal Analysis of Chain-of-Thought
- 主に分析が評価されている論文.
- Large Language Models are Zero-Shot Reasoners
- 提案と検証されたプロンプト手法、Zero-shot-CoT
- PaLM: Scaling Language Modeling with Pathways
- Pathwaysという新しいMLシステムで学習した大規模言語モデル.
- Self-Consistency Improves Chain of Thought Reasoning in Language Models
- 一つの言語モデルからCoTのサンプリングを抽出し、それらのアンサンブルを行った、自己アンサンブルとも言える手法.
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- Chain-of-Thout (CoT)という思考の連鎖プロンプトで精度の向上が検証された.
流れが少しでも把握できるように、一番新しいものから並べて複数の関連性がある論文を紹介しています.ここでは、幾つかの要点のみを記載しています.論文を読む前にこれらを把握することで、皆さんが内容を素早く吸収できることを目的としています.
ReAct: Synergizing Reasoning and Acting in Language Models
著者:Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, Yuan Cao
発行日:2022年10月06日
最終更新日:2023年03月10日
URL:http://arxiv.org/pdf/2210.03629v3
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning

幾つかの要点:
- ICLR 2023で発表された学会論文であり、言語的推論とアクションを組み合わせることで、人間の認知において重要な役割を果たす能力を実現することを目的としています.
- この研究では、新しいアプローチ「ReAct」を提案し、推論トレースとタスク固有のアクションを交互に生成することで、両者の間により大きなシナジーを生み出すことを探求しています.
- ReActは、
- 大規模言語モデルにおいて推論と行動を協調させるためのシンプルで効果的な方法である.
- 質問応答、事実検証、テキストベースのゲーム、ウェブページのナビゲーションなどのタスクにおいて、単純なベースラインよりも解釈可能性の高い人間らしいタスク解決軌跡を生成することができました.
- 追加のトレーニングデータによる微調整実験を行い、ReActがより多くのタスクに対応できるようにする可能性を示しました.
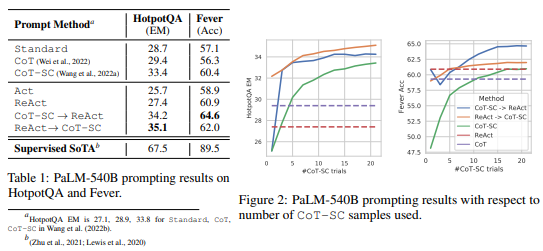
- 外部環境との相互作用を通じて推論をサポートする情報を取得し、推論と行動のシナジーを実証することで、ReAct Prompting For HotpotQA and Feverにおいて、高いEMスコアを達成したことが示されています.
- 手動で推論トレースとアクションを注釈付けすることの難しさに対処するため、ReActによって生成された3,000の軌跡を使用して、PaLM-8/62Bなどの小規模な言語モデルを微調整するブートストラップアプローチを採用しました.
- また、本研究では、ReActのトレーニングデータを用いて、標準的なプロンプティング、Chain-of-thoughtプロンプティング、Acting-onlyプロンプティングなどの複数のベースラインを構築し、それらと比較することで、ReActがより高い解釈可能性を持つことが示されました.
- さらに、ReActとCoT-SCを組み合わせることで、モデルが内部的な知識と外部的な知識を組み合わせることができることが示されました.
- PaLM-540Bをベースモデルとして、ReActがActよりも優れた結果を示すことが表1に示されています.
- マルチホップ質問応答、ファクトチェック、インタラクティブな意思決定タスクにおける多様な実験を通じて、ReActが解釈可能な意思決定トレースを伴う優れたパフォーマンスを発揮することを示した.
その他のノート
- 人間の知能のユニークな特徴は、タスク指向の行動と言語的推論をシームレスに組み合わせる能力である.
- この能力は、自己調整や戦略化を可能にするために人間の認知に重要な役割を果たすと理論化されている.
- また、作業記憶を維持するためにも重要である.
- 例えば、キッチンで料理を作る場合、言語で推論することで進捗状況を追跡したり、計画を調整したりすることができる.
- 人間は、料理のレシピを見て、冷蔵庫を開いて、材料を確認することで、理由を支持し、質問に答えるための文書を作成することができる.
- この「行動」と「推論」の緊密なシナジーにより、人間は新しいタスクを素早く学習し、以前に見たことのない状況や情報の不確実性に直面しても堅牢な意思決定や推論を行うことができる.
- 最近の研究結果は、自律システムで言語的推論とインタラクティブな意思決定を組み合わせる可能性が示唆されている.
- プロジェクトサイトとコード:https://react-lm.github.io.
OpenReviewのコメントの要約:
URL:https://openreview.net/forum?id=WE_vluYUL-X
利点:
- 論文の主張や記述は、正確で適切にサポートされています.
- 論文の貢献は、重要であり、一部は以前の研究に存在しますが、新しい側面もあります.
- ReActは、単独でも一部のタスクにおいてはかなりうまく機能しますが、自己整合的なChain of ThoughtはしばしばReAct単独よりも優れた性能を発揮し、かなりの性能向上をもたらします.
- 最高のモデルは、データセットの性能を最大化するためのヒューリスティックスを使用して、CoTとReActのスマートな組み合わせを使用します(
ReAct -> CoT--SC戦略を参照).これにより、ReAct単独の性能はやや劣るものの、依然としてコミュニティにとって有用な貢献だと思われます. - ReActは、APIコマンドの許容範囲を事前に定義するためにプロンプティングに大きく依存しています.
- 論文の貢献は、重要であり、以前の研究に存在しないものもあります.
欠点:
- PaLM 540Bに関する研究は、主に推論タスクとテキストベースのシーケンシャルな意思決定タスクに焦点を当てていますが、他のタスクにおいてどの程度有効であるかは不明です.また、PaLM 540Bは、大規模なデータセットを必要とするため、データセットが限られている場合には使用できない可能性があります.
- ReActとCoTの貢献度についての詳細な分析が不足しており、改善の余地があります.
- ReActのプロンプティングは、トレースから外れると正確性が低下する可能性があります.
- ReActは、単独でうまく機能する場合がありますが、CoTとの組み合わせが最適であることが示されています.また、この手法は、プロンプト内にアクションの使用例が必要であるため、アクション空間が制約されていない環境では使用できない可能性があります.
- 再現性の欠如. PaLM 540B、PaLM-8B、PaLM 62Bは一般に公開されていないため、この研究の再現性が制限されています.より小さなオープンソースの言語モデル(例:GPT-J-6B)を使用して微調整の結果を実施することで、この論文を大幅に強化することができます.また、アクセス可能な商用API(例:OpenAI、Cohere微調整サービス)を介して微調整を行うこともできます.
Language Models Are Greedy Reasoners: A Systematic Formal Analysis of Chain-of-Thought
著者:Abulhair Saparov, He He
発行日:2022年10月03日
最終更新日:2023年03月02日
URL:http://arxiv.org/pdf/2210.01240v4
カテゴリ:Computation and Language

幾つかの要点:
- 大規模言語モデル(LLM)は、思考の連鎖プロンプト(中間推論ステップを含む例)を与えられた場合に、驚くべき推論能力を示しています.
- 既存のベンチマークは、数学的推論などの下流タスクの正確さを評価することによって、推論能力を間接的に評価しています.
- しかし、これらのモデルが答えをどのように得ているのか、生成された思考の連鎖に依存しているのか、単純なヒューリスティックに依存しているのかは不明です.
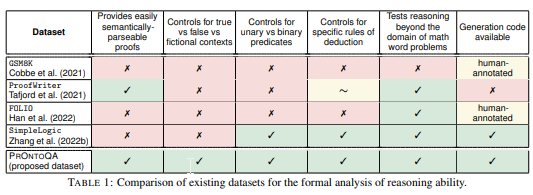
- LLMの推論能力を系統的に探索するために、我々は、一階論理で表現された合成世界モデルから生成された新しい合成質問応答データセットであるPrOntoQAを提供します.
- これにより、生成された思考の連鎖を形式的な解析のための記号的証明に解析することができます.
- InstructGPTとGPT-3に対する我々の分析は、LLMが正しい個々の推論ステップを行う能力が高いことを示しており、一般的には、架空の文脈でも推論能力を持っていることを示しています.
- しかし、複数の妥当な推論ステップがある場合、証明計画には困難がある.
- 人工知能は、異なるオプションを系統的に探索することができない.
- CoTの分析を容易にするために、Proof and Ontology-Generated Question-Answeringという新しい合成QAデータセットPRONTOQAを構築する.
- PRONTOQAは、
- 線形なオントロジーから生成された問題を含み、予測されたCoTの形式的な分析を容易にすることを目的としています.
- 自然言語で生成された例から構成されているため、自然言語を用いた推論にも価値があります.
- 特徴的な点は、LLMの推論における異なる側面を研究するために、いくつかの調整可能なツマミを備えたプログラム可能なデータセットであることです.
- PRONTOQAか生成されたすべての例は、すべての入力で独立して同一に生成される.
- PRONTOQAで例を生成する際に制御する変数がいくつかある.
- 自然言語生成を使用して、証明の例を生成することができる.生成された例は、トップダウン(つまり、先行順)またはボトムアップ(つまり、後行順)の順序で生成される. 順序は、生成された例の難易度に影響を与える.ボトムアップで生成された文は、ゴールドプルーフのステップと同じ順序に従う.一方、トップダウンで生成された文は順序が逆になり、タスクがより難しくなる可能性がある.
- フィクションの概念名(例えば、「猫」の代わりに「ワンパス」など)を使用して、事前学習中に獲得した知識からの混乱効果を回避する.ただし、フィクションのオントロジーに加えて、「真の」オントロジーと「偽の」オントロジーも生成される.真のオントロジーは実際の概念名を使用し、現実世界と一致する.偽のオントロジーは実際の概念名を使用するが、木構造はランダムプロセスによって生成される.オントロジーは実際の概念名を使用しますが、木構造はセクション3で説明されたランダムプロセスを使用して生成されるため、「すべての哺乳動物は猫である」といった誤った文を生成する可能性が非常に高いです.
- この論文の主要な貢献は、データセットではなく、データセットによって容易になる分析です.
その他の情報
- CoTの例をいくつか提示することで、引き出された推論により、LLMは標準的な質問回答プロンプティングよりもはるかに高い精度でラベルを予測することができる.しかし、これらのモデルがどの程度推論できるかは、いくつかの混乱要因があるため不明である.
- LLMsは、事前トレーニングを通じて既に知識を習得しており、単に答えを取り出すだけでなく、推論することができる可能性がある.
- この研究では、予測されたラベルではなく、予測された思考の連鎖(解釈可能な証明手順)を直接評価することにより、LLMsの推論能力を系統的に調査している.
- 分析コード、データ、データ生成スクリプト、およびモデル出力はすべて利用可能です.https://github.com/asaparov/prontoqa
OpenReviewのコメントの要約:
URL:https://openreview.net/forum?id=qFVVBzXxR2V
利点:
- 詳細な実験結果が得られ、モデルの推論能力が明らかになった.
- 独自のデータセットを使用することで、柔軟性と制御性が向上し、ヒューリスティックを緩和するために不正解を追加するなどの操作が可能になった.
- ProofWriterとは異なり、本研究では含意と論理積の推論能力、および単項述語と二項述語の推論能力の違いを測定することができる.
- 本研究では、複数のモデルを評価しており、text-ada-001、text-babbage-001、text-curie-001、davinci、text-davinci-001のモデルも評価している.
- モデルがオントロジー・ツリーから来ない概念に関するルールを無視するように学習する可能性があるが、本研究ではオントロジー・ツリーから切り離された概念を生成することで、新しい誤答を追加することができる.
- 予測されたCoTの各文を再帰的に降下解析し、生成プロセスからの単純な文法を使用して論理形式に変換することで、CoTの解析を行っている.また、解析できない証明ステップは不正解としてマークされる.興味深いことに、小さなモデルでは解析できない証明ステップが観察されたが、大きなモデルでは常に解析可能なCoT文を生成した.
- 最も寛容な精度指標がラベル精度と最も高い相関関係を持っていることから、ラベル精度が推論精度を測定する適切な方法であることが示唆されている.
- CoTの予測ステップに対して、beam search decodingを行うことで、より正確な予測が可能になることが示唆されている.
- データセットはProofWriterに比べてわずかな改善しかないが、データセット自体よりも、データセットを用いた分析が本研究の主要な貢献であることを強調する必要がある.
- ProofWriterは真実、矛盾、フィクションの例を区別していないため、全てのルールを含む例が存在するが、本研究ではこれらの区別を行っている.
欠点:
- 証明精度が推論能力を過小評価する傾向があるため、証明精度だけでモデルの評価をすることには限界がある.
- 予測されたCoTの各文を再帰的に降下解析し、生成プロセスからの単純な文法を使用して論理形式に変換することで、CoTの解析を行っているが、解析できない証明ステップがある場合についての説明が不十分である.また、サンプルが正しい形式でない場合にどうするかについても説明が不足している.
Large Language Models are Zero-Shot Reasoners
著者:Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, Yusuke Iwasawa
発行日:2022年05月24日
最終更新日:2023年01月29日
URL:http://arxiv.org/pdf/2205.11916v4
カテゴリ:Computation and Language, Artificial Intelligence, Machine Learning
幾つかの要点:
- 大規模言語モデル(LLM)は、自然言語処理(NLP)の多くの分野で広く使用されている.LLMは、タスク固有の例示による優れたフューショット学習者として一般的に知られている.
- CoTプロンプティングは、最近の技術であり、複雑な多段階の推論をステップバイステップの回答例を通じて引き出すことができる.CoTプロンプティングは、算術と象徴的推論の状態-of-the-artパフォーマンスを達成した.
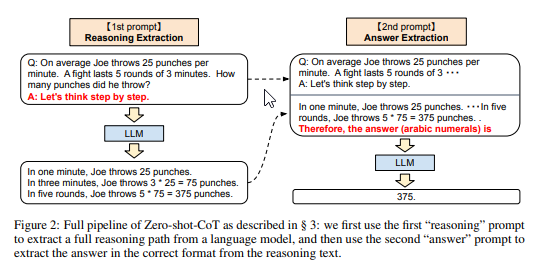
- LLMは、単に各回答の前に「ステップバイステップで考えてみましょう」と追加することで、ゼロショットの理由付けにも優れていることが示されている.
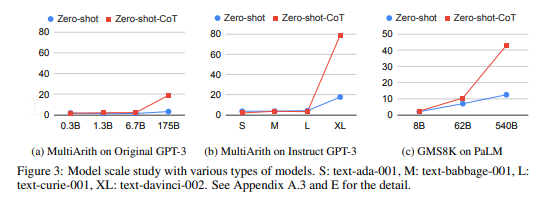
- 実験結果は、同じ単一のプロンプトテンプレートを使用したZero-shot-CoTが、算術(MultiArith、GSM8K、AQUA-RAT、SVAMP)、象徴的推論(Last Letter、Coin)を含む多様なベンチマーク推論タスクでゼロショットLLMパフォーマンスを大幅に上回ることを示している.
- Zero-shot-CoTは、手作りのフューショットの例を使用せずに、MultiArith、GSM8K、AQUA-RAT、SVAMPなどの数学的推論、記号的推論(最後の文字、コインフリップ)、および他の論理的推論タスク(日付理解、シャッフルされたオブジェクトの追跡)を含む、非常に多様な推論タスクに対して、InstructGPTモデル(text-davinci-002)を使用して、MultiArithの精度を17.7%から78.7%、GSM8Kの精度を10.4%から40.7%に向上させることができることを示しています.
- また、540BパラメータPaLMという別のオフシェルフの大規模モデルでも同様の改善が見られました.
- この単一のプロンプトの多様な推論タスクに対する汎用性は、未開発で研究されていないLLMの基本的なゼロショットの能力を示唆しており、単純なプロンプトで高レベルでマルチタスクの広範な認知能力が抽出される可能性があることを示唆しています.
- 最近の技術であるCoTプロンプティングは、ステップバイステップの回答例を通じて複雑な多段階の推論を引き出すためのものであり、LLMの標準的なスケーリング法に従わない難しいシステム2タスクである算術と象徴的推論において最高のパフォーマンスを達成しました.
- これらの成功はしばしばLLMのフューショット学習能力に帰せられますが、私たちは、単に各回答の前に「ステップバイステップで考えてみましょう」と追加することで、LLMがゼロショットの推論者であることを示します.
- 実験結果は、同じ単一のプロンプトテンプレートを使用した私たちのZero-shot-CoTが、算術(MultiArith、GSM8K、AQUA-RAT、SVAMP)を含む多様なベンチマーク推論タスクにおいて、ゼロショットLLMのパフォーマンスを大幅に上回ることを示しています.
その他の情報
- 本研究は、Zero-shot-CoTという新しい手法を提案し、多段階推論を促進することで、従来のCoTプロンプティングと異なり、few-shotの例を必要とせず、タスクに依存しないテンプレートを使用します.
- 本研究では、算術、常識、記号、その他の論理推論タスクの4つのカテゴリーから12のデータセットを使用して、Zero-shot-CoTプロンプティングの性能を評価しました.
- 17種類のモデルを使用し、Instruct-GPT3、original GPT3、PaLM、GPT-2、GPT-Neo、GPT-J、T0、OPTなどを実験に使用しました.
- Zero-shot-CoTを標準のZero-shotプロンプティングと比較し、その推論の効果を検証しました.
- コードは、https://github.com/kojima-takeshi188/zero_shot_cot
OpenReviewのコメントの要約:
URL:https://openreview.net/forum?id=e2TBb5y0yFf
利点
- GPT-3以外のモデルでも有効であることを検証するため、PaLM(540B)での追加実験を行った.詳細は「追加実験の結果」スレッドを参照してください.
- ゼロショット推論能力を示す徹底的な実験を行った論文があれば、レビュアーが指摘してくれると助かる.CoT論文[*d]では、タスク固有の少数のサンプルを用意することなしに、このような複雑な行動が現れることをNLPコミュニティは信じていなかったため、ゼロショットは考慮されていない.
- 新しいタスクに対しては、トレーニングデータに含まれていないため、汎化能力が限定的である可能性がある.
- この手法は、広範なタスクに適用可能であることがTable 1で示されており、詳細な結果はAppendix Bに記載されています.
欠点
- 評価能力に深刻な欠陥があるため、より多角的な分析が必要である.
- 人間の判断力を完全に置き換えることはできないため、論文の決定には限界がある.
- 論文の内容に対する主観的な評価を考慮していないため、公正性に欠ける可能性がある.
- プロンプトの選択によっては、結果が偏る可能性がある.
PaLM: Scaling Language Modeling with Pathways
著者:Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, Noah Fiedel
発行日:2022年04月05日
最終更新日:2022年10月05日
URL:http://arxiv.org/pdf/2204.02311v5
カテゴリ:Computation and Language
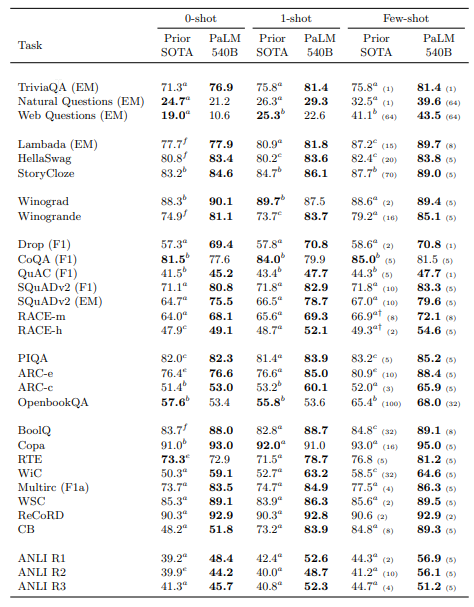
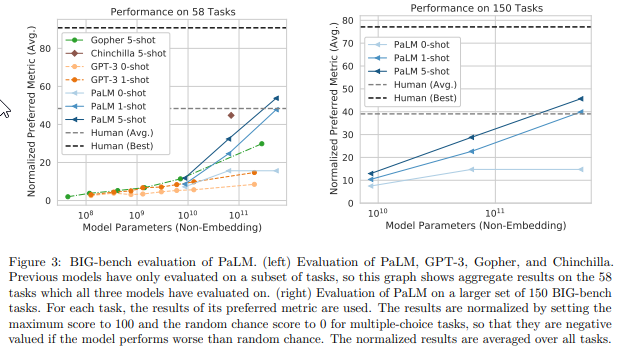
幾つかの要点:
- 大規模言語モデルは、少数のトレーニング例で多様な自然言語タスクにおいて驚異的なパフォーマンスを発揮することが示されている.
- 特定のアプリケーションにモデルを適応させるために必要なタスク固有のトレーニング例の数を劇的に減らすfew-shot learningを使用している.
- Pathwaysという複数のTPUポッドにわたる高効率なトレーニングを可能にする新しいMLシステムで学習した、5400億パラメータの密に活性化されたTransformer言語モデルを (Pathways Language Model) PaLMと呼んでいる.
- PALMは、
- 準的なTransformerモデルアーキテクチャをデコーダーのみのセットアップで使用し、各タイムステップが自身と過去のタイムステップにしかアテンションできないようにしている.他にも活性化関数や、Parallel Layers, Multi-Query Attention, RoPE Embedding など一部の改善を加えています.
- Pathwaysを使用して、6144 TPU v4チップでPaLMをトレーニングした.
- 私たちは、数百の言語理解と生成のベンチマークにおいて、スケーリングの継続的な利点を示し、最先端のfew-shot learningの結果を達成した.
- PaLM 540Bは、
- 一連のマルチステップの推論タスクで最先端のfinetunedを上回る突破口のパフォーマンスを発揮し、平均的な人間のパフォーマンスを上回る.
- 高品質で多様なテキストの780Bトークンをトレーニングデータとして使用し、540Bパラメータの密なTransformer言語モデルをトレーニングすることで、few-shot言語理解と生成の境界を押し上げることを目的としている.
- 多段階の推論タスクにおいて、平均的な人間のパフォーマンスを上回り、最近リリースされたBIG-benchベンチマークでも優れた成績を収めている.
- 多言語タスクやソースコード生成にも強い能力を持っており、様々なベンチマークでその能力を示している.
- 多くのBIG-benchタスクでは、モデルのスケールが大きくなるにつれて性能が急激に向上するという不連続な改善が見られた.
- さらに、バイアスや毒性に関する包括的な分析を提供し、モデルのスケールに関するトレーニングデータの記憶の程度を調べている.
- 大規模言語モデルに関連する倫理的考慮事項について議論し、緩和策についても検討している.
- 評価結果によると、PaLMは28の29の英語NLPタスクで、以前の大規模言語モデルの最高結果と比較して、最高のfew-shotパフォーマンスを発揮している.
その他の情報
- 近年、言語理解と生成のために訓練された非常に大きなニューラルネットワークは、様々なタスクで驚異的な結果を達成してきた.
- これらのモデルの多くは、BERT(Devlin et al.、2019)やT5(Raffel et al.、2020)などであり、大規模なテキストコーパスに対してインフィリング(「マスクされたLM」または「スパン破損」)の事前学習目的を使用してエンコーダーのみまたはエンコーダーデコーダーアーキテクチャで訓練され、通常はその後、1つ以上の特定のタスクに適応するために微調整される.
- これらのモデルは、数千の自然言語タスク全体でほぼ普遍的な最先端を達成しているが、欠点は、モデルを微調整するために多数のタスク固有のトレーニング例が必要であることである.
- GPT-3(Brown et al.、2020)は、非常に大きな自己回帰言語モデル(LM)が可能であることを示した.このクラスのモデルは、デコーダーのみのアーキテクチャでトレーニングされ、大規模なテキストコーパスで左から右に言語モデリングの目的でトレーニングされる.
- GPT-3以降、他の大規模な自己回帰言語モデルが開発され、最新技術を推進している.
- GLaM、Gopher、Chinchilla、Megatron-Turing NLGなどのモデルがある.
- Few-shot evaluationは、大規模なタスク固有のデータ収集やモデルパラメータの更新の必要性なしに、非常に強力な結果を達成することが示されている.
Self-Consistency Improves Chain of Thought Reasoning in Language Models
著者:Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, Denny Zhou
発行日:2022年03月21日
最終更新日:2023年03月07日
URL:http://arxiv.org/pdf/2203.11171v4
カテゴリ:Computation and Language, Artificial Intelligence
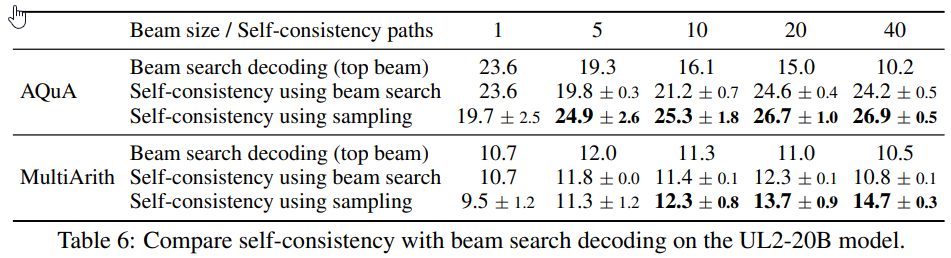
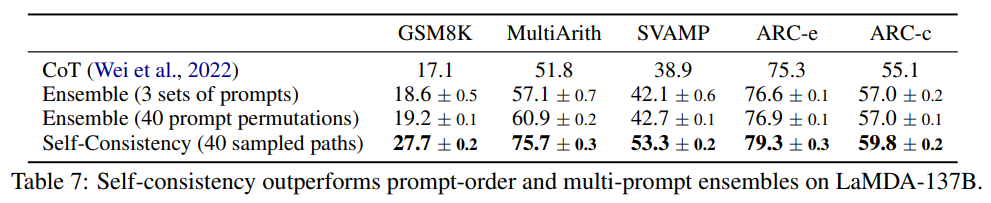

幾つかの要点:
- 論文では、Chain of Thoght (CoT)と事前学習された大規模言語モデルの組み合わせが、複雑な推論タスクにおいて有力な結果を出していることが述べられています.
- 本論文では、自己整合性(Self-Consistency)という新しいデコーディング戦略を提案している.これは、連鎖思考プロンプティングで用いられる単純な貪欲デコーディングを置き換えるものである.
- 自己整合性は、単にグリーディーデコーディングを取るのではなく、多様な推論パスをサンプリングし、その中から最も整合的な答えを選択する.複雑な推論問題には、一意の正しい答えに導く異なる思考方法が複数存在するという直感を利用している.
- 自己整合法は、
- 3つのステップから構成されています.まず、chain-of-thought (CoT) プロンプティングを使用して言語モデルをプロンプトします.次に、CoTプロンプティングの「greedy decode」を言語モデルのデコーダからサンプリングに置き換えて、多様な推論パスのセットを生成します.最後に、推論パスを周辺化し、最も一貫性のある回答を選択して最終的な回答セットを集約します.
- 通常のアンサンブル手法とは異なり、複数のモデルをトレーニングして各モデルの出力を集約するのではなく、単一の言語モデルの上で作動する「自己アンサンブル」のように機能します.
- 大規模な実証評価により、GSM8K(+17.9%)、SVAMP(+11.0%)、AQuA(+12.2%)、StrategyQA(+6.4%)およびARC-challenge(+3.9%)を含む一連の人気のある算術および常識推論ベンチマークで、連鎖思考プロンプティングの性能を著しく向上させることが示された.
- グリーディーデコーディングによる反復性や局所最適性を回避しながら、単一のサンプリング生成の確率性を緩和する.
- 実験では、トレーニングを行わずにfew-shot settingで算術推論タスクや常識推論タスクに取り組み、UL2やGPT-3、LaMDA-137B、PaLM-540Bなどの様々な言語モデルに対して、自己整合性を評価し、従来の手法よりも高い性能を発揮することが示されました.
- 特に、PaLM-540Bにおいては、異なる回答集約戦略の精度比較を行った結果、本手法が最も高い精度を示しました.
- 新たに加わった文脈により、オープンテキスト生成問題においても、本手法が適用可能であることが示唆されました.
- 算術推論タスクにおいては、言語モデルのスケールが大きくなるほど、自己整合性の効果がより顕著に現れ、UL2-20Bでは+3%-6%、LaMDA-137BやGPT-3では+9%-23%の絶対精度向上が見られました.
その他の情報
- サンプリングされる推論パスの数が増えるほど、性能が向上することが示され、推論パスの多様性の重要性が強調されました.
- 自己整合性がグリーディーデコーディングよりも豊富な推論パスを提供することが示されています.
- 論理的な推論パスを生成するために、従来のグリーディーデコーディング手法ではなく、「サンプリングとマージナライズ」デコーディング手法を提案する.
- この手法は、複数の異なる思考方法が同じ答えに導く場合、最終的な答えが正しいという人間の経験に類似している.
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
著者:Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou
発行日:2022年01月28日
最終更新日:2023年01月10日
URL:http://arxiv.org/pdf/2201.11903v6
カテゴリ:Computation and Language, Artificial Intelligence
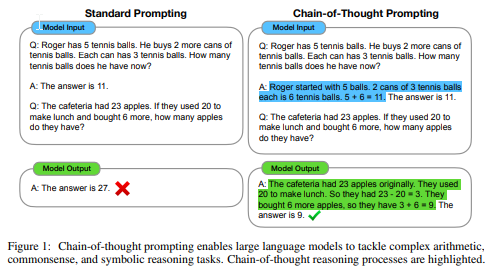
幾つかの要点:
- 大規模言語モデルが複雑な推論を行う能力を向上させるために、思考の連鎖を生成する方法を探求している.
- Chain of Thought (CoT), または思考の連鎖とは、中間の推論ステップのシリーズのことであり、十分に大きな言語モデルでは、思考の連鎖プロンプトと呼ばれる単純な方法によって自然に推論能力が現れることを示している.
- 思考の連鎖プロンプトでは、いくつかの思考の連鎖デモンストレーションがプロンプトとして提供される.
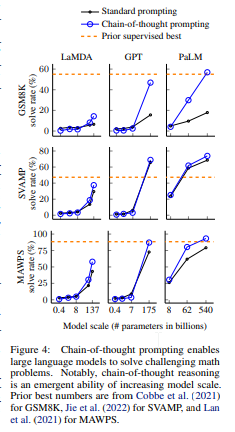
- 3つの大規模言語モデルでの実験では、思考の連鎖プロンプトが算術、常識、および象徴的推論タスクの範囲で性能を向上させることが示されている.
- 実験の結果、思考の連鎖プロンプトによる利益は著しい.たとえば、8つの思考の連鎖デモンストレーションで540Bパラメータの言語モデルをプロンプトすると、数学のワード問題のGSM8Kベンチマークで最新の精度を達成し、検証者を含むfinetuned GPT-3をも上回る.
- 大規模言語モデルは、複雑な算術、常識、および象徴的推論タスクに対処することができる.
- Chain-of-thoughtプロンプティングは、推論プロセスを強調する.
- チェーン・オブ・ソート・プロンプティングは、言語モデルにおける推論力を向上させるための簡単で広く適用可能な方法である.
- 算術、象徴的、常識的な推論に関する実験を通じて、チェーン・オブ・ソート・プロンプティングは、モデルのスケールによって生じる新しい性質であり、十分に大きな言語モデルが、通常はフラットなスケーリング曲線を持つ推論タスクを実行できるようになることを発見した.
- 言語モデルが実行できる推論タスクの範囲を広げることは、言語に基づく推論アプローチに関するさらなる研究を促すことを期待している.
その他の情報
- この論文は、36th Conference on Neural Information Processing Systems (NeurIPS 2022)で発表された.
- Finetuned GPT-3と先行研究の最高値はCobbe et al. (2021)から得られたものである.
- 両方のアイデアには重要な制限がある.
- 理由を加えたトレーニングやファインチューニングの方法では、高品質な理由の大量作成が必要であり、コストがかかる.
- Brown et al. (2020)で使用される従来のフューショットプロンプティング方法は、推論能力を必要とするタスクではうまく機能せず、言語モデルのスケールが増加しても大幅に改善されないことが多い.
- 大規模言語モデルは、タスクに関する自然言語データの数例で学習できることが示されている.
- プロンプティングのみのアプローチは、大規模なトレーニングデータセットを必要とせず、単一のモデルチェックポイントで多くのタスクを実行できるため、重要である.
- GSM8Kベンチマークの数学の単語問題において、PaLM 540Bを使用したチェーン・オブ・ソート・プロンプティングは、標準的なプロンプティングよりも大幅に優れた性能を発揮し、新しい最高性能を達成している.
- チェーン・オブ・ソート・プロンプティングの最も強力な結果は、モデルの規模によって出現することが示されている. モデルの規模が小さい場合、チェーン・オブ・ソート・プロンプティングは性能に影響を与えず、約100Bパラメータのモデルでのみ性能向上が見られる.
- より複雑な問題に対しては、チェーン・オブ・ソート・プロンプティングがより大きな性能向上をもたらす.
- MAWPSという問題に対して、GPT-3 175BとPaLM 540Bのchain-of-thought promptingを使用することで、従来のモデルよりも高い性能を発揮することができた.
- 一方、SingleOpというMAWPSのサブセットに対しては、性能の向上はほとんど見られなかった.


コメント