
ここで、紹介する論文は以下の6本となります.
ここでは、幾つかの要点のみを記載しています.気になる論文の選択に役立ったら良いと思います.論文を読む前に幾つかの要点を把握することで、皆さんが内容を素早く吸収できることも目的としています.
- Resurrecting Recurrent Neural Networks for Long Sequences
- Transformerの欠点を克服するためRNNが見直されている.従来のRNNに複数の改善を加えた Linear-Recurrent-Unit を提案し検証している.
- Meet in the Middle: A New Pre-training Paradigm
- 従来の因果マスキングなどとは、異なる新たなLLMの学習方法の検証.
- Eliciting Latent Predictions from Transformers with the Tuned Lens
- トランスフォーマーの予測が層ごとに、どのように洗練されるのかを分析する手法の提案と検証.過去のロジットレンズの改善版
- LERF: Language Embedded Radiance Fields
- Nerf+LLM、LERFは、言語クエリでD関連性マップをリアルタイムでインタラクティブに抽出することができる.詳細は https://www.lerf.io/ にて.
- An Overview on Language Models: Recent Developments and Outlook
- 自然言語モデルのこれまでの概要と研究の展望が記載されている資料.
- UPRISE: Universal Prompt Retrieval for Improving Zero-Shot Evaluation
- 与えられたゼロショットのタスクに対して自動的にプロンプトを取得する手法の提案と検証.
Resurrecting Recurrent Neural Networks for Long Sequences
著者:Antonio Orvieto, Samuel L Smith, Albert Gu, Anushan Fernando, Caglar Gulcehre, Razvan Pascanu, Soham De
発行日:2023年03月11日
最終更新日:2023年03月11日
URL:http://arxiv.org/pdf/2303.06349v1
カテゴリ:Machine Learning
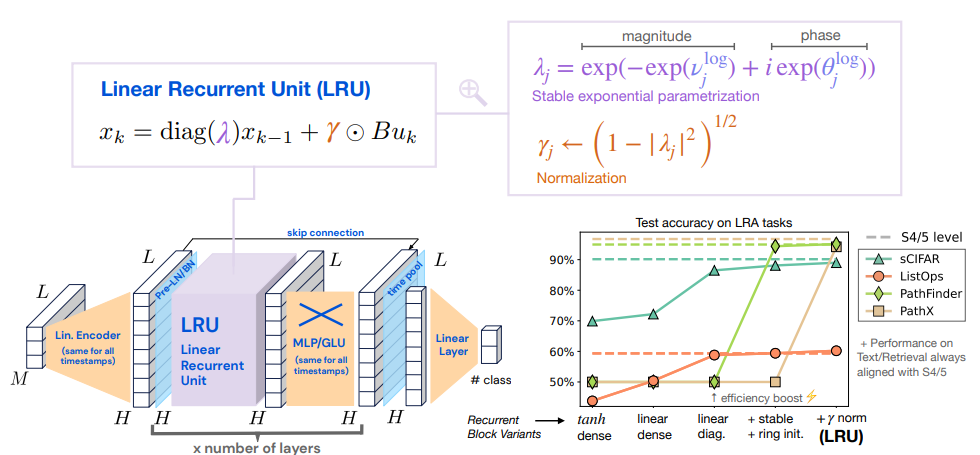
要点:
- RNNと比較した、Transformerの利点
- アテンション層はトレーニング中にスケールや並列処理がしやすい.
- シーケンス内の任意の2つのトークン間の相互作用は直接的なエッジでモデル化されるため、勾配消失問題に苦しむことはありません.
- RNNと比較した、Transformerの欠点
- アテンション層の主要な問題は、計算およびメモリのコストがシーケンス長𝐿に対して2次関数的にスケールすることです.したがって、トランスフォーマーを長いシーケンスに展開すると特に高価になります.シーケンス長に比例してスケールするRNNは、控えめなシーケンス長においても、推論時間で通常、トランスフォーマーよりも速く処理できます.
- 再帰ニューラルネットワーク(RNN)は、長いシーケンスに対して高速な推論を提供するが、最適化が困難でトレーニングが遅いとされています.
- deep state-space モデル(SSM)は、長いシーケンスモデリングタスクで驚くほど良いパフォーマンスを発揮し、高速な並列トレーニングとRNNのような高速推論の利点があるとされています.
- 本論文では、標準的な信号伝搬の議論を用いた深層RNNの注意深い設計により、深層SSMの印象的なパフォーマンスを長距離推論タスクで回復し、トレーニング速度も一致させることが示されています.
- Linear Recurrent UnitというRNNブロックを紹介し、Long Range Arenaベンチマークでのパフォーマンスと計算効率の両方にマッチする方法が示されています.
- この論文では、Linear Recurrent Unit(LRU)と呼ばれる新しいRNNレイヤーを紹介し、深層シーケンスモデルのコアレイヤーとして効果的かつ効率的に使用する方法が示されています.
- 線形化、対角化、安定した指数パラメータ化、および正規化などの変更が、特に長距離推論を必要とするタスクにおいて、性能を大幅に向上させることが、hRNNの一連のステップバイステップの変更に関する理論的な洞察力と広範な実験によって示されています.
- 私たちの再帰性は、現代の深層SSMと類似していますが、私たちの設計は、潜在的な連続時間システムの離散化や構造化された遷移行列に依存しません.
- 代わりに、私たちの改善は、ディープラーニングコミュニティで標準的な初期化とフォワードパス解析の議論に直接従い、Glorot-initialized RNNから始まるものです.
- 私たちの最終モデルは、すべての Long Range Arena(LRAタスクにおいて、現代のdeep state-space モデルの性能に匹敵することが示されています.
- 対角化された線形RNN層を使用することで、計算速度を大幅に向上させることが示されました.
Meet in the Middle: A New Pre-training Paradigm
著者:Anh Nguyen, Nikos Karampatziakis, Weizhu Chen
発行日:2023年03月13日
最終更新日:2023年03月13日
URL:http://arxiv.org/pdf/2303.07295v1
カテゴリ:Computation and Language, Machine Learning

要点:
- 言語モデルは、通常、自己回帰的な左から右への方法でトレーニングおよび適用され、次のトークンは前のトークンにのみ依存すると仮定されています.
- しかし、この仮定は、トレーニング中に完全なシーケンス情報を使用することの潜在的な利点と、推論中に両方の側面からの文脈を持つ可能性を無視しています.
- 本論文では、トレーニングデータの効率性とLMのインフィリングタスクの能力を共に向上させる技術を組み合わせた新しい事前トレーニングパラダイムが提案されています.
- Meet-In-The-Middle(MIM)という手法が提案されています.
- 多くのベースラインを上回ることが示され、infilling問題に対する効果的な解決策として、異なるドメインやタスクにおいて使用されます.
- Fill-In-The-Middle (FIM)よりも優れたレイテンシーで高品質の出力を生成することができます.
- 第一に、左から右へのLMの予測を、同じデータを逆順にトレーニングした右から左へのLMの予測と整合させるトレーニング目的があります.
- 第二に、両方のLMが中央で出会えるようにする双方向推論手順があります.
- プログラミングおよび自然言語モデルの両方についての広範な実験で、強力なベースラインを上回る効果が示されています.
- 本研究では、2つのデコーダー専用言語モデルを使用し、すべてのパラメータを共有し、前方モデル−→pと後方モデル←−pの両方をトレーニングします.
- トレーニング中のデータ効率を改善するために、共同正則化項を使用し、−→pと←−pが各トークンの語彙に対する予測確率分布で合意するように促します.
Eliciting Latent Predictions from Transformers with the Tuned Lens
著者:Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, Jacob Steinhardt
発行日:2023年03月14日
最終更新日:2023年03月15日
URL:http://arxiv.org/pdf/2303.08112v2
カテゴリ:Machine Learning
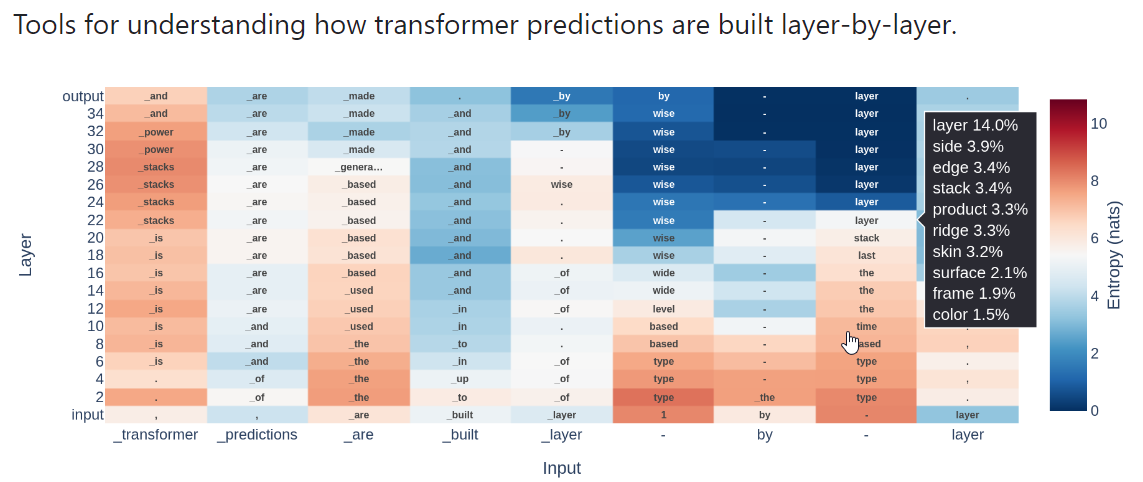
- この論文では、イテレーション推論の観点からトランスフォーマーを分析し、モデルの予測が層ごとにどのように洗練されるかを理解しようとしています.
- そのために、事前学習済みモデルの各ブロックに対してアフィンプローブをトレーニングし、すべての隠れ状態を語彙の分布にデコードすることが可能になりました.
- この手法は、以前の「ロジットレンズ」技術の改良版であり、有用な洞察を提供しましたが、しばしば脆弱でした.
- ロジットレンズは信頼性が低く、BLOOMやGPT Neoなどのモデルに対して適切な予測を引き出せないことがあります.
- この論文では、大規模言語モデルの機能について新しい解釈可能性研究ツールである「チューンド・レンズ」を紹介しました.これは、ログイット・レンズの代替品であり、本質的に今日使用されているほとんどの事前学習済み言語モデルから解釈可能な予測軌跡を引き出すことができます.
- この手法を、20Bパラメータまでのさまざまな自己回帰言語モデルでテストし、ロジットレンズよりも予測的で信頼性が高く、偏りがないことを示しました.
- 因果実験により、調整されたレンズがモデル自体と同様の特徴を使用していることを示しました.
- 潜在的な予測の軌跡を使用して、悪意のある入力を高い精度で検出できることも発見しました.
- すべてのコードは、https://github.com/AlignmentResearch/tuned-lens で入手可能です.
- tuned-lens ライブラリの一部として、最も一般的に使用されること前学習済みモデルの調整されたレンズチェックポイントがリリースされています.
LERF: Language Embedded Radiance Fields
著者:Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, Matthew Tancik
発行日:2023年03月16日
最終更新日:2023年03月16日
URL:http://arxiv.org/pdf/2303.09553v1
カテゴリ:Computer Vision and Pattern Recognition, Graphics

- LERF(Language Embedded Radiance Fields)の提案された方法により、NeRFに接地させることで、CLIPなどの既製モデルからの言語埋め込みを使用して、3Dでのオープンエンドの言語クエリが可能になります.
- LERFについて、
- オフシェルフのビジョン・ランゲージ・モデルであるCLIPの埋め込みを3Dシーンに最適化することによって、言語を基盤とする.
- COCOなどのデータセットを介した微調整や、マスク領域提案に頼る必要がなく、CLIPを直接利用することができます.
- CLIPの埋め込みを複数のスケールで保持するため、幅広い言語クエリを処理することができます.
- 位置と物理的なスケールの両方を入力として受け取り、単一のCLIPベクトルを出力する言語フィールドをNeRFと共同で最適化することによって構築されます.
- CLIPの埋め込みを複数のスケールで保持するため、幅広い言語クエリを処理することができます.トレーニング中、CLIPエンコーダーが異なるスケールの画像コンテキストを捉え、同じ3D位置を異なる言語埋め込みと関連付けるために、複数のスケールの特徴ピラミッドを使用します.
- テスト時には、言語フィールドを任意のスケールでクエリすることで、3D関連性マップを取得できます.
- LERFには追加の利点があり、複数のビューから複数のスケールでCLIP埋め込みを抽出するため、3D CLIP埋め込みを介して得られるテキストクエリの関連性マップは、2D CLIP埋め込みを介して得られるものよりもより局所化されています.
- LERFのゼロショット機能により、ロボット工学、ビジョン言語モデルの分析、3Dシーンとの相互作用など、潜在的な用途があります.
- LERFは、位置と物理的なスケールの両方を入力として受け取り、単一のCLIPベクトルを出力する言語フィールドをNeRFと共同で最適化することによって構築されます.
- LERFは、複数のビューにレンダリングすることなく、NeRFのベース実装を遅らせることなくトレーニングできます.
- トレーニングプロセスの完了後、LERFは、リアルタイムで広範な言語プロンプトの3D関連性マップを生成することができます.
- コードとデータはhttps://lerf.io
An Overview on Language Models: Recent Developments and Outlook
著者:Chengwei Wei, Yun-Cheng Wang, Bin Wang, C. -C. Jay Kuo
発行日:2023年03月10日
最終更新日:2023年03月10日
URL:http://arxiv.org/pdf/2303.05759v1
カテゴリ:Computation and Language
- 言語モデルは、自然言語処理において重要な役割が果たされます.
- Conventional Language Models (CLMs)とPre-trained Language Models (PLMs) について概要を提供し、5つの観点から研究が行われています.それは、1)言語単位、2)構造、3)トレーニング方法、4)評価方法、5)応用です.
- 説明可能で信頼性があり、ドメイン固有で軽量な言語モデルの必要性が強調されています.
- 言語モデリングは、単語のシーケンスに対する確率分布を研究するものであり、自然言語処理(NLP)における最も基本的なタスクの一つであり、長年の研究トピックでもあります.
- 開発された言語モデル(LM)は、テキスト生成、機械翻訳、音声認識、自然言語生成、質問応答システムなど、多くの計算言語学的問題に応用されます.
- 言語モデリングには、比較的小規模なコーパスセットに基づく統計的アプローチと、かなり大規模なコーパスセットに基づくデータ駆動アプローチの2つの主要なアプローチがあります.
- 異なる言語単位のレベルが紹介され、言語モデルのトレーニングに言語単位の予測がどのように使用されるかが調べられています.
- 言語モデルが採用するトークナイゼーション方法について議論されています.
- PLMは、
- 深層学習の発展により、大量の未ラベルのコーパスのコレクションで事前にトレーニングされ、一般的な知識を学習し、それが転移されます.
- 前処理や特徴量エンジニアリングなどの手間を省き、自然言語処理タスクにおいて高い性能を発揮することができます.
- 事前学習と微調整の2つのステップで構成されます.事前学習では、大規模なコーパスを用いて言語モデルを学習し、微調整では、タスクに応じてモデルを調整します.
- この概要論文は、2つの目的を持っています.一方で、最近開発されたPLMに焦点を当てるだけでなく、LMの基本的な概念、CLMからPLMへの移行、LMの最近の発展と応用について、この分野の初心者に包括的な概要を提供することを目的としています.他方で、NLP分野の経験豊富なエンジニアや研究者に将来の研究方向を明らかにし、展望を提供したいと考えています.
- ChatGPTによって提供される新しいサービスにより、LLMに対する関心が高まっているため、調査ではLLMも取り上げています.
- CLMを超えるいくつかのタイプのLMが紹介され、テキストシーケンスをより小さな言語単位に分解する一般的な方法について概説されます.
- LMのトレーニング手順が説明されます.
- 内在的および外在的な評価方法を含む一般的な評価方法が紹介されます.
- テキスト生成へのLMの応用について説明されています.
- LMの冗長性問題についてコメントし、効率的なLMの技術を分析しています.
- 下流アプリケーションには、例えば画像認識や自然言語処理などの応用分野が含まれています.
- LMで挙げられている問題の一つは、Out-Of-Vocabulary(OOV)問題です.
- 最近の研究者は、辞書に登録されていない場合は単語をサブワードに分解することを好んでいます.
- フレーズレベルの言語モデルは、共通の結合力のある単語のシーケンスをフレーズに置き換えることで、単語レベルのモデルよりも優れた性能を発揮します.フレーズレベルの言語モデルは、Automatic Speech Recognition(ASR)などのアプリケーションに適しています.
- ASR において、短い単語の認識エラーは長い単語よりも多いという指摘があります.フレーズは、構成要素よりも長い音素シーケンスを提供するため、ASRの認識エラーに対してより堅牢です.
- LM(言語モデル)では、文字、単語、サブワード、フレーズなどのより小さな言語単位を使用し、条件付き確率を利用してテキストシーケンスの確率を推定します.文レベルのLMは、連鎖規則の使用を避け、文の特徴を生成し、その後、文の確率を直接モデル化します.
UPRISE: Universal Prompt Retrieval for Improving Zero-Shot Evaluation
著者:Daixuan Cheng, Shaohan Huang, Junyu Bi, Yuefeng Zhan, Jianfeng Liu, Yujing Wang, Hao Sun, Furu Wei, Denvy Deng, Qi Zhang
発行日:2023年03月15日
最終更新日:2023年03月22日
URL:http://arxiv.org/pdf/2303.08518v2
カテゴリ:Computation and Language
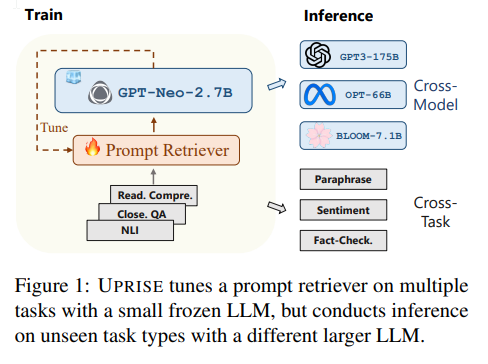
- 大規模言語モデル(LLM)は、印象的な能力を持つため人気がありますが、モデル固有の微調整やタスク固有のプロンプトエンジニアリングの必要性が一般化を妨げることがあります.
- UPRISE(Universal Prompt Retrieval for Improving zero-Shot Evaluation)は、軽量で多目的な抽出機を調整し、与えられたゼロショットのタスクに対して自動的にプロンプトを取得することで、汎用性を提供します.
- UPRISEは、多様なタスクセットで調整され、未知のタスクタイプでテストされるクロスタスクおよびクロスモデルシナリオで汎用性を示します.
- UPRISEは、BLOOM-7.1B、OPT-66B、GPT3-175Bなどのはるかに大きなスケールのLLMの異なるLLMで、小さな凍結LLMであるGPT-Neo-2.7Bを使用して抽出を行います.
- ChatGPTでの実験においてUPRISEは幻覚問題を緩和することが示され、最も強力なLLMでも改善の可能性があることを示唆しています.
- モデルとコードはhttps://github.com/microsoft/LMOpsで利用可能です.


コメント