
はじめに
近年の深層学習によるパラダイムシフトによって、以前は、人が試行錯誤して設計した特徴量や、アルゴリズムによってモデルの精度向上を図っていました.近年の計算資源やスケーラビリティの向上により、膨大なデータを用いて、畳み込み層などによる表現学習(特徴量抽出)が自動的に行われるようになりました.これは、「どの特徴量やアルゴリズムを使うか?」から「どのアーキテクチャを使うか?」へのパラダイムシフトが起きたと言えます.
アーキテクチャの設計またはチューニングは、今のところ人が試行錯誤しています.この過程も自動化させたいというのがサーチの目的です.既に過去には、人が作成するネットワークを超えて、state of the art (SOTA)の精度結果を残しており、例として、よくコンペなどでも用いられる[3]EfficientNetのベースとなるモデルはアーキテクチャサーチによるものです.
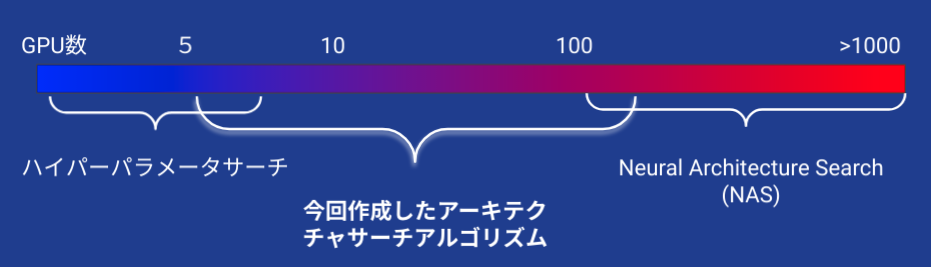
典型的にネットワークの検索は、数多くの深層学習モデルを作成するため現実的な期間でサーチを行うには、数百から数千個のGPUを用いるなど某大な計算資源が必要となります.各ネットワークの学習の高速化がとても重要な課題となり様々な工夫が必須です.サーチする範囲が大きいと計算時間は必然的に長くなります.
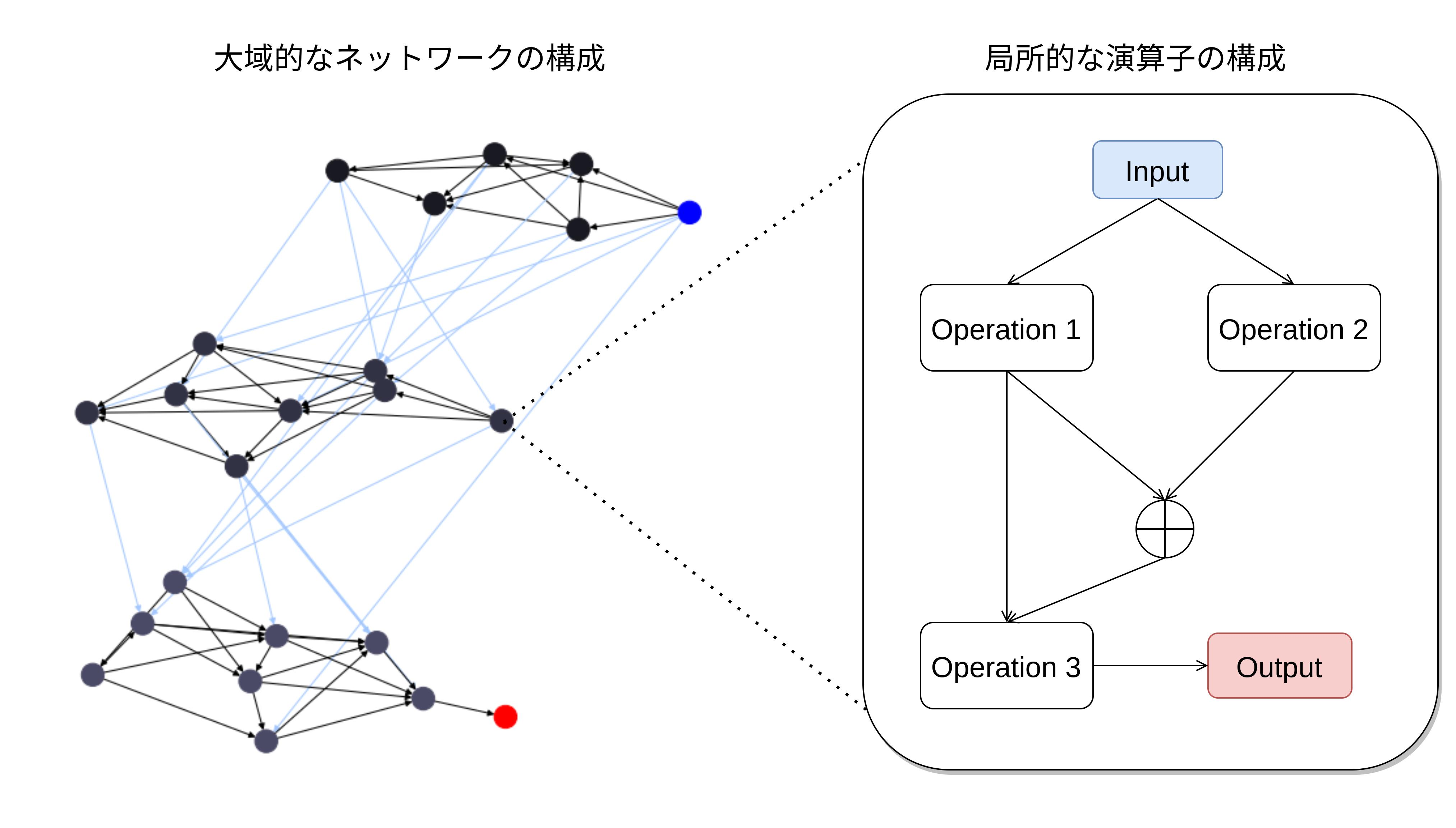
ここで、作成したサーチアルゴリズムでは、細かい局所的な演算子の構成のみをサーチの対象とするのではなく、より大域的なネットワーク構成のサーチのみに絞っています.パラメータ数に制約を与えてサーチすることもできるので、ライトウェイトで高速に学習できるモデルの検索も可能にしました.
いちよう、ハイパーパラメータチューニング、ネットワークトポロジーやノード内の演算子の最適化が一括にできるように設計しましたが、サーチ空間が大きすぎると良い解に収束する速度が落ちるので、結局の所、全てを含めての同時ば最適化は行いませんでした.
計算量としては、以下のように、典型的なサーチ(NAS)とハイパーパラメータチューニングの間になるようにサーチ空間を設定するようにしています.
一般的にアーキテクチャサーチに用いる最適化アルゴリズムは、強化学習(マルコフ決定過程での報酬の最大化)か、遺伝的アルゴリズム(進化論を模擬した突然変異や交叉による最適化)が主流となっています.ここでは、[1]を基にした非同期的遺伝的アルゴリズムをネットワークサーチを導入しました.非同期的であるため、多数のGPUだけでなく、アルゴリズムを複数のサーバーへ展開することが容易なので、とても便利です.突然変異では、親ネットワークの構成などに比較的小さい変化を与え、重みの情報も部分的に子孫へと継承させていく仕組みを組み込みました.徐々にノード (パラメータ)を追加したり、削除することでノンパラメトリックな学習を模擬しています.
実験結果
ベンチマークは、こちらのQIITAの記事を元に作成しております.アーキテクチャサーチでは、「テストデータ」に対しての評価を元に最適化を行うので間接的な情報の漏れが生じ、テストデータへ過剰に適合してしまいます.よって、普段よりもかなり大きめにテストデータを設け、高速化のため学習データを少なく設けていますので、他者が行った実験などとの公正な比較は出来ないことをご了承下さい.
タスク: 画像セグメンテーション
データ: https://www.kaggle.com/c/data-science-bowl-2018
ベンチマーク
ネットワーク:VGG UNET++
パラメータ数:9,163,329
IOU Score(テストへの精度):0.843
学習エポック数:240
アーキテクチャサーチ
サーチアルゴリズム:非同期的遺伝的アルゴリズム
サーチ空間:ネットワークグラフの構成+MobileNetV2 or ResNetノード演算子
集団の個体数:100
パラメータ数範囲:500,000 - 20,000,000
学習エポック数:120ここでは、各ノード内部の演算子の構成をサーチするのではなく、ノード同士の繋がり方を検索していきます.各ノードの演算子は、MobileNetV2やResNetブロックを用いています.
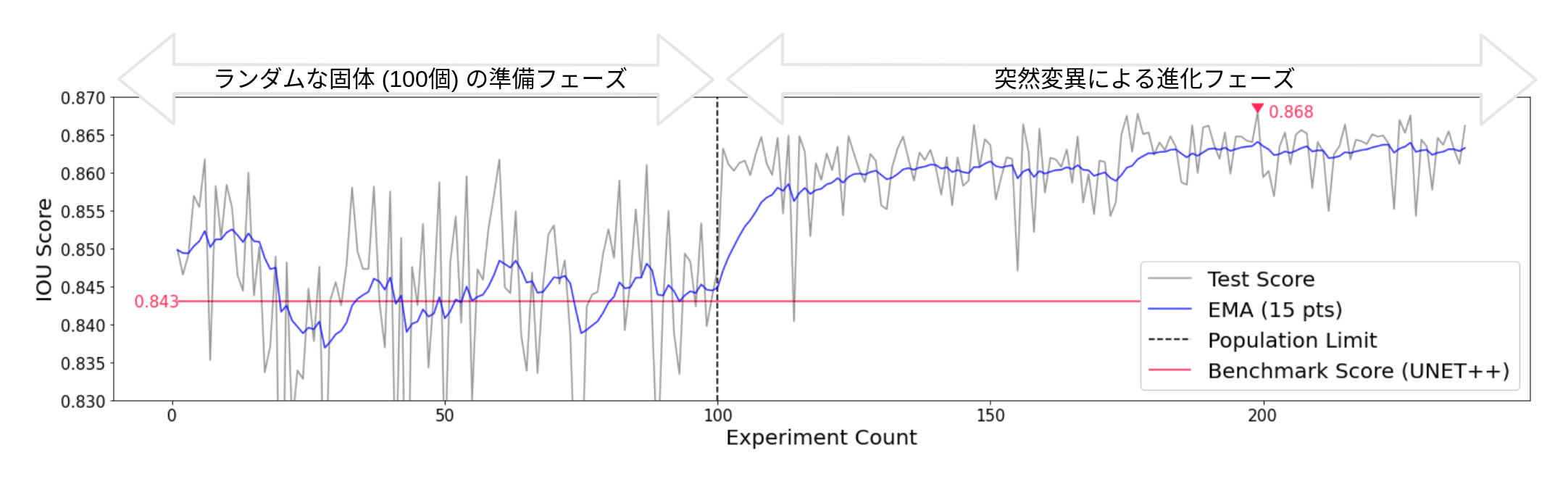
実験経過と精度を表したグラフは以下となりました.
初めに作成される100固体はランダムに生成される初期集団で、その後に進化フェーズが始まります.初期集団で既にベンチマークを超えているネットワークが度々出現しているのが分かります.過去の他のタスクを用いた実験でも、必ずと言ってよいほど、早期のランダムサーチフェーズでベンチマークを超えるネットワークが現れていたことを鑑みるとランダムサーチのみでも容易に人が選択したものより優れたネットワークが生成されるようです.
進化フェーズでの精度のばらつきは初期フェーズより大きく下がり、ある程度収束しています.精度は殆ど横ばいになっていますが、EMAを見ると若干上がっていく傾向が見られます.最高IOUスコアは0.868となり、ベンチマークより若干高くなった程度でした.過去の実験からも、UNET++のように既にそのタスクに対して優れたネットワークが発見されている場合は大きく見積もっても5%の精度向上しかサーチでは得られないと考えています.よって、一般的なタスク、例えばImageNetでの画像認識とかではなく、より特化したタスクまたはデータに対してより大きく力を発揮できることが想定されます.
一番高い精度を出したネットワーク構成は以下のグラフとなりました.ここで、青のノードは入力層、赤は出力層です.色の付いているグラフのエッジは、青がダウンサンプル層で赤がアップサンプル層となっております.
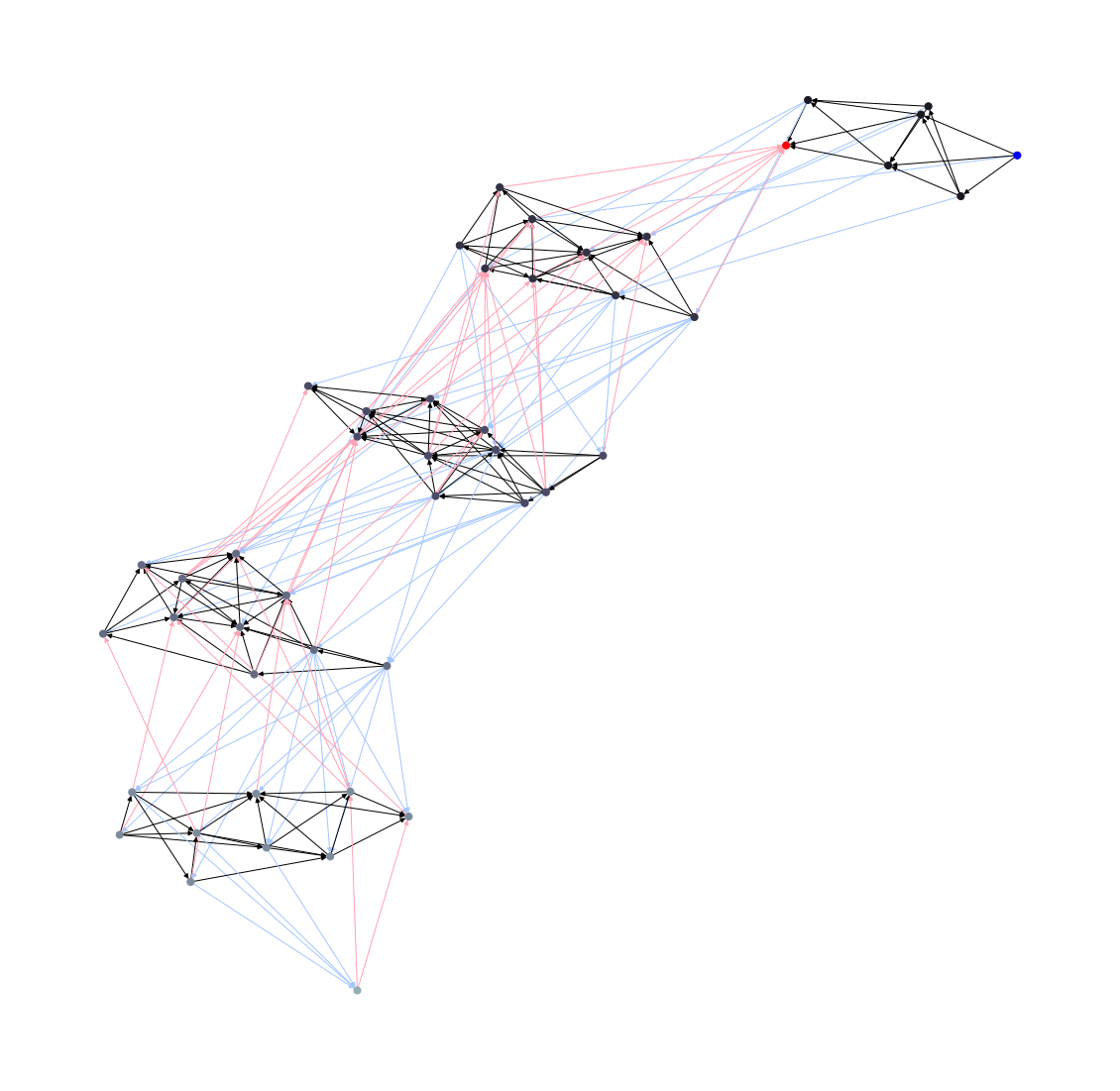
ネットワーク構成としてベンチマークと明らかに違いが見えるのは、アップサンプル層(赤い線)の繋がり方です.最下層の葉ノード(赤い出力ノード)に一つ上の層から全てのアップサンプリング層が結合されているのが分かります.どちらかと言うと、進化のプロセスでダウンサンプリング層の方が好んで追加され、アップサンプリングが最後の方に追い詰められていった様な印象があります.UNET++では逆です.定量的に数を比較すると次となります.
1位のネットワーク:
ダウンサンプリング(Encoder)エッジ数:56
アップサンプリング(Decoder)エッジ数:34
UNET++:
ダウンサンプリング(Encoder)エッジ数:4
アップサンプリング(Decoder)エッジ数:10ダウンサンプリングは上層に情報を伝搬し抽象度を高めるEncoderと捉え、アップサンプリングは下層に伝搬するDecoderと考えた時、今回のサーチ結果はベンチマークと比較すると、かなりEncoderよりに計算複雑度が偏っている様に思えます.よって、このタスクにおいて、DecodingよりもEncodingを強化にした方が良いのではないかという仮説を立てることができます.勿論、進化の過程でたまたまそのようなネットワークが選定されていった可能性もあるので、今回の結果で有意性を示せているわけでなく、別途にテストを設けて検証していく必要があります.
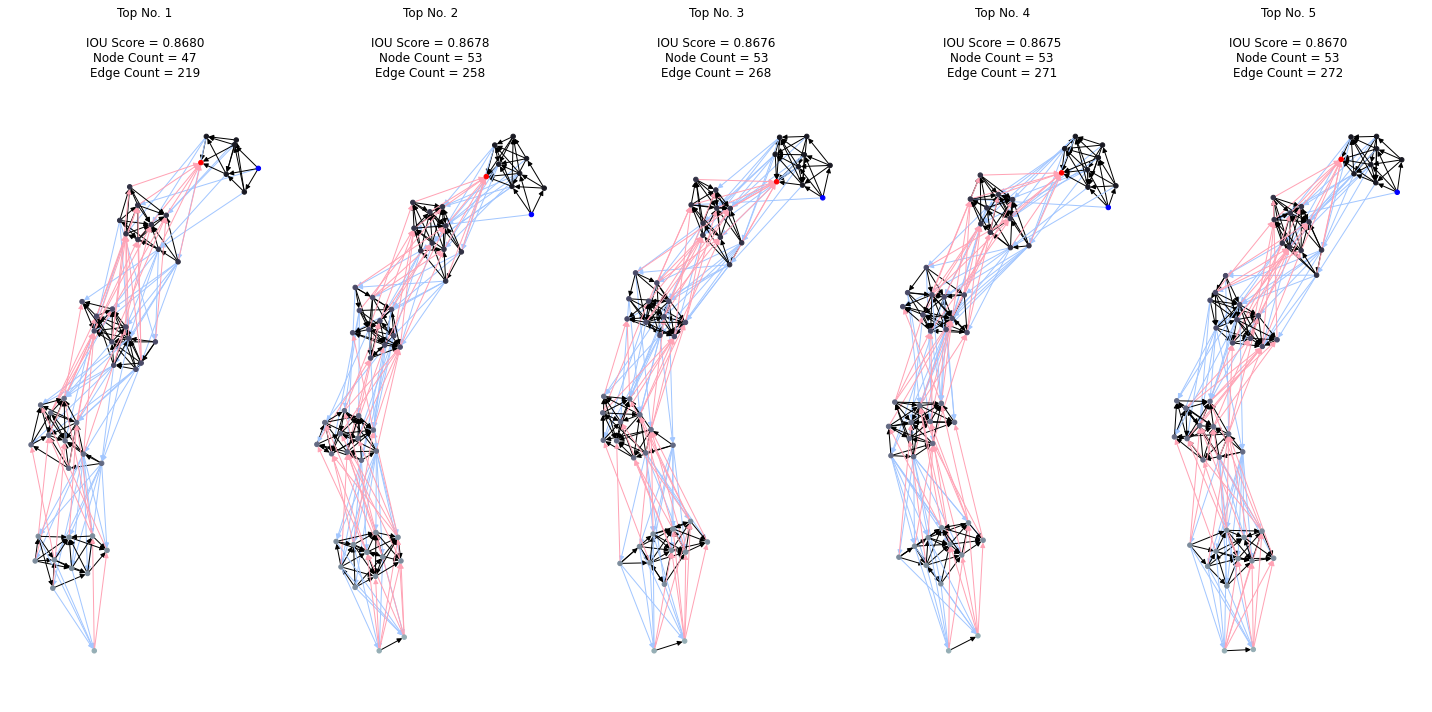
以下に上位群と下位群のネットワークたちを表しています.
ベスト5
ワースト5
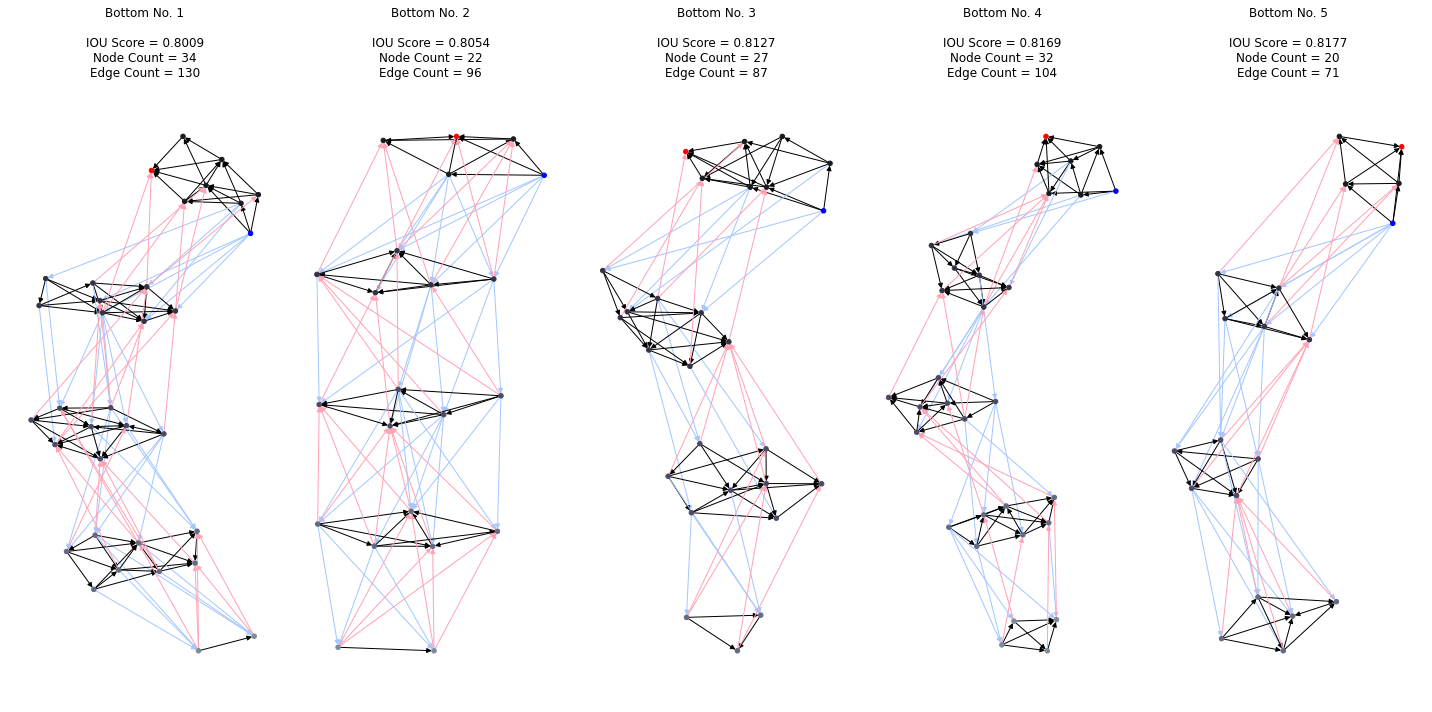
上位群では、下位群と比較して、より多くのノードやエッジが見られます.果たしてこれは、単にパラメータ数が多いネットワークの精度が高いという結果なのでしょうか? 上位群は、突然変異による進化の過程で、細かくノードが追加されたり削除されたりしますが、どちらかと言うと追加される確立の方が高く設定されているので結果的に大きなネットワークとなったと考えられます.よって、突然変異の区間を省き、初期のランダムな固体に対するパラメータ数と精度の関係を調べるのが妥当であると言えます.それを表したグラフは次となります.

これによると、パラメータ数と精度の相関性は見られません.ここには記載しておりませんが、過去の実験でも同じ見解が得られていました.何が高い精度へと繋がったのかを検証するのは現状難しいと考えていますが、研究で試されていた例として[2]による分類タスクなどで、quasi-1d graphs (Q1D)という指標を用いて精度を良し悪しを推定することが提案されているようでした.どのようなネットワークが優位であるかが早期の段階で分かれば、サーチ速度を上げることができます.逆に悪いものが分かれば早期に省くことで時間を節約できます.[4]では、学習する以前にネットワークを評価することで、病的なものをサーチから省くことが検証されています.
まとめ
- アーキテクチャサーチは自動機械学習の一つで、従来の人が設計するという枠組みから、仮説などによるサーチ空間の設定への移り変わりです.
- 初期に人が選定したネットワークの精度を容易に超えられる.より良い解が無数に存在しているがサーチなしでは見逃されています.
- 既にそのタスクに適切なネットワークが発見されている場合は、それ程大きな精度向上は期待できない.必要な計算資源を考慮するとコスパが悪いが、人がチューニングを行う人件費よりは、年々下がる計算資源コストを考えると安くなるか既に安いと思われます.
- 一般的なタスクより特化したものに、より大きく力を発揮できそうです.
- 注意点として、ここで用いた複雑なグラフによるアーキテクチャはGPUが得意とする並列処理を上手く活かせませんでした.今回用いた比較的小さなデータセットで結果は出せますが、少し大きくなると極端に遅くなるので使えません.
今後やってみたいこと
- GPUの並列処理に適切なアーキテクチャに絞りたい.
- より多彩な帰納的バイアスを持つ演算子をサーチに含めたい.
参考文献:
[1]E. Real, A. Aggarwal, Y. Huang, and Q. V. Le, “Regularized Evolution for Image Classifier Architecture Search,” arXiv:1802.01548 [cs], Feb. 2019, Accessed: Jul. 24, 2020. [Online]. Available: http://arxiv.org/abs/1802.01548
[2]R. A. Janik and A. Nowak, “Analyzing Neural Networks Based on Random Graphs,” arXiv:2002.08104 [cs, q-bio, stat], Dec. 2020, Accessed: Dec. 05, 2020. [Online]. Available: http://arxiv.org/abs/2002.08104
[3]M. Tan and Q. V. Le, “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks,” arXiv:1905.11946 [cs, stat], Nov. 2019, Accessed: May 17, 2020. [Online]. Available: http://arxiv.org/abs/1905.11946
[4]J. Mellor, J. Turner, A. Storkey, and E. J. Crowley, “Neural Architecture Search without Training,” arXiv:2006.04647 [cs, stat], Feb. 2021, Accessed: Mar. 17, 2021. [Online]. Available: http://arxiv.org/abs/2006.04647


コメント